
Parallel and Practical Approach of Efficient Image Chaotic Encryption Based on Message Passing Interface (MPI)


Abstract
:1. Introduction
2. Related Work
2.1. Stream Ciphers Algorithms
2.2. Related Papers
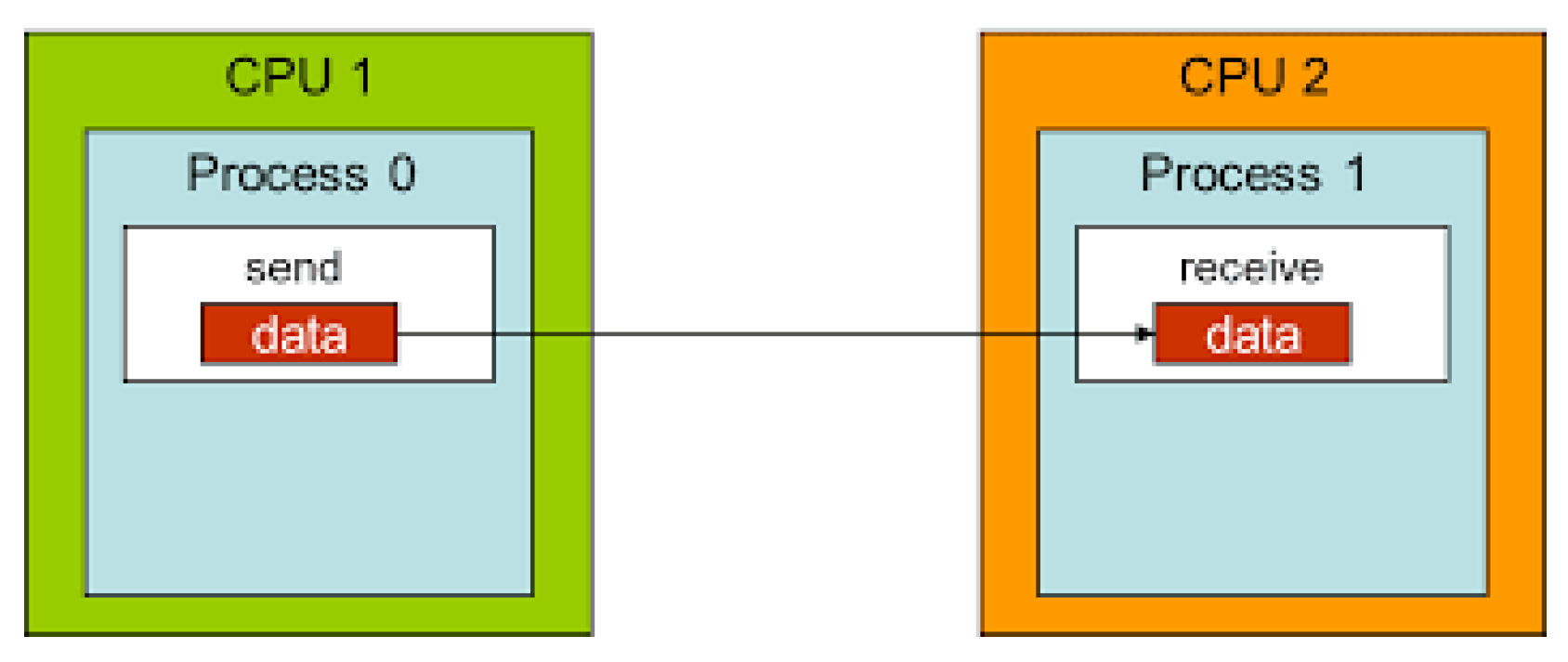
3. Parallel Programming Models and Techniques
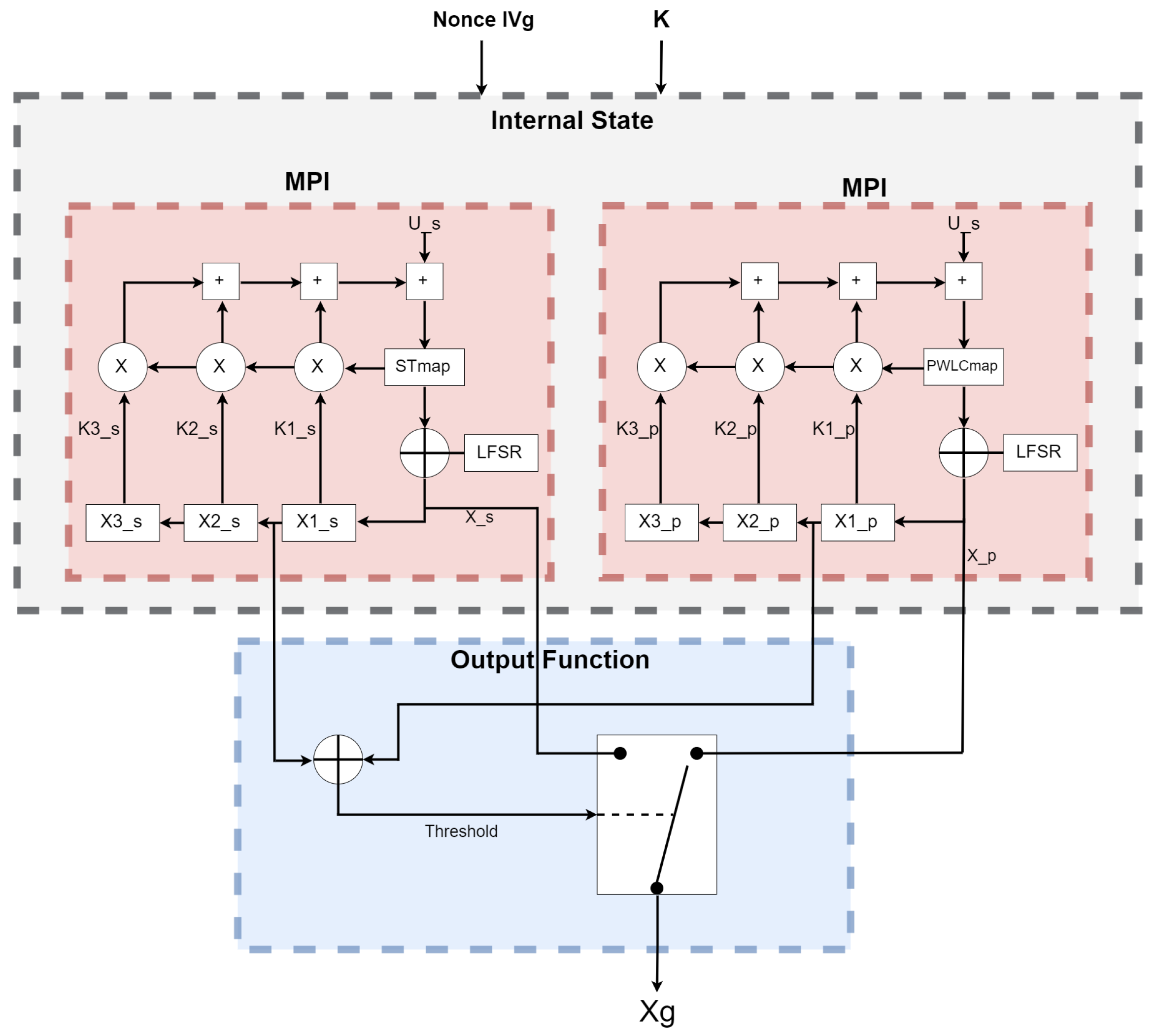
4. Proposed Parallel Chaos Crypto System
| Algorithm 1 PARALLEL IMAGE CHAOS ENCRYPTION ALGORITHM |
| Input: clear image Output: Scrambled Encrypted image
|
5. Performance Computation of Proposed Parallel Computing
5.1. Speed-Up Calculations
5.2. Amdahl’s Law
6. Security
6.1. Keyspace
6.2. Key Security and Sensitivity Attack
6.3. Information Entropy
7. Statistical Analysis
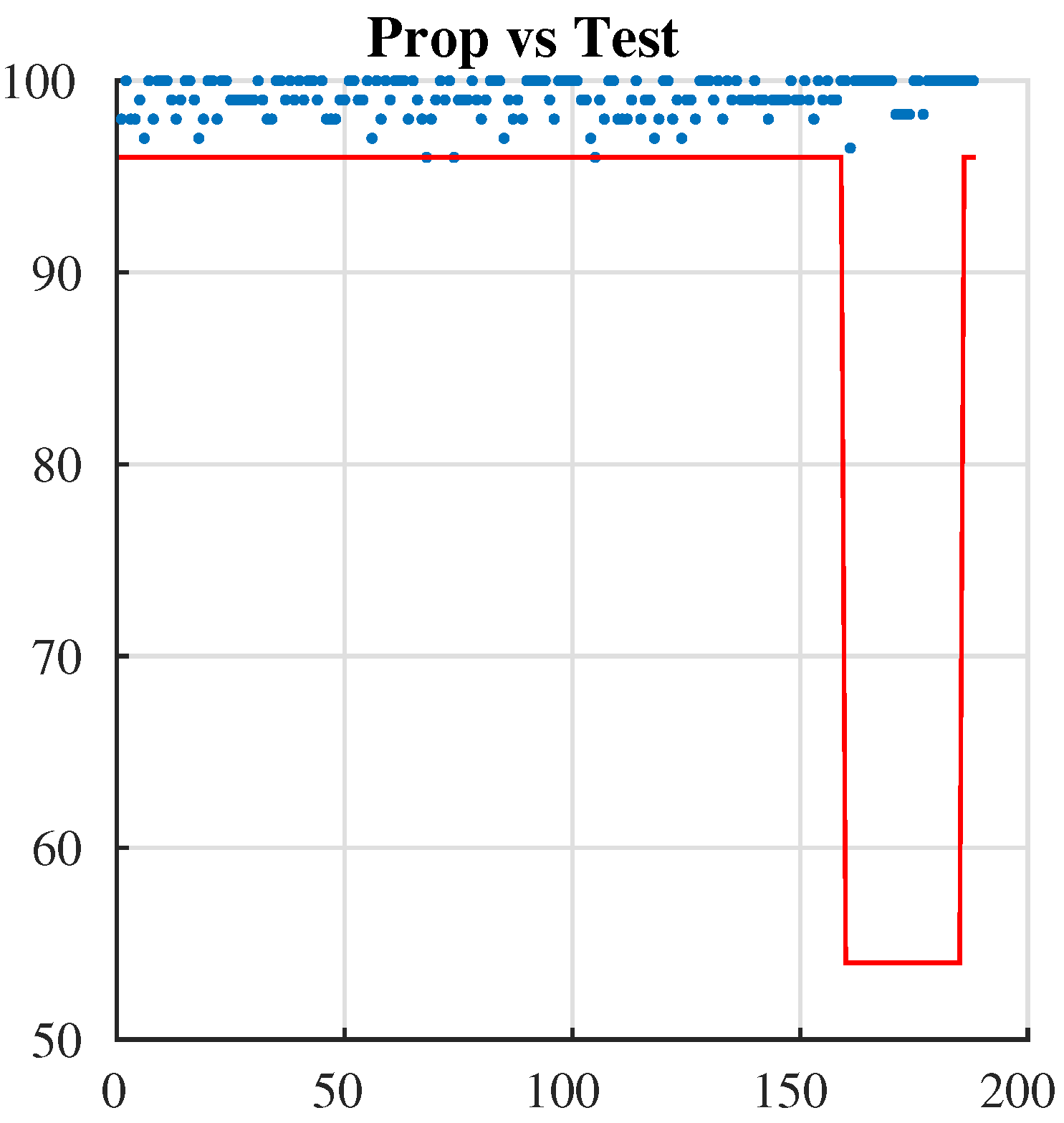
7.1. NIST Test
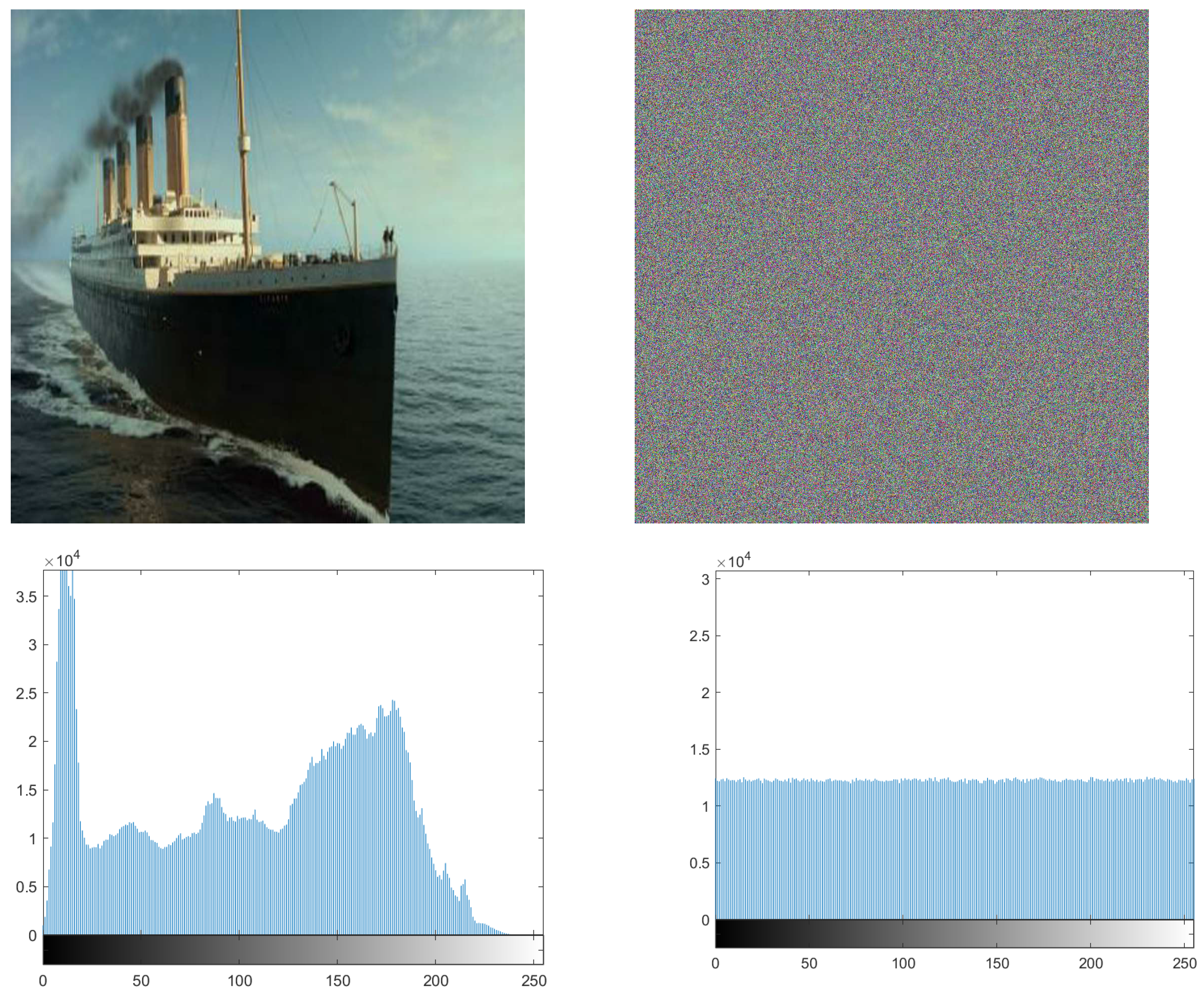
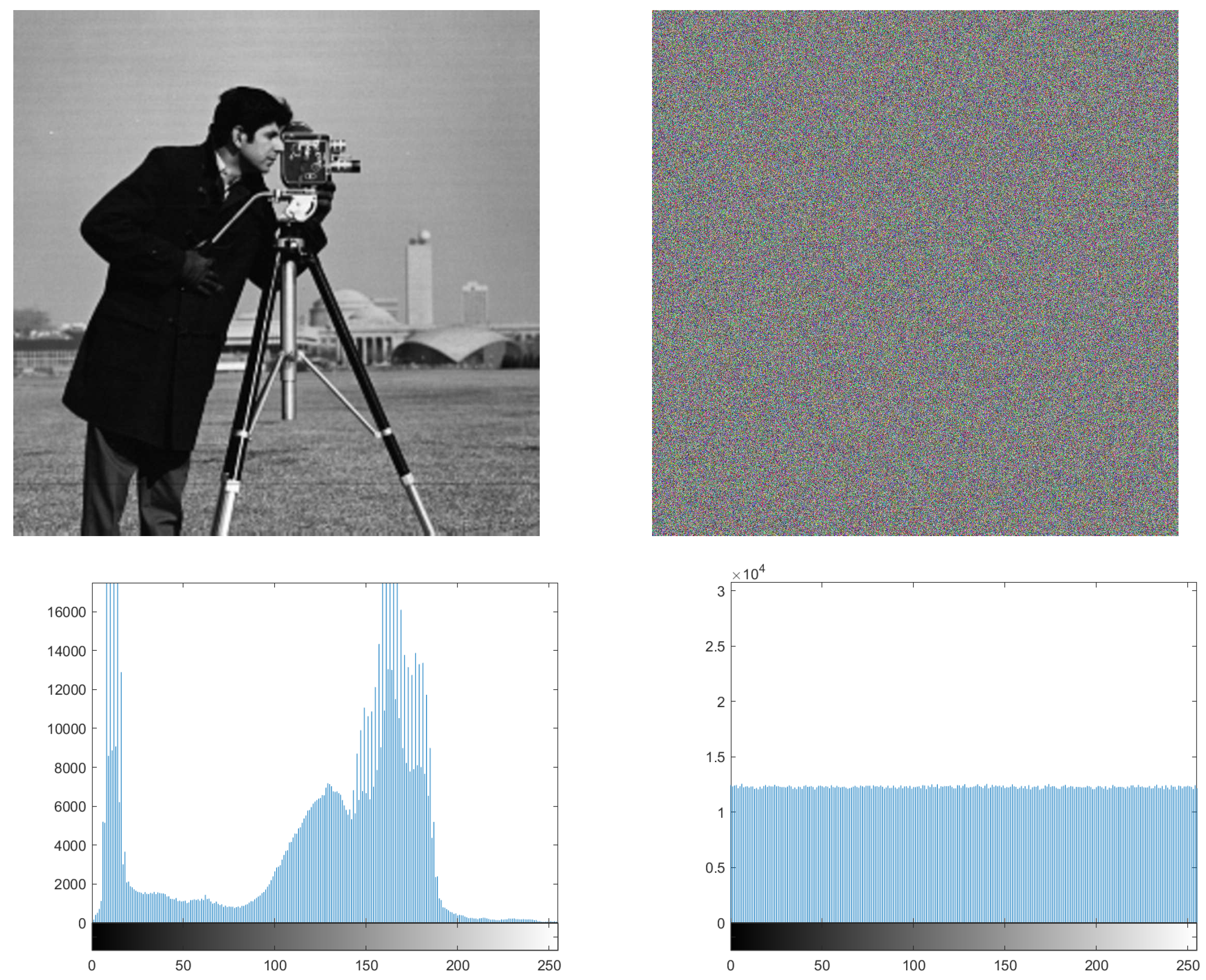
7.2. Chi-Square Test and Histogram
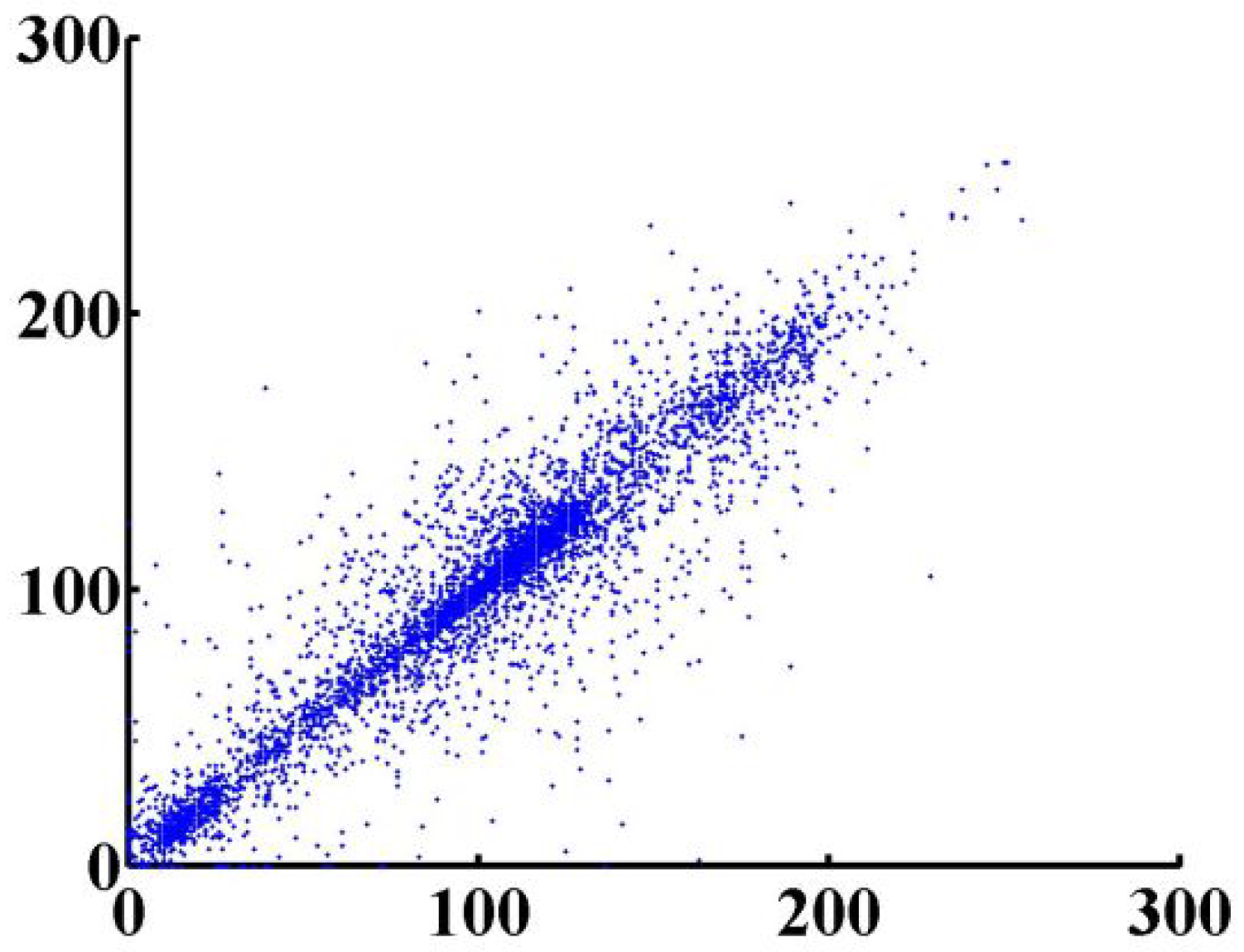
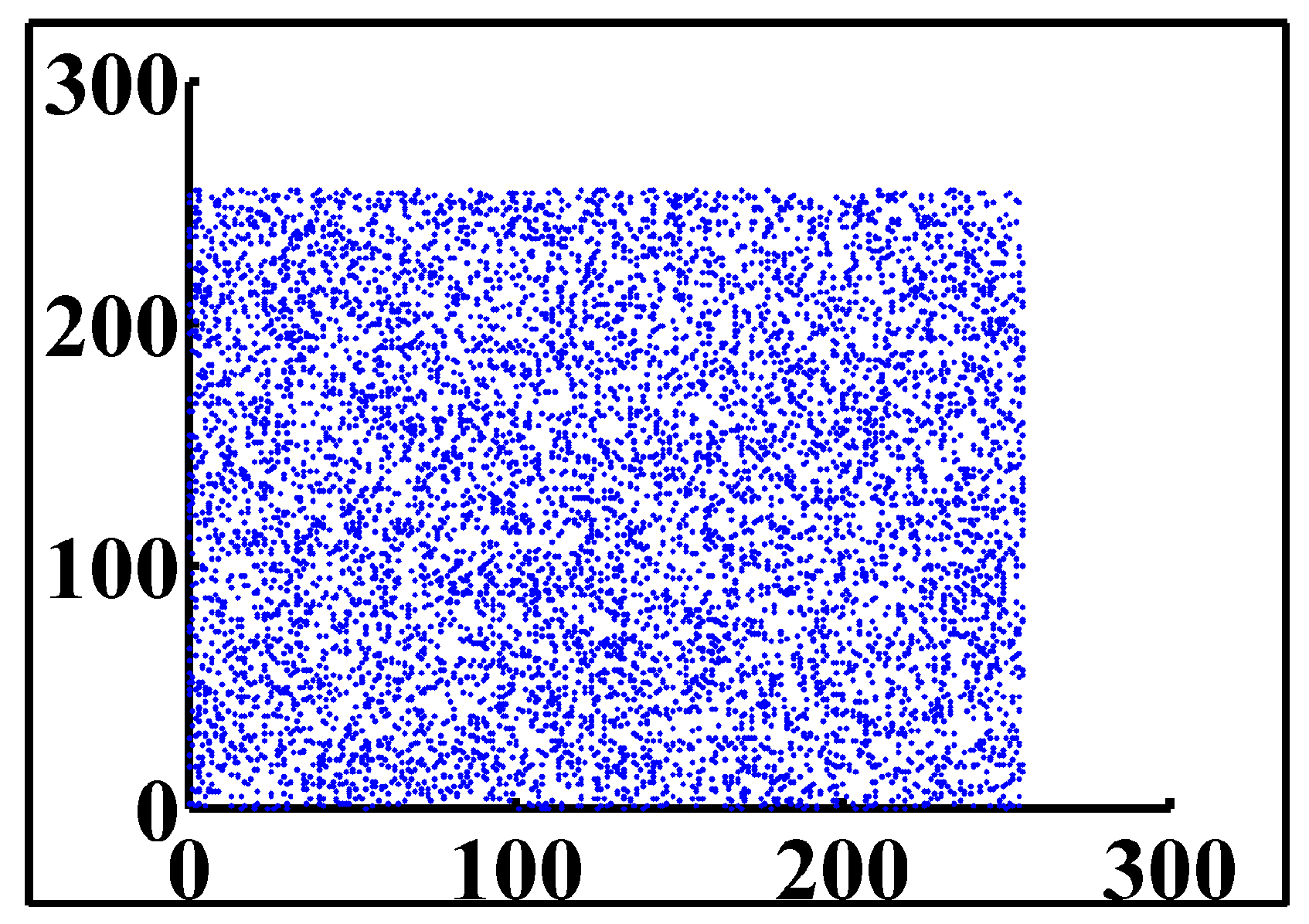
8. Correlation Analysis
9. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Venkateswaran, R.; Sundaram, V. Information Security: Text Encryption and Decryption with poly substitution method and combining the features of Cryptography. Int. J. Comput. Appl. 2010, 3, 28–31. [Google Scholar] [CrossRef]
- Damico, T.M. A brief history of cryptography. Inq. J. 2009, 1, 1/1. [Google Scholar]
- AbuTaha, M.; Farajallah, M.; Tahboub, R.; Odeh, M. Survey Paper: Cryptography Is the Science of Information Security. 2011. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.227.7620&rep=rep1&type=pdf (accessed on 10 December 2021).
- Apampa, K.M.; Wills, G.; Argles, D. Towards security goals in summative e-assessment security. In Proceedings of the 2009 International Conference for Internet Technology and Secured Transactions, (ICITST), London, UK, 9–12 November 2009; pp. 1–5. [Google Scholar]
- Sumra, I.A.; Hasbullah, H.B.; AbManan, J.B. Attacks on security goals (confidentiality, integrity, availability) in VANET: A survey. In Vehicular Ad-Hoc Networks for Smart Cities; Springer: Berlin/Heidelberg, Germany, 2015; pp. 51–61. [Google Scholar]
- Carter, B.A.; Kassin, A.; Magoc, T. Asymetric Cryptosystems. 2007. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.131.6626&rep=rep1&type=pdf (accessed on 20 January 2022).
- Fujisaki, E.; Okamoto, T. Secure integration of asymmetric and symmetric encryption schemes. In Annual International Cryptology Conference; Springer: Berlin/Heidelberg, Germany, 1999; pp. 537–554. [Google Scholar]
- Brandt, F. Efficient cryptographic protocol design based on distributed El Gamal encryption. In International Conference on Information Security and Cryptology; Springer: Berlin/Heidelberg, Germany, 2005; pp. 32–47. [Google Scholar]
- Agrawal, E.; Pal, P.R. A Secure and Fast Approach for Encryption and Decryption of Message Communication. Int. J. Eng. Sci. 2017, 7, 11481. [Google Scholar]
- Forouzan, B.A. Cryptography & Network Security; McGraw-Hill, Inc.: New York, NY, USA, 2007. [Google Scholar]
- Khan, A.G.; Basharat, S.; Riaz, M.U. Analysis of asymmetric cryptography in information security based on computational study to ensure confidentiality during information exchange. Int. J. Sci. Eng. Res. 2018, 9, 992–999. [Google Scholar]
- Chandra, S.; Bhattacharyya, S.; Paira, S.; Alam, S.S. A study and analysis on symmetric cryptography. In Proceedings of the 2014 International Conference on Science Engineering and Management Research (ICSEMR), Chennai, India, 27–29 November 2014; pp. 1–8. [Google Scholar]
- Masood, F.; Ahmad, J.; Shah, S.A.; Jamal, S.S.; Hussain, I. A novel hybrid secure image encryption based on julia set of fractals and 3D Lorenz chaotic map. Entropy 2020, 22, 274. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Manifavas, C.; Hatzivasilis, G.; Fysarakis, K.; Papaefstathiou, Y. A survey of lightweight stream ciphers for embedded systems. Secur. Commun. Netw. 2016, 9, 1226–1246. [Google Scholar] [CrossRef] [Green Version]
- Rezaeipour, D.; Rushdan Md Said, M. The block cipher algorithm-properties, encryption efficiency analysis and security evaluation. JOurnal Adv. Appl. Math. Sci. 2010, 4, 129–137. [Google Scholar]
- Kumar, M.; Aggarwal, A.; Garg, A. A review on various digital image encryption techniques and security criteria. Int. J. Comput. Appl. 2014, 96. [Google Scholar] [CrossRef]
- Avasare, M.G.; Kelkar, V.V. Image encryption using chaos theory. In Proceedings of the 2015 International Conference on Communication, Information & Computing Technology (ICCICT), Mumbai, India, 15–17 January 2015; pp. 1–6. [Google Scholar]
- Ahmad, I.; Shahabuddin, S.; Kumar, T.; Okwuibe, J.; Gurtov, A.; Ylianttila, M. Security for 5G and beyond. IEEE Commun. Surv. Tutor. 2019, 21, 3682–3722. [Google Scholar] [CrossRef]
- Misra, A.; Gupta, A.; Rai, D. Analysing the parameters of chaos based image encryption schemes. World Appl. Program. 2011, 1, 294–299. [Google Scholar]
- Bernstein, D.J. The Salsa20 Family of Stream Ciphers, New Stream Cipher Designs: The eSTREAM Finalists; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Boesgaard, M.; Vesterager, M.; Zenner, E. The Rabbit stream cipher. In New Stream Cipher Designs; Springer: Berlin/Heidelberg, Germany, 2008; pp. 69–83. [Google Scholar]
- Jolfaei, A.; Vizandan, A.; Mirghadri, A. Image encryption using HC-128 and HC-256 stream ciphers. Int. J. Electron. Secur. Digit. Forensics 2012, 4, 19–42. [Google Scholar] [CrossRef]
- Taha, M.A.; Assad, S.E.; Queudet, A.; Deforges, O. Design and efficient implementation of a chaos-based stream cipher. Int. J. Internet Technol. Secur. Trans. 2017, 7, 89–114. [Google Scholar] [CrossRef]
- Abutaha, M.; El Assad, S.; Jallouli, O.; Queudet, A.; Deforges, O. Design of a pseudo-chaotic number generator as a random number generator. In Proceedings of the 2016 International Conference on Communications (COMM), Bucharest, Romania, 9–10 June 2016; pp. 401–404. [Google Scholar]
- Burak, D. Parallelization of an encryption algorithm based on a spatiotemporal chaotic system and a chaotic neural network. Procedia Comput. Sci. 2015, 51, 2888–2892. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Song, D.; Xu, Y. A parallel encryption algorithm for dual-core processor based on chaotic map. In Fourth International Conference on Machine Vision (ICMV 2011): Computer Vision and Image Analysis; Pattern Recognition and Basic Technologies; International Society for Optics and Photonics: Bellingham, WA, USA, 2012; Volume 8350, p. 83500B. [Google Scholar]
- Çavuşoğlu, Ü.; Kaçar, S. A novel parallel image encryption algorithm based on chaos. Clust. Comput. 2019, 22, 1211–1223. [Google Scholar] [CrossRef]
- Elrefaey, A.; Sarhan, A.; El-Shennawy, N.M. Improving the speed of chaotic-maps-based image encryption using parallelization. In Proceedings of the 2017 13th International Computer Engineering Conference (ICENCO), Giza, Egypt, 27–28 December 2017; pp. 61–66. [Google Scholar]
- Masood, F.; Driss, M.; Boulila, W.; Ahmad, J.; Rehman, S.U.; Jan, S.U.; Qayyum, A.; Buchanan, W.J. A lightweight chaos-based medical image encryption scheme using random shuffling and XOR operations. Wirel. Pers. Commun. 2021, 1–28. [Google Scholar] [CrossRef]
- Chandra, R.; Dagum, L.; Kohr, D.; Menon, R.; Maydan, D.; McDonald, J. Parallel Programming in OpenMP; Morgan Kaufmann: Burlington, MA, USA, 2001. [Google Scholar]
- Lewis, B.; Berg, D.J. PThreads Primer; Sun Microsystems Inc.: Santa Clara, CA, USA, 1996. [Google Scholar]
- Pacheco, P. An Introduction to Parallel Programming; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Grama, A.; Kumar, V.; Gupta, A.; Karypis, G. Introduction to Parallel Computing; Pearson Education: London, UK, 2003. [Google Scholar]
- Shi, Y. Reevaluating Amdahl’s Law and Gustafson’s Law; (MS: 38-24); Computer Sciences Department, Temple University: Philadelphia, PA, USA, 1996. [Google Scholar]
- Wang, X.; Zhu, X.; Wu, X.; Zhang, Y. Image encryption algorithm based on multiple mixed hash functions and cyclic shift. Opt. Lasers Eng. 2018, 107, 370–379. [Google Scholar] [CrossRef]
- Guesmi, R.; Farah, M.A.B.; Kachouri, A.; Samet, M. A novel chaos-based image encryption using DNA sequence operation and Secure Hash Algorithm SHA-2. Nonlinear Dyn. 2016, 83, 1123–1136. [Google Scholar] [CrossRef]
- Curiac, D.I.; Volosencu, C. Chaotic trajectory design for monitoring an arbitrary number of specified locations using points of interest. Math. Probl. Eng. 2012, 2012, 940276. [Google Scholar] [CrossRef]
- Curiac, D.I.; Iercan, D.; Dranga, O.; Dragan, F.; Banias, O. Chaos-based cryptography: End of the road? In Proceedings of the The International Conference on Emerging Security Information, Systems, and Technologies (SECUREWARE 2007), Valencia, Spain, 14–20 October 2007; pp. 71–76. [Google Scholar]
- Zhu, S.; Zhu, C.; Wang, W. A new image encryption algorithm based on chaos and secure hash SHA-256. Entropy 2018, 20, 716. [Google Scholar] [CrossRef] [Green Version]
- Wu, Y.; Noonan, J.P.; Agaian, S. NPCR and UACI randomness tests for image encryption. Cyber J. Multidiscip. J. Sci. Technol. J. Sel. Areas Telecommun. (JSAT) 2011, 1, 31–38. [Google Scholar]
- Liao, X.; Kulsoom, A.; Ullah, S. A modified (Dual) fusion technique for image encryption using SHA-256 hash and multiple chaotic maps. Multimed. Tools Appl. 2016, 75, 11241–11266. [Google Scholar]
- Chen, G.; Mao, Y.; Chui, C.K. A symmetric image encryption scheme based on 3D chaotic cat maps. Chaos Solitons Fractals 2004, 21, 749–761. [Google Scholar] [CrossRef]
- Belazi, A.; Abd El-Latif, A.A.; Belghith, S. A novel image encryption scheme based on substitution-permutation network and chaos. Signal Process. 2016, 128, 155–170. [Google Scholar] [CrossRef]
- Song, C.Y.; Qiao, Y.L.; Zhang, X.Z. An image encryption scheme based on new spatiotemporal chaos. Opt.-Int. J. Light Electron Opt. 2013, 124, 3329–3334. [Google Scholar] [CrossRef]
- Hua, Z.; Zhou, Y. Image encryption using 2D Logistic-adjusted-Sine map. Inf. Sci. 2016, 339, 237–253. [Google Scholar] [CrossRef]
- Ahmad, J.; Hwang, S.O. A secure image encryption scheme based on chaotic maps and affine transformation. Multimed. Tools Appl. 2016, 75, 13951–13976. [Google Scholar] [CrossRef]
- Ghazvini, M.; Mirzadi, M.; Parvar, N. A modified method for image encryption based on chaotic map and genetic algorithm. Multimed. Tools Appl. 2020, 79, 26927–26950. [Google Scholar] [CrossRef]
- Xiao, S.; Yu, Z.; Deng, Y. Design and analysis of a novel chaos-based image encryption algorithm via switch control mechanism. Secur. Commun. Netw. 2020, 2020, 7913061. [Google Scholar] [CrossRef] [Green Version]
- You, L.; Yang, E.; Wang, G. A novel parallel image encryption algorithm based on hybrid chaotic maps with OpenCL implementation. Soft Comput. 2020, 24, 12413–12427. [Google Scholar] [CrossRef]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef] [Green Version]
- Barker, E.B.; Kelsey, J.M. Recommendation for Random Number Generation Using Deterministic Random Bit Generators (Revised); US Department of Commerce, Technology Administration, National Institute of Standards and Technology: Gaithersburg, MD, USA, 2007.
- Rukhin, A.; Soto, J.; Nechvatal, J.; Smid, M.; Barker, E. A Statistical Test Suite for Random and Pseudorandom Number Generators for Cryptographic Applications; Technical report; Booz-Allen and Hamilton Inc.: McLean, VA, USA, 2001. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
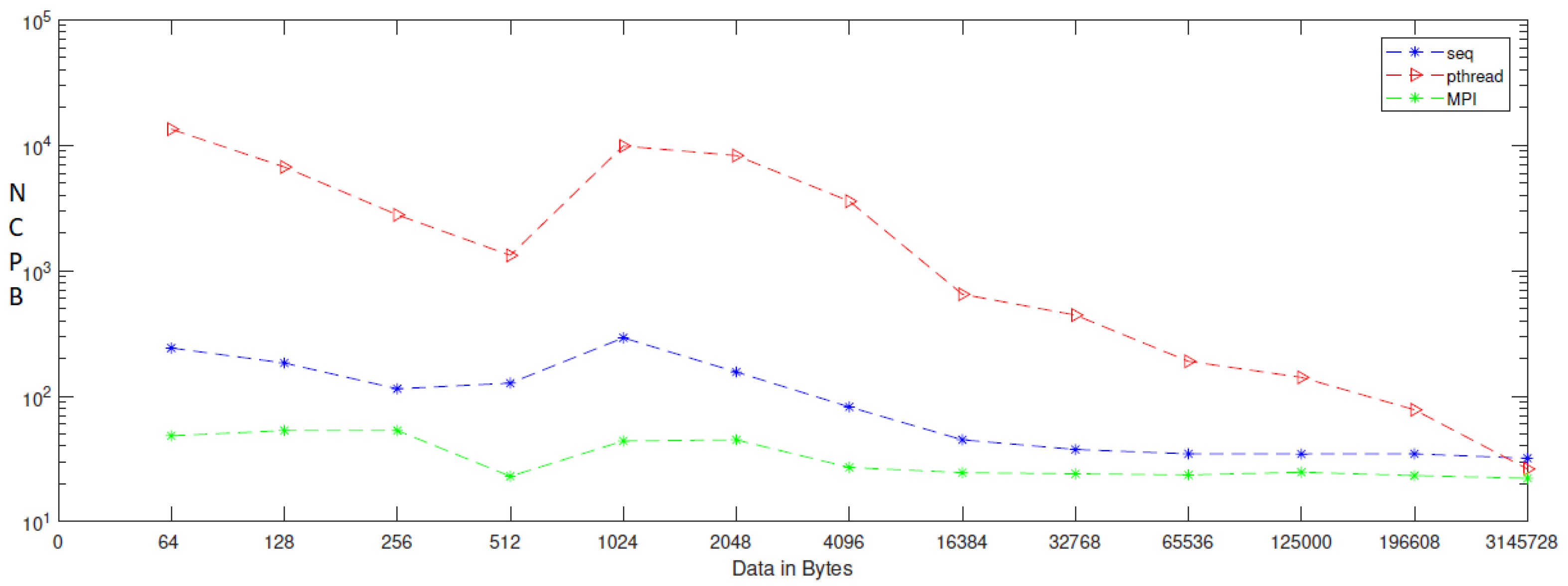
| Data | NCpB_Seq | NCpB_Pthread | NCpB_MPI |
|---|---|---|---|
| 64 | 242.1 | 13,463.2 | 48.4 |
| 128 | 184.0 | 6726.8 | 53.3 |
| 256 | 114.6 | 2791.9 | 53.3 |
| 512 | 127.1 | 1326.9 | 23.0 |
| 1024 | 292.0 | 9879.8 | 44.0 |
| 2048 | 155.9 | 8295.0 | 44.9 |
| 4096 | 82.1 | 3586.4 | 27.1 |
| 16,384 | 44.9 | 649.9 | 24.6 |
| 32,768 | 37.6 | 443.6 | 24.1 |
| 65,536 | 34.7 | 189.8 | 23.6 |
| 125,000 | 34.6 | 141.4 | 24.8 |
| 196,608 | 34.7 | 78.0 | 23.3 |
| 3,145,728 | 32.0 | 26.3 | 22.2 |
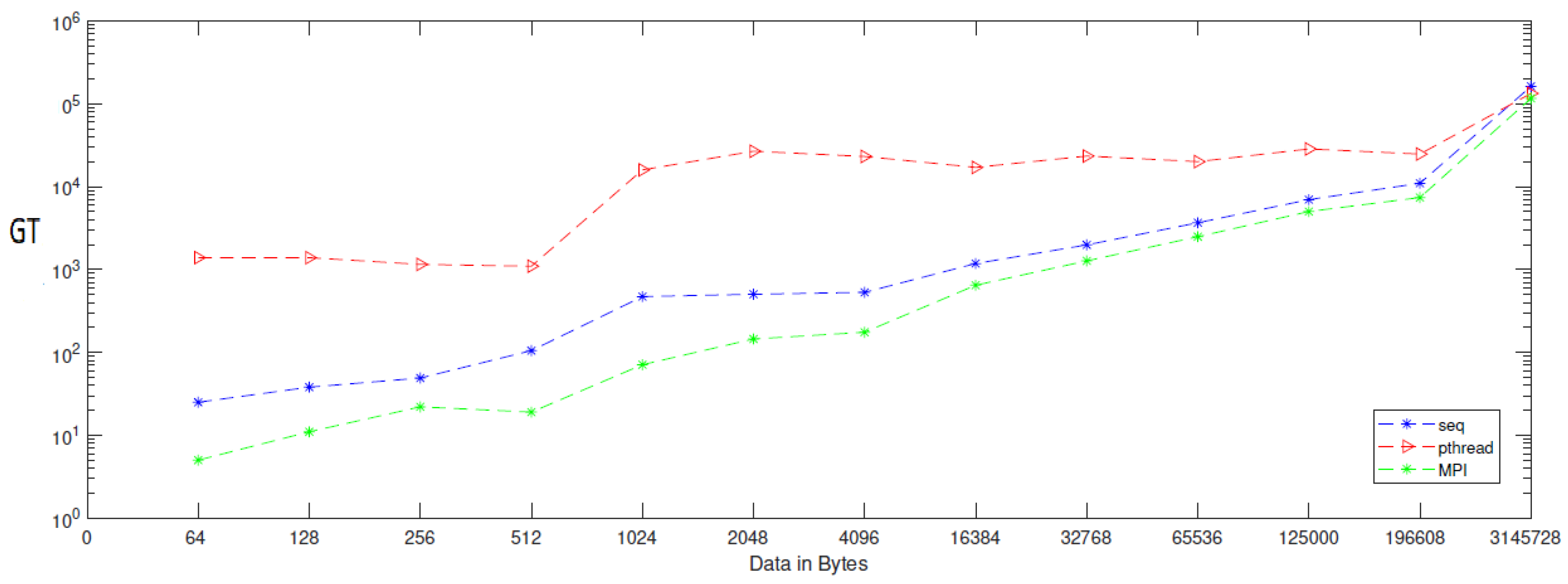
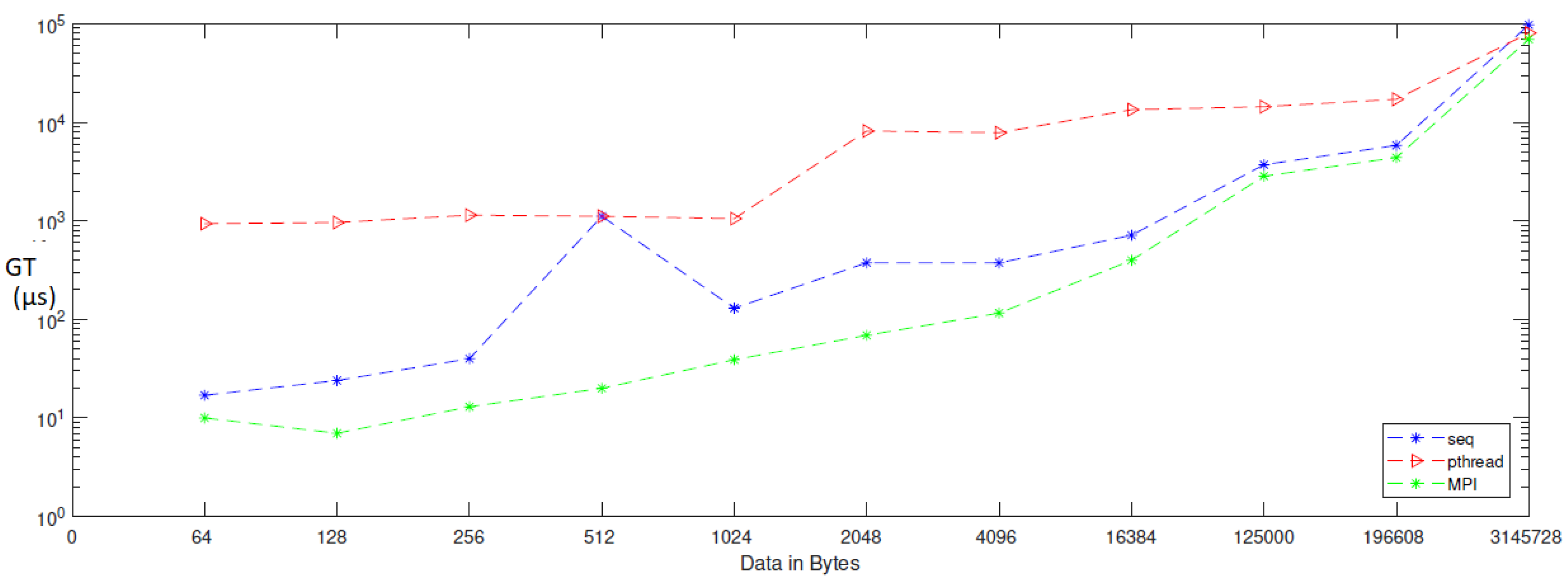
| Data | Gen_Time_Seq | Gen_Time_Pthread | Gen_Time_MPI |
|---|---|---|---|
| 64 | 25 | 1390 | 5 |
| 128 | 38 | 1389 | 11 |
| 256 | 49 | 1153 | 22 |
| 512 | 105 | 1096 | 19 |
| 1024 | 471 | 15,938 | 71 |
| 2048 | 503 | 26,763 | 145 |
| 4096 | 530 | 23,142 | 175 |
| 16,384 | 1180 | 17,090 | 646 |
| 32,768 | 1982 | 23,400 | 1271 |
| 65,536 | 3665 | 20,052 | 2489 |
| 125,000 | 6973 | 28,523 | 5008 |
| 196,608 | 10,990 | 24,748 | 7391 |
| 3,145,728 | 162,322 | 133,493 | 116,401 |
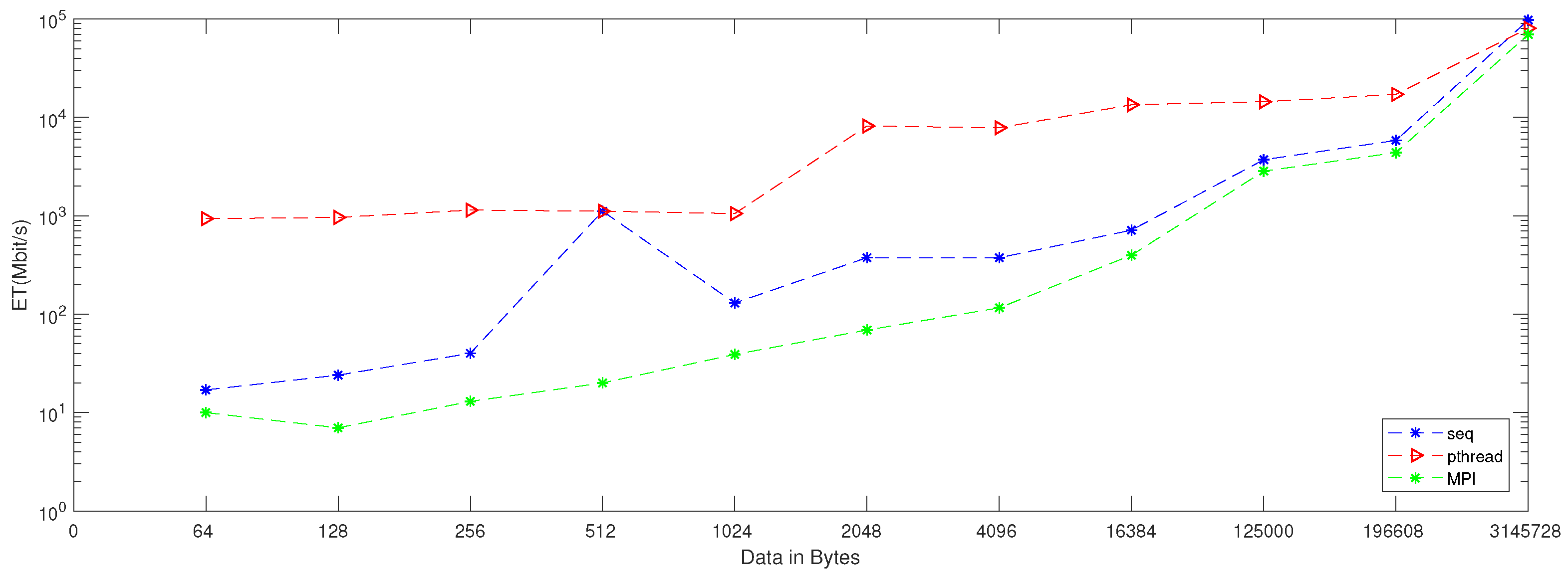
| Algorithm | Image Size | Enc_Time (Ms) | ET (Mbit/s) | NCpB |
|---|---|---|---|---|
| Rabbit | 811.3 | 1848.8 | 9.5 | |
| 3256 | 1842.6 | 9.5 | ||
| 12,950 | 1853.9 | 9.5 | ||
| HC-128 | 1221 | 1228.1 | 14.4 | |
| 4895 | 1225.6 | 14.4 | ||
| 19,647 | 1221.5 | 14.4 | ||
| Salsa 20/12 | 836.4 | 1793.4 | 9.8 | |
| 3389 | 1770 | 9.8 | ||
| 13,483 | 1779.9 | 9.8 | ||
| AbuTaha Chaos Stream Cipher(Seq) | 5838 | 1077.63 | 18.4 | |
| — | — | — | ||
| 97,584 | 1031.55 | 19.2 | ||
| AbuTaha Chaos Stream Cipher(Pthread) | 17,148 | 366.88 | 54.1 | |
| — | — | — | ||
| 80,568 | 1249.41 | 16.7 | ||
| Parallel Proposed Chaos CryptoSystem(MPI) | 4387 | 1434.06 | 13.8 | |
| — | — | 21.2 | ||
| 69,631 | 1445.65 | 13.2 |
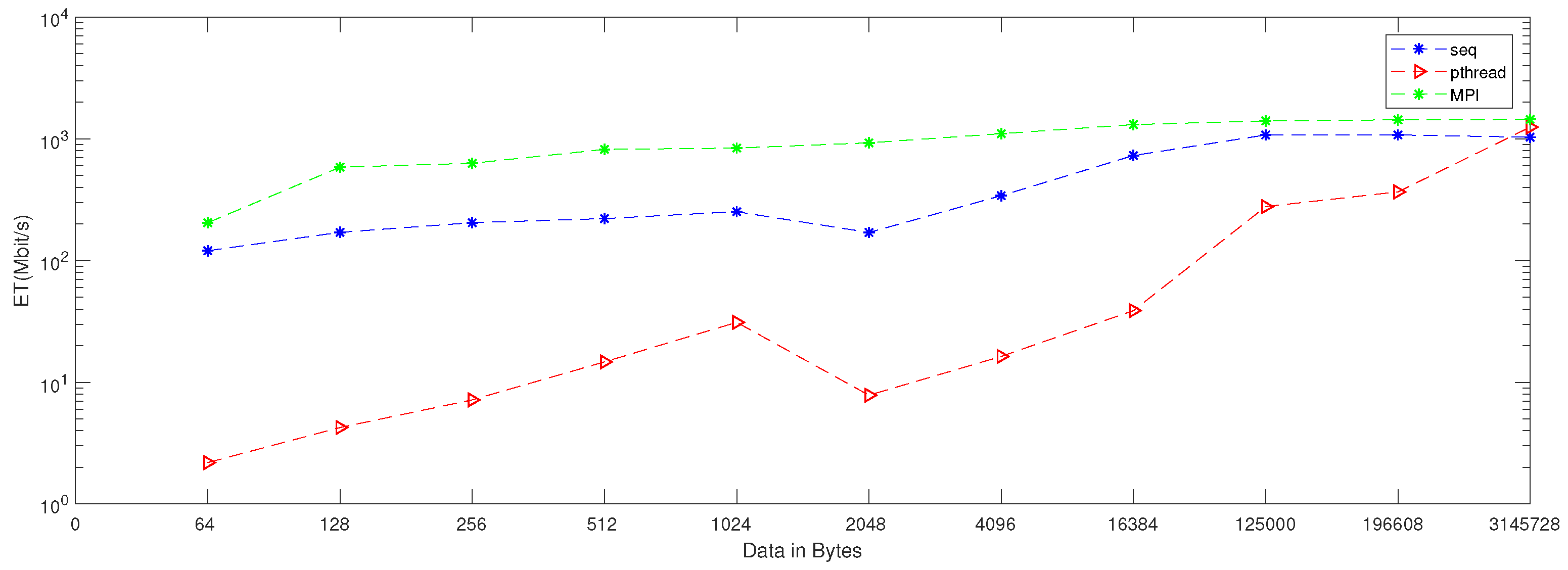
| Data | BR_Seq | BR_Pthread | BR_MPI |
|---|---|---|---|
| 64 | 81.92 | 1.47 | 409.60 |
| 128 | 107.79 | 2.95 | 372.36 |
| 256 | 173.06 | 7.10 | 372.36 |
| 512 | 156.04 | 14.95 | 862.32 |
| 1024 | 67.94 | 2.01 | 450.70 |
| 2048 | 127.24 | 2.39 | 441.38 |
| 4096 | 241.51 | 5.53 | 731.43 |
| 16,384 | 442.03 | 30.52 | 807.43 |
| 32,768 | 527.95 | 44.72 | 823.29 |
| 65,536 | 571.90 | 104.53 | 842.11 |
| 125,000 | 573.64 | 140.24 | 798.72 |
| 196,608 | 572.45 | 254.21 | 851.20 |
| 3,145,728 | 620.14 | 754.07 | 864.79 |
| Data | NCpB_Seq | NCpB_Pthread | NCpB_MPI |
|---|---|---|---|
| 64 | 164.7 | 9065.9 | 96.9 |
| 128 | 116.2 | 4663.7 | 33.9 |
| 256 | 96.9 | 2767.7 | 31.5 |
| 512 | 89.6 | 1348.7 | 24.2 |
| 1024 | 78.7 | 638.0 | 23.6 |
| 2048 | 116.5 | 2532.9 | 21.4 |
| 4096 | 58.1 | 1215.3 | 18.0 |
| 16,384 | 27.2 | 510.9 | 15.1 |
| 125,000 | 18.4 | 71.5 | 14.1 |
| 196,608 | 18.4 | 54.1 | 13.8 |
| 3,145,728 | 19.2 | 16.7 | 13.2 |
| Data | Gen_Time_Seq | Gen_Time_Pthread | Gen_Time_MPI |
|---|---|---|---|
| 64 | 17 | 936 | 10 |
| 128 | 24 | 963 | 7 |
| 256 | 40 | 1143 | 13 |
| 512 | 1114 | 1114 | 20 |
| 1024 | 130 | 1054 | 39 |
| 2048 | 376 | 8172 | 69 |
| 4096 | 375 | 7842 | 116 |
| 16,384 | 715 | 13,435 | 398 |
| 125,000 | 3714 | 14,416 | 2844 |
| 19,6608 | 5838 | 17,148 | 4387 |
| 3,145,728 | 97,584 | 80,568 | 69,631 |
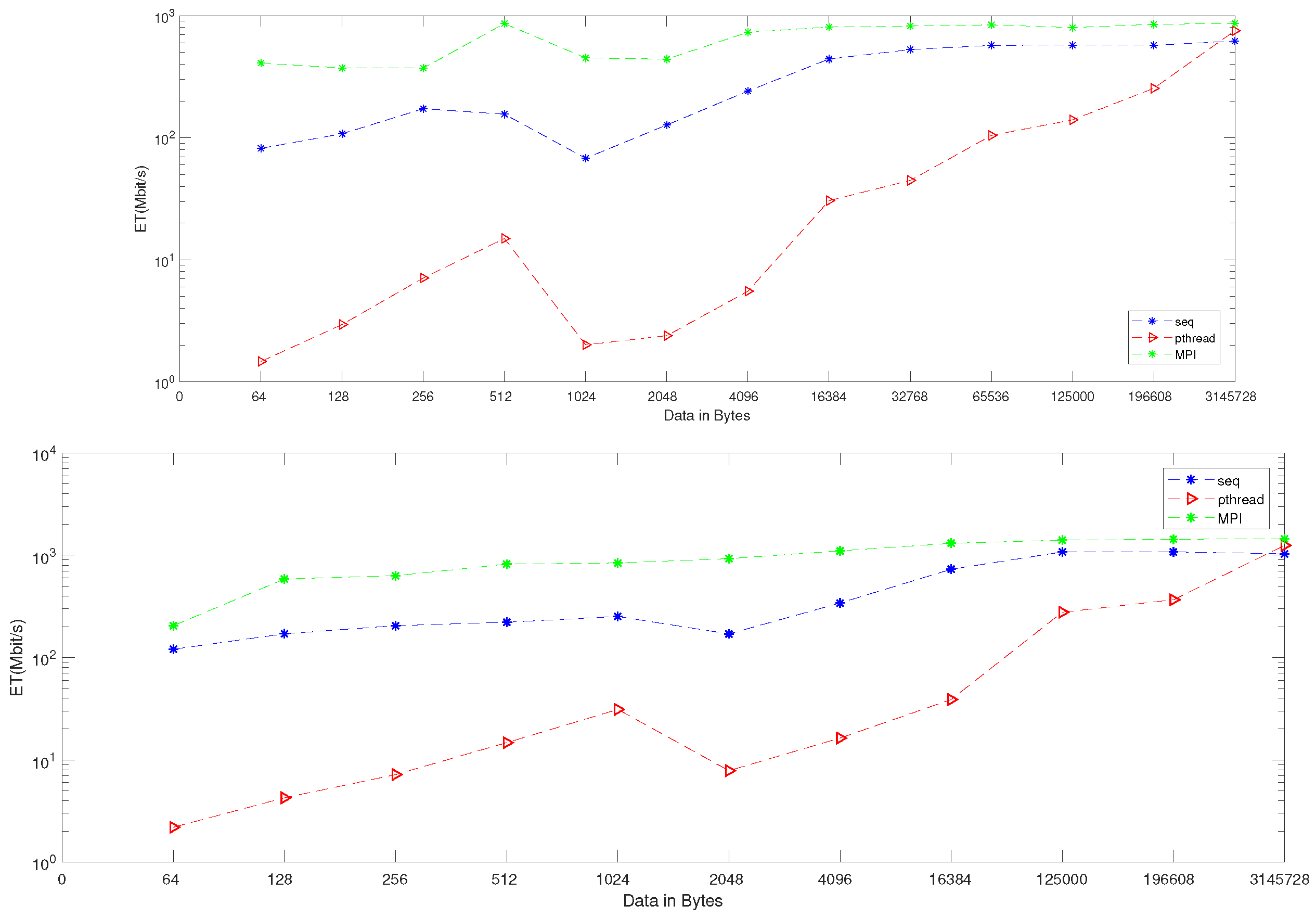
| Data | BR_Seq | BR_Pthread | BR_MPI |
|---|---|---|---|
| 64 | 120.47 | 2.19 | 204.80 |
| 128 | 170.67 | 4.25 | 585.14 |
| 256 | 204.80 | 7.17 | 630.15 |
| 512 | 221.41 | 14.71 | 819.20 |
| 1024 | 252.06 | 31.09 | 840.21 |
| 2048 | 170.21 | 7.83 | 927.54 |
| 4096 | 341.33 | 16.32 | 1103.45 |
| 16,384 | 729.51 | 38.82 | 1310.55 |
| 125,000 | 1077.01 | 277.47 | 1406.47 |
| 196,608 | 1077.63 | 366.88 | 1434.06 |
| 3,145,728 | 1031.55 | 1249.41 | 1445.65 |
| Encryption Algorithm | Keyspace |
|---|---|
| Proposed Algorithm | |
| Wange et al.’s Algorithm [35] | |
| Guesmi et al.’s Algorithm [36] | |
| Curiac et al.’s Algorithm [37] | |
| Curiacet al.’s Algorithm [38] | |
| Zhu et al.’s Algorithm [39] |
| Cryptosystem | NPCR | UACI |
|---|---|---|
| Proposed Cipher Cryptosystem | 99.665 | 33.459 |
| [41] | 99.4 | 32.7 |
| [42] | 99.1 | 32.8 |
| [43] | 98.8 | 31.7 |
| [44] | 99.1 | 32.8 |
| [45] | 99.6 | 33.1 |
| [46] | 99.6 | 33.3 |
| [47] | 99.6 | 33.3 |
| [47] | 99.6 | 33.3 |
| [48] | 99.64 | 33.4 |
| [49] | 99.66 | 33.43 |
| Ciphered Image | Sharukhan | Titanic | Photographer | Manhattan | Cameraman | Boat | Lena |
|---|---|---|---|---|---|---|---|
| entropy | 7.9999 | 7.9999 | 7.9999 | 7.9999 | 7.9998 | 7.9997 | 7.9999 |
| Encryption Method | Information Entropy |
|---|---|
| Proposed Algorithm | 7.9999 |
| [41] | 7.9973 |
| [42] | 7.9975 |
| [43] | 7.9977 |
| [44] | 7.9973 |
| [45] | 7.9982 |
| [46] | 7.99 |
| [47] | 7.990 |
| [48] | 7.908 |
| Test | p_Value | Proportion |
|---|---|---|
| Frequency test | 0.494 | 97.000 |
| Block-frequency test | 0.760 | 100.000 |
| Cumulative-sums test | 0.797 | 97.000 |
| Runs test | 0.596 | 99.000 |
| Longest-run test | 0.699 | 98.000 |
| Rank test | 0.029 | 100.000 |
| FFT test | 0.834 | 98.0000 |
| Nonperiodic-templates | 0.479 | 99.000 |
| Overlapping-templates | 0.237 | 96.000 |
| Universal | 0.494 | 98.000 |
| Approximate entropy | 0.740 | 99.000 |
| Random-excursions | 0.223 | 99.375 |
| Random-excursions-variant | 0.428 | 98.925 |
| Serial test | 0.828 | 99.500 |
| Linear-complexity | 0.834 | 100.000 |
| Image | Experimental Value | Theoretical Value |
|---|---|---|
| Titanic | 245.8750 | 293.247835 |
| Titanic | 279.1621 | 293.247835 |
| Titanic | 283.5923 | 293.247835 |
| Photographer | 252.1406 | 293.247835 |
| Photographer | 243.8066 | 293.247835 |
| Photographer | 251.6162 | 293.247835 |
| Manhattan | 264.6719 | 293.247835 |
| Manhattan | 254.6660 | 293.247835 |
| Manhattan | 257.3975 | 293.247835 |
| Sharukhan | 252.9531 | 293.247835 |
| Sharukhan | 228.9316 | 293.247835 |
| Sharukhan | 245.7544 | 293.247835 |
| Plain/Ciphered Image | Horizontal | Vertical | Diagonal |
|---|---|---|---|
| Lena | 0.96606/0.035 | 0.96613/0.026 | 0.96619/0.027 |
| Boat | 0.99605/0.022 | 0.99703/0.019 | 0.99671/0.020 |
| Cameraman | 0.96618/0.036 | 0.96771/0.028 | 0.96767/0.022 |
| Peppers | 0.96608/0.019 | 0.96612/0.031 | 0.96647/0.011 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abutaha, M.; Amar, I.; AlQahtani, S. Parallel and Practical Approach of Efficient Image Chaotic Encryption Based on Message Passing Interface (MPI). Entropy 2022, 24, 566. https://doi.org/10.3390/e24040566
Abutaha M, Amar I, AlQahtani S. Parallel and Practical Approach of Efficient Image Chaotic Encryption Based on Message Passing Interface (MPI). Entropy. 2022; 24(4):566. https://doi.org/10.3390/e24040566
Chicago/Turabian StyleAbutaha, Mohammed, Islam Amar, and Salman AlQahtani. 2022. "Parallel and Practical Approach of Efficient Image Chaotic Encryption Based on Message Passing Interface (MPI)" Entropy 24, no. 4: 566. https://doi.org/10.3390/e24040566
APA StyleAbutaha, M., Amar, I., & AlQahtani, S. (2022). Parallel and Practical Approach of Efficient Image Chaotic Encryption Based on Message Passing Interface (MPI). Entropy, 24(4), 566. https://doi.org/10.3390/e24040566