


Energy Dispatch for CCHP System in Summer Based on Deep Reinforcement Learning

Abstract
:1. Introduction
- We focus on the energy dispatch for the CCHP system in summer (EDCS) and formulate the EDSC problem as a Markov decision process (MDP), in which the load uncertainty, energy cost, demand charge, and energy balance are considered.
- DRL algorithm DoubleDQN is used to solve the formulated MDP and make dispatch strategies for the CCHP system. In contrast to previous study works, the proposed method directly makes decisions based on the current state, getting rid of the dependence on the accuracy of prediction information and model description.
- By comparing with the DQN-based method and benchmark policies, the advantages of the proposed method in computational efficiency, total intra-month cost saving, and peak power purchase control are verified.
- From the aspects of dealing with unseen physical environments, load fluctuation, and sudden unit failure, the potential of application in real scenarios is discussed.
2. EDCS Problem Formulation
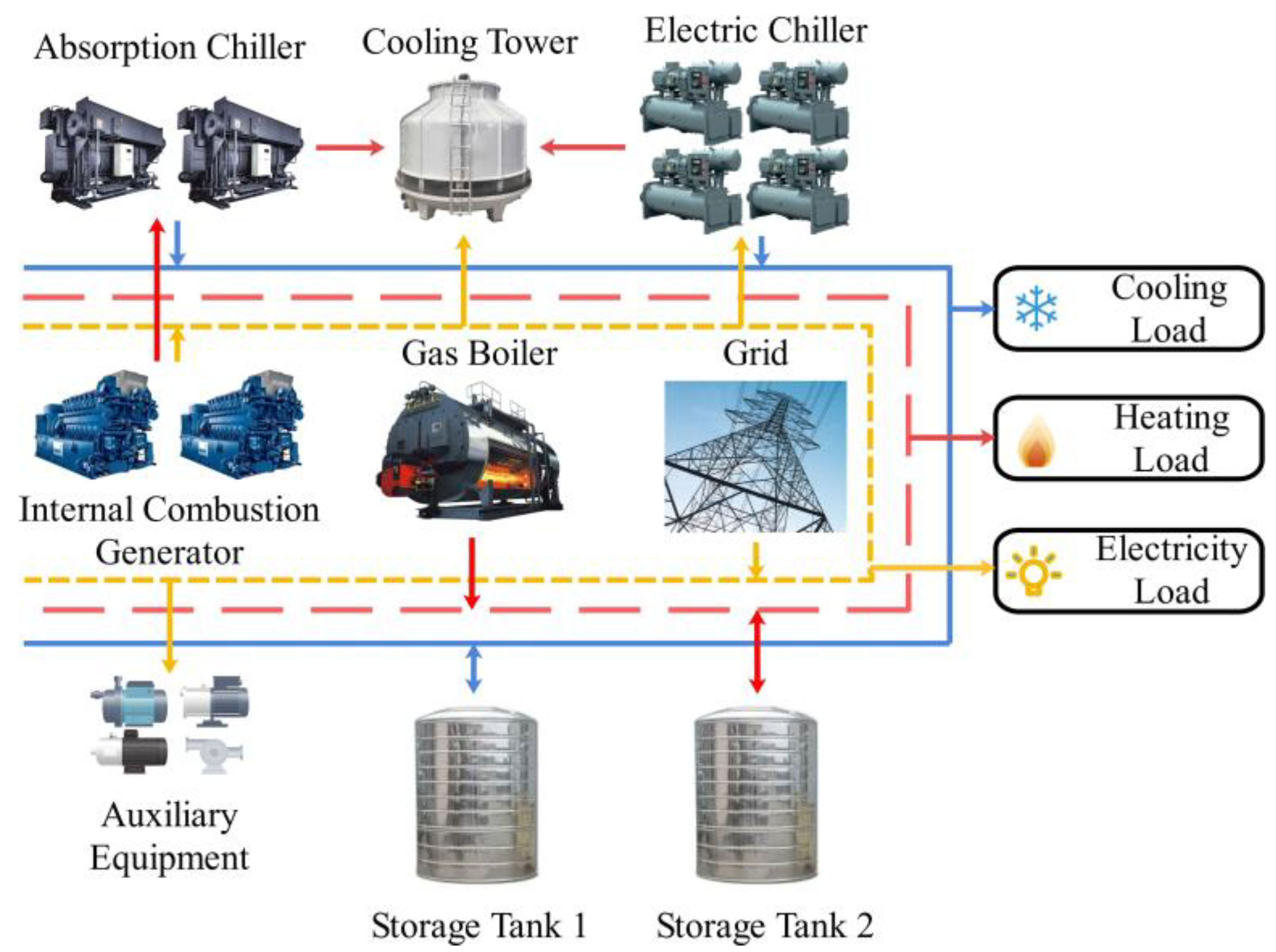
2.1. System Description
2.1.1. Structure of CCHP System
2.1.2. Mathematical Model of Key Unit
2.2. Objective Function
2.3. Constraints
2.3.1. Energy balance Constraints
2.3.2. Operational Constraints
3. DRL-Based EDSC Method
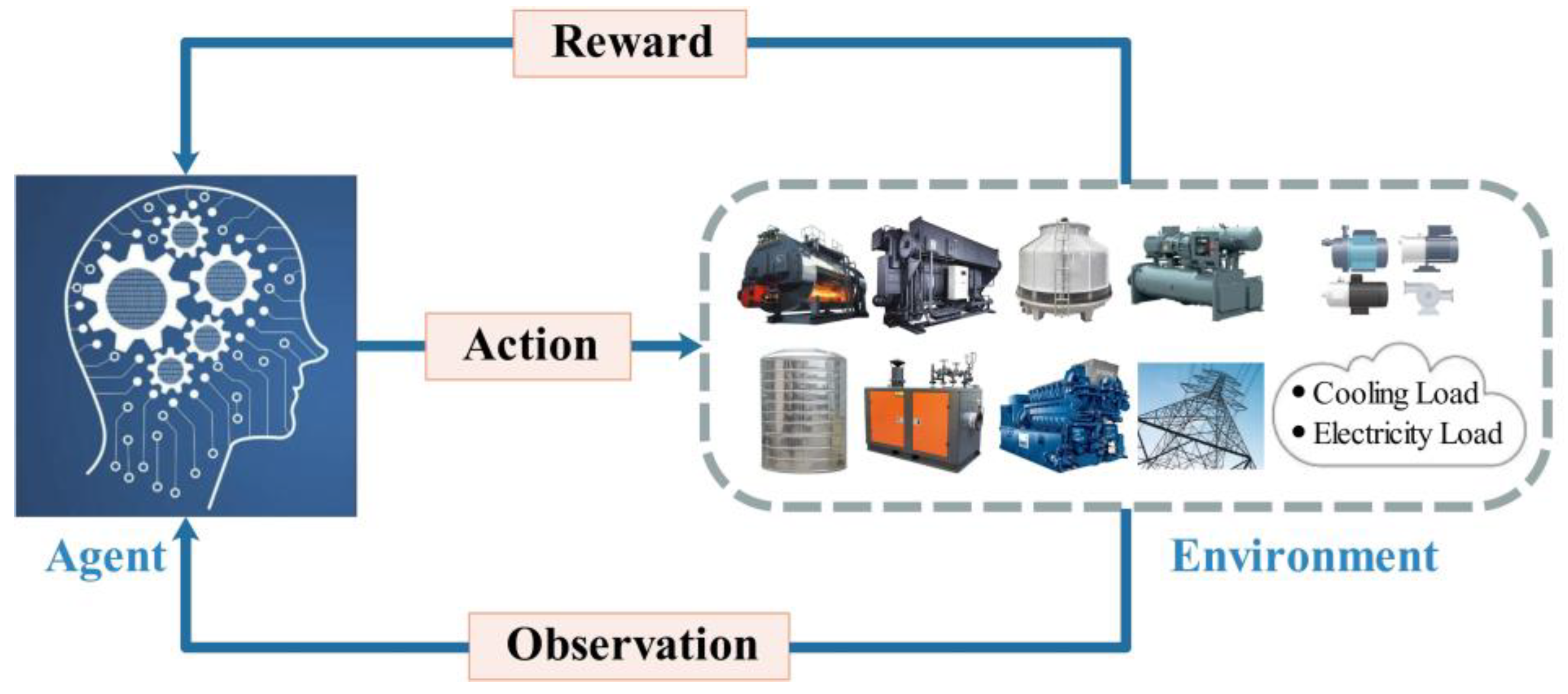
3.1. Converting of EDCS Problem into MDP
3.2. DRL Solution
3.2.1. A Brief Review of DRL
3.2.2. Basic Principles of Value-Based DRL Algorithm
3.2.3. Realizing EDCS with DoubleDQN
| Algorithm 1 Offline-training process of the DoubleDQN algorithm | |
| 1: | Initialize parameters of Q network () and target network (). |
| 2: | for episode = 1 to M do: |
| 3: | Initialize . |
| 4: | for t = 1 to T do: |
| 5: | Select action at given using the greedy policy. |
| 6: | Execute in the CCHP environment and transit to the next state . |
| 7: | Get reward . |
| 8: | Store the experience () in the experience replay buffer. |
| 9: | Extract a mini-batch of experience () with the size N from the experience replay buffer. |
| 10: | Calculate the loss function: . |
| 11: | Update the weights of the Q network: . |
| 12: | Copy the weights into the target network every fixed number of time steps: |
| 13: | end for |
| 14: | end for |
| Algorithm 2 Decision-making procedure of the proposed method | |
| Input: | Environment state observation of time step t. |
| Output: | Dispatch decision for energy supply units. |
| 1: | Load the weights of the Q network trained by Algorithm 1. |
| 2: | for time step = 1 to T do: |
| 3: | Select action . |
| 4: | Execute in the CCHP environment and transit to the next state . |
| 5: | Get reward . |
| 6: | end for |
4. Case Study
4.1. Simulation Setup
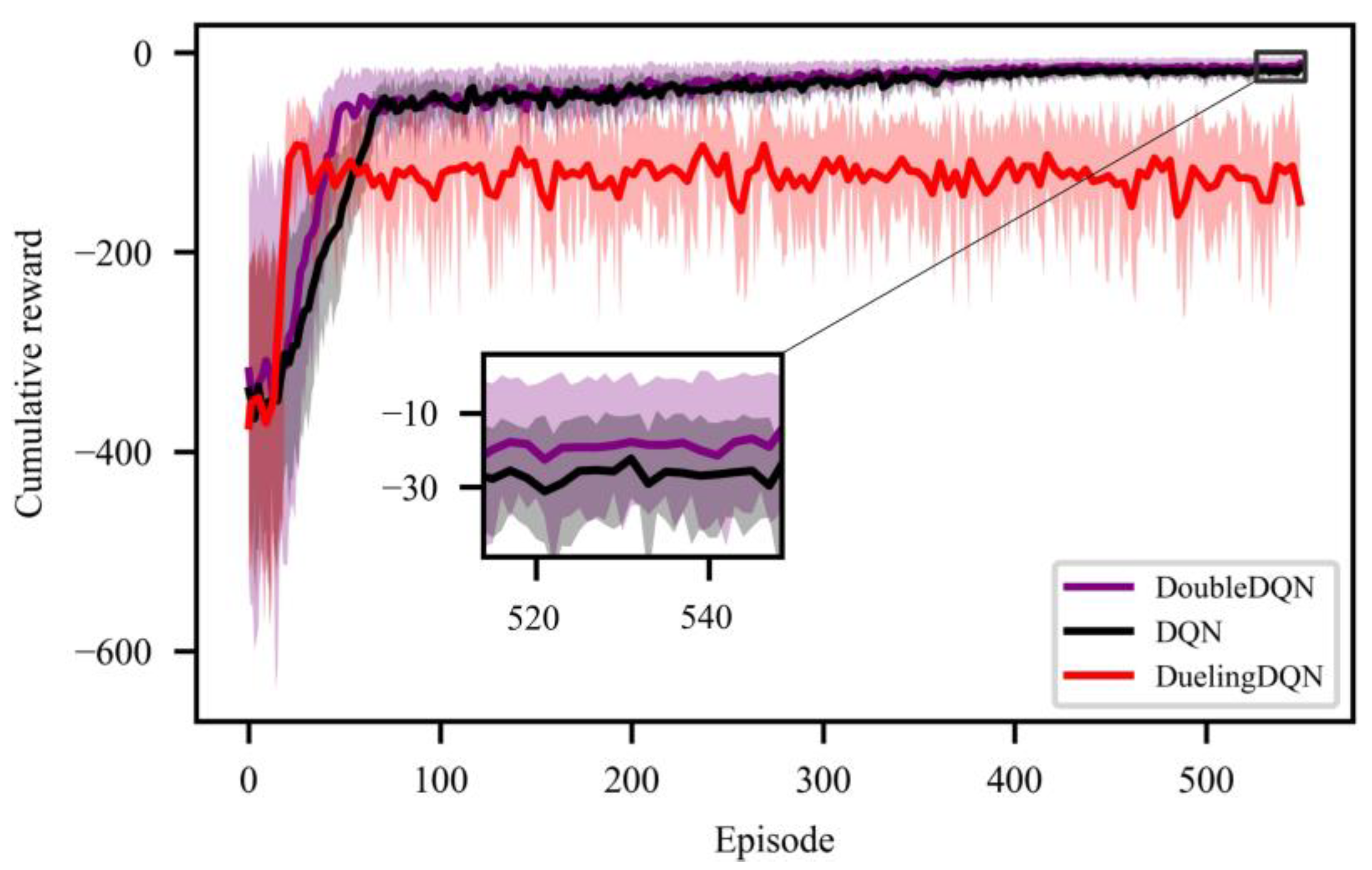
4.2. Off-Line Training Process
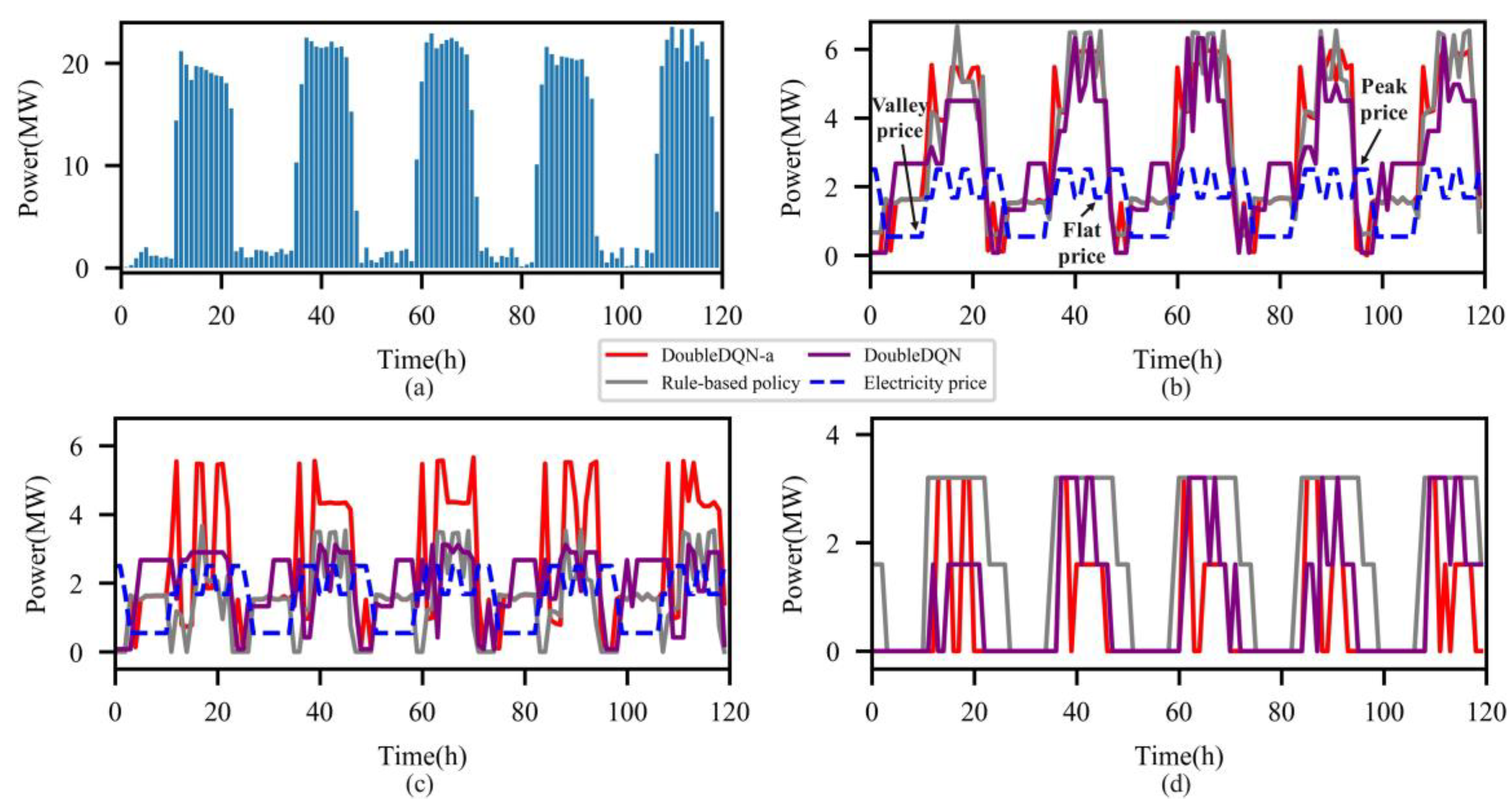
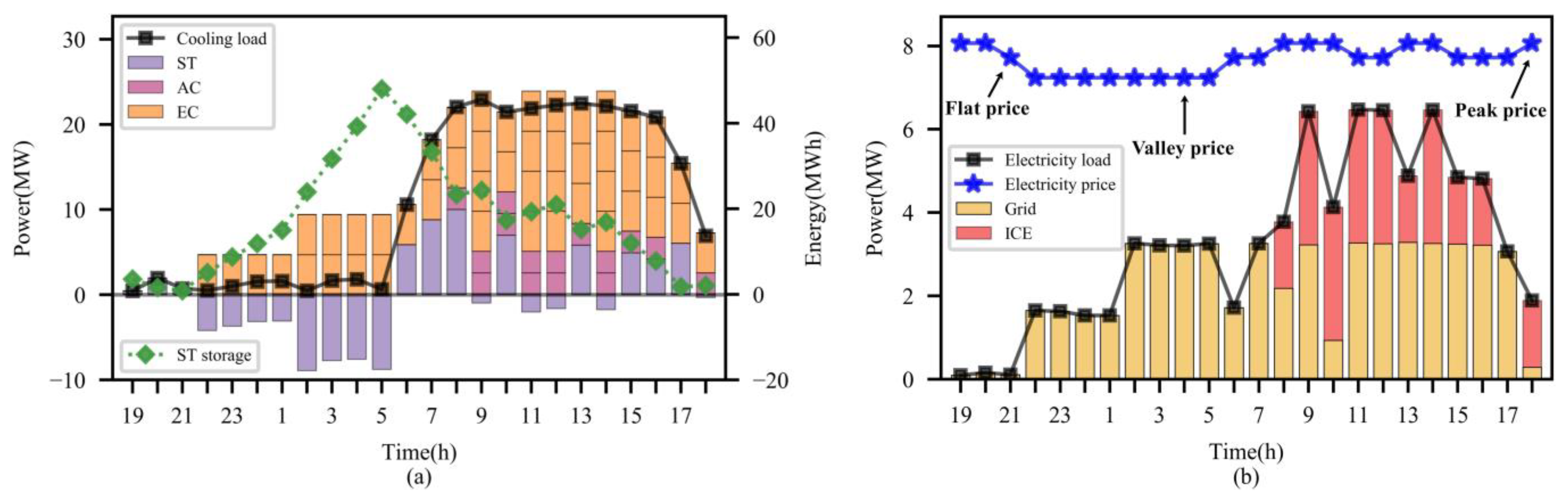
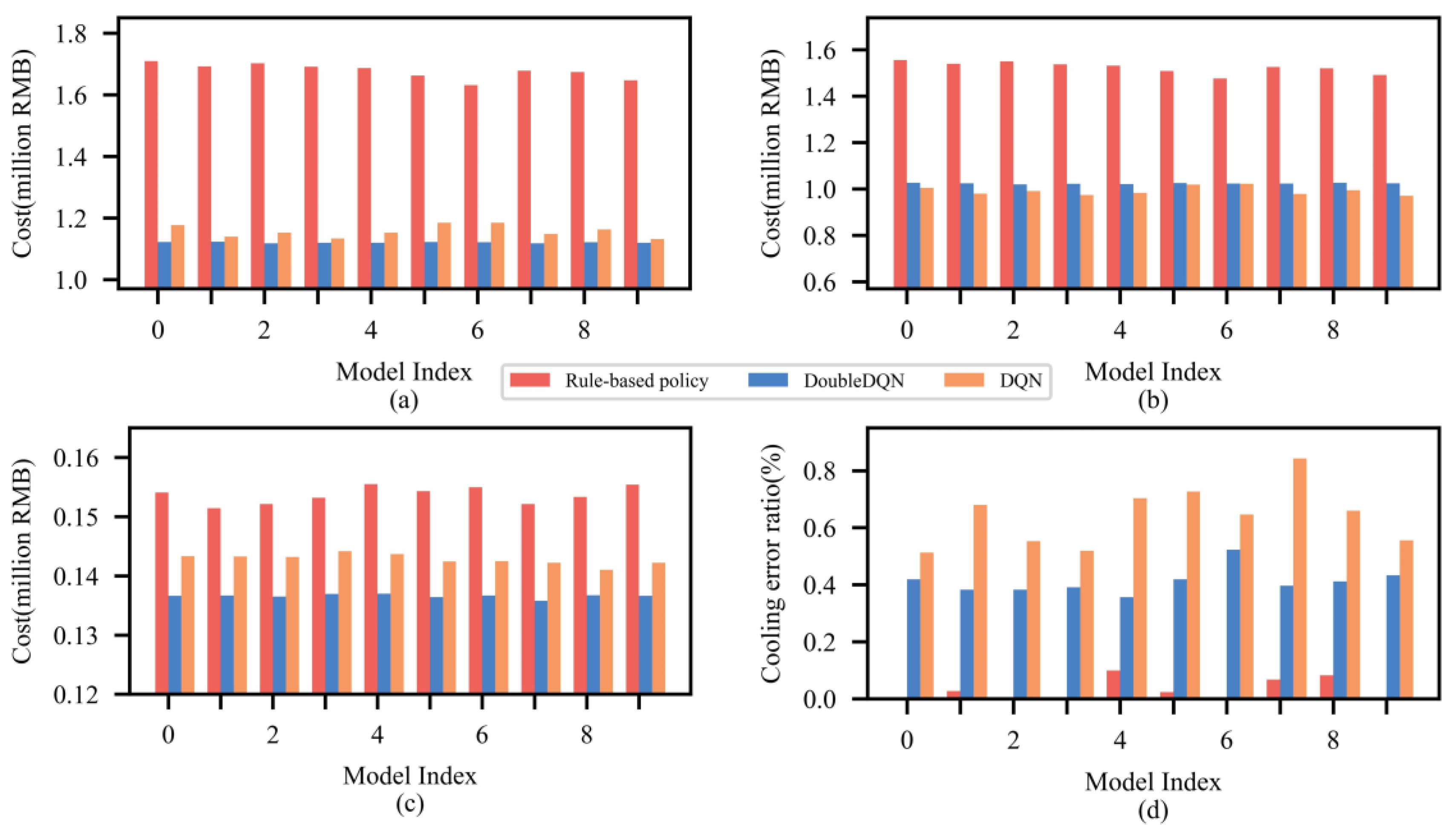
4.3. Dispatch Result Evaluation
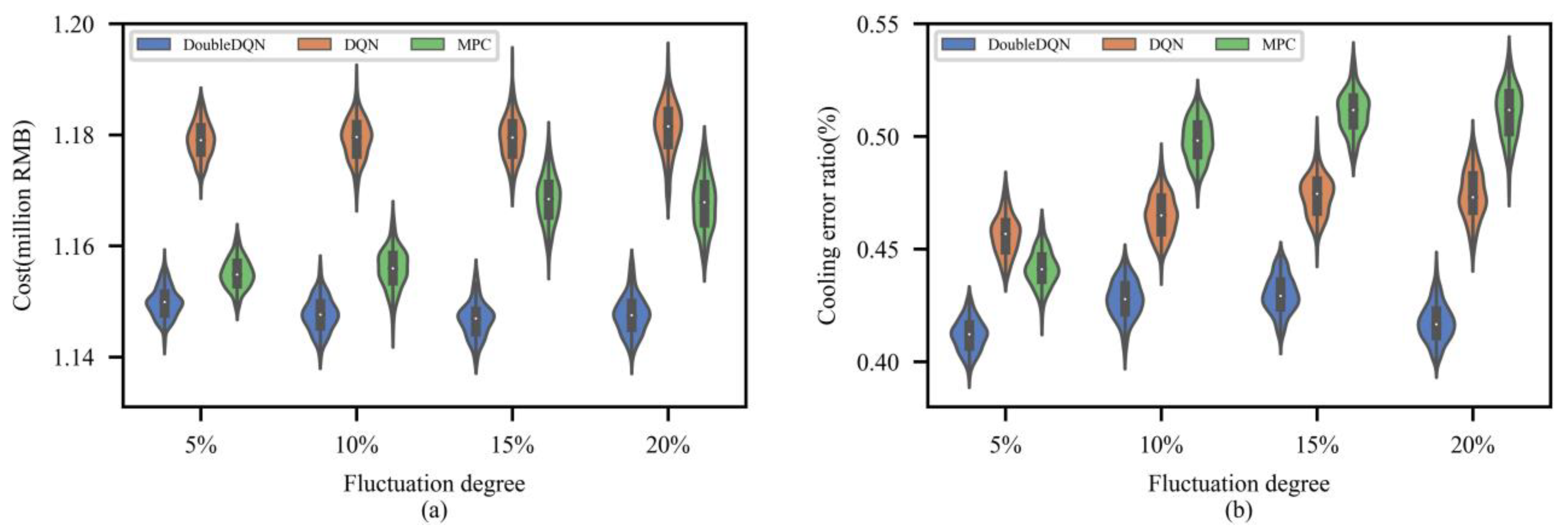
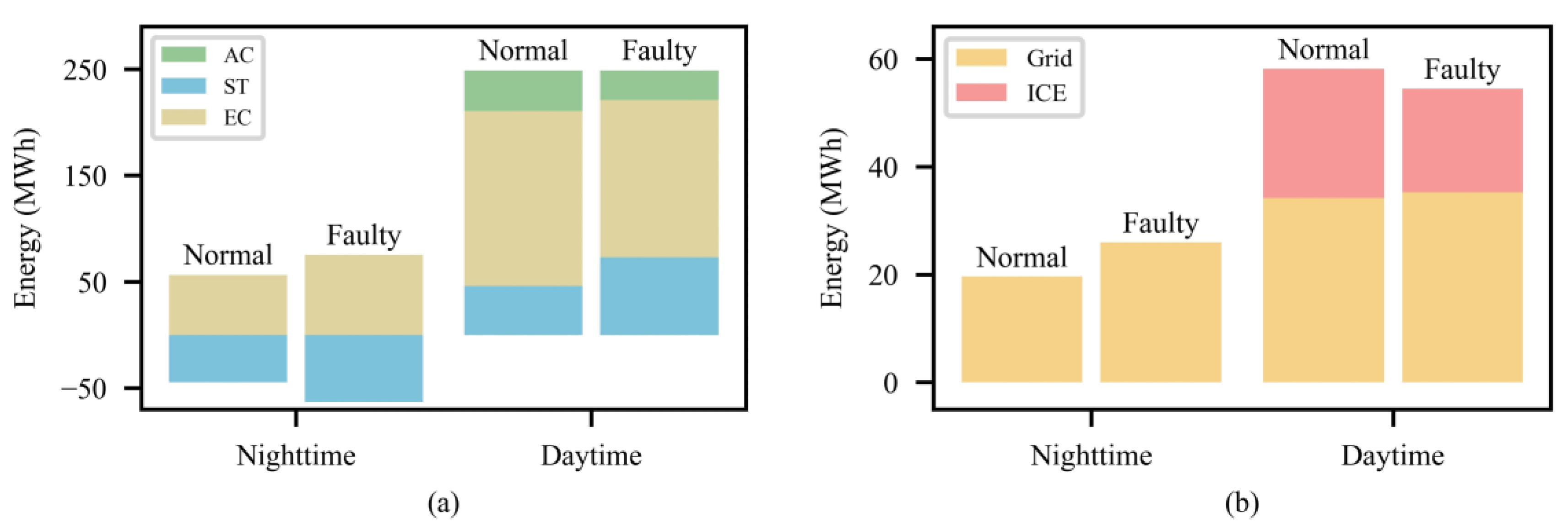
4.4. Extending the Proposed Method to Different Scenarios
4.4.1. Scenario C1
4.4.2. Scenario C2
4.4.3. Scenario C3
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Nomenclature
| AC | absorption chiller | peak electric power purchase in last t time steps, kW | |
| AE | auxiliary equipment | ||
| CCHP | combined cooling, heating and power | cooling load, kW | |
| COP | coefficient of performance | cooling output of ith running AC, kW | |
| CT | cooling tower | cooling output of ith running EC, kW | |
| DC | demand charge | rated cooling generation of EC, kW | |
| DRL | Deep reinforcement learning | storing/releasing power of ST, kW | |
| EC | electric chiller | low-grade waste heat, kW | |
| ECT | energy cost | state-action value function | |
| GB | gas boiler | received reward at time step t | |
| ICE | internal combustion engine | environment state at time step t | |
| ST | storage tank | gas consumption of ith running ICE, m3/h | |
| selected action of agent at time step t | electric power consumption coefficients | ||
| cost at time step t, RMB | difference between supply and demand of cooling power, kW | ||
| total cost, RMB | |||
| remaining energy storage of ST, kW | low calorific value of natural gas, kWh/m3 | ||
| number of running ACs | threshold of peak electric power purchase, kW | ||
| number of running ECs | electric efficiency of ICE | ||
| number of running ICEs | extra penalty of reward function | ||
| electricity load, kW | weighting factors of reward function | ||
| electric power consumption of supply unit, kW | unit price of demand charge, RMB/kW | ||
| allocated electric power consumption of supply unit, kW | natural gas price, RMB/m3 | ||
| purchasing electricity price, RMB/kWh | |||
| electric power consumption of ith running EC, kW | selling electricity price, RMB/kWh | ||
| discount factor | |||
| exchanging electric power with the grid, kW | learning factor | ||
| electric power output of ith running ICE, kW | / | weight parameters of Q network/target network | |
| rated electric power generation, kW |
References
- Zhang, D.; Zhang, B.; Zheng, Y.; Zhang, R.; Liu, P.; An, Z. Economic assessment and regional adaptability analysis of CCHP system coupled with biomass-gas based on year-round performance. Sustain. Energy Technol. Assess. 2021, 45, 101141. [Google Scholar] [CrossRef]
- Jalili, M.; Ghasempour, R.; Ahmadi, M.H.; Chitsaz, A.; Holagh, S.G. An integrated CCHP system based on biomass and natural gas co-firing: Exergetic and thermo-economic assessments in the framework of energy nexus. Energy Nexus 2022, 5, 100016. [Google Scholar] [CrossRef]
- Gu, W.; Lu, S.; Wu, Z.; Zhang, X.; Zhou, J.; Zhao, B.; Wang, J. Residential CCHP microgrid with load aggregator: Operation mode, pricing strategy, and optimal dispatch. Appl. Energy 2017, 205, 173–186. [Google Scholar] [CrossRef]
- Li, L.; Mu, H.; Gao, W.; Li, M. Optimization and analysis of CCHP system based on energy loads coupling of residential and office buildings. Appl. Energy 2014, 136, 206–216. [Google Scholar] [CrossRef]
- Wang, X.; Xu, Y.; Fu, Z.; Guo, J.; Bao, Z.; Li, W.; Zhu, Y. A dynamic interactive optimization model of CCHP system involving demand-side and supply-side impacts of climate change. Part II: Application to a hospital in Shanghai, China. Energy Convers. Manag. 2022, 252, 115139. [Google Scholar] [CrossRef]
- Saberi, K.; Pashaei-Didani, H.; Nourollahi, R.; Zare, K.; Nojavan, S. Optimal performance of CCHP based microgrid considering environmental issue in the presence of real time demand response. Sustain. Cities Soc. 2019, 45, 596–606. [Google Scholar] [CrossRef]
- Lu, S.; Gu, W.; Zhou, J.; Zhang, X.; Wu, C. Coordinated dispatch of multi-energy system with district heating network: Modeling and solution strategy. Energy 2018, 152, 358–370. [Google Scholar] [CrossRef] [Green Version]
- Shan, J.; Lu, R. Multi-objective economic optimization scheduling of CCHP micro-grid based on improved bee colony algorithm considering the selection of hybrid energy storage system. Energy Rep. 2021, 7, 326–341. [Google Scholar] [CrossRef]
- Kang, L.; Yuan, X.; Sun, K.; Zhang, X.; Zhao, J.; Deng, S.; Liu, W.; Wang, Y. Feed-forward active operation optimization for CCHP system considering thermal load forecasting. Energy 2022, 254, 124234. [Google Scholar] [CrossRef]
- Ghersi, D.E.; Amoura, M.; Loubar, K.; Desideri, U.; Tazerout, M. Multi-objective optimization of CCHP system with hybrid chiller under new electric load following operation strategy. Energy 2021, 219, 119574. [Google Scholar] [CrossRef]
- Li, Y.; Tian, R.; Wei, M.; Xu, F.; Zheng, S.; Song, P.; Yang, B. An improved operation strategy for CCHP system based on high-speed railways station case study. Energy Convers. Manag. 2020, 216, 112936. [Google Scholar] [CrossRef]
- Wang, J.; Yang, Y. A hybrid operating strategy of combined cooling, heating and power system for multiple demands considering domestic hot water preferentially: A case study. Energy 2017, 122, 444–457. [Google Scholar] [CrossRef]
- Lin, H.; Yang, C.; Xu, X. A new optimization model of CCHP system based on genetic algorithm. Sustain. Cities Soc. 2020, 52, 101811. [Google Scholar] [CrossRef]
- Zhu, G.; Chow, T.-T. Design optimization and two-stage control strategy on combined cooling, heating and power system. Energy Convers. Manag. 2019, 199, 111869. [Google Scholar] [CrossRef]
- Ma, D.; Zhang, L.; Sun, B. An interval scheduling method for the CCHP system containing renewable energy sources based on model predictive control. Energy 2021, 236, 121418. [Google Scholar] [CrossRef]
- Hu, K.; Wang, B.; Cao, S.; Li, W.; Wang, L. A novel model predictive control strategy for multi-time scale optimal scheduling of integrated energy system. Energy Rep. 2022, 8, 7420–7433. [Google Scholar] [CrossRef]
- Majidi, M.; Mohammadi-Ivatloo, B.; Anvari-Moghaddam, A. Optimal robust operation of combined heat and power systems with demand response programs. Appl. Therm. Eng. 2019, 149, 1359–1369. [Google Scholar] [CrossRef]
- Siqin, Z.; Niu, D.; Wang, X.; Zhen, H.; Li, M.; Wang, J. A two-stage distributionally robust optimization model for P2G-CCHP microgrid considering uncertainty and carbon emission. Energy 2022, 260, 124796. [Google Scholar] [CrossRef]
- Cheng, Z.; Jia, D.; Li, Z.; Si, J.; Xu, S. Multi-time scale dynamic robust optimal scheduling of CCHP microgrid based on rolling optimization. Int. J. Electr. Power Energy Syst. 2022, 139, 107957. [Google Scholar] [CrossRef]
- Batista Abikarram, J.; McConky, K.; Proano, R. Energy cost minimization for unrelated parallel machine scheduling under real time and demand charge pricing. J. Clean. Prod. 2019, 208, 232–242. [Google Scholar] [CrossRef]
- van Zoest, V.; El Gohary, F.; Ngai, E.C.H.; Bartusch, C. Demand charges and user flexibility—Exploring differences in electricity consumer types and load patterns within the Swedish commercial sector. Appl. Energy 2021, 302, 117543. [Google Scholar] [CrossRef]
- Hledik, R. Rediscovering Residential Demand Charges. Electr. J. 2014, 27, 82–96. [Google Scholar] [CrossRef]
- Zhang, Y.; Augenbroe, G. Optimal demand charge reduction for commercial buildings through a combination of efficiency and flexibility measures. Appl. Energy 2018, 221, 180–194. [Google Scholar] [CrossRef]
- Maldonado-Ramirez, A.; Rios-Cabrera, R.; Lopez-Juarez, I. A visual path-following learning approach for industrial robots using DRL. Robot. Comput. Manuf. 2021, 71, 102130. [Google Scholar] [CrossRef]
- Fuchs, A.; Heider, Y.; Wang, K.; Sun, W.; Kaliske, M. DNN2: A hyper-parameter reinforcement learning game for self-design of neural network based elasto-plastic constitutive descriptions. Comput. Struct. 2021, 249, 106505. [Google Scholar] [CrossRef]
- Guo, Y.; Ma, J. DRL-TP3: A learning and control framework for signalized intersections with mixed connected automated traffic. Transp. Res. Part C: Emerg. Technol. 2021, 132, 103416. [Google Scholar] [CrossRef]
- Alabdullah, M.H.; Abido, M.A. Microgrid energy management using deep Q-network reinforcement learning. Alex. Eng. J. 2022, 61, 9069–9078. [Google Scholar] [CrossRef]
- Gao, G.; Li, J.; Wen, Y. DeepComfort: Energy-Efficient Thermal Comfort Control in Buildings Via Reinforcement Learning. IEEE Internet Things J. 2020, 7, 8472–8484. [Google Scholar] [CrossRef]
- Yang, T.; Zhao, L.; Li, W.; Zomaya, A.Y. Dynamic energy dispatch strategy for integrated energy system based on improved deep reinforcement learning. Energy 2021, 235, 121377. [Google Scholar] [CrossRef]
- Hasanvand, S.; Rafiei, M.; Gheisarnejad, M.; Khooban, M.-H. Reliable Power Scheduling of an Emission-Free Ship: Multiobjective Deep Reinforcement Learning. IEEE Trans. Transp. Electrification 2020, 6, 832–843. [Google Scholar] [CrossRef]
- Guo, C.; Wang, X.; Zheng, Y.; Zhang, F. Real-time optimal energy management of microgrid with uncertainties based on deep reinforcement learning. Energy 2022, 238, 121873. [Google Scholar] [CrossRef]
- Zhou, S.; Hu, Z.; Gu, W.; Jiang, M.; Chen, M.; Hong, Q.; Booth, C. Combined heat and power system intelligent economic dispatch: A deep reinforcement learning approach. Int. J. Electr. Power Energy Syst. 2020, 120, 106016. [Google Scholar] [CrossRef]
- Ma, J.; Qin, J.; Salsbury, T.; Xu, P. Demand reduction in building energy systems based on economic model predictive control. Chem. Eng. Sci. 2012, 67, 92–100. [Google Scholar] [CrossRef]
- Jiang, Z.; Risbeck, M.J.; Ramamurti, V.; Murugesan, S.; Amores, J.; Zhang, C.; Lee, Y.M.; Drees, K.H. Building HVAC control with reinforcement learning for reduction of energy cost and demand charge. Energy Build. 2021, 239, 110833. [Google Scholar] [CrossRef]
- Yang, T.; Zhao, L.; Li, W.; Wu, J.; Zomaya, A.Y. Towards healthy and cost-effective indoor environment management in smart homes: A deep reinforcement learning approach. Appl. Energy 2021, 300, 117335. [Google Scholar] [CrossRef]
- Tan, H.; Zhang, H.; Peng, J.; Jiang, Z.; Wu, Y. Energy management of hybrid electric bus based on deep reinforcement learning in continuous state and action space. Energy Convers. Manag. 2019, 195, 548–560. [Google Scholar] [CrossRef]
- Du, Y.; Zandi, H.; Kotevska, O.; Kurte, K.; Munk, J.; Amasyali, K.; Mckee, E.; Li, F. Intelligent multi-zone residential HVAC control strategy based on deep reinforcement learning. Appl. Energy 2021, 281, 116117. [Google Scholar] [CrossRef]
- Carta, S.; Ferreira, A.; Podda, A.S.; Recupero, D.R.; Sanna, A. Multi-DQN: An ensemble of Deep Q-learning agents for stock market forecasting. Expert Syst. Appl. 2021, 164, 113820. [Google Scholar] [CrossRef]
- Tong, Z.; Ye, F.; Liu, B.; Cai, J.; Mei, J. DDQN-TS: A novel bi-objective intelligent scheduling algorithm in the cloud environment. Neurocomputing 2021, 455, 419–430. [Google Scholar] [CrossRef]
- Ding, Y.; Ma, L.; Ma, J.; Suo, M.; Tao, L.; Cheng, Y.; Lu, C. Intelligent fault diagnosis for rotating machinery using deep Q-network based health state classification: A deep reinforcement learning approach. Adv. Eng. Informatics 2019, 42, 100977. [Google Scholar] [CrossRef]
- Han, S.; Zhou, W.; Lu, J.; Liu, J.; Lü, S. NROWAN-DQN: A stable noisy network with noise reduction and online weight adjustment for exploration. Expert Syst. Appl. 2022, 203. [Google Scholar] [CrossRef]
- Park, S.; Yoo, Y.; Pyo, C.-W. Applying DQN solutions in fog-based vehicular networks: Scheduling, caching, and collision control. Veh. Commun. 2022, 33, 100397. [Google Scholar] [CrossRef]
- Zhang, W.; Gai, J.; Zhang, Z.; Tang, L.; Liao, Q.; Ding, Y. Double-DQN based path smoothing and tracking control method for robotic vehicle navigation. Comput. Electron. Agric. 2019, 166. [Google Scholar] [CrossRef]
- Dong, P.; Chen, Z.-M.; Liao, X.-W.; Yu, W. A deep reinforcement learning (DRL) based approach for well-testing interpretation to evaluate reservoir parameters. Pet. Sci. 2022, 19, 264–278. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| 0.46 | 0.013, 474.293, 1.615 | ||
| 2, 4, 2 | −1.021, 1312.225, 0.005 | ||
| (kW) | 1600, 4700 | 0.005, 0.062, 2.970 | |
| (kWh) | 10,000 | 5.2 | |
| (kWh) | 70,000 | 1.3 |
| Description | Training Value | Description | Training Value |
|---|---|---|---|
| Size of input | 5 | Mini-batch size | 128 |
| No. of hidden layers | 3 | Discount factor | 0.925 |
| Size of each hidden layer | 128, 512, 128 | Learning rate | 0.0005 |
| Size of output | 2 | Weights of reward | : 510−5, : 610−4, : 0.002, : 3300 |
| Activation function for each hidden layer | ReLU | Optimizer | Adam |
| Method | Total Cost (RMB) | Energy Cost (RMB) | Demand Charge (RMB) | Rate of Cooling Error (%) | Total Online Running Time (s) | Total Offline Training Time (s) |
|---|---|---|---|---|---|---|
| Rule-based policy | 1,678,249 | 1,524,251 | 153,998 | 0 | 20.27 | - |
| DoubleDQN | 1,152,830 | 1,013,176 | 139,654 | 0.312 | 1.44 | 973 |
| DoubleDQN-a | 1,256,845 | 995,455 | 261,390 | 0.608 | 1.46 | 995 |
| DQN | 1,154,421 | 1,011,638 | 142,783 | 0.550 | 1.41 | 1204 |
| DQN-a | 1,263,219 | 993,489 | 262,730 | 0.652 | 1.53 | 1013 |
| Unit Failure (A, B) | Probability (%) |
|---|---|
| (4, 1) | 35 |
| (3, 2) | 15 |
| (3, 1) | 5 |
| Method | Total Cost (RMB) | Ratio of Cooling Error (%) | ||||
|---|---|---|---|---|---|---|
| Min | Mean | Max | Min | Mean | Max | |
| DoubleDQN | 1,148,908 | 1,152,980 | 1,158,866 | 0.292 | 0.412 | 0.531 |
| DQN | 1,168,379 | 1,185,324 | 1,189,573 | 0.358 | 0.659 | 1.031 |
| Rule-based policy | 1,644,612 | 1,683,547 | 1,691,356 | 0.014 | 0.305 | 0.804 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, W.; Lin, Y. Energy Dispatch for CCHP System in Summer Based on Deep Reinforcement Learning. Entropy 2023, 25, 544. https://doi.org/10.3390/e25030544
Gao W, Lin Y. Energy Dispatch for CCHP System in Summer Based on Deep Reinforcement Learning. Entropy. 2023; 25(3):544. https://doi.org/10.3390/e25030544
Chicago/Turabian StyleGao, Wenzhong, and Yifan Lin. 2023. "Energy Dispatch for CCHP System in Summer Based on Deep Reinforcement Learning" Entropy 25, no. 3: 544. https://doi.org/10.3390/e25030544
APA StyleGao, W., & Lin, Y. (2023). Energy Dispatch for CCHP System in Summer Based on Deep Reinforcement Learning. Entropy, 25(3), 544. https://doi.org/10.3390/e25030544