
Grammatical Gender Disambiguates Syntactically Similar Nouns


Abstract
:1. Introduction
2. Materials and Methods
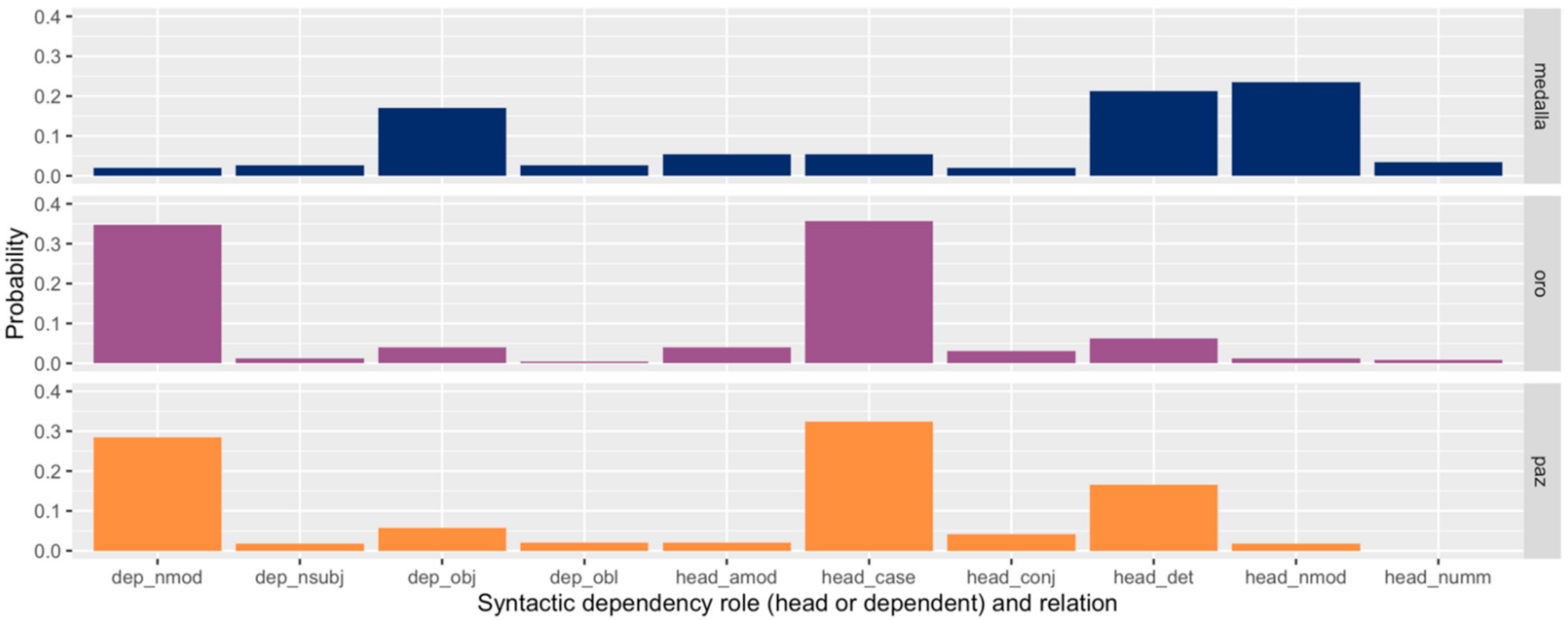
2.1. Distance Measures
2.2. Correlational Analysis
2.3. Mixed-Effects Regression Analysis
- An increase in orthographic distance predicts a decrease in probability of gender sameness;
- An increase in semantic distance predicts a decrease in probability of gender sameness;
- An increase in syntactic distance predicts an increase in probability of gender sameness;
- The probability of gender sameness is lower in three-gender languages than it is in two-gender languages. (This follows logically from the principle that—all else being equal—a greater number of classes means it will be less likely that two randomly chosen elements belong to the same class.)
3. Discussion
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Corbett, G.G. Gender; Cambridge University Press: Cambridge, UK, 1991. [Google Scholar]
- Dye, M.; Milin, P.; Futrell, R.; Ramscar, M. A functional theory of gender paradigms. In Perspectives on Morphological Structure: Data and Analyses; Kiefer, F., Blevins, J.P., Bartos, H., Eds.; Brill: Leiden, The Netherlands, 2017; pp. 212–239. [Google Scholar]
- Heath, J. Some functional relationships in grammar. Language 1975, 51, 128–149. [Google Scholar] [CrossRef]
- Zubin, D.; Köpcke, K.-M. Gender and folk taxonomy: The indexical relation between grammatical and lexical categorization. In Noun Classification and Categorization: Proceedings of a Symposium on Categorization and Noun Classification, Eugene, OR, USA, October 1983; (Typological Studies in Language 7); Craig, C., Ed.; John Benjamins: Philadelphia, PA, USA, 1986; pp. 139–180. [Google Scholar]
- Arnon, I.; Ramscar, M. Granularity and the acquisition of grammatical gender: How order of acquisition affects what gets learned. Cognition 2012, 122, 292–305. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bates, E.; Devescovi, A.; Hernandez, A.; Pizzamiglio, L. Gender priming in Italian. Percept. Psychophys. 1996, 58, 992–1004. [Google Scholar] [CrossRef] [Green Version]
- Grosjean, F.; Dommergues, J.Y.; Cornu, E.; Guillelmon, D.; Besson, C. The gender-marking effect in spoken word recognition. Percept. Psychophys. 1994, 56, 590–598. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schriefers, H. Syntactic processes in the production of noun phrases. J. Exp. Psychol. Learn. Mem. Cogn. 1993, 19, 841–850. [Google Scholar] [CrossRef]
- Van Berkum, J.J.A.; Brown, C.M.; Zwitserlood, P.; Kooijman, V.; Hagoort, P. Anticipating upcoming words in discourse: Evidence from erps and reading times. J. Exp. Psychol. Learn. Mem. Cogn. 2005, 31, 443–467. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wicha, N.Y.Y.; Moreno, E.M.; Kutas, M. Anticipating words and their gender: An event-related brain potential study of semantic integration, gender expectancy, and gender agreement in Spanish sentence reading. J. Cogn. Neurosci. 2004, 16, 1272–1288. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Futrell, R. German Grammatical Gender as a Nominal Protection Device. Undergraduate Thesis, Stanford University, Stanford, CA, USA, 2010. [Google Scholar]
- Dye, M.; Milin, P.; Futrell, R.; Ramscar, M. Alternative solutions to a language design problem: The role of adjectives and gender marking in efficient communication. Top. Cogn. Sci. 2018, 10, 209–224. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jaeger, T.F. Redundancy and reduction: Speakers manage syntactic information density. Cogn. Psychol. 2010, 61, 23–62. [Google Scholar] [CrossRef] [Green Version]
- Levy, R. Expectation-based syntactic comprehension. Cognition 2008, 106, 1126–1177. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Levy, R.; Jaeger, T.F. Speakers optimize information density through syntactic reduction. In Advances in Neural Information Processing Systems; Schölkopf, B., Platt, J., Hoffman, T., Eds.; MIT Press: Cambridge, MA, USA, 2007; pp. 849–856. [Google Scholar]
- Williams, A.; Cotterell, R.; Wolf-Sonkin, L.; Blasi, D.; Wallach, H. Quantifying the semantic core of gender systems. In Proceedings of the 2019 Conference on Empirical METHODS in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (Emnlp-Ijcnlp), Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Hong Kong, China, 2019; pp. 5734–5739. [Google Scholar]
- Levy, R. A noisy-channel model of human sentence comprehension under uncertain input. In Proceedings of the 2008 Conference on Empirical Methods in Natural Language Processing, Honolulu, HI, USA, 25–27 October 2008; Association for Computational Linguistics: Stroudsburg, PA, USA, 2008; pp. 234–243. [Google Scholar]
- Borer, H. Structuring Sense Volume 1: In Name Only; Oxford University Press: Oxford, UK, 2005. [Google Scholar]
- Bresnan, J. Lexical-Functional Syntax; Blackwell: Oxford, UK, 2001. [Google Scholar]
- Chomsky, N. The Minimalist Program; MIT Press: Cambridge, MA, USA, 1995. [Google Scholar]
- Kay, P. The limits of (construction) grammar. In The Oxford Handbook of Construction Grammar; Hoffmann, T., Trousdale, G., Eds.; Oxford University Press: Oxford, UK, 2013; pp. 32–48. [Google Scholar]
- Marantz, A. No escape from syntax: Don’t try morphological analysis in the privacy of your own lexicon. Univ. Pa. Work. Pap. Linguist. 1997, 4, 201–225. [Google Scholar]
- Pollard, C.; Sag, I.A. Head-Driven Phrase Structure Grammar; The University of Chicago Press: Chicago, IL, USA, 1994. [Google Scholar]
- Ramchand, G. Verb Meaning and the Lexicon: A First Phase Syntax; Cambridge University Press: Cambridge, UK, 2008. [Google Scholar]
- Chomsky, N. Aspects of the Theory of Syntax; MIT Press: Cambridge, MA, USA, 1965. [Google Scholar]
- Stabler, E.P. Two models of minimalist, incremental syntactic analysis. Top. Cogn. Sci. 2013, 5, 611–633. [Google Scholar] [CrossRef] [PubMed]
- Diessel, H. Usage-based construction grammar. In Handbook of Cognitive Linguistics; Dabrowska, E., Divjak, D., Eds.; De Gruyter: Boston, MA, USA, 2015; pp. 295–321. [Google Scholar]
- Goldberg, A. Constructions at Work: The Nature of Generalization in Language; Oxford University Press: New York, NY, USA, 2006. [Google Scholar]
- Langacker, R.W. Foundations of Cognitive Grammar, Volume I: Theoretical Prerequisites; Stanford University Press: Stanford, CA, USA, 1987. [Google Scholar]
- Bates, E.; MacWhinney, B. Functionalism and the competition model. In The Crosslinguistic Study of Sentence Processing; MacWhinney, B., Bates, E., Eds.; Cambridge University Press: New York, NY, USA, 1989; pp. 3–76. [Google Scholar]
- Bybee, J. Language, Usage, and Cognition; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar]
- McDonald, S.; Shillcock, R. Contextual Distinctiveness: A New Lexical Property Computed from Large Corpora; School of Informatics, University of Edinburgh: Edinburgh, UK, 2001. [Google Scholar]
- McDonald, S.; Shillcock, R. Rethinking the word frequency effect: The neglected role of distributional information in lexical processing. Lang. Speech 2001, 44, 295–322. [Google Scholar] [CrossRef] [PubMed]
- Baayen, R.H.; Milin, P.; Filipovic-Durdevic, D.; Hendrix, P.; Marelli, M. An amorphous model for morphological processing in visual comprehension based on naive discriminative learning. Psychol. Rev. 2011, 118, 438–482. [Google Scholar] [CrossRef] [Green Version]
- Milin, P.; Filipovic-Durdevic, D.; Moscoso del Prado Martín, F. The simultaneous effects of inflectional paradigms and classes on lexical recognition: Evidence from Serbian. J. Mem. Lang. 2009, 60, 50–64. [Google Scholar] [CrossRef] [Green Version]
- Moscoso del Prado Martín, F.; Kostic, A.; Baayen, R.H. Putting the bits together: An information theoretical perspective on morphological processing. Cognition 2004, 94, 1–18. [Google Scholar] [CrossRef] [Green Version]
- Kostic, A.; Markovic, T.; Baucal, A. Inflectional morphology and word meaning: Orthogonal or co-implicative cognitive domains? In Morphological Structure in Language Processing; Baayen, R.H., Schreuder, R., Eds.; Mouton de Gruyter: New York, NY, USA, 2003; pp. 1–44. [Google Scholar]
- Baayen, R.H.; Feldman, L.B.; Schreuder, R. Morphological influences on the recognition of monosyllabic monomorphemic words. J. Mem. Lang. 2006, 55, 290–313. [Google Scholar] [CrossRef] [Green Version]
- Lester, N.; del Prado Martín, F.M. Constructional paradigms affect visual lexical decision latencies in English. In Proceedings of the 37th Annual Meeting of the Cognitive Science Society, Pasadena, CA, USA, 22–25 July 2015; Cognitive Science Society: Austin, TX, USA, 2015; pp. 1320–1325. [Google Scholar]
- Lester, N.; del Prado Martín, F.M. Syntactic flexibility in the noun: Evidence from picture naming. In Proceedings of the 38th Annual Conference of the Cognitive Science Society, Philadelphia, PA, USA, 10–13 August 2016; Cognitive Science Society: Philadelphia, PA, USA, 2016; pp. 2585–2590. [Google Scholar]
- Lester, N.; Feldman, L.; del Prado Martín, F.M. You can take a noun out of syntax…: Syntactic similarity effects in lexical priming. In Proceedings of the 39th Annual Conference of the Cognitive Science Society, London, UK, 26–29 July 2017; Cognitive Science Society: London, UK, 2017; pp. 2537–2542. [Google Scholar]
- Lester, N. The Syntactic Bits of Nouns: How Prior Syntactic Distributions Affect Comprehension, Production, and Acquisition. Doctoral Dissertation, University of California Santa Barbara, Santa Barbara, CA, USA, 2018. [Google Scholar]
- Hudson, R. Language Networks: The New word Grammar; Oxford University Press: Oxford, UK, 2007. [Google Scholar]
- Mel’cuk, I. Dependency Syntax: Theory and Practice; The SUNY Press: Albany, NY, USA, 1988. [Google Scholar]
- Nivre, J. Dependency Grammar and Dependency Parsing; Technical Report MSI Report 05133; School of Mathematics & Systems Engineering, Växjö University: Växjö, Sweden, 2005. [Google Scholar]
- Tesniere, L. L ’Ements de Syntaxe Structurale; Klincksieck: Paris, France, 1959. [Google Scholar]
- Sinnemäki, K. Complexity trade-offs in core argument marking. In Language Complexity: Typology, Contact, Change; Miestamo, M., Sinnemäki, K., Karlsson, F., Eds.; John Benjamins: Amsterdam, The Netherlands, 2008; pp. 67–88. [Google Scholar]
- Koplenig, A.; Meyer, P.; Wolfer, S.; Müller-Spitzer, C. The statistical trade-off between word order and word structure: Large-scale evidence for the principle of least effort. PLoS ONE 2017, 12, e0173614. [Google Scholar] [CrossRef]
- Fedzechkina, M.; Newport, E.L.; Jaeger, T.F. Balancing effort and information transmission during language acquisition: Evidence from word order and case marking. Cogn. Sci. 2017, 41, 416–446. [Google Scholar] [CrossRef] [Green Version]
- Lester, N.; Auderset, S.; Rogers, P. Case inflection and the functional indeterminacy of nouns: A cross-linguistic analysis. In Proceedings of the 40th Annual Conference of the Cognitive Science Society, Madison, WI, USA, 25–28 July 2018; Cognitive Science Society: Madison, WI, USA, 2018; pp. 2029–2034. [Google Scholar]
- De Marneffe, M.C.; Manning, C.D.; Nivre, J.; Zeman, D. Universal dependencies. Comput. Linguist. 2021, 47, 255–308. [Google Scholar] [CrossRef]
- Hausser, J.; Strimmer, K. Entropy inference and the James-Stein estimator, with application to nonlinear gene association networks. J. Mach. Learn. Res. 2009, 10, 1469–1484. [Google Scholar]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching word vectors with subword information. arXiv 2016, arXiv:1607.04606. [Google Scholar] [CrossRef] [Green Version]
- Dautriche, I.; Mahowald, K.; Gibson, E.; Piantadosi, S.T. Wordform similarity increases with semantic similarity: An analysis of 100 languages. Cogn. Sci. 2016, 41, 2149–2169. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Davison, A.C.; Hinkley, D.V. Bootstrap Methods and Their Application; Cambridge University Press: Cambridge, UK, 1997. [Google Scholar]
- North, B.V.; Curtis, D.; Sham, P.C. A note on the calculation of empirical P values from Monte Carlo procedures. Am. J. Hum. Genet. 2002, 71, 439–441. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Eberhard, D.M.; Simons, G.F.; Fennig, C.D. Ethnologue: Languages of the World, 24th ed.; SIL International: Dallas, TX, USA, 2021. [Google Scholar]
- Fox, J.; Weisberg, S. An R Companion to Applied Regression, 3rd ed.; Sage: Thousand Oaks, CA, USA, 2019. [Google Scholar]
- Mahowald, K.; Dautriche, I.; Gibson, E.; Piantadosi, S.T. Wordforms are structured for efficient use. Cogn. Sci. 2018, 42, 3116–3134. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dingemanse, M.; Blasi, D.E.; Lupyan, G.; Christiansen, M.H.; Monaghan, P. Arbitrariness, iconicity, and systematicity in language. Trends Cogn. Sci. 2005, 19, 603–615. [Google Scholar] [CrossRef] [Green Version]
- Gibson, E.; Bergen, L.; Piantadosi, S.T. Rational integration of noisy evidence and prior semantic expectations in sentence interpretation. Proc. Natl. Acad. Sci. USA 2013, 110, 8051–8056. [Google Scholar] [CrossRef] [Green Version]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Technol. J. 1948, 27, 379–423. [Google Scholar] [CrossRef] [Green Version]
- Dautriche, I.; Mahowald, K.; Gibson, E.; Piantadosi, S.T. Words cluster phonetically beyond phonotactic regularities. Cognition 2017, 163, 128–145. [Google Scholar] [CrossRef] [Green Version]
- Coady, J.A.; Aslin, R.N. Young children’s sensitivity to probabilistic phonotactics in the developing lexicon. J. Exp. Child Psychol. 2004, 89, 183–213. [Google Scholar] [CrossRef] [Green Version]
- Storkel, H.L. Do children acquire dense neighborhoods? An investigation of similarity neighborhoods in lexical acquisition. Appl. Psycholinguist. 2004, 25, 201–221. [Google Scholar] [CrossRef] [Green Version]
- Storkel, H.L.; Armbrüster, J.; Hogan, T. Differentiating phonotactic probability and neighborhood density in adult word learning. J. Speech Lang. Hear. Res. 2006, 49, 1175–1192. [Google Scholar] [CrossRef] [Green Version]
- Storkel, H.L.; Hoover, J.R. An online calculator to compute phonotactic probability and neighborhood density on the basis of child corpora of spoken American English. Behav. Res. Methods 2010, 42, 497–506. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Storkel, H.L.; Lee, S.-Y. The independent effects of phonotactic probability and neighbourhood density on lexical acquisition by preschool children. Lang. Cogn. Process. 2011, 26, 191–211. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vitevitch, M.S.; Chan, K.Y.; Roodenrys, S. Complex network structure influences processing in long-term and short-term memory. J. Mem. Lang. 2012, 67, 30–44. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dell, G.S.; Gordon, J.K. Neighbors in the lexicon: Friends or foes? In Phonetics and Phonology in Language Comprehension and Production: Differences and Similarities; Schiller, N.O., Meyer, A.S., Eds.; De Gruyter Mouton: New York, NY, USA, 2011; pp. 9–38. [Google Scholar]
- Gahl, S.; Yao, Y.; Johnson, K. Why reduce? Phonological neighborhood density and phonetic reduction in spontaneous speech. J. Mem. Lang. 2012, 66, 789–806. [Google Scholar] [CrossRef] [Green Version]
- Stemberger, J.P. Neighbourhood effects on error rates in speech production. Brain Lang. 2004, 90, 413–422. [Google Scholar] [CrossRef]
- Vitevitch, M.S. The influence of phonological similarity neighborhoods on speech production. J. Exp. Psychol. Learn. Mem. Cogn. 2002, 28, 735–747. [Google Scholar] [CrossRef]
- Vitevitch, M.S.; Sommers, M.S. The facilitative influence of phonological similarity and neighborhood frequency in speech production in younger and older adults. Mem. Cogn. 2003, 31, 491–504. [Google Scholar] [CrossRef] [Green Version]
- Sadat, J.; Martin, C.D.; Costa, A.; Alario, F.-X. Reconciling phonological neighborhood effects in speech production through single trial analysis. Cogn. Psychol. 2014, 68, 33–58. [Google Scholar] [CrossRef] [Green Version]
- Luce, P.A.; Pisoni, D.B. Recognizing spoken words: The neighborhood activation model. Ear Hear. 1998, 19, 1–36. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vitevitch, M.S.; Luce, P.A. When words compete: Levels of processing in perception of spoken words. Brain Lang. 1998, 9, 325–329. [Google Scholar] [CrossRef]
- Vitevitch, M.S.; Luce, P.A.; Pisoni, D.B.; Auer, E.T. Phonotactics, neighborhood activation, and lexical access for spoken words. Brain Lang. 1999, 68, 306–311. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Flemming, E. Contrast and Perceptual Distinctiveness. Phonetically Based Phonology; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Graff, P. Communicative Efficiency in the Lexicon. Doctoral Dissertation, Massachusetts Institute of Technology, Cambridge, MA, USA, 2012. [Google Scholar]
- Lindblom, B. Phonetic universals in vowel systems. In Experimental Phonology; Ohala, J., Jaeger, J., Eds.; Academic Press: Orlando, FL, USA, 1986; pp. 13–44. [Google Scholar]
- Wedel, A.; Kaplan, A.; Jackson, S. High functional load inhibits phonological contrast loss: A corpus study. Cognition 2013, 128, 179–186. [Google Scholar] [CrossRef]
- Monaghan, P.; Shillcock, R.C.; Christiansen, M.H.; Kirby, S. How arbitrary is language. Philos. Trans. R. Soc. B 2014, 369, 20130299. [Google Scholar] [CrossRef] [Green Version]
- Shillcock, R.; Kirby, S.; McDonald, S.; Brew, C. Filled pauses and their status in the mental lexicon. In Disfluency in Spontaneous Speech (diss’01); ISCA: Edinburgh, UK, 2001; pp. 53–56. [Google Scholar]
- Tamariz, M. Exploring systematicity between phonological and context-cooccurrence representations of the mental lexicon. The Ment. Lex. 2008, 3, 259–278. [Google Scholar] [CrossRef] [Green Version]
- Hockett, C. The origin of speech. Sci. Am. 1960, 203, 88–96. [Google Scholar] [CrossRef]
- de Saussure, F. Course in General Linguistics; McGraw-Hill: New York, NY, USA, 1916. [Google Scholar]
- Imai, M.; Kita, S. The sound symbolism bootstrapping hypothesis for language acquisition and language evolution. Philos. Trans. R. Soc. B Biol. Sci. 2014, 369, 20130298. [Google Scholar] [CrossRef] [Green Version]
- Imai, M.; Kita, S.; Nagumo, M.; Okada, H. Sound symbolism facilitates early verb learning. Cognition 2008, 109, 54–65. [Google Scholar] [CrossRef]
- Nielsen, A.; Rendall, D. The source and magnitude of sound-symbolic biases in processing artificial word material and their implications for language learning and transmission. Lang. Cogn. 2012, 4, 115–125. [Google Scholar] [CrossRef]
- Nygaard, L.C.; Cook, A.E.; Namy, L.L. Sound to meaning correspondences facilitate word learning. Cognition 2009, 112, 181–186. [Google Scholar] [CrossRef] [PubMed]
- Monaghan, P.; Christiansen, M.H.; Fitneva, S.A. The arbitrariness of the sign: Learning advantages from the structure of the vocabulary. J. Exp. Psychol. Gen. 2011, 140, 325–347. [Google Scholar] [CrossRef] [PubMed]
- Monaghan, P.; Maddock, K.; Walker, P. The role of sound symbolism in language learning. J. Exp. Psychol. Learn. Mem. Cogn. 2012, 38, 1152–1164. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Swingley, D.; Aslin, R.N. Lexical competition in young children’s word learning. Cogn. Psychol. 2007, 54, 99–132. [Google Scholar] [CrossRef]
- Kirby, S.; Tamariz, M.; Cornish, H.; Smith, K. Compression and communication in the cultural evolution of linguistic structure. Cognition 2015, 141, 87–102. [Google Scholar] [CrossRef] [Green Version]
- Tamariz, M.; Kirby, S. Culture: Copying, compression, and conventionality. Cogn. Sci. 2015, 39, 171–183. [Google Scholar] [CrossRef]
- Dell, G.S.; Reich, P.A. Stages in sentence production: An analysis of speech error data. Cognition 1981, 20, 611–629. [Google Scholar] [CrossRef]
- Goldrick, M.; Rapp, B. A restricted interaction account (ria) of spoken word production: The best of both worlds. Aphasiology 2002, 16, 20–55. [Google Scholar] [CrossRef]
- Schwartz, M.F.; Dell, G.S.; Martin, N.; Gahl, S.; Sobel, P. A case-series test of the interactive two-step model of lexical access: Evidence from picture naming. J. Mem. Lang. 2006, 54, 228–264. [Google Scholar] [CrossRef]
- Vigliocco, G.; Antonini, T.; Garrett, M.F. Grammatical Gender Is on the Tip of Italian Tongues. Psychol. Sci. 1997, 8, 314–317. [Google Scholar] [CrossRef]
- Christiansen, M.H.; Chater, N. Language as shaped by the brain. Behav. Brain Sci. 2008, 31, 489–508. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gibson, E.; Futrell, R.; Piantadosi, S.P.; Dautriche, I.; Mahowald, K.; Bergen, L.; Levy, R. How efficiency shapes human language. Trends Cogn. Sci. 2019, 23, 389–407. [Google Scholar] [CrossRef] [PubMed]
- Chater, N.; Christiansen, M.H. Language acquisition meets language evolution. Cogn. Sci. 2010, 34, 1131–1157. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Enfield, N.J. Natural Causes of Language: Frames, Biases and Cultural Transmission (Conceptual Foundations of Language Science 1); Language Science Press: Berlin, Germany, 2014. [Google Scholar]
- Enfield, N.J. The Utility of Meaning: What Words Mean and Why; Oxford University Press: Oxford, UK, 2015. [Google Scholar]
- Zipf, G.K. The Psycho-Biology of Language; Houghton Mifflin: Boston, MA, USA, 1935. [Google Scholar]
- Kirby, S.; Cornish, H.; Smith, K. Cumulative cultural evolution in the laboratory: An experimental approach to the origins of structure in human language. Proc. Natl. Acad. Sci. USA 2008, 105, 10681–10686. [Google Scholar] [CrossRef] [Green Version]
- Kirby, S.; Hurford, J.R. The emergence of linguistic structure: An overview of the iterated learning model. In Simulating the Evolution of Language; Cangelosi, A., Parisi, D., Eds.; Springer: London, UK, 2002; pp. 121–147. [Google Scholar]
- Smith, K.; Kirby, S.; Brighton, H. Iterated learning: A framework for the emergence of language. Artif. Life 2003, 9, 371–386. [Google Scholar] [CrossRef]
- Winters, J.; Kirby, S.; Smith, K. Languages adapt to their contextual niche. Lang. Cogn. 2015, 7, 415–449. [Google Scholar] [CrossRef] [Green Version]
- Silvey, C.; Kirby, S.; Smith, K. Word meanings evolve to selectively preserve distinctions on salient dimensions. Cogn. Sci. 2015, 39, 212–226. [Google Scholar] [CrossRef] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| β | 95% CI (Lower) | 95% CI (Upper) | SD (Family) | SD (Language) | |
|---|---|---|---|---|---|
| Intercept | 0.202 | 0.060 | 0.344 | 0.000 | 0.002 |
| Orthographic distance | −0.217 | −0.315 | −0.119 | 0.159 | 0.067 |
| Semantic distance | −0.277 | −0.387 | −0.166 | 0.169 | 0.121 |
| Syntactic distance | 0.081 | 0.053 | 0.109 | 0.000 | 0.078 |
| Number of genders (2) | - | - | - | 0.153 | 0.148 |
| Number of genders (3) | −0.745 | −0.897 | −0.592 | 0.012 | 0.096 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rogers, P.G.; Gries, S.T. Grammatical Gender Disambiguates Syntactically Similar Nouns. Entropy 2022, 24, 520. https://doi.org/10.3390/e24040520
Rogers PG, Gries ST. Grammatical Gender Disambiguates Syntactically Similar Nouns. Entropy. 2022; 24(4):520. https://doi.org/10.3390/e24040520
Chicago/Turabian StyleRogers, Phillip G., and Stefan Th. Gries. 2022. "Grammatical Gender Disambiguates Syntactically Similar Nouns" Entropy 24, no. 4: 520. https://doi.org/10.3390/e24040520
APA StyleRogers, P. G., & Gries, S. T. (2022). Grammatical Gender Disambiguates Syntactically Similar Nouns. Entropy, 24(4), 520. https://doi.org/10.3390/e24040520