1. Introduction
A challenge in many domains of science and engineering is to study the causality of observed variables in the form of multivariate time series. Granger causality has been the key concept for this, where Granger causality from one variable to another suggests that the former improves the prediction ahead in time of the latter. Many methods have been developed based on the Granger causality idea to identify directional interactions among variables from their time series (see [
1] for a recent comparative study of many Granger causality measures) and have been applied in various fields, such as economics [
2], medical sciences [
3], and earth sciences [
4]. Of particular interest are measures of direct Granger causality that estimate the causal effect of the driving to the response variable that cannot be explained by the other observed variables. The estimated direct causal effects can then be used to form connections between the nodes being the observed variables in a causality network that estimates the connectivity (coupling) structure of the underlying system.
The studies on the Granger causality typically regard the continuous-valued time series, and often the number
K of the time series is relatively high, and the underlying system is complex [
5,
6]. However, in some applications, the observations are discrete valued, e.g., the sign of the financial index return, the levels of precipitation, the counts of spikes in the electroencephalogram, and the counts of significant earthquake occurrences within successive time intervals. In this work, we propose an appropriate method to estimate the direct Granger causality on discrete-valued multivariate time series.
In the analysis of discrete-valued multivariate time series, termed symbol sequences when no order of discrete values is assumed, the causality effects are estimated typically in terms of the fitted model. Different approaches have been proposed for the form of the probability distribution models based on strong assumptions about the structure of the system, i.e., a multivariate Markov chain. One of the most known approaches giving a model of reduced form is the mixture transition distribution (MTD) [
7], which restricts the initially large number of parameters, assuming that there is only an effect of each lag variable separately [
8,
9]. Recently, the MTD was adapted for the causality estimation in [
10,
11] and discussed in the review in [
12]. Other approaches assume the Poisson distribution [
13,
14] and the negative binomial distribution [
15,
16]. In the category of autoregressive models are Pegram’s autoregressive models [
17,
18] and multivariate integer-valued autoregressive models (MINAR) [
19,
20]. Another proposed method, which, however, simplifies the problem to a linear one, is the so-called CUTE method [
21]. Having obtained the model under given restrictions, one can then identify the causality of a driving variable to the response variable from the existence of lag terms of the driving variable in the model form.
Here, we follow a different approach and estimate the causality relationships directly using the information measures of mutual information (MI) and conditional MI (CMI). These measures have been employed to estimate causality and derive causality networks from continuous-valued time series [
1,
22,
23]. For discrete-valued time series, MI and CMI have been used, e.g., for the estimation of the Markov chain order [
24] and the estimation of autocorrelation in conjunction with Pegram’s autoregressive models [
25]. They have also been used on discrete data derived from continuous-valued time series, either as ranks of components of embedding vectors [
26,
27] or as ordinal patterns [
28,
29,
30]. However, we are not aware of any work on using information measures for a causality analysis of discrete-valued multivariate time series or symbol sequences (there is a reference to this in the supplementary material in [
31]).
The framework of the proposed analysis is the estimation of the direct causality of a discrete driving variable
X to a discrete response variable
Y from the symbol sequences of
K observed discrete variables, where
X and
Y are two of them. The direct causality implies the dependence of
Y at one time step ahead,
, on
X at some lag
,
that cannot be explained by any other variable at any lag. In the model setting, the direct causality is identified by the presence of the term
in the model for
. In the information theory setting, it is identified by the presence of significant information of
for the response
that cannot be explained by other lag variables, which is quantified by the CMI of
and
given the other lag variables. We develop this idea in a progressive algorithm that builds a set of the most informative lag variables for
, called the discrete partial conditional mutual information from mixed embedding (DPMIME), based on a similar measure called the PMIME for continuous variables [
32,
33]. The presence of lag variables
(for one or more different lags
) in the derived set, the so-called mixed embedding vector, identifies the existence of the direct causality from
X to
Y, and the relative contribution of the lag variables of
X in explaining
conditioned on the other components of the mixed embedding vector (regarding the other
variables) quantifies the strength of this relationship. Further, we develop a parametric significance test for the CMI of the selected lag variable and
at each step of the DPMIME algorithm, which does not have an analogue in the PMIME regarding continuous variables.
In the evaluation of the DPMIME with Monte Carlo simulations, we compare the DPMIME to PMIME on discretized time series from continuous-valued systems and also discrete-valued time series generated by multivariate sparse Markov chains and MTD and MINAR systems, with a predefined coupling structure. We also compare the parametric significance test to the resampling significance test in the DPMIME. Further, we form the causality networks of five capital markets from the DPMIME, using the sign of the change in the respective daily indices, as well as other causality measures (computed on the values of the indices), and we compare the networks from each measure before and after the global financial crisis of 2008.
The structure of the paper is as follows. First, in
Section 2, we present the proposed measure DPMIME along with the resampling and parametric test for the CMI. In
Section 3, we assess the efficiency of the proposed DPMIME measure with a resampling and parametric test and compare the DPMIME to the PMIME in a simulation study. The results of the application regarding the global financial crisis are presented in
Section 4, and finally, in
Section 5, the main conclusions are drawn.
2. Discrete Partial Mutual Information from Mixed Embedding
In this section, we present the measure of discrete partial mutual information from mixed embedding (DPMIME), the parametric significance test, and the resampling significance test used in the DPMIME. We also present performance indices for the causality measure when all the causal effects are estimated for all possible directed pairs of the K observed discrete variables.
2.1. Iterative Algorithm for the Computation of DPMIME
Let , be the observations of a stochastic process on K discrete random variables , typically a multivariate Markov chain. The discrete variables can be nominal or ordinal, and for convenience hereafter, we refer to the data as multivariate symbol sequence.
We are interested in defining a measure for the direct causality from X to Y, where X and Y are any of the K observed discrete variables. For a sufficiently large number of lags L, we formulate the set of candidate lag variables that may have information explaining the response Y at one time step ahead, . The set has components (’·’ denotes multiplication), , , . The algorithm DPMIME aims to build up progressively the so-called mixed embedding vector, i.e., a subset of of the most informative lag variables explaining .
In the first step, the first lag variable to enter
is the one that maximizes the MI with
,
and
(the superscript denotes the iteration, equal to the cardinality of the set). The MI of two variables
X and
Y is defined in terms of entropy and probability mass functions (pmfs) as [
34]
where
is the entropy of
X, the sum is over all values
x and
y of
X and
Y,
is the joint pmf of
, and
is the pmf of
X. The pmfs are assumed to regard the multinomial probability distribution and are estimated by the maximum likelihood estimate, where the probability for each value or pair of values is simply given by the relative frequency of occurrence in the sample (the multivariate symbol sequence). In the subsequent steps, the CMI instead of the MI is used to find the new component to enter
. Suppose that at step
j, the
j most relevant lag variables to
are found forming
. The next component to be added to
is one of the components in
(the
components except the
j components already selected) that maximizes the CMI to
, i.e., the mutual information of the candidate
w and
conditioned on the components in
The CMI of two variables
X and
Y given a third variable
Z is defined in terms of entropy and pmfs as [
34]
At each step, when the lag variable is selected, using (
1) for the first step and (
2) for the subsequent steps, a significance test is run for the MI in (
1) and the CMI in (
2). The parametric and resampling significance tests are presented in detail later in this section. For the step
, where
is found in (
2), if the CMI
is found statistically significant by the parametric or resampling test, the
is augmented as
. Otherwise, there is no significant lag variable to be added to the mixed embedding vector and the algorithm terminates, giving the mixed embedding vector
.
The components of the mixed embedding vector
obtained upon termination of the algorithm are grouped in lag variables of the driving variable
X,
, the response variable
Y,
, and all other
variables,
, expressed as
. If
is empty, i.e., no-lag variable
has information to explain
in view of the other lag variables, there is no direct causality from
X to
Y. Otherwise, we quantify the direct causality from
X to
Y as the proportion of the information of
explained by the lag variables of
X. The measure DPMIME is thus defined as
In the following, we present the resampling test and the parametric test for the significance of the CMI of the response and the selected component given the components already selected in , .
2.2. Randomization Test for the Significance of CMI
First, we do not assume any asymptotic parametric distribution of the estimate of
under the null hypothesis
. Thus, the empirical distribution of the estimate of
is formed by resampling on the initial sample of the variables
,
and
. For this, we follow the resampling scheme of the so-called time-shifted surrogates for the significance test for correlation or causality [
35,
36]. The resampling is actually applied only to
. To retain both the marginal distribution and intra-dependence (autocorrelation) of
and destroy any inter-dependence to
and
, we shift cyclically the symbol sequence of
by a random step
k[
35] (We do not consider here the case of periodic or periodic-like symbol sequences, where this randomization scheme is problematic, as it is likely that the generated surrogate symbol sequence is similar to the original symbol sequence.). Thus, for the original symbol sequence
of
, a randomized (surrogate) symbol sequence for the random step
k is
We derive a number
Q of such randomized symbol sequences and compute for each of them the corresponding estimates of
under the
, denoted
These
Q values form the empirical null distribution of the estimate of
. The
is rejected if the estimate of
on the original data is at the right tail of the empirical null distribution. To assess this, we use rank ordering, where
is the rank of the estimate of
in the ordered list of the
values, assuming ascending order. The
p-value of the one-sided test is
(using the correction in [
37] to avoid extreme values such as
when the original value is last in the ordered list, which is formally not correct). The DPMIME measure in Equation (
3) derived using resampling test of CMI is denoted DPMIMErt.
2.3. Parametric Test for the Significance of CMI
Entropy and MI on discrete variables are well-studied quantities and there is rich literature about the statistical properties and distribution of their estimates. For the significance test for the CMI
for three discrete scalar or vector variables
X,
Y, and
Z, the most prominent of the parametric null distribution approximations are worked out in [
38], namely the Gaussian and Gamma distributions. For the Gamma null distribution, following the work in [
39], it turns out that
follows approximately the Gamma distribution
where
n is the sample size and
is the number of the possible discrete values of
X. Further, it follows that
is also approximately Gamma distributed
We use the Gamma distribution to approximate the null distribution of the estimate of
for the significance test of CMI, setting
,
and
as
X,
Y, and
Z, respectively, in Equation (
4). The parametric significance test is right-sided, as is for the resampling significance test, and the
p-value is the complementary of the Gamma cumulative density function for the value of the estimate of
. The DPMIME measure in Equation (
3) derived using the parametric test of CMI is denoted DPMIMEpt. Both tests in the computation of DPMIMErt and DPMIMEpt are performed at the significance level
.
2.4. Statistical Evaluation of Method Accuracy
For a system of
K variables, there are
ordered pairs of variables to estimate causality. In the simulations of known systems, we know the true interactions between the system variables from the system equations. We further assume that the causal effects in each realization of the system match the designed interactions. Though this cannot be established analytically, former simulations have shown that for weak coupling, below the limit of generalized synchronization, the match holds [
1]. Thus, we can assess the match of the
estimated causal effects to the true causal dependencies using performance indices. Here, we consider the indices of specificity, sensitivity, Matthews correlation coefficient, F-measure, and Hamming distance. All the indices refer to binary entries, i.e., there is causal effect or not, so we do not use the magnitude of DPMIME in (
3), but only if it is positive or not.
The sensitivity is the proportion of the true causal effects (true positives, TPs) correctly identified as such, given as sens = TP/(TP + FN), where FN (false negative) denotes the number of pairs having true causal effects but have gone undetected. The specificity is the proportion of the pairs correctly not being identified as having causal effects (true negatives, TNs), given as spec = TN/(TN + FP), where FP (false positive) denotes the number of pairs found falsely to have causal effects. For the perfect match of estimated and true causality, sensitivity and specificity are one. The Matthews correlation coefficient (MCC) weighs sensitivity and specificity [
40]
MCC ranges from −1 to 1. If MCC = 1, there is perfect identification of the pairs of true and no causality; if MCC = −1, there is total disagreement and pairs of no causality are identified as pairs of causality and vice versa, whereas MCC at the zero level indicates random assignment of pairs to causal and non-causal effects. The F-measure is the harmonic mean of precision and sensitivity. The precision, also called positive predictive value, is the number of detected true causal effects divided by the total number of detected casual effects, F = TP/(TP + FP). The F-measure (FM) ranges from 0 to 1. If FM = 1, there is perfect identification of the pairs of true causality, whereas if FM = 0, no true coupling is detected. The Hamming distance (HD) is the sum of false positives (FPs) and false negatives (FNs). Thus, HD obtains non-negative integer values bounded below by zero (perfect identification) and above by if all pairs are misclassified.
3. Simulations
One of the aims of the simulation study is to assess whether and how the DPMIME on discrete-valued time series attains the causality estimation accuracy of PMIME on the respective continuous-valued time series. Therefore, we generate discrete-valued time series on the basis of the causality structure of a continuous-valued time series. The continuous-valued time series is generated by a known dynamical system so that the original causal interactions are given by the system equations. In the simulation study, we consider four different ways to generate discrete-valued time series aiming at having the original causal interactions, as presented below.
- (1)
Continuous to Discrete by quantization (Con2Dis): The multivariate symbol sequence of a predefined number of symbols M is directly derived by quantization of the values of the multivariate continuous-valued time series of K observed variables. The range of values of each variable is partitioned to M equiprobable intervals and each interval is assigned to one of the M symbols.
- (2)
Realization of estimated sparse Markov Chain (SparseMC): The multivariate symbol sequence is generated as a realization of a Markov chain of reduced form estimated on the Con2Dis multivariate symbol sequence (as derived above from the continuous-valued multivariate time series). First, the transition probability matrix of a Markov chain of predefined order L is estimated on the Con2Dis multivariate symbol sequence. An entry in this matrix regards the probability of a symbol of the response variable conditioned on the ‘word’ of size of L last symbols of all K variables. For M discrete symbols, the size of the transition probability matrix for one of the K response variables is . The causal interactions in the original dynamical system assign zero transition probabilities to words that contain non-existing causal interactions so that the Markov chain has a reduced form as the lag variables are less (or much less for a sparse causality network) than . For example, let us assume the case of , , and and the true lag causal relationships for the response are , , and . The full form of the Markov chain comprises conditioned probabilities for each of the two symbols of , but we estimate only the probabilities as the lag variables , , and are not considered to have any causal effect on . Even for a sparse causality network (few true lag causal relationships), the multivariate Markov chain can only be estimated for relatively small values of K, L, and M. Once the sparse transition probability matrix is formed, the generation of a multivariate symbol sequence of length n goes as follows. The first L symbols for each of the K variables are chosen randomly, and they assign to the initial condition. Then, for times , , the new symbol of each of the K variables is drawn according to the estimated conditioned probabilities. Finally, the first T symbols for each variable are assigned to a transient period and are omitted to form the SparseMC multivariate symbol sequence of length n.
- (3)
Realization of estimated mixture transition distribution model (MTD): Instead of determining the multivariate Markov chain of reduced form in SparseMC, a specific and operatively more tractable form called mixture transition distribution model (MTD) has been proposed [
41]. In essence, instead of determining the transition probability from the word of the causal lag variables to the response variable, the MTD determines the transition probability from each causal lag variable to the response variable. Here, as lag variable, we consider any lag of the driving variable to the response in the true dynamical system, e.g., for the example above for the driving variable
to the response
, we consider both lags of
(assuming
) and not only the true lag one. In its full form, the MTD assumes that the state probability distribution of the
j-th variable at time
(response variable) depends on the state probability distribution of all
K variables at the last
L times as
where
is the transition probability from
to
, and
is a parameter giving the weight on
in determining
, and for
, the following holds
. We restrict the full form of MTD by dropping from the sum the variables that are non-causal to
, preserving that the remaining
sum up to one. Thus,
denotes the strength of lag causality from
to
. Further, after a simulation study for the optimal tolerance threshold
, we determine
, and if
, we set
to omit terms having small coefficients. In this way, we attempt to retain only significant dependencies of the response on the lag variables. We use the estimated MTD model as the generating process and generate a multivariate symbol sequence. To fit MTD to the Con2Dis multivariate symbol sequence, we use the package
package in R language [
42], implementing the fitting of higher-order multivariate Markov chains as described in [
43,
44].
- (4)
Realization of estimated multivariate integer-autoregressive system (MINAR): Another simplified form of the multivariate Markov chain is given by the multivariate integer-autoregressive systems (MINAR) [
19]. Here, we do not estimate MINAR from the Con2Dis multivariate symbol sequence, as done for the sparse multivariate Markov chain (SparseMC) and the MTD process, but define the MINAR of order one, MINAR(1), by setting to zero the coefficients that regard no-lag causality in the original dynamical system. Therefore, the
j-th variable at time
t is given as
for
, where
are the coefficients of MINAR(1) (set to zero if the corresponding driver–response relationship does not exist in the original dynamical system), ∘ denotes the thinning operator (The thinning operator defines that
is the sum of
x Bernoulli outcomes of probability
a.), and
is a random variable taking integer values from a given distribution (here, we set the discrete uniform of two symbols). We note that the way the integer-valued sequence is generated does not determine a fixed number of integer values for each of the
K variables so that the generated multivariate symbol sequence does not have a predefined number
M of symbols.
The multivariate symbol sequences of all four types are generated under the condition of preserving the coupling structure of the original continuous-valued system. However, only the first type Con2Dis directly preserves the original coupling structure, as the Con2Dis multivariate symbol sequence is directly converted from the continuous-valued realization of the original system. For the other three types, a restricted model is first fitted to the Con2Dis multivariate symbol sequence, which is then used to generate a multivariate symbol sequence. Among the three models, the sparse Markov chain (SparseMC) is best constrained to preserve the original coupling structure. The other two models, the MTD and MINAR, are included in the study as there are known models for discrete-valued time series, adapted here to the given coupling structure. However, the MTD does not preserve the exact lag coupling structure of the original system and the MINAR generates multivariate symbol sequences of varying number of symbols at each realization so that the estimation of the causality structure with the DPMIME on the MTD and MINAR multivariate symbol sequences is not expected to be accurate.
We compute the DPMIME on each multivariate symbol sequence and evaluate the statistical accuracy of the DPMIME to estimate the true variable interactions and subsequently the true coupling network. Further, we compute also the PMIME on the initial continuous-valued time series and examine whether DPMIME can attain the accuracy of PMIME.
3.1. The Simulation Setup
In the simulation study, we use as the original dynamical system the coupled Hénon maps [
33,
45] and consider four settings regarding different connectivity structures for
(here, the
K variables constitute the
K subsystems being coupled). We also consider a vector stochastic process as a fifth generating system.
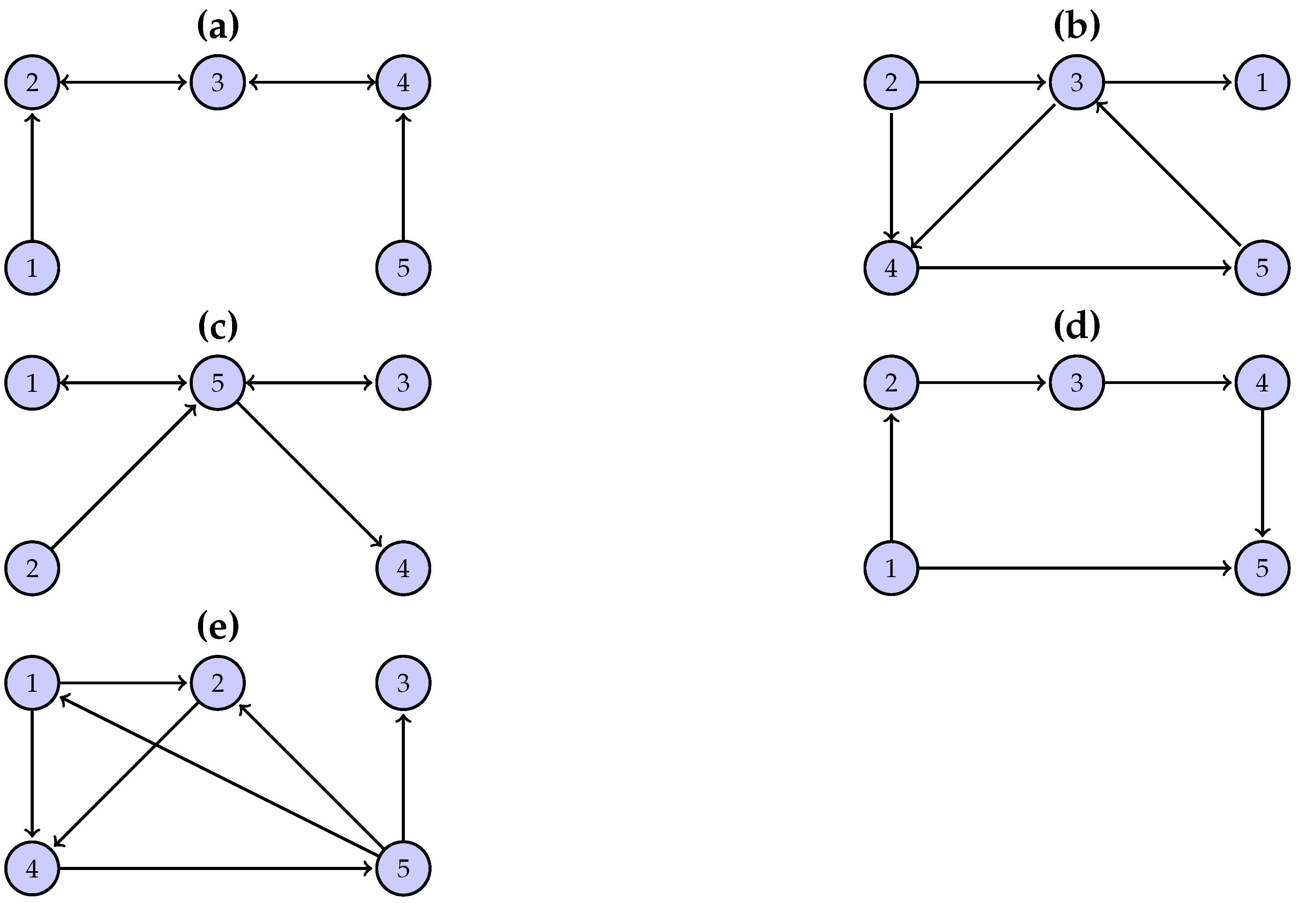
The first system (S1) has an open-chain structure of
coupled Hénon maps, as shown in
Figure 1a, defined as
The first and last variable in the chain of variables drives its adjacent variable and each of the other variables drive the adjacent variable to its left and right. The coupling strength C is set to 0.2 regarding weak coupling.
The second system (S2) has a randomly chosen structure, as shown in
Figure 1b, and it is defined as
The coupling strength C is set to 0.5. There is no predefined pattern for the interactions of the variables, other than the number of interactions being six, as for S1.
The other two systems, S3 and S4, also have a randomly chosen structure similar to S1 (see
Figure 1c,d). S3 is defined as
and S4 is defined as
The coupling strength C is set to 0.5 for S3 and 0.4 for S4. System S3 has node 5 as a hub (three in-coming and three out-going connections) and system S4 has a causal chain from node 1, to 2, to 3, to 4.
The fifth system (S5) is a vector autoregressive process on
variables (model 1 in [
46]), and it is defined as
The terms
are white noise with zero mean. The connectivity structure of S5 is shown in
Figure 1e.
To derive statistically stable results, we generate 100 realizations for each system and for different time-series lengths n. The number of symbols (M) for the discretization of the continuous-valued multivariate time series is 2 and 4, respectively. For the discretization, an equiprobable partition is used so that when , all values of the time series larger than the median are set to 0 and the rest to 1, and when , the quartiles of the time series define the four symbols.
3.2. An Illustrative Example
The performance of the DPMIME is first illustrated with a specific example, focusing on the first two equations of system S1 and thus considering as a response in the DPMIME (and PMIME) only the first and second variable. We consider only the first type (Con2Dis) for the generation of the multivariate symbol sequence with
symbols and length
. The parametric test for the significance of each component to be added to the mixed embedding vector is used (DPMIMEpt), and the maximum lag is
. The PMIME is computed for the same
on the continuous-valued time series (before discretization).
Table 1 shows the frequency of occurrence of any of the 25 lag terms in the mixed embedding vector of DPMIMEpt and PMIME for the response
and
in 100 Monte Carlo realizations. For the true lag terms, i.e., the terms that occur in the system equations, the frequencies are highlighted.
The variable depends on the variables and , which are selected by both algorithms of DPMIMEpt and PMIME in all realizations (frequency 100). The DPMIMEpt selects also the lag terms , , and of the response variable, but their inclusion in the mixed embedding vector does not result in any false causal effects. (It turns out that it is hard to find the exact lag components of the driving variable in the case of discrete-valued time series, which questions the use of DPMIME for building the input of a regression model to the response.) No other lag terms are found (the maximum frequency is one).
The second equation of S1 defines the dependence of on , , , and . For as response, both algorithms do not include the lag term in the mixed embedding vector (frequency 6 for DPMIMEpt and 1 for PMIME) but include instead (frequency 84 for DPMIMEpt and 99 for PMIME) so that the variable is represented in the mixed embedding vector and the correct causal effect from to is established. The lag terms and are always present in the mixed embedding vector for both algorithms ( occurs less frequently at 91% for DPMIMEpt) and terms of larger lag of occur for DPMIMEpt at a smaller frequency. The representation of in the mixed embedding vector is spread over the two first lags for PMIME and to the first four lags for DPMIMEpt so that though the true lag term is not well identified (frequency 32 and 44 for DPMIMEpt and PMIME, respectively), the causal effect from to is well established. The variables and are not represented in the mixed embedding vector, and thus both DPMIMEpt and PMIME correctly find no causal effect from these variables to .
The example shows that the two algorithms have a similar performance, with DPMIMEpt tending to include more lag terms of the causal variables, but both algorithms do not include lag terms of variables that have no causal effect on the response variable.
3.3. System 1
The example above is for the first two variables of S1, and in the following, we compute DPMIMEpt and PMIME for all
response variables of S1 and detect the presence of causal effects by the presence of a lag term (or terms) of the driving variable in the mixed embedding vector for the response variable. The true causal effects as derived by the equations of S1 are
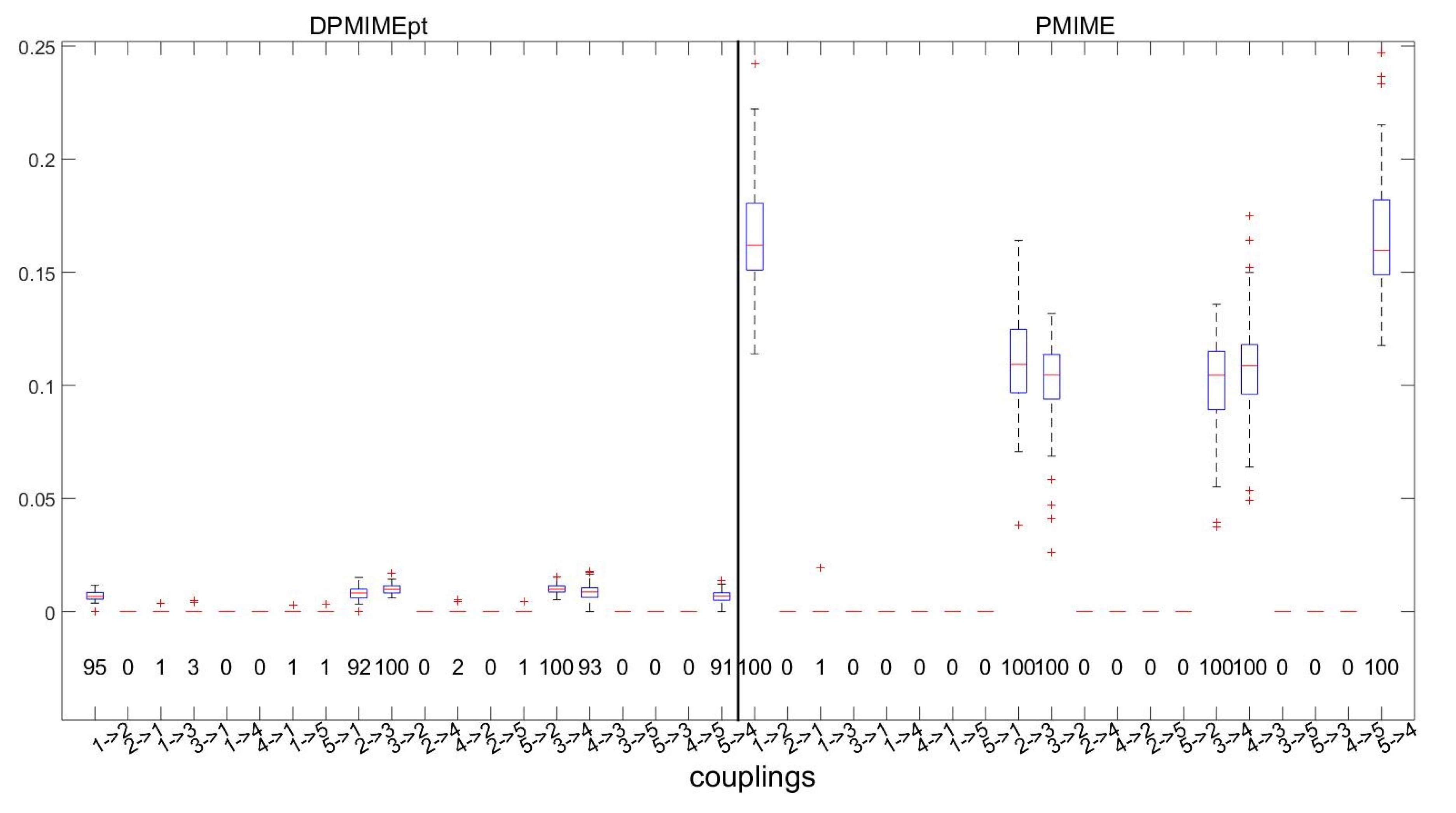
, and
. The distribution of the DPMIMEpt and PMIME (in the form of boxplots) and the rate of detection of causal effects (numbers under the boxplots) for all 20 directed variable pairs are shown in
Figure 2.
Both measures perfectly define the non-existent causal effects with a percentage of detection less than
. The DPMIMEpt detects the true causal effects in high percentages, approaching the perfect identification achieved by PMIME. However, as seen by the size of the boxplots, the DPMIME obtains smaller values than the PMIME. Though both are defined by the same CMI to MI ratio in (
3), this ratio is smaller for the DPMIME.
To quantify the performance of the DPMIMEpt and PMIME at each realization of S1, we calculate the performance indices sens, spec, MCC, FM, and HD on the 20 binary directed connections, where six of them are true. In
Table 2, the average indices over the 100 realizations of S1 for
are shown for both measures.
For the DPMIMEpt using , both sensitivity and specificity are very high, and the overall indices are high as well, e.g., the HD shows that more often none or less often one causal effect out of 20 causal effects is misclassified (average HD is 0.38). Thus, the performance of the DPMIMEpt is close to the almost perfect performance of the PMIME.
Next, we compare the parametric test (PT) and resampling test (RT) for the CMI used in the DPMIME as the criterion to terminate the algorithm building the mixed embedding vector. We consider the four types for generating multivariate symbol sequences (Con2Dis, SparseMC, MTD, and MINAR) and for
and
symbols. The latter does not apply to MINAR as the generated sequences have not a predefined number of symbols (integers). In the comparison, we again use as reference (gold standard) the PMIME, because this is computed directly on the continuous-valued time series, whereas the DPMIMEpt and DPMIMErt are computed on the discrete-valued time series. We also examine the performance of measures for different time-series lengths
n. Here, we only report results for the performance index MCC in
Table 3.
The DPMIMEpt and DPMIMErt fail to define the pairs with causal and non-causal effects when applied to the multivariate symbol sequences generated by the MTD. As already mentioned, the MTD model fails to preserve the causality of the original system and, in turn, the generated discrete-valued sequences do not allow for the estimation of the true causal effects. For example, for when , the performance indices sens, spec, MCC, FM, and HD are 0.36, 0.60, −0.03, 0.31, and 9.41, respectively, indicating a very low specificity. The DPMIME using either significance test on the Con2Dis sequences scores similarly in the MCC and at a lower level than the PMIME, converging to the highest level with the increase of n. This holds for both and , but for , the performance of DPMIME is worse than that of PMIME and the difference decreases with n, indicating that for a larger number of symbols longer time series are needed. The accuracy of DPMIME on the SparseMC sequences is similar as for the Con2Dis sequences when , but for , the accuracy does not improve with n unlike in the case of Con2Dis. The DPMIME performs better on MINAR sequences than on MTD sequences, especially when the resampling significance test is used in DPMIME. In this particular case, the parametric test is not as accurate as the resampling test. The finding that DPMIMEpt and DPMIMErt (except in the case of MINAR) perform similarly has practical importance because we can rely on DPMIMEpt and save computation time, which for long time series and many observed variables, DPMIMErt would be computationally very intensive.
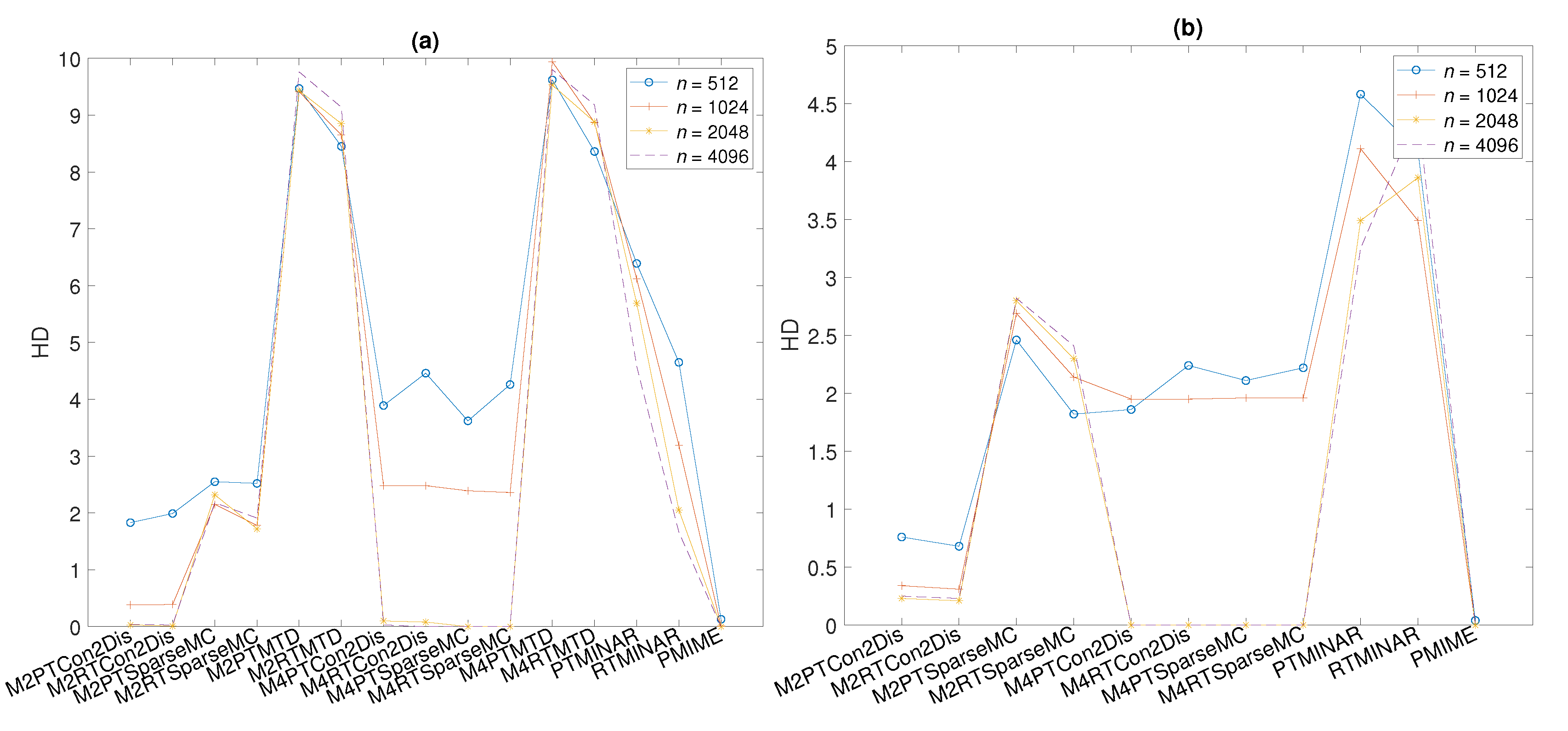
Similar results as for MCC in
Table 3 are obtained using the performance index HD, as shown in
Figure 3a. The misclassification is larger when the time series gets smaller (from 4096 to 512) for the same number of symbols
M, and when
M gets larger (from 2 to 4) for the same
n. However, the HD is at the same level for all these settings for DPMIMEpt and DPMIMErt, and for both measures, it converges to zero (no misclassification of all 20 variable pairs) for
, as does PMIME even for small
n.
3.4. System 2
System S2 differs from S1 in that it has a randomly chosen coupling structure. We show the summary results of the performance index MCC in
Table 4 and the HD in
Figure 3b. The performance of DPMIMEpt and DPMIMErt on the Con2Dis and SparseMC sequences is similar to that on system S1 for the different settings of time-series length
n and number of symbols
M (the MTDs are not included in the results due to their poor performance in the previous system). The accuracy in detecting the true causal effects is better for smaller
M when
n is small, converging to the highest performance level with
n and faster for
(MCC = 1 and HD = 0). The highest level is again attained by PMIME even for the smallest time-series length
. For the smallest
, the performance of DPMIMEpt and DPMIMErt is better for system S2 than for system S1. Another difference to system S1 is that for the largest tested
, the DPMIMEpt and DPMIMErt reach the highest level for
but not for
, indicating that once there is enough data, the use of the largest number of symbols allows for a better detection of the causal effects. For system S2, the DPMIMEpt and DPMIMErt on the MINAR sequences give similar MCC scores that do not tend to get higher with
n, unlike the respective scores for system S1. This lack of improvement with
n in the causality estimation on MINAR sequences is attributed to the varying number of integers of the generated time series increasing with
n so that the number of symbols
M is relatively large compared to the length of time series
n.
3.5. System 3 and System 4
Systems S3 and S4 also have a randomly chosen structure, as with system S2. The summary results of the performance index MCC are shown in
Table 5 for S2 and
Table 6 for S3.
For the different settings of both S2 and S3, the generation of symbol sequences by Con2Dis and SparseMC, the number of symbols and , and the time-series lengths n, the DPMIMEpt and DPMIMErt always perform similarly and less accurately than the PMIME. There are however differences in the DPMIME in Con2Dis and SparseMC with respect to M. As for S1 and S2, for both S3 and S4, the DPMIME on SparseMC symbol sequences tends to perform better for than for , and this occurs more consistently for a larger n. On the other hand, the DPMIME on Con2Dis symbol sequences tends to perform better for than for , particularly for a smaller n. For a larger n, for S3, the best performance is observed for Con2Dis and , and for S4, SparseMC and .
3.6. System 5
System S5 is a five-dimensional vector autoregressive process of order 4. This system is chosen in order to examine the performance of the causality measures in a linear stochastic system. The summary results of the performance index MCC are presented in
Table 7. First, it is worth noting that the PMIME does not reach the highest accuracy level as for the nonlinear deterministic systems S1–S4, but the MCC ranges from 0.76 to 0.78 for the different
n. The highest accuracy level is attained by the DPMIMEpt for a smaller
n and the DPMIMEpt for a larger
n on the Con2Dis symbol sequences when
. For
, the randomization test tends to outperform the parametric test for a larger
n and attains the maximum MCC = 1. On the other hand, when
, the accuracy of both tests is at the same level and does not improve significantly with the increase of
n as does for PMIME.
3.7. Effect of Observational Noise
In the last part of the simulation study, we investigate the effect of observational noise, restricting to observational noise on the original continuous-valued time series. We consider system S1 and add to each of the five generated time series white Gaussian noise with standard deviation (SD) being a given percentage of the SD of the time series. The Con2Dis approach with
is then applied to derive the symbol sequences of different lengths
n and the DPMIME is applied using the parametric test (DPMIMEpt) and randomization test (DPMIMErt). In
Table 8, the results are presented, including the PMIME measure as well. The type of test does not seem to affect the performance of the DPMIME for all different noise levels. For noise levels up to 10%, the MCC is rather stable and effectively the same as for the noise-free symbol sequences and decreases with a further increase in noise level (20% and 40%) for all different
n. However, even for the high noise level of 40% when
, the MCC is 0.8 for DPMIMEpt and 0.85 for DPMIMErt and close to the MCC for PMIME at 0.89. Overall, a smooth decrease in the accuracy of the DPMIME is observed with the increase in the level of observational noise, which suggests the appropriateness of DPMIME for real-world symbol sequences.
4. Application to Real Data
We consider a real-world application to compare DPMIME to other causality measures. These are the linear direct causality measure called the conditional Granger causality index (CGCI) [
47,
48], the information-based direct causality measure of partial transfer entropy (PTE) [
49], and finally, the original partial mutual information from mixed embedding (PMIME).
The dataset is the Morgan Stanley Capital International (MSCI) market capitalization weighted index of five selected markets in Europe and South America: Greece, Germany, France, UK, and USA. Specifically, we consider two datasets: the first one is in the time period 1 January 2004 to 31 January 2008 and the second one in the period from 3 March 2008 to 30 March 2012. The separation was made with regard to the occurrence of the global financial crisis (GFC), also referred to as the Great Recession, dated from the beginning of year 2008 to year 2013 [
50]. The two selected periods are therefore called preGFC and postGFC. The interest here is to study whether and how each of the causality measures detects changes in the connectivity structure in the system of the five markets from preGFC to postGFC. Each dataset comprises
n=1065 observations, which correspond to daily returns (first differences in the logarithms of the indices). For DPMIME, the data were discretized to two symbols: 1 if the return is positive and 0 otherwise. For consistency, the amount of past information denoted
L is the same for all causality measures and set to
, where for DPMIME and PMIME
L stands for the maximum lag, for PTE it stands for the embedding dimension, and for CGCI it stands for the order of the (restricted and unrestricted) vector autoregressive (VAR) model.
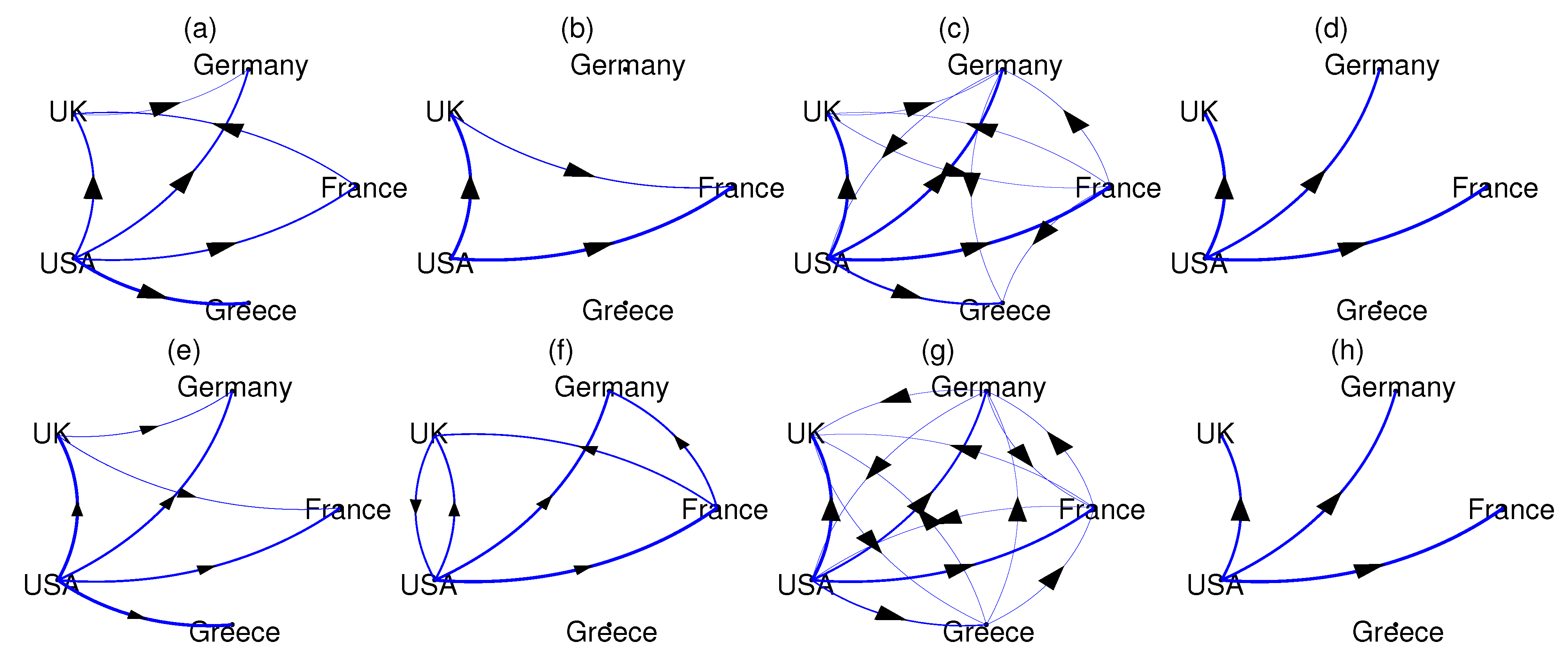
The causality measures DPMIMEpt, PMIME, CGCI, and PTE are computed for each pair of national markets in the preGFC and postGFC periods. While DPMIME and PMIME assign zero to the non-significant causal relationships, CGCI and PTE require a threshold, here given by the parametric significance test for CGCI and the resampling significance test for PTE (the time-shifted surrogates as for the significance of CMI in DPMIMErt). Then, the causality networks are formed drawing weighted connections with weights being the value of the significant measure, and the networks are shown in
Figure 4 for the preGFC and postGFC periods.
All causality measures suggest the USA market has a causal effect on many other markets before and after the GFC. In the DPMIMEpt networks (
Figure 4a,e), there is in additional causal effect from UK to Germany in both the preGFC and postGFC periods, while the driving from France to UK in preGFC reverses in the postGFC period. Regarding the latter, the PMIME networks show the opposite, UK to France in preGFC and France to UK in postGFC (
Figure 4b,f). The PMIME networks show no causal effect of USA on Greece in both periods, which has no straightforward interpretation. In the postGFC period, the PMIME finds a bidirectional causal relationship for the USA and UK. The CGCI measure gives almost full networks in both periods (
Figure 4c,g), failing to reveal any particular connectivity structure in the system of the five national markets. On the other hand, the PTE turns out to be the most conservative measure, giving only the causal effect of the USA to UK, Germany and France (not Greece) in both periods (
Figure 4d,h).
The DPMIMErt gave similar results to DPMIMEpt (not shown here). We repeated the same analysis for the DPMIME and , and the results were stable. Overall, the DPMIME estimates reasonable causal relationships, the USA to all four other markets in both periods, whereas the PMIME and PTE exclude Greece, and the UK and France causal relationship changes direction from preGFC to postGFC.
5. Discussion
In this study, we propose a Granger causality measure for discrete-valued multivariate time series or multivariate symbol sequences based on partial mutual information from a mixed embedding named DPMIME. The rationale is to build the so-called mixed embedding vector that has as components the lag terms of the observed variables that best explain the response ahead in time. To quantify the causality of a driving variable to a response variable in view of all the observed variables, we first check whether the lag terms of the driving variable are included in the mixed embedding vector. If there are not any, then the measure is zero and there is no causal effect, whereas if there are, then the proportion of the information on the response explained by these lag terms determines the strength of the causal effect from the driving to the response. For the termination of the algorithm building the mixed embedding vector, we develop a parametric test using a Gamma approximation of the asymptotic null distribution of the conditional mutual information, CMI (information of the tested lag term and the response given the other lag terms already included in the mixed embedding vector). This is a main difference to the PMIME, the analogue of the same algorithm already developed by our team for continuous-valued time series. The PMIME employs a resampling significance test as there is no parametric approximation of the null distribution of the CMI for continuous variables. Another main difference to the PMIME is that for discrete-valued time series, we use a different estimate for the information measures of the mutual information, MI, and CMI used in the algorithm, i.e., we use the maximum likelihood estimate for the probabilities of all discrete probability distributions involved in the definition of the MI and CMI, whereas in the PMIME, the nearest neighbor estimate [
51] is used for the entropies involved in the definition of the MI and CMI. We develop two versions of the DPMIME, one using the parametric significance test for the termination criterion, denoted DPMIMEpt, and another using the resampling significance test, denoted DPMIMErt, as for the PMIME.
The previous studies of our research team have showed that the PMIME is one of the most appropriate measures to estimate direct causality in multivariate time series and particularly in the setting of high-dimensional time series (many observed variables) [
1,
27,
52]. Therefore, to evaluate the proposed measure DPMIME for the causality of discrete-valued multivariate time series and multivariate symbol sequences, we compare it to the PMIME. For the simulations, dynamical systems of continuous-valued variables were used to generate multivariate time series and compute on them the PMIME. Then, the discrete-valued time series were generated by discretizing the continuous-valued time series, denoted Con2Dis. Moreover, systems for the generation of discrete-valued time series were fitted to the Con2Dis multivariate sequence: the sparse Markov Chain (SparseMC), the mixture transition distribution models (MTD), and the multivariate integer-autoregressive systems (MINAR). The simulations showed that the MTD cannot preserve the original coupling structure, whereas the varying number of integers (assigned to symbols) of the MINAR sequences complicates the use of the DPMIME on these sequences. The SparseMC sequences could preserve sufficiently well the coupling structure in the discrete-valued (Con2Dis) and continuous-valued time series, as the DPMIME could detect the original causality relationships almost as well in the SparseMC sequences as in the Con2Dis sequences. Thus, the main focus in the simulation study was on the performance of the DPMIMEpt and DPMIMErt (for the parametric and resampling significance test) on the Con2Dis multivariate symbol sequences, as compared to the PMIME, where the latter has the role of golden standard as it is computed on the complete available information from the system, i.e., the continuous-valued time series. Further, we assess whether the DPMIMEpt can perform as well as the DPMIMErt, as the DPMIMEpt is much faster to compute and would be preferred in applications.
The simulation systems are coupled Hénon maps of five subsystems, one with an open-chain coupling structure and the other three with a different randomly chosen coupling structure, as well as a vector autoregressive process (VAR) on five variables. The performance indices were computed on binary causality estimates (presence or absence of causal effect) for all pairs of variables (subsystems). The average of the performance indices over 100 realizations for each setting of the time-series length n and number of symbols M from the discretization were reported. The results on all the simulated systems showed that the DPMIMEpt scores lower than the PMIME, as expected, but converges to the performance level of the PMIME with an increasing n, except for the VAR system where the accuracy of the DPMIMEpt in detecting the true causal effects is better when and similar to the PMIME when . The difference to the PMIME is larger for a small n and larger M (going from 2 to 4 symbols), which is anticipated as the discretization smooths out information in the time series about the evolution of the underlying system. However, the convergence of the DPMIME to the PMIME for a data size of indicates that the proposed measure can be used in applications with a moderate length of the discrete-valued time series that can have an even high dimension (we tested here for five subsystems).
The finding that the DPMIMEpt and DPMIMErt perform similarly has high practical relevance. The DPMIME is based on multiple computations of the CMI on progressively higher dimensions that are computationally intensive. If we had to rely on the DPMIMErt, the computation time at each iteration of the algorithm would be multiplied with the number of the resampled data used for the resampling significance test. In applications on long sequences of many symbols, the computation time may be prohibitively long using the DPMIMErt with, say, 100 resampling sequences for each test, but it would be approximately 100 times less when using the DPMIMEpt. Thus, the DPMIMEpt is an appropriate measure to estimate the direct causality in many symbol sequences.
The DPMIME was further applied and compared to other causality measures (PMIME, CGCI, and PTE) in one real-world application. We used data from the Morgan Stanley Capital International market capitalization weighted index of five national markets to examine the causality structure of the system of the five markets before and after the start of the global financial crisis. The proposed measure DPMIME detects the crucial role of the US market before and after the start of the global financial crisis without being as conservative as the PTE and without giving full networks as the CGCI.









{kind=link}
{kind=link}
{kind=link}
{kind=link}