1. Introduction
As an absolutely necessary part of the modern financial system, insurance is one of the most effective ways for people to manage risks, such that it plays a significant role in our daily life. A very important task of insurance companies is to quantitatively analyze future claims. Consequently, risk theory has become an active research field of actuarial science. For the classical mathematical risk model, the so-called Lundberg–Cramér surplus process has the following form:
in which
is the initial capital of an insurance portfolio,
is the constant rate of premium income,
is a homogeneous Poisson process with intensity
, the total claim numbers are denoted up to time
t, and
describes the size of the
ith claim. In the literature, Asmussen and Albrecher [
1] presented excellent reviews about this well-known and important model.
In model (
1), independent structures are usually assumed. For example, the claim amount
is a sequence of non-negative independent and identically distributed (i.i.d.) random variables, and the claim numbers of different periods are assumed to be a sequence of i.i.d. random variables. However, these are not always true in practice because of the increasing complexity of individual risks. To avoid this restriction, a growing number of actuaries have been paying attention to the model with dependent risks. As stated in Yang and Zhang [
2], there are mainly two kinds of correlation in insurance: one is the correlation among lines of businesses, and the other is temporal dependence, such as the correlation between the current claim and the previous claims. For recent works about the first type of correlation, Refs. [
3,
4] studied the dependence among individual risks, Refs. [
5,
6] discussed the two-dimensional risk models with dependent surplus processes, and [
7,
8] examined the risk models that have multiple classes of insurance business with thinning dependence structure. The relevant results have been used in a variety of actuarial areas, including, among others, value at risk, dividend strategies, reinsurance, capital allocation, etc.
In this paper, we focus on the second type. To deal with this problem, the use of a time series is a critical method. Gerber [
9] considered the calculation of ruin probabilities in a Gaussian linear risk model; Gourieroux and Jasiak [
10] applied the integer-valued time series model to update the premiums in vehicle insurance; and many researchers have extensively revisited the relevant results afterwards. Considering that the compound distributions are the cornerstones of a great number of risk models in risk theory, Cossette et al. [
11] proposed some new discrete-time risk models, where the first-order integer-valued moving average (INMA(1)) and first-order integer-valued autoregressive (INAR(1)) processes are used to describe the dependence structures among the number of claims for each period. The authors derived expressions for the functions that allow people to find the Lundberg adjustment coefficients and discussed the Lundberg approximation formulas for infinite-time ruin probabilities. Along the same line, Cossette et al. [
12] determined the distributions of aggregate claim amount and provided an effective way to measure some related risk quantities, including VaR, TVaR, and the stop-loss premium. Shi and Wang [
13] gave an approximation method for the risk model with the Poisson INAR(1) claim number process in order to obtain the upper bound of the infinite-time ruin probability. Zhang et al. [
14] solved the problem of optimal reinsurance strategy for the risk model with the INMA(1) claim number process. Afterwards, Hu et al. [
15] and Chen and Hu [
16] further generalized this kind of model by replacing the Poisson innovations with compound Poisson innovations in the INAR(1) and INMA(1) claim number processes, respectively. Guan and Hu [
17] even utilized an INAR(1) process with an arbitrary innovations’ distribution to specify the temporal dependence among the claim numbers.
In the papers mentioned above, it should be noted that the incomes of all the risk models are linear functions of time
t, because the premiums are collected continuously with positive deterministic constant rate
c, providing great convenience for risk analysis. However, this assumption is obviously lacking in terms of describing the real situation of insurance portfolios; for example, it cannot capture the uncertainty of the customers’ arrivals. As an alternative to a fixed premium rate, Boikov [
18] supposesed that the premium income also follows a compound Poisson process and calculates the ruin probability. From then on, the risk models with stochastic premiums have been extensively improved by many actuaries. Wang et al. [
19] studied the investment problem of such models. Labbé and Sendova [
20] discussed the Gerber–Shiu function. Zhao and Yin [
21] proposed a renewal risk model with stochastic incomes. Recently, Su et al. [
22] provided a statistical method for estimating the Gerber–Shiu function; Ragulina [
23] investigated the De Vylder approximation for the ruin probability and a constant dividend strategy in the risk model with stochastic premiums; and Dibu and Jacob [
24] focused on a double barrier hybrid dividend strategy. Wang et al. [
25] quantitatively assessed the impact of the stochastic income process on some ruin quantities in detail.
Similar to the classical risk model, the premium numbers of different periods are commonly set to be a sequence of i.i.d. random variables in the aforementioned papers. To better characterize the uncertainty and capture the variability of an insurer’s income process, Guan and Wang [
26] proposed modeling the temporal dependence among the premium numbers of each period by a Poisson INAR(1) process. In this paper, we follow this trend of research. We also aim to study a new dependent risk model with stochastic premiums based on time series for count random variables, in which the INAR(1) process and INMA(1) process are applied to fit the temporal dependence among the premium numbers and the temporal dependence among the claim numbers of consecutive periods, respectively. Our goal is to approximate the infinite-time ruin probability of the proposed surplus process by the Lundberg adjustment coefficient and discuss the asymptotic formula for the finite-time ruin probability when the claim sizes follow distributions with heavy tails.
Our model generalizes the classical discrete-time surplus process of an insurance portfolio with stochastic premiums to a new dependent risk model, and our results extend what has been studied in the existing literature. The contributions of our paper mainly include the following two aspects:
In contrast to the assumption that either claim numbers or premium numbers have a temporally dependent structure, we propose a new risk model of an insurance portfolio with both claim numbers and premium numbers being dependent within the integer-valued time series framework, which is more flexible in insurance practice.
In addition to studying the distribution of the aggregate claims, the Lundberg adjustment coefficient, and the Lundberg approximation formula for the infinite-time ruin probability in the case of light-tailed claim sizes, we also explore the large deviations of the aggregate claims and the asymptotic formula for the finite-time ruin probability when the claim sizes are heavy-tailed, which enlarges the applicability of the risk model.
The remainder of the paper is organized as follows:
Section 2 introduces our concerned risk model and considers some probabilistic properties of the proposed model.
Section 3 defines the Lundberg adjustment coefficient via the solution of an explicit equation.
Section 4 establishes an exponential asymptotic estimation for the infinite-time ruin probability.
Section 5 studies the large deviations of the aggregate claims when the claim sizes follow a class of heavy-tailed distributions and presents an asymptotic formula for the finite-time ruin probability.
Section 6 illustrates the main results by numerical simulations.
Section 7 finally concludes this paper.
2. Risk Model and Basic Properties
In this section, we first describe the new dependent risk model, and then, provide some moment results of the premiums and claims. Let
be the surplus of an insurance portfolio at the end of period
t, and we define the surplus process by the dynamic equation
where
is the initial surplus level;
aggregates the premiums during period
t, in which
counts the number of individual income and
represents the amount of the
kth premium income for the insurance portfolio during period
t;
is the aggregate claims during period
t, in which
denotes the number of claims and
is the size of the
jth payment to the insured in period
t. For mathematical tractability, the following assumptions are made:
(1) Both and are arrays of i.i.d. random variables, which have the same distributions as non-negative X and Y, respectively.
(2) , , , and are mutually independent.
The dependence structures of the model are constructed in the following ways:
(i)
constitutes a Poisson INAR(1) process that satisfies
where the so-called binomial thinning operator “∘” is given by
in which the following statements are true:
The thinning parameter .
is an array of i.i.d. Bernoulli random variables with mean .
is a sequence of i.i.d. Poisson random variables with mean .
, and are independent.
(ii)
constitutes a Poisson INMA(1) process that satisfies
where “∘” is similarly defined by
in which the following are true:
The thinning parameter .
is an array of i.i.d. Bernoulli random variables with mean .
is a sequence of i.i.d. Poisson random variables with mean .
and are independent.
Remark 1. Time series analysis is one of the most important methods for dealing with dependent data and has attracted a lot of interest during the last decades. However, the classical real-valued time series models with continuous ranges can not account for discreteness, so they are of limited use for fitting the premium numbers and the claim numbers, which are typical count random variables fairly common in practice. Their poor performances in modeling this class of data mainly include: (1) the data generating mechanism can not be explained; (2) the approximate errors are big; and (3) the forecast results are not integer-valued. Therefore, models and methods for integer-valued time series have been covered by a large number of papers in recent years. Refs. [27,28,29,30] present comprehensive surveys on this fascinating research area. As two core models of integer-valued time series, INAR(1) process and INMA(1) process have been extensively applied in the literature of actuarial science, and the relevant results have been widely used in a variety of risk management. Remark 2. The INAR(1) process (3) shows that the premium number in period t is composed of two parts: denotes the new incomes arriving between period and t, and presents a random proportion of the premium number in the previous period. This can be reasonably explained for the insurance practice that states: every insured entity could continue to pay a premium with probability α; or withdraw from the contract with probability in the next period. When , (3) becomes , meaning that the premium number in period t could be totally determined by , and our model (2) will reduce to the classical discrete-time risk model with stochastic premiums, where the premium numbers of different periods are independent (please see Appendix A for details). Remark 3. The INMA(1) process (5) reveals that the claim number in period t also consists of two parts: is the new claim during period t, and indicates the claims of period that could produce another accident with probability β in period t. Instead of (3), we use the INMA(1) process (5) to fit the temporal dependence among the claim numbers for each period, considering that the insured parties cannot receive benefits every year for some insurance products. Taking unemployment insurance as an example, every time the claimant is out of work, they could receive the benefits for up to 2 years, if the premiums for at least 1 year have been paid. Another appropriate example might be some medical insurance contracts, which state that no matter how long the patient stays in the hospital, the insurer would pay the benefits for at most (for instance) 2 months. Similarly, if , our proposed model will reduce to the classical case, where the claim numbers of different periods are independent. As stated in Al-Osh and Alzaid [
31], under the condition of
, it follows that the process of premium numbers
is a stationary and ergodic Markov chain. Furthermore, if we assume
, then
is also Poisson distributed with mean
. Hence, by the law of iterated expectation and the assumption that
and
are independent, it is easy to find that
Meanwhile, by the law of total variance, we can obtain
Furthermore, Al-Osh and Alzaid [
31] show that
from which we can obtain
Similarly, for the process of claim numbers
, under the condition of
, its marginal distribution is uniquely determined by the law of
. Therefore, the assumption of
will result in
being Poisson distributed with a mean of
. Consequently, by the same method to drive (
7)–(
9), we have
and
These results are consistent with those in [
11].
3. Definition of the Lundberg Adjustment Coefficient
In this section, we first consider how to calculate the moment generating functions (m.g.f.) of the aggregate premiums and aggregate claims up to period t, and then, define the Lundberg adjustment coefficient of the proposed dependent risk model with stochastic premiums based on time series for count random variables by means of a equation.
After recursive calculation, we can rewrite model (
2) as
in which
and
represent the aggregate premium incomes and aggregate claim payments up to time
t, respectively. As for the m.g.f. of
and
, by the definition, we have that
where
denotes the m.g.f. of
X and
presents the probability generating function (p.g.f.) of the total premium number up to period
t of the proposed model (
2).
Similarly, it holds that
where
denotes the m.g.f. of
Y, and
presents the p.m.f. of the total claim number up to period
t of the proposed model (
2).
In order to compute and , we find the explicit expressions for and in the following two lemmas, respectively.
Lemma 1. For , when , the p.g.f. of is given by Proof. Since
, it is obvious that
When
, we denote
By the property of the binomial thinning operator (see Scotto et al. [
28] for example), we can rewrite
as
For the p.g.f. calculation, we have
in which
and
.
Combining (
15)–(
17), it follows that
Moreover, from the definition
, it is easy to find that
Then, recursive calculation results in
Finally, inserting (
19) into (
18), we can obtain
This completes the proof. □
Lemma 2. For , when , the p.g.f. of is given by Proof. By (
5), it holds that
which follows from
,
and
The proof then is completed. □
To further analyze the insurance portfolio, we write
and let
Then, the positive solution to the equation
can be defined as the Lundberg adjustment coefficient, which is denoted by
R and can be used to approximate the infinite-time ruin probability of the proposed model (
2). The following result gives the explicit expression for
.
Proof. Due to the non-negativity of
r and
X, it follows that
Then, by Lemma 1, we have
On the other hand, from (
13) and (
20), we obtain
Then, combining (
24) and (
25) with (
21) and (
22) yields
This completes the proof. □
Remark 4. When , the proposed model (2) degenerates to the discrete-time risk model based on the Poisson INMA(1) process studied by [11,14], where only the temporal dependence among the claim numbers of consecutive periods is considered. Consequently, (23) becomeswhich corresponds to (7) in [11,14]. Remark 5. When , the proposed model (2) reduces to the discrete-time risk model with stochastic premiums and dependence based on the Poisson INAR(1) process studied by [26], where only the temporal dependence among the premium numbers of consecutive periods is considered. As a result, (23) becomeswhich corresponds to (3.10) in [26]. 4. Lundberg Approximation Formula for the Infinite-Time Ruin Probability
Let the ruin time of our proposed surplus process (
2) be
if
goes below 0 at least once; otherwise, take
. As a consequence, the infinite-time ruin probability
is defined by
Ruin probability
is well-known as one of the most common and important quantities used to measure the riskiness of an insurance portfolio in the risk-theoretic context. However, as can be seen from the expression (
11), our proposed model releases the condition that
and
are independent of
, which is a key but defective assumption in the classical risk model with stochastic premiums and allows for the temporal dependence among the premium numbers and claim numbers. Therefore,
and
are correlated with
, and
is no longer a Lévy process with stationary independent increments in our model. Consequently, it is not easy to derive the upper bounds and explicit expression for the infinite-time ruin probability such as those in some classical models. As an efficient alternative, the following result gives an asymptotic estimation for
of our proposed model (
2).
Theorem 2. In the discrete-time dependent risk model with stochastic premiums based on the Poisson INAR(1) process and Poisson INMA(1) process, ifwe can obtain the Lundberg approximation formula for the infinite-time ruin probability , which has the following expression:where u and R are the initial capital and the Lundberg adjustment coefficient, respectively. Proof. According to Theorem 2.1 in Müller and Pflug [
32], it is sufficient for us to prove that the equation
has a unique positive solution, which can be defined as the Lundberg adjustment coefficient
R. To this end, we derive the following four properties of the function
.
Firstly, noting that
, we have
Secondly, it is easy to calculate that
Together with the fact
and
, we obtain
Thirdly, it is easy to verify the convexity of , which results from the fact that is convex and the definition of .
Finally, when the m.g.f. of
Y exists, i.e., there exists some quantity
,
, such that
is finite for all
with
then, it holds that
Therefore, it can be concluded that there exists a unique positive solution to the equation
, and then, (
27) follows immediately. □
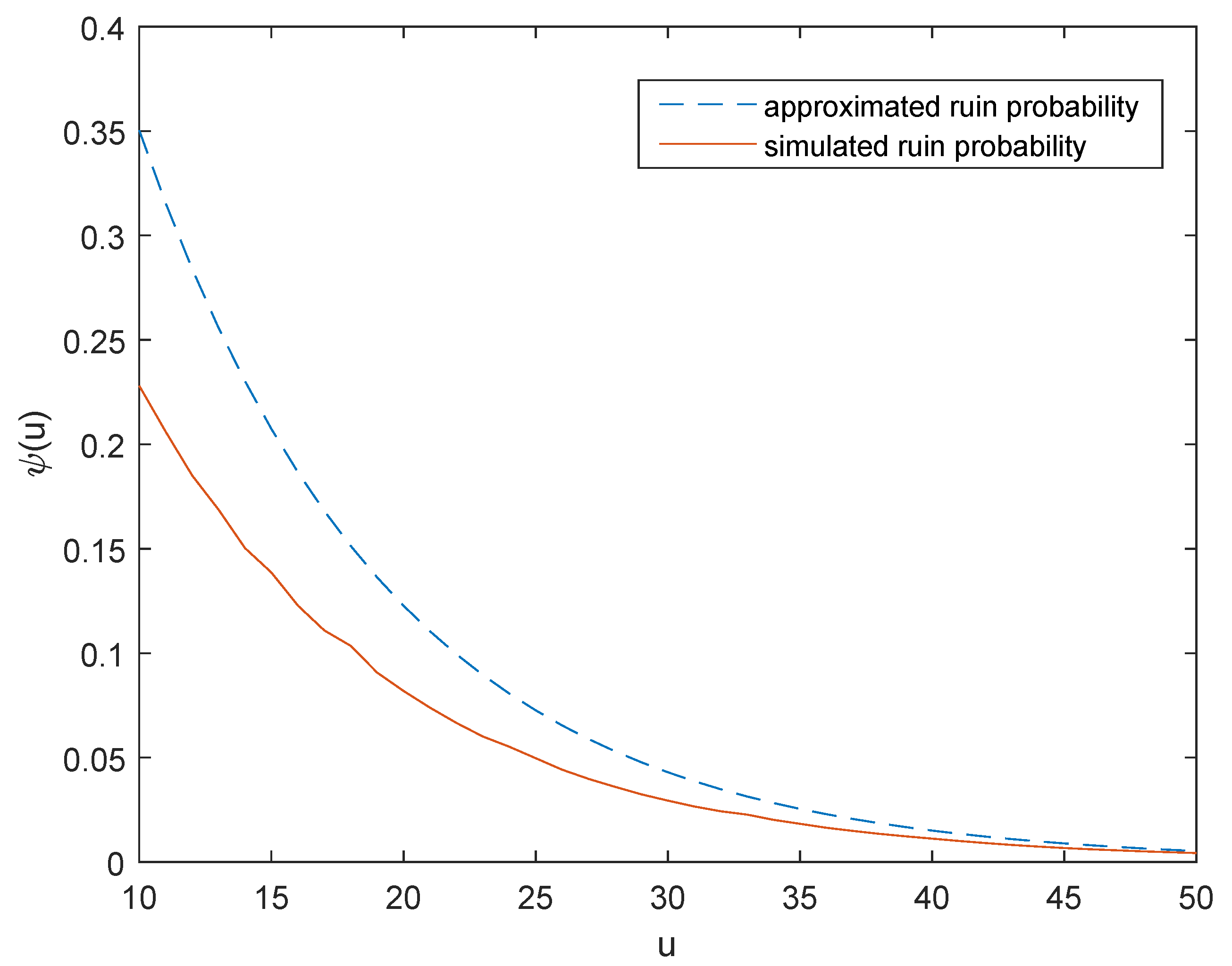
Remark 6. In risk and ruin theory, the assumption (26) is the so-called relative safety loading condition, which implies that the expected premium incomes should be more than the expected claim expenses to guarantee that the insurance company can operate normally and profitably. Remark 7. As a result of the approximation formula (27), we can asymptotically estimate the infinite-time ruin probability byif the initial surplus u becomes large enough. From (
9) and (
10), it can be seen that the thinning parameters
and
could quantitatively measure the degree of the dependence in the risk model (
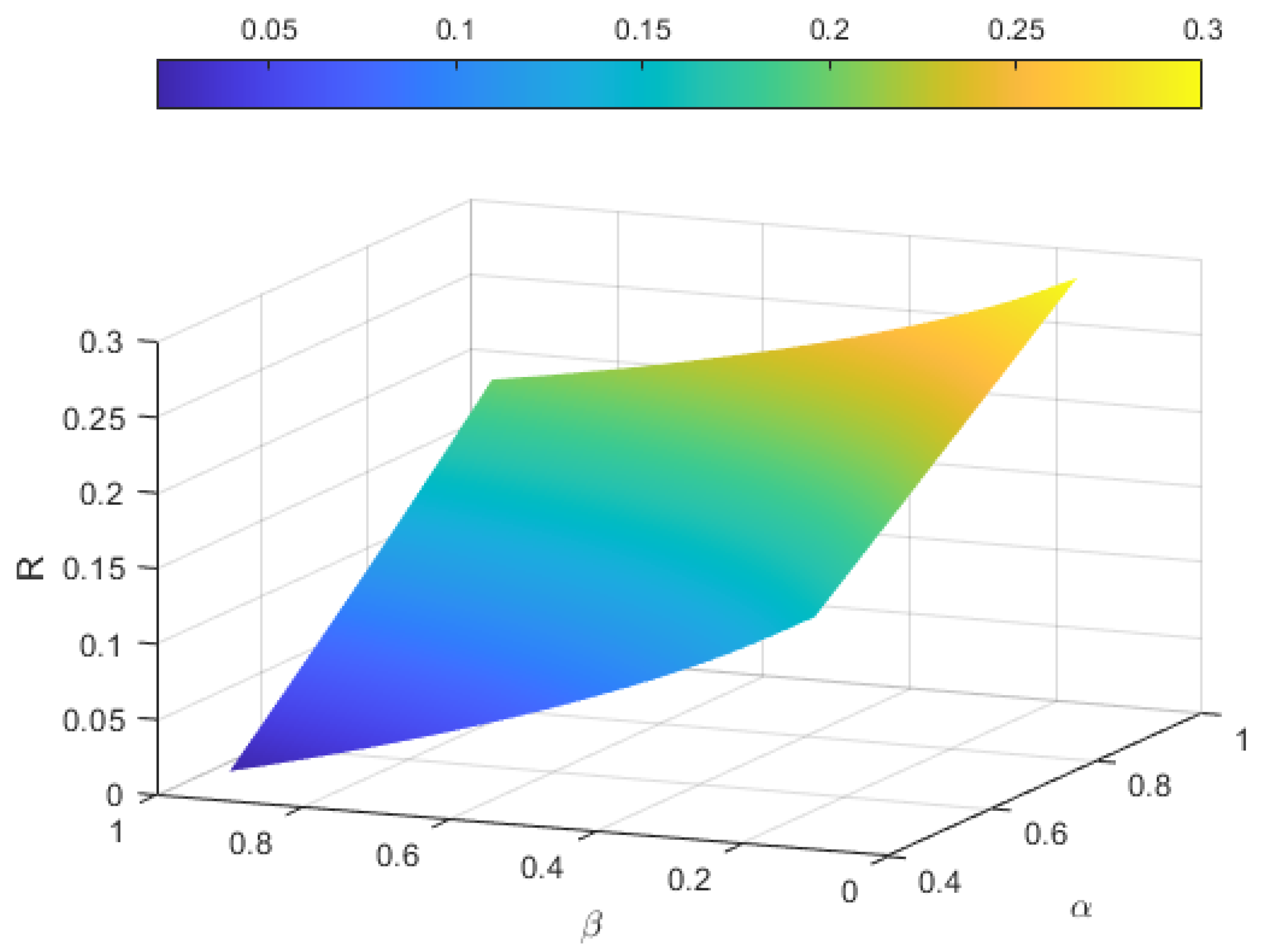
2); hence, it is necessary for us to discuss their impacts on the adjustment coefficient and further on the risk of the insurance portfolio.
Proposition 1. As a function of the two thinning parameters, the Lundberg adjustment coefficient R of our proposed risk model (2) increases with respect to α and decreases with respect to β. Proof. For convenience, we now rewrite
as
; the Lundberg adjustment coefficient
R is determined by
and can be taken as a function of
and
. By the properties derived in the proof of Theorem 2, we know that
Meanwhile, with
in mind, it follows that
. Thus, we take the partial derivative of
with respect to variable
and then have
As a result, using implicit function theorem, it holds that
implying that
R increases with respect to
.
Similarly, because
for
, taking the partial derivative of
with respect to variable
yields
from which we apply implicit function theorem again and obtain
meaning that
R decreases with respect to
. □
Remark 8. As shown in Proposition 1, the degree of riskiness can be measured and quantified by the Lundberg adjustment coefficient R, in the sense that it decreases with the thinning parameter α, while it increases with the thinning parameter β. In insurance practice, it can be naturally explained that when α increases, the insured parties would like to renew their insurance contracts with a higher probability in the next period, which would lower the risk of the portfolio. On the contrary, when β increases, a reported claim becomes more likely to produce another insurance accident in the next period, which could make the portfolio much riskier.
5. Asymptotic Formula for the Finite-Time Ruin Probability
In this section, we turn our focus to the case of heavy-tailed claim sizes, which are frequently used in insurance practice for catastrophe risks, such as earthquakes, hurricanes, floods, financial crises, agricultural disasters, and so on. In these instances, the Lundberg adjustment coefficient and Lundberg approximation estimation for infinite-time ruin probability can no longer be applied because
(the m.g.f. of
Y) does not exist for
. Therefore, increasing numbers of researchers have increasingly paid close attention to the precise large deviations in the aggregate of claims, as well as the asymptotic formulas for infinite-time and finite-time ruin probabilities. The relevant study was initiated by Klüppelberg and Mikosch [
33] and then has been revisited by many researchers afterwards. We refer to Chen et al. [
34] and Fu et al. [
35] for some recent contributions on this topic. Cheng and Wang [
36], Yang et al. [
37], and Jing et al. [
38] considered the asymptotic ruin probabilities in risk models with dependence among the claim sizes. Xun et al. [
39] obtained the uniformly asymptotic result of ruin probability in a general risk model with stochastic premiums. Yu [
40] derived the precise large deviations of the aggregate amount of claims for a risk model with the Poisson ARCH claim number process. Along the same line, in this section, we investigate our proposed model (
2) when the distribution of claim sizes belongs to a heavy-tailed class.
First, we give some brief notations. Let and be two positive functions. We denote if ; denote if ; denote if ; and denote if . We denote the common distribution functions of premium amount X and claim size Y with and , respectively.
Then, we recall a class of heavy-tailed distributions and one of its important properties. More detailed discussions can be found in Embrechts et al. [
41], Asmussen and Albrecher [
1], etc.
A distribution function
F on
is said to have a consistently varying tail, denoted by
, if
where
is the tail probability with
. The class
is a wide class of distributions commonly used in actuarial science, including the well-known Pareto, Burr, and loggamma distributions. Ng et al. [
42] established a very useful result for the distributions of class
, which is given in the following lemma.
Lemma 3. Suppose that is a sequence of i.i.d. non-negative random variables with common distribution function and . Taking , for any fixed , it holds uniformly for all thatin which the uniformity is understood in the following sense: Analogous to the infinite-time ruin probability
, for any fixed
, we define the finite-time ruin probability
of the discrete-time risk model (
2) as
In order to further study the asymptotic formula of
, which is also a core actuarial quantity, we revise Lemma 3 as follows.
Lemma 4. Suppose that is a sequence of i.i.d. non-negative random variables with the common distribution function and . Define ; then, for any fixed and , it holds uniformly for all that Proof. By the definition of class
, it follows for any fixed
and sufficiently large
y that
from which we can obtain
Hence, it holds that
Furthermore, by Lemma 3 and (
35), it follows that
The proof is then completed. □
Now, we give the precise large deviations of the aggregate claims,
, which is described in model (
11).
Theorem 3. For our proposed model (2), let and be the common distribution function and expectation of the claim sizes, respectively. Assuming and , then for any fixed and , it holds uniformly for all that Proof. Let
be a sequence of i.i.d. non-negative random variables, with their common distribution function denoted by
. Suppose that
is the characteristic function of
. With the same method to derive (
12) and (
13), we can obtain
where
is the characteristic function of
Y.
On the other hand, direct calculation leads to
We conclude after checking (
37) and (
38) that
where ”
” means the identical distribution.
For any
, we have
in which
denotes the maximum integer not exceeding
.
From Lemma 4, we know it holds uniformly for all
that
As for
, for
, we write
where
if
t is a even number, and
if
t is an odd number. From the definition, we know that
is a one-dependent stationary sequence with the common Poisson distribution of mean
and m.g.f
; then, it is easy to see that
and
are two sequences of i.i.d. random variables. Let
; by Cramér Theorem (Theorem 2.2.3 in Dembo and Zeitonui [
43]), we have
in which
.
Combining (
40)–(
42) gives
On the other hand, it holds that
in which
because of the fact that
obtained from the classical law of large numbers.
Then, combining (
44), (
45), and Lemma 4 yields
Generally, letting
in (
43) and (
46) and keeping (
39) in mind, we finally conclude that
Then, the proof is completed. □
With the help of the above conclusion, we can manifest the asymptotic formula for the finite-time ruin probability in the following theorem.
Theorem 4. Under the conditions of Theorem 3, for any fixed and , the asymptotic formulaholds uniformly for all as . Proof. From the definition of finite-time ruin probability, it is clear that
Noting that
and keeping (
9) in mind, for any
, we have
from which we can obtain
Then, for any
, if
t is sufficiently large such that
u is sufficiently large, it holds that
Furthermore, by Theorem 3 and let
, we have
Plugging (
49) into (
48) gives
On the other hand, for any fixed
and
, we have uniformly for all
that
which implies
Therefore, we complete the proof by combining (
50) and (
51). □
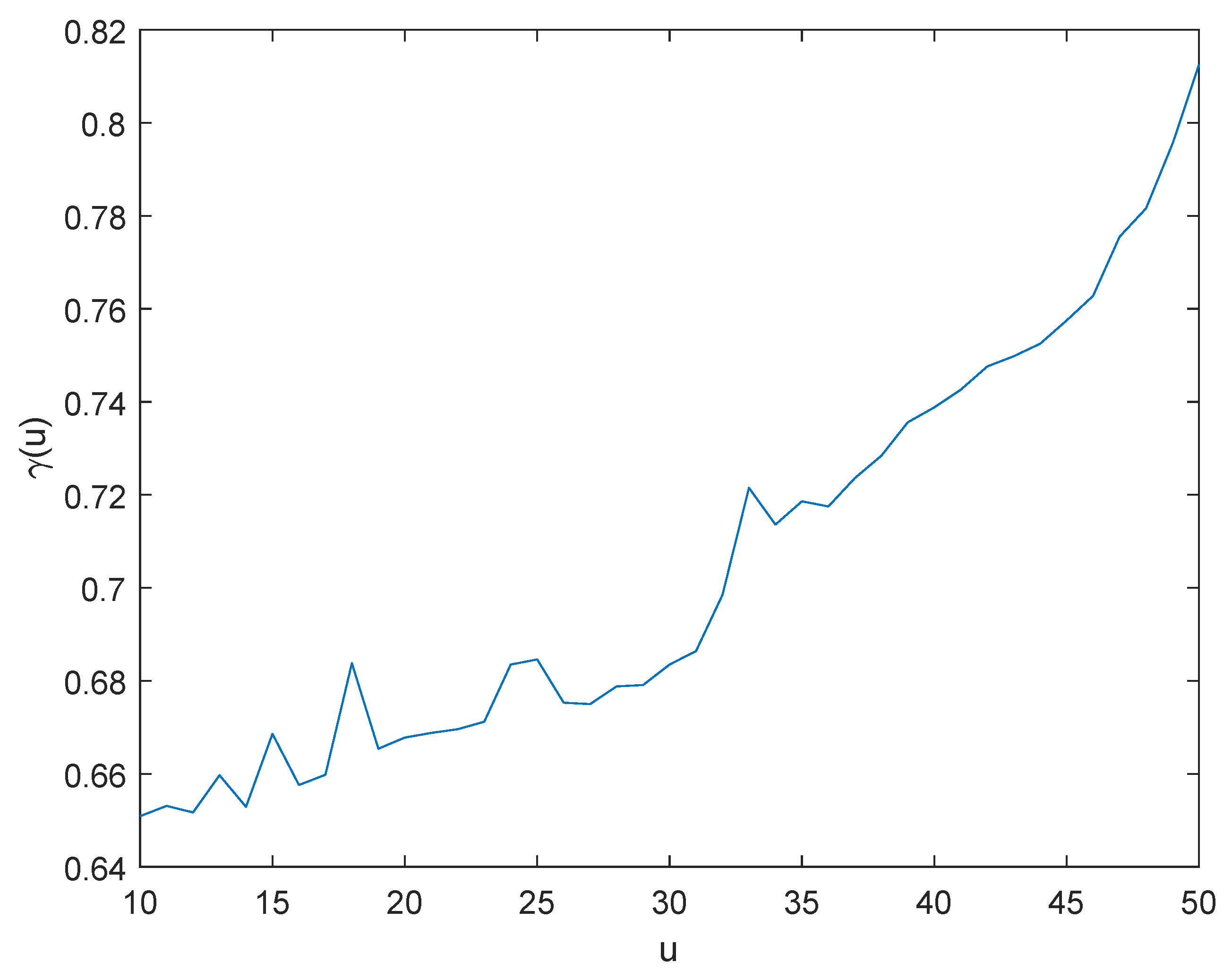
Remark 9. Applying Lemma 3 instead of Lemma 4 in Theorem 3, it is not difficult to see that the precise large deviation (36) also holds uniformly for all . In this paper, we restrict ourselves to the interval in order to provide convenience for investigating the finite-time ruin probability . Moreover, we can prove that the asymptotic formula (47) in Theorem 4 holds uniformly for all , which includes as a special case. In practice, when t is large enough, we can asymptotically estimate by , as the size of claims belong to the distributions of class and the insurer’s initial surplus is adequate in the sense of . 7. Conclusions
In this paper, we examine a generalization of the classical discrete-time risk model of an insurance portfolio with stochastic premiums, using a Poisson INAR(1) process and a Poisson INMA(1) process to fit the temporal dependence among the premium numbers and the temporal dependence among the claim numbers, respectively. We give the explicit expression for the function satisfied by the Lundberg adjustment coefficient and find the Lundberg approximation formula for the infinite-time ruin probability. Furthermore, we discuss and analyze the impact of the two thinning parameters and manifest that the dependence structure in the model has a significant influence on the risk of the surplus process in an insurance company. When the claim sizes follow a class of heavy-tailed distributions, we establish the large deviations of the aggregate claims and investigate the asymptotic formula for the finite-time ruin probability. In the numerical examples, we use MATLAB to randomly draw the sample paths of the proposed surplus process and compute estimates of the true ruin probabilities corresponding to different values of u using the Monte Carlo method. From the simulated results, it can be seen that the approximation formula and asymptotic formula we obtained are effective. Furthermore, these two formulas are much simpler to use for calculating and estimating the ruin probabilities than the Monte Carlo method.
As for future work, we could implement the same methodology by applying the time series for count data with other distributed innovations or an arbitrary innovations’ distribution. Generally, using the same approach as that in Lemma 1 and Lemma 2, we can extend (
14) and (
20) to
and
respectively. Therefore, if we could derive the explicit expression of
, the properties of the solution to the equation
can be discussed, and the adjustment coefficient can be obtained to measure the risk.
Additionally, we could adopt some higher-order processes to make the insurance risk model much more practical and flexible. In this situation, it becomes more challenging to find the expressions of and . As a consequence, there might be some difficulties in deriving and defining the adjustment coefficient for an insurance portfolio.
On the other hand, instead of fixing the distributions and the parameters to illustrate the results by simulation, we can use the real dataset to fit the distributions and obtain the statistical estimates of the parameters, so that the ruin problems of the risk model could be analyzed in a more scientific way.







{kind=link}
{kind=link}
{kind=link}