
Robust Trajectory Tracking Control for Continuous-Time Nonlinear Systems with State Constraints and Uncertain Disturbances


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- For robust tracking control problems, the CBF is applied to the tracking control system with uncertain disturbances so that the system can still have good tracking performance in the case of state constraints;
- Combining the traditional adaptive control method with the CBF, the CBF is directly extended to the original system, and the CBF is used as a penalty function to punish unsafe behavior;
- A new guaranteed cost robust adaptive tracking method with state constraints and uncertain disturbances is proposed to solve the safety HJB equation through the critic NN learning framework, and the critic NN parameters are guaranteed to be uniformly ultimately bounded (UUB) under the influence of state constraints and uncertain disturbances.
2. Preliminaries
2.1. Problem Statement
2.2. Control Barrier Function
3. Guaranteed Cost Robust Tracking Design with State Constraints and Uncertain Disturbances
3.1. Modified Robust Adaptive Tracking Control
3.2. State Constraints Analysis
4. Design of Guaranteed Cost Adaptive Critic NN Learning Framework
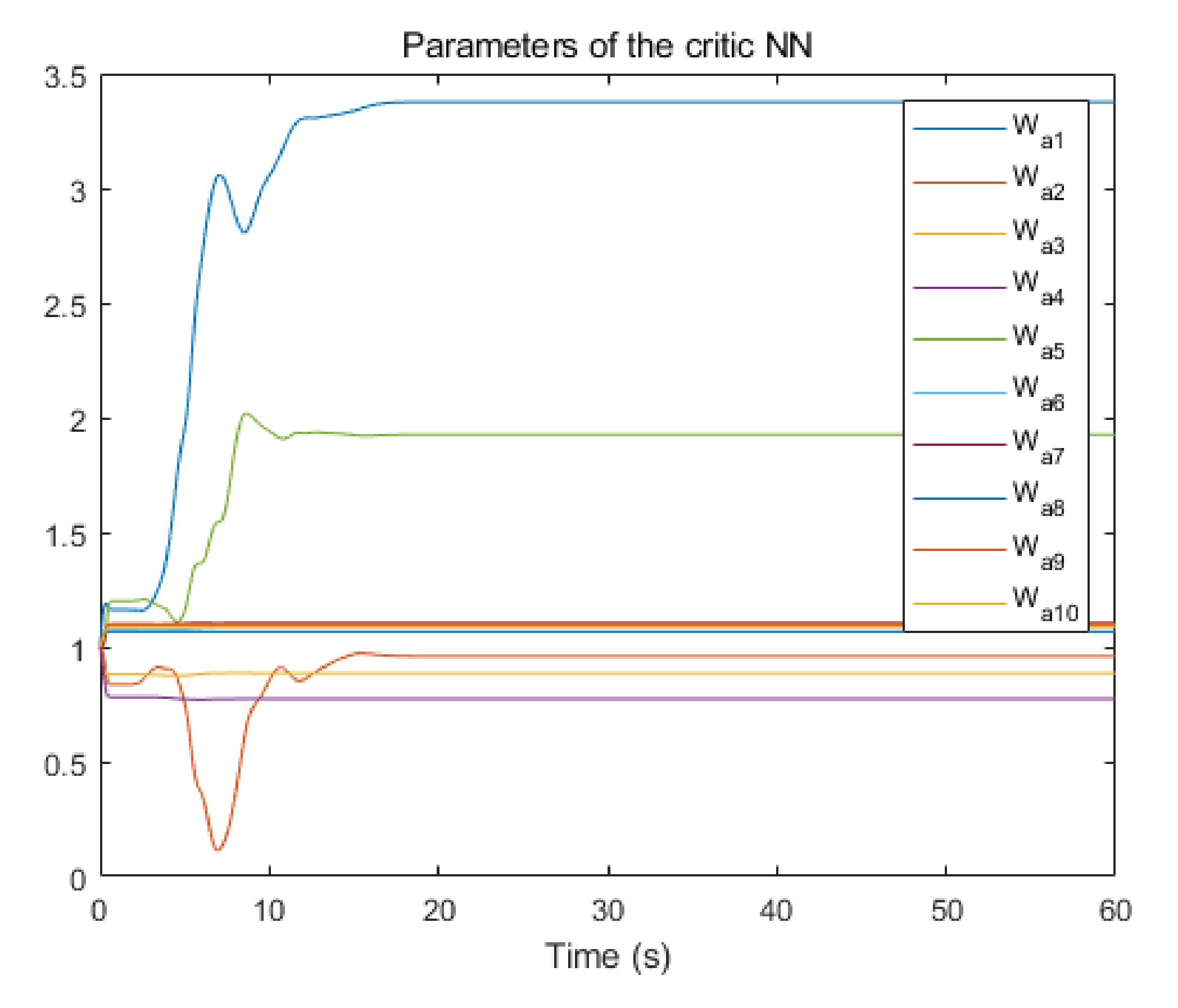
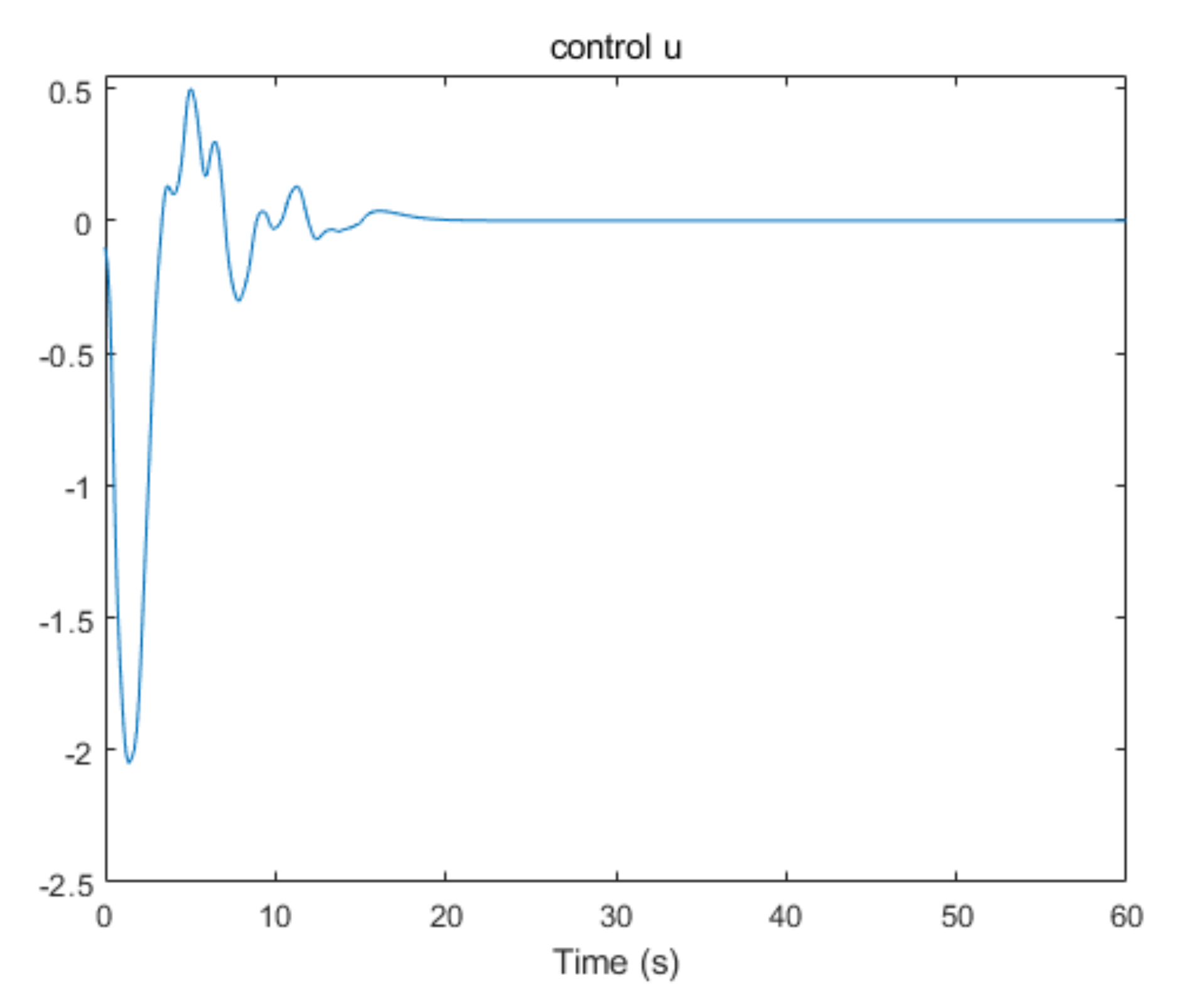
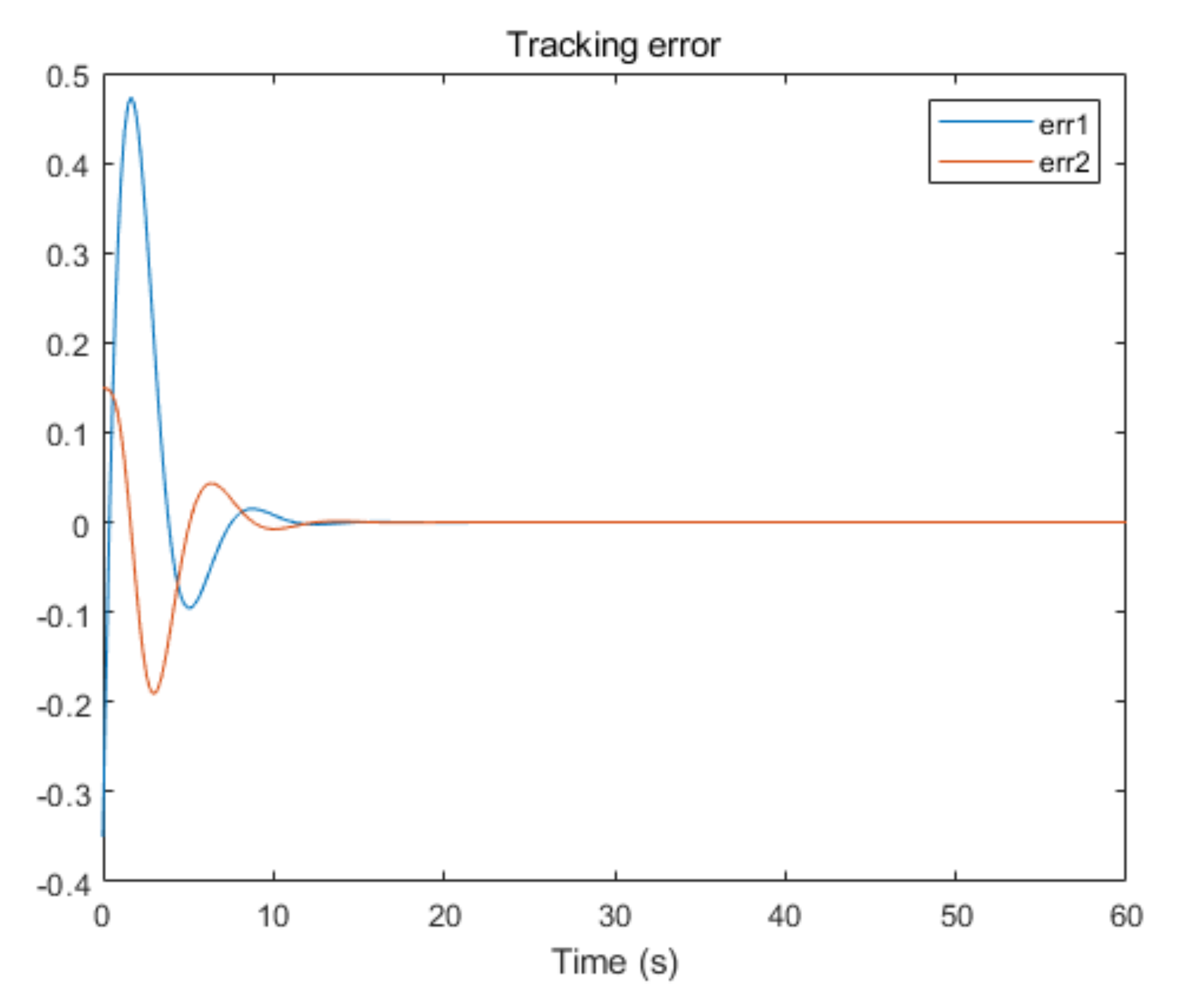
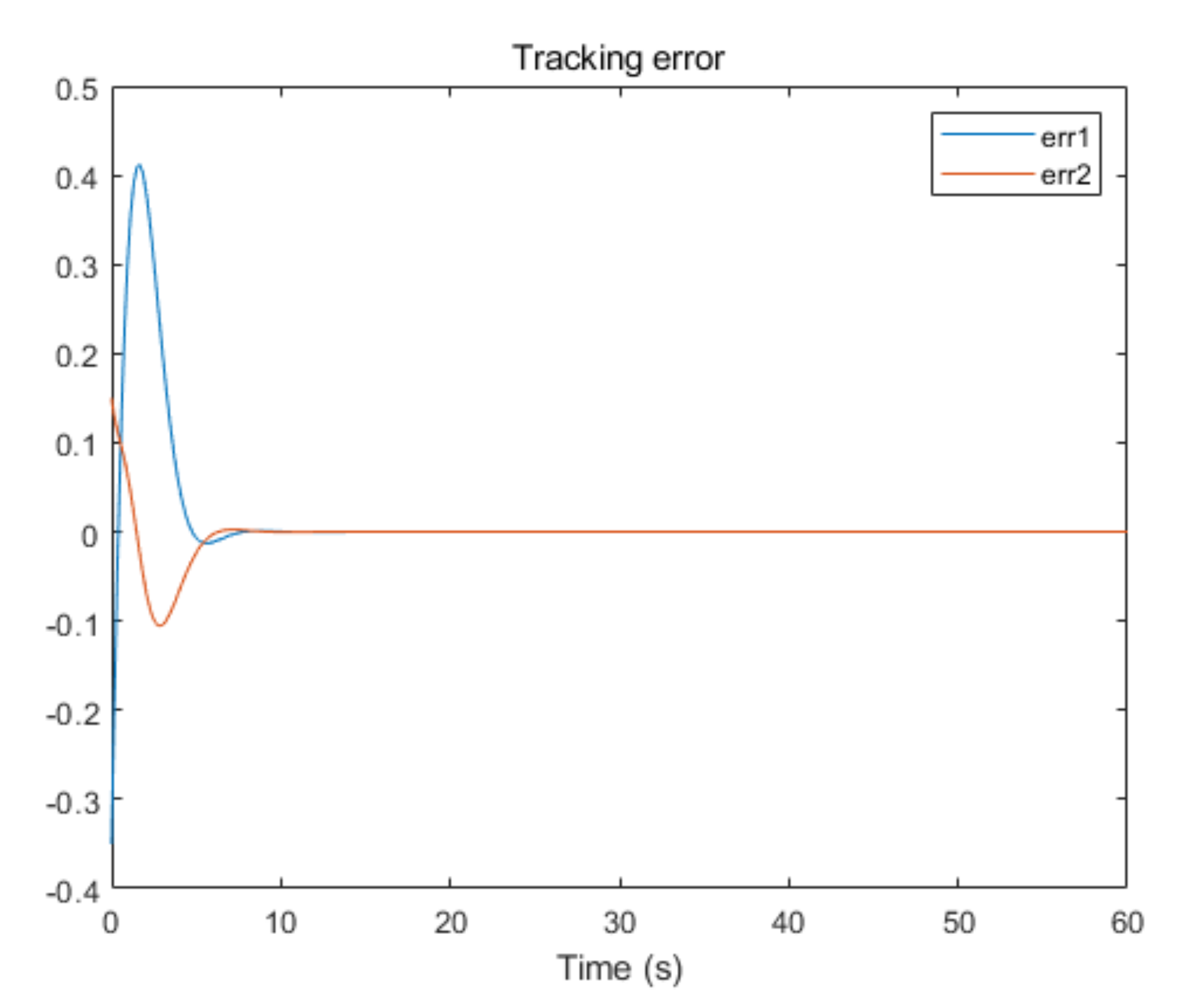
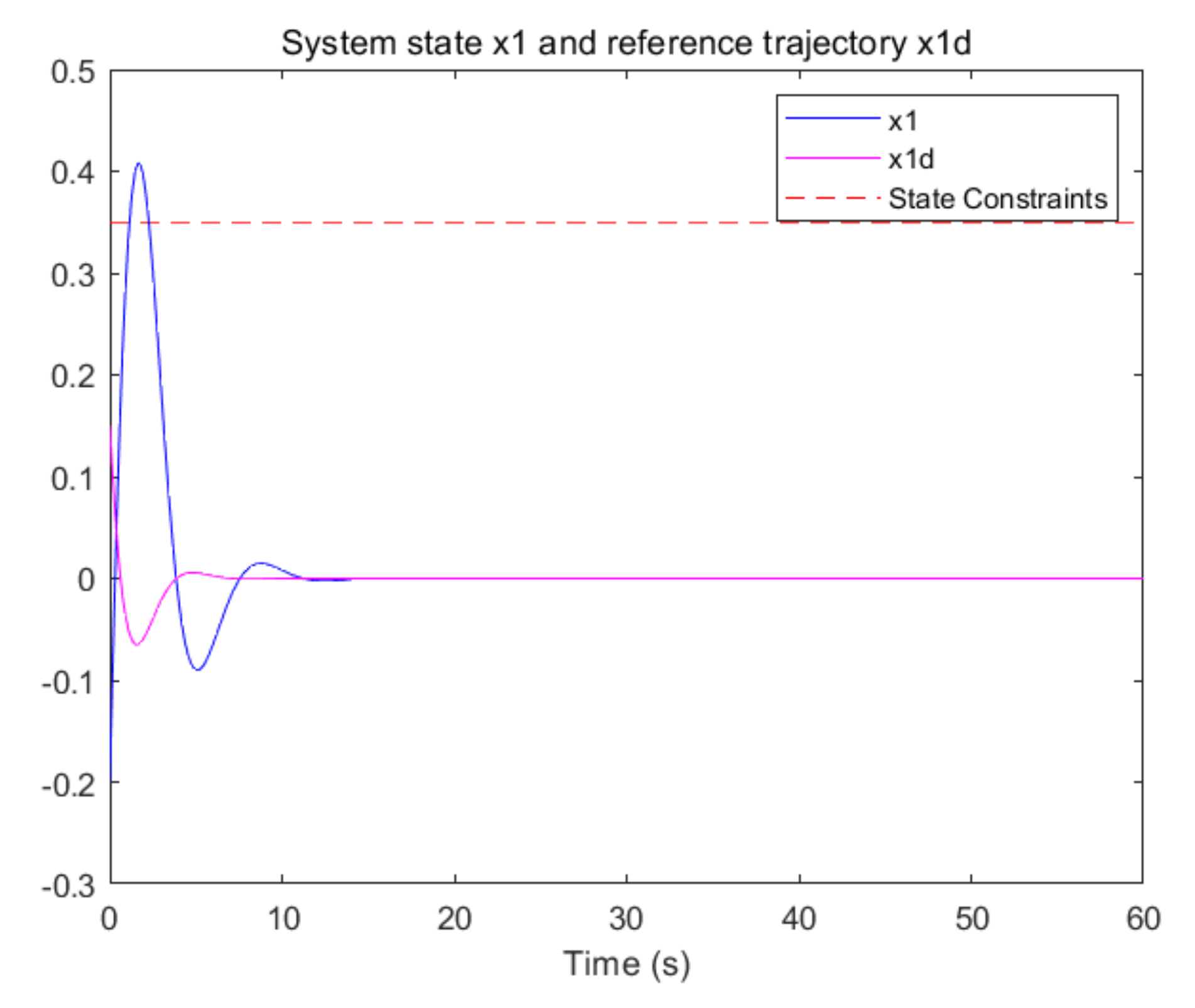
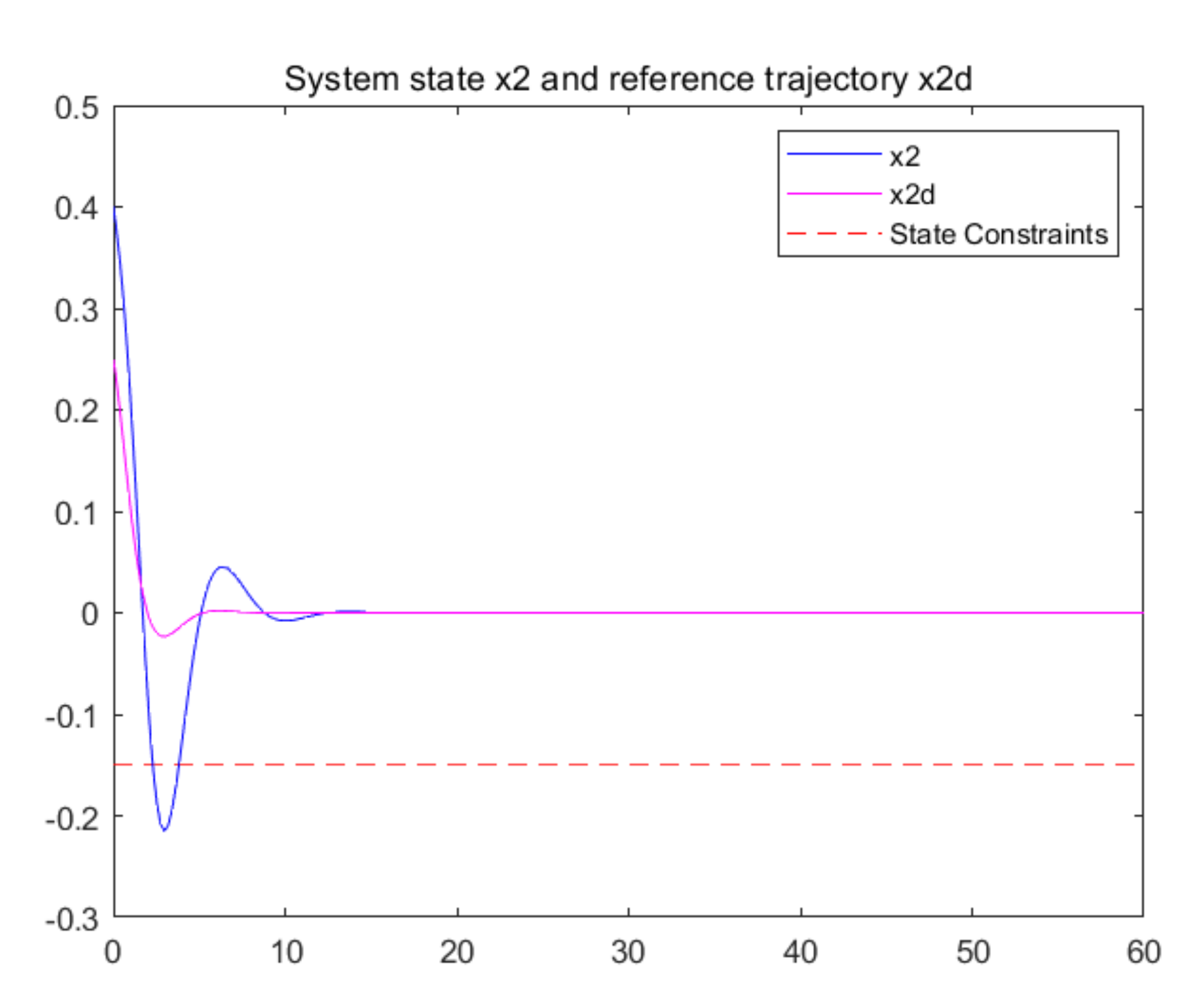
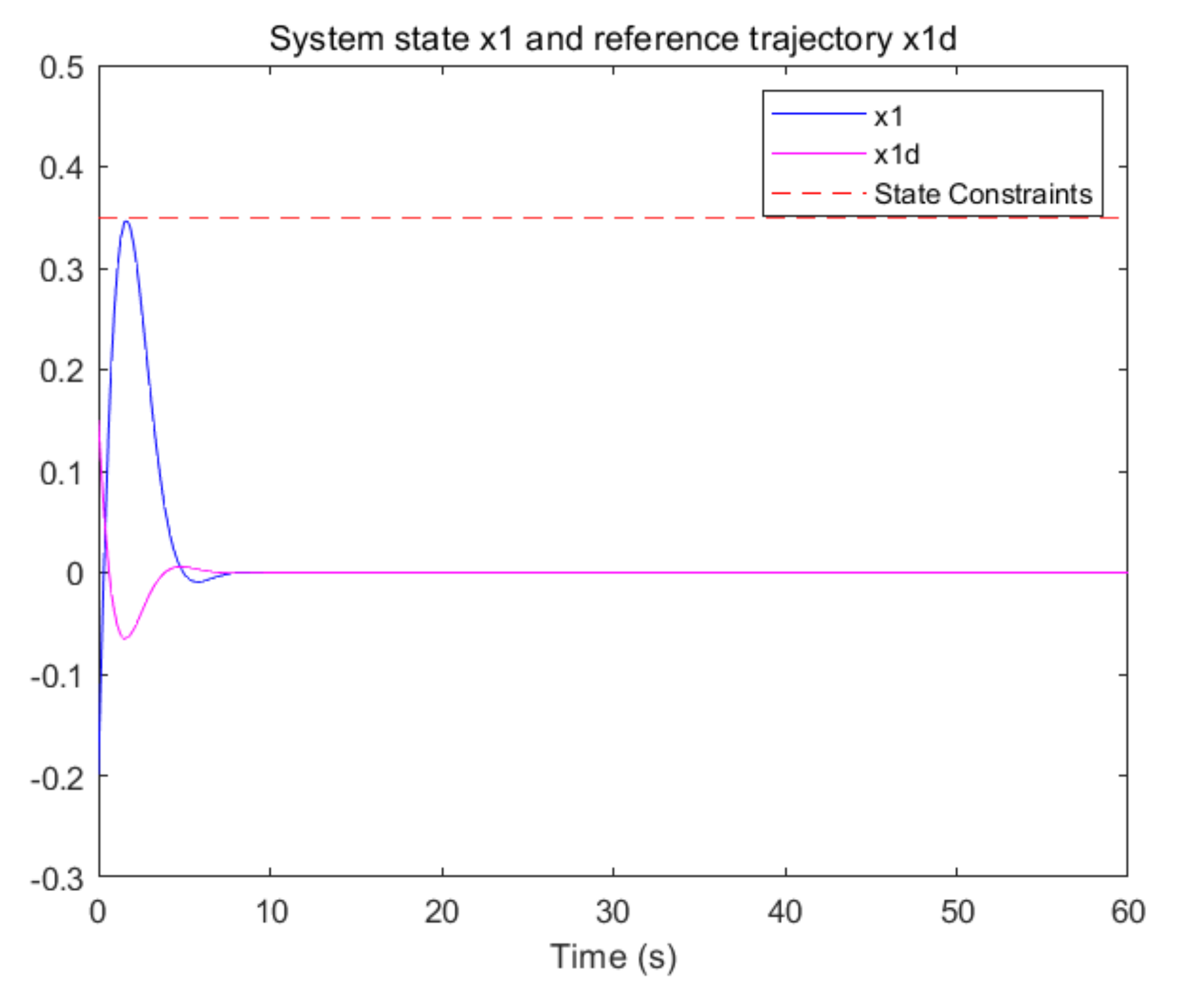
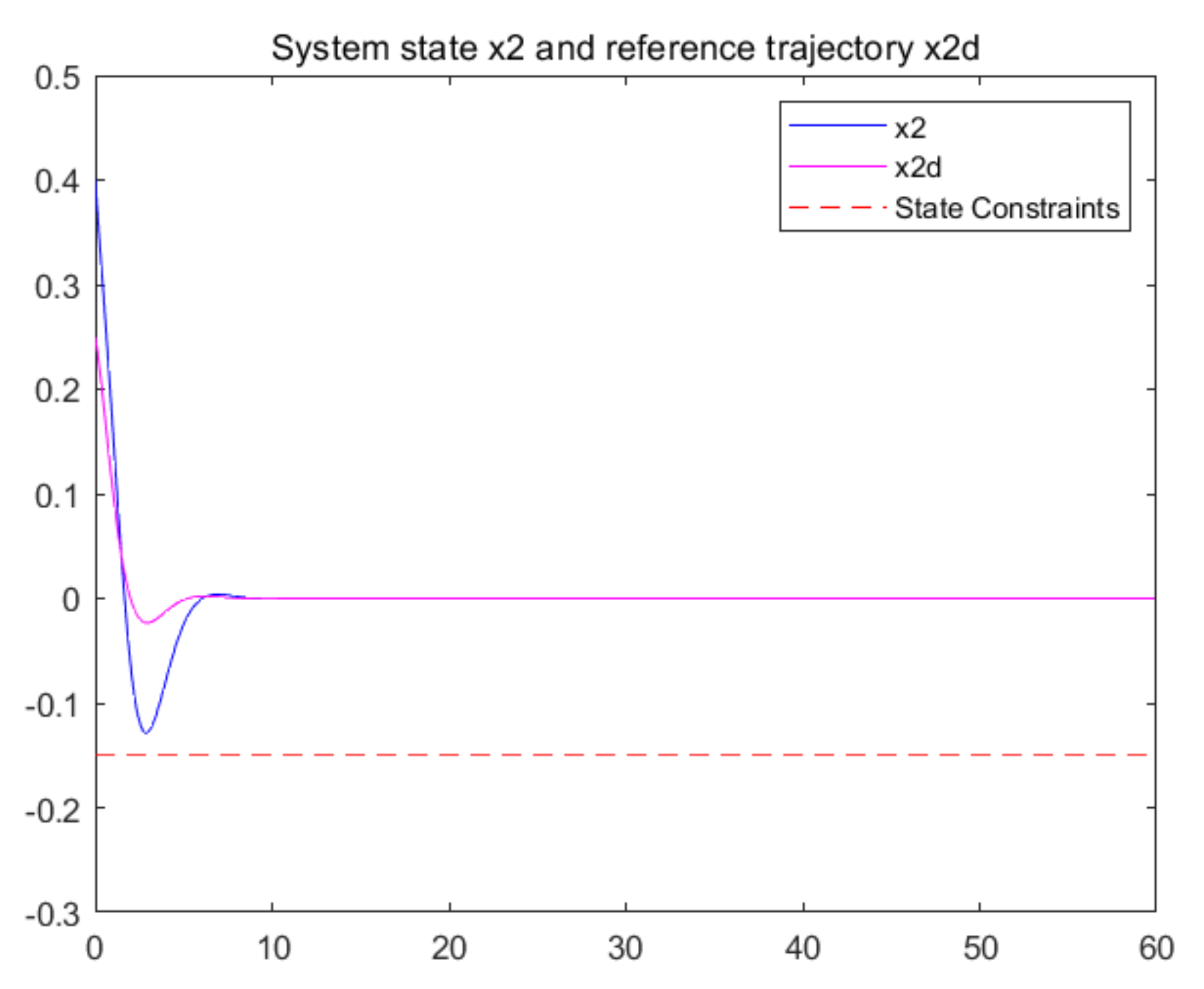
5. Simulation
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xie, R.; Tian, X.; Zhang, Q.; Pan, X. Research on longitudinal control algorithm for intelligent automatic driving. In Proceedings of the 2021 IEEE 4th International Conference on Automation, Electronics and Electrical Engineering (AUTEEE), Shenyang, China, 19–21 November 2021; pp. 664–667. [Google Scholar]
- Chen, Y.; Peng, H.; Grizzle, J. Obstacle Avoidance for Low-Speed Autonomous Vehicles with Barrier Function. IEEE Trans. Control Syst. Technol. 2018, 26, 194–206. [Google Scholar] [CrossRef]
- Molnar, T.G.; Cosner, R.K.; Singletary, A.W.; Ubellacker, W.; Ames, A.D. Model-Free Safety-Critical Control for Robotic Systems. IEEE Robot. Autom. Lett. 2022, 7, 944–951. [Google Scholar] [CrossRef]
- Ferraguti, F.; Landi, C.T.; Costi, S.; Bonfe, M.; Fantuzzi, C. Safety barrier functions and multi-camera tracking for human–robot shared environment. Robot. Auton. Syst. 2020, 124, 103388. [Google Scholar] [CrossRef]
- Liu, D.; Xue, S.; Zhao, B.; Luo, B.; Wei, Q. Adaptive Dynamic Programming for Control: A Survey and Recent Advances. IEEE Trans. Syst. Man Cybern. Syst. 2021, 51, 142–160. [Google Scholar] [CrossRef]
- Zhang, H.; Zhang, X.; Luo, Y. An overview of research on adaptive dynamic programming. Acta Autom. Sin. 2013, 39, 303–311. [Google Scholar] [CrossRef]
- Wang, F.Y.; Zhang, H.; Liu, D. Adaptive dynamic programming: An introduction. IEEE Comput. Intell. Mag. 2009, 4, 39–47. [Google Scholar] [CrossRef]
- Vamvoudakis, K.G.; Lewis, F.L. Online actor-critic algorithm to solve the continuous-time infinite horizon optimal control problem. Automatica 2010, 46, 878–888. [Google Scholar] [CrossRef]
- Mehraeen, S.; Dierks, T.; Jagannathan, S.; Crow, M.L. Zero-Sum Two-Player Game Theoretic Formulation of Affine Nonlinear Discrete-Time Systems Using Neural Networks. IEEE Trans. Cybern. 2013, 43, 1641–1655. [Google Scholar] [CrossRef]
- Munos, R.; Baird, L.; Moore, A. Gradient descent approaches to neural-net-based solutions of the Hamilton Jacobi Bellman equation. In Proceedings of the International Joint Conference on Neural Networks, Washington, DC, USA, 10–16 July 1999; pp. 2152–2157. [Google Scholar]
- Wei, Q.; Liu, D.; Lin, H. Value iteration adaptive dynamic programming for optimal control of discrete-time nonlinear systems. IEEE Trans. Cybern. 2016, 46, 840–853. [Google Scholar] [CrossRef]
- Wei, Q.; Liao, Z.; Yang, Z.; Li, B.; Liu, D. Continuous-time time-varying policy iteration. IEEE Trans. Cybern. 2020, 50, 4958–4971. [Google Scholar] [CrossRef]
- Kiumarsi, B.; Lewis, F.L.; Modares, H.; Karimpour, A.; Naghibi, S. Reinforcement Q-learning for optimal tracking control of linear discrete-time systems with unknown dynamics. Automatica 2014, 50, 1167–1175. [Google Scholar] [CrossRef]
- Wei, Q.; Song, R.; Yan, P. Data-Driven Zero-Sum Neuro-Optimal Control for a Class of Continuous-Time Unknown Nonlinear Systems With Disturbance Using ADP. IEEE Trans. Neural Netw. Learn. Syst. 2016, 27, 444–458. [Google Scholar] [CrossRef] [PubMed]
- Modares, H.; Lewis, F.L. Linear Quadratic Tracking Control of Partially-Unknown Continuous-Time Systems Using Reinforcement Learning. IEEE Trans. Autom. Control 2014, 59, 3051–3056. [Google Scholar] [CrossRef]
- Qin, C.; Zhang, H.; Luo, Y. Online optimal tracking control of continuous-time linear systems with unknown dynamics by using adaptive dynamic programming. Int. J. Control 2014, 87, 1000–1009. [Google Scholar] [CrossRef]
- Cui, L.; Xie, X.; Wang, X.; Luo, Y.; Liu, J. Event-triggered single-network ADP method for constrained optimal tracking control of continuous-time non-linear systems. Appl. Math. Comput. 2019, 352, 220–234. [Google Scholar] [CrossRef]
- Wang, D.; Liu, D.; Zhang, Y.; Li, H. Neural network robust tracking control with adaptive critic framework for uncertain nonlinear systems. Neural Netw. 2018, 97, 11–18. [Google Scholar] [CrossRef] [PubMed]
- Zhao, J.; Na, J.; Gao, G. Robust tracking control of uncertain nonlinear systems with adaptive dynamic programming. Neurocomputing 2022, 471, 21–30. [Google Scholar] [CrossRef]
- Wang, D.; Liu, D.; Li, H.; Ma, H. Adaptive dynamic programming for infinite horizon optimal robust guaranteed cost control of a class of uncertain nonlinear systems. In Proceedings of the American Control Conference, Chicago, IL, USA, 1–3 July 2015; pp. 2900–2905. [Google Scholar]
- Modares, H.; Lewis, F.L.; Jiang, Z. H∞ Tracking Control of Completely Unknown Continuous-Time Systems via Off-Policy Reinforcement Learning. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 2550–2562. [Google Scholar] [CrossRef]
- Wang, F.; Gu, Q.; Huang, B.; Wei, Q.; Zhou, T. Adaptive Event-Triggered Near-Optimal Tracking Control for Unknown Continuous-Time Nonlinear Systems. IEEE Access 2022, 10, 9506–9518. [Google Scholar] [CrossRef]
- Modares, H.; Lewis, F.L. Optimal tracking control of nonlinear partially-unknown constrained-input systems using integral reinforcement learning. Automatica 2014, 50, 1780–1792. [Google Scholar] [CrossRef]
- Wang, D.; Mu, C. Adaptive-Critic-Based Robust Trajectory Tracking of Uncertain Dynamics and Its Application to A Spring-Mass-Damper System. IEEE Trans. Ind. Electron. 2018, 65, 654–663. [Google Scholar] [CrossRef]
- Lu, K.; Liu, C.; Sun, J.; Li, C.; Ma, C. Compensator-based approximate optimal control for affine nonlinear systems with input constraints and unmatched disturbances. Trans. Inst. Meas. Control 2020, 42, 3024–3034. [Google Scholar] [CrossRef]
- Liu, D.; Wang, D.; Wang, F.; Li, H.; Yang, X. Neural-Network-Based Online HJB Solution for Optimal Robust Guaranteed Cost Control of Continuous-Time Uncertain Nonlinear Systems. IEEE Trans. Cybern. 2014, 44, 2834–2847. [Google Scholar] [CrossRef] [PubMed]
- Yang, X.; Liu, D.; Wei, Q. Online approximate optimal control for affine nonlinear systems with unknown internal dynamics using adaptive dynamic programming. IET Control Theory Appl. 2014, 8, 1676–1688. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Y.; Zhao, D.; Li, X. Using reinforcement learning techniques to solve continuous-time nonlinear optimal tracking problem without system dynamics. IET Control Theory Appl. 2016, 10, 1339–1347. [Google Scholar] [CrossRef]
- Marvi, Z.; Kiumarsi, B. Safe Off-policy Reinforcement Learning Using Barrier Functions. In Proceedings of the 2020 American Control Conference (ACC), Denver, USA, 1–3 July 2020; pp. 2176–2181. [Google Scholar]
- Yang, Y.; Ding, D.; Xiong, H.; Yin, Y.; Wunsch, D. Online barrier-actor-critic learning for H∞ control with full-state constraints and input saturation. J. Frankl. Inst. 2020, 357, 3316–3344. [Google Scholar] [CrossRef]
- Ames, A.D.; Grizzle, J.W.; Tabuada, P. Control barrier function based quadratic programs with application to adaptive cruise control. In Proceedings of the 53rd IEEE Conference on Decision and Control, Los Angeles, CA, USA, 15–17 December 2014; pp. 6271–6278. [Google Scholar]
- Yang, Y.; Vamvoudakis, K.; Modares, H. Safe reinforcement learning for dynamical games. Int. J. Robust Nonlinear 2020, 30, 3706–3726. [Google Scholar] [CrossRef]
- Srinivasan, M.; Coogan, S. Control of Mobile Robots Using Barrier Functions Under Temporal Logic Specifications. IEEE Trans. Robot. 2021, 37, 363–374. [Google Scholar] [CrossRef]
- Cohen, M.; Belta, C. Approximate Optimal Control for Safety-Critical Systems with Control Barrier Functions. In Proceedings of the 59th IEEE Conference on Decision and Control (CDC), Jeju, Korea, 14–18 December 2020; pp. 2062–2067. [Google Scholar]
- Ames, A.D.; Coogan, S.; Egerstedt, M.; Notomista, G.; Sreenath, K.; Tabuada, P. Control Barrier Functions: Theory and Applications. In Proceedings of the 18th European Control Conference (ECC), Naples, Italy, 25–28 June 2019; pp. 3420–3431. [Google Scholar]
- Xu, J.; Wang, J.; Rao, J.; Zhong, Y.; Wang, H. Adaptive dynamic programming for optimal control of discrete-time nonlinear system with state constraints based on control barrier function. Int. J. Robust Nonlinear Control 2022, 32, 3408–3424. [Google Scholar] [CrossRef]
- Yang, X.; Liu, D.; Wei, Q.; Wang, D. Guaranteed cost neural tracking control for a class of uncertain nonlinear systems using adaptive dynamic programming. Neurocomputing 2016, 198, 80–90. [Google Scholar] [CrossRef]
- Lewis, F.L.; Vrabie, D.L.; Syrmos, V.L. Optimal Control, 3rd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2012; pp. 277–279. [Google Scholar]
- Lewis, F.L.; Jagannathan, S.; Yesildirek, A. Neural Network Control of Robot Manipulators and Nonlinear Systems; Taylor& Francis: London, UK, 1999. [Google Scholar]








Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qin, C.; Qiao, X.; Wang, J.; Zhang, D. Robust Trajectory Tracking Control for Continuous-Time Nonlinear Systems with State Constraints and Uncertain Disturbances. Entropy 2022, 24, 816. https://doi.org/10.3390/e24060816
Qin C, Qiao X, Wang J, Zhang D. Robust Trajectory Tracking Control for Continuous-Time Nonlinear Systems with State Constraints and Uncertain Disturbances. Entropy. 2022; 24(6):816. https://doi.org/10.3390/e24060816
Chicago/Turabian StyleQin, Chunbin, Xiaopeng Qiao, Jinguang Wang, and Dehua Zhang. 2022. "Robust Trajectory Tracking Control for Continuous-Time Nonlinear Systems with State Constraints and Uncertain Disturbances" Entropy 24, no. 6: 816. https://doi.org/10.3390/e24060816
APA StyleQin, C., Qiao, X., Wang, J., & Zhang, D. (2022). Robust Trajectory Tracking Control for Continuous-Time Nonlinear Systems with State Constraints and Uncertain Disturbances. Entropy, 24(6), 816. https://doi.org/10.3390/e24060816