
DrawnNet: Offline Hand-Drawn Diagram Recognition Based on Keypoint Prediction of Aggregating Geometric Characteristics



Abstract
:1. Introduction
- We propose a unified CNN-based keypoint-based detector DrawnNet to enable offline hand-drawn diagram recognition, which can not only accurately recognize individual symbols but also understand the whole structure of diagrams through arrow connections.
- Two novel keypoint pooling module are proposed, which are expected to explicitly encode and aggregate geometric characteristics within diagrams for various keypoint prediction.
- An arrow orientation prediction branch is proposed to enable diagram structure understanding through predicting which direction each arrow points to.
- Experiment results show that DrawnNet achieves , , and recognition rate improvements compared with the state-of-the-art methods across benchmarks of FC-A, FC-B, and FA, respectively, outperforming existing diagram recognition systems on each metric.
2. Related Work
2.1. Diagram Recognition
2.1.1. Online Recognition
2.1.2. Offline Recognition
2.2. CNN-Based Object Detection
2.3. Feature Aggregation
3. DrawnNet for Diagram Recognition
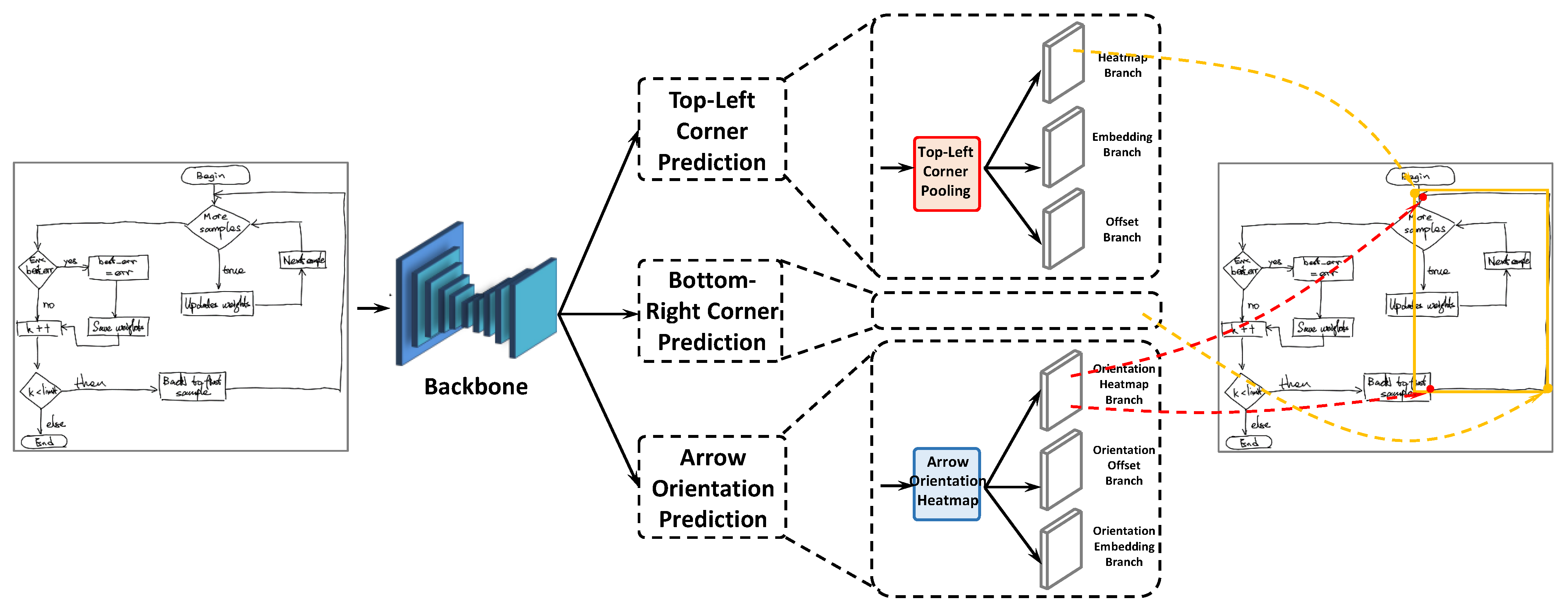
3.1. Network Architecture
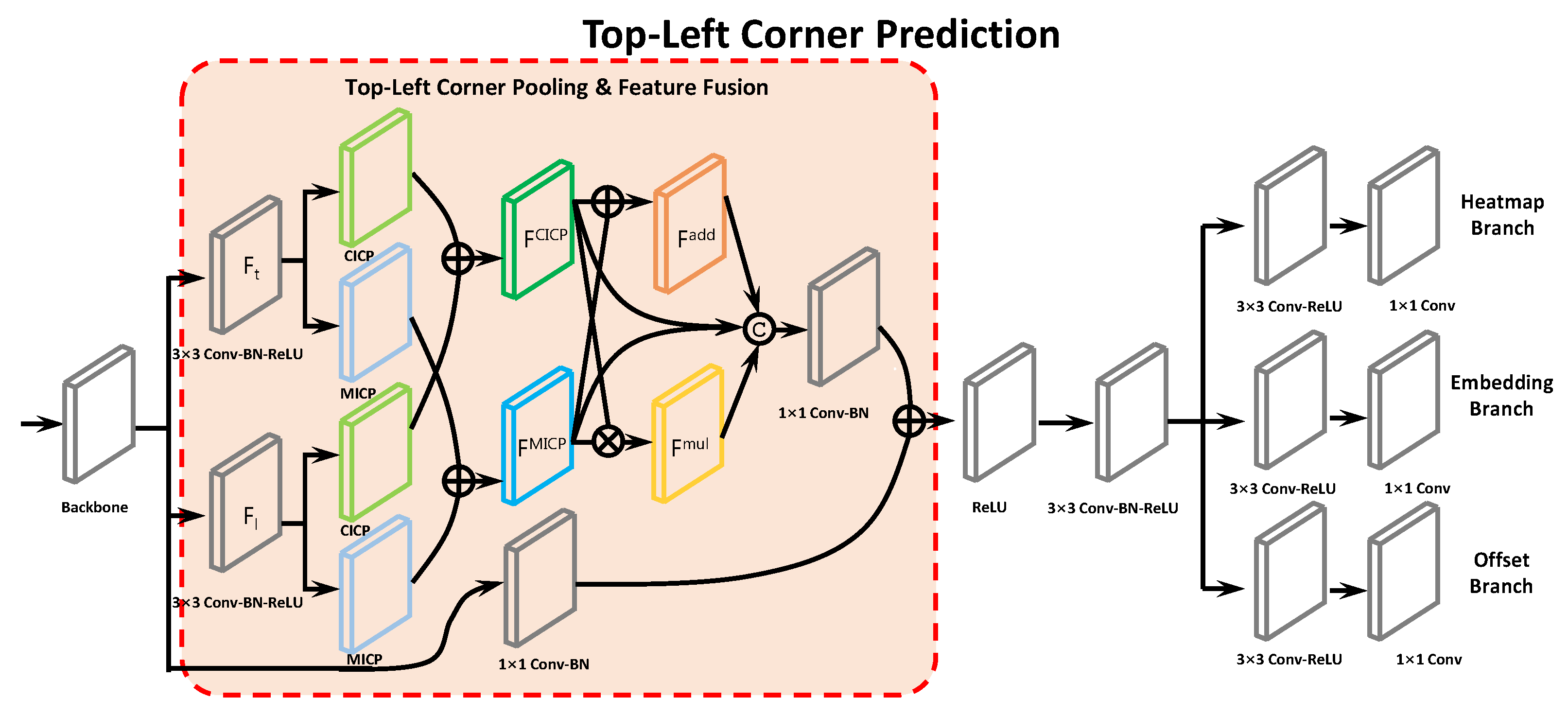
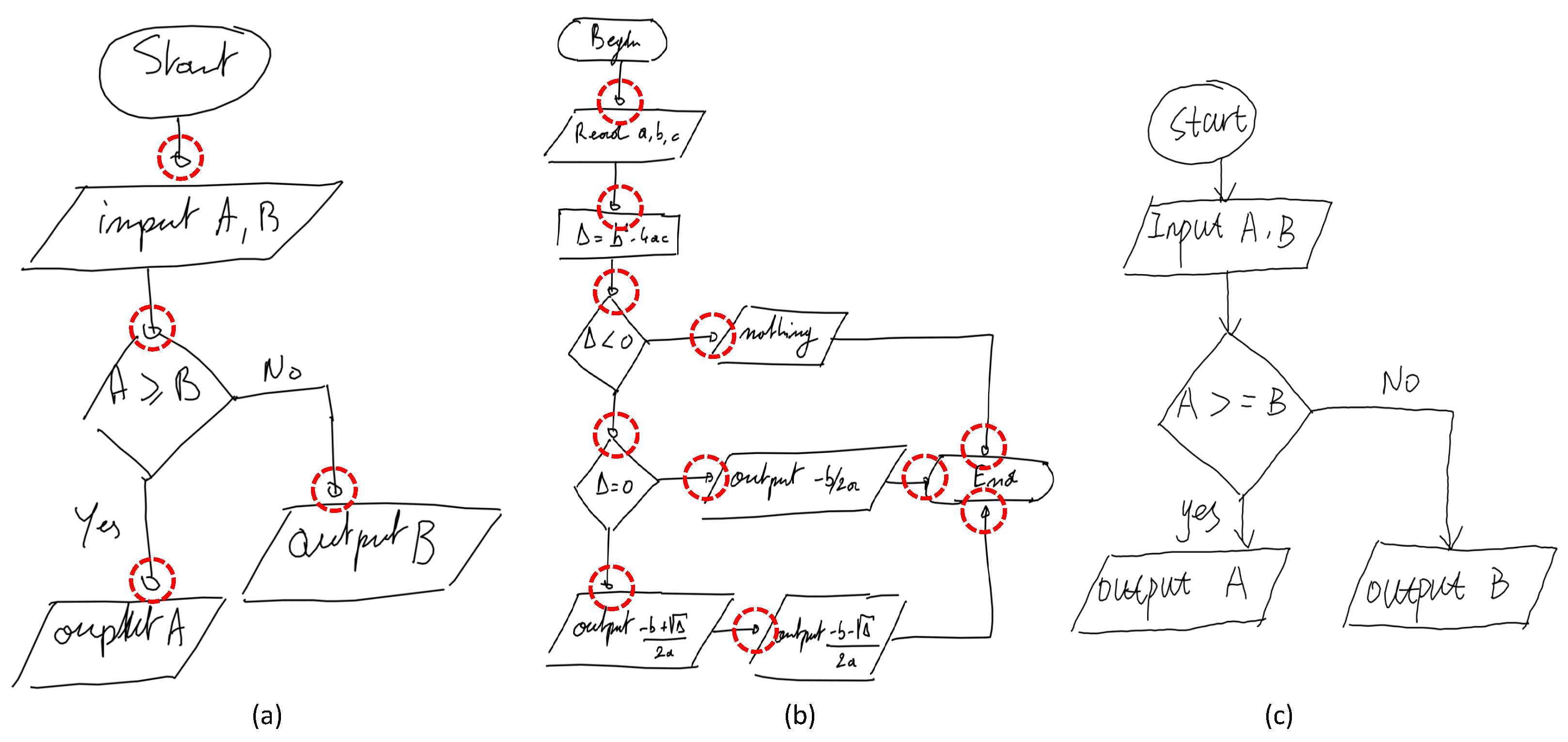
3.2. Corner Keypoint Prediction
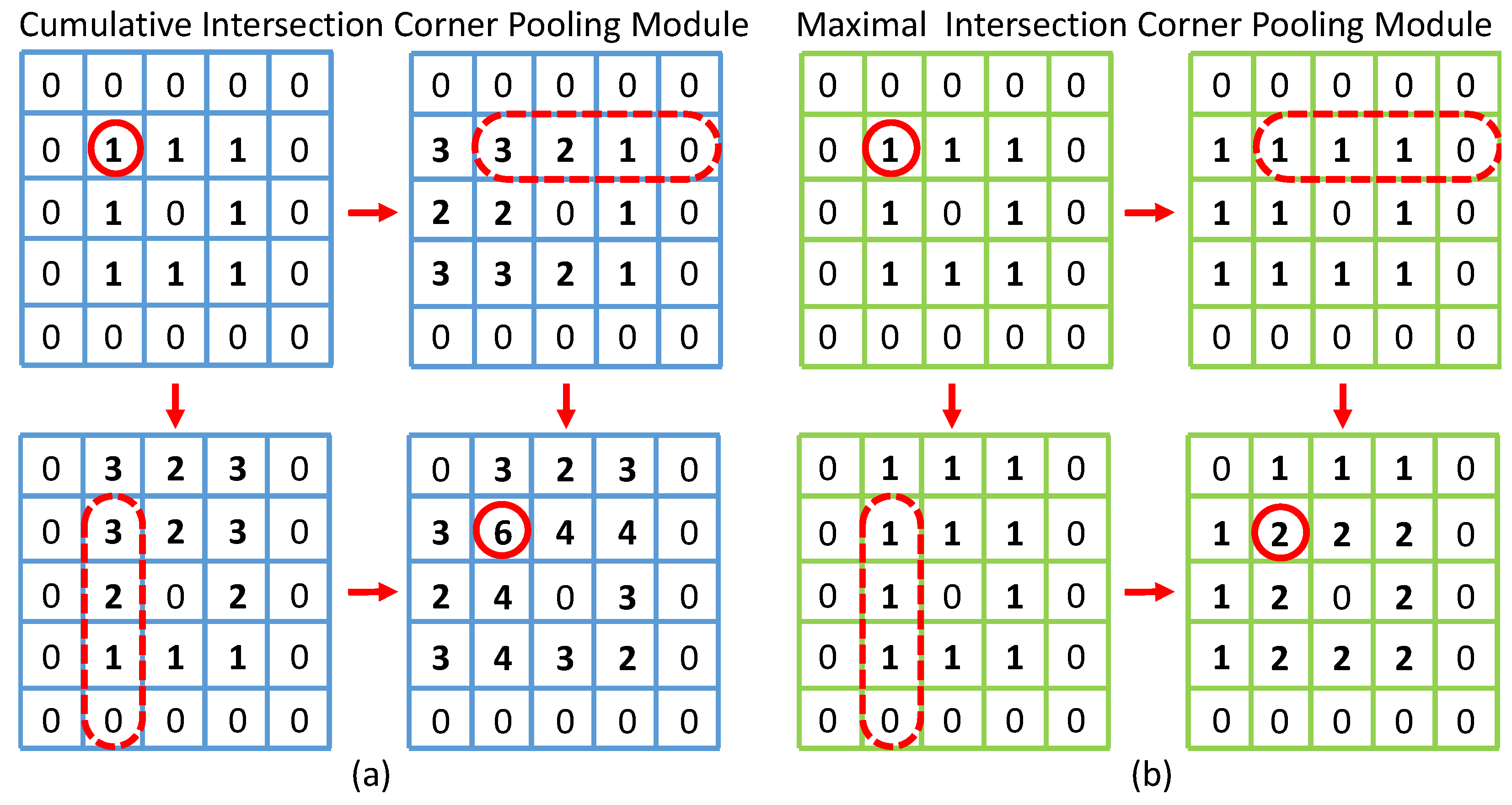
3.2.1. Intersection Corner Pooling
3.2.2. Geometric Characteristics Aggregation
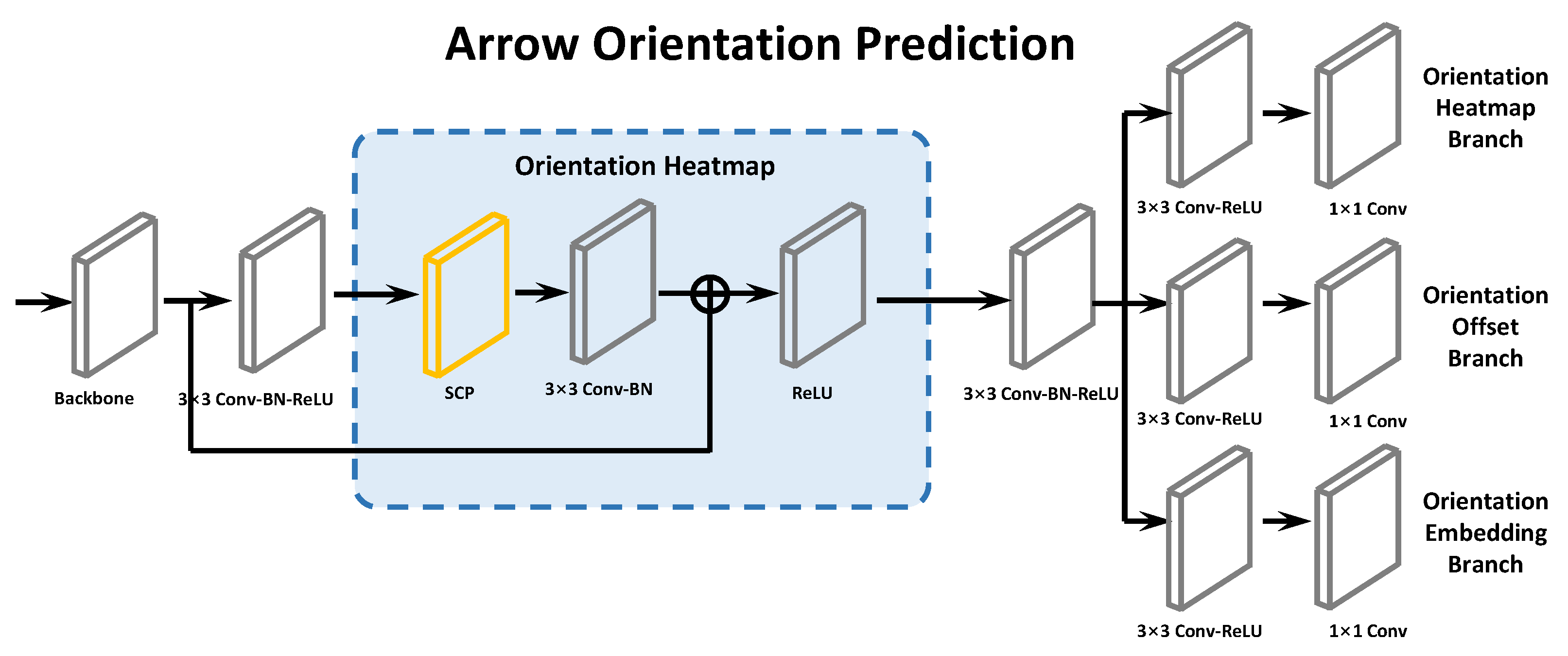
3.3. Arrow Orientation Prediction
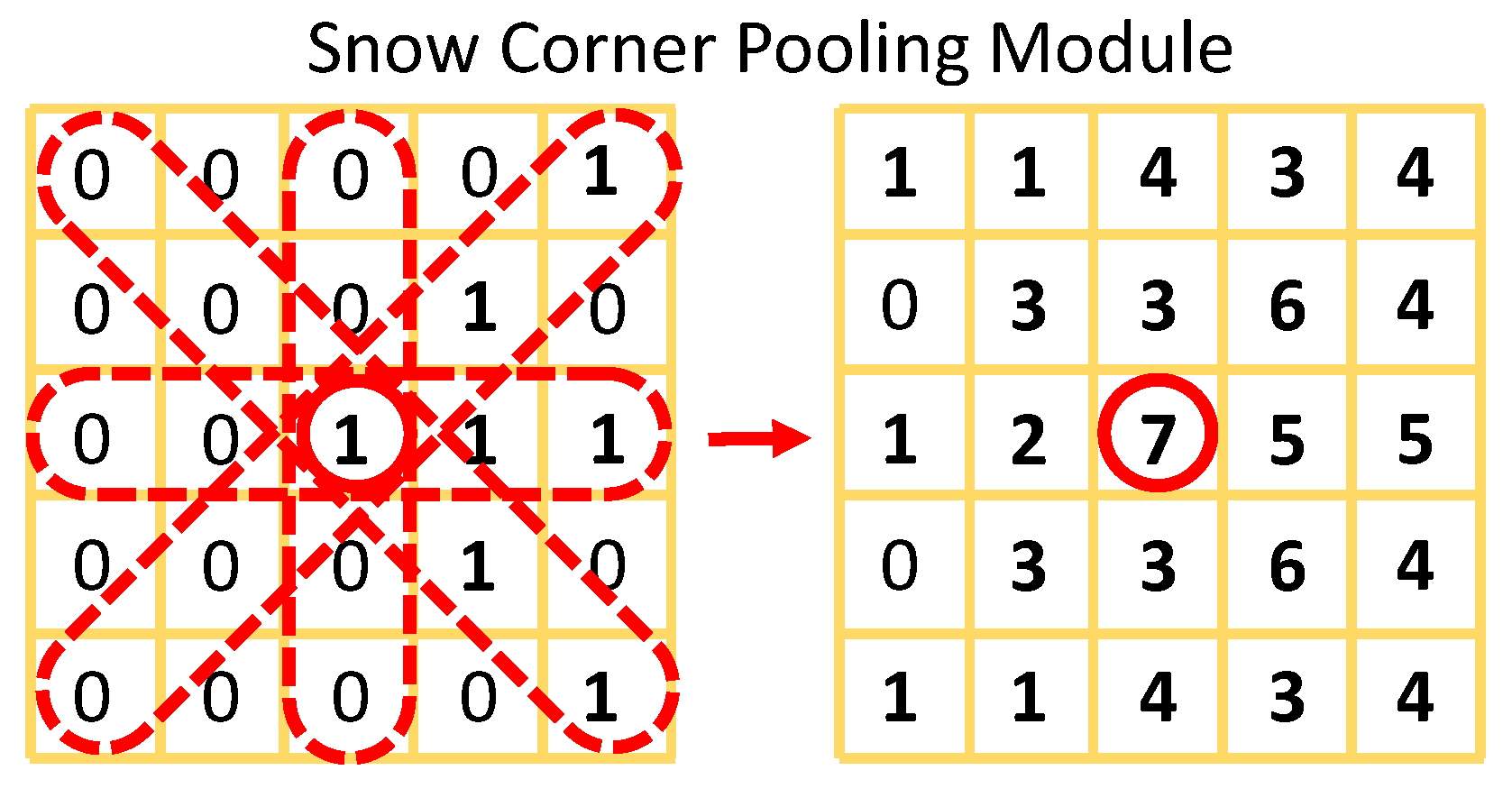
3.3.1. Snow Corner Pooling
3.3.2. Arrow Orientation Prediction
4. Experiments
4.1. Training
4.2. Inference
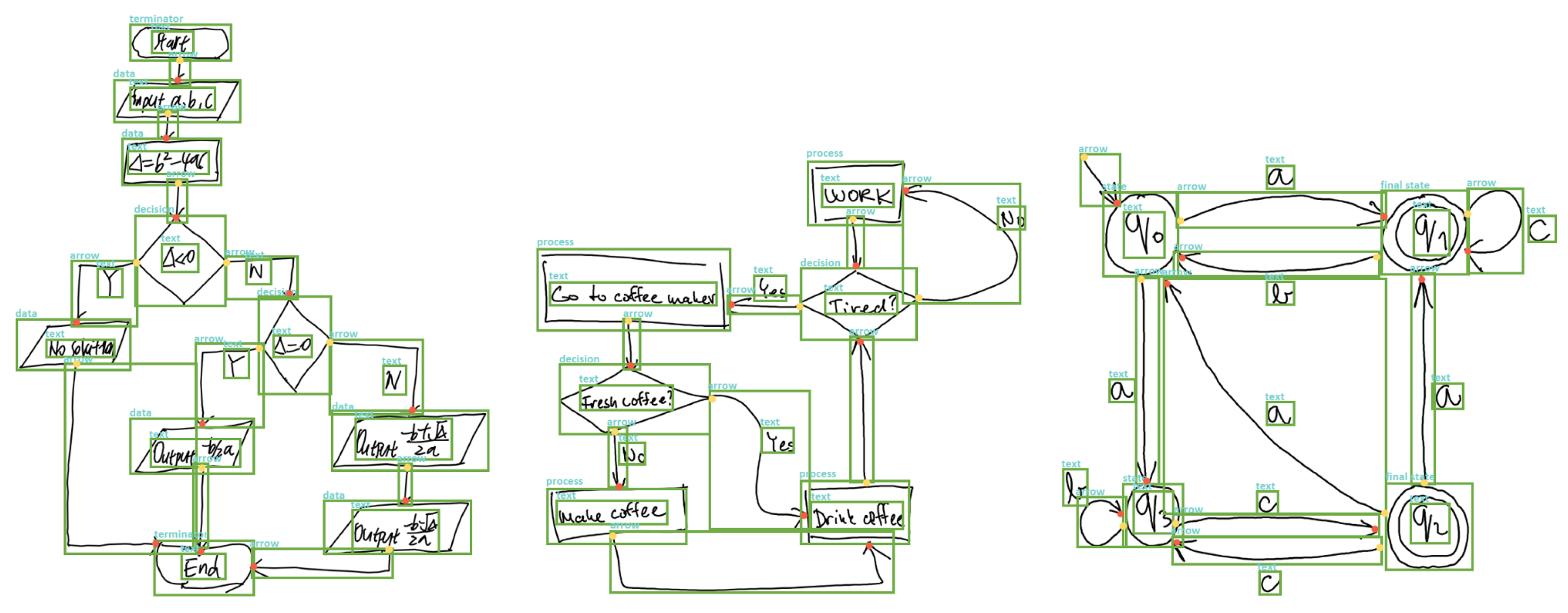
4.3. Datasets
4.4. Evaluation Metrics
5. Evaluation Analysis
5.1. Diagram Recognition
5.2. Symbol Recognition
5.3. Ablation Study
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Networks |
| DCN | Deformable Convolution Networks |
| RoI | Region of Interest |
| ICP | Intersection Corner Pooling |
| CICP | Cumulative Intersection Corner Pooling |
| MICP | Maximal Intersection Corner Pooling |
| SCP | Snow Corner Pooling |
References
- Nawar, H. Designing a Generative Pictographic Language. In Design, User Experience, and Usability: Designing Interactions, Proceedings of the 7th International Conference, DUXU 2018, Held as Part of HCI International 2018, Las Vegas, NV, USA, 15–20 July 2018; Proceedings, Part II; Marcus, A., Wang, W., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; Volume 10919, pp. 285–296. [Google Scholar] [CrossRef]
- Bresler, M.; Průša, D.; Hlavác, V. Recognizing Off-Line Flowcharts by Reconstructing Strokes and Using On-Line Recognition Techniques. In Proceedings of the 15th International Conference on Frontiers in Handwriting Recognition, Shenzhen, China, 23–26 October 2016; pp. 48–53. [Google Scholar] [CrossRef]
- Wang, C.; Mouchère, H.; Viard-Gaudin, C.; Jin, L. Combined Segmentation and Recognition of Online Handwritten Diagrams with High Order Markov Random Field. In Proceedings of the 15th International Conference on Frontiers in Handwriting Recognition, Shenzhen, China, 23–26 October 2016; pp. 252–257. [Google Scholar] [CrossRef]
- Wang, C.; Mouchère, H.; Lemaitre, A.; Viard-Gaudin, C. Online flowchart understanding by combining max-margin Markov random field with grammatical analysis. Int. J. Document Anal. Recognit. 2017, 20, 123–136. [Google Scholar] [CrossRef]
- Bresler, M.; Průša, D.; Hlavác, V. Online recognition of sketched arrow-connected diagrams. Int. J. Document Anal. Recognit. 2016, 19, 253–267. [Google Scholar] [CrossRef]
- Schäfer, B.; Keuper, M.; Stuckenschmidt, H. Arrow R-CNN for handwritten diagram recognition. Int. J. Document Anal. Recognit. 2021, 24, 3–17. [Google Scholar] [CrossRef]
- Wu, J.; Wang, C.; Zhang, L.; Rui, Y. Offline Sketch Parsing via Shapeness Estimation. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; Yang, Q., Wooldridge, M.J., Eds.; AAAI Press: Palo Alto, CA, USA, 2015; pp. 1200–1207. [Google Scholar]
- Lemaitre, A.; Mouchère, H.; Camillerapp, J.; Coüasnon, B. Interest of Syntactic Knowledge for On-Line Flowchart Recognition. In Graphics Recognition. New Trends and Challenges, Proceedings of the 9th International Workshop, GREC 2011, Seoul, Korea, 15–16 September 2011; Revised Selected Papers; Kwon, Y., Ogier, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; Volume 7423, pp. 89–98. [Google Scholar] [CrossRef] [Green Version]
- Bresler, M.; Průša, D.; Hlavác, V. Modeling Flowchart Structure Recognition as a Max-Sum Problem. In Proceedings of the 12th International Conference on Document Analysis and Recognition, Washington, DC, USA, 25–28 August 2013; pp. 1215–1219. [Google Scholar] [CrossRef]
- Bresler, M.; Phan, T.V.; Průša, D.; Nakagawa, M.; Hlavác, V. Recognition System for On-Line Sketched Diagrams. In Proceedings of the 14th International Conference on Frontiers in Handwriting Recognition, Crete, Greece, 1–4 September 2014; pp. 563–568. [Google Scholar] [CrossRef]
- Julca-Aguilar, F.D.; Hirata, N.S.T. Symbol Detection in Online Handwritten Graphics Using Faster R-CNN. In Proceedings of the 13th IAPR International Workshop on Document Analysis Systems, Vienna, Austria, 24–27 April 2018; pp. 151–156. [Google Scholar] [CrossRef] [Green Version]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. In Computer Vision—ECCV 2018, Proceedings of the 15th European Conference, Munich, Germany, 8–14 September 2018; Proceedings, Part XIV; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; Volume 11218, pp. 765–781. [Google Scholar] [CrossRef] [Green Version]
- Awal, A.; Feng, G.; Mouchère, H.; Viard-Gaudin, C. First experiments on a new online handwritten flowchart database. In Document Recognition and Retrieval XVIII, Proceedings of the IS&T-SPIE Electronic Imaging Symposium, San Jose, CA, USA, 26–27 January 2011; Agam, G., Viard-Gaudin, C., Eds.; SPIE: Bellingham, WA, USA, 2011; Volume 7874, p. 78740A. [Google Scholar] [CrossRef]
- Carton, C.; Lemaitre, A.; Coüasnon, B. Fusion of Statistical and Structural Information for Flowchart Recognition. In Proceedings of the 12th International Conference on Document Analysis and Recognition, Washington, DC, USA, 25–28 August 2013; pp. 1210–1214. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R.B. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Advances in Neural Information Processing Systems 28, Proceedings of the Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; Cortes, C., Lawrence, N.D., Lee, D.D., Sugiyama, M., Garnett, R., Eds.; MIT Press: Cambridge, MA, USA, 2015; pp. 91–99. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R.B. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.E.; Fu, C.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2016; Volume 9905, pp. 21–37. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint Triplets for Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6568–6577. [Google Scholar] [CrossRef] [Green Version]
- Zhou, X.; Zhuo, J.; Krähenbühl, P. Bottom-Up Object Detection by Grouping Extreme and Center Points. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 850–859. [Google Scholar] [CrossRef] [Green Version]
- Maninis, K.; Caelles, S.; Pont-Tuset, J.; Gool, L.V. Deep Extreme Cut: From Extreme Points to Object Segmentation. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 616–625. [Google Scholar] [CrossRef] [Green Version]
- Yang, Z.; Liu, S.; Hu, H.; Wang, L.; Lin, S. RepPoints: Point Set Representation for Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9656–9665. [Google Scholar] [CrossRef] [Green Version]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar] [CrossRef] [Green Version]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Advances in Neural Information Processing Systems 30, Proceedings of the Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., von Luxburg, U., Bengio, S., Wallach, H.M., Fergus, R., Vishwanathan, S.V.N., Garnett, R., Eds.; Mit Press: Cambridge, MA, USA, 2017; pp. 5998–6008. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the 9th International Conference on Learning Representations, Virtual, 3–7 May 2021. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. arXiv 2021, arXiv:2103.14030. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Computer Vision—ECCV 2020, Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part I; Vedaldi, A., Bischof, H., Brox, T., Frahm, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12346, pp. 213–229. [Google Scholar] [CrossRef]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. In Proceedings of the 9th International Conference on Learning Representations, Virtual, 3–7 May 2021. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.; et al. Rethinking Semantic Segmentation From a Sequence-to-Sequence Perspective With Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 6881–6890. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked Hourglass Networks for Human Pose Estimation. In Computer Vision—ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part VIII; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2016; Volume 9912, pp. 483–499. [Google Scholar] [CrossRef] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Proceedings of the 18th International Conference Munich, Germany, 5–9 October 2015; Proceedings, Part III; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer: Berlin/Heidelberg, Germany, 2015; Volume 9351, pp. 234–241. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Cao, P.; Wang, J.; Zaïane, O.R. UCTransNet: Rethinking the Skip Connections in U-Net from a Channel-wise Perspective with Transformer. arXiv 2021, arXiv:2109.04335. [Google Scholar]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. UNet++: A Nested U-Net Architecture for Medical Image Segmentation. In Deep Learning in Medical Image Analysis-and-Multimodal Learning for Clinical Decision Support, Proceedings of the 4th International Workshop, DLMIA 2018, and 8th International Workshop, ML-CDS 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, 20 September 2018; Stoyanov, D., Taylor, Z., Carneiro, G., Syeda-Mahmood, T.F., Martel, A.L., Maier-Hein, L., Tavares, J.M.R.S., Bradley, A.P., Papa, J.P., Belagiannis, V., et al., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; Volume 11045, pp. 3–11. [Google Scholar] [CrossRef] [Green Version]
- Huang, H.; Lin, L.; Tong, R.; Hu, H.; Zhang, Q.; Iwamoto, Y.; Han, X.; Chen, Y.; Wu, J. UNet 3+: A Full-Scale Connected UNet for Medical Image Segmentation. In Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing, Barcelona, Spain, 4–8 May 2020; pp. 1055–1059. [Google Scholar] [CrossRef]
- Öztürk, Ş. Image Inpainting based Compact Hash Code Learning using Modified U-Net. In Proceedings of the 2020 4th International Symposium on Multidisciplinary Studies and Innovative Technologies (ISMSIT), Istanbul, Turkey, 22–24 October 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Beal, J.; Kim, E.; Tzeng, E.; Park, D.H.; Zhai, A.; Kislyuk, D. Toward Transformer-Based Object Detection. arXiv 2020, arXiv:2012.09958. [Google Scholar]
- Lin, T.; Dollár, P.; Girshick, R.B.; He, K.; Hariharan, B.; Belongie, S.J. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar] [CrossRef] [Green Version]
- Treisman, A.M.; Gelade, G. A feature-integration theory of attention. Cogn. Psychol. 1980, 12, 97–136. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef] [Green Version]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Wang, W.; Zhao, S.; Shen, J.; Hoi, S.C.H.; Borji, A. Salient Object Detection With Pyramid Attention and Salient Edges. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Hu, Z.; Bors, A.G. Conditional Attention for Content-based Image Retrieval. In Proceedings of the 31st British Machine Vision Conference 2020, Virtual, 7–10 September 2020; BMVA Press: London, UK, 2020. [Google Scholar]
- Liu, G.; Yang, J.; Li, Z. Content-based image retrieval using computational visual attention model. Pattern Recognit. 2015, 48, 2554–2566. [Google Scholar] [CrossRef]
- ÖZTÜRK, Ş.; Alhudhaif, A.; Polat, K. Attention-based end-to-end CNN framework for content-based X-ray image retrieval. Turk. J. Electr. Eng. Comput. Sci. 2021, 29, 2680–2693. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3146–3154. [Google Scholar] [CrossRef] [Green Version]
- Hu, M.; Li, Y.; Fang, L.; Wang, S. A2-FPN: Attention Aggregation Based Feature Pyramid Network for Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 15343–15352. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image Super-Resolution Using Very Deep Residual Channel Attention Networks. arXiv 2018, arXiv:1807.02758. [Google Scholar]
- Dai, T.; Cai, J.; Zhang, Y.; Xia, S.T.; Zhang, L. Second-Order Attention Network for Single Image Super-Resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Computer Vision—ECCV 2018, Proceedings of the 15th European Conference, Munich, Germany, 8–14 September 2018; Proceedings, Part VII; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; Volume 11211, pp. 3–19. [Google Scholar] [CrossRef] [Green Version]
- Gao, Z.; Xie, J.; Wang, Q.; Li, P. Global Second-Order Pooling Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3024–3033. [Google Scholar] [CrossRef] [Green Version]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Vedaldi, A. Gather-Excite: Exploiting Feature Context in Convolutional Neural Networks. In Advances in Neural Information Processing Systems 31, Proceedings of the Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, Montréal, QC, Canada, 3–8 December 2018; Bengio, S., Wallach, H.M., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Mit Press: Cambridge, MA, USA, 2018; pp. 9423–9433. [Google Scholar]
- Xu, T.; Takano, W. Graph Stacked Hourglass Networks for 3D Human Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 16105–16114. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.E.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.; Goyal, P.; Girshick, R.B.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar] [CrossRef] [Green Version]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32, Proceedings of the Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019; Wallach, H.M., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E.B., Garnett, R., Eds.; Mit Press: Cambridge, MA, USA, 2019; pp. 8024–8035. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS—Improving Object Detection with One Line of Code. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5562–5570. [Google Scholar] [CrossRef] [Green Version]
- He, Y.; Zhang, X.; Savvides, M.; Kitani, K. Softer-NMS: Rethinking Bounding Box Regression for Accurate Object Detection. arXiv 2018, arXiv:1809.08545. [Google Scholar]
- Julca-Aguilar, F.D.; Mouchère, H.; Viard-Gaudin, C.; Hirata, N.S.T. A general framework for the recognition of online handwritten graphics. Int. J. Doc. Anal. Recognit. 2020, 23, 143–160. [Google Scholar] [CrossRef] [Green Version]
- Karlinsky, L.; Shtok, J.; Tzur, Y.; Tzadok, A. Fine-Grained Recognition of Thousands of Object Categories with Single-Example Training. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 965–974. [Google Scholar] [CrossRef]
- Liu, X.; Wang, J.; Wen, S.; Ding, E.; Lin, Y. Localizing by Describing: Attribute-Guided Attention Localization for Fine-Grained Recognition. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Singh, S.P., Markovitch, S., Eds.; AAAI Press: Palo Alto, CA, USA, 2017; pp. 4190–4196. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| FC_A | FC_B | FA | |
|---|---|---|---|
| Wang et al. [4] | 5.8 | - | - |
| Julca-Aguilar et al. [64] | 34.0 | - | - |
| Martin Bresler et al. [2] | - | 37.7 | - |
| Martin Bresler et al. [5] | 59.1 | 67.9 | 79.8 |
| Bernhard Schafer et al. [6] | 68.4 | 78.6 | 83.3 |
| DrawnNet | 70.8 | 80.9 | 85.0 |
| [7] | [10] | [3] | [6] | DrawnNet | |||
|---|---|---|---|---|---|---|---|
| Class | Recall | Recall | Recall | Precision | Recall | Precision | Recall |
| Arrow | 80.3 | 74.4 | 83.4 | 94.7 | 96.0 | 95.7 | 97.1 |
| Connection | 73.4 | 93.6 | 79.8 | 99.2 | 100 | 99.6 | 100 |
| Data | 78.5 | 91.7 | 84.4 | 100 | 99.7 | 99.9 | 99.8 |
| Decision | 78.9 | 74.1 | 76.9 | 100 | 99.5 | 100 | 99.7 |
| Process | 88.3 | 87.2 | 89.2 | 99.8 | 100 | 100 | 100 |
| Terminator | 90.6 | 88.1 | 80.8 | 100 | 100 | 100 | 100 |
| Text | 86.0 | 87.9 | 85.8 | 99.3 | 99.1 | 99.3 | 99.1 |
| Total | 83.2 | 82.8 | 84.3 | 97.9 | 98.3 | 98.4 | 98.8 |
| [2] | [6] | DrawnNet | ||||
|---|---|---|---|---|---|---|
| Class | Precision | Recall | Precision | Recall | Precision | Recall |
| Arrow | 85.1 | 84.3 | 98.0 | 98.0 | 98.6 | 98.7 |
| Connection | 61.0 | 86.6 | 100 | 100 | 100 | 100 |
| Data | 79.7 | 94.4 | 100 | 94.9 | 100 | 95.8 |
| Decision | 83.2 | 96.9 | 100 | 100 | 100 | 100 |
| Process | 88.6 | 98.8 | 95.5 | 100 | 96.4 | 100 |
| Terminator | 71.9 | 93.6 | 100 | 100 | 100 | 100 |
| Text | 99.5 | 93.7 | 99.2 | 99.3 | 99.5 | 99.5 |
| Total | 95.0 | 91.3 | 98.7 | 98.7 | 99.0 | 99.1 |
| [10] | [3] | [6] | DrawnNet | |||
|---|---|---|---|---|---|---|
| Class | Recall | Recall | Precision | Recall | Precision | Recall |
| Arrow | 84.4 | 95.3 | 98.4 | 98.4 | 98.6 | 98.7 |
| Final state | 93.8 | 89.1 | 100 | 100 | 100 | 100 |
| State | 94.5 | 91.2 | 100 | 100 | 100 | 100 |
| Text | 96.0 | 98.1 | 99.6 | 99.7 | 99.6 | 99.7 |
| Total | 92.2 | 95.8 | 99.3 | 99.3 | 99.5 | 99.4 |
| CICP | SCP | FC-A | FC-B | FA |
|---|---|---|---|---|
| - | - | 68.8 | 78.8 | 83.7 |
| √ | - | 69.5 | 79.1 | 84.1 |
| - | √ | 70.2 | 80.3 | 84.3 |
| √ | √ | 70.8 | 80.9 | 85.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fang, J.; Feng, Z.; Cai, B. DrawnNet: Offline Hand-Drawn Diagram Recognition Based on Keypoint Prediction of Aggregating Geometric Characteristics. Entropy 2022, 24, 425. https://doi.org/10.3390/e24030425
Fang J, Feng Z, Cai B. DrawnNet: Offline Hand-Drawn Diagram Recognition Based on Keypoint Prediction of Aggregating Geometric Characteristics. Entropy. 2022; 24(3):425. https://doi.org/10.3390/e24030425
Chicago/Turabian StyleFang, Jiaqi, Zhen Feng, and Bo Cai. 2022. "DrawnNet: Offline Hand-Drawn Diagram Recognition Based on Keypoint Prediction of Aggregating Geometric Characteristics" Entropy 24, no. 3: 425. https://doi.org/10.3390/e24030425
APA StyleFang, J., Feng, Z., & Cai, B. (2022). DrawnNet: Offline Hand-Drawn Diagram Recognition Based on Keypoint Prediction of Aggregating Geometric Characteristics. Entropy, 24(3), 425. https://doi.org/10.3390/e24030425