

Detecting Information Relays in Deep Neural Networks



{kind=link}
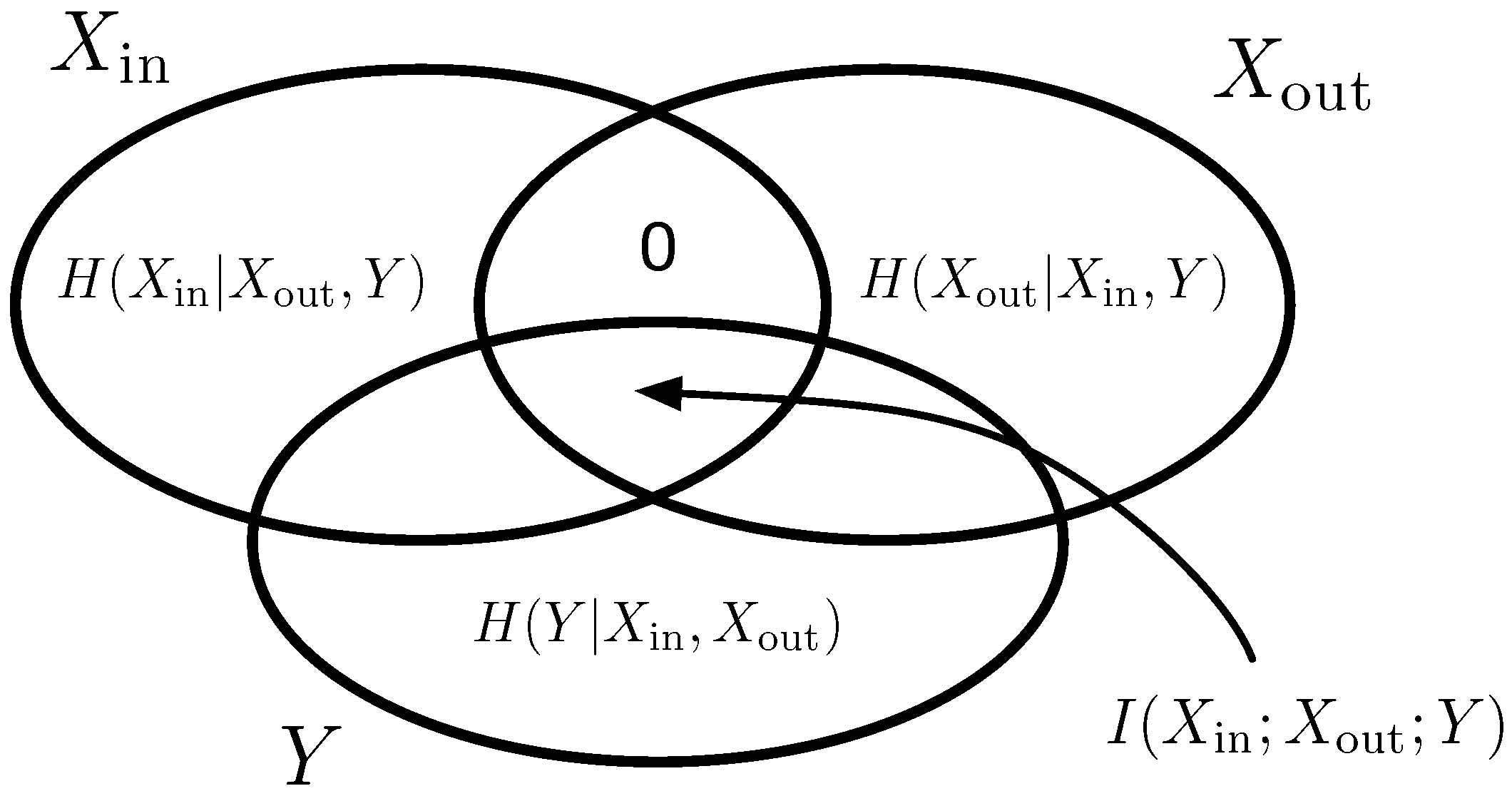{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Methods
2.1. Training Artificial Neural Networks
2.2. Composing an Artificial Neural Network from Specialized Networks
2.3. Information-Theoretic Measure of Computational Modules
2.4. Shrinking Subset Aggregation Algorithm
| Algorithm 1: Shrinking Subset Aggregation Algorithm. |
| Require: |
| |
| while do |
| for do |
| (see Equation (3)) |
| end for |
| end while |
2.5. Knockout Analysis
2.6. Coarse-Graining Continuous Variables
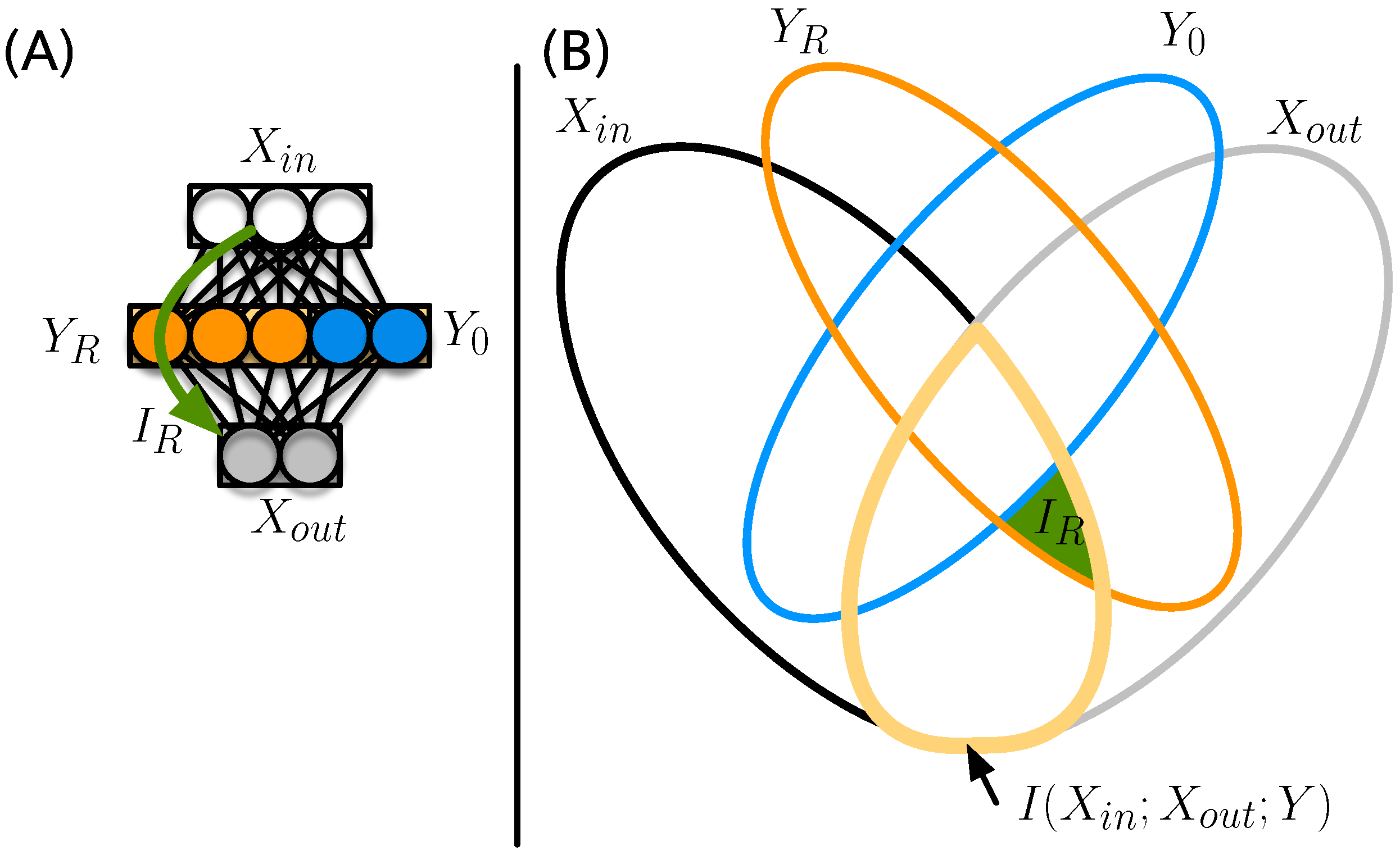
2.7. Aggregated Relay Information
3. Results
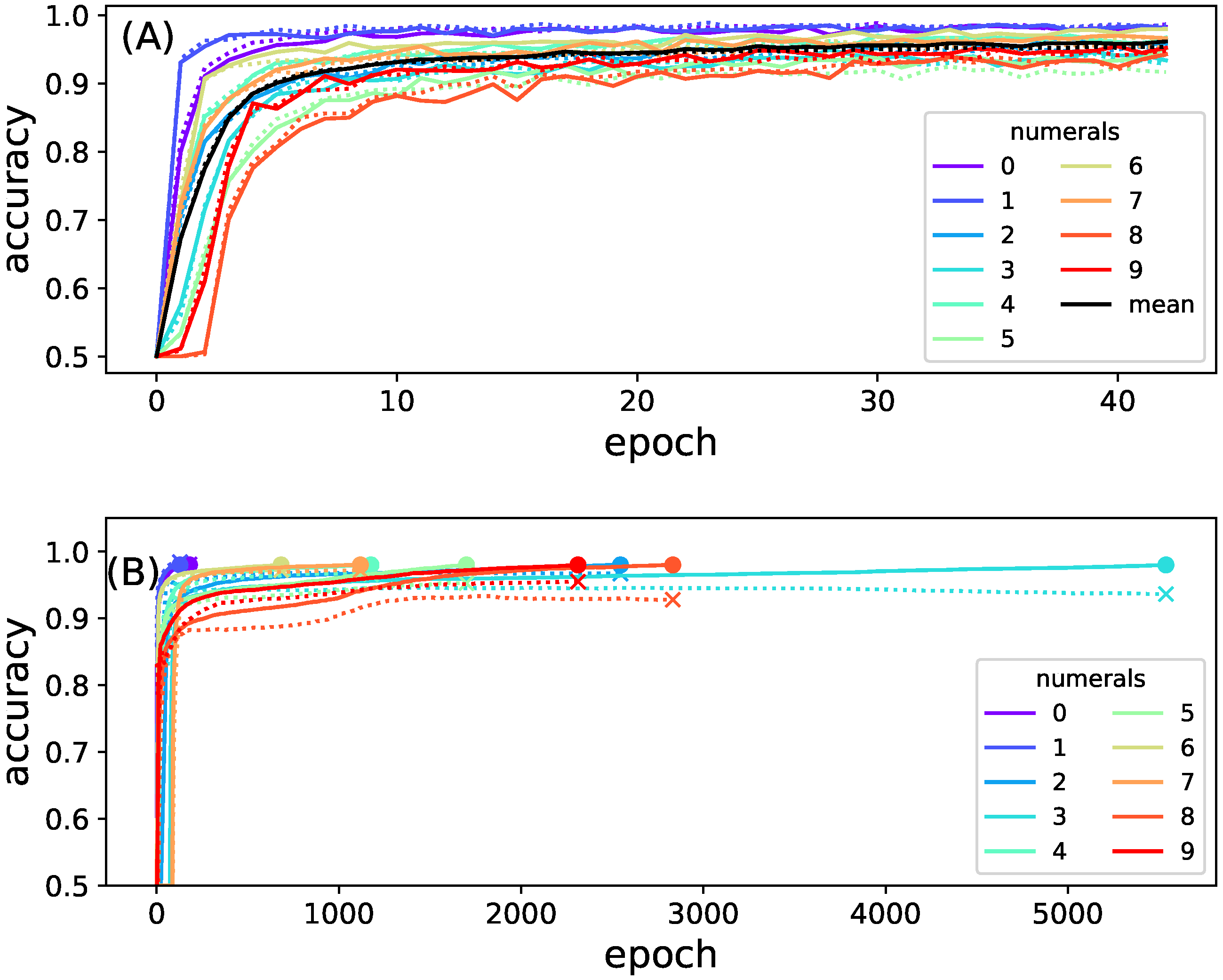
3.1. Identification of Information Relays
3.2. Information Relays Are Critical for the Function of the Neural Network
4. Discussion
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
Appendix B. Sampling Large State Spaces

References
- Castelvecchi, D. Can we open the black box of AI? Nature 2016, 538, 20–223. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Adadi, A.; Berrada, M. Peeking inside the black-box: A survey on explainable artificial intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Schreiber, T. Measuring information transfer. Phys. Rev. Lett. 2000, 85, 461. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Amblard, P.O.; Michel, O.J. On directed information theory and Granger causality graphs. J. Comput. Neurosci. 2011, 30, 7–16. [Google Scholar] [CrossRef]
- Tehrani-Saleh, A.; Adami, C. Can transfer entropy infer information flow in neuronal circuits for cognitive processing? Entropy 2020, 22, 385. [Google Scholar] [CrossRef] [Green Version]
- Hintze, A.; Adami, C. Cryptic information transfer in differently-trained recurrent neural networks. In Proceedings of the 2020 7th International Conference on Soft Computing & Machine Intelligence (ISCMI), Stockholm, Sweden, 14–15 November 2020; pp. 115–120. [Google Scholar]
- McDonnell, M.D.; Ikeda, S.; Manton, J.H. An introductory review of information theory in the context of computational neuroscience. Biol. Cybern. 2011, 105, 55–70. [Google Scholar] [CrossRef] [Green Version]
- Dimitrov, A.G.; Lazar, A.A.; Victor, J.D. Information theory in neuroscience. J. Comput. Neurosci. 2011, 30, 1–5. [Google Scholar] [CrossRef]
- Timme, N.M.; Lapish, C. A tutorial for information theory in neuroscience. eNeuro 2018, 5, PMC6131830. [Google Scholar] [CrossRef]
- Bialek, W.; Nemenman, I.; Tishby, N. Predictability, complexity, and learning. Neural Comput. 2001, 13, 2409–2463. [Google Scholar] [CrossRef]
- Ay, N.; Bertschinger, N.; Der, R.; Güttler, F.; Olbrich, E. Predictive information and explorative behavior of autonomous robots. Eur. Phys. J. B 2008, 63, 329–339. [Google Scholar] [CrossRef] [Green Version]
- Tononi, G. Integrated information theory. Scholarpedia 2015, 10, 4164. [Google Scholar] [CrossRef]
- Fan, J. An information theory account of cognitive control. Front. Hum. Neurosci. 2014, 8, 680. [Google Scholar] [CrossRef] [Green Version]
- Borst, A.; Theunissen, F.E. Information theory and neural coding. Nat. Neurosci. 1999, 2, 947–957. [Google Scholar] [CrossRef]
- Marstaller, L.; Hintze, A.; Adami, C. The evolution of representation in simple cognitive networks. Neural Comput. 2013, 25, 2079–2107. [Google Scholar] [CrossRef] [Green Version]
- Sporns, O. Structure and function of complex brain networks. Dialogues Clin. Neurosci. 2022, 15, 247–262. [Google Scholar] [CrossRef]
- Hagmann, P.; Cammoun, L.; Gigandet, X.; Meuli, R.; Honey, C.J.; Wedeen, V.J.; Sporns, O. Mapping the structural core of human cerebral cortex. PLoS Biol. 2008, 6, e159. [Google Scholar] [CrossRef]
- Sporns, O.; Betzel, R.F. Modular Brain Networks. Annu. Rev. Psychol. 2016, 67, 613–640. [Google Scholar] [CrossRef] [Green Version]
- Logothetis, N.K. What we can do and what we cannot do with fMRI. Nature 2008, 453, 869–878. [Google Scholar] [CrossRef]
- He, Y.; Wang, J.; Wang, L.; Chen, Z.J.; Yan, C.; Yang, H.; Tang, H.; Zhu, C.; Gong, Q.; Zang, Y.; et al. Uncovering intrinsic modular organization of spontaneous brain activity in humans. PLoS ONE 2009, 4, e5226. [Google Scholar] [CrossRef] [Green Version]
- Thatcher, R.W. Neuropsychiatry and quantitative EEG in the 21st Century. Neuropsychiatry 2011, 1, 495–514. [Google Scholar] [CrossRef]
- Shine, J.M.; Li, M.; Koyejo, O.; Fulcher, B.; Lizier, J.T. Nonlinear reconfiguration of network edges, topology and information content during an artificial learning task. Brain Inform. 2021, 8, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Hintze, A.; Kirkpatrick, D.; Adami, C. The structure of evolved representations across different substrates for artificial intelligence. In Proceedings of the Proceedings Artificial Life 16, Beppu, Japan, 1–4 February 2018; Ikegami, T., Virgo, N., Witkowski, O., Oka, M., Suzuki, R., Iizuka, H., Eds.; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Kirkpatrick, D.; Hintze, A. The role of ambient noise in the evolution of robust mental representations in cognitive systems. In Proceedings of the ALIFE 2019: The 2019 Conference on Artificial Life, Newcastle-upon-Tyne, UK, 29 July–2 August 2019; MIT Press: Cambridge, MA, USA, 2019; pp. 432–439. [Google Scholar]
- CG, N.; Lundrigan, B.; Smale, L.; Hintze, A. The effect of periodic changes in the fitness landscape on brain structure and function. In Proceedings of the ALIFE 2018: The 2018 Conference on Artificial Life, Tokyo, Japan, 22–28 July 2018; pp. 469–476. [Google Scholar]
- McCloskey, M.; Cohen, N.J. Catastrophic interference in connectionist networks: The sequential learning problem. In Psychology of Learning and Motivation; Elsevier: Amsterdam, The Netherlands, 1989; Volume 24, pp. 109–165. [Google Scholar]
- French, R.M. Catastrophic forgetting in connectionist networks. Trends Cogn. Sci. 1999, 3, 128–135. [Google Scholar] [CrossRef] [PubMed]
- Stanley, K.O.; Clune, J.; Lehman, J.; Miikkulainen, R. Designing neural networks through neuroevolution. Nat. Mach. Intell. 2019, 1, 24–35. [Google Scholar] [CrossRef] [Green Version]
- Hintze, A.; Adami, C. Evolution of complex modular biological networks. PLoS Comput. Biol. 2008, 4, e23. [Google Scholar] [CrossRef] [Green Version]
- Ellefsen, K.O.; Mouret, J.B.; Clune, J. Neural modularity helps organisms evolve to learn new skills without forgetting old skills. PLoS Comput. Biol. 2015, 11, e1004128. [Google Scholar] [CrossRef] [Green Version]
- Hintze, A. The Role Weights Play in Catastrophic Forgetting. In Proceedings of the 2021 8th International Conference on Soft Computing & Machine Intelligence (ISCMI), Cairo, Egypt, 26–27 November 2021; pp. 160–166. [Google Scholar]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Parisi, G.I.; Kemker, R.; Part, J.L.; Kanan, C.; Wermter, S. Continual lifelong learning with neural networks: A review. Neural Netw. 2019, 113, 54–71. [Google Scholar] [CrossRef]
- Kirkpatrick, J.; Pascanu, R.; Rabinowitz, N.; Veness, J.; Desjardins, G.; Rusu, A.A.; Milan, K.; Quan, J.; Ramalho, T.; Grabska-Barwinska, A.; et al. Overcoming catastrophic forgetting in neural networks. Proc. Natl. Acad. Sci. USA 2017, 114, 3521–3526. [Google Scholar] [CrossRef] [Green Version]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should I trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Golden, R.; Delanois, J.E.; Sanda, P.; Bazhenov, M. Sleep prevents catastrophic forgetting in spiking neural networks by forming a joint synaptic weight representation. PLoS Comput. Biol. 2022, 18, e1010628. [Google Scholar] [CrossRef]
- Kemker, R.; McClure, M.; Abitino, A.; Hayes, T.; Kanan, C. Measuring catastrophic forgetting in neural networks. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 3390–3398. [Google Scholar]
- Bohm, C.; Kirkpatrick, D.; Cao, V.; Adami, C. Information fragmentation, encryption and information flow in complex biological networks. Entropy 2022, 24, 735. [Google Scholar] [CrossRef]
- Sella, M. Tracing Computations in Deep Neural Networks. Master’s Thesis, School of Information and Engineering, Dalarna University, Falun, Sweden, 2022. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2015; Bengio, Y., LeCun, Y., Eds.; [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef] [Green Version]
- Paninski, L. Estimation of entropy and mutual information. Neural Comput. 2003, 15, 1191–1253. [Google Scholar] [CrossRef] [Green Version]
- Bohm, C.; Kirkpatrick, D.; Hintze, A. Understanding memories of the past in the context of different complex neural network architectures. Neural Comput. 2022, 34, 754–780. [Google Scholar] [CrossRef]
- Chapman, S.; Knoester, D.; Hintze, A.; Adami, C. Evolution of an artificial visual cortex for image recognition. In Proceedings of the ECAL 2013: The Twelfth European Conference on Artificial Life, Taormina, Italy, 2–6 September 2013; pp. 1067–1074. [Google Scholar]
- Basharin, G.P. On a statistical estimate for the entropy of a sequence of independent random variables. Theory Probab. Applic. 1959, 4, 333–337. [Google Scholar] [CrossRef]








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hintze, A.; Adami, C. Detecting Information Relays in Deep Neural Networks. Entropy 2023, 25, 401. https://doi.org/10.3390/e25030401
Hintze A, Adami C. Detecting Information Relays in Deep Neural Networks. Entropy. 2023; 25(3):401. https://doi.org/10.3390/e25030401
Chicago/Turabian StyleHintze, Arend, and Christoph Adami. 2023. "Detecting Information Relays in Deep Neural Networks" Entropy 25, no. 3: 401. https://doi.org/10.3390/e25030401
APA StyleHintze, A., & Adami, C. (2023). Detecting Information Relays in Deep Neural Networks. Entropy, 25(3), 401. https://doi.org/10.3390/e25030401