
A Satellite Incipient Fault Detection Method Based on Decomposed Kullback–Leibler Divergence



Abstract
:1. Introduction
- We analyzed the necessity and feasibility of decomposing the KL divergence in the optimization model.
- We constructed two distribution models for subfunctions and .
- The effectiveness of the proposed method was verified through a numerical case and a real satellite fault case.
2. Preliminary
2.1. Generalized Rayleigh Quotient (GRQ)
2.2. Original Optimization Model
3. Incipient Fault-Detection Method Based on Decomposed KL Divergence
3.1. Decomposed KL Divergence
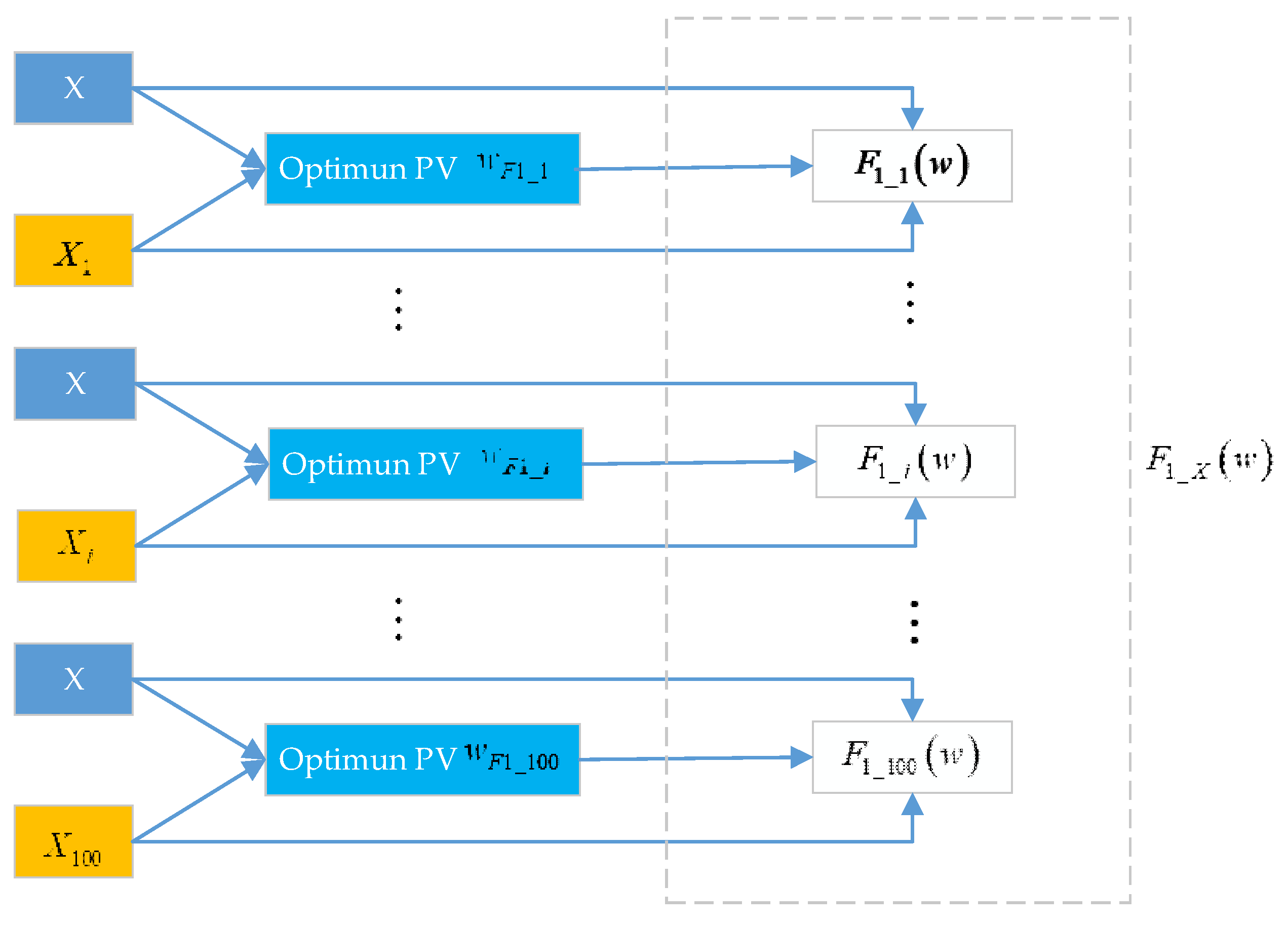
3.2. Construction of Fault Detection Models
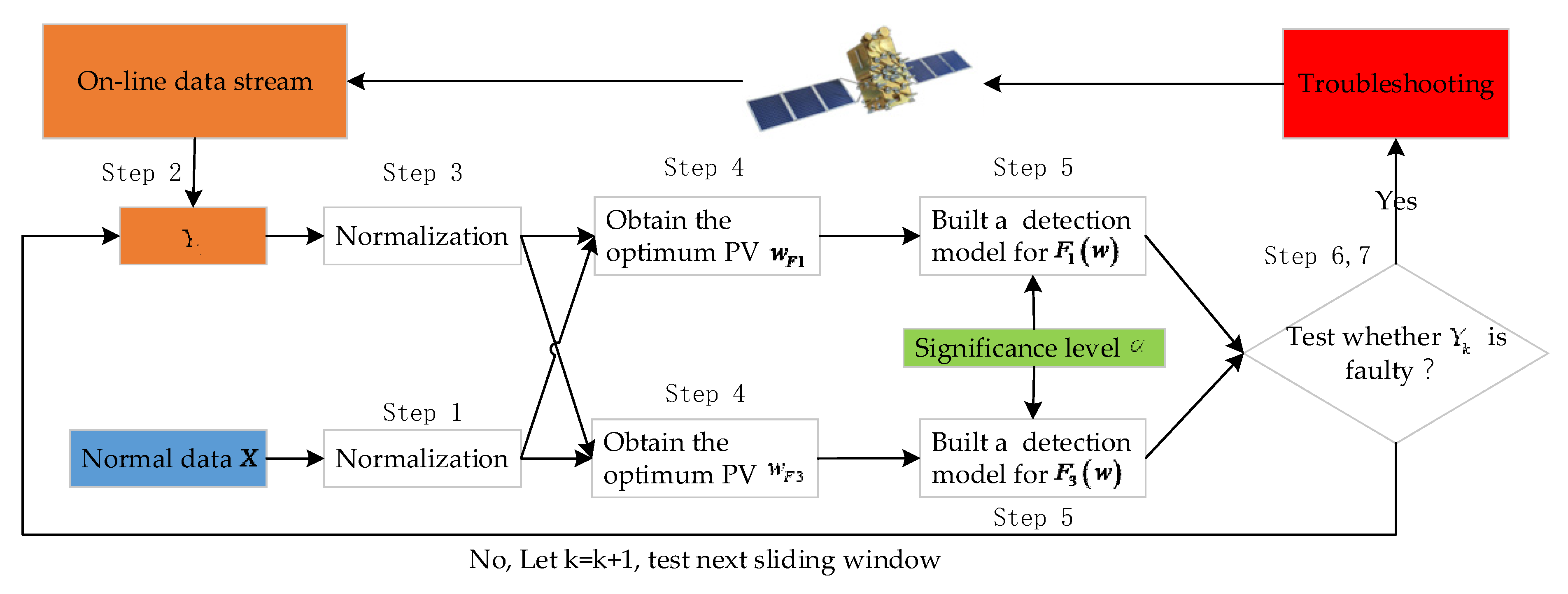
3.3. Overall Fault Detection Process
- Z-score normalization is performed for each parameter of the normal historical data , and is obtained.
- The online data are extracted by a sliding window with the length of .
- The on-line data are normalized by Z-score to obtain .
- Two optimum PVs and between and are obtained by using the property of the GRQ, as stated in Section 3.1.
- Two fault detection thresholds and are set by using the chi-square test with a significance level .
- Equations (12) and (13) are used to calculate the actual values and of and .
- The potential existence of a fault in is tested according to Equations (27) and (28). If at least one of two fault detection models detect fault, the online data can be considered to be faulty. Otherwise, is normal. Let ; the online data of the next sliding window is tested from steps 2 to 7.
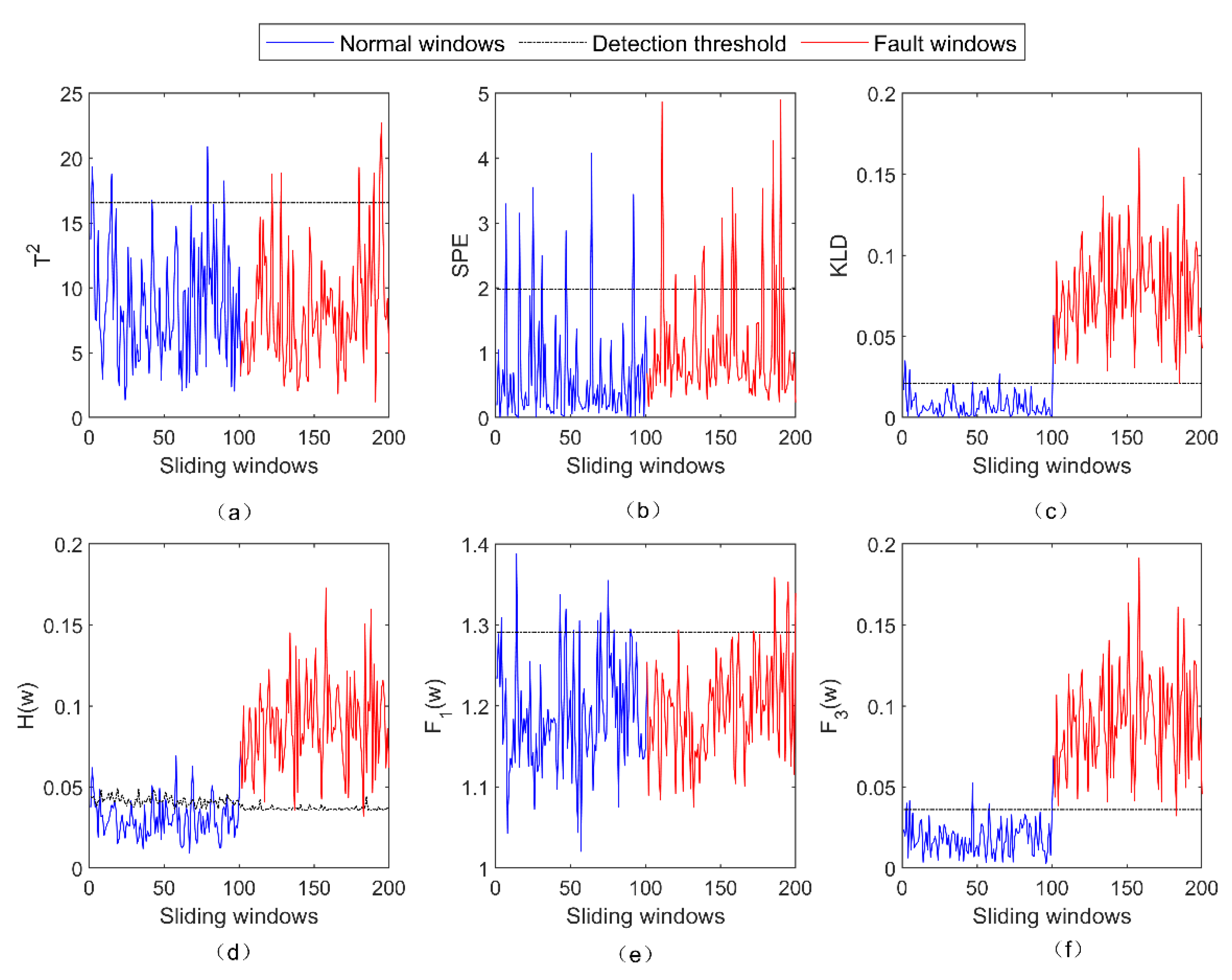
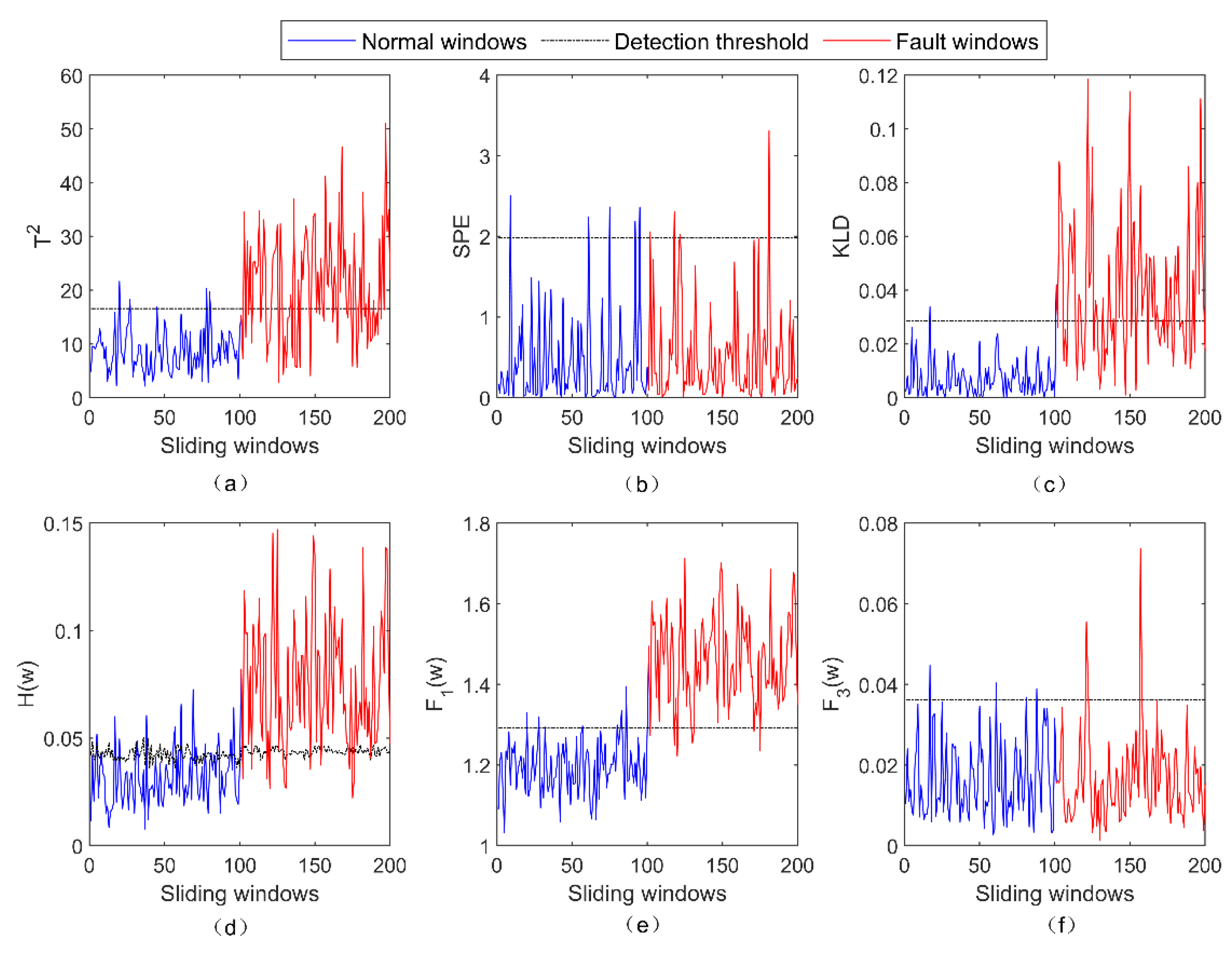
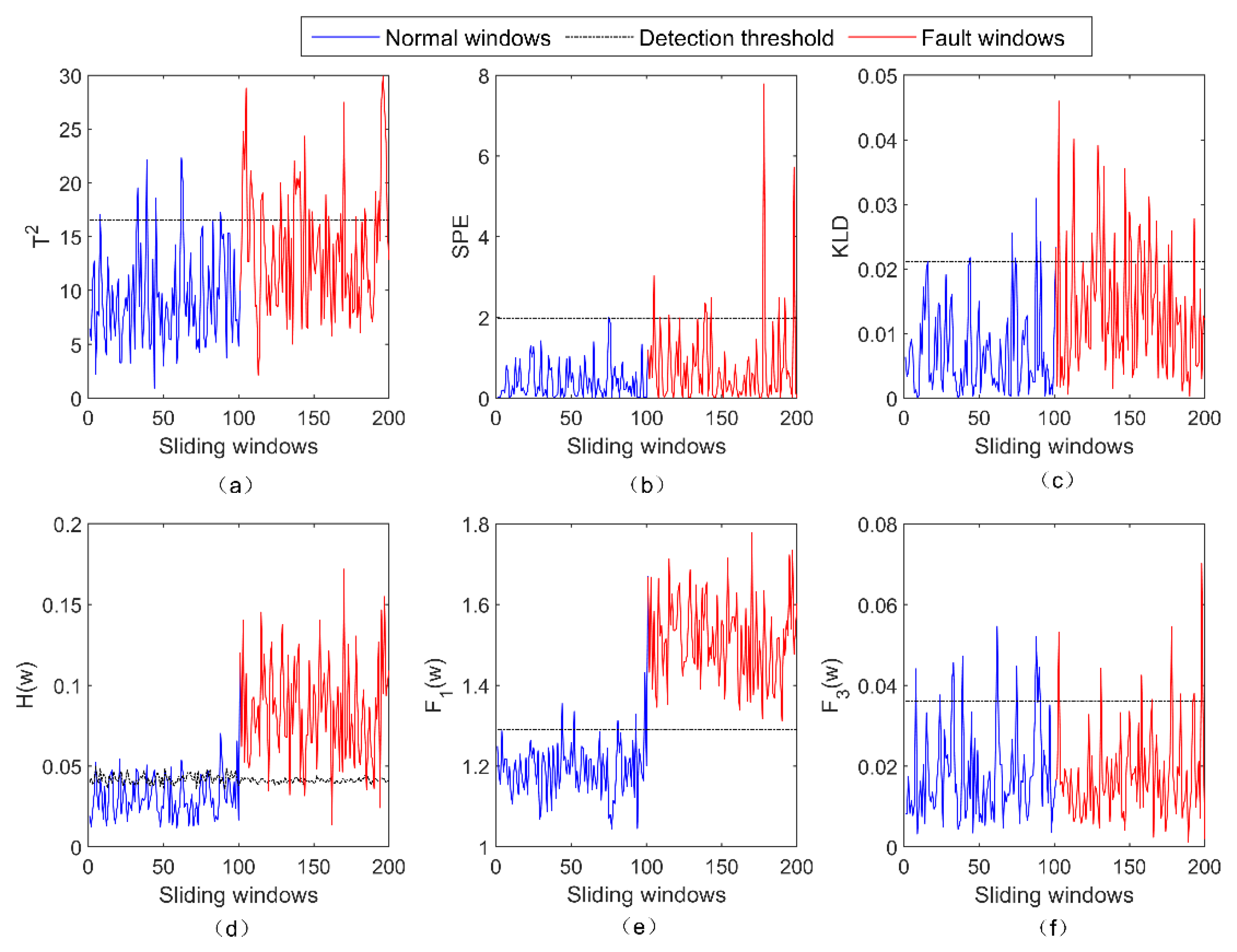
4. Results and Analysis
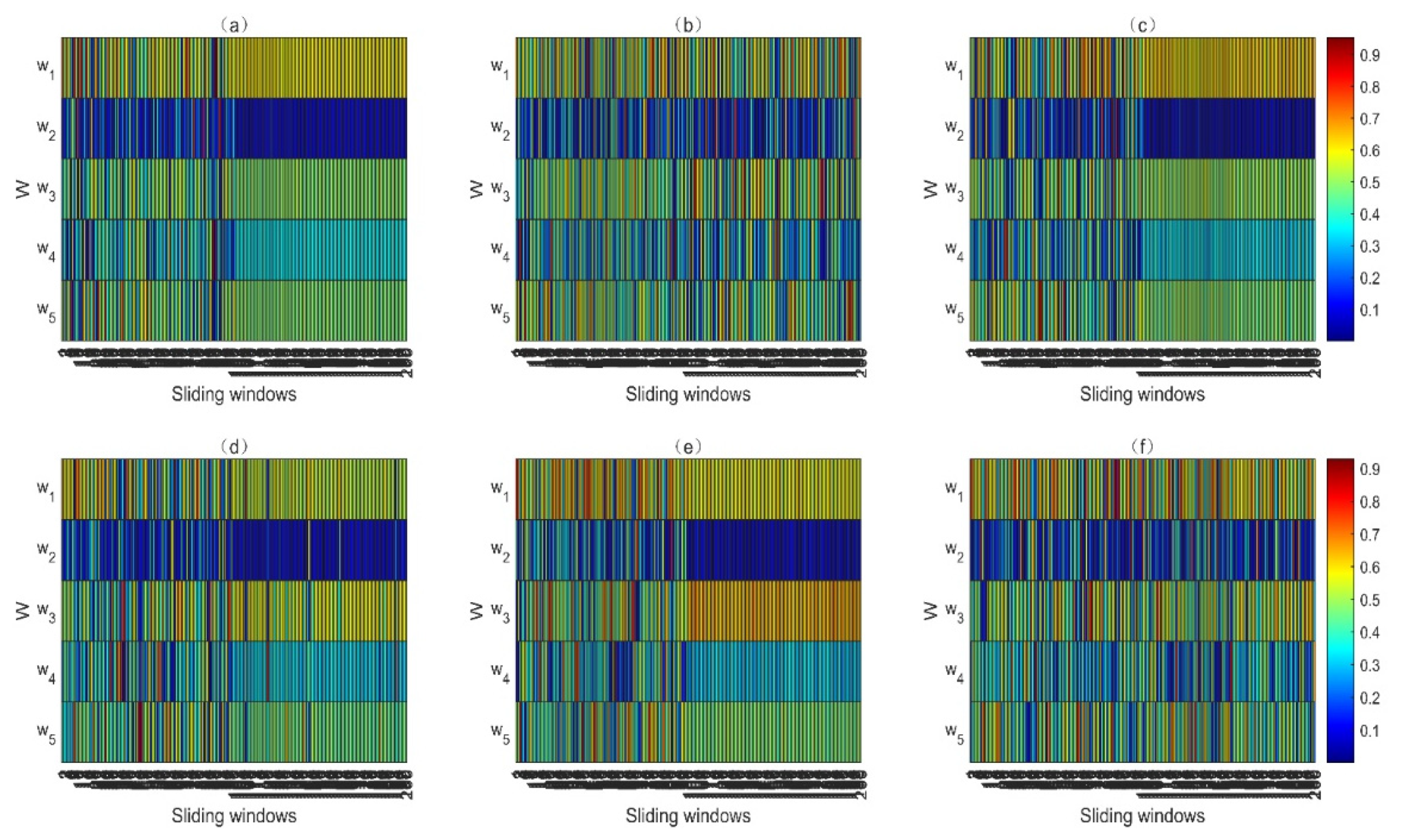
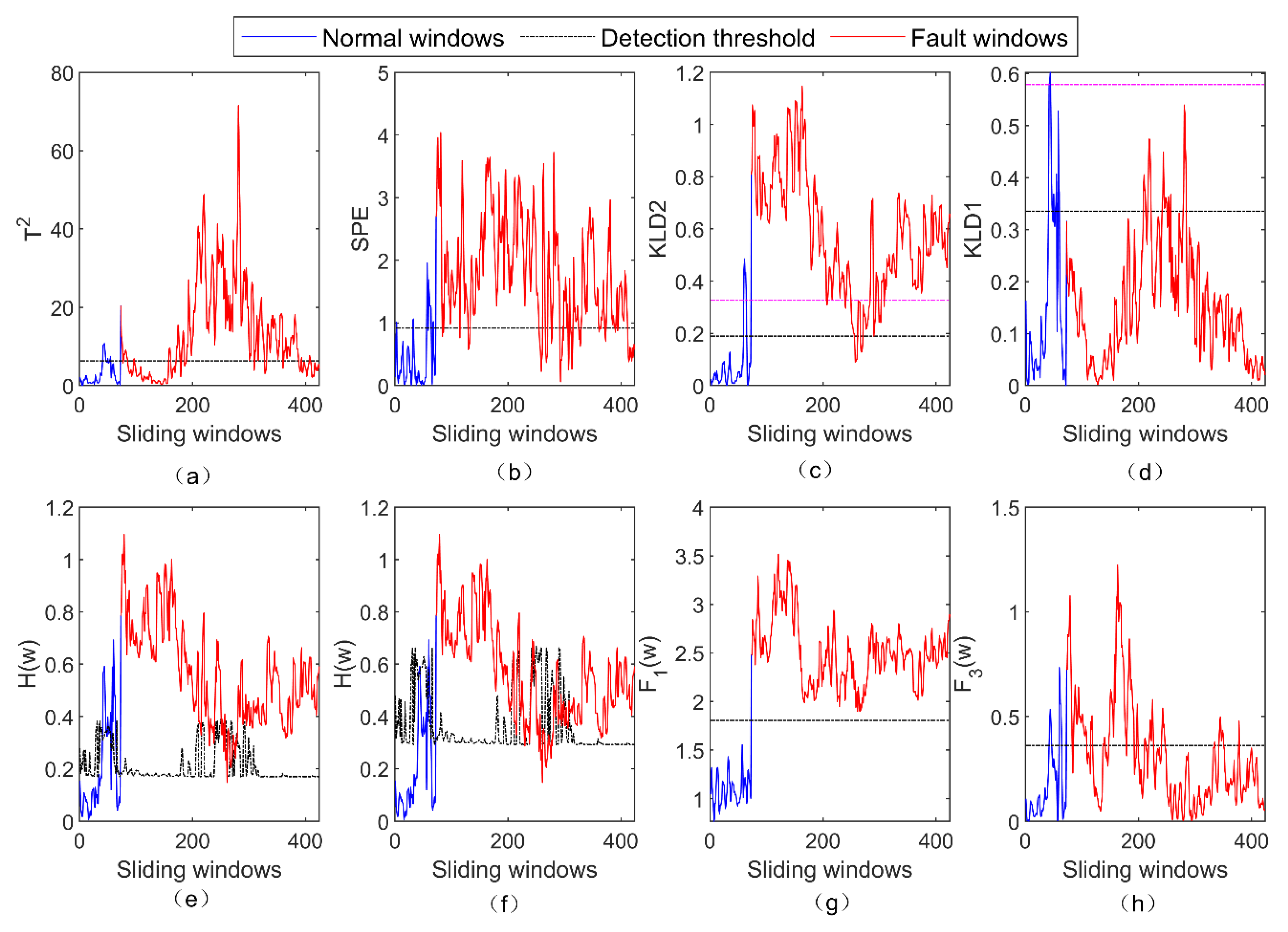
4.1. Numerical Case
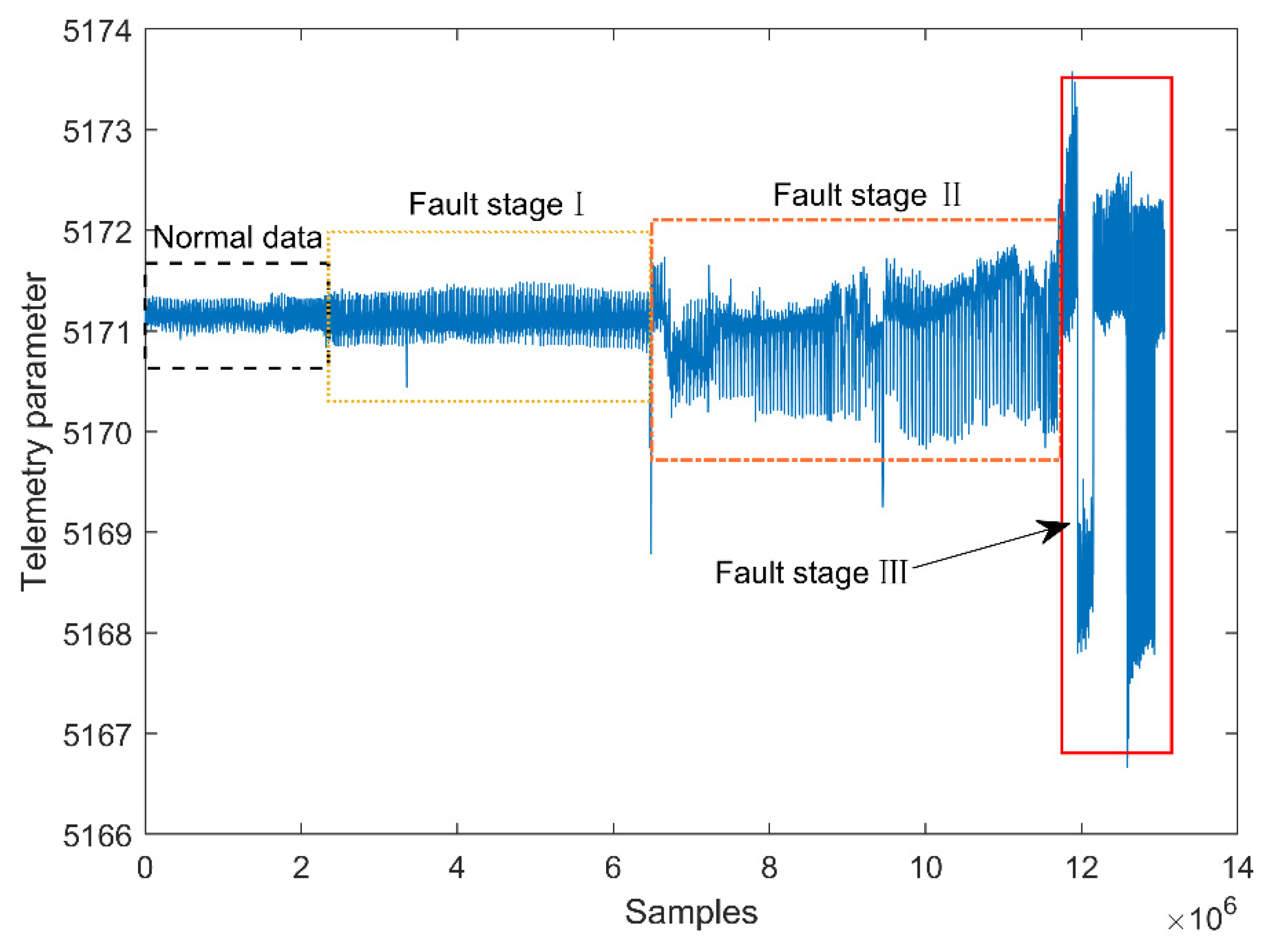
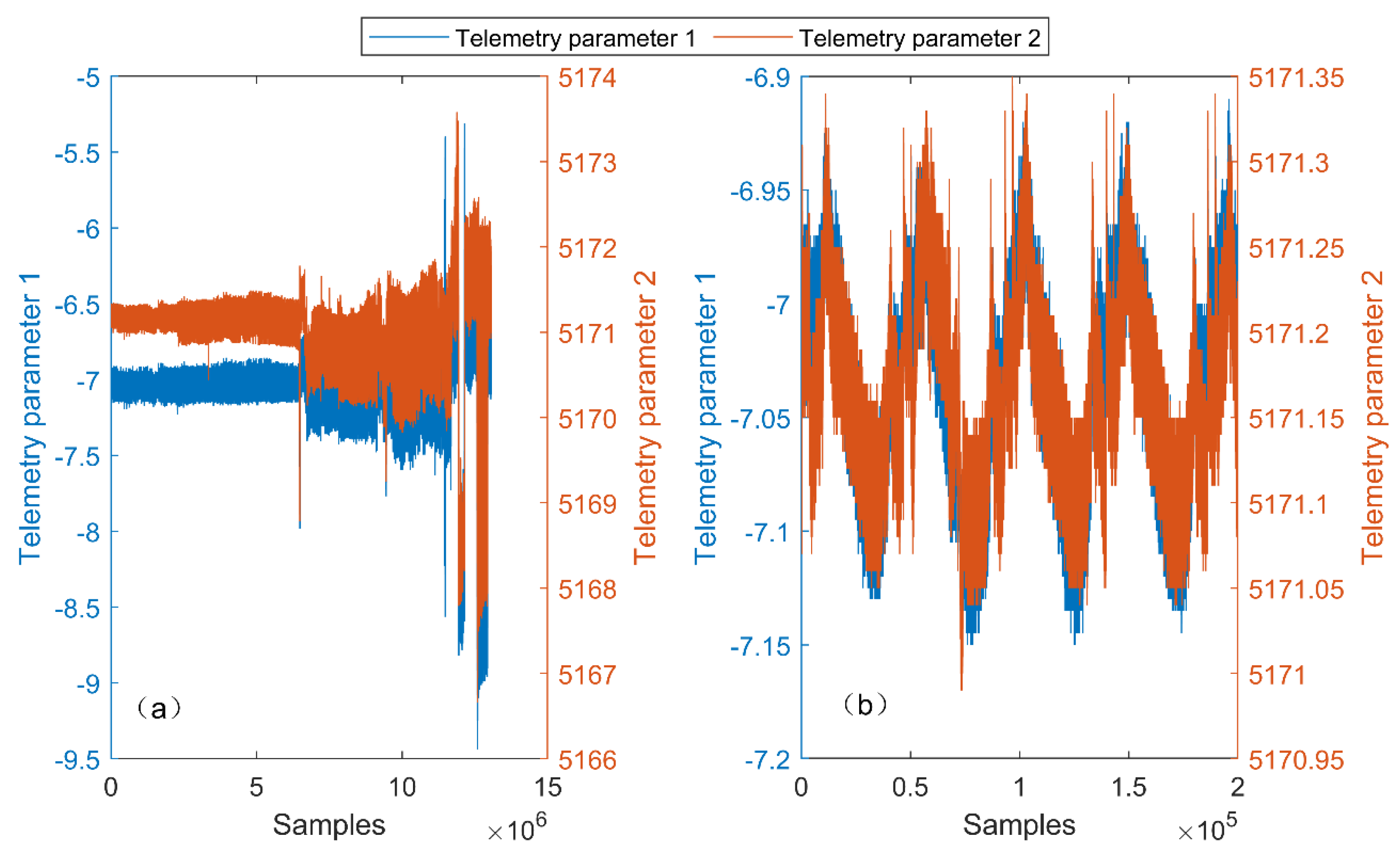
4.2. Real Satellite Fault Case
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| Abbreviation | Description |
| KL | Kullback–Leibler |
| PCA | principal component analysis |
| PV | projection vector |
| GRQ | generalized Rayleigh quotient |
| FDR | fault detection rate |
| FAR | false alarm rate |
References
- Yang, Y.; Mao, Y.; Sun, B. Basic performance and future developments of BeiDou global navigation satellite system. Satell. Navig. 2020, 1, 1. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Chen, H.; Zhu, Z. Modeling research of satellite-to-ground quantum key distribution constellations. Acta Astronaut. 2021, 180, 470–481. [Google Scholar] [CrossRef]
- Chen, H.; Yong, B.; Shen, Y.; Liu, J.; Hong, Y.; Zhang, J. Comparison analysis of six purely satellite-derived global precipitation estimates. J. Hydrol. 2020, 581, 124376. [Google Scholar] [CrossRef]
- Burke, M.; Driscoll, A.; Lobell, D.B.; Ermon, S. Using satellite imagery to understand and promote sustainable development. Science 2021, 371, 6535. [Google Scholar] [CrossRef] [PubMed]
- Ezhilarasu, C.M.; Skaf, Z.; Jennions, I.K. The application of reasoning to aerospace Integrated Vehicle Health Management (IVHM): Challenges and opportunities. Prog. Aeronaut. Sci. 2019, 105, 60–73. [Google Scholar] [CrossRef]
- Tafazoli, M. A study of on-orbit spacecraft failures. Acta Astronaut. 2009, 64, 195–205. [Google Scholar] [CrossRef]
- Li, E.-H.; Li, Y.-Z.; Li, T.-T.; Li, J.-X.; Zhai, Z.-Z.; Li, T. Intelligent analysis algorithm for satellite health under time-varying and extremely high thermal loads. Entropy 2019, 21, 983. [Google Scholar] [CrossRef] [Green Version]
- Safaeipour, H.; Forouzanfar, M.; Casavola, A. A survey and classification of incipient fault diagnosis approaches. J. Process Control 2021, 97, 1–16. [Google Scholar] [CrossRef]
- Peng, Z.; Lu, Y.; Miller, A.; Zhao, T.; Johnson, C. Formal specification and quantitative analysis of a constellation of navigation satellites. Qual. Reliab. Eng. Int. 2016, 32, 345–361. [Google Scholar] [CrossRef] [Green Version]
- Cayrac, D.; Dubois, D.; Prade, H. Handling uncertainty with possibility theory and fuzzy sets in a satellite fault diagnosis application. IEEE Trans. Fuzzy Syst. 1996, 4, 251–269. [Google Scholar] [CrossRef] [Green Version]
- Chen, R.H.; Ng, H.K.; Speyer, J.L.; Guntur, L.S.; Carpenter, R. Health monitoring of a satellite system. J. Guid. Control. Dynam. 2006, 29, 593–605. [Google Scholar] [CrossRef] [Green Version]
- Schwabacher, M.; Oza, N.; Matthews, B. Unsupervised anomaly detection for liquid-fueled rocket propulsion health monitoring. J. Aeros. Comp. Inf. Com. 2009, 6, 464–482. [Google Scholar] [CrossRef] [Green Version]
- Pang, J.; Liu, D.; Peng, Y.; Peng, X. Collective anomalies detection for sensing series of spacecraft telemetry with the fusion of probability prediction and Markov chain model. Sensors 2019, 19, 722. [Google Scholar] [CrossRef] [Green Version]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. ACM Comput. Surv. 2009, 41, 1–58. [Google Scholar] [CrossRef]
- Verzola, I.; Donati, A.; Martinez, J.; Schubert, M.; Somodi, L. Project Sibyl: A Novelty Detection System for Human Spaceflight Operations. In Proceedings of the 14th International Conference on Space Operations, Daejeon, Korea, 16–20 May 2016; p. 2405. [Google Scholar]
- Hayden, S.; Sweet, A.; Christa, S. Livingstone model-based diagnosis of Earth Observing One. In Proceedings of the AIAA 1st Intelligent Systems Technical Conference, Chicago, IL, USA, 20–22 September 2004; p. 6225. [Google Scholar]
- Deb, S.; Pattipati, K.R.; Shrestha, R. QSI’s integrated diagnostics toolset. In Proceedings of the 1997 IEEE Autotestcon Proceedings AUTOTESTCON’97. IEEE Systems Readiness Technology Conference. Systems Readiness Supporting Global Needs and Awareness in the 21st Century, Anaheim, CA, USA, 22–25 September 1997; pp. 408–421. [Google Scholar]
- Cheng, C.; Wang, J.; Chen, H.; Chen, Z.; Luo, H.; Xie, P. A review of intelligent fault diagnosis for high-speed trains: Qualitative approaches. Entropy 2021, 23, 1. [Google Scholar] [CrossRef] [PubMed]
- Muthusamy, V.; Kumar, K.D. A novel data-driven method for fault detection and isolation of control moment gyroscopes onboard satellites. Acta Astronaut. 2021, 180, 604–621. [Google Scholar] [CrossRef]
- Ibrahim, S.K.; Ahmed, A.; Zeidan, M.A.E.; Ziedan, I.E. Machine learning techniques for satellite fault diagnosis. Ain. Shams. Eng. J. 2020, 11, 45–56. [Google Scholar] [CrossRef]
- Pang, J.; Liu, D.; Peng, Y.; Peng, X. Anomaly detection based on uncertainty fusion for univariate monitoring series. Measurement 2017, 95, 280–292. [Google Scholar] [CrossRef]
- Hundman, K.; Constantinou, V.; Laporte, C.; Colwell, I.; Soderstrom, T. Detecting spacecraft anomalies using lstms and nonparametric dynamic thresholding. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 387–395. [Google Scholar]
- Chen, H.; Jiang, B.; Lu, N. An improved incipient fault detection method based on Kullback–Leibler divergence. ISA Trans. 2018, 79, 127–136. [Google Scholar] [CrossRef]
- Chen, H.; Jiang, B.; Lu, N.; Mao, Z. Deep PCA based real-time incipient fault detection and diagnosis methodology for electrical drive in high-speed trains. IEEE Trans. Veh. Technol. 2018, 67, 4819–4830. [Google Scholar] [CrossRef]
- Shang, J.; Chen, M.; Ji, H.; Zhou, D. Recursive transformed component statistical analysis for incipient fault detection. Automatica 2017, 80, 313–327. [Google Scholar] [CrossRef]
- Ji, H.; He, X.; Shang, J.; Zhou, D. Incipient fault detection with smoothing techniques in statistical process monitoring. Control Eng. Pract. 2017, 62, 11–21. [Google Scholar] [CrossRef]
- Harmouche, J.; Delpha, C.; Diallo, D. Incipient fault detection and diagnosis based on Kullback–Leibler divergence using principal component analysis: Part I. Signal Process. 2014, 94, 278–287. [Google Scholar] [CrossRef]
- Gautam, S.; Tamboli, P.K.; Patankar, V.H.; Roy, K.; Duttagupta, S.P. Sensors Incipient Fault Detection and Isolation Using Kalman Filter and Kullback–Leibler Divergence. IEEE Trans. Nucl. Sci. 2019, 66, 782–794. [Google Scholar] [CrossRef]
- Deng, X.; Cai, P.; Cao, Y.; Wang, P. Two-step localized kernel principal component analysis based incipient fault diagnosis for nonlinear industrial processes. Ind. Eng. Chem. Res. 2020, 59, 5956–5968. [Google Scholar] [CrossRef]
- Zhang, G.; Yang, Q.; Li, G.; Leng, J.; Wang, L. A Satellite Incipient Fault Detection Method Based on Local Optimum Projection Vector and Kullback–Leibler Divergence. Appl. Sci. 2021, 11, 797. [Google Scholar] [CrossRef]
- Hart, P.E.; Stork, D.G.; Duda, R.O. Pattern Classification; Wiley Hoboken: Hoboken, NJ, USA, 2000. [Google Scholar]
- Watkins, D.S. Fundamentals of Matrix Computations, 2nd ed.; John Wiley & Sons: New York, NY, USA, 2002. [Google Scholar]
- Wang, L.-F.; Xia, Y. A linear-time algorithm for globally maximizing the sum of a generalized rayleigh quotient and a quadratic form on the unit sphere. SIAM J. Optim. 2019, 29, 1844–1869. [Google Scholar] [CrossRef]
- Jolliffe, I. Principal Component Analysis, 2nd ed.; Springer: New York, NY, USA, 2002. [Google Scholar]
- Casella, G.; Berger, R.L. Statistical Inference, 2nd ed.; Duxbury Press: Pacific Grove, CA, USA, 2002. [Google Scholar]
- Nassar, B.; Hussein, W.; Mokhtar, M. Space telemetry anomaly detection based on statistical PCA algorithm. In Proceedings of the International Journal of Electronics and Communication Engineering, Paris, France, 27–28 August 2015; pp. 637–645. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Faults | Evaluation Indexes | PCA + T2 | PCA + SPE | PCA + KLD | LOPVKLD | Proposed Method | |
|---|---|---|---|---|---|---|---|
| F1(w) | F3(w) | ||||||
| FDR (%) | 5.76 | 17.02 | 97.41 | 94.63 | 7.41 | 96.67 | |
| FAR (%) | 4.49 | 7.67 | 11.90 | 15.76 | 8.5 | 5.56 | |
| Time consumption | 0 (μs) | 0 (μs) | 0 (μs) | 68.5 (ms) | 18.42 (μs) | 24.26 (μs) | |
| FDR (%) | 58.46 | 25.96 | 79.36 | 89.08 | 95.99 | 8.41 | |
| FAR (%) | 4.41 | 8.05 | 11.58 | 14.84 | 7.17 | 5.80 | |
| Time consumption | 0 (μs) | 0 (μs) | 0 (μs) | 70.8 (ms) | 18.20 (μs) | 23.75 (μs) | |
| FDR (%) | 27.56 | 20.87 | 30.37 | 90.91 | 97.81 | 7.25 | |
| FAR (%) | 4.61 | 7.68 | 11.50 | 15.82 | 7.53 | 5.88 | |
| Time consumption | 0 (μs) | 0 (μs) | 0 (μs) | 71.7 (ms) | 18.31 (μs) | 23.99 (μs) | |
| Evaluation Indexes | PCA + T2 | PCA + SPE | PCA + KLD | LOPVKLD | Proposed Method | |||
|---|---|---|---|---|---|---|---|---|
| α = 0.05 | α = 0.01 | α = 0.05 | α = 0.01 | F1(w) | F3(w) | |||
| FDR (%) | 63.46 | 83.85 | 97.16 | 85.65 | 95.17 | 85.51 | 100 | 32.95 |
| FAR (%) | 14.08 | 16.9 | 25 | 11.11 | 26.39 | 12.50 | 0 | 13.89 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, G.; Yang, Q.; Li, G.; Leng, J.; Yan, M. A Satellite Incipient Fault Detection Method Based on Decomposed Kullback–Leibler Divergence. Entropy 2021, 23, 1194. https://doi.org/10.3390/e23091194
Zhang G, Yang Q, Li G, Leng J, Yan M. A Satellite Incipient Fault Detection Method Based on Decomposed Kullback–Leibler Divergence. Entropy. 2021; 23(9):1194. https://doi.org/10.3390/e23091194
Chicago/Turabian StyleZhang, Ge, Qiong Yang, Guotong Li, Jiaxing Leng, and Mubiao Yan. 2021. "A Satellite Incipient Fault Detection Method Based on Decomposed Kullback–Leibler Divergence" Entropy 23, no. 9: 1194. https://doi.org/10.3390/e23091194
APA StyleZhang, G., Yang, Q., Li, G., Leng, J., & Yan, M. (2021). A Satellite Incipient Fault Detection Method Based on Decomposed Kullback–Leibler Divergence. Entropy, 23(9), 1194. https://doi.org/10.3390/e23091194