1. Introduction
Rolling bearings are common connecting and fixing parts in rotating machinery, which have the advantages of high running precision, good substitutability, low price and scale production [
1]. However, due to the influence of alternating load, machining error, improper installation and other factors, the rolling bearing will be damaged during the working process. The rotating machine will not work properly, and a catastrophic accident may even occur [
2]. Furthermore, the vibration signals of the rolling bearings are usually nonlinear and non-stationary with the existence of various nonlinear factors (such as material strength and skid friction), and early faults are always submerged by strong background noise, which could increase the difficulty of fault diagnosis [
3]. Therefore, it has become an urgent problem to find effective methods of rolling bearing early fault feature extraction and pattern recognition. In recent years, the fault diagnosis method based on machine learning has attracted much attention in the field of rolling bearing early fault diagnosis. These methods mainly include three steps: feature extraction, descent and pattern recognition [
4,
5]. With the development of nonlinear technology, many nonlinear dynamic methods based on statistical parameter estimation have been applied to extract fault features [
6,
7,
8,
9]. The most popular technique are correlation dimension and entropy-based measurement. Nevertheless, reliable estimation of correlation dimensions requires a long-term time series, which brings great limitations to the analysis of short-term vibration signals. Entropy-based measures include sample entropy, fuzzy entropy, permutation entropy, etc. The initial entropy-based measurement only completes a single-scale analysis, which typically assigns the highest value to highly unpredictable random signals rather than structurally complex signals. Hence, the single-scale entropy metric could not physically quantify the complexity of the time series [
10]. Costa et al. proposed multi-scale entropy (MSE) algorithm in [
10,
11] and applied it to rolling bearing fault diagnosis for the first time in [
12]. According to the MSE algorithm, the original time series is initially divided into non-overlapping segments with a length of (called proportional factor). Next, the time series of coarse granularity is obtained by calculating the average value of each fragment. Finally, the sample entropy of coarse-grained time series at each scale is calculated. The application of mean square error in feature extraction of mechanical vibration signal is also successful. The mean square error and adaptive neuro fuzzy inference is employed to detect rolling bearing faults and determine their severity [
13]. Hsieh et al. utilized the mean square error curve to identify some characteristic defect of the high-speed spindle [
14]. The traditional MSE algorithms will shorten the data set and produce uncertain short-term data values when large scale factors are utilized. To make up for these shortcomings, Wu et al. proposed an improved multi-scale entropy to obtain more template vectors [
15]. However, the improved multiscale algorithm greatly increases the computation time. Later, composite multiscale sample entropy (CMSE) [
16] and refined composite multi-scale sample entropy (RCMSE) [
17] are developed for novel coarse-grained processes. Wang et al. proposed a modified multiscale weighted permutation entropy for rolling bearing fault diagnosis [
18].
It is necessary to employ a classifier when performing pattern recognition in a low-dimensional feature set. Many classifiers have been proposed and applied to the fault detection process in rotating machinery, such as expert system [
19], artificial neural network [
20], and fuzzy logic classifier [
21]. However, these classifiers have some drawbacks (e.g., local optimal solution, low convergence rate and significant overfitting). The above contents limit their application in pattern recognition rolling bearing fault detection. Probabilistic neural network (PNN) is a supervised neural network that is commonly used in pattern recognition [
22]. Because of its parallel distributed processing, self-learning and self-organization, the PNN model has good application potential in fault diagnosis. Compared with traditional neural network learning methods, the PNN model learning process mainly employs Parzen nonparametric probability density function estimation [
23] and Bayes classification rules [
24]. The PNN model will converge to a Bayes classifier if there are enough training samples.
Machine learning is a growing field that attempts to extract knowledge from data sets. It is usually in the form of algorithms that predict results. The tasks of machine learning include classification, regression, clustering, time series prediction and so on. In the classification task, the ideal prediction result is the class of each instance in the dataset. In general, the classifier goes through at least two stages: training and validation. The coyote optimization algorithm (COA), which was introduced by Pierezan and Coelho, is mainly inspired by the coyotes living in North America [
25]. The COA finds a solution to the optimization problem by learning from the social organization of coyotes and their adaptation to the environment. The COA is a population-based algorithm divided into population intelligence and evolutionary heuristics. Furthermore, it has different algorithmic structures that focus on social structures and coyote-communicated experiences rather than just catching prey, similar to other AI algorithms such as grey wolf optimizer [
26]. In [
25], it suggests that intrinsic factors (gender, social status, and populations to which coyotes belong) and extrinsic factors (e.g., snow depth, snow hardness, temperature, and cadaver biomass) influence coyote activity. Hence, the COA mechanism is designed according to the social conditions of coyotes, which means the decision variables of the global optimization problem. From an optimization perspective, each coyote corresponds to a feasible solution. The quality of each coyote’s social conditions the result of the application of the objective function in the social condition. The optimal social condition is the global solution of the problem.
In contrast to existing researches, a rolling bearing early fault diagnosis model based on complete ensemble intrinsic time-scale decomposition with adaptive noise (CEITDAN), refined composite multi-scale approximate entropy (RCMAE) and improved coyote optimization algorithm based probabilistic neural network (ICOA-PNN) is proposed in this paper. The RCMAE proposed in the paper could reduce the possibility of inducing uncertain entropy and is well suitable for bearing early fault diagnosis. In the improved coyote optimization algorithm, we employed a differential evolution algorithm instead of the traditional greedy iterative algorithm and utilized the dynamic adjustment of the coyote method to optimize the process of coyote removal and acceptance, which improves the optimization effect of coyote optimization algorithm. The model consists of three steps (feature extraction, descent and pattern recognition). Firstly, the original signal is decomposed by CEITDAN, and the RCMAE, approximate period and approximate energy are calculated and constructed to construct the original three-dimensional collection. Finally, this three-dimensional collection automatically identifies fault types as input for ICOA-PNN machine learning. The fault diagnosis experiment of the rolling bearing shows that the proposed method has a higher recognition accuracy for bearing conditions under various working conditions.
The structure of the paper is as follows:
Section 2 introduces the principle of CEITDAN algorithm.
Section 3 introduces the RCMAE, approximate period and approximate energy, and verifies the effectiveness of the algorithm by noise signal analysis experiment. In
Section 4 and
Section 5, a new fault diagnosis method of rolling bearing is proposed.
Section 6 gives the experimental evaluation. We conclude in
Section 7.
2. CEITDAN—Based Signal Decomposition
In order to pre-process the noisy signal, this article uses the CEITDAN method to decompose the signal [
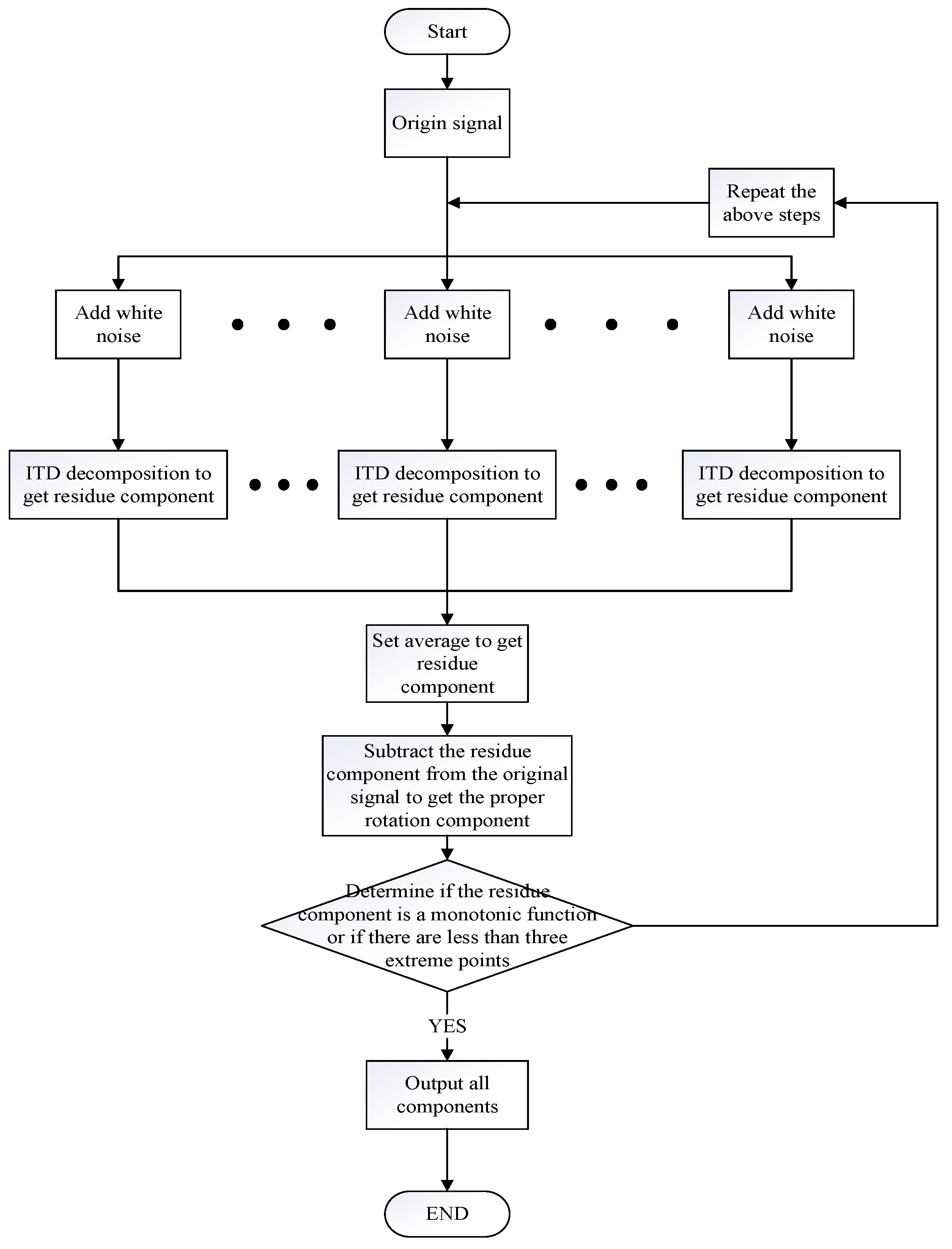
27]. The residual component is obtained, white noise is added to the residual component, and the same operation is performed, until the residual component is a monotonic function or the extreme points are less than three. The proper rotation component can accurately define the instantaneous information of the signal and is repeated several times in this manner.
The core idea of CEITDAN method denoising is that by adding a group of white noise to the original signal, the added white noise can be adaptively decomposed together with the noise part of the original signal during the decomposition process. Firstly, proper rotation components (PRCs) of white noise preprocessed by intrinsic time-scale decomposition (ITD) are added in different decomposition stages. This process can help ITD to establish a global scale reference. Then, ITD is used to decompose the noise-added input signal into a PRC and a residual. Theoretically, according to the filter structure of ITD, most of the added noise and the signal components approximately proportional to the added noise are extracted into PRCs. Therefore, there is almost no added noise in the residual component. CEITDAN calculates the final PRC as the difference between the signal to be decomposed and the average value of the residual obtained by decomposition. Therefore, compared with ITD and complete ensemble empirical mode decomposition with adaptive noise (CEEMDAN), PRC extracted by CEITDAN has a more appropriate scale and contains less residual noise. In addition, due to the pretreatment of ITD, the increased noise does not include the local average. This can reduce the number of filtering iterations in each stage.
Step 1. First round of noise addition:
is the first order proper rotation component decomposed by ITD which from white noise with a certain SNR, where
is the number of noise additions, is superimposed onto the original signal
. As the average value is used as the residue component of the method, then, the first-order component of the origin signal is obtained as follows:
is the corresponding order of ITD decomposition white noise.
is used as
and
the noise-adding amplitude coefficient,
represents the residue component obtained by ITD decomposing signal
.
is the signal with white noise. The proper component at this time are as follows:
Step 2. Second round of noise addition: The second-order PR components of white noise
are superimposed onto
, and the first-order component of the mixed signal are obtained by ITD decomposition. The average is used as the second residue component of this method’s residue component, as follows:
The second-order proper component obtained at this time are as follows:
Step 3.
-th round of noise addition: The
-th -order PR components of white noise
are superimposed onto the remaining terms
. Then, the first-order component of the signal with adaptive white noise is obtained by ITD decomposition, and the average value is taken as the
-order residue component of the method, as follows:
The remaining items obtained at this time are as follows:
Step 4. Repeat steps 1–3 several times until the residual component is a monotonic function or the number of extreme points in this residual component is fewer than three. The final remaining term is as follows:
At this point, the entire CEITDAN decomposition process ends.
The final shifted terms are as follows:
Equation (8) elucidates the original signal as the sum of a series of PR components and the remainder; thus, it completes the CEITDAN method. The error of reconstructing the original signal by its decomposition result is theoretically zero.
The decomposition steps of the proposed method are shown in
Figure 1.
4. ICOA-PNN Pattern Recognition
In order to realize the intelligent fault diagnosis of rolling bearing, it is necessary to utilize classifier to identify the fault type. PNN classifier based on Bayesian strategy has good computational power and does not require backpropagation optimization parameters and training weights. It is applied to rolling bearing pattern recognition in this paper. There is an important parameter (i.e., the smoothing factor ) that needs to be preset first before using the PNN. The smoothing factor greatly affects the recognition ability of probabilistic neural network models. Clearly, these two parameters have a great influence on PNN final pattern recognition results. To improve the PNN’s fault recognition ability, this section proposes an ICOA-PNN algorithm that uses the ICOA algorithm to determine the best parameters.
4.1. Coyote Optimization Algorithm
The COA, proposed by Pierezan et al. in 2018, is a new intelligent optimization algorithm that could simulate coyote social life, growth, death, group expulsion and acceptance [
25]. COA divides the population into several subgroups through random grouping. It can be found that COA could achieve better optimization results in benchmark function optimization. By determining the coyote of the sub-group and cultural trends and randomly selecting two coyotes, these four factors will affect the growth of the coyotes, and we can then adjust the growth process based on the social adaptability of the coyotes. The birth of coyotes is affected by two randomly selected fathers and environmental variation. In terms of social adaptability, if the newborn coyote is better than the old and incompetent coyote, the old coyote dies; otherwise, the newborn coyote dies. Among the subgroups, according to a certain probability, some coyotes will be driven away by the group and accepted by other groups, thus changing the grouping state of the coyotes. Through the continuous evolution of the process of growth, death, expulsion, and acceptance, the coyote which is the most suitable for the social environment is obtained as the best solution to the optimization problem.
In COA, each coyote represents a candidate solution, and each solution vector is composed of coyote social state factors. These state factors include coyote internal and external factors, each state factor represents a decision variable, state factors constitute a solution vector with decision variables, and each coyote is measured by social adaptability. The COA is mainly divided into four stages: the random initialization and random grouping of suburban wolves, the growth of coyotes in the group, the life and death of the coyotes, and the group expulsion and acceptance of the coyotes.
- (1)
Initialize and group randomly.
Here, we set parameters such as the number of suburban wolves
, the number of suburban wolves in the group
, and the maximum number of iterations
. The initial social state factors of each coyote are set immediately because COA is a random algorithm, as shown in Formula (24). The social adaptability of brown coyotes was calculated and randomly divided into groups:
where
and
denote the lower and upper bounds, respectively, of the
state factor of the coyotes;
; and
is a random number with uniform distribution in
.
- (2)
The growth of coyotes in the group. Here, we determine the optimal coyote
in the group, calculate the cultural trends of the group, randomly select two coyotes, and affect the growth of coyotes using these four factors. The calculation of the cultural trends of the group is shown in Formula (25):
where
is a matrix with
rows and
rows and columns, which represents
solution vectors;
represents the
column of matrix
; and
represents the median. In the process of coyote growth, we first calculate the difference
between the best coyote
in the group and one randomly selected coyote in the group, along with the cultural trend between the group and the other random coyote in group
, as shown in Formula (26). Then, the coyotes in the group grow under the influence of
and
, as shown in Formula (27):
where
and
represent two different random coyote markers, and
represents the best coyote
coyote in the group:
where
and
are random weights of
and
, respectively;
and
are random numbers with uniform distribution in
. After each coyote in the group grows, the algorithm calculates the social adaptability and adopts greedy selection, as shown in Formula (28). By retaining the high-quality coyotes to participate in the growth of the other coyotes in the group, the convergence speed of the algorithm is accelerated:
- (3)
Life and death of coyotes. Two important evolution processes in nature are birth and death. In COA, the ages of the coyotes are measured in years. After each group of coyotes grows, a newborn coyote is born. The births and deaths of the coyotes are shown in Algorithm 1. The birth of new coyotes is influenced by the social conditions and social environments of two randomly selected parents. Newborn coyotes are produced in the manner shown in Formula (29):
where
and
are two randomly different coyotes in group
;
and
are two random dimensions of newborn coyotes;
is the dispersion probability; and
is the association probability, as shown in formula (30). Here, scattered association probability affects the diversity of newborn coyotes;
is the random number of the
dimension of the decision variable; and
is the random number with uniform distribution on
,as shown in Algorithm 1:
- (4)
Coyotes are driven away and accepted. At first, the coyotes are randomly assigned to each group, but some of the coyotes leave and join other groups. The probability of coyotes being expelled and accepted by the group is expressed by
, as shown in Formula (31). This mechanism facilitates the exchange of information among COA groups and promotes the interactions between coyotes among species:
| Algorithm 1. birth and death of coyotes |
| Start |
| Calculate and |
| If |
| Then, the newborn coyote survives, the only coyote in dies, and the age of the superior coyote is 0. |
| If |
| The newborn coyote survived, the oldest coyote with the worst social adaptability in died, and the age of the excellent coyote was 0 |
| Otherwise |
| The newborn coyote died |
| End |
After initialization and random grouping, the growth of coyotes, the life and death of coyotes, and the expulsion and acceptance of coyotes are carried out successively. If the iteration termination condition is reached, the optimal coyote is output; otherwise, jump to (3).
As can be seen from the above steps, COA has the following advantages: (a) COA has a better search model and framework. Coyotes are randomly divided into several sub-groups, and cultural communication is carried out through expulsion and acceptance after all groups of coyotes grow. Compared with algorithms such as PSO, this search model and framework has stronger exploration ability. (b) COA guides the growth of coyotes through wolves and cultural trends. This algorithm has strong local search ability. (c) COA. The generation of newborn coyotes emerges from the joint action of two randomly selected parents, the coyotes, and random mutations in the social environment, so the algorithm has certain global search ability. (d) The COA updates each coyote in the group. Compared with the particle swarm optimization (PSO) with a similar structure, the update method for COA is simple. (e) The COA was randomly grouped after initialization, and the coyotes in the group were randomly expelled and accepted, allowing the information between the groups to be exchanged.
COA shows strong optimization ability in the process of solving optimization problems. However, COA is a recent algorithm and needs to be improved and perfected. For example, there are the following problems in solving complex optimization problems: (a) The growth process of coyotes in COA affects the growth of coyotes by calculating the differences between the intra-group coyote and the cultural trends and random selection of two coyotes in the group; moreover, the convergence speed of the algorithm is slow. (b) When guided by the intra-group coyote and group culture trend, the intra-group coyote and group culture trends may be the local optimal solution, leading to the local optimal of the algorithm. (c) The COA using the dynamic greedy algorithm accelerates the convergence speed to a certain extent but increases the probability of falling into the local optimal.
4.2. Probabilistic Neural Network (PNN)
The PNN algorithm belongs to a supervised learning pattern recognition algorithm in the field of machine learning. The PNN algorithm principle is mainly based on Bayesian minimum risk decision theory and artificial neural network (ANN) model. The probability density of sample population distribution is calculated by Parzen window estimation method to achieve the purpose of pattern classification. The learning process could be summarized as follows.
- (1)
The feature matrix of learning samples is normalized first and the number of training samples for each fault is set as
. The feature vector dimension of each sample is
and the input feature matrix is recorded as
.
Calculate the module of each eigenvector in the input matrix and the matrix
is obtained.
Combine with (32) and (33), the normalized matrix C is obtained.
- (2)
The normalized sample data is input into the mode layer of probabilistic neural network. Assuming that the input sample matrix to be identified is
, the normalized matrix is such as Formula (34). Calculate the Euclidean distance between the sample matrix
and the training sample
. The operation process is as (35) and (36).
- (3)
Utilizing the radial basis function as the activation function. The normalized sample to be identified and the training sample are activated to obtain the initial probability matrix
.
- (4)
After the above steps, the output value of the mode layer is calculated. According to (37), the initial probability sum of which fault type belongs to the identified sample in the probabilistic neural network is calculated. The number of fault types representing the training samples, each of which is
.
- (5)
According to the sum of the initial probability, a maximum probability of the -th sample to be identified to class could be calculated. PNN is a classification network model which employs training samples to calculate the maximum estimated probability. For probabilistic neural networks, when the training sample is known, that is, the number of neurons in the pattern layer is determined, once the smoothing factor is determined, the parameters and structure of the PNN network are also determined. Therefore, improving the ability of probabilistic neural network fault identification could optimize the parameters of the smoothing factor of the PNN network.
4.3. Improved Coyote Optimization Algorithm Based on Probabilistic Neural Network (ICOA-PNN)
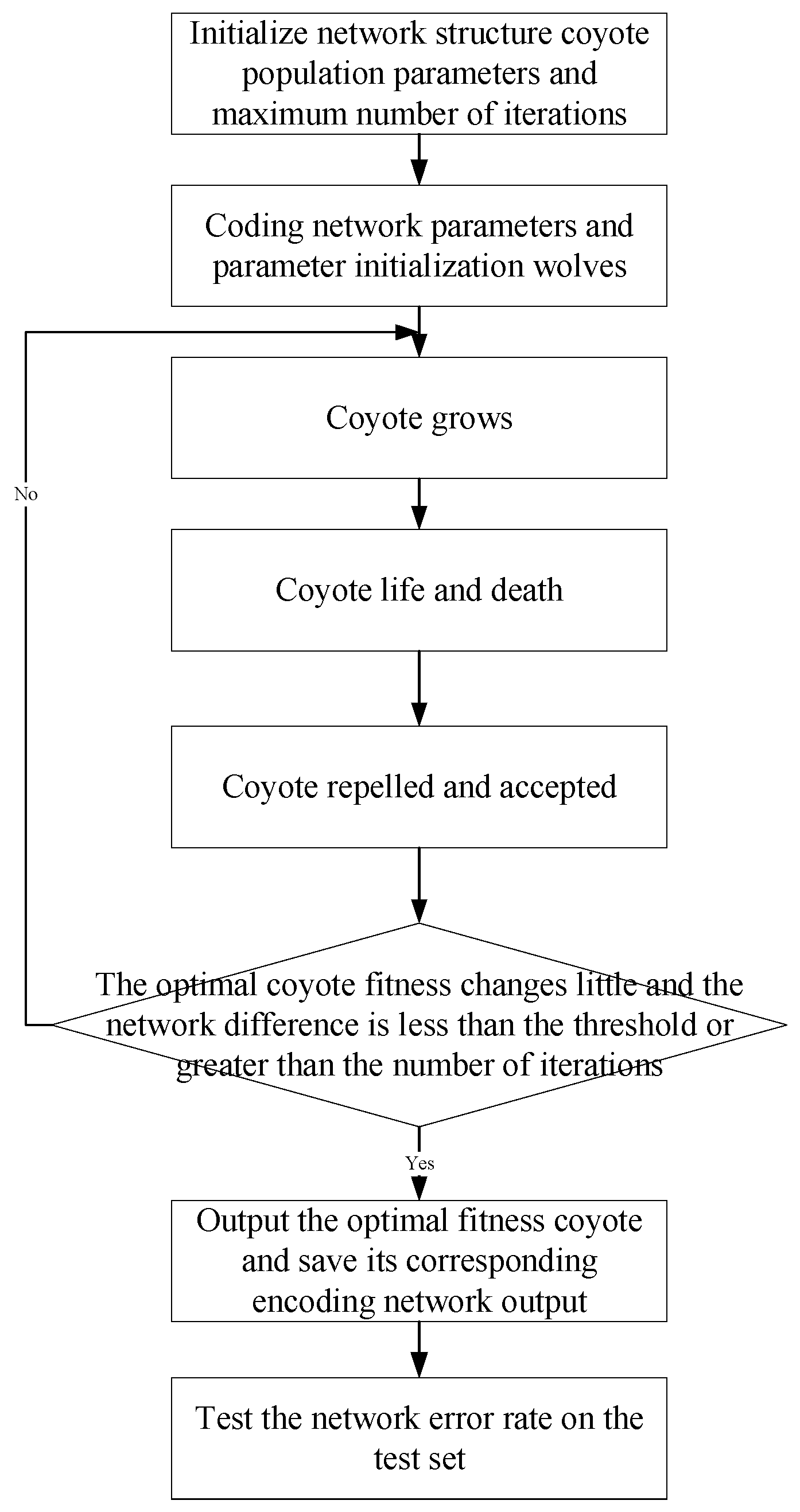
In order to avoid the greedy algorithm from falling into the local optimal solution, the improved method proposed in this paper optimizes the iterative greedy algorithm in the growth of the coyotes in the group in the traditional coyote optimization algorithm for the survival of the fittest and the coyote’s life and death two parts, using differential evolution algorithm Substitute. In order to improve the operability of the traditional coyote optimization algorithm, this paper uses the dynamic adjustment of the coyote within the group to replace the coyote in the traditional coyote optimization algorithm. The ICOA consists of two steps: parameter initialization, coyote swarm and coyote growth.
Step 1: Set parameter initialization and random initialization of coyote groups. Set parameters, such as coyote group size
, coyote group number
, the coyotes’ number in each group
and
, where
. Then initialize the coyote group randomly. The randomization operation of
-th dimension of
-th coyote in
-th group is described below. Finally, the social fitness value
of each coyote
is calculated, see another formula.
where
and
represent the lower and upper bound of the coyotes’
-th dimensional social state factor.
.
is search space dimension.
is a random number uniformly distributed in
.
is adaptation function.
Step 2: Effects of the optimal coyote
, group culture trends
and two randomly selected coyotes
,
on coyotes growth. That is, the growth of coyotes in the group is affected by
and
. Equation (41) is the calculation of
. The median of all coyotes corresponding to social factors in each factor group (the sequence of social factors after ranking), so
is also called the median coyote. Equation (42) is the calculation of
and
. Equation (43) is the growth of coyotes.
is the current global optimal coyote, which representing the difference between a randomly selected coyote (
) and
in the group.
and
are random numbers generated by a Gaussian (normal) distribution with 0 mean variance.
represents new solutions generated by the growth of each coyote within the group under the combined action of
and
.
Then the differential evolution is employed to recombine the population evolution according to the differences between individuals to obtain a competitive intermediate population. The offspring and fathers obtain the next generation population through competition and are more competitive. The difference method is as follows:
Step 1: Variation. Select two different individuals
and
. Combining them with
, the individuals to be mutated after the difference scaling.
where
is the current number of iterations.
is the mutation operator in
.
,
,
are random integers in
that are not equal to each other and are not
.
is population size.
Step 2: Cross-cutting. Determining the mutation gene is provided by
or
by comparing the crossover operator with the random number. The crossover process is as follows.
where
is a cross operator in
.
is a random number in
.
Step 3: Selection. The competition between the middle individual
and
is obtained by mutation and cross operation. If the parent is superior to the newly acquired offspring, the parent is retained to the next generation, otherwise the offspring is retained to the next generation. The individual selection of coyotes is shown in (46).
The COA has multiple parameters to be adjusted, which is not easy to operate. Among the improved COA, there are two main parameters,
and
, which have great influence on the optimization performance. When N is fixed,
if
is certain. That is, the bigger the
, the smaller the
and growth operations, while the effect of global solution is enhanced group by group, and mining is strong. In order to improve the operability of the COA, the parameters
and
are dynamically adjusted in this paper. Set
, then
and
should be the factor of 100. According to [
25], the number of wolves in each group could not exceed 14, so
could only be 4,5 and 10. Considering that it takes at least three coyotes to grow, including two randomly selected coyotes and the best coyotes in the group,
. When
, the optional coyote range is limited, so the most likely values of
are 5 and 10. The dynamic adjustment parameter scheme is shown in Algorithm 2. The pseudo-code for dynamically adjusting parameters
and
is as follow.
| Algorithm 2. Dynamically adjust parameters |
| 1. IF in later period of searching |
| 2. |
| 3. ELSE in early period of searching |
| 4. |
| 5. END IF |
| 6. and random grouping |
During the later period of searching, , then The number of groups enhances the positive feedback of the global solution and the local search ability is enhanced. During the early period of searching, the number of groups is small, the positive feedback of global solution is weakened, and the global search ability is enhanced. The dynamic adjustment of coyote numbers’ parameters in the inner suburb of the group not only improves the maneuverability, but also could better balance the exploration and mining ability. In addition, random grouping after dynamic adjustment of parameters could save the coyote group removal and acceptance process, and there is no need to adjust , which could improve the operability.
As above, a new ICOA-PNN classifier is designed in the paper in view of the advantages of the improved coyote optimization algorithm and PNN. Since both the COA algorithm and the PNN algorithm have good robustness [
22,
25], the ICOA algorithm proposed in this paper simplifies the process of the COA algorithm without changing its robustness, so the ICOA-PNN method proposed in this paper inherits the above two methods. The advantages of strong robustness also have better robustness. The description is as follows.
- (1)
Data preprocessing. Data sets are divided into training sets and test sets. The training set and the test set are normalized to . Employing the following formula: , where and represent the original and normalized feature sets respectively. The and represent the maximum and minimum eigenvalues respectively.
- (2)
Initialize the number of coyotes to 100. The maximum number of iterations is 1000. Coyote parameters are selected as random numbers between .
- (3)
Calculate the fitness value of each coyote. To evaluate the quality of each coyote, the average error recognition rate of the training sample is defined as fitness function. This average error recognition rate is achieved by following the triple cross validation process. Given the factors, the PNN parameter optimization problem is formulated as the problem of minimizing fitness functions.
- (4)
Select the adaptive optimal suburban coyote in the current iteration and consider its location as the current target location .
- (5)
Normalize the distance between coyotes to . The location of each coyote is updated in each iteration. Update the fitness values for each coyote according to Formula (40). If the updated coyote fitness value is better than the target, the updated coyote will replace the previous coyote. Otherwise, the previous coyotes continue to update.
- (6)
Determine whether the iterative stop condition is satisfied. If the maximum number of iterations is reached, the loop will terminate and the best target position is the output. Otherwise, the algorithm returns to step (2) until the iterative stop condition is satisfied.
- (7)
Establish the best PNN prediction model by and then identify the test data set.
The flowchart of ICOA-PNN is shown in
Figure 5.
6. Experimental Research
Case I: CWRU database fault diagnosis
To test the ICOA-PNN performance of the classifier, the experimental data of the rolling bearings are extracted from the CWRU database (see
Table 1 for a specific description). The complete experimental platform is shown in
Figure 7. The bearing parameters are shown in
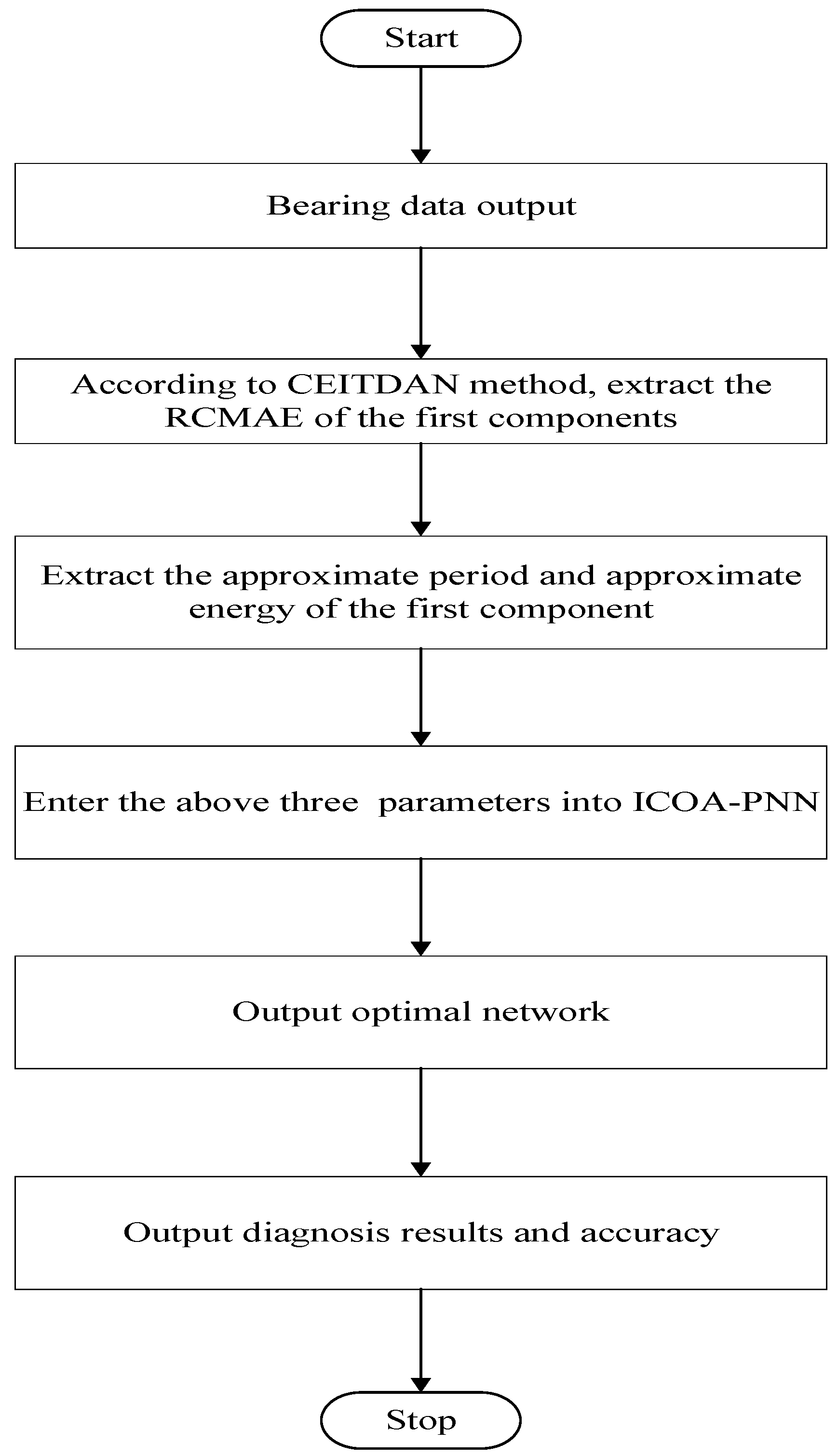
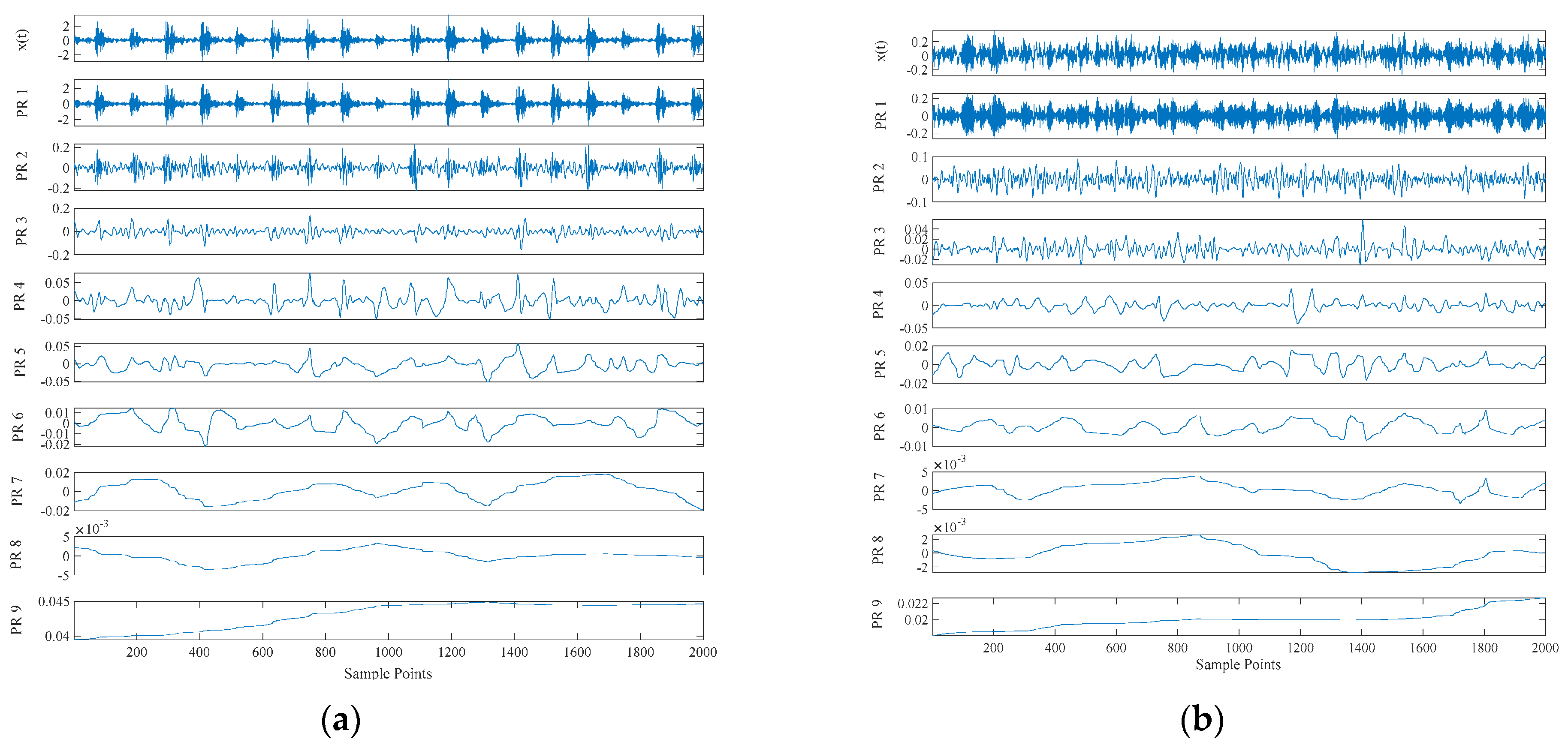
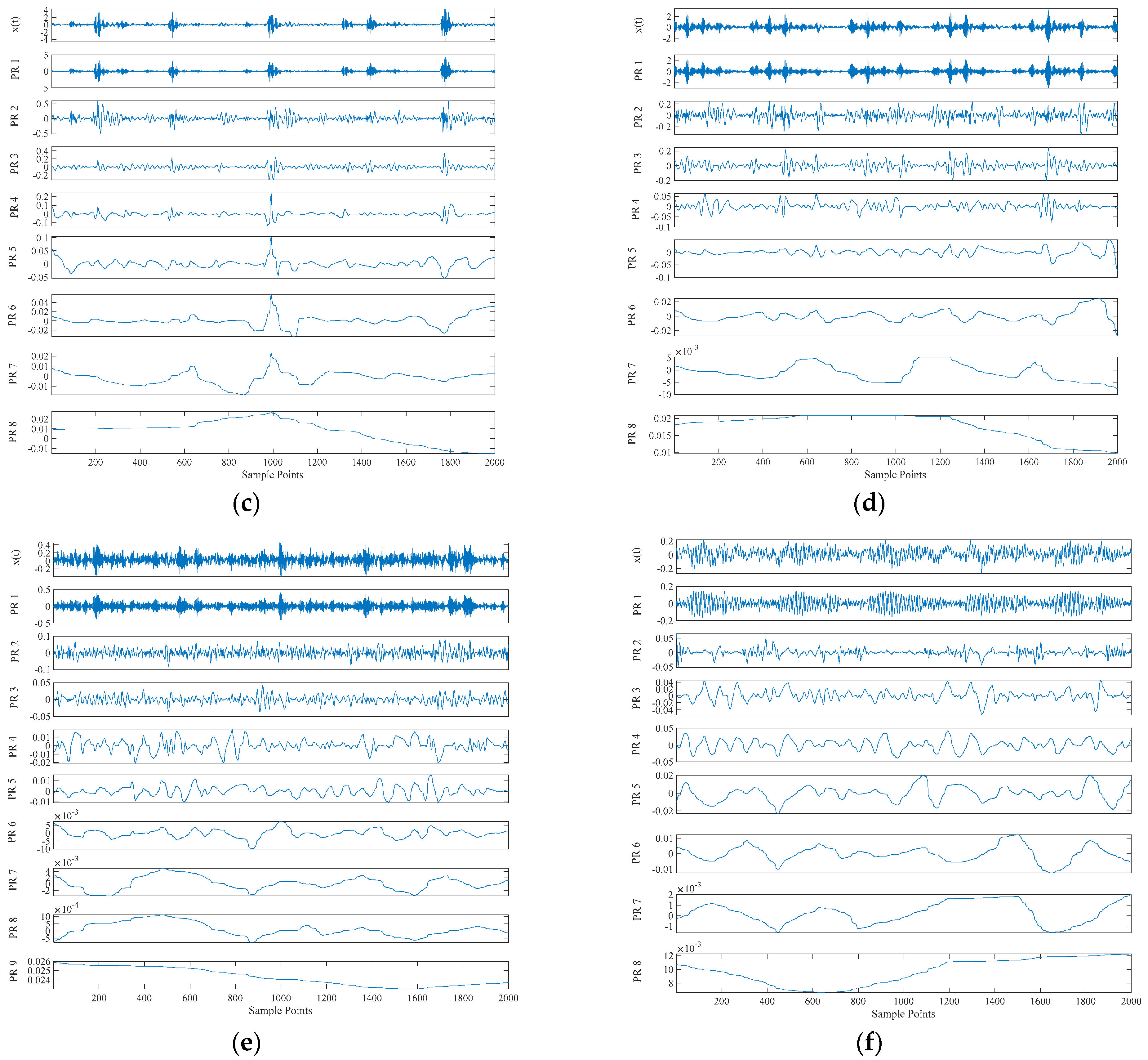
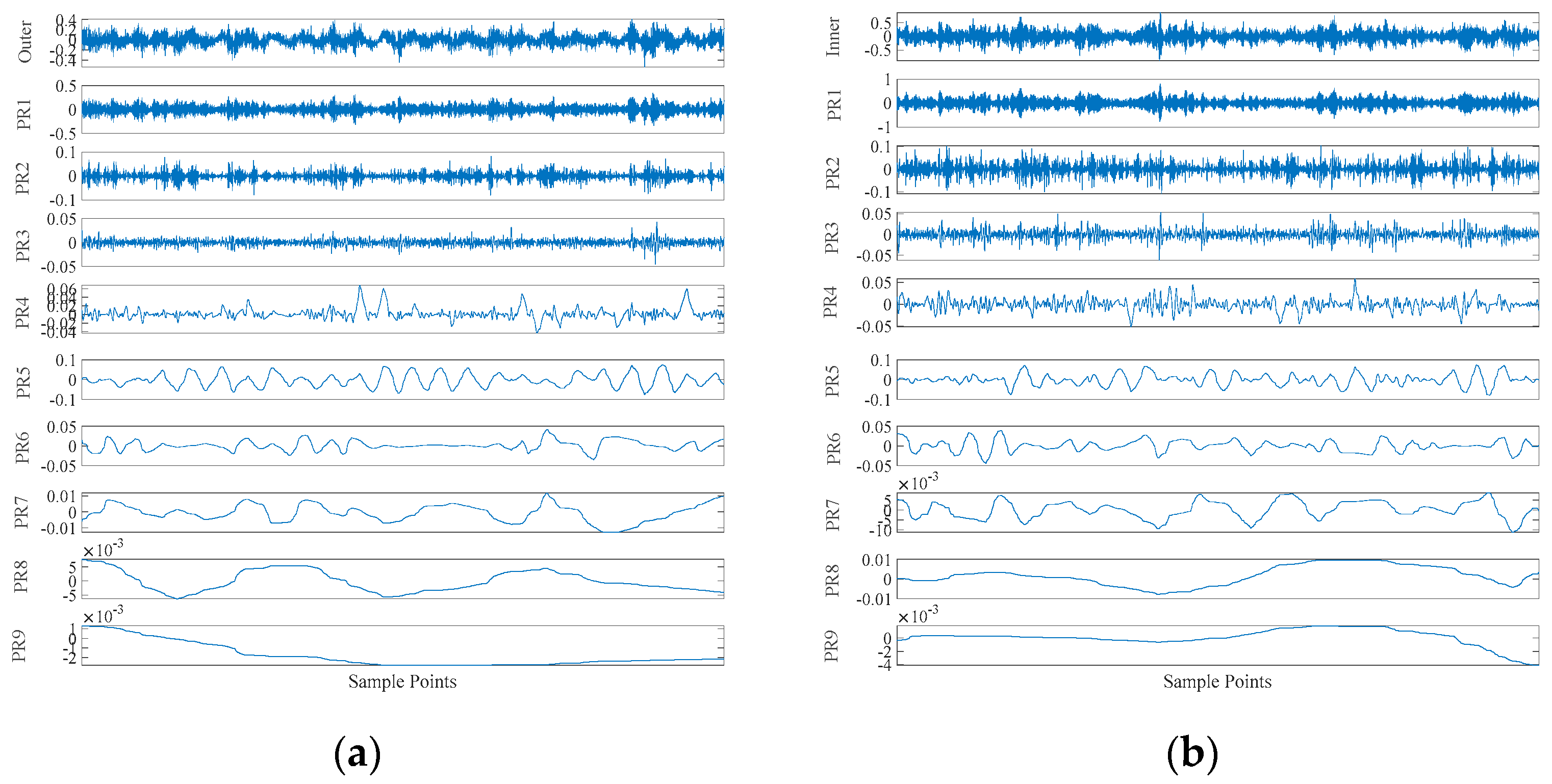
Table 2. In this experiment, operating conditions of the speed system set to 1797 rpm/min and the sampling frequency is set to 12 K. Firstly, decompose signals by CEITDAN. The first component contains the most important information about vibration. These abnormal faults will cause the sampling data of the system to deviate from the normal noise. The energy of abnormal vibration is also mainly reflected in the main component of the signal.
Each component’s signature features include RCMAE values, vibration period and vibration energy. We choose the approximate energy (i.e., the energy of the abnormal signal) and approximate period (i.e., the frequency of occurrence of the abnormal signal) of the RCMAE value of the first PRC in the CEITDAN decomposition result. For the purpose of verifying the superiority of the proposed optimization PNN method and feature parameter selection, they are compared with PNN, particle swarm optimization based probabilistic neural network (PSO-PNN), firefly algorithm based probabilistic neural network (FA-PNN), chicken swarm optimization based probabilistic neural network (CSO-PNN) and grey wolf optimization based probabilistic neural network (GWO-PNN) respectively.
Figure 8 shows the time domain waveforms of six working conditions of rolling bearings. Apparently, it is not easy to distinguish the working state of rolling bearing based on time domain waveform. Given the factors, the proposed method is applied to the fault diagnosis process.
The PNN used in this paper is divided into five layers, and the number of feature input layers is 3. The output classification results are 4 categories: normal, inner ring fault, outer ring fault, rolling body fault. The maximum number of iterations of the coyote algorithm is 1000 and the coyote population is 100. It is randomly divided into 10 groups and the parameters are initialized to random numbers between . In order to verify the superiority of the method proposed in the paper, two kinds of classification are carried out. Firstly, three different outer ring fault sizes are classified, and then the different fault locations and normal states are classified.
In addition, according to
Figure 9, the following results can be obtained.
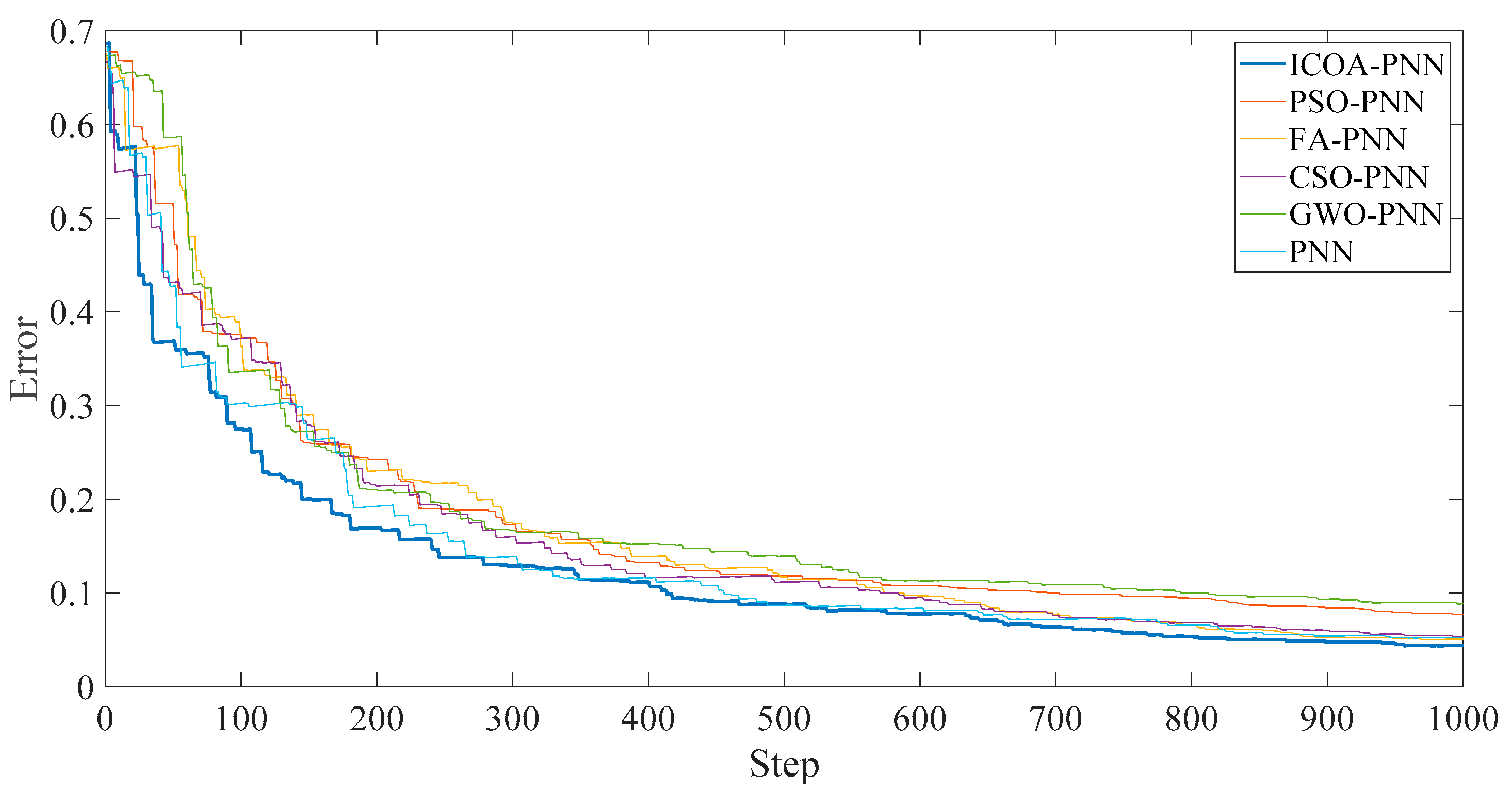
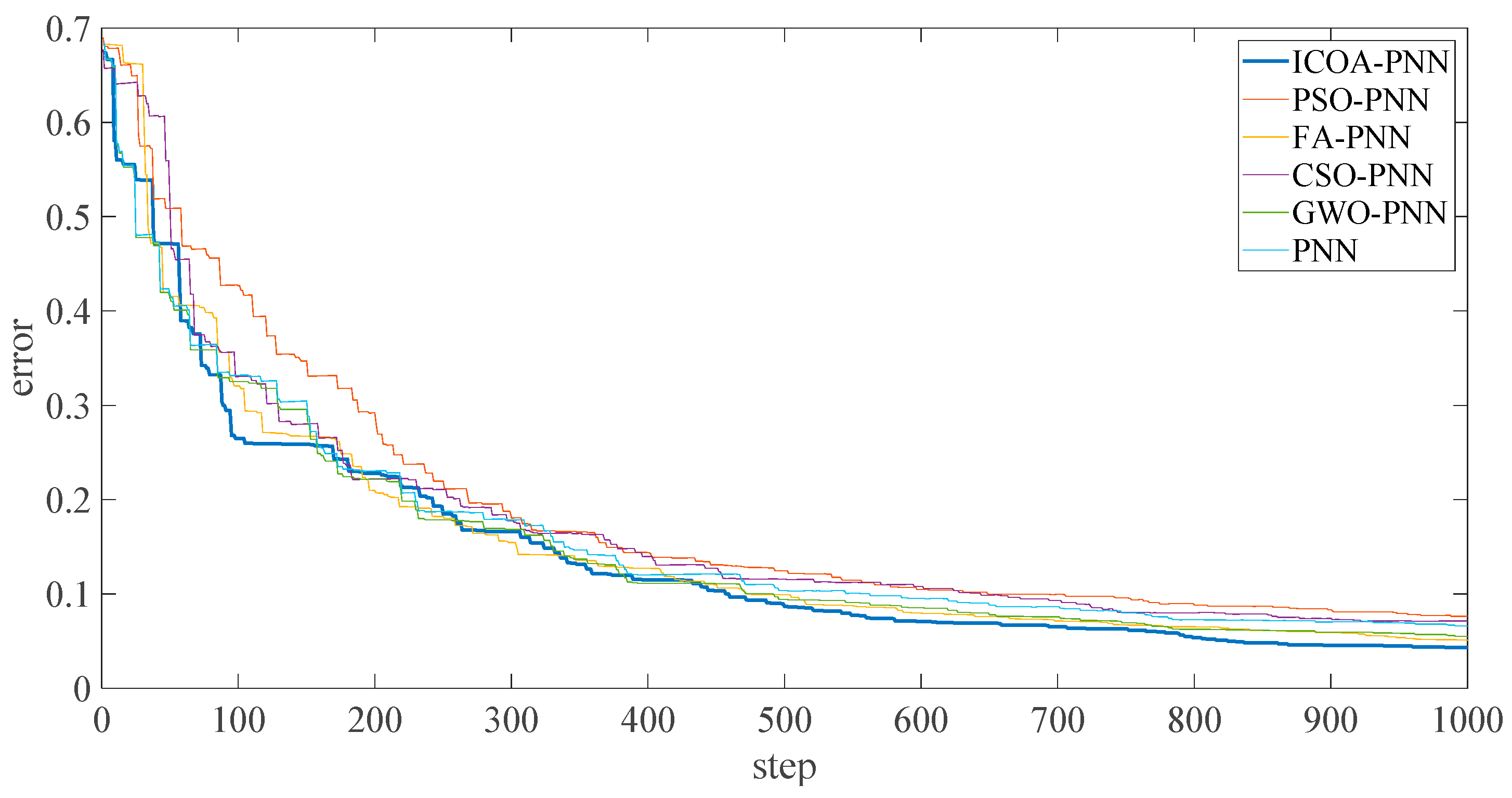
Figure 10 shows that the final average fitness value (i.e., average error recognition rate) of ICOA-PNN classifiers under three different outer ring fault sizes is significantly lower than that of other optimized PNN classifiers. It confirms the effectiveness and feasibility of the proposed algorithm for PNN parameter optimization. Firstly, the average recognition accuracy of the PNN classifier based on optimization is significantly higher than that of the original PNN classifier, which indicates that the PNN classifier based on optimization could overcome the problem of parameter selection of the original PNN classifier. Secondly, compared with other PNN classifiers based on optimization, ICOA-PNN classifier has the highest average recognition accuracy for test samples, which verifies its superiority over other PNN classifiers based on optimization.
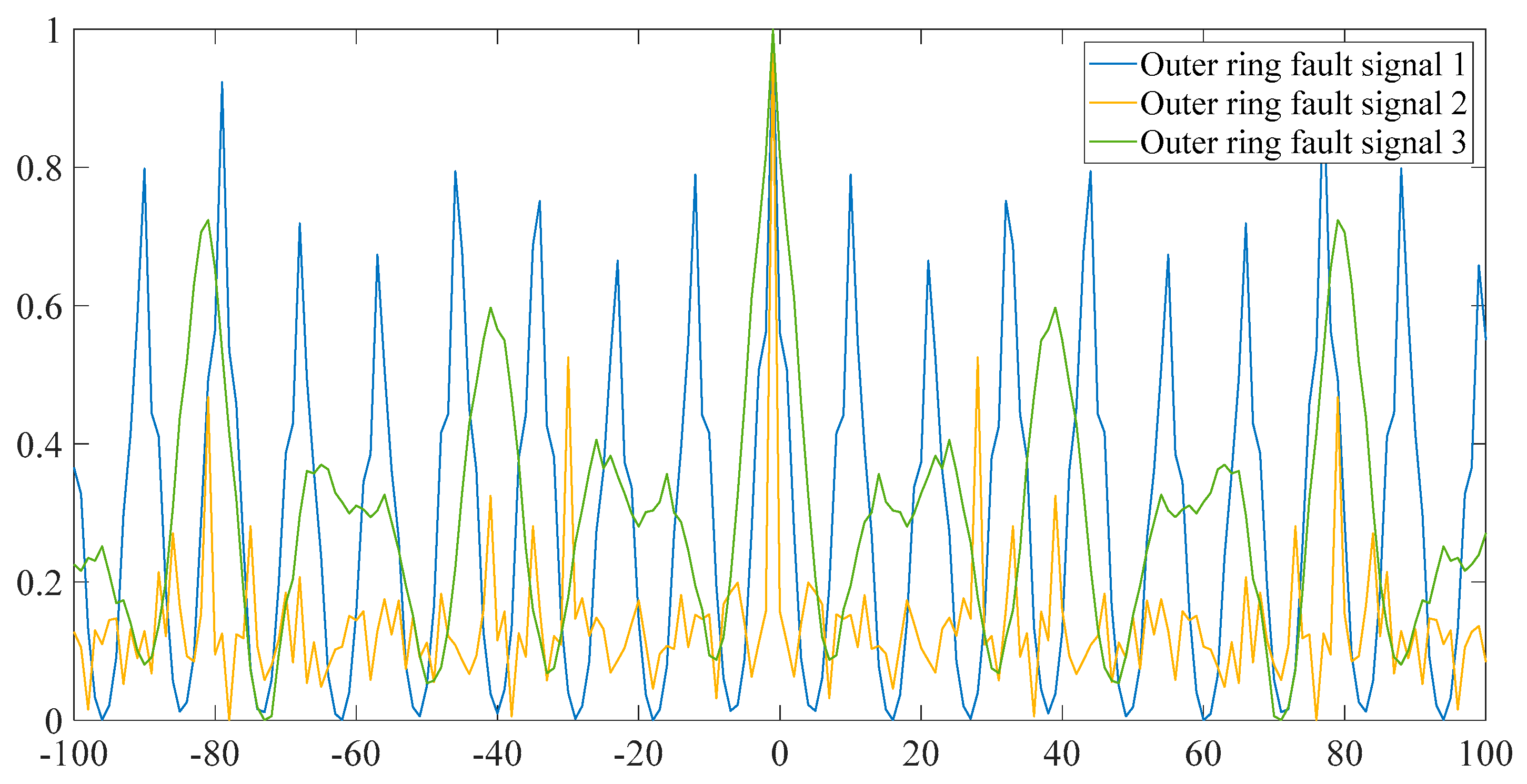
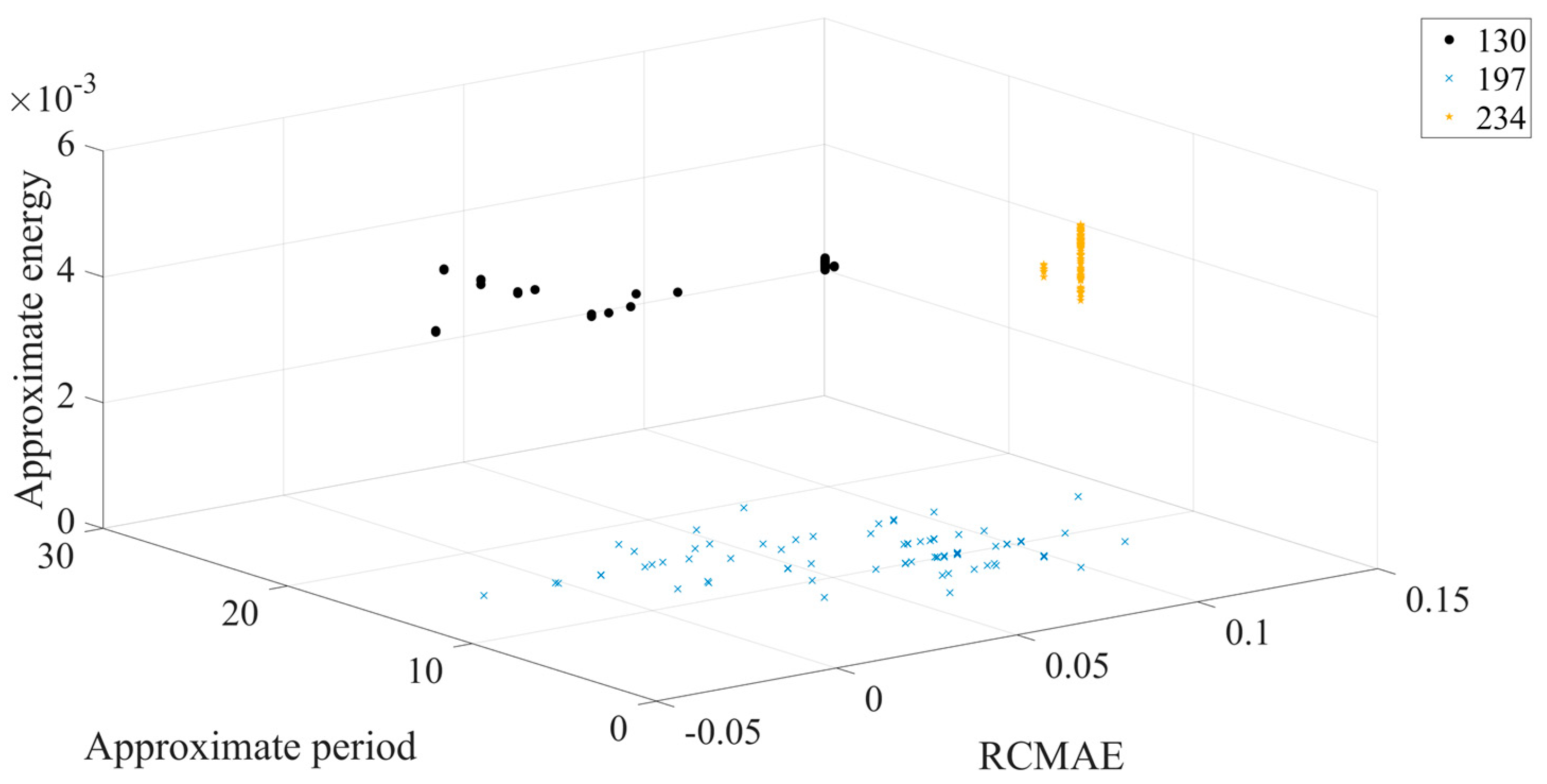
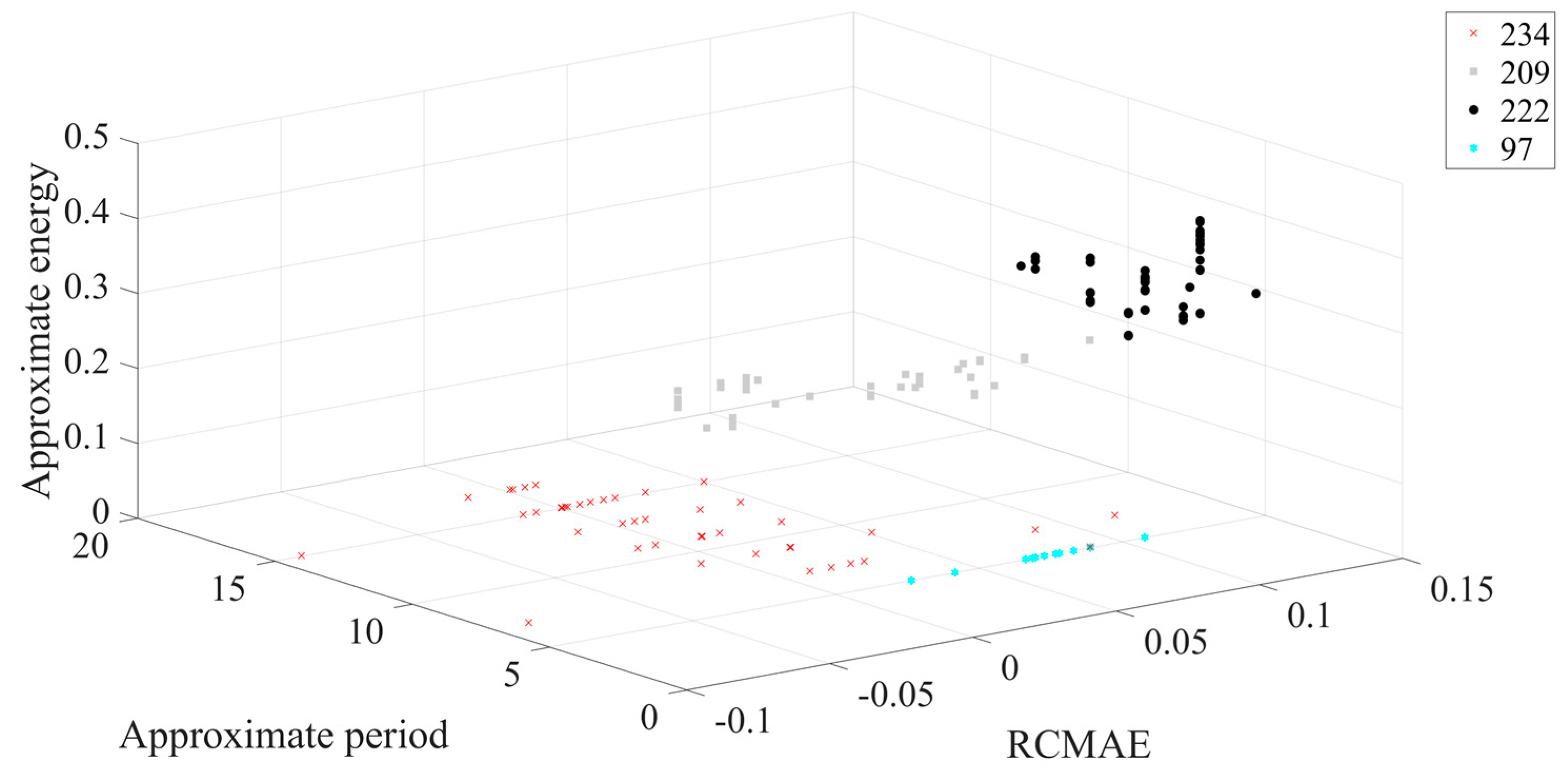
The different colors in
Figure 11 represent different outer ring fault sizes, and the outer ring fault sizes correspond to those shown in
Table 1.
Figure 11 shows that in 3D space, three different outer ring fault sizes are clearly separated from each other, and the aggregation of each working condition is better. Next, the feature set is input to the ICOA-PNN classifier for pattern recognition, and the results are shown in
Table 3. It shows that the average recognition accuracy of 3600 test samples is 94.90%.
The above experimental results of rolling bearing fault diagnosis fully confirm the superiority of fault diagnosis methods based on RCMAE and approximate energy, approximate period, and ICOA-PNN. Similarly, it is obvious that the pattern recognition effect of ICOA-PNN is obviously better than that of PNN, PSO-PNN, FA-PNN, CSO-PNN and GWO-PNN classifiers. Through the above classification of different outer ring fault dimensions, the method proposed in this paper can be effectively utilized in bearing fault diagnosis. In order to further verify the effectiveness of this method, the bearing fault data including normal working conditions and three different position faults are classified below.
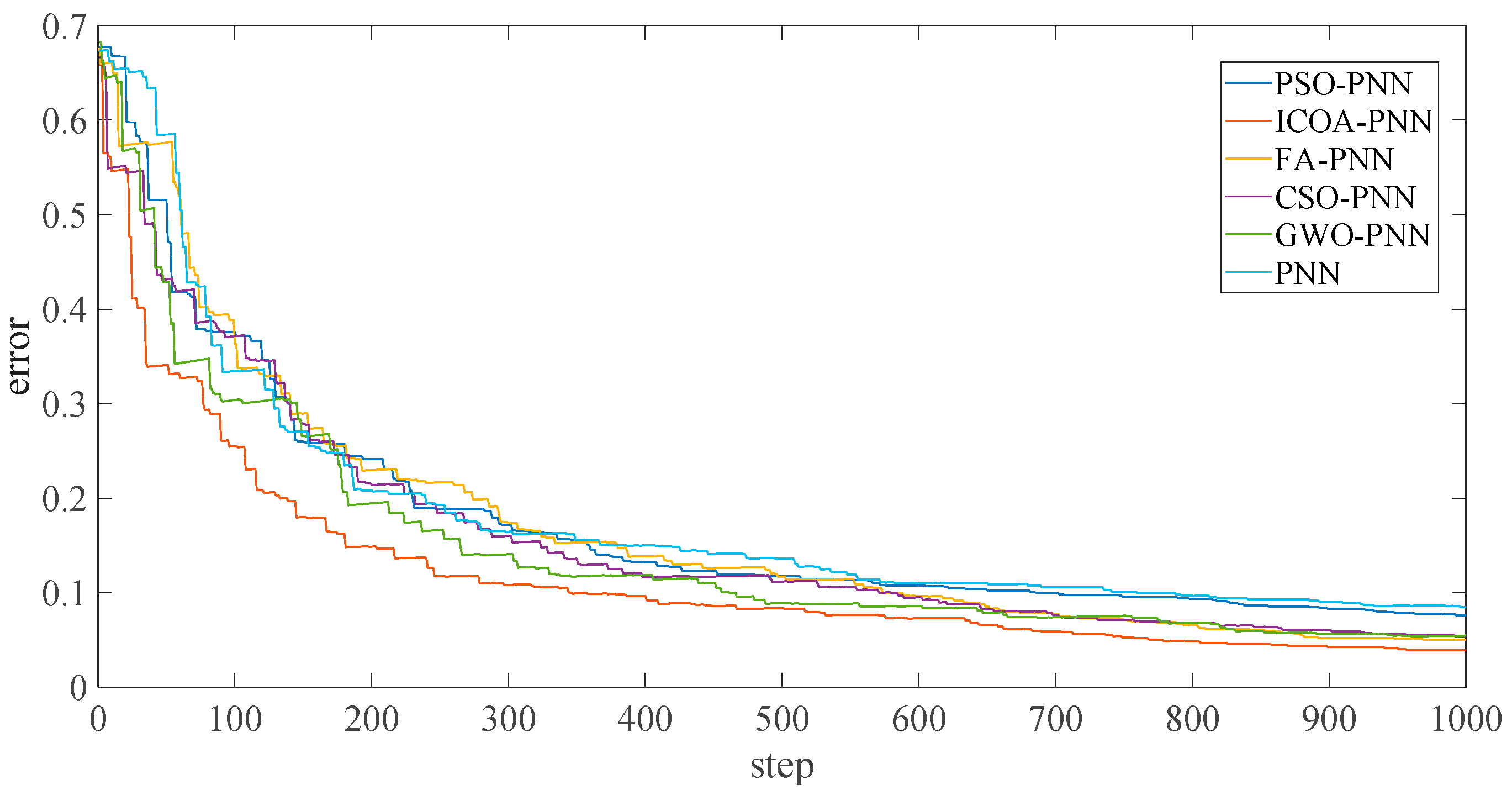
Figure 12 shows the final average adaptation value of the ICOA-PNN classifier under different position fault dimensions of three bearings, including normal working conditions (that is, average error recognition rate). It can be found that the average fitness value is significantly lower than other PNN classifiers based on optimization, which confirms the effectiveness and feasibility of the proposed algorithm for PNN parameter optimization. In addition, according to
Figure 12, the following results can be obtained. Firstly, the average recognition accuracy of the PNN classifier based on optimization is significantly higher than that of the original PNN classifier, which indicates that the PNN classifier based on optimization could overcome the problem of parameter selection of the original PNN classifier. Secondly, compared with other PNN classifiers based on optimization, ICOA-PNN classifier has the highest average recognition accuracy for test samples, which verifies its superiority over other PNN classifiers based on optimization.
Figure 13 shows that in three-dimensional space, the classification results are obviously separated from each other under four different fault types, and the aggregation of each working condition is better. Next, the feature set is input to the ICOA-PNN classifier for pattern recognition, and the results are shown in
Table 4.
Table 4 shows that the average recognition accuracy of 3600 test samples is 96.15%.
Case II: Engineering simulation experiment platform fault diagnosis
The test platform includes two parts: the test platform and the measurement system. The test platform is composed of the test bench and the control system.
Figure 14 shows the physical diagram of the test bench, which is mainly composed of the tested bearing, the accompanying bearing, the test spindle, the bearing outer ring fixture, the driving unit and the loading system. During the test, a group of 4 sets of bearings were divided into two sets of tested bearings and two sets of accompanying bearings. The two sets of loading systems load the tested bearings respectively. The driving unit provides power for the whole test bench, and the radial force is provided for the tested bearing by the loading system, which makes the spindle drive the bearing to rotate, and the vibration signal of the bearing in the rotation process is obtained by the vibration sensor. Among them, the driving unit can provide the range of bearing speed is 1000 rpm to 20,000 rpm, and can be adjusted continuously. The loading range of the loading system is that the loading precision can be adjusted continuously. The working limit temperature of the test-bed is 250 °C.
The ultimate goal of this paper is to improve the accuracy of bearing fault diagnosis under weak faults under strong background noise. Since the early failures of bearings are generally scratches caused by the friction between the rolling elements and the inner or outer ring, the occurrence of cage and rolling element failures mostly occurs in the middle and late stages, and is accompanied by the characteristic frequency of the inner and outer ring failures, which is a composite failure. So, this experiment only diagnoses the early inner and outer ring faults of the bearing. In order to further verify the method proposed in this article, this part uses the bearing engineering simulation experiment platform built by our laboratory to carry out the experiment. Bearing parameters are shown in
Table 5. The failure of the bearing in this experiment is shown in
Figure 15.
This part of the experiment is divided into two times, one is the outer ring fault, and the other is the inner ring fault. The sampling frequency was 8192 Hz, and the data length was 4096 points. The bearing rotation speed was 3000 rpm. The CEITDAN method is used for decomposition, and the RCMAE, approximate period and approximate energy of the first rotation component with the largest correlation coefficient are extracted. Two parameters are input into ICOA-PNN method for fault diagnosis.
In addition, according to
Figure 16, the following results can be obtained. As before, this section uses the same comparison criteria.
Figure 17 shows that under two different bearing failures, the final average fit value of the ICOA-PNN classifier (i.e., the average error recognition rate) is significantly lower than other optimized PNN classifiers. It is confirmed that the effectiveness and feasibility of the proposed algorithm for PNN parameter optimization are consistent with the previous calculation results of the CWRU database. First, the average recognition accuracy of the optimized PNN classifier is significantly higher than the original PNN classifier, which shows that the optimized PNN classifier can overcome the parameter selection problem of the original PNN classifier. Secondly, compared with other PNN classifiers based on optimization, the ICOA-PNN classifier has the highest average recognition accuracy of test samples, thus proving its superiority over other PNN classifiers based on optimization.
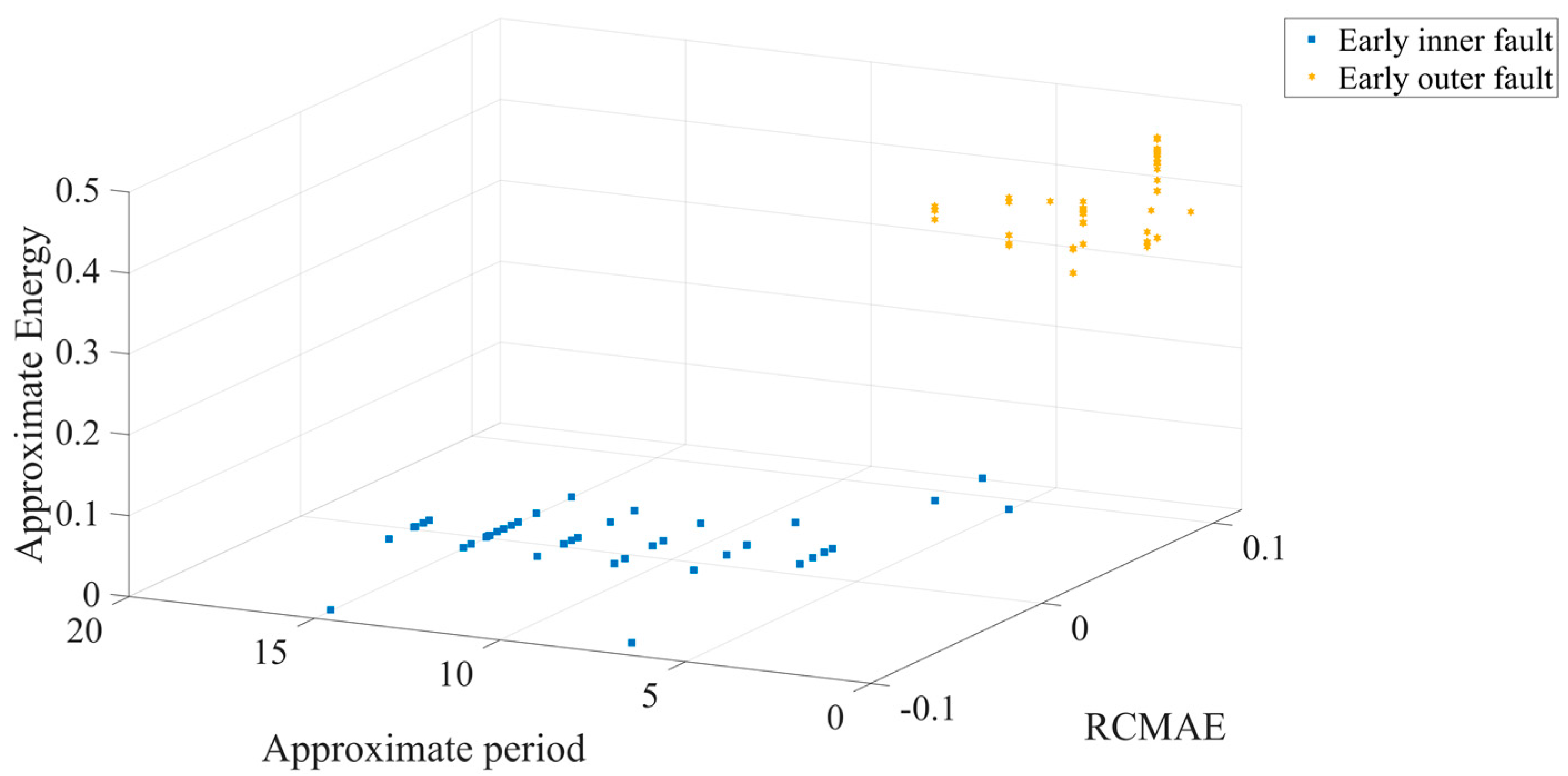
The different colors in
Figure 18 represent different bearing faults.
Figure 18 shows that in 3D space, two different early failures are clearly separated from each other, and the aggregation of each working condition is better. Next, the feature set is input to the ICOA-PNN classifier for pattern recognition, and the results are shown in
Table 6. It shows that the average recognition accuracy of 3600 test samples is 93.9%. Because the early bearing faults are covered in strong background noise, this greatly increases the difficulty of fault diagnosis, which also requires the characteristic parameters to be minimized by noise interference. The method proposed in this paper can effectively improve the accuracy of fault diagnosis, and it performs well in comparison with other algorithms. Other algorithms are all interfered by noise to varying degrees, resulting in a significant decrease in diagnostic accuracy.
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}