
Dynamics of Remote Communication: Movement Coordination in Video-Mediated and Face-to-Face Conversations

 , ,
, ,
Abstract
:
1. Introduction
1.1. Dynamics of Video-Mediated Interactions
1.2. Current Study and Hypotheses
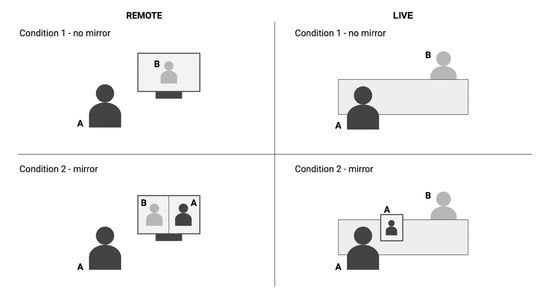
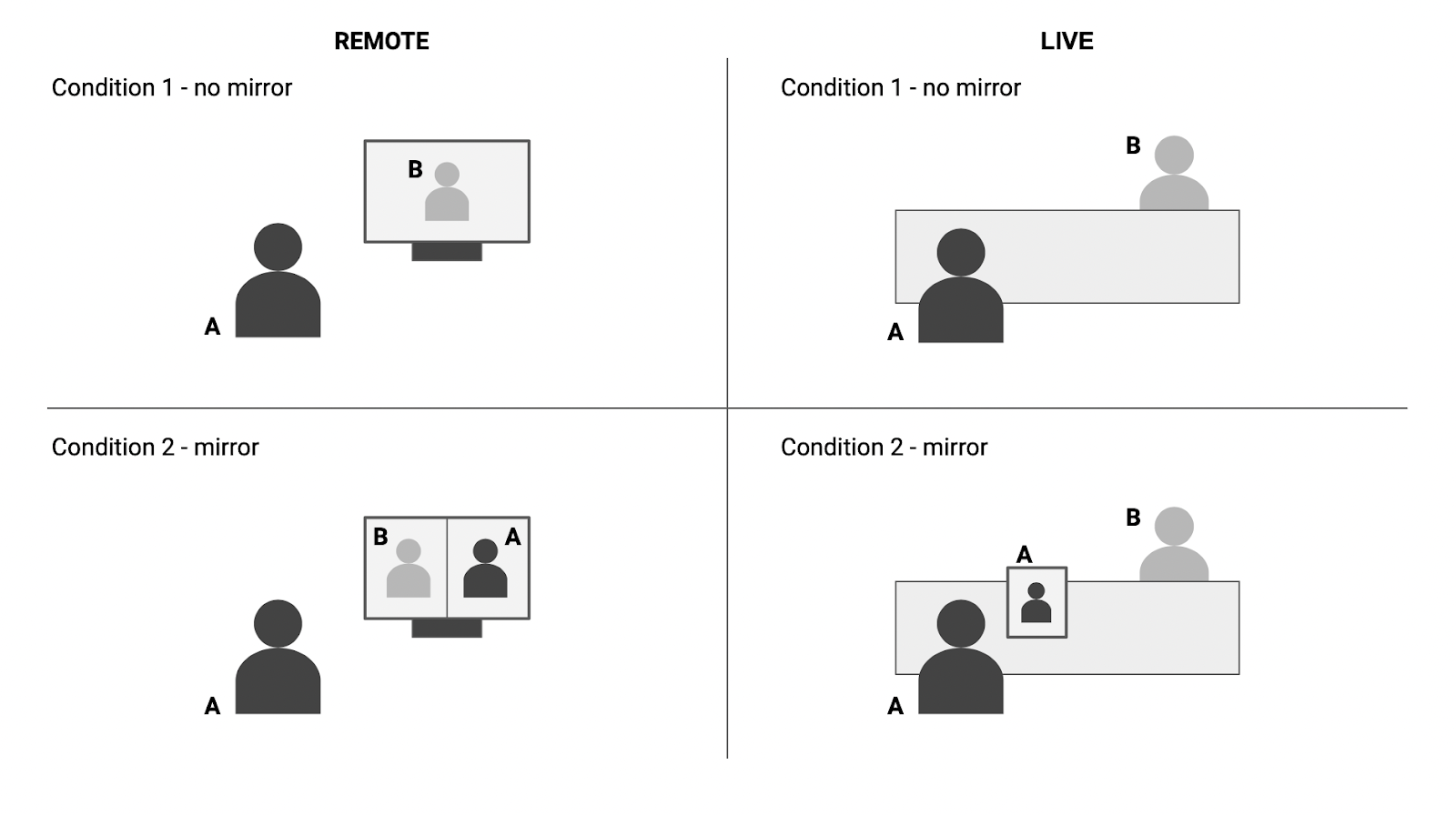
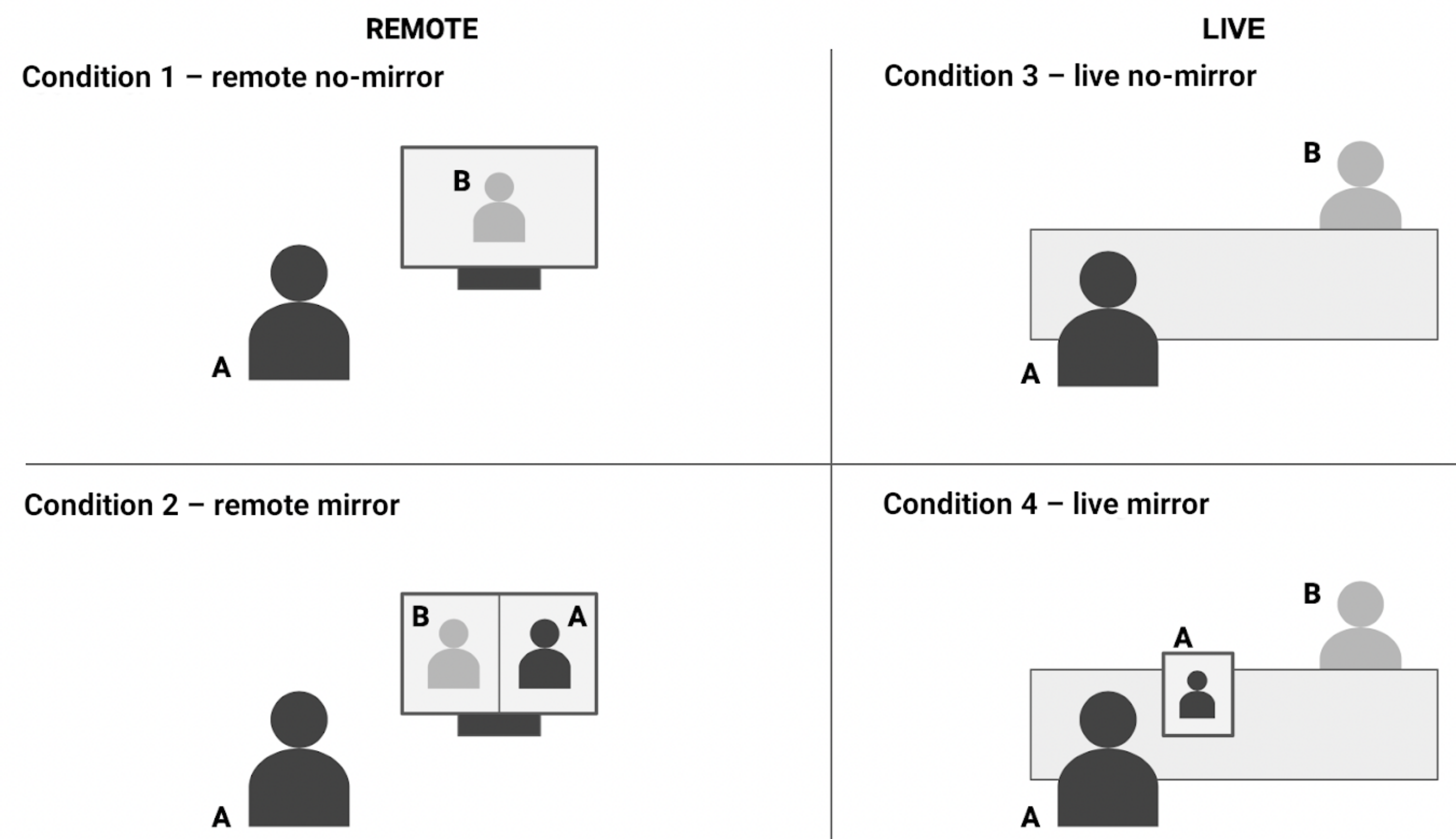
2. Materials and Methods
2.1. Participants and Setup
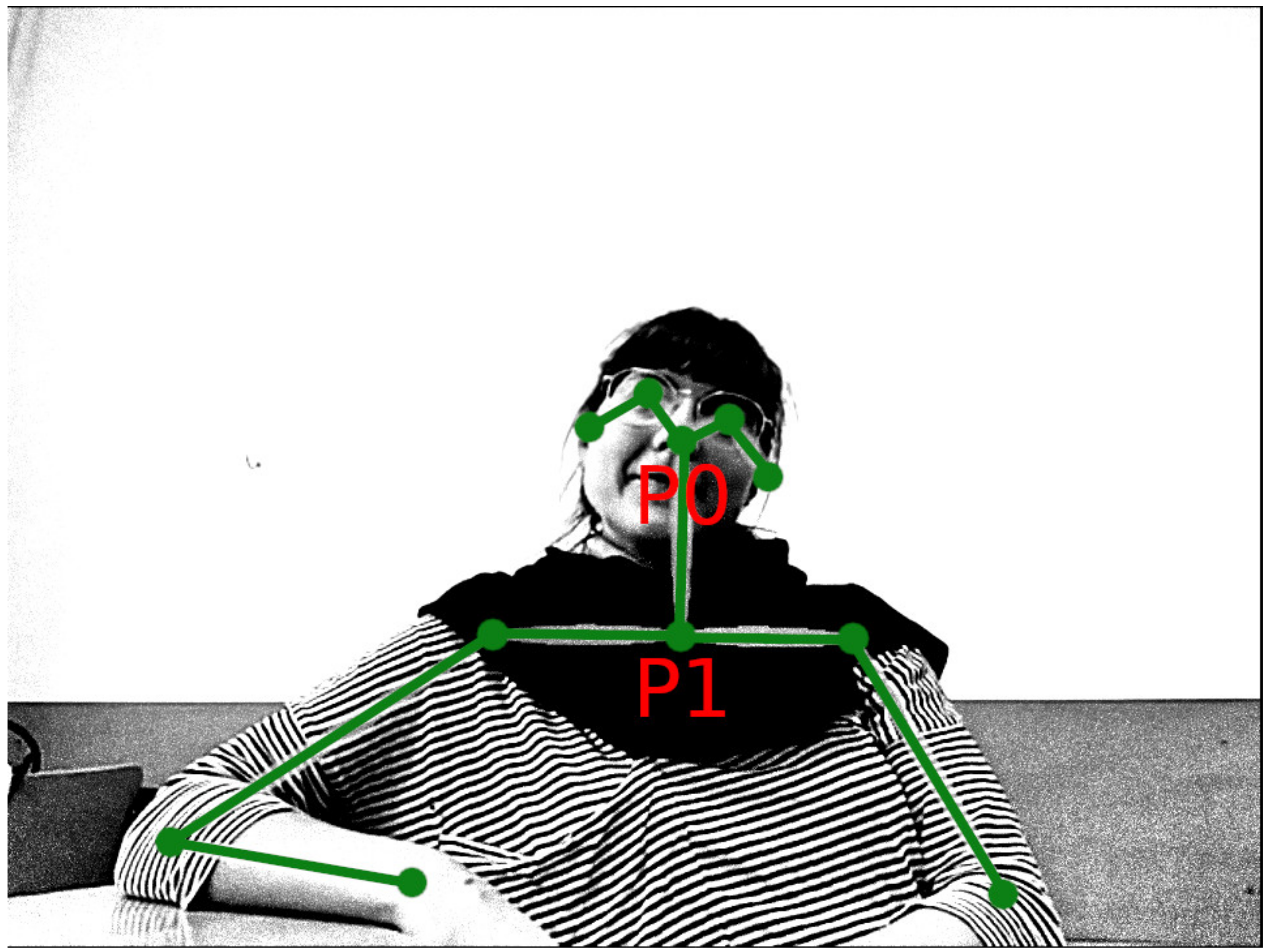
2.2. Movement Tracking
2.3. Measures and Data Analysis Techniques
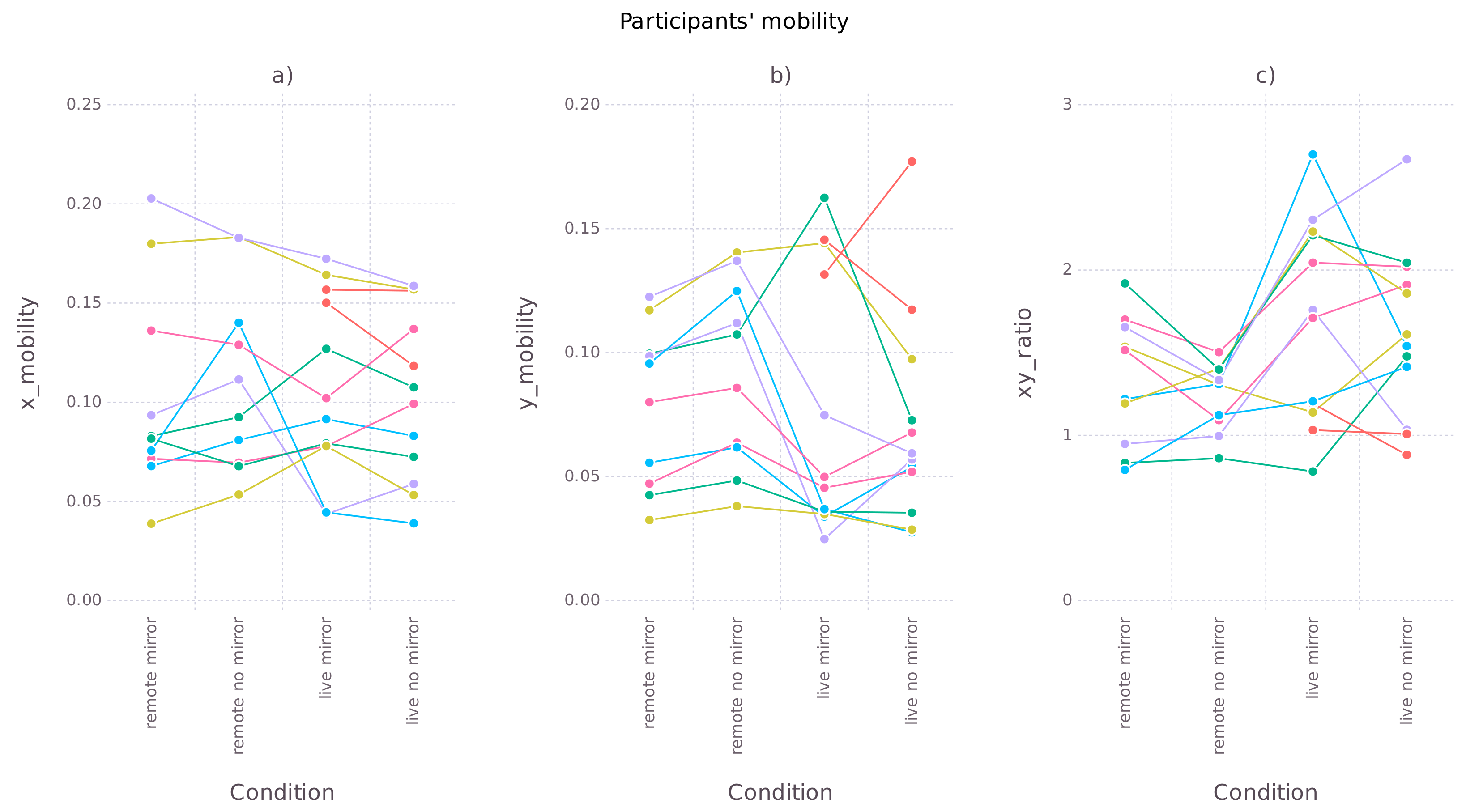
- Horizontal mobility—standard deviation of the horizontal P0 coordinate divided by the average P0-P1 distance. It is interpreted as a general indicator of participant mobility.
- Vertical mobility—standard deviation of the vertical P0 coordinate divided by the average P0-P1 distance. It is interpreted as an indicator of communicative nodding gestures.
- Horizontal-vertical mobility ratio—ratio between horizontal and vertical mobility. It is interpreted as a ratio between overall movement and communicative nodding gestures.
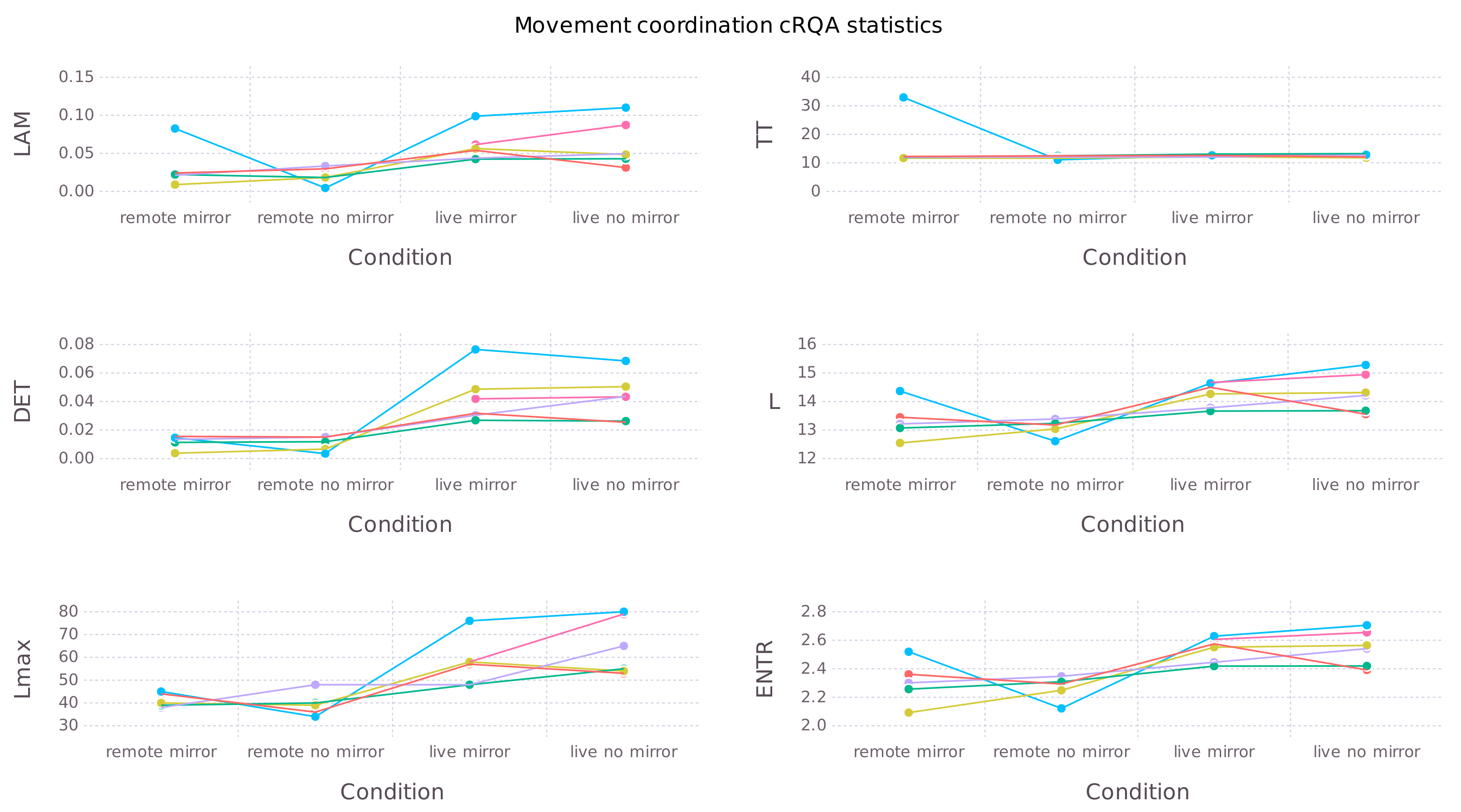
- Determinism, fraction of recurrent points forming diagonal lines.A large DET means that there are stable episodes of coordination and that coordination is more predictable. In interaction it suggests that partners may anticipate each other’s actions and successfully maintain coordination.
- Entropy of the distribution of diagonal line lengths.A large ENTR means that the coordination is more complex with more characteristic patterns of coordination. This suggests that the interaction process is more varied.
- Average length of a diagonal line.A large L means that the episodes of coordination are longer on average.
- Lmax – maximum length of a diagonal line. A large Lmax means that it is possible to maintain coordination for a longer time.
- Laminarity, fraction of recurrent points forming vertical lines.Vertical lines form when one participant remains in the same state (moving uniformly or being still) for some time. A large LAM indicates that participants’ movement is steadier.
- Trapping time, average length of a vertical line.A large TT means that the episodes of steady movement are longer on average.
3. Results
3.1. Horizontal and Vertical Mobility
3.2. Interpersonal Movement Coordination
4. Discussion
Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Fusaroli, R.; Rączaszek-Leonardi, J.; Tylén, K. Dialog as Interpersonal Synergy. New Ideas Psychol. 2014, 32, 147–157. [Google Scholar] [CrossRef] [Green Version]
- De Jaegher, H.; Di Paolo, E. Participatory Sense-Making. Phenomenol. Cogn. Sci. 2007, 6, 485–507. [Google Scholar] [CrossRef]
- Trevarthen, C. Communication and Cooperation in Early Infancy: A Description of Primary Intersubjectivity. In Before Speech: The Beginning of Human Communication; Bullowa, M., Ed.; Cambridge University Press: London, UK, 1979; pp. 321–347. [Google Scholar]
- Oullier, O.; de Guzman, G.C.; Jantzen, K.J.; Lagarde, J.; Kelso, J.S. Social Coordination Dynamics: Measuring Human Bonding. Soc. Neurosci. 2008, 3, 178–192. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- López Pérez, D.; Leonardi, G.; Niedźwiecka, A.; Radkowska, A.; Rączaszek-Leonardi, J.; Tomalski, P. Combining Recurrence Analysis and Automatic Movement Extraction from Video Recordings to Study Behavioral Coupling in Face-to-Face Parent-Child Interactions. Front. Psychol. 2017, 8, 2228. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jensen, T.W. Emotion in Languaging: Languaging as Affective, Adaptive, and Flexible Behavior in Social Interaction. Front. Psychol. 2014, 5, 720. [Google Scholar] [CrossRef] [Green Version]
- Bernieri, F.J. Coordinated Movement and Rapport in Teacher-Student Interactions. J. Nonverbal Behav. 1988, 12, 120–138. [Google Scholar] [CrossRef]
- Latif, N.; Barbosa, A.V.; Vatiokiotis-Bateson, E.; Castelhano, M.S.; Munhall, K.G. Movement Coordination during Conversation. PLoS ONE 2014, 9, e105036. [Google Scholar] [CrossRef]
- Fujiwara, K.; Daibo, I. Empathic Accuracy and Interpersonal Coordination: Behavior Matching Can Enhance Accuracy but Interactional Synchrony May Not. J. Soc. Psychol. 2021, 162, 71–88. [Google Scholar] [CrossRef]
- Fusaroli, R.; Bjørndahl, J.S.; Roepstorff, A.; Tylén, K. A Heart for Interaction: Shared Physiological Dynamics and Behavioral Coordination in a Collective, Creative Construction Task. J. Exp. Psychol. Hum. Percept. Perform. 2016, 42, 1297–1310. [Google Scholar] [CrossRef] [Green Version]
- Rączaszek-Leonardi, J.; Krzesicka, J.; Klamann, N.; Ziembowicz, K.; Denkiewicz, M.; Kukiełka, M.; Zubek, J. Cultural Artifacts Transform Embodied Practice: How a Sommelier Card Shapes the Behavior of Dyads Engaged in Wine Tasting. Front. Psychol. 2019, 10, 2671. [Google Scholar] [CrossRef]
- Ramseyer, F.; Tschacher, W. Nonverbal Synchrony in Psychotherapy: Coordinated Body Movement Reflects Relationship Quality and Outcome. J. Consult. Clin. Psychol. 2011, 79, 284–295. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- De Jaegher, H.; Di Paolo, E.; Gallagher, S. Can Social Interaction Constitute Social Cognition? Trends Cogn. Sci. 2010, 14, 441–447. [Google Scholar] [CrossRef] [PubMed]
- Porter, R. Business Meetings: A Comparison of the Effectiveness of Audio and Video Conferencing in Dispersed Teams. Ph.D. Thesis, University of Maine, Orono, ME, USA, 2012. [Google Scholar]
- Sherman, L.E.; Michikyan, M.; Greenfield, P.M. The Effects of Text, Audio, Video, and in-Person Communication on Bonding between Friends. Cyberpsychol. J. Psychosoc. Res. Cyberspace 2013, 7. [Google Scholar] [CrossRef]
- Burgoon, J.K.; Bonito, J.A.; Ramirez, A., Jr.; Dunbar, N.E.; Kam, K.; Fischer, J. Testing the Interactivity Principle: Effects of Mediation, Propinquity, and Verbal and Nonverbal Modalities in Interpersonal Interaction. J. Commun. 2002, 52, 657–677. [Google Scholar] [CrossRef]
- Chillcoat, Y.; DeWine, S. Teleconferencing and Interpersonal Communication Perception. J. Appl. Commun. Res. 1985, 13, 14–32. [Google Scholar] [CrossRef]
- Federman, M. On the Media Effects of Immigration and Refugee Board Hearings via Videoconference. J. Refug. Stud. 2006, 19, 433–452. [Google Scholar] [CrossRef]
- Bailenson, J.N. Nonverbal Overload: A Theoretical Argument for the Causes of Zoom Fatigue. Technol. Mind Behav. 2021, 2. [Google Scholar] [CrossRef]
- Nesher Shoshan, H.; Wehrt, W. Understanding “Zoom Fatigue”: A Mixed-Method Approach. Appl. Psychol. 2021. [Google Scholar] [CrossRef]
- Fauville, G.; Luo, M.; Muller Queiroz, A.C.; Bailenson, J.; Hancock, J. Zoom Exhaustion & Fatigue Scale. SSRN Electron. J. 2021, 4, 100119. [Google Scholar] [CrossRef]
- Fauville, G.; Luo, M.; Muller Queiroz, A.C.; Bailenson, J.N.; Hancock, J. Nonverbal Mechanisms Predict Zoom Fatigue and Explain Why Women Experience Higher Levels than Men; SSRN Scholarly Paper ID 3820035; Social Science Research Network: Rochester, NY, USA, 2021. [Google Scholar] [CrossRef]
- Riedl, R. On the Stress Potential of Videoconferencing: Definition and Root Causes of Zoom Fatigue. Electron. Mark. 2021. [Google Scholar] [CrossRef]
- Burgoon, J.K.; Bonito, J.A.; Bengtsson, B.; Ramirez, A.; Dunbar, N.E.; Miczo, N. Testing the Interactivity Model: Communication Processes, Partner Assessments, and the Quality of Collaborative Work. J. Manag. Inf. Syst. 1999, 16, 33–56. [Google Scholar] [CrossRef]
- Froese, T.; Di Paolo, E.A. Toward Minimally Social Behavior: Social Psychology Meets Evolutionary Robotics. In Advances in Artificial Life. Darwin Meets von Neumann; Lecture Notes in Computer Science; Kampis, G., Karsai, I., Szathmáry, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 426–433. [Google Scholar] [CrossRef] [Green Version]
- Gibson, J.J. The Ecological Approach to Visual Perception; Houghton Mifflin: Boston, MA, USA, 1979. [Google Scholar]
- Rączaszek-Leonardi, J.; Nomikou, I.; Rohlfing, K.J. Young Children’s Dialogical Actions: The Beginnings of Purposeful Intersubjectivity. IEEE Trans. Auton. Ment. Dev. 2013, 5, 210–221. [Google Scholar] [CrossRef]
- Rietveld, E.; Kiverstein, J. A Rich Landscape of Affordances. Ecol. Psychol. 2014, 26, 325–352. [Google Scholar] [CrossRef]
- Accessing Meeting and Phone Statistics. 2021. Available online: https://support.zoom.us/hc/en-us/articles/202920719-Accessing-meeting-and-phone-statistics (accessed on 20 January 2022).
- Kohrs, C.; Angenstein, N.; Brechmann, A. Delays in Human-Computer Interaction and Their Effects on Brain Activity. PLoS ONE 2016, 11, e0146250. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hirshfield, L.M.; Bobko, P.; Barelka, A.; Hirshfield, S.H.; Farrington, M.T.; Gulbronson, S.; Paverman, D. Using Noninvasive Brain Measurement to Explore the Psychological Effects of Computer Malfunctions on Users during Human-Computer Interactions. Adv. Hum. Comput. Interact. 2014, 2014, 2. [Google Scholar] [CrossRef] [Green Version]
- Boland, J.E.; Fonseca, P.; Mermelstein, I.; Williamson, M. Zoom Disrupts the Rhythm of Conversation. J. Exp. Psychol. Gen. 2021. [Google Scholar] [CrossRef]
- Clayman, S.E. Sequence and Solidarity. In Advances in Group Processes; Emerald Group Publishing Limited: Bingley, UK, 2002; Volume 19, pp. 229–253. [Google Scholar] [CrossRef]
- Kendrick, K.H.; Torreira, F. The Timing and Construction of Preference: A Quantitative Study. Discourse Process. 2015, 52, 255–289. [Google Scholar] [CrossRef] [Green Version]
- Schoenenberg, K.; Raake, A.; Koeppe, J. Why Are You so Slow?—Misattribution of Transmission Delay to Attributes of the Conversation Partner at the Far-End. Int. J. Hum. Comput. Stud. 2014, 72, 477–487. [Google Scholar] [CrossRef]
- Hessels, R.S. How Does Gaze to Faces Support Face-to-Face Interaction? A Review and Perspective. Psychon. Bull. Rev. 2020, 27, 856–881. [Google Scholar] [CrossRef]
- Rączaszek-Leonardi, J.; Nomikou, I. Beyond Mechanistic Interaction: Value-Based Constraints on Meaning in Language. Front. Psychol. 2015, 6, 1579. [Google Scholar] [CrossRef] [Green Version]
- Clark, H.H.; Wilkes-Gibbs, D. Referring as a Collaborative Process. Cognition 1986, 22, 1–39. [Google Scholar] [CrossRef]
- Bavelas, J.B. Gestures as Part of Speech: Methodological Implications. Res. Lang. Soc. Interact. 1994, 27, 201–221. [Google Scholar] [CrossRef]
- Wagner, P.; Malisz, Z.; Kopp, S. Gesture and Speech in Interaction: An Overview. Speech Commun. 2014, 57, 209–232. [Google Scholar] [CrossRef]
- Wlodarczak, M.; Buschmeier, H.; Malisz, Z.; Kopp, S.; Wagner, P. Listener Head Gestures and Verbal Feedback Expressions in a Distraction Task. In Proceedings of the Interdisciplinary Workshop on Feedback Behaviors in Dialog, INTERSPEECH2012 Satellite Workshop, Portland, OR, USA, 9–13 September 2012. [Google Scholar]
- Duncan, S. Some Signals and Rules for Taking Speaking Turns in Conversations. J. Personal. Soc. Psychol. 1972, 23, 283–292. [Google Scholar] [CrossRef]
- Osugi, T.; Kawahara, J.I. Effects of Head Nodding and Shaking Motions on Perceptions of Likeability and Approachability. Perception 2018, 47, 16–29. [Google Scholar] [CrossRef] [Green Version]
- Moretti, S.; Greco, A. Truth Is in the Head. A Nod and Shake Compatibility Effect. Acta Psychol. 2018, 185, 203–218. [Google Scholar] [CrossRef]
- Moretti, S.; Greco, A. Nodding and Shaking of the Head as Simulated Approach and Avoidance Responses. Acta Psychol. 2020, 203, 102988. [Google Scholar] [CrossRef]
- Andonova, E.; Taylor, H.A. Nodding in Dis/Agreement: A Tale of Two Cultures. Cogn. Process. 2012, 13, 79–82. [Google Scholar] [CrossRef]
- Oppezzo, M.; Schwartz, D.L. Give Your Ideas Some Legs: The Positive Effect of Walking on Creative Thinking. J. Exp. Psychol. Learn. Mem. Cogn. 2014, 40, 1142–1152. [Google Scholar] [CrossRef] [Green Version]
- Nomikou, I.; Leonardi, G.; Rohlfing, K.J.; Rączaszek-Leonardi, J. Constructing Interaction: The Development of Gaze Dynamics. Infant Child Dev. 2016, 25, 277–295. [Google Scholar] [CrossRef] [Green Version]
- Ingram, R.E.; Cruet, D.; Johnson, B.R.; Wisnicki, K.S. Self-Focused Attention, Gender, Gender Role, and Vulnerability to Negative Affect. J. Personal. Soc. Psychol. 1988, 55, 967–978. [Google Scholar] [CrossRef]
- Fejfar, M.; Hoyle, R. Effect of Private Self-Awareness on Negative Affect and Self-Referent Attribution: A Quantitative Review. Personal. Soc. Psychol. Rev. 2000, 4, 132–142. [Google Scholar] [CrossRef]
- Gonzales, A.L.; Hancock, J.T. Mirror, Mirror on My Facebook Wall: Effects of Exposure to Facebook on Self-Esteem. Cyberpsychol. Behav. Soc. Netw. 2011, 14, 79–83. [Google Scholar] [CrossRef] [PubMed]
- Horn, R.; Behrend, T. Video Killed the Interview Star: Does Picture-in-Picture Affect Interview Performance? Pers. Assess. Decis. 2017, 3, 5. [Google Scholar] [CrossRef] [Green Version]
- Kuhn, K.M. The Constant Mirror: Self-view and Attitudes to Virtual Meetings. Comput. Hum. Behav. 2022, 128, 107110. [Google Scholar] [CrossRef]
- Weltzien, S.; Marsh, L.E.; Hood, B. Thinking of Me: Self-focus Reduces Sharing and Helping in Seven- to Eight-Year-Olds. PLoS ONE 2018, 13, e0189752. [Google Scholar] [CrossRef] [Green Version]
- Gibbons, F.X.; Wicklund, R.A. Self-Focused Attention and Helping Behavior. J. Personal. Soc. Psychol. 1982, 43, 462–474. [Google Scholar] [CrossRef]
- Cao, Z.; Hidalgo, G.; Simon, T.; Wei, S.E.; Sheikh, Y. OpenPose: Realtime Multi-Person 2D Pose Estimation Using Part Affinity Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 172–186. [Google Scholar] [CrossRef] [Green Version]
- Fusaro, M.; Vallotton, C.D.; Harris, P.L. Beside the Point: Mothers’ Head Nodding and Shaking Gestures during Parent–Child Play. Infant Behav. Dev. 2014, 37, 235–247. [Google Scholar] [CrossRef]
- Marwan, N.; Carmen Romano, M.; Thiel, M.; Kurths, J. Recurrence Plots for the Analysis of Complex Systems. Phys. Rep. 2007, 438, 237–329. [Google Scholar] [CrossRef]
- Wallot, S. Multidimensional Cross-Recurrence Quantification Analysis (MdCRQA)—A Method for Quantifying Correlation between Multivariate Time-Series. Multivar. Behav. Res. 2019, 54, 173–191. [Google Scholar] [CrossRef] [PubMed]
- Kennel, M.B.; Brown, R.; Abarbanel, H.D.I. Determining Embedding Dimension for Phase-Space Reconstruction Using a Geometrical Construction. Phys. Rev. A 1992, 45, 3403–3411. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Datseris, G. DynamicalSystems.Jl: A Julia Software Library for Chaos and Nonlinear Dynamics. J. Open Source Softw. 2018, 3, 598. [Google Scholar] [CrossRef]
- Bates, D.; Alday, P.; Kleinschmidt, D.; José Bayoán Santiago Calderón, P.; Zhan, L.; Noack, A.; Arslan, A.; Bouchet-Valat, M.; Kelman, T.; Baldassari, A.; et al. JuliaStats/MixedModels.Jl: V4.6.0. Zenodo. 2022. Available online: https://zenodo.org/record/5825693#.YlZkn9NBxPY (accessed on 20 January 2022).
- Tschacher, W.; Rees, G.M.; Ramseyer, F. Nonverbal Synchrony and Affect in Dyadic Interactions. Front. Psychol. 2014, 5, 1323. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Weber, F.; Haering, C.; Thomaschke, R. Improving the Human–Computer Dialogue With Increased Temporal Predictability. Hum. Factors 2013, 55, 881–892. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Beugher, S.D.; Brône, G.; Goedemé, T. A Semi-Automatic Annotation Tool for Unobtrusive Gesture Analysis. Lang. Resour. Eval. 2018, 52, 433–460. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Est. | SE | z | p | σ | |
|---|---|---|---|---|---|
| Horizontal mobility | |||||
| (Intercept) | 0.1046 | 0.0126 | 8.27 | <10−15 | 0.0398 |
| remote | 0.0088 | 0.0066 | 1.33 | 0.1825 | |
| no mirror | 0.0015 | 0.0063 | 0.24 | 0.8104 | |
| Residual | 0.0210 | ||||
| Vertical mobility | |||||
| (Intercept) | 0.0724 | 0.0123 | 5.87 | <10−8 | 0.0374 |
| remote | 0.0235 | 0.0074 | 3.19 | 0.0014 | |
| no mirror | 0.0024 | 0.0071 | 0.35 | 0.7295 | |
| Residual | 0.0235 | ||||
| Horizontal-vertical mobility ratio | |||||
| (Intercept) | 1.6989 | 0.1281 | 13.27 | <10−39 | 0.3627 |
| remote | −0.4709 | 0.0910 | −5.18 | <10−6 | |
| no mirror | −0.0827 | 0.0876 | −0.94 | 0.3450 | |
| Residual | 0.2906 | ||||
| Est. | SE | z | p | σ | |
|---|---|---|---|---|---|
| ENTR | |||||
| (Intercept) | 2.5486 | 0.0362 | 70.41 | <10−99 | 0.0000 |
| remote | −0.2672 | 0.0418 | −6.39 | <10−9 | |
| no mirror | −0.0138 | 0.0418 | −0.33 | 0.7408 | |
| Residual | 0.1024 | ||||
| DET | |||||
| (Intercept) | 0.0429 | 0.0042 | 10.23 | <10−23 | 0.0043 |
| remote | −0.0323 | 0.0044 | −7.33 | <10−12 | |
| no mirror | −0.0001 | 0.0044 | −0.03 | 0.9776 | |
| Residual | 0.0108 | ||||
| L | |||||
| (Intercept) | 14.3208 | 0.1730 | 82.78 | <10−99 | 0.1239 |
| remote | −1.1179 | 0.1910 | −5.85 | <10−8 | |
| no mirror | −0.0553 | 0.1910 | −0.29 | 0.7720 | |
| Residual | 0.4679 | ||||
| Lmax | |||||
| (Intercept) | 59.5000 | 2.9122 | 20.43 | <10−92 | 1.5260 |
| remote | −21.5000 | 3.2848 | −6.55 | <10−10 | |
| no mirror | 2.8333 | 3.2848 | 0.86 | 0.3884 | |
| Residual | 8.0462 | ||||
| LAM | |||||
| (Intercept) | 0.0593 | 0.0088 | 6.71 | <10−10 | 0.0120 |
| remote | −0.0315 | 0.0085 | −3.71 | 0.0002 | |
| no mirror | 0.0024 | 0.0085 | 0.28 | 0.7764 | |
| Residual | 0.0208 | ||||
| TT | |||||
| (Intercept) | 13.0525 | 1.5470 | 8.44 | <10−16 | 0.0000 |
| remote | 2.1017 | 1.7863 | 1.18 | 0.2394 | |
| no mirror | −0.9629 | 1.7863 | −0.54 | 0.5899 | |
| Residual | 4.3755 | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zubek, J.; Nagórska, E.; Komorowska-Mach, J.; Skowrońska, K.; Zieliński, K.; Rączaszek-Leonardi, J. Dynamics of Remote Communication: Movement Coordination in Video-Mediated and Face-to-Face Conversations. Entropy 2022, 24, 559. https://doi.org/10.3390/e24040559
Zubek J, Nagórska E, Komorowska-Mach J, Skowrońska K, Zieliński K, Rączaszek-Leonardi J. Dynamics of Remote Communication: Movement Coordination in Video-Mediated and Face-to-Face Conversations. Entropy. 2022; 24(4):559. https://doi.org/10.3390/e24040559
Chicago/Turabian StyleZubek, Julian, Ewa Nagórska, Joanna Komorowska-Mach, Katarzyna Skowrońska, Konrad Zieliński, and Joanna Rączaszek-Leonardi. 2022. "Dynamics of Remote Communication: Movement Coordination in Video-Mediated and Face-to-Face Conversations" Entropy 24, no. 4: 559. https://doi.org/10.3390/e24040559
APA StyleZubek, J., Nagórska, E., Komorowska-Mach, J., Skowrońska, K., Zieliński, K., & Rączaszek-Leonardi, J. (2022). Dynamics of Remote Communication: Movement Coordination in Video-Mediated and Face-to-Face Conversations. Entropy, 24(4), 559. https://doi.org/10.3390/e24040559