In this section, we introduce our method in two steps. First, we introduce the process of calculating the similarity matrix. Then, we introduce the multi-scale aggregation graph neural network method based on the similarity matrix.
3.1. Calculating Similarity Matrix
Following the notation in
Section 2,
is the feature matrix, composed of the features of all labeled and unlabeled nodes, where
is the c-dimensional feature vector of node
and
is the number of all nodes. The graph structure is represented by the adjacency matrix
. Generally, the feature similarity between two nodes is compared by calculating their feature distance. The smaller the feature distance is, the greater the similarity, and conversely, the smaller the similarity. In our model, we use the Manhattan distance to calculate the feature similarity between two nodes.
Nodes
and
are adjacent nodes in the graph, and the Manhattan distance between their features can be gained by the following formula:
Calculating the similarity coefficient between nodes
and
via
where
is the smoothing parameter. By Equation (7), a smaller feature distance will obtain a larger similarity coefficient.
The similarity matrix
is defined by
where
means that nodes
and
are adjacent nodes in the graph, similarity coefficient
of adjacent nodes
and
is calculated by Equations (6) and (7).
Algorithm 1 describes the process of calculating the similarity matrix . Note that the input feature matrix needs to be normalized before calculating the similarity matrix. Otherwise, if the similarity gap of different neighboring nodes is too great, it will lead to lower classification accuracy. Actually, can be regarded as an adjacency matrix with weights. is used in feature propagation, which can distinguish the relative importance of neighbors based on the similarity of original features between the target node and neighbors. These neighbors with higher similarity tend to play a more important role in feature propagation.
| Algorithm 1. Calcul ate Similarity Matrix |
| 1: Input: feature matrix , adjacency matrix |
| 2: output: similarity matrix |
| 3: Perform normalization with diagonal matrix |
| 4: Initialize with zeros |
| 5: for to
do |
| 6: = Non-zero() // is the set of 1-hop neighbors of node |
| 7: for in do |
| 8: // calculating the feature distance of nodes and |
| 9: // calculating the feature similarity of nodes and |
| 10: end for |
| 11: end for |
| 12: return |
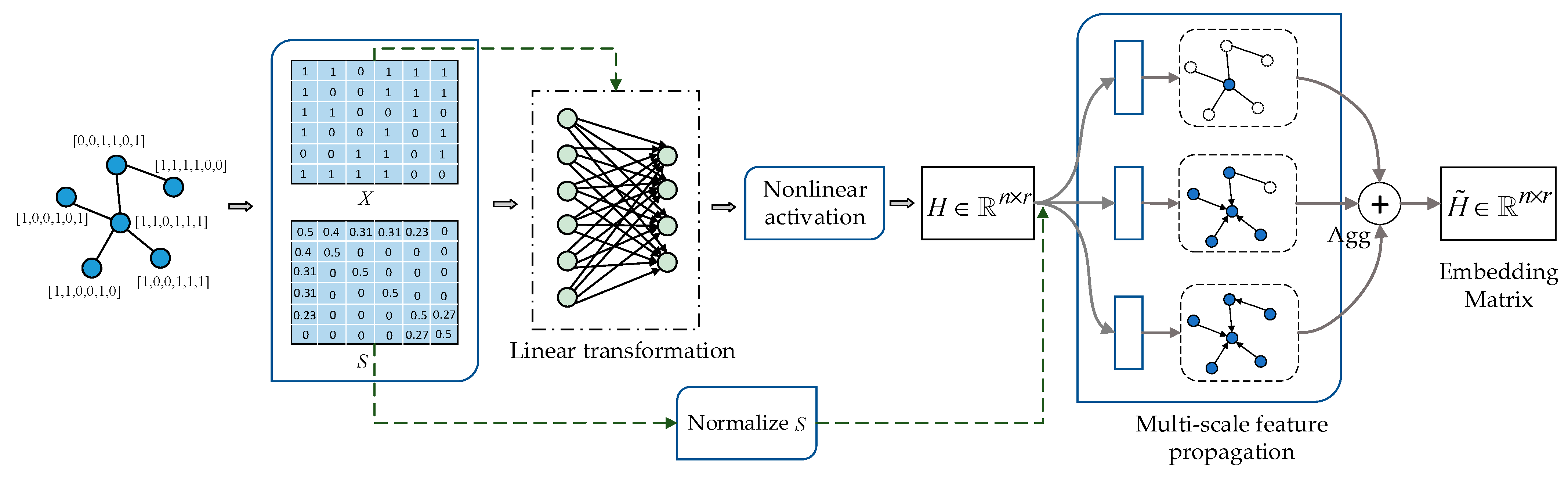
We need to use the similarity matrix (calculated in Algorithm 1) for the proposed architecture to perform multi-scale feature propagation, specific as shown in
Figure 2, where
represents the feature matrix and
represents the feature matrix and represents the similarity matrix. First, we need to perform linear transformation and nonlinear activation on the feature matrix
to obtain the hidden feature representation
, where
represents the number of nodes in the graph and
represents the hidden feature dimensions. Next we use the normalized similarity matrix to perform multi-scale feature propagation on hidden feature representation
. Then we use an aggregator to aggregate the output of multi-scale feature propagation to generate an embedding matrix
. In
Figure 2, “
” means aggregator, here we use mean-pooling as aggregator. For the proposed method, we will describe it in further detail in
Section 3.2.
3.2. MAGN Model
In the GCN, hidden representations of each layer are aggregated among neighbors that are one hop away. This implies that after
K layers, a node extracts feature information from all nodes that are
K hops away in the graph. Each GCN layer has only a size-1 feature extractor, so more layers are needed to obtain adequate global information. Different from GCN, we explore a set of size-1 up to size-
K feature extractors in each layer to extract multi-scale neighborhood features for node representations. Considering that if only a size-
K feature extractor is used, the resulting model is linear; this linear approximation leads to information loss and classification accuracy degradation. For example, the SGC [
15] model only uses a fixed size-
K feature extractor. Although the training time of the SGC model is reduced to a record low, its performance on some benchmark datasets is degraded compared with GCN. In contrast, using a set of size-1 up to size-
K feature extractors (e.g., in our MAGN) can avoid the linear approximation and increase the representation ability. More importantly, our model needs fewer layers to obtain adequate global information.
We first normalize the similarity matrix
, and let
denote the “normalized” similarity matrix:
where
is a diagonal matrix and
. For the overall model, we consider a multi-layer MAGN with the following layer-wise propagation rule:
where
is the feature representation of the (
)-th layer;
equals to the input feature matrix
.
is a layer-specific trainable weight matrix, and
denotes ReLU activation function. Note that the input feature matrix
consists of all node features (i.e. labeled and unlabeled), and we can utilize the similarity matrix to combine feature information from labeled and unlabeled nodes to generate node embedding.
represents the
k-th power of
and we define
as the identity matrix;
to
represent a set of size-1 up to size-
K feature extractors, which are used to extract multi-scale neighborhood features. When
, calculating the
k-th power of
can transfer the similarity from 1-hop neighbors to
k-hop neighbors, which is equivalent to adding an edge directly connected to the
k-hop neighbors for each node. Therefore, our model can directly obtain feature information from
k-hop neighbors for each node by learning the
k-th power of
. With the increase in
k, the scope of feature extraction (i.e., feature propagation) gradually expands, which can capture more global information.
In each MAGN layer, feature representations are updated in four stages: linear transformation (i.e., feature learning), nonlinear activation, feature propagation, and multi-scale aggregation. We adopt a strategy of learning first and then propagating, using a trainable weight matrix to perform linear transformation to degrade the feature dimensions, and then perform multi-scale feature propagation on low-dimensional features. Compared with the strategy of propagating first and then learning, using this method can reduce computational complexity and shorten the training time. We describe each step in detail.
Linear transformation and nonlinear activation. Each MAGN layer first performs linear transformation by a trainable weight matrix
to learn node features. Then, a nonlinear activation function ReLU is applied pointwise before outputting hidden representation
:
In particular,
and
when
.
Feature propagation and multi-scale aggregation. After the feature transformation, we use the “normalized” similarity matrix
to generate a set of size-1 up to size-
K feature extractors for multi-scale feature propagation. Then, a mean-pooling operation is applied to aggregate hidden representation
and the output of multi-scale feature propagation. In summary, the final feature representation updating rule of the
t-th layer is:
where
to
denote feature propagation on different scales of the graph and can directly obtain feature information across near or distant neighbors.
is added to keep more of its own feature information for each node.
represents the probability of starting at node
to complete
steps of the random walk and finally reaching node
. The
k-th power of
contains statistics from the
k-th step of a random walk on the graph. Therefore,
to
can combine information from different step-sizes (i.e., graph scales). The output row-vector of individual node
is:
where
is an empty set if
; otherwise, it is the set of
k-hops neighbors of node
. For an individual node, its final feature representation in the
t-th layer is the aggregation of multi-hops neighbors’ features and its own features.
It is worth noting that the propagation scheme of this model does not require any additional parameters (i.e., trainable weights) to train, in contrast to models such as GCN, which usually require more parameters for each additional propagation function. Therefore, each layer of this model can propagate farther with very few parameters.
Prediction function. The output layer is similar to GCN, and we use a softmax function to predict the labels. The class prediction
of a
t-layer MAGN can be written as:
Loss function. The loss function is defined as the cross-entropy of prediction over the labeled nodes:
where
is the set of labeled nodes used as the training set and
is the number of classes.
represents the corresponding true label matrix for the training set, and
is 1 if the node
belongs to class
; otherwise, it is 0.
is the predicted probability that node
is of class
.
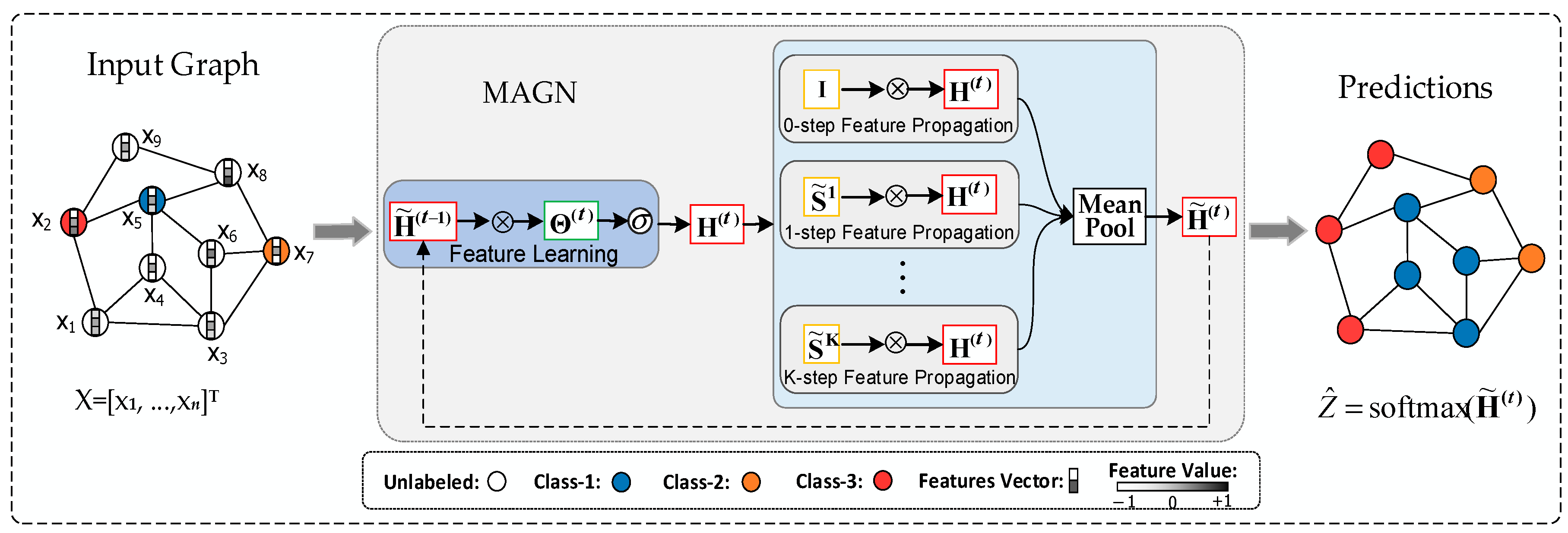
Our model can learn based on the features of both labeled and unlabeled nodes simultaneously, and only use the training set labels to calculate the loss (i.e., only the training set labels are used for learning). Therefore, our model is a semi-supervised learning method for graphs. The proposed MAGN model for semi-supervised learning is schematically depicted in
Figure 3, on the left is an input graph, in the middle is a
t-layer MAGN model, and on the right is an output graph, where
is the normalized similarity matrix,
is the identity matrix and equal
.
is the matrix-matrix multiply operator, and
is the ReLU activation function.
is the input feature representation,
, and
is the output feature representation. Overall,
Figure 3 shows that labeled and unlabeled nodes are used to predict the labels of unlabeled nodes via the MAGN model.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}