


Few Shot Class Incremental Learning via Efficient Prototype Replay and Calibration


Abstract
:1. Introduction
- We design a holistic three-stage training scheme for few shot class incremental learning, which can be applied as a generalized pipeline to enhance the quality of prototypes in a step-by-step way.
- To avoid overfitting, we introduce a pre-training stage with strong augmentations and a meta-training stage with implicit prototype calibration which reduce overlap among features of different categories.
- To mitigate catastrophic forgetting, we perform prototype storage and replay together with an explicit prototype rectification by leveraging both base and novel knowledge in the incremental-training stage.
- The experimental results on CIFAR-100 and miniImageNet datasets demonstrate that our EPRC significantly boosts the classification performance compared with existing mainstream FSCIL methods.
2. Related Work
2.1. Few Shot Learning
2.2. Few Shot Class Incremental Learning
2.3. Prototype Calibration in Metric Learning
3. Materials and Methods
3.1. Problem Definition
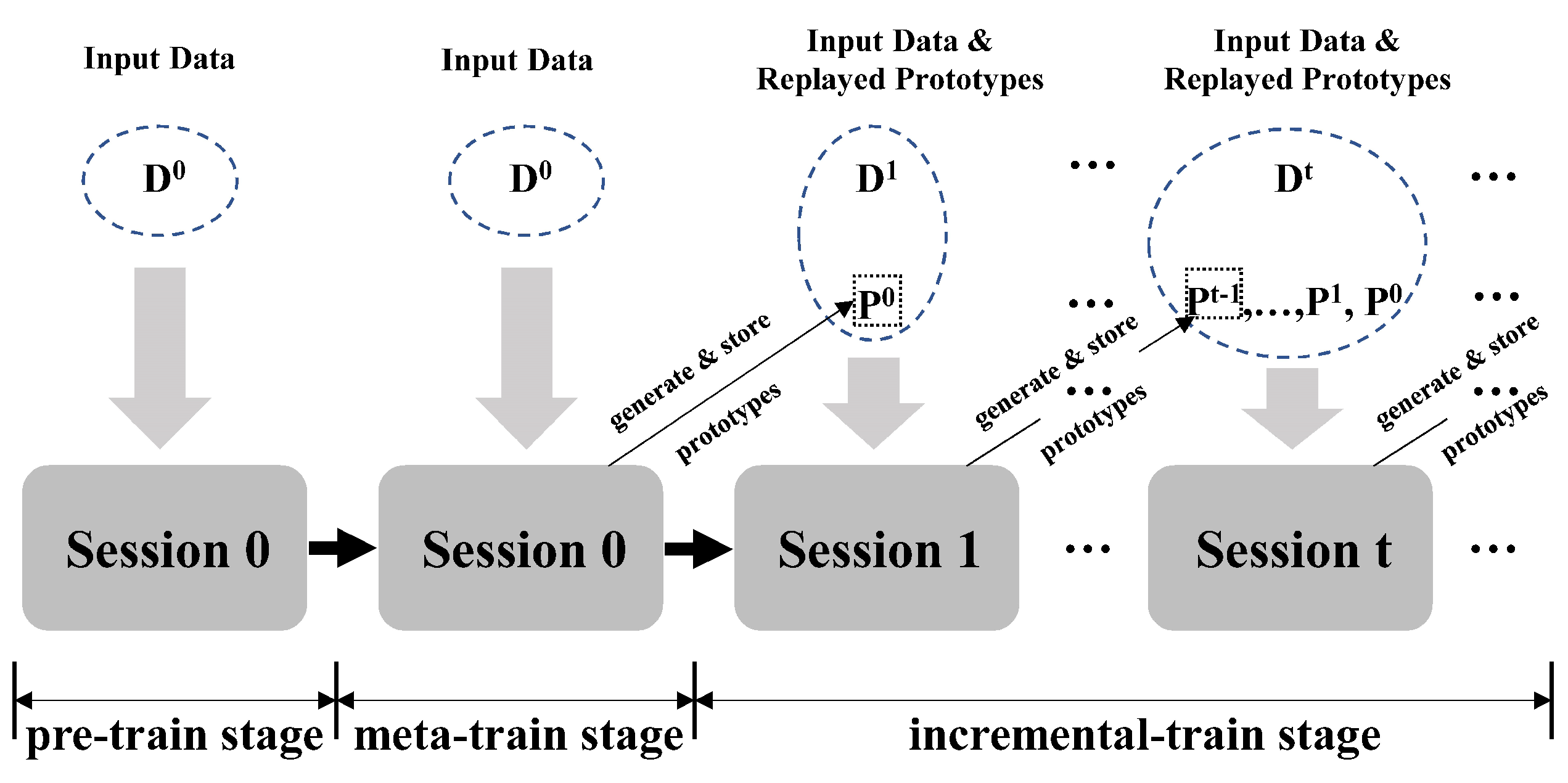
3.2. Overview of EPRC
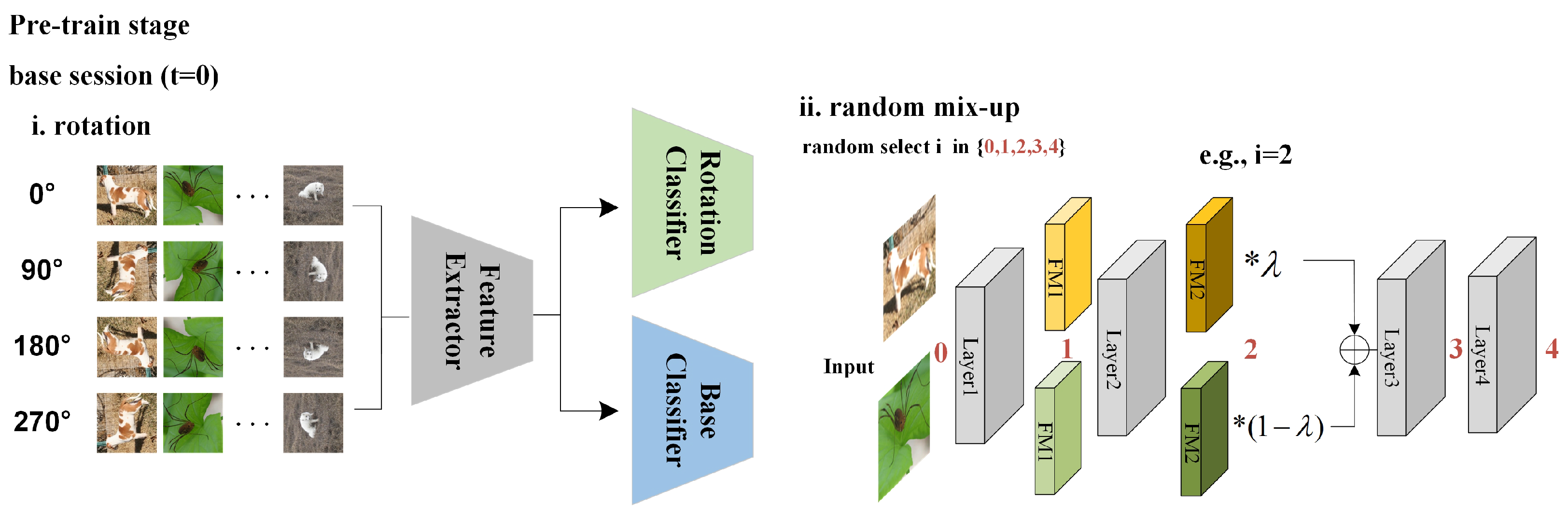
3.2.1. Efficient Pre-Training Strategy
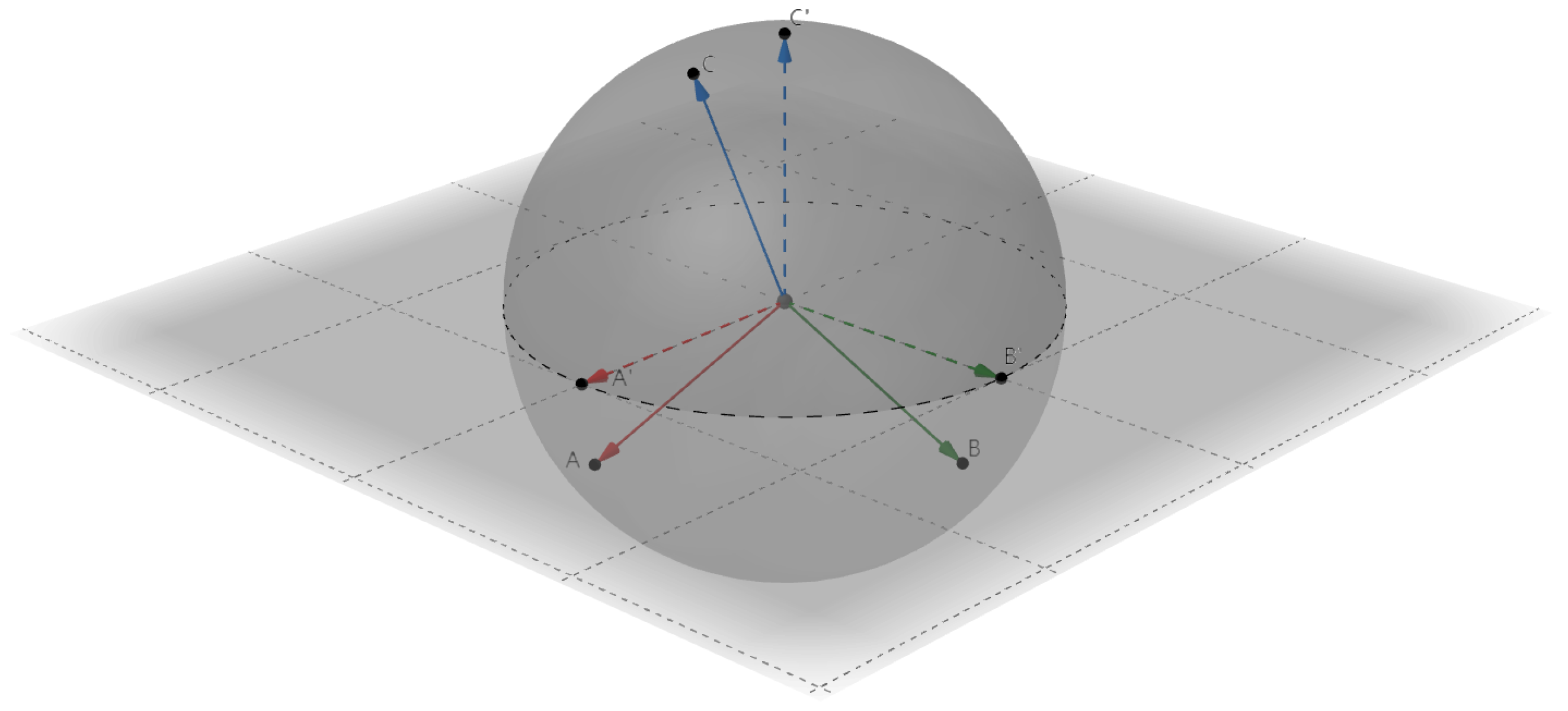
3.2.2. Implicit Prototype Calibration in Meta-Training Stage
3.2.3. Explicit Prototype Replay and Calibration in the Incremental-Training Stage
4. Results
4.1. Datasets and Experimental Settings
4.2. Implementation Details
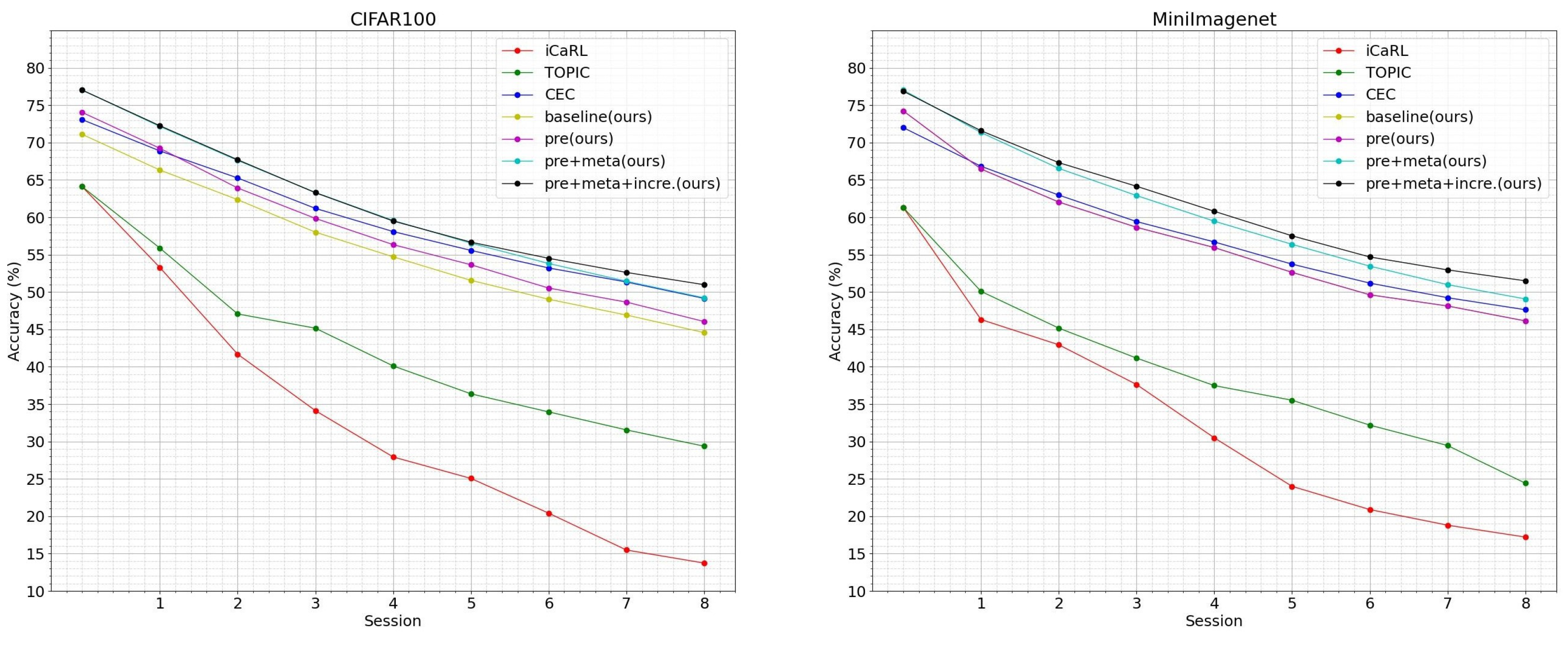
4.3. Performance Comparison
4.4. Qualitative Analysis
4.5. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pan, S.J.; Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 2009, 22, 1345–1359. [Google Scholar] [CrossRef]
- Fei-Fei, L.; Fergus, R.; Perona, P. One-shot learning of object categories. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 594–611. [Google Scholar] [CrossRef] [PubMed]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese neural networks for one-shot image recognition. In Proceedings of the ICML Deep Learning Workshop, Lille, France, 6–11 July 2015; Volume 2. [Google Scholar]
- Polikar, R.; Upda, L.; Upda, S.S.; Honavar, V. Learn++: An incremental learning algorithm for supervised neural networks. IEEE Trans. Syst. Man, Cybern. Part C Appl. Rev. 2001, 31, 497–508. [Google Scholar] [CrossRef]
- McCloskey, M.; Cohen, N.J. Catastrophic interference in connectionist networks: The sequential learning problem. In Psychology of Learning and Motivation; Elsevier: Amsterdam, The Netherlands, 1989; Volume 24, pp. 109–165. [Google Scholar]
- Goodfellow, I.J.; Mirza, M.; Xiao, D.; Courville, A.; Bengio, Y. An empirical investigation of catastrophic forgetting in gradient-based neural networks. arXiv 2013, arXiv:1312.6211. [Google Scholar]
- Mallya, A.; Lazebnik, S. Packnet: Adding multiple tasks to a single network by iterative pruning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7765–7773. [Google Scholar]
- Dhar, P.; Singh, R.V.; Peng, K.C.; Wu, Z.; Chellappa, R. Learning without memorizing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5138–5146. [Google Scholar]
- Douillard, A.; Cord, M.; Ollion, C.; Robert, T.; Valle, E. Podnet: Pooled outputs distillation for small-tasks incremental learning. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XX 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 86–102. [Google Scholar]
- Rebuffi, S.A.; Kolesnikov, A.; Sperl, G.; Lampert, C.H. icarl: Incremental classifier and representation learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2001–2010. [Google Scholar]
- Liu, X.; Wu, C.; Menta, M.; Herranz, L.; Raducanu, B.; Bagdanov, A.D.; Jui, S.; de Weijer, J.v. Generative feature replay for class-incremental learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 226–227. [Google Scholar]
- Chen, J.; Zhang, R.; Mao, Y.; Xu, J. Contrastnet: A contrastive learning framework for few-shot text classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; Volume 36, pp. 10492–10500. [Google Scholar]
- Zhang, M.; Zhang, J.; Lu, Z.; Xiang, T.; Ding, M.; Huang, S. IEPT: Instance-level and episode-level pretext tasks for few-shot learning. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Wierstra, D. Matching networks for one shot learning. Adv. Neural Inf. Process. Syst. 2016, 29, 3630–3638. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R.S. Prototypical networks for few-shot learning. arXiv 2017, arXiv:1703.05175. [Google Scholar]
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.H.; Hospedales, T.M. Learning to compare: Relation network for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1199–1208. [Google Scholar]
- Xing, C.; Rostamzadeh, N.; Oreshkin, B.; Pinheiro, P.O. Adaptive cross-modal few-shot learning. Adv. Neural Inf. Process. Syst. 2019, 32, 4847–4857. [Google Scholar]
- Wang, Q.; Chen, K. Zero-shot visual recognition via bidirectional latent embedding. Int. J. Comput. Vis. 2017, 124, 356–383. [Google Scholar] [CrossRef]
- Zhang, C.; Cai, Y.; Lin, G.; Shen, C. Deepemd: Few-shot image classification with differentiable earth mover’s distance and structured classifiers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12203–12213. [Google Scholar]
- Wang, Q.; Breckon, T. Unsupervised domain adaptation via structured prediction based selective pseudo-labeling. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 6243–6250. [Google Scholar]
- Zhang, H.; Koniusz, P.; Jian, S.; Li, H.; Torr, P.H. Rethinking class relations: Absolute-relative supervised and unsupervised few-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 19–25 June 2021; pp. 9432–9441. [Google Scholar]
- Garcia, V.; Bruna, J. Few-shot learning with graph neural networks. arXiv 2017, arXiv:1711.04043. [Google Scholar]
- Kim, J.; Kim, T.; Kim, S.; Yoo, C.D. Edge-labeling graph neural network for few-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11–20. [Google Scholar]
- Liu, Y.; Lee, J.; Park, M.; Kim, S.; Yang, E.; Hwang, S.J.; Yang, Y. Learning to propagate labels: Transductive propagation network for few-shot learning. arXiv 2018, arXiv:1805.10002. [Google Scholar]
- Ma, Y.; Bai, S.; An, S.; Liu, W.; Liu, A.; Zhen, X.; Liu, X. Transductive Relation-Propagation Network for Few-shot Learning. In Proceedings of the IJCAI, Online, 7–15 January 2021; pp. 804–810. [Google Scholar]
- Tang, S.; Chen, D.; Bai, L.; Liu, K.; Ge, Y.; Ouyang, W. Mutual crf-gnn for few-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 19–25 June 2021; pp. 2329–2339. [Google Scholar]
- Lu, J.; Gong, P.; Ye, J.; Zhang, C. Learning from very few samples: A survey. arXiv 2020, arXiv:2009.02653. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Jamal, M.A.; Qi, G.J. Task agnostic meta-learning for few-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11719–11727. [Google Scholar]
- Jiang, X.; Havaei, M.; Varno, F.; Chartrand, G.; Chapados, N.; Matwin, S. Learning to learn with conditional class dependencies. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Rusu, A.A.; Rao, D.; Sygnowski, J.; Vinyals, O.; Pascanu, R.; Osindero, S.; Hadsell, R. Meta-learning with latent embedding optimization. arXiv 2018, arXiv:1807.05960. [Google Scholar]
- Lee, K.; Maji, S.; Ravichandran, A.; Soatto, S. Meta-learning with differentiable convex optimization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10657–10665. [Google Scholar]
- Oh, J.; Yoo, H.; Kim, C.; Yun, S.Y. Boil: Towards representation change for few-shot learning. arXiv 2020, arXiv:2008.08882. [Google Scholar]
- Liu, H.; Gu, L.; Chi, Z.; Wang, Y.; Yu, Y.; Chen, J.; Tang, J. Few-shot class-incremental learning via entropy-regularized data-free replay. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part XXIV. Springer: Berlin/Heidelberg, Germany, 2022; pp. 146–162. [Google Scholar]
- Zhu, K.; Cao, Y.; Zhai, W.; Cheng, J.; Zha, Z.J. Self-promoted prototype refinement for few-shot class-incremental learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 20–25 June 2021; pp. 6801–6810. [Google Scholar]
- Zhang, C.; Song, N.; Lin, G.; Zheng, Y.; Pan, P.; Xu, Y. Few-shot incremental learning with continually evolved classifiers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 20–25 June 2021; pp. 12455–12464. [Google Scholar]
- Chi, Z.; Gu, L.; Liu, H.; Wang, Y.; Yu, Y.; Tang, J. MetaFSCIL: A meta-learning approach for few-shot class incremental learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 14166–14175. [Google Scholar]
- Tao, X.; Hong, X.; Chang, X.; Dong, S.; Wei, X.; Gong, Y. Few-shot class-incremental learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12183–12192. [Google Scholar]
- Kirkpatrick, J.; Pascanu, R.; Rabinowitz, N.; Veness, J.; Desjardins, G.; Rusu, A.A.; Milan, K.; Quan, J.; Ramalho, T.; Grabska-Barwinska, A.; et al. Overcoming catastrophic forgetting in neural networks. Proc. Natl. Acad. Sci. USA 2017, 114, 3521–3526. [Google Scholar] [CrossRef] [PubMed]
- Tao, X.; Chang, X.; Hong, X.; Wei, X.; Gong, Y. Topology-preserving class-incremental learning. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XIX 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 254–270. [Google Scholar]
- Pellegrini, L.; Graffieti, G.; Lomonaco, V.; Maltoni, D. Latent replay for real-time continual learning. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 10203–10209. [Google Scholar]
- Iscen, A.; Zhang, J.; Lazebnik, S.; Schmid, C. Memory-efficient incremental learning through feature adaptation. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XVI 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 699–715. [Google Scholar]
- Zhu, F.; Zhang, X.Y.; Wang, C.; Yin, F.; Liu, C.L. Prototype augmentation and self-supervision for incremental learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Online, 20–25 June 2021; pp. 5871–5880. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Liu, J.; Song, L.; Qin, Y. Prototype rectification for few-shot learning. arXiv 2019, arXiv:1911.10713. [Google Scholar]
- Wang, Y.; Zhang, L.; Yao, Y.; Fu, Y. How to trust unlabeled data instance credibility inference for few-shot learning. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 6240–6253. [Google Scholar] [CrossRef]
- Yang, S.; Liu, L.; Xu, M. Free lunch for few-shot learning: Distribution calibration. arXiv 2021, arXiv:2101.06395. [Google Scholar]
- Hu, Y.; Gripon, V.; Pateux, S. Leveraging the feature distribution in transfer-based few-shot learning. In Proceedings of the International Conference on Artificial Neural Networks, Bratislava, Slovakia, 14–17 September 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 487–499. [Google Scholar]
- Lazarou, M.; Stathaki, T.; Avrithis, Y. Iterative label cleaning for transductive and semi-supervised few-shot learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Online, 20–25 June 2021; pp. 8751–8760. [Google Scholar]
- Verma, V.; Lamb, A.; Beckham, C.; Najafi, A.; Mitliagkas, I.; Lopez-Paz, D.; Bengio, Y. Manifold mixup: Better representations by interpolating hidden states. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 10–15 June 2019; pp. 6438–6447. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. 2009. Available online: http://www.cs.utoronto.ca/~kriz/learning-features-2009-TR.pdf (accessed on 7 May 2023).
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Hou, S.; Pan, X.; Loy, C.C.; Wang, Z.; Lin, D. Learning a unified classifier incrementally via rebalancing. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 831–839. [Google Scholar]
- Liu, P.; Yuan, W.; Fu, J.; Jiang, Z.; Hayashi, H.; Neubig, G. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. arXiv 2021, arXiv:2107.13586. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Accuracy in Each Session (%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
| iCaRL [10] | 64.10 | 53.28 | 41.69 | 34.13 | 27.93 | 25.06 | 20.41 | 15.48 | 13.73 |
| NCM [53] | 64.10 | 53.05 | 43.96 | 36.97 | 31.61 | 16.73 | 21.23 | 16.78 | 13.54 |
| TOPIC [38] | 64.10 | 55.88 | 47.07 | 45.16 | 40.11 | 36.38 | 33.96 | 31.55 | 29.37 |
| SPPR [35] | 64.10 | 65.86 | 61.36 | 57.45 | 53.69 | 50.75 | 48.58 | 45.66 | 43.25 |
| CEC [36] | 73.07 | 68.88 | 65.26 | 61.19 | 58.09 | 55.57 | 53.22 | 51.34 | 49.14 |
| MetaFSCIL [37] | 74.50 | 70.10 | 66.84 | 62.77 | 59.48 | 56.52 | 54.36 | 52.56 | 49.97 |
| Data-free Replay [34] | 74.40 | 70.20 | 66.54 | 62.51 | 59.71 | 56.58 | 54.52 | 52.39 | 50.14 |
| EPRC | 77.02 | 72.25 | 67.70 | 63.29 | 59.50 | 56.67 | 54.51 | 52.62 | 50.98 |
| Methods | Accuracy in each session (%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
| iCaRL [10] | 61.31 | 46.32 | 42.94 | 37.63 | 30.49 | 24.00 | 20.89 | 18.80 | 17.21 |
| NCM [53] | 61.31 | 47.80 | 39.30 | 31.90 | 25.70 | 21.40 | 18.70 | 17.20 | 14.17 |
| TOPIC [38] | 61.31 | 50.09 | 45.17 | 41.16 | 37.48 | 35.52 | 32.19 | 29.46 | 24.42 |
| SPPR [35] | 61.45 | 63.80 | 59.53 | 55.53 | 52.50 | 49.60 | 46.69 | 43.79 | 41.92 |
| CEC [36] | 72.00 | 66.83 | 62.97 | 59.43 | 56.70 | 53.73 | 51.19 | 49.24 | 47.63 |
| MetaFSCIL [37] | 72.04 | 67.94 | 63.77 | 60.29 | 57.58 | 55.16 | 52.79 | 50.79 | 49.19 |
| Data-free Replay [34] | 71.84 | 67.12 | 63.21 | 59.77 | 57.01 | 53.95 | 51.55 | 49.52 | 48.21 |
| EPRC | 76.87 | 71.58 | 67.31 | 64.15 | 60.80 | 57.52 | 54.69 | 52.96 | 51.50 |
| Methods | Accuracy in Each Session (%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
| Baseline | 71.10 | 66.32 | 62.36 | 58.01 | 54.71 | 51.56 | 49.03 | 46.92 | 44.57 |
| Pre | 74.04 | 69.23 | 63.92 | 59.85 | 56.34 | 53.65 | 50.53 | 48.65 | 46.05 |
| Pre + Meta () | 75.87 | 70.82 | 66.09 | 61.60 | 57.81 | 54.67 | 51.97 | 49.47 | 47.10 |
| Pre + Meta + Incre. () | 76.00 | 71.29 | 66.36 | 62.35 | 58.77 | 55.92 | 53.50 | 50.97 | 49.02 |
| Pre + Meta () | 77.03 | 72.15 | 67.61 | 63.32 | 59.58 | 56.54 | 53.82 | 51.44 | 49.22 |
| Pre + Meta + Incre. () | 77.02 | 72.25 | 67.70 | 63.29 | 59.50 | 56.67 | 54.51 | 52.62 | 50.98 |
| Methods | Accuracy in Each Session (%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
| Baseline | 71.02 | 63.72 | 58.60 | 55.64 | 53.16 | 50.72 | 47.50 | 45.62 | 44.42 |
| Pre | 74.24 | 66.46 | 62.04 | 58.66 | 55.95 | 52.63 | 49.63 | 48.13 | 46.13 |
| Pre + Meta () | 76.92 | 71.15 | 66.00 | 61.69 | 58.30 | 54.72 | 51.79 | 49.16 | 46.93 |
| Pre + Meta + Incre. () | 77.08 | 71.60 | 67.24 | 63.79 | 60.31 | 56.81 | 54.16 | 52.34 | 50.38 |
| Pre + Meta () | 77.03 | 71.34 | 66.54 | 62.91 | 59.48 | 56.38 | 53.46 | 50.99 | 49.07 |
| Pre + Meta + Incre. () | 76.87 | 71.58 | 67.31 | 64.15 | 60.80 | 57.52 | 54.69 | 52.96 | 51.50 |
| Dimension | Accuracy in Each Session (%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
| 32 | 74.70 | 69.13 | 64.44 | 59.64 | 56.02 | 52.96 | 50.34 | 47.75 | 45.13 |
| 64 | 76.50 | 71.55 | 65.96 | 62.05 | 58.15 | 55.85 | 53.13 | 50.13 | 47.95 |
| 128 | 76.83 | 71.93 | 66.46 | 62.94 | 59.30 | 56.55 | 54.20 | 52.34 | 49.55 |
| 256 | 77.01 | 72.03 | 67.56 | 62.95 | 59.60 | 56.63 | 54.50 | 52.20 | 50.24 |
| 512 | 77.02 | 72.25 | 67.70 | 63.29 | 59.50 | 56.67 | 54.51 | 52.62 | 50.98 |
| Value | Accuracy in Each Session (%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
| 0.1 | 69.53 | 63.86 | 59.57 | 54.25 | 50.95 | 46.14 | 43.84 | 41.69 | 37.54 |
| 1 | 71.95 | 67.05 | 62.94 | 58.51 | 55.40 | 51.85 | 49.09 | 47.07 | 44.20 |
| 5 | 74.68 | 70.91 | 65.85 | 61.55 | 58.74 | 55.89 | 53.13 | 50.94 | 48.05 |
| 10 | 77.02 | 72.25 | 67.70 | 63.29 | 59.50 | 56.67 | 54.51 | 52.62 | 50.98 |
| 20 | 75.98 | 71.25 | 66.94 | 62.81 | 59.12 | 56.39 | 53.70 | 51.32 | 49.24 |
| 50 | 75.23 | 70.94 | 66.63 | 62.64 | 59.08 | 56.29 | 53.79 | 51.65 | 49.40 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, W.; Gu, X. Few Shot Class Incremental Learning via Efficient Prototype Replay and Calibration. Entropy 2023, 25, 776. https://doi.org/10.3390/e25050776
Zhang W, Gu X. Few Shot Class Incremental Learning via Efficient Prototype Replay and Calibration. Entropy. 2023; 25(5):776. https://doi.org/10.3390/e25050776
Chicago/Turabian StyleZhang, Wei, and Xiaodong Gu. 2023. "Few Shot Class Incremental Learning via Efficient Prototype Replay and Calibration" Entropy 25, no. 5: 776. https://doi.org/10.3390/e25050776
APA StyleZhang, W., & Gu, X. (2023). Few Shot Class Incremental Learning via Efficient Prototype Replay and Calibration. Entropy, 25(5), 776. https://doi.org/10.3390/e25050776