
Stochastic Expectation Maximization Algorithm for Linear Mixed-Effects Model with Interactions in the Presence of Incomplete Data



Abstract
:1. Introduction
- Step E:
- This step is called the expectation (E) step, where we are interested in finding the expected value of the unobserved or unknown variables given the observed data and the value of the parameters.
- Step M:
- This step is called the maximization (M) step; in this step, we maximize the expected log-likelihood by using the estimation of the unknown data carried out in the previous step. These parameter estimates are then used to determine the distribution of the unknown variables in the next iteration.
2. Methodology
2.1. EM Algorithm
- −
- Let be the independent and identically distributed (i.i.d.) observations of likelihood .
- −
- The maximization of is impossible.
- −
- We consider hidden data which make the maximization of the likelihood of the complete data possible when known.
- −
- As we do not know these data z, we estimate the likelihood of the complete data by taking into account all the known information so the estimator is given as follows (E step):where is the vector of the parameters at iteration .
- −
- Finally, we maximize this estimated likelihood to determine the new value of the parameter (M step). Thus, the transition from iteration to iteration k in the algorithm consists in determining the parameters vector at iteration k, :where is chosen arbitrarily. When one of these two steps are impossible to complete, we can consider an extension form of the EM algorithm such as the SAEM, SEM or MCEM algorithms. In the next subsection, we derive the SAEM algorithm into the formula of the EM algorithm.
2.1.1. SAEM Algorithm
- First, we sample a realization of the latent variable from the conditional distribution () of z given y, using the value of the parameter at iteration .
- Second, by using the realization from the first step, we update the value of (see, (1)) through a stochastic approximation procedure.
- Initialization step: Initialize in a fixed compact set.
- Simulation step: simulate from the conditional distribution .
- Stochastic approximation step: compute the quantitywhere is the number of simulations at each iteration.
- Maximization step: update the parameter value according to .
2.1.2. SEM Algorithm
- Step E:
- Compute the conditional density ;
- Step S:
- Draw from the conditional distribution, then obtain the complete sample ;
- Step M:
- Update the parameters by maximizing the likelihood function based on the complete vector .
2.1.3. MCEM Algorithm
2.2. Incomplete Data
2.2.1. Censoring
2.2.2. Missing Data
3. Main Results
3.1. The Proposed Model
3.2. Specific Cases
3.2.1. Case 1: Fixed–Fixed Interaction
3.2.2. Case 2: No Interactions
3.3. SEM Algorithm
| Algorithm 1 SEM algorithm: N is the number of iterations of the SEM algorithm, M is the burn-in level, is the response vector, G is the number of iterations of Gibbs sampling, is the response vector with respect to the ith random variable, and fixed is the summation of the fixed effects with the fixed interaction part. |
| Input: N, M, , and G. 1: Random initialization of 2: for do 3: for do 4: draw from , , ) 5: draw from , , 6: draw from , , 7: end for output: obtained from sampled (,) 8: 9: end for 10: output: |
3.4. SAEM Algorithm
| Algorithm 2 SAEM algorithm: N is the number of iterations of the SEM algorithm, M is the burn-in level, is the response vector, G is the number of iterations of Gibbs’s sampling, is the decreasing sequence, is the response vector with respect to the ith random variable, and fixed is the summation of the fixed effects with the fixed interaction part. |
| Input: N, M, , and G. 1: Random initialization of 2: for do 3: for do 4: draw from , , ) 5: draw from , , 6: draw from , , 7: end for output: obtained from sampled (,) 8: 9: end for 10: output: |
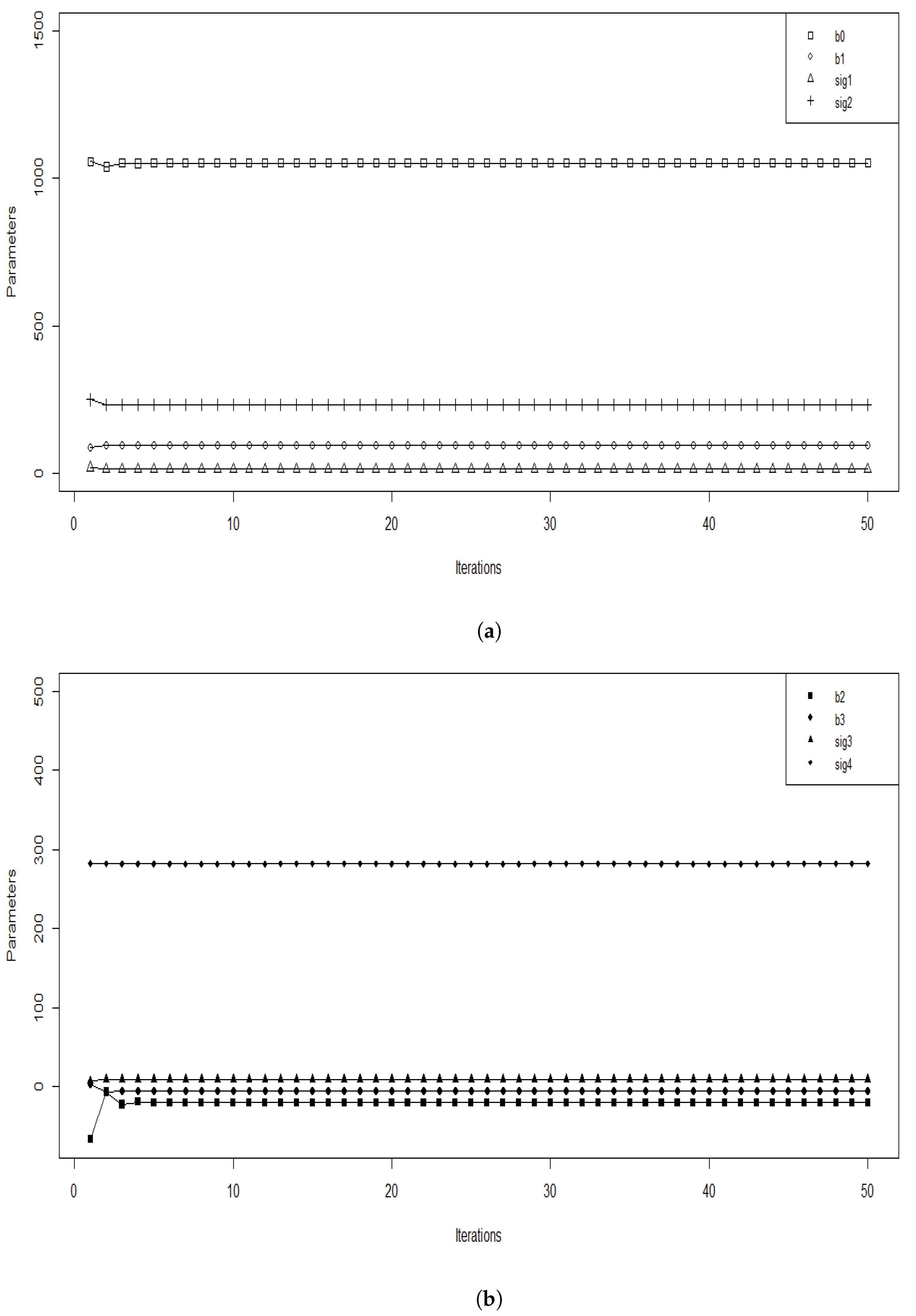
4. Convergence of Parameters
Implementation
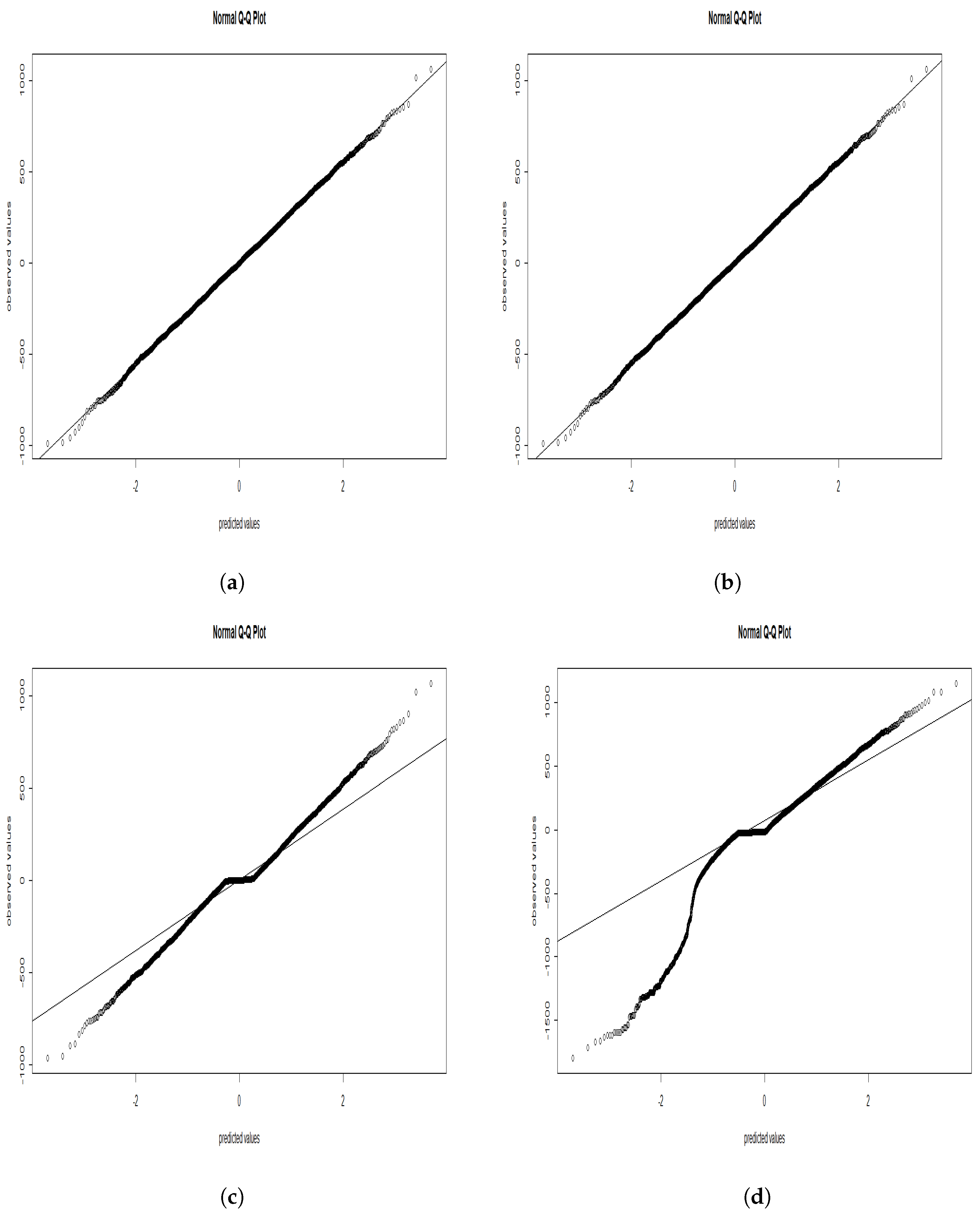
5. Numerical Experiment
5.1. Simulated Data
5.2. Real Data
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1. Models Extension
Appendix A.2. Missing Data Types and Imputations
Appendix A.3. Henderson’s Approach
Appendix A.4. Model Simplification
Appendix A.5. R Source Code
References
- Donders, F.C. On the speed of mental processes. Acta Psychol. 1969, 30, 412–431. [Google Scholar] [CrossRef] [PubMed]
- Roelofs, A. One hundred fifty years after Donders: Insignts form unpublished data, a replication, and modeling of his reaction times. Acta Psychol. 2018, 191, 228–233. [Google Scholar] [CrossRef] [PubMed]
- Baayen, R.H.; Davidson, D.J.; Bates, D.M. Mixed-effects modeling with crossed random effects for subjects and items. J. Mem. Lang. 2008, 29, 390–412. [Google Scholar] [CrossRef] [Green Version]
- Perret, C.; Solier, C. Application of a Bayesian approach for exploring the impact of syllable frequency in handwritten picture naming. J. Cogn. Psychol. 2022, 34, 622–635. [Google Scholar] [CrossRef]
- Ratcliff, R. Methods for dealing with reaction time outliers. Psychol. Bull. 1993, 114, 510–532. [Google Scholar] [CrossRef]
- Van Selst, M.; Jolicoeur, P. A solution to the effect of the size on outlier elimination. Q. J. Exp. Psychol. 1994, 47, 631–650. [Google Scholar] [CrossRef]
- Barr, D.J.; Levy, R.; Scheepers, C.; Tily, H.J. Random effects structure for confirmatory hypothesis testing: Keep it maximal. J. Mem. Lang. 2013, 68, 255–278. [Google Scholar] [CrossRef] [Green Version]
- Dempster, A.P.; Rubin, D.B.; Tsutakawa, R.K. Estimation in Covariance Components Models. J. Am. Stat. Assoc. 1981, 76, 341–353. [Google Scholar] [CrossRef]
- West, T.B.; Welch, B.K.; Galecki, T.A. Linear Mixed Models, A Practical Guide Using Statistical Software; Chapman & Hall: New York, NY, USA, 2006. [Google Scholar]
- Jiang, J.; Wand, M.P.; Bhaskaran, A. Usable and precise asymptotics for generalized linear mixed model analysis and design. J. R. Stat. Soc. Ser. B 2022, 84, 55–82. [Google Scholar] [CrossRef]
- Faraway, J.J. Extending the Linear Model with R, 2nd ed.; CRC Press: Boca Raton, FL, USA, 2016. [Google Scholar]
- Jiang, J. Asymptotic Analysis of Mixed Effects Models; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar]
- McCulloch, C.E.; Searle, S.R.; Neuhaus, J.M. Generalized, Linear, and Mixed Models, 2nd ed.; John Wiley & Sons: New York, NY, USA, 2008. [Google Scholar]
- Stroup, W.W. Generalized Linear Mixed Models; CRC Press: Boca Raton, FL, USA, 2013. [Google Scholar]
- Bates, D.; Mächler, M.; Bolker, M.B.; Walker, C.S. Fitting Linear Mixed-Effects Models Using lme4. J. Stat. Softw. 2015, 67, 1–48. [Google Scholar] [CrossRef]
- Boik, J.R. The Analysis of Two-Factor Interactions in Fixed Effects Linear Models. J. Educ. Stat. 1993, 18, 1–40. [Google Scholar] [CrossRef]
- Yi, Q.; Panzarella, T. Estimating Sample Size for Tests on Trends across Repeated Measurements with Missing Data Based on the Interaction Term in a Mixed Model; Elsevier: Amsterdam, The Netherlands, 2002; Volume 23, pp. 481–496. [Google Scholar]
- Robin, G.; Josse, J.; Moulines, E.; Tibshirani, R. Main effects and interactions in mixed and incomplete data frames. J. Am. Stat. Assoc. 2019, 115, 1292–1303. [Google Scholar] [CrossRef] [Green Version]
- Giesselmann, M.; Schmidt-Catran, A.W. Interactions in fixed effects regression models. Sociol. Methods Res. 2022, 51, 1100–1127. [Google Scholar] [CrossRef]
- Martin, D.A.; Quinn, M.K.; Park, H.J. MCMCpack: Markov chain Monte Carlo in R. J. Stat. Softw. 2011, 42, 22. [Google Scholar] [CrossRef] [Green Version]
- Hadfield, J.D. MCMC methods for multi-response generalized linear mixed models: The MCMCglmm R package. J. Stat. Softw. 2010, 33, 1–22. [Google Scholar] [CrossRef] [Green Version]
- Khodadadian, A.; Parvizi, M.; Teshnehlab, M.; Heitzinger, C. Rational Design of Field-Effect Sensors Using Partial Differential Equations, Bayesian Inversion, and Artificial Neural Networks. Sensors 2022, 22, 4785. [Google Scholar] [CrossRef]
- Noii, N.; Khodadadian, A.; Ulloa, J.; Aldakheel, F.; Wick, T.; Francois, S.; Wriggers, P. Bayesian Inversion with Open-Source Codes for Various One-Dimensional Model Problems in Computational Mechanics. Arch. Comput. Methods Eng. 2022, 29, 4285–4318. [Google Scholar] [CrossRef]
- Matuschek, H.; Kliegl, R.; Vasishth, S.; Baayen, H.; Bates, D. Balancing Type I error and power in linear mixed models. J. Mem. Lang. 2017, 94, 305–315. [Google Scholar] [CrossRef]
- Dempster, A.; Laird, N.; Rubin, D. Maximum-likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B 1977, 39, 1–38. [Google Scholar]
- Delyon, B.; Lavielle, M.; Moulines, E. Convergence of a stochastic approximation version of the EM algorithm. Ann. Stat. 1999, 1, 94–128. [Google Scholar] [CrossRef]
- Lavielle, M.; Mbogning, C. An improved SAEM algorithm for maximum likelihood estimation in mixtures of non linear mixed effects models. Stat. Comput. 2014, 24, 693–707. [Google Scholar] [CrossRef]
- Robbins, H.; Monro, S. A Stochastic Approximation Method. Ann. Math. Stat. 1951, 22, 400–407. [Google Scholar] [CrossRef]
- Bhatnagar, S.; Prasad, H.; Prashanth, L. Stochastic Recursive Algorithms for Optimization; Springer: Heidelberg, Germay, 2013; Volume 434, pp. 17–28. [Google Scholar]
- Celeux, G.; Diebolt, J. The SEM algorithm: A probabilistic teacher algorithm derived from the EM algorithm for the mixture problem. Comput. Stat. Q. 1985, 2, 73–82. [Google Scholar]
- Wei, G.; Tanner, M. A Monte-Carlo implementation of the EM algorithm and the Poor’s Man’s data augmentation algorithm. J. Am. Stat. Assoc. 1990, 85, 699–704. [Google Scholar] [CrossRef]
- Bennett, D.A. How can I deal with missing data in my study. Aust. N. Z. J. Public Health 2001, 25, 464–469. [Google Scholar] [CrossRef] [PubMed]
- Slaoui, Y.; Nuel, G. Parameter Estimation in a Hierarchical Random Intercept Model with Censored Response: An Approach using a SEM Algorithm and Gibbs Sampling. Sankhya Indian J. Stat. 2014, 76, 210–233. [Google Scholar] [CrossRef]
- Foulley, J.L. Mixed Model Methodology. Part I: Linear Mixed Models. In Technical Report; Université de Montpellier: Montpellier, France, 2015. [Google Scholar]
- Grund, S.; Lüdtke, O.; Robitzsch, A. Multiple imputation of missing data in multilevel models with the R package mdmb: A flexible sequential modeling approach. Behav. Res. Meth. 2021, 53, 2631–2649. [Google Scholar] [CrossRef]
- Santos, F. L’algorithme EM: Une Courte Présentation; CNRS, UMR, 5199; PACEA: Talence, France, 2015. [Google Scholar]
- Celeux, G.; Diebolt, J. Une Version de Type Recuit Simule de L’algorithme EM. Ph.D. Thesis, INRIA, Le Chesnay, France, 1989. [Google Scholar]
- Celeux, G.; Chauveau, D.; Diebolt, J. On Stochastic Versions of the EM Algorithm. Ph.D. Thesis, INRIA, Le Chesnay, France, 1995. [Google Scholar]
- Celeux, G.; Diebolt, J. A stochastic approximation type EM algorithm for the mixture problem. Stoch. Int. J. Probab. Stoch. Process. 1992, 41, 119–134. [Google Scholar] [CrossRef] [Green Version]
- Richard, F.; Samson, A.; Cuénod, A.C. A SAEM algorithm for the estimation of template and deformation parameters in medical image sequences. Stat. Comput. 2009, 19, 465–478. [Google Scholar] [CrossRef]
- Panhart, X.; Samson, A. Extension of the SAEM algorithm for nonlinear mixed models with 2 levels of random effects. Biostatistics 2008, 10, 121–135. [Google Scholar] [CrossRef] [Green Version]
- Betancourt, M. A conceptual introduction to Hamiltonian Monte Carlo. arXiv 2017, arXiv:1701.02434. [Google Scholar]
- Metropolis, N.; Rosenbluth, A.W.; Rosenbluth, M.N.; Teller, A.H.; Teller, E. Equation of State Calculations by Fast Computing Machines. J. Chem. Phys. 1953, 21, 1087–1092. [Google Scholar] [CrossRef] [Green Version]
- Hastings, W.K. Monte Carlo sampling methods using Markov Chains and their applications. Biometrika 1970, 57, 97–109. [Google Scholar] [CrossRef]
- Roberts, O.G.; Rosenthal, S.J. General state space Markov chains and MCMC algorithms. Probab. Surv. 2004, 1, 20–71. [Google Scholar] [CrossRef] [Green Version]
- Andrieu, C.; De Freitas, N.; Doucet, A.; Jordan, M. An Introduction to MCMC for Machine Learning. KAP 2003, 50, 5–43. [Google Scholar]
- Perret, C.; Bonin, P. Which variables should be controlled for to investigate picture naming in adults? A Bayesian meta-analysis. Behav. Res. Methods 2019, 51, 2533–2545. [Google Scholar] [CrossRef]
- Schafer, L.J.; Graham, W.J. Missing Data: Our View of the State of the Art. Psychol. Methods 2002, 7, 147–177. [Google Scholar] [CrossRef]
- Enders, C.K. Applied Missing Data Analysis; Guilford Press: New York, NY, USA, 2010. [Google Scholar]
- Little, R.J.; Rubin, D.B. Statistical Analysis with Missing Data; John Wiley & Sons: Hoboken, NJ, USA, 2019; Volume 793. [Google Scholar]
- Zhang, X. Tutorial: How to Generate Missing Data For Simulation Studies. 2021. Available online: https://files.osf.io/v1/resources/rq6yb/providers/osfstorage/60e93adf600da501810a8ea4?format=pdf&action=download&direct&version=1 (accessed on 8 February 2023).



{kind=link}
{kind=link}
| Reference | SEM | SAEM | MCMC | SEM | SAEM | MCMC | SEM | SAEM | MCMC | |||
| b | 1045 | 1044 | 1045 | 1068 | 1044 | 1043 | 1010 | 1047 | 1047 | 822.8 | ||
| b | 93.16 | 93.54 | 88.51 | 48.82 | 93.91 | 89.37 | 41.25 | 93.51 | 88.84 | 77.96 | ||
| b | −52.28 | −51.30 | −42.33 | −36.75 | −52.50 | −47.30 | 51.49 | −30.27 | −51.66 | 18.26 | ||
| b | 2.80 | 3.17 | −0.18 | 6.92 | 4.43 | 5.52 | −14.44 | −1.79 | 5.02 | −18.20 | ||
| sig | 14.57 | 14.65 | 14.43 | 5.29 | 14.65 | 12.54 | 12.56 | 14.70 | 12.17 | 11.30 | ||
| sig | 230.8 | 231.7 | 225.9 | 350.5 | 231.1 | 223.0 | 430.5 | 233.2 | 219.0 | 538.7 | ||
| sig | 9.79 | 9.81 | 9.84 | 2.80 | 9.80 | 8.13 | 8.61 | 9.81 | 9.12 | 8.94 | ||
| sig | 282.0 | 282.0 | 275.5 | 283.1 | 282.0 | 269.4 | 277.8 | 282.0 | 253.5 | 253.9 | ||
| MAE | 0 | 0.421 | 3.637 | 28.07 | 0.505 | 4.628 | 51.84 | 3.935 | 6.575 | 83.64 | ||
| LCor | 1 | 0.999 | 0.999 | 0.992 | 0.999 | 0.999 | 0.971 | 0.999 | 0.999 | 0.915 | ||
| RCor | 1 | 1 | 1 | 0.904 | 1 | 1 | 0.738 | 1 | 1 | 0.833 | ||
| SEM | SAEM | MCMC | SEM | SAEM | MCMC | SEM | SAEM | MCMC | SEM | SAEM | MCMC | |
| b | 1044 | 1038 | 1004 | 1069 | 1037 | 1019 | 1069 | 1036 | 963 | 1078 | 1038 | 780 |
| b | 93.30 | 94.33 | 93.79 | 87.57 | 90.04 | 52.82 | 88.07 | 90.90 | 45.29 | 86.52 | 90.75 | 80.88 |
| b | −46.69 | −53.57 | −49.05 | −49.96 | −42.94 | −28.23 | −52.68 | −47.94 | 55.58 | −32.18 | −50.21 | 26.67 |
| b | 1.04 | 4.58 | 6.55 | 8.27 | 1.27 | 8.63 | 9.70 | 6.75 | −11.90 | 3.82 | 5.61 | −15.79 |
| sig | 15.19 | 13.65 | 16.59 | 15.25 | 17.02 | 8.34 | 15.36 | 13.93 | 16.19 | 15.79 | 12.80 | 4.10 |
| sig | 231.0 | 223.7 | 213.6 | 229.8 | 218.7 | 332.4 | 228.9 | 216.0 | 412.7 | 232.4 | 211.9 | 518.8 |
| sig | 9.94 | 7.93 | 11.07 | 9.97 | 8.63 | 5.05 | 9.95 | 7.52 | 10.61 | 10.11 | 8.42 | 6.56 |
| sig | 282.4 | 281.4 | 347.6 | 282.6 | 275.0 | 349.4 | 282.6 | 268.7 | 342.2 | 282.6 | 253.2 | 317.6 |
| MAE | 1.146 | 2.646 | 16.78 | 4.970 | 5.516 | 34.43 | 5.089 | 6.287 | 62.03 | 8.118 | 8.108 | 88.97 |
| LCor | 0.999 | 0.999 | 0.996 | 0.999 | 0.999 | 0.991 | 0.999 | 0.999 | 0.971 | 0.999 | 0.999 | 0.911 |
| RCor | 1 | 1 | 1 | 1 | 1 | 0.928 | 1 | 1 | 0.738 | 1 | 1 | 0.809 |
| SEM | SAEM | MCMC | SEM | SAEM | MCMC | SEM | SAEM | MCMC | SEM | SAEM | MCMC | |
| b | 1070 | 1037 | 981 | 1069 | 1035 | 999 | 1070 | 1034 | 938 | 1080 | 1037 | 759 |
| b | 86.59 | 94.05 | 90.52 | 87.58 | 90.27 | 50.902 | 88.10 | 90.80 | 46.43 | 86.29 | 90.33 | 81.31 |
| b | −45.96 | −50.70 | −62.01 | −45.00 | −39.50 | −44.14 | −47.79 | −44.57 | 45.21 | −28.34 | −48.01 | 23.38 |
| b | 6.79 | 5.26 | 12.25 | 6.69 | 1.46 | 14.45 | 8.13 | 6.78 | −8.83 | 2.53 | 5.81 | −16.26 |
| sig | 14.80 | 24.43 | 4.36 | 14.97 | 27.35 | 25.00 | 15.15 | 22.09 | 30.51 | 15.93 | 21.39 | 18.64 |
| sig | 228.7 | 220.1 | 205.1 | 230.0 | 215.3 | 323.1 | 229.1 | 212.5 | 401.1 | 232.5 | 208.7 | 506.5 |
| sig | 9.79 | 11.46 | 5.94 | 9.89 | 12.10 | 6.336 | 9.88 | 10.16 | 13.87 | 10.11 | 10.50 | 8.73 |
| sig | 282.4 | 279.6 | 398.0 | 282.5 | 273.2 | 389.6 | 282.5 | 267.2 | 379.8 | 282.5 | 251.8 | 354.3 |
| MAE | 5.608 | 4.699 | 30.12 | 5.387 | 8.279 | 40.15 | 5.424 | 8.191 | 68.85 | 8.747 | 9.636 | 93.20 |
| LCor | 0.999 | 0.999 | 0.990 | 0.999 | 0.999 | 0.987 | 0.999 | 0.999 | 0.969 | 0.999 | 0.999 | 0.908 |
| RCor | 1 | 1 | 0.904 | 1 | 1 | 0.976 | 1 | 1 | 0.833 | 1 | 1 | 0.833 |
| SEM | SAEM | MCMC | SEM | SAEM | MCMC | SEM | SAEM | MCMC | SEM | SAEM | MCMC | |
| b | 1045 | 1035 | 896 | 1045 | 1044 | 908 | 1045 | 1036 | 857 | 1051 | 1039 | 687 |
| b | 93.34 | 94.05 | 100.8 | 93.70 | 80.78 | 64.43 | 94.05 | 90.14 | 57.35 | 92.78 | 89.41 | 91.59 |
| b | −35.09 | −38.36 | 2.54 | −34.54 | −128.87 | 21.66 | −36.11 | −34.79 | 97.19 | −19.91 | −39.24 | 85.55 |
| b | −1.82 | 1.90 | −16.60 | −1.55 | 39.61 | −13.36 | −0.36 | 4.00 | −31.09 | −4.73 | 3.67 | −42.98 |
| sig | 12.12 | 26.88 | 29.49 | 12.44 | 11.70 | 39.89 | 12.62 | 25.58 | 33.25 | 13.62 | 26.53 | 22.49 |
| sig | 230.9 | 211.4 | 204.7 | 231.8 | 118.2 | 315.9 | 231.3 | 204.4 | 387.9 | 233.1 | 200.9 | 485.3 |
| sig | 8.84 | 11.33 | 8.95 | 8.98 | 5.15 | 11.48 | 9.03 | 10.91 | 10.93 | 9.41 | 11.76 | 6.227 |
| sig | 282.3 | 276.2 | 465.9 | 282.3 | 265.3 | 453.6 | 282.3 | 264.0 | 442.2 | 282.4 | 249.2 | 411.6 |
| MAE | 3.261 | 8.002 | 57.07 | 3.374 | 32.83 | 67.38 | 2.994 | 10.905 | 93.01 | 6.343 | 12.47 | 117.2 |
| LCor | 0.999 | 0.999 | 0.969 | 0.999 | 0.991 | 0.969 | 0.999 | 0.999 | 0.944 | 0.999 | 0.998 | 0.873 |
| RCor | 1 | 1 | 0.976 | 1 | 0.9285 | 0.928 | 1 | 1 | 0.761 | 1 | 1 | 0.833 |
| KE | SEM | SAEM | MCMC | |
|---|---|---|---|---|
| b | 852.5 | 875.7 | 892.334 | 1298 |
| b | 146.6 | 134.2 | 120.4 | −161.4 |
| b | 158.6 | 126.1 | 79.63 | −335.3 |
| b | −58.12 | −42.08 | −26.72 | 146.6 |
| sig | 184.3 | 196.0 | 203.5 | 216.9 |
| sig | 133.0 | 127.8 | 94.87 | 221.05 |
| sig | 37.05 | 28.67 | 32.84 | 66.13 |
| sig | 279.5 | 302.5 | 262.9 | 516.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zakkour, A.; Perret, C.; Slaoui, Y. Stochastic Expectation Maximization Algorithm for Linear Mixed-Effects Model with Interactions in the Presence of Incomplete Data. Entropy 2023, 25, 473. https://doi.org/10.3390/e25030473
Zakkour A, Perret C, Slaoui Y. Stochastic Expectation Maximization Algorithm for Linear Mixed-Effects Model with Interactions in the Presence of Incomplete Data. Entropy. 2023; 25(3):473. https://doi.org/10.3390/e25030473
Chicago/Turabian StyleZakkour, Alandra, Cyril Perret, and Yousri Slaoui. 2023. "Stochastic Expectation Maximization Algorithm for Linear Mixed-Effects Model with Interactions in the Presence of Incomplete Data" Entropy 25, no. 3: 473. https://doi.org/10.3390/e25030473
APA StyleZakkour, A., Perret, C., & Slaoui, Y. (2023). Stochastic Expectation Maximization Algorithm for Linear Mixed-Effects Model with Interactions in the Presence of Incomplete Data. Entropy, 25(3), 473. https://doi.org/10.3390/e25030473