
Investigating Multi-Level Semantic Extraction with Squash Capsules for Short Text Classification


Abstract
:1. Introduction
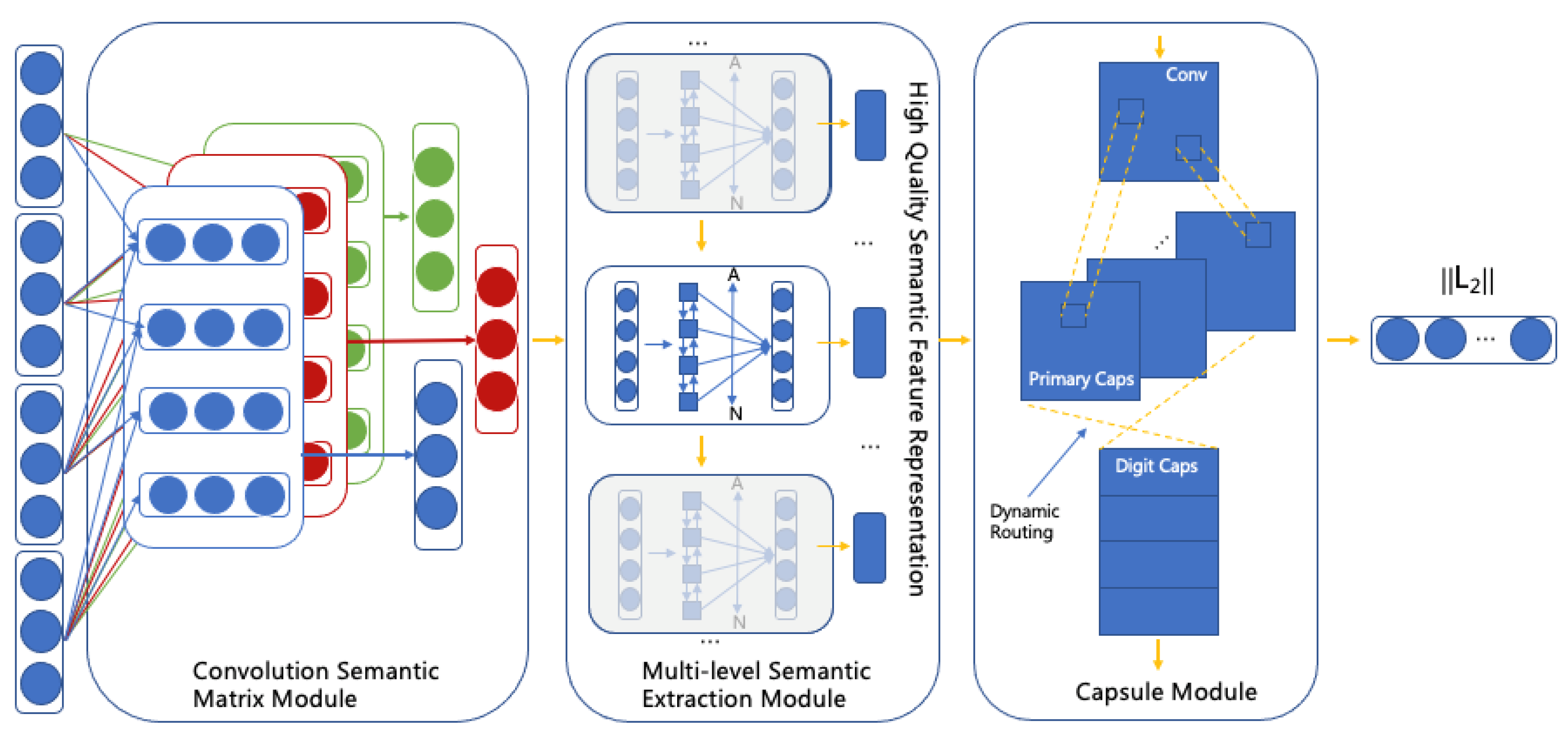
- It proposes a new classification model from the aspect of short text representation, global feature extraction and local feature extraction. It uses convolutional networks to extract shallow features, and introducing a multi-level semantic extraction framework that includes the encoding layer, interaction layer and concatenation layer. It is combined with the capsule network to obtain high-level local information. It extracts short text semantics to maximize the possibilities within the limited text and improve the quality of the feature representation.
- It explores the optimal depth of semantic feature extraction for short text classification based on a multi-level semantic framework.
- Experiments were carried out on four public datasets and quantitative comparative experiments were carried out, and considerable results were obtained.
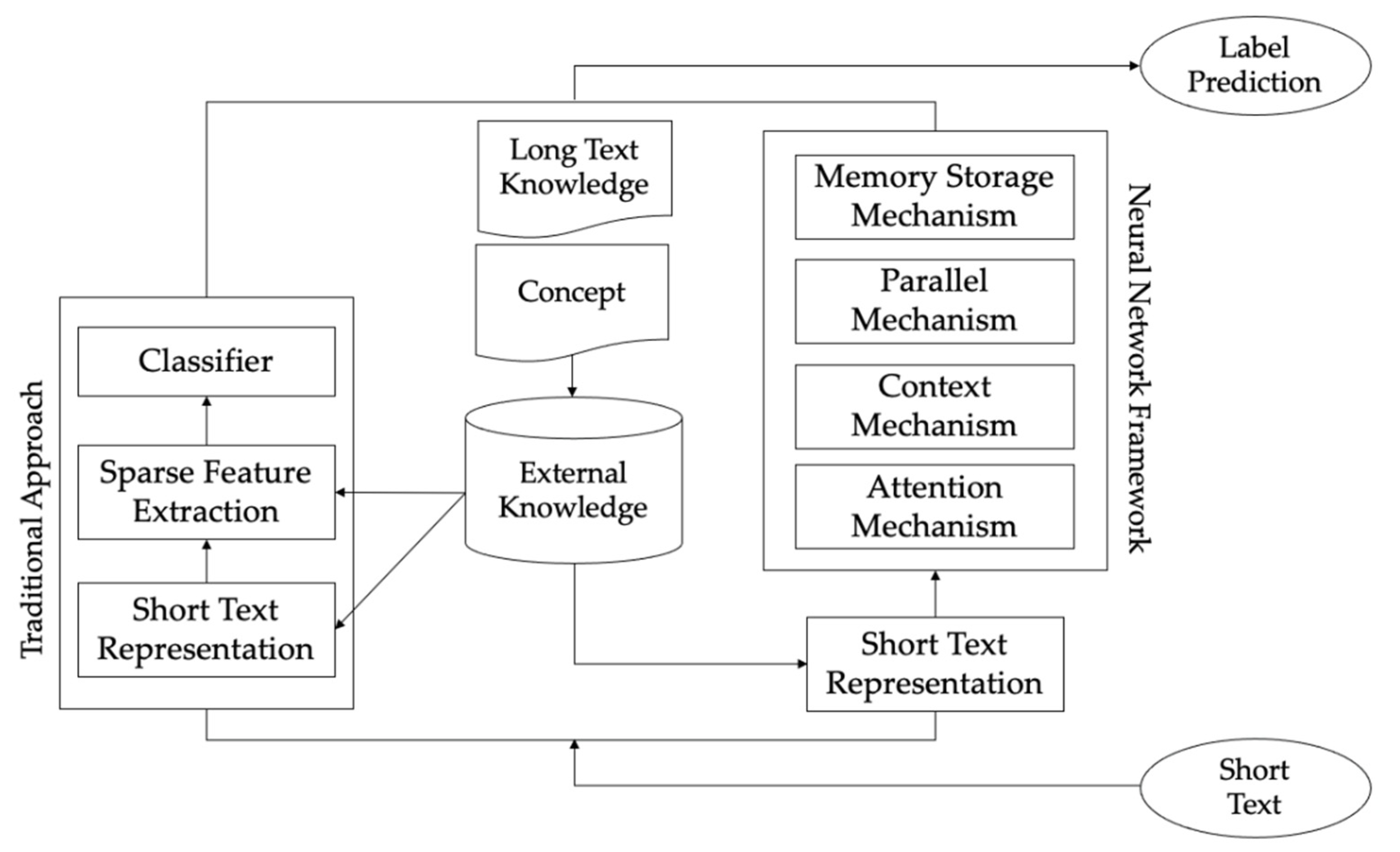
2. Related Work
2.1. Short Text Classification based on Deep Learning
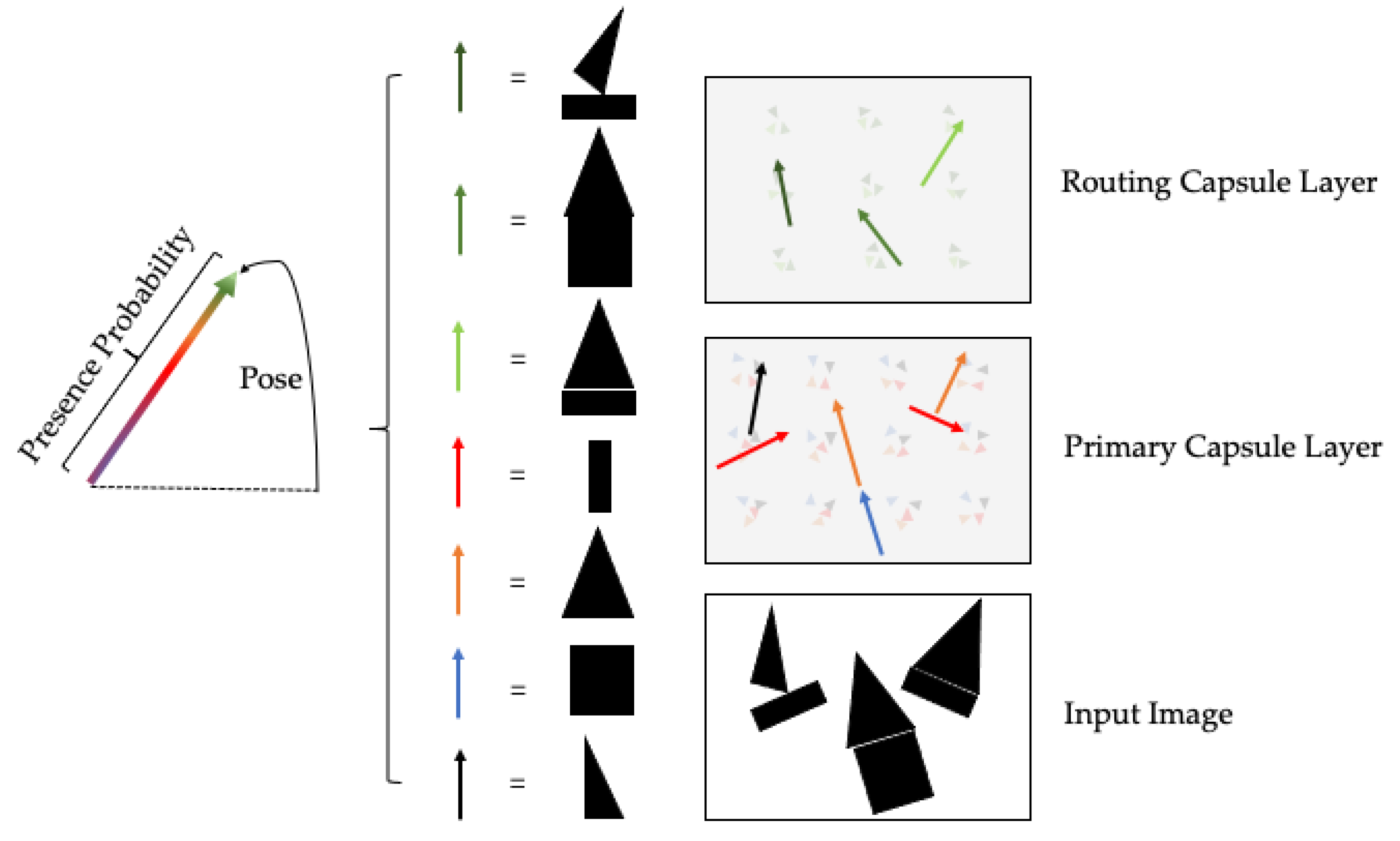
2.2. The Capsule Network for Text Classification
3. Methodology
3.1. The Convolution Semantic Matrix Module (CSMM)
3.2. The Multi-Level Semantic Extraction Module (MlSEM)
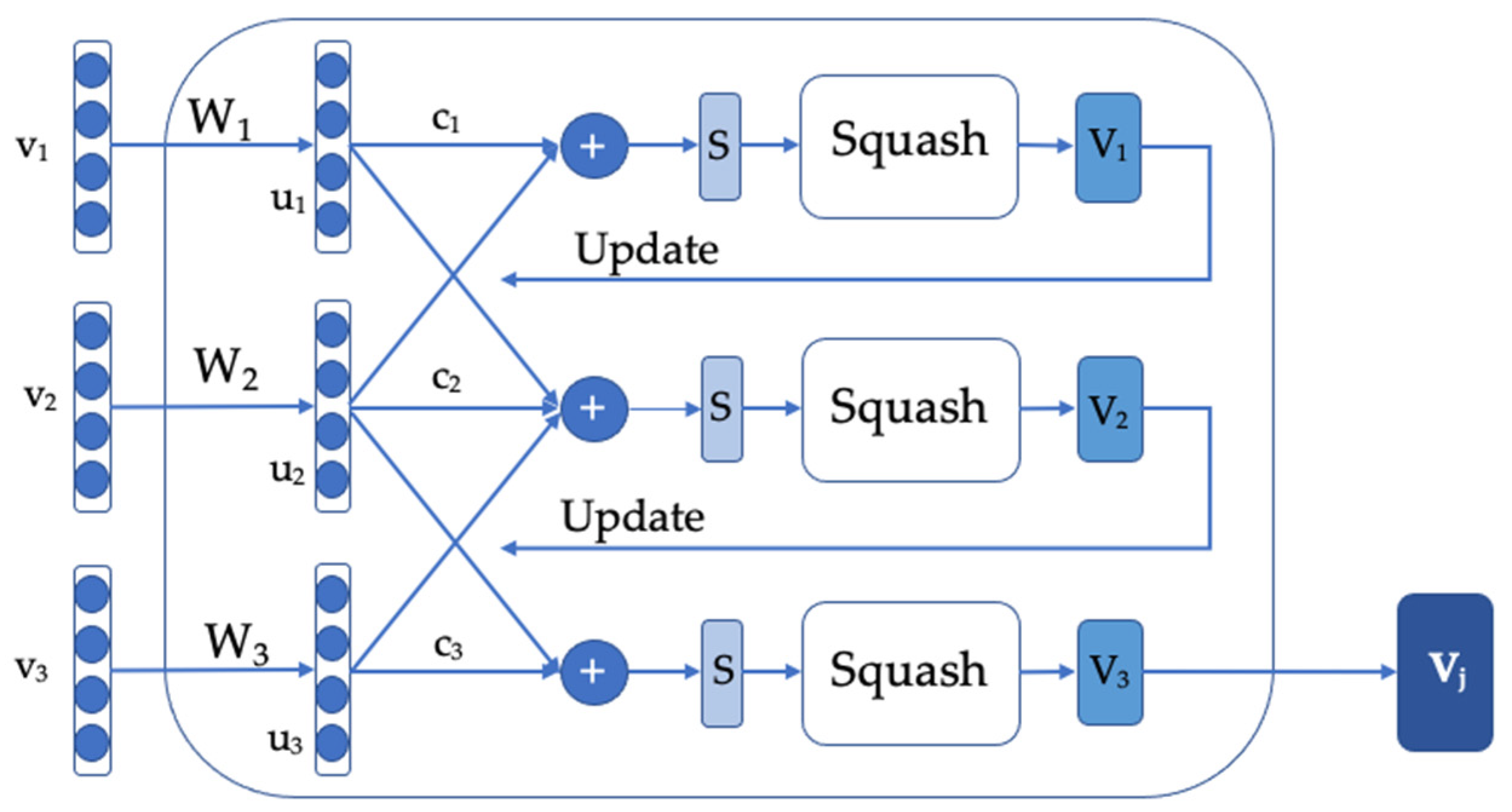
3.3. The Capsule Module (CM)
| Algorithm 1: Short text classification algorithm based on the capsule and multi-level semantic extraction. |
| Input: Short text data Output: The probability distribution of the classification category. |
| 1: Data preprocessing. |
| 2: Embed each short text data then obtain M = [, , …, ]. |
| 3: Input short text into the convolution layer for feature extraction, then obtain the feature mapping X = [, , …, ]. |
| 4: Input the original short text and convolution features into the multi-layer semantic feature module and define the optimal depth parameter: |
| for do The input passes through the encoding layer, interaction layer, concatenate layer return Interaction for do Feed the input to the convolution layer and obtain the output Connect with a capsule layer by the dynamic routing algorithm Algorithm ROUTING () begin for all capsule i in layer and capsule in layer (): . for iterations do for all capsule in layer : for all capsule in layer : for all capsule in layer : for all capsule in layer and capsule in layer : return End Calculate the probability distribution of the classification category. end for |
4. Experimental Procedure and Results
4.1. Datasets
4.2. Model Configurations
4.3. Baseline Methods
4.4. Exerimental Results
4.5. Discussion
4.5.1. Ablation Study
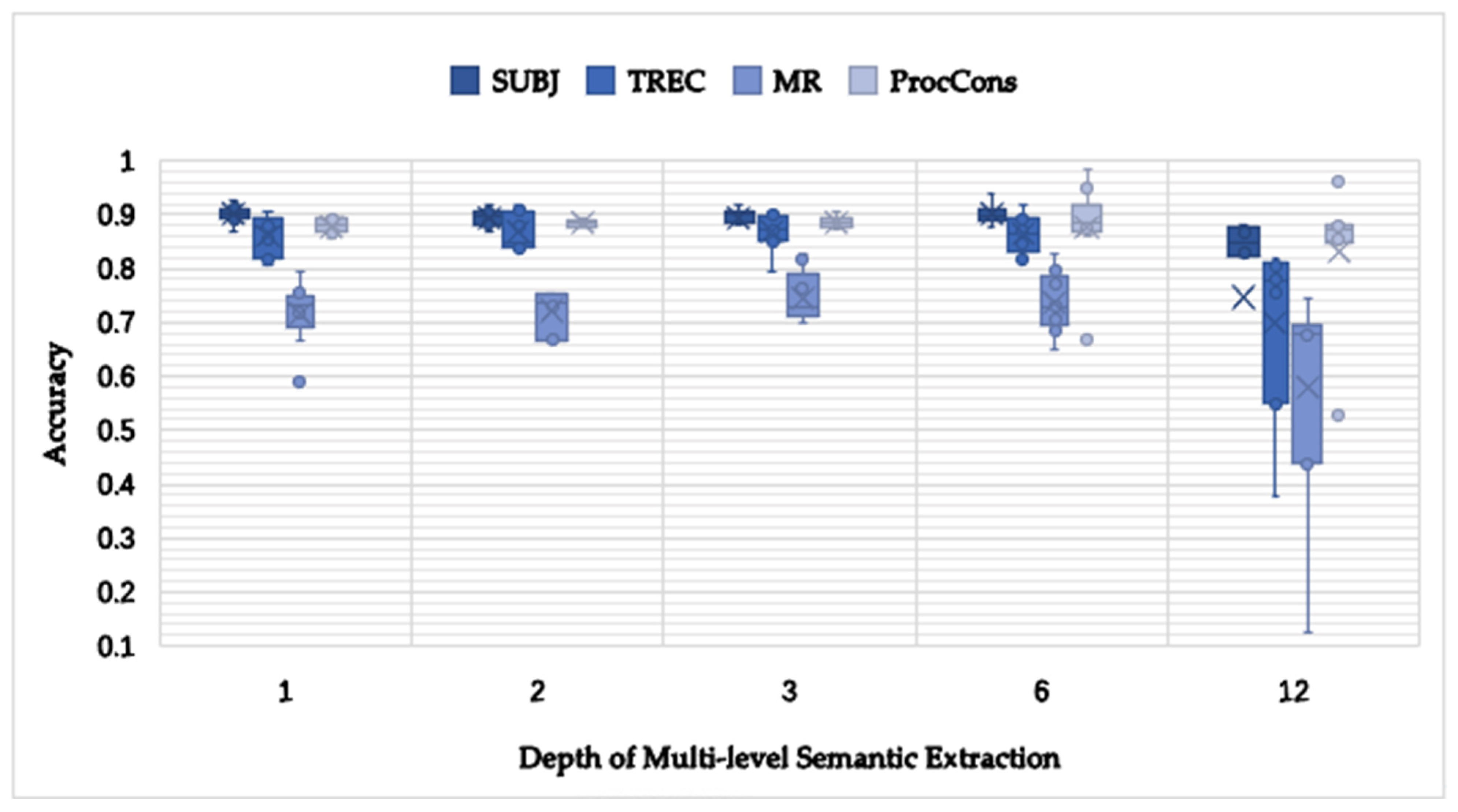
4.5.2. The Depth of the MlSEM Study
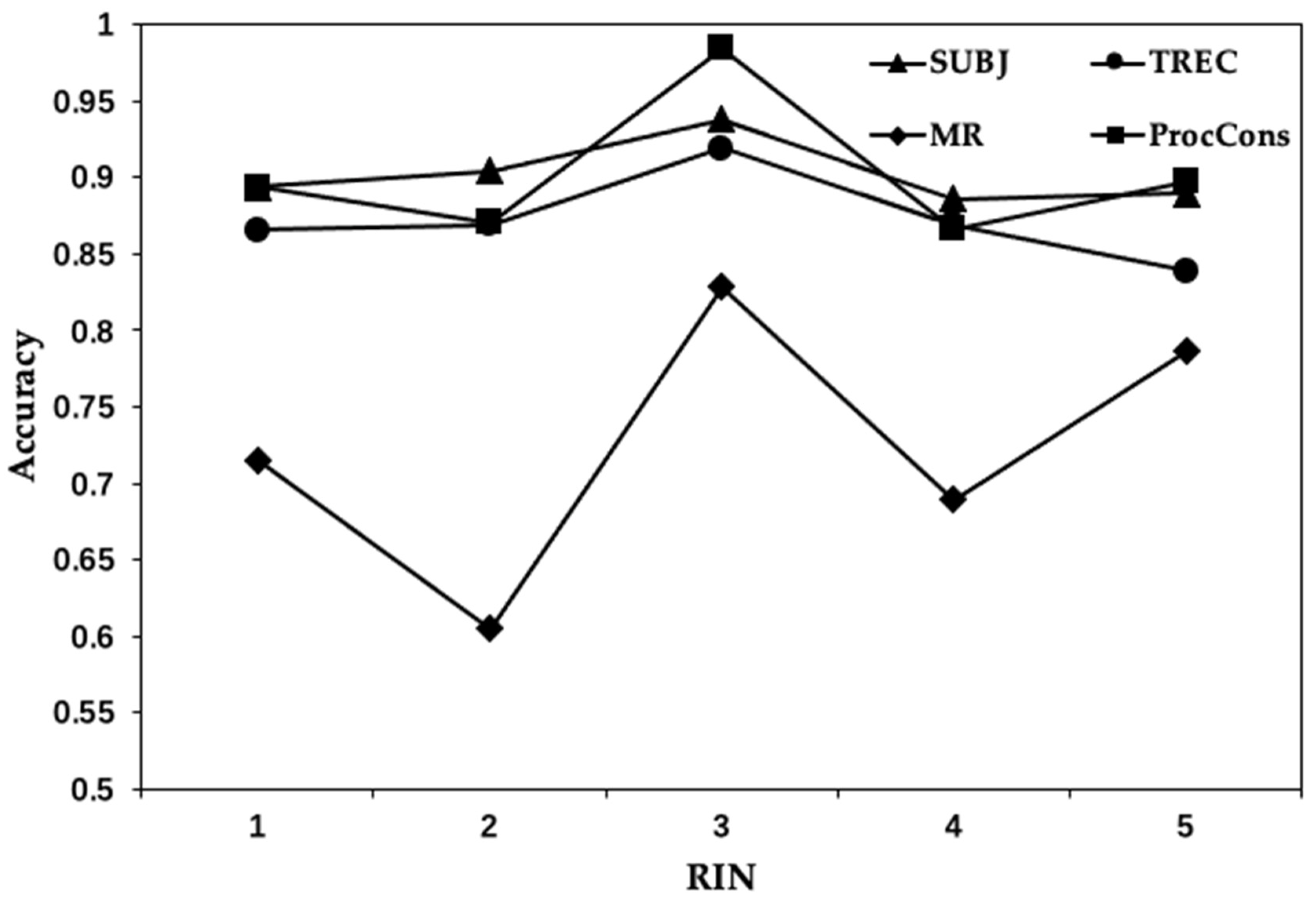
4.5.3. The Effect of Routing in CM
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shi, T.; Kang, K.; Choo, J.; Reddy, C.K. Short-text topic modeling via non-negative matrix factorization enriched with local word-context correlations. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 1105–1114. [Google Scholar]
- Qiang, J.P.; Qian, Z.Y.; Yuan, Y.H.; Wu, X.D. Short text topic modeling techniques, applications, and performance: A survey. IEEE Trans. Knowl. Data Eng. 2022, 34, 1427–1445. [Google Scholar] [CrossRef]
- Wu, Y.J.; Li, J.; Wu, J.; Chang, J. Siamese capsule networks with global and local features for text classification. Neurocomputing 2020, 390, 88–98. [Google Scholar] [CrossRef]
- Tian, Y.W.; Zhang, Z. Text classification model based on BERT-capsule with integrated deep learning. In Proceedings of the 2021 IEEE 16th Conference on Industrial Electronics and Applications, Chengdu, China, 1–4 August 2021; pp. 106–111. [Google Scholar]
- Xu, J.Y.; Cai, Y.; Wu, X.; Lei, X.; Huang, Q.B.; Leung, H.; Li, Q. Incorporating context-relevant concepts into convolutional neural networks for short text classification. Neurocomputing 2020, 386, 42–53. [Google Scholar] [CrossRef]
- Samant, S.S.; Bhanu Murthy, N.L.; Malapati, A. Improving term weighting schemes for short text classification in vector space model. IEEE Access 2017, 7, 166578–166592. [Google Scholar] [CrossRef]
- Zhu, Y.; Li, Y.; Yue, Y.Z.; Qiang, J.P.; Yuan, Y.H. A hybrid classification method via character embedding in Chinese short text with few words. IEEE Access 2020, 8, 92120–92128. [Google Scholar] [CrossRef]
- Hu, Y.B.; Li, Y.; Yang, T.; Pan, Q. Short text classification with a convolutional neural networks based method. In Proceedings of the 2018 15th International Conference on Control, Automation, Robotics and Vision (ICARCV), Singapore, 18–21 November 2018; pp. 1432–1435. [Google Scholar]
- Edo-Osagie, O.; Lake, I.; Edeghere, O.; Iglesia, B.D.L. Attention-based recurrent neural networks (RNNs) for short text classification: An application in public health monitoring. In Proceedings of the International Work-Conference on Artificial Neural Networks, Gran Canaria, Spain, 12–14 June 2019; pp. 895–911. [Google Scholar]
- Zhang, H. Neural network-based tree translation for knowledge base construction. IEEE Access 2021, 9, 38706–38717. [Google Scholar] [CrossRef]
- Yang, T.C.; Hu, L.M.; Shi, C.; Ji, H.Y. HGAT: Heterogeneous graph attention networks for semi-supervised short text classification. ACM Trans. Inf. Syst. 2021, 39, 1–29. [Google Scholar] [CrossRef]
- Chen, L.M.; Xiu, B.X.; Ding, Z.Y. Multiple weak supervision for short text classification. Appl. Intell. 2022, 1, 1–16. [Google Scholar] [CrossRef]
- Liu, Y.; Li, P.; Hu, X.G. Combining context-relevant features with multi-stage attention network for short text classification. Comput. Speech Lang. 2022, 71, 101268. [Google Scholar] [CrossRef]
- Škrlj, B.; Martinc, M.; Kralj, J.; Lavrač, N.; Pollak, S. tax2vec: Constructing interpretable features from taxonomies for short text classification. Comput. Speech Lang. 2021, 65, 101104. [Google Scholar] [CrossRef]
- Feng, X. Label oriented hierarchical attention neural network for short text classification. Acad. J. Eng. Technol. Sci. 2022, 5, 53–62. [Google Scholar]
- Zheng, X.; Wang, B.; Du, X.; Lu, X. Mutual attention inception network for remote sensing visual question answering. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar] [CrossRef]
- Ye, Y.; Ren, X.; Zhu, B.; Tang, T.; Tan, X.; Gui, Y.; Yao, Q. An adaptive attention fusion mechanism convolutional network for object detection in remote sensing images. Remote Sens. 2022, 14, 516. [Google Scholar] [CrossRef]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic routing between capsules. In Proceedings of the 2017 Conference, Advances in Neural Information Processing Systems, Los Angeles, CA, USA, 4–9 December 2017; pp. 3856–3866. [Google Scholar]
- Zhao, W.; Ye, J.B.; Yang, M.; Lei, Z.Y.; Zhang, S.F.; Zhao, Z. Investigating capsule networks with dynamic routing for text classification. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Brussels, Belgium, 4 September–31 October 2018; pp. 3110–3119. [Google Scholar]
- Jia, X.D.; Li, W. Attention enhanced capsule network for text classification by encoding syntactic dependency trees with graph convolutional neural network. PeerJ Comput. Sci. 2022, 7, e831. [Google Scholar] [CrossRef] [PubMed]
- Gangwar, A.K.; Vadlamani, R. A novel BGCapsule network for text classification. SN Comput. Sci. 2022, 3, 1–12. [Google Scholar] [CrossRef]
- Du, C.N.; Sun, H.F.; Wang, J.Y.; Qi, Q.; Liao, J.X.; Xu, T.; Liu, M. Capsule network with interactive attention for aspect-level sentiment classification. In Proceedings of the 2019 conference on Empirical Methods in Natural Language Processing and 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 5488–5497. [Google Scholar]
- Zheng, W.S.; Zheng, Z.B.; Wan, H.; Chen, C. Dynamically route hierarchical structure representation to attentive capsule for text classification. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI-19. International Joint Conferences on Artificial Intelligence Organization, Macau, China, 10–16 August 2019; pp. 5464–5470. [Google Scholar]
- Chen, Z.; Qian, T.Y. Transfer capsule network for aspect level sentiment classification. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 547–556. [Google Scholar]
- Du, Y.P.; Zhao, X.Z.; He, M.; Guo, W.Y. A novel capsule based hybrid neural network for sentiment classification. IEEE Access 2019, 7, 39321–39328. [Google Scholar] [CrossRef]
- Zhang, B.W.; Xu, X.F.; Yang, M.; Chen, X.J.; Ye, Y.M. Cross-domain sentiment classification by capsule network with semantic rules. IEEE Access 2018, 6, 58284–58294. [Google Scholar] [CrossRef]
- Jain, D.K.; Jain, R.; Upadhyay, Y.; Kathuria, A.; Lan, X.Y. Deep refinement: Capsule network with attention mechanism-based system for text classification. Neural Comput. Appl. 2020, 32, 1839–1856. [Google Scholar] [CrossRef]
- Kim, J.; Jang, S.; Park, E.; Choi, S. Text classification using capsules. Neurocomputing 2020, 376, 214–221. [Google Scholar] [CrossRef] [Green Version]
- Zheng, L.; Wu, Y.H.; Peng, B.; Chen, X.; Sun, Z.Y.; Liu, Y.; Yu, D.L. SeCNN: A semantic CNN parser for code comment generation. J. Syst. Softw. 2021, 181, 111036. [Google Scholar]
- Kattenborn, T.; Leitloff, J.; Schiefer, F.; Hinz, S. Review on Convolutional Neural Networks (CNN) in vegetation remote sensing. ISPRS J. Photogramm. Remote Sens. 2021, 173, 24–49. [Google Scholar] [CrossRef]
- Rahman, S.; Chakraborty, P. Bangla document classification using deep recurrent neural network with BiLSTM. In Proceedings of the International Conference on Machine Intelligence and Data Science Applications, Dehradun, India, 4–5 September 2020; pp. 507–519. [Google Scholar]
- Liang, Y.J.; Li, H.H.; Guo, B.; Yu, Z.W.; Zheng, X.L.; Samtani, S.; Zeng, D.D. Fusion of heterogeneous attention mechanisms in multi-view convolutional neural network for text classification. Inf. Sci. 2021, 548, 295–312. [Google Scholar] [CrossRef]
- Mensah, K.P.; Adebayo, F.A.; Ayidzoe, A.M.; Baagyire, Y.E. Capsule network—A survey. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 1295–1310. [Google Scholar]
- Pang, B.; Lee, L. A sentimental education: Sentiment analysis using subjectivity summarization based on minimum cuts. In Proceedings of the Association for Computational Linguistics, Barcelona, Spain, 21–26 July 2004; pp. 271–278. [Google Scholar]
- Li, X.; Roth, D. Learning question classifiers. In Proceedings of the 19th International Conference on Computational Linguistics, Taipei, Taiwan, 24 August–1 September, 2002; pp. 1–7. [Google Scholar]
- Pang, B.; Lee, L.; Vaithyanathan, S. Thumbs up? Sentiment classification using machine learning techniques. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Philadelphia, PA, USA, 6–7 July 2002; pp. 79–86. [Google Scholar]
- Kim, Y. Convolutional neural networks for sentence classification. In Proceedings of the 2014 Conference on Empirical Methods Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]
- Qian, Q.; Huang, M.; Lei, J.; Zhu, X. Linguistically regularized lstms for sentiment classification. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, QC, Canada, 30 July–4 August 2017; pp. 1679–1689. [Google Scholar]
- Miyato, T.; Dai, A.M.; Goodfellow, L. Adversarial training methods for semi-supervised text classification. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Shen, T.; Zhou, T.Y.; Long, G.D.; Jiang, J.; Zhang, C.Q. Bi-directional block self-attention for fast and memory-efficient sequence modeling. In Proceedings of the International Conference and Learning Representations, Vancouver, QC, Canada, 30 April–3 May 2018. [Google Scholar]
- Huang, M.L.; Qiao, Q.; Zhu, X.Y. Encoding syntactic knowledge in neural networks for sentiment classification. ACM Trans. Inf. Syst. 2017, 35, 1–27. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, U.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Li, X.; Li, Z.; Xie, H. Merging statistical feature via adaptive gate for improved text classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Shenzhen, China, 2–9 February 2021; pp. 13288–13296. [Google Scholar]
- Zhang, Y.; Yu, X.; Cui, Z.; Wu, S.; Wen, Z.; Wang, L. Every document owns its structure: Inductive text classification via graph neural networks. arXiv 2020, arXiv:2004.13826. [Google Scholar]
- Lu, Z.; Du, P.; Nie, J.Y. VGCN-BERT: Augmenting BERT with graph embedding for text classification. In Proceedings of the 42nd European Conference on IR Research, Lisbon, Portugal, 14–17 April 2020; pp. 369–382. [Google Scholar]
- Yang, T.; Hu, L.; Shi, C.; Ji, H.; Li, X.; Nie, L. Heterogeneous graph attention networks for semi-supervised short text classification. In Proceedings of the Empirical Methods in Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 4820–4829. [Google Scholar]
- Zhao, H.; Xie, J.; Wang, H. Graph convolutional network based on multi-head pooling for short text classification. IEEE Access 2022, 10, 11947–11956. [Google Scholar] [CrossRef]
- Li, J.; Zhang, D.Z.; Wulamu, A. Short text paraphrase identification model based on RDN-MESIM. Comput. Intell. Neurosci. 2021, 2021, 6865287. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Type | Classes | DS | ASL |
|---|---|---|---|---|
| SUBJ | Snippets of movie reviews | 2 | 10,000 | 13 |
| TREC | Question | 6 | 5952 | 5 |
| MR | Review sentences | 2 | 10,662 | 10 |
| ProcCons | Short text | 2 | 45,875 | 6 |
| Model | SUBJ | TREC | MR | ProcCons |
|---|---|---|---|---|
| CNN for SC [37] | 0.9000 | 0.9120 | 0.8110 | - |
| LR-Bi-LSTM [38] | 0.9022 | 0.9134 | 0.8222 | 0.9694 |
| VA LSTM [39] | 0.9110 | - | 0.8340 | 0.9765 |
| Bi-BloSAN * [40] | - | 0.9100 | 0.7966 | - |
| TE-LSTM+c,p [41] | 0.8878 | 0.9024 | 0.8220 | 0.8989 |
| Transformer [42] | 0.8803 | 0.8738 | 0.8190 | 0.9683 |
| Transformer +AGN [43] | 0.8897 | 0.8885 | 0.8222 | 0.9667 |
| TextING [44] | 0.9029 | 0.7832 | 0.7790 | 0.9465 |
| VGCN-BERT [45] | 0.9013 | 0.8982 | 0.8666 | 0.9667 |
| HGAT [46] | 0.8347 | 0.7072 | 0.6273 | - |
| MP-GCN [47] | 0.9117 | 0.7980 | 0.7802 | 0.9479 |
| CapsNet (EMR) | 0.8070 | 0.6658 | 0.5787 | - |
| CapsNet (DR) | 0.8900 | 0.7650 | 0.7300 | 0.9163 |
| Ours | 0.9380 | 0.9194 | 0.8281 | 0.9843 |
| Depth | Embed | Epoch | SUBJ | TREC | MR | ProcCons |
|---|---|---|---|---|---|---|
| 6 | 20 | 5 | 0.9020 | 0.8187 | 0.6484 | 0.8818 |
| 10 | 0.8980 | 0.8187 | 0.7958 | 0.8588 | ||
| 15 | 0.8940 | 0.8691 | 0.8281 | 0.6673 | ||
| 20 | 0.8920 | 0.8456 | 0.7059 | 0.9475 | ||
| 25 | 0.9100 | 0.8657 | 0.7453 | 0.9843 | ||
| 200 | 5 | 0.9380 | 0.8557 | 0.7734 | 0.8918 | |
| 10 | 0.8840 | 0.8926 | 0.6835 | 0.8884 | ||
| 15 | 0.9100 | 0.9194 | 0.7228 | 0.8862 | ||
| 20 | 0.8759 | 0.8926 | 0.7284 | 0.8748 | ||
| 25 | 0.8980 | 0.9194 | 0.7340 | 0.8801 | ||
| 12 | 20 | 5 | 0.1039 | 0.3791 | 0.1235 | 0.8827 |
| 10 | 0.8760 | 0.7550 | 0.4382 | 0.8718 | ||
| 15 | 0.8799 | 0.8120 | 0.6966 | 0.9607 | ||
| 20 | 0.8299 | 0.8053 | 0.6797 | 0.8801 | ||
| 25 | 0.8459 | 0.7785 | 0.6966 | 0.5274 | ||
| 200 | 5 | 0.1260 | 0.5503 | 0.7434 | 0.8500 | |
| 10 | 0.8240 | 0.8187 | 0.6760 | 0.8526 | ||
| 15 | 0.8300 | 0.8624 | 0.6610 | 0.8823 | ||
| 20 | 0.8359 | 0.8859 | 0.7097 | 0.8731 | ||
| 25 | 0.8680 | 0.8187 | 0.6985 | 0.8700 |
| Dataset | DME | ES | E | BS |
|---|---|---|---|---|
| SUBJ | 6 | 200 | 5 | 100 |
| TREC | 6 | 200 | 15 | 100 |
| MR | 6 | 20 | 15 | 100 |
| ProcCons | 6 | 20 | 25 | 100 |
| Structure | SUBJ | TREC | MR | ProcCons |
|---|---|---|---|---|
| Ours | 0.9380 | 0.9194 | 0.8281 | 0.9843 |
| -CSMM | 0.9019 | 0.8288 | 0.7930 | 0.8905 |
| -MlSEM | 0.8699 | 0.7214 | 0.7303 | 0.8805 |
| -CM | 0.9019 | 0.9026 | 0.7340 | 0.8809 |
| -CSMM-MlSEM | 0.8559 | 0.7281 | 0.7322 | 0.8757 |
| -CSMM-CM | 0.8679 | 0.8590 | 0.7059 | 0.8630 |
| -MlSEM-CM | 0.8620 | 0.8523 | 0.7303 | 0.8740 |
| -CSMM+ (D-MlSEM) | 0.8760 | 0.8691 | 0.6947 | 0.8731 |
| -CSMM-MlSEM+BiGRU | 0.9120 | 0.6174 | 0.6516 | 0.8857 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Zhang, D.; Wulamu, A. Investigating Multi-Level Semantic Extraction with Squash Capsules for Short Text Classification. Entropy 2022, 24, 590. https://doi.org/10.3390/e24050590
Li J, Zhang D, Wulamu A. Investigating Multi-Level Semantic Extraction with Squash Capsules for Short Text Classification. Entropy. 2022; 24(5):590. https://doi.org/10.3390/e24050590
Chicago/Turabian StyleLi, Jing, Dezheng Zhang, and Aziguli Wulamu. 2022. "Investigating Multi-Level Semantic Extraction with Squash Capsules for Short Text Classification" Entropy 24, no. 5: 590. https://doi.org/10.3390/e24050590
APA StyleLi, J., Zhang, D., & Wulamu, A. (2022). Investigating Multi-Level Semantic Extraction with Squash Capsules for Short Text Classification. Entropy, 24(5), 590. https://doi.org/10.3390/e24050590