




Multi-Focus Image Fusion Based on Hessian Matrix Decomposition and Salient Difference Focus Detection



Abstract
:1. Introduction
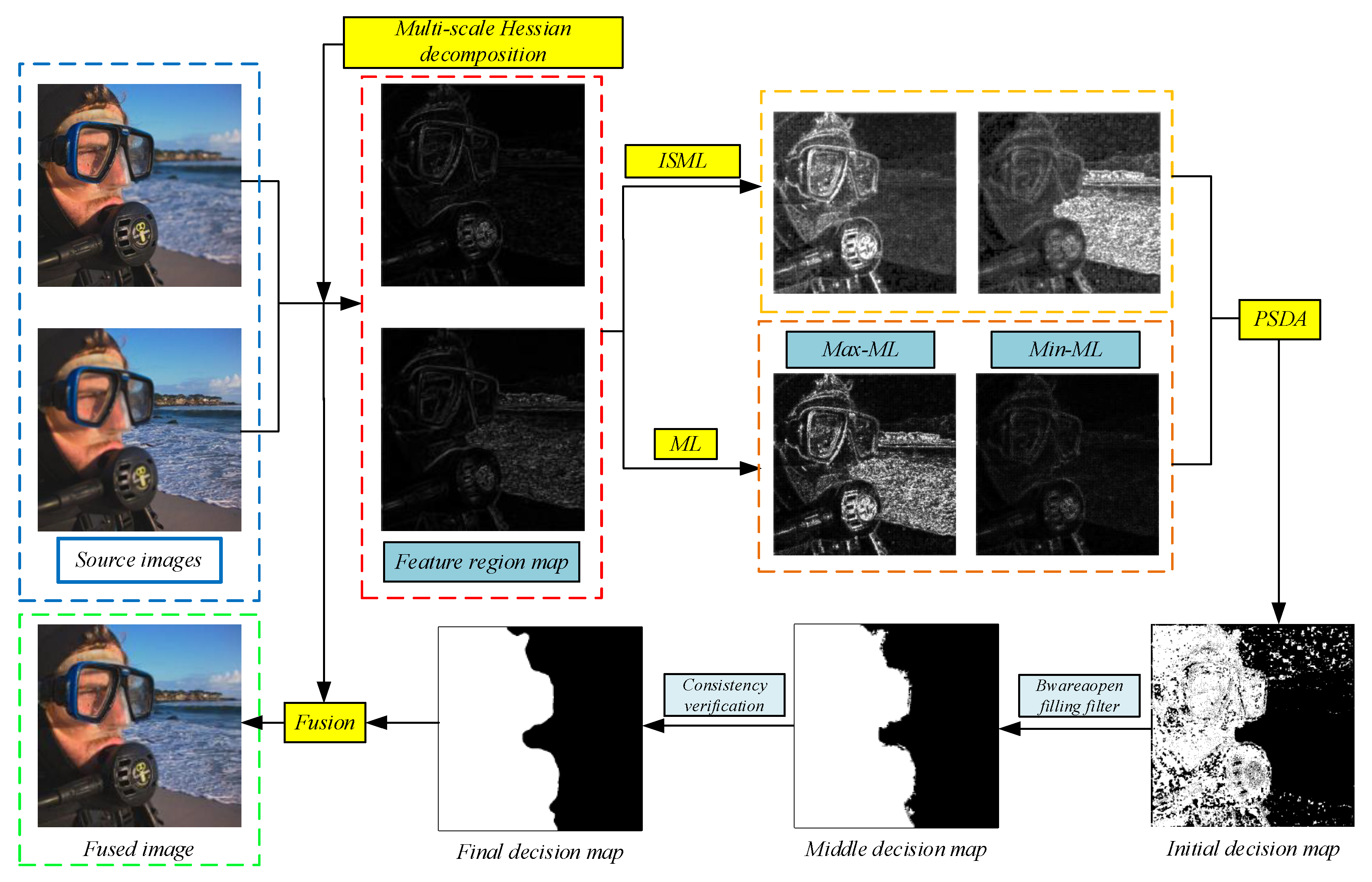
- A simple yet effective multi-focus image fusion method based on the Hessian-matrix with salient-difference focus detection is proposed.
- A pixel salient-difference maximization and minimization analysis scheme is proposed to weaken the influence of pixels with similar activity levels at the focus boundary. It can effectively distinguish pixels in the focus and out-of-focus regions and produce high-quality focus decision maps.
- An adaptive multiscale-consistency-verification scheme is designed in the postprocessing stage, which can adaptively optimize the initial decision maps of different sizes, solving the limitations caused by fixed parameters.
2. Related Works
Hessian Matrix and Image Decomposing
3. Proposed Multi-Focus Image Fusion Method
3.1. Overview
3.2. Significant Information Expression
3.3. Pixel Salient Difference Analysis (PSDA)
3.4. Focused Decision Map Optimization
3.4.1. Step 1—Small Area Removal Filter
3.4.2. Step 2—Adaptive multiscale consistency verification
3.5. Fusion Result Reconstruction
4. Experiments
4.1. Experimental Setup
4.1.1. Image Datasets
4.1.2. Compared Methods
- Multi-focus image fusion based on NSCT and residual removal [12] (NSCT-RR).
- Multiscale weighted gradient-based fusion for multi-focus images [22] (MWGF).
- Multi-focus image fusion by Hessian matrix based decomposition [26] (HMD).
- Guided filter-based multi-focus image fusion through focus region detection [24] (GFDF).
- Analysis–synthesis dictionary-pair learning and patch saliency measure for image fusion [16] (YMY).
- Image fusion with convolutional sparse representation [17] (CSR).
- Ensemble of CNN for multi-focus image fusion [6] (ECNN).
- Towards reducing severe defocus spread effects for multi-focus image fusion via an optimization based strategy [5] (MFF-SSIM).
- MFF-GAN: An unsupervised generative adversarial network with adaptive and gradient joint constraints for multi-focus image fusion [4] (MFF-GAN).
- U2Fusion: A unified unsupervised image fusion network [31] (U2Fusion).
- IFCNN: A general image fusion framework based on convolutional neural network [32] (IFCNN).
4.1.3. Objective Evaluation Metrics
- Normalized mutual information (QMI) [33].
- Nonlinear correlation information entropy (QNCIE) [34].
- Gradient-based fusion performance (QG) [35].
- Image fusion metric based on a multiscale scheme (QM) [36].
- Image fusion metric based on phase congruency (QP) [37].
- Average gradient (AG) [38].
- Chen–Blum metric (QCB) [39].
- Chen-Varshney metric (QCV) [40].
4.1.4. Parametric Analysis
4.2. Subjective Analysis of the Fusion Results
4.3. Objective Analysis of the Fusion Results
4.4. Robustness Test to Defocus Spread Effect (DSE)
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, Y.; Wang, L.; Cheng, J.; Li, C.; Chen, X. Multi-focus image fusion: A Survey of the state of the art. Inf. Fusion 2020, 64, 71–91. [Google Scholar] [CrossRef]
- Zhang, H.; Xu, H.; Tian, X.; Jiang, J.; Ma, J. Image fusion meets deep learning: A survey and perspective. Inf. Fusion 2021, 76, 323–336. [Google Scholar] [CrossRef]
- Li, J.; Guo, X.; Lu, G.; Zhang, B.; Xu, Y.; Wu, F.; Zhang, D. DRPL: Deep Regression Pair Learning for Multi-Focus Image Fusion. IEEE Trans. Image Process. 2020, 29, 4816–4831. [Google Scholar] [CrossRef]
- Zhang, H.; Le, Z.; Shao, Z.; Xu, H.; Ma, J. MFF-GAN: An unsupervised generative adversarial network with adaptive and gradient joint constraints for multi-focus image fusion. Inf. Fusion 2020, 66, 40–53. [Google Scholar] [CrossRef]
- Xu, S.; Ji, L.; Wang, Z.; Li, P.; Sun, K.; Zhang, C.; Zhang, J. Towards Reducing Severe Defocus Spread Effects for Multi-Focus Image Fusion via an Optimization Based Strategy. IEEE Trans. Comput. Imaging 2020, 6, 1561–1570. [Google Scholar] [CrossRef]
- Amin-Naji, M.; Aghagolzadeh, A.; Ezoji, M. Ensemble of CNN for multi-focus image fusion. Inf. Fusion 2019, 51, 201–214. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Peng, H.; Wang, Z. Multi-focus image fusion with a deep convolutional neural network. Inf. Fusion 2017, 36, 191–207. [Google Scholar] [CrossRef]
- Zhang, X. Deep Learning-based Multi-focus Image Fusion: A Survey and A Comparative Study. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 4819–4838. [Google Scholar] [CrossRef]
- Xu, H.; Wang, Y.; Wu, Y.; Qian, Y. Infrared and multi-type images fusion algorithm based on contrast pyramid transform. Infrared Phys. Technol. 2016, 78, 133–146. [Google Scholar] [CrossRef]
- Burt, P.; Adelson, E. The Laplacian Pyramid as a Compact Image Code. IEEE Trans. Commun. 1983, 31, 532–540. [Google Scholar] [CrossRef]
- Haghighat, M.B.A.; Aghagolzadeh, A.; Seyedarabi, H. Multi-focus image fusion for visual sensor networks in DCT domain. Comput. Electr. Eng. 2011, 37, 789–797. [Google Scholar] [CrossRef]
- Li, X.; Zhou, F.; Tan, H.; Chen, Y.; Zuo, W. Multi-focus image fusion based on nonsubsampled contourlet transform and residual removal. Signal Process. 2021, 184, 108062. [Google Scholar] [CrossRef]
- Liu, S.; Wang, J.; Lu, Y.; Li, H.; Zhao, J.; Zhu, Z. Multi-Focus Image Fusion Based on Adaptive Dual-Channel Spiking Cortical Model in Non-Subsampled Shearlet Domain. IEEE Access 2019, 7, 56367–56388. [Google Scholar] [CrossRef]
- Li, X.; Zhou, F.; Tan, H. Joint image fusion and denoising via three-layer decomposition and sparse representation. Knowl.-Based Syst. 2021, 224, 107087. [Google Scholar] [CrossRef]
- Bin, Y.; Shutao, L. Multifocus Image Fusion and Restoration With Sparse Representation. IEEE Trans. Instrum. Meas. 2010, 59, 884–892. [Google Scholar]
- Zhang, Y.; Yang, M.; Li, N.; Yu, Z. Analysis-synthesis dictionary pair learning and patch saliency measure for image fusion. Signal Process. 2019, 167, 107327. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Ward, R.K.; Wang, Z.J. Image Fusion With Convolutional Sparse Representation. IEEE Signal Process. Lett. 2016, 23, 1882–1886. [Google Scholar] [CrossRef]
- Li, H.; He, X.; Tao, D.; Tang, Y.; Wang, R. Joint medical image fusion, denoising and enhancement via discriminative low-rank sparse dictionaries learning. Pattern Recognit. 2018, 79, 130–146. [Google Scholar] [CrossRef]
- Li, H.; Wang, Y.; Yang, Z.; Wang, R.; Li, X.; Tao, D. Discriminative Dictionary Learning-Based Multiple Component Decomposition for Detail-Preserving Noisy Image Fusion. IEEE Trans. Instrum. Meas. 2020, 69, 1082–1102. [Google Scholar] [CrossRef]
- Yong, Y.; Yue, Q.; Huang, S.; Lin, P. Measurement. Multiple Visual Features Measurement With Gradient Domain Guided Filtering for Multisensor Image Fusion. IEEE Trans. Instrum. Meas. 2017, 66, 691–703. [Google Scholar] [CrossRef]
- Ma, J.; Zhou, Z.; Wang, B.; Dong, M. Multi-focus image fusion based on multi-scale focus measures and generalized random walk. In Proceedings of the 2017 36th Chinese Control Conference (CCC), Dalian, China, 26–28 July 2017. [Google Scholar]
- Zhou, Z.; Li, S.; Wang, B. Multi-scale weighted gradient-based fusion for multi-focus images. Inf. Fusion 2014, 20, 60–72. [Google Scholar] [CrossRef]
- Wang, J.; Qu, H.; Wei, Y.; Xie, M.; Xu, J.; Zhang, Z. Multi-focus image fusion based on quad-tree decomposition and edge-weighted focus measure. Signal Process. 2022, 198, 108590. [Google Scholar] [CrossRef]
- Qiu, X.; Li, M.; Zhang, L.; Yuan, X. Guided filter-based multi-focus image fusion through focus region detection. Signal Process. Image Commun. 2018, 72, 35–46. [Google Scholar] [CrossRef]
- Zhang, Y.; Bai, X.; Wang, T. Boundary finding based multi-focus image fusion through multi-scale morphological focus-measure. Inf. Fusion 2017, 35, 81–101. [Google Scholar] [CrossRef]
- Xiao, B.; Ou, G.; Tang, H.; Bi, X.; Li, W. Multi-Focus Image Fusion by Hessian Matrix Based Decomposition. IEEE Trans. Multimedia 2019, 22, 285–297. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Kong, W.; Chen, Y.; Lei, Y. Medical image fusion using guided filter random walks and spatial frequency in framelet domain. Signal Process. 2020, 181, 107921. [Google Scholar] [CrossRef]
- Li, H.; Manjunath, B.S.; Mitra, S.K. Multisensor Image Fusion Using the Wavelet Transform. Graph. Models Image Process. 1995, 57, 235–245. [Google Scholar] [CrossRef]
- Nejati, M.; Samavi, S.; Shirani, S. Multi-focus image fusion using dictionary-based sparse representation. Inf. Fusion 2015, 25, 72–84. [Google Scholar] [CrossRef]
- Xu, H.; Ma, J.; Jiang, J.; Guo, X.; Ling, H. U2Fusion: A Unified Unsupervised Image Fusion Network. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 502–518. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, Y.; Sun, P.; Yan, H.; Zhao, X.; Zhang, L. IFCNN: A general image fusion framework based on convolutional neural network. Inf. Fusion 2019, 54, 99–118. [Google Scholar] [CrossRef]
- Qu, G.; Zhang, D.; Yan, P. Information measure for performance of image fusion. Electron. Lett. 2002, 38, 313–315. [Google Scholar] [CrossRef] [Green Version]
- Wang, Q.; Shen, Y.; Jin, J. Performance evaluation of image fusion techniques. Image Fusion Algorithms Appl. 2008, 19, 469–492. [Google Scholar]
- Xydeas, C.S.; Petrovic, V. Objective image fusion performance measure. Electron. Lett. 2000, 56, 181–193. [Google Scholar] [CrossRef] [Green Version]
- Wang, P.W.; Liu, B. A novel image fusion metric based on multi-scale analysis. In Proceedings of the International Conference on Signal Processing, Beijing, China, 26–29 October 2008. [Google Scholar]
- Zhao, J.; Laganiere, R.; Liu, Z. Performance assessment of combinative pixel-level image fusion based on an absolute feature measurement. Int. J. Innov. Comput. Inf. Control. 2006, 3, 1433–1447. [Google Scholar]
- Cui, G.; Feng, H.; Xu, Z.; Li, Q.; Chen, Y. Detail preserved fusion of visible and infrared images using regional saliency extraction and multi-scale image decomposition. Opt. Commun. 2015, 341, 199–209. [Google Scholar] [CrossRef]
- Yin, C.; Blum, R.S. A New Automated Quality Assessment Algorithm for Night Vision Image Fusion. In Proceedings of the 41st Annual Conference on Information Sciences and Systems, 2007, CISS ‘07, Baltimore, MD, USA, 14–16 March 2007. [Google Scholar]
- Chen, H.; Varshney, P.K. A human perception inspired quality metric for image fusion based on regional information. Inf. Fusion 2007, 8, 193–207. [Google Scholar] [CrossRef]
- Xu, S.; Wei, X.; Zhang, C.; Liu, J.; Zhang, J. MFFW: A new dataset for multi-focus image fusion. arXiv Prepr. 2020, arXiv:2002.04780. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| T | QMI | QNICE | QG | QM | QP | AG | QCB | QCV |
|---|---|---|---|---|---|---|---|---|
| 15 | 1.1703 | 0.8447 | 0.7266 | 2.9721 | 0.8501 | 6.9495 | 0.8085 | 20.6197 |
| 17 | 1.1675 | 0.8443 | 0.7261 | 2.9743 | 0.8526 | 6.9556 | 0.8088 | 17.3249 |
| 19 | 1.1656 | 0.8441 | 0.7253 | 2.9747 | 0.8519 | 6.9479 | 0.8077 | 16.5342 |
| 21 | 1.1646 | 0.8440 | 0.7244 | 2.9744 | 0.8499 | 6.9369 | 0.8078 | 16.5145 |
| 23 | 1.1637 | 0.8438 | 0.7232 | 0.9737 | 0.8478 | 6.9235 | 0.8076 | 16.7755 |
| Method | Lytro Dataset | |||||||
|---|---|---|---|---|---|---|---|---|
| QMI | QNICE | QG | QM | QP | AG | QCB | QCV | |
| NSCT-RR [12] | 1.1558(3) | 0.8433(3) | 0.7233(2) | 2.9745(2) | 0.8537(2) | 6.9235 | 0.8077(2) | 16.5356(3) |
| MWGF [22] | 1.0800 | 0.8388 | 0.6962 | 2.9657 | 0.8299 | 6.8161 | 0.7883 | 19.0492 |
| HMD [26] | 1.1617(2) | 0.8436(2) | 0.7229(3) | 2.9749 | 0.8517(4) | 6.9344(4) | 0.8070(3) | 16.0576(2) |
| GFDF [24] | 1.1433(4) | 0.8424(4) | 0.7169 | 2.9723(4) | 0.8540 | 6.9003 | 0.8055(4) | 15.8881 |
| YMY [16] | 0.9575 | 0.8308 | 0.6841 | 2.9450 | 0.8420 | 6.3056 | 0.7548 | 24.9025 |
| CSR [17] | 0.9271 | 0.8293 | 0.6267 | 2.9477 | 0.8317 | 6.2769 | 0.703 | 23.3846 |
| ECNN [6] | 1.1091 | 0.8403 | 0.7052 | 2.9698 | 0.831 | 6.9172 | 0.7981 | 16.5572(4) |
| MFF-SSIM [5] | 1.1056 | 0.8402 | 0.7202(4) | 2.9722 | 0.8509 | 6.9664 | 0.7994 | 17.1171 |
| [4] | 0.8549 | 0.8258 | 0.5934 | 2.9133 | 0.7698 | 6.9411(3) | 0.6526 | 67.8443 |
| U2Fusion [31] | 0.7777 | 0.8224 | 0.5612 | 2.8988 | 0.7112 | 6.5318 | 0.6456 | 40.3313 |
| IFCNN [32] | 0.9336 | 0.8296 | 0.6673 | 2.9538 | 0.8273 | 6.8747 | 0.7296 | 19.956 |
| Proposed | 1.1675 | 0.8443 | 0.7261 | 2.9743(3) | 0.8526(3) | 6.9556(2) | 0.8088 | 17.3249 |
| Methods | Grayscale Dataset | |||||||
|---|---|---|---|---|---|---|---|---|
| QMI | QNICE | QG | QM | QP | AG | QCB | QCV | |
| NSCT-RR [12] | 1.2438(3) | 0.8488(2) | 0.7395(4) | 2.9666(2) | 0.8967(2) | 8.0313 | 0.8188(3) | 38.02 |
| MWGF [22] | 1.156 | 0.8433 | 0.7228 | 2.9511 | 0.8928 | 7.7235 | 0.8048 | 52.1807 |
| HMD [26] | 1.2497(2) | 0.8487(3) | 0.7423(2) | 2.967 | 0.8958(3) | 8.0079 | 0.8245(2) | 37.2895(4) |
| GFDF [24] | 1.2166(4) | 0.8472(4) | 0.7401(3) | 2.9661(3) | 0.8983 | 7.9566 | 0.8245(2) | 35.7523 |
| YMY [16] | 1.0062 | 0.8336 | 0.6841 | 2.9494 | 0.8867 | 7.4494 | 0.774 | 37.4149 |
| CSR [17] | 1.0222 | 0.8347 | 0.6343 | 2.9581 | 0.8871 | 7.6903 | 0.7654 | 35.9312(2) |
| ECNN [6] | 0.8323 | 0.8259 | 0.5408 | 2.9266 | 0.7732 | 8.1873(3) | 0.7494 | 37.4752 |
| MFF-SSIM [5] | 0.995 | 0.8337 | 0.6633 | 2.9552 | 0.8787 | 8.087(4) | 0.7934 | 37.2547(3) |
| MFF-GAN [4] | 0.843 | 0.8264 | 0.5769 | 2.9055 | 0.8132 | 8.7637 | 0.7015 | 62.7001 |
| U2Fusion [31] | 0.7634 | 0.8232 | 0.5525 | 2.8793 | 0.7735 | 7.4846 | 0.614 | 115.0738 |
| IFCNN [32] | 0.9349 | 0.8305 | 0.6586 | 2.9408 | 0.8608 | 8.3031(2) | 0.7341 | 40.6426 |
| Proposed | 1.2559 | 0.8500 | 0.7444 | 2.9653(4) | 0.8939(4) | 8.001 | 0.8263 | 38.9546 |
| Methods | MFFW Dataset | |||||||
|---|---|---|---|---|---|---|---|---|
| QMI | QNICE | QG | QM | QP | AG | QCB | QCV | |
| NSCT-RR [12] | 1.0951(3) | 0.8363(3) | 0.6723 | 2.9606(2) | 0.7580 | 7.7225(4) | 0.7335(4) | 109.7688(4) |
| MWGF [22] | 1.0355 | 0.8329 | 0.6855(4) | 2.9433 | 0.7848 | 7.5424 | 0.7464(2) | 404.5932 |
| HMD [26] | 1.1189(2) | 0.8392(2) | 0.6936(2) | 2.9520(3) | 0.7602(4) | 7.7240(3) | 0.7395 | 402.4889 |
| GFDF [24] | 1.0511(4) | 0.8341(4) | 0.6873(3) | 2.9621 | 0.7778(2) | 7.6493 | 0.7426(3) | 104.9676(2) |
| YMY [16] | 0.8589 | 0.8238 | 0.6168 | 2.9346 | 0.7110 | 7.0522 | 0.6704 | 123.4168 |
| CSR [17] | 0.7110 | 0.8181 | 0.5052 | 2.9142 | 0.6152 | 7.0623 | 0.5539 | 180.1241 |
| ECNN [6] | 0.7441 | 0.8192 | 0.4697 | 2.9198 | 0.5585 | 7.6325 | 0.6758 | 107.0475(3) |
| MFF-SSIM [5] | 0.8266 | 0.8225 | 0.5688 | 2.9441 | 0.6868 | 7.8036(2) | 0.7099 | 104.8533 |
| MFF-GAN [4] | 0.7043 | 0.8174 | 0.3973 | 2.8535 | 0.4950 | 9.0122 | 0.5616 | 239.3639 |
| U2Fusion [31] | 0.7258 | 0.8183 | 0.4754 | 2.8684 | 0.5743 | 7.1704 | 0.5764 | 192.0370 |
| IFCNN [32] | 0.7811 | 0.8204 | 0.5170 | 2.9179 | 0.6292 | 7.7187 | 0.6362 | 123.2416 |
| Proposed | 1.1316 | 0.8405 | 0.6990 | 2.9485(4) | 0.7620(3) | 7.7067 | 0.7481 | 417.1856 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Wang, X.; Cheng, X.; Tan, H.; Li, X. Multi-Focus Image Fusion Based on Hessian Matrix Decomposition and Salient Difference Focus Detection. Entropy 2022, 24, 1527. https://doi.org/10.3390/e24111527
Li X, Wang X, Cheng X, Tan H, Li X. Multi-Focus Image Fusion Based on Hessian Matrix Decomposition and Salient Difference Focus Detection. Entropy. 2022; 24(11):1527. https://doi.org/10.3390/e24111527
Chicago/Turabian StyleLi, Xilai, Xiaopan Wang, Xiaoqi Cheng, Haishu Tan, and Xiaosong Li. 2022. "Multi-Focus Image Fusion Based on Hessian Matrix Decomposition and Salient Difference Focus Detection" Entropy 24, no. 11: 1527. https://doi.org/10.3390/e24111527
APA StyleLi, X., Wang, X., Cheng, X., Tan, H., & Li, X. (2022). Multi-Focus Image Fusion Based on Hessian Matrix Decomposition and Salient Difference Focus Detection. Entropy, 24(11), 1527. https://doi.org/10.3390/e24111527