1. Introduction
CNN is a widely used neural network architecture which is formulated by biologists Huber and Wiesel in their early work on cat visual cortices. It can be applied to many problems in image classification and segmentation [
1,
2,
3] and natural language processing (NLP) [
4,
5]. However, designing CNN structures completely manually is a complex task. For example, traditional network designs, such as LeNet [
6], AlexNet [
7], and ResNet [
8]. These networks not only rely heavily on existing deep learning architectures when designing manually but also require the re-selection of appropriate structures and hyperparameters for specific tasks.
However, owing to the high-dimensional properties of the neural networks, neuroevolution is mainly employed for reinforcement learning of shallow networks. Stanley et al. attempted to address this question with hypercubic-enhanced topological neuroevolution (HyperNEAT) [
9], which acts as an indirect coding method that can generate millions of networks, but still has a low fitness for optimal CNNs and is therefore considered more suitable as a feature extractor.
In 2016, some academics proposed an approach that would allow the network structure to be constructed not by humans, but by giving the machine some basic elements of a neural network and allowing it to automatically construct a better network. This approach is called neural architecture search (NAS) [
10,
11], which combines and selects the basic elements of a neural network by taking them into a limited search space and finally arriving at a network with good network performance. However, it is necessary to constantly try and combine different architectures in the process, which consumes a lot of time and requires a powerful amount of computation.
In perceptual tasks, the success of deep learning is closely connected to the automation of the feature extraction process, where hierarchical feature extractors automatically acquire the information that we need in an end-to-end manner. However, as we manually design increasingly complex neural architectures for specific tasks, our demand for architecture engineering is growing. NAS enables automated neural network architecture design and thus is the next step in the automation of machine learning. NAS can be considered as a subdomain of AutoML. Most modern deep neural network architectures are created based on human experience, and most of them require a long and tedious iterative experimentation process, while NAS enables the automatic generation of effective deep learning frameworks for specific tasks without any human intervention.
There are many methods to perform an automatic search by combining reinforcement learning, intelligent optimization algorithms, and gradient descent with CNNs. Baker et al. suggest a reinforcement learning (RL)-based metamodeling approach for automatically designing CNN architectures, called MetaQNN [
12], by training an agent to sequentially determine the types of layers and their parameters. NASNet [
13] uses validation accuracy as a reward signal, a recursive network of controllers optimized by policy gradients to generate the best neural structure description. EvoCNN [
14] combines with the design of CNNs, which use GA for searching CNN structures with particular operations. IPPSO [
15] is the first method to use particle swarm optimization (PSO) [
16,
17,
18] in the design of CNN networks. It is inspired by the IP address setting, where each layer of the CNN is assigned an IP address. By the above setting, a new coding method is set. In addition, it uses PSO to automatically search for the optimal structure of the CNN at variable lengths without any human intervention in the process. However, this algorithm has limitations on particle length, and cannot be encoded at variable lengths, and the results are limited to three data sets. Based on the IPPSO drawbacks, psoCNN [
19] proposes a new difference and velocity operator, respectively, and uses variable-length particles to explore the optimal solution of the CNN architecture. However, the main drawback is that the search space is only a combination of existing schemes and does not make maximum use of the solution space. Therefore, Lawrence et al. [
20] use the group operation in psoCNN to maximize the search solution space and reduce the computational cost to a certain extent, but it is limited by the length of the particle size.
With deeper research in NAS, some studies are increasingly proved to be not perfect. Therefore, some more mature and complete solutions have been proposed in related works. ENAS [
21] proposes a faster and more efficient search network structure using weight sharing, by which the time to obtain the optimal subnetwork is reduced. However, this approach may lead to weight shifts. DNS [
22] reduces the drawbacks coming from ENAS by modularizing the search space. Although these above algorithms obtain better results on the corresponding data sets respectively, on the one hand, the time and space cost is relatively high, and on the other hand, there is no good way to deal with the continuous space search problem, and our algorithm solves these two problems relatively well.
Based on two metrics, classification accuracy and search speed, and finding the balance between the two metrics, We use the AO and GA to maximize the exploration of the CNN optimal structure, which we call HAGCNN. The primary contributions of this paper are as follows:
We design a new binary-based particle-encoding strategy that can efficiently encode CNN structures and develop new evolutionary computation algorithms based on the new encoding strategy;
A new approach to position updating is proposed, which focuses on combining the AO with GA. Crossover, Mutation, and Selection operations are added before the position update, thus allowing various directions and scales to search the solution space and increase the chances of diverse network formation;
The inclusion of skip connections allows the algorithm to search for reasonable CNN architectures at variable lengths and generate new models, which break the constraint of the fixed-length encoding of traditional AO;
To obtain better network performance, we introduce the residual block structure and group strategy, which enables us to explore deeper network structures sensibly.
The remainder of this paper is as follows:
Section 2 provides a detailed description of the AO, GA, CNN, and residual block.
Section 3 describes the proposed HAGCNN algorithm in detail. In
Section 4, we introduce the experimental details we have performed.
Section 5, we conclude and analyze the experimental results.
Section 6 summarizes the whole paper and presents future works.
2. Background
2.1. CNN Introduction
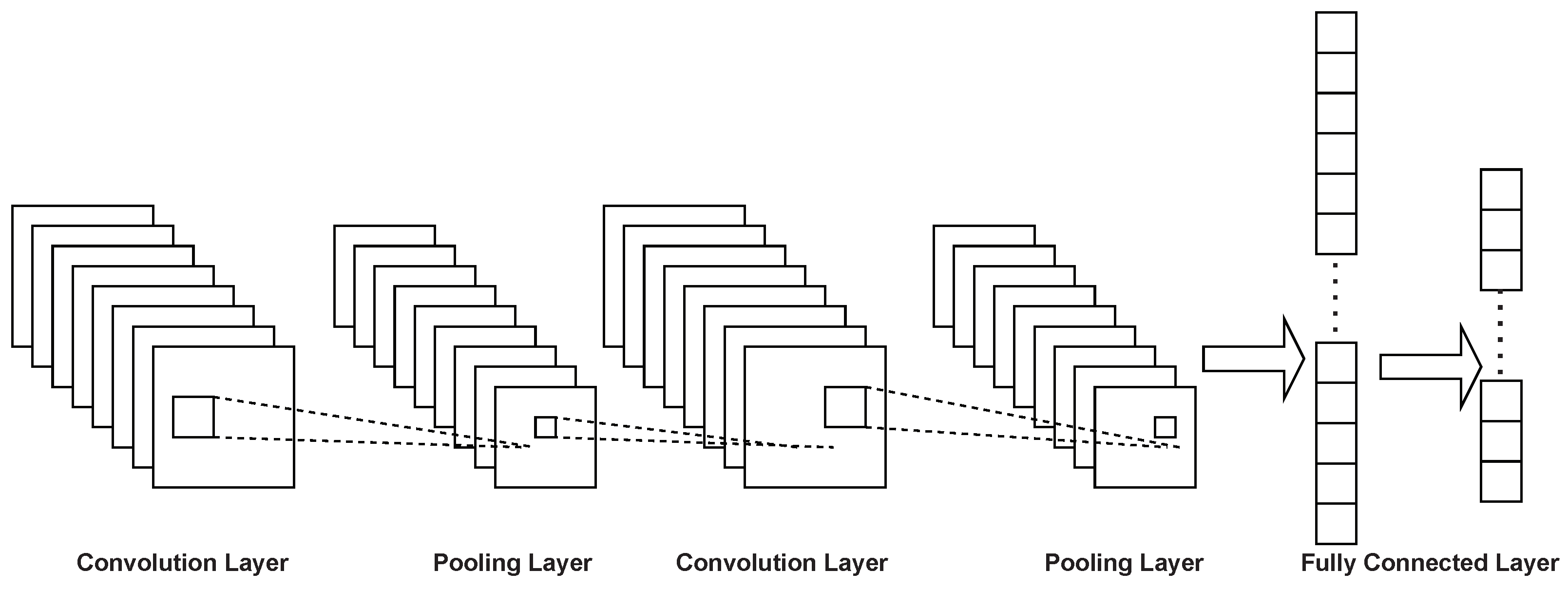
CNN [
23,
24,
25,
26] was proposed in the 1960s and discovered by Hubel and Wiesel while studying neurons in the cat brain cortex for local sensitivity and an orientation selection. CNN does not require to be manually designed during the whole-feature extraction but is processed by convolution operation directly. Deep convolutional neural networks mainly contain input layers, pooling layers, fully connected layers, convolutional layers, and an output layer. The input layer is used to receive the input data and the convolution layer is mainly used to perform feature extraction on the data. The data downsampling process is performed on the pooling layer. The fully connected layer is a deep network with the multi-Layer perceptron (MLP) [
27,
28,
29]. Furthermore, it is mainly implemented through the activation function to the final output layer. The structure of CNN is shown in
Figure 1. Deep convolutional neural networks stack various layers on top of each other and the output of each layer is calculated as the sum of the product of the input of each layer and the internal weights, all of which will be used as input to the next layer, resulting in a recognition classification result.
In training a CNN, tens of thousands of parameters may have to be processed because of the different architectures. It may take hours or even days, so it is important to develop an automatic search mechanism.
2.2. Residual Block
ResNet [
8] is made up of a series of residual blocks, and a residual block can be expressed by Equation (
1).
The residual block is classified into two parts, which are the direct mapping and the residual section. Among them, is the residual section that consists of two to three convolution operations.
In a convolutional network,
may not have the same number of feature maps as
, and it is then necessary to use the convolution of
for dimensioning up or down, in which case the residual block representation is given in Equation (
2).
where,
, and
is the
convolution operation. However, generally this is only used when lifting the dimension.
2.3. Genetic Algorithm (GA)
The genetic algorithm (GA) [
30,
31] is a population-based optimization search algorithm derived from natural selection. It uses the concept of survival of the fittest. It tries to exploit the most suitable individuals through iteration, and it abstracts the problem space as a population of individuals. GA converts the original group of individuals to a group of individuals where each individual stands for the solution of the problem waiting to be solved. The computation is achieved by cycling through individuals in a population using crossover, variation, and selection.
To determine whether a particular string will be involved in the reproduction process, a selection operation is proposed. Here, there are many ways to select the best chromosome, for example roulette wheel selection, rank selection, tournament selection, Boltzmann selection, steady-state selection, and elitist selection, etc.
The crossover operation is implemented mainly by combining genetic information from two or more parents to generate offspring. This includes signal point, uniform, partial matching, two-point and k-point orders, crossover with priority retention, reduction of substitution, shuffling, and cycling.
The mutation operation is used to maintain genetic diversity from one population to the next. The well-known mutation operations are simple inversions, substitutions, and hybrid mutations.
2.4. Aquila Optimizer (AO)
The Aquila optimizer (AO) [
32,
33] is a population-based optimizer proposed in 2021. It is inspired by Aquila’s social behavior of catching prey. Similar to other population-based metaheuristics, the algorithm begins with
N individuals and the initial population is
X. We perform this initialization process in Equation (
3):
where
and
are the upper and lower bounds of the
j-th exploration space,
is a randomly generated parameter in the range from 0 to 1, and
is the whole search space dimension.
The algorithm is divided into two processes: exploration and exploitation, in which there are four main implementation strategies. The algorithm can determine the possibilities of transferring the exploration stage to the exploitation stage by judging the condition . where t and T stand for the current iteration and the maximum number of iterations, respectively.
In the first strategy, the Aquila discriminates the prey region and selects the best hunting area by a vertical swoop of high-altitude soaring. This strategy considers the average agent
and the best agent
in the process of exploration. The mathematical equation is as Equation (
4):
where
,
denote the position of the individual at the
-th iteration number and the best solved individual obtained at the
t-th iteration, respectively.
shows the average value of the current solution position at the
t-th iteration, which is calculated by Equation (
5).
t and
T indicate the current and maximum number of iterations, and
is a random value between 0 and 1.
is the dimension size and
N is the number of candidate solution.
In the second strategy, the individual position is updated on the basis of the L
vy flight
distribution and
. A mathematical formulation of this strategy is given by Equation (
6)
where
is the position of the
i-th individual at the
-th iteration.
is the L
vy flight distribution function and
D represents the dimensional space, specifically calculated by Equation (
7).
is the random individual sampled in the range
at the
i-th iteration.
x and
y are computed by Equations (
9) and (
10), respectively.
In Equation (
7),
s is a constant with a value of
.
u and
v are random numbers ranging from 0 to 1.
is calculated by Equation (
8). In Equations (
9) and (
10),
r is calculated by Equation (
11),
is calculated by Equation (
12),
is used to fix the count of search cycles, whose value is taken between 1 and 20, and
U is a small amount that is fixed at
.
is a small value of
, and
is an integer from 1 to the length of the search space (
).
The third strategy is mainly based on Aquila’s low flying and slow falling attacks. This action is expressed mathematically as Equation (
13):
where
and
denote the adjustment parameters of the exploitation process.
The fourth strategy refers to Aquila’s behavior of walking and catching prey. This behavior is mathematically shown in Equation (
14):
where Equation (
15) is the
expression. Equations (
16) and (
17) represent
and
, respectively.
is the L
vy flight distribution function calculated using Equation (
7).
t and
T present the current iteration and the maximum number of iterations respectively.
3. The Proposed Algorithm
This section introduces the main parts of our proposed algorithm separately, mainly including six parts: convolutional layer representation, the block structure, the grouping strategy, the position update representation, the fitness representation, and the decoding.
3.1. Convolutional Layer Representation
When we consider the design of algorithms that handle complex structures (e.g., CNN architectures), it is important to choose an appropriate encoding method to represent the CNN architecture and to avoid additional hard-coded management rules to ensure a reasonable construction of the architecture. In this paper, we directly represent each block in the CNN with a binary encoding and use evolutionary computation to update the encoding for the purpose of tuning the neural network architecture. For each training, testing, and evaluation using CNN, the model is compiled from an array containing the details of each layer in the particle. However, only different CNN structures can be found using this method. Therefore, we search the relevant hyperparameters of each layer at the same time.
We use a binary expression to represent the actual meaning of what each layer represents. Each of the different types of the layer is represented by a three-bit binary encoding, with three bits representing the eight possible options, each containing at least one activation-function layer, two convolutional layers, and one regularization layer.
Where the binary number ‘000’ indicates that the average pooling layer is selected; ‘001’ indicates we use the maximum pooling layer in the architecture; ‘010’ indicates that the skip-connection layer is used; ‘011’ indicates the selection of a convolutional layer with a convolutional kernel size of
and a padding value of one; ‘100’ means a convolutional layer with a kernel size of
and a padding value of two; ‘101’ shows a convolutional layer whose kernel size is
and padding value is four; ‘110’ implies choosing a convolutional layer having a kernel size of
, a padding value of two, and a dilation size of two; and ‘111’ indicates selecting a convolutional layer with a kernel size of
, a padding value of four, and a dilation size of two. The specific representation is shown in
Table 1. The details of the operation will be shown in Algorithm 1.
| Algorithm 1 The pseudo code of HAGCNN |
Initialize: The dimension of each individual is D, and each individual is initialized with D random numbers, . represents the fitness function of the individual , The current number of iterations is , the maximum number of iterations is M, and R is the number of iterations executing the communication strategy. Iteration: - 1:
whiledo - 2:
for to N do - 3:
Decode the individual and generate the corresponding network. - 4:
Train the network using the training dataset. - 5:
The network is tested on the test data set, and the accuracy is returned as the fitness value. - 6:
for to N do - 7:
Update the mean value of the current solution . - 8:
if then - 9:
if then - 10:
is performed OR operate bit by bit with . - 11:
The results were mutated randomly. - 12:
Then cross operate the mutation result with . - 13:
The encoding of the particle representation is divided into n groups and a pooling layer is inserted in the last position of each group that satisfies the condition. - 14:
Calculate the fitness value of the new individual. If the value is better than , update with the individual. - 15:
else - 16:
Random mutation of into several bits. - 17:
The encoding of the particle representation is divided into n groups and a pooling layer is inserted in the last position of each group that satisfies the condition. - 18:
Calculate the fitness value of the new individual. If the value is better than , update with the individual. - 19:
else - 20:
if then - 21:
Update the mean value of the current solution . - 22:
The optimal individual and the average individual are XORed. - 23:
The result of XOR is crossed with random binary coding, and the crossing position is controlled to be in the second half of the coding. - 24:
The encoding of the particle representation is divided into n groups and a pooling layer is inserted in the last position of each group that satisfies the condition. - 25:
Calculate the fitness value of the new individual. If the value is better than , update with the individual. - 26:
else - 27:
Random mutation of into several bits, and the number of mutations should not exceed half of the total number.
Output: The global best individual , and the best fitness value . |
Since the particle length is fixed after initialization, to search the CNN structure at variable length and to increase the possibility of searching, this paper achieves this purpose by using the inclusion of a skip-connection layer by setting the skip-connection layer to be denoted by ‘010’; if this layer is selected, the output of the previous layer is copied directly to the next layer, which is equivalent to reducing the actual number of valid layers in the whole network by one layer and thus achieving a variable length search.
The number of output channels per convolutional layer is another parameter that has a large impact on the network performance. Therefore, our algorithm also includes this parameter in the search space. Similarly, we convert the number of output channels of the convolutional layers to binary and concatenate it to the convolution type. Thus, our encoding string becomes a -bit binary string, where a complete convolution block is represented by bits, which contain three bits of binary for the convolution type and X bits for the number of output channels of the layer. Here L denotes the number of layers present in the network and X remains fixed during a search.
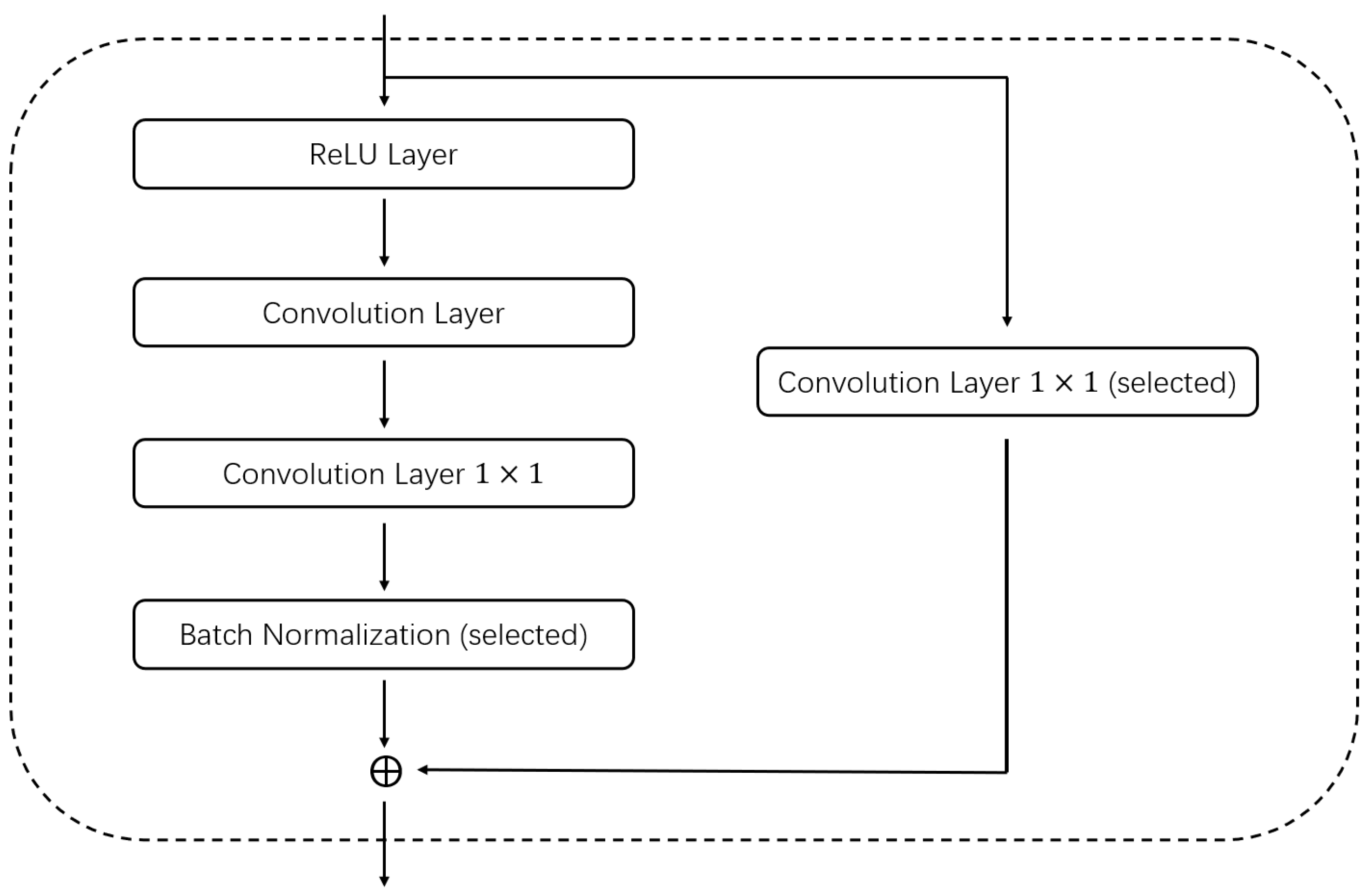
3.2. Block Structure
In past studies, researchers have often combined a number of fixed layers together to form block structures, and using such block structures can dramatically improve the performance of the network. In this article, we also used a similar structure. We combine the convolution layer, batch-normalization layer, and activation layer into a base convolution block. Furthermore, when encoding, we encode only the convolution block and not the separate convolution layers. When combining these layers, we consider both the convolution kernel size, stride size, padding, and dilation to ensure that the resolution of the input block is the same as the resolution of the block output. To further improve the performance of the convolution block, we incorporate the idea of a residual block, and our convolution block similarly copies the input and adds it to the output of the convolution layer. We add a
convolution layer for channel fusion so that the number of input channels is the same as the number of output channels for direct summation for blocks where the number of input channels is different from the number of output channels. For example,
Figure 2 shows a basic block structure. An example of a network with different encoding methods after combining different block structures is shown in
Figure 3. As shown in
Figure 3, the numbers indicate the basic block structures, and the corresponding codes are shown after each structure.
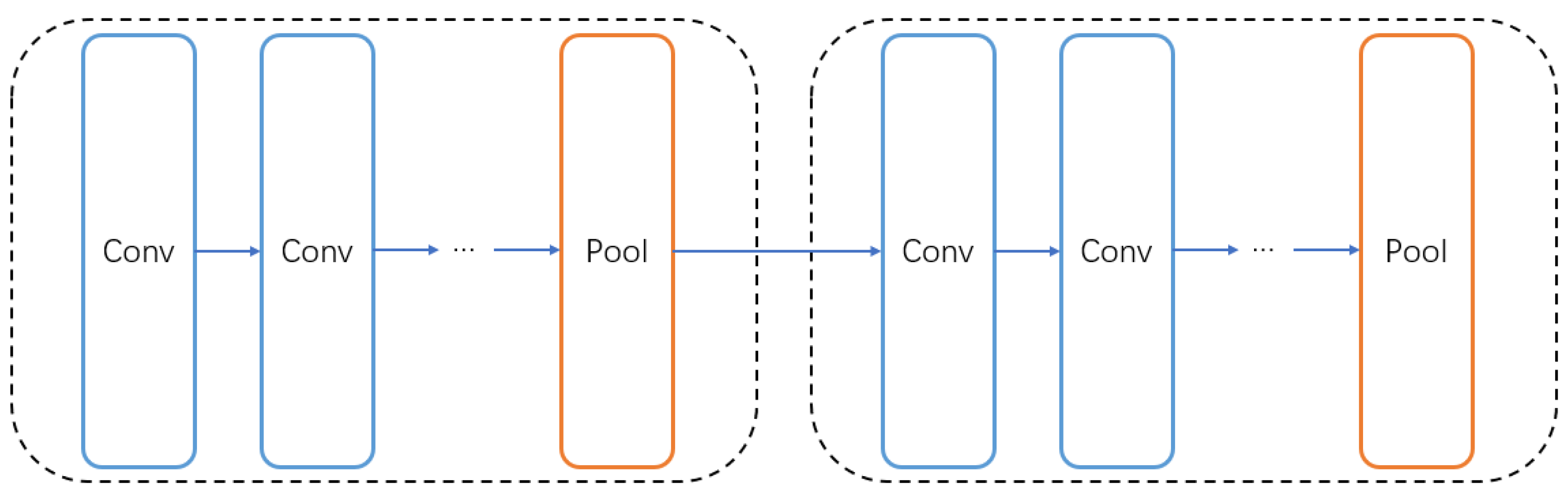
3.3. Grouping Strategy
In order to generate better architectures, we group the searched architectures. The purpose of grouping is to reasonably intersperse the pooling layers in the network structure to make our network achieve better results. We divide all the layers into
n groups, assuming that the whole network contains
L layers (including skip connections), there are
layers in each group, and we detect whether the last layer in each group is a pooling layer to avoid adding redundant pooling layers repeatedly.
Figure 4 shows an example of grouping the entire network structure, and we make sure that the last layer of each group is the pooling layer.
3.4. Location Update Representation
After representing the CNN structure with a string of binary characters, this string is used as input to the evolutionary computation algorithm formula, and several operations are performed during the bring-up process. Algorithm 1 further describes this part of the specific process.
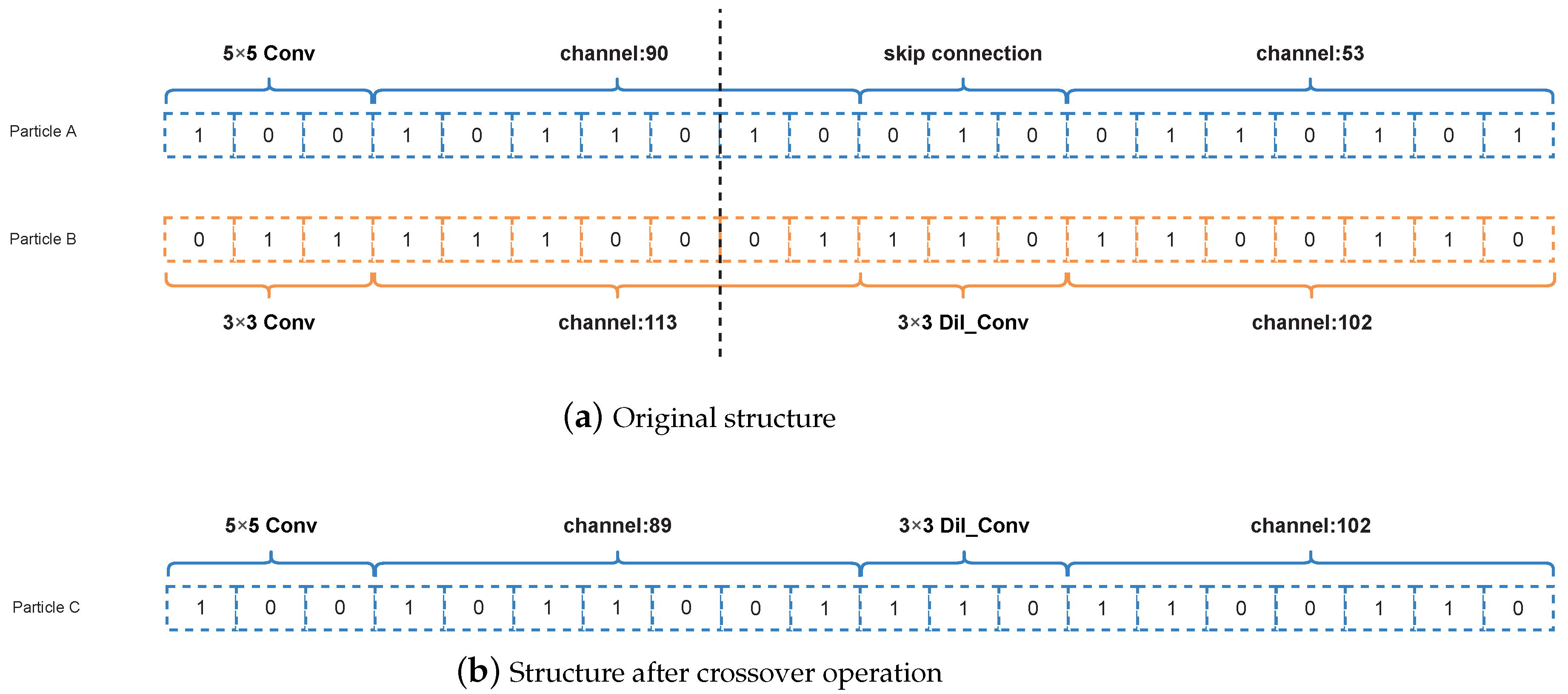
3.4.1. Crossover Operation
If the current particle position is multiplied by an arbitrary constant which is more than 1 in the formula, the algorithm performs a crossover operation. Note that it is rounded upwards to obtain the final constant if the current particle position is multiplied by a fractional number. Furthermore, we assume the length of the constant part is
C and the length of the non-constant part is
. Then, the two coded strings are first truncated according to the constant digit and we cross-patch the two intercepted strings following the behavior of the chromosome crossover. Assuming the code
A is
, and the code
B is
. If the truncation is from the
i-th bit, the results after crossing
and
are as follows,
,
. The specific operation is shown in
Figure 5.
Figure 5a represents the initial structure of any two individuals and
Figure 5b represents the encoded structure of two individuals after the crossover operation.
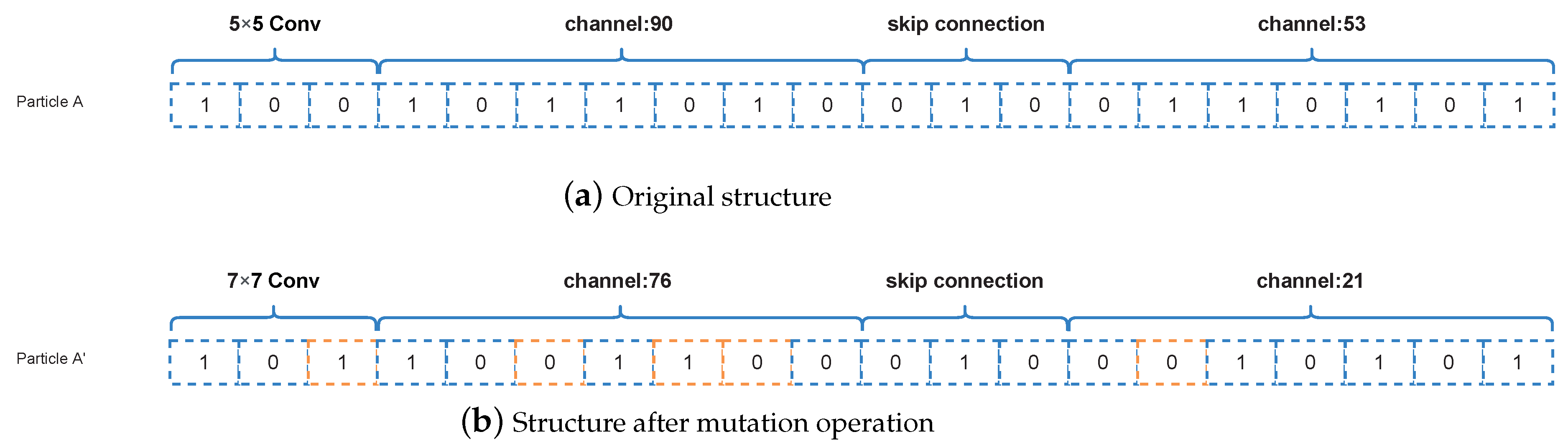
3.4.2. Mutation Operations
Mutation Operation of Random Number
If the current particle position is multiplied by a random number from zero to one, the algorithm performs a mutation operation. Here we use a random number that is subject to a uniform distribution. Furthermore, the bits 0 to
are randomly selected for the mutation. In this process, the parameter
represents the dimension of the algorithm. The specific mutation is that the original 0 bit becomes 1 and the 1 bit becomes 0 for the mutation operation. Assuming a code of
, we randomly selected 2 bits for mutation. The result may be
,
, or
. The specific representation is shown in
Figure 6.
Figure 6a represents the original structure before the mutation operations and
Figure 6b represents the structure after the mutation operations, where the orange part in
Figure 6b is the coding of the mutation.
Mutation Operation of Lvy Flight
If the current particle position is multiplied by a L
vy flight [
34,
35] operand in the formula, the CNN structure corresponding to the best CNN structure is encoded as a mutation operation. The specific variation is performed in the same way as the random number mutation operation.
3.4.3. Selection Operation
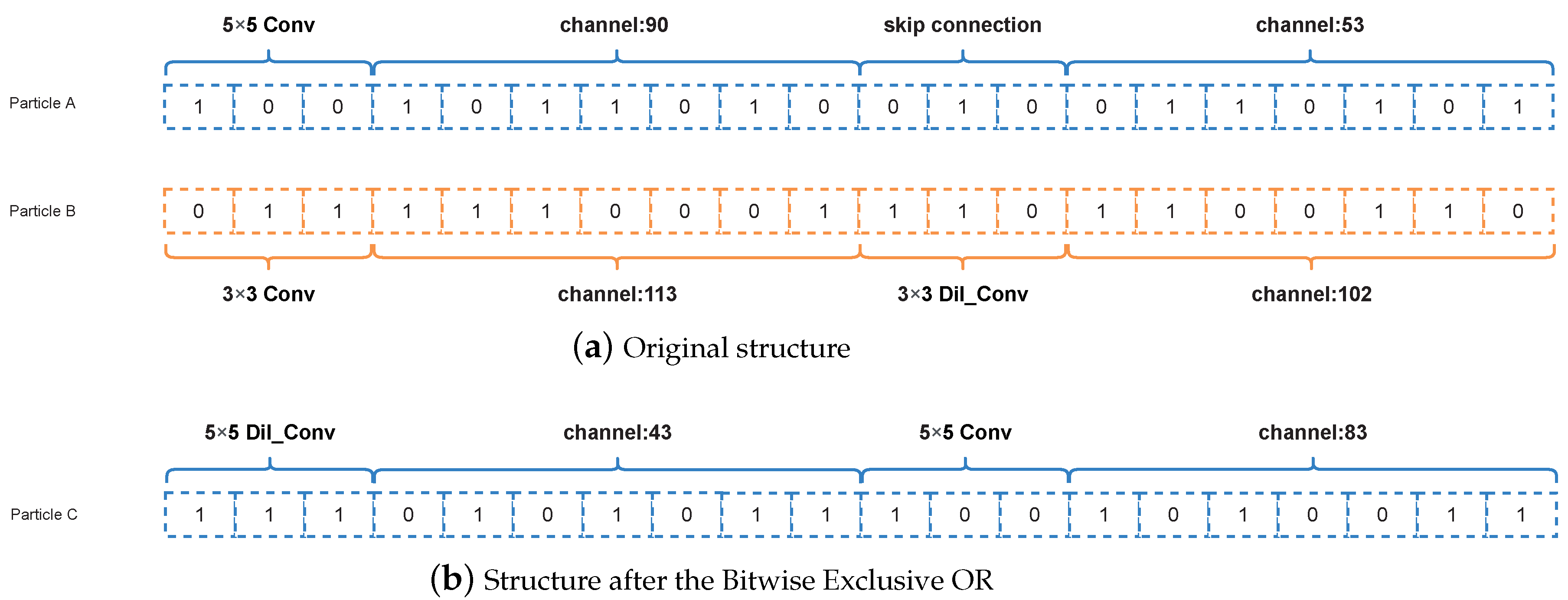
If two particle positions are added or subtracted in the formula, the selection operation is performed. In this case, if the two-particle positions are subtracted, the operation is the Bitwise Exclusive OR operation. If the two-particle positions are added, the operation is the Bitwise OR operation.
Bitwise Exclusive OR
The operation of the Bitwise Exclusive OR is an operation in which two numbers participating in an operation are converted to binary
and then subjected to the Exclusive OR operation, as long as 1 is given when the numbers in the corresponding bits are not the same and 0 when they are the same. Assuming the two codes are
,
, the result is
. The details of the relevant operation are more prominently represented in
Figure 7, where particle
A and particle
B represent the positions of two random particles. When the positions of the two particles are subtracted, the Bitwise Exclusive OR operation is performed, the result is shown in
Figure 7b.
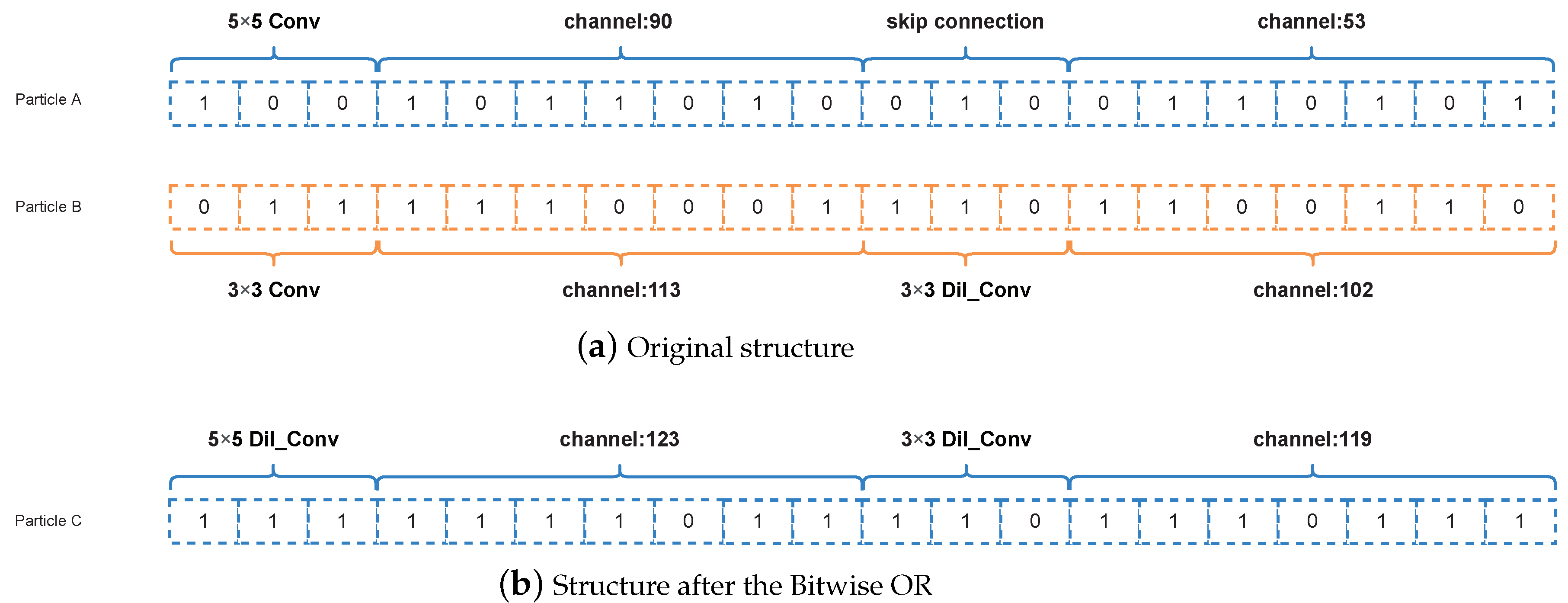
Bitwise OR
The Bitwise OR is similar to the Bitwise Exclusive OR, in which is the AND operation is changed to OR operation. When the two bits are 0, the bit is 0, the rest of the cases the bit is 1. Assuming the two codes are
,
, the result is
. Similarly, when the positions of the two particles are added together, the Bitwise OR operation is performed, the result is shown in
Figure 8b.
3.5. Fitness Evaluation
After iterations of the algorithm, the encoding will change and the changed encoding still corresponds to specific network architecture. The network uses the Adam optimizer to adjust the trainable parameters in the network and CosineAnnealing is used to adjust the learning rate. For the first 10 epochs we let the learning rate decrease from a predetermined maximum to a predetermined minimum, and for the last 10 epochs we let the learning rate increase from the minimum to the maximum. To speed up the network training, each network structure searched by the algorithm during the iterative process is set to an epoch value of one. When the iteration of the algorithm is completed, the epoch value used for training the best-obtained network structure is set to 100. The loss function used for training is set to the cross-entropy loss, and the return value of this function is used as the fitness value. The return value of this function is used as the fitness value to guide the execution of the evolutionary computation algorithm. Finally, we transfer part of the training set as input to the network, train the network, and return the fitness value.
3.6. Decoding
According to
Table 1, the different binary strings can be decoded into the corresponding layer and the corresponding parameter information, and these strings represent the parameter values for this layer. After decoding all the interfaces, the final CNN structure is achieved by concatenating all the decoding layers in the best global case. By concatenating all decoding layers in the same order as the interfaces in the particle vector, the final CNN architecture can be obtained.
5. Experiment and Analysis
To have a clearer view of the effect of the proposed model, we analyze the effect of the proposed algorithm from five perspectives: experimental results, comparison experiment with baseline model, visualization of experimental results, comparison of the effect of random evolution and the proposed algorithm, and the change of the algorithm position with the number of iterations, respectively.
5.1. Experimental Results
We search through 20 particles with 10 iterations in the search space and train the network structure obtained from the search with 100 epochs and 200 epochs on the MNIST and CIFAR-10 datasets, respectively. We compare the performance of the best CNN structure searched by our proposed algorithm in terms of error rate, parameters, and search speed.
The experimental results show that the automatically generated CNN model reached an error rate of on the MNIST dataset with parameters and a search speed of 0.5 h/1 GPU.
Experimental results based on the CIFAR-10 dataset show that the automatically generated CNN model has an error rate of with parameters and a search speed of 12 h/1 GPU. To find a better architecture, the parameters used are different from those used in the experiment on the MNIST dataset. When we search the optimal network architecture for the MNIST dataset, we conduct 1-epoch training on the searched network. In CIFAR-10 dataset search architecture, the network accuracy after 1-epoch training can not guide the evolutionary computing algorithm to find a better structure, which makes the evolutionary computing algorithm fall into local optimization. Therefore, we train 20 epochs for each searched network and return the obtained accuracy as a fitness value to the evolutionary computing algorithm. Similarly, because it is more difficult to train the network on the CIFAR-10 dataset than on the MNIST dataset, it needs more rounds of training to obtain a satisfactory accuracy. Therefore, the optimal architecture that can be found at the end of the iteration of the evolutionary computing algorithm is trained 200 epochs.
5.2. Comparison Experiment with Baseline Model
On the MINIST dataset, we compare our obtained CNN model with the current CNN network-generated models in manual and automatic modes, respectively. As shown in
Table 4, firstly, our model results in an error rate on the test set that exceeds the baseline LeNet-5 and ResNet, and it is also near to the results of the two advanced CapsNet and DropConnect. In the comparison with the automatically generated model, we can find that our proposed model is not only lower in error than IPPSO, psoCNN, and GeNet, but also lower in the number of parameters than the currently known IPPSO and psoCNN in terms of the number of parameters, and nearly three times the number of psoCNN parameters. Additionally, the speed of searching for the optimal structure is much higher than that of the three known NAS models. This indicates that our proposed algorithm can find a better architecture for the image classification task.
On the CIFAR-10 dataset, we compare the results of the proposed algorithm with those of current state-of-the-art neural architecture search algorithms. As shown in
Table 5, although our proposed algorithm still has a large gap from these advanced search models in the item of error rate, we only beat VGGNet, GeNet, and CoDeepNEAT, but compared to MetaQNN, NASNet, and Large-Scale Evolution, we spend substantially less time to. Therefore, our proposed algorithm still has practical significance.
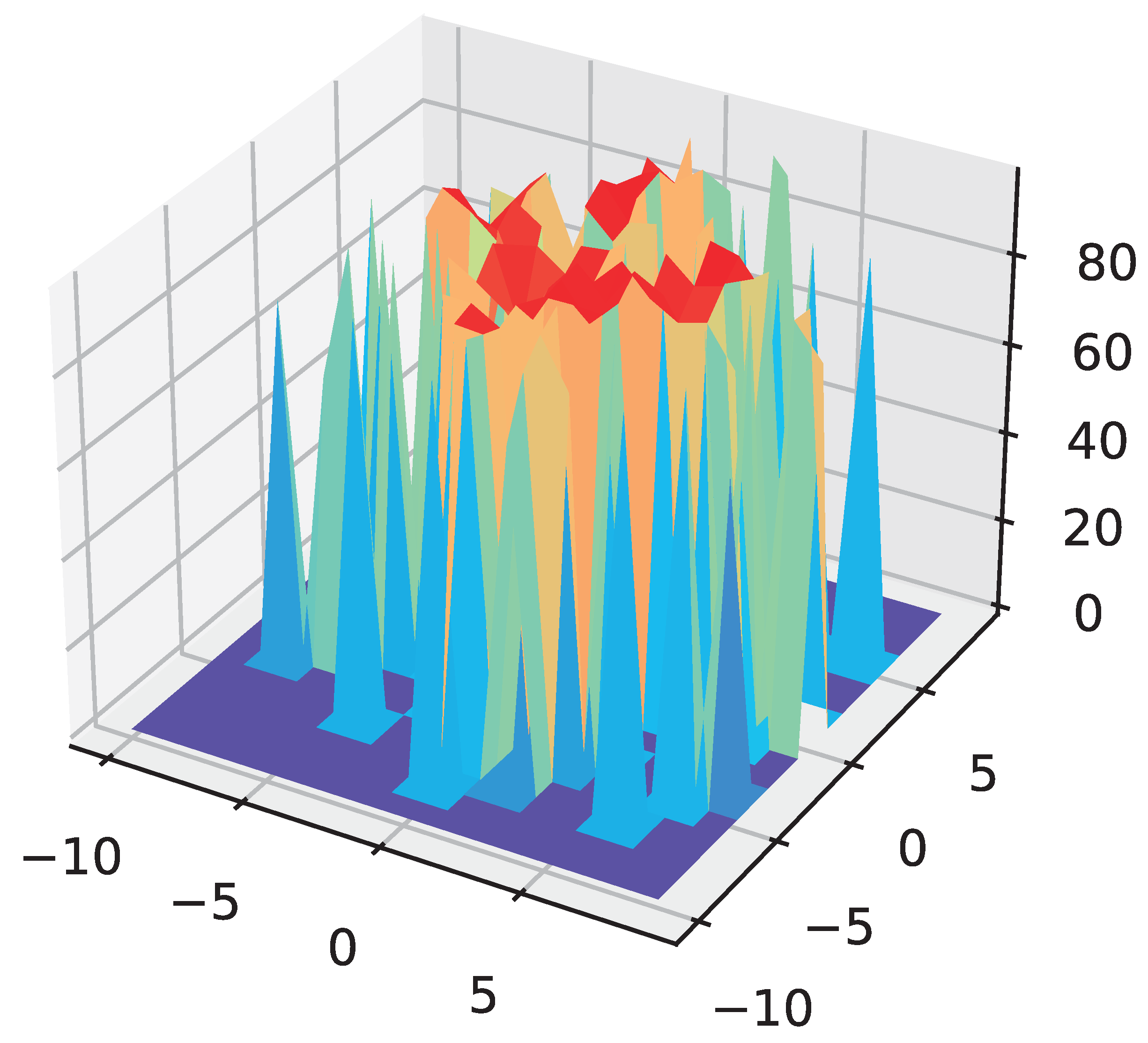
5.3. Visualisation of Results
To explore the trajectory trends of the particles in the evolutionary computation, we visualize the particles that varied with the number of iterations. We chose the principal component analysis (PCA) [
48,
49] method, which selects the two most important components from all the particle dimensions to form a three-dimensional landscape.
As shown in
Figure 9, the
x and
y axes indicate the two extracted dimensions respectively, while the
z axis indicates the accuracy of the network corresponding to that particle on the test set. This visualization shows the accuracy of the network obtained after the 1 epoch of training for different particle positions.
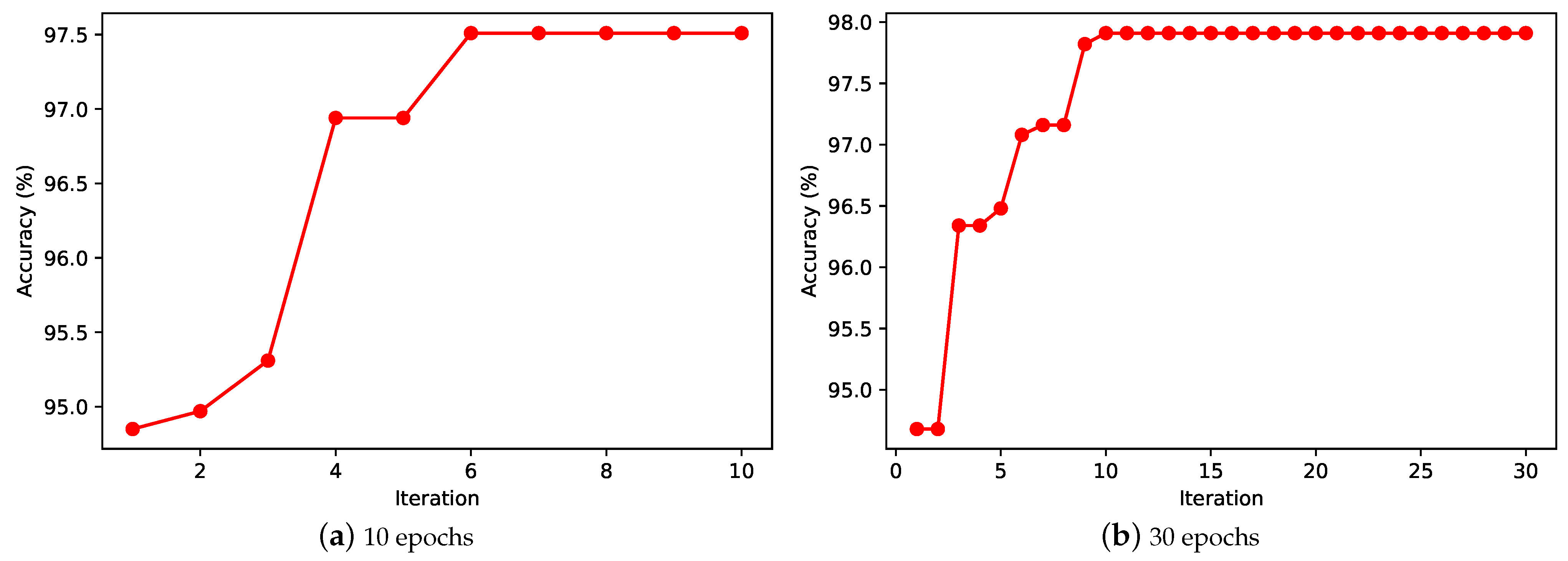
To investigate the effect of the number of iterations on the search algorithm, we delay the number of iterations to 30 and re-run the experiment. The results are shown in
Figure 10. Under the result of 1-epoch training, the horizontal coordinate indicates the current number of iterations and the vertical coordinate indicates the best network accuracy on the test set that can be found in that iteration. When the number of iterations is 10, our proposed algorithm converges in the 6-th generation, and when the number of iterations is extended to 30, the algorithm still converges within 10 generations. This indicates that our proposed algorithm can converge to the optimal value quickly. This also means that our proposed algorithm is applicable to solve the neural architecture search problem.
5.4. Comparison Experiment between Random Evolution and Proposed Algorithm
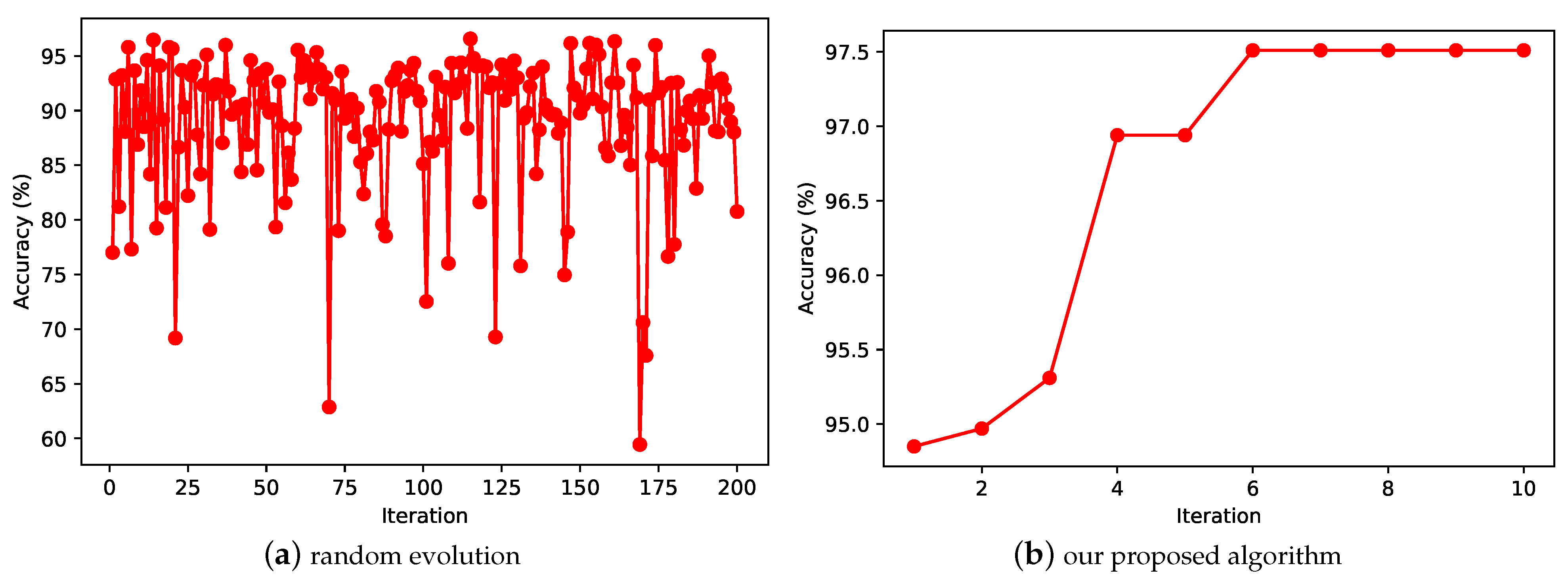
As shown in
Figure 11,
Figure 11a shows the accuracy of the test set using the random evolution approach on the MNIST dataset using 20 particles with 10 iterations, and
Figure 11b shows the accuracy of the test set obtained using the proposed model on the MNIST dataset under the same conditions. The comparison of the two subplots in the figure shows that our proposed CNN evolution model has a significant improvement, finally reaching
on the MNIST dataset, and using random evolution can only reach
on the MNIST dataset. We can also see from the figure that random search exhibits a high degree of disorder. The evolutionary computation algorithm, on the other hand, can use the information from the previous iteration to search for better network architecture in a more optimal direction. This shows the great advantage of evolutionary computing in searching neural network architectures. We believe that if we set up the algorithm using a larger number of iterations, we may have better evolutionary results.
5.5. Position Movement Analysis of Particles from One Generation to Another
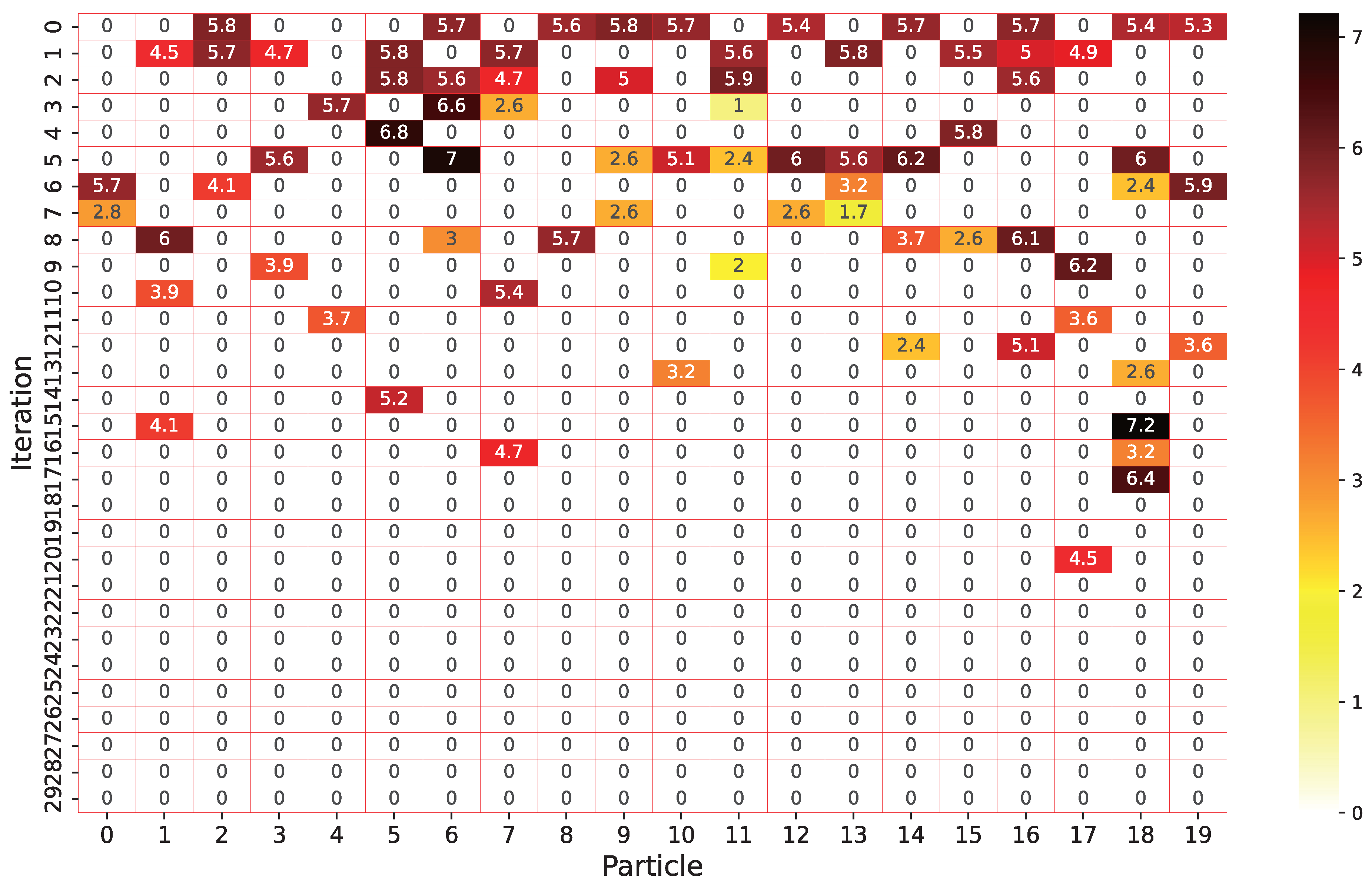
To observe the patterns of the network architecture found by our proposed algorithm, we study the evolution process, how each particle changed in each generation, and compare the distance each particle moved in each generation. The result is shown in
Figure 12. In this part of the experiment, we record the position of each particle after each iteration and calculated the distance of all particles from their positions after the previous iteration. According to the experimental data, in all 30 iterations, the average distance moved by each particle is
, the maximum distance moved is
, and the minimum distance moved is 1. On average, each particle moved
times during all iterations. This shows that the proposed algorithm can effectively explore the entire architecture space.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}