
Multi-Objective Multi-Instance Learning: A New Approach to Machine Learning for eSports



Abstract
:1. Introduction
2. Related Work
2.1. Literature Review
2.2. Background Information
2.2.1. League of Legends
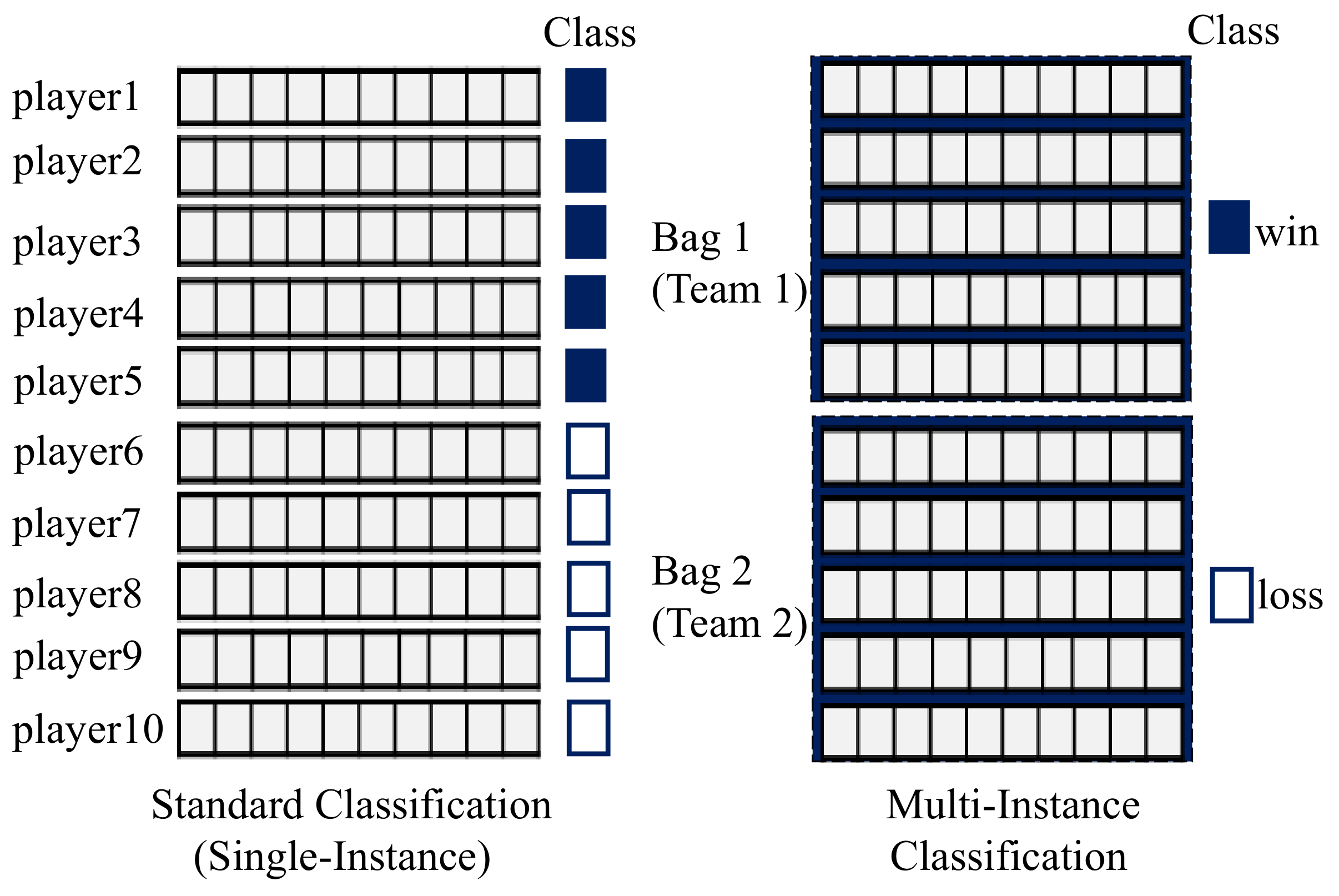
2.2.2. Multi-Objective and Multi-Instance Learning
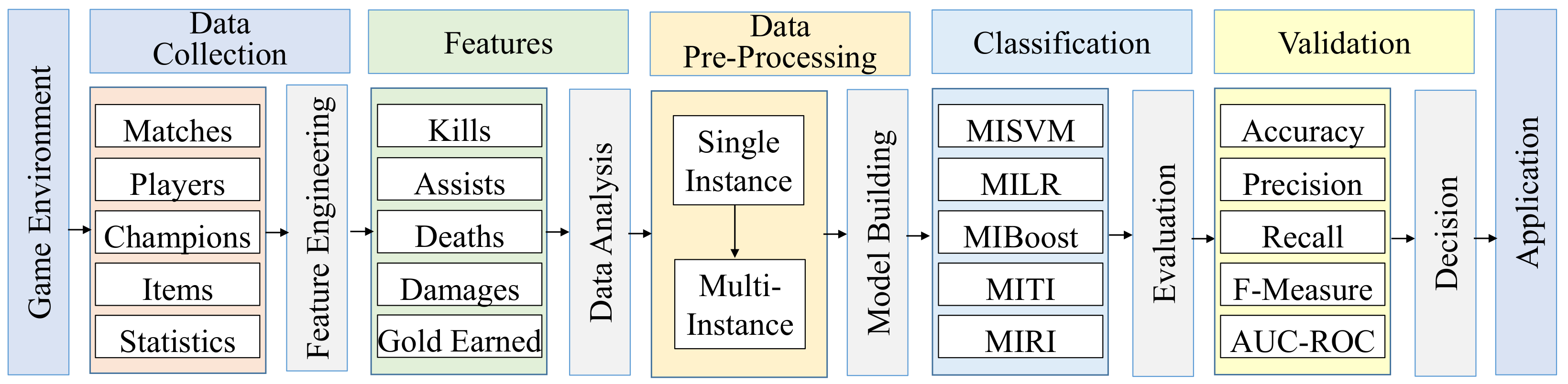
3. Materials and Methods
3.1. The Proposed Approach
3.2. Formal Description of the Proposed Approach
| Algorithm 1: Multi-Objective Multi-Instance Learning (MOMIL) |
Inputs: S: single-instace data T: test set containing b bags m: the number of players in a team n: the number of bags in the training set Outputs: Y: predicted class labels on given query bags Begin: for:tondo  |
3.3. Advantages of the Proposed Approach
- The proposed approach utilizes multi-instance learning to predict the match outcome in eSports for the first time. Thereby, it expands the standard classification task in the field of eSports.
- MOMIL is designed for team-level classification. This property increases the performance of the predictive model, since team collaboration is essential in completing game missions and achieving final success.
- eSports games are continuously updated, and the major game changes make the previous models obsolete. The proposed model overcomes this limitation by using data collected over short time periods.
- Another advantage of MOMIL is its implementation simplicity. After converting single-instance data into multi-instance data in a straightforward manner, any multi-instance learning algorithm can be applied easily.
- An important advantage of the proposed MOMIL method is that it is designed for analyzing any type of data that are suitable for win prediction. Therefore, it can be easily applied without having any background information. It does not require any specific knowledge or assumption for the given data. Therefore, it can be widely applied to many different eSports games such as LoL, Dota 2, Destiny, PUBG, and Counter-Strike.
- One of the key advantages is that it can be used for feature engineering which means identifying the most significant features for win prediction among the available features in the training bag set.
- Another advantage of MOMIL is its ability to deal with non-linear and complex win prediction problems.
3.4. Multi-Instance Classification Algorithms
- Multi-Instance AdaBoost (MIBoost) [41]: As an upgraded version of the AdaBoost algorithm, it takes into consideration the geometric mean of the posterior of instances inside a bag. Naturally, the class label of a bag is predicted in two steps. In the first step, the algorithm finds instance-level class probabilities for the separate instances in a bag. In the second step, it combines the instance-level probability forecasts into bag-level probability for assigning a label to this bag.
- Multi-Instance Support Vector Machine (MISVM) [42]: First, the algorithm assigns the class label of the bag to each instance in this bag as its initial class label. Afterward, it applies the SVM solution for all the instances in positive bags and then reassigns the class labels of instances based on the SVM result. The objective in MISVM can be written as follows:where b is the bias vector, w is the projection matrix, are the slack variables of the support vector machine, and is the class label of the training pattern .
- Multi-Instance Logistic Regression (MILR) [43]: It performs collective multi-instance assumption by using logistic regression (LR) when evaluating bag-level probabilities. The instance-level class probability with parameters is calculated as follows:where w is a vector of feature weights, b is a bias parameter, is the jth instance of the ith bag. The bag-level probability is estimated by using a softmax function, which combines the probabilities of the instances in the bag as follows:where is a constant related to the softmax approximation, is the posterior probability that the ith bag is positive for binary classification, and n is the number of bags in the training set.
- Multi-Instance Tree Inducer (MITI) [44]: This algorithm builds a decision tree in a best-first strategy by using a simple priority queue. It applies a splitting criterion to divide each internal node data point into subsets. At the beginning of the algorithm, a weight is assigned to each instance such that which is the inverse of the size of the bag b. After that, a weighted Gini-impurity metric is calculated for a set S as follows:where and denote the negative and positive instances in S, respectively.
- Multi-Instance Rule Inducer (MIRI) [45]: MIRI is an algorithm inspired by MITI. It is a multi-instance learner that benefits from partial MITI trees and generates a compact set of classification rules.
- Summary Statistics for Propositionalization (SimpleMI) [46]: This method maps the instances in a bag to a single feature vector by analyzing statistical properties. Therefore, the basic idea is to transform a bag into a vector form first and then classify it by using a standard learner.
- Multi-Instance Wrapper (MIWrapper) [47]: This algorithm assigns a weight to the instances in the bags. A class probability is calculated by the propositional model for each instance in the bag. After that, the predicted probabilities of instances are then averaged to assign a label to the bag.
- Citation K-Nearest Neighbours (CitationKNN) [48]: It is an adapted version of KNN for MIL problems. To predict the class label of a query bag, the algorithm considers not only the nearest bags (called references), but also other bags that regard the query bag as one of their nearest neighbors (called citers). CitationKNN uses the Hausdorff measure to calculate the distance between two bags as follows:where B and indicate two bags, i.e., and ; p and q are the number of instances in each bag, respectively; b and are two different feature vectors; and and are instances from each bag.
- Two-Level-Classification (TLC) [49]: In the first level, the instances in each bag are re-represented by a meta-instance by encoding the relationships among them. In the second level, the algorithm induces a function to capture the interactions between the meta-instance and the class label of the bag. TLC requires the selection of a partition generator (i.e., C4.5) and a classifier (i.e., LogitBoost) with decision stumps [50].
4. Experimental Studies
- Experiment 1—To show the superiority of MOMIL, we compared the multi-instance classification methods with their standard (single-instance) counterparts.
- Experiment 2—We determined the best MIL algorithm by comparing alternative ones.
- Experiment 3—We identified the most important factors that affect the victory in the matches in LoL.
4.1. Dataset Description
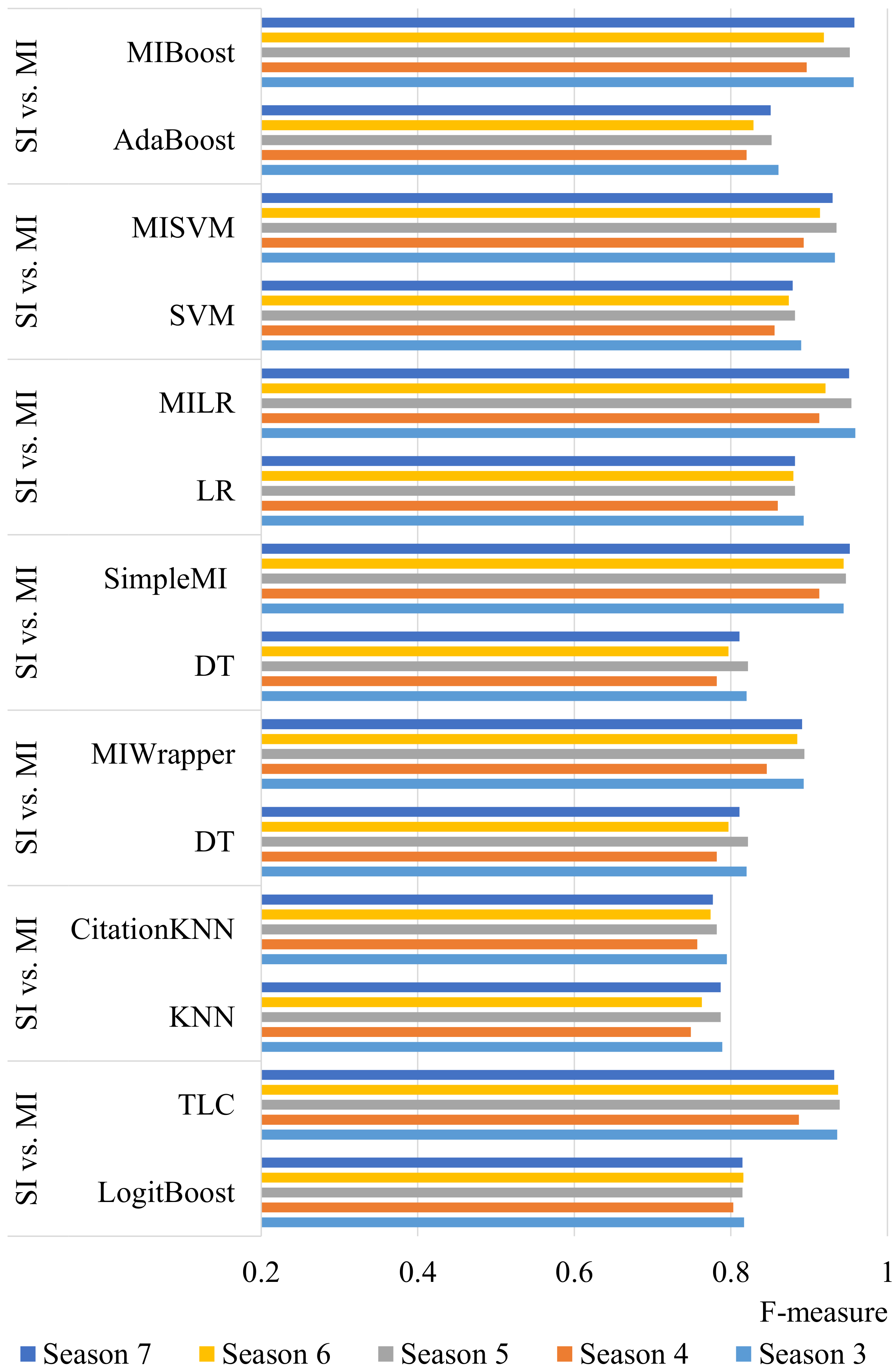
4.2. Comparison of Single-Instance and Multi-Instance Classification
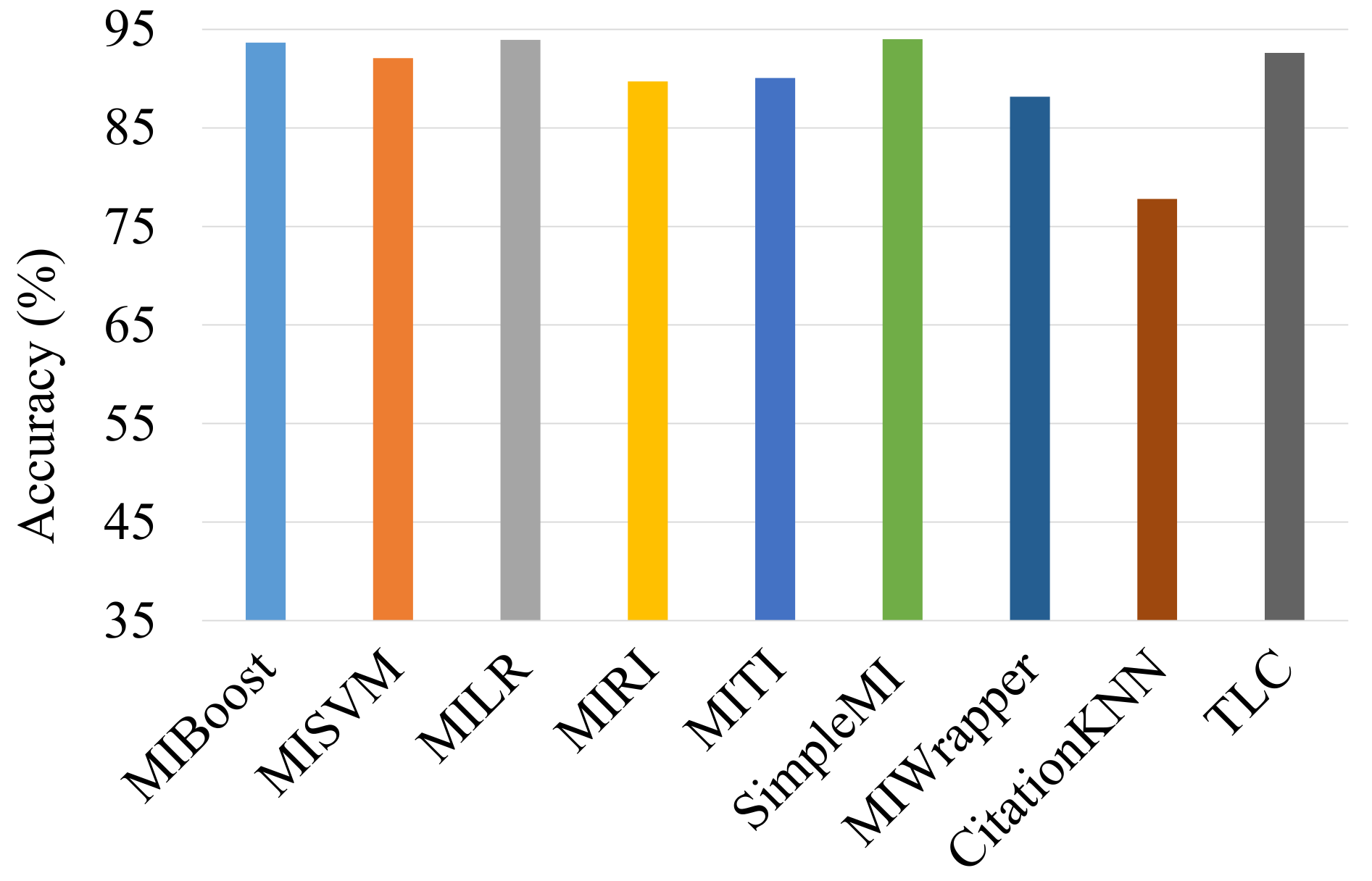
4.3. Comparison of Multi-Instance Classification Algorithms
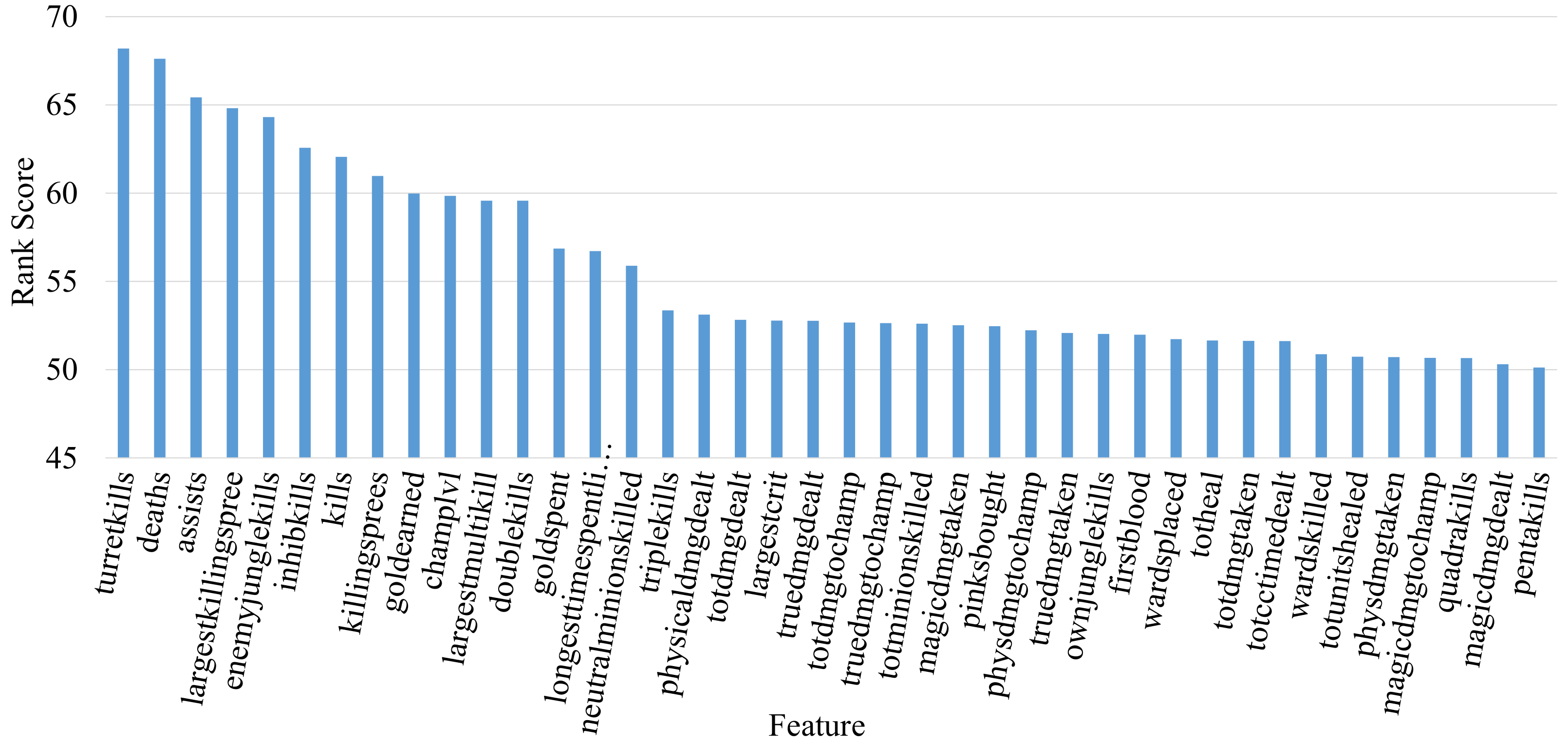
4.4. Factor Analysis
4.5. Comparison of Our Study with the State-of-the-Art Studies
5. Conclusions and Future Work
- The experimental results showed that the multi-instance-based classification approach outperformed the standard classification approach for winner prediction in terms of accuracy and F-measure.
- The proposed MOMIL approach achieved up to 95% accuracy for match outcome prediction in LoL seasons.
- Among multi-instance learning algorithms, the SimpleMI method achieved the highest accuracy in terms of the seasonal average. The MILR and MIBoost methods followed it.
- The most important factors for win prediction are the number of turret kills, deaths per min, and assists per minute.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Reitman, J.G.; Anderson-Coto, M.J.; Wu, M.; Lee, J.S.; Steinkuehler, C. Esports research: A literature review. Games Cult. 2020, 15, 32–50. [Google Scholar] [CrossRef]
- Schubert, M.; Drachen, A.; Mahlmann, T. Esports analytics through encounter detection. In Proceedings of the MIT Sloan Sports Analytics Conference, Boston, MA, USA, 11 March 2016; pp. 1–18. [Google Scholar]
- Saiz-Alvarez, J.M.; Palma-Ruiz, J.M.; Valles-Baca, H.G.; Fierro-Ramirez, L.A. Knowledge Management in the Esports Industry: Sustainability, Continuity, and Achievement of Competitive Results. Sustainability 2021, 13, 10890. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, R. Economic Sources behind the Esports Industry. In Proceedings of the 7th International Conference on Financial Innovation and Economic Development, Harbin, China, 14–16 January 2022; pp. 643–648. [Google Scholar]
- Keiper, M.C.; Manning, R.D.; Jenny, S.; Olrich, T.; Croft, C. No reason to LoL at LoL: The addition of esports to intercollegiate athletic departments. J. Study Sports Athletes Edu. 2017, 11, 143–160. [Google Scholar] [CrossRef]
- Hodge, V.J.; Devlin, S.; Sephton, N.; Block, F.; Cowling, P.; Drachen, A. Win prediction in multi-player esports: Live professional match prediction. IEEE Trans. Games 2021, 13, 368–379. [Google Scholar] [CrossRef] [Green Version]
- Xia, B.; Wang, H.; Zhou, R. What contributes to success in MOBA games? An empirical study of Defense of the Ancients 2. Games Cult. 2019, 14, 498–522. [Google Scholar] [CrossRef]
- Smerdov, A.; Somov, A.; Burnaev, E.; Zhou, B.; Lokuwicz, P. Detecting video game player burnout with the use of sensor data and machine learning. IEEE Internet Things J. 2021, 8, 16680–16691. [Google Scholar] [CrossRef]
- Maymin, P.Z. Smart kills and worthless deaths: ESports analytics for League of Legends. J. Quant. Anal. Sports 2021, 17, 11–27. [Google Scholar] [CrossRef]
- Viggiato, M.; Bezemer, C.-P. Trouncing in Dota 2: An investigation of blowout matches. In Proceedings of the 16th AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment, Worcester, MA, USA, 19–23 October 2020; pp. 294–300. [Google Scholar]
- Kho, L.C.; Kasihmuddin, M.S.M.; Mansor, M.A.; Sathasivam, S. Logic mining in League of Legends. Pertanika J. Sci. Technol. 2020, 28, 211–225. [Google Scholar]
- Kang, S.-K.; Lee, J.-H. An e-sports video highlight generator using win-loss probability model. In Proceedings of the 35th Annual ACM Symposium on Applied Computing, Brno, Czech Republic, 30 March–3 April 2020; pp. 915–922. [Google Scholar]
- Cardoso, G.M.M. Predicao do Resultado Utilizando KNN: Analise do Jogo League of Legends. Master’s Thesis, Instituto Federal de Educacao, Bambui, Brazil, 2019. [Google Scholar]
- Clark, N.; Macdonald, B.; Kloo, I. A Bayesian adjusted plus-minus analysis for the esport Dota 2. J. Quant. Anal. Sports 2020, 16, 325–341. [Google Scholar] [CrossRef]
- Sanchez-Ruiz, A.A.; Miranda, A. A machine learning approach to predict the winner in StarCraft based on influence maps. Entertain. Comput. 2017, 19, 29–41. [Google Scholar] [CrossRef]
- Smerdov, A.; Zhou, B.; Lukowicz, P.; Somov, A. Collection and validation of psycophysiological data from professional and amateur players: A multimodal esports dataset. arXiv 2021, arXiv:2011.00958. [Google Scholar]
- Khromov, N.; Korotin, A.; Lange, A.; Stepanov, A.; Burnaev, E.; Somov, A. Esports athletes and players: A comparative study. IEEE Pervasive Comput. 2019, 18, 31–39. [Google Scholar] [CrossRef]
- Liu, J.X.; Huang, J.X.; Chen, R.Y.; Liu, T.; Zhou, L. A two-stage real-time prediction method for multiplayer shooting e-sports. In Proceedings of the 20th International Conference on Electronic Business, Hong Kong, China, 5–8 December 2020; pp. 9–18. [Google Scholar]
- Katona, A.; Spick, R.; Hodge, V.J.; Demediuk, S.; Block, F.; Drachen, A.; Walker, J.A. Time to die: Death prediction in Dota 2 using deep learning. In Proceedings of the IEEE Conference on Games, London, UK, 20–23 August 2019; pp. 1–8. [Google Scholar]
- Carbonneau, M.-A.; Cheplygina, V.; Grangera, E.; Gagnon, G. Multiple instance learning: A survey of problem characteristics and applications. Pattern Recognit. 2018, 77, 329–353. [Google Scholar] [CrossRef] [Green Version]
- Li, S.; Duan, L.; Zhang, W.; Wang, W. Multi-attribute context-aware item recommendation method based on deep learning. In Proceedings of the 5th International Conference on Pattern Recognition and Artificial Intelligence, Chengdu, China, 19–21 August 2022; pp. 12–19. [Google Scholar]
- Duan, L.; Li, S.; Zhang, W.; Wang, W. MOBA game item recommendation via relationaware graph attention network. In Proceedings of the IEEE Conference on Games (CoG), Beijing, China, 21–24 August 2022; pp. 338–344. [Google Scholar]
- Villa, A.; Araujo, V.; Cattan, F.; Parra, D. Interpretable contextual team aware item recommendation application in multiplayer online battle arena games. In Proceedings of the 14th ACM Conference on Recommender Systems, Rio de Janeiro, Brazil, 22 September 2020; pp. 503–508. [Google Scholar]
- Araujo, V.; Rios, F.; Parra, D. Data mining for item recommendation in MOBA games. In Proceedings of the 13th ACM Conference on Recommender Systems, Copenhagen, Denmark, 16–20 September 2019; pp. 393–397. [Google Scholar]
- Ke, C.H.; Deng, H.; Xu, C.; Li, J.; Gu, X.; Yadamsuren, B.; Klabjan, D.; Sifa, R.; Drachen, A.; Demediuk, S. DOTA 2 match prediction through deep learning team fight models. In Proceedings of the IEEE Conference on Games, Beijing, China, 21–24 August 2022; pp. 96–103. [Google Scholar]
- Hitar-Garcia, J.-A.; Moran-Fernandez, L.; Bolon-Canedo, V. Machine Learning Methods for Predicting League of Legends Game Outcome. IEEE Trans. Games 2023, 1, 1–11. [Google Scholar] [CrossRef]
- Ghazali, N.F.; Sanat, N.; Asari, M.A. Esports analytics on playerunknown’s battlegrounds player placement prediction using machine learning approach. Int. J. Hum. Technol. Interact. 2021, 5, 1–10. [Google Scholar]
- Dikananda, A.R.; Ali, I.; Rinaldi, R.A. Genre e-sport gaming tournament classification using machine learning technique based on decision tree, naive Bayes, and random forest algorithm. In Proceedings of the Annual Conference on Computer Science and Engineering Technology, Medan, Indonesia, 23 September 2020; pp. 1–8. [Google Scholar]
- Demediuk, S.; York, P.; Drachen, A.; Walker, J.A.; Block, F. Role identification for accurate analysis in Dota 2. In Proceedings of the 15th AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment, Atlanta, Georgia, 8–12 October 2019; pp. 130–138. [Google Scholar]
- Mora-Cantallops, M.; Sicilia, M.-A. Player-centric networks in League of Legends. Soc. Netw. 2018, 55, 149–159. [Google Scholar] [CrossRef]
- Kadan, A.M.; Li, L.; Chen, T. Modeling and analysis of features of team play strategies in eSports applications. Mod. Inf. Technol. IT-Educ. 2018, 14, 397–407. [Google Scholar]
- Demediuk, S.; Murrin, A.; Bulger, D.; Hitchens, M.; Drachen, A.; Raffe, W.L.; Tamassia, M. Player retention in League of Legends: A study using survival analysis. In Proceedings of the Australasian Computer Science Week Multiconference, New York, NY, USA, 29 January–2 February 2018; pp. 1–9. [Google Scholar]
- Yao, W.; Wang, Y.; Zhu, M.; Cao, Y.; Zeng, D. Goal or Miss? A Bernoulli Distribution for In-Game Outcome Prediction in Soccer. Entropy 2022, 24, 971. [Google Scholar] [CrossRef]
- Li, S.-F.; Huang, M.-L.; Li, Y.-Z. Exploring and Selecting Features to Predict the Next Outcomes of MLB Games. Entropy 2022, 24, 288. [Google Scholar] [CrossRef]
- Xiang, Y.; Chen, Q.; Wang, X.; Qin, Y. Distant Supervision for Relation Extraction with Ranking-Based Methods. Entropy 2016, 18, 204. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Z.; Zhao, Y. Multi-Graph Multi-Label Learning Based on Entropy. Entropy 2018, 20, 245. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Deng, W.; Ni, H.; Liu, Y.; Chen, H.; Zhao, H. An adaptive differential evolution algorithm based on belief space and generalized opposition-based learning for resource allocation. Appl. Soft Comput. 2022, 127, 109419. [Google Scholar] [CrossRef]
- Deng, W.; Zhang, L.; Zhou, X.; Zhou, Y.; Sun, Y.; Zhu, W.; Chen, H.; Deng, W.; Chen, H.; Zhao, H. Multi-strategy particle swarm and ant colony hybrid optimization for airport taxiway planning problem. Inf. Sci. 2022, 612, 576–593. [Google Scholar] [CrossRef]
- Lan, X.; Duan, L.; Chen, W.; Qin, R.; Nummenmaa, T.; Nummenmaa, J. A Player Behavior Model for Predicting Win-Loss Outcome in MOBA Games. Proceedings of 14th International Conference on Advanced Data Mining and Applications, Nanjing, China, 16–18 November 2018; pp. 474–488. [Google Scholar]
- Gu, Y.; Liu, Q.; Zhang, K.; Huang, Z.; Wu, R.; Tao, J. NeuralAC: Learning Cooperation and Competition Effects for Match Outcome Prediction. In Proceedings of the 35th AAAI Conference on Artificial Intelligence, Palo Alto, CA, USA, 2–9 February 2021; pp. 4072–4080. [Google Scholar]
- Xu, X.; Frank, E. Logistic regression and boosting for labeled bags of instances. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 26–28 May 2004; pp. 272–281. [Google Scholar]
- Andrews, S.; Tsochantaridis, I.; Hofmann, T. Support vector machines for multiple-instance learning. In Proceedings of the 15th International Conference on Neural Information Processing Systems, Cambridge, MA, USA, 9–14 December 2002; pp. 577–584. [Google Scholar]
- Ray, S.; Craven, M. Supervised versus multiple instance learning: An empirical comparison. In Proceedings of the 22nd International Conference on Machine Learning, New York, NY, USA, 7–11 August 2005; pp. 697–704. [Google Scholar]
- Blockeel, H.; Page, D.; Srinivasan, A. Multi-instance tree learning. In Proceedings of the 22nd International Conference on Machine Learning, New York, NY, USA, 7 August 2005; pp. 57–64. [Google Scholar]
- Bjerring, L.; Frank, E. Beyond trees: Adopting MITI to learn rules and ensemble classifiers for multi-instance data. In Proceedings of the Australasian Joint Conference on Artificial Intelligence, Perth, Australia, 5–8 December 2011; pp. 41–50. [Google Scholar]
- Dong, L. A comparison of multi-instance learning algorithms. Master’s Thesis, The University of Waikato, Hamilton, New Zealand, 2006. [Google Scholar]
- Frank, E.; Xu, X. Applying Propositional Learning Algorithms to Multi-Instance Data; Technical Report; University of Waikato: Hamilton, New Zealand, 2003. [Google Scholar]
- Wang, J.; Zucker, J. Solving the multiple-instance problem: A lazy learning approach. In Proceedings of the International Conference on Machine Learning, San Francisco, CA, USA, 29 June–2 July 2000; pp. 1119–1126. [Google Scholar]
- Weidmann, N.; Frank, E.; Pfahringer, B. A two-level learning method for generalized multi-instance problems. In Proceedings of the European Conference on Machine Learning, Dubrovnik, Croatia, 22–26 September 2003; pp. 468–479. [Google Scholar]
- Witten, I.H.; Frank, E.; Hall, M.A. Data Mining: Practical Machine Learning Tools and Techniques; Morgan Kaufmann: Cambridge, MA, USA, 2016. [Google Scholar]
- Yu, Y.; Hao, Z.; Li, G.; Liu, Y.; Yang, R.; Liu, H. Optimal search mapping among sensors in heterogeneous smart homes. Math. Biosci. Eng. 2022, 20, 1960–1980. [Google Scholar] [CrossRef]
- Do, T.D.; Wang, S.I.; Yu, D.S.; McMillian, M.G.; McMahan, R.P. Using Machine Learning to Predict Game Outcomes Based on Player-Champion Experience in League of Legends. In Proceedings of the 16th International Conference on the Foundations of Digital GamesAugust, Montreal, QC, Canada, 3–6 August 2021; pp. 1–5. [Google Scholar]
- Kim, C.; Lee, S. Predicting Win-Loss of League of Legends Using Bidirectional LSTM Embedding. KIPS Trans. Software Data Eng. 2020, 9, 61–68. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Year | Description | Task | Algorithm | Game | MIL | Season | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| CF | R | CL | LoL | Dota2 | Other | Based | |||||
| [26] | 2023 | Predicting match outcome | √ | SVM, NB, KNN, NN | √ | X | X | ||||
| [25] | 2022 | Predicting match outcome | √ | LSTM | √ | X | X | ||||
| [8] | 2021 | Predicting whether the player will win or lose | √ | LR, KNN, NN | √ | X | X | ||||
| [9] | 2021 | Predicting in-game win probability | √ | LR | √ | X | X | ||||
| [27] | 2021 | Predicting the placement of players | √ | DT, LR, SVM | PUBG | X | X | ||||
| [28] | 2021 | Classifying eSports games | √ | DT, NB, RF | √ | √ | CS | X | X | ||
| [14] | 2020 | Predicting match outcome | √ | BHR | √ | X | X | ||||
| [11] | 2020 | Modelling the results (win/lose) of the game | √ | NN | √ | X | X | ||||
| [16] | 2020 | Predicting the player skill and re-identification | √ | LR, KNN, SVM, RF, NB | √ | X | X | ||||
| [12] | 2020 | Predicting match outcome | √ | CNN, NN, CART | √ | X | X | ||||
| [18] | 2020 | Predicting the players’ rankings | √ | RF, GBM | PUBG | X | X | ||||
| [10] | 2020 | Predicting match outcome | √ | GBM, RF, LR | √ | X | X | ||||
| [23] | 2020 | Recommending items | √ | DT, LR, NN, CNN | √ | X | X | ||||
| [13] | 2019 | Predicting match outcome | √ | KNN | √ | X | X | ||||
| [29] | 2019 | Identifying roles | √ | K-Means | √ | X | X | ||||
| [17] | 2019 | Predicting the player skill | √ | ERT | CS | X | X | ||||
| [7] | 2019 | Predicting match outcome | √ | CART, LR | √ | X | X | ||||
| [6] | 2019 | Predicting match outcome | √ | LR, RF, GBM | √ | X | X | ||||
| [19] | 2019 | Predicting a player will die in the next 5 s | √ | DNN | √ | X | X | ||||
| [24] | 2019 | Recommending items | √ | Apriori, Eclat, DT, LR, NN | √ | X | X | ||||
| [30] | 2018 | Clustering player-centric networks | √ | Affinity Propagation | √ | X | X | ||||
| [31] | 2018 | Predicting round results | √ | DT, RF, KNN, PCA | CS | X | X | ||||
| [32] | 2018 | Predicting player churn | √ | MECR | √ | X | X | ||||
| [15] | 2017 | Predicting match outcome | √ | LDA, QDA, SVM, KNN, Weighted KNN | Star Craft | X | X | ||||
| Proposed | Predicting match outcome | √ | MIBoost, MISVM, MILR, MIRI, MITI, SimpleMI, MIWrapper, CitationKNN, TLC | √ | √ | √ | |||||
| MIBoost | AdaBoost | MISVM | SVM | MILR | LR | SimpleMI | DT | |
|---|---|---|---|---|---|---|---|---|
| Season 3 | 95.69 | 86.09 | 93.28 | 88.99 | 95.88 | 89.32 | 94.45 | 81.98 |
| Season 4 | 89.68 | 81.98 | 89.28 | 85.58 | 91.29 | 86.03 | 91.29 | 78.18 |
| Season 5 | 95.23 | 85.16 | 93.45 | 88.22 | 95.39 | 88.19 | 94.74 | 82.16 |
| Season 6 | 91.87 | 82.87 | 91.37 | 87.41 | 92.07 | 88.01 | 94.38 | 79.74 |
| Season 7 | 95.88 | 85.06 | 93.03 | 87.92 | 95.06 | 88.17 | 95.21 | 81.14 |
| MIWrapper | DT | Citation KNN | KNN | TLC | Logit Boost | |||
| Season 3 | 89.26 | 81.98 | 79.53 | 78.92 | 93.63 | 81.75 | ||
| Season 4 | 84.58 | 78.18 | 75.87 | 74.91 | 88.74 | 80.27 | ||
| Season 5 | 89.43 | 82.16 | 78.27 | 78.71 | 93.93 | 81.50 | ||
| Season 6 | 88.55 | 79.74 | 77.51 | 76.37 | 93.67 | 81.61 | ||
| Season 7 | 89.06 | 81.14 | 77.76 | 78.70 | 93.16 | 81.49 |
| Ref. | Year | Algorithm | Existing Method | Proposed Method |
|---|---|---|---|---|
| F-Measure | F-Measure | |||
| [21] | 2022 | Multi-attribute Context-aware Item Rec. (MCIR) | 0.616 | 0.903 |
| F-Measure | F-Measure | |||
| [22] | 2022 | Relation-aware Graph Attention Network | 0.626 | 0.903 |
| F-Measure | F-Measure | |||
| [23] | 2020 | Decision Tree Logistic Regression Artificial Neural Network Convolutional Neural Networks Team-aware Transformer-based Item Rec. (TTIR) | 0.379 0.468 0.566 0.586 0.596 | 0.903 |
| F-Measure | F-Measure | |||
| [24] | 2019 | Apriori Equivalence Class Transform. Decision Tree Logistic Regression Artificial Neural Network | 0.48 0.48 0.38 0.43 0.53 | 0.903 |
| Accuracy | Accuracy | |||
| [13] | 2019 | K-Nearest Neighbors | 58.00% | 90.23% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Birant, K.U.; Birant, D. Multi-Objective Multi-Instance Learning: A New Approach to Machine Learning for eSports. Entropy 2023, 25, 28. https://doi.org/10.3390/e25010028
Birant KU, Birant D. Multi-Objective Multi-Instance Learning: A New Approach to Machine Learning for eSports. Entropy. 2023; 25(1):28. https://doi.org/10.3390/e25010028
Chicago/Turabian StyleBirant, Kokten Ulas, and Derya Birant. 2023. "Multi-Objective Multi-Instance Learning: A New Approach to Machine Learning for eSports" Entropy 25, no. 1: 28. https://doi.org/10.3390/e25010028
APA StyleBirant, K. U., & Birant, D. (2023). Multi-Objective Multi-Instance Learning: A New Approach to Machine Learning for eSports. Entropy, 25(1), 28. https://doi.org/10.3390/e25010028