1. Introduction
The term dynamical similarity refers to the degree to which the dynamics governing the evolution of a system over a period of time resembles the dynamics of another system, or the dynamics of the same system over a different period of time. Two fundamental problems of time series analysis are how best to measure dynamical similarity, and how to infer a given measure from noisy time series data. We address both problems, first by presenting a new metric of dynamical similarity that is indicative of underlying causal structure and that is well posed whether one is comparing two deterministic or two stochastic dynamical systems, and then by providing a range of tools for estimating this metric from data.
There is no uniquely best measure of dynamical similarity since the aptness of any given measure is relative to its intended use. However, there is broad interest in measures that are sensitive to the causal structure of a system in the sense of which variables directly determine the values (or stochastic distributions over the values) of other variables and with what functional form. For instance, the field of change detection is concerned with determining if and when the causal structure of a dynamical system has changed, as for example when an ecosystem (or climate) has been perturbed by external forcing, or when a mechanical component has begun to fail [
1]. This amounts to determining whether one and the same system at a later time is dynamically similar to itself at an earlier time. Classically, this problem has been pursued under the assumption that the behavior of some stochastic system before and after a rapid change in parameter values is stationary [
2], though progress has been made on the problem without the assumption of stationarity [
3]. From the perspective of deterministic complex systems, the problem of change detection manifests as either the problem of detecting incipient bifurcations [
4] or transitions between regions of the system’s attractor [
5]. The more general problem encompassing both approaches is the detection of change in the structure of a dynamical system without assumptions of determinism or stationarity, such as detecting incipient bifurcation in an arbitrary stochastic dynamical system [
6]. In general, we want to know whether a given system will continue to evolve and respond to perturbations in the same way as it did before.
It has been recognized for some time that it is often more important to know the degree of difference in dynamics after a change rather than the mere fact of change [
7]. While change detection is often treated as a binary statistical decision problem [
8], explicit measures of dynamical similarity have been used to assess whether a dynamical shift is practically (as opposed to statistically) significant [
7]. Implicitly, such a notion of dynamical similarity plays a central role in system identification, where it is often important to know at the outset whether the system in question can be described with sufficient fidelity using a linear model [
9], or in other words, whether the system is sufficiently dynamically similar to a linear one. Similarly, it is important to know the effective order of the dynamical process of interest in contexts where acquiring data points in a time series is expensive, such as community ecology, in order to know how long of a time series will be needed to fit a reliable model [
10]. Relatedly, the degree of nonlinearity and chaos exhibited by a system is essential for managing error in system control or prediction [
11,
12,
13,
14]. Each of these problems—identifying effective order, nonlinearity, and chaos—can be seen in terms of dynamical similarity. Whether a system is strongly nonlinear is equivalent to asking whether and to what degree it is dynamically similar to a strongly nonlinear system and mutatis mutandis for effective order and chaos.
Whatever the appropriate measure of dynamical similarity, the problem of estimating its value from data is made more difficult with increasing sampling noise, and becomes significantly more challenging to address for stochastic systems. Model validation is notoriously difficult for stochastic systems [
15,
16]. Model validation amounts to assessing the similarity between one system—the model—whose dynamics is exactly characterized, and a target system with unknown dynamical properties; a valid model is one whose dynamics matches that of the target. The difficulty of this comparison is only compounded when one attempts to determine the similarity between two systems, both with unknown dynamics. Furthermore, existing techniques for detecting change or assessing, e.g., nonlinearity, are highly sensitive to sampling noise [
2,
17].
We here describe a general metric of dynamical similarity that is well posed for both stochastic and deterministic dynamical systems and which is sensitive to the effective order of dynamics, the degree of nonlinearity, and the presence of chaos. Importantly, this metric can be informative of these dynamical features even when only partial information about the dynamical state of a system is tracked, or a lossy function of the dynamical variables is observed, or in other words, if the system is only “partially observed” [
18]. We introduce a variety of algorithms to show that this metric can be learned in a range of contexts, from situations in which one has full control of the dynamical system and complete dynamical information to situations in which only partial information is available for passively observed systems. We also demonstrate how this metric can be applied to the problem of change detection in this range of circumstances, and how it can be deployed to rapidly map out the varieties of dynamical behavior as a function of parameter values for a given dynamical model.
3. Theory and Algorithms
3.1. Stochastic Dynamical Kinds
Dynamical kinds partition the space of possible dynamical systems based on their causal structure. However, as defined above, sameness of dynamical kind is binary; it does not indicate the degree to which two systems that are not of the same kind differ in their causal structure. It also fails to apply to systems with stochastic dynamics. This latter problem can be addressed with a more expansive definition of dynamical kind. Previously, it has been suggested that the definition of dynamical similarity should be generalized to accommodate stochastic dynamics [
69]. When restricted to dynamical symmetries with respect to time (other types of symmetry are considered in [
69]), that proposed definition reduces to the following:
Definition 2. Let V be a set of random variables, Ω the set of states that can be jointly realized by the variables in V, and Γ the space of probability distributions over Ω. Let be an intervention on the variables in . The transformation σ is a dynamical symmetry with respect to time if and only if σ has the following property: for all initial joint distributions , the final joint probability distribution over V, , is the same whether σ is applied at time and then time evolution evolves the joint distribution, or the system is first allowed to evolve over an interval Δ, and then σ is applied. This property is represented in the following commutative diagram: We accept this definition, and use it to develop a natural metric over dynamical systems that solves the problem of degree. Specifically, we present a metric based on Definition 2 that provides a well-grounded degree of causal difference, and show that it is sensitive to variations in linearity, effective order, and the presence of chaos.
3.2. Constructing a Metric of Dynamical Similarity
Consider a dynamical system described by
n variables, some of which may be derivatives or time-lagged versions of other variables. The states of such a system can be represented by
n-dimensional vectors
. Let
be the space of probability density functions over
. We say that such a system is
stochastically state-determined (SSD) if and only if the (possibly stochastic) dynamics of the system is such that the probability density
over possible states at time
is completely determined by the density
over states at
. In other words, for an SSD system there exists a map,
that, for any
advances the probability density over states of the system from
to
(“random dynamical systems” in the sense defined in [
74] are thus SSD, though we do not insist that SSD systems be measure preserving). According to Definition 2, any function,
that commutes with this map is a dynamical symmetry of the system. More precisely,
is a dynamical symmetry of a system if, for every
where
is the probability distribution that results from successive application of the maps
and then
to the original distribution
(and similarly for
). This property is represented in by the following commutative diagram:
Consider two probability densities,
and
, connected by one such dynamical symmetry at time
. We call a time series
untransformed if, for every
, it is the value of a random variable distributed according to
. In other words, an untransformed time series is a time series for a system that evolves from an initial value selected according to the distribution
. Similarly, we call a time series
transformed if, for every
, it is the value of a random variable distributed according to
. We focus on a particular probability density function that relates the time evolution of untransformed and transformed time series. Specifically, if one of
n distinct times,
, in the evolution of the system is selected at random from a uniform distribution over the
n possibilities, we seek the probability density that any untransformed time series exhibits a system state
and any given transformed time series presents a system state
at the same time. This joint density is given by:
Denote the cumulative distribution corresponding to
by
. This distribution for any given dynamical system is shaped by its causal structure. In order to compare the degree to which dynamical structure differs between systems, our approach is to compare
. A suitable metric for doing so is the energy distance [
75,
76,
77].
The energy distance for any two cumulative distributions,
and
over random variables
and
is defined as follows:
where
and
are equivalent in distribution to
and
. The square root of the right hand side of Equation (
6),
, is a proper metric, and is zero if and only if
.
We define the dynamical distance, , according to the identity
where the random variable
(equivalent in distribution to
) has values in the
-dimensional space of joint states
, and similarly for
. For two systems A and B, if at each time index
i,
, then the difference between
and
and thus any difference between
and
must be due entirely to the action of the respective symmetries,
and
. In that case, measuring the dynamical distance
provides a quantitative comparison of the symmetries of systems A and B, and thus of the underlying casual structure that gives rise to them.
In general, an energy distance can be estimated by computing the sample mean for each of the expectation values on the right-hand side of Equation (
6). For a sample of
p points from system A and
q from system B, there are
pairwise distances for estimating
,
for estimating
, and
for estimating the cross-term,
.
Accordingly, can be estimated using a sample of -dimensional vectors,
from system A and from system B, where is the i-th point in a time series from system A beginning with an initial value drawn according to and is the contemporaneous i-th point in a time series from system A beginning with an initial value drawn according to , and similarly for system B.
3.3. Temporal Scale Matching
The density depends on both the time-evolution operators and the particular dynamical symmetry, , that maps to . In general, two distinct systems will differ with respect to , and so despite beginning with the same distribution it is impossible to find later times such that . However, if is sufficiently smooth and the means of the two distributions overlap over some nonempty time interval, then it is possible to find n times and (such that and for some positive constants ) for which . In particular, one could sample each system over a sufficiently short interval of time relative to the natural scale of its dynamics in order to limit the evolution of each system to within acceptable deviation from the shared starting condition.
If the times
are externally determined (as is often the case with data received for analysis by someone other than the experimenter or for data acquired by instrumentation with a fixed sampling period) but multiple time series are available from each system, then the same end can be achieved approximately by truncating or clipping one of the two sets of time series so as to effectively alter the time scale on which the corresponding system is sampled. We introduce an algorithm based again on an energy distance as defined in Equation (
6). Suppose systems A and B are originally sampled at regular intervals at
, and for both systems, a number
s of untransformed and a number
s of transformed time series are provided. Then we seek the index
m for either A or B such that the following condition holds. If each time series in the untransformed set (from A or B) is truncated at
and for each index
i of the truncated set of time series and each index,
, of the intact set of time series (from B or A) the energy distance between the sets of values at those indices is computed and the results averaged over
i, there is no choice of
m for either system A or system B that yields a lower average. The objective of clipping in this way is similar in spirit to the objective of dynamic time warping (to select a mapping of the indices of one time series to those of another that minimizes the sum of distances between the matched pairs) [
78]. However, dynamic time warping requires that the first and last indices of the two time series compared coincide (leaving the overall time interval over which the system evolves intact), and unevenly alters the sampling interval throughout a given time series. Furthermore, dynamic time warping is not defined for ensembles of replicates from each system, while the energy distance is apt for comparing the similarity of
and
at each
given multiple time series samples from
A and
B. We therefore use the average energy distance over time to find an appropriate cut point for one or the other ensemble of time series.
If the set of transformed time series replicates for each system are clipped to match their corresponding untransformed curves, then the difference in
between the two systems is driven by the unknown dynamical symmetry,
. For all numerical experiments reported here, we used the clipping algorithm expressed in Algorithm 1 when comparing time series from two systems. More specifically, we used Algorithm 1 to determine the optimal length at which to cut untransformed time series samples from
A with the samples from
B held fixed, and then repeated the process to determine the best length to cut samples from
B with
A held fixed. We ultimately clipped the data of whichever of the two systems resulted in the lowest value of
after clipping.
| Algorithm 1: Clipping for temporal scale matching. |
![Entropy 23 01191 i001]() |
3.4. Partial Information and Degrees of Control
To make use of the dynamical similarity metric to compare physical systems, one needs an appropriate collection of time series. Ideally, one would obtain multiple untransformed and transformed time series for each system beginning with initial values identically and independently distributed according to and , respectively, and where each system is sampled over a length of time such that for the pair of systems A and B to be compared, at each time index i. If one has control over the initial conditions (the ability to intervene on the system), this is manageable. However, in many cases of interest, this is impossible. Furthermore, it is often the case that the variables in terms of which systems are described fail to satisfy the SSD condition because the set is incomplete or amounts to a noninvertible function of an SSD set. We describe methods for estimating our dynamical symmetry metric for every combination of these conditions.
3.4.1. SSD Variable Set and Full Control of the Initial Distribution
At one extreme, we are provided full control over the initial conditions from which each time series for an SSD set of variables begins. In this case, the simplest approach is to take multiple time series samples from each system, half of which begin with an untransformed initial value of and half of which begin at the transformed initial value, . The clipping algorithm described above can then be applied and the dynamical distance estimated by using the resulting sets of time series to provide a sample of contemporaneous untransformed and transformed states, , for each system.
3.4.2. SSD Variable Set and No Control of the Initial Distribution
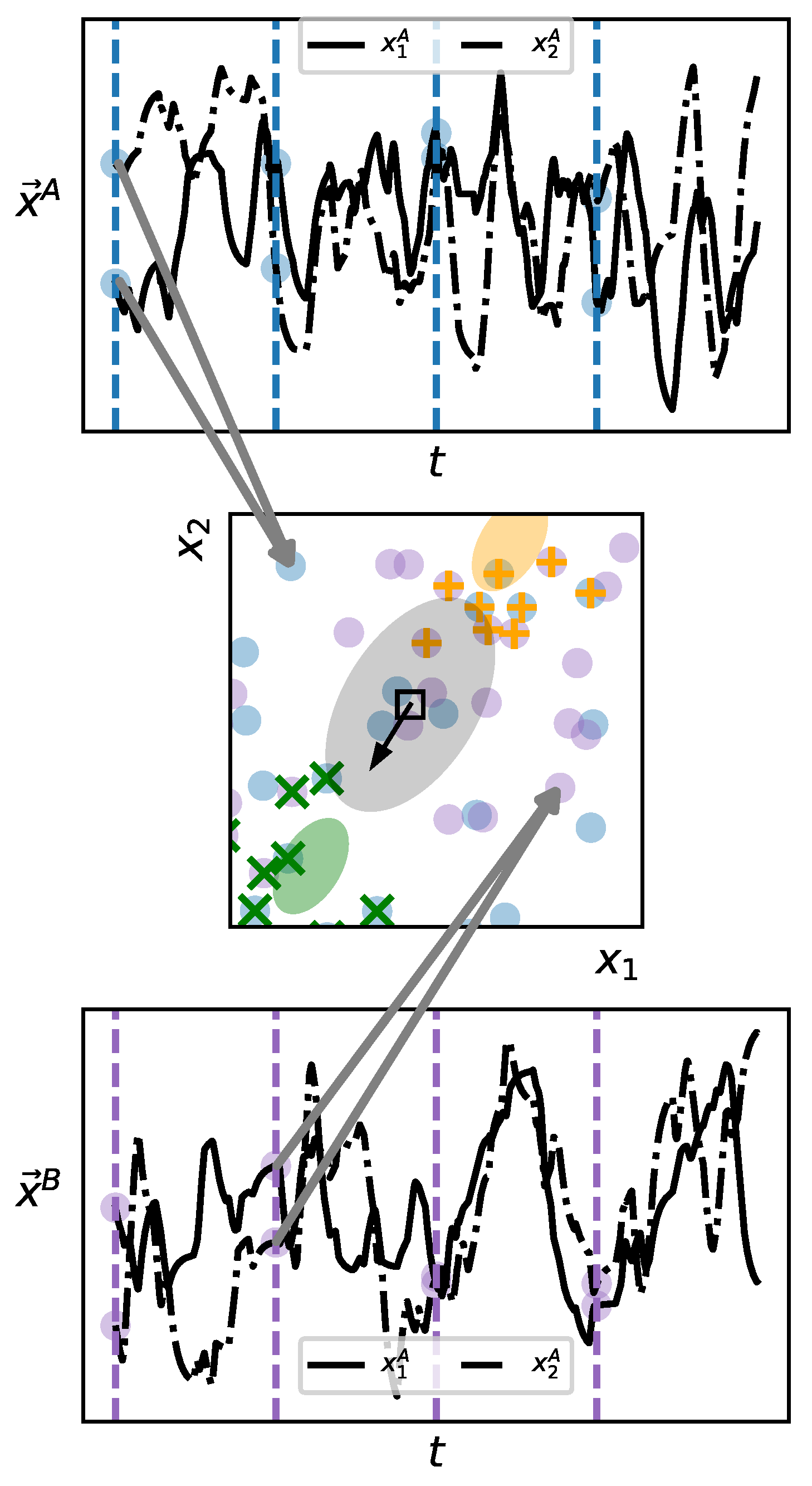
Even if a set of variables is known or suspected to be SSD, it is often or typically the case that time series are provided for analysis without the ability to manipulate the system to select specific initial values. In the most difficult case, only a single extended time series is available. While one cannot set the initial conditions of such a passively observed system, one can—under the additional assumption that the dynamics of the system are autonomous—imagine that subsequences within the given time series are each an initialization of that system. By carefully selecting such subsequences as instances of a system’s untransformed and transformed time series, it is still possible to estimate .
In describing the algorithm, we assume that two systems (A and B) are to be compared, but the method generalizes straightforwardly to arbitrarily many systems for which one seeks to estimate pairwise commensurable dynamical distances. First, the time series for both systems A and B are broken into subsequences of uniform length
l. To select a subset of these sequences that will be treated as the untransformed set of replicates and the subset that will be treated as the transformed set for each system, we pool the initial values of all subsequences and compute the normalized eigenvector
with the largest eigenvalue
for the covariance matrix
as well as the overall mean
of the pool. We then compute two new means,
and
where
is a metaparameter controlling the degree of separation between the means of the two new distributions. Throughout, we have used a default value of
unless otherwise noted. We compute the singular value decomposition of the original
covariance matrix
where
U and
are real,
orthogonal matrices and
S is an
diagonal matrix with the singular values of
along the diagonal. We then construct a new covariance matrix,
where
is a second metaparameter determining the relative spread of the constructed distributions. We use
unless otherwise indicated. Finally, for each system A and B, a set of untransformed replicates is chosen by selecting from the candidate subsequences those whose initial values have the highest density according to the
n-dimensional normal distribution with mean
and covariance matrix
. Likewise, a set of transformed replicates is selected based on their density according to the
n-dimensional normal distribution with mean
and covariance matrix
. This selection procedure is detailed in Algorithm 2. Once sets of replicates have been chosen in this way, the dynamical distance can be estimated as usual. This procedure is shown schematically in
Figure 1 and presented in detail in Algorithm 2.
| Algorithm 2: Choose untransformed and transformed representatives from data. |
![Entropy 23 01191 i002]() |
3.4.3. Non-SSD Variable Set and Full Control of the Initial Distribution
Not every set of variables captures enough about the dynamically or causally relevant aspects of a physical system to determine future states (or distributions over future states) from the state (or distribution over states) at a given time. When dynamical variables go unobserved or when an observed set of variables is a lossy function of a complete set then the set of variables will generally fail to meet the SSD condition. We generically refer to such a set of variables as “partial” and the systems they describe as “partially observed.” While the methods described above for estimating do not work directly for partial variable sets, it is still possible in many circumstances to use the dynamical distance to discriminate among partially observed systems. For a system that is not SSD, the distribution over states at a time t does not uniquely determine the distribution at a later time . However, when the failure to meet the SSD condition is because the system is partially observed, there exists an unknown set of variables the states of which would uniquely determine when supplemented by the observed variables. If transformed and untransformed time series can be obtained for each of two systems where the marginal distribution over the unobserved variables at is the same for both sets of untransformed series and the same for both sets of transformed series, then differences in the apparent values of will still be driven by the dynamical symmetries of the systems.
Given control of the initial state of each system to be compared, it is often the case that the procedure for setting the initial state in terms of the partial set of variables does fix a distribution over the unobserved variables. While this cannot be guaranteed, it can be tested given sufficient numbers of untransformed and transformed time series by verifying a fixed distribution over later times for a given initial (partial) state. The procedure for systems for which it is possible to intervene to set initial conditions but which are suspected of failing the SSD condition is thus to acquire multiple time series samples for each system for each initial condition, and then to estimate as above.
3.4.4. Non-SSD Variable Set and No Control of the Initial Distribution
The most difficult scenario for accurately assessing dynamical similarity, regardless of the method used, is the case in which data are passively acquired such that there is no opportunity to set initial conditions and partially observed such that the given system of variables is therefore non-SSD. Even in this context, it is still possible to estimate at the price of some additional assumptions about the systems under consideration, namely that the all dynamical variables are bounded, that the dynamics is such that given sufficient time the system will pass nearby any system state previously observed, and that for any observed state there is a stationary distribution over states of the unobserved variables. Such a bounded system observed over a sufficiently long time will often exhibit an approximately stationary “distribution of distributions” that makes it appear SSD. For example, observing only the angular position of a pendulum does not determine its future position (angular position alone is not a state-determined set of variables). However, watching the pendulum swing for a while, one builds up a time series in which, from nonextremal positions, it moves left half the time and right half the time. So the system, though not state-determined, appears SSD. A similar situation obtains for stochastic dynamics.
Given that the available time series is long enough to meet these assumptions, then the dynamical distance
can be estimated using the same algorithm as described in
Section 3.4.2 for the case of a passively observed, SSD set of variables.
3.5. Change Detection
The methods for computing
described above for conditions in which there is no control over the initial distribution can be used to detect changes in dynamics manifest in an extended time series. To identify such change points, a rolling window method can be used. For a window width of
w and a lag (the space between the leading and trailing window) of
l and a discrete time series,
, we treat the subsequences
and
as time series from separate systems, and compute the value of
between them using the method of either
Section 3.4.2 or
Section 3.4.4, depending on whether the system is thought to be SSD. The appropriate window width depends upon how many replicates are required, and the minimum length of each. The best choice for the lag
l will depend on the time over which the change in dynamical structure occurs. If
l is shorter than the transition period, then both the leading and trailing windows will contain part of the transitional dynamics as they pass over the change, which tends to suppress the elevation of
, making it easier to miss the transition. If
l is overly large, then it limits one’s ability to pinpoint the time of transition.
5. Discussion
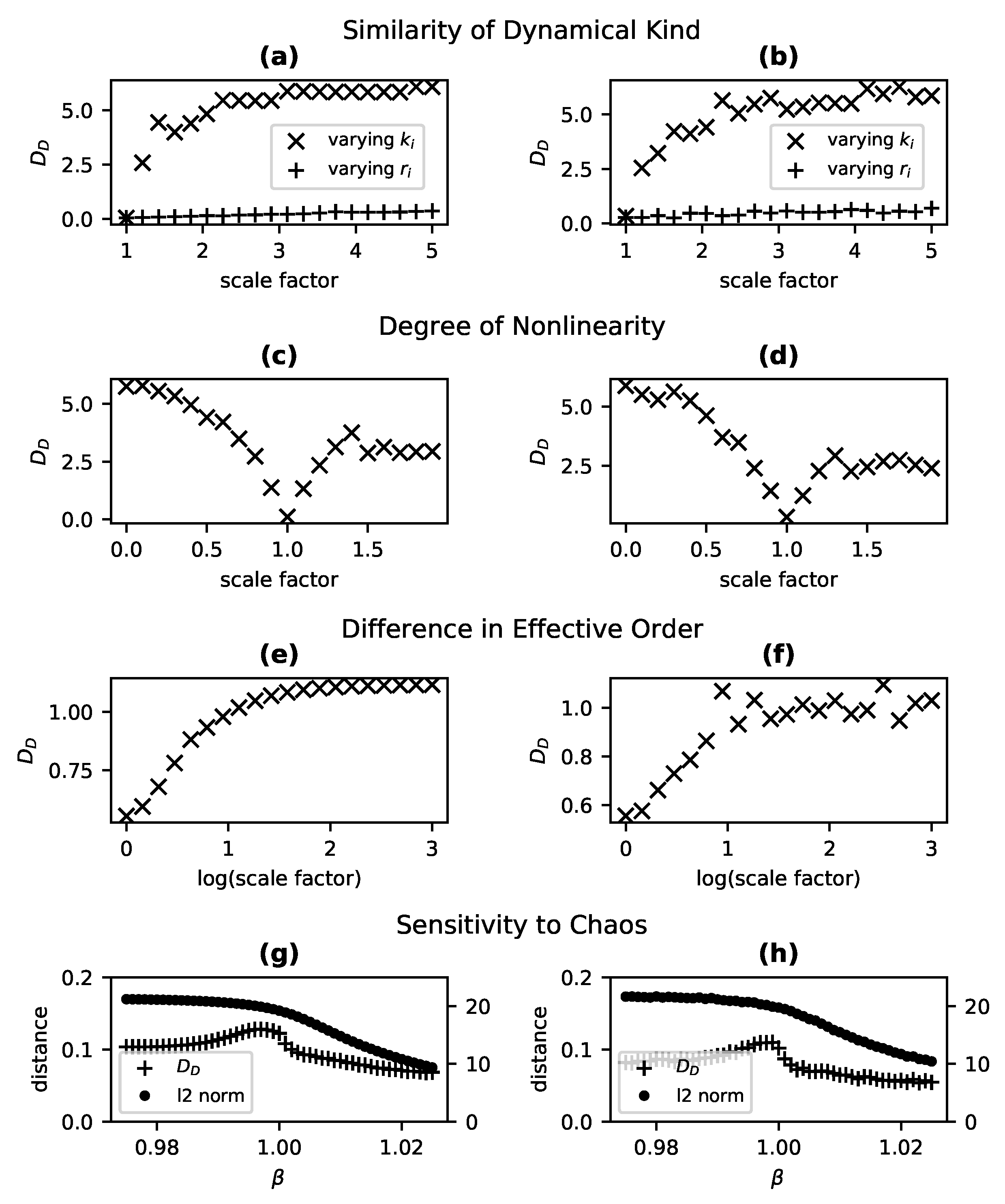
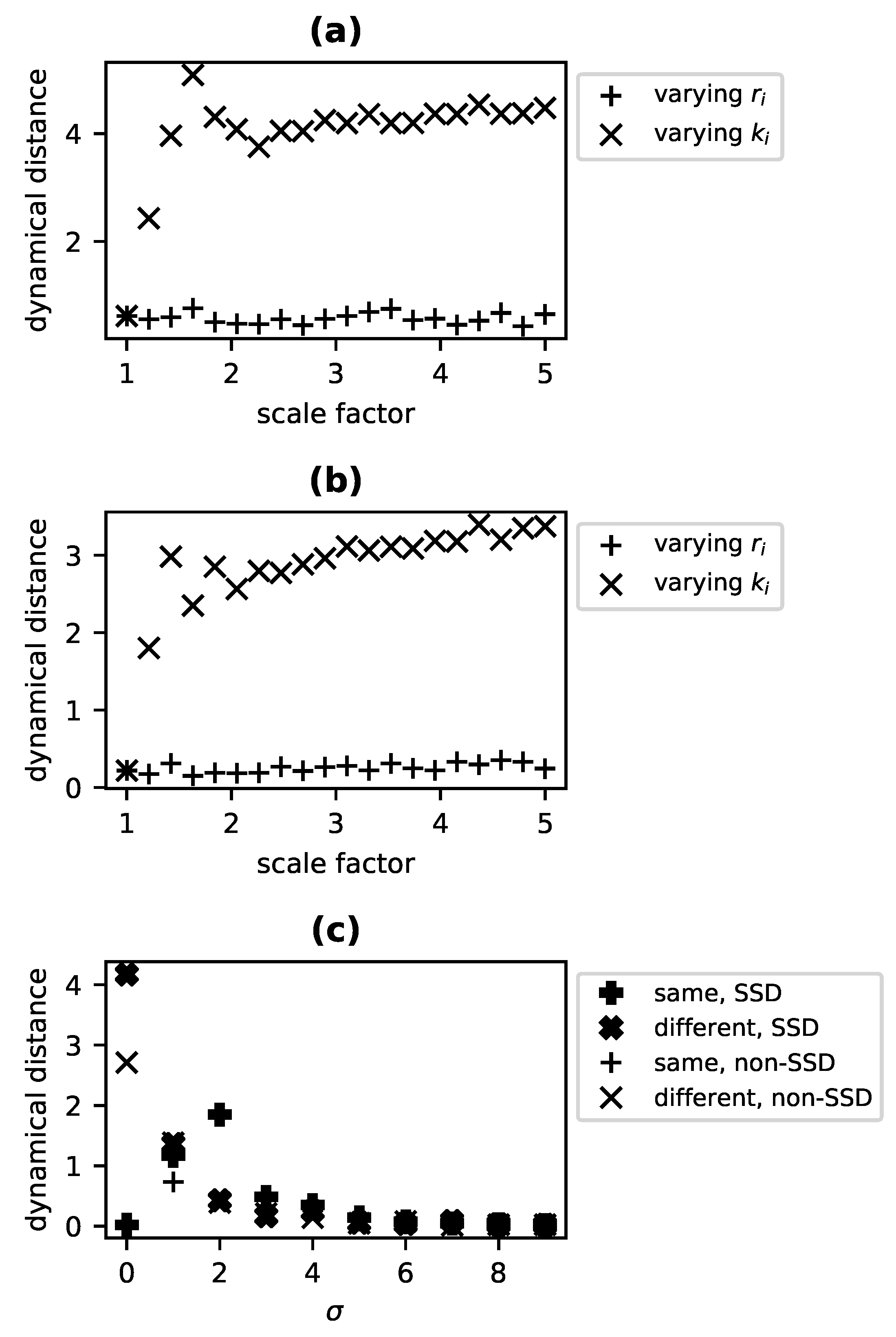
The concept of a degree of dynamical similarity implicitly underwrites methods for solving a variety of problems, including detection of structural change, model selection and validation, and the discrimination of nonlinearity, effective order, and chaos in a system of interest. While there exist a range of bespoke metrics, measures, and methods for probing or comparing each of these aspects for one or more systems of interest, we propose the first generic metric of dynamical similarity sensitive to all of these aspects.
The dynamical distance,
is constructed of two parts. In the first place, we define a special cumulative probability density,
, for each dynamical system we wish to compare, such that the density in question differs if and only if the two dynamical systems differ with respect to their underlying dynamical symmetries. The latter are physical transformations of a system that commute with its time evolution, and are diagnostic of the underlying causal structure that generates the dynamics. Thus, the density
is an indicator of causal structure. The second component of
is the choice of a suitable metric for comparing
between two systems. For this, we deploy the energy distance defined by [
75].
We have demonstrated that
is an indicator of the degree of similarity of the so-called dynamical kinds to which two systems belong. Specifically,
if and only two systems belong to the same dynamical kind and thus share a portion of their causal structure. More importantly, the use of
to assess dynamical kind improves upon the binary test of [
73] by providing a degree to which two systems differ in dynamical kind and thus underlying causal structure. We have also demonstrated that
is sensitive to each of the traditional dynamical features mentioned above: nonlinearity, chaos, and effective order. Specifically,
increases as two systems diverge in character along one of these dimensions, e.g., with respect to the degree of nonlinearity or the presence of chaos.
The proposed metric offers a number of unique advantages when it comes to detecting differences in these dynamical features from time series data. The metric is model free and domain general. It works in the presence of significant sampling noise, and the very same metric applies to both state-determined and stochastic systems. A disadvantage, however, lies in its comparative nature and the fact that a mere difference in cannot be attributed to one or another aspect of dynamics (or the causal structure generating the dynamics) without additional information. However, with suitable reference systems—whether physical or modeled—or with assumptions about the plausible class of models, this can be overcome. For instance, divergence in from a linear reference model for a system known to be nonchaotic and first order suggests nonlinearity. This approach requires no stronger assumptions than the specialist methods for detecting, e.g., linearity, and comes with the advantage of robustness to noise and of having a single tool equally applicable to state-determined and stochastic dynamics.
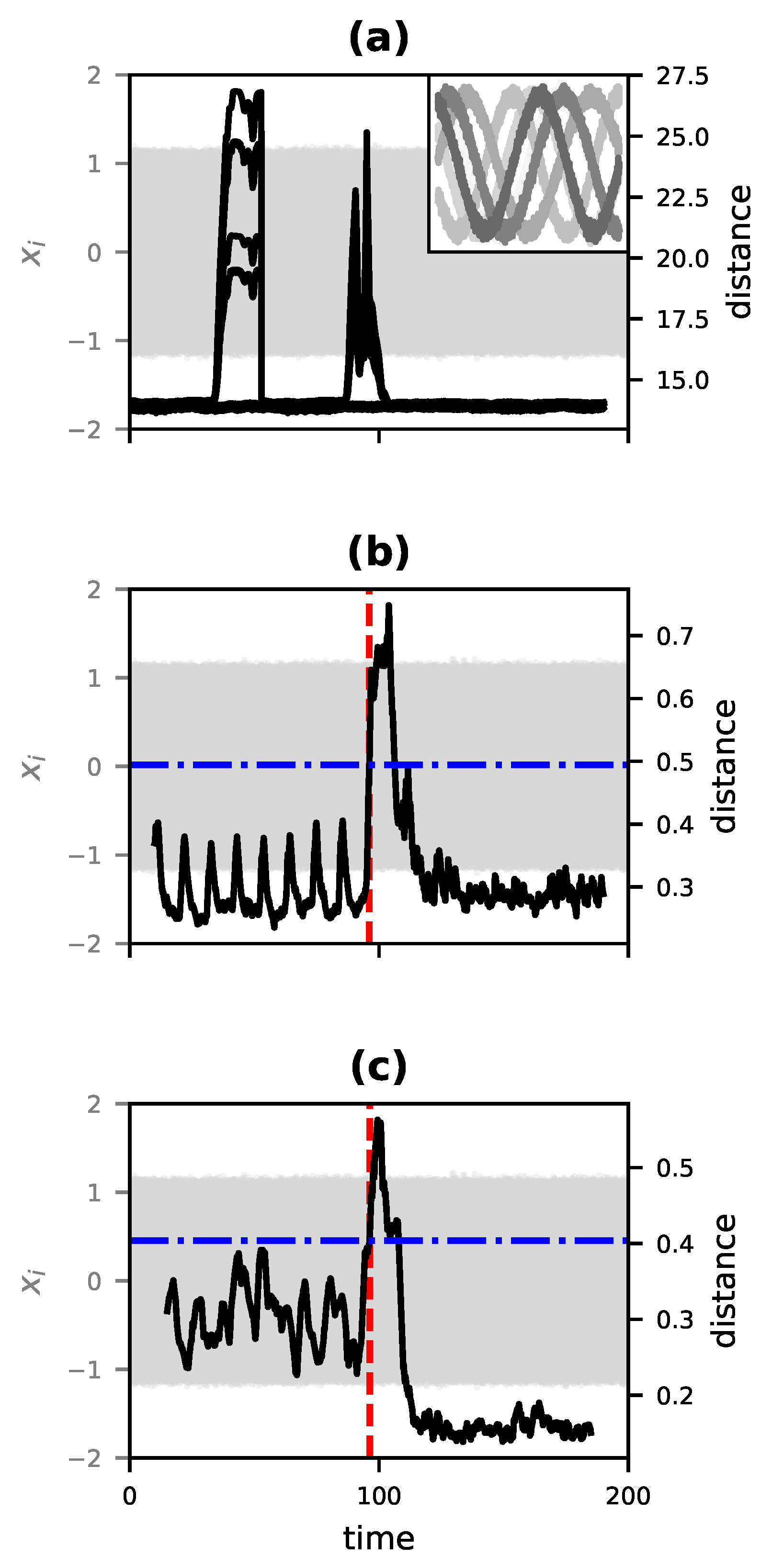
The greatest advantage of
is that it reflects structural features of the dynamics, whether deterministic or stochastic, and is otherwise indifferent to the shape or statistical properties of time series. To make this point clear, consider time series from three different Kuramoto oscillator systems, as shown in
Figure 6. Each system, A, B, and C, comprises three phase oscillators governed by the equation,
where
i ranges from 1 to 3 [
84]. The figure shows each phase,
, in rectangular coordinates as a pair of curves corresponding to
and
as functions of time.
For Systems A and C,
and the oscillators are coupled. For System C, the natural frequencies
are twice the corresponding values for System A. However, the causal structure is the same; each oscillator influences every other oscillator. For System B, on the other hand,
and the three oscillators are independent; none influences any other. Yet in terms of the statistics and gross appearance of trajectories, System C stands out as the exception. The dynamical distance proposed here is sensitive to the causal structure and not the appearance of the trajectories.
Table 1 shows the values of
for each pairwise comparison of the three systems, computed using the single time series given for each system and the methods described in
Section 3.4.2. The distances between A and B and between B and C are an order of magnitude greater than that between A and C. In other words, the dynamical distance
sees A and C, the systems with coupled oscillators, as similar and System B, which has the aberrant causal structure, as the standout. The second column of the table shows that this is not a matter of simply comparing time series statistics; the difference in mean values of the systems would suggest that A and B are most similar. More compellingly, the third column shows the minimum value of the globalized distance (the summed
-norm normalized by path length) between each pair of time series after dynamical time warping using the dtw-python package [
85]. This method, which is effective at detecting the relative similarity of time series shapes, identifies Systems A and B as the most similar. This is not wrong. Rather it is the correct answer to a question different from that which
addresses. The dynamical distance is concerned with similarity in the underlying dynamics, not with the similarity of particular time series those dynamics happen to produce.
There remain a number of open questions not addressed by the results reported here. It is unclear how best to leverage simultaneously the strengths of a general metric like
and the power of specialized tests. It should be possible to systematically bootstrap model identification by using
to rapidly and robustly identify systems or models with similar dynamics and then deploying more powerful but limited specialized methods for determining, e.g., the effective order needed. Additionally, the methods described in
Section 3.4.4 for working with passively obtained data (in circumstances where intervening on the system or controlling boundary conditions is impossible) rely on metaparameters that must be tuned. How to do this efficiently, both in terms of computational complexity and the amount of data, remains to be determined. There are also a variety of questions concerning stochastic dynamical systems. It is known that the type of noise (additive or multiplicative) in a stochastic differential equation can dramatically shape gross features such as the onset of chaos and the types of bifurcations as well as the detailed evolution of probability densities over time. The dynamical symmetries that underwrite the distance
are shaped by these time evolutions. However, the relative sensitivity of
to the two types of noise is unknown, as is the ability to distinguish such dynamical noise, i.e., stochastic elements in the generating process of a time series, from noise in the measurement of a system. A likely candidate for investigating these questions in simulation involves numerically extracting the time evolution of probability density functions for a given system of stochastic differential equations using the Fokker–Planck equation [
6]. However, it remains uncertain whether these methods would suggest a means of using
to distinguish the underlying dynamical differences between systems with different types of dynamical noise from empirically given time series.
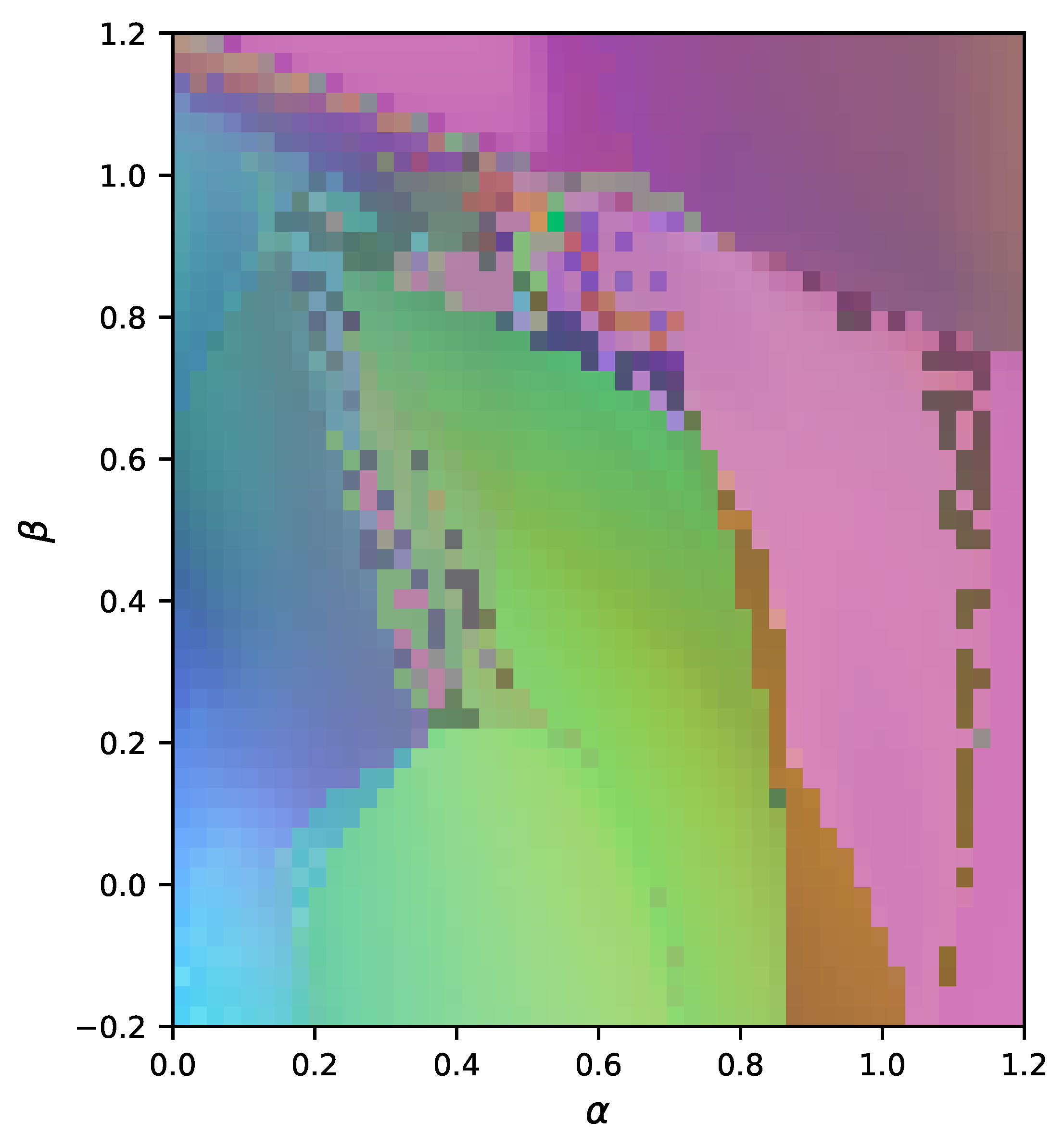
Despite the aforementioned unknowns, the proposed metric is immediately useful for a range of applications. As demonstrated in
Figure 3, the dynamical distance
can be used to systematically identify regions of the parameter space of a family of models with a common dynamical character, sometimes with surprising discontinuities. For instance, there are a scattering of points in the region
that are similar in dynamical behavior to versions of the four-species Lotka–Volterra model with radically different parameterizations (
). Similarly,
can be used with empirical time series data to cluster physical systems with unknown underlying causal structure into classes likely to be described by similar dynamical models. This facilitates development of such models. Additionally,
can be used to validate models—especially stochastic models—when the ground truth is unknown and only time series from a target system are available, similar to the related approach of [
69]. Insofar as time series produced with the model diverge in
from time series measured from the target system, one can determine whether a model correctly captures the causal structure regardless of how well the model is able to mimic any particular trajectory. Finally, perhaps the most promising application of the dynamical distance metric is detecting structural change. We demonstrated using fully and partially observed Kuramoto phase oscillator systems (
Section 4.7) that
can identify points in a time series at which the underlying generative dynamics changes. The dynamical distance is uniquely apt for detecting a genuine change in the underlying causal structure rather than a shift to a previously unobserved portion of the system’s phase space. This is precisely what is needed to identify, e.g., a change in ecosystem dynamics portending collapse or recovery, or a shift in the behavior of a volcano system suggesting worrisome internal structural changes. This list is only suggestive; there are myriad uses for a general metric of dynamical similarity that is tied to underlying causal structure, can be inferred from passively acquired time series observations, is robust under measurement noise, and is applicable to state-determined and stochastic dynamics alike.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}