1. Introduction
Restricted Mean Survival Time (
RMST), the average survival time up to a given time point, is hailed as a model-free statistic, which is easy to interpret causally when summarizing survival data [
1].
has observed a resurgence in practical applications as an alternative to classical analysis based on log-rank tests or Proportional Hazard (PH) models when assessing between-group differences in survival analysis [
2,
3]. For clinical trial planning, the power of different analysis methods needs to be considered. There are indications that log-rank or PH tests generally have higher statistical power than
; however, this depends on the setting [
4,
5]. When estimated non-parametrically,
is less efficient than hazard-based methods estimated via semi- or fully parametric models under the proportional hazards assumption [
6].
The heavy reliance on non-parametric or semi-parametric methods in a survival analysis has drawn some criticism [
7,
8]; however, as Meier and collaborators [
9] point out, it is a rather challenging task to identify the correct parametric form for a certain problem. In addition, the censoring affects the efficacy of both parametric and non-parametric
estimators. Gardiner [
10] used Kolmogorov–Smirnov, Andersen-Darling and Cramér-von Mises statistics to assess the goodness-of-fit of parametric distributions against the empirical Kaplan–Meier alternative prior to estimating
. Nemes and collaborators [
11] concluded in a simulation study that, under model miss-specification, the non-parametric
estimator has superior efficacy in terms of the mean squared error (
) compared to parametric alternatives. The authors also concluded that parametric estimators reduce type II error rates (i.e., increased statistical power) if the correct distribution is identified. The percentage of censoring and the choice of restriction time are acknowledged by the authors to directly affect the comparability of parametric and non-parametric estimators.
The
offers an objective way to compare estimators in simulation studies where the true value of a parameter of interest is known. However, the validity of
comparisons is limited in practical situations, as the bias generally is unknown and is difficult to estimate. Building upon the Focused Information Criterion (
) by Claeskens and Hjort [
12], Jullum and Hjort [
13] developed a framework for objective comparison and model selection among parametric and non-parametric models, and this latest development of
is at the core of our study.
does not attempt to assess the overall fit of candidate models to observed data. Instead, candidate models are ranked based on the estimated precision of a parameter of primary interest. This ‘focus’ parameter does not need to be a specified parameter of a distribution, but can be any scalar summary of the data. As
captures the survival patterns in a single scalar measure,
offers a feasible framework for model selection.
In this paper, building upon Claeskens and Hjort [
12] and Jullum and Hjort [
13], we aim to establish the
framework for the model selection for
. We describe the mathematical framework needed for implementation. Thereafter, we look at factors affecting the performance of
, such as censoring type and rate as well as sample size. In addition, as with a real-life application, we illustrate possible gains in efficacy by using the parametric
estimators suggested by
without compromising interpretability. We also provide an indicative discussion of the interplay between the maximum follow-up time and chosen restriction time.
3. Focused Information Criterion for RMST
We now aim to deduce the
for
. We look at properties of the non-parametric estimator
and a parametric alternative denoted by
. As
based on Jullum and Hjort [
13], we note that
Here,
are zero mean normal variables with dimensions 1 and
p. Next, we need to establish estimators for the parameters in Equation (
9). For the variance of the non-parametric
, the empirical analogue of
is a natural choice. Here,
is the influence function of a statistical functional
given by
if this limit exists. Reid [
16] was first to provide
for censored data, and for the restricted mean survival time. Building upon the representation of the cumulative hazard function as a functional of two subsurvival functions
and
by Peterson [
17], Reid [
16] gives
with
and
. This reduces to the well known Greenwood plug-in estimator, which, as Eaton and collaborators [
5] demonstrated based on Monte Carlo simulations, is closest to empirical and asymptotic variances. The Greenwood estimator is given by
The variance of the parametric estimator is defined from a model-agnostic viewpoint. The influence function of
is given by
with
With the delta-method, this gives
For the co-variance
In Equation (
9) we made the claim that
has a limit normal distribution with a mean zero of a certain variance, implicitly assuming that
is asymptotically unbiased.
Generally, non-parametric estimators are unbiased; however, this is not true for the Kaplan–Meier integrals [
14]. Meier [
18] specified that
is “nearly unbiased” at a rate of
.
Gill [
19] provided stronger bounds for the bias
where
is the probability that the at risk set is empty.
Mauro [
20] demonstrated that
. Zhou [
21] was first to provide a lower bound for the bias
Stute [
22] provided and improved version of the lower bound of the bias in the form of
It is evident that if there is no censoring, the terms of the lower bound vanish, and as the bias is strictly negative,
is unbiased. This is expected as in this case
. However, it is also evident that when censoring is present, the Kaplan–Meier integral can have a non-negligible large sample size bias. Maximum bias is observed at
, the least upper bound of support for the distribution function of
T. In real life applications
. Additionally, the bias is more evident when
G has short tails compared to
F. As a result
, or
on the interval
is negligible and we can assume that the bias of
.
The parametric estimator is asymptotically unbiased and based on Equation (
9) for the bias
, we have
where
.
Although,
is an approximately unbiased estimator for
b, typically
overestimates
with
. Jullum and Hjort [
13] noted that it is theoretically possible that
and introduced the following correction
in order to truncate negative estimates (i.e., no bias) to zero.
After we have established the necessary estimators, we can confirm the
scores for the
as
Clinical trials mainly aim to compare two (or more) treatment arms, e.g., to test the difference in restricted means survival times between two groups (denoted 1 and 2, below)
If
is estimated based on non-parametric models, then
while if we use parametric estimators then
Naturally, a mix of distributions or a mix of parametric and non-parametric estimators is possible.
4. Operating Characteristics of FIC for RMST
Jullum and Hjort [
13] (Corollary 1) provided the upper probability limit of
selecting the true parametric model over the non-parametric one (
) as
. Likely,
is influenced by several factors that limit the amount of information available in the data. In the following, we assess how censoring and sample size affect
. In addition, we discuss how the choice of
and the relationship between
and maximum follow-up time (
) might affect
.
The characteristics of the variance estimators for
have direct implications on
. The Greenwood variance estimator (Equation (
12)) is a sum of a sequence of overlapping squared areas from
to
weighed by the square of the coefficient of the variation of
at
. As noted previously,
. When we have Type I censoring, the support set for
and
coincide. If
, then the domain of the non-parametric estimator is
, while for the parametric estimator it is
. The proportion of the total Fisher Information contained in the censored data is just the proportion of observations that are not censored [
23], and given
we have
where
and if
then
. If the parametric model is correct, and follow-up is not restricted to
(i.e., random censoring) with
,
ought to select the true parametric estimator with higher probability.
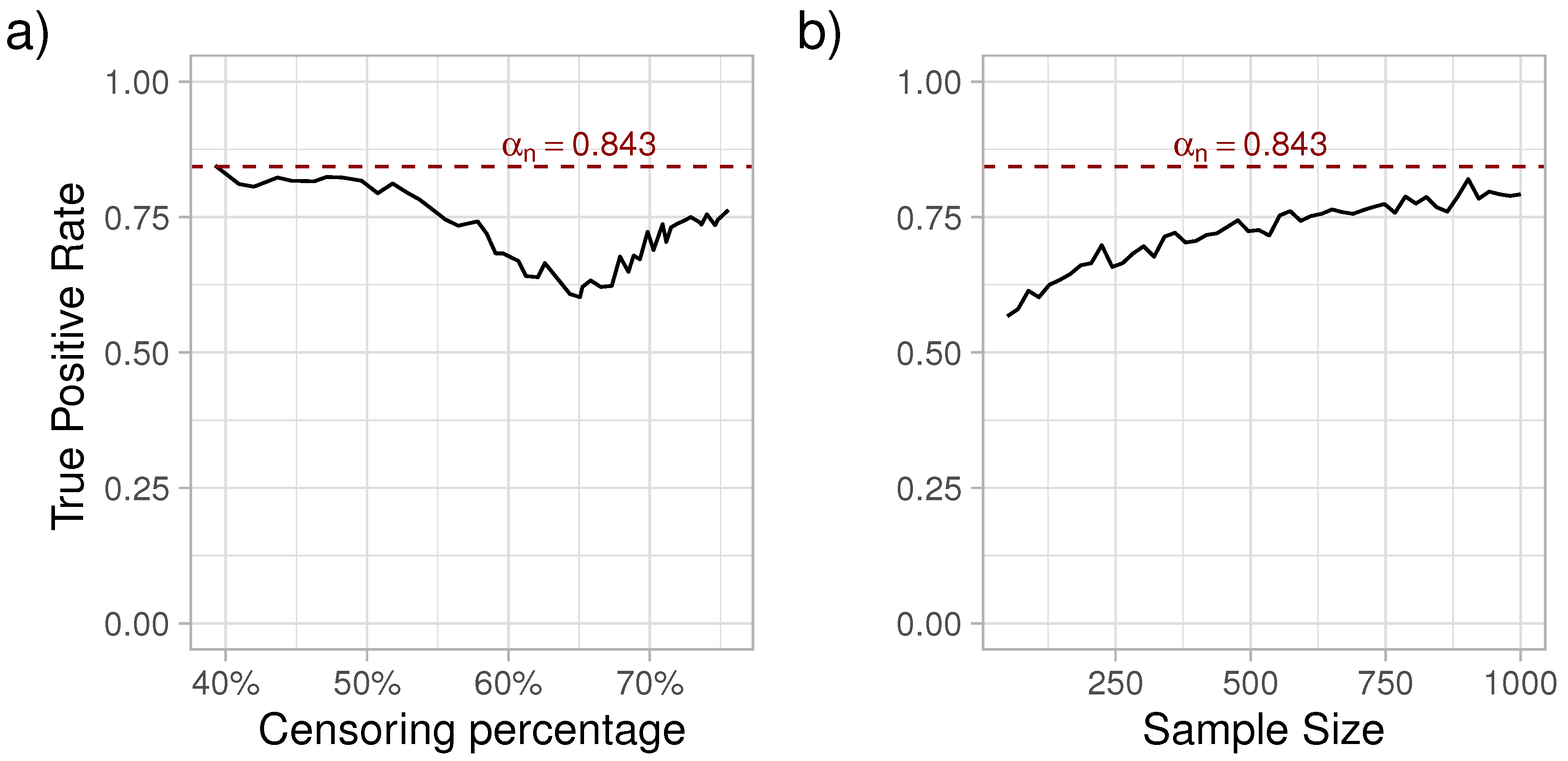
Within a reasonable restriction time, we expect that is directly affected by the percent of censored observations and sample size. Here, we consider a scenario where we assume that the maximum follow-up time is , mirroring a clinical trial with Type I censoring at . The actual observed time for subject j is and , a mix of Type I and random censoring. We assume exponential survival times with and Type I censoring at , and evaluate a series of random exponential censoring times with hazard with increments of 0.029. This resulted in a minimum overall censoring of 36.7%, and a maximum censoring of 75%. For each , we simulated a data set with and estimated for the non-parametric and for the exponential . The simulations were repeated 1000 times. The aim was to assess the true positive rate of choosing between the (true) exponential and the non-parametric alternative.
As it can be observed in
Figure 1, with increasing censoring, the sensitivity of
initially decreased, reaching a minimum at around 60% of censoring, followed by an increase in sensitivity. Next, with the censoring percentage at the point where the sensitivity was the lowest (
), we simulated survival data with varying sample sizes from 50 to 1000 subjects and estimated
. Each sample size was simulated 1000 times. As expected, the true positive rate of choosing the exponential distribution increased with the sample size. For a more detailed look at the patterns recorded in
Figure 1, please see the
Appendix A.
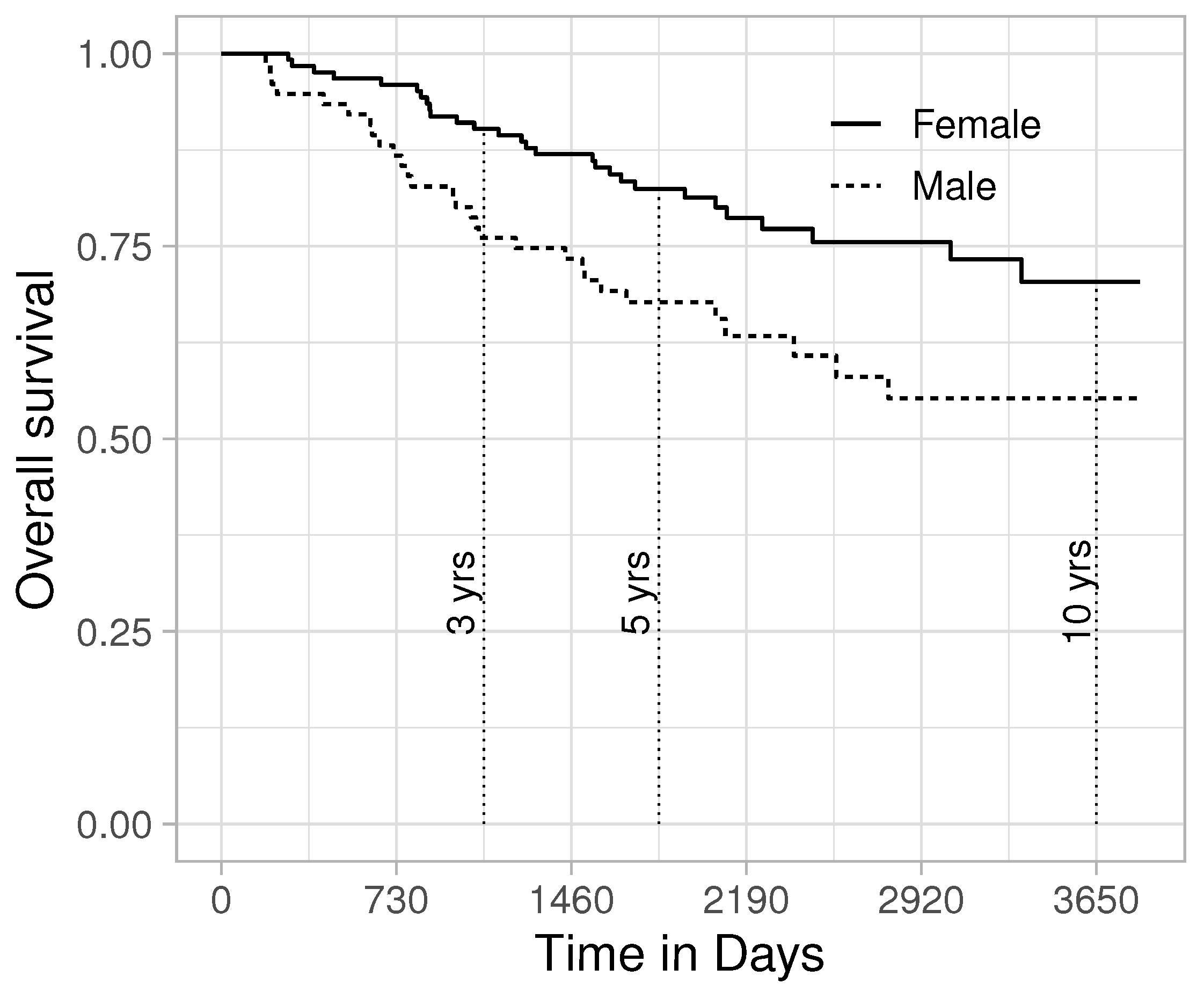
5. Practical Application
The survival rate of melanoma has increased in recent decades, with approximately two-thirds of the patients surviving 5 years or more after diagnosis, with women generally having better survival than men [
24]. Using a data set compiled by Drzewiecki and collaborators [
25], we will assess the possibility to improve the efficiency of an
analysis of sex-specific survival. Data from 126 female and 79 male melanoma patients are included in the analysis (data can be found in the “timereg” R package). As can be observed in
Figure 2, females have better survival prospects than males. Next, we analyse whether the restricted mean survival time at 3, 5 and 10 years differ between the sexes. As competing models, we consider the non-parametric estimator and the Exponential, Weibull, Gamma, Generalized Gamma and Log-logistic distributions. The combination of the Exponential distribution for men and Gamma distribution for women was flagged by
as a better alternative than the purely non-parametric estimators (
Table 1).
On average, women had 65 days longer survival in the initial 3 years. The bias of the parametric estimator was negligible (0.7 days). Additionally, the parametric model reduced the 95 % confidence interval (CI) length with 27.5%, a considerable gain.
On average, women had 165 days longer survival in the initial 5 years. Just as for the 3-year survival, the Exponential-Gamma combination best described the data at 5 years, and reduced the 95% CI length with 18%. However, it should be noted that the bias was 14 days, which is an 8.5% bias. At 10 years, the difference between men and women increased to 15.5 months. Still, parametric estimation increased the efficiency; however, the reduction in CI length was less than 1%, a very minor gain compared to the non-parametric estimator.
6. Discussions
In this paper, we have introduced the
[
12,
13] as a tool for the model selection for
. While
has a well established theory and is applicable in a wide range of areas, using
as a tool for selection of the best
model has some characteristics that need to be considered. First, we need to consider that the non-parametric
estimator is not consistent and is biased. Likely, this will have minor implications in practical applications; nevertheless, researchers should consider this aspect. If the at risk set at the chosen restriction time
is the empty set or contains very few participants, the bias can be non-negligible. Second, the censoring percentage and type of censoring (type II or random, possibly hybrid) affects the efficiency of parametric and non-parametric estimators differently. Third, the variance of the Kaplan–Meier survival curve at any time
t is based on information up to
. The parametric survival curve estimator use information up to
in the case of Type I censoring, or
in the case of random censoring.
Jullum and Hjort [
13] concluded that the upper probability limit of
selecting the true parametric model over the non-parametric one (
) to be
, a probability that was replicated in our simulations. This probability was obtained when the exponential estimator was tested against the non-parametric estimator in a setting when the exponential model was the true one and the censoring was due the restriction at
. We observed that
was dependent on the censoring percentage. In addition, reaching
is sample size dependent.
In clinical trials of chronic diseases,
coincides with the end of the follow-up. In observational studies, often
, thus the information contained in
might offer an extra advantage for the parametric variance estimator. However, the same information in
might bias the parametric survival estimate up to
and induce bias in
. This is more apparent when outliers are present, which usually appear on the right tail of the distribution. This depends on the assumed distribution, as Aranda [
26] highlighted, where, e.g., exponential survival curves are less affected than Weibull survival curves.
As illustrated by the analysis of the melanoma data, selected the best fitted model that minimizes . However, just as Akaike or the Bayesian Information Criterion (AIC and BIC), it offers a ranking of competing models, but not a direct gauge of model fit or quality. At the 10-year restriction time, the parametric estimator was ranked first, but the statistical gains (i.e., lower ) of choosing the parametric estimator was negligible. Only looking at ranks is likely not enough, but one should consider the distance between the competing models on the scale. Just as with AIC and BIC, this requires further research.
One practical difficulty of parametric estimation of the
lies in the selection of parametric distribution(s). A set of competing parametric families can be selected based on subject-specific disease knowledge and by graphical examination of the hazard. The aim should not be to identify the true underlying distribution that generated the data, but to identify families of distributions with similar shapes [
27] and by simultaneously looking at the bias and variance with
to decide how much model miss-specification can be tolerated [
28] in order to increase efficiency.
In conclusion, we advocate the adaptation of the framework for model selection for . Studies with relatively short restriction times (i.e., restriction time shorter than the mean/median survival time) can greatly benefit from moving from a non-parametric estimation to a parametric one. It is relatively easy to identify families of distributions with similar shapes as the observed data for shorter follow-times, which would decrease the bias. In observational studies where , we recommend a first analysis to be conducted so that the support set of both parametric and non-parametric estimators is . This setting will likely result in a smaller bias for the parametric estimator and would aid interpretability. Naturally, as trades off bias against variance, a reduced variance might outweigh the bias of the parametric estimator on . Yet another argument for restricting attention to is that the distribution that selects might convey important medical/biological information.






{kind=link}
{kind=link}
{kind=link}