1. Introduction
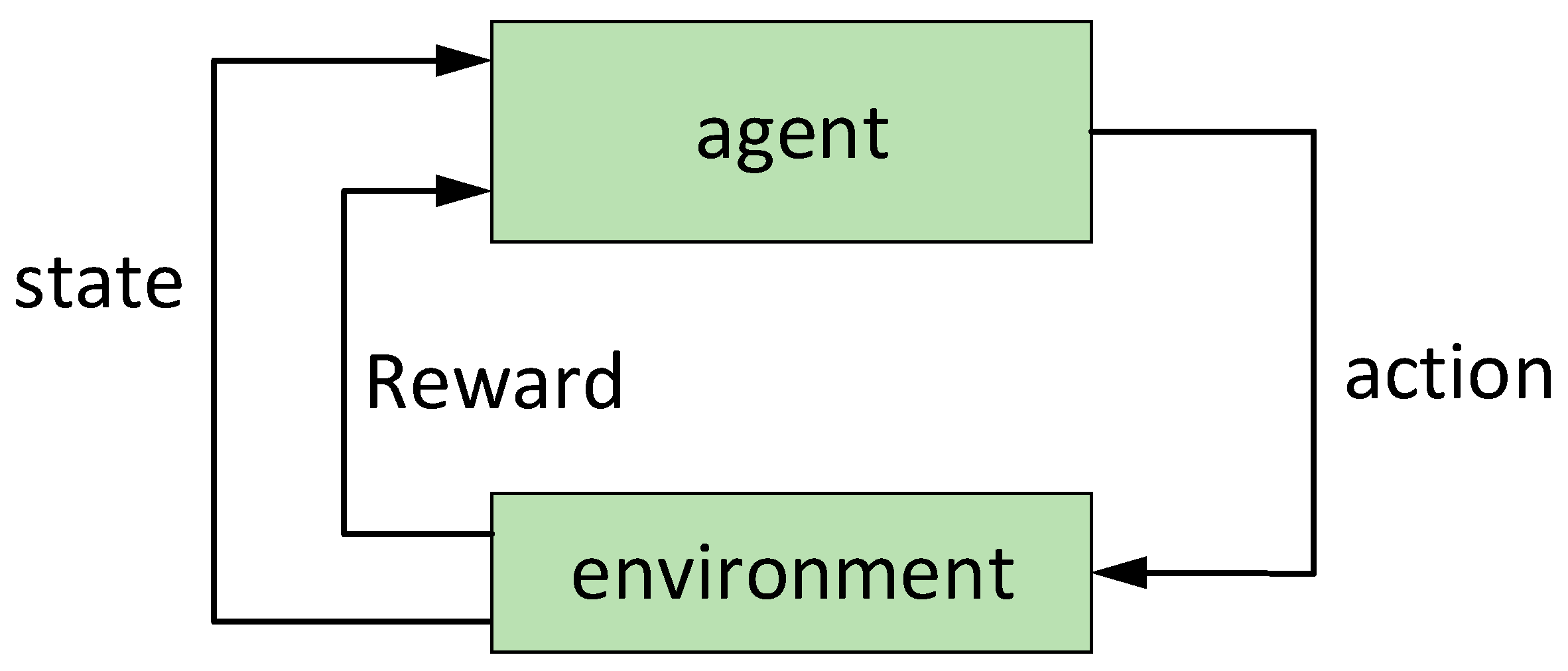
In recent years, deep reinforcement learning has developed rapidly in the field of artificial intelligence. By applying multilayer neural networks to approximate the value function of reinforcement learning, the perception ability of deep learning and the decision-making ability of reinforcement learning can be effectively combined, such as Atari games [
1,
2], complex robot motion control [
3], and the application of AlphaGo intelligence in Go [
4], etc.
Compared with single-agent reinforcement learning, multi-agent reinforcement learning algorithms can communicate, cooperate, and complete tasks together. Current mainstream multi-agent cooperative control algorithms include Lenient Deep Q Network (DQN) [
5], Value-Decomposition Networks (VDN) [
6], Q Mixing Network (QMIX) [
7], Deep Recurrent Q-Network (DRQN) [
8], Counterfactual Multi-Agent Policy (COMA) [
9], Multi-Agent Deep Deterministic Policy Gradient (MADDPG) [
10], Multi-Agent Proximal Policy Optimization (MAPPO) [
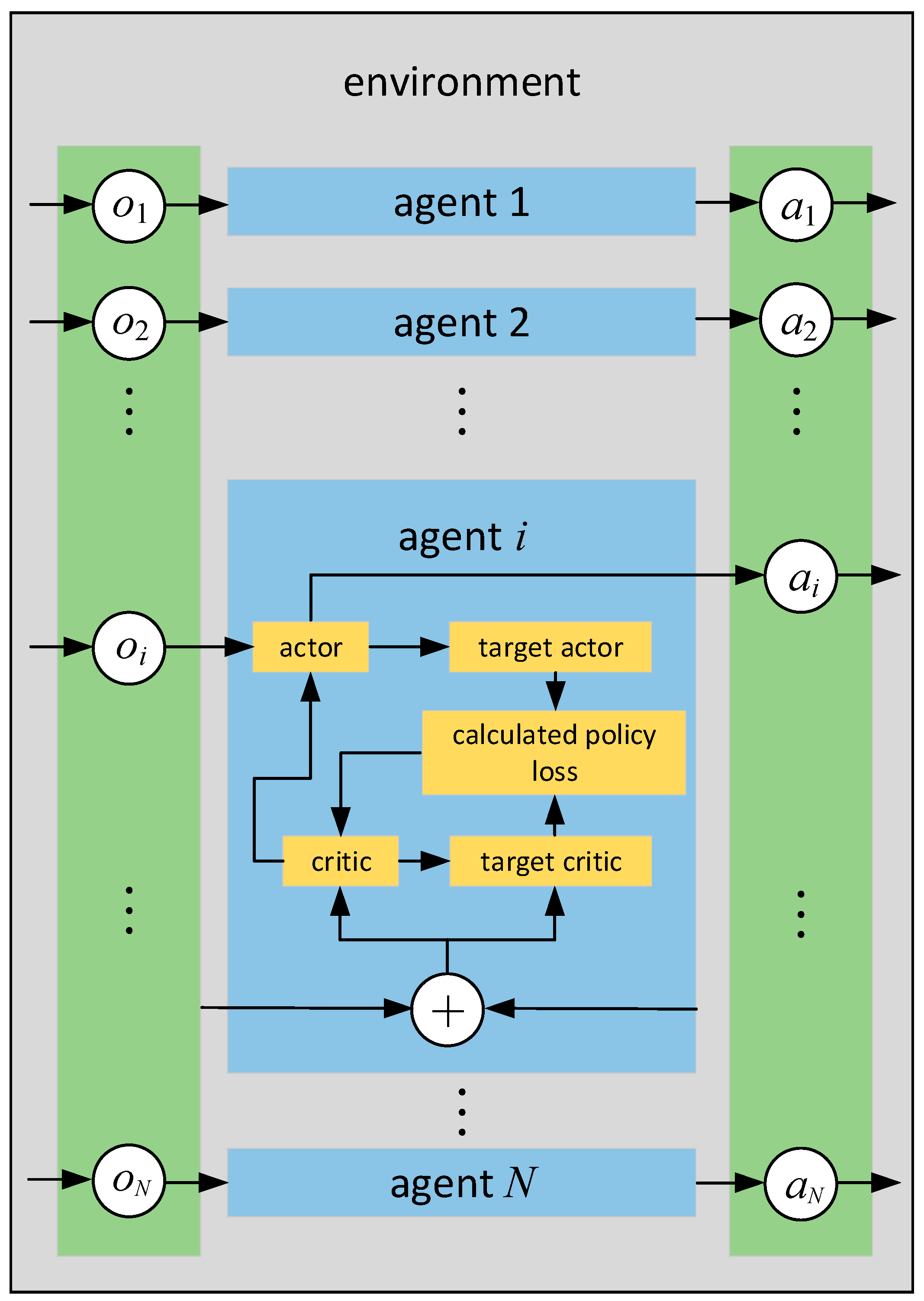
11], etc. Compared to other algorithms, the Multi-Agent Deep Deterministic Policy Gradient (MADDPG) algorithm can also be applied to cooperative cooperation and competitive adversarial scenarios, and global observation and policy functions between agents can be used to accelerate the convergence of actor network and critic network in the training process [
12], and can use the mechanism of centralized training and decentralized execution to enhance the stability and convergence of the algorithm, which has a broader application prospect in the current field of artificial intelligence field.
In applying reinforcement learning algorithms to real-world problem solving, the algorithms consume a lot of training time and training costs in interacting with the real environment (e.g., crash loss in training self-driving vehicles). To address this problem, we use curriculum learning in the reinforcement learning training process to facilitate the transfer of experience between samples.
Curriculum learning is distinguished by the ability to control the order of task selection and creation fully, thus optimizing the performance of the reinforcement learning target task [
13]. When a reinforcement learning agent is faced with a difficult task, curriculum learning can assign auxiliary tasks to the agent to gradually guide its learning trajectory from easy to complex tasks until the target task is solved. At the 2009 International Conference on Machine Learning, Bengio et al. pointed out that the curriculum learning approach can be viewed as a special kind of continuous optimization approach that can start with smoother (i.e., simpler) optimization problems and gradually add coarser (i.e., more difficult), non-convex (norm) optimization problems to eventually perform the optimization of the target task [
14].
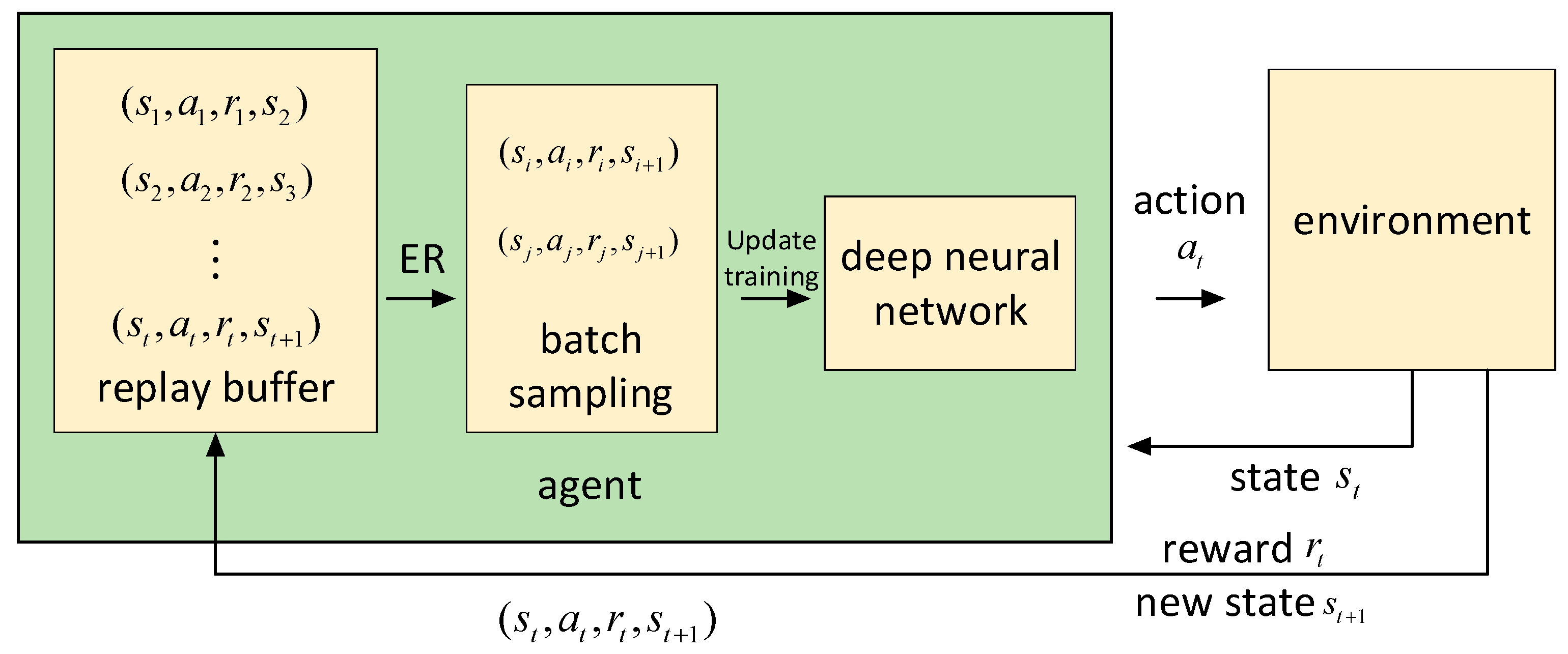
Current mainstream multi-agent deep reinforcement learning algorithms can reduce the correlation between training samples and ensure independence between samples by applying the experience replay buffer mechanism in the model fitting process [
15]. Automatic curriculum learning [
14] can build a task sampler based on the experience replay buffer. According to the curriculum learning rule, extract the most suitable tasks for the current reinforcement learning agent from the experience replay buffer from easy to difficult for neural network training. In this way, the sum of the cumulative reward value of the agent is maximized, and the learning efficiency and robustness of deep reinforcement learning are improved.
To reasonably sort the learning order of task samples in automatic curriculum learning, this paper proposes an automatic curriculum learning method based on K-Fold Cross Validation, which can be combined with a deep reinforcement learning algorithm based on the experience replay buffer represented by MADDPG to improve the performance of reinforcement learning agents for task training.
This method defines the simple curriculum learning task as a task that the current reinforcement learning model can solve well, and divides automatic curriculum learning into the curriculum difficulty evaluation stage and the curriculum sorting stage. In the evaluation stage of curriculum difficulty, dividing the state training samples in the replay buffer space into equal parts, multiple model networks are trained in parallel. With the rest of the teacher network model, the curriculum difficulty of the target state sample is evaluated, scored, and summed by a loss function and sum it up as the basis for the evaluation of the problem of task samples; In the stage of curriculum sorting, through the K-level classification of state samples from easy to difficult, the sample capacity in each difficulty category is randomly sampled for model learning. Finally, the training curriculums of the reinforcement learning algorithm are sorted from easy to difficult. Due to the applicability of the MADDPG algorithm in dealing with most multi-agent cooperative/competition problems, this paper uses the MADDPG algorithm as the basic reinforcement learning algorithm to combine the curriculum learning framework based on K-Fold cross validation and proposes a curriculum reinforcement learning algorithm based on K-Fold cross validation (KFCV-CL).
To test the effectiveness and feasibility of the KFCV-CL algorithm proposed in this paper, we applied it in two multi-agent reinforcement learning environments to verify its versatility and practicality. In the research process of the curriculum reinforcement learning method based on K-Fold cross validation, our research difficulties were the design of the curriculum ranking criteria and the design of the algorithm details of the sample ranking in the experience replay buffer, during which we compared the strengths and weaknesses of the existing algorithm research and proposed a new method of curriculum reinforcement learning based on the existing research. The experimental results show that the automatic curriculum learning method based on K-Fold cross validation can reflect more robust learning efficiency and robustness in combination with the MADDPG algorithm, which can shorten the training time and improve the learning performance.
The automatic curriculum learning mechanism based on K-Fold Cross Validation has the following characteristics:
- (1)
In sorting deep-reinforcement learning curriculums, this method can distinguish difficulty based on mutual measurement between target tasks, maintain the independence of task samples in the difficulty evaluation process, avoid interference with prior experience in curriculum sorting, and has better versatility for tasks.
- (2)
This method adopts the method of sampling from the replay buffer space in the process of automatic curriculum learning, which can be applied to the current mainstream multi-agent deep reinforcement learning algorithm (based on the replay buffer space mechanism), and has good algorithm applicability.
The rest of this paper is as follows.
Section 2 introduces related work, and
Section 3 presents the MADDPG algorithm and the basic concepts of automatic curriculum learning.
Section 4 introduces the automatic curriculum learning method based on K-Fold Cross Validation in detail.
Section 5 compares and analyzes experimental results and discusses them accordingly, and
Section 6 presents the conclusions.
2. Related Work
The concept of an easy-to-difficult training method can be traced back to the curriculum learning method proposed by a scientific research team led by Bengio, a leader in machine learning, at the International Conference on Machine Learning (ICML) in 2009 [
14]. In the learning process, the curriculum can be regarded as a sequence of the training process. The teacher model divides the entire machine learning task into several subparts. Bengio et al. have proven the advantages of curriculum policy in image classification and language modeling through experiments. This inspired us to design reinforcement learning tasks using curriculum learning algorithms.
In the early stages of the application of curriculum learning to the reinforcement learning process, most people adopt the method of human-designed curriculum for curriculum sorting instead of automatically generating curriculum by agents, including learning to execute short programs [
16] and finding the shortest paths in graphs [
17]. By experimenting with applied methods of curriculum learning, Felipe et al. [
18] proposed that curriculums can be automatically generated from object-oriented task descriptions, using the generated curriculums to reuse knowledge across tasks, Jiayu Chen et al. [
19] perform curriculum updates and agent number expansion in the process of automatic curriculum learning, Daphna et al. [
20] proposed the Inference Curriculum (IC) method, a way of transferring knowledge from another network, trained on different tasks.
Regarding the design method of curriculum reinforcement learning, our method is similar to the safe curriculum reinforcement learning method proposed by Matteo Turchetta et al. [
21], the teacher-student curriculum learning presented by Tambet Matiisen et al. [
22], and the curriculum reinforcement learning policy learning proposed by Sanmit Narvekar et al. [
23] is relatively close. Our method divides reinforcement learning curriculum sorting into two stages, curriculum difficulty assessment and curriculum sorting by stages. Matteo Turchetta et al. avoided the dangerous policy of student network by resetting the controller, Tambet Matiisen et al. set teacher-student curriculum learning method, the teacher model selects the task with the highest learning slope from the given task set for students to learn, Sanmit Narvekar et al. defined the curriculum sorting problem as a Markov Decision Problem (MDP). The above methods are pretty different from our proposed KFCV-CL method by extending the model to handle reinforcement learning problems.
Our method can optimize curriculum learning in two aspects: model assessment and model selection. Traditional curriculum learning mainly conducts model assessment through autonomous assessment and heuristic assessment, and the heuristic assessment method requires direct curriculum sample assessment based on experts’ empirical knowledge, which suffers from intense subjectivity and weak generalization ability. In contrast, the model autonomous assessment method conducts a direct curriculum sample. The autonomous model evaluation method directly assesses the curriculum sample through student models, which suffer from inefficient data utilization and overfitting problems. Our approach uses time difference error as the curriculum evaluation criterion and the K-fold cross validation method, which can avoid the overfitting problem caused by the autonomous assessment model, thus obtaining a more reasonable and accurate assessment of the student model and improving the accuracy of curriculum selection in curriculum learning.
4. Curriculum Reinforcement Learning Algorithm Based on K-Fold Cross Validation
This paper proposes a general curriculum learning framework, the K-Fold Cross Validation Curriculum Learning (KFCV-CL) framework, which can be applied to multi-agent deep reinforcement learning problems based on the replay buffer mechanism. By analyzing the temporal difference loss values of all training state samples in the cooperative/competitive task, we found that the reinforcement learning agent can quickly grasp the state task (simple task) whose initial state is closer to the final state after a few rounds of training, but it is difficult to grasp the state task (a difficult task) whose initial state is far from the final state during the whole training process. Based on this correlation, this work proposes a K-Fold Cross Validation method to define the state task difficulty. The K-Fold Cross Validation curriculum learning framework is divided into two stages: curriculum difficulty evaluation and curriculum sorting.
For all target tasks, let be the training set of all state samples used for training and be the set of parameters of the neural network model used for training. In the curriculum difficulty evaluation stage, a curriculum difficulty score is given to each state sample in , and is used as the difficulty level score set corresponding to all state samples in the training set . In the curriculum sorting stage, based on the above difficulty level scores, is divided into a series of task curriculum sets from easy to difficult for training, and finally, the expected complex task training effect is obtained.
4.1. Assessment of Curriculum Difficulty
The difficulty of a curriculum task sample can be determined by many elements, for example, the distance between the initial state of each agent and the final state, the number, and location of obstacles in the environment, the sparsity of rewards, etc. The difficulty of curriculum tasks can be distinguished explicitly by setting a difficulty evaluation function. However, traditional difficulty assessment methods have the following problems. First, the weight coefficients between the difficulty factors are not easy to assign. For example, it is difficult to distinguish the influence between the degree of reward sparsity and the number of obstacles. Second, traditional methods are not universal for multi-agent reinforcement learning problems in different environments, and the influence of factors needs to be reevaluated.
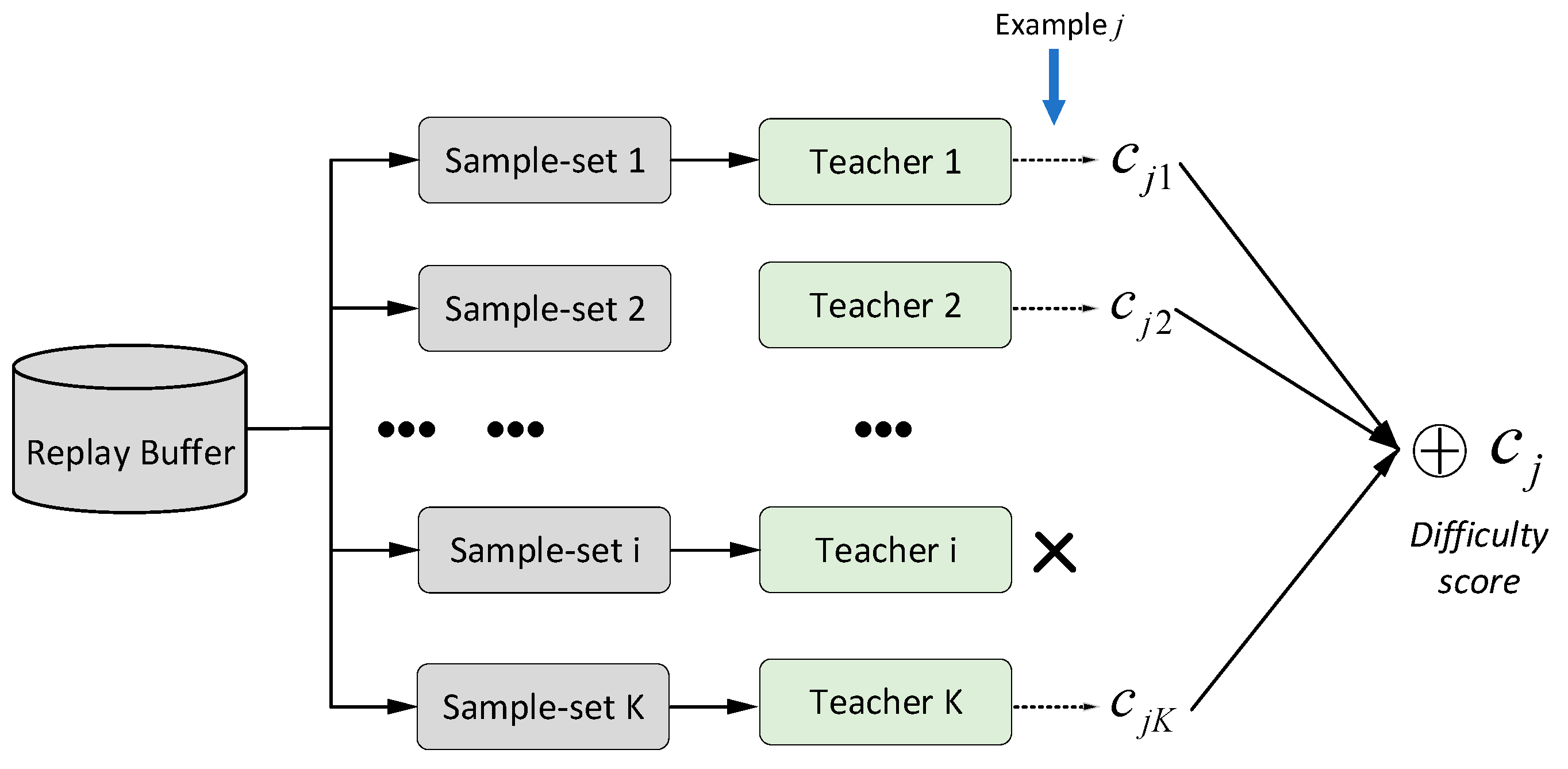
The curriculum difficulty evaluation method proposed in this paper can evaluate the relative difficulty of the target sample through the teacher network formed by the remaining samples, avoid the subjective bias caused by the assignment of the weight coefficient, and improve the versatility of the difficulty evaluation method.
The MADDPG algorithm belongs to the Temporal Difference (TD) algorithm, which uses the estimated reward function
to update the value function
(TD(0))
where
is called TD target and
is called TD error.
We take the absolute value of temporal difference error as the evaluation reference for the difficulty of the curriculum task because the state sample with a significant total value of temporal difference error may harm the fitting of the training model. There are the following reasons: 1. In a complex environment, the reward value is easily affected by random noise, which may affect the real network training and lead to deviations in target network training; 2. In the stochastic gradient descent process of deep neural networks, state samples with larger absolute values of temporal difference errors require smaller update steps to reach the global minimum of gradient descent.
To evaluate the difficulty of the curriculum, the state sample training set
in experience replay buffer space in the reinforcement learning algorithm is equally divided into
parts,
, and the
training sample subsets are used for parallel training of the reinforcement learning model respectively,
, and the resulting
network models are called teacher network models, which are used to evaluate the samples in the target student network model. The training process of the teacher network model is described as follows:
where
represents the loss function of temporal difference error,
represents the experience samples drawn from the training set of state samples in the experience replay buffer
, and
represents the
reinforcement learning models trained by a subset of
training samples, respectively.
After the teacher network training is completed, the difficulty evaluation of curriculum task samples is carried out. The task sample
is included in the
th subset, the teacher network corresponding to the
th subset is removed, and the remaining
teacher models are used to estimate the score of the curriculum task sample
, and the
scores are obtained. The scoring process of each teacher model for the target curriculum task sample
is expressed as follows:
where
represents the score of the target curriculum task sample
by the teacher network corresponding to the
th subset,
represents the
value obtained by inputting the state
and action value
into the teacher model,
represents the action taken by the
th agent, and
represents the discount factor, then the difficulty score corresponding to the task sample
is defined as the sum of the scores of all remaining teacher training models:
As a result, the curriculum difficulty score corresponding to the task sample
can be obtained. Since teacher training models are carried out independently in the scoring process, the influence of the data contained in the task sample
on the task sample, the difficulty score can be avoided, the robustness and accuracy of the scoring result can be improved, and it has good versatility.
Figure 4 shows the framework for assessing the difficulty of curriculum tasks.
4.2. Curriculum Sorting Rules
In this section, we divide the training samples in the experience buffer space into multiple stages for reinforcement learning training according to the difficulty scores corresponding to the previously calculated curriculum task samples. , at each stage of training, the random sampling method is still used for model training for this part of the state samples to ensure the independent and identical distribution of the samples and avoid overfitting.
After estimating the difficulty of all training task samples according to the task curriculum difficulty measurement method in the previous section, the training samples are sorted in difficulty order from low to high, the task samples are divided into training sets, , and the training sets are sorted from easy to difficult.
For task state samples, this hierarchical structure of difficulty scores can directly reflect the inherent difficulty distribution corresponding to the training sample set. After that, we divide the learning of the curriculum into
stages. For each learning stage, random sampling is conducted from the training set of the corresponding difficulty for periodic training of the neural network. After the training period
is reached, the final stage of training is carried out through the set
of the original training samples. The training set is used to ensure the convergence of the model to finally realize the curriculum reinforcement learning process from easy to difficult.
4.3. Algorithm Framework and Process
The pseudocode of the KFCV-CL algorithm is as follows (Algorithm 1):
| Algorithm 1: KFCV-CL algorithm |
| for to do |
| Initialize a random process for reinforcement learning action exploration |
| for to do |
| for each agent , select the action w.r.t the current policy |
| The agent conducts action , transfers to the next state and obtains the reward |
| Store into buffer space |
| |
| Divide the experience samples in into equal parts, |
Teacher models are trained for , the parameters are
|
The score of each experience sample is obtained
|
| Sort the experience samples and divide them into training sets |
| for agent to do |
| Sampling a minibatch of experience quadruples from |
Calculate the expected action reward of each experience sample
|
Minimize loss function to update Critic network parameters
|
Update the Actor network parameters by the following gradient function
|
| end for |
Update the target network parameters of each agent
|
| end for |
| end for |
In summary, we can learn curriculum tasks from easy to difficult through the difficulty assessment and curriculum sorting process. Next, we will conduct simulation experiments in two cooperative/competitive task environments.
5. Experiment
We conduct simulation validation of the curriculum reinforcement learning algorithm based on K-Fold cross validation in two experimental environments in multi-agent particle world environment [
30]. Each group of experiments is carried out in Ubuntu18.04.3+PyTorch+OpenAI environment, the hardware environment is IntelCore i7-9700K+GeForceRTX2080+64G memory, the test environment tasks are the cooperative task (Hard Spread), and adversarial task (Grassland), the birth positions of agents are randomly generated, and obstacles are randomly added, which can better enhance the difficulty combined with the algorithm simulation needs in this paper.
The reinforcement learning testing process does not have an input dataset but relies on data interaction with a simulated environment. The learning performance of the reinforcement learning algorithm can be measured from two aspects: 1. The cumulative reward value changes with the number of training episodes. Under the premise of the same number of training episodes, the higher the total reward value obtained by agents, the better the training effect, and the faster the convergence speed; 2. From the actual performance of the agents in the simulation environment, the agents can cooperate and compete in the environment and have better performance, indicating that the training efficiency of the algorithm is higher. The key hyperparameters set for the RL training process are listed in
Table 1.
5.1. Hard Spread Experiment
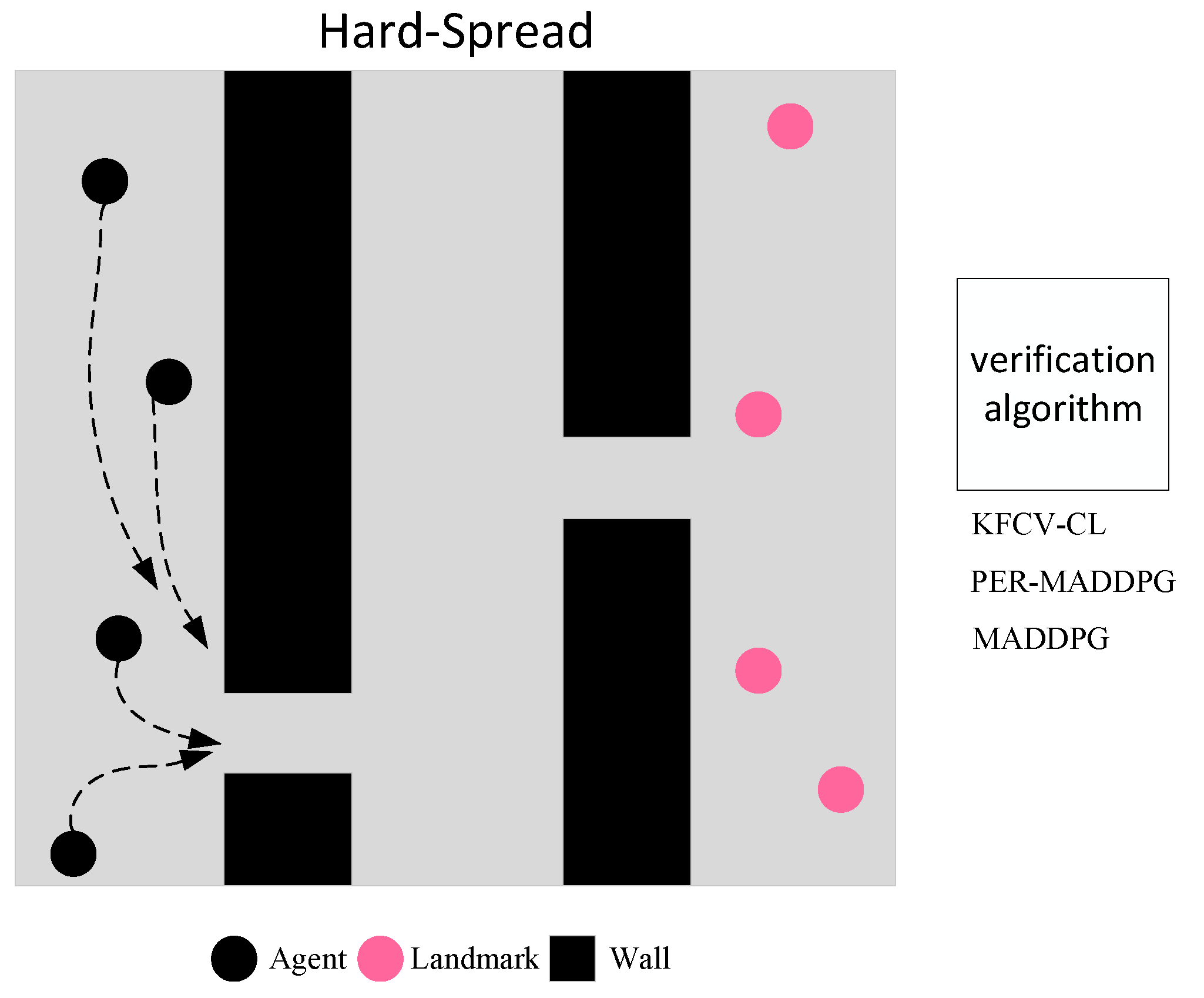
The multi-agent cooperation experiment adopts the “Hard Spread” environment. As shown in
Figure 5, in a square two-dimensional plane with a side length of 6, the plane is isolated into three parts by randomly adding walls, and N agents and N landmarks are generated randomly in the plane. The agents can only observe the landmark position but cannot observe the wall. The learning goal of agents is to reach a landmark position in the shortest time and to avoid collision with other agents or walls. To achieve the overall training goal as soon as possible, each agent needs to consider the distance to the nearest landmark and, at the same time, consider the relative positions of other agents and the target to obtain the globally optimal policy and avoid falling into the trap of local minimum.
The reward obtained by each agent at each time step consists of three parts, including 1. the distance between the agent and the nearest landmark; 2. whether the agent collides with other agents or walls; 3. whether the agent has reached a landmark location. The closer the distance between the agents and the landmarks, the higher the reward, and the environment gives a positive reward to the agent that covers the landmark and a negative reward to the agent that collides. The agent collision reward is defined as follows:
The agent coverage landmark reward is defined as follows:
Let the distance between agent
and landmark
be
,
, represents the closer the agent
is to the nearest target
, the greater the reward value it gets. Then the reward function of agent
at each moment is
In the value of the equation, represents the eigenvector corresponding to the shortest distance.
As shown in
Figure 5, in the
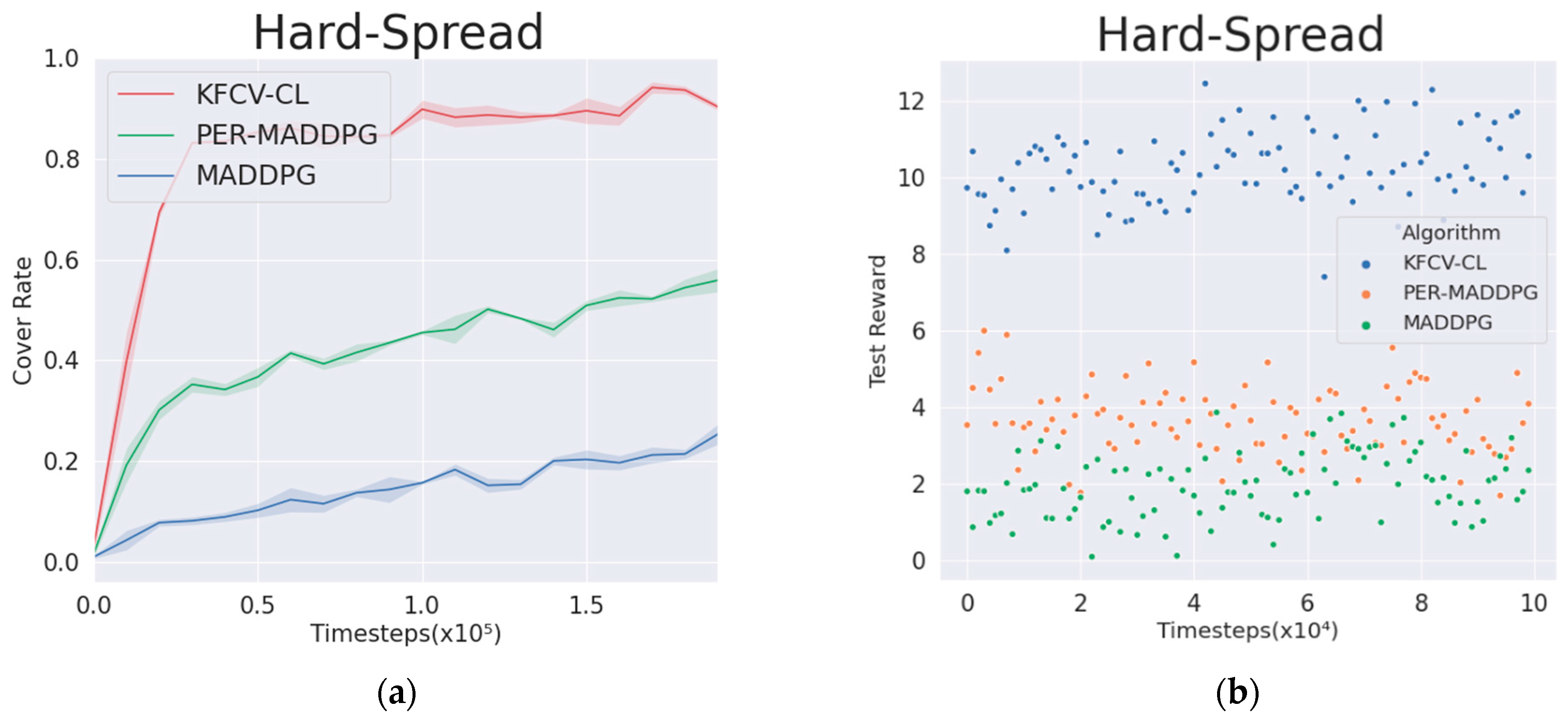
environment, the KFCV-CL, PER-MADDPG, and MADDPG algorithms are used to control the movement of the agent. Under the same number of training episodes, the algorithm that obtains a higher cumulative reward value and the cover rate has higher training performance and faster model convergence.
Figure 6a shows the average cover rate curves of the three algorithms after
rounds of training. It can be seen from the figure that the coverage of the KFCV-CL algorithm can be significantly improved compared with the PER-MADDPG and MADDPG algorithms after sorting the curriculums from easy to difficult.
Table 1 shows the average number of collisions in each step, the average minimum distance between the agent and the nearest landmark, and the average number of landmarks covered by the agent after
rounds of training and 10,000 random rounds of experiments based on the policies learned by the agents. From the results in
Table 2, the agents controlled by the KFCV-CL algorithm can significantly improve the three indicators. As shown in the figure, the test reward obtained by the agent performing random 10,000 rounds of experiments can be stably maintained at a high level, which means that the agents can learn a better policy.
Figure 6b is a scatter diagram of the test reward obtained by the agents performing random 10,000 rounds of experiments.
5.2. Grassland Experiment
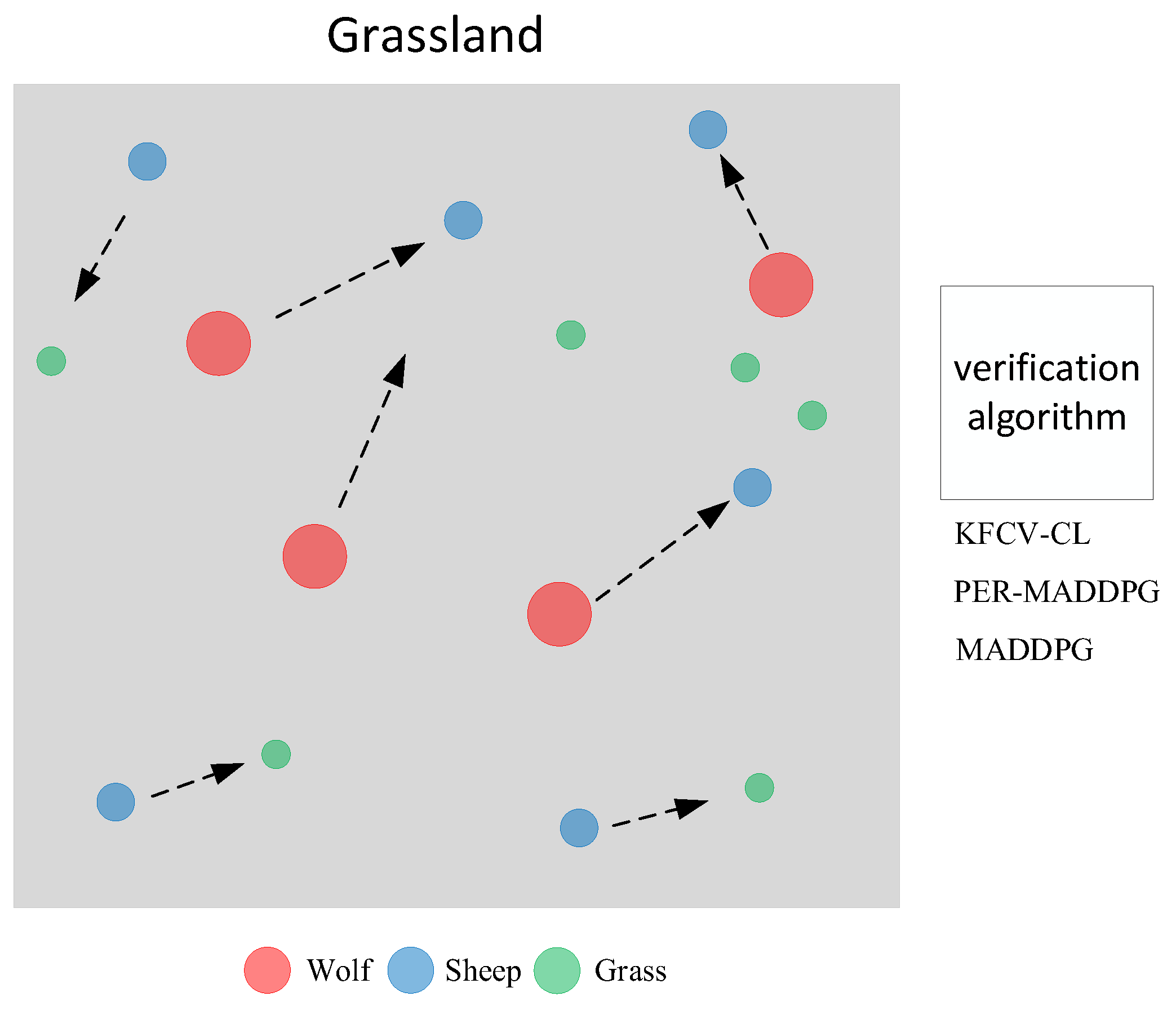
In a cooperative training environment, the agent’s policy will continue to mature along with the training process, and the cumulative reward value will continue to increase. In a multi-agent adversarial environment, the agent’s policy will also be affected by the opponent’s agent policy, and the convergence speed of the two policies is not synchronized, so the cumulative reward value will fluctuate and will have higher requirements for algorithm training performance, the KFCV-CL algorithm can effectively improve the learning performance of agents in the mutual game.
The multi-agent adversarial experiment adopts the “grassland” experiment, which is adapted from the classic experiment “predator-prey” in the MPE environment and improves the confrontation and training difficulty of the experimental environment by introducing grass and allowing the agent (sheep) to die. In the two-dimensional plane [0, 1], there are sheep, wolves and piles of grass, where the sheep move twice as fast as the wolf, and the grass stays in place.
All environments in the grassland experiment are entirely observable. The agent needs to adjust its policy according to the opponent’s policy and the partner’s policy and respond to the global state. As the number of wolves increases, it becomes increasingly difficult for sheep to survive. At the same time, the sheep become more brilliant, which will also reversely motivate the wolves to improve their policies. The reward value of the wolf depends on the distance between it and the sheep and whether the sheep are caught. The smaller the distance between each other, the greater the reward value.
Let the distance between the wolf
and the sheep
be
, then
When a wolf collides with (eats) a sheep, the wolf will receive a higher reward value for it. At the same time, the sheep will receive a negative reward value (penalty). Reward value for successfully colliding (eating) the sheep of the wolf is as follows:
To maintain the excellent operation of the training environment and prevent the agent from giving up learning a better policy because of escaping the boundary, a large negative reward value (penalty) is imposed on the agent that escapes the boundary of the two-dimensional plane. The size of the penalty depends on how far the agent leaves the boundary, and the boundary reward is
When the sheep encounters (eats) grass, it will get a reward value. After the grass is eaten by sheep, it will respawn in another random area.
In the grassland experiment, wolves cooperate to complete the predation task. Since the overall reward value is prioritized in the environment, the instantaneous higher reward of the individual agent can be sacrificed, so the distance taken when defining the reward value is the minimum distance between the wolves and sheep, and the reward function of the wolf
is
The movement speed of the sheep group is faster than that of the wolf group, and the movement range has boundaries. Therefore, to maximize the overall reward value of the sheep group, considering the sum of the distances from the wolves in the environment, the reward function of sheep
is:
In the above equation, represents the eigenvector corresponding to the shortest distance.
In the reinforcement learning environment, the KFCV-CL, PER-MADDPG, and MADDPG algorithms are used to control wolves to move and compete with sheep trained by other baseline algorithms. The average reward value for wolves is used as the wolf evaluation index, and the average reward value for sheep is used as the sheep evaluation index.
Figure 7 shows a schematic diagram of the training in the adversarial environment training.
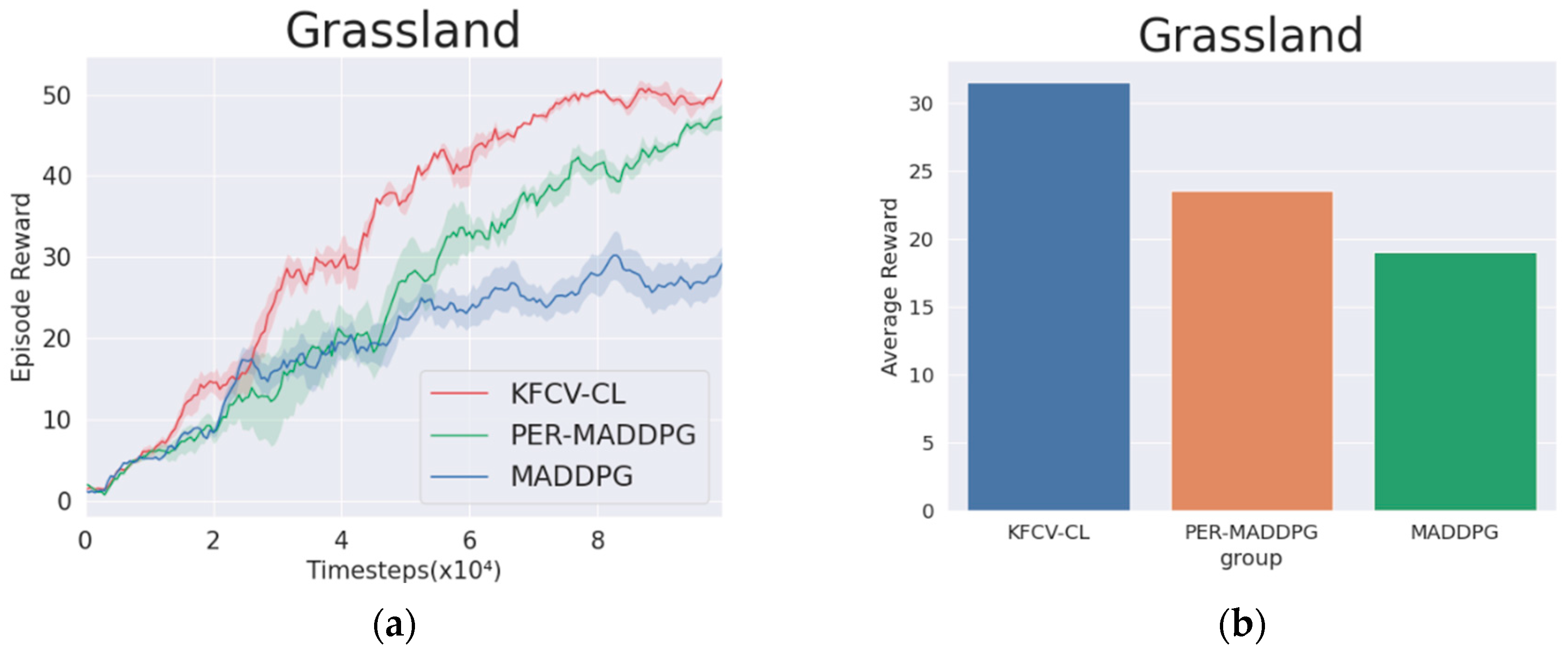
In the environment of
, the KFCV-CL, PER-MADDPG, and MADDPG algorithms are used to control the wolves to move and compete with the sheep trained by MADDPG. The curves in
Figure 8a represent the trend of the reward value obtained by the wolf agent corresponding to the three algorithms in
rounds, the legend of (b) illustrates the histogram of the average reward value obtained by the three algorithms in 10,000 rounds. From the reward value curves of the adversarial experiment, it can be concluded that due to asynchrony in the algorithm training process, the reward value curve has a fluctuating upward process. The red curve corresponding to the KFCV-CL algorithm is significantly higher than the reward curves corresponding to the other two algorithms. The average reward value of KFCV-CL is 1.34 times that of PER-MADDPG and 1.65 times that of MADDPG, which shows that the performance of the KFCV-CL algorithm is significantly better than the other two algorithms.
As shown in
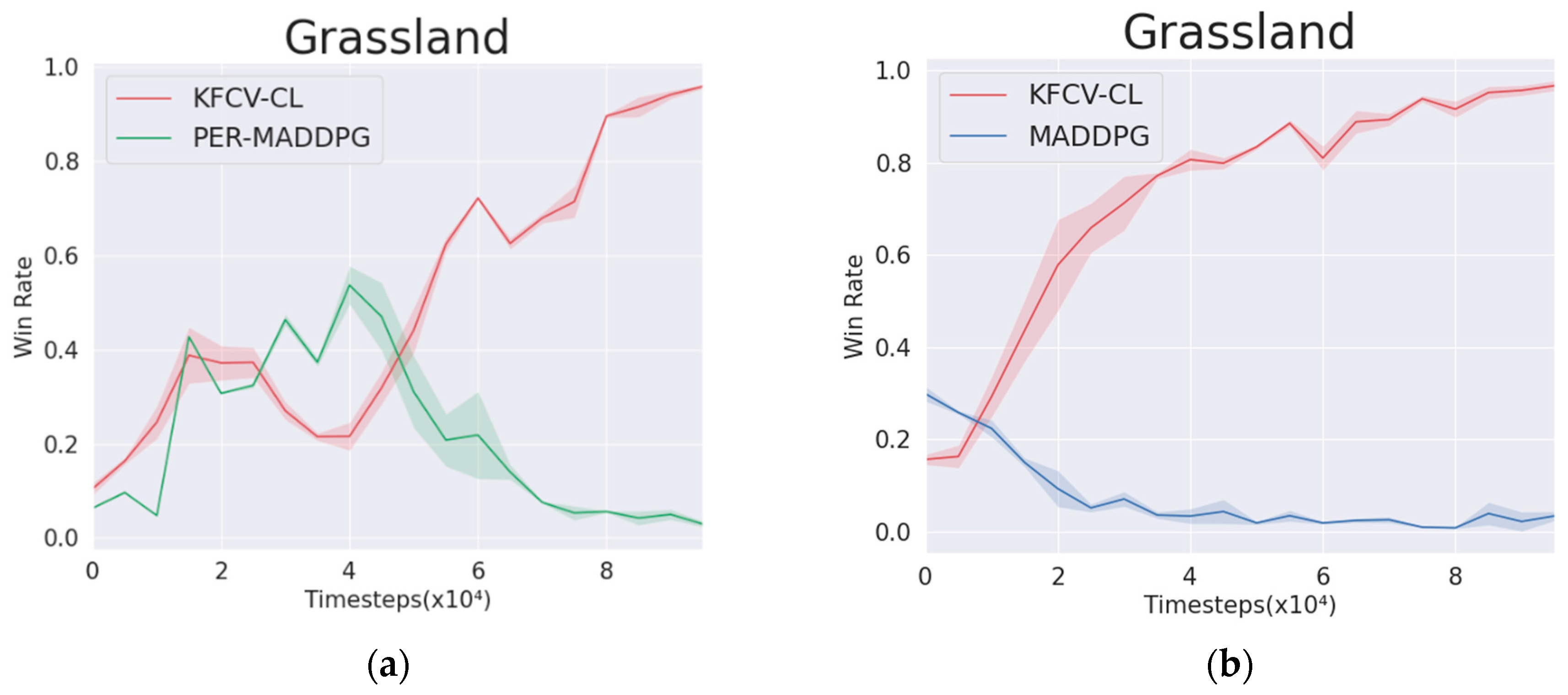
Figure 9, in the environment of
, the KFCV-CL algorithm is used to control the wolf agent, and the PER-MADDPG and MADDPG algorithms are used to control the sheep agent, respectively, and the winning rate curves corresponding to the wolf and sheep are obtained. From the winning rate curves, the wolf agent controlled by the KFCV-CL can gain an advantage in a short time (20,000 rounds) against the sheep agent controlled by the MADDPG algorithm, and the winning rate is stable above 0.85. However, when the wolf agent controlled by KFCV-CL fights against the sheep agent controlled by PER-MADDPG, it wins and loses in the early stage but can learn better policies in the later stage, thereby gaining an advantage in the confrontation. It can be seen that the performance of the KFCV-CL algorithm is significantly better than the other two algorithms.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}