
Multisensor Estimation Fusion on Statistical Manifold


Abstract
:1. Introduction
- (i)
- To exploit the non-Euclidean characteristics of probabilistic space and the decouple feature of Manhattan distance, we formulate a novel information-geometric criterion for fusion and discuss its inherent advantages.
- (ii)
- We derive the explicit expression for the MHD-based projection from a point onto the MED submanifold with a fixed mean, and then develop two fusion methods MHDP-I and MHDP-E by relaxing the fusion criterion, which both have the same mean estimation fusion, but differ in the form of the fused covariance. A fixed point iteration is given to obtain this fused mean.
- (iii)
- The MHDP-I obtains the fused covariance using a robust fixed point iterative algorithm with theoretical convergence, while the MHDP-E provides an explicit expression for the fused covariance by introducing a Lie algebraic structure. We also provide a crucial theorem presenting the exponential mapping and logarithmic mapping on the MED submanifold with a fixed mean.
- (iv)
- Simulations indicate that the two proposed information-geometric methods outperform some existing fusion methods under non-Gaussian distributions.
Notations
2. Preliminaries
2.1. Statistical Manifold and Fisher Metric
2.2. Information Geometry of Elliptical Distributions
- (i)
- for the MGGD, , ;
- (ii)
- and for the MTD, .
- (i)
- If , then
- (ii)
- If , thenwhere,
2.3. Some Submanifolds of Elliptical Distributions
2.4. Manhattan Distances
3. Fusion Criterion
3.1. Information-Geometric Criterion
- (i)
- (ii)
- As a tight upper bound for the Rao distance on the MED manifold, the minimal MHD (28) can be efficiently computed numerically. Moreover, its superior approximation performance has been fully verified by comparison with the Rao distances on the manifolds of MTDs and MGGDs (see [43] for more details).
3.2. Decoupling Fusion Criterion
- (i)
- (ii)
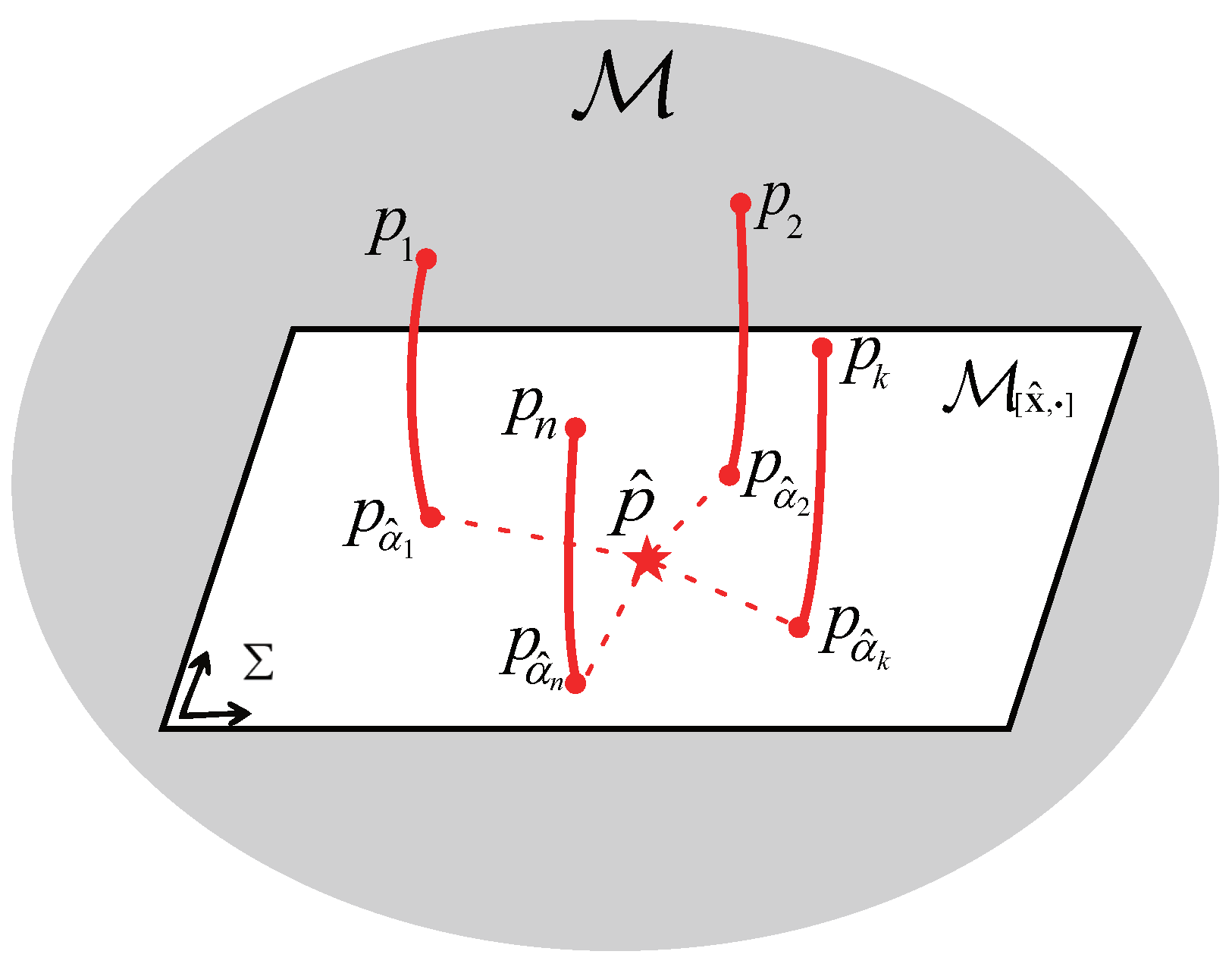
- The inner minimizations in (39) project each local density onto the MED submanifold with some common fixed mean to obtain its substitute . An appropriate candidate for the specified mean variable is selected by the outer optimization, minimizing the sum of MHDPDs from the local posterior densities onto .
- (i)
- The covariance fusion (41) is indeed performed on the space , since the Rao distance of only depends on the coordinate . Moreover, the Riemannian mean (also called Riemannian center of mass) of data points in , which is the unique global minimizer of with a geodesic distance on (see [52,53]), has been widely studied on the manifold of covariance matrices [54].
- (ii)
- The criterion gives a robust alternative for the center of mass, called the Riemannian median [55,56]. Both the Riemannian mean and the Riemannian median have been successfully applied to signal detection (e.g., [57,58]) and have shown their own advantages. However when only two sensors (i.e., ) are considered, any point lying on the shortest geodesic segment between two points and can be regarded as the Riemannian median, which seems quite undesirable for fusion. In addition, the final mean fusion (39) does not contradict this claim owing to its adopting the MHDPD as the cost function.
- (iii)
- Due to the intractable root operation within the geodesic distance , the squared geodesic distance is considered for the convenience of solving the optimization problem (41). As illustrated in Section 4.2, we develop an efficient iterative strategy for the fused scatter estimate in the criterion (41) with at least linear convergence.
4. Two MHDP-Based Fusion Methods
4.1. Mean Estimation Fusion
| Algorithm 1: MHDP-based mean estimation fusion. |
 |
4.2. Iterative Solution for Covariance Estimation Fusion
| Algorithm 2: MHDP-I fusion algorithm. |
 |
4.3. Explicit Solution for Covariance Estimation Fusion
- (i)
- Multiplication operation: , for any ;
- (ii)
- Inverse operation: , for any ;
- (iii)
- Identity element: .
- (i)
- Move the MHDPs into some neighborhood of the identity element via using a left translation by the sought-for scatter estimate to obtain . Then, all can be shifted to by the lifting mapping at e, obtaining the vectors for
- (ii)
- The arithmetic average of is the best way to minimize the total displacements from each to the sought-for on the Lie algebra owing to the linear structure of (see, e.g., [60]), hence or equivalently,
- (i)
- Let be a non-singular matrix. The metric on originated from (23) is invariant under the congruent transformation: for any .
- (ii)
- The exponential mapping and logarithmic mapping on are, respectively, given byfor any and .
| Algorithm 3: MHDP-E fusion algorithm. |
| Input: Output: , 1 Compute using Algorithm 1; 2 Compute using Equation (40); 3 Set ; 4 Compute using Equation (65); 5 return , |
5. Numerical Examples
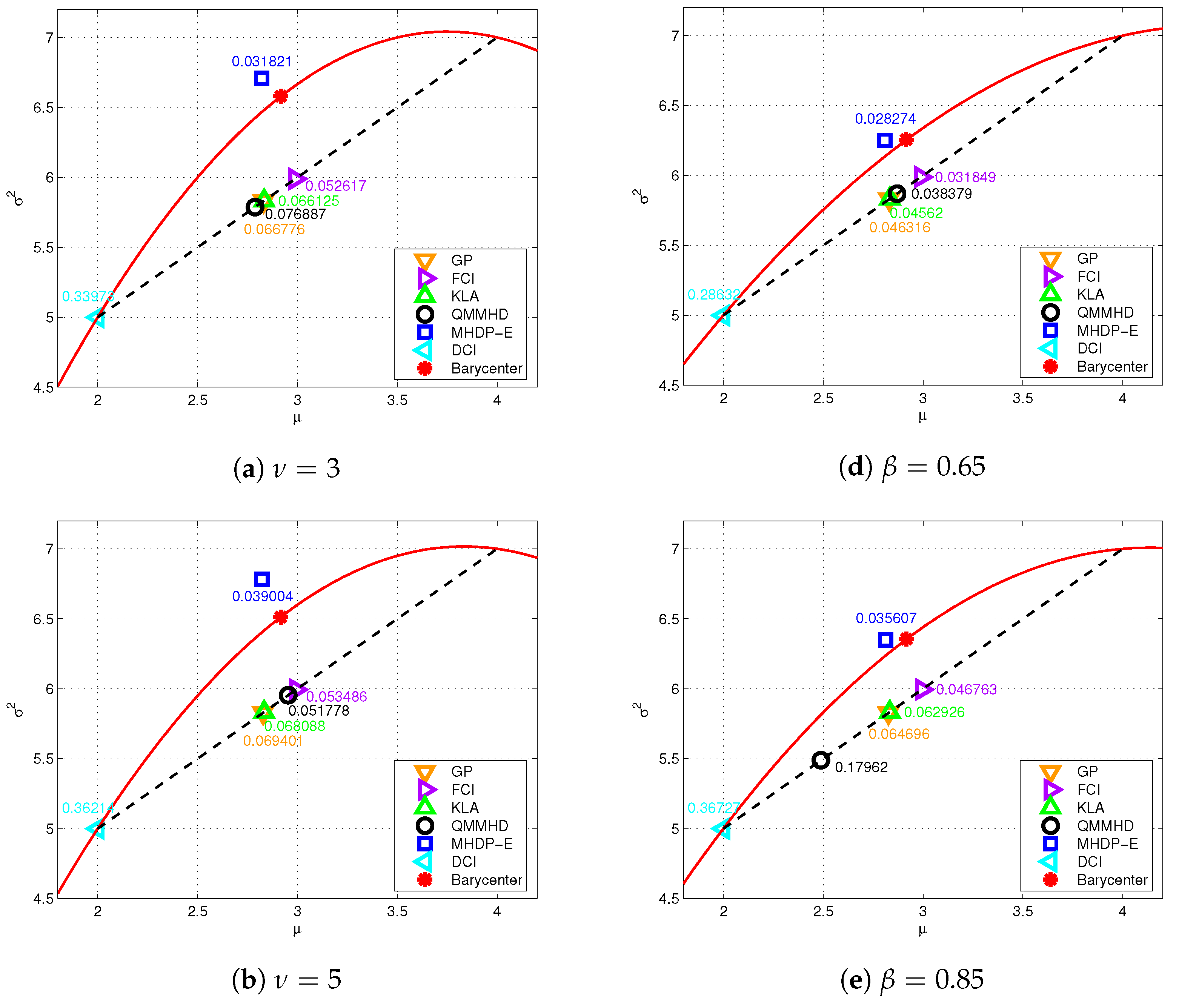
5.1. Static Target Tracking
- (i)
- The MTD has the degree of freedom (DOF) parameter (the higher , the lower the heavy-tailed level), and is almost equivalent to the Gaussian distribution as tends to infinity. As depicted in subfigures (a), (b) and (c), the MHDP-E is consistently superior to other methods regardless of the DOF, since the fused density of the MHDP-E is closest to the informative barycenter.
- (ii)
- The MGGD has the shape parameter (the higher , the lower the heavy-tailed level) and corresponds to the Gaussian distribution when . Similar to the MTD, subfigures (d), (e) and (f) show the MHDP-E outperforms other fusion methods for different shape parameters.
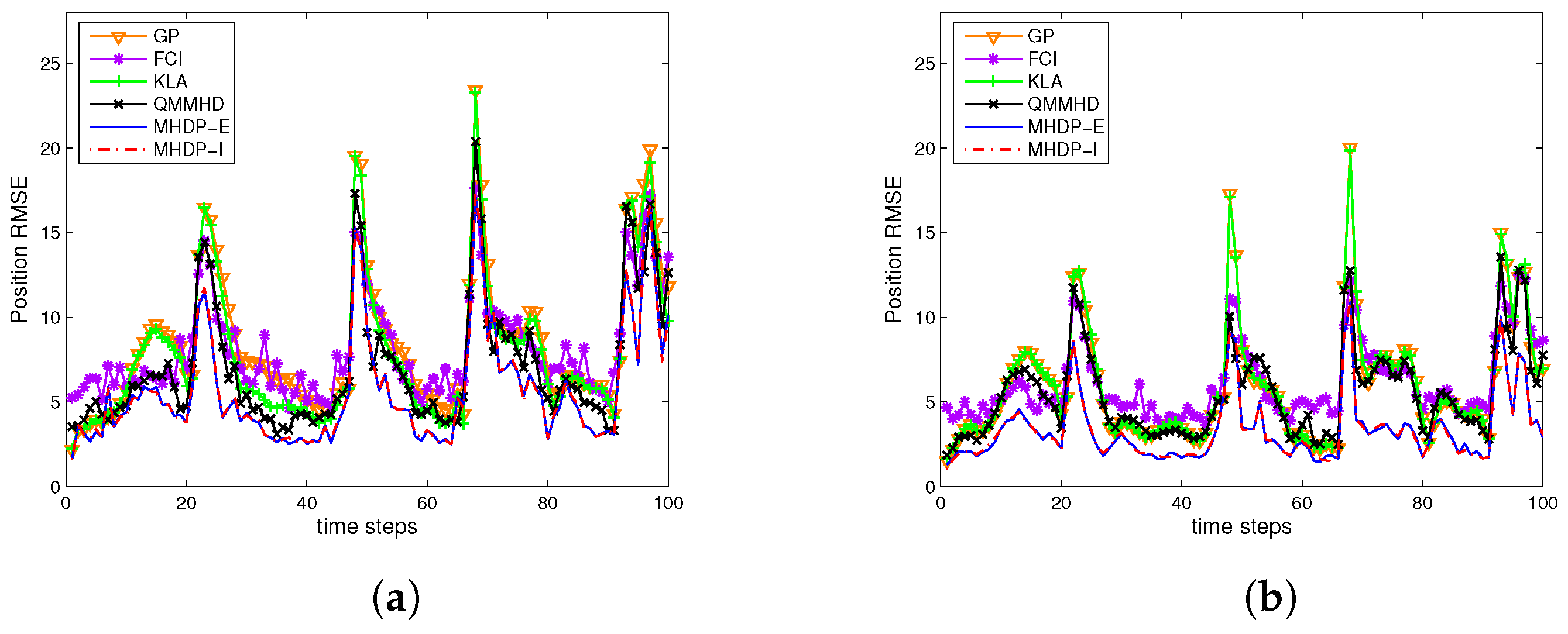
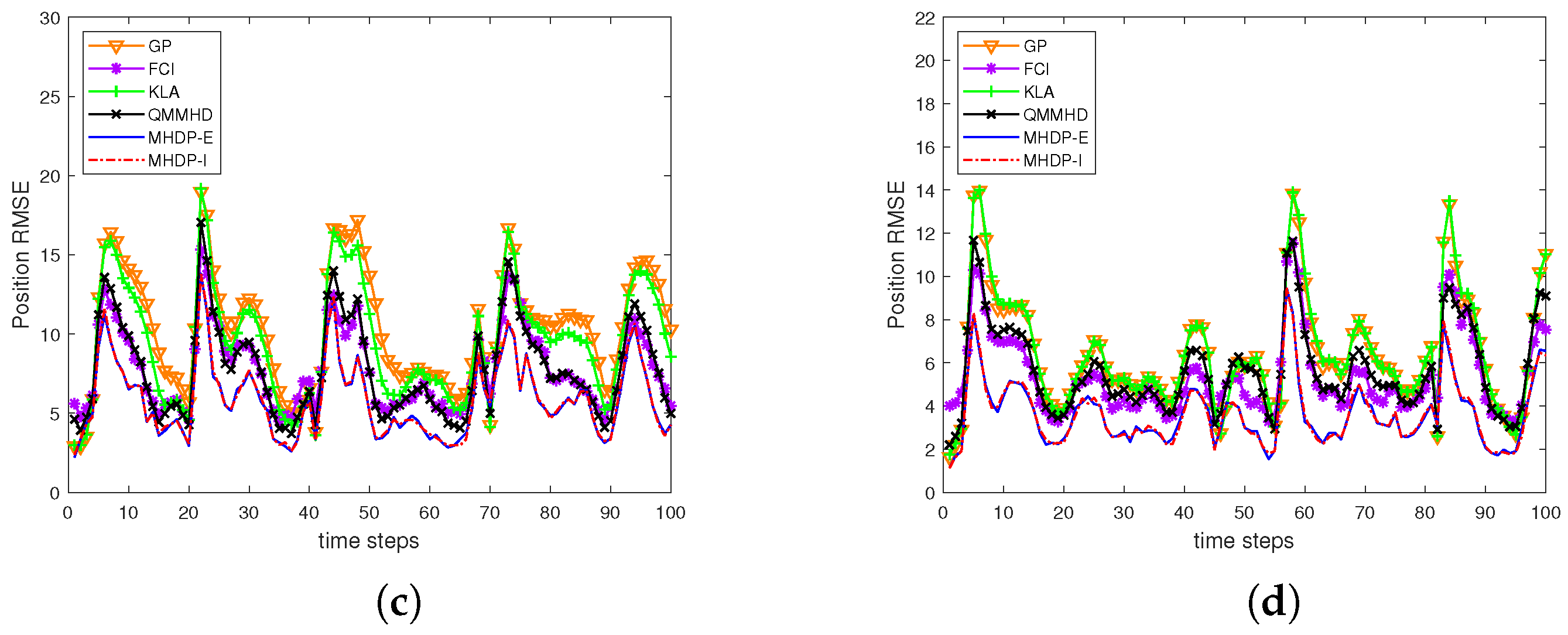
5.2. Dynamic Target Tracking
- (i)
- Case I (two sensors, i.e., ): The variances and , the measurement matricesand the two filters are initialized as
- (ii)
- Case II (three sensors, i.e., ): The system parameters have the same settings as Case I, and also
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Proof of Theorem 1
Appendix B. Proof of Theorem 2
Appendix C. Proof of Theorem 3
Appendix D. Proof of Theorem 4
Appendix E. Proof of Theorem 5
Appendix F. Proof of Theorem 6
References
- Du, J.; Fang, M.; Yu, Y.; Lu, G. An adaptive two-scale biomedical image fusion method with statistical comparisons. Comput. Methods Programs Biomed. 2020, 196, 105603. [Google Scholar] [CrossRef] [PubMed]
- Zhao, F.; Zhao, W.; Yao, L.; Liu, Y. Self-supervised feature adaption for infrared and visible image fusion. Inf. Fusion 2021, 76, 189–203. [Google Scholar] [CrossRef]
- Shafran-Nathan, R.; Etzion, Y.; Broday, D. Fusion of land use regression modeling output and wireless distributed sensor network measurements into a high spatiotemporally-resolved NO2 product. Environ. Pollut. 2021, 271, 116334. [Google Scholar] [CrossRef]
- Xiao, K.; Wang, R.; Deng, H.; Zhang, L.; Yang, C. Energy-aware scheduling for information fusion in wireless sensor network surveillance. Inf. Fusion 2019, 48, 95–106. [Google Scholar] [CrossRef]
- Salcedo-Sanz, S.; Ghamisi, P.; Piles, M.; Werner, M.; Cuadra, L.; Moreno-Martínez, A.; Izquierdo-Verdiguier, E.; Muñoz-Marí, J.; Mosavi, A.; Camps-Valls, G. Machine learning information fusion in earth observation: A comprehensive review of methods, applications and data sources. Inf. Fusion 2020, 63, 256–272. [Google Scholar] [CrossRef]
- Liggins, M.E.; Hall, D.L.; Llinas, J. (Eds.) Handbook of Multisensor Data Fusion: Theory and Practice, 2nd ed.; CRC Press: Boca Raton, FL, USA, 2009. [Google Scholar]
- Li, G.; Battistelli, G.; Yi, W.; Kong, L. Distributed multi-sensor multi-view fusion based on generalized covariance intersection. Signal Process. 2020, 166, 107246. [Google Scholar] [CrossRef]
- Bar-Shalom, Y.; Campo, L. The effect of the common process noise on the two-sensor fused-track covariance. IEEE Trans. Aerosp. Electron. Syst. 1986, 22, 803–805. [Google Scholar] [CrossRef]
- Li, X.R.; Zhu, Y.; Wang, J.; Han, C. Optimal linear estimation fusion—Part I: Unified fusion rules. IEEE Trans. Inf. Theory 2003, 49, 2192–2208. [Google Scholar] [CrossRef]
- Julier, S.J.; Uhlmann, J.K. A non-divergent estimation algorithm in the presence of unknown correlations. In Proceedings of the 1997 American Control Conference, Albuquerque, NM, USA, 6 June 1997; pp. 2369–2373. [Google Scholar]
- Reinhardt, M.; Noack, B.; Arambel, P.O.; Hanebeck, U.D. Minimum covariance bounds for the fusion under unknown correlations. IEEE Signal Process. Lett. 2015, 22, 1210–1214. [Google Scholar] [CrossRef]
- Julier, S.J.; Uhlmann, J.K. General decentralized data fusion with covariance intersection (CI). In Handbook of Multisensor Data Fusion: Theory and Practice; CRC Press: Boca Raton, FL, USA, 2001; pp. 12.1–12.5. [Google Scholar]
- Chong, C.Y.; Mori, S. Convex combination and covariance intersection algorithms in distributed fusion. In Proceedings of the 4th International Conference of Information Fusion, Sun City, South Africa, 1–4 November 2001; Volume 1, pp. 11–18. [Google Scholar]
- Eldar, Y.C.; Beck, A.; Teboulle, M. A minimax Chebyshev estimator for bounded error estimation. IEEE Trans. Signal Process. 2008, 56, 1388–1397. [Google Scholar] [CrossRef]
- Wang, Y.; Li, X.R. Distributed estimation fusion under unknown cross-correlation: An analytic center approach. In Proceedings of the 13th International Conference on Information Fusion, Edinburgh, UK, 26–29 July 2010; pp. 1–8. [Google Scholar]
- Hurley, M.B. An information theoretic justification for covariance intersection and its generalization. In Proceedings of the 5th International Conference on Information Fusion, Annapolis, MA, USA, 8–11 July 2002; pp. 505–511. [Google Scholar]
- Wang, Y.; Li, X.R. A fast and fault-tolerant convex combination fusion algorithm under unknown cross-correlation. In Proceedings of the 12th International Conference on Information Fusion, Seattle, WA, USA, 6–9 July 2009; pp. 571–578. [Google Scholar]
- Battistelli, G.; Chisci, L. Kullback–Leibler average, consensus on probability densities, and distributed state estimation with guaranteed stability. Automatica 2014, 50, 707–718. [Google Scholar] [CrossRef]
- Costa, S.I.R.; Santos, S.A.; Strapasson, J.E. Fisher information distance: A geometrical reading. Discret. Appl. Math. 2015, 197, 59–69. [Google Scholar] [CrossRef]
- Bishop, A.N. Information fusion via the Wasserstein barycenter in the space of probability measures: Direct fusion of empirical measures and Gaussian fusion with unknown correlation. In Proceedings of the 17th International Conference on Information Fusion, Salamanca, Spain, 7–10 July 2014; pp. 1–7. [Google Scholar]
- Takatsu, A. Wasserstein geometry of Gaussian measures. Osaka J. Math. 2011, 48, 1005–1026. [Google Scholar]
- Puccetti, G.; Rüschendorf, L.; Vanduffel, S. On the computation of Wasserstein barycenters. J. Multivar. Anal. 2020, 176, 104581. [Google Scholar] [CrossRef]
- Amari, S.I.; Kurata, K.; Nagaoka, H. Information geometry of Boltzmann machines. IEEE Trans. Neural Netw. 1992, 3, 260–271. [Google Scholar] [CrossRef]
- Amari, S.I. Information geometry of the EM and em algorithms for neural networks. Neural Netw. 1995, 8, 1379–1408. [Google Scholar] [CrossRef]
- Cheng, Y.; Wang, X.; Morelande, M.; Moran, B. Information geometry of target tracking sensor networks. Inf. Fusion 2013, 14, 311–326. [Google Scholar] [CrossRef]
- Eilders, M.J. Decentralized Riemannian Particle Filtering with Applications to Multi-Agent Localization. Ph.D. Thesis, Air Force Institute of Technology, Dayton, OH, USA, 2012. [Google Scholar]
- Amari, S.I.; Kawanabe, M. Information geometry of estimating functions in semi-parametric statistical models. Bernoulli 1997, 3, 29–54. [Google Scholar] [CrossRef]
- Rong, Y.; Tang, M.; Zhou, J. Intrinsic losses based on information geometry and their applications. Entropy 2017, 19, 405. [Google Scholar] [CrossRef] [Green Version]
- Gómez, E.; Gomez-Viilegas, M.A.; Marín, J.M. A multivariate generalization of the power exponential family of distributions. Commun. Stat.–Theory Methods 1998, 27, 589–600. [Google Scholar] [CrossRef]
- Samuel, K. Multivariate t-Distributions and Their Applications; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Kotz, S.; Kozubowski, T.J.; Podgórski, K. (Eds.) The Laplace Distribution and Generalizations: A Revisit with Applications to Communications, Economics, Engineering, and Finance; Birkhäuser: Boston, MA, USA, 2001. [Google Scholar]
- Wen, C.; Cheng, X.; Xu, D. Filter design based on characteristic functions for one class of multi-dimensional nonlinear non-Gaussian systems. Automatica 2017, 82, 171–180. [Google Scholar] [CrossRef]
- Chen, B.; Liu, X.; Zhao, H.; Príncipe, J.C. Maximum correntropy Kalman filter. Automatica 2017, 76, 70–77. [Google Scholar] [CrossRef] [Green Version]
- Agamennoni, G.; Nieto, J.I.; Nebot, E.M. Approximate inference in state-space models with heavy-tailed noise. IEEE Trans. Signal Process. 2012, 60, 5024–5037. [Google Scholar] [CrossRef]
- Do, M.N.; Vetterli, M. Wavelet-based texture retrieval using generalized Gaussian density and Kullback–Leibler distance. IEEE Trans. Image Process. 2002, 11, 146–158. [Google Scholar] [CrossRef] [Green Version]
- Tzagkarakis, G.; Beferull-Lozano, B.; Tsakalides, P. Rotation-invariant texture retrieval with Gaussianized steerable pyramids. IEEE Trans. Image Process. 2006, 15, 2702–2718. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Verdoolaege, G.; Scheunders, P. Geodesics on the manifold of multivariate generalized Gaussian distributions with an application to multicomponent texture discrimination. Int. J. Comput. Vis. 2011, 95, 265–286. [Google Scholar] [CrossRef] [Green Version]
- Xue, C.; Huang, Y.; Zhu, F.; Zhang, Y.; Chambers, J.A. An outlier-robust Kalman filter with adaptive selection of elliptically contoured distributions. IEEE Trans. Signal Process. 2022, 70, 994–1009. [Google Scholar] [CrossRef]
- Huang, Y.; Zhang, Y.; Zhao, Y.; Chambers, J.A. A novel outlier-robust Kalman filtering framework based on statistical similarity measure. IEEE Trans. Signal Process. 2021, 66, 2677–2692. [Google Scholar] [CrossRef]
- Zhu, F.; Huang, Y.; Xue, C.; Mihaylova, L.; Chambers, J.A. A sliding window variational outlier-robust Kalman filter based on Student’s t noise modelling. IEEE Trans. Signal Process. 2022, 58, 4835–4849. [Google Scholar]
- Huang, Y.; Zhang, Y.; Zhao, Y.; Chambers, J.A. A novel robust Gaussian–Student’s t mixture distribution based Kalman filter. IEEE Trans. Signal Process. 2019, 67, 3606–3620. [Google Scholar] [CrossRef]
- Tang, M.; Rong, Y.; Zhou, J.; Li, X.R. Information geometric approach to multisensor estimation fusion. IEEE Trans. Signal Process. 2019, 67, 279–292. [Google Scholar] [CrossRef]
- Chen, X.; Zhou, J.; Hu, S. Upper bounds for Rao distance on the manifold of multivariate elliptical distributions. Automatica 2021, 129, 109604. [Google Scholar] [CrossRef]
- Amari, S.I.; Nagaoka, H. Methods of Information Geometry; American Mathematical Society: Providence, RI, USA, 2000. [Google Scholar]
- Absil, P.A.; Mahony, R.; Sepulchre, R. Optimization Algorithms on Matrix Manifolds; Princeton University Press: Princeton, NJ, USA, 2009. [Google Scholar]
- Mitchell, A.F.S. The information matrix, skewness tensor and α-connections for the general multivariate elliptic distribution. Ann. Inst. Stat. Math. 1989, 41, 289–304. [Google Scholar] [CrossRef]
- Calvo, M.; Oller, J.M. A distance between elliptical distributions based in an embedding into the Siegel group. J. Comput. Appl. Math. 2002, 145, 319–334. [Google Scholar] [CrossRef] [Green Version]
- Berkane, M.; Oden, K.; Bentler, P.M. Geodesic estimation in elliptical distributions. J. Multivar. Anal. 1997, 63, 35–46. [Google Scholar] [CrossRef] [Green Version]
- Huang, Y.; Zhang, Y.; Ning, L.; Chambers, J.A. Robust Student’s t based nonlinear filter and smoother. IEEE Trans. Aerosp. Electron. Syst. 2016, 52, 2586–2596. [Google Scholar] [CrossRef] [Green Version]
- Huang, Y.; Zhang, Y.; Chambers, J.A. A novel Kullback–Leibler divergence minimization-based adaptive Student’s t-filter. IEEE Trans. Signal Process. 2019, 67, 5417–5432. [Google Scholar] [CrossRef]
- Schweppe, F.C. Uncertain Dynamic Systems; Prentice Hall: Englewood Cliffs, NJ, USA, 1973. [Google Scholar]
- Moakher, M. A differential geometric approach to the geometric mean of symmetric positive-definite matrices. SIAM J. Matrix Anal. Appl. 2005, 26, 735–747. [Google Scholar] [CrossRef] [Green Version]
- Said, S.; Bombrun, L.; Berthoumieu, Y.; Manton, J.H. Riemannian Gaussian distributions on the space of symmetric positive definite matrices. IEEE Trans. Inf. Theory 2017, 63, 2153–2170. [Google Scholar] [CrossRef] [Green Version]
- Ilea, I.; Bombrun, L.; Terebes, R.; Borda, M.; Germain, C. An M-estimator for robust centroid estimation on the manifold of covariance matrices. IEEE Signal Process. Lett. 2016, 23, 1255–1259. [Google Scholar] [CrossRef] [Green Version]
- Fletcher, P.T.; Venkatasubramanian, S.; Joshi, S. The geometric median on Riemannian manifolds with application to robust atlas estimation. Neuroimage 2009, 45, S143–S152. [Google Scholar] [CrossRef] [Green Version]
- Hajri, H.; Ilea, I.; Said, S.; Bombrun, L.; Berthoumieu, Y. Riemannian Laplace distribution on the space of symmetric positive definite matrices. Entropy 2016, 18, 98. [Google Scholar] [CrossRef]
- Arnaudon, M.; Barbaresco, F.; Yang, L. Riemannian medians and means with applications to radar signal processing. IEEE J. Sel. Top. Signal Process. 2013, 7, 595–604. [Google Scholar] [CrossRef]
- Wong, K.M.; Zhang, J.K.; Liang, J.; Jiang, H. Mean and median of PSD matrices on a Riemannian manifold: Application to detection of narrow-band sonar signals. IEEE Trans. Signal Process. 2017, 65, 6536–6550. [Google Scholar] [CrossRef] [Green Version]
- Grove, K.; Karcher, H.; Ruh, E. Jacobi fields and Finsler metrics on compact Lie groups with an application to differentiable pinching problems. Math. Ann. 1974, 211, 7–21. [Google Scholar] [CrossRef]
- Arsigny, V.; Fillard, P.; Pennec, X.; Ayache, N. Geometric means in a novel vector space structure on symmetric positive-definite matrices. SIAM J. Matrix Anal. Appl. 2007, 29, 328–347. [Google Scholar] [CrossRef] [Green Version]
- Li, P.; Wang, Q.; Zeng, H.; Zhang, L. Local log-Euclidean multivariate Gaussian descriptor and its application to image classification. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 803–817. [Google Scholar] [CrossRef]
- Skovgaard, L.T. A Riemannian geometry of the multivariate normal model. Scand. J. Stat. 1984, 11, 211–223. [Google Scholar]
- Hunter, D.R.; Lange, K. A tutorial on MM algorithms. Am. Stat. 2004, 58, 30–37. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | STF | GSTMDKF | ||
|---|---|---|---|---|
| Case I | Case II | Case I | Case II | |
| DCI | ||||
| GP | ||||
| FCI | ||||
| KLA | ||||
| QMMHD | ||||
| MHDP-E | ||||
| MHDP-I | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, X.; Zhou, J. Multisensor Estimation Fusion on Statistical Manifold. Entropy 2022, 24, 1802. https://doi.org/10.3390/e24121802
Chen X, Zhou J. Multisensor Estimation Fusion on Statistical Manifold. Entropy. 2022; 24(12):1802. https://doi.org/10.3390/e24121802
Chicago/Turabian StyleChen, Xiangbing, and Jie Zhou. 2022. "Multisensor Estimation Fusion on Statistical Manifold" Entropy 24, no. 12: 1802. https://doi.org/10.3390/e24121802
APA StyleChen, X., & Zhou, J. (2022). Multisensor Estimation Fusion on Statistical Manifold. Entropy, 24(12), 1802. https://doi.org/10.3390/e24121802