
Improvement of Contact Tracing with Citizen’s Distributed Risk Maps


Abstract
:1. Introduction
- advantages: precise information is available on the movements of people and their contacts, known or unknown, allowing the tracking and control of people;
- drawbacks: a threat to privacy.
- advantages: some privacy is maintained;
- drawbacks: the administration does not receive global data or statistics. Moreover, the information is available a posteriori, which makes prevention difficult (it prevents propagation, but not contagion).
- advantages: (i) privacy is maintained, (ii) the administration obtains aggregated information at the time, and (iii) the citizenry and the administration have the same data (transparency);
- drawbacks: the first exchange contains the data of only one node (in case someones hacks it and retrieves the information), and a critical mass is necessary.
2. Review of Contact Tracing Apps
- voluntary: users opt-in to use the app or all citizens are compelled to download and use it;
- limitations: data have constraints to be used for purposes other than public health;
- destroyed: the data are automatically deleted in a reasonable amount of time or the the users can manually delete their data;
- minimized: the app collects only the information it needs;
- transparent: it has clear, publicly available policies and design, and open-source code base.
3. Collaborative Risk Map Generation
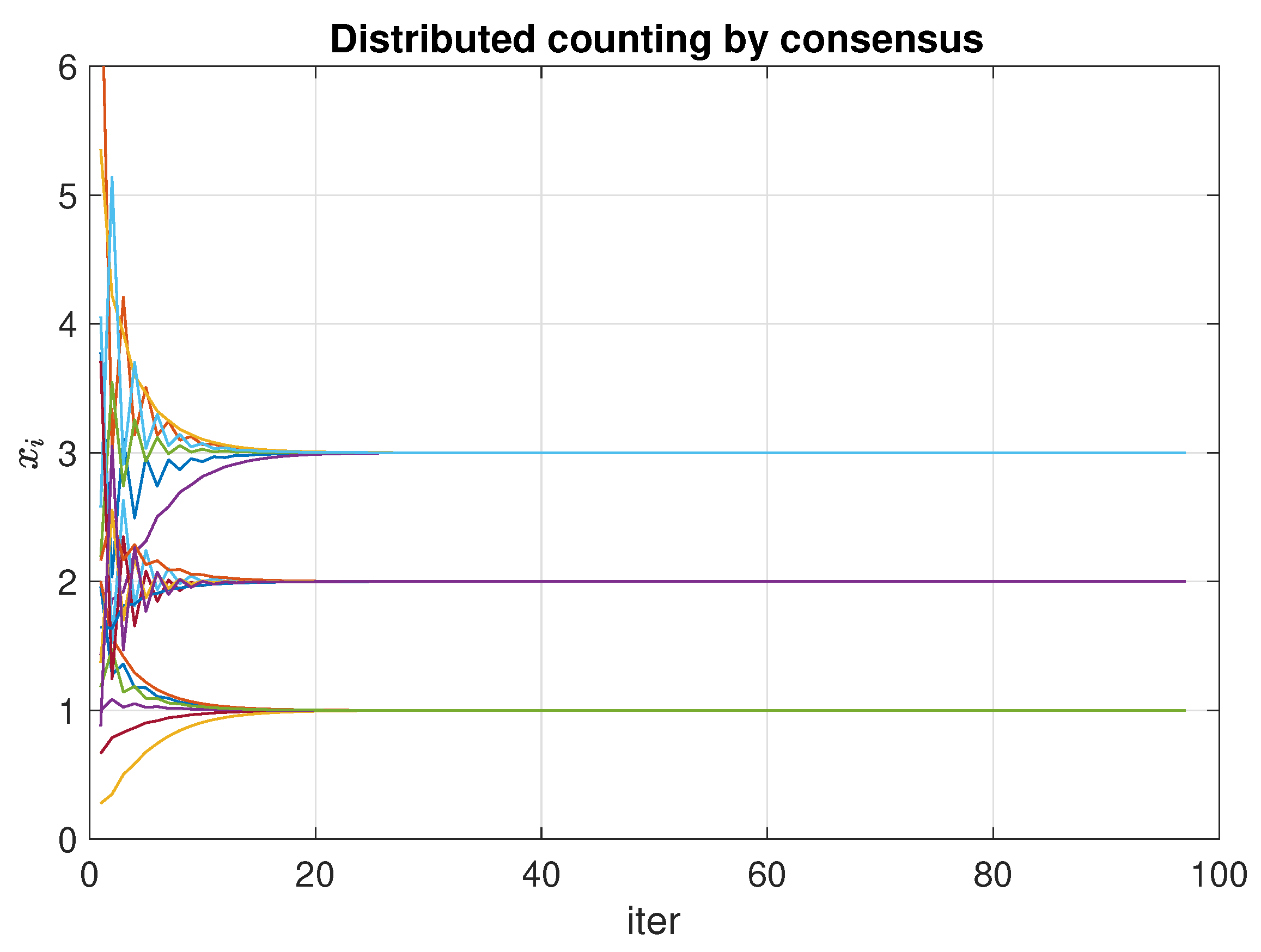
3.1. Consensus as a Distributed Counting Mechanism
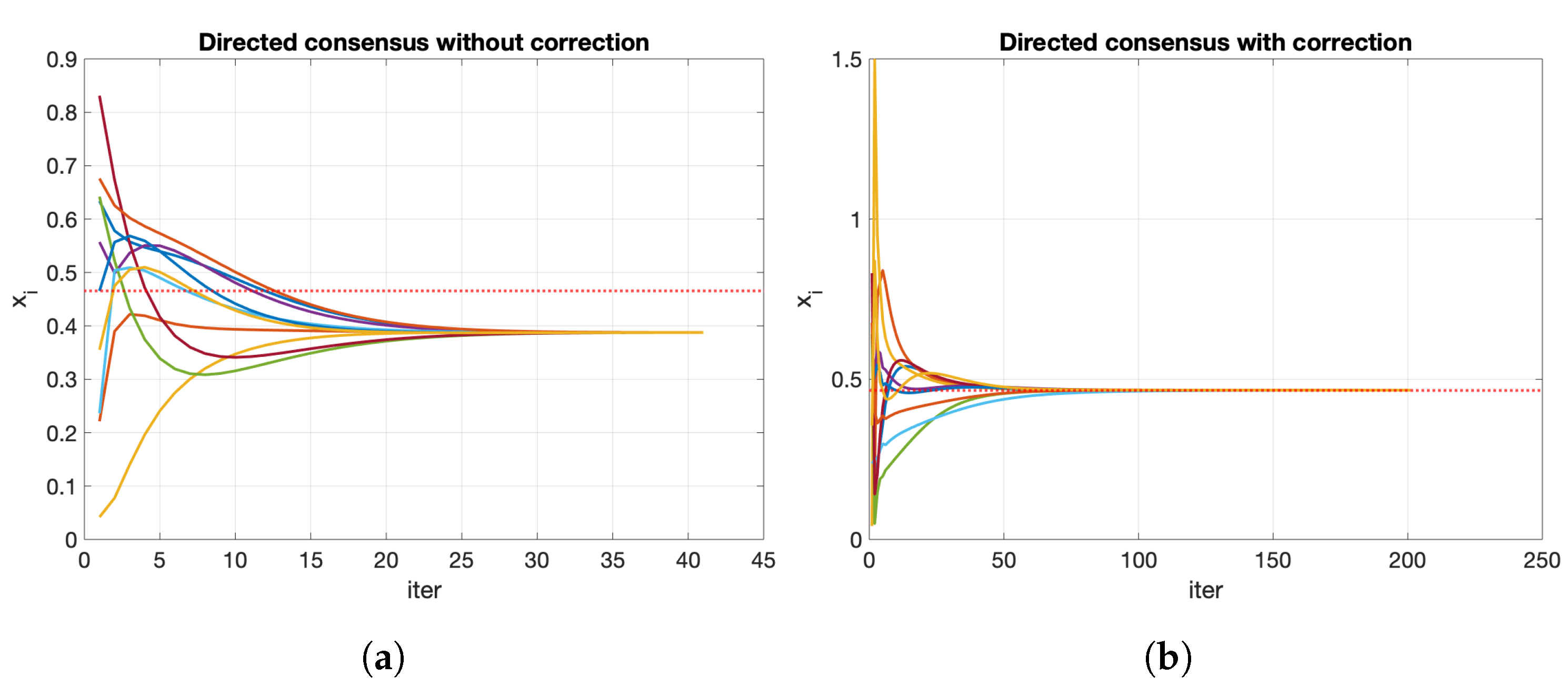
3.2. Consensus on Directed Networks
| Algorithm 1 Matrix scaling and consensus (collective) |
|
- 1.
- the calculation of , in lines 3 and 10;
- 2.
- the definition of the matrix , as a local variation of the Perron matrix, in line 4;
- 3.
- how updates, in line 8.
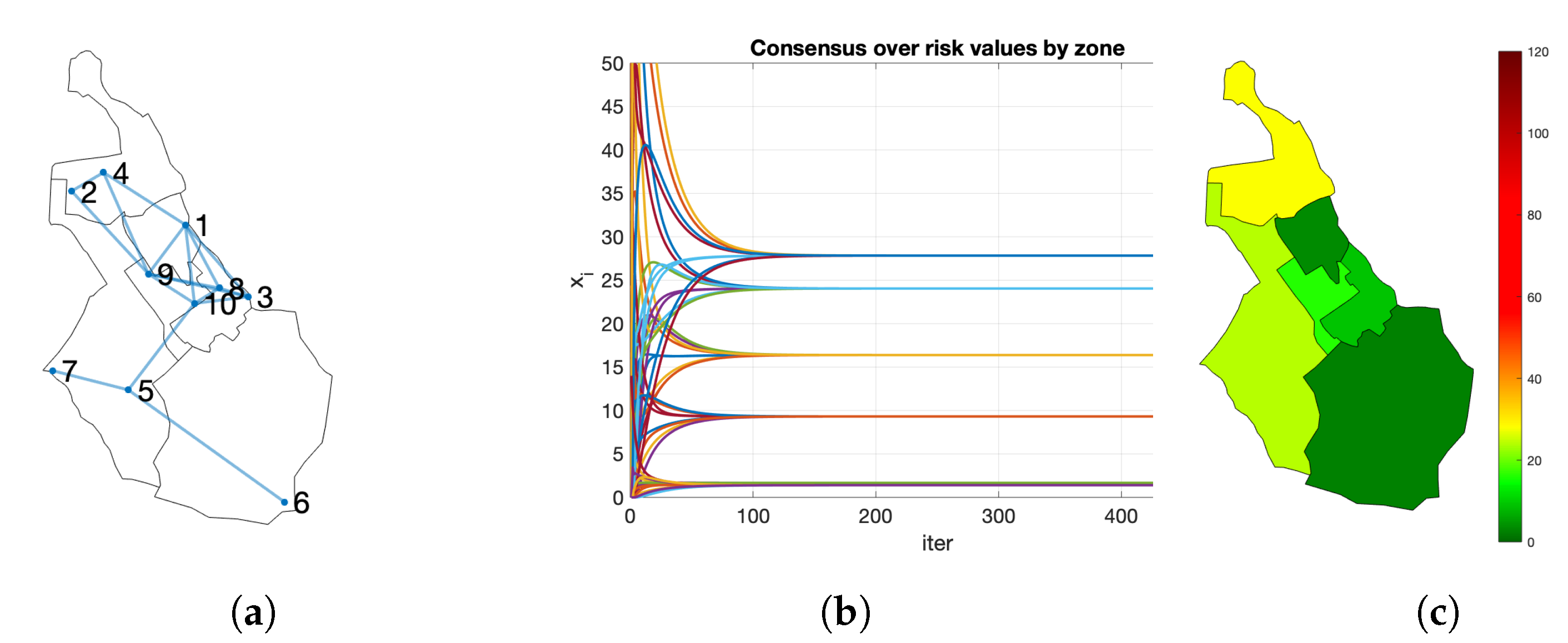
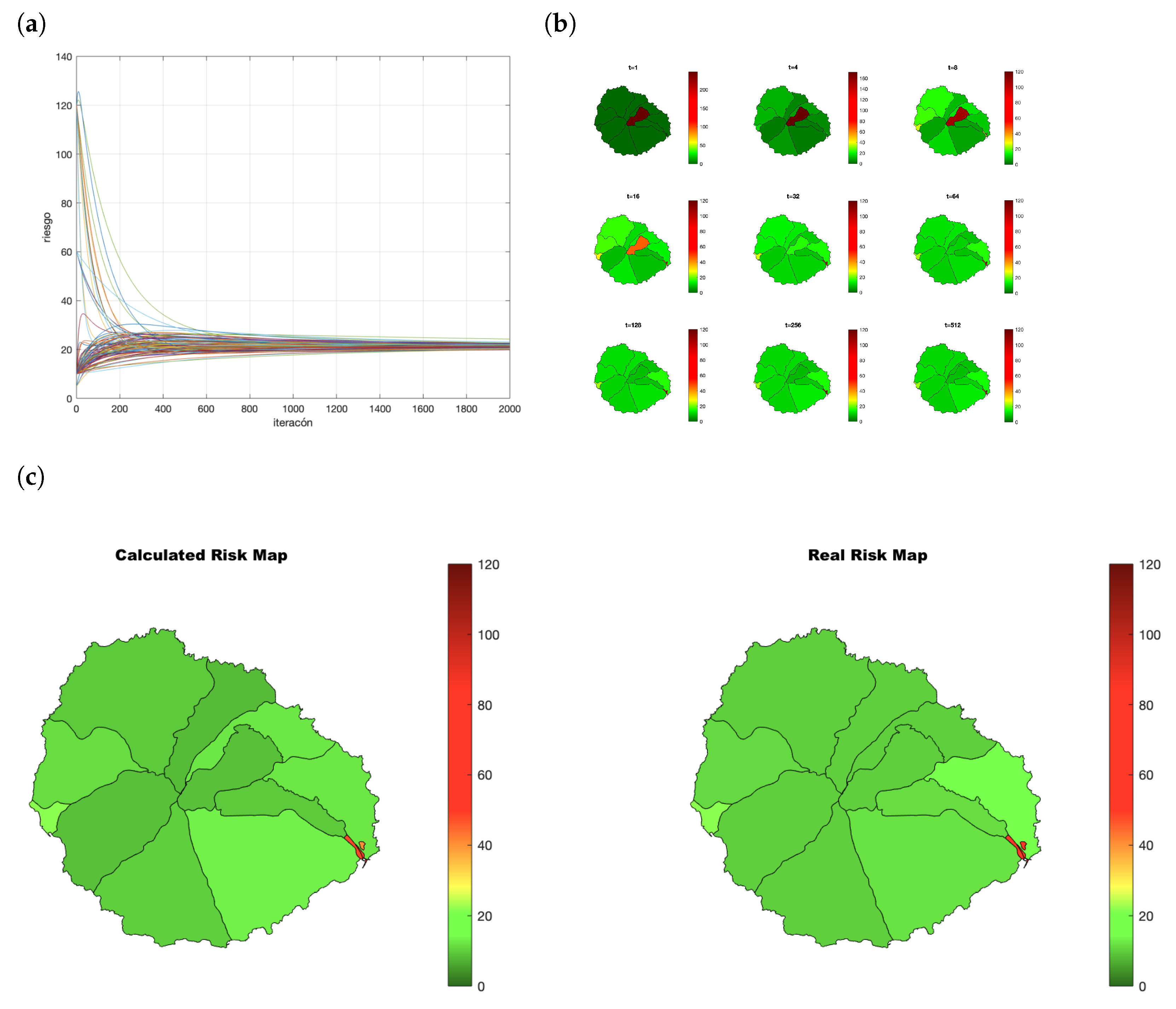
3.3. Map Generation
- the nodes of the network are the population: the inhabitants of the city;
- the map (a town, an island or any other region) is divided into m zones. For instance, postal codes in a city;
- each node i has a vector with as many components as zones, that is, m components;
- using the algorithm of Section 3.1, all inhabitants calculate the same vector that aggregates the information of the zones. For instance, sum the values for each postal codes;
- we use a directed network, so the algorithm used is the variation of Section 3.2.
- : risk index of node .
- : vector with the risk map values in node i.
- : complete risk map calculated in node i.
| Algorithm 2 Risk map creation |
|
- 1.
- the position of in corresponds to its census district;
- 2.
- each node executes a local version of Algorithm 1;
- 3.
- the first exchange is the only moment in which vectors contain individual values: the risk and the census district of i. We assume that there are no privacy concerns since the node would share this information with its trusted neighbors;
- 4.
- in the following exchanges, the received vectors contains aggregated information. As the neighbors of j remain unknown for i, it is complicated to track back the data.
4. Results
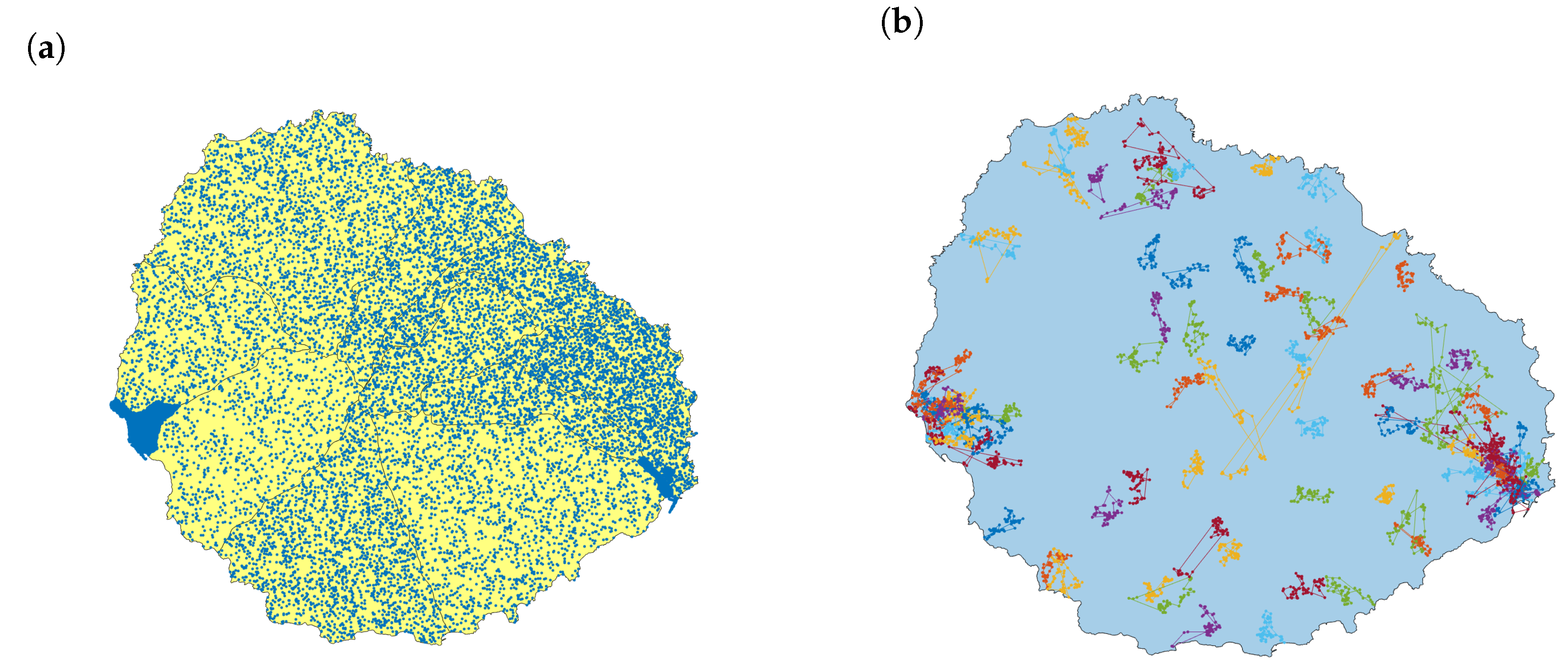
4.1. Population and Infection Model
- 1.
- Lévy flights model properly the commuting movements of the people;
- 2.
- any person has the same probability to get infected;
- 3.
- the propagation of SARS-Cov-2 follows an SEIR model.
- Susceptible (S): a person that has not the disease and can be infected;
- Exposed (E): someone that has been in contact with an infected person. He or she cannot infect others yet;
- Infected (I): someone with symptoms that can infect other people;
- Recovered (R): people cured that are immune to the disease.
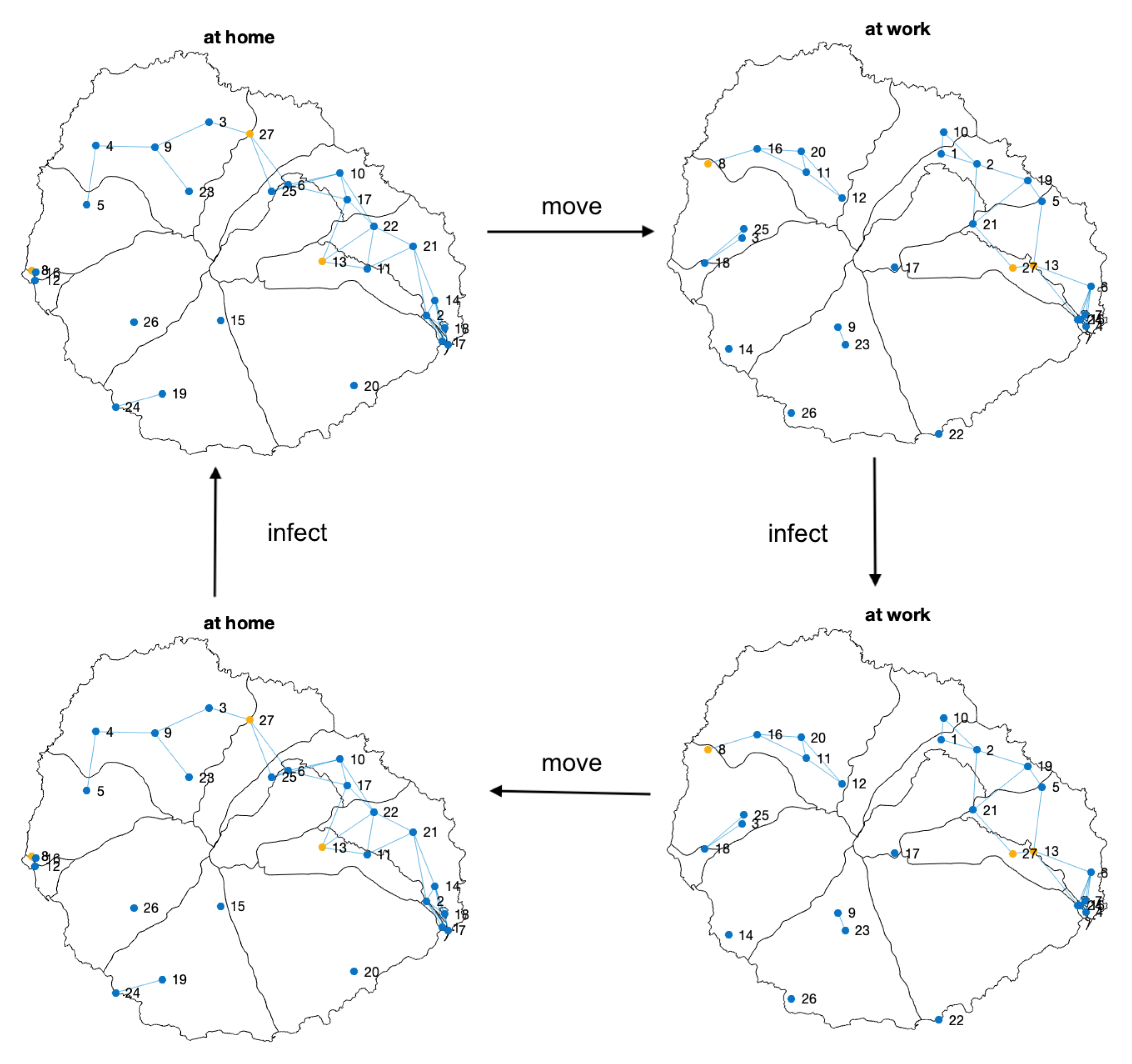
- 1.
- People start at their home location;
- 2.
- They move along the day, interacting with the other persons;
- 3.
- Nodes update their state according to the epidemic model and the contact matrix;
- 4.
- They go back to their home locations;
- 5.
- A new infection stage is performed at home.
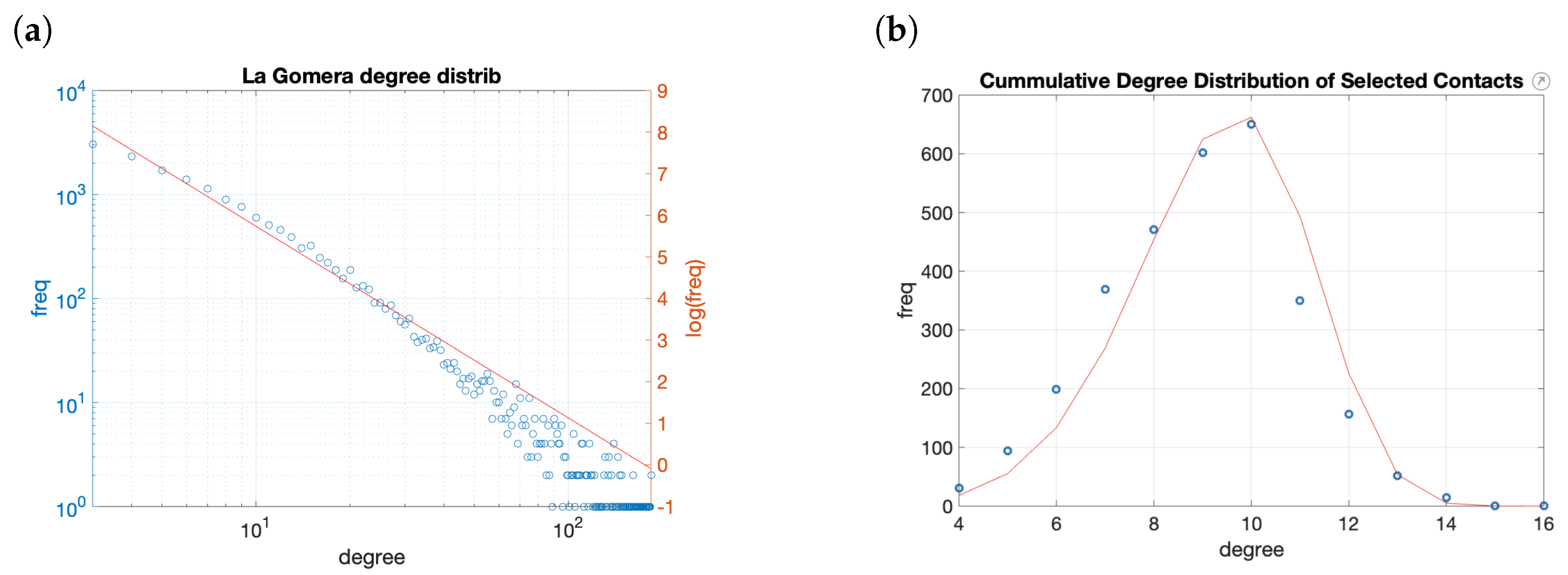
4.2. Risk Map Creation
- only a subset of the population participates in the creation of risk maps;
- people has an small subset of confident contacts among family, friends, and colleagues from work or studies;
- risk values are uniformly distributed among all the population.
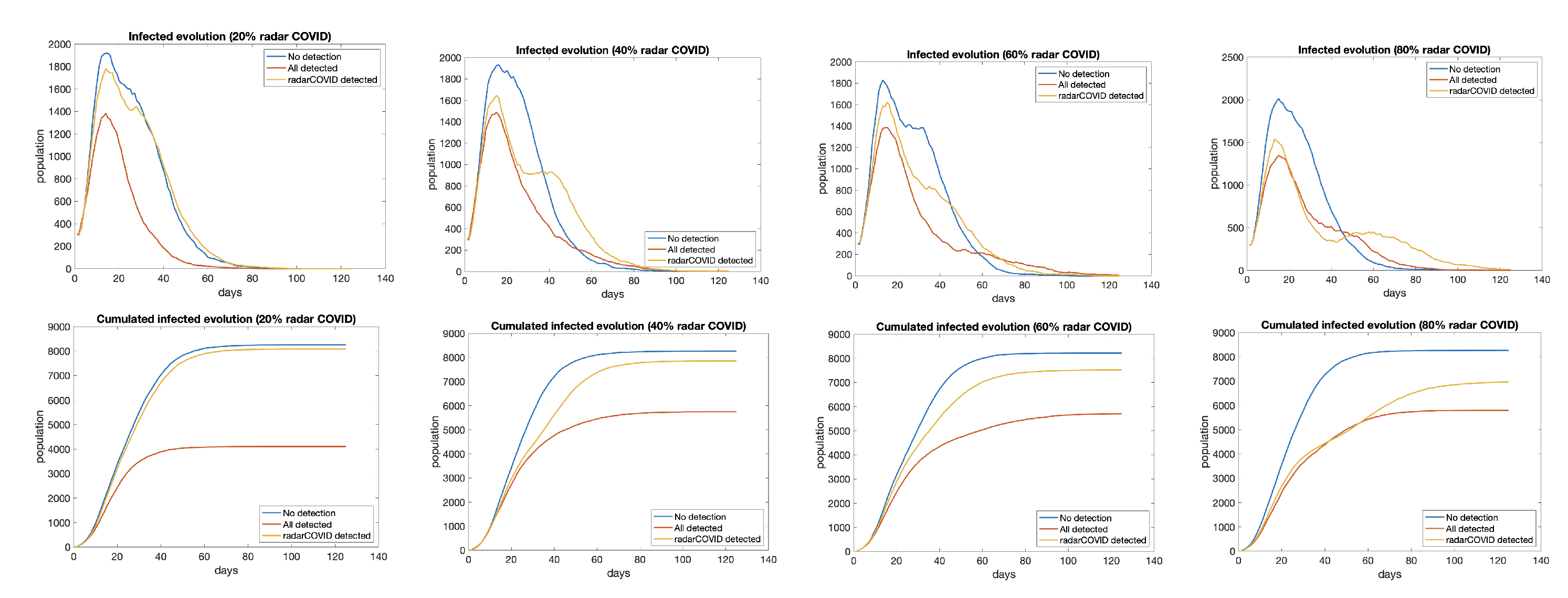
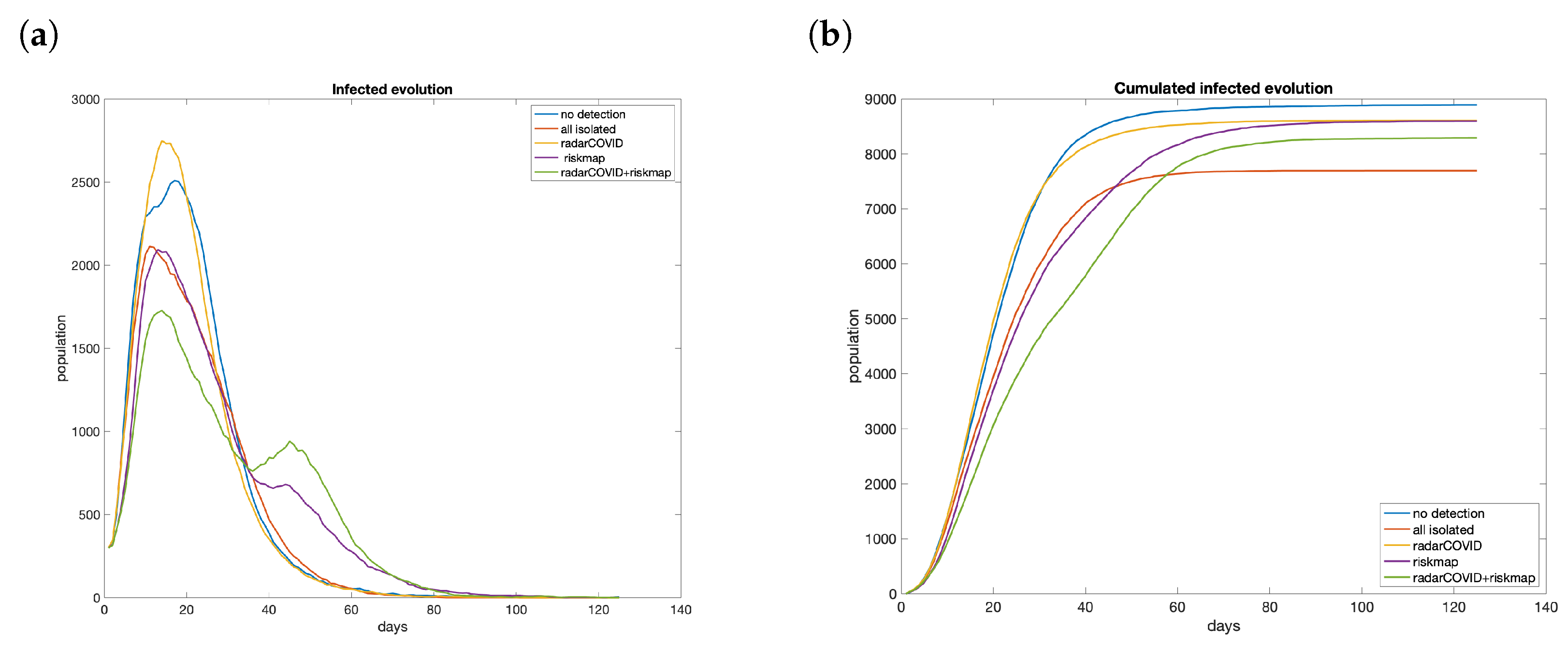
4.3. Evolution with Contact Tracing App Active
- worst case (blue): no measures taken;
- best case (red): all infected detected and isolated;
- isolation of traced users (yellow): people with contact tracing app isolated 48 h after the first symptom appears, as well as all other persons that have been in contact with them.
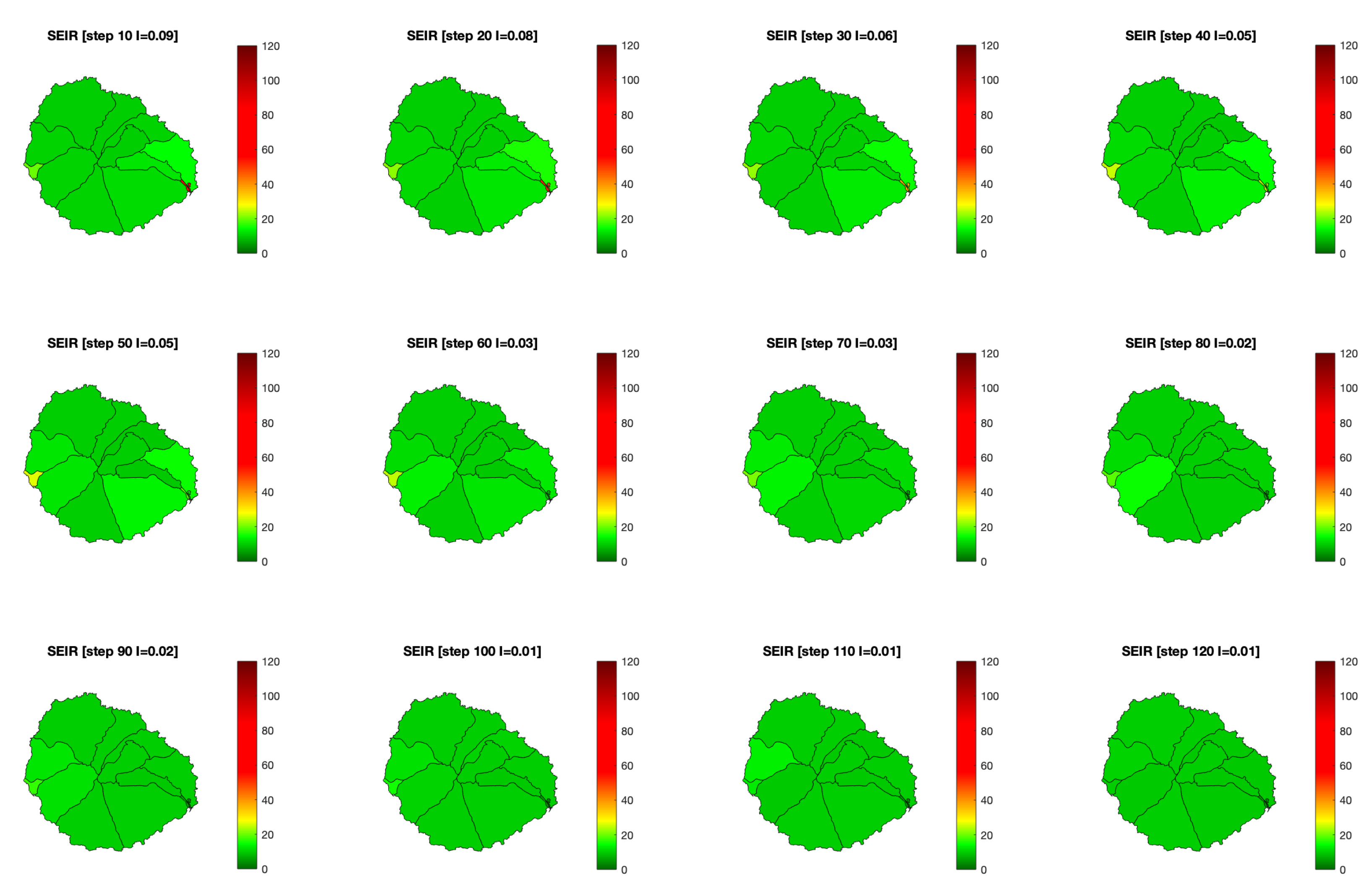
4.4. Effect of Risk Maps in Infections
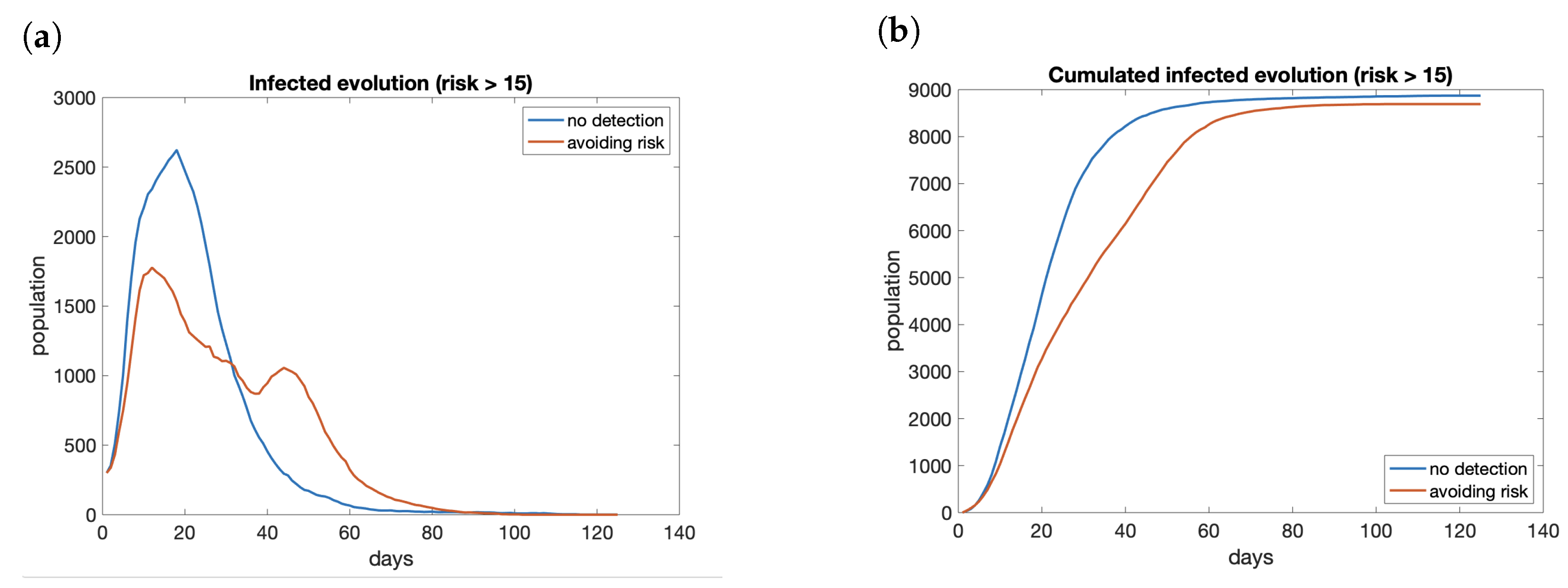
4.5. Contact Tracing and Risk Maps Combined
- people that live in an area with medium or high risk do not go out from it;
- people that live in a low-risk area move freely but do not enter risky ones;
- tracing app notifies exposure in 48 h. People that receive a warning from the application isolate themselves and stay at home.
5. Conclusions
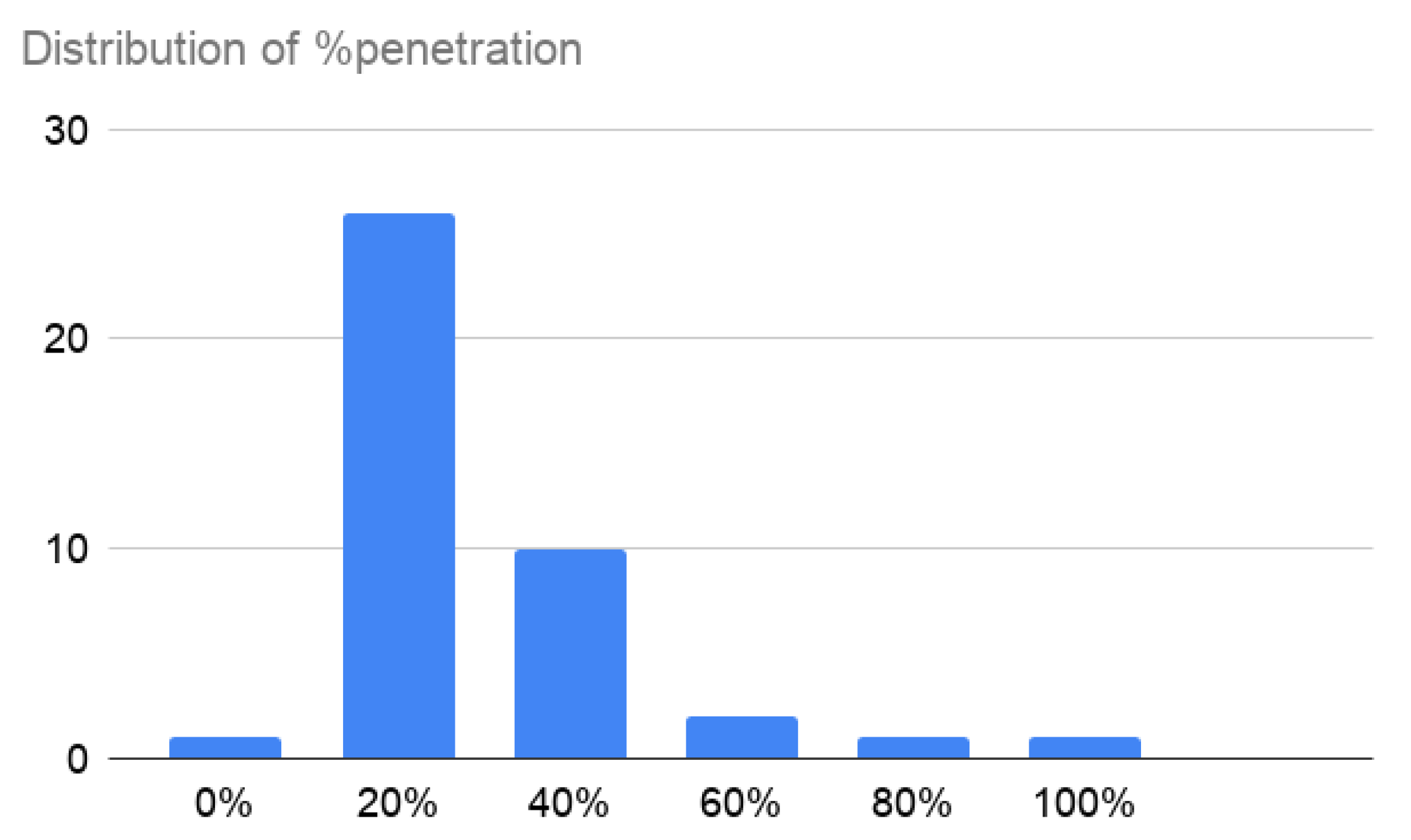
- A relatively high percentage of users is necessary for it to be effective. If we consider that approximately 70% of the population has a smartphone, we would be talking about the need to install it on 55% of the devices, something like 19 million users—an unattainable figure if we look at the percentages that have been achieved in the countries around us. It is necessary to combine it with other tools so that a lower rate is sufficient.
- Availability of risk maps reduces the peak of infections, but not the total number. Despite its benefits to control the saturation of the health system, it is not enough to stop the transmission.
- The combination of the information from risk maps to avoid areas with a high index of infections and alerts of exposure obtain good results even with relatively low penetration of the apps.
- A high number of users implies an increased number of alerts. The health system must be prepared to deal with them and test all suspicious persons.
- tracking applications are not a substitute for professionals but a supplement. We do not need contact tracing apps to alert about cases in the family, work colleagues, or friends. It is beneficial to identify possible contacts with strangers: on public transport, in stores, or entertainment venues.
- This type of application is vital in the early stages of the epidemic but is overflowing when there is community transmission.
- Contact tracings are safe applications, but that does not exempt us from privacy threats by social engineering mechanisms, such as the scenarios that appear in Anonymous tracing, a dangerous oxymoron, or also by the platform itself, as is the case of Google Play Services, as indicated in the report ’Contact Tracing App Privacy: Europe’s GAEN Contact Tracing Apps shares what Data.’ So do not be confident and take the same precautions as with other apps.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Vinuesa, R.; Theodorou, A.; Battaglini, M.; Dignum, V. A socio-technical framework for digital contact tracing. Results Eng. 2020, 8, 100163. [Google Scholar] [CrossRef]
- The European Data Protection Board. Guidelines 04/2020 on the Use of Location Data and Contact Tracing Tools in the Context of the COVID-19 Outbreak. Available online: https://edpb.europa.eu/our-work-tools/our-documents/usmernenia/guidelines-042020-use-location-data-and-contact-tracing{_}en (accessed on 1 June 2020).
- Klonowska, K.; Bindt, P. The COVID-19 Pandemic: Two Waves of Technological Responses in the European Union. Hague Centre for Strategic Studies, 2020. Available online: www.jstor.org/stable/resrep24004 (accessed on 17 May 2021).
- Simko, L.; Calo, R.; Roesner, F.; Kohno, T. COVID-19 Contact Tracing and Privacy: Studying Opinion and Preferences. 2020. Available online: https://arxiv.org/abs/2005.06056 (accessed on 17 May 2021).
- Apple; Google. Exposure Notifications: Using Technology to Help Public Health Authorities Fight COVID-19. Available online: https://www.google.com/covid19/exposurenotifications/ (accessed on 1 June 2020).
- Apple; Google. Privacy-Preserving Contact Tracing. Available online: https://www.apple.com/covid19/contacttracing (accessed on 1 June 2020).
- Rivest, R.L.; Weitzner, D.J.; Ivers, L.C.; Soibelman, I.; Zissman, M.A. PACT: Private Automated Contact Tracing. Available online: pact.mit.edu (accessed on 1 June 2020).
- Chan, J.; Foster, D.; Gollakota, S.; Horvitz, E.; Jaeger, J.; Kakade, S.; Kohno, T.; Langford, J.; Larson, J.; Sharma, P.; et al. Tracing. 2020. Available online: https://arxiv.org/abs/2004.03544 (accessed on 17 May 2021).
- Pan-European Privacy-Preserving Proximity Tracing. Available online: https://www.pepp-pt.org/ (accessed on 1 June 2020).
- Castelluccia, C.; Bielova, N.; Boutet, A.; Cunche, M.; Lauradoux, C.; Le Métayer, D.; Roca, V. ROBERT: ROBust and privacy-presERving proximity Tracing. Available online: https://hal.inria.fr/hal-02611265/file/ROBERT-v1.1.pdf (accessed on 17 May 2021).
- WeTrace. Privacy-Preserving Bluetooth Covid-19 Contract Tracing Application. Available online: https://wetrace.ch/ (accessed on 1 June 2020).
- Troncoso, C.; Payer, M.; Hubaux, J.P.; Salath, M.; Larus, J.; Bugnion, E.; Lueks, W.; Stadler, T.; Pyrgelis, A.; Antonioli, D.; et al. Decentralized Privacy-Preserving Proximity Tracing. April 2020. Available online: https://github.com/DP-3T/documents/DP3T/ (accessed on 17 May 2021).
- Ferretti, L.; Wymant, C.; Kendall, M.; Zhao, L.; Nurtay, A.; Abeler-Dörner, L.; Parker, M.; Bonsall, D.; Fraser, C. Quantifying SARS-CoV-2 transmission suggests epidemic control with digital contact tracing. Science 2020, 368. [Google Scholar] [CrossRef] [Green Version]
- Olfati-Saber, R.; Fax, J.A.; Murray, R.M. Consensus and Cooperation in Networked Multi-Agent Systems. Proc. IEEE 2007, 95, 215–233. [Google Scholar] [CrossRef] [Green Version]
- O’Neill, P.H.; Ryan-Mosley, T.; Johnson, B. A Flood of Coronavirus Apps Are Tracking Us. Now It’s Time to Keep Track of Them. Available online: https://www.technologyreview.com/2020/05/07/1000961/launching-mittr-covid-tracing-tracker/ (accessed on 7 May 2020).
- Dominguez-Garcia, A.D.; Hadjicostis, C.N. Distributed Matrix Scaling and Application to Average Consensus in Directed Graphs. IEEE Trans. Autom. Control 2013, 58, 667–681. [Google Scholar] [CrossRef]
- Rodríguez, P.; Graña, S.; Alvarez-León, E.E.; Battaglini, M.; Darias, F.J.; Hernán, M.A.; López, R.; Llaneza, P.; Martín, M.C.; Ramirez-Rubio, O.; et al. A population-based controlled experiment assessing the epidemiological impact of digital contact tracing. Nat. Commun. 2021, 12, 587. [Google Scholar] [CrossRef] [PubMed]
- González, M.; Hidalgo, C.; Barabási, A. Understanding individual human mobility patterns. Nature 2008, 453, 779–782. [Google Scholar] [CrossRef] [PubMed]
- McCulloch, J.H. On the Parametrization of the Afocal Stable Distributions. Bull. Lond. Math. Soc. 1996, 28, 651–655. [Google Scholar] [CrossRef]
- Yang, Z.; Zeng, Z.; Wang, K.; Wong, S.S.; Liang, W.; Zanin, M.; Liu, P.; Cao, X.; Gao, Z.; Mai, Z.; et al. Modified SEIR and AI prediction of the epidemics trend of COVID-19 in China under public health interventions. J. Thorac. Dis. 2020, 12, 165. [Google Scholar] [CrossRef] [PubMed]
- Gondim, J.A.; Machado, L. Optimal quarantine strategies for the COVID-19 pandemic in a population with a discrete age structure. Chaos Solitons Fractals 2020, 140, 110166. [Google Scholar] [CrossRef] [PubMed]
- Brugnago, E.L.; da Silva, R.M.; Manchein, C.; Beims, M.W. How relevant is the decision of containment measures against COVID-19 applied ahead of time? Chaos Solitons Fractals 2020, 140, 110164. [Google Scholar] [CrossRef] [PubMed]
- Gómez-Gardeñes, J.; Soriano-Paños, D.; Arenas, A. Critical regimes driven by recurrent mobility patterns of reaction–diffusion processes in networks. Nat. Phys. 2018, 14, 391–395. [Google Scholar] [CrossRef] [Green Version]
- Zipfel, C.M.; Colizza, V.; Bansal, S. Health inequities in influenza transmission and surveillance. PLoS Comput. Biol. 2021, 17, e1008642. [Google Scholar] [CrossRef] [PubMed]
- Xu, K.; Liu, L.; Liang, X. Complex networks: A mixture of power-law and Weibull distributions. arXiv 2009, arXiv:0908.0588. [Google Scholar]
- Vu, D.Q.; Asuncion, A.U.; Hunter, D.R.; Smyth, P. Dynamic Egocentric Models for Citation Networks. In Proceedings of the 28th International Conference on Machine Learning, ICML 2011, Bellevue, WA, USA, 28 June–2 July 2011; Getoor, L., Scheffer, T., Eds.; Omnipress: Madison, WI, USA, 2011; pp. 857–864. [Google Scholar]
- Rebollo, M.; Carrascosa, C.; Palomares, A. Consensus for Collaborative Creation of Risk Maps for COVID-19. In Trustworthy AI-Integrating Learning, Optimization and Reasoning; Heintz, F., Milano, M., O’Sullivan, B., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2021; pp. 32–48. [Google Scholar]
- Hinch, R.; Probert, W.; Nurtay, A.; Kendall, M.; Wymant, C.; Hall, M.; Lythgoe, K.; Cruz, A.B.; Zhao, L.; Stewartm, A.; et al. Effective Configurations of a Digital Contact Tracing App: A report to NHSX; Technical Report; University of Oxford: Oxford, UK, 2020. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
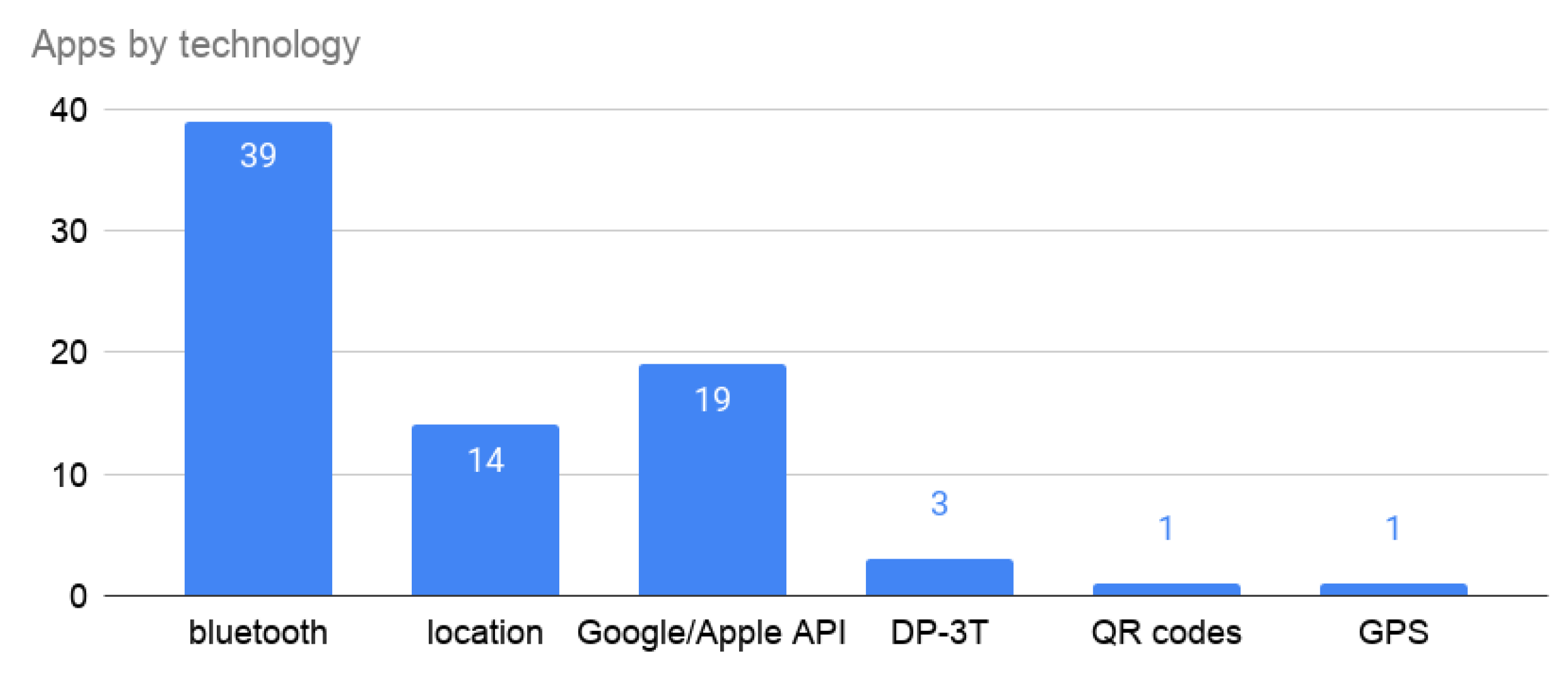
| Name | Location | Continent | Dep | Users | Pen | Tech | Voluntary | Limited | Min | Transp | Central | Status | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Algeria’s App | Algeria | Africa | Launched | ||||||||||
| COVIDSafe | Australia | Australia | gov | 7,160,909 | 28.64% | Bluetooth | Y | Y | Y | Y | Y | Centralized | Launched |
| Stopp Corona | Austria | Europe | ong | 600,000 | 6.77% | Bluetooth, Google/Apple | Y | Y | Y | Y | Y | Decentralized | Launched |
| BeAware | Bahrain | Asia | gov | 400,000 | 25.49% | Bluetooth, Location | Y | Y | N | N | Centralized | Launched | |
| Corona Tracer BD | Bangladesh | Asia | priv | 500,000 | 0.3% | Bluetooth, GPS | Y | Y | N | N | Centralized | Launched | |
| Coronalert | Belgium | Europe | gov | 970,000 | 8.37% | Bluetooth, Google/Apple, DP3T | Y | Y | Y | Y | Y | Decentralized | Launched |
| ViruSafe | Bulgaria | Europe | priv, gov | 55,000 | 0.79% | Location | Y | Y | Y | N | Y | Centralized | Launched |
| COVID Alert | Canada | America | priv | 5,314,026 | 14.03% | Bluetooth, Google/Apple | Y | Y | Y | Y | Y | Decentralized | Launched |
| Chinese health code system | China | Asia | gov | Location, Data mining | N | N | N | N | N | Centralized | Launched | ||
| CovTracer | Cyprus | Europe | acad | 9000 | 0.77% | Location | Y | N | Y | Y | Y | Decentralized | Launched |
| eRouska | Czech Republic | Europe | gov | 240,000 | 2.25% | Bluetooth | Y | Y | Y | Y | Y | Decentralized | Launched |
| Smitte|stop | Denmark | Europe | priv | 619,000 | 10.69% | Bluetooth, Google/Apple | Y | Y | Y | Y | Y | Decentralized | Launched |
| HOIA | Estonia | Europe | priv | 250,944 | 18.88% | Bluetooth, DP-3T, Google/Apple | Y | Y | Y | Decentralized | Launched | ||
| CareFiji | Fiji | Asia | gov | 27,000 | 3.06% | Bluetooth | Y | Y | Y | Decentralized | Launched | ||
| Koronavilkku | Finland | Europe | gov, priv | 2,500,000 | 45.31% | Bluetooth, Google/Apple | Y | Y | Y | Y | Y | Decentralized | Launched |
| TousAntiCovid | France | Europe | acad | 2,400,000 | 3.58% | Bluetooth | Y | Y | Y | Y | Y | Centralized | Re-launched |
| Corona-Warn-App | Germany | Europe | priv | 18,000,000 | 21.68% | Bluetooth, Google/Apple | Y | Y | Y | Y | Y | Decentralized | Launched |
| GH COVID-19 Tracker | Ghana | Africa | gov | Location | Y | N | N | N | Launched | ||||
| Beat Covid Gibraltar | Gibraltar | Europe | priv | 9000 | 26.69% | Bluetooth | Y | Y | Y | Y | Y | Decentralized | Launched |
| VirusRadar | Hungary | Europe | gov, priv | 35,000 | 0.36% | Bluetooth | Y | Y | Y | Y | Centralized | Launched | |
| Rakning C-19 | Iceland | Europe | gov | 140,000 | 38.45% | Location | Y | Y | Y | Y | Y | Both? | Launched |
| Aarogya Setu | India | Asia | gov | 163,000,000 | 12.05% | Bluetooth, Location | N | Y | Y | N | N | Centralized | Launched |
| PeduliLindungi | Indonesia | Asia | gov | 4,600,000 | 1.72% | Bluetooth, Location | Y | N | N | N | N | Centralized | Launched |
| AC19 | Iran | Asia | acad | 0 | 0.00% | NA | N | N | N | N | N | Launched | |
| Covid Tracker | Ireland | Europe | gov | 1,300,000 | 26.33% | Bluetooth, Google/Apple | Y | Y | Y | Y | Y | Decentralized | Launched |
| HaMagen 2.0 | Israel | Asia | gov | 2,000,000 | 22.51% | Location | N | Y | Y | Y | Y | Centralized | Launched |
| Immuni | Italy | Europe | priv | 9,769,449 | 16.19% | Bluetooth, Google/Apple | Y | Y | Y | Y | Y | Decentralized | Launched |
| COCOA | Japan | Asia | gov | 7,700,000 | 6.09% | Bluetooth, Google/Apple | Y | Y | Y | Y | Y | Decentralized | Launched |
| Shlonik | Kuwait | Asia | gov | Location | Y | N | N | N | Centralized | Launched | |||
| MyTrace | Malaysia | Asia | gov | 100,000 | 0.32% | Bluetooth | Y | N | Y | N | N | Decentralized | Launched |
| CovidRadar | Mexico | America | gov | 50,000 | 0.04% | Bluetooth | Y | N | N | N | N | Centralized | Launched |
| NZ COVID Tracer | New Zealand | Australia | gov | 605,751 | 12.45% | Bluetooth, QR codes, Google/Apple | Y | Y | Y | N | Y | Centralized | Launched |
| StopKorona | North Macedonia | Europe | priv | Bluetooth | Y | Y | Y | Y | Y | Decentralized | Launched | ||
| StopCOVID NI | Northern Ireland | Europe | gov | Bluetooth, Google/Apple | Y | Decentralized | Launched | ||||||
| Smittestopp | Norway | Europe | gov | 158,000 | 2.94% | Bluetooth, Google/Apple | Y | Y | Y | Y | Y | Decentralized | Launched |
| StaySafe | Philippines | Asia | priv | 2,000,000 | 1.87% | Bluetooth | Y | N | N | N | N | Decentralized | Launched |
| ProteGO Safe | Poland | Europe | gov | 725,000 | 1.91% | Bluetooth, Google/Apple | Y | Y | Y | Y | Y | Decentralized | Launched |
| Ehteraz | Qatar | Asia | gov | 2,531,620 | 91.00% | Bluetooth, Location | N | N | N | N | Centralized | Launched | |
| Tawakkalna | Saudi Arabia | Asia | gov | 7,000,000 | 20.77% | Location | Y | N | Y | N | N | Centralized | Launched |
| Tabaud | Saudi Arabia | Asia | gov | Bluetooth, Google/Apple | Y | Y | Y | Y | N | Decentralized | Launched | ||
| TraceTogether | Singapore | Asia | gov | 4,511,200 | 80.00% | Bluetooth, BlueTrace | N | N | Y | N | Y | Centralized | Launched |
| COVID Alert SA | South Africa | Africa | gov | 600,000 | 1.0% | Bluetooth, Google/Apple | Y | Y | Y | Y | Decentralized | Launched | |
| RadarCOVID | Spain | Europe | priv | 7.033.536 | 17% | Bluetooth, DP-3T, Google/Apple | Y | Y | Y | Y | Decentralized | Launched | |
| SwissCovid | Switzerland | Europe | acad | 1,600,000 | 18.67% | Bluetooth, DP-3T, Google/Apple | Y | Y | Y | Y | Y | Decentralized | Launched |
| MorChana | Thailand | Asia | gov | 3,690,000 | 53.15% | Bluetooth, Location | Y | N | N | Decentralized | Launched | ||
| E7mi | Tunisia | Asia | gov | 23,140 | 0.20% | Bluetooth | Y | Y | Y | N | N | Centralized | Launched |
| Hayat Eve Sığar | Turkey | Asia | gov | 14,186,000 | 17.30% | Bluetooth, Location | N | N | N | Y | N | Centralized | Launched |
| TraceCovid | UAE | America | gov | Bluetooth | N | Y | N | Decentralized | Launched | ||||
| NHS COVID-19 App | UK | Europe | gov | 19,000,000 | 28.51% | Bluetooth, Google/Apple | Y | Y | Y | Y | Y | Decentralized | Launched |
| BlueZone | Vietnam | Asia | gov | 20,000,000 | 20.93% | Bluetooth | Y | Y | N | N | Y | Decentralized | Launched |
| | | ||||
|---|---|---|---|---|
| 0 | 0 | 0 | 1 | |
| 1 | 0 | 0 | 0 | |
| 0 | 1 | 0 | 0 | |
| 1 | 0 | 0 | 0 | |
| 0 | 0 | 1 | 0 | |
| 0 | 0 | 1 | 0 | |
| 1 | 0 | 0 | 0 | |
| total | 3 | 1 | 2 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 45 | 0 | 0 | 0 | |
| 10 | 8.1 | 12.3 | 8.6 | 13.2 | 9.5 | 49.2 | 48.3 | 40.1 | 12.5 | 22 | 9.6 | 11.4 | 8.8 | |
| R | 9.9 | 10.1 | 9.9 | 9.9 | 12.2 | 11.3 | 50.3 | 55.6 | 53.1 | 15.4 | 21.8 | 9.9 | 10.9 | 10.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rebollo, M.; Benito, R.M.; Losada, J.C.; Galeano, J. Improvement of Contact Tracing with Citizen’s Distributed Risk Maps. Entropy 2021, 23, 638. https://doi.org/10.3390/e23050638
Rebollo M, Benito RM, Losada JC, Galeano J. Improvement of Contact Tracing with Citizen’s Distributed Risk Maps. Entropy. 2021; 23(5):638. https://doi.org/10.3390/e23050638
Chicago/Turabian StyleRebollo, Miguel, Rosa María Benito, Juan Carlos Losada, and Javier Galeano. 2021. "Improvement of Contact Tracing with Citizen’s Distributed Risk Maps" Entropy 23, no. 5: 638. https://doi.org/10.3390/e23050638
APA StyleRebollo, M., Benito, R. M., Losada, J. C., & Galeano, J. (2021). Improvement of Contact Tracing with Citizen’s Distributed Risk Maps. Entropy, 23(5), 638. https://doi.org/10.3390/e23050638