1. Introduction
Network structure can effectively model complex inter-entity relationships, such as social networks between users [
1], e-commerce networks between users and products [
2], citation networks between publications [
3], biological networks [
4], etc. These networks have been utilized for a range of data-mining applications, including vertex classification [
5], link prediction [
6], user search [
7] and recommendation systems [
2].
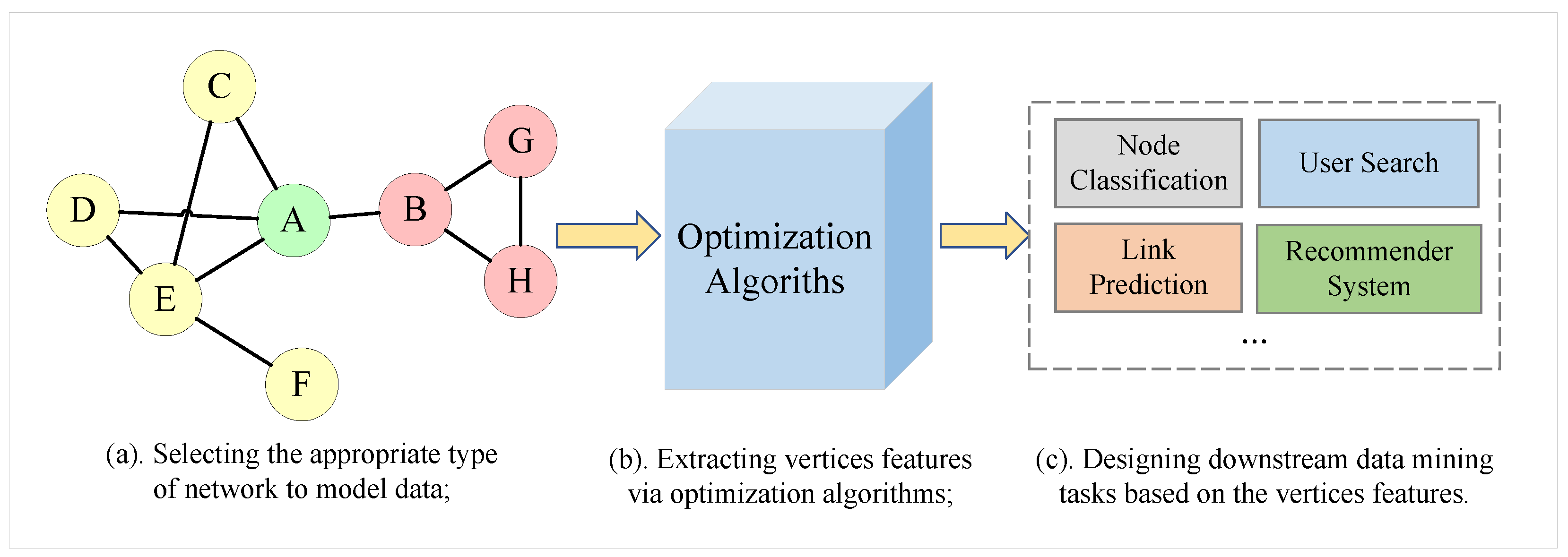
Figure 1 depicts the three processes of network data mining.
The second step is the most crucial since the capability of acquired features to characterize the network has a significant effect on the execution of subsequent tasks. Traditional supervised matrix decomposition-based network analysis approaches strongly bind the second and third phases, and employ specialized algorithms for a variety of downstream tasks and network types. However, as information technology advances, networks become more diverse, extensive, and sparse, which makes labeling all vertices, and performing matrix decomposition, impractical and time-consuming. In addition, approach migration is precluded by the great bond between algorithms and downstream tasks. In recent years, unsupervised network representation learning (NRL) approaches [
9,
10,
11,
12], which are based on random walk and shallow neural language models, have been extensively researched and have achieved great success. These approaches separate the second and third phases, and focus on extracting representative low-dimensional latent features for vertices. The resulting features can then be directly incorporated into further vector-based data mining algorithms for subsequent tasks. In general, random walks on a network are run to generate vertex sequences that contain information about the network’s structure, and then a neural language model is trained [
13] by modeling the co-occurrence of vertices pairs on the sequences to extract structural features for the vertices. Despite the fact that these methods have demonstrated their efficacy, they suffer from the three flaws listed below: First, because the random walk is a Markov process based on a static probability distribution without considering previous walk history, the sampled vertex sequences are prone to losing vertex neighborhood structure information; second, because the feature extraction capability of the shallow language model is limited, only local structural features can be learned, while global structural features are ignored; and third, in order to incorporate the vertex attribute information into network representation, a specific attribute fusion algorithm has to be designed for different downstream tasks and attribute types, which raises the design complexity of the approach.
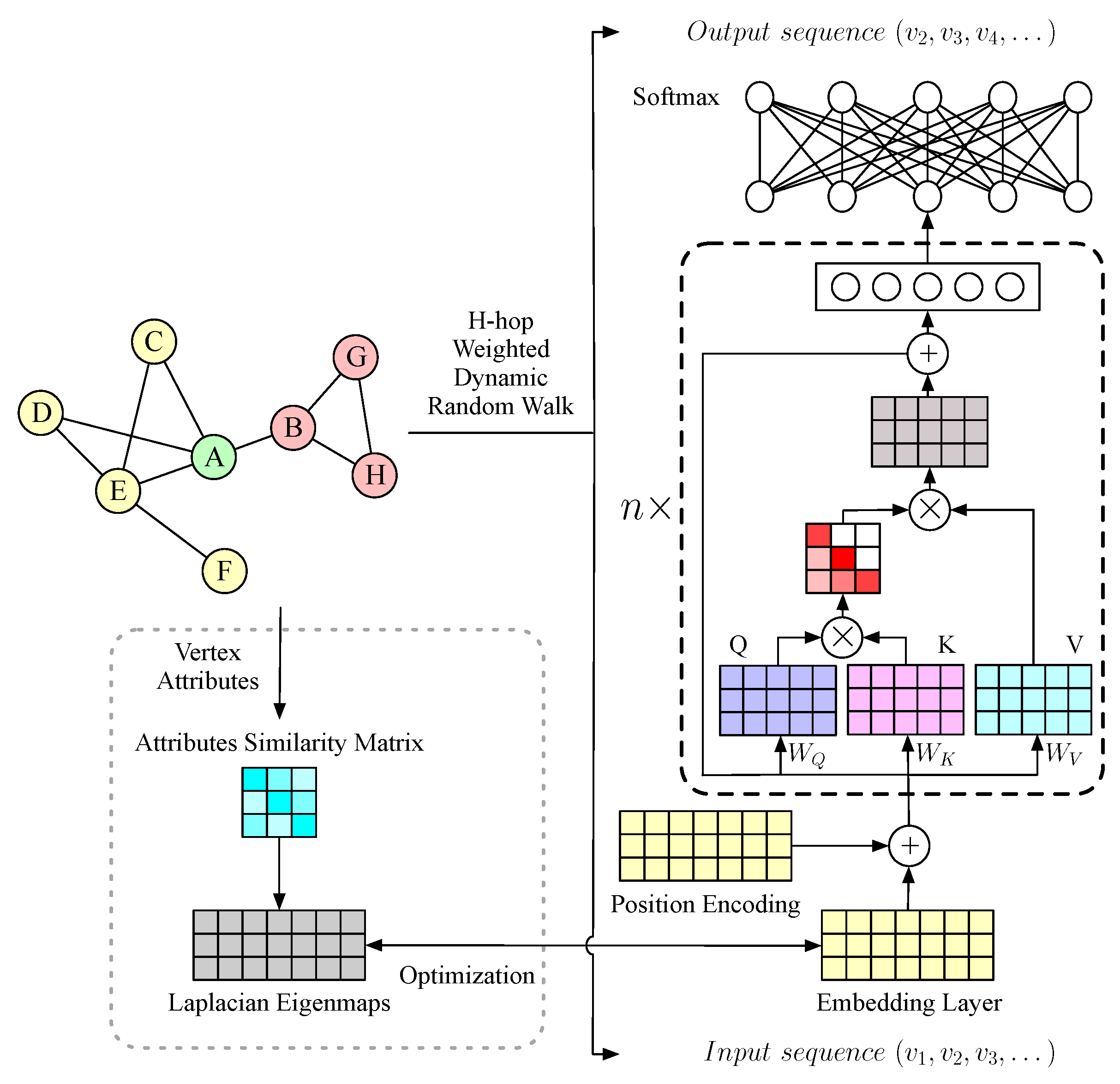
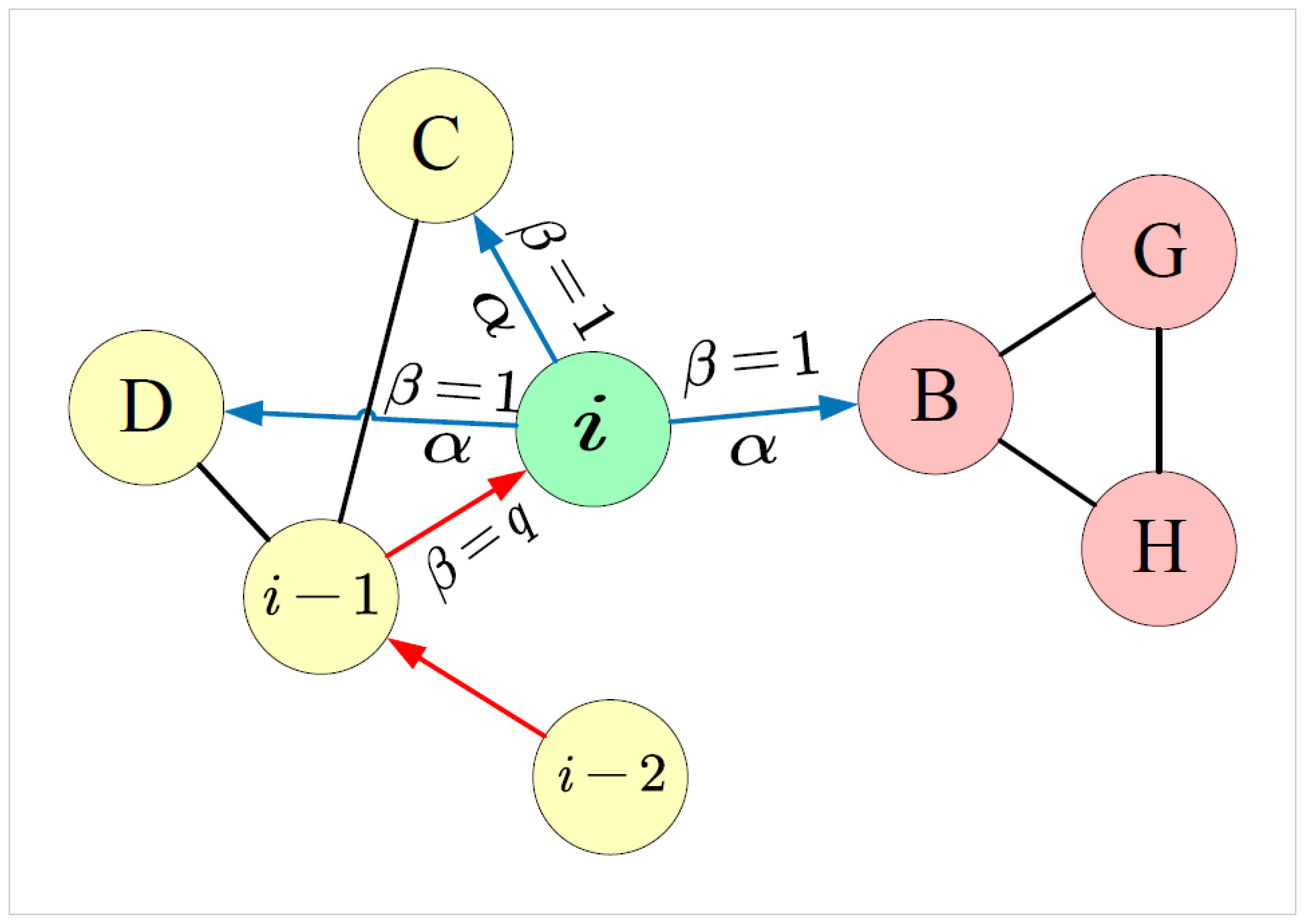
To address the aforementioned issues, we propose a general NRL approach called dynamic structure and vertex attributes fusion network embedding (dSAFNE). First, based on a newly defined asymmetric second-order vertex approximity, we design an
h-hop weighted dynamic random walk strategy, which incorporates a series of previously walked vertices to dynamically calculate the sampling probability of each vertex and assign a higher walk probability to the more similar ones. The sampled vertex sequences are then fed into a self-attention-based sequence prediction model. Vertex representations, which preserve both local and global structural characteristics, can be learned through a fake task that predicts the next walked vertex based on the previous vertex sequence. Moreover, in order for our model to effectively extract vertex attribute features of various types, we introduce a vertex attributes-driven Laplacian space optimization. It first leverages the state-of-the-art (SOTA) learning models for different types of data (e.g., residual neural network (ResNet) [
14] for images, bidirectional encoder representations from Transformer (BERT) [
15] for text, etc.) to extract vertex attribute features. Then, it uses the pairwise feature similarities of the vertices to optimize the vertex representations so that vertices with a higher attribute similarity are represented more closely in the feature space. Finally, we validate the effectiveness of the dSAFNE framework on various datasets through different downstream tasks. This paper’s major contributions are outlined below.
To address the issue of too much randomness in random walk that is based on a static probability distribution Markov process, we first design an asymmetric second-order proximity that reflects vertex similarity while retaining role information, and then propose an h-hop weighted dynamic random walk strategy based on this similarity. It incorporates a series of historical vertices to dynamically calculate the sampling probability of each vertex, and allocates higher walk probabilities to vertices with high similarities, leading to fully capturing the vertex neighborhood structure information.
To address the issue that the shallow language model adopted by the majority of unsupervised NRL approaches can only extract short-range local structural features of vertices, we model learning network structural features from vertex sequences as a sequence prediction problem and develop a sequence prediction model based on the self-attention mechanism with reference to the structure of the Transformer [
16] encoder, which can handle both short-range and long-range dependence problems in order to simultaneously learn the multi-granularity structural features of vertices.
To address the issue of underutilization of vertex attribute information, we propose a vertex attribute-driven Laplacian optimization that constrains the NRL training process by vertex attribute similarity in order to obtain distributed representations of vertices containing vertex attribute features.
To evaluate the proposed dSAFNE model, we conducted a series of experiments on vertex classification and visualization over a variety of different types of datasets, and obtained excellent results when compared to the baseline methods.
The rest of this paper is organized as follows:
Section 2 describes related work.
Section 3 explains the essential concepts that help to understand this paper.
Section 4 introduces each module of the dSAFNE framework in detail.
Section 5 presents and analyses the experimental results.
Section 6 summarizes the work in this paper.
2. Related Work
In this section, we briefly describe the related NRL approaches, which are classified into matrix-factorization-based models and shallow neural embedding models according to implementation characteristics.
The matrix-factorization-based models [
17,
18,
19,
20,
21] first used different types of relational matrices [
20] to preserve the network information, and then applied matrix factorization to obtain vertex representations. Belkin et al. [
17] utilized Laplacian spectral decomposition to discover non-linear low-dimensional representations for the input network data. To learn community-oriented vertex representation, Tang et al. [
18] performed a decomposition of the modularity matrix. Donnat et al. [
19] embedded vertex neighborhood structure into a low-dimensional space and preserved structural role proximity by leveraging spectral graph wavelet diffusion patterns. Yang et al. [
20] executed inductive matrix decomposition [
22] on the vertex context matrix to preserve both network structure and vertex text attribute characteristics in the vertex representation vector. Zhang et al. [
21] focused on the weakness of ignoring the homophily property in [
20], and suggested a regularization term that simultaneously integrates homophily, structural context and vertex content to extract network representations. Although the matrix-factorization-based approach can effectively extract the global structural features of networks, these methods are challenging to be deployed to large networks since matrix factorization requires a great deal of computing and memory resources. In the meantime, the design of relational matrices will have a direct impact on the performance of matrix factorization, introducing an extra contingency.
The shallow neural embedding models [
9,
10,
11,
12,
23,
24,
25,
26] seek an embedding matrix, which can be considered as a vertex representation by a row or column vector. Typically, they first extract vertex sequences by performing random walks on the network to capture network structure. Based on the assumption that the comparable context-sharing vertices in random walk sequences should be closely represented in the low-dimension feature space, they then train a shallow neural language model on the sequences to optimize the embedding matrix, i.e., to maximize the log-likelihood of context vertices when given a target vertex. Perozzi et al. [
9] performed truncated random walk on the network to generate vertex sequences, in which the co-occurrence frequencies of vertex-context pairs indicated their relevance. To further extract the vertex representation, they generalized the idea of a word embedding model (i.e., Skip-Gram [
27]) over the vertex sequences. Cao et al. [
23] followed the idea of [
9] and extended the Skip-Gram model to capture
k-step high-order vertex proximity, with the goal of making vertices that shared common
k-step neighbors proximate in the embedding space. In contrast to the rigid strategy of truncated random that defines the neighborhood (context) for each vertex, Grover et al. [
10] introduced a biased random walk to balance breadth-first search (BFS) and depth-first search (DFS) [
28], and then applied Skip-Gram to learn the vertex feature from random walk sequences. To preserve the structural role proximity of vertices, Ribeiro et al. [
11] first encoded vertex structural role proximity into a multi-layer graph, where the edge weights of each unique graph were defined by the structural role difference, and then executed [
9] at each layer to learn vertex representations.
In order to incorporate vertex labels with network structure, Li et al. [
24] proposed learning discriminative network representations by concurrently optimizing the objective of [
9] and supporting vector classification. Pan et al. [
25] adapted a paragraph vector model [
29] to capture vertex textual content and label information, and then jointly optimized the objective of [
9] to simultaneously encode network structure, vertex label and attribute information into a vertex representation. Sun et al. [
12] exploited long short-term memory (LSTM) [
30] to maintain the transfer possibilities among the vertices. To further improve the extraction of the network’s local structural features, they devised a Laplacian-supervised embedding space optimization. Rozemberczki et al. [
26] proposed a Euler walk for executing a Euler tour in the diffusion subgraph centered on each vertex.
In comparison to matrix factorization-based models, shallow neural embedding models are more robust since they are unaffected by artificially constructed relation matrices. Moreover, since random walk can be easily applied to large-scale networks, the scalability of such approaches is considerably enhanced. Despite this, there still remain a series of shortcomings. These models do not consider the effect of a series of historical vertices on the sampling probability when performing random walks, leading to the loss of community structure. Limited by the feature extraction ability and receptive field of the shallow neural language model, only local structural features of the network can be extracted. In addition, it is necessary to design attribute fusion strategies specifically for a variety of downstream tasks and attribute types.
Motivated by the aforementioned investigations, we are committed to addressing the following issues of previous shallow neural embedding methods, including the loss of community structure resulting from the static-probability-distribution-based random walk, the inability to simultaneously learn multi-grained structural features, and the task-specific vertex attribute integration algorithm requirements.
3. Preliminaries
In this section, we summarize some essential concepts and define the research problem.
Definition 1 (Network). A network can be formally represented as a triplet , which consists of a vertex set of n vertices, an edge set , and a vertex attributes set where denotes the attributes of vertex . Each object in E indicates that there exists an edge, which is attached with a weight , from vertex to . In an unweighted network, if else .
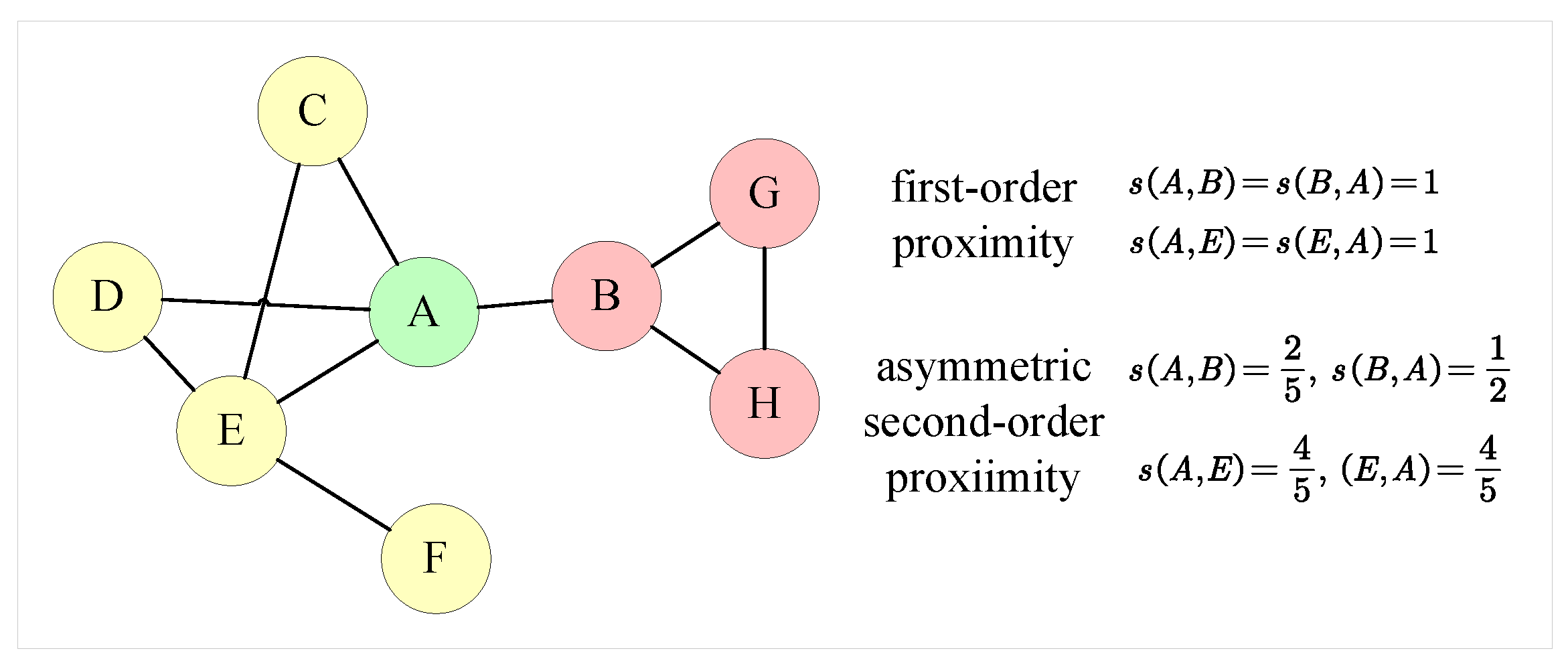
Definition 2 (Vertex Proximity)
. In real-world networks, many vertex proximities exist, including first-order, second-order, and higher-order proximities, etc. The first-order proximity function can be used to determine the direct connectedness of two vertices, which is often specified as the weight of the connecting edge. The second-order proximity of two vertices indicates the distance between their adjacent distributions [31]. Higher-order proximity between two vertices can be defined as the k-step probability of transitioning between them [32]. Definition 3 (Structure and Vertex Attributes Fusion Network Embedding). The structure and vertex attributes fusion network embedding task attempts to learn a low-dimensional representation matrix for a given network , where . The row vector is treated as the representation of vertex . should preserve both the structural information and vertex attribute information. In other words, the vertices that share common neighbors, or have similar attributes, should be represented closely in the low-dimension feature space.
6. Summary and Discussion
This paper proposes a general NRL framework dSAFNE, which focuses on the shortcomings of previous NRL methods, including the excessive randomness of the random walk process based on symmetric node similarity and static probability distribution, the inability to simultaneously learn multi-grained structural features, and inefficient vertex attribute utilization. The proposed dSAFNE framework mainly consists of three modules: an h-hop weighted dynamic random walk, a masked self-attention-based prediction model and a vertex attributes-driven Laplacian space optimization. Based on the well-designed asymmetric second-order similarity, which reflects vertex similarity while maintaining social role information, the proposed h-hop weighted dynamic random walk can capture the community structure information effectively. Due to the wide receptive field of the self-attentive mechanism, the prediction model can simultaneously learn the co-occurrence relationship between the target vertex and the short-range/long-range contextual vertices, leading to the extraction of multi-grained structural features. In addition, the proposed vertex-attributes-driven Laplacian space optimization paradigm makes it simple to integrate different types of vertex attributes into the vertex representation, hence ensuring the future generalizability of the model. Furthermore, extensive experiments were conducted on five benchmarking datasets. The experimental results demonstrated that dSAFNE is capable of learning more representational vertex features than the state-of-the-art competing approaches.
While these experimental results are encouraging, some limitations of the proposed dSAFNE framework remain. On the one hand, similar to the regular Transformer, the self-attention-based prediction model suffers from the quadratic complexity with the length of random walk sequence, which restricts the possibility to capture the global structure of large-scale networks by extending the length of random walk sequences, particularly in scenarios where computational resources are constrained. Therefore, the development of a more efficient prediction model and network sampling strategies are necessary. On the other hand, the present version of dSAFNE is only applicable to homogeneous networks and does not account for the heterogeneity of vertices and edges. It is crucial to extend dSAFNE to heterogeneous networks in order to improve the generalizability. Finally, in addition to node visualization and classification, NRL has a vast array of downstream tasks, such as link prediction, temporal prediction and recommender system, etc. The efficiency of the proposed dSAFNE framework with respect to these downstream tasks needs to be further explored. We leave this for future investigations.





 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}