
Contingency Table Analysis and Inference via Double Index Measures



Abstract
:1. Introduction
2. Restricted Minimum -Power Divergence Estimator
- are the constrained functions on the s-dimensional parameter , , and ;
- There exists a value , such that ;
- Each constraint function has continuous second partial derivatives;
- The and matricesare of full rank;
- p() has continuous second partial derivatives in a neighbourhood of ;
- satisfies the Birch regularity conditions (see Appendix A and [22]).
3. Statistical Inference
- .
Asymptotic Theory of the Dual Divergence Test Statistic
4. Cross Tabulations and Dual Divergence Test Statistic
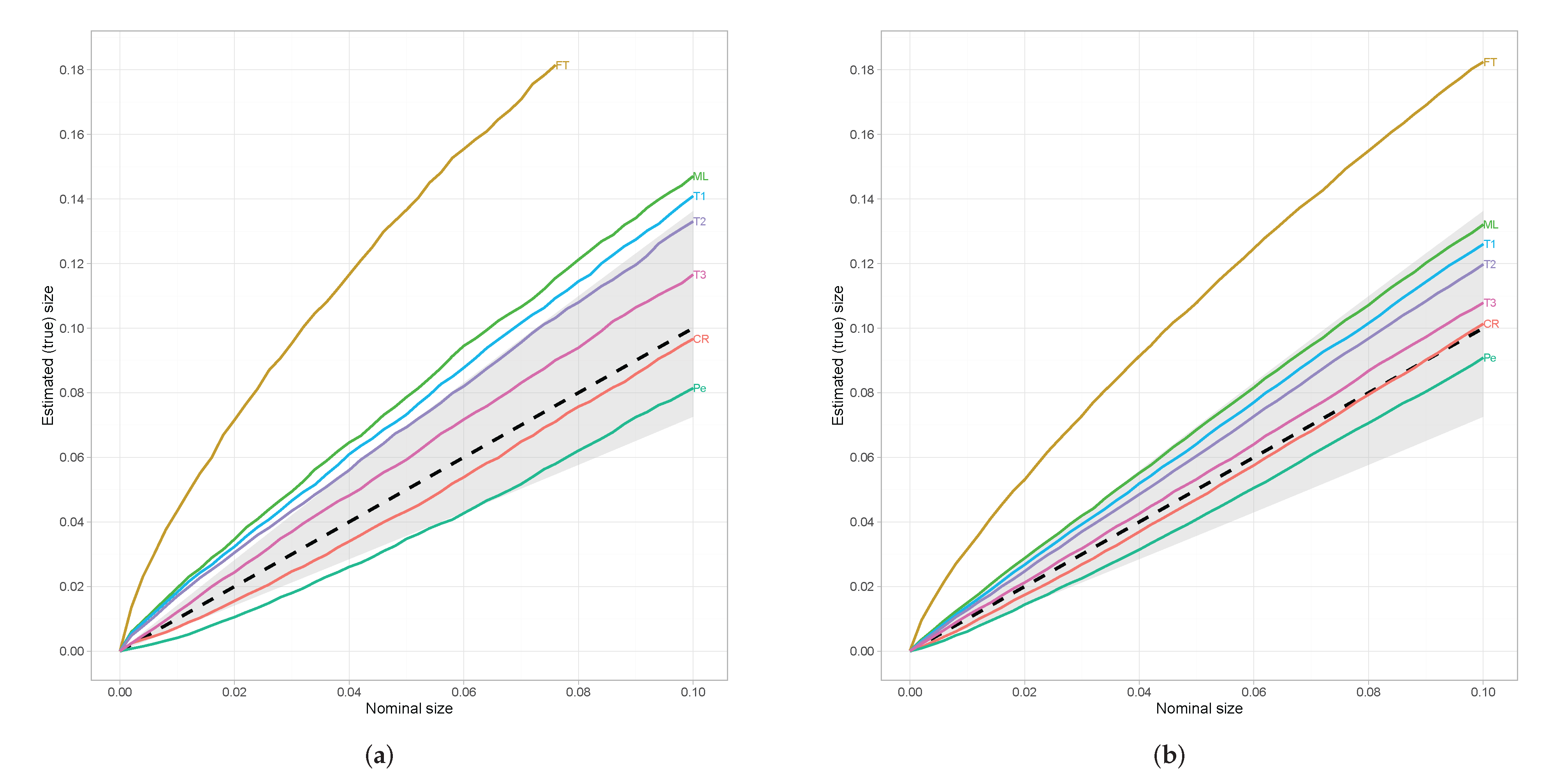
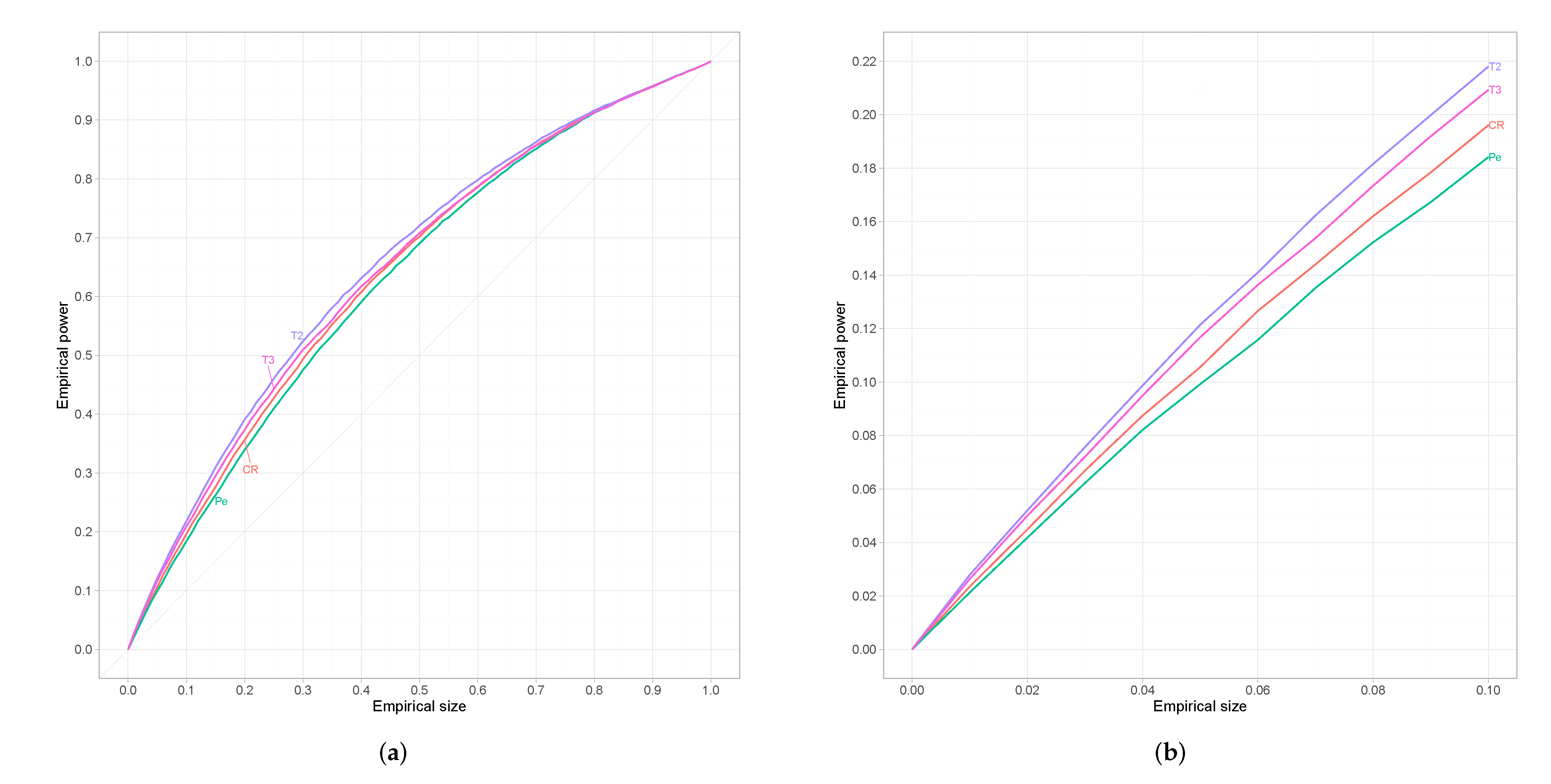
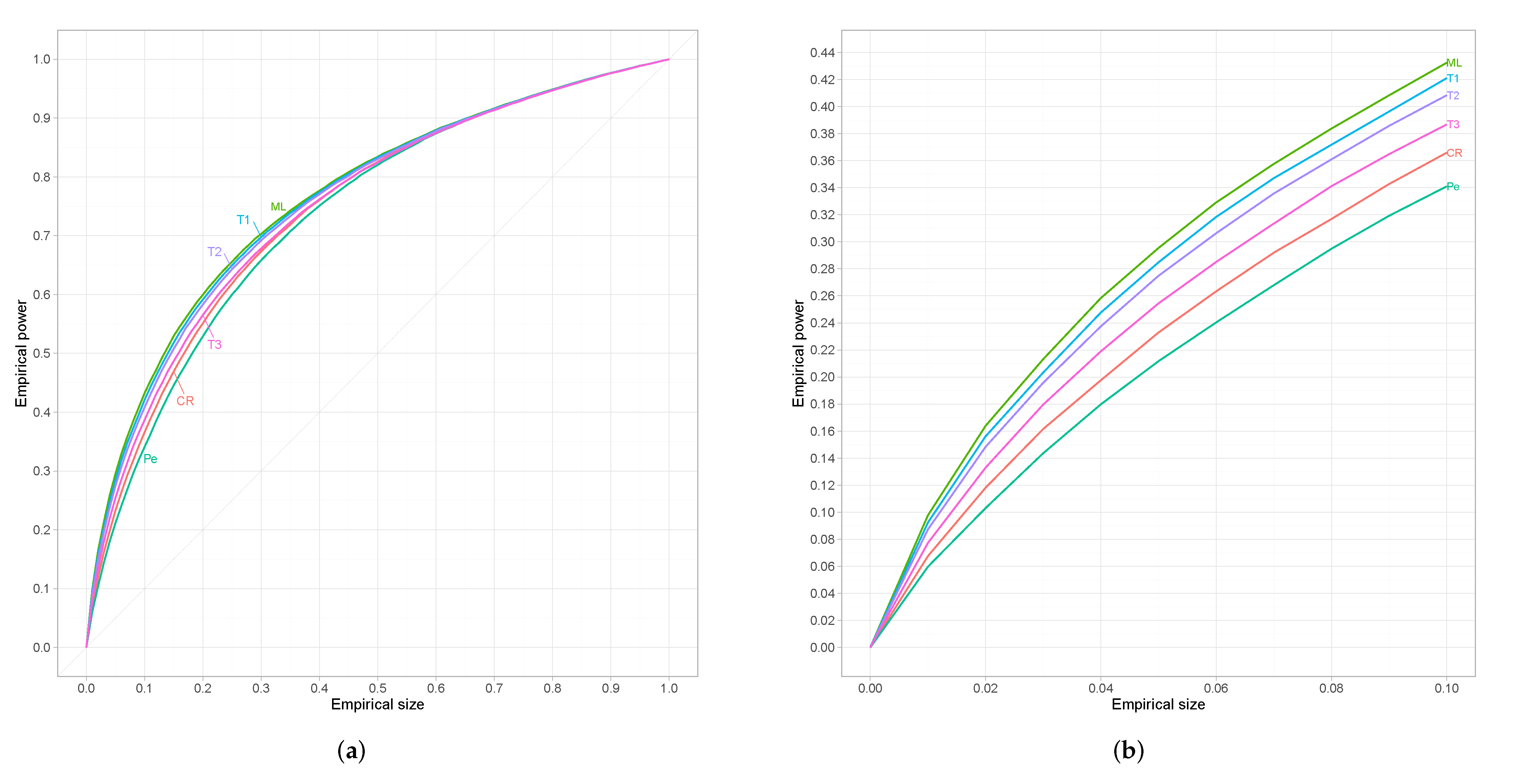
Simulation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
- The point is an interior point of ;
- for ;
- The mapping is totally differentiable at so that the partial derivatives of with respect to each exist at and has a linear approximation at given byas .
- The Jacobian matrixis of full rank;
- The mapping inverse to exists and is continuous at ;
- The mapping is continuous at every point .
References
- Salicru, M.; Morales, D.; Menendez, M.; Pardo, L. On the Applications of Divergence Type Measures in Testing Statistical Hypotheses. J. Multivar. Anal. 1994, 51, 372–391. [Google Scholar] [CrossRef] [Green Version]
- Contreras-Reyes, J.E.; Kahrari, F.; Cortés, D.D. On the modified skew-normal-Cauchy distribution: Properties, inference and applications. Commun. Stat. Theory Methods 2021, 50, 3615–3631. [Google Scholar] [CrossRef]
- Mattheou, K.; Karagrigoriou, A. A New Family of Divergence Measures for Tests of Fit. Aust. N. Z. J. Stat. 2010, 52, 187–200. [Google Scholar] [CrossRef]
- Csiszár, I. Eine Informationstheoretische Ungleichung und Ihre Anwendung auf Beweis der Ergodizitaet von Markoffschen Ketten. Magyer Tud. Akad. Mat. Kut. Int. Koezl. 1963, 8, 85–108. [Google Scholar]
- Kullback, S.; Leibler, R.A. On Information and Sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Cressie, N.; Read, T.R.C. Multinomial Goodness-of-Fit Tests. J. R. Stat. Soc. Ser. B Methodol. 1984, 46, 440–464. [Google Scholar] [CrossRef]
- Pearson, K. On the criterion that a given system of deviations from the probable in the case of a correlated system of variables is such that it can be reasonably supposed to have arisen from random sampling. Lond. Edinb. Dublin Philos. Mag. J. Sci. 1900, 50, 157–175. [Google Scholar] [CrossRef] [Green Version]
- Basu, A.; Harris, I.R.; Hjort, N.L.; Jones, M.C. Robust and Efficient Estimation by Minimising a Density Power Divergence. Biometrika 1998, 85, 549–559. [Google Scholar] [CrossRef] [Green Version]
- Pardo, L. Statistical Inference Based on Divergence Measures; Chapman and Hall/CRC: New York, NY, USA, 2006. [Google Scholar]
- Morales, D.; Pardo, L.; Vajda, I. Asymptotic Divergence of Estimates of Discrete Distributions. J. Stat. Plan. Inference 1995, 48, 347–369. [Google Scholar] [CrossRef]
- Meselidis, C.; Karagrigoriou, A. Statistical Inference for Multinomial Populations Based on a Double Index Family of Test Statistics. J. Stat. Comput. Simul. 2020, 90, 1773–1792. [Google Scholar] [CrossRef]
- Pardo, J.; Pardo, L.; Zografos, K. Minimum φ-divergence Estimators with Constraints in Multinomial Populations. J. Stat. Plan. Inference 2002, 104, 221–237. [Google Scholar] [CrossRef]
- Read, T.R.; Cressie, N.A. Goodness-of-Fit Statistics for Discrete Multivariate Data; Springer: New York, NY, USA, 1988. [Google Scholar]
- Alin, A.; Kurt, S. Ordinary and Penalized Minimum Power-divergence Estimators in Two-way Contingency Tables. Comput. Stat. 2008, 23, 455–468. [Google Scholar] [CrossRef]
- Toma, A. Optimal Robust M-estimators Using Divergences. Stat. Probab. Lett. 2009, 79, 1–5. [Google Scholar] [CrossRef] [Green Version]
- Jiménez-Gamero, M.; Pino-Mejías, R.; Alba-Fernández, V.; Moreno-Rebollo, J. Minimum ϕ-divergence Estimation in Misspecified Multinomial Models. Comput. Stat. Data Anal. 2011, 55, 3365–3378. [Google Scholar] [CrossRef]
- Kim, B.; Lee, S. Minimum density power divergence estimator for covariance matrix based on skew t distribution. Stat. Methods Appl. 2014, 23, 565–575. [Google Scholar] [CrossRef]
- Neath, A.A.; Cavanaugh, J.E.; Weyhaupt, A.G. Model Evaluation, Discrepancy Function Estimation, and Social Choice Theory. Comput. Stat. 2015, 30, 231–249. [Google Scholar] [CrossRef]
- Ghosh, A. Divergence based robust estimation of the tail index through an exponential regression model. Stat. Methods Appl. 2016, 26, 181–213. [Google Scholar] [CrossRef] [Green Version]
- Jiménez-Gamero, M.D.; Batsidis, A. Minimum Distance Estimators for Count Data Based on the Probability Generating Function with Applications. Metrika 2017, 80, 503–545. [Google Scholar] [CrossRef]
- Basu, A.; Ghosh, A.; Mandal, A.; Martin, N.; Pardo, L. Robust Wald-type tests in GLM with random design based on minimum density power divergence estimators. Stat. Methods Appl. 2021, 30, 973–1005. [Google Scholar] [CrossRef]
- Birch, M.W. A New Proof of the Pearson-Fisher Theorem. Ann. Math. Stat. 1964, 35, 817–824. [Google Scholar] [CrossRef]
- Krantz, S.G.; Parks, H.R. The Implicit Function Theorem: History, Theory, and Applications; Birkhäuser: Basel, Swiztherland, 2013. [Google Scholar]
- Ferguson, T.S. A Course in Large Sample Theory; Chapman and Hall: Boca Raton, FL, USA, 1996. [Google Scholar]
- McManus, D.A. Who Invented Local Power Analysis? Econom. Theory 1991, 7, 265–268. [Google Scholar] [CrossRef]
- Neyman, J. “Smooth” Test for Goodness of Fit. Scand. Actuar. J. 1937, 1937, 149–199. [Google Scholar] [CrossRef]
- Pardo, J.A. An approach to multiway contingency tables based on φ-divergence test statistics. J. Multivar. Anal. 2010, 101, 2305–2319. [Google Scholar] [CrossRef] [Green Version]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2016. [Google Scholar]
- Johnson, S.G. The NLopt Nonlinear-Optimization Package. 2014. Available online: http://ab-initio.mit.edu/nlopt (accessed on 27 March 2022).
- Dale, J.R. Asymptotic Normality of Goodness-of-Fit Statistics for Sparse Product Multinomials. J. R. Stat. Soc. Ser. B Methodol. 1986, 48, 48–59. [Google Scholar] [CrossRef]
- Batsidis, A.; Martin, N.; Pardo Llorente, L.; Zografos, K. φ-Divergence Based Procedure for Parametric Change-Point Problems. Methodol. Comput. Appl. Probab. 2016, 18, 21–35. [Google Scholar] [CrossRef] [Green Version]
- Lloyd, C.J. Estimating test power adjusted for size. J. Stat. Comput. Simul. 2005, 75, 921–933. [Google Scholar] [CrossRef]
- Dubrova, Y.E.; Grant, G.; Chumak, A.A.; Stezhka, V.A.; Karakasian, A.N. Elevated Minisatellite Mutation Rate in the Post-Chernobyl Families from Ukraine. Am. J. Hum. Genet. 2002, 71, 801–809. [Google Scholar] [CrossRef] [Green Version]
- Znaor, A.; Brennan, P.; Gajalakshmi, V.; Mathew, A.; Shanta, V.; Varghese, C.; Boffetta, P. Independent and combined effects of tobacco smoking, chewing and alcohol drinking on the risk of oral, pharyngeal and esophageal cancers in Indian men. Int. J. Cancer 2003, 105, 681–686. [Google Scholar] [CrossRef]
- Merková, M. Use of Investment Controlling and its Impact into Business Performance. Procedia Econ. Financ. 2015, 34, 608–614. [Google Scholar] [CrossRef] [Green Version]
- Geenens, G.; Simar, L. Nonparametric tests for conditional independence in two-way contingency tables. J. Multivar. Anal. 2010, 101, 765–788. [Google Scholar] [CrossRef] [Green Version]
- Bartolucci, F.; Scaccia, L. Testing for positive association in contingency tables with fixed margins. Comput. Stat. Data Anal. 2004, 47, 195–210. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
| 0.01 | 0.05 | 0.10 | 0.50 | 1.50 | 0.01 | 0.05 | 0.10 | 0.50 | 1.50 | |||
| 8.256 | 8.257 | 8.260 | 8.263 | 9.216 | 13.856 | 7.863 | 7.865 | 7.878 | 7.920 | 8.927 | 13.192 | |
| 0.01 | 8.207 | 8.206 | 8.209 | 8.224 | 9.224 | 13.623 | 7.753 | 7.754 | 7.763 | 7.817 | 8.797 | 12.930 |
| 0.05 | 7.896 | 7.849 | 7.879 | 7.886 | 8.719 | 12.916 | 7.340 | 7.334 | 7.327 | 7.350 | 8.313 | 12.277 |
| 0.10 | 7.403 | 7.404 | 7.378 | 7.356 | 8.046 | 11.994 | 6.965 | 6.959 | 6.940 | 6.934 | 7.675 | 11.364 |
| 0.50 | 3.873 | 3.850 | 3.769 | 3.612 | 3.023 | 4.050 | 3.857 | 3.819 | 3.722 | 3.604 | 3.191 | 4.304 |
| 1.50 | 0.920 | 0.893 | 0.807 | 0.758 | 0.509 | 0.202 | 1.046 | 1.019 | 0.948 | 0.885 | 0.602 | 0.203 |
| 7.016 | 7.016 | 7.027 | 7.055 | 7.887 | 11.362 | 6.858 | 6.858 | 6.870 | 6.908 | 7.732 | 11.099 | |
| 0.01 | 6.933 | 6.933 | 6.940 | 6.957 | 7.778 | 11.183 | 6.760 | 6.760 | 6.770 | 6.805 | 7.601 | 10.941 |
| 0.05 | 6.590 | 6.589 | 6.580 | 6.593 | 7.342 | 10.505 | 6.427 | 6.422 | 6.415 | 6.426 | 7.153 | 10.340 |
| 0.10 | 6.246 | 6.239 | 6.228 | 6.222 | 6.794 | 9.758 | 6.082 | 6.070 | 6.053 | 6.043 | 6.612 | 9.586 |
| 0.50 | 3.854 | 3.832 | 3.762 | 3.661 | 3.367 | 4.362 | 3.813 | 3.789 | 3.716 | 3.635 | 3.331 | 4.269 |
| 1.50 | 1.172 | 1.160 | 1.115 | 1.066 | 0.760 | 0.383 | 1.183 | 1.170 | 1.119 | 1.068 | 0.773 | 0.437 |
| Sample size | ||||||||
| 14.715 | 8.261 | 4.219 | 3.140 | 18.366 | 9.072 | 4.200 | 2.966 | |
| 13.664 | 7.865 | 4.333 | 3.477 | 19.674 | 9.846 | 4.783 | 3.646 | |
| 11.154 | 7.016 | 4.722 | 4.059 | 21.920 | 12.192 | 6.935 | 5.548 | |
| 10.787 | 6.858 | 4.703 | 4.082 | 22.467 | 12.992 | 7.471 | 6.081 | |
| 29.707 | 14.936 | 7.096 | 4.910 | 47.859 | 26.721 | 13.789 | 9.704 | |
| 35.768 | 18.966 | 9.469 | 7.118 | 62.810 | 38.023 | 20.147 | 15.296 | |
| 48.366 | 31.513 | 18.780 | 15.030 | 85.773 | 69.599 | 47.644 | 39.481 | |
| 50.821 | 35.381 | 22.367 | 18.217 | 89.108 | 76.685 | 57.000 | 48.451 | |
| 0.01 | 0.05 | 0.10 | 0.50 | 1.50 | 0.01 | 0.05 | 0.10 | 0.50 | 1.50 | |||
| 9.073 | 9.072 | 9.071 | 9.076 | 9.993 | 15.062 | 9.846 | 9.846 | 9.868 | 9.895 | 10.924 | 15.729 | |
| 0.01 | 8.990 | 8.989 | 8.988 | 9.006 | 9.948 | 14.724 | 9.630 | 9.630 | 9.651 | 9.727 | 10.712 | 15.343 |
| 0.05 | 8.350 | 8.278 | 8.340 | 8.357 | 9.231 | 13.819 | 9.033 | 9.008 | 8.990 | 9.022 | 9.876 | 14.332 |
| 0.10 | 7.694 | 7.696 | 7.626 | 7.616 | 8.273 | 12.656 | 8.225 | 8.216 | 8.194 | 8.188 | 8.890 | 13.111 |
| 0.50 | 3.751 | 3.717 | 3.607 | 3.418 | 2.889 | 4.199 | 3.797 | 3.761 | 3.656 | 3.581 | 3.252 | 4.620 |
| 1.50 | 0.793 | 0.764 | 0.676 | 0.630 | 0.415 | 0.163 | 0.820 | 0.810 | 0.756 | 0.718 | 0.479 | 0.158 |
| 12.192 | 12.193 | 12.207 | 12.231 | 13.142 | 17.775 | 12.992 | 12.992 | 13.003 | 13.052 | 14.014 | 18.490 | |
| 0.01 | 11.935 | 11.934 | 11.942 | 11.979 | 12.853 | 17.387 | 12.724 | 12.724 | 12.730 | 12.764 | 13.721 | 18.148 |
| 0.05 | 11.075 | 11.075 | 11.069 | 11.074 | 11.844 | 16.046 | 11.799 | 11.786 | 11.760 | 11.768 | 12.628 | 16.815 |
| 0.10 | 10.072 | 10.060 | 10.039 | 10.022 | 10.565 | 14.549 | 10.747 | 10.729 | 10.688 | 10.669 | 11.218 | 15.183 |
| 0.50 | 4.863 | 4.842 | 4.743 | 4.648 | 4.342 | 5.815 | 5.214 | 5.179 | 5.078 | 4.977 | 4.648 | 6.116 |
| 1.50 | 0.979 | 0.970 | 0.928 | 0.890 | 0.662 | 0.379 | 1.032 | 1.019 | 0.978 | 0.928 | 0.693 | 0.412 |
| 0.01 | 0.05 | 0.10 | 0.50 | 1.50 | 0.01 | 0.05 | 0.10 | 0.50 | 1.50 | |||
| 14.928 | 14.937 | 14.932 | 14.944 | 16.186 | 22.900 | 18.965 | 18.964 | 19.004 | 19.042 | 20.607 | 27.684 | |
| 0.01 | 14.807 | 14.813 | 14.808 | 14.833 | 16.117 | 22.486 | 18.565 | 18.564 | 18.598 | 18.702 | 20.235 | 27.069 |
| 0.05 | 13.711 | 13.583 | 13.726 | 13.735 | 14.939 | 21.143 | 17.436 | 17.383 | 17.360 | 17.422 | 18.733 | 25.365 |
| 0.10 | 12.612 | 12.619 | 12.529 | 12.525 | 13.217 | 19.545 | 15.794 | 15.767 | 15.743 | 15.726 | 16.869 | 23.368 |
| 0.50 | 6.088 | 5.994 | 5.811 | 5.416 | 4.553 | 6.403 | 6.879 | 6.821 | 6.656 | 6.473 | 5.912 | 8.458 |
| 1.50 | 1.118 | 1.077 | 0.944 | 0.889 | 0.553 | 0.215 | 1.275 | 1.240 | 1.152 | 1.081 | 0.729 | 0.260 |
| 31.513 | 31.518 | 31.533 | 31.608 | 33.469 | 40.799 | 35.381 | 35.381 | 35.404 | 35.465 | 37.411 | 44.556 | |
| 0.01 | 30.904 | 30.903 | 30.925 | 30.999 | 32.868 | 40.221 | 34.848 | 34.845 | 34.863 | 34.941 | 36.744 | 43.942 |
| 0.05 | 28.949 | 28.946 | 28.938 | 28.956 | 30.509 | 37.756 | 32.727 | 32.716 | 32.697 | 32.715 | 34.310 | 41.510 |
| 0.10 | 26.504 | 26.485 | 26.434 | 26.398 | 27.631 | 34.747 | 30.146 | 30.110 | 30.051 | 30.014 | 31.289 | 38.456 |
| 0.50 | 11.949 | 11.867 | 11.598 | 11.409 | 10.830 | 14.703 | 14.052 | 13.966 | 13.632 | 13.321 | 12.731 | 16.901 |
| 1.50 | 1.797 | 1.761 | 1.692 | 1.578 | 1.142 | 0.716 | 1.973 | 1.945 | 1.870 | 1.776 | 1.295 | 0.838 |
| 0.01 | 0.05 | 0.10 | 0.50 | 1.50 | 0.01 | 0.05 | 0.10 | 0.50 | 1.50 | |||
| 26.712 | 26.710 | 26.707 | 26.711 | 28.495 | 37.924 | 38.017 | 38.016 | 38.132 | 38.191 | 40.982 | 50.954 | |
| 0.01 | 26.589 | 26.586 | 26.585 | 26.613 | 28.718 | 37.421 | 37.365 | 37.364 | 37.456 | 37.645 | 40.482 | 50.206 |
| 0.05 | 25.437 | 25.267 | 25.531 | 25.502 | 27.170 | 35.979 | 35.674 | 35.559 | 35.526 | 35.643 | 38.260 | 48.187 |
| 0.10 | 24.287 | 24.284 | 24.232 | 24.172 | 24.868 | 33.946 | 33.014 | 32.939 | 32.867 | 32.854 | 35.184 | 45.569 |
| 0.50 | 12.003 | 11.780 | 11.424 | 10.772 | 8.807 | 11.665 | 14.353 | 14.226 | 13.870 | 13.560 | 12.312 | 16.886 |
| 1.50 | 1.731 | 1.662 | 1.489 | 1.422 | 0.904 | 0.298 | 2.268 | 2.226 | 2.026 | 1.916 | 1.387 | 0.506 |
| 69.599 | 69.605 | 69.637 | 69.755 | 72.196 | 79.363 | 76.685 | 76.685 | 76.731 | 76.805 | 78.802 | 84.683 | |
| 0.01 | 68.923 | 68.923 | 68.954 | 69.049 | 71.518 | 79.003 | 76.177 | 76.173 | 76.192 | 76.264 | 78.143 | 84.344 |
| 0.05 | 66.310 | 66.309 | 66.306 | 66.365 | 68.576 | 77.069 | 73.760 | 73.745 | 73.732 | 73.766 | 75.748 | 82.751 |
| 0.10 | 62.500 | 62.455 | 62.372 | 62.343 | 64.660 | 74.161 | 70.295 | 70.264 | 70.144 | 70.131 | 72.172 | 80.319 |
| 0.50 | 30.094 | 29.904 | 29.349 | 28.848 | 27.895 | 36.902 | 36.612 | 36.465 | 35.792 | 35.073 | 34.056 | 43.732 |
| 1.50 | 3.748 | 3.678 | 3.472 | 3.210 | 2.269 | 1.562 | 4.349 | 4.274 | 4.017 | 3.747 | 2.665 | 1.927 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Meselidis, C.; Karagrigoriou, A. Contingency Table Analysis and Inference via Double Index Measures. Entropy 2022, 24, 477. https://doi.org/10.3390/e24040477
Meselidis C, Karagrigoriou A. Contingency Table Analysis and Inference via Double Index Measures. Entropy. 2022; 24(4):477. https://doi.org/10.3390/e24040477
Chicago/Turabian StyleMeselidis, Christos, and Alex Karagrigoriou. 2022. "Contingency Table Analysis and Inference via Double Index Measures" Entropy 24, no. 4: 477. https://doi.org/10.3390/e24040477
APA StyleMeselidis, C., & Karagrigoriou, A. (2022). Contingency Table Analysis and Inference via Double Index Measures. Entropy, 24(4), 477. https://doi.org/10.3390/e24040477