3.1.2. Different True Levels of Coverage of Intervals
We shall further investigate the properties of the direct and equivalence tests when testing experts’ calibration on eliciting
credible intervals when the true levels of coverage are different than
. This is interesting both from a theoretical point of view, as well as from a practical perspective, as it is often claimed (sometimes with proof offered) that experts are either over- or under-confident. Here, we assess the outcomes of the direct and equivalence tests when testing calibration, when eliciting
credible intervals at smaller true levels of coverage. This corresponds to the situation when experts’ assessments are overconfident.
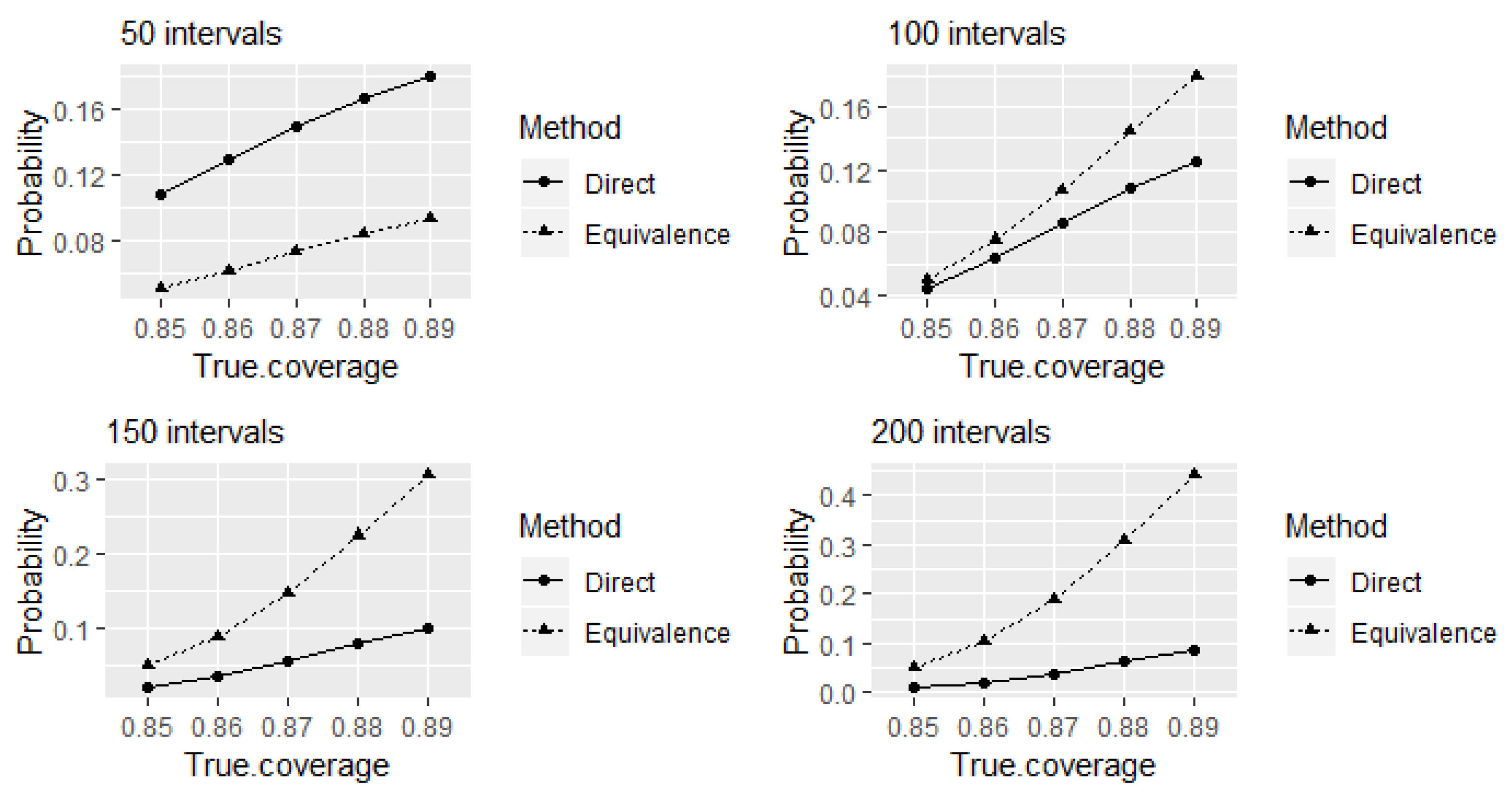
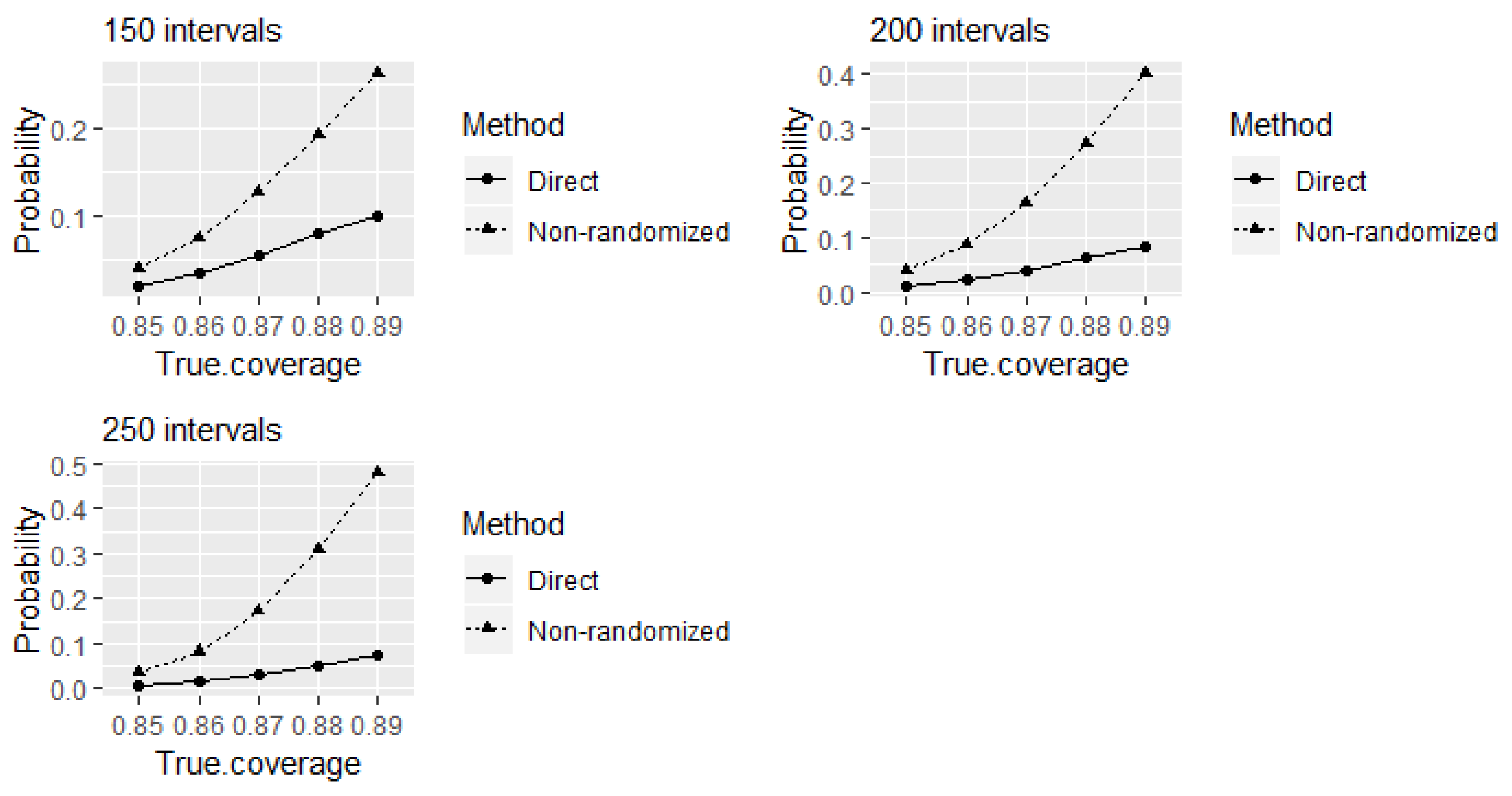
Figure 2 shows the probabilities of identifying the experts as
well-calibrated when the true levels of coverage are between
and
. The comparison between the tests is presented for different choices for the number of elicited intervals. Even though larger variations from true coverage may occur in practice, here we only investigate a 0.05 deviation from true coverage probabilities. The reason behind this choice is the intention to expose a potential problem of the equivalence test to produce higher probabilities of incorrectly identifying experts as well-calibrated compared to the direct test.
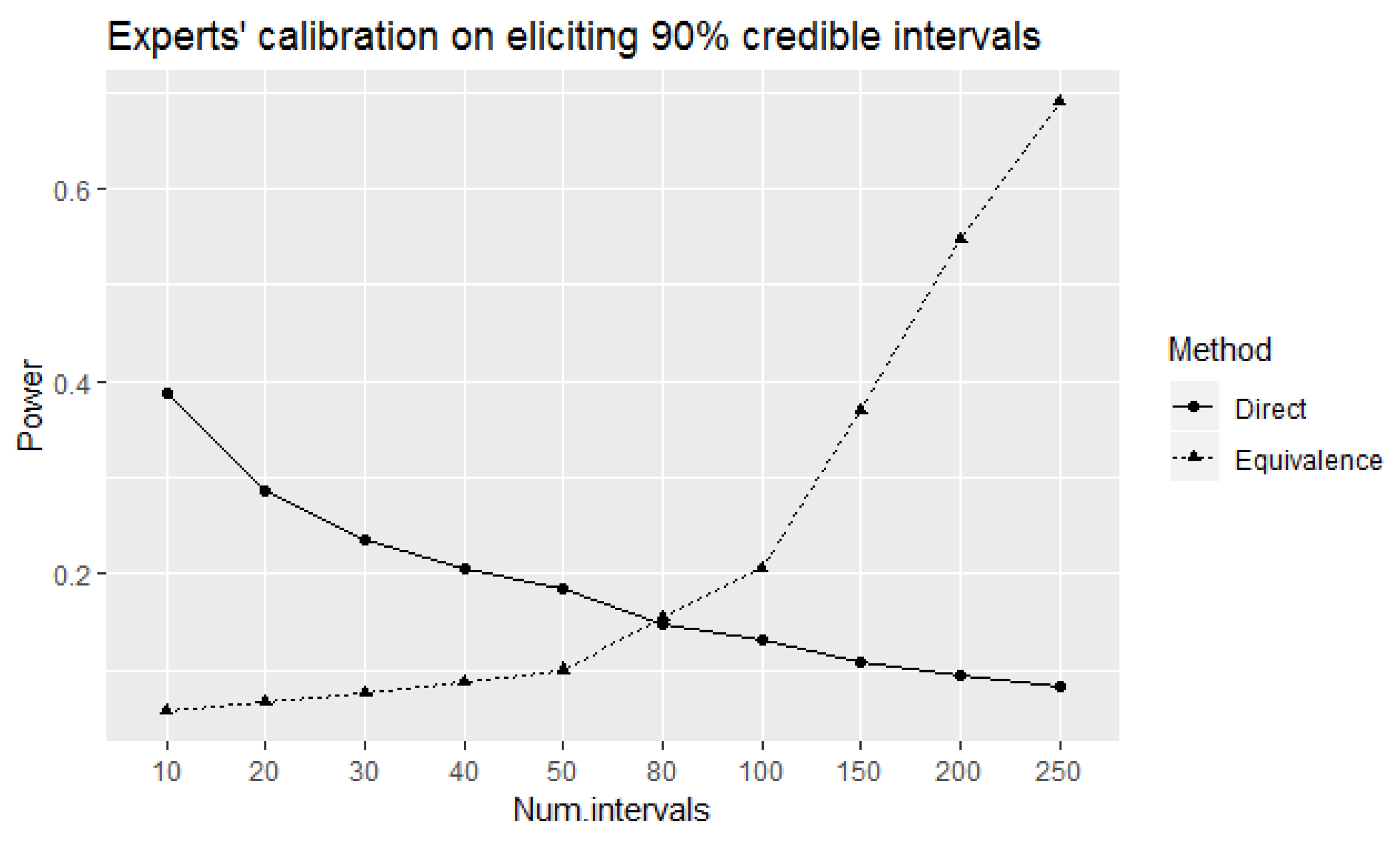
As discussed above, comparatively higher values of power to correctly identify
well-calibrated experts at
true level of coverage of elicited intervals can be obtained using the equivalence test compared to the direct test for 80 or more intervals. A trade-off seems to be that this is achieved at the expense of receiving comparatively higher probabilities of incorrectly identifying the experts as
well-calibrated at true levels of coverage remain between 85% and 89% from the test (see
Figure 2). Furthermore, these probabilities increase with the increase of number of elicited intervals. The alternative hypothesis of the equivalence test
to declare equivalence (that is, to declare an expert as well-calibrated) at
coverage probability with the acceptable margin of deviation
around the reference value
contains values between
to
(refer the
Section 2.2 for details). Therefore, from the equivalence test point of view, the probabilities of identifying experts as
well-calibrated at different true levels of coverage of elicited intervals within this range can be considered as the values of power (the probabilities of rejecting the null hypotheses when they are false) of the test at corresponding values in the rejection region of the test. Therefore, receiving comparatively higher probabilities of incorrectly identifying the experts as
well-calibrated at true levels of coverage remain between 85% and 89% here happens due to a characteristic of the equivalence test.
Let us now focus on the type I error probabilities (the probabilities of incorrectly accepting the alternative hypothesis when one of the null hypotheses is true) of the equivalence test given in
Figure 2. Observe that type I error probabilities of incorrectly identifying the experts as
well calibrated are approximately equal to the size of the test 0.05 at
true level of coverage of intervals which is on the border of the rejection region of the test. Direct comparison of observed hit rates of experts’ elicited intervals with the intended coverage probability of credible intervals without considering the random variation of hit rates cannot be considered as testing experts’ calibration statistically.
However, we can implement the direct test as a special form of the equivalence test. By this we mean that in each case, the rejection region is bounded above and below, and we reject the null hypothesis if the observed value is within that region. In the case of the direct test, the region is a single value of in this instance.
If we consider the direct test as a special case of the equivalence test, then the probabilities given in
Figure 2 of the direct test can be considered as type I error probabilities of incorrectly identifying the experts as
well-calibrated at the corresponding true levels of coverage of elicited intervals. Observe that the direct test has higher type I error probabilities of incorrectly identifying the experts as 90% well calibrated than the equivalence test for the considered true levels of coverage that are less than 90% at 50 intervals, even though the corresponding value of power to correctly identify well-calibrated experts was higher than the equivalence test as shown in
Figure 1. It can also be observed that these type I error probabilities tend to decrease with an increase in the number of elicited intervals. However, this property of decreasing probabilities over the increase of number of elicited intervals is applicable to the probabilities of correctly identifying 90% well-calibrated experts at the 90% true level of coverage of elicited intervals as well. We can overcome this problem using the equivalence test if we can accept observing higher probabilities of incorrectly identifying the experts as 90% well-calibrated at true levels of coverage of elicited intervals are only within 0.05 deviation as observed above.
Even though the above problem can be overcome using the equivalence instead of the direct test, the equivalence test has the disadvantage of needing many more elicited intervals to obtain reasonably higher values of power to correctly identify well-calibrated experts. However, the application of the direct test implies that a reduced the number of elicited intervals is better (since this is how we obtain higher values of power to correctly identify well-calibrated experts). Rigorous statistical analysis advice should not encourage a reduced number of observations to obtain better performance of the statistical test, unless the additional observations do not add any valid information. This is however not the case, and hence, the results of direct test should be used cautiously.
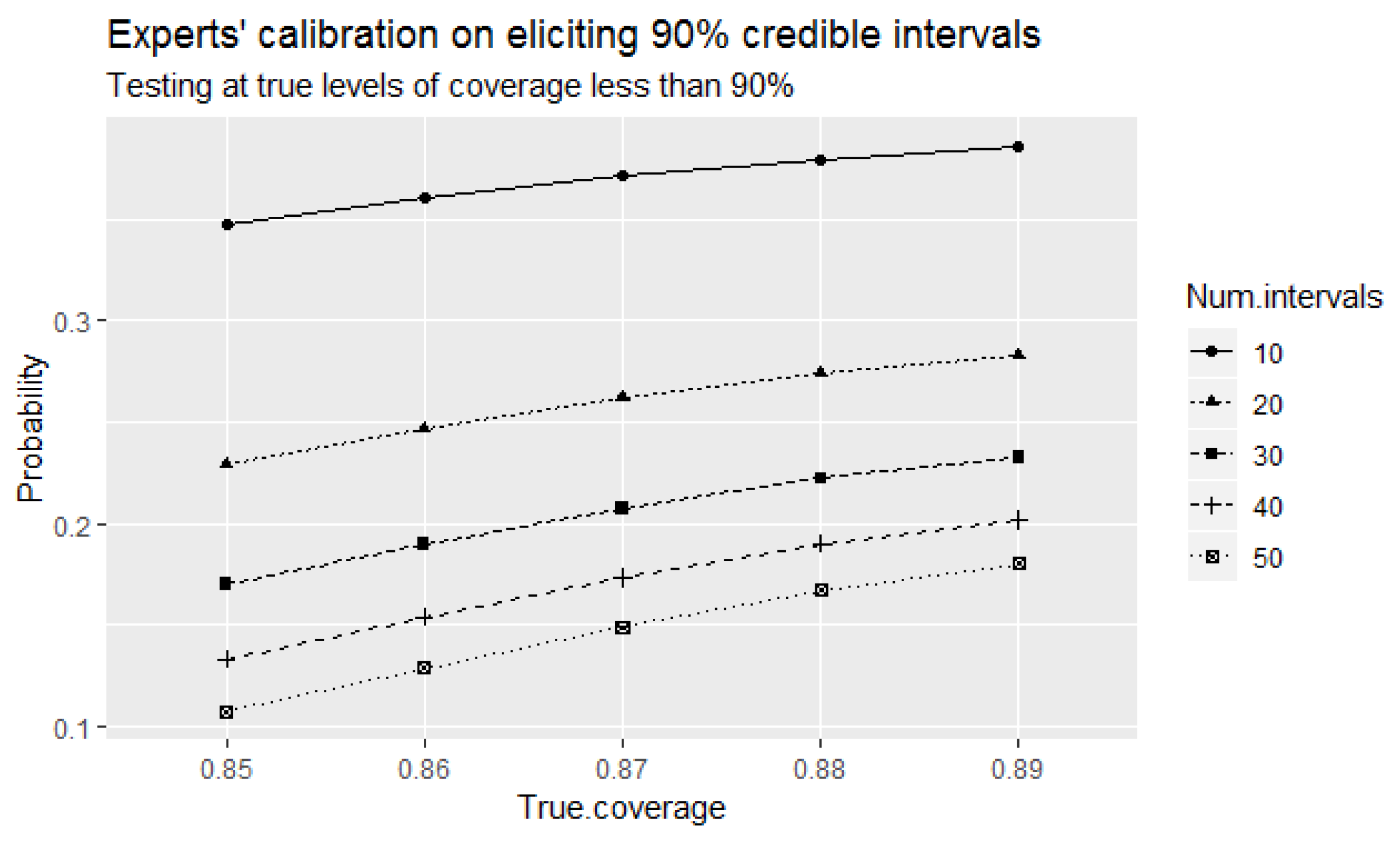
Let us further review the outcomes of the direct test when a small number of intervals is elicited.
Figure 3 indicates another problem of the direct test, and that is an increase in the type I error probabilities of incorrectly identifying the experts as
well-calibrated at the considered true levels of coverage of elicited intervals that are less than
with decreased number of elicited intervals. Observe that these probabilities are higher than the corresponding type I error probabilities at large number of elicited intervals shown in
Figure 2 above.
Considering the direct test as a special form of the equivalence test enables the computation of the size of the test. Because the alternative hypothesis is defined using a single value, in this instance, the power and the size of the direct test are equivalent. The only value in the rejection region is . Therefore, power can only be computed at as Pr (reject |). The alternative hypothesis with a single value of determines the two null hypotheses to be: or . The maximum type I error (or the size of the test) occurs at the border values of the null hypotheses. Here, the border value is . Thus, the size of the test equals Pr (reject |). We consider the fact that the size is equal to the power (in the strict sense) as another reason to be suspicious of the direct test.
However, the equivalence test becomes a better option when a large (larger than 50) number of intervals is elicited. From a practical point of view, this equates with asking at least 50 calibration questions on top of the target questions in an expert elicitation. This is an incredible elicitation burden for the experts and, to our knowledge, it is rarely (if ever) undertaken. It is much more realistic for elicitations to contain between 10 and 30 calibration questions.
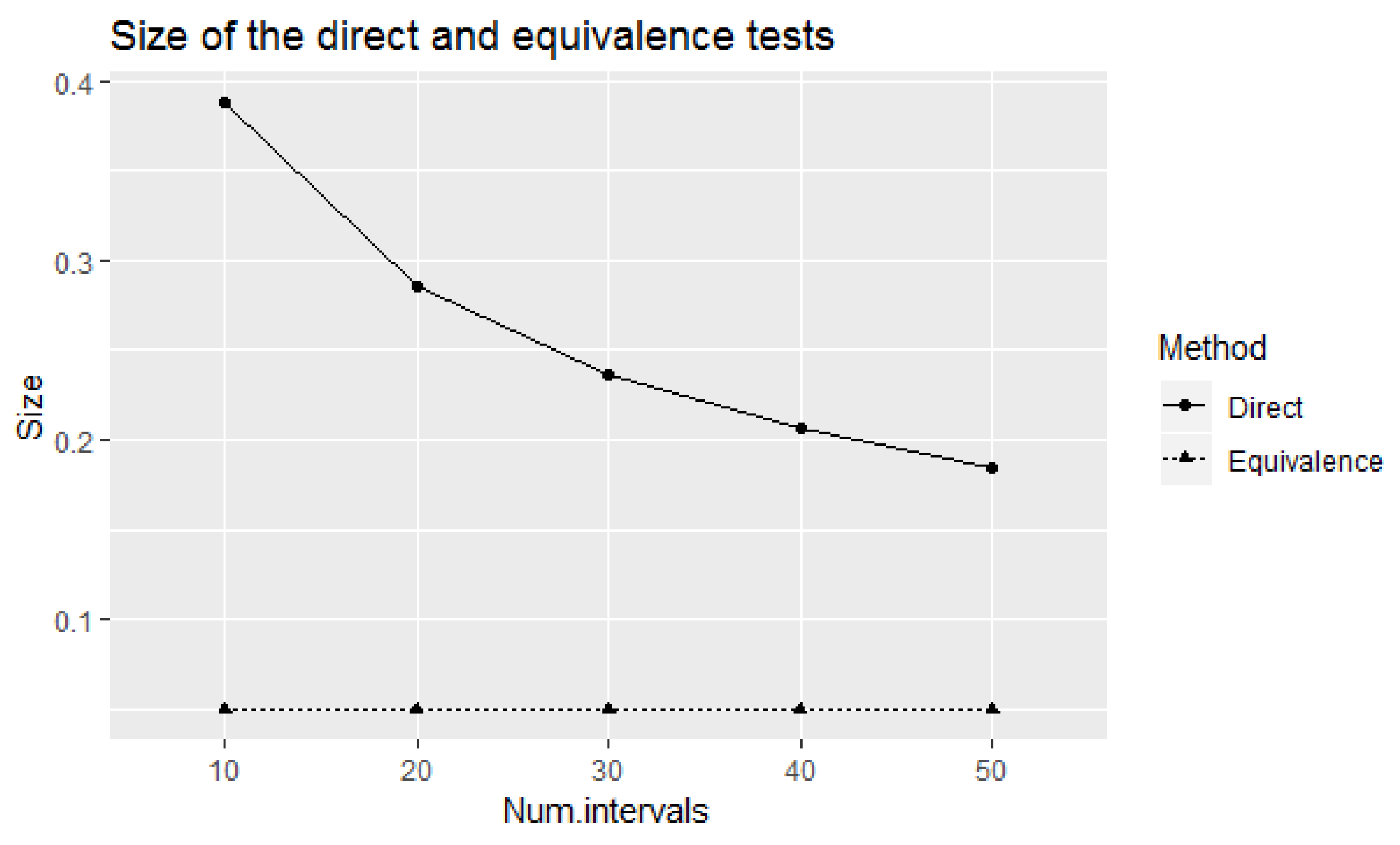
Figure 4 compares the size of the direct and equivalence tests at small number of elicited intervals. Observe that the size of the direct test decreases with the increase of number of elicited intervals. Therefore, if we apply the direct test to test experts’ calibration with small number of elicited intervals, the power of the test to correctly identify well-calibrated experts will not be sufficiently large. However, the size of the test which is equal to the value of the power should be considered as large from a statistical point of view. The equivalence test has lower values of power for the considered small number of elicited intervals with the fixed size of 0.05. If we increase the number of elicited intervals, the power of the equivalence test will be increased accordingly with the fixed size of 0.05. Therefore, the trade-off between the number of elicited intervals, power, and the size of the test is an important consideration in this context.
Similar patterns of results to the ones above were observed when testing experts’ calibration on eliciting credible intervals of quantities. More importantly, the observed values of power to correctly identify well-calibrated experts on eliciting credible intervals were lower than the corresponding values on eliciting credible intervals for the considered range of number of elicited intervals for both the direct and the equivalence tests. This is an acceptable result in general as the binomial probability of obtaining proportion of success under success probability is higher than that of obtaining proportion of success under success probability for a given number of trials.
According to this property of the binomial distribution, it can also be shown that the power of the tests to correctly identify well-calibrated experts will further reduce if we reduce the intended coverage probabilities of elicited intervals more. Hence, the power of both the direct and the equivalence tests depends on the intended coverage probability of elicited intervals. This is an interesting and intriguing result.
3.1.3. Improving on the Equivalence Test?
When discussing the implementation of the equivalence test using the number of intervals containing true values, we mentioned that the test is inconclusive for the boundaries of the rejection region. In these circumstances, randomization is required, and this randomization may be considered as another drawback. We therefore further analyze the situation when the non-randomized equivalence test with the rejection region of
is used.
Table 2 shows that the rejection regions for testing experts’ calibration on eliciting 90% credible intervals do not contain values greater than
and less than
for the number of elicited intervals less than or equal 80. Therefore, the non-randomized equivalence test with the rejection region of
can only be applied for 100 or more intervals.
According to
Figure 1, the equivalence test can only be considered more effective than the direct test for 100 or more intervals since the values of tests’ power are not considerably different at 80 intervals. Therefore, it seems meaningful to apply and observe the implications of the non-randomized equivalence test for 100 or more intervals.
Figure 5 plots the power of the direct and non-randomized equivalence tests. The tests have almost equal power at 100 intervals, with increasing power of the non-randomized equivalence test for more elicited intervals. However, its power is less than corresponding power of the equivalence test, due to the reduction of rejection regions.
Figure 6 indicates the probabilities of the direct and non-randomized equivalence tests to identify the experts as 90% well-calibrated when true levels of coverage of elicited intervals that are less than 90% for large number of elicited intervals. The type I error probabilities of incorrectly identifying the experts as 90% well-calibrated at 85% true level of coverage of elicited intervals of the non-randomized test are less than 0.05 for the considered number of elicited intervals. It implies that the significance level of the non-randomized test is less than the nominal value 0.05. Therefore, the test is conservative with reduced power of rejecting the null hypotheses when they are false.
From this perspective, the non-randomized equivalence test offers another (better) alternative to the direct test, when a very large number of intervals are elicited. This is a very appealing theoretical (rather than practical) alternative.
3.1.4. Test Properties Established through the Simulation Study
The focus of this analysis was to assess the properties of several statistical tests that can be used to identify well calibrated experts.
The results of the above analyses show that the direct test (i.e., the direct comparison of experts’ hit rates) has substantial methodological problems. The test has low power to correctly identify well-calibrated experts and more importantly, the power decreases as the number of elicited intervals increases. This is a contradictory result from a statistical point of view.
The equivalence test of a single binomial proportion can be used instead to overcome these problems. However, power curves of the equivalence test show that many more elicited intervals are needed in this case, which is a practical impediment. Furthermore, the exact application of the binomial test for equivalence usually requires a randomized outcome if the observed coverage is on the border of the rejection region, an aspect of testing that may be distasteful to many analysts.
To summarize, testing whether experts are well calibrated or not proves to be a very challenging problem when balancing practicalities against statistical rigour. The direct test can be generalized to an equivalence test, which allows a formal test of the null hypothesis that the expert is not well calibrated. However, this requires a prohibitive number of calibration questions.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}