



Convolutional Models with Multi-Feature Fusion for Effective Link Prediction in Knowledge Graph Embedding


Abstract
:1. Introduction
- We innovatively introduce convolutional operators to knowledge graph embedding (KGE) link prediction. This advancement bridges the gap between the shortcomings of shallow and densely connected architectures, harnessing the benefits of convolutional operators, such as parameter efficiency, superior scalability, robustness against overfitting, and the flexibility to craft intricate models deciphering complex relationships in knowledge graphs.
- We propose assimilating graph structure information into the convolutional framework. By leveraging edges constructed from co-occurrence patterns or a broader graph structure, our model incorporates the rich context of neighboring entity information. The introduction of a new graph structure task and the provision to integrate edge information in the convolutional input further bolster the model’s predictive prowess.
2. Related Work
2.1. Graph-Based Neural Networks for Knowledge Graph Embeddings
2.2. Applications of Convolutional Neural Networks in Various Domains
3. Methodology
3.1. Problem Statement
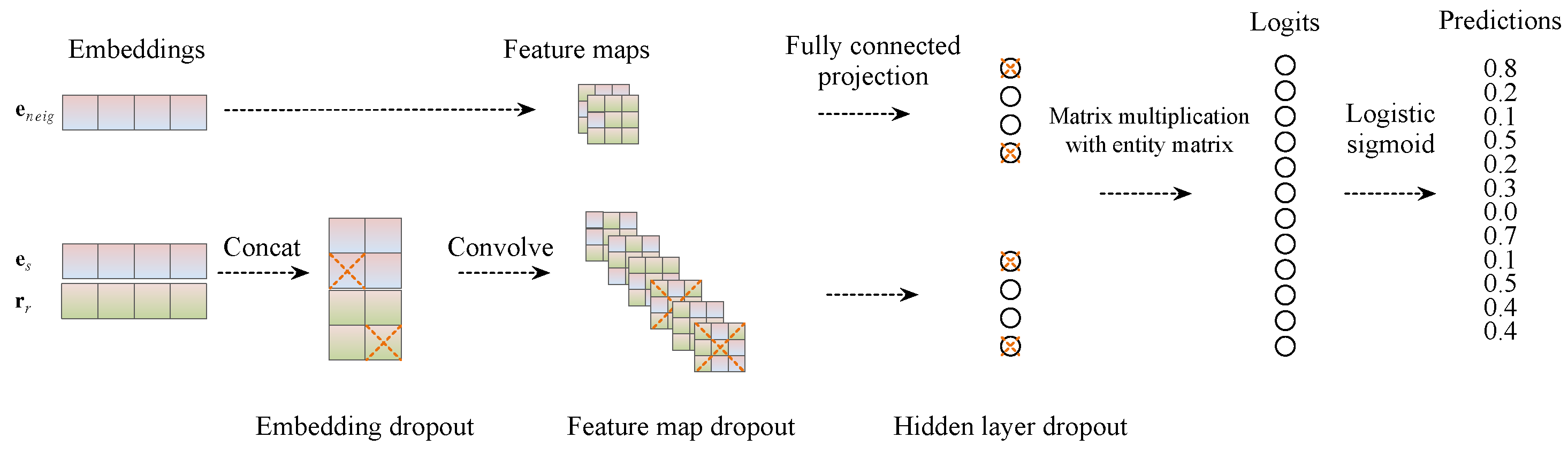
3.2. Convolutional 2D Knowledge Graph Embeddings
3.2.1. Motivation for Incorporating Neighboring Information
- Richer semantic capturing: Each entity’s relationship with its neighbors provides valuable semantic information that is otherwise overlooked if only direct embeddings are used. By tapping into this, we ensure that subtler, context-specific nuances in relationships are captured.
- Enhanced predictive power: Knowledge graphs often have complex and interwoven relationships. Considering the surrounding context (i.e., neighboring entities), our model gains more predictive power, especially in densely interconnected graph regions where simple entity–relation–entity predictions might be ambiguous.
- Robustness to sparse data: In scenarios where certain entities have limited direct relationships, leveraging neighboring information can supplement the lack of direct data, making predictions more robust and informed.
- Model generalization: Incorporating neighboring information can lead to better generalization. By understanding the broader context in which an entity exists, the model is less likely to overfit specific triples and can generalize better to unseen or rare triples.
- Handling dynamic knowledge graphs: Entities may form new relationships as knowledge graphs evolve. A model cognizant of neighboring contexts can adapt more swiftly to such changes, ensuring that predictions remain relevant even as the graph’s topology evolves.
3.2.2. Extraction and Processing of Neighbor Information
- Direct convolution with neighbor nodes.
- Convolution with the average embedding of neighbor nodes, wherein we first calculate embeddings for each neighbor and then compute their average. This is designed considering potential weight differences amongst neighbors.
3.2.3. Detailed Feed-Forward Process
3.2.4. Rationale behind 2D Convolution
- Pattern recognition: Traditional embeddings, while effective, may fail to capture intricate patterns when considering higher dimensions. Two-dimensional convolutions excel in identifying localized patterns within embeddings, which better captures nuanced relationships between entities in the context of knowledge graphs.
- Spatial hierarchies: Two-dimensional convolutional layers can identify hierarchical structures within the embedding space. This is particularly important in knowledge graphs, where relationships can have hierarchical or layered nuances. For instance, “being a part of” versus “being affiliated with” might manifest differently in the embedding space, and 2D convolutions can tease these differences.
- Parameter efficiency: By reshaping embeddings into 2D structures and applying convolutions, the model can capture spatial relationships with fewer parameters than fully connected layers. This can lead to faster training and less overfitting.
- Translational invariance: One of the hallmark features of convolutional layers is their ability to detect features irrespective of their position in the input. In the context of our embeddings, this ensures that important relational cues are captured irrespective of their positioning within the high-dimensional space.
- Adaptive feature learning: Two-dimensional convolutions automatically learn features from the data rather than relying on handcrafted features. This adaptability is essential in knowledge graphs, where the diversity of relationships and entities can be vast and unpredictable.
3.3. Loss Function
4. Experiments
4.1. Knowledge Graph Datasets
4.2. Experimental Setup
4.3. Results and Analysis
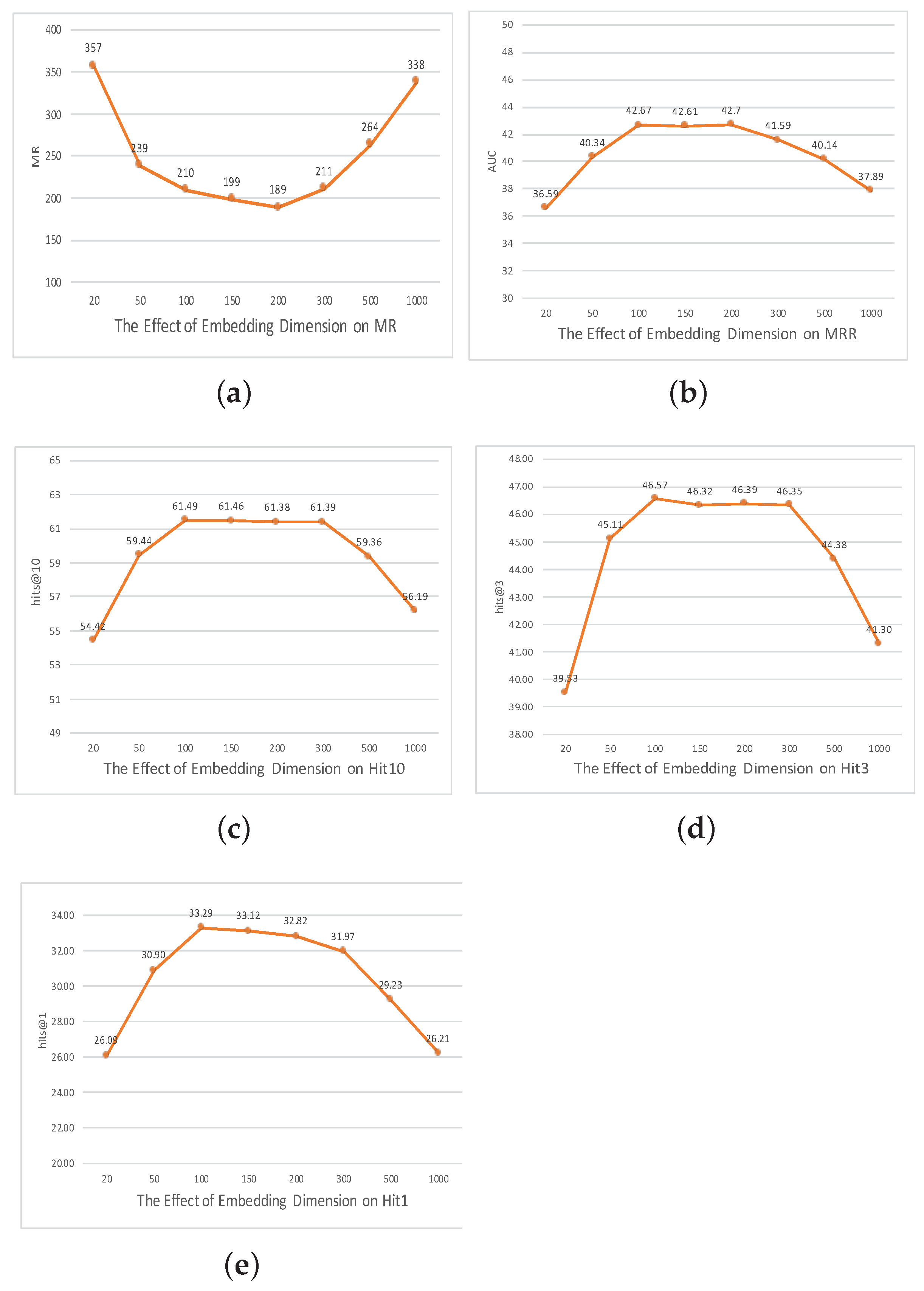
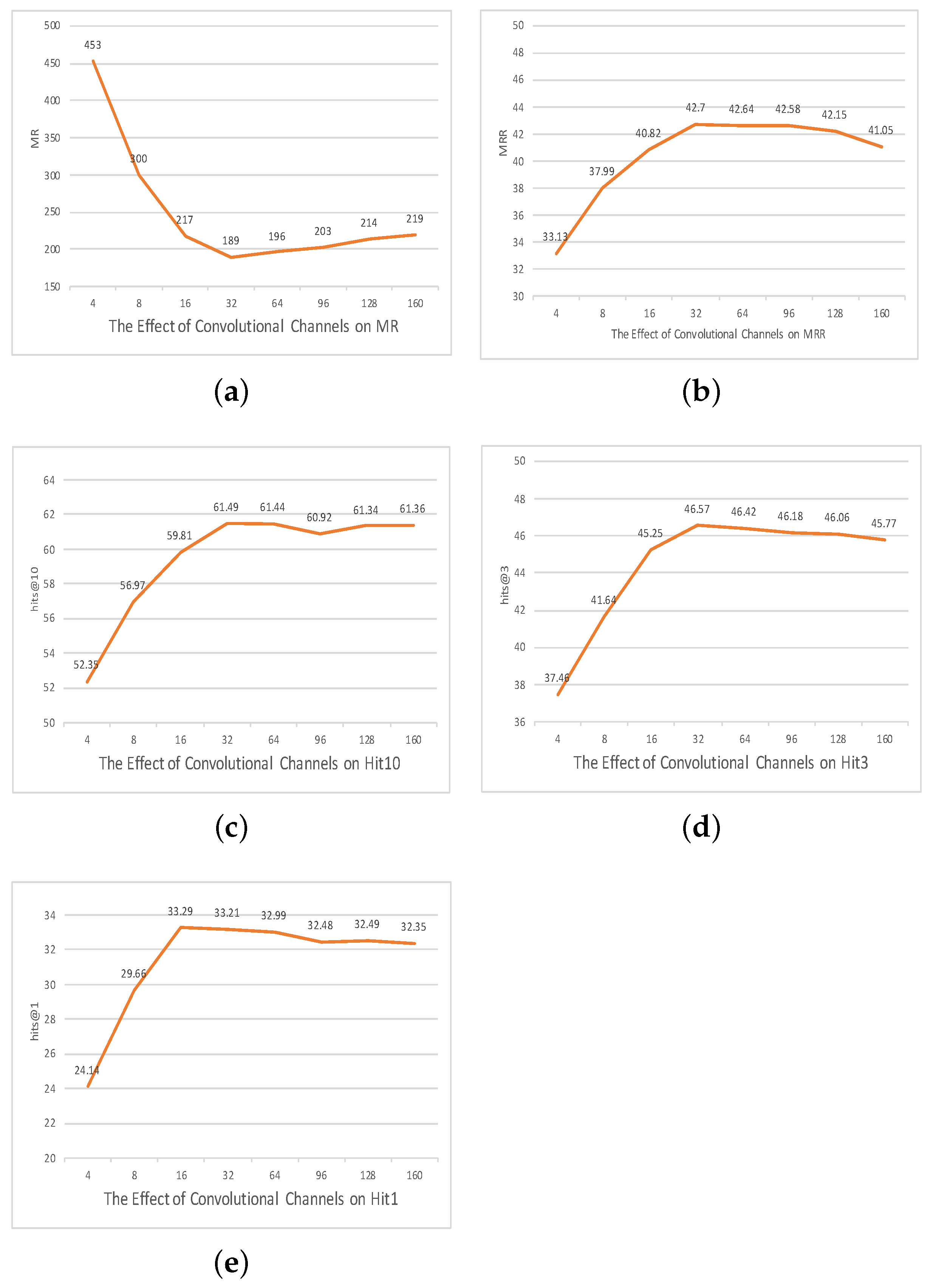
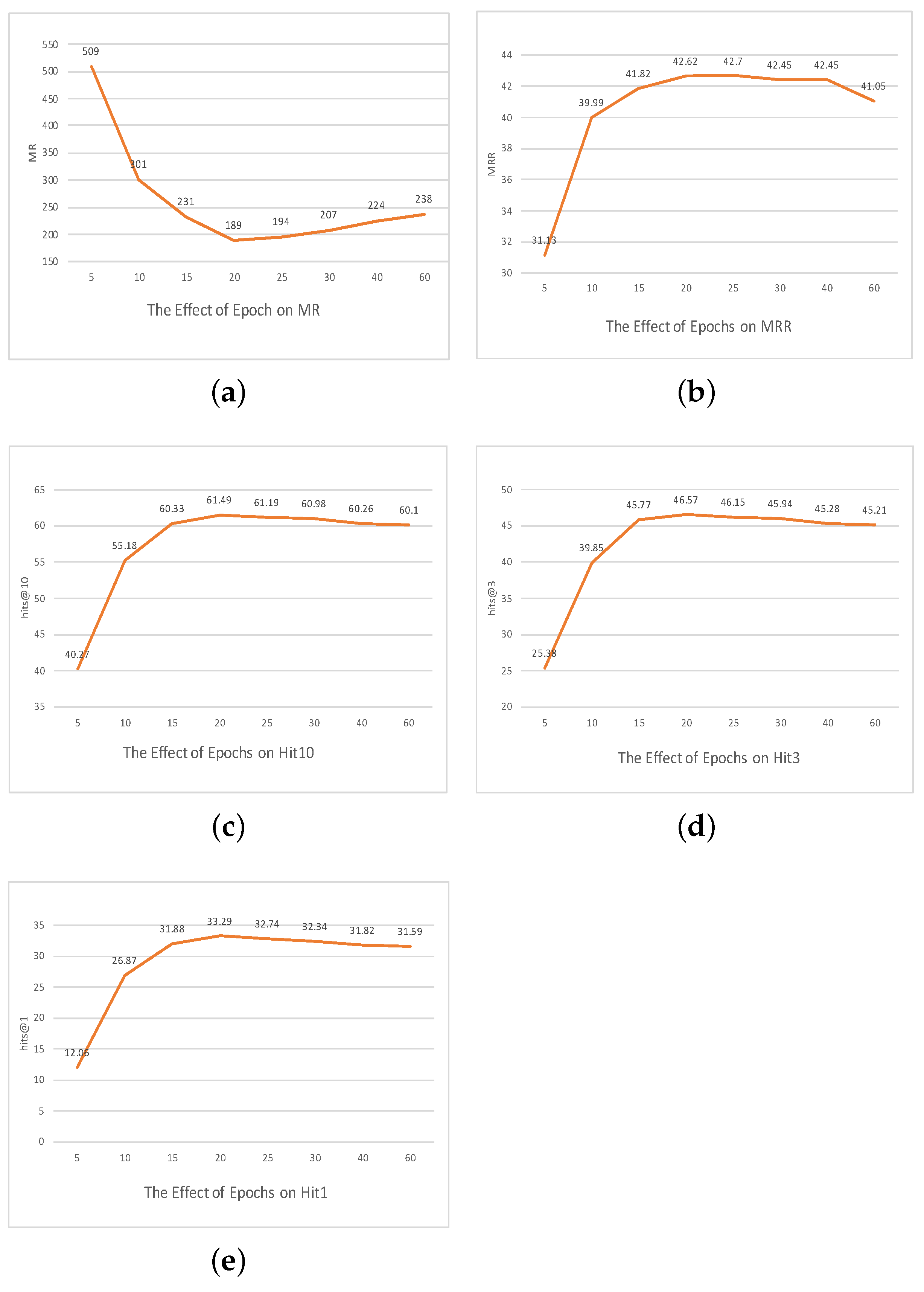
5. Ablation Study
The Effect of Parameters
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kumar, A.; Singh, S.S.; Singh, K.; Biswas, B. Link prediction techniques, applications, and performance: A survey. Phys. Stat. Mech. Appl. 2020, 553, 124289. [Google Scholar] [CrossRef]
- Wang, Q.; Mao, Z.; Wang, B.; Guo, L. Knowledge graph embedding: A survey of approaches and applications. IEEE Trans. Knowl. Data Eng. 2017, 29, 2724–2743. [Google Scholar] [CrossRef]
- Yu, Q.; Li, Z.; Sheng, J.; Sun, J.; Slamu, W. YuQ: A Chinese-Uyghur Medical-Domain Neural Machine Translation Dataset Towards Knowledge-Driven. In Proceedings of the Machine Translation: 16th China Conference, CCMT 2020, Hohhot, China, 10–12 October 2020; Revised Selected Papers 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 37–54. [Google Scholar]
- Wang, H.; Cui, Z.; Liu, R.; Fang, L.; Sha, Y. A Multi-type Transferable Method for Missing Link Prediction in Heterogeneous Social Networks. IEEE Trans. Knowl. Data Eng. 2023, 35, 10981–10991. [Google Scholar] [CrossRef]
- Ke, Z.; Li, Z.; Zhou, C.; Sheng, J.; Silamu, W.; Guo, Q. Rumor detection on social media via fused semantic information and a propagation heterogeneous graph. Symmetry 2020, 12, 1806. [Google Scholar] [CrossRef]
- Ke, Z.; Sheng, J.; Li, Z.; Silamu, W.; Guo, Q. Knowledge-guided sentiment analysis via learning from natural language explanations. IEEE Access 2021, 9, 3570–3578. [Google Scholar] [CrossRef]
- Su, Z.; Zheng, X.; Ai, J.; Shen, Y.; Zhang, X. Link prediction in recommender systems based on vector similarity. Phys. Stat. Mech. Appl. 2020, 560, 125154. [Google Scholar] [CrossRef]
- Yang, Z.; Wang, Y.; Liu, G.; Li, Z.; Wang, X. Recommendation model based on multi-grained interaction that fuses users’ dynamic interests. Int. J. Mach. Learn. Cybern. 2023, 14, 3071–3085. [Google Scholar] [CrossRef]
- Zheng, K.; Zhang, X.L.; Wang, L.; You, Z.H.; Ji, B.Y.; Liang, X.; Li, Z.W. SPRDA: A link prediction approach based on the structural perturbation to infer disease-associated Piwi-interacting RNAs. Briefings Bioinform. 2023, 24, bbac498. [Google Scholar] [CrossRef]
- Baghershahi, P.; Hosseini, R.; Moradi, H. Self-attention presents low-dimensional knowledge graph embeddings for link prediction. Knowl.-Based Syst. 2023, 260, 110124. [Google Scholar] [CrossRef]
- He, Z.; Yu, J.; Gu, T.; Li, Z.; Du, X.; Li, P. Query cost estimation in graph databases via emphasizing query dependencies by using a neural reasoning network. Concurr. Comput. Pract. Exp. 2023, 35, e7817. [Google Scholar] [CrossRef]
- Li, Z.; Li, X.; Sheng, J.; Slamu, W. AgglutiFiT: Efficient low-resource agglutinative language model fine-tuning. IEEE Access 2020, 8, 148489–148499. [Google Scholar] [CrossRef]
- Li, X.; Li, Z.; Sheng, J.; Slamu, W. Low-resource text classification via cross-lingual language model fine-tuning. In Proceedings of the China National Conference on Chinese Computational Linguistics, Hainan, China, 30 October–1 November 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 231–246. [Google Scholar]
- Li, Z.; Maimaiti, M.; Sheng, J.; Ke, Z.; Silamu, W.; Wang, Q.; Li, X. An empirical study on deep neural network models for chinese dialogue generation. Symmetry 2020, 12, 1756. [Google Scholar] [CrossRef]
- Sheng, J.; Wumaier, A.; Li, Z. Poise: Efficient cross-domain Chinese named entity recognization via transfer learning. Symmetry 2020, 12, 1673. [Google Scholar] [CrossRef]
- Zhang, Z.; Cai, Y.; Gong, W. Semi-supervised learning with graph convolutional extreme learning machines. Expert Syst. Appl. 2023, 213, 119164. [Google Scholar] [CrossRef]
- Dai, T.; Zhao, J.; Li, D.; Tian, S.; Zhao, X.; Pan, S. Heterogeneous deep graph convolutional network with citation relational BERT for COVID-19 inline citation recommendation. Expert Syst. Appl. 2023, 213, 118841. [Google Scholar] [CrossRef]
- Kamigaito, H.; Hayashi, K. Comprehensive analysis of negative sampling in knowledge graph representation learning. In Proceedings of the International Conference on Machine Learning. PMLR, Baltimore, MA, USA, 17–23 July 2022; pp. 10661–10675. [Google Scholar]
- Yang, Z.; Ding, M.; Zhou, C.; Yang, H.; Zhou, J.; Tang, J. Understanding negative sampling in graph representation learning. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual, 6–10 July 2020; pp. 1666–1676. [Google Scholar]
- Chen, X.; Jiang, J.Y.; Wang, W. Scalable Graph Representation Learning via Locality-Sensitive Hashing. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management, Atlanta, GA, USA, 17–21 October 2022; pp. 3878–3882. [Google Scholar]
- Wang, M.; Qiu, L.; Wang, X. A survey on knowledge graph embeddings for link prediction. Symmetry 2021, 13, 485. [Google Scholar] [CrossRef]
- Yang, B.; Yih, S.W.t.; He, X.; Gao, J.; Deng, L. Embedding Entities and Relations for Learning and Inference in Knowledge Bases. In Proceedings of the International Conference on Learning Representations (ICLR) 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Trouillon, T.; Welbl, J.; Riedel, S.; Gaussier, É.; Bouchard, G. Complex embeddings for simple link prediction. In Proceedings of the International Conference on Machine Learning. PMLR, New York, NY, USA, 20–22 June 2016; pp. 2071–2080. [Google Scholar]
- Trivedi, R.; Dai, H.; Wang, Y.; Song, L. Know-evolve: Deep temporal reasoning for dynamic knowledge graphs. In Proceedings of the International Conference on Machine Learning. PMLR, Sydney, Australia, 6–11 August 2017; pp. 3462–3471. [Google Scholar]
- Pareja, A.; Domeniconi, G.; Chen, J.; Ma, T.; Suzumura, T.; Kanezashi, H.; Kaler, T.; Schardl, T.; Leiserson, C. Evolvegcn: Evolving graph convolutional networks for dynamic graphs. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 5363–5370. [Google Scholar]
- Nickel, M.; Rosasco, L.; Poggio, T. Holographic embeddings of knowledge graphs. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning. PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11976–11986. [Google Scholar]
- Dettmers, T.; Minervini, P.; Stenetorp, P.; Riedel, S. Convolutional 2d knowledge graph embeddings. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Liu, Z. Knowledge Graph Embedding with Graph Convolutional Networks and Attention Mechanisms. arXiv 2022, arXiv:2203.10456. [Google Scholar]
- Zhang, Y. Hierarchical Graph Convolutional Networks for Knowledge Graph Embeddings. arXiv 2022, arXiv:2204.05678. [Google Scholar]
- Li, L.; Wang, Z. Knowledge Relation Rank Enhanced Heterogeneous Learning Interaction Modeling for Neural Graph Forgetting Knowledge Tracing. arXiv 2023, arXiv:2304.03945. [Google Scholar]
- Kikuta, D.; Suzumura, T.; Rahman, M.M.; Hirate, Y.; Abrol, S.; Kondapaka, M.; Ebisu, T.; Loyola, P. KQGC: Knowledge Graph Embedding with Smoothing Effects of Graph Convolutions for Recommendation. arXiv 2022, arXiv:2205.12102. [Google Scholar]
- Wang, J. Knowledge Graph Embeddings with Conv2D Layers. arXiv 2022, arXiv:2205.02345. [Google Scholar]
- Liu, H. Graph Neural Networks for Knowledge Graph Embeddings with Convolutional Layers. arXiv 2022, arXiv:2206.01456. [Google Scholar]
- Zhang, X.; Wen, S.; Yan, L.; Feng, J.; Xia, Y. A hybrid-convolution spatial–temporal recurrent network for traffic flow prediction. Comput. J. 2022, bxac171. [Google Scholar] [CrossRef]
- Shen, Y.; Ding, N.; Zheng, H.T.; Li, Y.; Yang, M. Modeling relation paths for knowledge graph completion. IEEE Trans. Knowl. Data Eng. 2020, 33, 3607–3617. [Google Scholar] [CrossRef]
- Lu, S.; Ding, Y.; Liu, M.; Yin, Z.; Yin, L.; Zheng, W. Multiscale feature extraction and fusion of image and text in VQA. Int. J. Comput. Intell. Syst. 2023, 16, 54. [Google Scholar] [CrossRef]
- Guo, F.; Zhou, W.; Lu, Q.; Zhang, C. Path extension similarity link prediction method based on matrix algebra in directed networks. Comput. Commun. 2022, 187, 83–92. [Google Scholar] [CrossRef]
- Wu, D.; He, Y.; Luo, X. A Graph-Incorporated Latent Factor Analysis Model for High-Dimensional and Sparse Data. IEEE Trans. Emerg. Top. Comput. 2023, 1–12. [Google Scholar] [CrossRef]
- Wu, D.; Zhang, P.; He, Y.; Luo, X. A double-space and double-norm ensembled latent factor model for highly accurate web service QoS prediction. IEEE Trans. Serv. Comput. 2022, 16, 802–814. [Google Scholar] [CrossRef]
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating embeddings for modeling multi-relational data. Adv. Neural Inf. Process. Syst. 2013, 26. [Google Scholar]
- Mahdisoltani, F.; Biega, J.; Suchanek, F. Yago3: A knowledge base from multilingual wikipedias. In Proceedings of the 7th Biennial Conference on Innovative Data Systems Research. CIDR Conference, Asilomar, CA, USA, 4–7 January 2014. [Google Scholar]
- Niepert, M. Discriminative gaifman models. arXiv 2016, arXiv:1610.09369. [Google Scholar]
- Liu, H.; Wu, Y.; Yang, Y. Analogical inference for multi-relational embeddings. In Proceedings of the International Conference on Machine Learning. PMLR, Sydney, NSW, Australia, 6–11 August 2017; pp. 2168–2178. [Google Scholar]
- Schlichtkrull, M.; Kipf, T.N.; Bloem, P.; Van Den Berg, R.; Titov, I.; Welling, M. Modeling relational data with graph convolutional networks. In Proceedings of the Semantic Web: 15th International Conference, ESWC 2018, Heraklion, Crete, Greece, 3–7 June 2018; Proceedings 15. Springer: Berlin/Heidelberg, Germany, 2018; pp. 593–607. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| WN18 | FB15k | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Hits | Hits | |||||||||
| MR | MRR | @10 | @3 | @1 | MR | MRR | @10 | @3 | @1 | |
| TransE [42] | - | 0.495 | 0.943 | 0.888 | 0.113 | - | 0.463 | 0.749 | 0.578 | 0.297 |
| DistMult [22] | 902 | 0.822 | 0.936 | 0.914 | 0.728 | 97 | 0.654 | 0.824 | 0.733 | 0.546 |
| CompEx [23] | - | 0.941 | 0.947 | 0.936 | 0.936 | - | 0.692 | 0.840 | 0.759 | 0.599 |
| Gaifman [44] | 352 | - | 0.939 | - | 0.761 | 75 | - | 0.842 | - | 0.692 |
| ANALOGY [45] | - | 0.942 | 0.947 | 0.944 | 0.939 | - | 0.725 | 0.854 | 0.785 | 0.646 |
| R-GCN [46] | - | 0.814 | 0.964 | 0.929 | 0.697 | - | 0.696 | 0.842 | 0.760 | 0.601 |
| ConvE [29] | 374 | 0.943 | 0.956 | 0.946 | 0.935 | 51 | 0.657 | 0.831 | 0.723 | 0.558 |
| Ours | 293 | 0.954 | 0.962 | 0.951 | 0.942 | 47 | 0.717 | 0.884 | 0.788 | 0.711 |
| WN18RR | FB15k-237 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Hits | Hits | |||||||||
| MR | MRR | @10 | @3 | @1 | MR | MRR | @10 | @3 | @1 | |
| TransE [42] | - | 0.23 | 0.52 | 0.36 | 0.06 | - | 0.310 | 0.495 | 0.345 | 0.218 |
| DistMult [22] | 5110 | 0.43 | 0.49 | 0.44 | 0.39 | 254 | 0.241 | 0.419 | 0.263 | 0.155 |
| ComplEx [23] | 5261 | 0.44 | 0.51 | 0.46 | 0.41 | 339 | 0.247 | 0.428 | 0.275 | 0.158 |
| R-GCN [46] | - | - | - | - | - | - | 0.248 | 0.417 | 0.258 | 0.153 |
| ConvE [29] | 4187 | 0.43 | 0.52 | 0.44 | 0.40 | 244 | 0.325 | 0.501 | 0.356 | 0.237 |
| Ours | 3245 | 0.47 | 0.51 | 0.47 | 0.44 | 189 | 0.427 | 0.615 | 0.466 | 0.333 |
| YAGO3-10 | |||||
|---|---|---|---|---|---|
| Hits | |||||
| MR | MRR | @10 | @3 | @1 | |
| DistMult [22] | 5926 | 0.34 | 0.54 | 0.38 | 0.24 |
| ComplEx [23] | 6351 | 0.36 | 0.55 | 0.40 | 0.26 |
| ConvE [29] | 1676 | 0.44 | 0.62 | 0.49 | 0.35 |
| Ours | 1396 | 0.47 | 0.65 | 0.54 | 0.43 |
| Neighbor Aggregation | Relation | Neighbor Convolution | Mean Pooling | MR | MRR | Hits10 | Hits3 | Hits1 | |
|---|---|---|---|---|---|---|---|---|---|
| raw | 233.73 | 0.4041 | 0.6003 | 0.4468 | 0.3041 | ||||
| raw+agg+conv | ✓ | ✓ | 201.61 | 0.4234 | 0.6083 | 0.4657 | 0.3285 | ||
| raw+agg+conv+relation | ✓ | ✓ | ✓ | 256.05 | 0.4090 | 0.5942 | 0.4506 | 0.3156 | |
| raw+agg+pooling+relation | ✓ | ✓ | ✓ | 216.94 | 0.4073 | 0.5980 | 0.4452 | 0.3134 | |
| raw+agg+pooling | ✓ | ✓ | 189.25 | 0.4270 | 0.6149 | 0.4657 | 0.3329 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, Q.; Liao, Y.; Li, Z.; Lin, H.; Liang, S. Convolutional Models with Multi-Feature Fusion for Effective Link Prediction in Knowledge Graph Embedding. Entropy 2023, 25, 1472. https://doi.org/10.3390/e25101472
Guo Q, Liao Y, Li Z, Lin H, Liang S. Convolutional Models with Multi-Feature Fusion for Effective Link Prediction in Knowledge Graph Embedding. Entropy. 2023; 25(10):1472. https://doi.org/10.3390/e25101472
Chicago/Turabian StyleGuo, Qinglang, Yong Liao, Zhe Li, Hui Lin, and Shenglin Liang. 2023. "Convolutional Models with Multi-Feature Fusion for Effective Link Prediction in Knowledge Graph Embedding" Entropy 25, no. 10: 1472. https://doi.org/10.3390/e25101472
APA StyleGuo, Q., Liao, Y., Li, Z., Lin, H., & Liang, S. (2023). Convolutional Models with Multi-Feature Fusion for Effective Link Prediction in Knowledge Graph Embedding. Entropy, 25(10), 1472. https://doi.org/10.3390/e25101472