1. Introduction
Recently, the Internet of things (IoT) has been widely used in the field of industrial manufacturing, environment monitoring, and home automation. In these applications, the sensors generate and transmit new status updates to the destination, where the freshness of the status updates is crucial for the destination to track the state of the environment and to make decisions. Thus, a new information freshness metric, namely age of information (AoI), was proposed in [
1] to measure the freshness of updates from the receiver’s perspective. There are two widely used metrics, i.e., the average peak AoI [
2] and the average AoI [
3]. In general, the smaller the AoI is, the fresher the received updates are.
AoI was originally investigated in [
1] for updating the status in vehicular networks. Considering the impact of the queueing system, the authors in [
4] investigated the system performance under the M/M/1 and M/M/1/2 queueing systems with a first-come-first-served (FCFS) policy. Furthermore, the work of [
5] studied how to keep the updates fresh by analyzing some general update policies, such as the zero-wait policy. The authors of [
6] considered the optimal schedule problem for a more general cost that is the weighted sum of the transmission cost and the tracking inaccuracy for the information source. However, these works assumed that the communication channel is not error-prone. In practice, status updates are delivered through an erroneous wireless channel, which suffers from fading, interference, and noises. Therefore, the received updates may not be decoded correctly, which induces information aging and energy consumption.
There are several works that considered the erroneous channel [
7,
8]. The authors in [
9] considered multiple communication channels and investigated the optimal coding and decoding schemes. The channel with an independent and identical packet error rate over time was considered in [
10,
11]. The work of [
12] considered the impact of fading channels in packet transmission. A Markov channel was investigated in [
13], where threshold policy was proven to be optimal, and a simulation-based approach was proposed to compute the corresponding threshold. However, how the information of channel quality should be exploited to improve system performance in information freshness remains to be investigated.
Channel quality indicator (CQI) feedback is commonly used in wireless communication systems [
14]. In block fading channels, the channel quality, generally reported by the terminal, is highly relevant to the packet error rate (PER) [
15] or, namely, the block error rate (BLER). It is probable that a received packet fails to be decoded when the channel suffers from a poor condition. However, a transmitter with the channel quality information is able to keep idle when there is deep fading, thereby saving energy. The channel quantization was also considered in [
12,
13], where the channel was quantized into multiple states. However, the decision making was not dependent on the channel state in [
12], while [
13] did not consider the freshness of information. These motivate us to introduce the information of channel quality into the design of the updating policy.
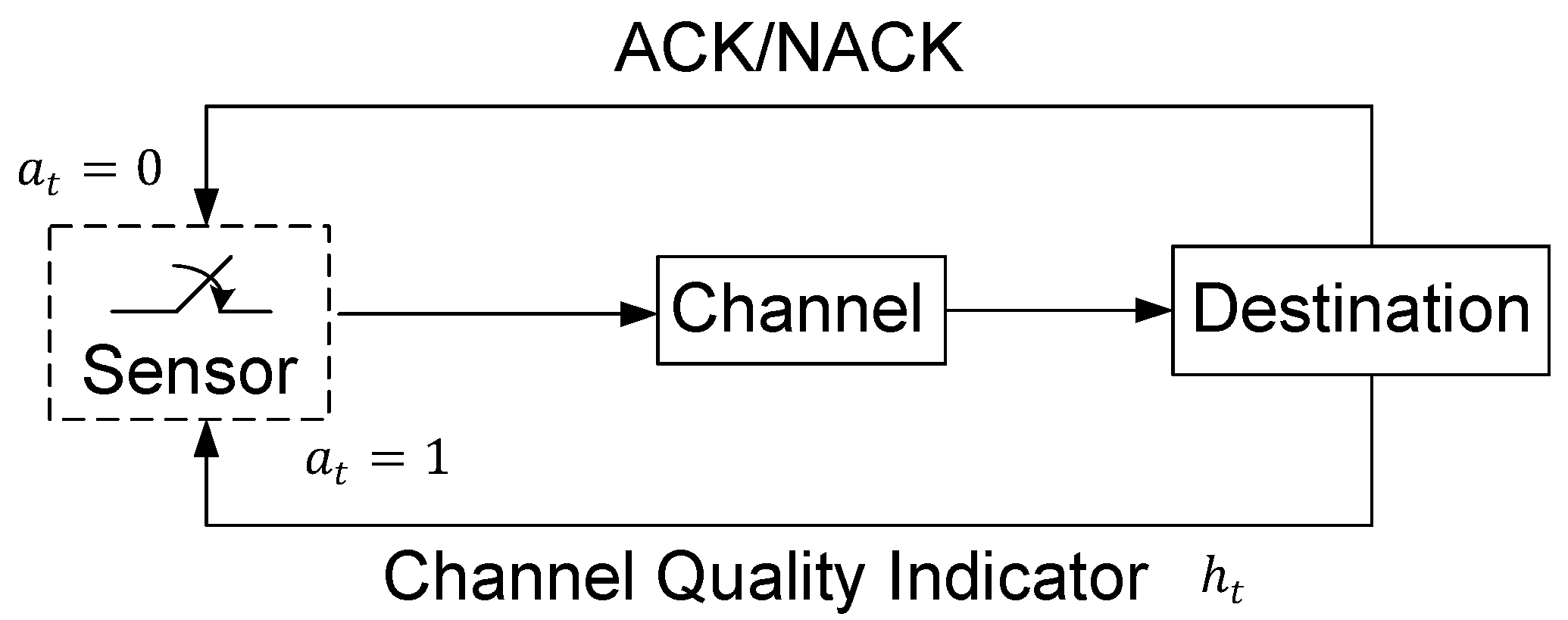
In this paper, a status update system with channel quality feedback is considered. In particular, the channel condition is quantized into multiple states, and the destination feeds the channel quality back to the sensor before the sensor updates the status. Our problem is to investigate the channel quality-based optimal status update policy, which minimizes the weighted sum of the AoI and the energy consumption. Our key contributions are summarized as follows:
An average cost Markov decision process (MDP) is formulated to model this problem. Due to the infinite countable states and unbounded cost of the MDP, which makes analysis difficult, the discounted version of the original problem is first investigated, and the existence of the stationary and deterministic policy to the original problem is then proven. Furthermore, it is proven that the optimal policy is a threshold structure policy with respect to the AoI for each channel state by showing the monotonic property of the value function. We also prove that the threshold is a non-increasing function of channel state.
By utilizing the threshold structure, a structure-aware policy iteration algorithm is proposed to efficiently obtain the optimal updating policy. Nevertheless, a numerical-based algorithm which directly computes the thresholds by non-linear fractional programming is also derived. Simulation results reveal the effects of system parameters and show that our proposed policy performs better than the zero-wait policy and periodic policy.
The rest of this paper is organized as follows. In
Section 2, the system model is presented and the optimal updating problem is formulated. In
Section 3, the optimal updating policy is proven to be of a threshold structure, and a threshold-based policy iteration algorithm is proposed to find the optimal policy.
Section 4 presents the simulation results. Finally, we summarize our conclusions in
Section 5.
3. Optimal Updating Policy
This section aims to investigate the optimal updating policy for the problem formulated in above section. In this section, our investigating problem is first formulated into an infinite horizon average cost MDP, and the existence of a stationary and deterministic policy that minimizes the average cost is proven. Then, the non-decreasing property of the value function is derived. Based on this property, we prove that the optimal update policy is of a threshold structure with respect to AoI, and the optimal threshold is a non-increasing function of the channel state. Aiming to reduce the computational complexity, a structure-aware policy iteration algorithm is proposed to find the optimal policy. Moreover, non-linear fractional programming is employed to directly compute the optimal thresholds in a special case where the channel is quantized into two states.
3.1. MDP Formulation
The Markov decision process (MDP) is typically applied to address the optimal decision problem when the investigation problem can be characterized by the evolution of the system state and the cost is per-stage. The optimization problem in (
5) can be formulated as an infinite horizon average cost MDP, which is elaborated in the following.
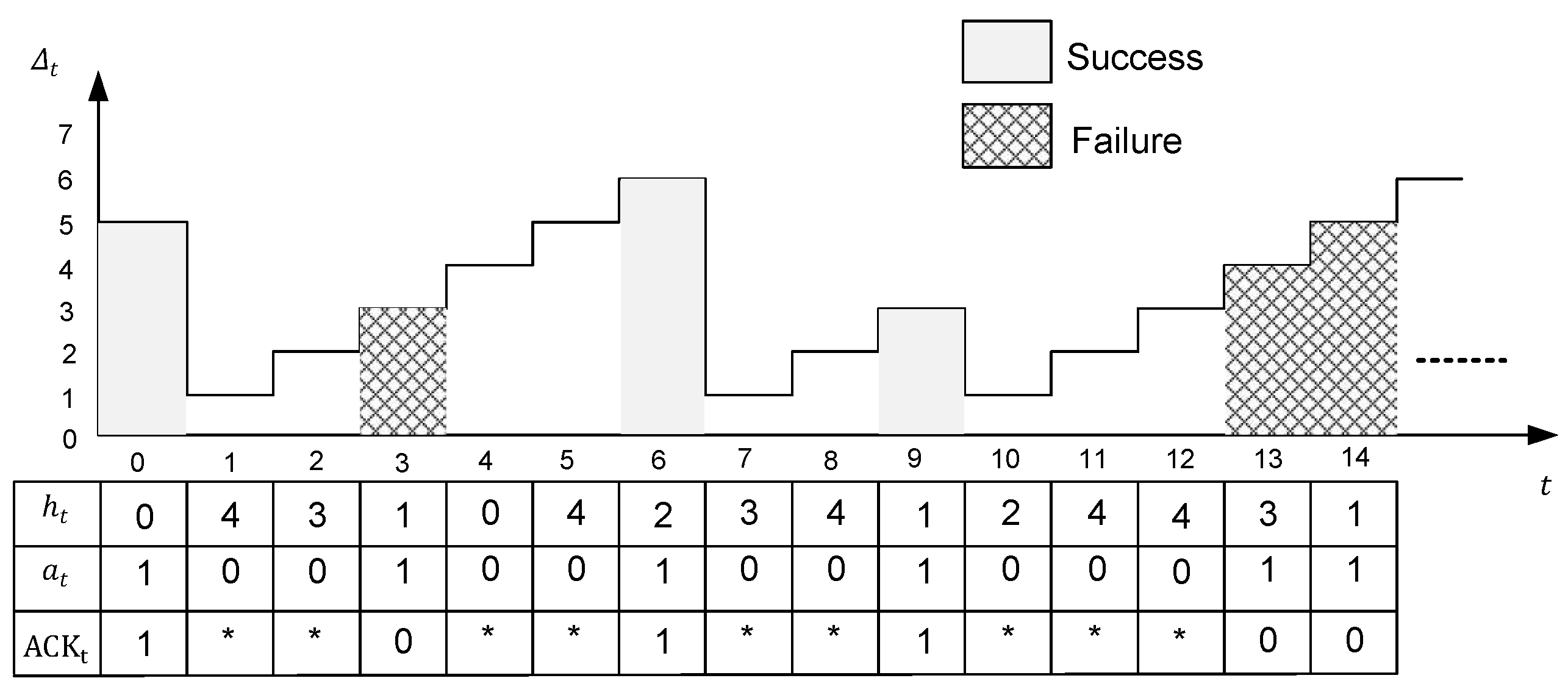
States: The state of the MDP in slot t is defined as , which takes values in . Hence, the state space is countable and infinite.
Actions: The set of actions chosen in slot t is .
Transition Probability: Let
be the transition probability that the state
in slot
t transits to
in slot
after taking action
. According to the evolution of AoI in (
4), the transition probability is given by
Cost: The instantaneous cost
at state
given action
in slot
t is
For an MDP with infinite states and unbounded cost, it is not guaranteed to have a stationary and deterministic policy that attains the minimum average cost in general. Fortunately, we can prove the existence of stationary and deterministic policy in next sub-section.
3.2. The Existence of Stationary and Deterministic Policy
For rigorous mathematical analysis, this section is purposed to prove the existence of a stationary and deterministic optimal policy. According to [
16], we first analyze the associated discounted cost problem of the original MDP. The expectation of discount cost with respect to discounted factor
and initial state
under a policy
is given by
where
is the decision made in state
under policy
, and
is the discounted factor. We first verify that
is finite for any policy and all
.
Lemma 1. Given , for any policy π and all , we have Proof. By definition, the instantaneous cost in state
given action
is
Therefore,
holds. Combined with the fact that the AoI increases, at most, linearly at each slot for any policy, we have
which completes the proof. □
Let denote the minimum expected discounted cost. By Lemma 1, holds for every and .
According to [
16] (Proposition 1), we have
which implies that
satisfies the Bellman equation.
can be solved via a value iteration algorithm. In particular, we define
, and for all
, we have
where
is related to the right-hand-side (RHS) of the discounted cost optimality equation. Then,
for every
and
.
Now, we can use the value iteration algorithm to establish the monotonic properties of
Lemma 2. For all Δ and i, we haveand for all and i, we have Based on Lemmas 1 and 2, we are ready to show that the MDP has a stationary and deterministic optimal policy in the following theorem.
Theorem 1. For the MDP in (5), there exists a stationary and deterministic optimal policy that minimizes the long-term average cost. Moreover, there exists a finite constant for all states , where λ is independent of the initial state, and a value function , such thatholds for all . 3.3. Structural Analysis
According to Theorem 1, the optimal policy for the average cost problem satisfies the following equation
where
Similar to Lemma 2, the monotonic property of the value function is given in the following lemma.
Lemma 3. Given the channel state i, for any , we have Proof. This proof follows the same procedure of Lemma 2, with one exception being that the value iteration algorithm is based on Equation (
17). □
Moreover, based on Lemma 3, the property of the increment of the value function is established in following lemma.
Lemma 4. Given the channel state i, for any , we have Proof. We first examine the relation between the state-action value functions, i.e.,
and
. Specifically, based on Lemma 3, we have
and
Since
, we complete the proof. □
Our main result is presented in the following theorem.
Theorem 2. For any given channel state i, there exists a threshold , such that when , the optimal action is to generate and transmit a new update, i.e., , and when , the optimal action is to remain idle, i.e., . Moreover, the optimal threshold is a non-increasing function of channel state i, i.e., holds for all and .
According to Theorem 2, the sensor will not update the status until the AoI exceeds the threshold. Moreover, if the channel condition is not good, i.e., channel state i is small, the sensor will wait for a longer time before it samples and transmits the status update packet so as to reduce the energy consumption because of a higher probability of transmission failure.
Based on the threshold structure, we can reduce the computational complexity of the policy iteration algorithm to find the optimal policy. The details of the algorithm are presented in Algorithm 1.
| Algorithm 1 Policy iteration algorithm (PIA) based on the threshold structure. |
- 1:
Initialization: Set , iteration threshold , and initialize the value function and policy for all state - 2:
repeat - 3:
. - 4:
Based on last iterative value function , compute the current value function by calculating the following equations. - 5:
- 6:
until for all - 7:
fordo - 8:
if and then - 9:
. - 10:
else - 11:
- 12:
end if - 13:
end for - 14:
- 15:
return the optimal policy
|
3.4. Computing the Thresholds for a Special Case
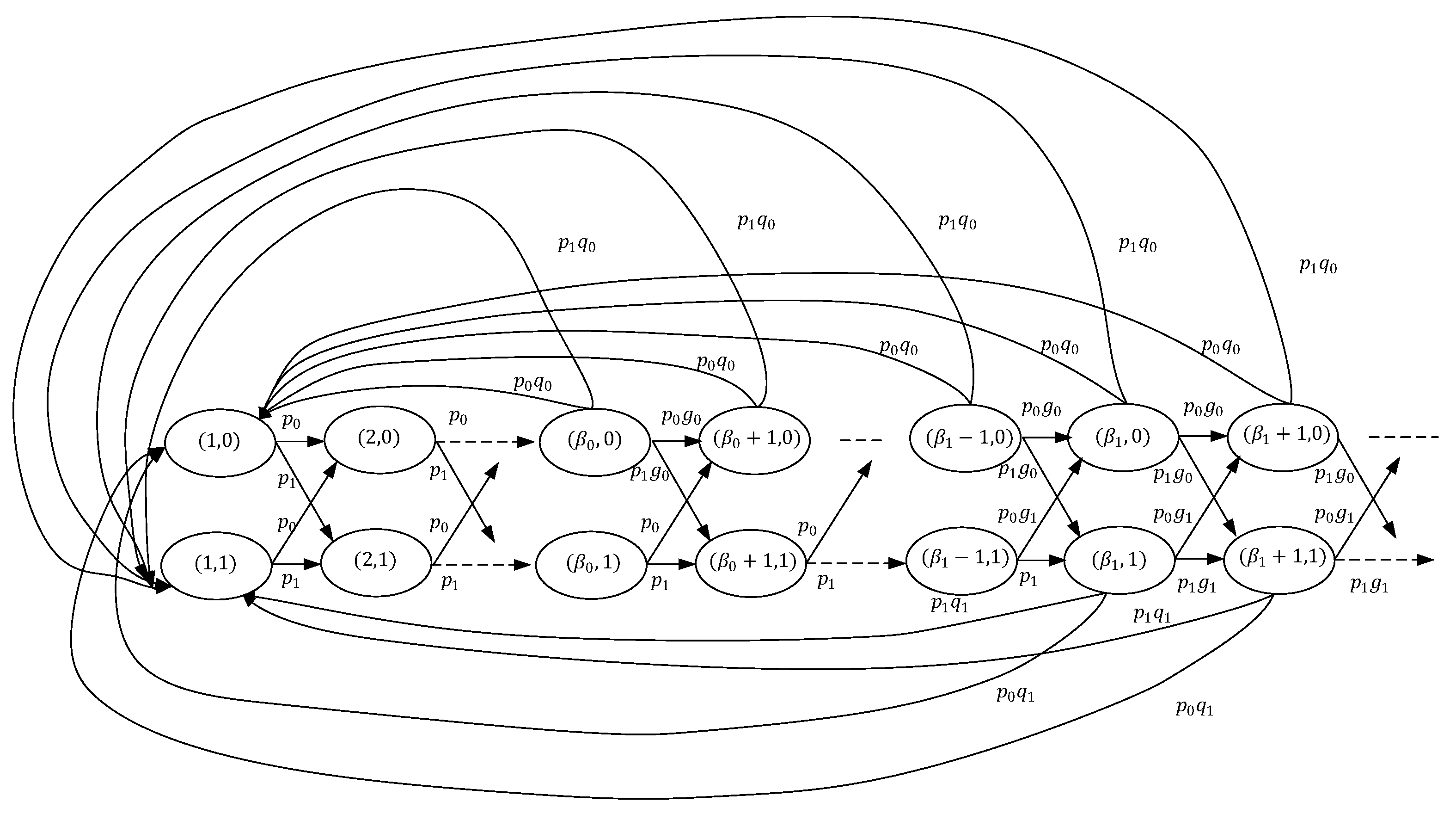
In the above section, we have proven that the optimal policy has a threshold structure. Given the thresholds
, a Markov chain can be induced by the threshold policy. A special Markov chain is depicted in
Figure 3, where the channel has two states. By leveraging the Markov chain, we first derive the average cost of the special case, which is summarized in the following theorem.
Theorem 3. Let be the steady state probability of state of the corresponding Markov chain with two states and be the threshold with respect to the channel state, respectively. The steady state probability is given bywhere , , , and satisfies following equation:The average cost then is given bywhereand Therefore, the closed form of the average cost is a function of thresholds. By linear search or gradient descent algorithm, the numerical solution of optimal thresholds can be obtained. However, computing its gradient directly requires a large amount of computation till convergence. Here, a nonlinear fractional programming (NLP) [
17] based algorithm which can efficiently obtain the numerical solution is proposed.
Let
. We can rewrite the cost function as a fractional form, where the numerator is denoted as
, and the denominator term is
. The solution to an NLP problem with the form in the following
is related to the optimization problem (
31)
where the following assumption should also be satisfied:
Define the function
with variable
q as
According to [
17],
is a strictly monotonic decreasing function and is convex over
. Furthermore, we have
if, and only if,
Then, the algorithm can be described by two steps. The first step is to solve a convex optimization problem with a one dimensional parameter by a bisection method. The second step is to solve a high dimensional optimization problem by a gradient descent method.
According to [
17], a bisection method can be used to solve the optimal
, under the assumption that the value of function
can be obtained exactly for given
q. We will actually use the gradient descent algorithm to obtain the numerical solution of
since the global search method may not perform in polynomial time. As a trick, we alternate the optimization variables of thresholds
by the variables of the decrement of thresholds, i.e.,
. To summarize, the numerical-based method for computing the optimal thresholds is given by Algorithm 2.
| Algorithm 2 Numerical computation of the optimal thresholds. |
| Input: |
| Output: |
- 1:
Let , and . Define - 2:
Let the iteration starts with , search range of q. - 3:
whiledo - 4:
; - 5:
ifthen - 6:
; - 7:
else - 8:
; - 9:
end if - 10:
ifthen - 11:
- 12:
break; - 13:
end if - 14:
; - 15:
end while
|
4. Simulation Results and Discussions
In this section, the simulation results are presented to investigate the impacts of the system parameters. We also compare the optimal policy with the zero-wait policy and periodic policy, where the zero-wait policy immediately generates an update at each time slot and the periodic policy keeps a constant interval between two updates.
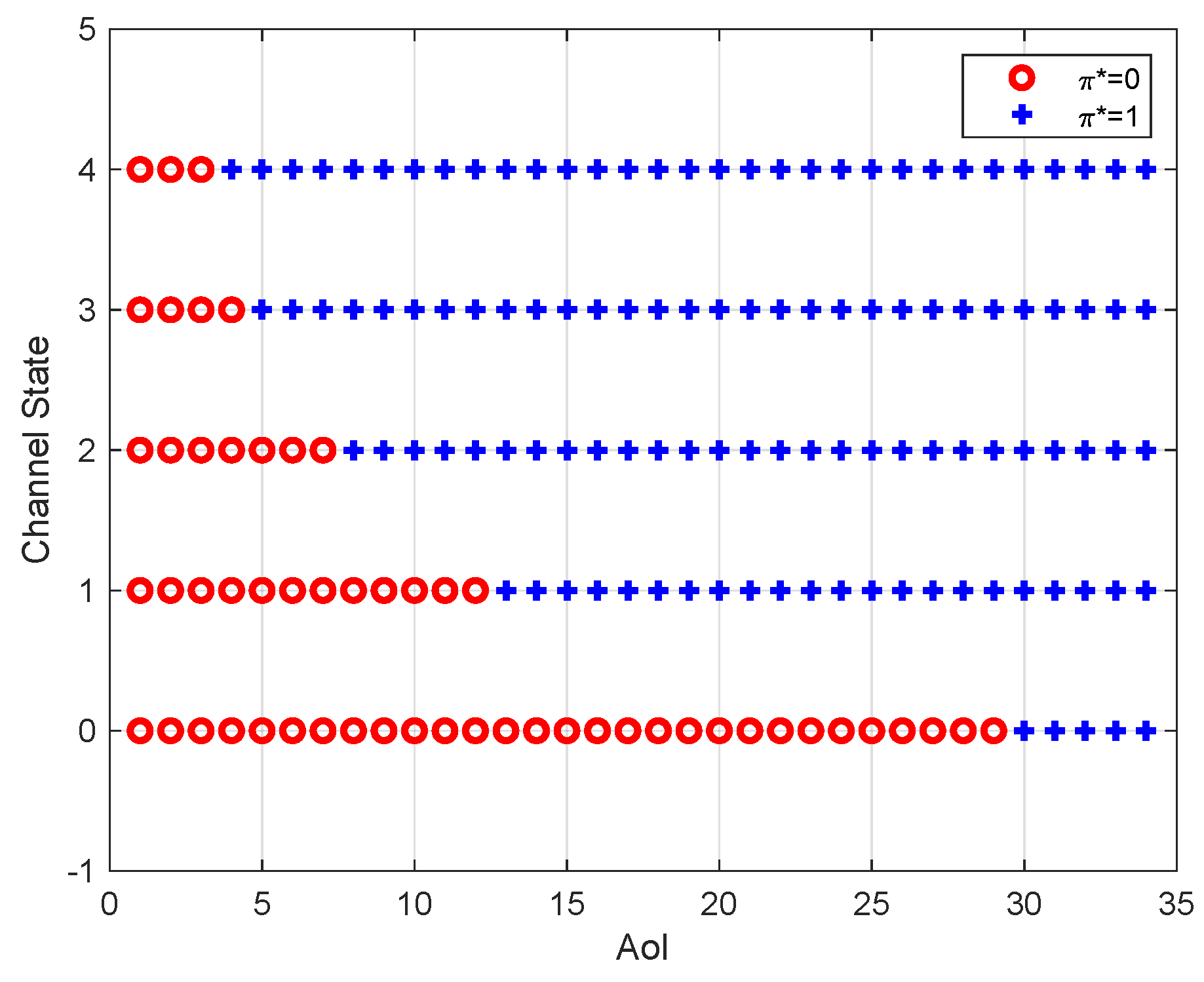
Figure 4 depicts the optimal policy for different AoI and channel states, where the number of channel states is 5. It can be seen that, for each channel state, the optimal policy has a threshold structure with respect to the AoI. In particular, when the AoI is small, it is not beneficial for the sensor to generate and transmit a new update because the energy consumption dominates the total cost. We can also see that the threshold is non-increasing with the channel state. In other words, if the channel condition is better, the threshold is smaller. This is because the success probability of packet transmission increases with the channel state.
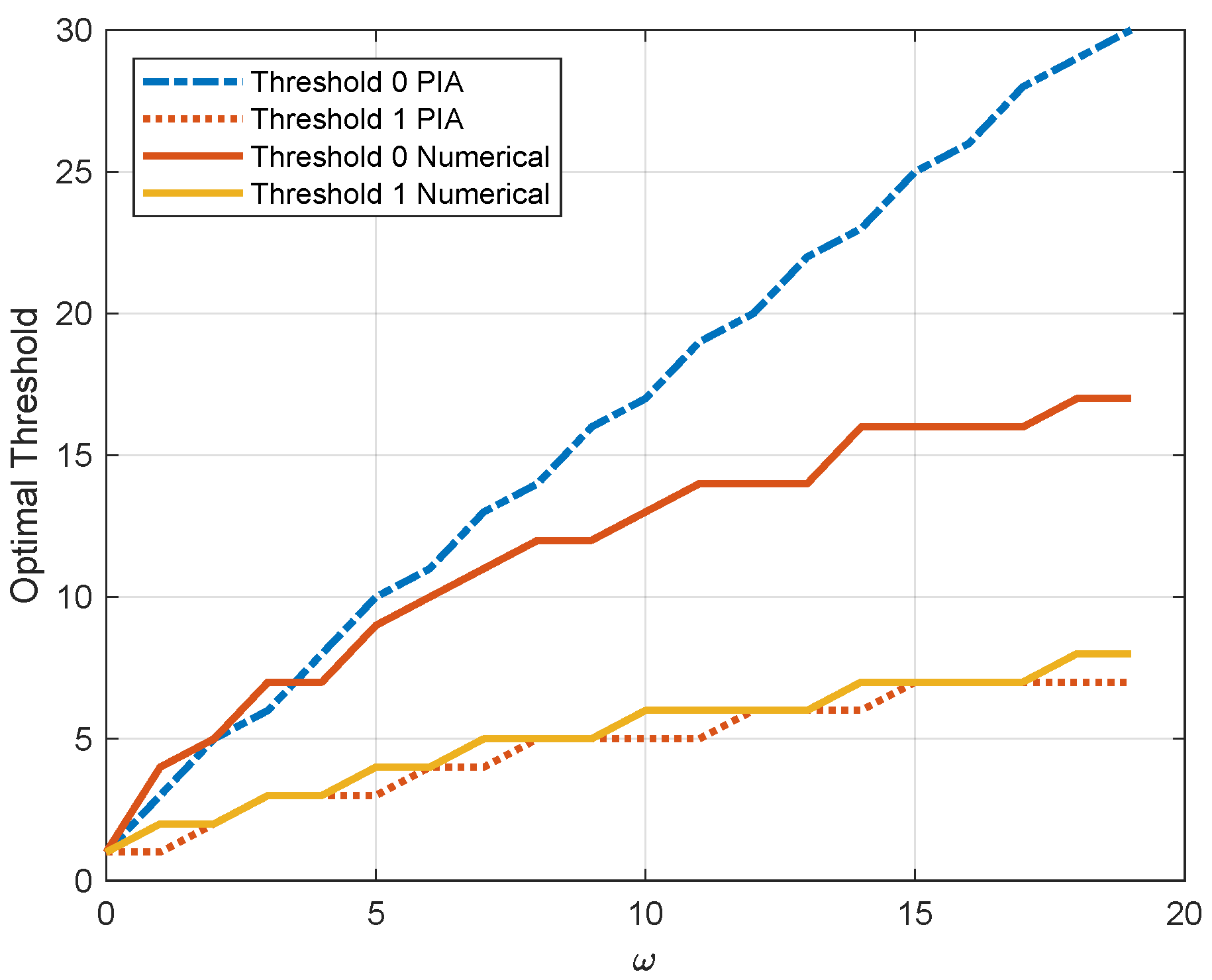
Figure 5 illustrates the thresholds for the MDP with two channel states with respect to the weighting factor
, in which the two dashed lines are obtained by PIA and the other two solid lines are obtained by the proposed numerical algorithm. Both of the thresholds grow with the increasing of
. Since the energy consumption has more weight, it is not efficient to update when the AoI is small. On the contrary, when
decreases, the AoI dominates and the thresholds decline. In particular, both of the thresholds equal 1 when
. In this case, the optimal policy reduces to the zero-wait policy. We can also see that the value of the threshold for channel state 1 of the numerical algorithm is close to the optimal solution. In contrast, the value of the threshold for channel state 0 gradually deviates from the optimal value.
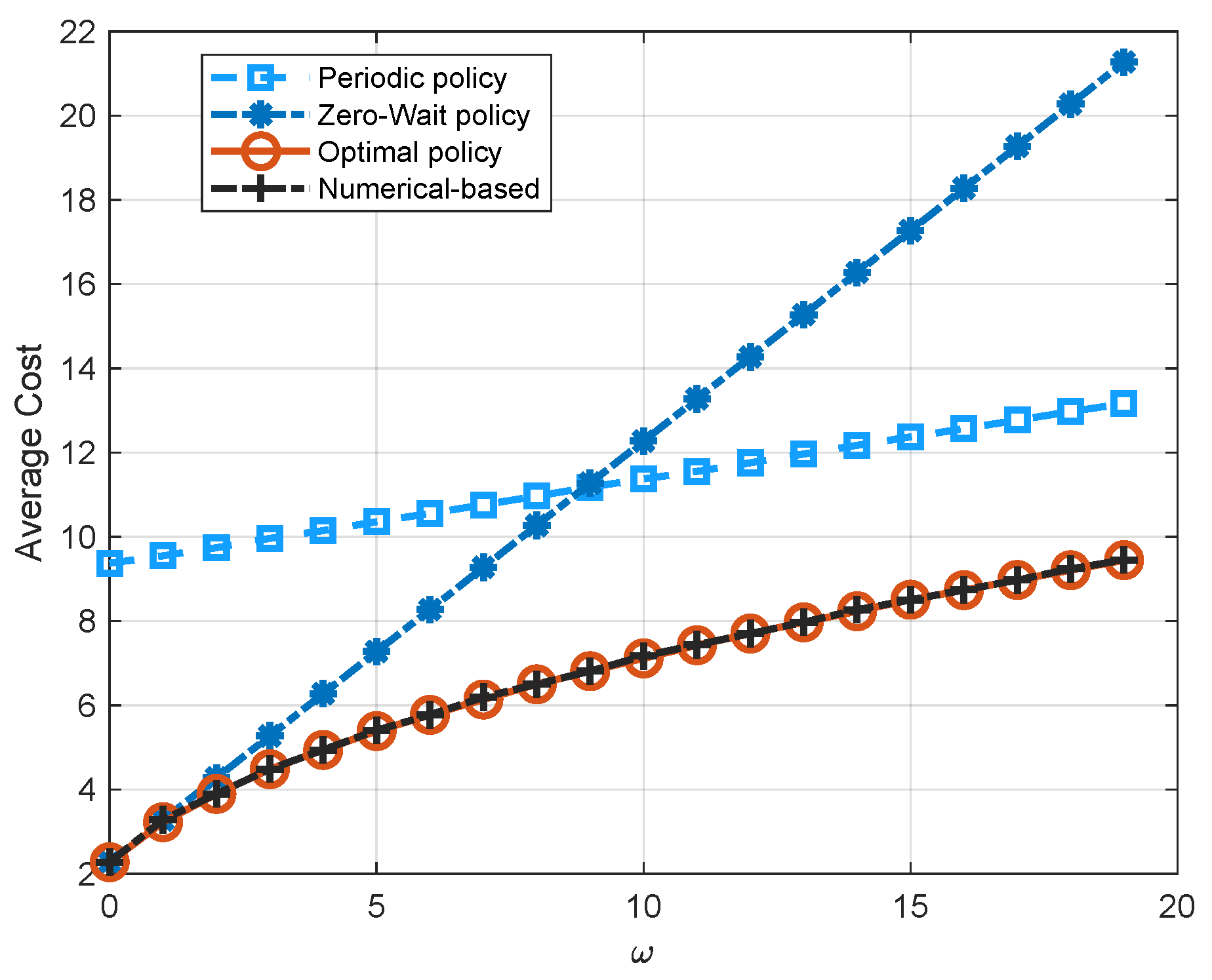
Figure 6 illustrates the performance comparison of four policies, i.e., the zero-wait policy, the periodic policy, the numerical-based policy, and the optimal policy, with respect to the weighting factor
. It is easy to see that the optimal policy has the lowest average cost. As we see in
Figure 6, the zero-wait policy has the same performance with the optimal policy when
. As
increases, the average cost of all three policies increases. However, the increment of the zero-wait policy is larger than the periodic policy and the optimal policy due to the frequent transmission in the zero-wait policy. Although the thresholds obtained by the PIA and the numerical algorithm are not exactly the same as shown in
Figure 5, the performance of the numerical-based algorithm also coincides with the optimal policy. This is because the threshold for channel state 1 exists in the quadratic term of the cost function, while the threshold for channel state 0 exists in the negative exponential term of the cost function. As a result, the threshold for channel state 1 has a much more significant effect on the system performance.
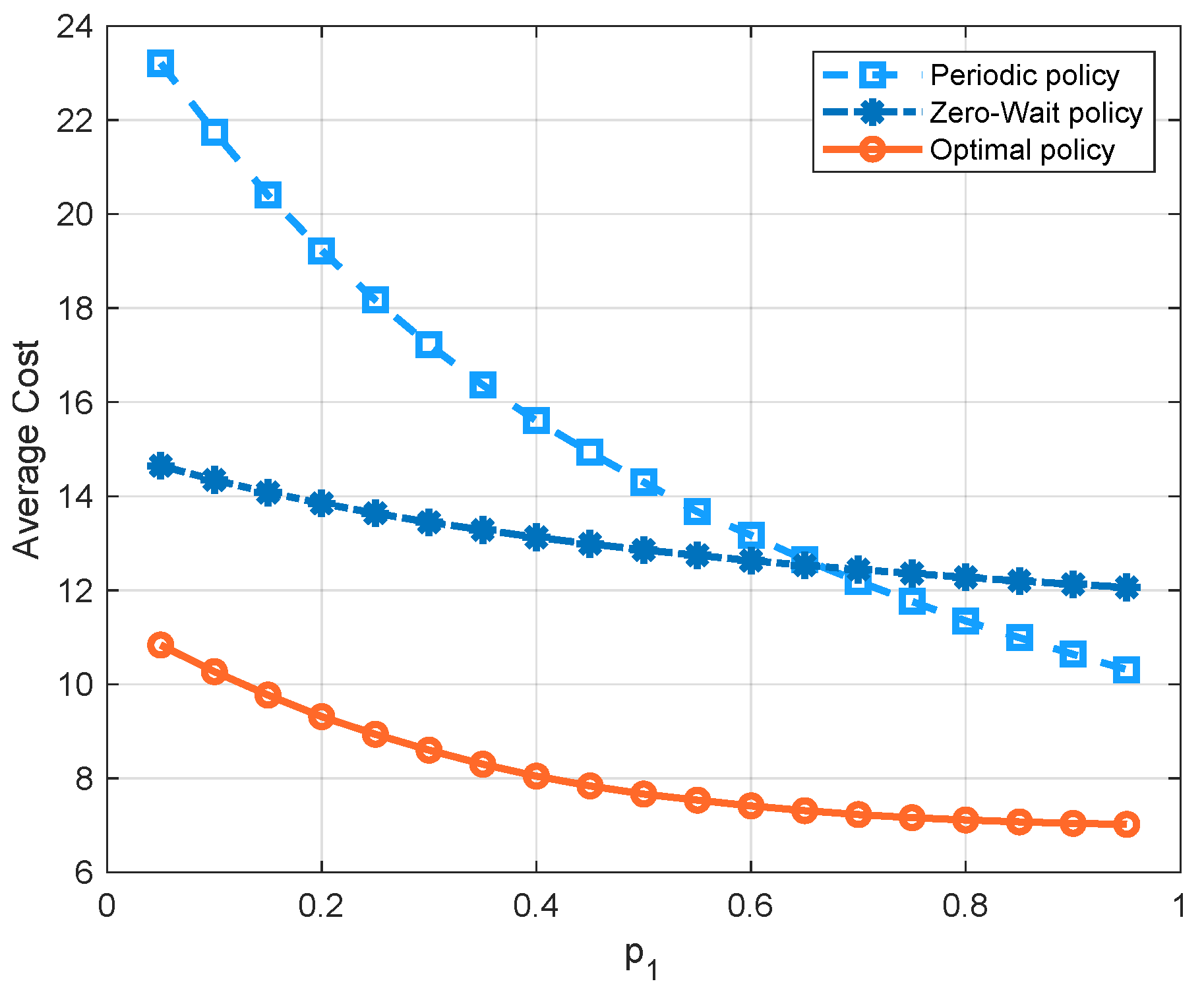
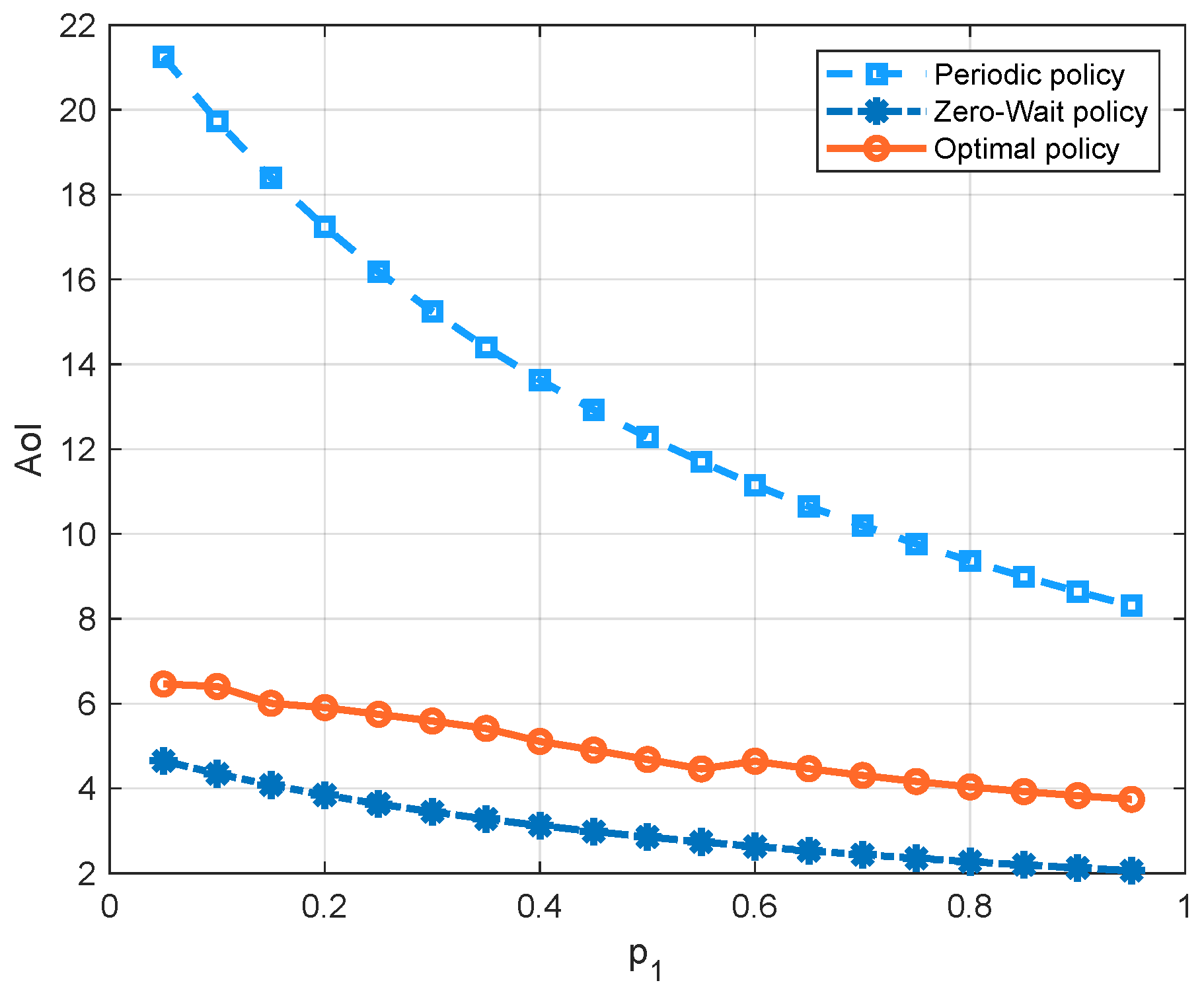
Figure 7 compares the three policies with respect to the probability
of the channel being in state 1. Since there is a higher probability that the channel has a good quality as
increases, the average cost of all three policies decreases. We can see that, in the regime of
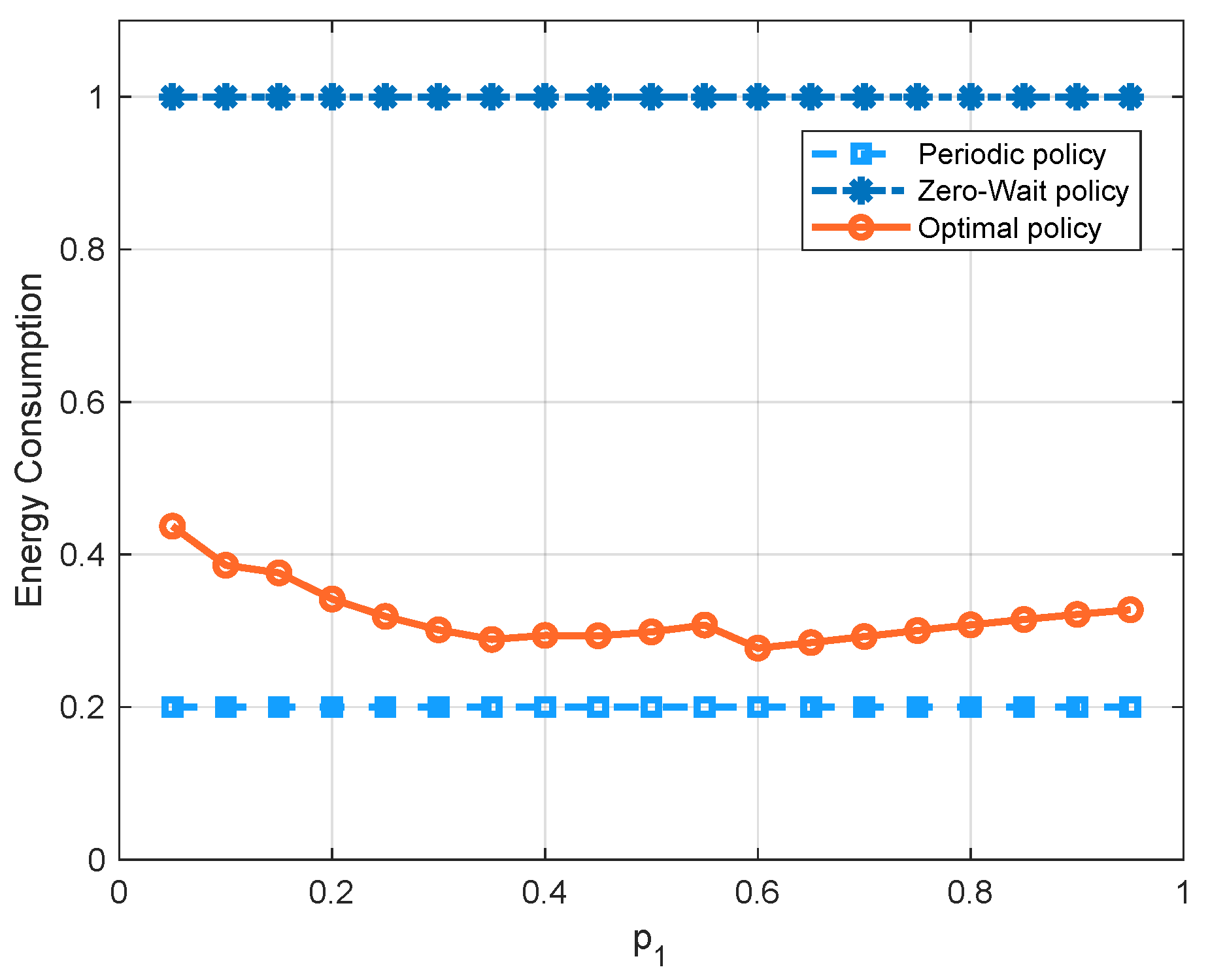
, the optimal policy has the lowest average cost, because it can achieve a good balance between the AoI and the energy consumption. We can also see that the cost of the periodic policy is greater than the zero-wait policy first, and smaller later. To further demonstrate these curves, we separate the energy consumption term and AoI term into different figures, i.e.,
Figure 8 and
Figure 9. We see that the update cost of the zero-wait policy is smaller than that of the periodic policy, but the AoI of the zero-wait policy has a smaller decrease with respect to
than the periodic policy.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








