1. Introduction
In a communication network, linear network coding (LNC) advocates intermediate nodes to linearly combine received messages before transmission, so as to improve various network performances, such as increasing network throughput, reliability, and reducing transmission delay. Random linear network coding (RLNC) provides a distributed and asymptotically optimal approach for linear coding with coefficients randomly selected from a base field [
1]. It shows the potential to improve the performance of unreliable or topologically unknown networks such as D2D networks [
2], ad hoc networks [
3], and wireless broadcast networks [
4,
5,
6,
7].
One of the reasons that hinder the large-scale practical applications of RLNC is the compatibility issue of different computational overheads. In complex network environments, there exist heterogeneous devices with different computational powers. Specifically, sources and certain receivers usually have ample computational powers while a large number of intermediate nodes and other receivers are computationally constrained such as the data collectors in ad hoc networks or low-cost devices in the Internet of Things paradigm [
8]. It turns out that the coding compatibility among heterogeneous devices with different computational powers has to be considered in RLNC design.
This paper proposes a novel framework for scalable RLNC design based on embedded fields. The adjective scalable means that the finite fields chosen in the encoding process are not limited to a single base field but a set of embedded fields which consists of a large finite field and all its subfields. The encoding process at the source consists of two stages. In stage 1, based on a precoding matrix, all original packets are linearly combined over different finite fields to form precoded packets. In stage 2, the final packets to be transmitted are formed by randomly combining the precoded packets over GF(2). The heterogeneous receivers can recover the original packets over different fields under different computational constraints.
It is worthwhile to remark that prior to this work, there have been studies [
9,
10,
11,
12,
13,
14] that have taken different fields into account in the course of RLNC design. On one hand, the so-called Telescopic codes [
9,
10,
11] and Revolving codes [
12] considered different fields aiming at reducing the decoding complexity. However, they assume that all receivers have the same decoding capability, that is, they need support the arithmetic over the largest defined finite field. On the other hand, a flexible RLNC scheme called Fulcrum [
13,
14] makes use of GF(2) and its extension field GF(
) for code design and it supports receivers to decode over both fields. Actually, Fulcrum can be regarded as a special instance in our proposed framework, while the decoding rule over GF(2) considered therein is weaker than the one proposed in this paper. In addition, there is limited discussion on the construction of an optimal encoding matrix in Fulcrum.
The main contributions of this paper are summarized as follows.
We mathematically justify how to make the arithmetic over different finite fields compatible.
We derive a necessary and sufficient condition for decodability at a receiver over different finite fields. In particular, the proposed decoding rule over GF(2) is stronger than the one proposed in Fulcrum.
We theoretically study the construction of an optimal precoding matrix in terms of the decodability performance.
By numerical analysis in classical wireless broadcast networks, we demonstrate that the proposed scalable RLNC not only guarantees a better decoding compatibility over different fields compared with classical RLNC over a single field, but also provides a better decoding performance over GF(2) in terms of smaller average completion delay compared with Fulcrum.
In numerical analysis, we also take the sparsity of the received binary coding vector into consideration, and demonstrate that for a large enough batch size, this sparsity does not affect the completion delay performance much in a wireless broadcast network.
This paper is structured as follows.
Section 2 reviews the mathematical fundamentals of embedded fields.
Section 3 first presents the general principles of the proposed scalable RLNC framework and then formulates the encoding and decoding process.
Section 4 investigates the design of an optimal precoding matrix.
Section 5 numerically analyzes the proposed scalable RLNC and compares its performance with classical RLNC over a single finite field as well as Fulcrum. Moreover, we take the sparsity into consideration and illustrate the influence on its performance. Conclusion is given in
Section 6.
3. Framework Description
3.1. General Principles
In this paper, we focus on the construction of a general scalable RLNC framework over embedded fields, so we attempt to alleviate the influence of specific models of networks. In the course of framework description, we merely classify the nodes in a network into three types: a unique source node, intermediate nodes and receiver nodes. Assume that the source has the highest computational power, so that it can generate coded packets over embedded fields. The intermediate nodes in the network just recode the received data packets over GF(2), so as to fully reduce the overall computational complexities in the network. The heterogeneous receivers have different decoding capabilities. Under its own computational constraint, every receiver can judge whether sufficient coded packets have been received for decoding. More importantly, even though a receiver may not have sufficient computational power to deal with the arithmetic in a larger field over which some received packets are coded, it can still fully utilize these packets instead of directly throwing away in the process of decoding. For instance, assume that two received packets and are respectively equal to and , where are original packets generated by the source node and is an element not equal to 0 and 1 in the field GF(). For the receiver under the strongest field constraint GF(2), the original packet can be recovered by instead of directly throwing , away. Consequently, the proposed scalable RLNC framework not only ensures the decoding capabilities of heterogeneous network devices but also fully reduces the required number of received packets for decoding.
3.2. Encoding and Recoding
In every batch, the source
s has
n original packets
, each of which is an
M-dimensional column vector over GF(2), to be transmitted to receivers. Without loss of generality, assume
M is divisible by
, which can be achieved by padding dummy bits into every packet. With increasing
D, the double exponentially increasing packet length
M may cause the practical issue of an excessive padding overhead. Such an issue can be effectively solved based on the methods proposed in [
16,
17].
The encoding process at s has two stages. First, based on , for each , extra precoded packets are generated based on coding coefficients selected from GF(). In this process, every original packet is regarded as a vector of symbols, each of which consists of bits and represents an element in GF(). The multiplication of by a coefficient in GF() is thus realized by symbol-wise multiplication. Note that when , the coefficients in GF() also appear in GF(), but the coding arithmetic changes. The mathematical fundamentals in the previous section guarantee the coding compatibility which will be illustrated in the next example.
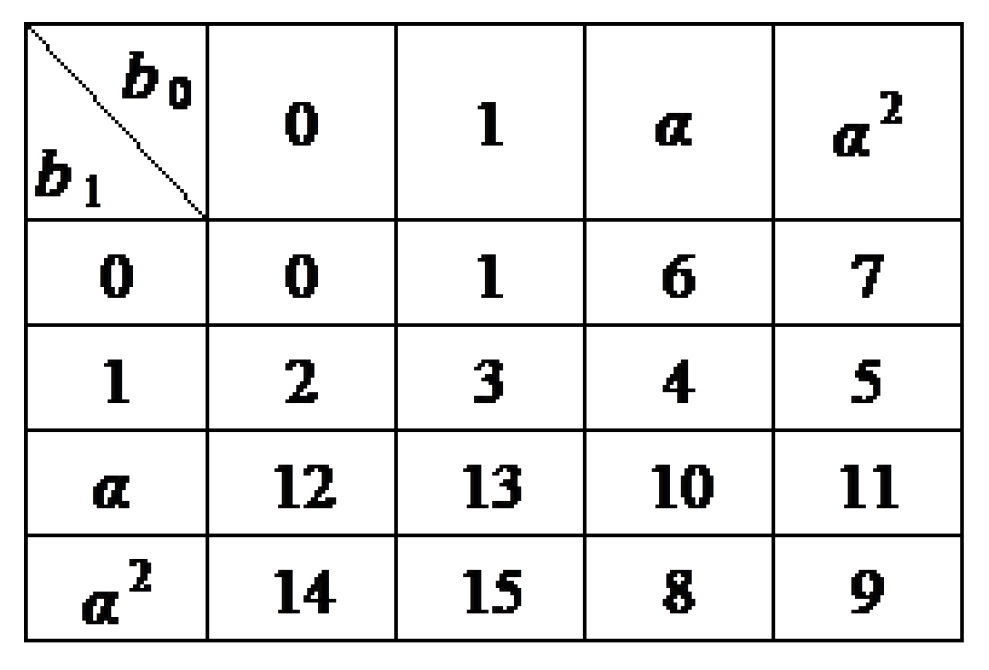
Example 2. Assume , , and . Based on two original packets and , a precoded packet is to be generated over by the linear combination . First regard and as vectors of 2 symbols over GF(), that is, and . Then,According to Figure 1, in GF(), and . As every element in GF() = GF() can be uniquely expressed as , , every four-dimensional vector over GF(2) as the following element in GF(16)Based on this rule, and . Consequently, , which is over GF(4) and over GF(2), same as (1) obtained by the GF(4) arithmetic. After stage 1, there are a total of precoded packets, the first n of which are just the original packets. Let denote the precoding matrix for the N precoded packets, where refers to the identity matrix and is a coefficient matrix defined over GF().
In stage 2, every coded packet
the source finally sends out is a random GF(2)-linear combination of the
N precoded packets, that is,
for some randomly generated
N-dimensional column vector
over GF(2), which is referred to as the
coding vector for packet
. For a
systematic scheme, the first
n coded packets
transmitted by the source are just
n original packets, that is, the coding vector for
is just an
N-dimensional unit vector with the
position equal to 1. Every coded packet will affix its coding vector to its header. In contrast, the information of precoding matrix
can either be affixed to the header of every packet or presettled to be known at every receiver.
At an intermediate node, the coded packets it transmits are GF(2)-linear combinations of its received packets. Specifically, if an intermediate node receives coded packets
with respective coding vectors
, then it will recode them to generate a new coded packet
to be transmitted as
where
are random binary coefficients. The concomitant coding vector for
is
.
It is worthwhile to note that prior to this work, a flexible RLNC scheme called Fulcrum has been investigated in [
13,
14]. Fulcrum can be regarded as a special instance in our proposed framework with the setting
and
.
3.3. Decoding
Define a linear map
by
for every column vector
. The notation
also applies to a set
of vectors:
.
Moreover, let , , denote the vector subspace of spanned by unit vectors where a unit vector refers to an N-dimensional vector with the only nonzero entry at position j.
For a receiver t, assume is the largest field for computation, and m packets have been received. Let denote the matrix over GF(2) obtained by columnwise juxtaposition of the coding vectors of the m received packets, and the column space (over GF(2)) of .
In order to recover original packets under the field constraint GF(), we need make use of coding packets with coding vectors in rather than in . This is because the lower entries in every coding vector corresponds to the original precoded packets generated by the source over a larger field than GF(). We next characterize the following necessary and sufficient condition for decodability at t up to field constraint GF().
Theorem 1. Based on the m received packets, the original n source packets can be recovered at t if and only if Proof. First assume (
2) holds. Then, there must exist n vectors, denoted by
in
such that
Consequently, there exists an
matrix
over GF(2) such that
, and (
3) implies the full rank
n of
. As the last
rows in
are all zero, the elements in
belong to GF(
), and hence there exists an
matrix
over GF(
) subject to
, that is, the original packets can be recovered at
t.
Next assume that the original
n packets can be recovered at
t. Then, there exists an
matrix
over GF(
) such that
. Further,
can be written as
, where
,
are over GF(
) and of respective size
and
. Thus,
is a matrix over GF(
) of full rank
n. Recall that none of the elements in the last
columns in
is in GF(
). Thus, every element in
belonging to GF(
) implies that the last
rows in
are all zero. Moreover, as
is defined over GF(2), we can further deduce that
can be written as
for an
matrix
over GF(2) and an
matrix
over GF(
), such that the last
rows in
are all zero too, that is, the columns in
belong to
. In addition, the full rank of
implies the full rank of
. Equation (
2) is thus proved to hold. ☐
Based on the above theorem, we can further characterize the following equivalent condition for decodability at a receiver from the perspective of matrix rank. For , denote by the submatrix of obtained by restricting to the last rows.
Corollary 1. Based on the m received packets, the original n source packets can be recovered at t if and only ifwhere is an matrix whose columns constitute a basis for the kernel of the column space of such that . Note that the column space of
are exactly the subspace
in (
2), and all entries in the last
rows of
are zero, so the computation of (
4) only involve arithmetic over GF(
). Moreover, in order to check (
4), it suffices to select
linearly independent column vectors in
, juxtapose them into a matrix
, and check whether
. With the number
m of received packets at
t increasing, the matrix
and
can be established in the following iterative way.
Algorithm 1. Denote by the N-dimensional coding vector over GF(2) for the received packet at receiver t. Without loss of generality, assume that there is at least one non-zero entry in . Let denote the vector restricted from to the last entries. The next procedure efficiently produces desired and .
Initialization. Let , , and be empty matrices. They are to consist of a m rows, N rows, N rows and rows respectively.
Iteration. Consider the case that the packet with coding vector is just received, and assume receiver t has dealt with the former coding vectors . Perform either of the following two depending on .
If is a zero vector, then update asand respectively append a zero column vector to and to on the right. Further check whether is a GF(2)-linear combination of columns in . If so, keep unchanged. Otherwise, update as . The iteration for the current value of m completes.
If is not a zero vector, check whether it is a GF(2)-linear combination of columns in . If no, respectively update , and asand the iteration for the current value of m completes. Otherwise, perform the following steps. First compute an -dimensional vector subject to , and then update as Further compute a new vector , and respectively append a zero column vector to and to on the right. Check whether is a GF(2)-linear combination of columns in . If so, keep unchanged. Otherwise, update as . The iteration for the current value of m completes.
Note that after the above procedure, the sum of the number of nonzero columns in and the number of columns in is m. The nonzero columns of keep to form a basis of the column space of . The columns of keep to form a basis of the null space spanned by columns of . The columns in keep to be a basis of the column space of , where .
Example 3. Assume that , , and . The precoding matrix is designed aswhere β is a primitive element in GF() and , which can be regarded as a primitive element of . Assume that at a receiver t, GF() is the largest field for computation, and 4 packets have been received with the columnwise juxtaposition of the respective coding vectors prescribed byAs herein, the aforementioned iterative approach can yield the following and concomitant :where the columns of form a basis for the subspace . Consequently, . Since in GF(), , that is, (4) does not hold. Therefore, the receiver requires to receive more packets before decoding all original packets. Assume is the coding vector for the received packet. Then, the matrix is dynamically updated tobut there is no change for , because belongs to the column space of . Assume is the coding vector for the received packet. First, dynamically update toThen, as does not belong to the column space of , update as :Consequently, , and it has full rank 3, so the receiver can recover the source packets. Actually, in this case, the source packets can be recovered by merely GF(2)-based operations. In two special cases that
and
,
i.e., receiver
t has the highest and the lowest computational power respectively, (
4) degenerates to a more concise form.
Corollary 2. When , (4) is equivalent toWhen , (4) is equivalent to Recall that Fulcrum [
13,
14] can be regarded as a special RLNC scheme of our framework. One may notice that in Fulcrum, the decoding rule over GF(2) at a receiver is
which is sufficient but not necessary. In contrast, (
9) is both necessary and sufficient. As to be seen in
Section 5, there is an observable performance gain when (
9) is adopted as the decoding rule instead of (
10). Moreover, our proposed scalable RLNC is more flexible than Fulcrum, because the receivers with intermediate computational power can fully utilize its decoding capability to decode over intermediate fields (rather than only over GF(2)), so that the number of required coded packets can be reduced.
3.4. Decoding Complexity Analysis
In this subsection, we briefly analyze the computational complexity of the proposed scalable RLNC scheme at receiver
t with the field constraint GF(
). We assume that after a sufficiently large recoding process over GF(2), the last
r positions in every received binary column vector
, which corresponds to the
r precoded packets generated over the larger fields than GF(2), are nonzero. According to Corollary 1, when enough coded packets have been received such that the condition
is satisfied, receiver
t can recover all original packets by linear combining
n coded packets over GF(
). Accordingly, it requires at most
multiplications and
additions over GF(
) in the decoding process. Following the same consideration in [
4,
18,
19], we assume that it respectively takes
and
binary operations to realize addition and multiplication between two elements in GF(
). Consequently, the total number of required binary operations can be characterized as
to recover every
M-bit original packet.
Herein, we did not consider the complexity to compute the inverse matrix of
because in practice the packet length
M is much larger than
n, and this convention has also been adopted in [
4,
19] for computational complexity analysis.
4. Optimal Construction of Precoding Matrix
Based on the analysis in the previous section, we are motivated to carefully design such a precoding matrix that the full rank of is equivalent to the full rank of , which can optimize the decodability performance for fixed parameters n and N. To achieve this goal, for the precoding matrix , we first introduce the following condition that is stronger than the conventional maximal distance separable (MDS) property.
Definition 1. An matrix over GF() is said to be MDS under GF(2)-mapping if for any full-rank matrix over GF(2), .
Recall that if
satisfies the conventional MDS property, all
n columns in it are linearly independent. Obviously, the conventional MDS property is a prerequisite for the proposed MDS property under GF(2)-mapping. However, Example 3 demonstrates an MDS matrix
that is not MDS under GF(2)-mapping. To the best of our knowledge, except for a brief attempt in [
13], there is no prior literature involving the construction of a matrix satisfying the MDS property under GF(2)-mapping. We next characterize an equivalent condition on the MDS property under GF(2)-mapping, so as to facilitate the explicit construction. Given an
matrix
, let
denote the set of row vectors generated by
:
For every
, let
denote its null space in
.
Theorem 2. An matrix is MDS under GF(2)-mapping if and only if Proof. We prove the theorem in a contrapositive argument. Assume that there exists a nonzero such that , and let be a row vector over GF() satisfying . Then, we can select n linearly independent column vectors over GF(2) from . Write . Thus, , so that is not full rank n, i.e., is not MDS under GF(2)-mapping.
Assume that is not MDS under GF(2)-mapping, and let be a full rank matrix over GF(2) subject to . Then, there exists an n-dimensional row vector such that . Write , so that . Since is full rank n, there are at least n linearly independent vectors (which are the columns of ) belonging to , i.e., . ☐
For , let denote the number of elements in belonging to , and define an indicator which is set to 1 if consists of an element equal to 1 and set to 0 otherwise. The following is a useful corollary of Theorem 2.
Corollary 3. If an matrix is MDS under GF(2)-mapping, then the followings hold Proof. Assume there is a nonzero
with
,
i.e.,
. Define a new vector
by restricting to its components belonging to GF(2), so that the dimension of
is
. Thus, the dimension of the null space of
in
is
, which is no smaller than
n. Correspondingly,
, a contradiction to the MDS property under GF(2)-mapping for
according to (
12).
If there is a nonzero
belonging to
, then
so that (
13) cannot hold as
, and thus
cannot be MDS under GF(2)-mapping. ☐
Conditions (
13) and (
14) are insufficient for the MDS property under GF(2)-mapping. The key reason is the possibility of the following
For this reason, we should pay more attention in the matrix design to avoid the involvement of those elements in (
15). The special case
is easier to manipulate.
Proposition 1. When , an matrix is MDS under GF(2)-mapping if and only if (14) holds. Proof. The necessity has been shown in Corollary 3. To prove sufficiency, assume (
14) holds for
defined in (
11) based on
. Let
be an arbitrary vector in
. As (
14) holds,
. In the case
, there must be at least one element in
equal to 1, because otherwise we can find another vector in
with all elements in GF(2), a contradiction to (
14). Thus,
for this case. Consider the case
. Without loss of generality, write
with
. We can assume
not all identical, because otherwise we can again find another vector in
with all elements in GF(2), a contradiction to (
14). Moreover, for arbitrary two elements
,
if and only if
. Hence, there are at most
linearly independent vectors in
that are in the null space of
, which further implies
. We have proved (
12) and thus the considered
is MDS under GF(2)-mapping. ☐
Corollary 4. When , there exists a systematic matrix over GF() that is MDS under GF(2)-mapping if and only if .
Proof. Assume
. Define an
n-dimensional column vector
, where
is a primitive element of GF(
). In this way, all elements in
are distinct and every GF(2)-combination
among them does not belong to GF(2). By Proposition 1,
is an MDS matrix under GF(2)-mapping. When
, let
be an arbitrary
n-dimensional vector in GF(
). In order to make
MDS under GF(2)-mapping, according to (
14) in Corollary 3, there is not any element
belonging to GF(2). If there is a basis, say
of GF(
) in
, then 1 can be written as a GF(2)-linear combination of the basis, so that (
14) does not hold. If there is not a basis of GF(
) in
, then there exists an
n-dimensional nonzero row vector
over GF(2) subject to
, so that (
14) does not hold either. Thus, it is impossible for
to be MDS under GF(2)-mapping. ☐
Based on the above corollary, the required field size is exponentially larger than N in the construction of an systematic MDS matrix under GF(2)-mapping. This implies that it is infeasible to construct such a practical precoding matrix for large N. For this reason, it is alternative to choose to randomly generate , which may cause a near-optimal decodability behavior as illustrated in the next example.
Example 4. Define the following vectors and over GF() in which α is a primitive element. It can be checked that both matrices and are MDS under GF(2)-mapping. Although the matrix is not MDS under GF(2)-mapping, among 42435 7-dimensional subspaces of , there are only 127 instances to break the desired MDS property, that is, every basis for each of the instances forms a matrix with .
5. Numerical Analysis
In this section, we numerically analyze the performance of applying the proposed systematic scalable RLNC scheme to a wireless broadcast network, which is a classical model to demonstrate the advantage of RLNC [
4,
5,
6,
7]. The number
n of original packets in a batch is varied from
to 24. In every timeslot, the source broadcasts one packet to all receivers. The memoryless and independent packet loss probability for every receiver is
, that is, in every timeslot, every receiver can successfully receive a packet with probability
. We consider the scheme with parameters
,
where
. In the
precoding matrix
, the entries in
and
are randomly selected from GF(
) and GF(
), respectively. In the numerical analysis of scalable RLNC, the single source
s has
n original packets to be broadcast to a total of 30 receivers with different decoding capabilities. Specifically, the 30 receivers fall into 3 different groups and the 10 receivers in every group has the same decoding capability, and can decode based on the decoding rule (
4) over GF(2), GF(
) and GF(
), respectively. In the first
n timeslots, the source broadcasts
n original packets, whose coding vectors are
-dimensional unit vectors, to all receivers. Starting from timeslot
, the source broadcasts coded packets, each of which is generated based on a random
N-dimensional column vector
over GF(2), till all the receivers can recover the
n original packets. Herein, for every parameter setting and every considered RLNC scheme, we conduct 1200 independent rounds of simulation which result in
confidence intervals.
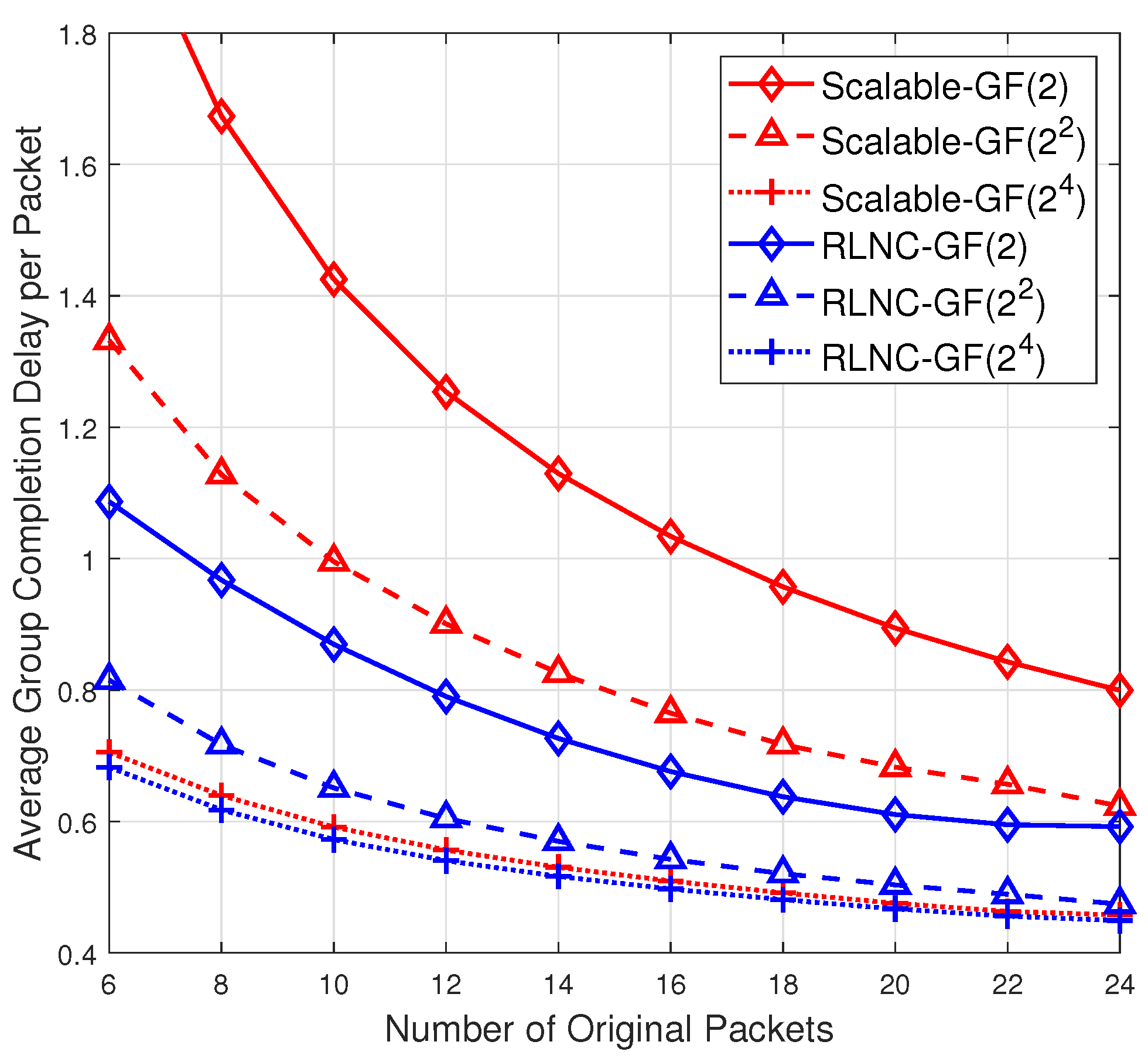
Figure 2 depicts the average group completion delay per packet for the 3 groups of receivers, respectively labeled as “Scalable-GF(
)”,
of the considered scalable RLNC scheme. The group completion delay means the number of extra coded packets the source broadcasts till all the 10 receivers in the group can recover
n original packets. For a better comparison, the figure also depicts the average group completion delay per packet, labeled as “RLNC-GF(
)”, for a group of 10 receivers of three
different classical systematic RLNC schemes over different fields GF(
),
. Recall that in the classical systematic RLNC scheme over GF(
), the source first broadcasts
n original packets and then randomly coded packets with
n-dimensional coding vectors over GF(
). One may observe from
Figure 2 that for the case of GF(
), the average completion delay of scalable RLNC is almost same as the classical RLNC. Over other smaller fields, even though scalable RLNC yields higher average completion delay than classical RLNC, it simultaneously guarantees the decoding compatibility at heterogeneous receivers, which cannot be endowed by classical RLNC schemes. For instance, assume that the source adopts classical RLNC over GF(
) to generate coded packets. On one hand, the group of receivers with decoding capability constrained to GF(2) will fail to recover the original packets. On the other hand, the groups of receivers with decoding capability over GF(
) cannot fully utilize their higher computational power so that the average completion delay cannot be further reduced compared with decoding over GF(
). As a result, the performance loss for the cases of smaller fields in our proposed scalable RLNC compared to classical RLNC is the cost of decoding compatibility over different fields.
For the considered systematic scalable RLNC scheme, recall that for decoding over GF(2) in the proposed scalable RLNC, Equation (
9) obtained in Sec. III is a necessary and sufficient rule while Equation (
10), originally adopted in [
13,
14] for Fulcrum decoding, is a non-necessary rule.
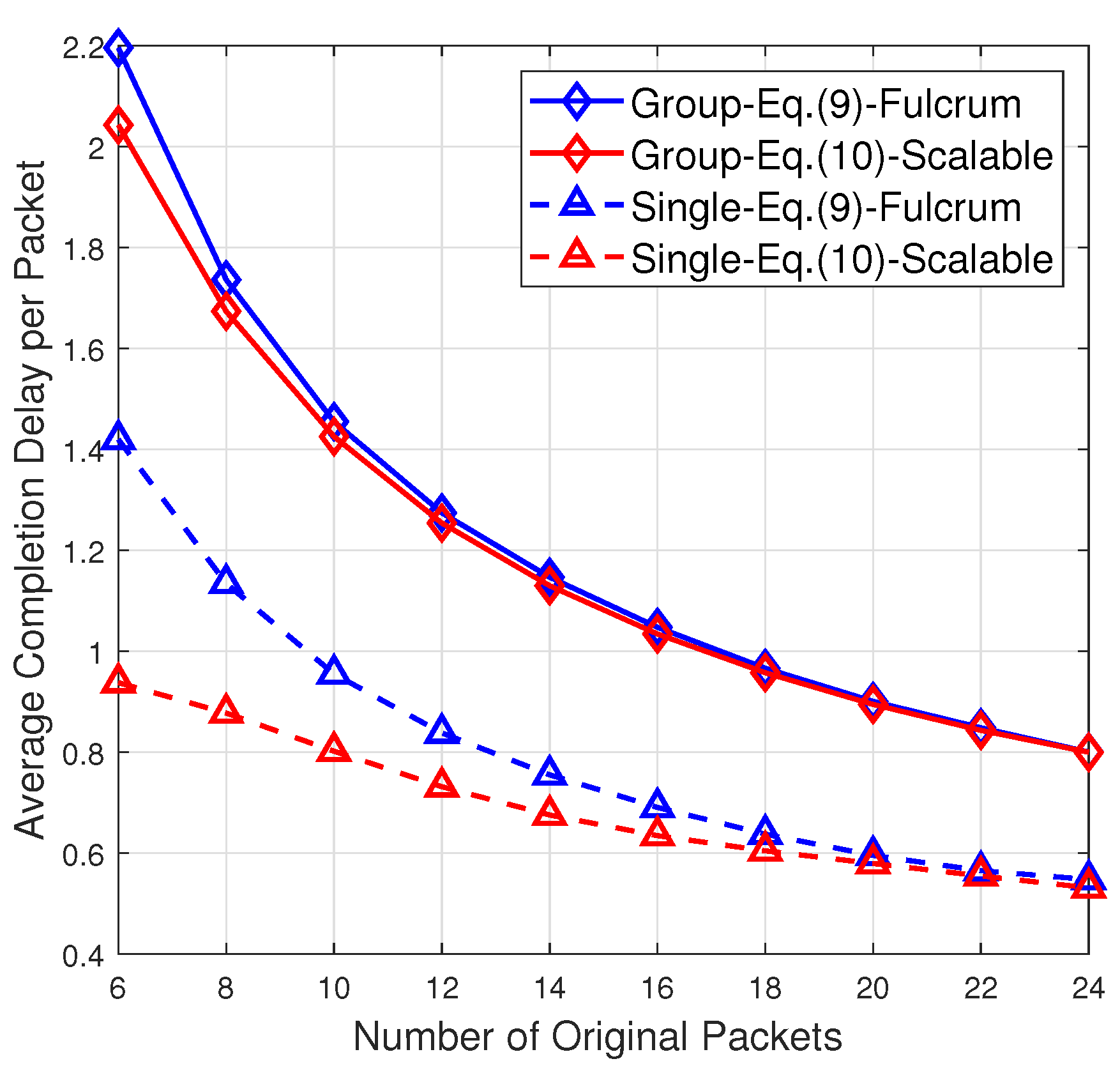
Figure 3 compares the average group completion delay per packet for 10 receivers as well as the average completion delay per packet at a single receiver when the receivers adopt different decoding rules (
9) and (
10) over GF(2). For the average completion delay at a single receiver, a noticeable performance gain can be observed. In particular, when the number of original packets is less than 10, the average completion delay at a single receiver is reduced by more than
based on the decoding rule (
9) instead of (
10). For the average group completion delay, the performance gain by adopting (
9) instead of (
10) becomes less obvious because it is offset by the increasing number of receivers in a group. Compared with Fulcrum, which only supports decoding over the smallest field GF(2) or the largest field GF(
), in addition to the performance gain illustrated in
Figure 3, our proposed scalable RLNC is more flexible. This is because the receivers with intermediate computational power can fully utilize its decoding capability to decode over intermediate fields (rather than only over GF(2)), so that the average completion delay can be reduced.
In the remaining part of this section, we shall analyze the performance of our scalable RLNC scheme by adjusting the sparsity of , which controls to the probability for every component in to be one. Specifically, for every packet to be transmitted by the source, the expected number of precoded packets to form it is . In previous analysis of this section, is set to . We next consider a more sparse with .
According to the work in [
20], given that there are
-dimensional linearly independent binary vectors with sparsity
, the probability that a new randomly generated
-dimensional binary coding vector
with sparsity
is linearly independent with them is lower bounded by
This bound indicates that except for the case
i close to
, the lower bound keeps very close to 1. Further, at the end of Sec. IV, we have illustrated that a random
will bring a near-optimal decodability behavior, that is, the full rank of
will lead to the full rank of
with high probability. As a result, although our proposed scalable RLNC scheme with two-stage encoding process is different from the conventional sparse RLNC described in [
20], we are motivated to bring the
sparsity into our proposed scheme and attempt to meet a balance between completion delay and decoding complexity. The work in [
14] has taken the sparsity into consideration in their performance analysis of Fulcrum, which is a special instance of our proposed scalable RLNC scheme.
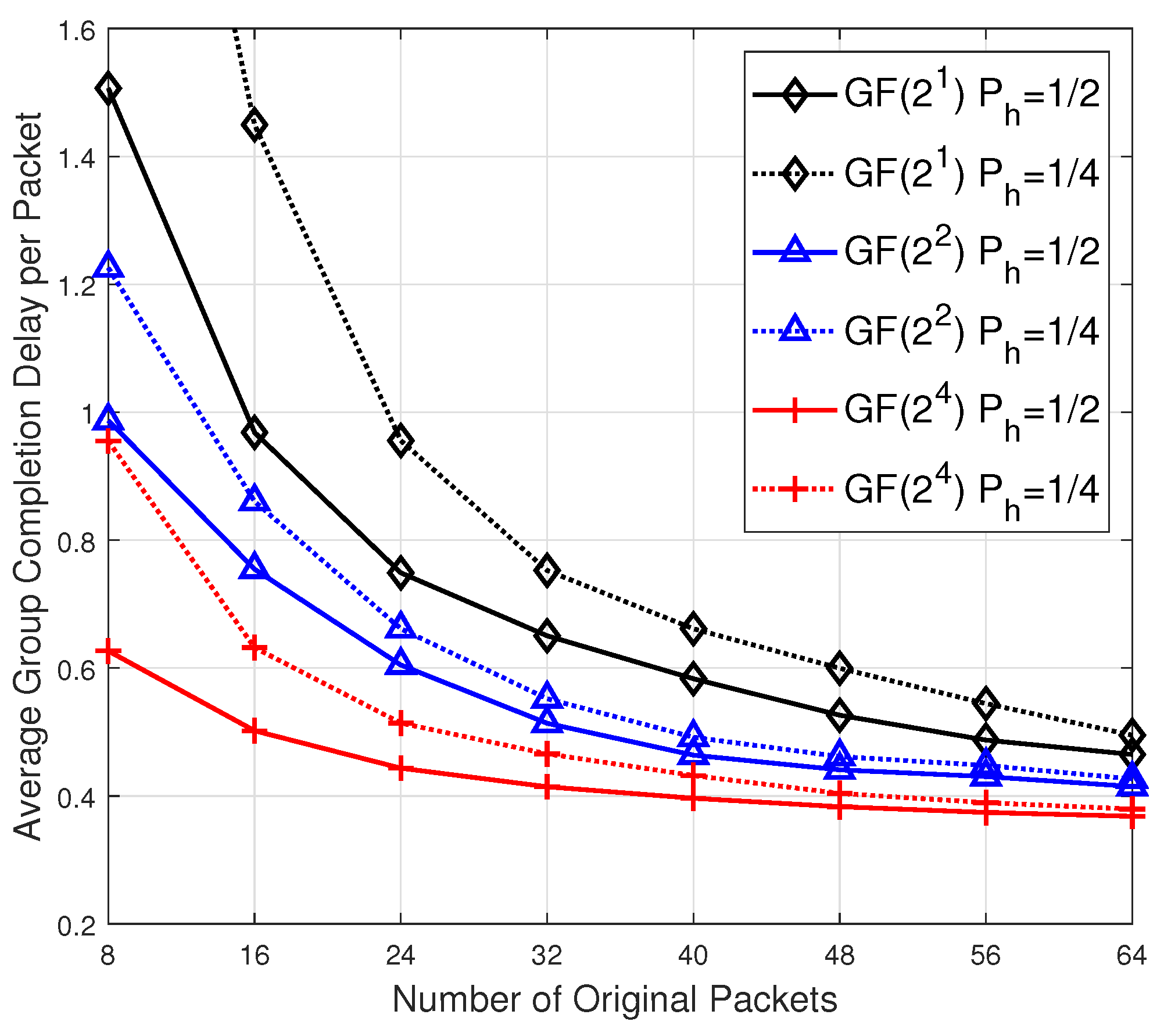
In simulation, besides the consideration of sparsity
, we also extend the value range of
n from
to
and set
. All other parameter settings are same as those in
Figure 2. The 3 solid curves in
Figure 4 illustrate the average group completion delay per packet for the 3 groups of 10 receivers under different field constraints GF(2), GF(
) and GF(
) for scalable RLNC with sparsity
. The 3 dotted curves in
Figure 4 illustrate the completion delay performance under different field constraints GF(2), GF(
) and GF(
) for scalable RLNC with
. It is interesting to observe that with the batch size
n increasing, under the same decoding constraint (
i.e., two curves in the same color), the completion delay performance for the case
will converge to the case
. This result indicates that the lower bound in (
16) is rather loose when
i is close to
, and moreover, for a large enough batch size
n, a more sparse vector
will not affect the completion delay performance much in a wireless broadcast network.





{kind=link}
{kind=link}
{kind=link}
{kind=link}



