



Three-Dimensional Face Recognition Using Solid Harmonic Wavelet Scattering and Homotopy Dictionary Learning


Abstract
:1. Introduction
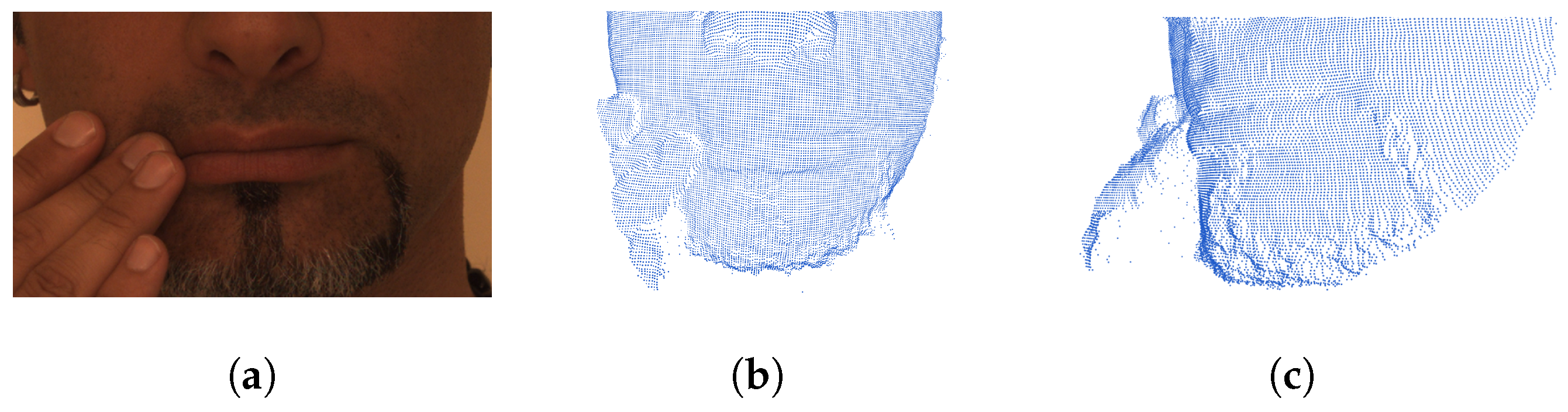
- Inspired by the high-resolution texture discrimination, this paper proposes a novel process–model approach to obtain the discriminative and stable facial features from pure point coordination representation for automatic face recognition; here, the facial shape clues are enhanced in a regularized domain.
- We modify the original holistic solid harmonic wavelet scattering transform approach into a windowed integral function to provide a higher-resolution representation.
- We learned a 3D facial texton dictionary, which is specifically based on the co-occurrences of filter responses across different extrinsic perturbances, e.g., head pose/illumination variation/occlusion, and succeed in achieving competitive recognition accuracy compared with alternative currently available methods.
2. Related Works
2.1. Point Cloud Deep Learning
2.2. Dictionary Learning on Scattering Coefficients
2.3. 3D Face Recognition
3. Materials and Methods
3.1. The Stochastic Process Model on Point Cloud Faces
| Algorithm 1 The Local Lattice Operation: |
|

| Algorithm 2 Windowed Solid Harmonic Wavelet Scattering |
|
3.2. Piece-Wise Smoothed Solid Harmonic Scattering Coefficient Representation
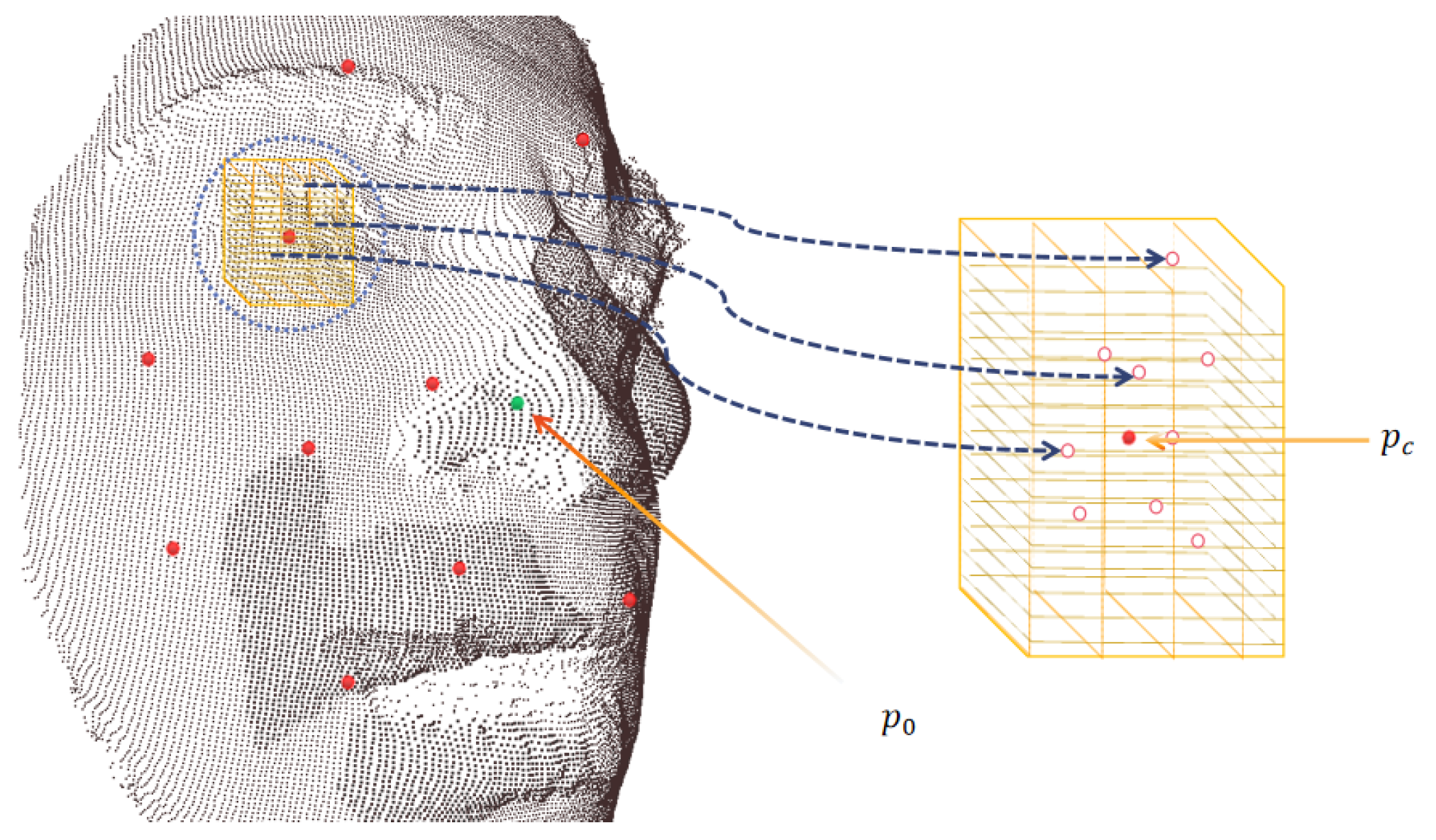
3.3. Constructing a Local Dictionary with Semi-Supervised Sparse Coding on Scattering Coefficients
| Algorithm 3 Dictionary learning on local facial coefficients |
|
4. Results
4.1. The Evaluation Protocol and Metrics
4.2. Implementations
- (1)
- The 3D solid scattering coefficient representation: As introduced in Section 2, we transformed the raw point cloud into representative zero-, first-, and second-order cascades of the solid harmonic scattering coefficients (shown in Figure 5); the implementation was based on an open-source framework [34].
- (2)
- The sparse dictionary learning structure is demonstrated in Figure 6. It remained a very wide feature vector when we directly input a batch of scattering coefficients into the ISTC layer; therefore, we applied a convolution operation with batch normalization to reduce it to . Furthermore, it included learned parameters. The N was set to 3 since it was experimentally sufficient to allow the sparsity to reach the extremum.
4.3. Hyperparameter Tuning Process
- (1)
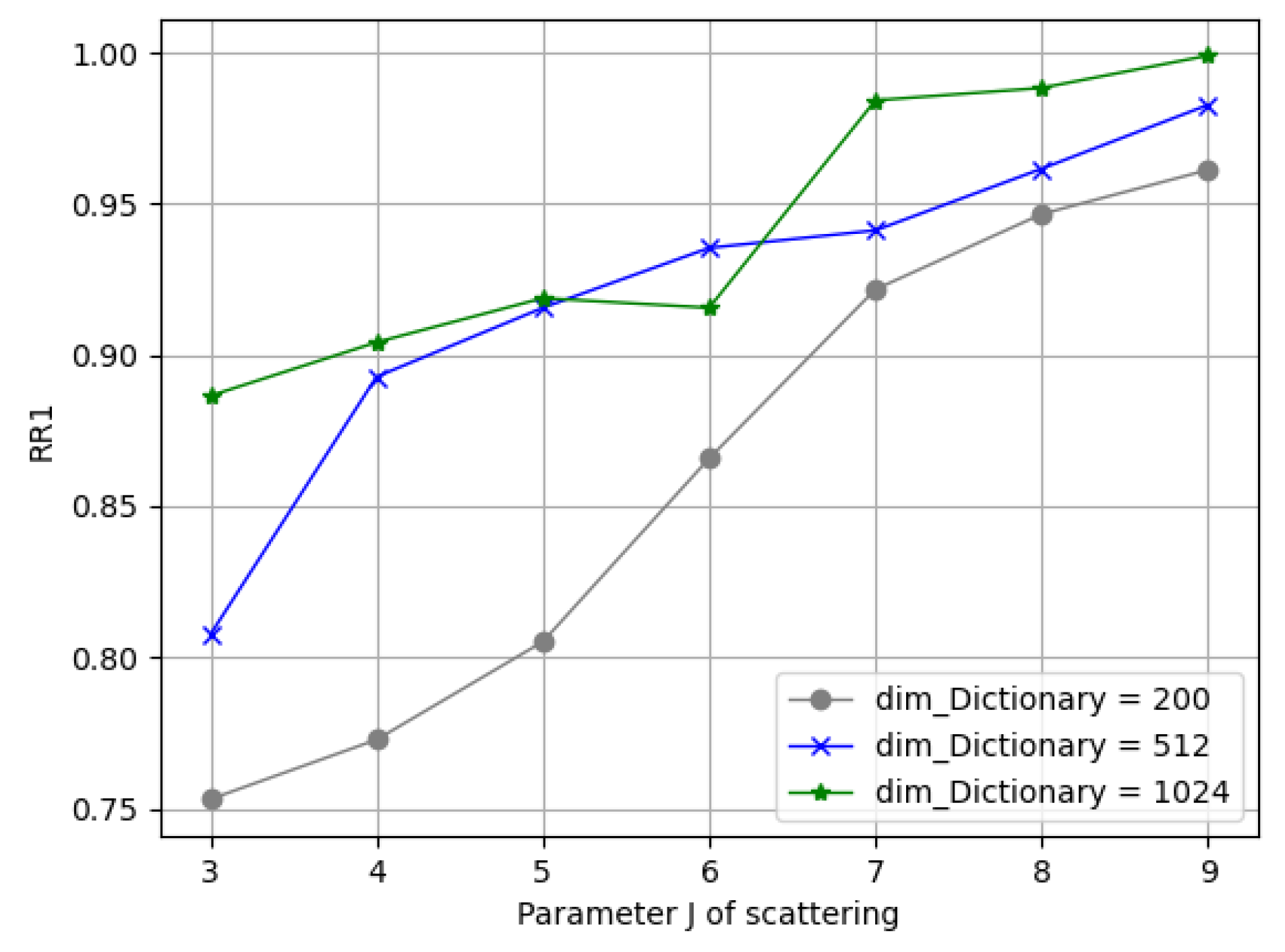
- Parameters in Solid Harmonic Scattering: Figure 10 demonstrates the rank-1 recognition rate on the Bosphorus dataset by training the network with J = 3, 4, 5, 6, 7, 8, 9 values under C = 128. It can be seen that the dimension of each sub-dictionary had to be subsequent to satisfy overcompleteness; it can be seen from the blue/green lines that when and , the recognition rate barely grows.
- (2)
- Parameters in Sparse Dictionary Coding: We fixed ; here, we found that a variation in J in (5, 7, 9) reached its best spot on . Figure 11 depicts the varying performance; we applied [J = 7, = 150, C = 128, = 512] as the principle experimental configuration of this framework.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RR1 | ||
|---|---|---|


4.4. Comparison with Other Methods
- (1)
- Results on the FRGCv2 dataset: The FRGC v2.0 dataset [39] contained 4007 scans of 466 subjects in total; we followed its protocol to train on the Spring2003 partition and used the remaining data for testing. The results of running our proposed method and the state-of-the-art methods on the FRGC v2.0 dataset are shown in Table 2. The methods that used corresponding 2D photos are denoted as (2D+3D) and the ones that used a fine-tuning strategy are marked with (FT). Note that our approach required no information other than the positions of the point clouds; this property allowed for a much simpler sampling process in actual scenarios, whereas the illumination/rotation variants have been “compressed” in our representations. The recognition accuracy of our approach was also competitive with a rank-1 recognition rate of .
- (2)
- Results on the Bosphorus dataset: The Bosphorus dataset [38] has 4666 scans collected from 105 subjects, with very rich variants in expression, systematic variations in poses, and different types of occlusions.
| Method | RR1 | VR |
|---|---|---|
| Mian et al. [34] (2008) | ||
| Al-Osaimi. [41] (2016) | ||
| Ouamane et al. [42] (2017) | − | |
| Ouamane et al. [42] (2017) [2D+3D] | − | |
| Gilani and Miancite [3] (2018) | − | |
| Gilani and Mian [3] (2018) (FT) | − | |
| Cai et al. [1] (2019) (FT) | ||
| Yu et al. [2](2022) | ||
| Ours |
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cai, Y.; Lei, Y.; Yang, M.; You, Z.; Shan, S. A fast and robust 3D face recognition approach based on deeply learned face representation. Neurocomputing 2019, 363, 375–397. [Google Scholar]
- Yu, Y.; Da, F.; Zhang, Z. Few-data guided learning upon end-to-end point cloud network for 3D face recognition. Multimed. Tools Appl. 2022, 81, 12795–12814. [Google Scholar]
- Gilani, S.Z.; Mian, A. Learning from millions of 3D scans for large-scale 3D face recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Denver, CO, USA, 14–16 November 2018; pp. 1896–1905. [Google Scholar]
- Yang, X.; Huang, D.; Wang, Y.; Chen, L. Automatic 3d facial expression recognition using geometric scattering representation. In Proceedings of the 2015 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Ljubljana, Slovenia, 4–8 May 2015; IEEE: Piscataway, NJ, USA, 2015; Volume 1, pp. 1–6. [Google Scholar]
- Julesz, B. Visual pattern discrimination. IRE Trans. Inf. Theory 1962, 8, 84–92. [Google Scholar]
- Julesz, B. Textons, the elements of texture perception, and their interactions. Nature 1981, 290, 91–97. [Google Scholar]
- Leung, T.; Malik, J. Representing and recognizing the visual appearance of materials using three-dimensional textons. Int. J. Comput. Vis. 2001, 43, 29–44. [Google Scholar]
- Eickenberg, M.; Exarchakis, G.; Hirn, M.; Mallat, S.; Thiry, L. Solid harmonic wavelet scattering for predictions of molecule properties. J. Chem. Phys. 2018, 148, 241732. [Google Scholar]
- Zarka, J.; Thiry, L.; Angles, T.; Mallat, S. Deep network classification by scattering and homotopy dictionary learning. arXiv 2019, arXiv:1910.03561. [Google Scholar]
- Eldar, Y.; Lindenbaum, M.; Porat, M.; Zeevi, Y.Y. The farthest point strategy for progressive image sampling. IEEE Trans. Image Process. 1997, 6, 1305–1315. [Google Scholar]
- Bronstein, M.M.; Bruna, J.; LeCun, Y.; Szlam, A.; Vandergheynst, P. Geometric deep learning: Going beyond euclidean data. IEEE Signal Process. Mag. 2017, 34, 18–42. [Google Scholar]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3D shapenets: A deep representation for volumetric shapes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar]
- Hermosilla, P.; Ritschel, T.; Vázquez, P.P.; Vinacua, À.; Ropinski, T. Monte carlo convolution for learning on non-uniformly sampled point clouds. ACM Trans. Graph. (TOG) 2018, 37, 1–12. [Google Scholar]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic graph cnn for learning on point clouds. ACM Trans. Graph. (TOG) 2019, 38, 1–12. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4 December 2017; Volume 30, pp. 5105–5114. [Google Scholar]
- Lüthi, M.; Gerig, T.; Jud, C.; Vetter, T. Gaussian process morphable models. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1860–1873. [Google Scholar] [PubMed] [Green Version]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Su, H.; Jampani, V.; Sun, D.; Maji, S.; Kalogerakis, E.; Yang, M.H.; Kautz, J. Splatnet: Sparse lattice networks for point cloud processing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2530–2539. [Google Scholar]
- Mallat, S. Group invariant scattering. Commun. Pure Appl. Math. 2012, 65, 1331–1398. [Google Scholar]
- Bruna, J. Scattering Representations for Recognition. Ph.D. Thesis, Ecole Polytechnique X, (CMAP) Center Mathematics Appliquées, Paris, France, 2013. [Google Scholar]
- Oyallon, E.; Mallat, S. Deep roto-translation scattering for object classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2865–2873. [Google Scholar]
- De, S.; Bartók, A.P.; Csányi, G.; Ceriotti, M. Comparing molecules and solids across structural and alchemical space. Phys. Chem. Chem. Phys. 2016, 18, 13754–13769. [Google Scholar] [PubMed] [Green Version]
- Gao, F.; Wolf, G.; Hirn, M. Geometric scattering for graph data analysis. In Proceedings of the International Conference on Machine Learning, Long Beach, California, USA, 9–15 June 2019; PMLR: New York, NY, USA, 2019; pp. 2122–2131. [Google Scholar]
- Zou, D.; Lerman, G. Graph convolutional neural networks via scattering. Appl. Comput. Harmon. Anal. 2020, 49, 1046–1074. [Google Scholar]
- Mairal, J.; Ponce, J.; Sapiro, G.; Zisserman, A.; Bach, F. Supervised dictionary learning. In Proceedings of the 21st International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 8–10 December 2008; Volume 21. [Google Scholar]
- Patil, H.; Kothari, A.; Bhurchandi, K. 3-D face recognition: Features, databases, algorithms and challenges. Artif. Intell. Rev. 2015, 44, 393–441. [Google Scholar]
- Besl, P.J.; McKay, N.D. Method for registration of 3-D shapes. In Proceedings of the Sensor Fusion IV: Control Paradigms and Data Structures, Boston, MA, USA, 12–15 November 1991; SPIE: Bellingham, WA, USA, 1992; Volume 1611, pp. 586–606. [Google Scholar]
- Yue, X.; Biederman, I.; Mangini, M.C.; von der Malsburg, C.; Amir, O. Predicting the psychophysical similarity of faces and non-face complex shapes by image-based measures. Vis. Res. 2012, 55, 41–46. [Google Scholar] [CrossRef] [Green Version]
- Cai, L.; Da, F. Estimating inter-personal deformation with multi-scale modelling between expression for three-dimensional face recognition. IET Comput. Vis. 2012, 6, 468–479. [Google Scholar]
- Al-Osaimi, F.; Bennamoun, M.; Mian, A. An expression deformation approach to non-rigid 3D face recognition. Int. J. Comput. Vis. 2009, 81, 302–316. [Google Scholar] [CrossRef] [Green Version]
- Lei, Y.; Guo, Y.; Hayat, M.; Bennamoun, M.; Zhou, X. A two-phase weighted collaborative representation for 3D partial face recognition with single sample. Pattern Recognit. 2016, 52, 218–237. [Google Scholar] [CrossRef]
- Ocegueda, O.; Shah, S.K.; Kakadiaris, I.A. Which parts of the face give out your identity? In Proceedings of the CVPR, Barcelona, Spain, 6–13 November 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 641–648. [Google Scholar]
- Basri, R.; Jacobs, D.W. Lambertian reflectance and linear subspaces. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 218–233. [Google Scholar]
- Andreux, M.; Angles, T.; Exarchakis, G.; Leonarduzzi, R.; Rochette, G.; Thiry, L.; Zarka, J.; Mallat, S.; Andén, J.; Belilovsky, E.; et al. Kymatio: Scattering Transforms in Python. J. Mach. Learn. Res. 2020, 21, 1–6. [Google Scholar]
- Mallat, S.G.; Zhang, Z. Matching pursuits with time-frequency dictionaries. IEEE Trans. Signal Process. 1993, 41, 3397–3415. [Google Scholar] [CrossRef]
- Mairal, J.; Bach, F.; Ponce, J. Task-driven dictionary learning. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 791–804. [Google Scholar]
- Combettes, P.L.; Pesquet, J.C. Proximal splitting methods in signal processing. In Fixed-Point Algorithms for Inverse Problems in Science and Engineering; Springer: New York, NY, USA, 2011; pp. 185–212. [Google Scholar]
- Savran, A.; Alyüz, N.; Dibeklioğlu, H.; Çeliktutan, O.; Gökberk, B.; Sankur, B.; Akarun, L. Bosphorus database for 3D face analysis. In Proceedings of the European Workshop on Biometrics and Identity Management, Brandenburg, Germany, 8–10 March 2008; Springer: New York, NY, USA, 2008; pp. 47–56. [Google Scholar]
- Phillips, P.J.; Flynn, P.J.; Scruggs, T.; Bowyer, K.W.; Chang, J.; Hoffman, K.; Marques, J.; Min, J.; Worek, W. Overview of the face recognition grand challenge. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; IEEE: Piscataway, NJ, USA, 2005; Volume 1, pp. 947–954. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Al-Osaimi, F.R. A novel multi-purpose matching representation of local 3D surfaces: A rotationally invariant, efficient, and highly discriminative approach with an adjustable sensitivity. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Montreal, Canada, 7–12 December 2015; Volume 25, pp. 658–672. [Google Scholar]
- Ouamane, A.; Chouchane, A.; Boutellaa, E.; Belahcene, M.; Bourennane, S.; Hadid, A. Efficient tensor-based 2D + 3D face verification. IEEE Trans. Inf. Forensics Secur. 2017, 12, 2751–2762. [Google Scholar]








| Method | RR1 | VR |
|---|---|---|
| Mian et al. [34] (2008) | − | |
| Al-Osaimi [41] (2016) | ||
| Lei et al. [31] (2016) | − | |
| Ouamane et al. [42] (2017) [2D+3D] | − | |
| Gilani and Miancite [3] (2018) | − | |
| Gilani and Miancite [3] (2018) (FT) | − | |
| Cai et al. [1] (2019) (FT) | ||
| Yu et al. [2] (2022) | ||
| Ours |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, Y.; Cheng, P.; Yang, S.; Zhang, J. Three-Dimensional Face Recognition Using Solid Harmonic Wavelet Scattering and Homotopy Dictionary Learning. Entropy 2022, 24, 1646. https://doi.org/10.3390/e24111646
He Y, Cheng P, Yang S, Zhang J. Three-Dimensional Face Recognition Using Solid Harmonic Wavelet Scattering and Homotopy Dictionary Learning. Entropy. 2022; 24(11):1646. https://doi.org/10.3390/e24111646
Chicago/Turabian StyleHe, Yi, Peng Cheng, Shanmin Yang, and Jianwei Zhang. 2022. "Three-Dimensional Face Recognition Using Solid Harmonic Wavelet Scattering and Homotopy Dictionary Learning" Entropy 24, no. 11: 1646. https://doi.org/10.3390/e24111646
APA StyleHe, Y., Cheng, P., Yang, S., & Zhang, J. (2022). Three-Dimensional Face Recognition Using Solid Harmonic Wavelet Scattering and Homotopy Dictionary Learning. Entropy, 24(11), 1646. https://doi.org/10.3390/e24111646