


Predicting Bitcoin (BTC) Price in the Context of Economic Theories: A Machine Learning Approach

 , ,
, , 
Abstract
:1. Introduction
2. Literature Review
2.1. Underlying Theory of the Macroeconomic Indicators: Demand and Supply Theory
2.2. Underlying Theory of the Microeconomic Indicators: Microstructure Theory
2.3. Underlying Theory of Blockchain Information Indicators: Cost-Based Pricing Theory
2.4. Application of Machine Learning in Real-World Problem Solving
2.5. Related Work and Research Gap
3. Materials and Methods
3.1. Multilayer Perceptron
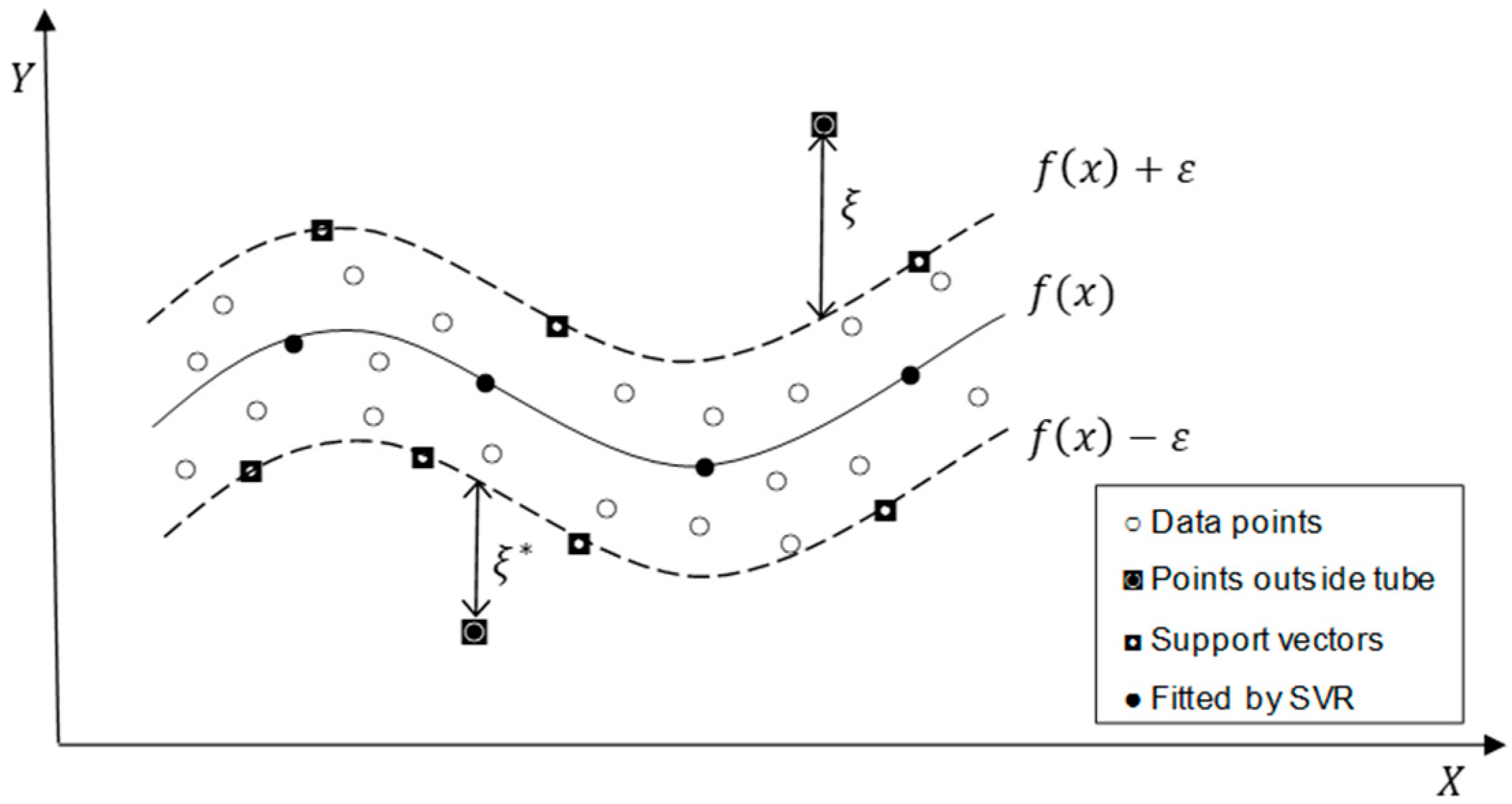
3.2. Support Vector Regression
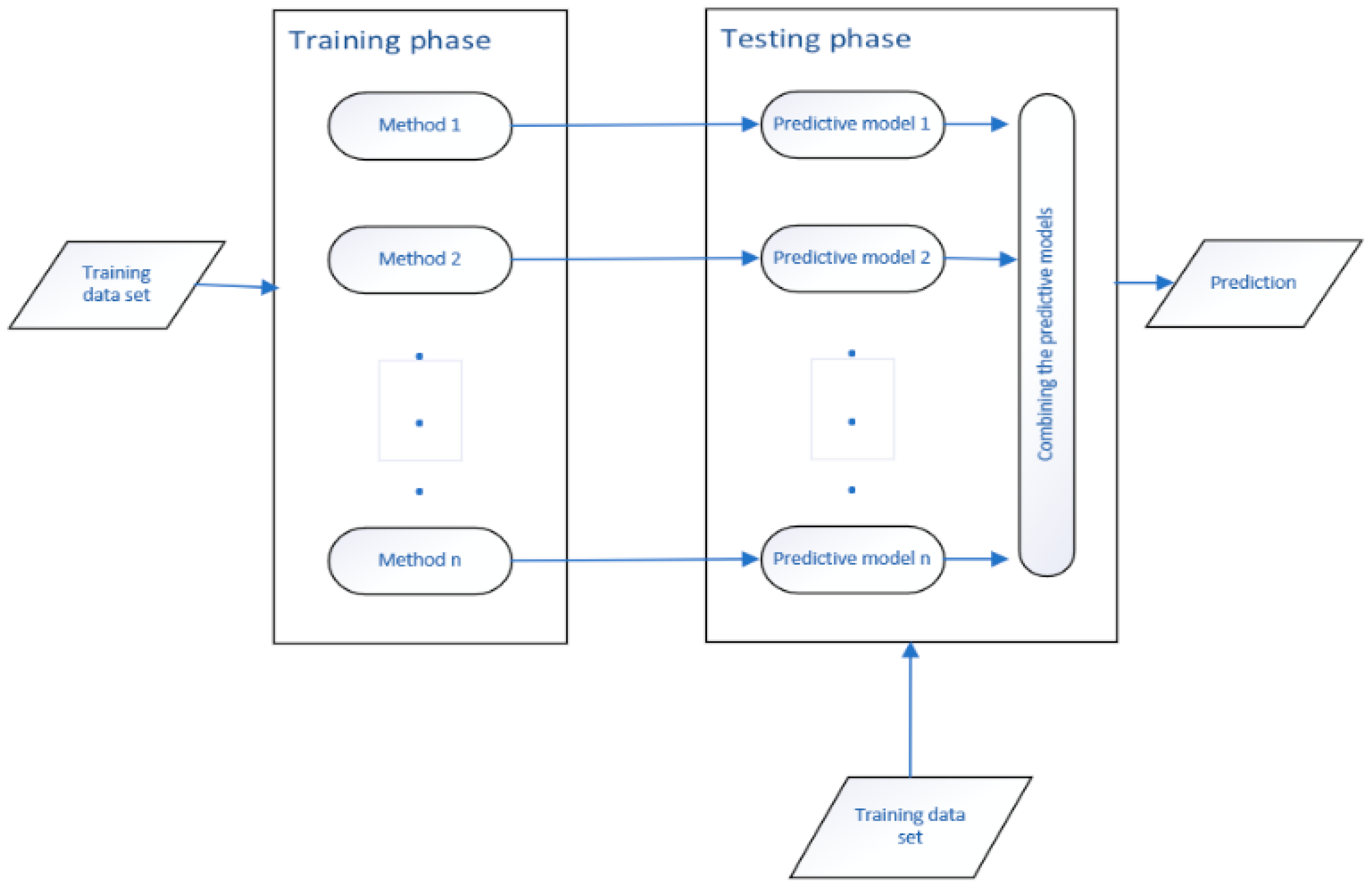
3.3. Ensemble Method
3.4. Feature Selection Methods
3.5. Model Evaluation
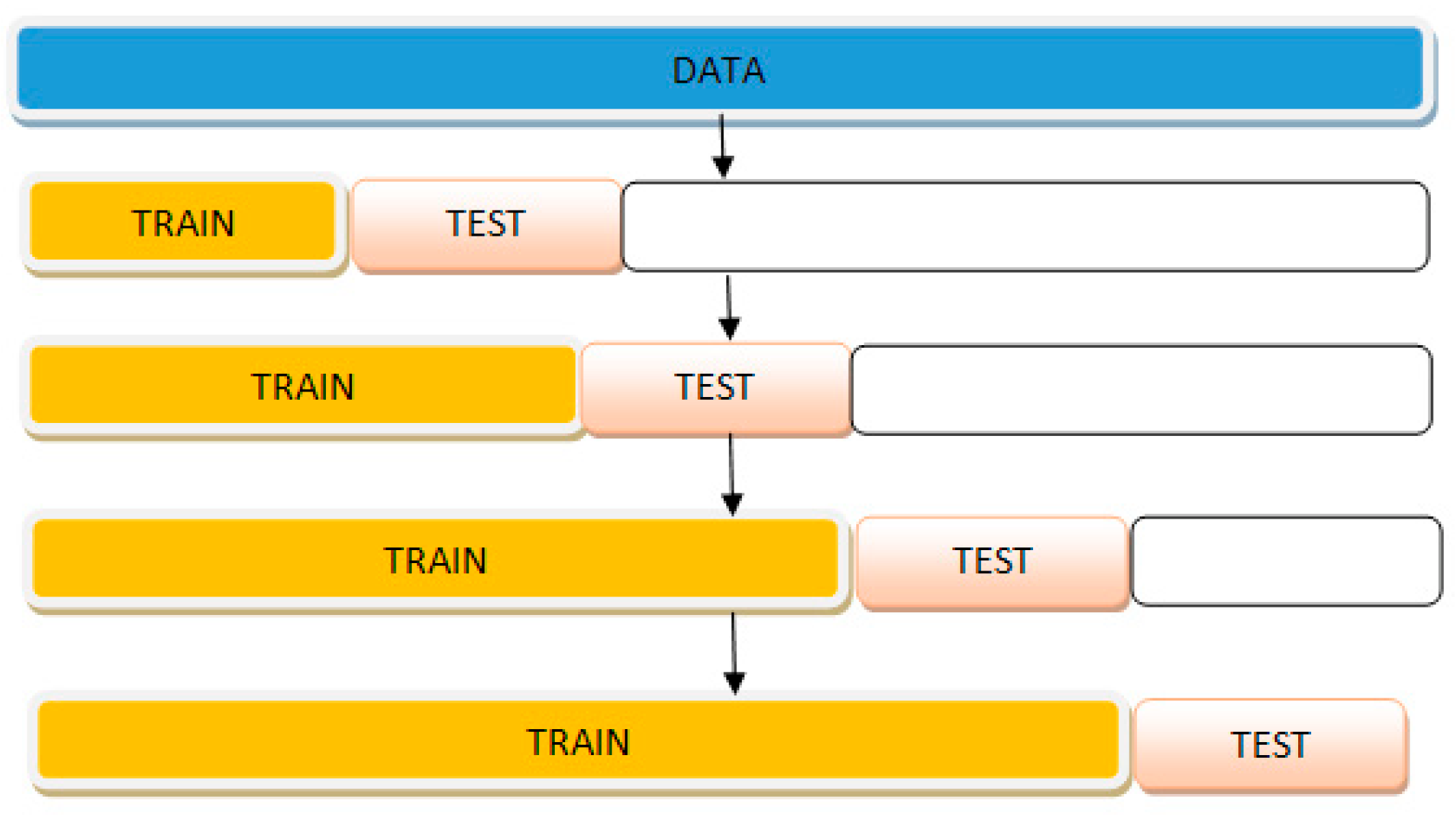
3.6. Model Validation
4. Results and Discussion
4.1. The BTC Price Prediction Problem Using OLS
4.1.1. Data Description
4.1.2. Feature Selection
4.1.3. OLS Regression for BTC Price Prediction
4.2. Proposed Comparative Analysis for Dataset 1
4.2.1. Data Description
4.2.2. Feature-Based Comparative Analysis
4.2.3. Category-Based Comparative Analysis
4.3. Proposed Comparative Analysis for Dataset 2
4.3.1. Data Description
4.3.2. Feature-Based Comparative Analysis
4.3.3. Category-Based Comparative Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1. Model 1. OLS Model Description

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Indicators | Min | Max | Mean | Std. Dev |
|---|---|---|---|---|
| BTCs in Circulation | 4,002,626.667 | 17,213,768.33 | 12,440,527.97 | 3,742,297.323 |
| Market Capitalization | 280,390.572 | 2.55 × 1011 | 23,117,501,754 | 49,243,267,354 |
| Block Size | 1 | 179,101.0913 | 47,145.66415 | 54,242.32369 |
| Average Block Size | 0.01 | 1.054375 | 0.409168031 | 0.354286668 |
| Orphaned Block | 0 | 2.071428571 | 0.361061508 | 0.556278003 |
| Transactions Per Block | 1.625 | 2208.7575 | 760.5240094 | 666.8726595 |
| Median Confirmation Time | 6.201875 | 16.96133333 | 9.397754898 | 2.300005847 |
| Hash Rate | 0.01 | 49,050,545.4 | 3,657,003.427 | 9,072,465.431 |
| Mining Difficulty | 797.7186667 | 6.32 × 1012 | 4.79166 × 1011 | 1.18908 × 1012 |
| Transaction Fee | 0.056875 | 591.31625 | 62.77254092 | 105.0417027 |
| Cost Per Transaction | 1.242 | 117.1433333 | 20.31455332 | 25.94717866 |
| Unique Addresses | 513.6666667 | 825,390.9375 | 224,455.5763 | 207,905.1755 |
| Total Transactions Per Day | 464.0666667 | 358,831.0625 | 11,5921.8508 | 100,973.4369 |
| Transaction Volume Excluding Popular Addresses | 464.0666667 | 341,004.75 | 107,356.0276 | 101,413.1972 |
| Total Output Value | 63,281.56267 | 11,338,010.91 | 1,650,410.836 | 1,539,818.478 |
| Estimated Transaction Value | 27,539.66667 | 997,305.9375 | 209,259.0939 | 130,674.3663 |
| Nasdaq Composite | 2286.248 | 7882.400667 | 4435.937597 | 1480.271196 |
| Dow Jones Industrial Average | 10,576.508 | 25,807.52933 | 16,784.42003 | 3980.41153 |
| S&P 500 | 1119.546667 | 2855.994 | 1880.952363 | 472.923476 |
| Gold Price Index | 1072.293333 | 1773.213333 | 1361.324703 | 184.7161172 |
| Crude Oil WTI | 30.485 | 110.3573333 | 74.41217956 | 23.3697773 |
| US Federal Funds Rate | 0.067142857 | 1.915333333 | 0.392972284 | 0.491999589 |
| Breakeven Inflation Rate | 1.302857143 | 2.586666667 | 2.011131634 | 0.298349738 |
| Variables | VIF |
|---|---|
| BTCs in Circulation | 7.98 |
| Market Capitalization | 27.44 * |
| Block Size | 7.68 |
| Average Block Size | 5.07 |
| Orphaned Block | 1.5 |
| Transactions Per Block | 39.11 * |
| Median Confirmation Time | 1.73 |
| Hash Rate | 52.36 * |
| Mining Difficulty | 51.45 * |
| Transaction Fee | 3.53 |
| Cost Per Transaction | 33.88 * |
| Unique Addresses | 9.75 |
| Total Transactions Per Day | 48.67 * |
| Transaction Volume Excluding Popular Addresses | 8.44 |
| Total Output Value | 2.4 |
| Estimated Transaction Value | 2.49 |
| Nasdaq Composite | 11.86 * |
| Dow Jones Industrial Average | 23.71 * |
| S&P 500 | 44.93 * |
| Gold Price Index | 2.32 |
| Crude Oil WTI | 2.16 |
| US Federal Funds Rate | 1.99 |
| Breakeven Inflation Rate | 2.97 |
| Variables | Model 1 | Model 2 | Model 3 | Model 4 | Model 5 | Model 6 | Model 7 | Model 8 | Model 9 |
|---|---|---|---|---|---|---|---|---|---|
| BTCs in Circulation | |||||||||
| Block Size | 0.268 ** (0.039) | 0.521 * (0.164) | 0.418 * (0.196) | 0.408 ** (0.038) | 0.443 ** (0.021) | 0.436 ** (0.024) | |||
| Transaction Fees | 0.131 *** (0.001) | 0.167 ** (0.05) | 0.158 ** (0.049) | 0.166 *** (0.002) | 0.155 ** (0.003) | ||||
| Unique Addresses | 1.021 *** (0.184) | ||||||||
| Total Number of Transactions | −0.023 . (0.012) | ||||||||
| Estimated Transaction Value | −0.096 ** (0.03) | −0.192 ** (0.071) | −0.179 * (0.070) | −0.149 * (0.062) | −0.242 ** (0.071) | −0.213 *** (0.004) | |||
| Cost Per Transaction | 0.781 ** (0.07) | ||||||||
| Mining Difficulty | 0.327 * (0.124) | ||||||||
| Market Capitalization | 1.00 *** (0.002) | ||||||||
| Hash Rate | 0.397 ** (0.126) | ||||||||
| Nasdaq Composite | 0.809 . (0.1) | ||||||||
| Dow Jones Industrial Average | 0.277 ** (0.024) | ||||||||
| S&P500 | 0.081 ** (0.038) | ||||||||
| Adjusted R2 | 0.91 | 0.67 | 0.81 | 0.73 | 0.68 | 0. 67 | 0.73 | 0.78 | 0.73 |
| Residual Standard Error | 0.044 | 0.1 | 0.001 | 0.023 | 0.087 | 0.10 | 0.099 | 0.089 | 0.089 |
| p-value | <2.2 × 10−16 | 5.56 × 10−11 | <2.2 × 10−16 | <2.2 × 10−16 | 1.073 × 10−14 | 7.28 × 10−10 | <2.2 × 10−16 | <2.2 × 10−16 | <2.2 × 10−15 |
Appendix A.2. Model 2. Model Description
| Indicators | Min | Max | Mean | Std. Dev |
|---|---|---|---|---|
| TWEXB | 91.45 | 96.87 | 93.90 | 1.25 |
| Gold Fixing Price | 1130.55 | 1304.55 | 1228.23 | 42.67 |
| DJIA | 17,888.28 | 21,271.97 | 20,055.42 | 951.69 |
| Brent Crude Oil Price | 41.61 | 56.34 | 51.27 | 3.57 |
| WTI | 43.29 | 54.48 | 50.13 | 2.84 |
| Trades Per Minute | 0.92 | 63.17 | 11.71 | 10.43 |
| Ask Sum (5%) | 750.97 | 6067.64 | 2737.32 | 1065.50 |
| Bid Sum (5%) | 567.64 | 5667.86 | 2378.06 | 989.71 |
| Bid–Ask Spread (10BTC) | 0.04 | 0.66 | 0.17 | 0.11 |
| Bid–Ask Spread (100BTC) | 0.30 | 2.90 | 0.78 | 0.45 |
| Buy0BTC | 767.00 | 41,552.00 | 8257.62 | 7121.62 |
| Sell0BTC | 559.00 | 49,411.00 | 8630.88 | 8091.82 |
| Buy1BTC | 160.00 | 7583.00 | 1820.29 | 1436.78 |
| Sell1BTC | 179.00 | 9272.00 | 1781.89 | 1600.48 |
| Buy5BTC | 35.00 | 2055.00 | 332.16 | 301.08 |
| Sell5BTC | 25.00 | 2553.00 | 354.77 | 365.67 |
| Buy10BTC | 1.00 | 685.00 | 94.53 | 86.32 |
| Sell10BTC | 2.00 | 838.00 | 93.58 | 109.68 |
| Momentum | 85.96 | 120.56 | 97.87 | 5.60 |
| CCI | −351.04 | 524.63 | 87.53 | 111.17 |
| Volume | 1,538,729.58 | 134,500,681.52 | 22,138,504.67 | 22,622,391.54 |
| SMA | 631.17 | 2867.59 | 1150.82 | 508.79 |
| Attributes | VIF | Genetic Search | Evolutionary Search | Best First Search |
|---|---|---|---|---|
| TWEXB | ✓ | ✓ | ||
| Gold-Fixing Price | ✓ | |||
| DJIA | ✓ | |||
| Brent Crude Oil Price | ✓ | ✓ | ✓ | |
| WTI | ||||
| Volume | ||||
| Trades Per Minute | ✓ | |||
| Ask sum (5BTC) | ✓ | |||
| Bid Sum (5BTC) | ||||
| Bid–Ask Spread (10BTC) | ✓ | ✓ | ✓ | ✓ |
| Bid–Ask Spread (100BTC) | ✓ | ✓ | ✓ | |
| Buy0BTC | ||||
| Sell0BTC | ✓ | |||
| Buy1BTC | ||||
| Sell1BTC | ✓ | |||
| Buy5BTC | ||||
| Sell5BTC | ||||
| Buy10BTC | ✓ | ✓ | ||
| Sum5BTCPrice | ✓ | ✓ | ✓ | |
| Sell10BTC | ✓ | ✓ | ||
| MTM | ✓ | |||
| CCI | ✓ | ✓ | ✓ | ✓ |
Appendix A.3. Model 3. Model Description
| Data | Min | Max | Mean | Std. Dev |
|---|---|---|---|---|
| S&P500 Index | 2581.00 | 2872.87 | 2711.50 | 63.73 |
| Nasdaq Composite | 6777.16 | 7637.86 | 7246.83 | 186.26 |
| DJIA Index | 23,533.20 | 26,616.71 | 24,842.04 | 676.33 |
| CAC 40 Index | 1425.12 | 5640.10 | 5297.19 | 527.43 |
| WTI | 59.19 | 72.24 | 65.03 | 3.34 |
| Gold Fixing Price | 1285.85 | 1360.25 | 1324.94 | 16.97 |
| Bid/Ask Spread (10BTC) | 0.21 | 0.68 | 0.36 | 0.12 |
| Ask Sum (10%) | 5.62 × 106 | 2.32 × 107 | 1.21 × 107 | 3.62 × 106 |
| Bid Sum (10%) | 9.71 × 106 | 2.65 × 107 | 1.49 × 107 | 3.34 × 106 |
| Trades Per Minute | 10.50 | 94.21 | 31.59 | 14.22 |
| Volatility | 7.80 | 154.64 | 39.35 | 25.15 |
| Volume | 3144.45 | 70961.37 | 3144.45 | 8830.17 |
| SMA | 1498.466429 | 14,907.4622 | 9030.497881 | 2036.55495 |
| Hash Rate | 1.63 × 1018 | 9.42 × 1018 | 3.89 × 1018 | 1.12 × 1018 |
| Mining Difficulty | 1.93 × 1012 | 4.94 × 1012 | 3.30 × 1012 | 7.27 × 1011 |
| Number of Transactions Per Block | 1.35 × 105 | 4.25 × 105 | 2.10 × 105 | 5.16 × 104 |
| Block Time | 7.48 | 12.22 | 9.34 | 0.86 |
| Attributes | Best First Search | PSO Search | Evolutionary Search |
| S&P500 Index | ✓ | ||
| Nasdaq Composite | |||
| DJIA Index | ✓ | ||
| CAC 40 Index | ✓ | ✓ | ✓ |
| WTI | ✓ | ✓ | |
| Gold Fixing Price | ✓ | ✓ | |
| Bid–Ask Spread (10BTC) | ✓ | ✓ | |
| Ask Sum within (10BTC) | ✓ | ||
| Bid Sum within (10BTC) | |||
| Trades Per Minute | ✓ | ✓ | ✓ |
| Volatility | ✓ | ✓ | ✓ |
| Volume | |||
| SMA | ✓ | ✓ | ✓ |
| Hash rate | |||
| Mining Difficulty | |||
| Number of Transactions | |||
| Block Time | ✓ | ✓ | ✓ |
References
- Rosenberg, J.M.; Krist, C. Combining machine learning and qualitative methods to elaborate students’ ideas about the generality of their model-based explanations. J. Sci. Educ. Technol. 2021, 30, 255–267. [Google Scholar] [CrossRef]
- Bertolini, R.; Finch, S.J.; Nehm, R.H. Testing the impact of novel assessment sources and machine learning methods on predictive outcome modeling in undergraduate biology. J. Sci. Educ. Technol. 2021, 30, 193–209. [Google Scholar] [CrossRef]
- Ashayer, A. Modeling and Prediction of Cryptocurrency Prices Using Machine Learning Techniques; East Carolina University Greenville: Greenville, NC, USA, 2019. [Google Scholar]
- Dutta, A.; Kumar, S.; Basu, M. A gated recurrent unit approach to bitcoin price prediction. J. Risk Financ. Manag. 2020, 13, 23. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Vergne, J.-P. Buzz factor or innovation potential: What explains cryptocurrencies’ returns? PLoS ONE 2017, 12, e0169556. [Google Scholar]
- Conrad, C.; Custovic, A.; Ghysels, E. Long-and short-term cryptocurrency volatility components: A GARCH-MIDAS analysis. J. Risk Financ. Manag. 2018, 11, 23. [Google Scholar] [CrossRef]
- Jang, H.; Lee, J. An empirical study on modeling and prediction of bitcoin prices with bayesian neural networks based on blockchain information. Ieee Access 2017, 6, 5427–5437. [Google Scholar] [CrossRef]
- Chen, Z.; Li, C.; Sun, W. Bitcoin price prediction using machine learning: An approach to sample dimension engineering. J. Comput. Appl. Math. 2020, 365, 112395. [Google Scholar] [CrossRef]
- Pang, Y.; Sundararaj, G.; Ren, J. Cryptocurrency price prediction using time series and social sentiment data. In Proceedings of the 6th IEEE/ACM International Conference on Big Data Computing, Applications and Technologies, Auckland, New Zealand, 2–5 December 2019; pp. 35–41. [Google Scholar]
- Antoniou, A.; Ergul, N.; Holmes, P.; Priestley, R. Technical analysis, trading volume and market efficiency: Evidence from an emerging market. Appl. Financ. Econ. 1997, 7, 361–365. [Google Scholar] [CrossRef]
- Buchholz, M.; Delaney, J.; Warren, J.; Parker, J. Bits and bets, information, price volatility, and demand for Bitcoin. Economics 2012, 312, 2–48. [Google Scholar]
- Nai Fovino, I.; Steri, G.; Fontana, A.; Ciaian, P.; Kancs, D.; Nordvik, J. On Virtual and Crypto Currencies: A General Overview, from the Technological Aspects to the Economic Implications; JRC Technical Report JRC9997: Ispra, Italy, 2015. [Google Scholar]
- Ciaian, P.; Rajcaniova, M.; Kancs, D.A. Virtual relationships: Short- and long-run evidence from BitCoin and altcoin markets. J. Int. Financ. Mark. Inst. Money 2018, 52, 173–195. [Google Scholar] [CrossRef]
- Keynes, J.M. The General Theory of Employment, Interest, and Money; Harcourt, Brace & World, Inc.: New York, NY, USA, 1936. [Google Scholar]
- Kristoufek, L. What are the main drivers of the Bitcoin price? Evidence from wavelet coherence analysis. PLoS ONE 2015, 10, e0123923. [Google Scholar] [CrossRef]
- Lyons, R.K. The Microstructure Approach to Exchange Rates; MIT Press: Cambridge, MA, USA, 2001; Volume 333. [Google Scholar]
- Marshall, A. Principles of Economics; Palgrave Macmillan: London, UK, 2013. [Google Scholar]
- Zhang, Y.-C. Toward a theory of marginally efficient markets. Phys. A Stat. Mech. Its Appl. 1999, 269, 30–44. [Google Scholar] [CrossRef]
- Amihud, Y.; Mendelson, H. Asset pricing and the bid-ask spread. J. Financ. Econ. 1986, 17, 223–249. [Google Scholar] [CrossRef]
- Reinganum, M.R. Market microstructure and asset pricing: An empirical investigation of NYSE and NASDAQ securities. J. Financ. Econ. 1990, 28, 127–147. [Google Scholar] [CrossRef]
- Dyhrberg, A.H.; Foley, S.; Svec, J. How investible is Bitcoin? Analyzing the liquidity and transaction costs of Bitcoin markets. Econ. Lett. 2018, 171, 140–143. [Google Scholar] [CrossRef]
- Scaillet, O.; Treccani, A.; Trevisan, C. High-frequency jump analysis of the bitcoin market. J. Financ. Econom. 2020, 18, 209–232. [Google Scholar]
- Guo, T.; Bifet, A.; Antulov-Fantulin, N. Bitcoin volatility forecasting with a glimpse into buy and sell orders. In Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM), Singapore, 17–20 November 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 989–994. [Google Scholar]
- Noble, P.M.; Gruca, T.S. Industrial pricing: Theory and managerial practice. Mark. Sci. 1999, 18, 435–454. [Google Scholar] [CrossRef] [Green Version]
- Hayes, A.S. Cryptocurrency value formation: An empirical study leading to a cost of production model for valuing bitcoin. Telemat. Inform. 2017, 34, 1308–1321. [Google Scholar] [CrossRef]
- Hayes, A.S. Bitcoin price and its marginal cost of production: Support for a fundamental value. Appl. Econ. Lett. 2019, 26, 554–560. [Google Scholar] [CrossRef] [Green Version]
- Yu, Y.; Rashidi, M.; Samali, B.; Yousefi, A.M.; Wang, W. Multi-image-feature-based hierarchical concrete crack identification framework using optimized SVM multi-classifiers and D–S fusion algorithm for bridge structures. Remote Sens. 2021, 13, 240. [Google Scholar] [CrossRef]
- Mohan, S.; Thirumalai, C.; Srivastava, G. Effective heart disease prediction using hybrid machine learning techniques. IEEE Access 2019, 7, 81542–81554. [Google Scholar] [CrossRef]
- Li, C.; He, Y.; Xiao, D.; Luo, Z.; Fan, J.; Liu, P.X. A novel hybrid approach of ABC with SCA for the parameter optimization of SVR in blind image quality assessment. Neural Comput. Appl. 2022, 34, 4165–4191. [Google Scholar] [CrossRef]
- Ebrahimpour, Z.; Wan, W.; Khoojine, A.S.; Hou, L. Twin hyper-ellipsoidal support vector machine for binary classification. IEEE Access 2020, 8, 87341–87353. [Google Scholar] [CrossRef]
- Yu, Y.; Li, Y.; Li, J.; Gu, X. Self-adaptive step fruit fly algorithm optimized support vector regression model for dynamic response prediction of magnetorheological elastomer base isolator. Neurocomputing 2016, 211, 41–52. [Google Scholar] [CrossRef] [Green Version]
- Chun, M.W.; Huat, N.C.; Pauline, O. Application of machine learning algorithm to prediction of thermal spring back of hot press forming. Res. Prog. Mech. Manuf. Eng. 2022, 3, 875–883. [Google Scholar]
- Shafiabady, N.; Lee, L.H.; Rajkumar, R.; Kallimani, V.; Akram, N.A.; Isa, D. Using unsupervised clustering approach to train the Support Vector Machine for text classification. Neurocomputing 2016, 211, 4–10. [Google Scholar] [CrossRef]
- Erfanian, S.; Ziaullah, M.; Tahir, M.A.; Ma, D. How does justice matter in developing supply chain trust and improving information sharing-an empirical study in Pakistan. Int. J. Manuf. Technol. Manag. 2021, 35, 354–368. [Google Scholar] [CrossRef]
- Razzaq, A.; Tang, Y.; Qing, P. Towards Sustainable Diets: Understanding the Cognitive Mechanism of Consumer Acceptance of Biofortified Foods and the Role of Nutrition Information. Int. J. Envion. Res. Pub. Health 2021, 18, 1175. [Google Scholar] [CrossRef]
- Aggarwal, D.; Chandrasekaran, S.; Annamalai, B. A complete empirical ensemble mode decomposition and support vector machine-based approach to predict Bitcoin prices. J. Behav. Exp. Financ. 2020, 27, 100335. [Google Scholar] [CrossRef]
- Jiang, X. Bitcoin price prediction based on deep learning methods. J. Math. Financ. 2019, 10, 132–139. [Google Scholar] [CrossRef] [Green Version]
- Munim, Z.H.; Shakil, M.H.; Alon, I. Next-day bitcoin price forecast. J. Risk Financ. Manag. 2019, 12, 103. [Google Scholar] [CrossRef] [Green Version]
- Huang, J.-Z.; Huang, W.; Ni, J. Predicting bitcoin returns using high-dimensional technical indicators. J. Financ. Data Sci. 2019, 5, 140–155. [Google Scholar] [CrossRef]
- Shen, Z.; Wan, Q.; Leatham, D.J. Bitcoin Return Volatility Forecasting: A Comparative Study of GARCH Model and Machine Learning Model. J. Risk Financ. Manag. 2019, 14, 337. [Google Scholar] [CrossRef]
- Mangla, N.; Bhat, A.; Avabratha, G.; Bhat, N. Bitcoin price prediction using machine learning. Int. J.l Inf. Comput. Sci. 2019, 6, 318–320. [Google Scholar]
- Siami-Namini, S.; Namin, A.S. Forecasting economics and financial time series: ARIMA vs. LSTM. arXiv 2018, arXiv:1803.06386. [Google Scholar]
- Pichl, L.; Kaizoji, T. Volatility analysis of bitcoin. Quant. Financ. Econ. 2017, 1, 474–485. [Google Scholar] [CrossRef]
- Indera, N.; Yassin, I.; Zabidi, A.; Rizman, Z. Non-linear autoregressive with exogeneous input (NARX) Bitcoin price prediction model using PSO-optimized parameters and moving average technical indicators. J. Fundam. Appl. Sci. 2017, 9, 791–808. [Google Scholar] [CrossRef]
- Razzaq, A.; Liu, H.; Zhou, Y.; Xiao, M.; Qing, P. The Competitiveness, Bargaining Power, and Contract Choice in Agricultural Water Markets in Pakistan: Implications for Price Discrimination and Environmental Sustainability. Front. Environ. Sci. 2022, 10, 670. [Google Scholar] [CrossRef]
- Rosenblatt, F. Two Theorems of Statistical Separability in the Perceptron; United States Department of Commerce: Washington, DC, USA, 1958.
- Smola, A.J.; Schölkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef] [Green Version]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer Science & Business Media: Berlin/Heidelberg, Germany, 1999. [Google Scholar]
- Hansen, L.K.; Salamon, P. Neural network ensembles. IEEE Trans. Pattern Anal. Mach. Intell. 1990, 12, 993–1001. [Google Scholar] [CrossRef] [Green Version]
- Wright, S. Correlation and Causation. J. Agric. Resour. 1921, 20, 557–585. [Google Scholar]
- Hyndman, R.J.; Koehler, A.B. Another look at measures of forecast accuracy. Int. J. Forecast. 2006, 22, 679–688. [Google Scholar] [CrossRef]
- Kuhn, M.; Johnson, K. Applied Predictive Modeling; Springer: Berlin/Heidelberg, Germany, 2013; Volume 26. [Google Scholar]





| Reference | Year | Methodologies | Data Categorization | Findings |
|---|---|---|---|---|
| Chen et al. [8] | 2020 | Logistic Regression and Linear Discriminant Analysis, Random Forest, XGBoost, Quadratic Discriminant Analysis, SVM, and Long Short-term Memory | Blockchain Information, Macroeconomic Indicators | Statistical methods outperform machine learning for BTC daily price prediction, while, Machine learning for BTC’s 5-min interval price prediction is superior to statistical methods, |
| Aggarwal et al. [36] | 2020 | SVM and decomposition (CEEMD) | technical indicators | The proposed method for short-term, midterm, and long term-prediction has a predictability power |
| Dutta et al. [4] | 2020 | Gated Recurring Unit, simple neural network (NN), LSTM | Blockchain Information, Macroeconomic Indicators, Technical Indicators | GRU outperforms the NN and LSTM for daily price prediction |
| Jiang, X. [37] | 2019 | MLP, LSTM, Gated Recurrent Network | Technical Indicators | |
| Munim et al. [38] | 2019 | ARIMA and neural network autoregression (NNAR) | Technical Indicators | ARIMA outperforms NNAR in daily price prediction |
| Huang et al. [39] | 2019 | A tree-based predictive mod buy and-hold strategy | Technical Indicators, | A tree-based predictive model for daily return outperform a buy and-hold strategy |
| Shen et al. [40] | 2019 | GARCH model, SMA, RNN | Technical Indicators | RNN method outperforms the GARCH model and SMA model for daily return prediction |
| Mangla et al. [41] | 2019 | Logistic regression, SVM, RNN, and ARIMA | Technical Indicators | ARIMA is better for next-day prediction, RNN better for weekly |
| Siami-Namini and Namin [42] | 2018 | ARIMA, long short-term memory (LSTM) | Technical Indicators | LSTM is superior to ARIMA for daily prediction |
| Jang and Lee [7] | 2017 | Bayesian neural networks (BNNs), SVR, and linear regression | Blockchain Information and macroeconomic indicators | BNN outperforms SVR and linear regression |
| Pichl and Kaizoji [43] | 2017 | Multilayer Perceptron | Technical Indicators | HARRVJ neural network captures well the dynamics of daily Realized Volatility as aggregated on the 5-min grid. |
| Indera et al. [44] | 2017 | MLP-based NARX | Technical Indicators | NARX has predictive power for daily price |
| Current Work | 2022 | OLS, MLP, ENSEMBLE, and SVR | Technical indicators, macroeconomic indicators, microstructure indicators, and blockchain information indicators | SVR beats the other models Macroeconomics and blockchain information have long term predictivity power There is no feature selection to improve the model |
| Accuracy Metrics | Formula |
|---|---|
| [50] | T is the size of a test dataset in out of sample prediction |
| Pearson’s r | |
| Root Mean Square Error (RMSE) [51] |
| Indicator Category | Indicator Name |
|---|---|
| Macroeconomic indicators | Market capitalization, BTCs in circulation, US federal funds rate, S&P500 stock market index, Nasdaq composite, DJIA stock market index, WTI, gold-fixing price, breakeven inflation rate, |
| Blockchain information indicators | Hash rate, mining difficulty, number of transactions per block, block size, average block size, median confirmation time, orphan blocks, cost per transaction, transaction fees, estimated transaction value (BTC), estimated transaction value (USD), total output value |
| Indicator Category | Indicator Name |
|---|---|
| Macro-Economic Indicators | Trade-weighted US Dollar Index, gold-fixing price, DJIA Index, Brent Crude oil price, WTI |
| Microeconomic Indicators | Trades per minute, bid/ask sum, bid–ask spread, buy/sell signals, |
| Technical Indicators | volume, MTM, CCI, SMA |
| Model Indicators | OLS | Ensemble Methods (Bagging) | SVR | MLP |
|---|---|---|---|---|
| All indicators | 8.86 (2.36) | 9.04 (1.97) | 8.68 (2.48) | 9.30 (2.20) |
| PCA Reduction | 8.79 (1.98) | 11.45 (2.48) | 8.59 (2.09) | 11.67 (2.31) |
| VIF | 15.97 (3.03) | 13.92 (3.00) | 16.01 (3.18) | 15.28 (4.57) |
| Genetic Search | 8.77 (2.23) | 9.45 (2.05) | 8.67 (2.27) | 10.11 (2.39) |
| Evolutionary Search | 8.72 (1.98) | 9.00 (2.06) | 8.68 (2.13) | 9.56 (2.39) |
| Best First | 8.80 (2.23) | 9.40 (2.07) | 8.68 (2.26) | 10.08 (2.49) |
| Model Indicators | OLS | Ensemble Methods (Bagging) | SVR | MLP |
|---|---|---|---|---|
| All Indicators | 0.88 (0.08) | 0.88 (0.07) | 0.89 (0.08) | 0.89(0.07) |
| PCA | 0.88 (0.06) | 0.88 (0.07) | 0.89 (0.07) | 0.80(0.09) |
| VIF | 0.56 (0.15) | 0.68 (0.17) | 0.55 (0.15) | 0.72(0.15) |
| Genetic Search | 0.88 (0.07) | 0.87 (0.07) | 0.88 (0.07) | 0.87(0.07) |
| Evolutionary Search | 0.88 (0.07) | 0.88 (0.07) | 0.89 (0.07) | 0.88(0.06) |
| Best First Search | 0.88 (0.07) | 0.87 (0.07) | 0.88 (0.07) | 0.87(0.07) |
| Indicators | Models |
|---|---|
| All Indicators | SVR, OLS, Ensemble methods, and MLP |
| PCA | SVR, OLS, Ensemble methods, and MLP |
| Genetic Search | SVR, OLS, Ensemble methods, and MLP |
| Evolutionary Search | SVR, OLS, Ensemble methods, and MLP |
| Best First Search | SVR, OLS, Ensemble methods, and MLP |
| Model Indicators | OLS | Ensemble Methods (Bagging) | SVR | MLP |
|---|---|---|---|---|
| All indicators | 8.86 (2.36) | 9.04 (1.97) | 8.68 (2.48) | 9.30 (2.20) |
| Macroeconomic indicators | 19.27 (3.55) | 18.54 (3.97) | 19.25 (3.79) | 20.74 (4.42) |
| Microeconomic indicators | 18.42 (3.76) | 16.04 (2.83) | 18.76 (3.99) | 17.35 (4.02) |
| Technical indicators | 8.72 (2.10) | 9.05 (2.14) | 8.68 (2.17) | 9.61 (2.39) |
| Model Indicators | OLS | Ensemble Methods (Bagging) | SVR | MLP |
|---|---|---|---|---|
| All Indicators | 0.88 (0.08) | 0.88 (0.07) | 0.89 (0.08) | 0.89 (0.07) |
| Macroeconomic Indicators | 0.06 (0.19) | 0.25 (0.29) | 0.09 (0.27) | 0.25 (0.22) |
| Microeconomic Indicators | 0.33 (0.19) | 0.53 (0.23) | 0.27 (0.21) | 0.61 (0.20) |
| Technical Indicators | 0.88 (0.07) | 0.88 (0.07) | 0.88 (0.07) | 0.88 (0.07) |
| Models | The Order of Indicators according to Their Impact on Prediction |
|---|---|
| OLS | Technical indicators, all indicators, microeconomic indicators, macroeconomic indicators |
| Ensemble methods | All indicators, technical indicators, microeconomic indicators, macroeconomic indicators |
| SVR | Technical indicators, all indicators, microeconomic indicators, macroeconomic indicators |
| MLP | All indicators, technical indicators, microeconomic indicators, macroeconomic indicators |
| Indicators | Models |
|---|---|
| All Indicators | SVR, OLS, Ensemble methods, and MLP |
| Technical Indicators | SVR, OLS, Ensemble methods, and MLP |
| Indicator Category | Indicator Name |
|---|---|
| Macroeconomic indicators | S&P500 index, Nasdaq Composite, DJIA index, CAC 40 Index, WTI, gold fixing price |
| Microeconomic indicators | Bid–ask spread (10BTC), ask sum (10%), bid sum (10%), trades per minute |
| Technical indicators | Volatility, volume, SMA |
| Blockchain information indicators | Hash rate, mining difficulty, number of transactions per block, block time |
| Model Indicators | OLS | Ensemble Methods (Bagging) | SVR | MLP |
|---|---|---|---|---|
| All Indicators | 157.36 (30.24) | 160.06 (36.52) | 154.49 (31.53) | 163.37 (44.62) |
| Best First | 161.36 (34.57) | 162.85 (38.69) | 158.87 (36.20) | 164.16 (40.37) |
| PCA Reduction | 160.48 (34.38) | 178.77 (40.04) | 160.26 (33.52) | 179.77 (45.12) |
| PSO Search | 160.70 (29.31) | 162.90 (37.43) | 158.06 (34.26) | 175.40 (43.50) |
| Evolutionary Search | 161.03 (31.97) | 162.43 (34.99) | 160.00 (38.76) | 169.70 (49.65) |
| Model Indicators | OLS | Ensemble Methods (Bagging) | SVR | MLP |
|---|---|---|---|---|
| All Indicators | 0.77 (0.13) | 0.74 (0.14) | 0.76 (0.13) | 0.77 (0.12) |
| Best First Search | 0.74 (0.16) | 0.72 (0.16) | 0.74 (0.14) | 0.77 (0.16) |
| PCA Reduction | 0.76 (0.13) | 0.65 (0.17) | 0.74 (0.13) | 0.76 (0.12) |
| PSO Search | 0.75 (0.14) | 0.72 (0.16) | 0.75 (0.13) | 0.73 (0.17) |
| Evolutionary Search | 0.74 (0.15) | 0.74 (0.13) | 0.74 (0.14) | 0.77 (0.16) |
| Datasets | Models |
|---|---|
| All Indicators | SVR, OLS, Ensemble methods, and MLP |
| Best First Search | SVR, OLS, Ensemble methods, and MLP |
| PCA Reduction | SVR, OLS, Ensemble methods, and MLP |
| PSO Search | SVR, OLS, Ensemble methods, and MLP |
| Evolutionary Search | SVR, OLS, Ensemble methods, and MLP |
| Model Indicators | OLS | Ensemble Learning | SVR | MLP |
|---|---|---|---|---|
| All indicators | 157.36 (30.24) | 160.06 (36.52) | 154.49 (31.53) | 174.37 (44.62) |
| Blockchain information indicators | 242.29 (46.77) | 243.07 (48.78) | 248.09 (51.72) | 281.13 (60.84) |
| Macroeconomic indicators | 251.56 (46.90) | 230.01 (43.84) | 249.30 (47.05) | 262.18 (59.76) |
| Microeconomic indicators | 198.61 (36.65) | 193.00 (36.62) | 197.99 (37.74) | 205.60 (48.95) |
| Technical indicators | 173.07 (41.11) | 161.97 (38.69) | 172.72 (40.78) | 191.32 (52.98) |
| Models Indicators | OLS | Ensemble Learning | SVR | MLP |
|---|---|---|---|---|
| All indicators | 0.75 (0.13) | 0.74 (0.14) | 0.76 (0.13) | 0.77 (0.12) |
| Blockchain information indicators | 0.11 (0.27) | 0.10 (0.24) | −0.01 (0.25) | −0.04 (0.26) |
| Macroeconomic indicators | −0.00 (0.25) | 0.23 (0.34) | 0.07 (0.32) | 0.21 (0.31) |
| Microeconomic indicators | 0.57 (0.23) | 0.58 (0.21) | 0.57 (0.22) | 0.60 (0.23) |
| Technical indicators | 0.68 (0.16) | 0.73 (0.14) | 0.69 (0.16) | 0.69 (0.16) |
| Models | Order of Indicators according to Their Impact on Prediction |
|---|---|
| OLS | All indicators, technical indicators, microeconomic indicators, blockchain information indicators, macroeconomic indicators |
| Ensemble methods | All indicators, technical indicators, microeconomic indicators, macroeconomic indicators, Blockchain information indicators |
| SVR | All indicators, technical indicators, microeconomic indicators, Blockchain information indicators, macroeconomic indicators |
| MLP | All indicators, technical indicators, microeconomic indicators, macroeconomic indicators, Blockchain information indicator |
| Indicators | Models |
|---|---|
| All indicators | SVR, OLS, Ensemble methods, and MLP |
| Technical indicators | SVR, OLS, Ensemble methods, and MLP |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Erfanian, S.; Zhou, Y.; Razzaq, A.; Abbas, A.; Safeer, A.A.; Li, T. Predicting Bitcoin (BTC) Price in the Context of Economic Theories: A Machine Learning Approach. Entropy 2022, 24, 1487. https://doi.org/10.3390/e24101487
Erfanian S, Zhou Y, Razzaq A, Abbas A, Safeer AA, Li T. Predicting Bitcoin (BTC) Price in the Context of Economic Theories: A Machine Learning Approach. Entropy. 2022; 24(10):1487. https://doi.org/10.3390/e24101487
Chicago/Turabian StyleErfanian, Sahar, Yewang Zhou, Amar Razzaq, Azhar Abbas, Asif Ali Safeer, and Teng Li. 2022. "Predicting Bitcoin (BTC) Price in the Context of Economic Theories: A Machine Learning Approach" Entropy 24, no. 10: 1487. https://doi.org/10.3390/e24101487
APA StyleErfanian, S., Zhou, Y., Razzaq, A., Abbas, A., Safeer, A. A., & Li, T. (2022). Predicting Bitcoin (BTC) Price in the Context of Economic Theories: A Machine Learning Approach. Entropy, 24(10), 1487. https://doi.org/10.3390/e24101487