




Deep Matrix Factorization Based on Convolutional Neural Networks for Image Inpainting

Abstract
:1. Introduction
- (1)
- Compared with existing methods, our proposed method is able to address the nonlinear data model problem faced by the traditional MC methods. It is also able to address the global structure problem in existing deep learning-based MC methods.
- (2)
- The proposed method can be pre-trained to learn the global image structure and underlying relationship between input matrix data with missing elements and the recovered output data. Once successfully trained, the network does not need to be optimized again in the subsequent image in-painting tasks, thereby providing a high-performance and easy-to-deploy nonlinear matrix completion solution.
- (3)
- To improve the performance of the proposed method, a new algorithm for pre-filling the missing elements of the image is proposed. This new padding method performs global analysis of the matrix data to predict the missing elements as their initial values, which improves the performance of matrix completion and image in-painting.
2. Related Work
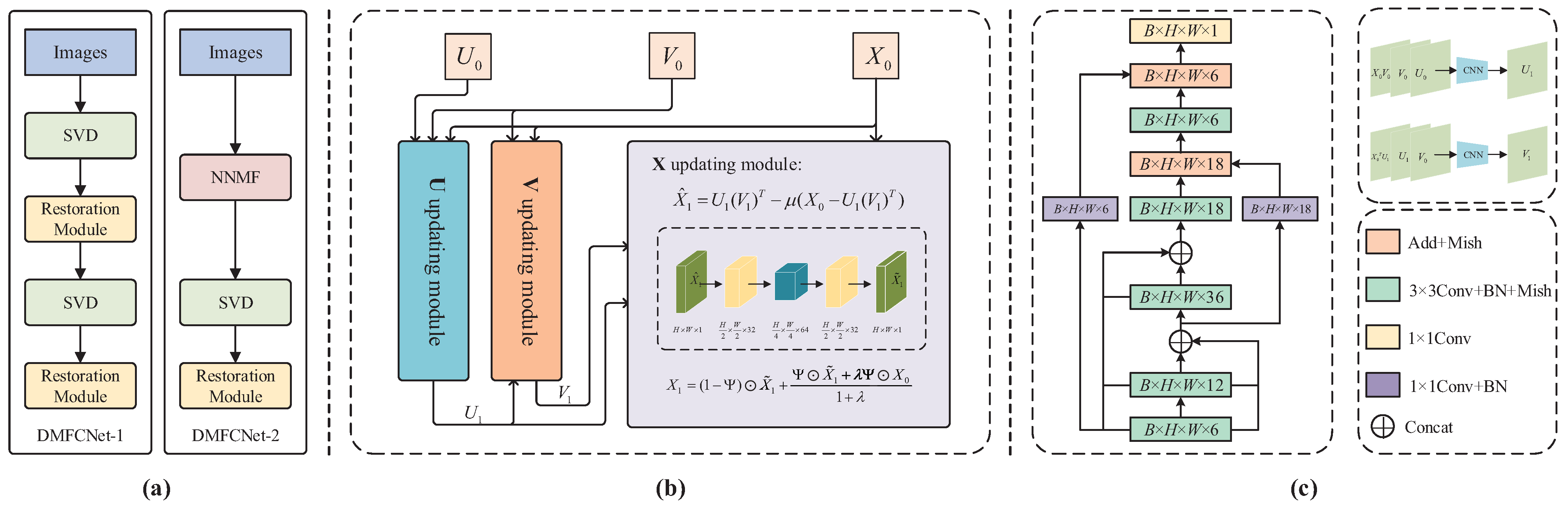
3. The Proposed Method
3.1. Mathematical Model of the DMFCNet Method
3.1.1. and Updating Modules
3.1.2. Updating Module
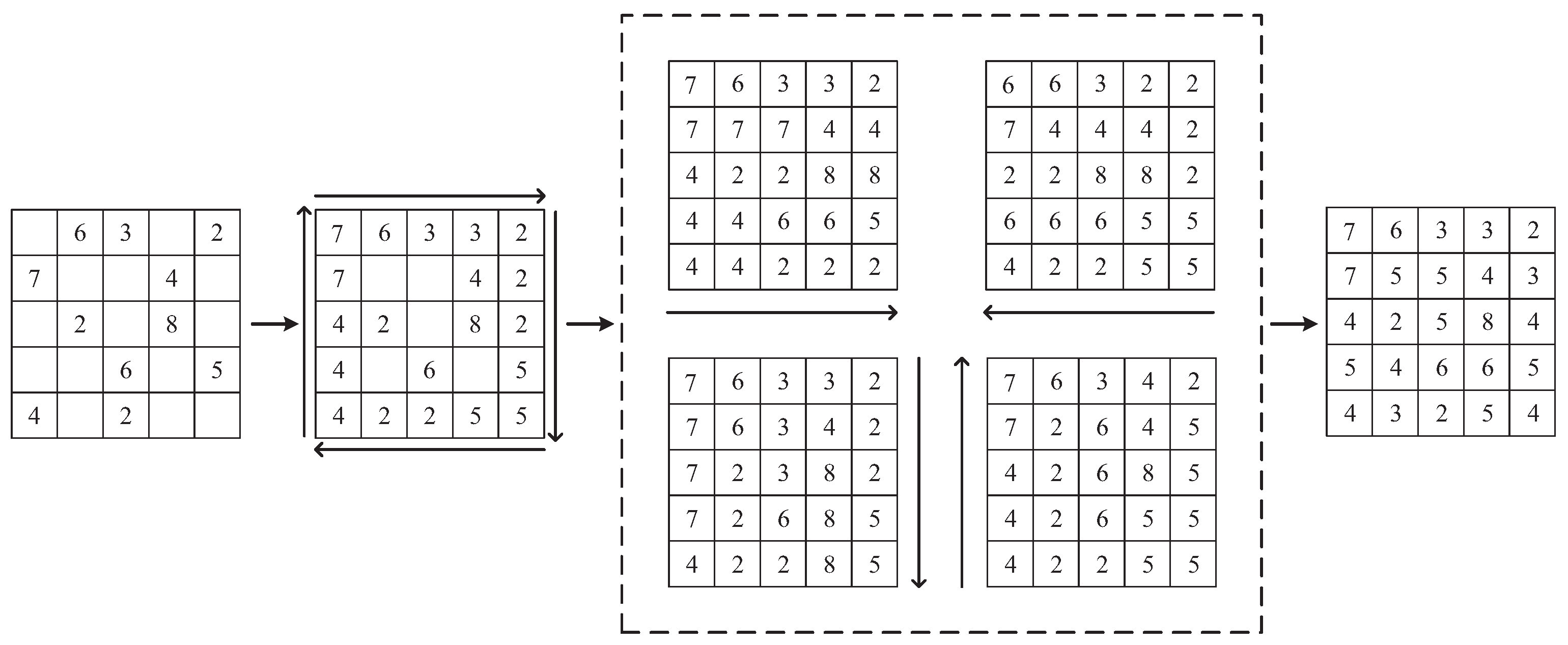
3.2. Pre-Filling
| Algorithm 1 DMFCNet-1 |
|
| Algorithm 2 DMFCNet-2 |
|
3.3. Loss Function
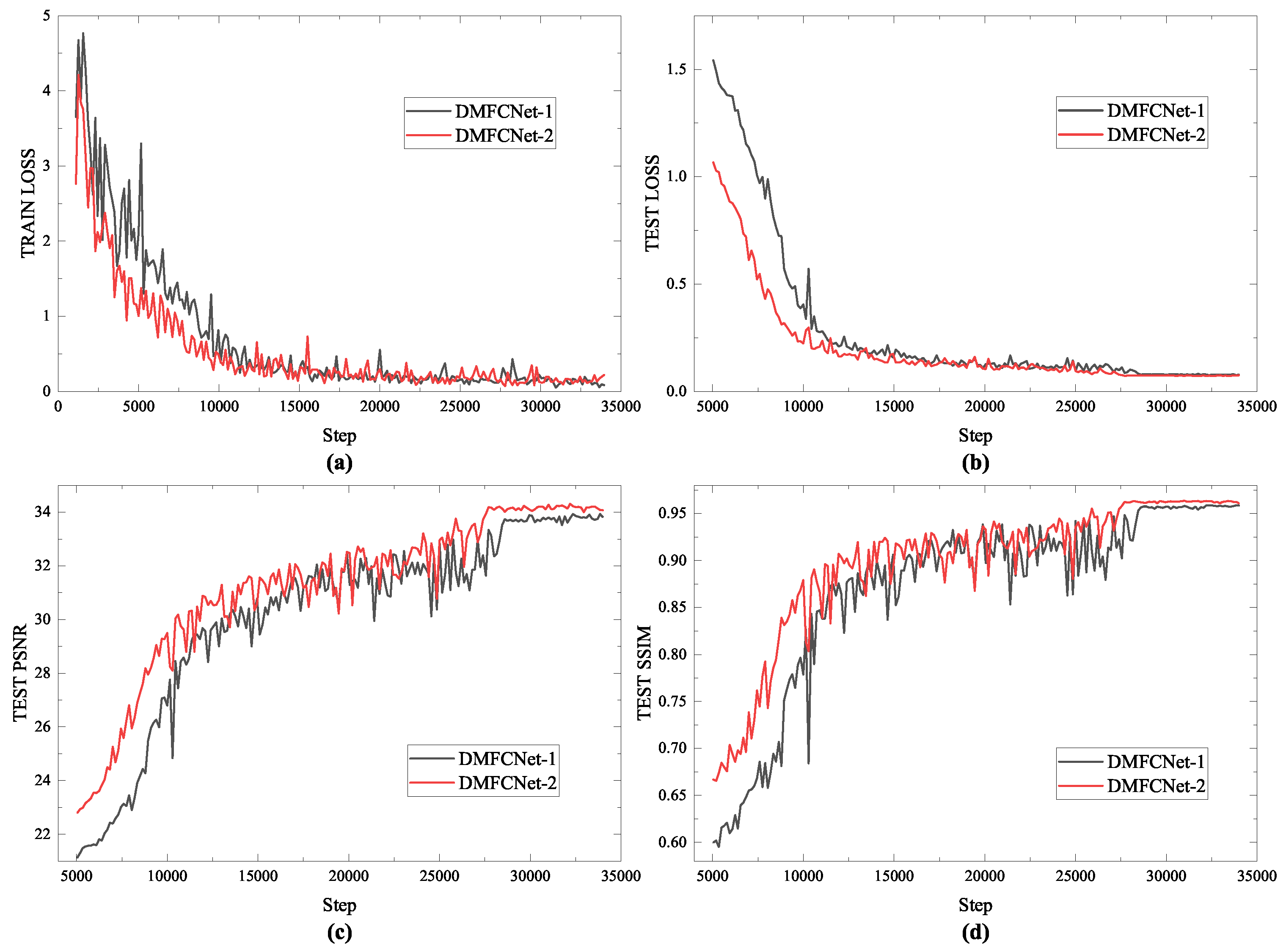
3.4. Training
4. Experiments
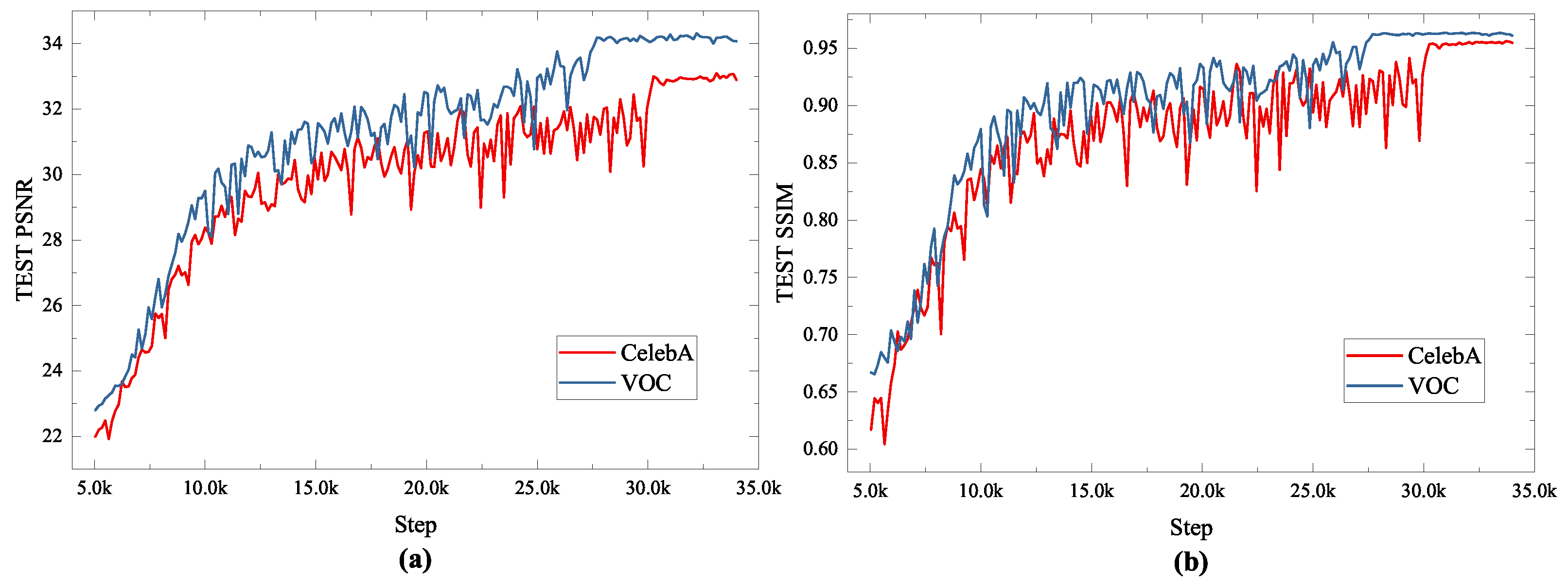
4.1. Datasets
4.2. Experimental Settings
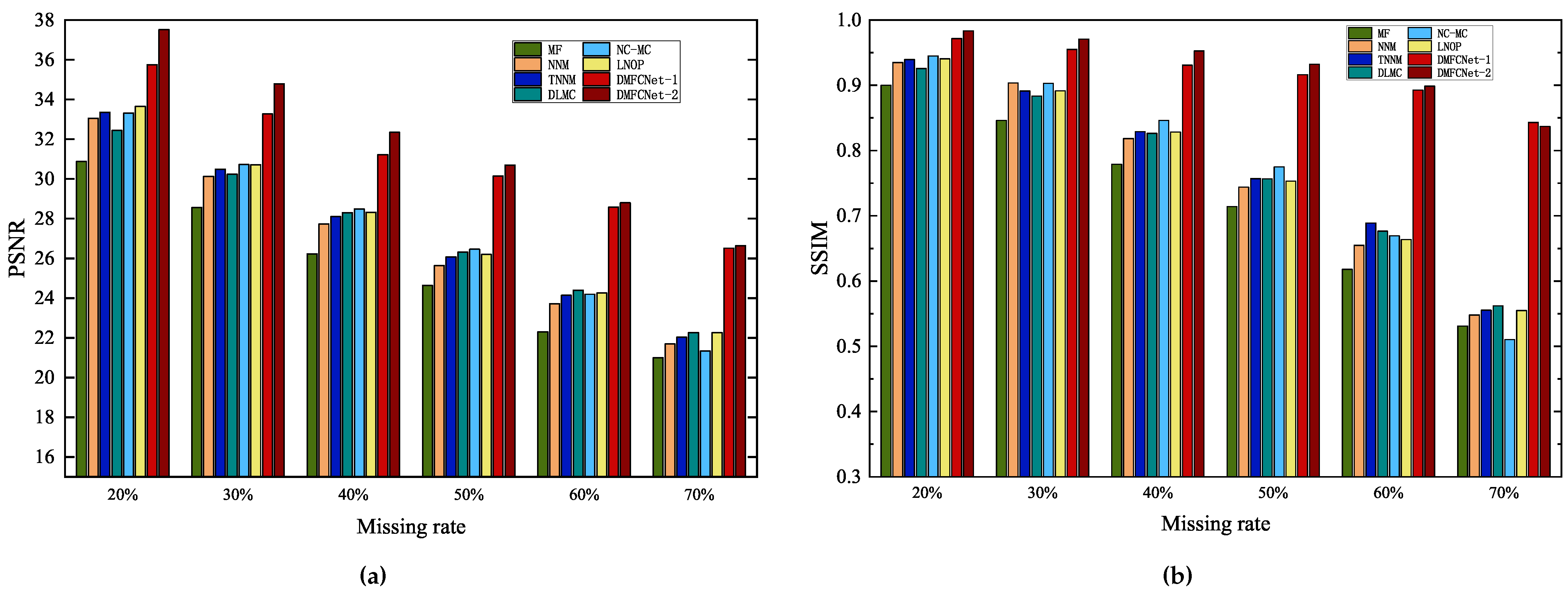
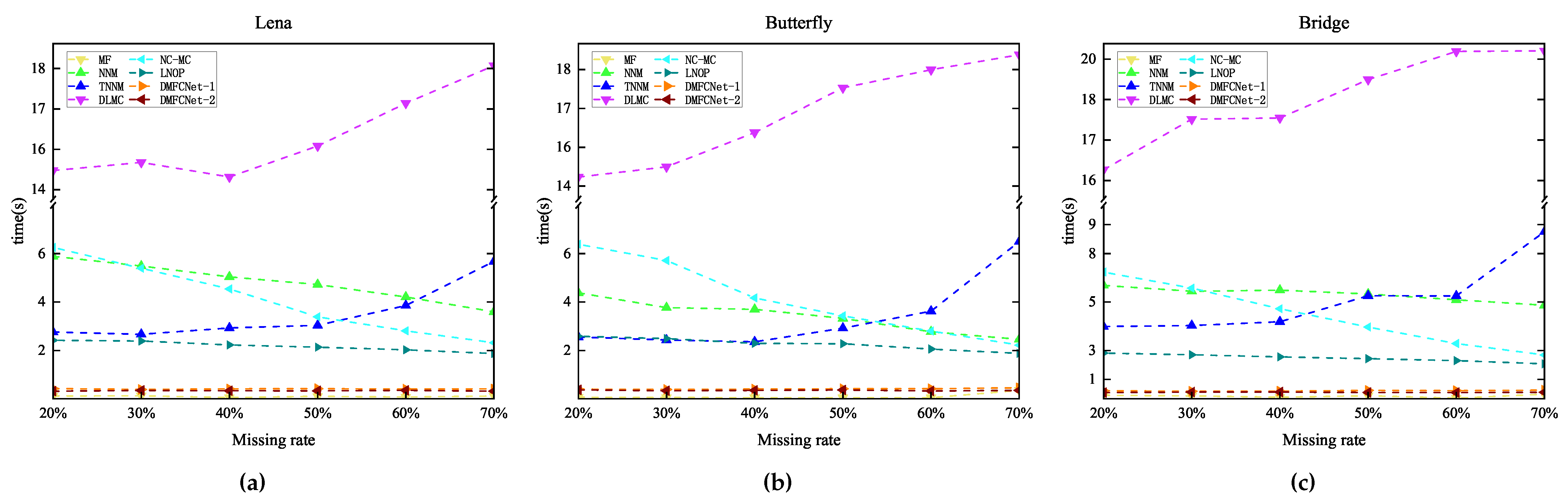
4.3. Image In-Painting
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Candes, E.J.; Recht, B. Exact matrix completion via convex optimization. Found. Comput. Math. 2009, 9, 717–772. [Google Scholar] [CrossRef] [Green Version]
- Fan, J.; Chow, T.W. Sparse subspace clustering for data with missing entries and high-rank matrix completion. Neural Netw. 2017, 93, 36–44. [Google Scholar] [CrossRef] [PubMed]
- Liu, G.; Li, P. Low-rank matrix completion in the presence of high coherence. IEEE Trans. Signal Process. 2016, 64, 5623–5633. [Google Scholar] [CrossRef]
- Lu, X.; Gong, T.; Yan, P.; Yuan, Y.; Li, X. Robust alternative minimization for matrix completion. IEEE Trans. Syst. Man Cybern. Part (Cybern.) 2012, 42, 939–949. [Google Scholar]
- Wang, H.; Zhao, R.; Cen, Y. Rank adaptive atomic decomposition for low-rank matrix completion and its application on image recovery. Neurocomputing 2014, 145, 374–380. [Google Scholar] [CrossRef]
- Lara-Cabrera, R.; González-Prieto, A.; Ortega, F.; Bobadilla, J. Evolving matrix-factorization-based collaborative filtering using genetic programming. Appl. Sci. 2020, 10, 675. [Google Scholar] [CrossRef] [Green Version]
- Zhang, D.; Liu, L.; Wei, Q.; Yang, Y.; Yang, P.; Liu, Q. Neighborhood aggregation collaborative filtering based on knowledge graph. Appl. Sci. 2020, 10, 3818. [Google Scholar] [CrossRef]
- Hu, Y.; Zhang, D.; Ye, J.; Li, X.; He, X. Fast and accurate matrix completion via truncated nuclear norm regularization. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 2117–2130. [Google Scholar] [CrossRef]
- Le Pendu, M.; Jiang, X.; Guillemot, C. Light field inpainting propagation via low rank matrix completion. IEEE Trans. Image Process. 2018, 27, 1981–1993. [Google Scholar] [CrossRef] [Green Version]
- Alameda-Pineda, X.; Ricci, E.; Yan, Y.; Sebe, N. Recognizing emotions from abstract paintings using non-linear matrix completion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5240–5248. [Google Scholar]
- Yang, Y.; Feng, Y.; Suykens, J.A. Correntropy based matrix completion. Entropy 2018, 20, 171. [Google Scholar] [CrossRef] [Green Version]
- Ji, H.; Liu, C.; Shen, Z.; Xu, Y. Robust video denoising using low rank matrix completion. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 1791–1798. [Google Scholar]
- Cabral, R.; De la Torre, F.; Costeira, J.P.; Bernardino, A. Matrix completion for weakly-supervised multi-label image classification. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 121–135. [Google Scholar] [CrossRef] [PubMed]
- Luo, Y.; Liu, T.; Tao, D.; Xu, C. Multiview matrix completion for multilabel image classification. IEEE Trans. Image Process. 2015, 24, 2355–2368. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Harvey, N.J.; Karger, D.R.; Yekhanin, S. The complexity of matrix completion. In Proceedings of the Seventeenth Annual ACM-SIAM Symposium on Discrete Algorithm, Alexandria, VA, USA, 9–12 January 2006; pp. 1103–1111. [Google Scholar]
- Lin, Z.; Chen, M.; Ma, Y. The augmented lagrange multiplier method for exact recovery of corrupted low-rank matrices. arXiv 2010, arXiv:1009.5055. [Google Scholar]
- Shen, Y.; Wen, Z.; Zhang, Y. Augmented Lagrangian alternating direction method for matrix separation based on low-rank factorization. Optim. Methods Softw. 2014, 29, 239–263. [Google Scholar] [CrossRef] [Green Version]
- Toh, K.C.; Yun, S. An accelerated proximal gradient algorithm for nuclear norm regularized linear least squares problem. Pac. J. Optim. 2010, 6, 615–640. [Google Scholar]
- Cai, J.F.; Candes, E.J.; Shen, Z. A singular value thresholding algorithm for matrix completion. SIAM J. Optim. 2010, 20, 1956–1982. [Google Scholar] [CrossRef]
- Chen, C.; He, B.; Yuan, X. Matrix completion via an alternating direction method. IMA J. Numer. Anal. 2012, 32, 227–245. [Google Scholar] [CrossRef]
- Wen, Z.; Yin, W.; Zhang, Y. Solving a low-rank factorization model for matrix completion by a nonlinear successive over-relaxation algorithm. Math. Program. Computn. 2012, 4, 333–361. [Google Scholar] [CrossRef]
- Han, H.; Huang, M.; Zhang, Y.; Bhatti, U.A. An extended-tag-induced matrix factorization technique for recommender systems. Information 2018, 9, 143. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Liu, Q.; Wu, R.; Chen, E.; Liu, C.; Huang, X.; Huang, Z. Confidence-aware matrix factorization for recommender systems. In Proceedings of the AAAI Conference on Artificial Intelligence, Orleans, LA, USA, 2–7 February 2018; Volume 32, p. 1. [Google Scholar]
- Luo, Z.; Zhou, M.; Li, S.; Xia, Y.; You, Z.; Zhu, Q.; Leung, H. An efficient second-order approach to factorize sparse matrices in recommender systems. IEEE Trans. Ind. Inform. 2015, 11, 946–956. [Google Scholar] [CrossRef]
- Luo, Z.; Zhou, M.; Li, S.; Xia, Y.; You, Z.; Zhu, Q. A nonnegative latent factor model for large-scale sparse matrices in recommender systems via alternating direction method. IEEE Trans. Neural Netw. Learn. Syst. 2015, 27, 579–592. [Google Scholar] [CrossRef]
- Cao, X.; Zhao, Q.; Meng, D.; Chen, Y.; Xu, Z. Robust low-rank matrix factorization under general mixture noise distributions. IEEE Trans. Image Process. 2016, 25, 4677–4690. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lawrence, N.; Hyvärinen, A. Probabilistic non-linear principal component analysis with Gaussian process latent variable models. J. Mach. Learn. Res. 2005, 6, 2005. [Google Scholar]
- Fan, J.; Chow, T. Deep learning based matrix completion. Neurocomputing 2017, 266, 540–549. [Google Scholar] [CrossRef]
- Fan, J.; Cheng, J. Matrix completion by deep matrix factorization. Neural Netw. 2018, 98, 34–41. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, D.M.; Tsiligianni, E.; Calderbank, R.; Deligiannis, N. Regularizing autoencoder-based matrix completion models via manifold learning. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018; pp. 1880–1884. [Google Scholar]
- Abavisani, M.; Patel, V.M. Deep sparse representation-based classification. IEEE Signal Process. Lett. 2019, 26, 948–952. [Google Scholar] [CrossRef] [Green Version]
- Bobadilla, J.; Alonso, S.; Hernando, A. Deep learning architecture for collaborative filtering recommender systems. Appl. Sci. 2020, 10, 2441. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S.; Yao, L.; Sun, A.; Tay, Y. Deep learning based recommender system: A survey and new perspectives. ACM Comput. Surv. (CSUR) 2019, 52, 1–38. [Google Scholar] [CrossRef] [Green Version]
- Sedhain, S.; Menon, A.K.; Sanner, S.; Xie, L. Autorec: Autoencoders meet collaborative filtering. In Proceedings of the 24th International Conference on World Wide Web, New York, NY, USA, 18–22 May 2015; pp. 111–112. [Google Scholar]
- Guo, D.; Lu, H.; Qu, X. A fast low rank Hankel matrix factorization reconstruction method for non-uniformly sampled magnetic resonance spectroscopy. IEEE Access 2017, 5, 16033–16039. [Google Scholar] [CrossRef]
- Huang, Y.; Zhao, J.; Wang, Z.; Guo, D.; Qu, X. Complex exponential signal recovery with deep hankel matrix factorization. arXiv 2020, arXiv:2007.06246. [Google Scholar]
- Signoretto, M.; Cevher, V.; Suykens, J.A. An SVD-free approach to a class of structured low rank matrix optimization problems with application to system identification. In Proceedings of the IEEE Conference on Decision and Control (CDC), Firenze, Italy, 10–13 December 2013. [Google Scholar]
- Lee, D.; Jin, K.H.; Kim, E.Y.; Park, S.H.; Ye, J.C. Acceleration of MR parameter mapping using annihilating filter-based low rank hankel matrix (ALOHA). Magn. Reson. Med. 2016, 76, 1848–1864. [Google Scholar] [CrossRef] [PubMed]
- Everingham, M.; Gool, L.V.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 3–338. [Google Scholar] [CrossRef] [Green Version]
- Everingham, M.; Eslami, S.A.; Gool, L.V.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Nie, F.; Hu, Z.; Li, X. Matrix completion based on non-convex low-rank approximation. IEEE Trans. Image Process. 2019, 28, 2378–2388. [Google Scholar] [CrossRef]
- Chen, L.; Jiang, X.; Liu, X.; Zhou, Z. Robust Low-Rank Tensor Recovery via Nonconvex Singular Value Minimization. IEEE Trans. Image Process. 2020, 29, 9044–9059. [Google Scholar] [CrossRef]
- Gu, K.; Zhai, G.; Yang, X.; Zhang, W. Using free energy principle for blind image quality assessment. IEEE Trans. Multimed. 2014, 17, 50–63. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep learning face attributes in the wild. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3730–3738. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Missing Rate | Images NO. | PSNR/SSIM | |||
|---|---|---|---|---|---|
| DMFCNet-1 | DMFCNet-2 | ||||
| 30% | 1 | 29.89/0.904 | 33.29/0.956 | 31.11/0.952 | 34.68/0.971 |
| 2 | 27.63/0.915 | 30.59/0.958 | 28.08/0.953 | 31.94/0.974 | |
| 3 | 30.80/0.908 | 33.44/0.959 | 32.21/0.963 | 35.29/0.973 | |
| 4 | 30.10/0.902 | 32.56/0.946 | 31.92/0.946 | 33.70/0.960 | |
| 5 | 32.52/0.875 | 36.47/0.956 | 35.59/0.968 | 38.32/0.976 | |
| Average | 30.19/0.901 | 33.27/0.955 | 31.78/0.956 | 34.78/0.971 | |
| 50% | 1 | 27.46/0.847 | 30.04/0.914 | 27.24/0.879 | 30.30/0.929 |
| 2 | 23.98/0.863 | 27.23/0.929 | 23.24/0.856 | 27.74/0.939 | |
| 3 | 27.97/0.852 | 30.19/0.921 | 27.77/0.896 | 31.00/0.938 | |
| 4 | 27.56/0.831 | 29.73/0.898 | 28.18/0.873 | 30.04/0.908 | |
| 5 | 29.85/0.804 | 33.54/0.919 | 31.58/0.923 | 34.39/0.947 | |
| Average | 27.37/0.840 | 30.14/0.916 | 27.60/0.885 | 30.69/0.932 | |
| 70% | 1 | 24.92/0.763 | 26.23/0.834 | 23.79/0.729 | 26.12/0.829 |
| 2 | 21.65/0.781 | 23.43/0.860 | 19.12/0.665 | 22.29/0.810 | |
| 3 | 25.02/0.770 | 26.62/0.861 | 23.94/0.744 | 26.66/0.853 | |
| 4 | 24.93/0.721 | 26.47/0.801 | 24.95/0.739 | 26.62/0.808 | |
| 5 | 27.70/0.746 | 29.82/0.859 | 28.14/0.832 | 31.47/0.884 | |
| Average | 24.84/0.756 | 26.51/0.843 | 23.99/0.742 | 26.63/0.837 | |
| Missing Rate | Images NO. | PSNR/SSIM | |||||||
|---|---|---|---|---|---|---|---|---|---|
| MF [21] | NNM [16] | TNNM [8] | DLMC [28] | NC-MC [41] | LNOP [42] | DMFCNet-1 | DMFCNet-2 | ||
| 20% | 1 | 29.72/0.890 | 32.06/0.929 | 32.30/0.935 | 31.22/0.913 | 32.05/0.939 | 32.55/0.934 | 35.60/0.972 | 37.57/0.984 |
| 2 | 26.10/0.831 | 29.24/0.896 | 29.60/0.904 | 29.09/0.888 | 29.85/0.912 | 30.12/0.906 | 33.35/0.972 | 35.03/0.985 | |
| 3 | 30.90/0.901 | 33.26/0.939 | 33.54/0.943 | 32.70/0.933 | 33.37/0.948 | 33.92/0.945 | 35.77/0.973 | 37.69/0.984 | |
| 4 | 31.99/0.938 | 33.39/0.951 | 33.63/0.954 | 32.26/0.938 | 33.73/0.959 | 33.81/0.955 | 34.97/0.969 | 36.20/0.978 | |
| 5 | 35.71/0.939 | 37.31/0.959 | 37.71/0.961 | 36.92/0.955 | 37.55/0.967 | 37.87/0.962 | 39.04/0.972 | 41.08/0.986 | |
| Average | 30.88/0.900 | 33.05/0.935 | 33.36/0.940 | 32.44/0.926 | 33.31/0.945 | 33.65/0.940 | 35.75/0.972 | 37.51/0.983 | |
| 30% | 1 | 27.42/0.822 | 29.37/0.873 | 29.68/0.883 | 29.35/0.867 | 29.69/0.893 | 29.82/0.881 | 33.29/0.956 | 34.68/0.971 |
| 2 | 23.91/0.762 | 25.80/0.916 | 26.14/0.827 | 26.46/0.825 | 26.70/0.842 | 26.54/0.827 | 30.59/0.958 | 31.94/0.974 | |
| 3 | 28.63/0.845 | 30.29/0.885 | 30.68/0.894 | 30.35/0.891 | 30.88/0.909 | 31.02/0.896 | 33.44/0.959 | 35.29/0.973 | |
| 4 | 29.54/0.895 | 30.72/0.913 | 31.07/0.919 | 30.34/0.903 | 31.31/0.927 | 31.15/0.920 | 32.56/0.946 | 33.70/0.960 | |
| 5 | 33.32/0.904 | 34.48/0.931 | 34.87/0.932 | 34.68/0.931 | 35.03/0.944 | 35.05/0.934 | 36.47/0.956 | 38.32/0.976 | |
| Average | 28.56/0.846 | 30.13/0.904 | 30.49/0.891 | 30.24/0.883 | 30.72/0.903 | 30.72/0.892 | 33.27/0.955 | 34.78/0.971 | |
| 40% | 1 | 25.84/0.771 | 27.13/0.804 | 27.43/0.818 | 27.40/0.799 | 27.70/0.836 | 27.56/0.812 | 31.00/0.932 | 32.10/0.952 |
| 2 | 21.04/0.655 | 23.16/0.718 | 23.44/0.732 | 23.93/0.730 | 23.96/0.740 | 23.87/0.732 | 28.68/0.937 | 29.17/0.953 | |
| 3 | 26.17/0.777 | 27.65/0.816 | 28.07/0.828 | 28.36/0.839 | 28.56/0.854 | 28.38/0.829 | 31.60/0.939 | 32.50/0.956 | |
| 4 | 27.36/0.842 | 28.69/0.865 | 29.04/0.874 | 28.79/0.863 | 29.42/0.889 | 29.14/0.874 | 30.57/0.916 | 31.81/0.940 | |
| 5 | 30.72/0.852 | 32.07/0.889 | 32.51/0.893 | 33.02/0.900 | 32.80/0.911 | 32.63/0.895 | 34.23/0.930 | 36.12/0.962 | |
| Average | 26.23/0.779 | 27.74/0.818 | 28.10/0.830 | 28.30/0.826 | 28.49/0.846 | 28.32/0.828 | 31.21/0.931 | 32.34/0.953 | |
| 50% | 1 | 24.01/0.685 | 25.07/0.717 | 25.37/0.731 | 25.10/0.703 | 25.54/0.746 | 25.42/0.722 | 30.04/0.914 | 30.30/0.929 |
| 2 | 19.65/0.588 | 20.95/0.626 | 21.27/0.635 | 21.75/0.639 | 21.56/0.634 | 21.57/0.632 | 27.23/0.929 | 27.74/0.939 | |
| 3 | 24.60/0.713 | 25.40/0.733 | 25.96/0.757 | 26.42/0.772 | 26.50/0.790 | 26.12/0.751 | 30.19/0.921 | 31.00/0.938 | |
| 4 | 25.69/0.784 | 26.82/0.805 | 27.26/0.819 | 27.08/0.812 | 27.63/0.837 | 27.29/0.816 | 29.73/0.898 | 30.04/0.908 | |
| 5 | 29.26/0.798 | 29.92/0.839 | 30.54/0.842 | 31.19/0.858 | 31.06/0.867 | 30.60/0.844 | 33.54/0.919 | 34.39/0.947 | |
| Average | 24.64/0.714 | 25.63/0.744 | 26.08/0.757 | 26.31/0.757 | 26.46/0.775 | 26.20/0.753 | 30.14/0.916 | 30.69/0.932 | |
| 60% | 1 | 22.27/0.618 | 23.21/0.624 | 23.50/0.642 | 23.31/0.623 | 23.53/0.643 | 23.52/0.631 | 28.17/0.889 | 28.27/0.893 |
| 2 | 16.75/0.468 | 18.81/0.518 | 19.04/0.527 | 19.36/0.530 | 18.39/0.481 | 19.28/0.524 | 25.48/0.907 | 25.34/0.901 | |
| 3 | 21.99/0.607 | 23.49/0.641 | 24.11/0.666 | 24.43/0.684 | 24.34/0.673 | 24.22/0.654 | 28.94/0.904 | 29.05/0.907 | |
| 4 | 24.04/0.704 | 24.94/0.722 | 25.33/0.739 | 25.37/0.735 | 25.55/0.754 | 25.41/0.736 | 28.23/0.862 | 28.45/0.868 | |
| 5 | 26.44/0.692 | 28.15/0.770 | 28.71/0.869 | 29.54/0.810 | 29.17/0.796 | 28.83/0.773 | 32.08/0.901 | 32.88/0.924 | |
| Average | 22.30/0.618 | 23.72/0.655 | 24.14/0.689 | 24.40/0.676 | 24.20/0.669 | 24.25/0.724 | 28.58/0.893 | 28.80/0.900 | |
| 70% | 1 | 21.04/0.520 | 21.41/0.515 | 21.82/0.532 | 21.50/0.494 | 21.17/0.476 | 21.85/0.518 | 26.23/0.834 | 26.12/0.829 |
| 2 | 15.50/0.384 | 16.77/0.404 | 16.84/0.405 | 17.04/0.406 | 15.10/0.312 | 17.25/0.412 | 23.43/0.860 | 22.29/0.810 | |
| 3 | 20.80/0.520 | 21.32/0.515 | 21.99/0.539 | 22.19/0.549 | 21.17/0.481 | 22.09/0.531 | 26.62/0.861 | 26.66/0.853 | |
| 4 | 22.59/0.617 | 23.16/0.623 | 23.38/0.636 | 23.50/0.642 | 23.12/0.620 | 23.57/0.634 | 26.47/0.801 | 26.62/0.808 | |
| 5 | 24.86/0.614 | 25.78/0.683 | 26.12/0.664 | 27.06/0.719 | 26.09/0.663 | 26.53/0.680 | 29.82/0.859 | 31.47/0.884 | |
| Average | 21.00/0.531 | 21.69/0.548 | 22.03/0.555 | 22.26/0.562 | 21.33/0.510 | 22.26/0.555 | 26.51/0.843 | 26.63/0.837 | |
| Image Size | Missing Rate | MF | NNM | TNNM | DLMC | NC-MC | LNOP | DMFCNet-1 | DMFCNet-2 |
|---|---|---|---|---|---|---|---|---|---|
| 256 × 256 | 30% | 0.095 | 4.905 | 2.974 | 16.129 | 5.651 | 2.384 | 0.390 | 0.341 |
| 50% | 0.096 | 4.340 | 3.455 | 17.429 | 3.507 | 2.165 | 0.420 | 0.339 | |
| 70% | 0.130 | 3.534 | 6.816 | 18.644 | 2.260 | 1.649 | 0.436 | 0.329 | |
| 512 × 512 | 30% | 0.288 | 23.380 | 12.416 | 59.581 | 48.207 | 9.120 | 1.763 | 1.019 |
| 50% | 0.199 | 18.998 | 17.128 | 69.528 | 23.970 | 8.302 | 1.661 | 1.015 | |
| 70% | 0.116 | 16.193 | 18.801 | 78.087 | 12.122 | 7.415 | 1.769 | 1.050 |
| Mask Type | Images NO. | PSNR/SSIM | ||||||
|---|---|---|---|---|---|---|---|---|
| MF | NNM | TNNM | DLMC | NC-MC | LNOP | DMFCNet-2 | ||
| Text Mask | 1 | 30.33/0.936 | 32.37/0.950 | 32.52/0.952 | 31.64/0.942 | 32.42/0.953 | 32.65/0.953 | 37.13/0.985 |
| 2 | 24.80/0.891 | 28.74/0.926 | 28.79/0.929 | 28.47/0.920 | 29.25/0.932 | 29.57/0.934 | 34.63/0.984 | |
| 3 | 30.27/0.930 | 31.97/0.947 | 32.49/0.956 | 32.27/0.948 | 32.75/0.958 | 32.57/0.955 | 35.17/0.985 | |
| 4 | 33.18/0.957 | 35.16/0.968 | 35.69/0.971 | 34.35/0.960 | 35.54/0.972 | 35.65/0.971 | 37.44/0.983 | |
| 5 | 34.30/0.949 | 37.54/0.975 | 38.31/0.975 | 37.96/0.974 | 38.70/0.979 | 38.45/0.977 | 40.82/0.990 | |
| Average | 30.58/0.933 | 33.16/0.953 | 33.56/0.957 | 32.94/0.949 | 33.73/0.959 | 33.78/0.958 | 37.04/0.985 | |
| Grid Mask | 1 | 29.19/0.899 | 32.95/0.942 | 32.96/0.944 | 33.22/0.928 | 32.62/0.943 | 33.20/0.943 | 37.11/0.983 |
| 2 | 23.22/0.812 | 29.30/0.914 | 29.52/0.918 | 28.92/0.902 | 29.75/0.917 | 30.11/0.919 | 34.34/0.986 | |
| 3 | 28.41/0.882 | 33.17/0.946 | 33.57/0.951 | 32.44/0.940 | 33.41/0.954 | 33.89/0.951 | 37.67/0.986 | |
| 4 | 31.01/0.933 | 34.39/0.962 | 34.59/0.964 | 33.39/0.952 | 34.71/0.966 | 34.72/0.964 | 36.75/0.980 | |
| 5 | 33.14/0.918 | 37.45/0.966 | 37.88/0.967 | 36.46/0.958 | 37.78/0.972 | 38.01/0.968 | 41.16/0.988 | |
| Average | 28.99/0.889 | 33.45/0.946 | 33.70/0.949 | 32.89/0.936 | 33.65/0.950 | 33.99/0.949 | 37.41/0.985 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, X.; Li, Z.; Wang, H. Deep Matrix Factorization Based on Convolutional Neural Networks for Image Inpainting. Entropy 2022, 24, 1500. https://doi.org/10.3390/e24101500
Ma X, Li Z, Wang H. Deep Matrix Factorization Based on Convolutional Neural Networks for Image Inpainting. Entropy. 2022; 24(10):1500. https://doi.org/10.3390/e24101500
Chicago/Turabian StyleMa, Xiaoxuan, Zhiwen Li, and Hengyou Wang. 2022. "Deep Matrix Factorization Based on Convolutional Neural Networks for Image Inpainting" Entropy 24, no. 10: 1500. https://doi.org/10.3390/e24101500
APA StyleMa, X., Li, Z., & Wang, H. (2022). Deep Matrix Factorization Based on Convolutional Neural Networks for Image Inpainting. Entropy, 24(10), 1500. https://doi.org/10.3390/e24101500