
Improved Local Search with Momentum for Bayesian Networks Structure Learning




Abstract
:1. Introduction
2. Background
2.1. Bayesian Networks
2.2. Scoring Function
3. Methodology
3.1. ILS over the DAG Space
| Algorithm 1 ILSG algorithm |
| input: Dataset D Output: Optimal structure and its score BIC 1: 2: 3: 4: while (termination condition is not met) do 5: 6: 7: 8: 9: if soft restart condition is met then 10: 11: end if 12: end while 13: return , BIC |
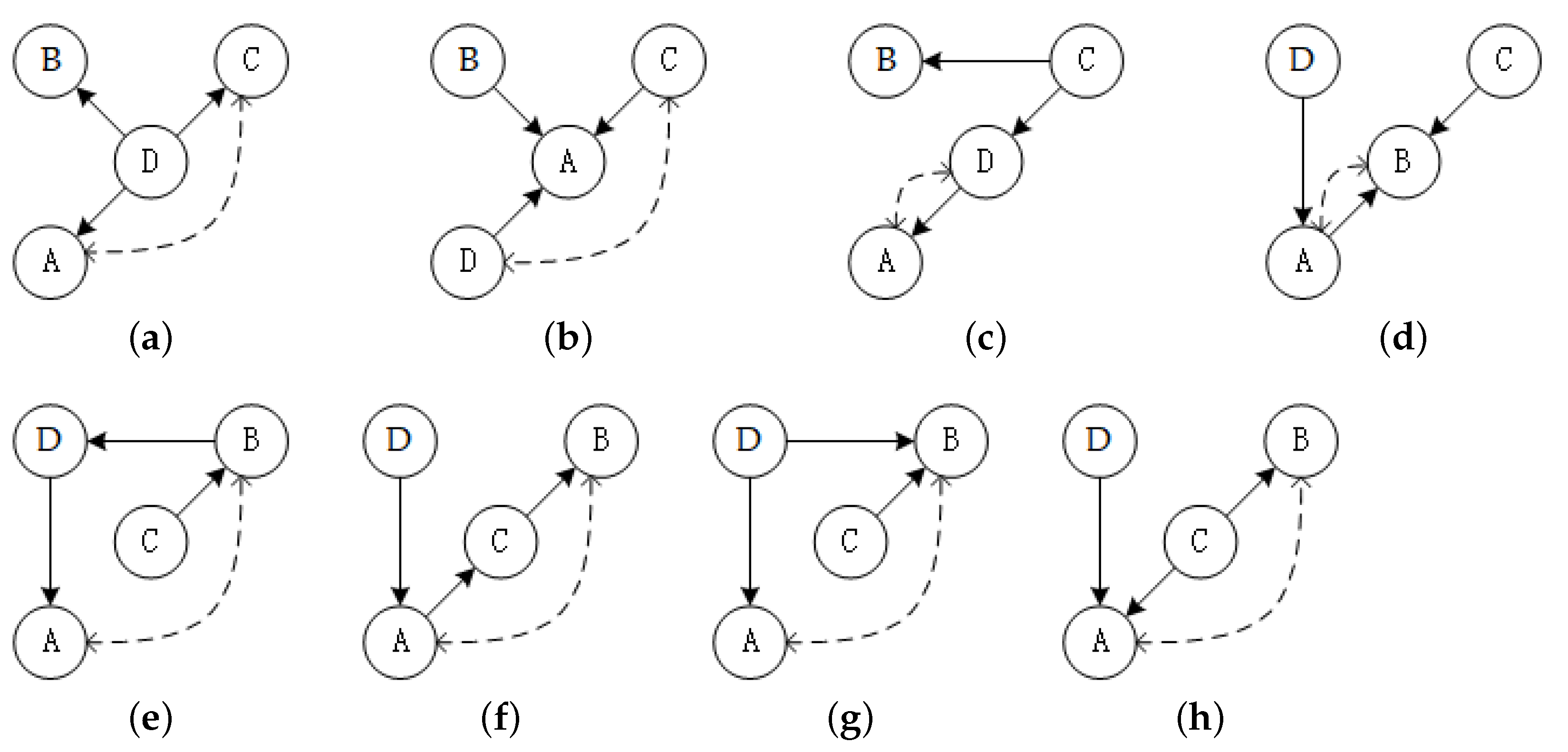
3.2. More Complex Operators
3.2.1. Leaf Operator
- All leaf nodes of DAG are found to avoid invalid operations.
- A node X to be processed is sampled without replacement from the remaining nodes.
- If the from-node of an edge is the selected node X, the edge is reversed by the Reverse operator.
3.2.2. Root Operator
3.2.3. Swap Operator
- The black and white lists are ascertained according to node X.
- The node Y to be swapped is sampled from the white list.
- To guarantee the legality of the result, resample the node Y if it breaks the legitimacy of DAG.
3.3. ILSG with Momentum
| Algorithm 2 Momentum algorithm |
| input: A DAG G to be processed, the number m of objects operated by Momentum Output: The DAG G’ has been processed 1: 2: for do 3: 4: 5: 6: end for 7: return G’ |
| Algorithm 3 ILSM algorithm |
| input: Dataset D, the number m of objects operated by Momentum Output: Optimal structure and its score BIC () 1: 2: 3: 4: while termination condition is not met do 5: 6: 7: 8: if the condition of changing stride is met then 9: 10: end if 11: if the condition of using Momentum is met then 12: 13: end if 14: if the restart condition is met then 15: 16: end if 17: end while 18: return , BIC ( |
4. Experimental Evaluation
4.1. Scoring Metrics
- True Positives (TP): the number of edges in the learned graph also present in the true graph.
- True Negatives (TN): the number of direct independencies discovered in the learned graph exist in the true graph.
- False Positives (FP): the number of edges in the learned graph not present in the true graph.
- False Negatives (FN): the number of edges not in the learned graph but present in the true graph.
4.2. Benchmark Data Sets of Experiments
4.3. BNSL Algorithms Considered
- PC-stable [9]: a modern and stable implementation of the state-of-the-art constraint-based algorithm called PC.
- IAMB-FDR [38]: a variant of IAMB, a constraint-based algorithm based on discovering Markov Blanket, adjusts the tests significance threshold with FDR. In the following it is abbreviated as IAMB.
- HC: the most popular local search algorithm adopted over the DAG space. As the results of HC are consistently unstable and not enough to compare with other solvers, we choose HC with restart but still abbreviate it as HC.
- MMHC: perhaps the most popular hybrid learning algorithm that combines the Max-Min Parents and Children algorithm and HC.
- Hybrid HPC (H2PC) [39]: a hybrid algorithm combines the HPC (to restrict the search space) and the HC (to find the optimal network structure in the restricted space).
- GOBNILP: it is a current state-of-the-art exact search approach based on integer linear programming. In the following it is abbreviated as ILP.
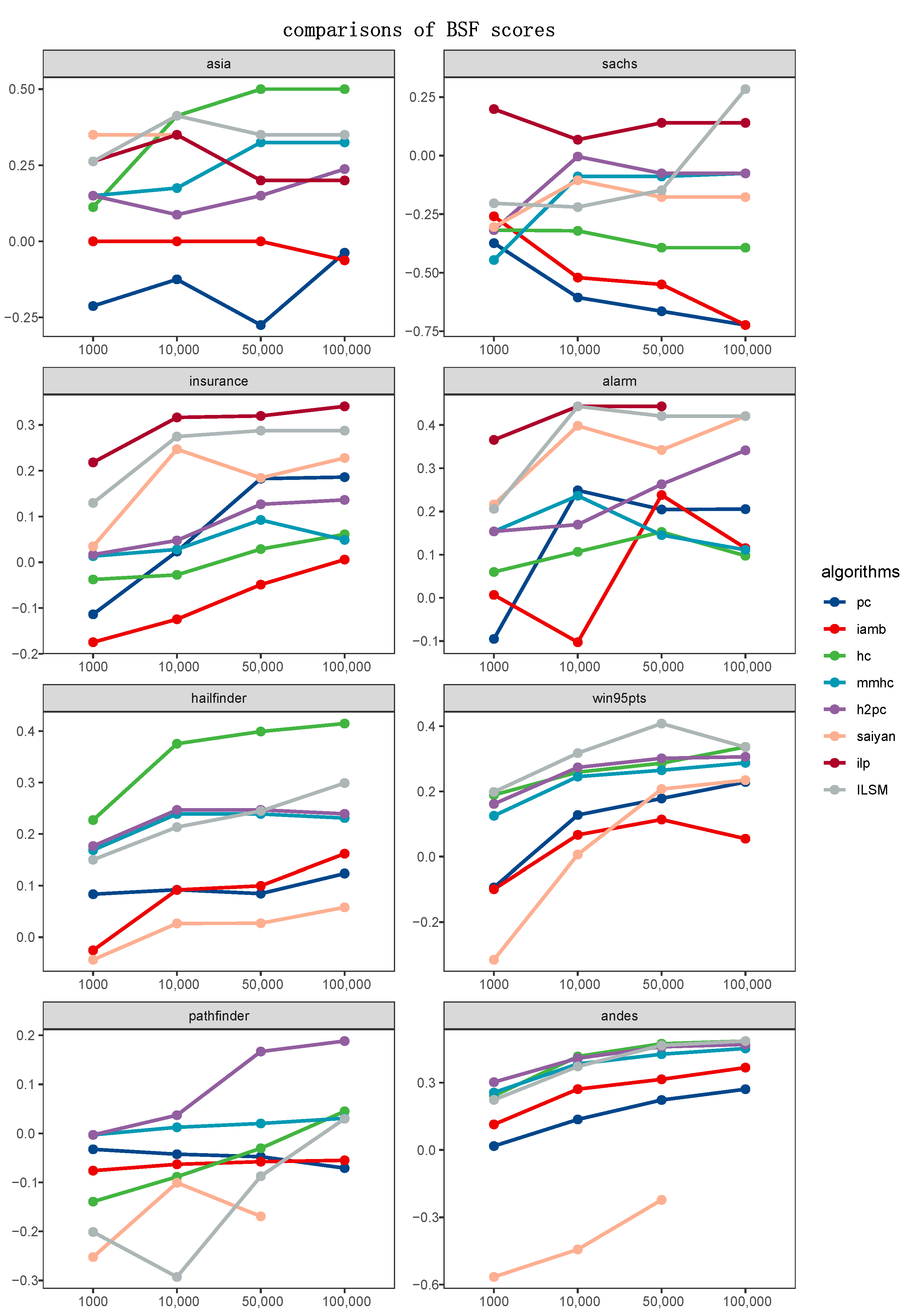
4.4. Experimental Results and Discussion
4.4.1. Comparisons of Operators
4.4.2. Comparisons of Algorithms
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| BIC | Bayesian information criterion |
| BNPL | Bayesian Networks parameter learning |
| BNs | Bayesian Networks |
| BNSL | Bayesian Networks structure learning |
| BSF | Balanced Scoring Function |
| DAG | directed acyclic graph |
| FN | False Negatives |
| FP | False Positives |
| GOBNILP | global optimal Bayesian Networks Integer linear programming |
| HC | Hill-climbing |
| ILS | Iterated local search |
| ILSG | ILS adopted over DAG |
| ILSM | ILSG with Momentum |
| MMHC | Max-Min Hill-climbing algorithm |
| TN | True Negatives |
| TP | True Positives |
| SHD | Structural Hamming Distance |
References
- Pearl, J. Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference; Elsevier: Amsterdam, The Netherlands, 2014. [Google Scholar]
- Nikovski, D. Constructing Bayesian networks for medical diagnosis from incomplete and partially correct statistics. IEEE Trans. Knowl. Data Eng. 2000, 12, 509–516. [Google Scholar] [CrossRef] [Green Version]
- Aguiar-Pulido, V.; A Seoane, J.; Gestal, M.; Dorado, J. Exploring patterns of epigenetic information with data mining techniques. Curr. Pharm. Des. 2013, 19, 779–789. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Maas, R.; Huemmer, C.; Hofmann, C.; Kellermann, W. On Bayesian networks in speech signal processing. In Proceedings of the Speech Communication; 11. ITG Symposium, Erlangen, Germany, 24–26 September 2014; pp. 1–4. [Google Scholar]
- Sekmen, A.; Challa, P. Assessment of adaptive human–robot interactions. Knowl.-Based Syst. 2013, 42, 49–59. [Google Scholar] [CrossRef]
- Su, C.; Andrew, A.; Karagas, M.R.; Borsuk, M.E. Using Bayesian networks to discover relations between genes, environment, and disease. Biodata Min. 2013, 6, 1–21. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chickering, M.; Heckerman, D.; Meek, C. Large-sample learning of Bayesian networks is NP-hard. J. Mach. Learn. Res. 2004, 5, 1287–1330. [Google Scholar]
- Spirtes, P.; Glymour, C.N.; Scheines, R.; Heckerman, D. Causation, Prediction, and Search; MIT Press: Cambridge, MA, USA, 2000. [Google Scholar]
- Colombo, D.; Maathuis, M.H. Order-independent constraint-based causal structure learning. J. Mach. Learn. Res. 2014, 15, 3741–3782. [Google Scholar]
- Tsamardinos, I.; Brown, L.E.; Aliferis, C.F. The max-min hill-climbing Bayesian network structure learning algorithm. Mach. Learn. 2006, 65, 31–78. [Google Scholar] [CrossRef] [Green Version]
- Scutari, M.; Graafland, C.E.; Gutiérrez, J.M. Who learns better Bayesian network structures: Accuracy and speed of structure learning algorithms. Int. J. Approx. Reason. 2019, 115, 235–253. [Google Scholar] [CrossRef] [Green Version]
- Koivisto, M.; Sood, K. Exact Bayesian structure discovery in Bayesian networks. J. Mach. Learn. Res. 2004, 5, 549–573. [Google Scholar]
- Silander, T.; Myllymaki, P. A simple approach for finding the globally optimal Bayesian network structure. arXiv 2012, arXiv:1206.6875. [Google Scholar]
- Wang, Z.; Gao, X.; Yang, Y.; Tan, X.; Chen, D. Learning Bayesian networks based on order graph with ancestral constraints. Knowl.-Based Syst. 2021, 211, 106515. [Google Scholar] [CrossRef]
- De Campos, C.P.; Ji, Q. Efficient structure learning of Bayesian networks using constraints. J. Mach. Learn. Res. 2011, 12, 663–689. [Google Scholar]
- Cussens, J. Bayesian network learning with cutting planes. arXiv 2012, arXiv:1202.3713. [Google Scholar]
- Jaakkola, T.; Sontag, D.; Globerson, A.; Meila, M. Learning Bayesian network structure using LP relaxations. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 358–365. [Google Scholar]
- Guo, Z.; Constantinou, A.C. Approximate learning of high dimensional Bayesian network structures via pruning of Candidate Parent Sets. Entropy 2020, 22, 1142. [Google Scholar] [CrossRef] [PubMed]
- Yuan, C.; Malone, B.; Wu, X. Learning optimal Bayesian networks using A* search. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence, Barcelona, Spain, 16–22 July 2011. [Google Scholar]
- Malone, B.; Yuan, C. Evaluating anytime algorithms for learning optimal Bayesian networks. arXiv 2013, arXiv:1309.6844. [Google Scholar]
- Tan, X.; Gao, X.; Wang, Z.; He, C. Bidirectional heuristic search to find the optimal Bayesian network structure. Neurocomputing 2021, 426, 35–46. [Google Scholar] [CrossRef]
- Heckerman, D. A tutorial on learning with Bayesian networks. In Innovations in Bayesian Networks; Springer: Berlin/Heidelberg, Germany, 2008; pp. 33–82. [Google Scholar]
- Chickering, D.M. A transformational characterization of equivalent Bayesian network structures. arXiv 2013, arXiv:1302.4938. [Google Scholar]
- Alonso-Barba, J.I.; Gámez, J.A.; Puerta, J.M. Scaling up the greedy equivalence search algorithm by constraining the search space of equivalence classes. Int. J. Approx. Reason. 2013, 54, 429–451. [Google Scholar] [CrossRef]
- Teyssier, M.; Koller, D. Ordering-based search: A simple and effective algorithm for learning Bayesian networks. arXiv 2012, arXiv:1207.1429. [Google Scholar]
- Scanagatta, M.; Corani, G.; Zaffalon, M. Improved local search in Bayesian networks structure learning. In Proceedings of the 3rd International Workshop on Advanced Methodologies for Bayesian Networks, Kyoto, Japan, 20–22 September 2017; pp. 45–56. [Google Scholar]
- Hoos, H.H.; Stützle, T. Stochastic local search: Foundations and applications; Elsevier: Amsterdam, The Netherlands, 2004. [Google Scholar]
- Lee, C.; van Beek, P. Metaheuristics for score-and-search Bayesian network structure learning. In Canadian Conference on Artificial Intelligence; Springer: Cham, Switzerland, 2017; pp. 129–141. [Google Scholar]
- Scanagatta, M.; de Campos, C.P.; Corani, G.; Zaffalon, M. Learning Bayesian Networks with Thousands of Variables. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 1864–1872. [Google Scholar]
- Koller, D.; Friedman, N. Probabilistic Graphical Models: Principles and Techniques; MIT Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Buntine, W. Theory refinement on Bayesian networks. In Uncertainty Proceedings 1991; Elsevier: Amsterdam, The Netherlands, 1991; pp. 52–60. [Google Scholar]
- Suzuki, J. A construction of Bayesian networks from databases based on an MDL principle. In Uncertainty in Artificial Intelligence; Elsevier: Amsterdam, The Netherlands, 1993; pp. 266–273. [Google Scholar]
- Schwarz, G. Estimating the dimension of a model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Akaike, H. Information theory and an extension of the maximum likelihood. principle. In Selected Papers of Hirotugu Akaike; Springer: New York, NY, USA, 1998; pp. 199–213. [Google Scholar]
- Scutari, M.; Denis, J.B. Bayesian Networks: With Examples in R; CRC Press: Boca Raton, FL, USA, 2014. [Google Scholar]
- Constantinou, A. Evaluating structure learning algorithms with a balanced scoring function. arXiv 2019, arXiv:1905.12666. [Google Scholar]
- Scanagatta, M.; Salmerón, A.; Stella, F. A survey on Bayesian network structure learning from data. Prog. Artif. Intell. 2019, 8, 425–439. [Google Scholar] [CrossRef]
- Pena, J.M. Learning gaussian graphical models of gene networks with false discovery rate control. In European Conference on Evolutionary Computation, Machine Learning and Data Mining in Bioinformatics; Springer: Berlin/Heidelberg, Germany, 2008; pp. 165–176. [Google Scholar]
- Gasse, M.; Aussem, A.; Elghazel, H. A hybrid algorithm for Bayesian network structure learning with application to multi-label learning. Expert Syst. Appl. 2014, 41, 6755–6772. [Google Scholar] [CrossRef] [Green Version]
- Constantinou, A.C. Learning Bayesian networks with the Saiyan algorithm. ACM Trans. Knowl. Discov. Data (TKDD) 2020, 14, 1–21. [Google Scholar] [CrossRef]
- Constantinou, A.C. Learning Bayesian Networks that enable full propagation of evidence. IEEE Access 2020, 8, 124845–124856. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Benchmark Data Sets D | Nodes n | Edges e | Parameters | Max In-Degree k | Max Out-Degree u |
|---|---|---|---|---|---|
| Asia | 8 | 8 | 18 | 2 | 2 |
| Sachs | 11 | 17 | 178 | 3 | 6 |
| Insurance | 27 | 52 | 984 | 3 | 6 |
| Alarm | 37 | 46 | 509 | 4 | 5 |
| Hailfinder | 56 | 66 | 2656 | 4 | 16 |
| Win95pts | 76 | 112 | 574 | 7 | 10 |
| Pathfinder | 109 | 195 | 77155 | 5 | 106 |
| Andes | 223 | 338 | 1175 | 6 | 12 |
| Network | A/D/R | Leaf | Root | Swap | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Max/Min/Mean | Max | Min | Mean | Max | Min | Mean | Max | Min | Mean | |
| Insurance | 1.00 | 7.00 | 1.00 | 2.36 | 3.00 | 1.00 | 2.10 | 11.00 | 4.00 | 4.69 |
| Alarm | 1.00 | 5.00 | 1.00 | 1.86 | 4.00 | 1.00 | 1.84 | 7.00 | 4.00 | 4.30 |
| Hailfinder | 1.00 | 16.00 | 1.00 | 1.74 | 4.00 | 1.00 | 1.68 | 20.00 | 4.00 | 4.40 |
| Win95pts | 1.00 | 10.00 | 1.00 | 1.74 | 7.00 | 1.00 | 2.66 | 5.00 | 4.00 | 4.00 |
| Pathfinder | 1.00 | 106.00 | 1.00 | 6.15 | 5.00 | 1.00 | 1.81 | 15.00 | 4.00 | 4.06 |
| Andes | 1.00 | 12.00 | 1.00 | 1.76 | 6.00 | 1.00 | 2.39 | 9.00 | 4.00 | 4.54 |
| m | Network | Add | Delete | Reverse | Leaf | Root | Swap | Momentum |
|---|---|---|---|---|---|---|---|---|
| n/5 | Insurance | 5 | 5 | 5 | 6 | 8 | 14 | 27 |
| Alarm | 7 | 7 | 7 | 9 | 11 | 29 | 42 | |
| Hailfinder | 11 | 11 | 11 | 9 | 18 | 30 | 58 | |
| Win95pts | 15 | 15 | 15 | 14 | 32 | 52 | 86 | |
| Pathfinder | 22 | 22 | 22 | 41 | 44 | 60 | 58 | |
| Andes | 45 | 45 | 45 | 61 | 100 | 164 | 252 | |
| n/2 | Insurance | 14 | 14 | 14 | 25 | 24 | 45 | 57 |
| Alarm | 19 | 19 | 19 | 15 | 24 | 42 | 66 | |
| Hailfinder | 28 | 28 | 28 | 32 | 32 | 64 | 89 | |
| Win95pts | 38 | 38 | 38 | 44 | 77 | 97 | 149 | |
| Pathfinder | 55 | 55 | 55 | 70 | 87 | 84 | 192 | |
| Andes | 112 | 112 | 112 | 116 | 201 | 340 | 422 | |
| n | Insurance | 27 | 27 | 27 | 28 | 38 | 61 | 72 |
| Alarm | 37 | 37 | 37 | 28 | 36 | 70 | 78 | |
| Hailfinder | 56 | 56 | 56 | 32 | 50 | 104 | 113 | |
| Win95pts | 76 | 76 | 76 | 63 | 88 | 164 | 178 | |
| Pathfinder | 109 | 109 | 109 | 175 | 140 | 140 | 216 | |
| Andes | 223 | 223 | 223 | 165 | 263 | 500 | 541 | |
| 2*n | Insurance | 54 | 52 | 52 | 29 | 47 | 73 | 83 |
| Alarm | 74 | 46 | 46 | 30 | 38 | 89 | 90 | |
| Hailfinder | 112 | 66 | 66 | 44 | 61 | 110 | 125 | |
| Win95pts | 152 | 112 | 112 | 66 | 108 | 191 | 204 | |
| Pathfinder | 218 | 195 | 195 | 179 | 174 | 157 | 253 | |
| Andes | 446 | 338 | 338 | 199 | 317 | 613 | 632 |
| Parameter | Description | Value |
|---|---|---|
| stride | The stride array of perturbation factors of ILSG | {n/10, n/5, n/2, n} |
| Objects operated by the factor, Momentum | n | |
| Number of non-improving steps until acting by Momentum | 20 | |
| Number of Momentum factors until a restart | 5 |
| Instances | PC | IAMB | MMHC | H2PC | Saiyan | HC | ILP | ILSM |
|---|---|---|---|---|---|---|---|---|
| Asia1000 | – | −2410.4 | −2369.3 | −2369.3 | −2203.5 | −2212.4 | −2200.6 | −2200.6 |
| Asia10000 | – | −24,678.5 | −24,011.0 | −24,240.1 | −22,394.2 | −22,392.1 | −22,392.1 | −22,392.1 |
| Asia50000 | – | −122,774.1 | −120,324.2 | −121,476.3 | −111,397.4 | −111,397.4 | −111,397.4 | −111,397.4 |
| Asia100000 | – | – | −242,298.2 | −242,345.3 | −223,830.3 | −223,830.3 | −223,830.3 | −223,830.3 |
| Sachs1000 | – | – | −8048.8 | −7787.6 | −7680.0 | −7690.7 | −7668.8 | −7668.8 |
| Sachs10000 | – | – | −74,294.1 | −72,665.5 | −72,678.6 | −72,825.0 | −72,665.5 | −72,665.5 |
| Sachs50000 | – | – | −363,763.4 | −359,445.9 | −359,459.9 | −359,633.0 | −359,445.9 | −359,445.9 |
| Sachs100000 | – | – | −718,719.1 | −718,719.1 | −18,737.0 | −718,915.0 | −718,719.1 | −718,719.1 |
| Insur1000 | – | – | −15,613.8 | −15,370.5 | −14,476.1 | −14,485.4 | −14,630.2 | −14,370.7 |
| Insur10000 | – | – | −145,705.6 | −137,720.0 | −135,150.0 | −134,404.2 | −133,976.6 | −133,644.2 |
| Insur50000 | – | – | −715,325.3 | −662,998.8 | −667,893.0 | −658529.1 | −657,485.5 | −657,234.2 |
| Insur100000 | – | – | −1,460,299.6 | −1,326,283.6 | −1,332,294.9 | −1,314,347.5 | −1,311,824 | −1,311,582.2 |
| Alarm1000 | – | – | −14,210.2 | −14,307.3 | −11,675.8 | −11,760.8 | −11,800.73 | −11,576.3 |
| Alarm10000 | – | – | −125,264.2 | −127,175.8 | −106,235.6 | −107,115.9 | −106,262.6 | −106,194.5 |
| Alarm50000 | – | – | −636,475.3 | −529,251.3 | −525,259.2 | −526,975.0 | −525,047.2 | −525,033.2 |
| Alarm100000 | – | – | −1,343,931.0 | −1,051,838.8 | −1,046,071.1 | −1,048,645.6 | OM | −1,045,778.0 |
| Hail1000 | – | – | −58,949.9 | −59,485.9 | −53,739.2 | −53,140.4 | OM | −53,129.9 |
| Hail10000 | – | – | −574,164.7 | −579,448.2 | −505,657.5 | −498,475.5 | OM | −498,175.8 |
| Hail50000 | – | – | −2,864,980.1 | −2,889,387.7 | −2,513,498.6 | −2,466,687.4 | OM | −2,466,261.8 |
| Hail100000 | – | – | −5,695,300.5 | −5,775,235.6 | −5,015,818.9 | −4,923,431.1 | OM | −4,923,074.2 |
| Win1000 | – | – | −12,789.4 | −13,135.8 | −10,935.8 | −10,089.8 | OM | −10,009.5 |
| Win10000 | – | – | −114,141.8 | −110,574.7 | −94,886.9 | −92,044.7 | OM | −91,505.9 |
| Win50000 | – | – | −538,549.6 | −530,922.4 | −472,611.6 | −454,162.3 | OM | −453,026.7 |
| Win100000 | – | – | −1,086,467.3 | −1,066,673.8 | −939,455.3 | −902,280.4 | OM | −902,066.0 |
| Path1000 | – | – | −54,335.0 | −52,546.5 | −43,024.6 | −35,421.7 | OM | −34,899.7 |
| Path10000 | – | – | −561,876.7 | −431,256.3 | −305,996.3 | −285,837.6 | OM | −280,420.0 |
| Path50000 | – | – | −2,757,244.8 | −1,798,515.5 | −1,412,298.9 | −1,287,241.1 | OM | −1,276,740.2 |
| Path100000 | – | – | −5,348,864.0 | −3,237,761.9 | OT | −2,504,395.6 | OM | −2,482,500.9 |
| Andes1000 | – | – | −100,713.3 | −98,971.9 | −131,976.9 | −95,568.9 | OM | −95,560.6 |
| Andes10000 | – | – | −958,957.8 | −954,721.2 | −1,013,158.6 | −933,735.1 | OM | −933,719.5 |
| Andes50000 | – | – | −4,817,602.8 | −4,738,844.0 | −4,823,995.3 | −4,645,111.4 | OM | −4,645,108.9 |
| Andes100000 | – | – | −9,500,828.1 | −9,429,374.3 | OT | −9,291,994.9 | OM | −9,291,994.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Gao, X.; Wang, Z.; Ru, X. Improved Local Search with Momentum for Bayesian Networks Structure Learning. Entropy 2021, 23, 750. https://doi.org/10.3390/e23060750
Liu X, Gao X, Wang Z, Ru X. Improved Local Search with Momentum for Bayesian Networks Structure Learning. Entropy. 2021; 23(6):750. https://doi.org/10.3390/e23060750
Chicago/Turabian StyleLiu, Xiaohan, Xiaoguang Gao, Zidong Wang, and Xinxin Ru. 2021. "Improved Local Search with Momentum for Bayesian Networks Structure Learning" Entropy 23, no. 6: 750. https://doi.org/10.3390/e23060750
APA StyleLiu, X., Gao, X., Wang, Z., & Ru, X. (2021). Improved Local Search with Momentum for Bayesian Networks Structure Learning. Entropy, 23(6), 750. https://doi.org/10.3390/e23060750