
Open Markov Chains: Cumulant Dynamics, Fluctuations and Correlations


{kind=link}
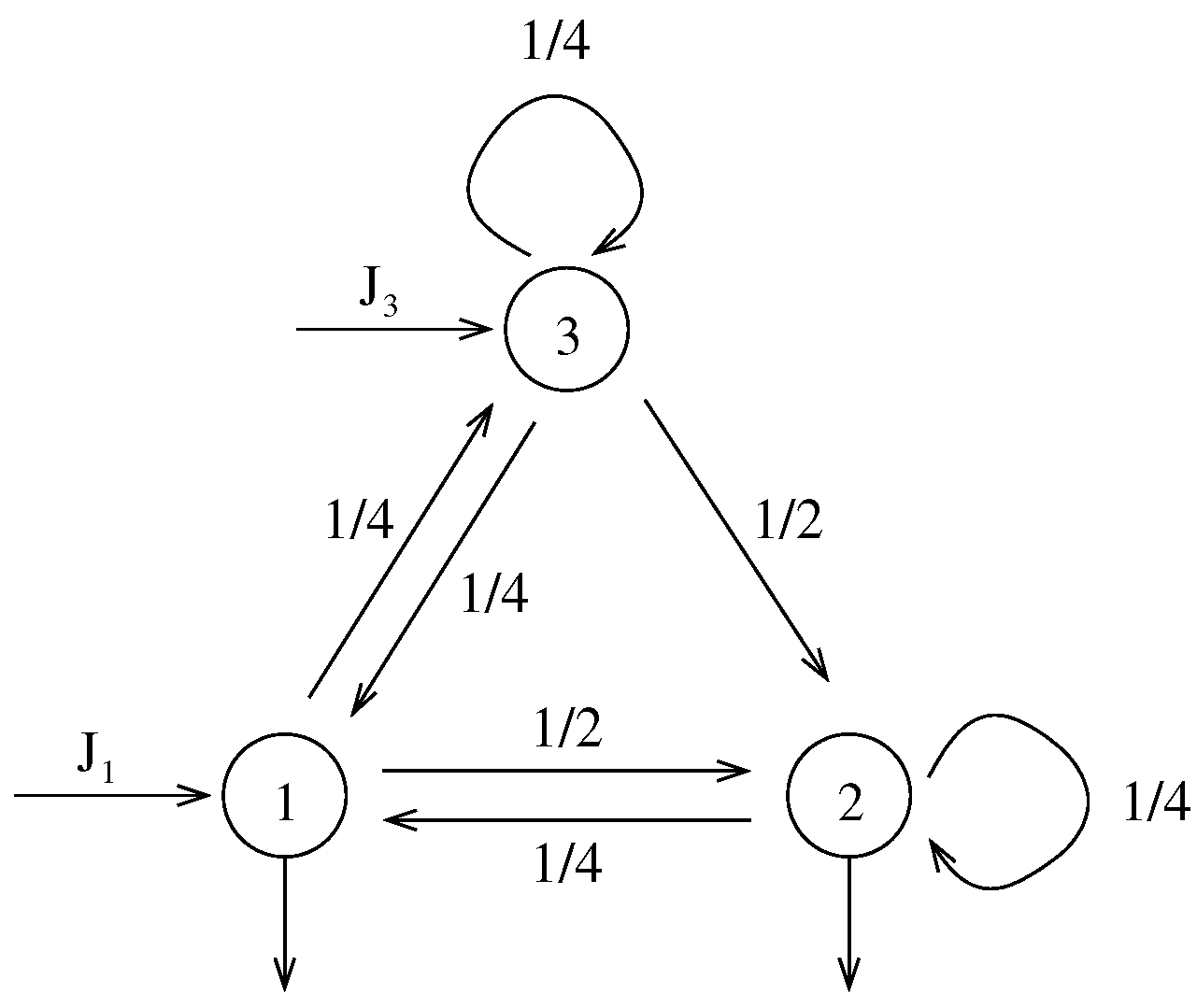{kind=link}
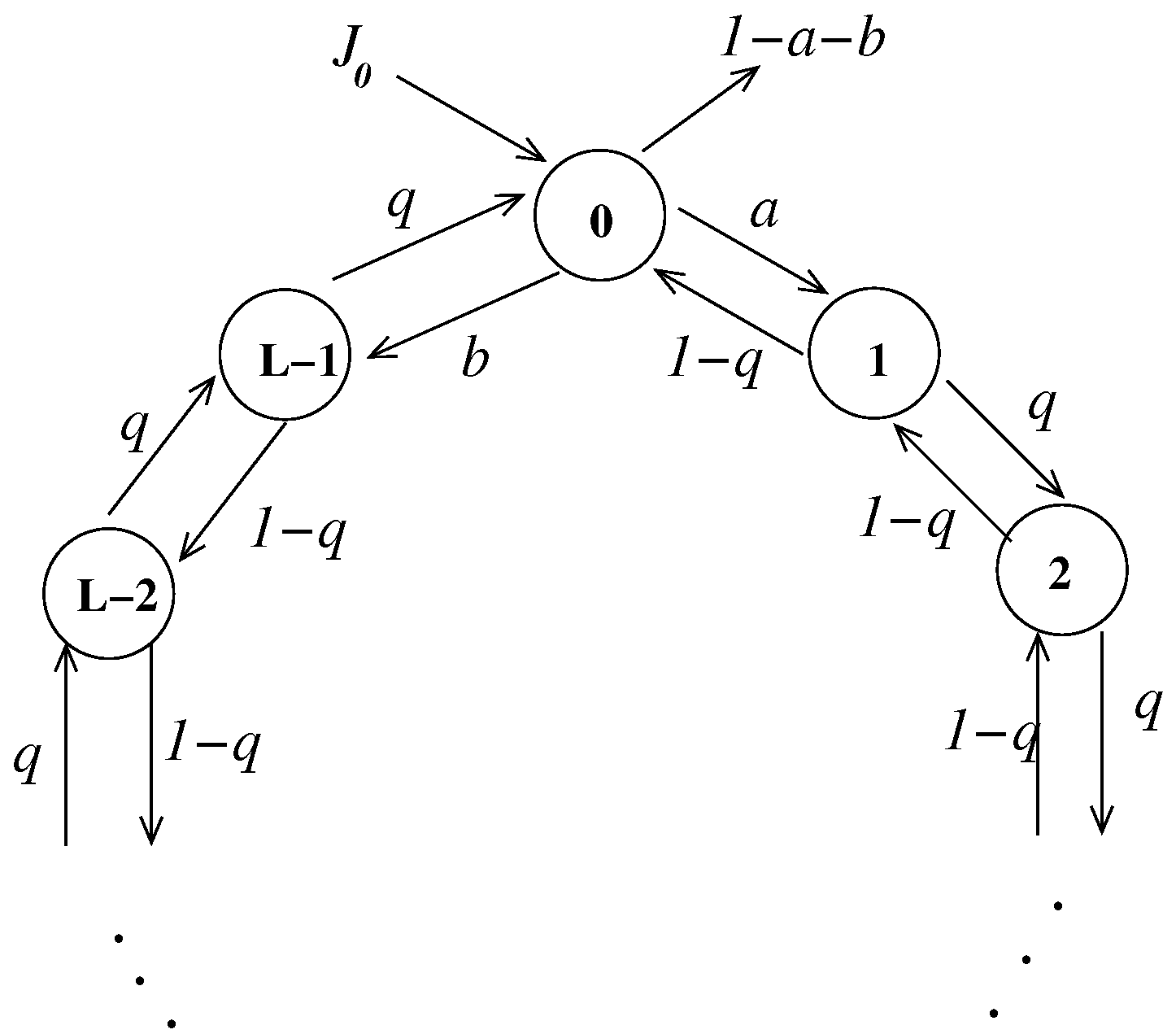{kind=link}
{kind=link}
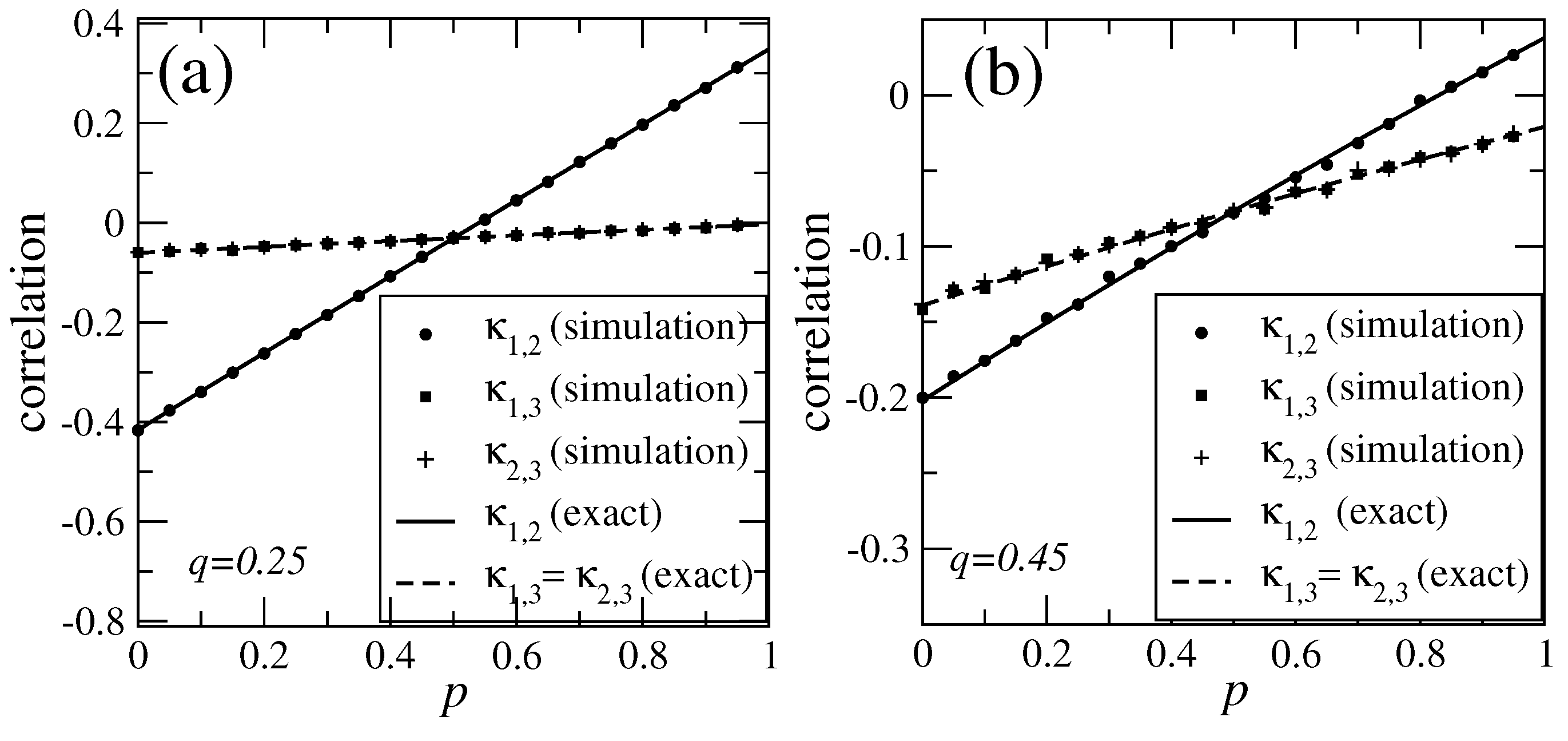{kind=link}
{kind=link}
Abstract
:1. Introduction
2. A Model for Open Markov Chains
3. The Evolution of the Particle Distribution
3.1. Evolution of the Moment Generating Function
3.2. Cumulant Dynamics
3.3. Distribution of Particles Leaving the State Space
4. The Influence of Incoming Particles on Time-Correlations
Time Correlations for the Open Markov Chain
5. Summary of Main Results
6. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
References
- Lemons, D.S.; Langevin, P. An Introduction to Stochastic Processes in Physics; JHU Press: Baltimore, MD, USA, 2002. [Google Scholar]
- Van Kampen, N.G. Stochastic Processes in Physics and Chemistry; Elsevier: Amsterdam, The Netherlands, 1992; Volume 1. [Google Scholar]
- Allen, L.J. An Introduction to Stochastic Processes with Applications to Biology; CRC Press: Hoboken, NJ, USA, 2010. [Google Scholar]
- Goel, N.S.; Richter-Dyn, N. Stochastic Models in Biology; Academic Press Inc.: London, UK, 1974. [Google Scholar]
- Jackman, S. Bayesian Analysis for the Social Sciences; John Wiley & Sons, Ltd.: West Sussex, UK, 2009; Volume 846. [Google Scholar] [CrossRef]
- Chib, S.; Greenberg, E. Markov Chain Monte Carlo Simulation Methods in Econometrics. Econ. Theory 1996, 12, 409–431. [Google Scholar] [CrossRef] [Green Version]
- Bartholomew, D.J. Stochastic Models for Social Processes; John Wiley & Sons, Ltd.: New York, NY, USA, 1982. [Google Scholar]
- Gani, J. Formulae for projecting enrollments and degrees awarded in universities. J. R. Stat. Soc. Ser. A (Gen.) 1963, 126, 400–409. [Google Scholar] [CrossRef]
- Guerreiro, G.; Mexia, J. An alternative approach to bonus malus. Discuss. Math. Probab. Stat. 2004, 24, 197–213. [Google Scholar] [CrossRef]
- Guerreiro, G.R.; Mexia, J.T.; de Fátima Miguens, M. Statistical approach for open bonus malus. ASTIN Bull. J. IAA 2014, 44, 63–83. [Google Scholar] [CrossRef]
- Guerreiro, G.R.; Mexia, J.T.; Miguens, M.F. Preliminary Results on Confidence Intervals for Open Bonus Malus. In Advances in Regression, Survival Analysis, Extreme Values, Markov Processes and Other Statistical Applications; Springer: Berlin/Heidelberg, Germany, 2013; pp. 223–230. [Google Scholar] [CrossRef] [Green Version]
- Guerreiro, G.; Mexia, J. Stochastic vortices in periodically reclassified populations. Discuss. Math. Probab. Stat. 2008, 28, 209–227. [Google Scholar] [CrossRef] [Green Version]
- Guerreiro, G.; Mexia, J.; Miguens, M. A model for open populations subject to periodical re-classifications. J. Stat. Theory Pract. 2010, 4, 303–321. [Google Scholar] [CrossRef]
- Guerreiro, G.R.; Mexia, J.T.; de Fátima Miguens, M. Stable Distributions for Open Populations Subject to Periodical Reclassifications. J. Stat. Theory Pract. 2012, 6, 621–635. [Google Scholar] [CrossRef]
- Pollard, J. Hierarchical population models with Poisson recruitment. J. Appl. Probab. 1967, 4, 209–213. [Google Scholar] [CrossRef]
- McClean, S.I. Continuous-time stochastic models of a multigrade population. J. Appl. Probab. 1978, 15, 26–37. [Google Scholar] [CrossRef]
- McClean, S.I. A continuous-time population model with Poisson recruitment. J. Appl. Probab. 1976, 13, 348–354. [Google Scholar] [CrossRef]
- Taylor, G.J.; McClean, S.I.; Millard, P.H. Using a continuous-time Markov model with Poisson arrivals to describe the movements of geriatric patients. Appl. Stoch. Models Data Anal. 1998, 14, 165–174. [Google Scholar] [CrossRef]
- Staff, P.; Vagholkar, M. Stationary distributions of open Markov processes in discrete time with application to hospital planning. J. Appl. Probab. 1971, 8, 668–680. [Google Scholar] [CrossRef]
- Vassiliou, P.C. On the limiting behaviour of a non-homogeneous Markovian manpower model with independent Poisson input. J. Appl. Probab. 1982, 19, 433–438. [Google Scholar] [CrossRef]
- Vassiliou, P.C. The evolution of the theory of non-homogeneous Markov systems. Appl. Stoch. Model. Data Anal. 1997, 13, 159–176. [Google Scholar] [CrossRef]
- Pollard, B.S. Open Markov processes: A compositional perspective on non-equilibrium steady states in biology. Entropy 2016, 18, 140. [Google Scholar] [CrossRef] [Green Version]
- Yakasai, B. Stationary population flow of a semi-open Markov Chain. J. Niger. Assoc. Math. Phys. 2005, 9, 395–398. [Google Scholar] [CrossRef]
- Esquível, M.; Guerreiro, G.; Fernandes, J. Open Markov Chain Scheme Models fed by Second Order Stationary and non Stationary Processes. REVSTAT 2017, 15, 277. [Google Scholar]
- Stadje, W. Stationarity of a stochastic population flow model. J. Appl. Probab. 1999, 36, 291–294. [Google Scholar] [CrossRef]
- Esquível, M.L.; Fernandes, J.M.; Guerreiro, G.R. On the evolution and asymptotic analysis of open Markov populations: Application to consumption credit. Stoch. Model. 2014, 30, 365–389. [Google Scholar] [CrossRef]
- Afonso, L.B.; Cardoso, R.M.; Egídio dos Reis, A.D.; Guerreiro, G.R. Ruin Probabilities And Capital Requirement for Open Automobile Portfolios With a Bonus-Malus System Based on Claim Counts. J. Risk Insur. 2020, 87, 501–522. [Google Scholar] [CrossRef]
- de Lourdes Centeno, M.; Manuel Andrade e Silva, J. Bonus systems in an open portfolio. Insur. Math. Econ. 2001, 28, 341–350. [Google Scholar] [CrossRef]
- Mehlmann, A. A note on the limiting behaviour of discrete-time Markovian manpower models with inhomogeneous independent Poisson input. J. Appl. Probab. 1977, 14, 611–613. [Google Scholar] [CrossRef]
- Floriani, E.; Lima, R.; Ourrad, O.; Spinelli, L. Flux through a Markov chain. Chaos Solitons Fractals 2016, 93, 136–146. [Google Scholar] [CrossRef] [Green Version]
- Baez, J.C.; Fong, B.; Pollard, B.S. A compositional framework for Markov processes. J. Math. Phys. 2016, 57, 033301. [Google Scholar] [CrossRef] [Green Version]
- Pollard, B.S.S. Open Markov Processes and Reaction Networks. Ph.D. Thesis, University of California, Riverside, CA, USA, 2017. [Google Scholar]
- Katok, A.; Hasselblatt, B. Introduction to the Modern Theory of Dynamical Systems; Cambridge University Press: Cambridge, UK, 1997; Volume 54. [Google Scholar]






Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Salgado-García, R. Open Markov Chains: Cumulant Dynamics, Fluctuations and Correlations. Entropy 2021, 23, 256. https://doi.org/10.3390/e23020256
Salgado-García R. Open Markov Chains: Cumulant Dynamics, Fluctuations and Correlations. Entropy. 2021; 23(2):256. https://doi.org/10.3390/e23020256
Chicago/Turabian StyleSalgado-García, Raúl. 2021. "Open Markov Chains: Cumulant Dynamics, Fluctuations and Correlations" Entropy 23, no. 2: 256. https://doi.org/10.3390/e23020256
APA StyleSalgado-García, R. (2021). Open Markov Chains: Cumulant Dynamics, Fluctuations and Correlations. Entropy, 23(2), 256. https://doi.org/10.3390/e23020256