
α-Geodesical Skew Divergence


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- Several symmetrized divergences or skew divergences are generalized from an information geometry perspective.
- It is proved that the natural skew divergence for the exponential family is equivalent to the scaled KL-divergence.
- Several properties of geometrically generalized skew divergence are proved. Specifically, the functional space associated with the proposed divergence is shown to be a Banach space.
2. α-Geodesical Skew Divergence
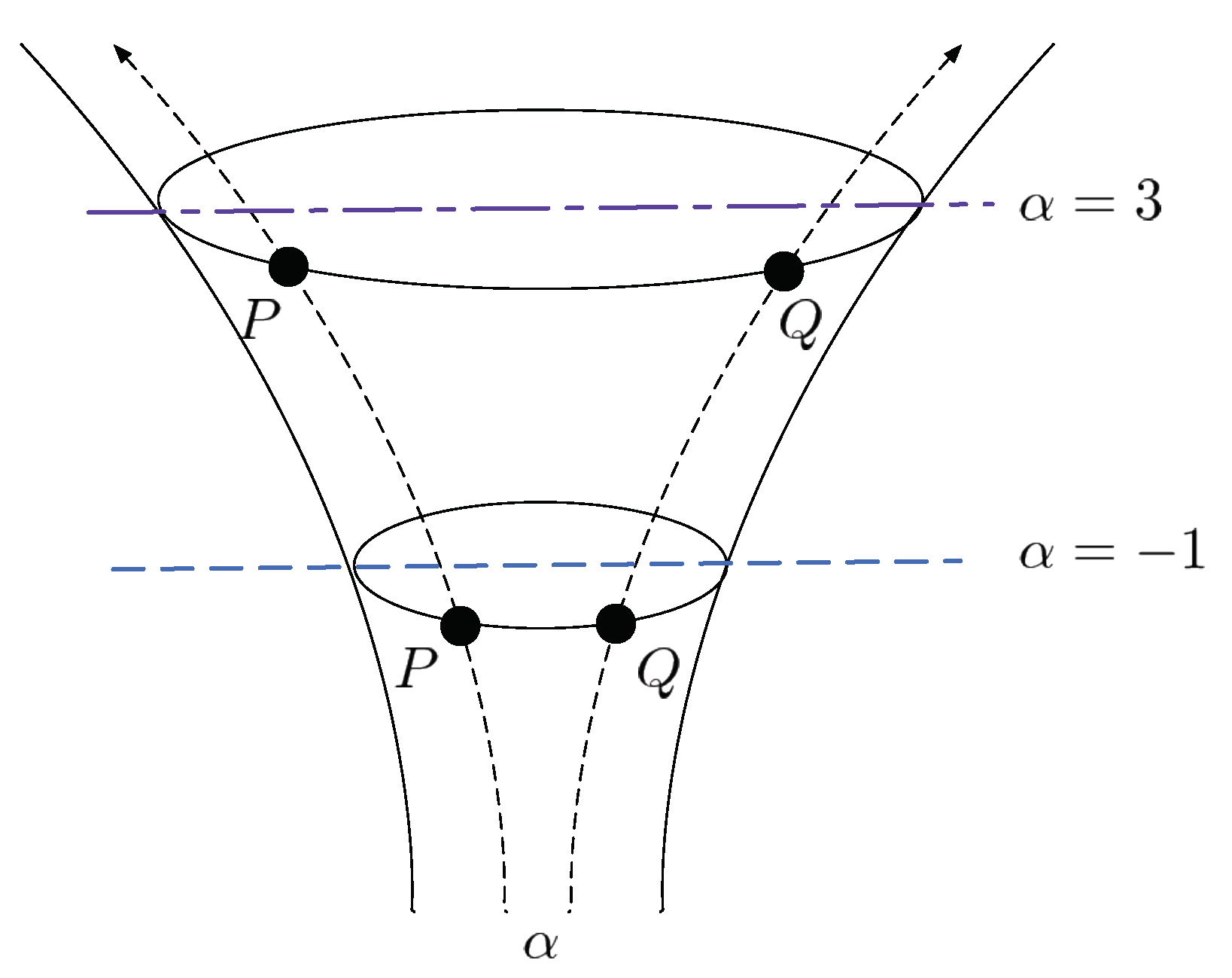
2.1. Statistical Manifold
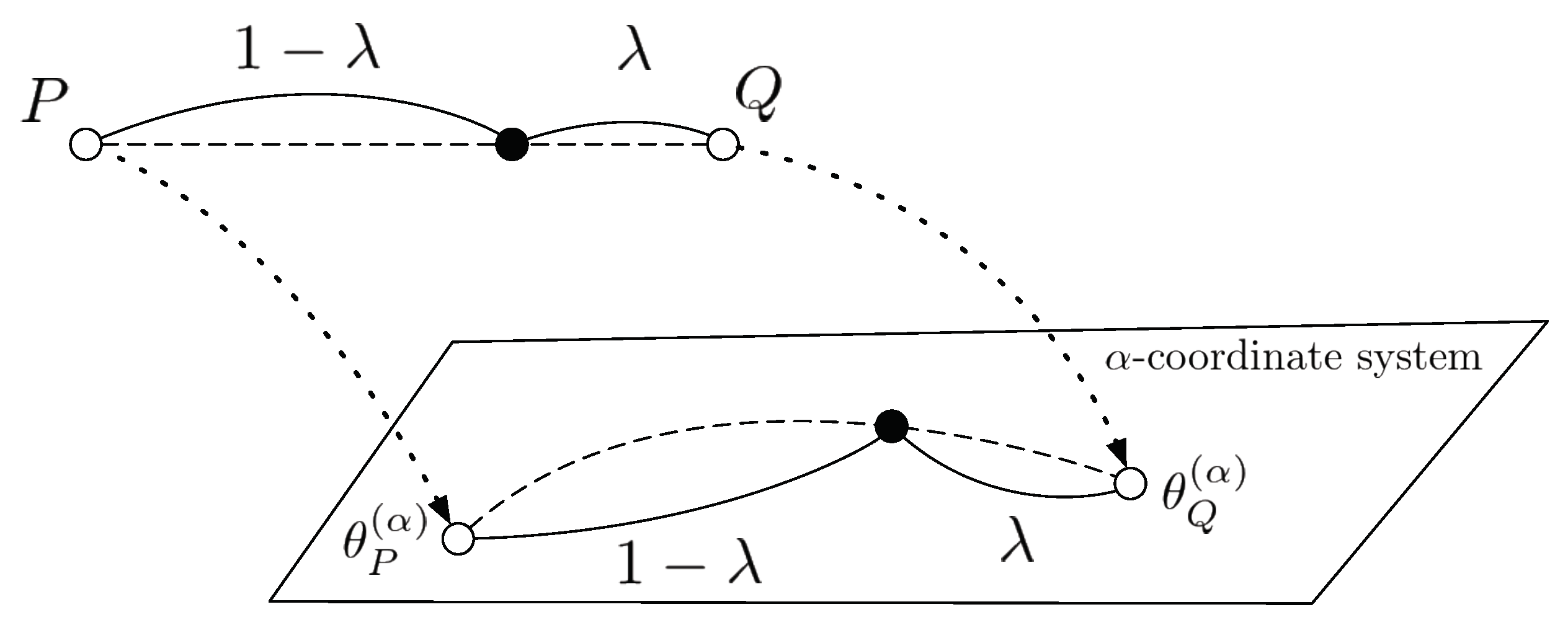
2.2. Generalization of Skew Divergences
2.3. Symmetrization of -Geodesical Skew Divergence
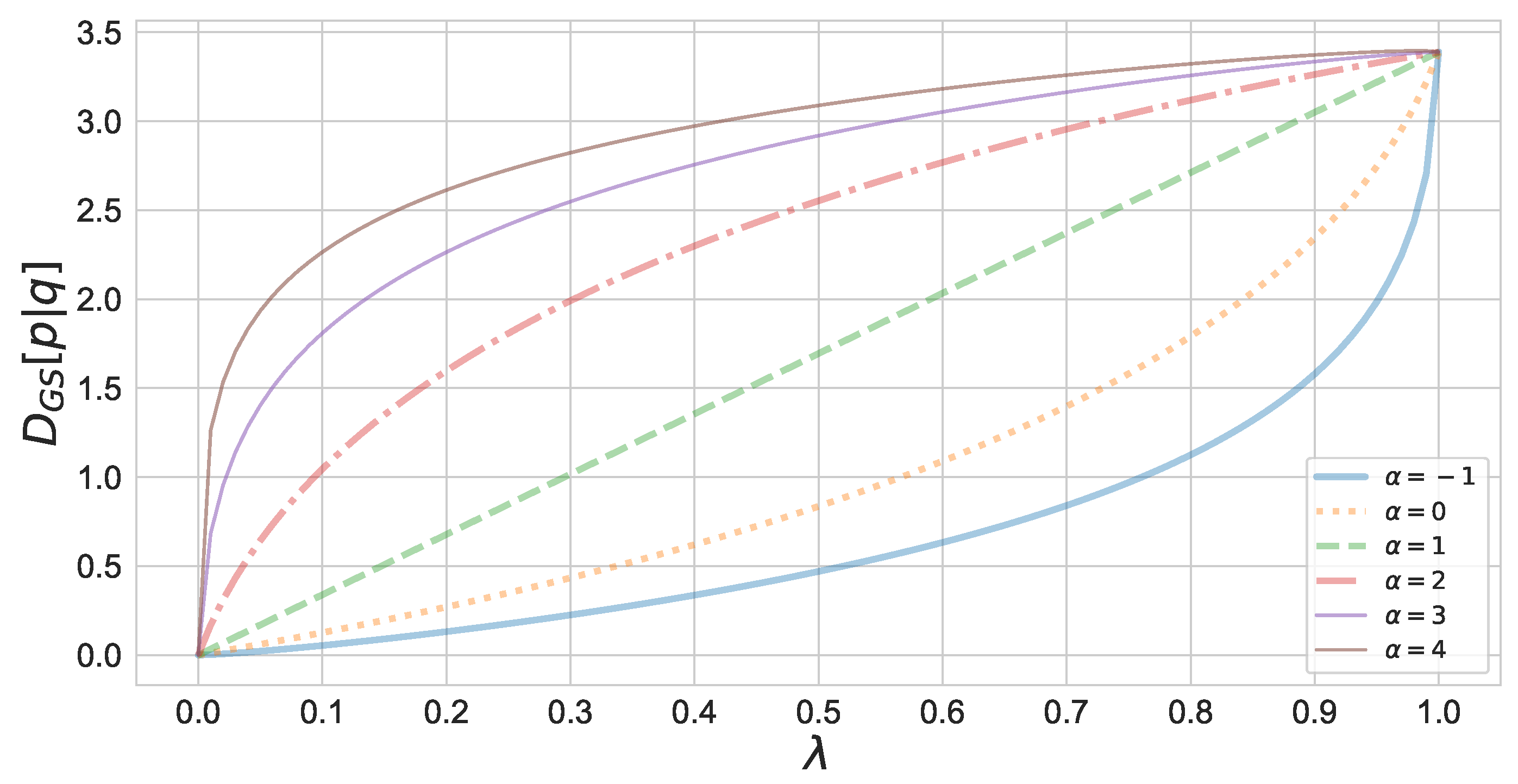
3. Properties of α-Geodesical Skew Divergence
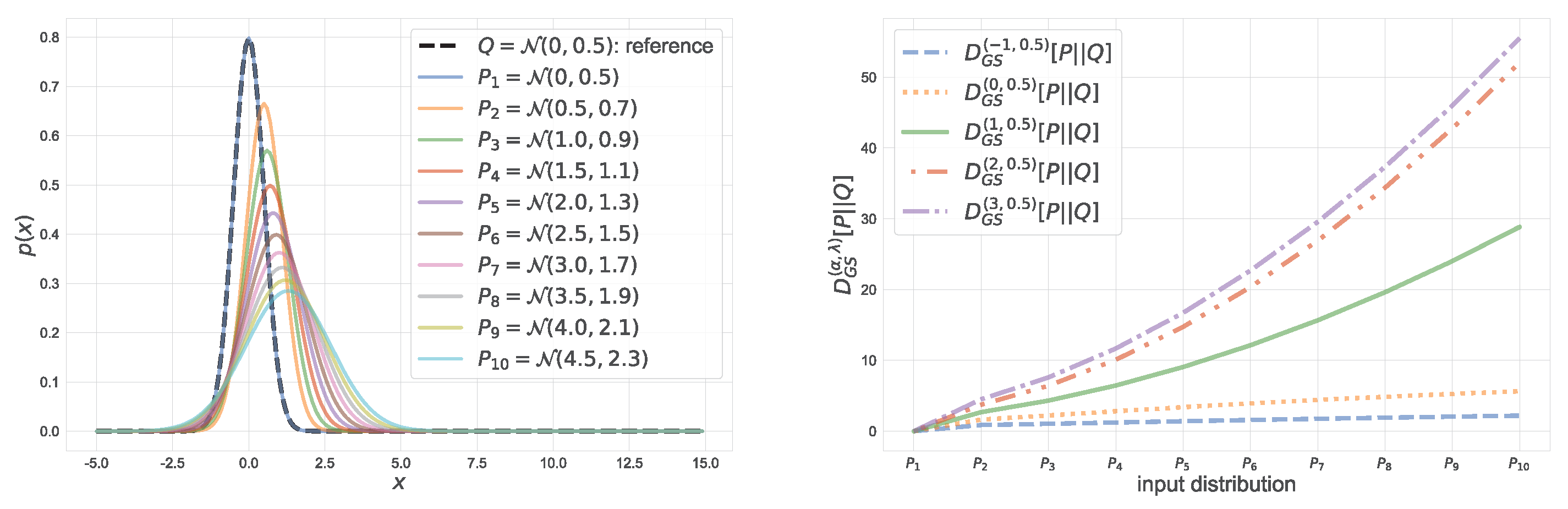
4. Natural α-Geodesical Skew Divergence for Exponential Family
5. Function Space Associated with the α-Geodesical Skew Divergence
6. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Deza, M.M.; Deza, E. Encyclopedia of distances. In Encyclopedia of Distances; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1–583. [Google Scholar]
- Basseville, M. Divergence measures for statistical data processing—An annotated bibliography. Signal Process. 2013, 93, 621–633. [Google Scholar] [CrossRef]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Sakamoto, Y.; Ishiguro, M.; Kitagawa, G. Akaike Information Criterion Statistics; D. Reidel: Dordrecht, The Netherlands, 1986; Volume 81, p. 26853. [Google Scholar]
- Goldberger, J.; Gordon, S.; Greenspan, H. An Efficient Image Similarity Measure Based on Approximations of KL-Divergence Between Two Gaussian Mixtures. ICCV 2003, 3, 487–493. [Google Scholar]
- Yu, D.; Yao, K.; Su, H.; Li, G.; Seide, F. KL-divergence regularized deep neural network adaptation for improved large vocabulary speech recognition. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 16–31 May 2013. [Google Scholar]
- Solanki, K.; Sullivan, K.; Madhow, U.; Manjunath, B.; Chandrasekaran, S. Provably secure steganography: Achieving zero KL divergence using statistical restoration. In Proceedings of the 2006 International Conference on Image Processing, Atlanta, GA, USA, 8–11 October 2006. [Google Scholar]
- Lin, J. Divergence measures based on the Shannon entropy. IEEE Trans. Inf. Theory 1991, 37, 145–151. [Google Scholar] [CrossRef] [Green Version]
- Menéndez, M.; Pardo, J.; Pardo, L.; Pardo, M. The jensen-shannon divergence. J. Frankl. Inst. 1997, 334, 307–318. [Google Scholar] [CrossRef]
- Nielsen, F. On the Jensen–Shannon symmetrization of distances relying on abstract means. Entropy 2019, 21, 485. [Google Scholar] [CrossRef] [Green Version]
- Jeffreys, H. An Invariant Form for the Prior Probability in Estimation Problems. Available online: https://royalsocietypublishing.org/doi/10.1098/rspa.1946.0056 (accessed on 24 April 2021).
- Chatzisavvas, K.C.; Moustakidis, C.C.; Panos, C. Information entropy, information distances, and complexity in atoms. J. Chem. Phys. 2005, 123, 174111. [Google Scholar] [CrossRef] [Green Version]
- Bigi, B. Using Kullback-Leibler distance for text categorization. In European Conference on Information Retrieval; Springer: Berlin/Heidelberg, Germany, 2003; pp. 305–319. [Google Scholar]
- Wang, F.; Vemuri, B.C.; Rangarajan, A. Groupwise point pattern registration using a novel CDF-based Jensen-Shannon divergence. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006. [Google Scholar]
- Nishii, R.; Eguchi, S. Image classification based on Markov random field models with Jeffreys divergence. J. Multivar. Anal. 2006, 97, 1997–2008. [Google Scholar] [CrossRef] [Green Version]
- Bayarri, M.; García-Donato, G. Generalization of Jeffreys divergence-based priors for Bayesian hypothesis testing. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2008, 70, 981–1003. [Google Scholar] [CrossRef]
- Nielsen, F. Jeffreys centroids: A closed-form expression for positive histograms and a guaranteed tight approximation for frequency histograms. IEEE Signal Process. Lett. 2013, 20, 657–660. [Google Scholar] [CrossRef] [Green Version]
- Nielsen, F. On a generalization of the Jensen–Shannon divergence and the Jensen–Shannon centroid. Entropy 2020, 22, 221. [Google Scholar] [CrossRef] [Green Version]
- Lee, L. Measures of distributional similarity. In Proceedings of the 37th Annual Meeting of the Association for Computational Linguistics on Computational Linguistics, College Park, MD, USA, 20–26 June 1999. [Google Scholar]
- Lee, L. On the Effectiveness of the Skew Divergence for Statistical Language Analysis. In Proceedings of the Eighth International Workshop on Artificial Intelligence and Statistics, Key West, FL, USA, 4–7 January 2001; pp. 176–783. [Google Scholar]
- Xiao, F.; Wu, Y.; Zhao, H.; Wang, R.; Jiang, S. Dual skew divergence loss for neural machine translation. arXiv 2019, arXiv:1908.08399. [Google Scholar]
- Carvalho, B.M.; Garduño, E.; Santos, I.O. Skew divergence-based fuzzy segmentation of rock samples. J. Phys. Conf. Ser. 2014, 490, 012010. [Google Scholar] [CrossRef]
- Revathi, P.; Hemalatha, M. Cotton leaf spot diseases detection utilizing feature selection with skew divergence method. Int. J. Sci. Eng. Technol. 2014, 3, 22–30. [Google Scholar]
- Ahmed, N.; Neville, J.; Kompella, R.R. Network Sampling via Edge-Based Node Selection with Graph Induction. Available online: https://docs.lib.purdue.edu/cgi/viewcontent.cgi?article=2743&context=cstech (accessed on 24 April 2021).
- Hughes, T.; Ramage, D. Lexical semantic relatedness with random graph walks. In Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL), Prague, Czech Republic, 28–30 June 2007. [Google Scholar]
- Audenaert, K.M. Quantum skew divergence. J. Math. Phys. 2014, 55, 112202. [Google Scholar] [CrossRef] [Green Version]
- Hardy, G.H.; Littlewood, J.E.; Pólya, G. Inequalities; Cambridge University Press: Cambridge, UK, 1952. [Google Scholar]
- Amari, S.I. Information Geometry and Its Applications; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Kolmogorov, A.N.; Castelnuovo, G. Sur la Notion de la Moyenne; Atti Accad. Naz: Lincei, French, 1930. [Google Scholar]
- Nagumo, M. Über eine klasse der mittelwerte. Jpn. J. Math. 1930, 7, 71–79. [Google Scholar] [CrossRef] [Green Version]
- Nielsen, F. Generalized Bhattacharyya and Chernoff upper bounds on Bayes error using quasi-arithmetic means. Pattern Recognit. Lett. 2014, 42, 25–34. [Google Scholar] [CrossRef] [Green Version]
- Amari, S.I. Differential-Geometrical Methods in Statistics; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012; Volume 28. [Google Scholar]
- Amari, S. Differential-geometrical methods in statistics. Lect. Notes Stat. 1985, 28, 1. [Google Scholar]
- Amari, S. α-Divergence Is Unique, Belonging to Both f-Divergence and Bregman Divergence Classes. IEEE Trans. Inf. Theory 2009, 55, 4925–4931. [Google Scholar] [CrossRef]
- Ay, N.; Jost, J.; Lê, H.V.; Schwachhöfer, L. Information Geometry; Springer International Publishing: Berlin/Heidelberg, Germany, 2017. [Google Scholar] [CrossRef]
- Morozova, E.A.; Chentsov, N.N. Markov invariant geometry on manifolds of states. J. Sov. Math. 1991, 56, 2648–2669. [Google Scholar] [CrossRef]
- Eguchi, S.; Komori, O. Path Connectedness on a Space of Probability Density Functions. In Lecture Notes in Computer Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 615–624. [Google Scholar] [CrossRef]
- Nielsen, F. On a Variational Definition for the Jensen-Shannon Symmetrization of Distances Based on the Information Radius. Entropy 2021, 23, 464. [Google Scholar] [CrossRef]
- Nielsen, F. A family of statistical symmetric divergences based on Jensen’s inequality. arXiv 2010, arXiv:1009.4004. [Google Scholar]
- Cover, T.M. Elements of Information Theory; John Wiley & Sons: Hoboken, NJ, USA, 1999. [Google Scholar]
- Brekelmans, R.; Masrani, V.; Bui, T.D.; Wood, F.D.; Galstyan, A.; Steeg, G.V.; Nielsen, F. Annealed Importance Sampling with q-Paths. arXiv 2020, arXiv:2012.07823. [Google Scholar]





Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kimura, M.; Hino, H. α-Geodesical Skew Divergence. Entropy 2021, 23, 528. https://doi.org/10.3390/e23050528
Kimura M, Hino H. α-Geodesical Skew Divergence. Entropy. 2021; 23(5):528. https://doi.org/10.3390/e23050528
Chicago/Turabian StyleKimura, Masanari, and Hideitsu Hino. 2021. "α-Geodesical Skew Divergence" Entropy 23, no. 5: 528. https://doi.org/10.3390/e23050528
APA StyleKimura, M., & Hino, H. (2021). α-Geodesical Skew Divergence. Entropy, 23(5), 528. https://doi.org/10.3390/e23050528