
Multi-Task Learning and Improved TextRank for Knowledge Graph Completion

Abstract
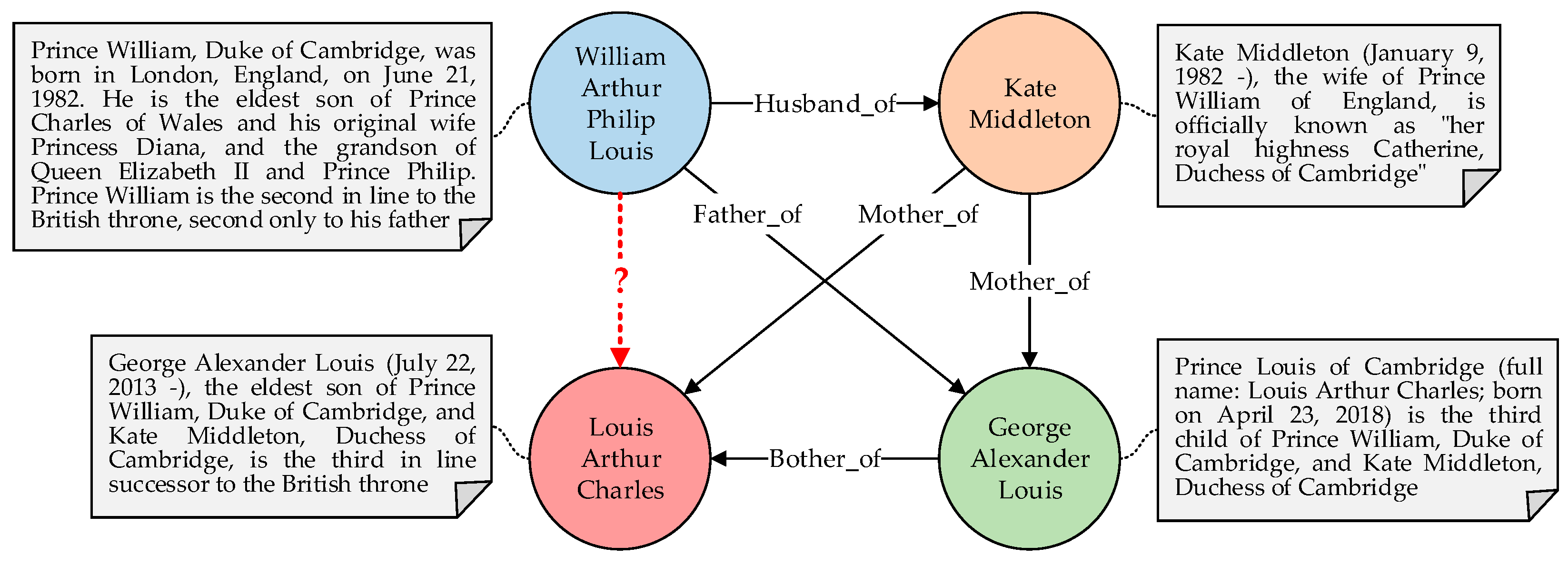
:1. Introduction
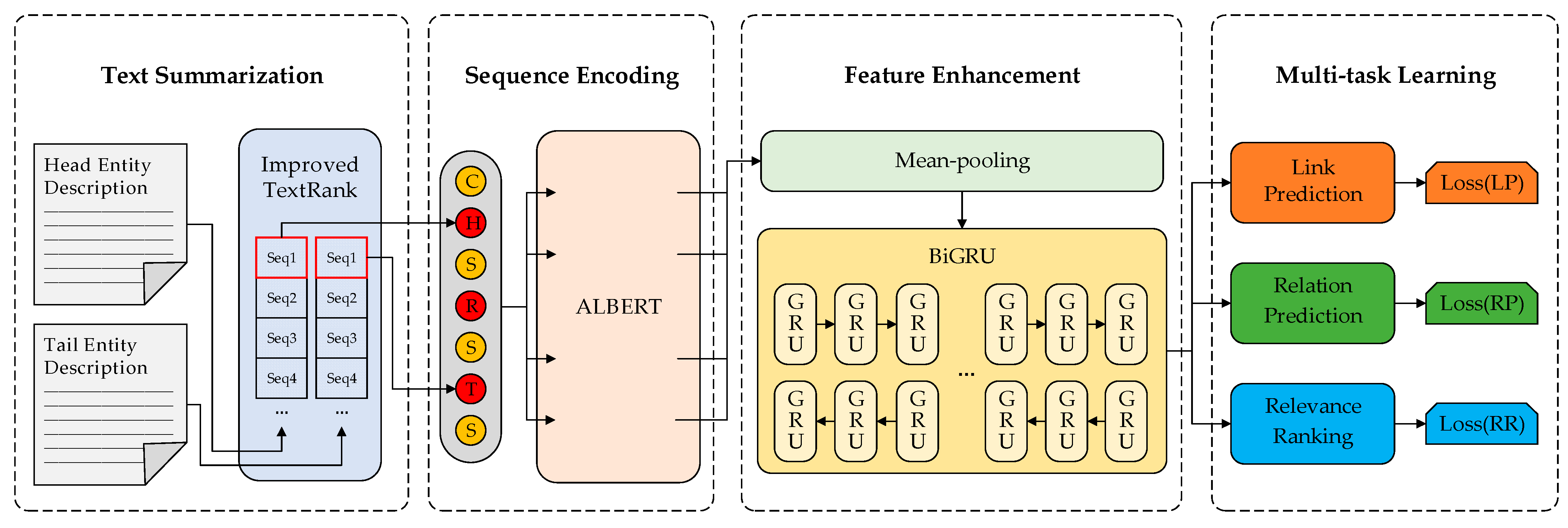
- We propose a new KGC model named MIT-KGC that applies ALBERT, multi-task-learning, improved TextRank, mean-pooling strategy, and BiGRU. The model uses the improved TextRank to distill brief texts from entity descriptions and applies ALBERT to accelerate the training. The mean-pooling strategy and BiGRU are appended to enhance triple features, and multi-task learning is utilized to optimize the model for predicting the missing triples.
- We modify the traditional TextRank algorithm to make it more adaptive for KGC, by appending entity name coverage and sentence position information.
- Our method improves link prediction results, with MR, Hit@10, and Hit@3 increased by 38, 1.3%, and 1.9% on WN18RR [8], while MR and Hit@10 were enhanced by 23 and 0.7% on FB15K-237 [8]. Additionally, on the dataset DBpedia50k [9], Hit@3 and Hit@1 were increased by 3.1% and 1.5%, respectively, using our method.
2. Related Work
2.1. Knowledge Graph Completion Model
2.2. Text Summarization Algorithm
2.3. Pre-Trained Language Model
3. Proposed Method
3.1. Text Summarization
3.2. Sequence Encoding
3.3. Feature Enhancement
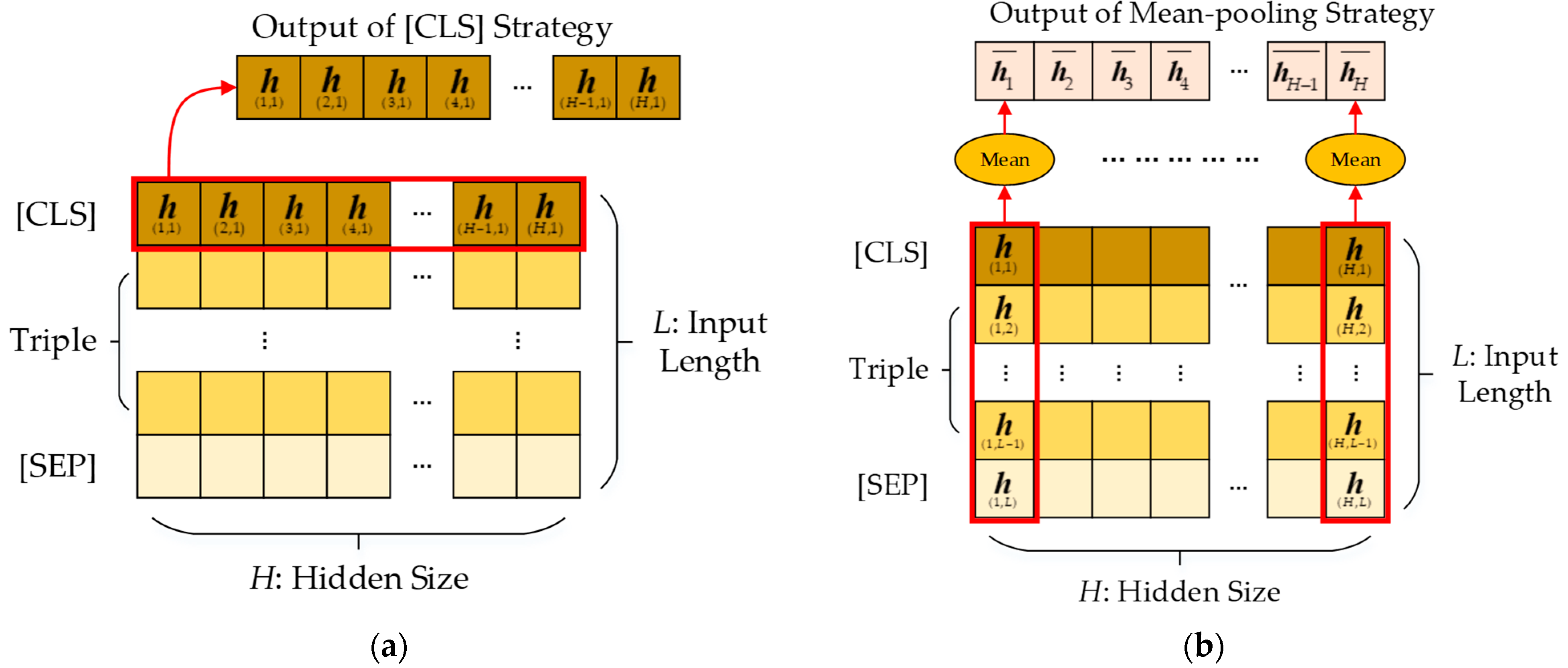
3.3.1. Mean-Pooling Strategy
3.3.2. Bidirectional Gated Recurrent Unit
3.4. Multi-Task Learning
3.4.1. Link Prediction
3.4.2. Relation Prediction
3.4.3. Relevance Ranking
4. Experiment and Analysis
4.1. Dataset
4.2. Baseline
4.3. Experimental Setting
4.4. Experiment Task and Evaluation Metrics
4.5. Link Prediction Result
4.6. Ablation Experiments
4.6.1. Training Tasks Strategy Experiment
4.6.2. Encoder Model Analysis
4.6.3. Text Summarization Analysis
4.6.4. Feature Enhancement Component Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Miller, G.A. WordNet: A lexical database for English. Commun. ACM 1995, 38, 39–41. [Google Scholar] [CrossRef]
- Bollacker, K.; Evans, C.; Paritosh, P.; Sturge, T.; Taylor, J. Freebase: A collaboratively created graph database for structuring human knowledge. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, Vancouver, BC, Canada, 9–12 June 2008; pp. 1247–1250. [Google Scholar]
- Liu, X.D.; He, P.C.; Chen, W.Z.; Gao, J.F. Multi-task deep neural networks for natural language understanding. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 4487–4496. [Google Scholar]
- Mihalcea, R.; Tarau, P. TextRank: Bringing Order into Texts. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain, 25–26 July 2004; pp. 401–411. [Google Scholar]
- Lan, Z.Z.; Chen, M.D.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. Albert: A lite bert for self-supervised learning of language representations. arXiv 2019, arXiv:1909.11942. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Annual Conference of the North American Chapter of the Association for Computational Linguistics, Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar]
- Cho, K.; Van, M.B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar]
- Dettmers, T.; Minervini, P.; Stenetorp, P.; Riedel, S. Convolutional 2d knowledge graph embeddings. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 1811–1818. [Google Scholar]
- Shah, H.; Villmow, J.; Ulges, A.; Schwanecke, U.; Shafait, F. An open-world extension to knowledge graph completion models. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 3044–3051. [Google Scholar]
- Meilicke, C.; Chekol, M.W.; Fink, M.; Stuckenschmidt, H. Anytime bottom-up rule learning for knowledge graph completion. In Proceedings of the 28th International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 3137–3143. [Google Scholar]
- Sadeghian, A.; Armandpour, M.; Ding, P.; Wang, D.Z. Drum: End-to end differentiable rule mining on knowledge graphs. In Proceedings of the 33rd Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 15347–15357. [Google Scholar]
- Lao, N.; Mitchell, T.; William, W.C. Random walk inference and learning in a large scale knowledge base. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, Edinburgh, UK, 27–31 July 2011; pp. 529–539. [Google Scholar]
- Liu, W.Y.; Daruna, A.; Kira, Z.; Chernova, S. Path ranking with attention to type hierarchies. In Proceedings of the 34th AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 2893–2900. [Google Scholar]
- Xiong, W.H.; Hoang, T.; Wang, W.Y. DeepPath: A reinforcement learning method for knowledge graph reasoning. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017; pp. 564–573. [Google Scholar]
- Lin, X.V.; Socher, R.; Xiong, C.M. Multi-hop knowledge graph reasoning with reward shaping. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 3243–3253. [Google Scholar]
- Bordes, A.; Usunier, N.; Garcia, D.A.; Weston, J.; Yakhnenko, O. Translating embeddings for modeling multi-relational data. Adv. Neural Inf. Processing Syst. 2013, 26, 2787–2795. [Google Scholar]
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge graph embedding by translating on hyperplanes. In Proceedings of the AAAI Conference on Artificial Intelligence, Quebec, QC, Canada, 27–31 July 2014. [Google Scholar]
- Yang, B.; Yih, W.; He, X.; Gao, J.; Deng, L. Embedding entities and relations for learning and inference in knowledge bases. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Trouillon, T.; Welbl, J.; Riedel, S.; Gaussier, É.; Bouchard, G. Complex embeddings for simple link prediction. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 2071–2080. [Google Scholar]
- Sun, Z.; Deng, Z.H.; Nie, J.Y.; Tang, J. Rotate: Knowledge graph embedding by relational rotation in complex space. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Xie, R.; Liu, Z.; Jia, J.; Luan, H.; Sun, M. Representation learning of knowledge graphs with entity descriptions. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Shi, B.; Weninger, T. Open-world knowledge graph completion. In Proceedings of the AAAI conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Yao, L.; Mao, C.; Luo, Y. KG-BERT: BERT for knowledge graph completion. arXiv 2019, arXiv:1909.03193. [Google Scholar]
- Kim, B.; Hong, T.; Ko, Y.; Seo, J. Multi-task learning for knowledge graph completion with pre-trained language models. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 13–18 September 2020; pp. 1737–1743. [Google Scholar]
- Brin, S. The PageRank citation ranking: Bringing order to the web. Proc. ASIS 1998, 98, 161–172. [Google Scholar]
- Li, H.; Tang, C.L.; Yang, X.; Wang, S. TextRank keyword extraction based on multi feature fusion. J. Intell. 2017, 36, 183–187. [Google Scholar]
- Xiong, A.; Liu, D.R.; Tian, H.K.; Liu, Z.Y.; Yu, P.; Kadoch, M. News keyword extraction algorithm based on semantic clustering and word graph model. Tsinghua Sci. Technol. 2021, 26, 886–893. [Google Scholar] [CrossRef]
- Zhao, Z.F.; Liu, P.P.; Li, X.S. Keywords extraction algorithm of railway literature based on improved TextRank. J. Beijing Jiaotong Univ. 2021, 45, 80–86. [Google Scholar]
- Fakhrezi, M.F.; Bijaksana, M.A.; Huda, A.F. Implementation of automatic text summarization with TextRank method in the development of Al-qur’an vocabulary encyclopedia. Procedia Comput. Sci. 2021, 179, 391–398. [Google Scholar] [CrossRef]
- Yang, Y.J.; Zhao, G.T.; Yuan, Z.Q. TextRank based keyword extraction method integrating semantic features. Comput. Eng. 2021, 47, 82–88. [Google Scholar]
- Bordoloi, M.; Chatterjee, P.C.; Biswas, S.K.; Purkayastha, B. Keyword extraction using supervised cumulative TextRank. Multimed. Tools Appl. 2020, 79, 31467–31496. [Google Scholar] [CrossRef]
- Liu, Z.Y.; Li, P.; Zheng, Y.B.; Sun, M. Clustering to find exemplar terms for keyphrase extraction. In Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–7 August 2009; pp. 257–266. [Google Scholar]
- Zhou, N.; Shi, W.Q.; Zhu, Z.Z. TextRank keyword extraction algorithm based on rough data-deduction. J. Chin. Inf. Processing 2020, 34, 44–52. [Google Scholar]
- Wang, H.C.; Hsiao, W.C.; Chang, S.H. Automatic paper writing based on a RNN and the TextRank algorithm. Appl. Soft Comput. 2020, 97, 106767. [Google Scholar] [CrossRef]
- Xiong, C.Q.; Li, X.; Li, Y.; Liu, G. Multi-documents summarization based on TextRank and its application in online argumentation platform. Int. J. Data Warehous. Min. 2018, 14, 69–89. [Google Scholar] [CrossRef]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving language understanding by generative pre-training. Comput. Lang. 2017, 4, 212–220. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.F.; Joshi, M.; Chen, D.Q.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Li, D.; Yi, M.; He, Y. LP-BERT: Multi-task Pre-training Knowledge Graph BERT for Link Prediction. arXiv 2022, arXiv:2201.04843. [Google Scholar]
- Liu, J.; Ning, X.; Zhang, W. XLNet for knowledge graph completion. In Proceedings of the 2021 2nd International Conference on Education, Knowledge and Information Management, Xiamen, China, 29–31 January 2021; pp. 644–648. [Google Scholar]
- Chen, Y.; Minervini, P.; Riedel, S.; Stenetorp, P. Relation prediction as an auxiliary training objective for improving multi-relational graph representations. arXiv 2021, arXiv:2110.02834. [Google Scholar]
- Lu, H.N.; Hu, H.L. Dense: An enhanced non-abelian group representation for knowledge graph embedding. arXiv 2020, arXiv:2008.04548. [Google Scholar]
- Schlichtkrull, M.; Kipf, T.N.; Bloem, P.; Berg, R.V.D.; Titov, I.; Welling, M. Modeling relational data with graph convolutional networks. In Proceedings of the European Semantic Web Conference, Heraklion, Greece, 3–7 June 2018; pp. 593–607. [Google Scholar]
- Wang, H.; Ren, H.; Leskovec, J. Relational message passing for knowledge graph completion. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Singapore, 14–18 August 2021; pp. 1697–1707. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Dataset | Entities | Relations | Train | Validation | Test |
|---|---|---|---|---|---|
| FB15k-237 | 14,541 | 237 | 272,115 | 17,535 | 20,466 |
| WN18RR | 40,943 | 11 | 86,835 | 3034 | 3134 |
| DBpedia50k | 24,624 | 351 | 32,388 | 123 | 2095 |
| Model | FB15k-237 | WN18RR | ||||||
|---|---|---|---|---|---|---|---|---|
| MR | Hit@10(%) | Hit@3(%) | Hit@1(%) | MR | Hit@10(%) | Hit@3(%) | Hit@1(%) | |
| MIT-KGC(ours) | 109 | 57.5 | 41.7 | 21.2 | 51 | 76.5 | 58.2 | 33.5 |
| LP-BERT(2022) | 154 | 49.0 | 33.6 | 22.3 | 92 | 75.2 | 56.3 | 34.3 |
| MTL-BERT(2020) | 132 | 45.8 | 29.8 | 17.2 | 89 | 59.7 | 38.3 | 20.3 |
| KG-XLNet(2021) | - | - | - | - | 108 | 51.8 | - | - |
| KG-BERT(2019) | 153 | 42.0 | - | - | 97 | 52.4 | 30.2 | 4.1 |
| RESCAL-N3-RP(2021) | 163 | 56.8 | 42.5 | 29.8 | - | 58.0 | 50.5 | 44.3 |
| DensE(2020) | 169 | 53.5 | 38.4 | 25.6 | 3052 | 57.9 | 50.8 | 44.3 |
| R-GCN(2018) | 600 | 30.0 | 18.1 | 10.0 | 6700 | 20.7 | 13.7 | 8.0 |
| RotatE(2018) | 177 | 53.3 | 37.5 | 24.1 | 3340 | 57.1 | 49.2 | 42.8 |
| ConvE(2018) | 245 | 49.7 | 34.1 | 22.5 | 4464 | 53.1 | 47 | 41.9 |
| ComplEx(2016) | 546 | 45.0 | 29.7 | 19.4 | 7882 | 53 | 46.9 | 40.9 |
| DistMult(2014) | 512 | 44.6 | 30.1 | 19.9 | 5110 | 49 | 44 | 39 |
| TransE(2013) | 323 | 44.1 | 37.6 | 19.8 | 3384 | 50.1 | - | - |
| Model | DBpedia50k | |||
|---|---|---|---|---|
| MR | Hit@10(%) | Hit@3(%) | Hit@1(%) | |
| MIT-KGC(ours) | 43 | 79.8 | 68.3 | 53.4 |
| OWE(2019) | - | 76.0 | 65.2 | 51.9 |
| ConMask(2018) | 16 | 81.0 | 64.5 | 47.1 |
| DKRL(2016) | 70 | 40.0 | - | - |
| Training Tasks | WN18RR | |||
|---|---|---|---|---|
| MR | Hit@10(%) | Hit@3(%) | Hit@1(%) | |
| LP + RP + RR | 51.4 | 76.5 | 58.2 | 33.5 |
| LP + RP | 74.6 | 67.8 | 50.9 | 29.6 |
| LP + RR | 54.2 | 74.7 | 55.2 | 30.7 |
| LP | 82.5 | 64.4 | 47.1 | 24.3 |
| Model | Type | Layers | Hidden | Embedding |
|---|---|---|---|---|
| ALBERT | large | 24 | 1024 | 128 |
| xlarge | 24 | 2048 | 128 | |
| BERT | large | 24 | 1024 | 1024 |
| xlarge | 24 | 2048 | 2048 |
| Encoder | WN18RR | ||||
|---|---|---|---|---|---|
| MR | Hit@10(%) | Hit@3(%) | Hit@1(%) | Speed | |
| 51.4 | 76.5 | 58.2 | 33.5 | 2.1× | |
| 92.4 | 65.9 | 43.1 | 23.0 | 6.2× | |
| 175.5 | 49.7 | 22.4 | 11.7 | 1.0× | |
| 61.7 | 69.6 | 52.5 | 31.3 | 3.4× | |
| Models | WN18RR | |||
|---|---|---|---|---|
| MR | Hit@10(%) | Hit@3(%) | Hit@1(%) | |
| MIT-KGC (improved TextRank) | 51.4 | 76.5 | 58.2 | 33.5 |
| MIT-KGC (original TextRank) | 60.6 | 73.1 | 54.5 | 29.1 |
| MIT-KGC (without TextRank) | 66.3 | 70.7 | 52.4 | 27.8 |
| Entities | Description | Extracted Description | Test Triples | Predicted Entities |
|---|---|---|---|---|
| protective 01887076 | protective, intended or adapted to afford protection of some kind; “a protective covering”; “the use of protective masks and equipment”; “protective coatings”; “kept the drunken sailor in protective custody”; “animals with protective coloring”; “protective tariffs” | protective, intended or adapted to afford protection of some kind. | [preventive] [_also_see] [protective] | [preventive] [unarmoured] [protectiveness] …… |
| element 03081021 | element, an artifact that is one of the individual parts of which a composite entity is made up; especially a part that can be separated from or attached to a system; “spare components for cars”; “a component or constituent element of a system” | element, an artifact that is one of the individual parts of which a composite entity is made up. | [supplement] [_hypernym] [element] | [supplement] [crystal] [oxide] …… |
| Halifax /m/0cdw6 | Halifax is a Minster town, within the Metropolitan Borough of Calderdale in West Yorkshire, England. It has an urban area population of 82,056 in the 2001 Census. It is well known as a centre of England’s woollen manufacture from the 15th century onward, originally dealing through the Halifax Piece Hall. Halifax is known for its Mackintosh chocolate and toffee, the Halifax bank, and the nearby Shibden Hall. | Halifax is a Minster town, within the Metropolitan Borough of Calderdale in West Yorkshire, England. | [United Kingdom] [/location/location/contains] [Halifax] | [United Kingdom] [United States of America] [London] …… |
| Sandra Bernhard /m/0m68w | Sandra Bernhard is an American comedian, singer, actress and author. She first gained attention in the late 1970s with her stand-up comedy in which she often bitterly critiques celebrity culture and political figures. Bernhard is number 97 on Comedy Central’s list of the 100 greatest standups of all time. | Sandra Bernhard is an American comedian, singer, actress and author. | [Sandra Bernhard] [/people/person/profession] [Actor-GB] | [Actor-GB] [Professor-GB] [Film Director] …… |
| Dataset | Summarization | Shortest Description | Longest Description | Average Length |
|---|---|---|---|---|
| FB15k-237 | No | 25 | 4019 | 864.8 |
| Yes | 8 | 1019 | 172.5 | |
| WN18RR | No | 9 | 534 | 89.8 |
| Yes | 9 | 519 | 64.7 |
| Models | WN18RR | |||
|---|---|---|---|---|
| MR | Hit@10(%) | Hit@3(%) | Hit@1(%) | |
| MIT-KGC | 51.4 | 76.5 | 58.2 | 33.5 |
| -BiGRU | 77.2 | 69.6 | 49.1 | 28.7 |
| -Mean-pooling | 88.7 | 65.8 | 44.0 | 21.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, H.; Zhang, X.; Wang, Y.; Zeng, D. Multi-Task Learning and Improved TextRank for Knowledge Graph Completion. Entropy 2022, 24, 1495. https://doi.org/10.3390/e24101495
Tian H, Zhang X, Wang Y, Zeng D. Multi-Task Learning and Improved TextRank for Knowledge Graph Completion. Entropy. 2022; 24(10):1495. https://doi.org/10.3390/e24101495
Chicago/Turabian StyleTian, Hao, Xiaoxiong Zhang, Yuhan Wang, and Daojian Zeng. 2022. "Multi-Task Learning and Improved TextRank for Knowledge Graph Completion" Entropy 24, no. 10: 1495. https://doi.org/10.3390/e24101495
APA StyleTian, H., Zhang, X., Wang, Y., & Zeng, D. (2022). Multi-Task Learning and Improved TextRank for Knowledge Graph Completion. Entropy, 24(10), 1495. https://doi.org/10.3390/e24101495