
A Stepwise Assessment of Parsimony and Fuzzy Entropy in Species Distribution Modelling


Abstract
:1. Introduction
2. Materials and Methods
2.1. Modelling Method
2.2. Entropy Calculations
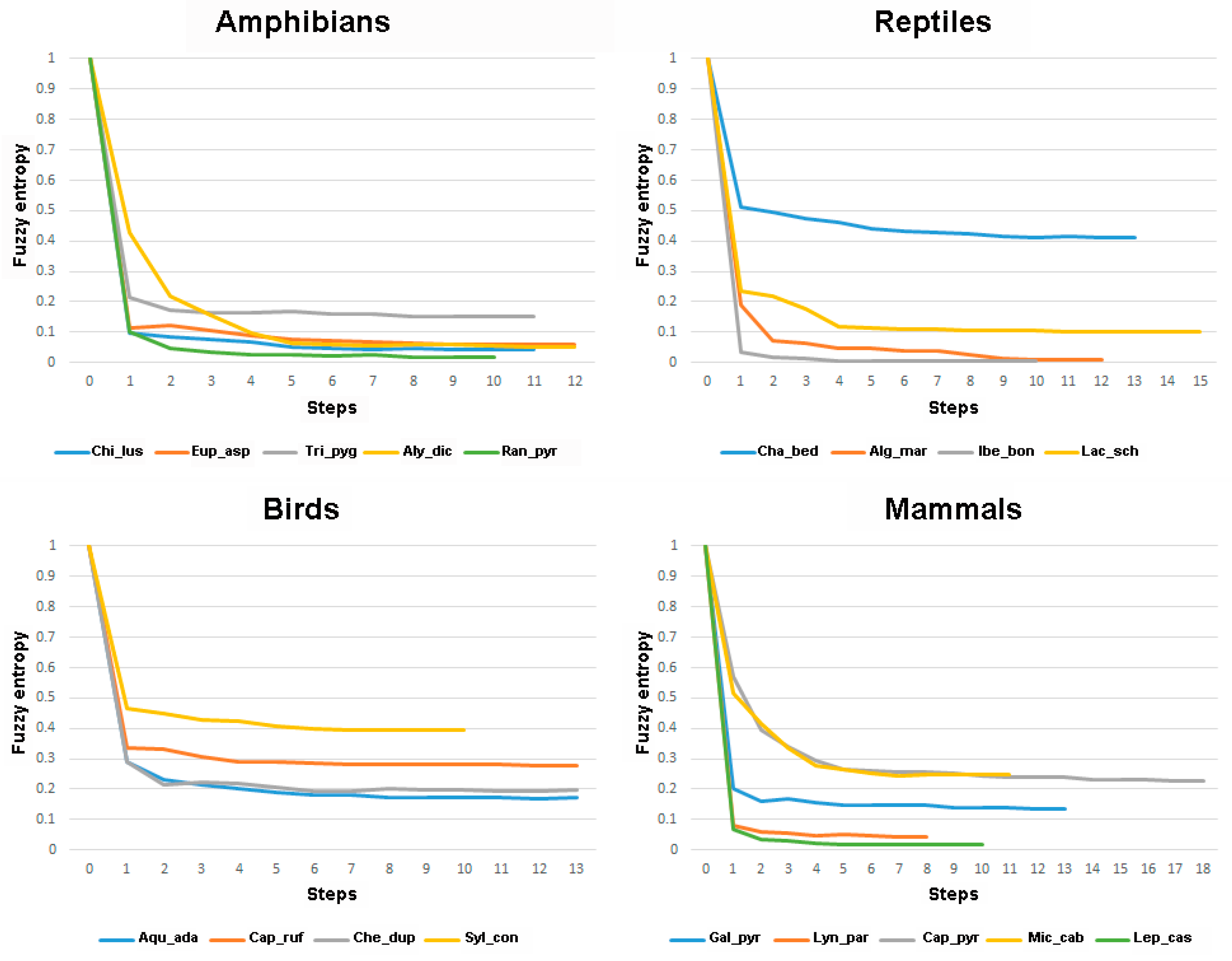
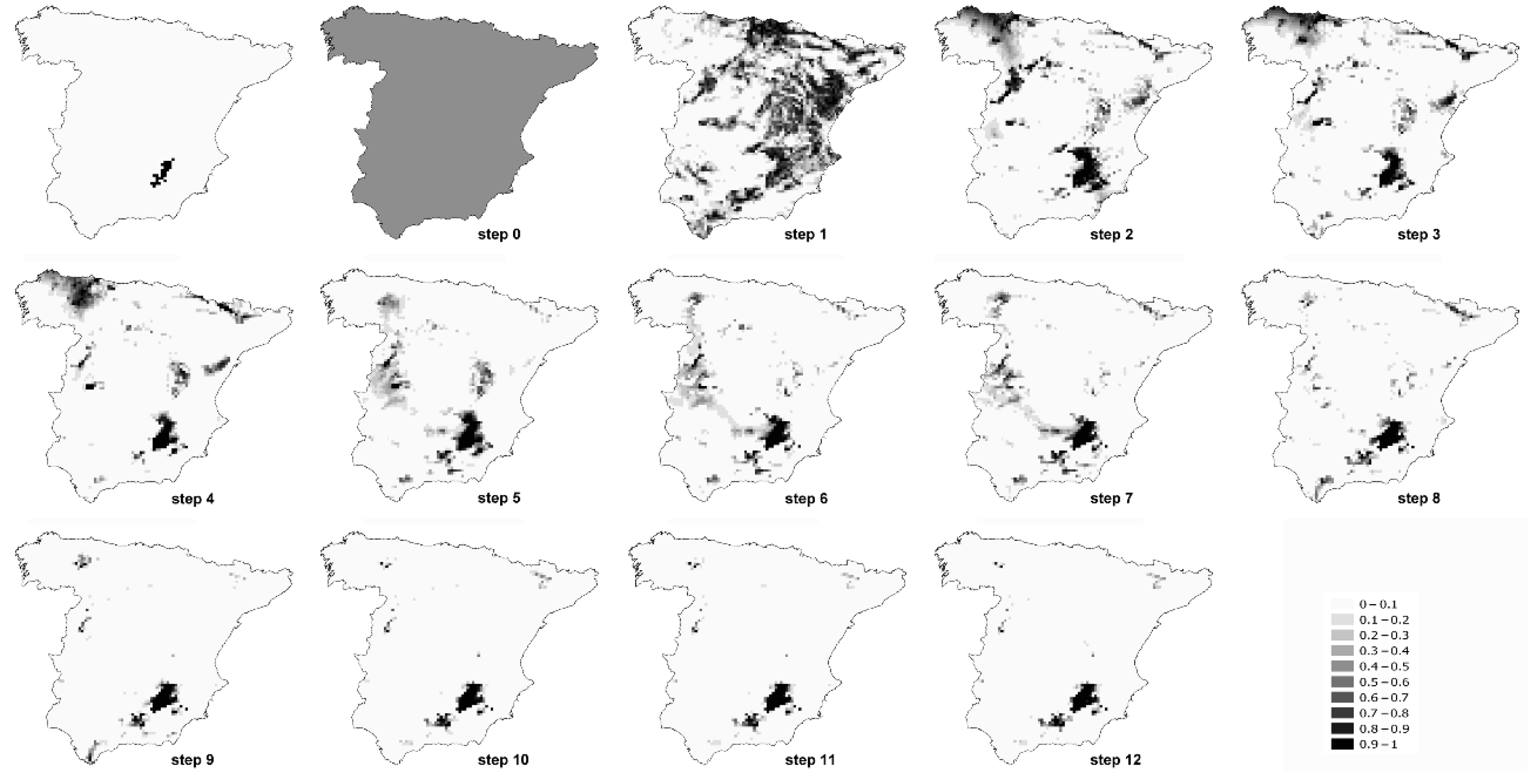
3. Results
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Muñoz, A.R.; Real, R.; Barbosa, A.M.; Vargas, J.M. Modelling the distribution of bonelli′s eagle in spain: Implications for conservation planning. Divers. Distrib. 2005, 11, 477–486. [Google Scholar] [CrossRef]
- Early, R.; Sax, D.F. Analysis of climate paths reveals potential limitations on species range shifts. Ecol. Lett. 2011, 14, 1125–1133. [Google Scholar] [CrossRef] [Green Version]
- Estrada, A.; Arroyo, B. Occurrence vs abundance models: Differences between species with varying aggregation patterns. Biol. Conserv. 2012, 152, 37–45. [Google Scholar] [CrossRef] [Green Version]
- Guarino, E.D.S.G.; Barbosa, A.M.; Waechter, J.L. Occurrence and abundance models of threatened plant species: Applications to mitigate the impact of hydroelectric power dams. Ecol. Model. 2012, 230, 22–33. [Google Scholar] [CrossRef]
- Estrada, A.; Delgado, M.P.; Arroyo, B.; Traba, J.; Morales, M.B. Forecasting large-scale habitat suitability of european bustards under climate change: The role of environmental and geographic variables. PLoS ONE 2016, 11, e0149810. [Google Scholar] [CrossRef] [Green Version]
- Barbet-Massin, M.; Thuiller, W.; Jiguet, F. The fate of european breeding birds under climate, land-use and dispersal scenarios. Glob. Chang. Biol. 2012, 18, 881–890. [Google Scholar] [CrossRef]
- Estrada, A.; Real, R.; Vargas, J.M. Assessing coincidence between priority conservation areas for vertebrate groups in a mediterranean hotspot. Biol. Conserv. 2011, 144, 1120–1129. [Google Scholar] [CrossRef]
- Araújo, M.B. Matching species with reserves–uncertainties from using data at different resolutions. Biol. Conserv. 2004, 118, 533–538. [Google Scholar] [CrossRef]
- Santos, H.; Rodrigues, L.; Jones, G.; Rebelo, H. Using species distribution modelling to predict bat fatality risk at wind farms. Biol. Conserv. 2013, 157, 178–186. [Google Scholar] [CrossRef]
- McCullagh, P.; Nelder, J.A. Generalised Linear Models, 2nd ed.; Chapman & Hall: London, UK, 1989. [Google Scholar]
- Hastie, T.; Tibshirani, R. Generalised additive models. Stat. Sci. 1986, 1, 297–310. [Google Scholar]
- Lek, S.; Guégan, J.F. Artificial neural networks as a tool in ecological modelling, an introduction. Ecol. Model. 1999, 120, 65–73. [Google Scholar] [CrossRef]
- Phillips, S.J.; Anderson, R.P.; Schapire, R.E. Maximum entropy modeling of species geographic distributions. Ecol. Model. 2006, 190, 231–259. [Google Scholar] [CrossRef] [Green Version]
- De′ath, G.; Fabricius, K.E. Classification and regression trees: A powerful yet simple technique for ecological data analysis. Ecology 2000, 81, 3178–3192. [Google Scholar] [CrossRef]
- Gouveia, S.F.; Rubalcaba, J.G.; Soukhovolsky, V.; Tarasova, O.; Barbosa, A.M.; Real, R. Ecophysics reload—Exploring applications of theoretical physics in macroecology. Ecol. Model. 2020, 424, 109032. [Google Scholar] [CrossRef]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef] [Green Version]
- Jaynes, E.T. Information theory and statistical mechanics. Phys. Rev. 1957, 106, 620–630. [Google Scholar] [CrossRef]
- Legendre, P.; Legendre, L. Numerical Ecology, 2nd ed.; Elsevier: Amsterdam, The Netherlands, 1998. [Google Scholar]
- Burnham, K.P.; Anderson, D.R. Model Selection and Multimodel Inference: A Practical Information-Theoretic Approach, 2nd ed.; Springer: New York, NY, USA, 2002. [Google Scholar]
- Schein, A.I.; Ungar, L.H. Active learning for logistic regression: An evaluation. Mach. Learn. 2007, 68, 235–265. [Google Scholar] [CrossRef]
- Rymarczyk, T.; Kozłowski, E.; Kłosowski, G.; Niderla, K. Logistic regression for machine learning in process tomography. Sensors 2019, 19, 3400. [Google Scholar] [CrossRef] [Green Version]
- Kosko, B. Fuzzy entropy and conditioning. Inf. Sci. 1986, 40, 165–174. [Google Scholar] [CrossRef]
- Real, R.; Barbosa, A.M.; Vargas, J.M. Obtaining environmental favourability functions from logistic regression. Environ. Ecol. Stat. 2006, 13, 237–245. [Google Scholar] [CrossRef]
- Acevedo, P.; Real, R. Favourability: Concept, distinctive characteristics and potential usefulness. Naturwissenschaften 2012, 99, 515–522. [Google Scholar] [CrossRef] [Green Version]
- Palomo, L.J.; Gisbert, J.; Blanco, J.C. Atlas y Libro rojo de los Mamíferos Terrestres de España; Dirección General para la Biodiversidad-SECEM-SECEMU: Madrid, Spain, 2007. [Google Scholar]
- Martí, R.; del Moral, J.C. Atlas de las aves Reproductoras de España; Dirección General de Conservación de la Naturaleza-Sociedad Española de Ornitología: Madrid, Spain, 2003. [Google Scholar]
- Pleguezuelos, J.M.; Márquez, R.; Lizana, M. Atlas y Libro Rojo de los Anfibios y Reptiles de España; Dirección General de Conservación de la Naturaleza-Asociación Herpetológica Española: Madrid, Spain, 2004. [Google Scholar]
- Benjamini, Y.; Hochberg, Y. Controlling the false discovery rate: A practical and powerful approach to multiple testing. J. R. Stat. Soc. B 1995, 57, 289–300. [Google Scholar] [CrossRef]
- Farfán, M.A.; Aliaga-Samanez, A.; Olivero, J.; Williams, D.; Dupain, J.; Guian, Z.; Fa, J.E. Spatial modelling for predicting potential wildlife distributions and human impacts in the dja forest reserve, cameroon. Biol. Conserv. 2019, 230, 104–112. [Google Scholar] [CrossRef]
- Moreno-Zarate, L.; Estrada, A.; Peach, W.; Arroyo, B. Spatial heterogeneity in population change of the globally-threatened european turtle-dove in spain: The role of environmental favourability and land use. Divers. Distrib. 2020, 26, 818–831. [Google Scholar] [CrossRef] [Green Version]
- Yamashita, T.; Yamashita, K.; Kamimura, R. A stepwise aic method for variable selection in linear regression. Commun. Stat.-Theory Methods 2007, 36, 2395–2403. [Google Scholar] [CrossRef]
- Shmueli, G. To explain or to predict? Stat. Sci. 2010, 25, 289–310. [Google Scholar] [CrossRef]
- Cramer, J.S. Predictive performance of the binary logit model in unbalanced samples. J. R. Stat. Soc. Ser. D (Stat.) 1999, 48, 85–94. [Google Scholar] [CrossRef]
- Robertson, M.P.; Villet, M.H.; Palmer, A.R. A fuzzy classification technique for predicting species′ distributions: Applications using invasive alien plants and indigenous insects. Divers. Distrib. 2004, 10, 461–474. [Google Scholar] [CrossRef] [Green Version]
- Estrada, A.; Real, R.; Vargas, J.M. Using crisp and fuzzy modelling to identify favourability hotspots useful to perform gap analysis. Biodivers. Conserv. 2008, 17, 857–871. [Google Scholar] [CrossRef] [Green Version]
- Real, R.; Márquez, A.L.; Olivero, J.; Estrada, A. Species distribution models in climate change scenarios are still not useful for informing policy planning: An uncertainty assessment using fuzzy logic. Ecography 2010, 33, 304–314. [Google Scholar] [CrossRef]
- Hosmer, D.W.; Lemeshow, S. Applied Logistic Regression, 2nd ed.; John Wiley and Sons, Inc.: New York, NY, USA, 2000. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing: Vienna, Austria, 2015. Available online: https://www.R-project.Org/ (accessed on 2 August 2021).
- Barbosa, A.M. Fuzzysim: Applying fuzzy logic to binary similarity indices in ecology. Methods Ecol. Evol. 2015, 6, 853–858. [Google Scholar] [CrossRef]
- Barbosa, A.M. Fuzzysim: Fuzzy Similarity in Species Distributions. R Package Version 1.7/r79. 2016. Available online: https://r-forge.R-project.Org/projects/fuzzysim/ (accessed on 2 August 2021).
- Barbosa, A.M.; Brown, J.A.; Jimenez-Valverde, A.; Real, R. Modeva: Model Evaluation and Analysis. R Package Version 1.2.3/r91. 2015. Available online: https://r-forge.R-project.Org/projects/modeva/ (accessed on 2 August 2021).
- Bivand, R.; Lewin-Koh, N. Maptools: Tools for Reading and Handling Spatial Objects. R Package Version 0.8-39. 2016. Available online: https://cran.R-project.Org/package=maptools (accessed on 2 August 2021).
- QGIS Development Team. Qgis Geographic Information System. Open Source Geospatial Foundation Project. 2016. Available online: http://qgis.Osgeo.Org (accessed on 2 August 2021).
- Zadeh, L.A. Fuzzy sets. Inf. Control. 1965, 8, 338–353. [Google Scholar] [CrossRef] [Green Version]
- Araújo, M.B.; Alagador, D.; Cabeza, M.; Nogué s-Bravo, D.; Thuiller, W. Climate change threatens european conservation areas. Ecol. Lett. 2011, 14, 484–492. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jiménez-Valverde, A.; Decae, A.E.; Arnedo, M.A. Environmental suitability of new reported localities of the funnelweb spider macrothele calpeiana: An assessment using potential distribution modelling with presence-only techniques. J. Biogeogr. 2011, 38, 1213–1223. [Google Scholar] [CrossRef]
- Thuiller, W.; Georges, D.; Engler, R. Biomod2: Ensemble Platform for Species Distribution Modeling. R package version 3.1-25. 2013. Available online: http://cran.R-project.Org/package=biomod2 (accessed on 2 August 2021).
- Romero, D.; Olivero, J.; Brito, J.C.; Real, R. Comparison of approaches to combine species distribution models based on different sets of predictors. Ecography 2016, 39, 561–571. [Google Scholar] [CrossRef]
- Jiménez-Valverde, A.; Nakazawa, Y.; Lira-Noriega, A.; Peterson, A.T. Environmental correlation structure and ecological niche model projections. Biodivers. Inform. 2009, 6, 28–35. [Google Scholar] [CrossRef]
- Araújo, M.B.; Thuiller, W.; Pearson, R.G. Climate warming and the decline of amphibians and reptiles in europe. J. Biogeogr. 2006, 33, 1712–1728. [Google Scholar] [CrossRef]
- Araújo, M.B.; Guisan, A. Five (or so) challenges for species distribution modelling. J. Biogeogr. 2006, 33, 1677–1688. [Google Scholar] [CrossRef]
- Pearson, R.G.; Dawson, T.P. Predicting the impacts of climate change on the distribution of species: Are bioclimate envelope models useful? Glob. Ecol. Biogeogr. 2003, 12, 361–371. [Google Scholar] [CrossRef] [Green Version]
- Austin, M.P.; Van Niel, K.P. Improving species distribution models for climate change studies: Variable selection and scale. J. Biogeogr. 2011, 38, 1–8. [Google Scholar] [CrossRef]
- Márquez, A.L.; Real, R.; Olivero, J.; Estrada, A. Combining climate with other influential factors for modelling the impact of climate change on species distribution. Clim. Chang. 2011, 108, 135–157. [Google Scholar] [CrossRef]
- Lobo, J.M.; Jiménez-Valverde, A.; Real, R. Auc: A misleading measure of the performance of predictive distribution models. Glob. Ecol. Biogeogr. 2008, 17, 145–151. [Google Scholar] [CrossRef]
- Jiménez-Valverde, A.; Acevedo, P.; Barbosa, A.M.; Lobo, J.M.; Real, R. Discrimination capacity in species distribution models depends on the representativeness of the environmental domain. Glob. Ecol. Biogeogr. 2013, 22, 508–516. [Google Scholar] [CrossRef] [Green Version]
- Boltzmann, L. Weitere studien uber das wirmegleichgewicht unter gasmolek~len. Wien. Ber. 1872, 66, 275–370. [Google Scholar]
- Boltzmann, L. Bemerkungen uber einige problems der mechanischen wirmetheorie. Wien. Ber. 1877, 75, 62–100. [Google Scholar]
- Boltzmann, L. Uber die beziehung zwischen dom zweiten hauptsatze der mechanischen wirmetheorie und der wahrchein-lichkeitsrechnung respective den sitzen dber des wgrmegleichgewicht. Weiner Ber. 1877, 76, 373–435. [Google Scholar]
- Boltzmann, L. Weitere bemerkungen uber einige plobleme der mechanischen wirmetheorie. Wien. Ber. 1878, 78, 7–46. [Google Scholar]
- Akaike, H. Prediction and Entropy; University of Wisconsin-Madison: Technical Summary Report; Mathematics Research Center: Madison, WI, USA, 1982. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Group | Species | Species Code | N | Total Steps | Step Lowest R |
|---|---|---|---|---|---|
| Amphibians | Chioglossa lusitanica | Chi_lus | 168 | 11 | 9 |
| Euproctus asper | Eup_asp | 189 | 12 | 12 | |
| Triturus pygmaeus | Tri_pyg | 470 | 11 | 11 | |
| Alytes dickhilleni | Aly_dic | 135 | 12 | 12 | |
| Rana pyrenaica | Ran_pyr | 24 | 10 | 10 | |
| Reptiles | Chalcides bedriagai | Cha_bed | 605 | 13 | 13 |
| Algyroides marchi | Alg_mar | 30 | 12 | 11 | |
| Iberolacerta bonnali | Ibe_bon | 25 | 10 | 5 | |
| Lacerta schreiberi | Lac_sch | 576 | 15 | 13 | |
| Birds | Aquila adalberti | Aqu_ada | 158 | 13 | 12 |
| Caprimulgus ruficollis | Cap_ruf | 1725 | 13 | 13 | |
| Chersophilus duponti | Che_dup | 237 | 13 | 6 | |
| Sylvia conspicillata | Syl_con | 1299 | 10 | 8 | |
| Mammals | Galemys pyrenaicus | Gal_pyr | 513 | 13 | 13 |
| Lynx pardinus | Lyn_par | 29 | 8 | 7 | |
| Capra pyrenaica | Cap_pyr | 647 | 18 | 18 | |
| Microtus cabrerae | Mic_cab | 272 | 11 | 7 | |
| Lepus castroviejoi | Lep_cas | 69 | 10 | 6 |
| Step | Variable | Cor_P | H | Cor_F | R | AIC |
|---|---|---|---|---|---|---|
| 0 | Intercept | - | 8.58 | - | 1 | 372.38 |
| 1 | +Calc | 0.169 | 7.39 | 0.224 | 0.1897 | 302.57 |
| 2 | +U500 | 0.621 | 5.61 | 0.406 | 0.0729 | 190.01 |
| 3 | +AET | 0.7396 | 5.19 | 0.446 | 0.0618 | 161.07 |
| 4 | +Alt | 0.837 | 4.85 | 0.468 | 0.0469 | 137.66 |
| 5 | +SISSum | 0.884 | 4.54 | 0.638 | 0.0465 | 116.82 |
| 6 | +Grav | 0.908 | 4.43 | 0.692 | 0.0391 | 110.61 |
| 7 | +CTI | 0.927 | 4.37 | 0.721 | 0.0378 | 107.92 |
| 8 | +Sil | 0.9395 | 4.28 | 0.839 | 0.0265 | 104.18 |
| 9 | +U100 | 0.971 | 4.14 | 0.906 | 0.0119 | 96.53 |
| 10 | +DTn20Aut | 0.994 | 4.090 | 0.990 | 0.00871 | 94.47 |
| 11 | −Calc | 0.996 | 4.095 | 0.992 | 0.00848 | 92.91 |
| 12 | −Alt | 1 | 4.12 | 1 | 0.00863 | 92.08 |
| Step | Variable | Cor_P | H | Cor_F | R | AIC |
|---|---|---|---|---|---|---|
| 0 | Intercept | - | 8.58 | - | 1 | 5909.44 |
| 1 | +DP10Aut | 0.824 | 8.35 | 0.878 | 0.467 | 5160.62 |
| 2 | +CTI | 0.891 | 8.32 | 0.916 | 0.451 | 5063.95 |
| 3 | +Sil | 0.913 | 8.31 | 0.943 | 0.429 | 5021.69 |
| 4 | +PSum | 0.932 | 8.30 | 0.955 | 0.425 | 4994.18 |
| 5 | +Alt | 0.957 | 8.29 | 0.968 | 0.406 | 4955.96 |
| 6 | +DHi | 0.972 | 8.28 | 0.980 | 0.400 | 4929.42 |
| 7 | +U500 | 0.983 | 8.276 | 0.989 | 0.3960 | 4911.05 |
| 8 | +TRan | 0.993 | 8.272 | 0.995 | 0.394 | 4894.74 |
| 9 | +PET | 0.997 | 8.271 | 0.998 | 0.395 | 4888.98 |
| 10 | +Grav | 1 | 8.270 | 1 | 0.3957 | 4885.93 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Estrada, A.; Real, R. A Stepwise Assessment of Parsimony and Fuzzy Entropy in Species Distribution Modelling. Entropy 2021, 23, 1014. https://doi.org/10.3390/e23081014
Estrada A, Real R. A Stepwise Assessment of Parsimony and Fuzzy Entropy in Species Distribution Modelling. Entropy. 2021; 23(8):1014. https://doi.org/10.3390/e23081014
Chicago/Turabian StyleEstrada, Alba, and Raimundo Real. 2021. "A Stepwise Assessment of Parsimony and Fuzzy Entropy in Species Distribution Modelling" Entropy 23, no. 8: 1014. https://doi.org/10.3390/e23081014
APA StyleEstrada, A., & Real, R. (2021). A Stepwise Assessment of Parsimony and Fuzzy Entropy in Species Distribution Modelling. Entropy, 23(8), 1014. https://doi.org/10.3390/e23081014