


Adapting Multiple Distributions for Bridging Emotions from Different Speech Corpora



Abstract
:1. Introduction
- We propose a novel transfer subspace learning method called MDAR to deal with cross-corpus SER tasks. The basic idea of MDAR is very straightforward, i.e., learning corpus invariant and emotion discriminative representations for both source and target speech samples belonging to different corpora such that the classifier learning based on the labeled source speech samples is also applicable to predicting the emotions of target speech signals.
- We present a new distribution difference alleviation regularization term called MDA for MDAR to guide the corpus invariant feature learning for the recognition of the emotions of speech signals. MDA collaboratively aligns marginal, fine emotion class-aware conditional, and rough emotion class-aware feature distributions between source and target speech samples.
- Three widely used speech emotion corpora, i.e., EmoDB, eNTERFACE, and CASIA, were used to design the cross-corpus SER tasks to evaluate the proposed MDAR. Extensive experiments were conducted to demonstrate the effectiveness and superior performance of MDAR in coping with cross-corpus SER tasks.
2. Related Works
2.1. Transfer Subspace Learning for Cross-Corpus SER
2.2. Deep Transfer Learning for Cross-Corpus SER
3. Proposed Method
3.1. Notations
3.2. Formulation of MDAR
- can be called the feature selection term. Minimizing helps the MDAR learn a row-sparse projection matrix, which suppresses the speech features contributing less to the distinction of different emotions, while highlighting the features contributing most to distinction.
- The other aspect is the multiple distribution adaption (MDA), which corresponds to the resting three terms. Among these, the first two terms are so-called joint distribution adaptions (JDA) [16,17,19,20]. JDA is a combination of the marginal distribution adaption and the fine emotion class-aware conditional adaption and has been demonstrated the effectiveness in coping with domain adaptation and other cross-domain recognition tasks. Our MDA can be viewed as an extension of JDA incorporating an additional rough emotion class-aware conditional distribution-adapted term, which enables further enhancement of the corpus invariant ability of the proposed MDAR.
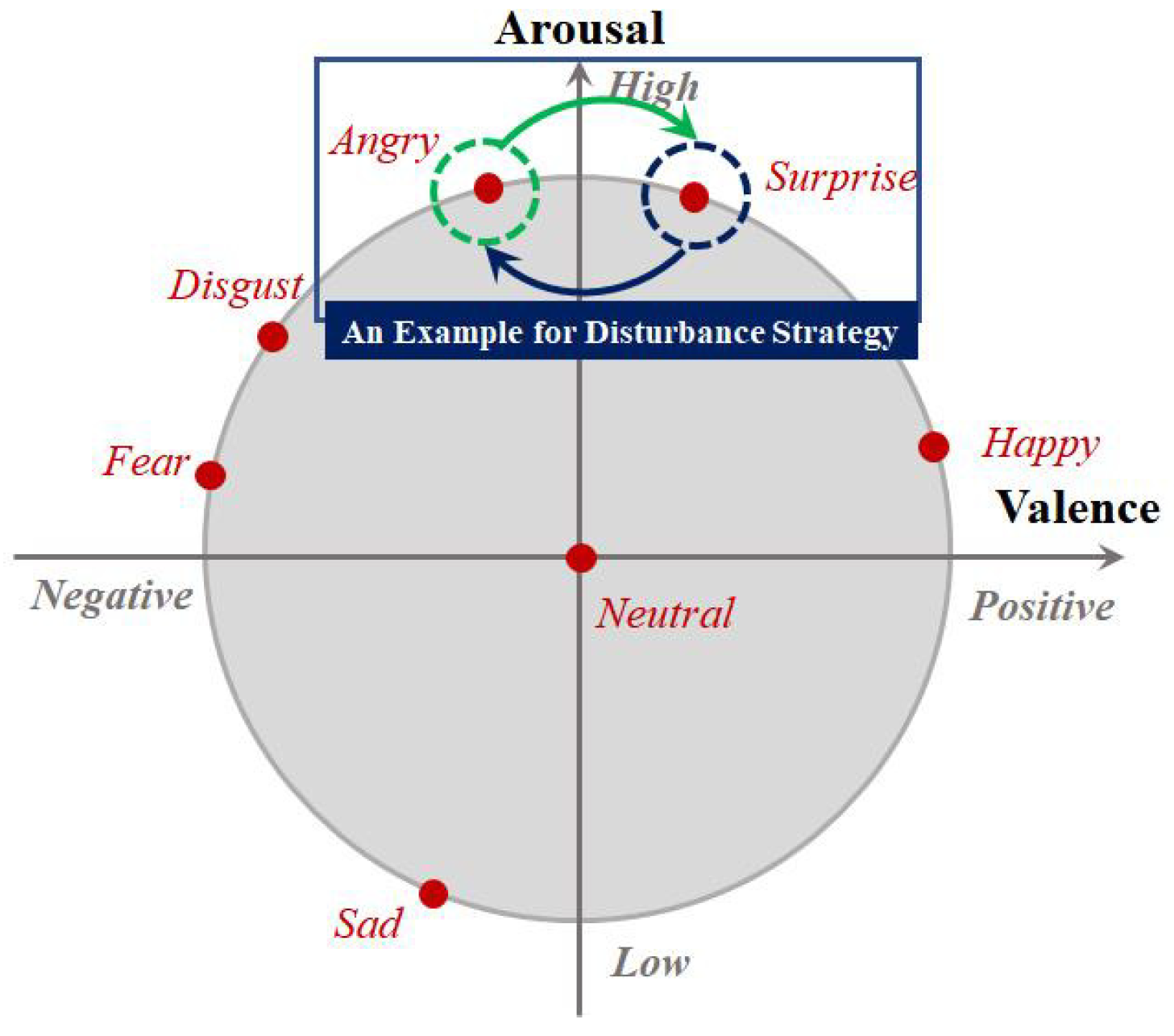
3.3. Disturbance Strategy for Constructing Rough Emotion Groups in MDA
3.4. Predicting the Target Emotion Label Using MDAR
3.5. Optimization of MDAR
- Solve the following optimization problem:where is a zero matrix, and .
| Algorithm 1 Complete updating rule for learning the optimal in Equation (10). |
Repeat the following steps until convergence:
|
4. Experiments
4.1. Speech Emotion Corpora and Experimental Protocol
- Speech Emotion Corpora: Three widely-used speech emotion corpora, i.e., EmoDB (Berlin) [9], eNTERFACE [21], and CASIA [10], were adopted to design cross-corpus SER tasks. EmoDB is a German corpus and was collected by Burkhardt et al. from TU Berlin, Germany. It consists of 535 acted speech samples from 10 speakers, including five females and five males. Each speech sample is assigned one of seven basic emotion labels, i.e., , , , , , , and . eNTERFACE is an English audio-visual emotion database consisting of 42 speakers from 14 different nationalities. The emotions involved are , , , , , and . In the experiments, we only adopted its audio subset. CASIA is a Chinese speech emotion corpus designed by the Institute of Automation, Chinese Academy of Science, China. It includes 1200 speech samples covering six basic emotions, i.e., , , , , , and .
- Task Detail: We used two of the above speech emotion corpora to serve as the source and target corpora, alternatively, and thus derived six typical cross-corpus SER tasks, i.e., , , , , , and , where B, E, and C are short for EmoDB, eNTERFACE, and CASIA, and the left and right corpora of the arrow correspond to the source and target corpora, respectively. It is of note that, since these corpora have different emotions, in each cross-corpus SER task, we extracted speech samples sharing the same emotion labels to ensure label consistency. The detailed sample statistical information of the selected speech emotion corpora is given in Table 1.
- Performance Metric: As for the performance metric, the unweighted average recall (UAR) [22], defined as the accuracy per class averaged by the total emotion class number, was chosen.
4.2. Comparison Methods and Implementation Detail
- TCA, GFK, and SA: For these three methods, the hyper-parameter, i.e., the reduced dimension, needed to be set. In the experiments, we searched it from , where is the maximal dimension.
- DoSL and JDAR: DoSL and JDAR have two trade-off parameters controlling the balance between the original loss function and two regularization terms, in which one corresponds to the sparsity and the other corresponds to feature distribution adaption. We searched them both from in the experiments.
- DAN and DSAN: DAN and DSAN both have a trade-off parameter to balance the original loss and the MMD regularization term. In the experiments, we set it by searching from .
- DANN: As for DANN, it also has only one trade-off parameter. We searched it from the parameter set throughout the experiments.
- DTTRN: Since the protocol in [20] was identical to ours, we used the results reported in their experiments for comparison.
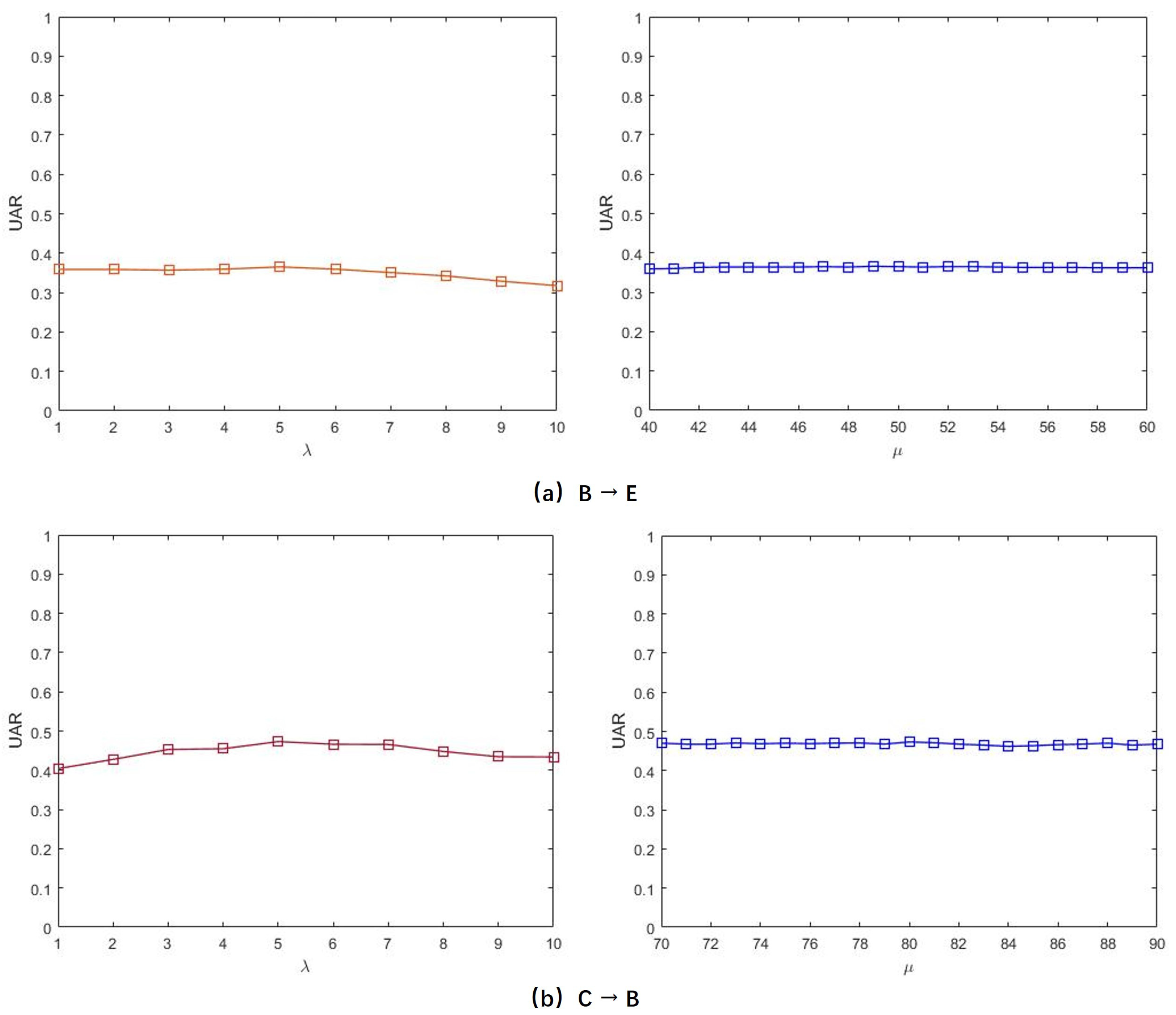
- MDAR: Similar to DoSL and JDAR, our MDAR also had two hyper-parameters, i.e., and . They were used to control the balance between the original regression loss function and the two regularization terms, including the feature selection and feature distribution difference alleviation terms. In the experiments, they were also both searched from the parameter interval . In addition, the rough emotion class number was set to 2 (- and -). The disturbance strategy for the two mixed rough emotion groups was performed as follows: Reassign from the - group to the - group for and , and from the - group to the - group for and . Switch and for and .
4.3. Results and Discussion
4.3.1. Comparison with Transfer Subspace Learning Methods
4.3.2. Comparison with Deep Transfer Learning Methods
4.3.3. Going Deeper into Disturbance Strategy in MDAR
4.3.4. Sensitivity Analysis of Trade-Off Parameters in MDAR
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- El Ayadi, M.; Kamel, M.S.; Karray, F. Survey on speech emotion recognition: Features, classification schemes, and databases. Pattern Recognit. 2011, 44, 572–587. [Google Scholar] [CrossRef]
- Schuller, B.W. Speech emotion recognition: Two decades in a nutshell, benchmarks, and ongoing trends. Commun. ACM 2018, 61, 90–99. [Google Scholar]
- Zong, Y.; Zheng, W.; Cui, Z.; Li, Q. Double sparse learning model for speech emotion recognition. Electron. Lett. 2016, 52, 1410–1412. [Google Scholar]
- Chen, M.; He, X.; Yang, J.; Zhang, H. 3-D Convolutional Recurrent Neural Networks With Attention Model for Speech Emotion Recognition. IEEE Signal Process. Lett. 2018, 25, 1440–1444. [Google Scholar] [CrossRef]
- Zhang, S.; Tao, X.; Chuang, Y.; Zhao, X. Learning deep multimodal affective features for spontaneous speech emotion recognition. Speech Commun. 2021, 127, 73–81. [Google Scholar]
- Li, D.; Zhou, Y.; Wang, Z.; Gao, D. Exploiting the potentialities of features for speech emotion recognition. Inf. Sci. 2021, 548, 328–343. [Google Scholar]
- Zhang, S.; Zhao, X.; Tian, Q. Spontaneous speech emotion recognition using multiscale deep convolutional LSTM. IEEE Trans. Affect. Comput. 2022, 13, 680–688. [Google Scholar]
- Lu, C.; Zong, Y.; Zheng, W.; Li, Y.; Tang, C.; Schuller, B.W. Domain Invariant Feature Learning for Speaker-Independent Speech Emotion Recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 30, 2217–2230. [Google Scholar]
- Burkhardt, F.; Paeschke, A.; Rolfes, M.; Sendlmeier, W.F.; Weiss, B. A database of German emotional speech. In Proceedings of the INTERSPEECH 2005, Lisbon, Portugal, 4–8 September 2005; pp. 1517–1520. [Google Scholar]
- Tao, J.; Liu, F.; Zhang, M.; Jia, H. Design of speech corpus for mandarin text to speech. In Proceedings of the Blizzard Challenge 2008 Workshop, Brisbane, Australia, 22–26 September 2008; pp. 1–4. [Google Scholar]
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar]
- Wang, M.; Deng, W. Deep visual domain adaptation: A survey. Neurocomputing 2018, 312, 135–153. [Google Scholar]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A comprehensive survey on transfer learning. Proc. IEEE 2020, 109, 43–76. [Google Scholar]
- Pan, S.J.; Tsang, I.W.; Kwok, J.T.; Yang, Q. Domain Adaptation via Transfer Component Analysis. IEEE Trans. Neural Netw. 2011, 22, 199–210. [Google Scholar] [CrossRef] [PubMed]
- Gong, B.; Shi, Y.; Sha, F.; Grauman, K. Geodesic flow kernel for unsupervised domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2066–2073. [Google Scholar]
- Zhang, J.; Jiang, L.; Zong, Y.; Zheng, W.; Zhao, L. Cross-Corpus Speech Emotion Recognition Using Joint Distribution Adaptive Regression. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 3790–3794. [Google Scholar] [CrossRef]
- Long, M.; Wang, J.; Ding, G.; Sun, J.; Yu, P.S. Transfer feature learning with joint distribution adaptation. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2200–2207. [Google Scholar]
- Zhang, T.; Zong, Y.; Zheng, W.; Chen, C.P.; Hong, X.; Tang, C.; Cui, Z.; Zhao, G. Cross-database micro-expression recognition: A benchmark. IEEE Trans. Knowl. Data Eng. 2022, 34, 544–559. [Google Scholar]
- Tan, Y.; Guo, L.; Gao, H.; Zhang, L. Deep coupled joint distribution adaptation network: A method for intelligent fault diagnosis between artificial and real damages. IEEE Trans. Instrum. Meas. 2020, 70, 1–12. [Google Scholar]
- Zhao, Y.; Wang, J.; Ye, R.; Zong, Y.; Zheng, W.; Zhao, L. Deep Transductive Transfer Regression Network for Cross-Corpus Speech Emotion Recognition. In Proceedings of the INTERSPEECH, Incheon, Korea, 18–22 September 2022. [Google Scholar]
- Martin, O.; Kotsia, I.; Macq, B.; Pitas, I. The eNTERFACE’05 Audio-Visual Emotion Database. In Proceedings of the 22nd International Conference on Data Engineering Workshops, Washington, DC, USA, 3–7 April 2006; p. 8. [Google Scholar]
- Schuller, B.; Vlasenko, B.; Eyben, F.; Wöllmer, M.; Stuhlsatz, A.; Wendemuth, A.; Rigoll, G. Cross-Corpus Acoustic Emotion Recognition: Variances and Strategies. IEEE Trans. Affect. Comput. 2010, 1, 119–131. [Google Scholar] [CrossRef]
- Hassan, A.; Damper, R.; Niranjan, M. On Acoustic Emotion Recognition: Compensating for Covariate Shift. IEEE Trans. Audio Speech Lang. Process. 2013, 21, 1458–1468. [Google Scholar] [CrossRef]
- Gretton, A.; Smola, A.; Huang, J.; Schmittfull, M.; Borgwardt, K.; Schölkopf, B. Covariate shift by kernel mean matching. Dataset Shift Mach. Learn. 2009, 3, 5. [Google Scholar]
- Kanamori, T.; Hido, S.; Sugiyama, M. A least-squares approach to direct importance estimation. J. Mach. Learn. Res. 2009, 10, 1391–1445. [Google Scholar]
- Tsuboi, Y.; Kashima, H.; Hido, S.; Bickel, S.; Sugiyama, M. Direct density ratio estimation for large-scale covariate shift adaptation. J. Inf. Process. 2009, 17, 138–155. [Google Scholar]
- Song, P. Transfer Linear Subspace Learning for Cross-Corpus Speech Emotion Recognition. IEEE Trans. Affect. Comput. 2019, 10, 265–275. [Google Scholar] [CrossRef]
- Deng, J.; Zhang, Z.; Eyben, F.; Schuller, B. Autoencoder-based Unsupervised Domain Adaptation for Speech Emotion Recognition. IEEE Signal Process. Lett. 2014, 21, 1068–1072. [Google Scholar] [CrossRef]
- Deng, J.; Xu, X.; Zhang, Z.; Frühholz, S.; Schuller, B. Universum Autoencoder-Based Domain Adaptation for Speech Emotion Recognition. IEEE Signal Process. Lett. 2017, 24, 500–504. [Google Scholar] [CrossRef]
- Gideon, J.; McInnis, M.G.; Provost, E.M. Improving Cross-Corpus Speech Emotion Recognition with Adversarial Discriminative Domain Generalization (ADDoG). IEEE Trans. Affect. Comput. 2021, 12, 1055–1068. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 1–11. [Google Scholar]
- Yang, L.; Shen, Y.; Mao, Y.; Cai, L. Hybrid Curriculum Learning for Emotion Recognition in Conversation. In Proceedings of the AAAI, Online. 22 February–1 March 2022. [Google Scholar]
- Lin, Z.; Liu, R.; Su, Z. Linearized alternating direction method with adaptive penalty for low-rank representation. Adv. Neural Inf. Process. Syst. 2011, 24, 1–9. [Google Scholar]
- Fernando, B.; Habrard, A.; Sebban, M.; Tuytelaars, T. Unsupervised visual domain adaptation using subspace alignment. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2960–2967. [Google Scholar]
- Liu, N.; Zong, Y.; Zhang, B.; Liu, L.; Chen, J.; Zhao, G.; Zhu, J. Unsupervised Cross-Corpus Speech Emotion Recognition Using Domain-Adaptive Subspace Learning. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5144–5148. [Google Scholar] [CrossRef] [Green Version]
- Schuller, B.; Steidl, S.; Batliner, A. The interspeech 2009 emotion challenge. In Proceedings of the INTERSPEECH, Brighton, UK, 6–10 September 2009. [Google Scholar]
- Schuller, B.; Steidl, S.; Batliner, A.; Burkhardt, F.; Devillers, L.; Müller, C.; Narayanan, S.S. The INTERSPEECH 2010 paralinguistic challenge. In Proceedings of the INTERSPEECH, Makuhari, Japan, 26–30 September 2010. [Google Scholar]
- Eyben, F.; Wöllmer, M.; Schuller, B. Opensmile: The munich versatile and fast open-source audio feature extractor. In Proceedings of the 18th ACM International Conference on Multimedia, Firenze, Italy, 25–29 October 2010; pp. 1459–1462. [Google Scholar]
- Long, M.; Cao, Y.; Wang, J.; Jordan, M. Learning transferable features with deep adaptation networks. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 7–9 July 2015; pp. 97–105. [Google Scholar]
- Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M. Domain-adversarial neural networks. arXiv 2014, arXiv:1412.4446. [Google Scholar]
- Sun, B.; Saenko, K. Deep coral: Correlation alignment for deep domain adaptation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2016; pp. 443–450. [Google Scholar]
- Zhu, Y.; Zhuang, F.; Wang, J.; Ke, G.; Chen, J.; Bian, J.; Xiong, H.; He, Q. Deep subdomain adaptation network for image classification. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 1713–1722. [Google Scholar]



{kind=link}
{kind=link}
| Tasks | Speech Corpus (# Samples from Each Emotion) | #Sample |
|---|---|---|
| B→E | EmoDB (AN: 127, SA: 62, FE: 69, HA: 71, DI: 46) | 375 |
| E→B | eNTERFACE (AN: 211, SA: 211, FE: 211, HA: 208, DI: 211) | 1052 |
| B→C | EmoDB (AN: 127, SA: 62, FE: 69, HA: 71, NE: 79) | 408 |
| C→B | CASIA (AN: 200, Sad: 200, FE: 200, HA: 200, NE: 200) | 1000 |
| E→C | eNTERFACE (AN: 211, SA: 211, FE: 211, HA: 208, SU: 211) | 1052 |
| C→E | CASIA (AN: 200, SA: 200, FE: 200, HA: 200, SU: 200) | 1000 |
| Method | B→ E | E→B | B→C | C→B | E→C | C→E | Average |
|---|---|---|---|---|---|---|---|
| SVM | 28.93 | 23.58 | 29.60 | 35.01 | 26.10 | 25.14 | 28.06 |
| TCA | 30.52 | 44.03 | 33.40 | 45.07 | 31.10 | 32.32 | 36.07 |
| GFK | 32.11 | 42.48 | 33.10 | 48.08 | 32.80 | 28.13 | 36.17 |
| SA | 33.50 | 43.89 | 35.80 | 49.03 | 32.60 | 28.17 | 36.33 |
| DoSL | 36.12 | 38.95 | 34.40 | 45.75 | 30.40 | 31.59 | 36.20 |
| JDAR | 36.33 | 39.97 | 31.10 | 46.29 | 32.40 | 31.50 | 36.27 |
| MDAR | 36.52 | 40.29 | 33.10 | 47.32 | 31.70 | 31.21 | 36.69 |
| Method | B→ E | E→B | B→C | C→B | E→C | C→E | Average |
|---|---|---|---|---|---|---|---|
| SVM | 34.50 | 28.13 | 35.30 | 35.29 | 24.30 | 26.81 | 30.73 |
| TCA | 32.60 | 44.53 | 40.50 | 51.47 | 33.20 | 29.77 | 38.68 |
| GFK | 36.01 | 40.11 | 40.00 | 45.93 | 33.00 | 29.09 | 37.35 |
| SA | 35.65 | 43.92 | 37.50 | 47.06 | 32.10 | 30.61 | 37.80 |
| DoSL | 36.82 | 43.33 | 36.80 | 48.45 | 35.60 | 33.91 | 39.15 |
| JDAR | 37.95 | 47.80 | 42.70 | 48.97 | 35.60 | 37.58 | 41.76 |
| MDAR | 38.90 | 48.95 | 43.00 | 49.52 | 35.80 | 37.30 | 42.26 |
| Method | B→ E | E→B | B→C | C→B | E→C | C→E | Average |
|---|---|---|---|---|---|---|---|
| AlexNet | 29.49 | 31.03 | 33.20 | 41.91 | 27.80 | 27.25 | 31.78 |
| DAN | 36.13 | 40.41 | 39.00 | 49.85 | 29.00 | 31.47 | 37.64 |
| DANN | 33.38 | 43.68 | 39.20 | 53.71 | 29.80 | 29.25 | 38.05 |
| Deep-CORAL | 35.03 | 43.38 | 38.30 | 48.28 | 31.00 | 30.89 | 37.81 |
| DSAN | 36.25 | 46.90 | 40.30 | 50.69 | 28.70 | 32.61 | 39.41 |
| DTTRN | 37.70 | 48.20 | 40.40 | 55.20 | 31.20 | 33.60 | 41.10 |
| MDAR + IS09 | 36.52 | 40.29 | 33.10 | 47.32 | 31.70 | 31.68 | 36.69 |
| MDAR + IS10 | 38.90 | 48.95 | 43.00 | 49.52 | 35.80 | 37.30 | 42.26 |
| Rough Emotion Groups | B→ E | E→B | B→C | C→B | E→C | C→E | Average |
|---|---|---|---|---|---|---|---|
| Proposed Modification | 36.52 | 40.29 | 33.10 | 47.32 | 31.70 | 31.68 | 36.69 |
| Original Version | 36.33 | 39.89 | 31.50 | 46.51 | 32.00 | 31.50 | 36.28 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zong, Y.; Lian, H.; Chang, H.; Lu, C.; Tang, C. Adapting Multiple Distributions for Bridging Emotions from Different Speech Corpora. Entropy 2022, 24, 1250. https://doi.org/10.3390/e24091250
Zong Y, Lian H, Chang H, Lu C, Tang C. Adapting Multiple Distributions for Bridging Emotions from Different Speech Corpora. Entropy. 2022; 24(9):1250. https://doi.org/10.3390/e24091250
Chicago/Turabian StyleZong, Yuan, Hailun Lian, Hongli Chang, Cheng Lu, and Chuangao Tang. 2022. "Adapting Multiple Distributions for Bridging Emotions from Different Speech Corpora" Entropy 24, no. 9: 1250. https://doi.org/10.3390/e24091250
APA StyleZong, Y., Lian, H., Chang, H., Lu, C., & Tang, C. (2022). Adapting Multiple Distributions for Bridging Emotions from Different Speech Corpora. Entropy, 24(9), 1250. https://doi.org/10.3390/e24091250