2.1. Ecological Couplings
To straightforwardly apply information theory, rather than represent the network as a graph, one uses an
incidence matrix
Y. The rows and column of such a matrix represent the species of the two trophic levels. For bipartite networks, the
n rows represent the species of one interaction level, while the
m columns represent the species of the other interaction level. An incidence matrix can contain information regarding the frequency or strength of the interactions (i.e., a weighted matrix) or solely indicate the presence or absence of an interaction (i.e., a binary matrix). Binary observations of interactions are more frequently recorded than weighted descriptions of interaction networks [
27]. A binary representation could be seen as a loss of information, as every interaction becomes equally important [
28]. However, taking the strength of interactions into account can also lead to mistakes, since the observed frequencies do not always reflect the true frequencies. Quantitative observations of interactions strongly depend on the sampling effort [
8], and they often result in undersampling [
29]. In this work, we opted to illustrate our methods on binary incidence matrices (possibly obtained through binarizing, i.e., mapping non-zero values to one).
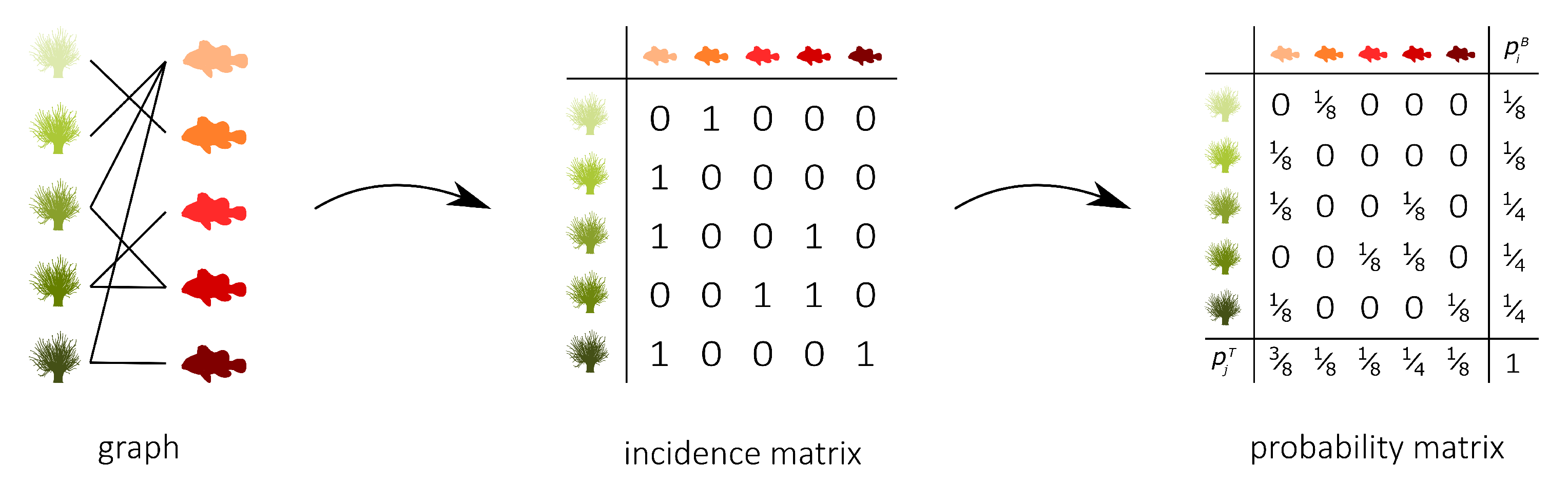
Figure 1 (middle) shows the binary incidence matrix
Y of the bipartite interaction network between anemone species and fish species. The
n rows and
m columns of the matrix
Y represent, respectively, the anemone species (i.e., the bottom interaction level) and the fish species (i.e., the top interaction level). A matrix element
is equal to 1 if the species
i of the bottom interaction level interacts with species
j of the top interaction level and it is equal to 0 otherwise. In the incidence matrix shown in
Figure 1 (middle), 1 indicates that anemone species
i is visited by fish species
j, while 0 indicates the opposite. However, an interaction between two species is not a pure yes–no event, as the interaction may be rare or depend on several local and behavioural circumstances. As such, we follow Poisot et al. [
30] and compute the
probability matrix
P of the joint distribution as
This value can be interpreted as the probability that species
i interacts with species
j.
In our earlier work, we called this normalized incidence matrix an
ecological coupling [
31]. This coupling arises from random and targeted interactions between the species and it is dependent on the relative species abundances.
In the context of mutualistic symbiosis between anemones and fishes, as shown in
Figure 1 (right),
is the probability that anemone species
i is visited by fish species
j. When interactions are associated with the energy transfers between trophic levels, as in food webs,
P can be interpreted as the probability distribution of the system’s energy flow. The incidence matrix reveals the distribution of the energy flow from the bottom of the network, the energy source, to the top of the network, the energy sink [
32].
The marginal distributions of both interaction levels can be computed as
where
is the probability that bottom species
i establishes an interaction and
is the probability that top species
j establishes an interaction. Note that we introduced two random variables,
B and
T, for the bottom species and the top species, respectively. The probability matrix
P can be augmented to indicate the marginal probabilities, as shown in
Figure 1 (right). In this matrix,
is the probability that anemon species
i is visited and
is the probability that a visit is made by fish species
j.
2.2. Information Theory for Interaction Networks
Given the above probabilistic interpretation, measures that were borrowed from the field of information theory can be applied to characterise interaction networks. Foremost, we recall the concept of
entropy, which is defined for a random variable
X, as
where
is the probability mass function of
X [
13]. By convention,
is evaluated as 0 [
33].
Therefore, values with zero probability will have no influence [
34]. The logarithm to the base two is commonly used [
35]. Therefore, we will drop the explicit notation of the base.
When base two is used, all of the information-theoretic measures are expressed in bits [
36].
Entropy conveys how much information is contained in an outcome and, thus, how surprising a particular outcome is [
18]. When the probabilities of all possible outcomes are equal (i.e.,
X is uniformly distributed), the entropy is maximal, since the effective outcome is the most difficult to guess [
34,
37]. Imagine the situation where a fish has to choose between a green and an orange anemone. The random variable
X represents the outcome of the experiment and
is the probability that
X takes value
x. If both anemone species are equally desirable, then the probability distribution
is uniform. The probability that the fish chooses the orange anemone is equal to the probability of choosing the green one, namely
. The entropy is now maximal, since every outcome is equally likely and, thus, equally surprising. When every outcome is of equal probability, we obtain the largest amount of information by observing the outcome of the experiment, since the effect was the hardest to predict. Suppose that the green anemone species would be less desirable, with the probability of being chosen equal to
. In that case, the entropy is reduced to 0.54 bits, which is less than the maximal entropy of one bit when both anemone species are equally desirable. The probability distribution is no longer uniform when one colour is preferred over the other, since it is much more likely that the fish chooses the orange anemone. The more the distribution deviates from the uniform distribution, the less information we obtain by observing the outcome, since we know better what outcome to expect. The entropy is equal to zero in the extreme case where the probability of selecting the orange anemone would be one. We obtain no new information from observing which colour the fish chooses, since we already knew that the outcome would be orange. We can extend this simple example of one fish choosing an interaction partner to an incidence matrix that represents multiple ecological interactions.
The entropies of the marginal distributions of the bottom species
B and the top species
T, the
marginal entropies, can be computed as
The
joint entropy of the bivariate distribution is computed as
The marginal entropies quantify the equality of the species at the bottom and top interaction level, or, in the context of mutualistic symbiosis between anemones and fishes, the equality of the anemone species and fish species, respectively. A large value indicates that the marginal distribution of the species of the interaction level is close to a uniform distribution. In contrast, a low value indicates that some species dominate the interactions more than others. On the other hand, joint entropy can be used to analyse the distribution of the interactions.
When the logarithm to base two is used, the entropy is expressed in bits. In this case, we can interpret entropy as the minimal number of yes–no questions that are, on average, required to learn the outcome of an experiment [
38]. For species interactions, this boils down to the average number of questions needed to identify an interaction or interaction partner. The answer to these questions is ‘yes’ (1) or ‘no’ (0), so one bit is needed to store the information. For example, suppose that an ecosystem contains four species (
a,
b,
c, and
d) that occur with relative frequencies
,
,
, and
. Because species
a is most abundant, the first question one might ask to identify a species is “Is it species
a?”. In the fifty percent of the cases that the answer is ‘yes’, one has identified the species using a single question. If the answer is ‘no’, then one has to ask additional questions. The next natural question would be “Is it species
b?”. Again, if the answer is ‘yes’, one has identified the species; otherwise, one has to pose a third question. This question could be “Is it species
c?”, which settles the matter as we were left with only two options (
c and
d). Because we can identify
a using a single question (50% of the cases),
b using two questions (25% of the cases), and
c and
d using three questions (12.5% of the cases each), we can identify the species using an average of 1.75 questions. Given that the entropy of this system equals
we know that this scheme is optimal. However, if the species would be present in equal proportions, this scheme would no longer be optimal, as it now requires 2.25 questions on average. In this case, a different set of questions, starting with, for example, “Is it species
a or
b?”, followed by a question to distinguish between the remaining two options, would be optimal. This scheme always requires two questions. Because the entropy of a uniform discrete distribution on a set of four elements is equal to 2, we know that we cannot improve this scheme. This interpretation of entropy expressed in bits as the average number of questions required to identify the interaction or interaction partner is also applicable to other information-theoretic measures, as presented later in this work.
The
conditional entropy of
B given
T, and vice versa, are defined as
and
These measures quantify the average uncertainty that remains regarding the top species when the bottom species is known and the average uncertainty that remains with regard to the bottom species when the top species is known, respectively. In the example of mutualistic symbiosis between anemones and fishes, these measures quantify the remaining uncertainty regarding the fish, respectively, anemone species, given that the anemone species, respectively, fish species, is known. Suppose that, for instance, each fish species visits a single anemone species and that each anemone species is visited by a single fish species. In that case, the marginal entropy of both anemone species and fish species is maximal, since both marginal distributions are uniform. However, the conditional entropy is zero because an anemone species is only visited by a single fish species. There is no freedom of choice. If we know the anemone species, then there is no more uncertainty regarding the interacting fish species, since each anemone species is only visited by one specific fish species. Conditional entropy can also be interpreted as the average number of questions needed to identify an interaction partner, as explained above. When the conditional entropy is zero, there is no freedom of choice and no uncertainty about the interaction partner. Therefore, no questions will need to be asked. A conditional entropy that is different from zero indicates that there is remaining uncertainty [
39], thus, freedom of choice, for the anemone species or fish species. In that case, questions are needed in order to identify the interaction partner since there are multiple possibilities.
The specificity of the interactions can be more directly quantified by the
mutual information:
which is symmetric with respect to
B and
T, i.e.,
, and that always satisfies
. Mutual information quantifies the average reduction in uncertainty regarding
B, given that
T is known, or vice versa. It expresses how much information about
B is conveyed by
T, or how much information regarding
T is conveyed by
B. When
B and
T are independent,
B holds no information about
T, or vice versa; therefore,
is equal to zero [
40]. Mutual information can be interpreted as a measure of the efficiency of an interaction network [
39], as high mutual information implies that the species are highly specialised towards a single or a few ecological partners [
41].
Finally, the
variation of information is defined as
This measure is the difference between the joint entropy and mutual information. It is the sum of the average remaining uncertainty regarding the bottom species and top species when, respectively, the top and bottom species are known. In the example of mutualistic symbiosis between anemones and fishes, it is the sum of the average remaining uncertainty about the anemone species when the fish species is known and the average remaining uncertainty about the fish species when the anemone species is known. It captures the residual freedom of choice of the species, and it can be interpreted as a measure of stability [
15]. The more redundant interactions, the higher the resistance of the network against the extinction of interaction partners [
3]. The variation of information and, thus, the stability of the network, can increase when the number of possible interaction partners of the species increases or when the interactions become more equally distributed, thus increasing the uncertainty.
Rearranging the formula above results in the relation between the joint entropy, mutual information, and variation of information:
This formula suggests a trade-off between mutual information (i.e., efficiency) and the variation of information (i.e., stability) for an interaction network with a given joint entropy. The ecological interpretation hereof will be discussed more extensively later in this section.
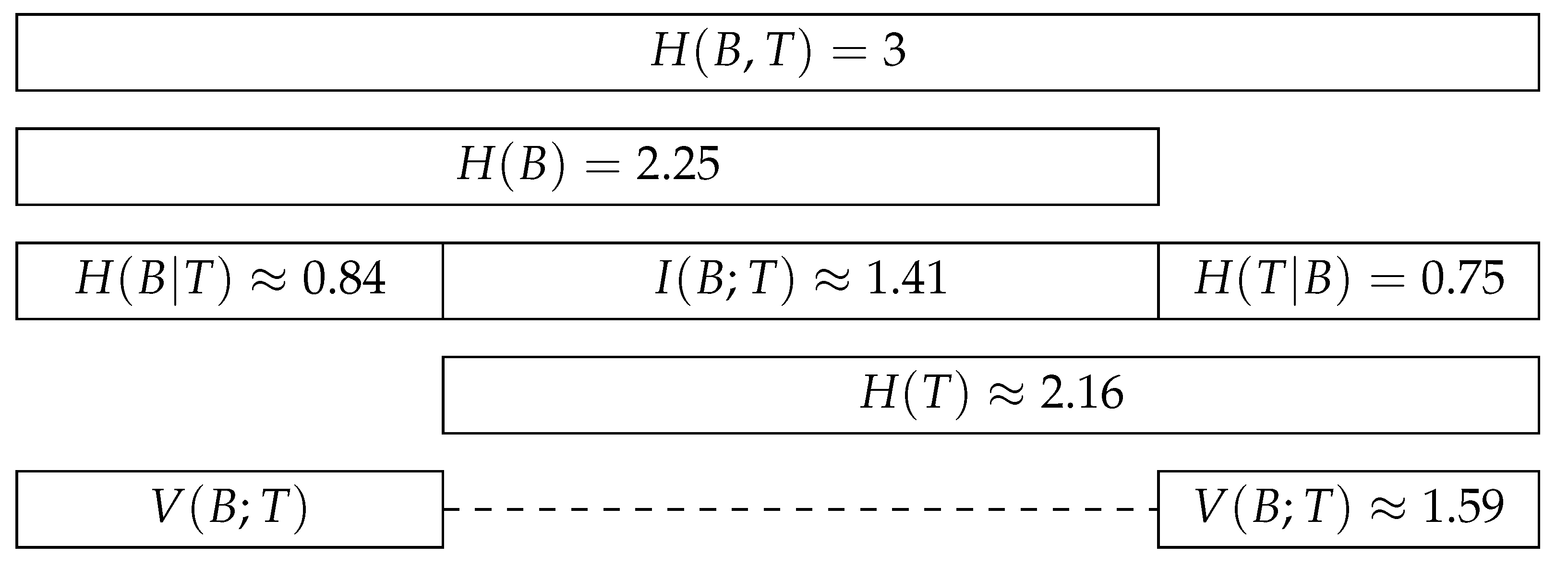
The information-theoretic decomposition of an interaction network can be visualised in a bar plot [
37], as opposed to more misleading Venn diagrams. This bar plot displays the relationships between the joint entropy, the marginal entropies, the conditional entropies, and the mutual information of an interaction network. The variation of information is indirectly represented, as it is the sum of the two conditional entropies. The barplot shown in
Figure 2 displays the information-theoretic decomposition of the interactions between the five anemone species and five fish species presented in
Figure 1. The contributions of the different components to the joint entropy and their relative importance can be analysed and interpreted using this plot.
The above-defined measures can be linked to a uniform distribution, whose entropy is always maximal. When the interactions are uniformly distributed over the
n species of the bottom interaction level, every species has the same probability of interaction
, namely
. Therefore, when the probability distribution is uniform, the marginal entropy of the bottom species can be computed as
Similarly, the marginal entropy of uniformly distributed top species can be computed as
Finally, every interaction is equally likely when the joint distribution is uniform. A network with
n bottom species and
m top species comprises
potential interactions. Therefore, in the case of a uniform joint distribution, every interaction has the same probability
, namely
. Thus, the joint entropy of the uniform distribution can be computed as
and it is equal to the sum of the two marginal entropies
and
.
The differences in entropy between the uniform distributions and the corresponding true distributions are defined as
These measures quantify how much each distribution deviates from the corresponding uniform distribution [
42]. Note that the difference for the joint distribution is not equal to the difference beweten the entropy of a uniform bivariate distribution and the joint entropy, but rather to the sum of the marginal differences in entropy. We can see
as the joint entropy of the random vector
, while assuming that
B and
T are independent. This renders the differences in entropy being additive, while joint entropy is not.
The difference in entropy as compared to a uniform distribution, the mutual information, and the variation of information are related by the following balance equation [
42]:
This can be demonstrated by combining the equations shown above:
The balance equation can be decomposed into the separate contributions of the marginal distributions of the bottom and top species:
Note that this equation also illustrates why the term
occurs twice in the global balance equation. These equations show how the maximal potential information of an ecological network is divided into a component expressing that some species are more important or active than others (D), a component that is related to the specific interactions between species (I) and a final component comprising the remaining freedom of the interactions (V).
Table 1 presents an overview of these components of the decomposition, for the marginal distributions as well as the joint distribution.
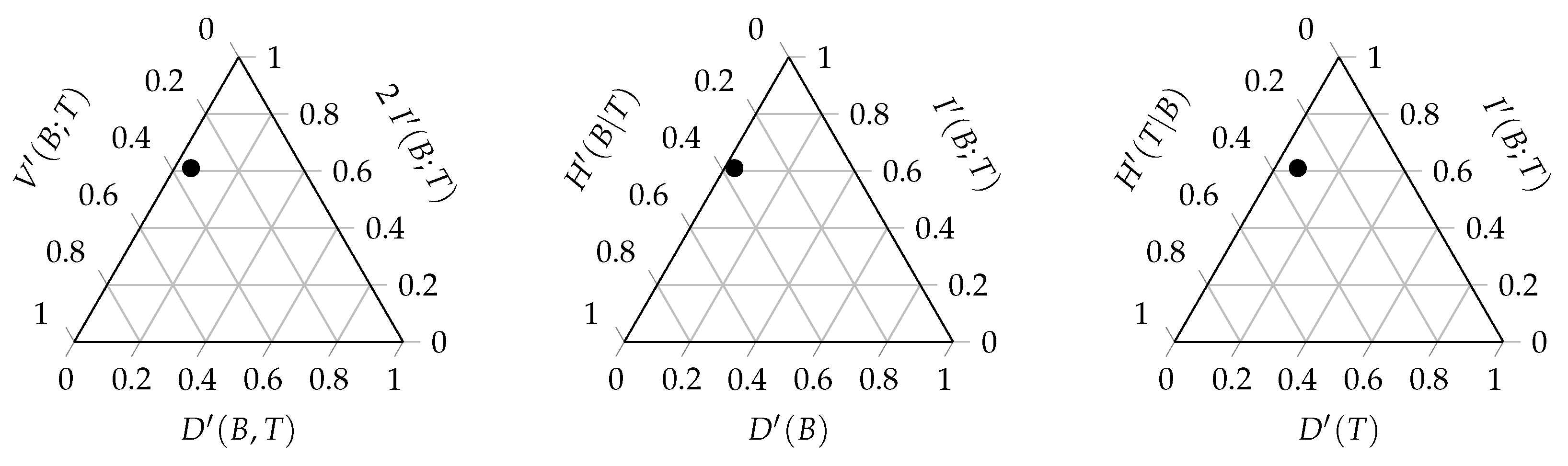
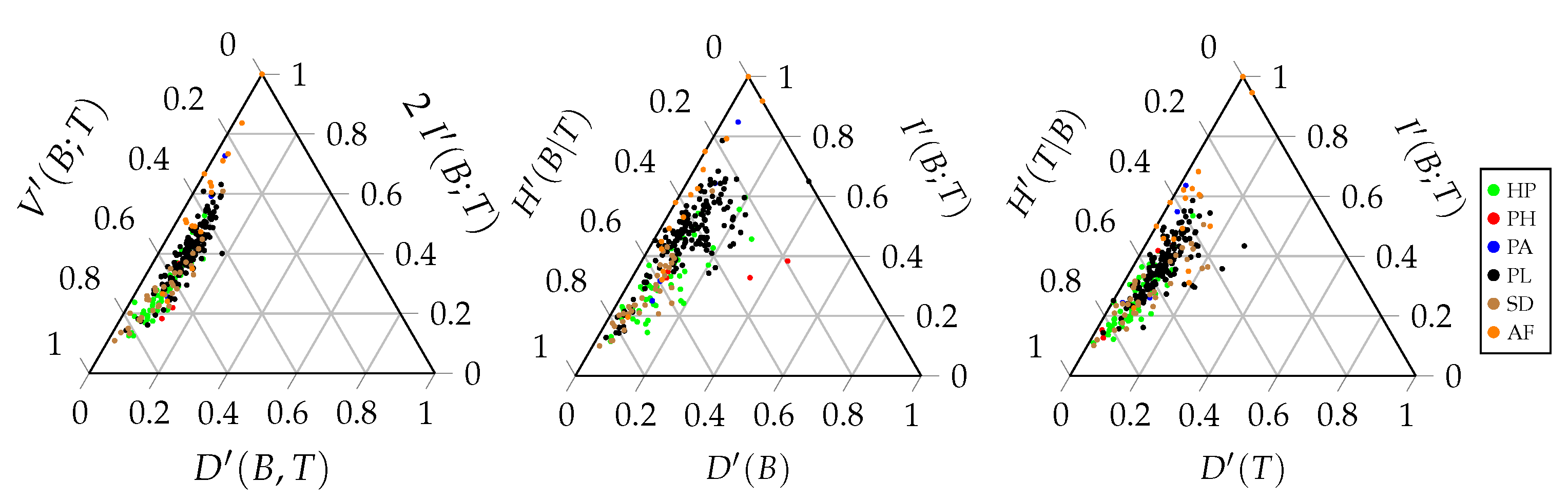
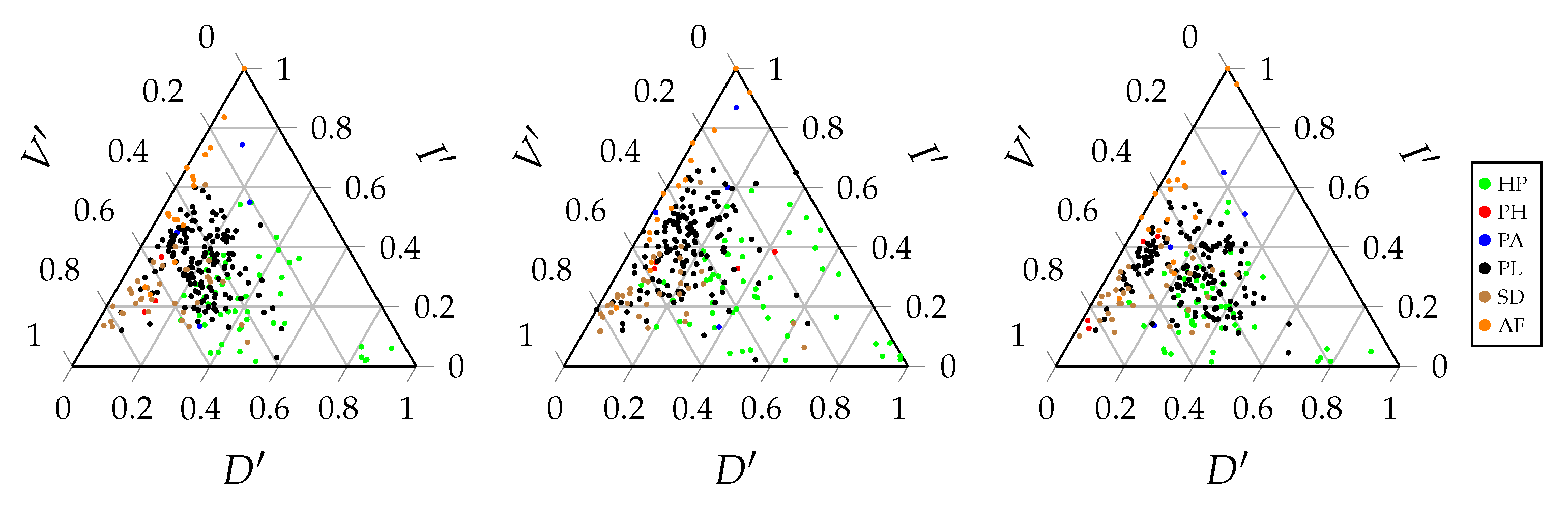
A ternary entropy diagram or entropy triangle plot can be used to visualise the different components of the balance equation. Each side of the triangle corresponds to one of these three components. The entropy triangle enables a direct comparison of different networks, since each network will be represented by a single dot in the triangle. Such a diagram can be constructed for the total balance equation, as well as for the marginal balance equations of the bottom and top interaction level.
Figure 3 displays these three entropy triangles. In order to determine the location of a network in the triangle, the balance equation is normalised by dividing all the components of the equation by the entropy of the corresponding uniform distribution [
42]. For the triangle of the joint distribution, the computation of the three coordinates of a network is based on the following normalised equation:
Recall that
. Each term of this sum corresponds to the coordinate of the network on one of the three sides of the triangle. Normalising the components of the balance equation by the maximal entropy results in values that are between zero and one that can be plotted on the triangle. The same applies for the balance equations of the marginal distributions:
A prime is added to the corresponding symbol to denote the normalised component, as used in the entropy triangle. For the total balance equation, this results in:
The left side of the entropy triangle corresponds to no deviation from the uniform distribution. The interactions of a network located at this side are uniformly distributed. Therefore, the potential freedom of choice is maximal. The bottom side of the entropy triangle corresponds to no mutual information between the interaction levels. The bottom species convey no information regarding the top species and
vice versa. This indicates that there is no specialisation in the network. Finally, the right side of the triangle corresponds to no variation of information. There is no residual freedom of choice for the bottom and top species. Therefore, the stability of the network is low. The location of a network on the triangle gives us information regarding the importance of the different components of the balance equation and, hence, the interaction network structure. Networks that are located close to each other on the triangle will have a similar structure.
Three fictive interaction networks with extreme distributions are added to the triangle shown in
Figure 4 in order to illustrate the use of the balance equation and the entropy triangle. These three extreme situations correspond to the three vertices of the triangle. To ease the interpretation, they are presented as interactions between anemone species and fish species.
Table 2 contains the corresponding incidence matrices and their information-theoretic decomposition. Note that the presented matrices are binary matrices. The observations need to be converted to probabilities before information theory can be applied.
The upper vertex of the triangle shown in
Figure 4 represents a network with a uniform distribution. Its variation of information is zero, while the mutual information is maximal. This situation corresponds to the left incidence matrix presented in
Table 2, which is an example of perfect specialisation. Each fish species interacts with one specific anemone species and
vice versa. The mutual information between the anemone species and fish species is maximal. If we know which fish species participated in an interaction, then we immediately know which anemone species was visited, as there is only one possibility. Similarly, if we know which anemone species was visited, then we immediately know the interacting fish species. Knowing the fish species reduces the uncertainty regarding the anemone species completely and knowing the anemone species reduces the uncertainty about the fish species completely. Therefore, the variation of information is equal to zero. There is no residual uncertainty and, thus, no freedom of choice. Such a network is maximally efficient, but vulnerable, since the limitations on possible interactions between the bottom and top species are very strict. In the absence of its specific anemone species, a fish species has no symbiotic partner. Because both marginal distributions are uniform, the deviation from the uniform distribution is zero.
The bottom-right vertex represents a network deviating maximally from the uniform distribution, while the mutual information and variation of information are zero. These characteristics correspond to the middle incidence matrix shown in
Table 2, where one interaction is dominating the network. The variation of information is again equal to zero, but the mutual information is now also zero. Knowing the anemone species does not further reduce the uncertainty regarding the fish species, since there is simply no uncertainty, as there is only one possible interaction. However, the deviation from the uniform distribution is maximal, since both marginal distributions deviate completely from the uniform distribution as one interaction dominates the network.
Finally, the bottom-left vertex represents a network with no mutual information between the interaction levels and a maximal variation of information, while the deviation from the uniform distributions is zero. Therefore, freedom of choice is maximal. The right incidence matrix that is presented in
Table 2 is an example of such a network, where each fish species interacts with every anemone species. The network is homogeneous, without any specialisation. Similar to the first incidence matrix, the deviation from the uniform distribution is equal to zero. However, the mutual information is now also zero. Knowing the anemone species does not reduce the uncertainty regarding the fish species, since every interaction is equally possible. On the other hand, the variation of information is maximal. In contrast to the left incidence matrix, this network has high stability. In the absence of one or even multiple anemone species, a fish species has plenty of other interaction options. The freedom of choice of the anemone species and fish species is not restricted at all. However, the network has a low efficiency as a result of the trade-off between stability and efficiency.
In
Figure 4, the real interaction network between the anemone species and fish species is also added to the entropy triangle. The network is located very close to the left side of the triangle, which indicated that the deviation from the uniform distribution is minimal. Its structure lies somewhere in between the homogeneous network structure where each fish species interacts with every anemone species and the perfectly specialised network where each fish species interacts with one specific anemone species, but is slightly closer to perfect specialisation. A visual comparison of the interaction networks that are shown in
Figure 4 supports this result.
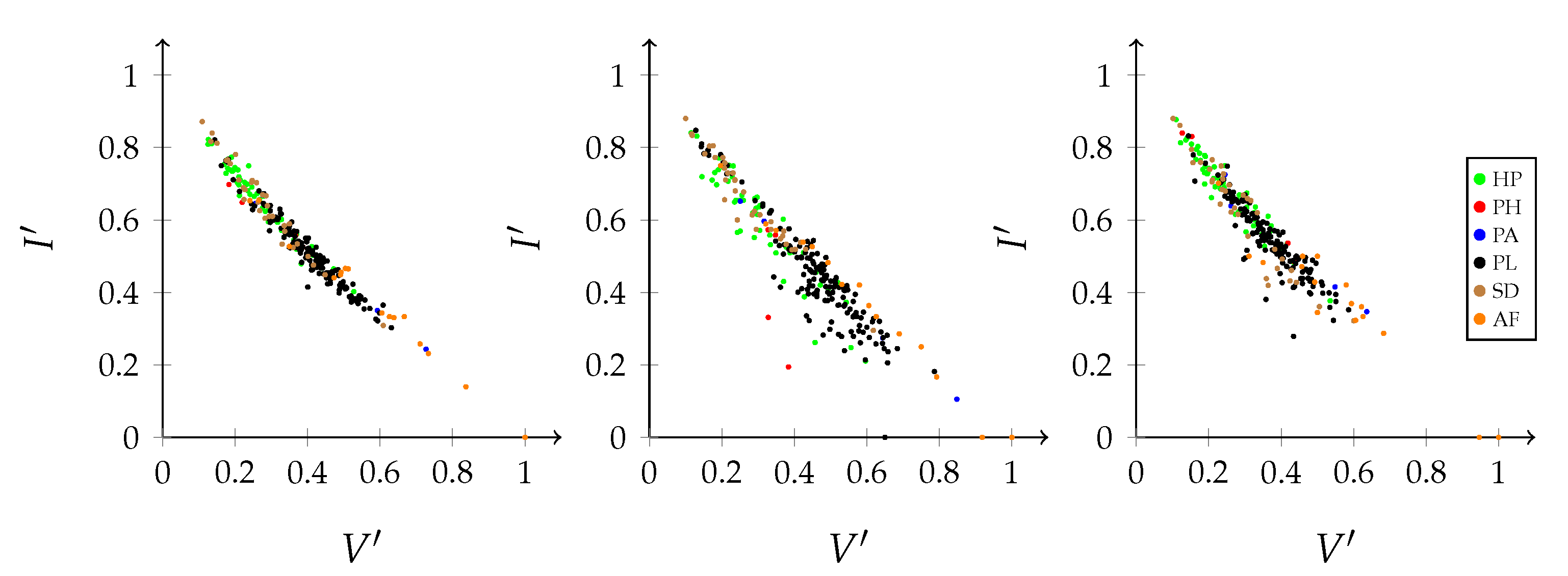
Figure 3 displays the entropy triangles of the joint distribution and the marginal distributions of this example. The black dot represents the real interaction network between anemone species and fish species. The three extreme interaction networks still correspond to the same three vertices of the triangle. Their location on the marginal triangles is the same as on the joint triangle because the marginal distributions of the bottom and top interaction level are identical in each network. Note that this is not always true and it entirely depends on the structure of the network. The location of the real interaction network is slightly different in the three triangles, but is still very similar. The marginal distribution of the top species deviates slightly more from the uniform distribution than the marginal distribution of the bottom species.
As demonstrated above, the balance equation indicates a trade-off between efficiency and stability: one comes at the cost of the other [
39,
43]. For example, Gorelick et al. [
44] used entropy and mutual information to quantify the division of labour. Their method is similar to the information-theoretic decomposition described above and the subsequent normalisation in the entropy triangle. When species have a wider variety of interaction partners, their freedom of choice becomes larger. Therefore, the overall network stability increases [
32], but the efficiency of the interactions decreases as they are less specialised [
44].
Figure 5 illustrates this antagonistic relation. In this graph, the deviation from the uniform distribution is assumed to be constant. Therefore, the joint entropy of the network and, thus, the diversity of the network, remains constant. The variation of information increases with an increasing freedom of choice at the expense of the contribution of the mutual information. In a changing environment, stability will be an essential network characteristic. However, in a stable environment, efficiency will be a key factor [
39]. The same graph can be constructed for the marginal distributions of the interaction levels, based on the decomposition of the balance equation into the separate contributions of the interaction levels.
Table 3 summarises the elements of the information-theoretic decomposition of an interaction network and their ecological interpretation. Example networks are added in order to aid the interpretation.
Vázquez et al. [
45] list several mechanisms that could explain the structure of an interaction network. The influence of these mechanisms can be linked to the components of the balance equation. The first mechanism, interaction neutrality, causes all individuals to have the same interaction probability. For binary incidence matrices, where the frequencies are not taken into account, this situation corresponds to a uniform distribution of the interactions and, thus,
, the left-hand side of the balance equation. Other mechanisms will influence the distribution of the interactions and, therefore, influence the individual contributions of the three components at the right-hand side of the balance equation. Trait matching, for example, results in some interactions being favoured, while other interactions are impossible. The mutual information will increase as interactions become more efficient. However, as a result of the trade-off, the variation of information and stability will decrease as interactions are restricted. The spatio-temporal distribution will also influence the interactions. Species cannot interact if they are not at the same location at the same time. This can also be taken into account in the information-theoretic decomposition. Location, as well as time, can be introduced as an additional variable, in addition to the bottom and top interaction levels
B and
T. It will impose a further restriction on the interactions, leading to increased mutual information and a decrease in the variation of information. This notion will be discussed in
Section 2.4. As mentioned before, Vázquez et al. [
45] also note that observed interaction networks do not always match the true interactions due to sampling artefacts. Therefore, sampling can also influence the observed interaction structure and information-theoretic decomposition.
2.4. Higher-Order Diversity
So far, only information-theoretic indices for two variables, which represent the bottom and top interaction levels, have been considered. However, the formulas introduced above can be easily extended to three or more variables. In the case of three variables, the third discrete variable
Z could represent an additional species level, but also a different influencing factor, such as the location of the interaction, the time, or an environmental variable. The
joint entropy of three variables can be computed as
Other information-theoretic measures can be extended by conditioning them on the third variable
Z. For example, for the mutual information, we have
In a similar way, we can compute
and
(for more information, see MacKay [
37] and Cover and Thomas [
38]). Note that, in our framework, we currently do not consider expressions, such as
and
. Only conditioning on a single variable is allowed. Some information theorists provide an interpretation for such multivariate measures [
46], although as of yet there does not seem to be a consensus. We leave the ecological interpretation of such measures for future work.
For instance, consider the case where
Z represents the location. By including this third variable in the indices, the influence of location on the uncertainty can be accounted for. In this way, entropy can be used to quantify alpha, beta, and gamma diversity. Alpha diversity is defined at a local scale, at a particular site [
22]. This can be expressed by the conditional entropy given that the location is known:
The alpha entropy
quantifies the remaining uncertainty regarding the interactions when their location is known. Beta diversity, on the other hand, expresses the differentiation between local networks [
22]. Therefore, beta entropy is the reduction in uncertainty that results from learning the location [
25]:
Using the chain rule for entropy [
38], it can be shown that
is also equal to the marginal entropy
of the location. Gamma diversity is the total diversity of an entire region. Because there is no knowledge regarding the location and, hence, also no reduction in uncertainty, gamma entropy can be quantified as
The relation between alpha, beta, and gamma entropy is given by:
These entropies can also be converted to effective numbers in the same way as above to be able to easily compare the alpha, beta, and gamma entropies, and interpret them as measures of interaction diversity:
By converting these entropies to effective numbers, the relation between alpha, beta, and gamma diversity, as proposed by Whittaker [
47], is retrieved:
Beta diversity can be quantified as the ratio between regional (i.e., gamma) and local (i.e., alpha) diversity [
48].
The effective numbers have an interesting interpretation. corresponds to the effective number of interactions over the networks, while represents the effective number of unique interactions per individual network. Subsequently, we can interpret as the effective number of unique networks.
Figure 6 presents two fictive incidence matrices for two different locations to illustrate the use of alpha, beta, and gamma entropy, and the conversion to effective numbers. The joint incidence matrix of the bottom interaction level, top interaction level, and location contains ten binary interactions. Therefore, the non-zero
values are equal to
. Alpha, beta and gamma entropy can be computed using the formulas that are derived above. As mentioned earlier, the entropies do not obey the doubling property. Converting them to effective numbers eases the interpretation.
Figure 6 presents the resulting values.
indicates that the interactions in the entire region, comprising the two locations, are almost twice as diverse as the local interactions. Inferring this directly from the value of
is less straightforward.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
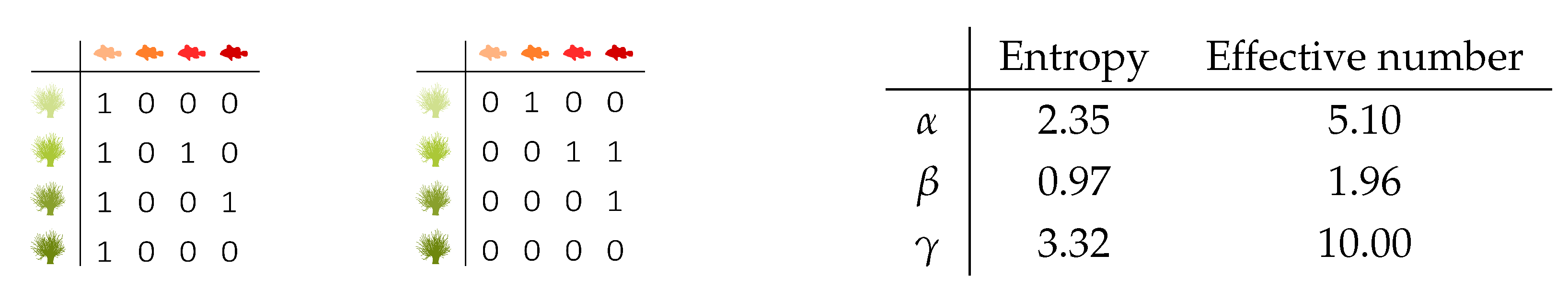{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







