1. Introduction
Gait recognition refers to the technology that identifies a person by analyzing his or her gait information. In the past decades, gait recognition technology has been widely used in various fields, including human identification, motion analysis, disease diagnosis, and human-computer interaction [
1,
2,
3]. As a new biometric feature recognition technology with potential, gait recognition has the advantages of being recognizable from a distance, easy to acquire, requiring low image quality, and not easy to hide. With the rapid development of computer vision technology, public security systems and intelligent video analysis systems combined with gait recognition have a wide technical demand in safeguarding public safety and improving the scientific management of smart cities [
4,
5,
6].
Currently, there are two main approaches to gait recognition technology: sensor-based approaches and video-based approaches. With the development of sensor technology, gait recognition technology has also made significant progress. Sensor-based approaches [
7,
8,
9] use multiple sensors, such as accelerometers, gyroscopes, and pressure sensors, to capture a variety of information about the human body, such as body posture, acceleration, angular velocity, and pressure distribution, which can provide rich recognition features for gait recognition. The method using sensor detection has better robustness and can be used both indoors and outdoors. However, the sensor-based approach requires high accuracy of the sensor and is susceptible to external interference. At the same time, wearing the sensors can easily subjectively affect a human subject’s movement habits, which leads to a larger error in recognition. In the security field, gait features can often only be obtained from short video information, so the method of wearing sensors also has strong limitations.
Video-based methods, on the other hand, obtain gait features from video data. Early methods used background subtraction to extract the main human silhouettes [
10,
11] and model the structure and transition process of gait silhouettes, including the gait energy image (GEI), frame difference entropy image, etc. The GEI and frame difference entropy images are used to represent the spatio-temporal series motion process of walking by combining the walking process of the detected object in the form of silhouette extraction into a new image. GEI is widely used in model-free gait recognition work. The advantage of this type of method is that the processing is relatively simple, using only traditional image processing methods to remove information such as background and human texture and focus on gait information. However, the recognition effect of this method depends on the completeness and continuity of the image, and it can easily lead to the loss of time-series information or misalignment during the modeling process, making the recognition accuracy much lower.
In recent years, with the development of hardware computing power and neural network research, the problems that can be solved using deep learning have become more extensive and numerous. These include the use of deep learning for more accurate image classification [
12], biometric techniques in more scenarios [
13,
14], sequence data processing [
15], etc. Similarly, research related to gait recognition using deep learning methods has become the mainstream approach in the field of gait recognition today. One of these methods is GaitSet, a depth set based gait recognition method proposed by Chao et al. [
16]. Firstly, spatial features are extracted from the original gait silhouette using a convolutional neural network, and then the spatial features are compressed and integrated in the timeseries dimension. The GaitSet algorithm proposes a new view of treating gait as a collection containing independent frames, without requiring the order of the frames or even integrating video frames from different scenes. Most of the previous research works have used the whole gait data of the human body as network input for feature extraction. In contrast, GaitPart, proposed by Fan et al. [
17], represents each part of the human body as an independent spatio-temporal series relationship. The highlight of GaitPart is that it focuses on the connections and differences in the shape of different parts of the human body while walking. This method of identifying gait through local modeling is easier to verify quantitatively. Some researchers have achieved gait recognition by studying the distribution patterns of position changes of body skeletal points [
18,
19,
20]. For example, using Microsoft’s Kinect, a video stream with the distribution of human skeletal points is output directly from the original video stream. Each joint of the body in the video stream is represented as a point in 3D space. Later, static data such as limb length and dynamic data such as limb movement patterns are analyzed. However, gait recognition is susceptible to various interference factors such as dress, the carrying of objects or backpacks, and multiple views, among which changes in views have the most obvious impact on recognition performance. In practical applications, it is quite difficult to capture long-time continuous and complete gait data under multiple views. Therefore, cross-view gait recognition is an important challenge. In addition to the approach of using convolutional neural networks for uniform feature extraction of data from all views, some researchers have also adopted the approach of introducing a generative adversarial network (GAN) [
21,
22] to model the distribution of multi-view data. A gait generative adversarial network (GaitGAN) proposed by Yu et al. [
23] normalizes the gait data from different views into gait data from lateral views. The method of converting multiple views into standard views by means of neural network learning before recognition has been proven to be effective. However, the details of the image cannot be expressed completely due to the lack of modeling the global relationship during the view conversion process. Moreover, as the span of the views increases, the error of the standard views obtained from the conversion becomes larger.
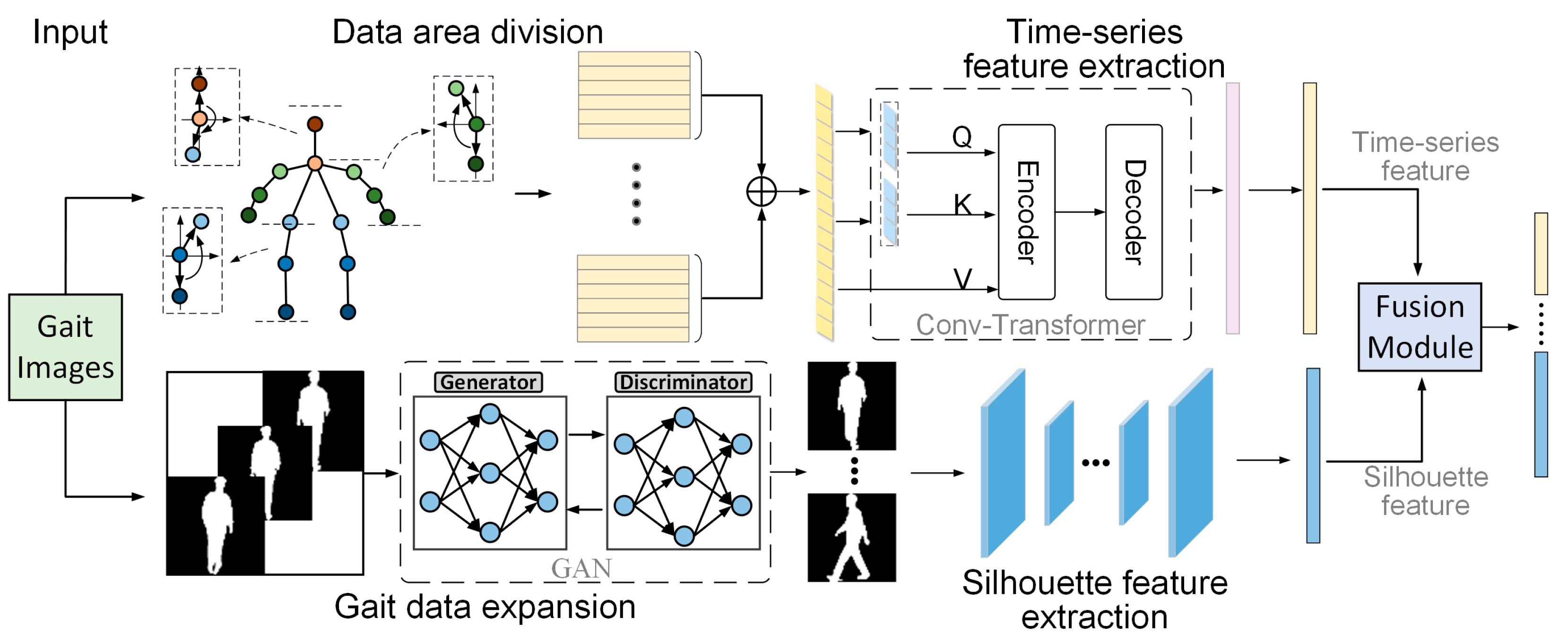
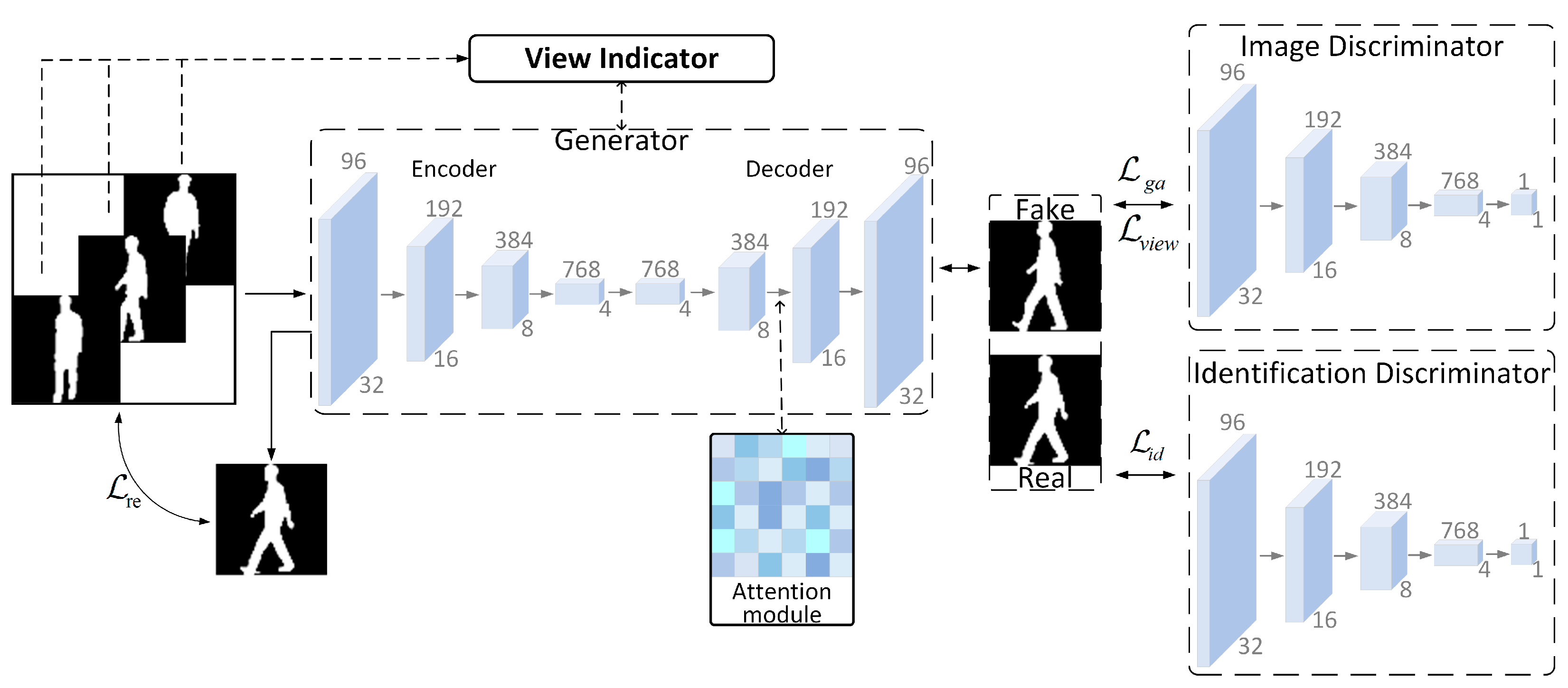
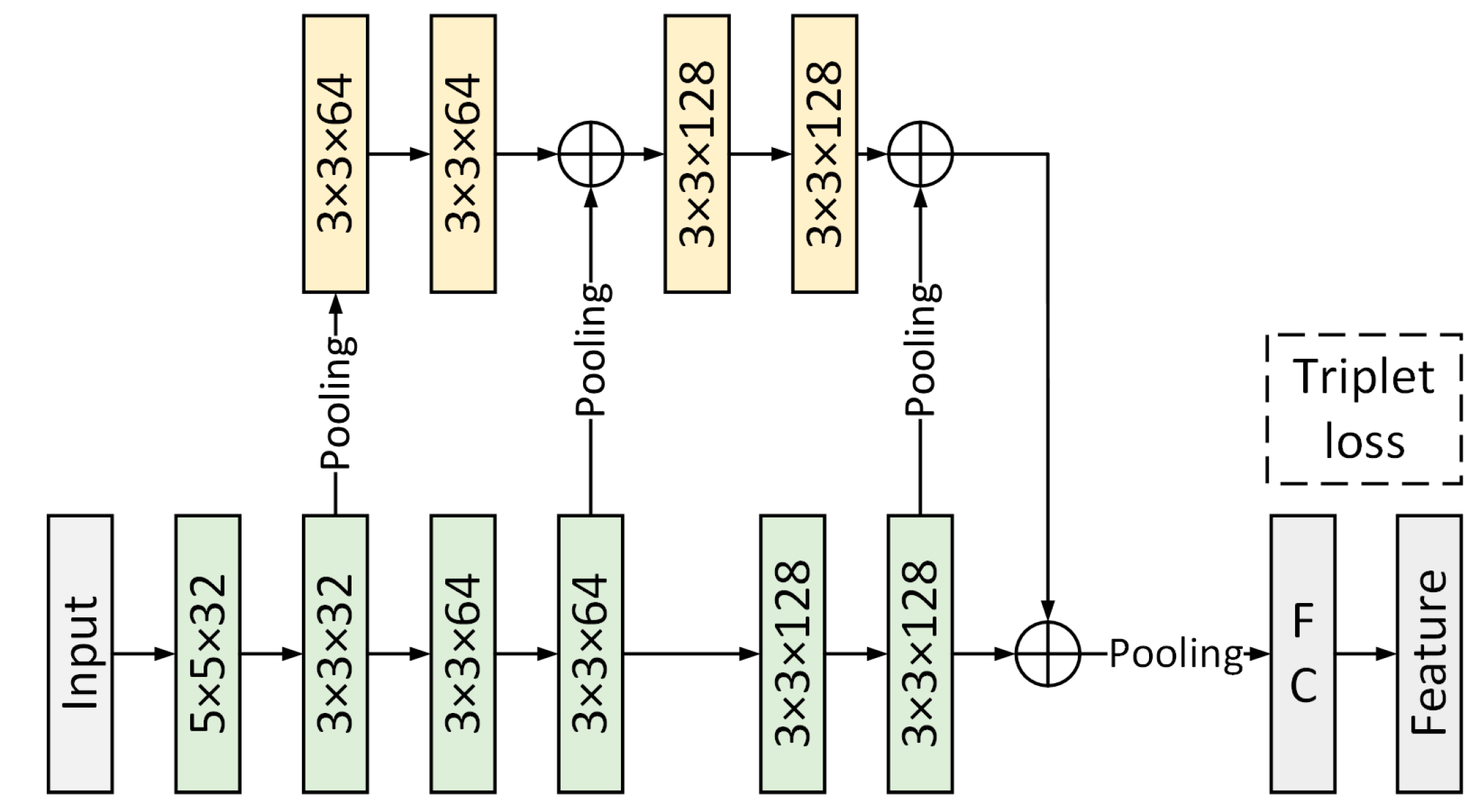
The above analysis suggests that to achieve more accurate and reliable gait recognition, it is most important to obtain gait data with complete time-series information and a sufficient amount of data. In order to achieve gait recognition under shorter input duration, a two-branch fusion gait recognition algorithm combining time-series data and silhouette information is proposed in this paper. The time-series information is modeled using a region coding network based on Transformer [
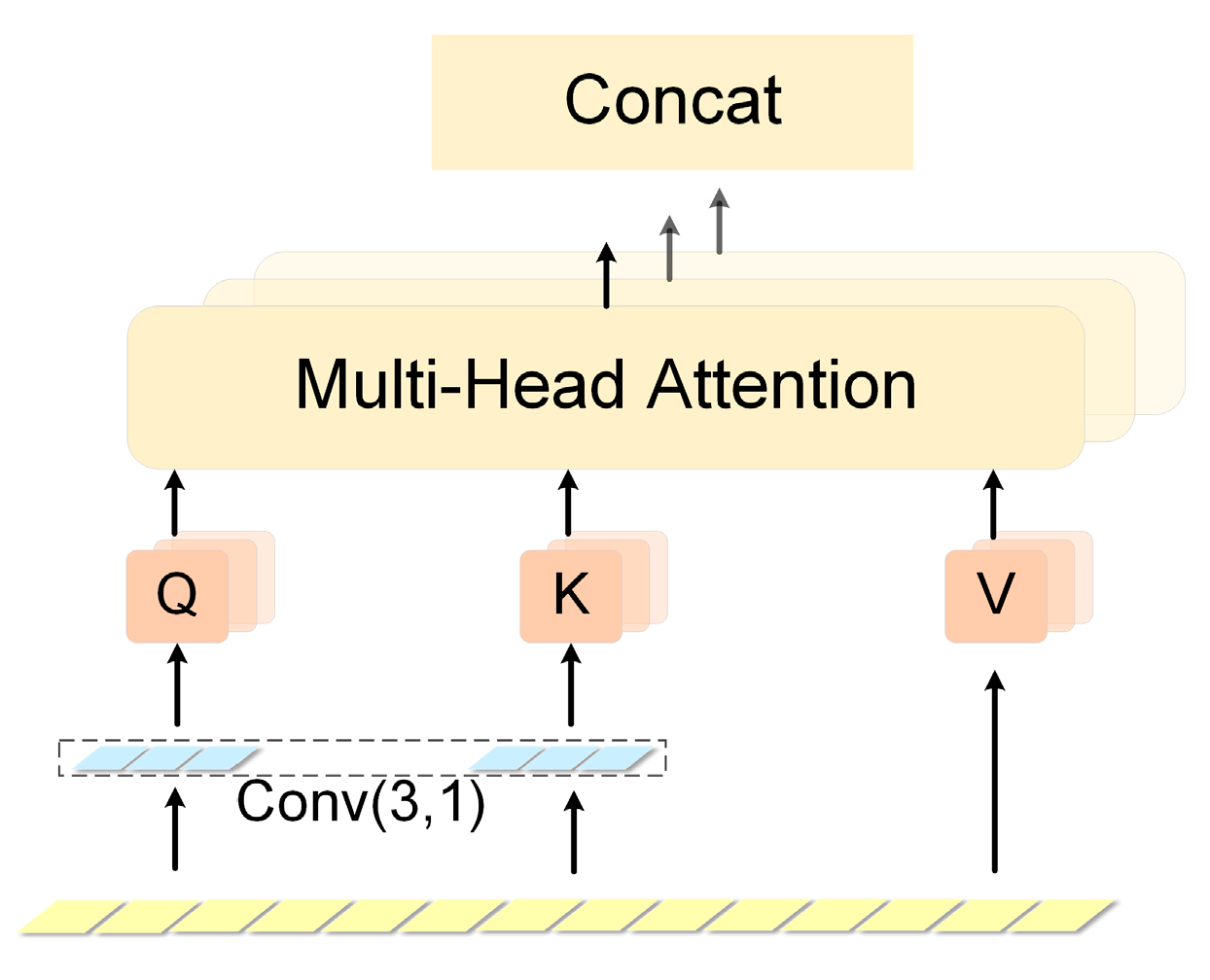
24]. The expansion and integration of the silhouette data is implemented using a generative adversarial network with an added attention mechanism. In order to make full use of the feature information of the two-branch network, a feature fusion module is designed in this paper for the two dimensions of time series and contour, which differ significantly.
In summary, the contributions of this paper can be summarized as the following four points:
A Transformer-based regional time-series coding network is designed. The joint position change information within and between each human region delineated in this paper is modeled, and effective time series features are extracted.
A GAN-based gait data expansion network is designed. Only short-duration gait video data are input, and the gait silhouette data under multiple views are obtained by continuous training of the generator and discriminator to further expand the existing gait dataset.
A feature fusion module based on bilinear matrix decomposition pooling is designed. The discrepancy between gait time-series features and contour features is effectively solved, and the data of both features are efficiently fused.
The time-series coding network and data expansion network are tested on the OUMVLP-Pose and CASIA-B datasets, respectively, to verify the effectiveness of the algorithm. Meanwhile, the algorithm is validated in this paper using gait data collected in real scenes. The results show the effectiveness of the algorithm in this paper.
3. Experiment
To evaluate the effectiveness of the time-series feature extraction network, the silhouette feature extraction network, and the two-branch feature fusion network in gait recognition, we conducted experiments on the OUMVLP-Pose dataset [
35] and the CASIA-B dataset [
36], as well as on data collected in real scenes.
3.1. Datasets
In order to verify the feature extraction capability of the previously mentioned regional time-series coding network and the effect of the gait silhouette image generation network, we selected the OUMVLP-Pose gait recognition dataset with human keypoint location sequence labels and the large gait dataset CASIA-B, consisting of gait silhouette maps for the single-branch network, respectively. Due to the lack of a public dataset containing both human keypoint annotations and gait silhouettes, for the validation of the fusion effect of the two-branch network, we acquired real-world videos of people walking. Based on the recorded videos, we created a small dataset of gait recognition containing both human keypoint data and gait silhouette images.
3.1.1. Public Datasets
The OU-MVLP dataset is a large multi-view pedestrian dataset created by Osaka University, Japan. The dataset contains 10,307 walkers, including 5114 males and 5193 females, distributed in different age groups. The dataset contains a total of 14 views with 15° intervals between the views, and OUMVLP-Pose is built on top of OUMVLP. The builder of the dataset used pre-trained models from OpenPose [
37] and AlphaPose [
38] to extract the human skeletal point location information from the RGB images of OUMVLP.
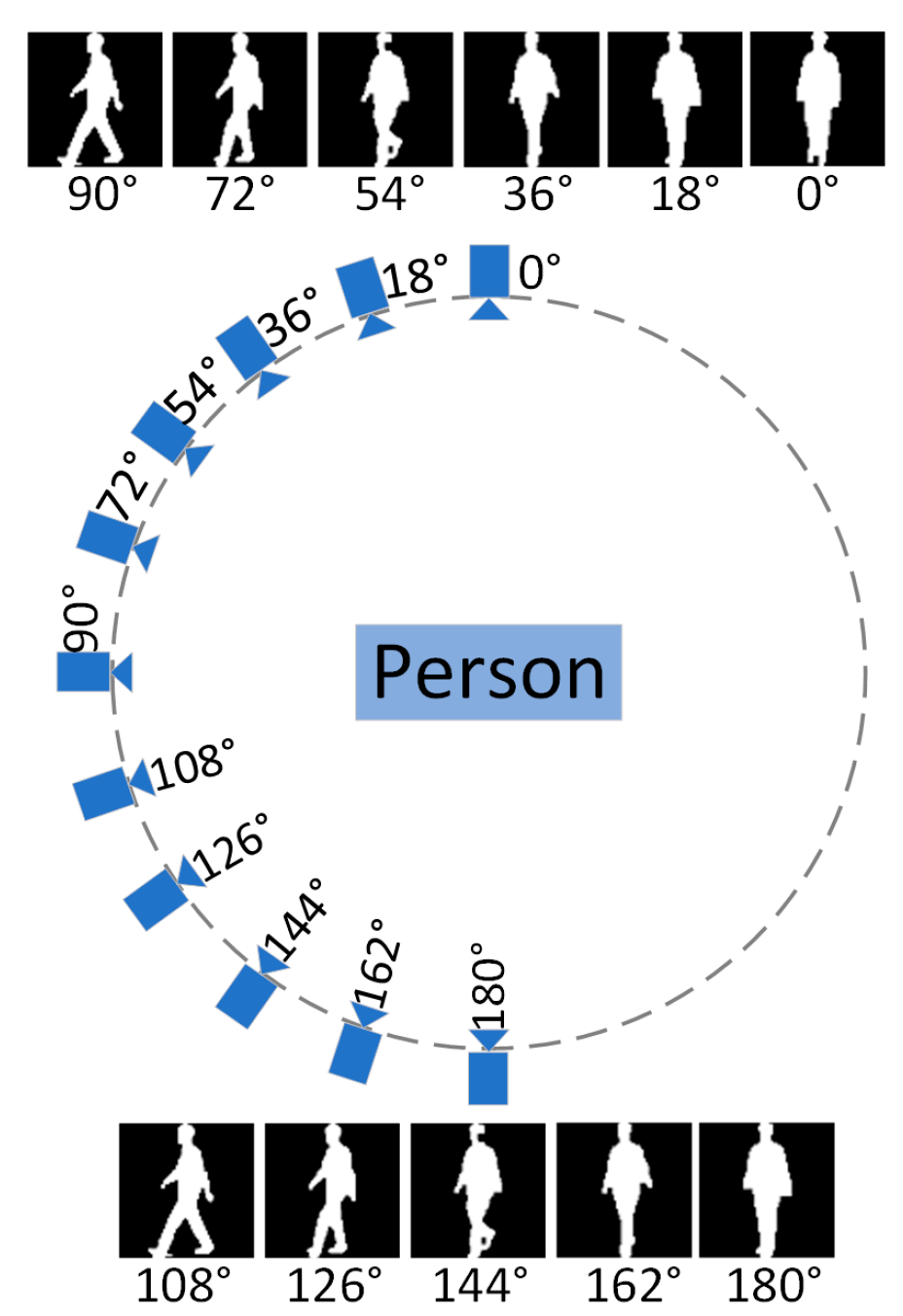
Figure 8 shows the schematic diagram of the OUMVLP-Pose dataset acquisition provided by the OU-ISIR biometric database website.
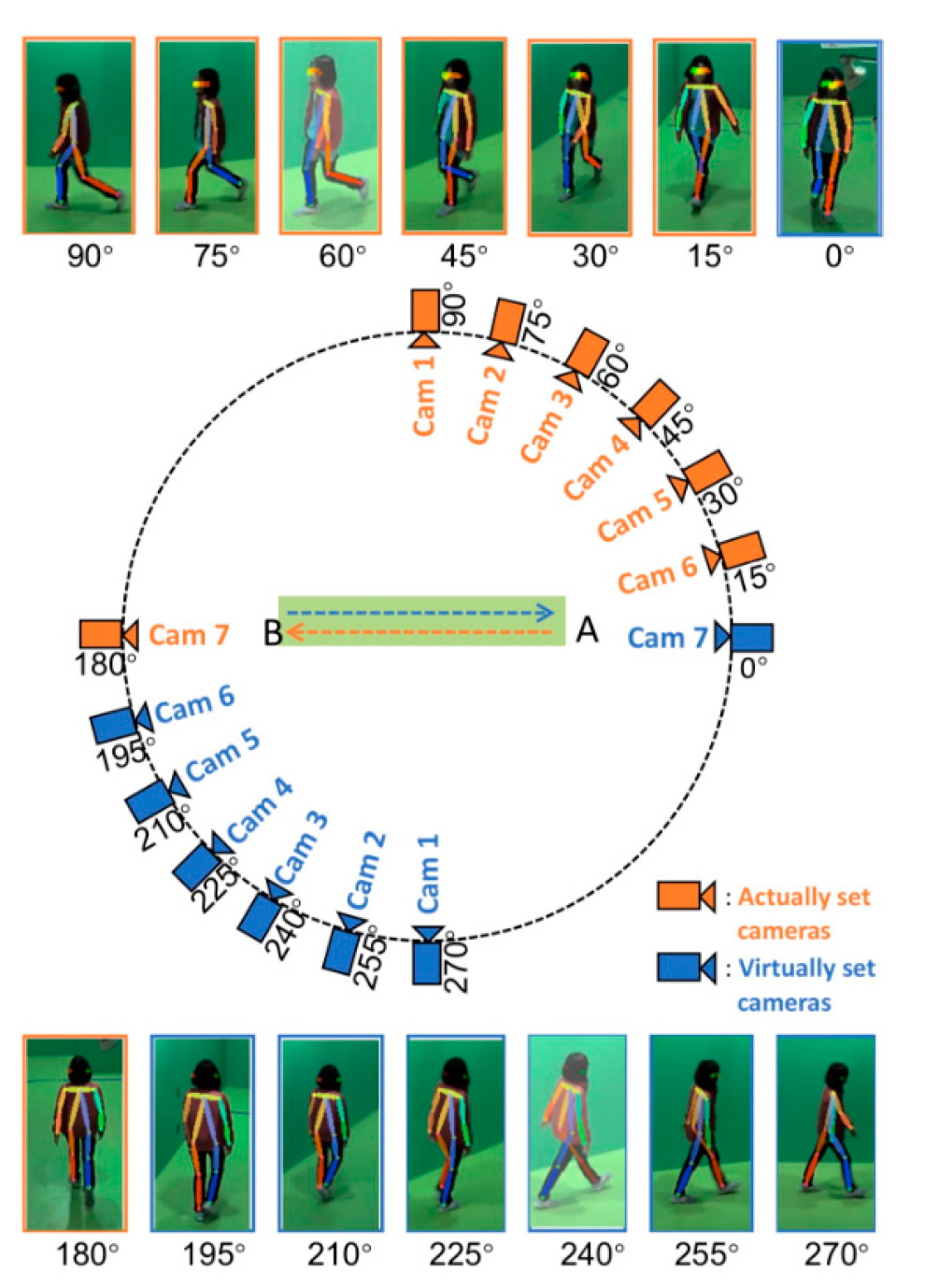
The CASIA-B dataset contains a total of 124 walkers and three walking states, including normal walking (NM) with six sequences per person, walking with a bag (BG) with two sequences per person, and walking while wearing a coat (CL), with two sequences per person. Each sequence for each pedestrian has 11 observed viewing angles with an angle range (0°, 18°, 36°, …, 180°) at 18° intervals.
Figure 9 shows a schematic of the gait silhouette acquisition environment in the CASIA-B dataset.
3.1.2. Test Data in Real Scenarios
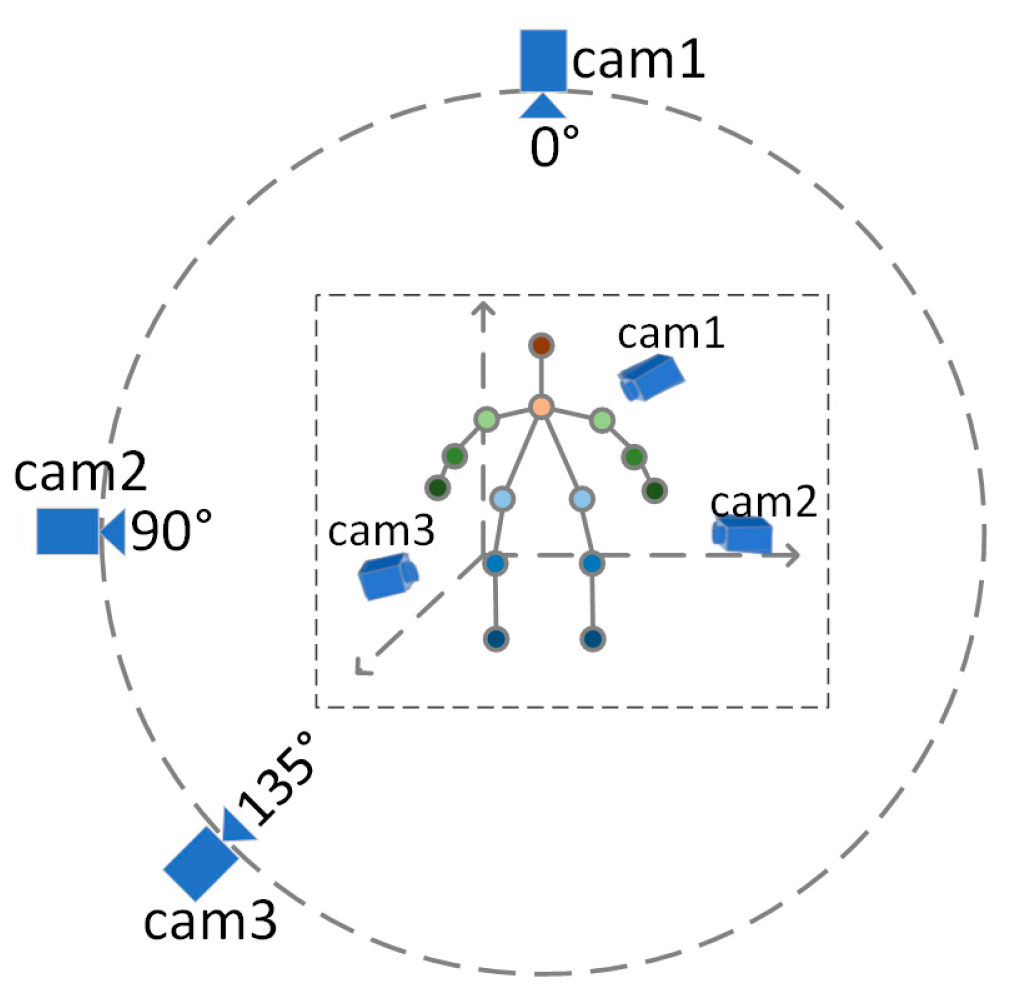
In order to evaluate the two-branch fusion model presented in the previous chapter, gait data were collected in a realistic scenario. The acquisition was performed by setting up a multi-view camera in a laboratory environment with nine subjects walking at a uniform speed on a walking machine. In order to simulate the process of real-life surveillance cameras on people, the camera views were located at 0°, 90°, and 135° of the subject’s body (0° directly in front of the body and increasing counterclockwise).
Figure 10 shows the schematic diagram of the acquisition environment for the test data.
3.2. Experimental Environment and Setup
The experimental environment is a Windows 10 operating system and Python 3.7 IDE; the deep learning framework uses Pytorch; to improve the model computing efficiency, an NVIDIA RTX3080Ti is used and CUDA11.0 and the corresponding cuDNN deep learning acceleration library is installed.
In the regional time-series coding branch network training, 20 walkers were randomly selected from the training sample in each iteration, and then 10 sequences were randomly selected from the data of each walker. After that, 20 consecutive frames were randomly selected from each sequence as the input data. The network used the Adam optimizer and the initial learning rate was set to 0.0002. In the data expansion network for silhouette images, firstly, the effectiveness of the generative adversarial network for generating images was evaluated. This was followed by a gait recognition test using the expanded dataset. During the training process, a total of 80,000 iterations were performed. The initial learning rate was 0.0001, and the learning rate was decayed to 0.1 times at the 60,000th iteration. The threshold distance of triplet loss was set to 0.2. The data set was divided by the large-sample training (LT) method [
16]. Data from the first 74 walkers were used for training, and data from the last 50 were used for testing.
3.3. Experimental Results and Analysis
This section presents the results of the experimental analysis of single-branch and two-branch fusion networks.
3.3.1. Recognition Effect Based on the Regional Time-Series Coding Network
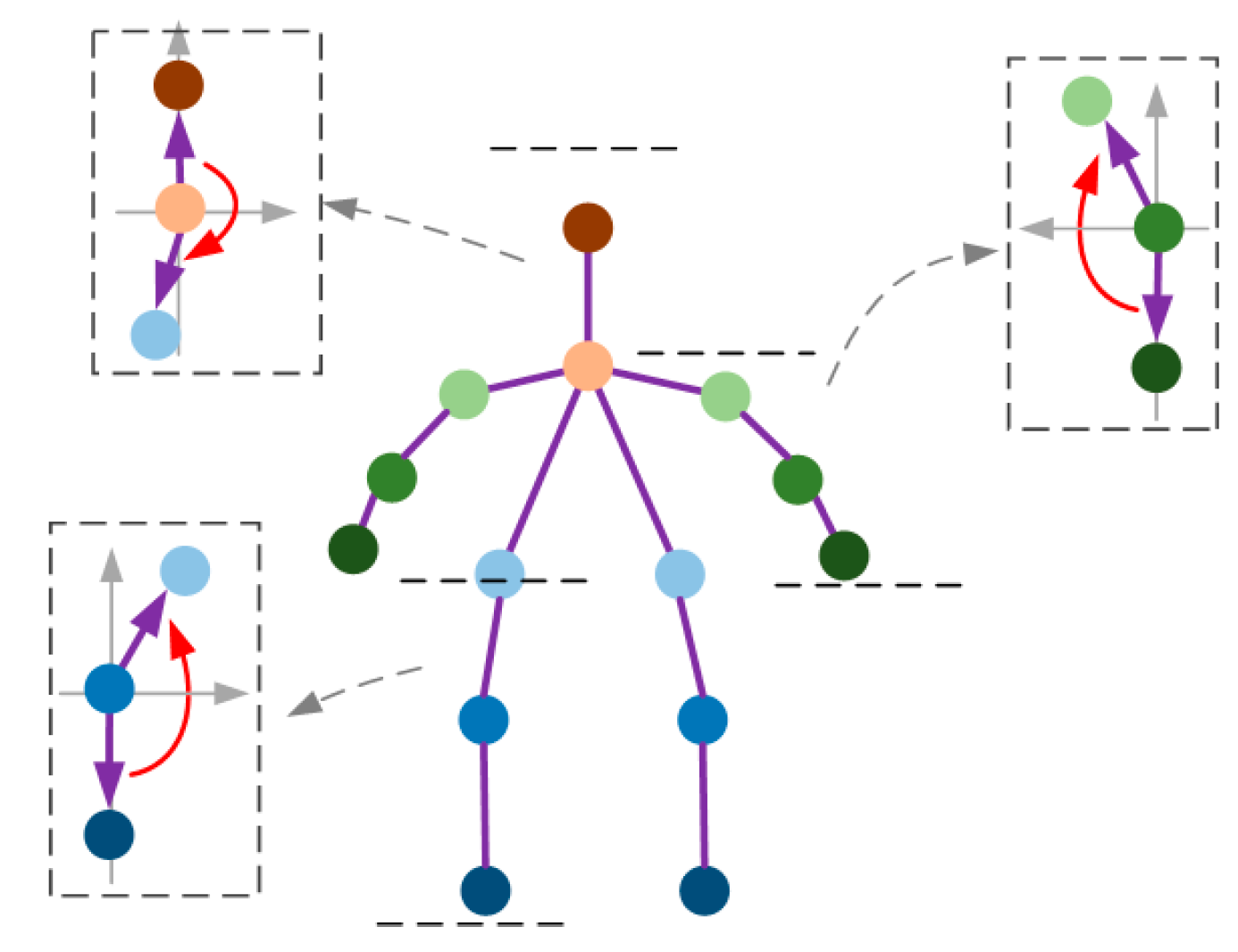
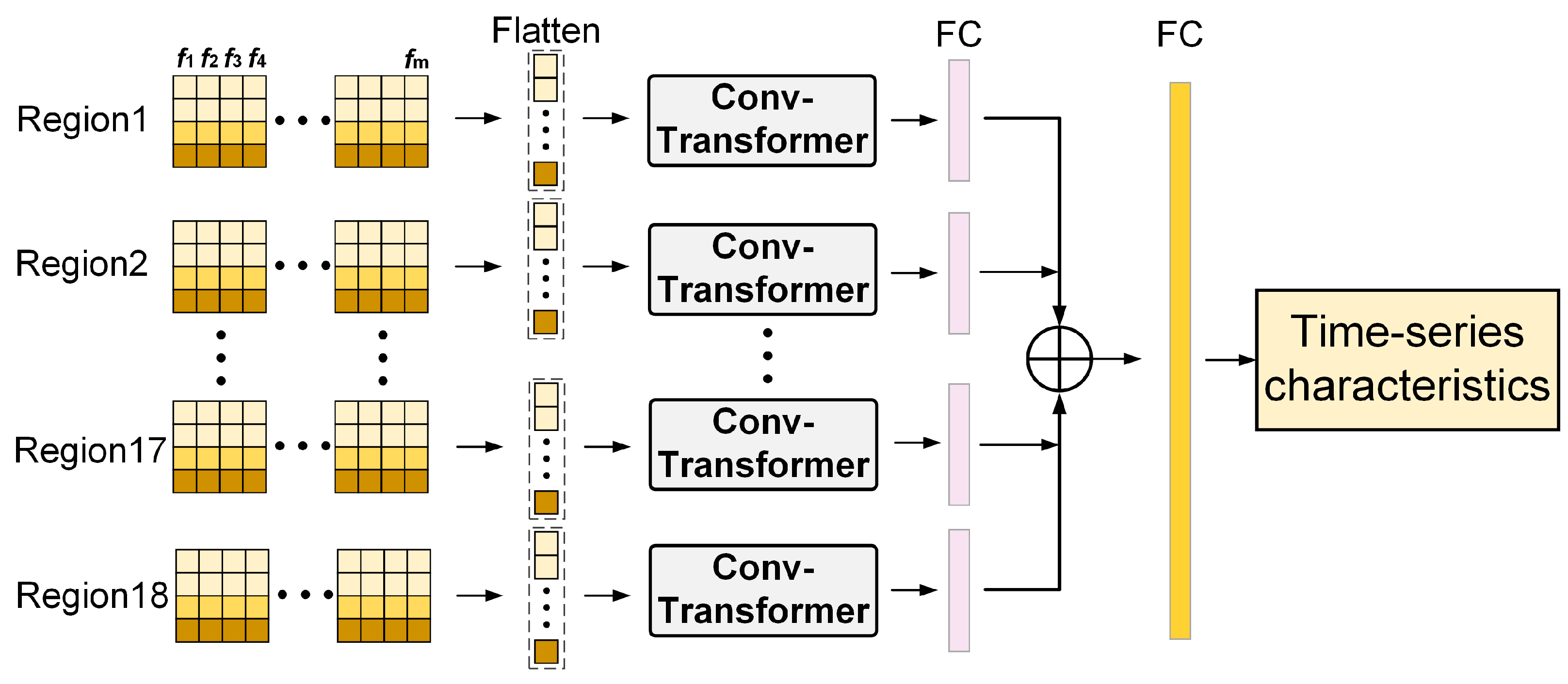
There are 18 human-joint-annotated positions in the OUMVLP-Pose dataset, but the left eye, right eye, left ear, and right ear data are not significantly helpful for gait recognition. Therefore, based on the human joint position settings in this paper, we used the annotation data of joints 0–13 extracted by the OpenPose algorithm in the OUMVLP-Pose dataset.
Figure 11,
Figure 12 and
Figure 13 show the change graphs of 50 frames of data in randomly selected individual regions calculated from 18 human regions divided according to
Table 1, respectively.
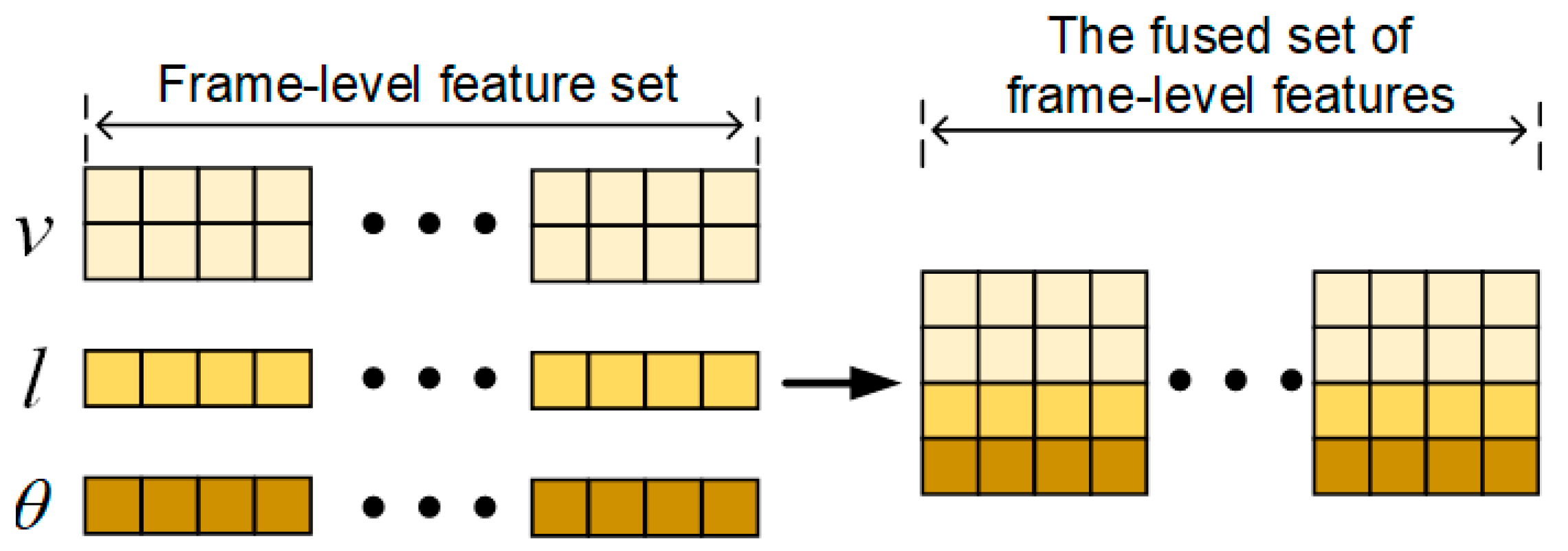
Figure 11 shows the variation curves of vectors, inter-joint distances, and joint angles obtained for each region.
Table 2 shows the accuracy of the time-series feature extraction branch designed in this paper on the OUMVLP-Pose dataset. We extracted the keypoint data annotated in the OUMVLP-Pose dataset into a uniform csv format data list in the form of sequence data as the input of the temporal feature extraction branch. Compared with LSTM and Transformer networks, which are commonly used for processing sequence data, the network we designed achieved relatively better results. In particular, the accuracy of Rank-1 is higher for 90° and 270°. The reason for this situation may be that when the OUMVLP-Pose dataset uses the OpenPose and AlphaPose algorithms to identify human keypoints, these two side views observe the human joints more obviously, which makes the extracted pixel location information of keypoints more accurate. To validate this idea, we used Noitom’s motion-capture suite to obtain real-time data streams of the movements from the accompanying software. The acquired data were normalized and calculated to obtain the human keypoint position information at the same pixel position coordinates as the OUMVLP-Pose dataset.
Figure 12 shows the comparative analysis of the human keypoint data captured by the sensor during the motion and the human keypoint data obtained using OpenPose and AlphaPose algorithms in the OUMVLP-Pose dataset. The evaluation index used for the comparison is PCKh, which is the proportion of the normalized distance between the keypoint data detected using the physical method and the data labeled in the dataset that is less than a set threshold, using the head distance as the normalized reference. The data from
[email protected] is considered correct when the distance between the positions of the two keypoints is less than 50% of the diagonal length of the bounding box of the head.
In
Figure 12, the PCKh results are mapped into the HSV color space, and the change in the value of PCKh is indicated by the color shade. The darkest color indicates that PCKh is equal to 0, and the lightest color indicates that PCKh is equal to 100. In this paper, we compared the data measured by the wearer, the data recognized by OpenPose in the dataset, and the data recognized by AlphaPose in the dataset, and the results shown in
Figure 12 were obtained after calculating and averaging the two. The difference between the data in the dataset and the real data can be seen in
Figure 12. It also confirms the problem related to the recognition effect proposed above.
3.3.2. Effect of the Multi-View Gait Image Generation Network
This section discusses the effect of the generation of our proposed gait silhouette images.
Figure 13 shows the generated fake images trained from the real images in the CASIA-B dataset.
In order to show the effectiveness of the image generation method proposed in this paper, the distribution of the generated data was evaluated using the Inception Score [
39]. Inception Score (IS) is a KL divergence (relative entropy) calculation of the data:
where
is the probability of the category output for a given generated image x, after feeding it into a pre-trained Inception classification network [
40], and
is the edge distribution, which represents the expectation of the probability of the category output by this pre-trained classification network for all generated images. If the generated image contains meaningful and clearly identifiable targets, the classification network should determine that image as a specific category with a high confidence level, so
should have a small entropy. In addition, for the generated images to be diverse,
should have a large entropy. If
has a large entropy and
has a small entropy, i.e., the generated images contain very many categories, and each image has a clear and high confidence category, then
and
have a large KL scatter.
Based on the above analysis, the IS entropy value is used to determine the degree of dispersion of the generated data relative to the standard data, using the data distribution of the gait silhouettes in each view in the data set as a benchmark. In the IS calculation, the larger the IS value, the closer the generated data is to the ideal state. Also, the Kernal MMD [
41] and Wasserstein distance [
42] methods were used in this paper to evaluate the quality of the generated images, and the evaluation results are displayed in
Table 3.
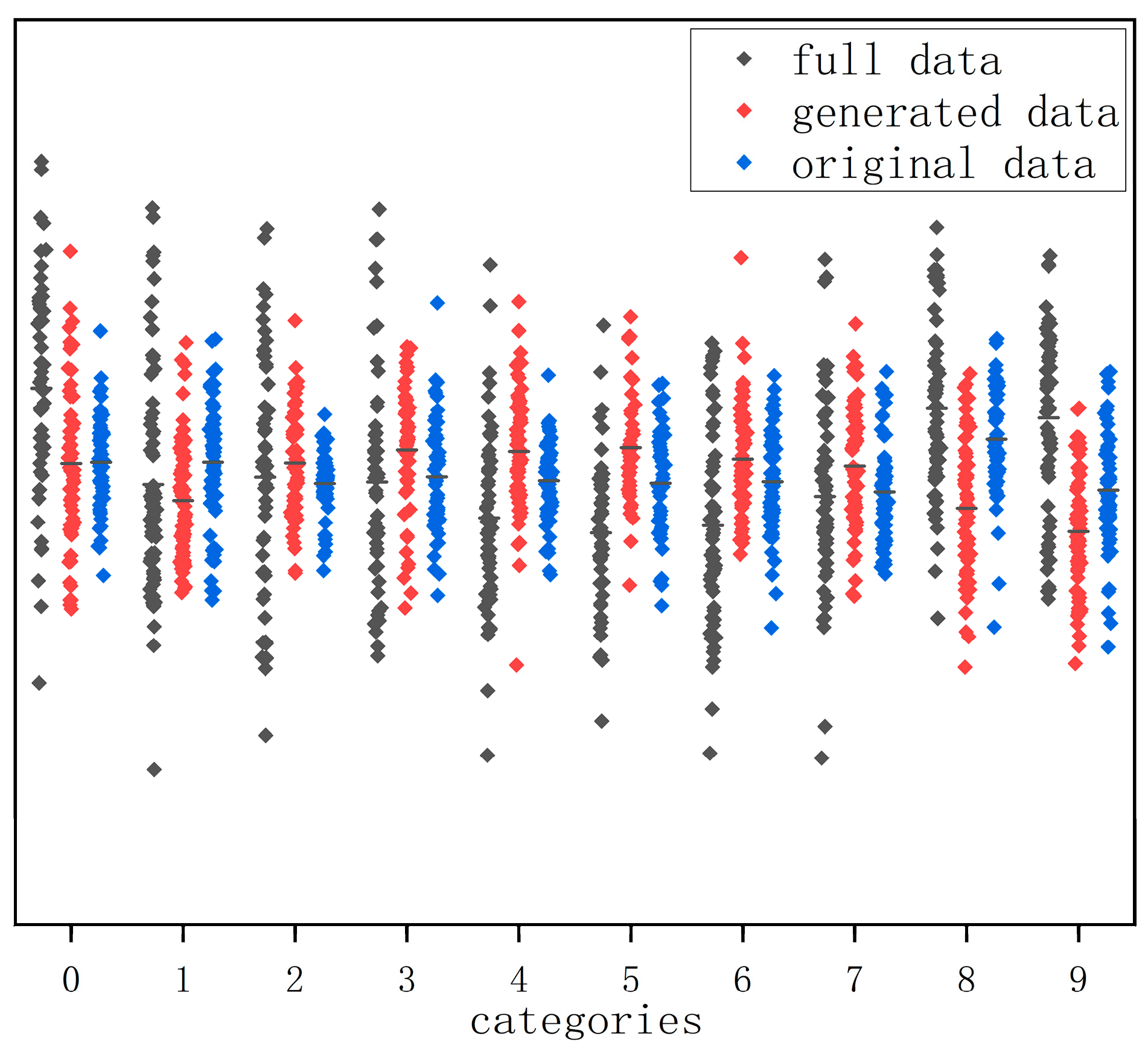
Figure 14 shows the gait data of 10 people randomly selected from the original dataset, the generated dataset, and the fused dataset, respectively. From
Figure 14, it can be seen that the distribution of gait silhouette data generated using the algorithm of this paper has a similar pattern to that of the same kind in the dataset and achieves the purpose of expanding the gait dataset in terms of quantity.
Finally, we conducted tests using the original dataset as well as the expanded gait silhouette dataset, and the results are shown in
Table 3. From
Table 4, it can be seen that the accuracy of recognition is higher after expanding the dataset due to the increase in data volume. However, compared to the 90° side view, the accuracy improvement is more obvious for the other views. This indicates that the side view exhibits richer and clearer silhouette information. Therefore, the silhouette data from each view can also be relearned afterwards and all converted to the 90° view for testing using gait energy images (GEI).
To better demonstrate the effectiveness of our design, we used the same method as GaitGAN to train and test our designed gait silhouette image generation network. The dataset used was CASIA-B and was divided into training set, gallery set, and probe set. In the experimental design of GaitGAN, three states, NM, BG and CL, were included. The gait data of the first 62 subjects were put into the training set, and the gait data of the remaining 62 subjects were put into the test set. In the test set, the first four sequences of each subject in one state were put into the gallery set, and the last two sequences were put into the probe set. By putting the data from the gallery set into the model, the corresponding features were output, and then the data from the probe set were also put into the model to get the corresponding features. The two features were compared and the corresponding similarity results were output.
Table 5,
Table 6 and
Table 7 show the results obtained after image generation using our gait silhouette image generation adversarial network and performing feature extraction and matching compared with the results obtained using GaitGAN. As can be seen from the table, our method achieves higher recognition rates than GaitGAN in most views. However, in the BG and CL states, the recognition rate of some views of GaitGAN is higher than that of our method. After the experiments, it can be seen that our gait silhouette graph generation network needs to be optimized compared to the GEI generation method of GaitGAN when strong disturbances are included. In future work, we will consider the simultaneous generation of silhouette images under different viewpoints as well as the synthesis of GEI under specific views to provide more sufficient data for improving the gait recognition process.
3.3.3. Testing of the Fusion Model in Real Scenarios
The testing in real scenarios was divided into two parts: quantitative assessment and qualitative assessment.
First was the quantitative evaluation part. By setting up cameras under three views of 0°, 90°, and 135° in an indoor environment, the data of keypoints of the human body were collected using OpenPose and the data under the three views was averaged. The silhouette extraction was performed by background subtraction.
Figure 15 shows our gait data collection in different views. In accordance with our laboratory regulations and data privacy instructions, we defocused the background of the images and mosaicked the volunteers’ faces. In addition, we visualized the extracted feature data for characterizing the relevant motion patterns. This is shown in
Figure 16.
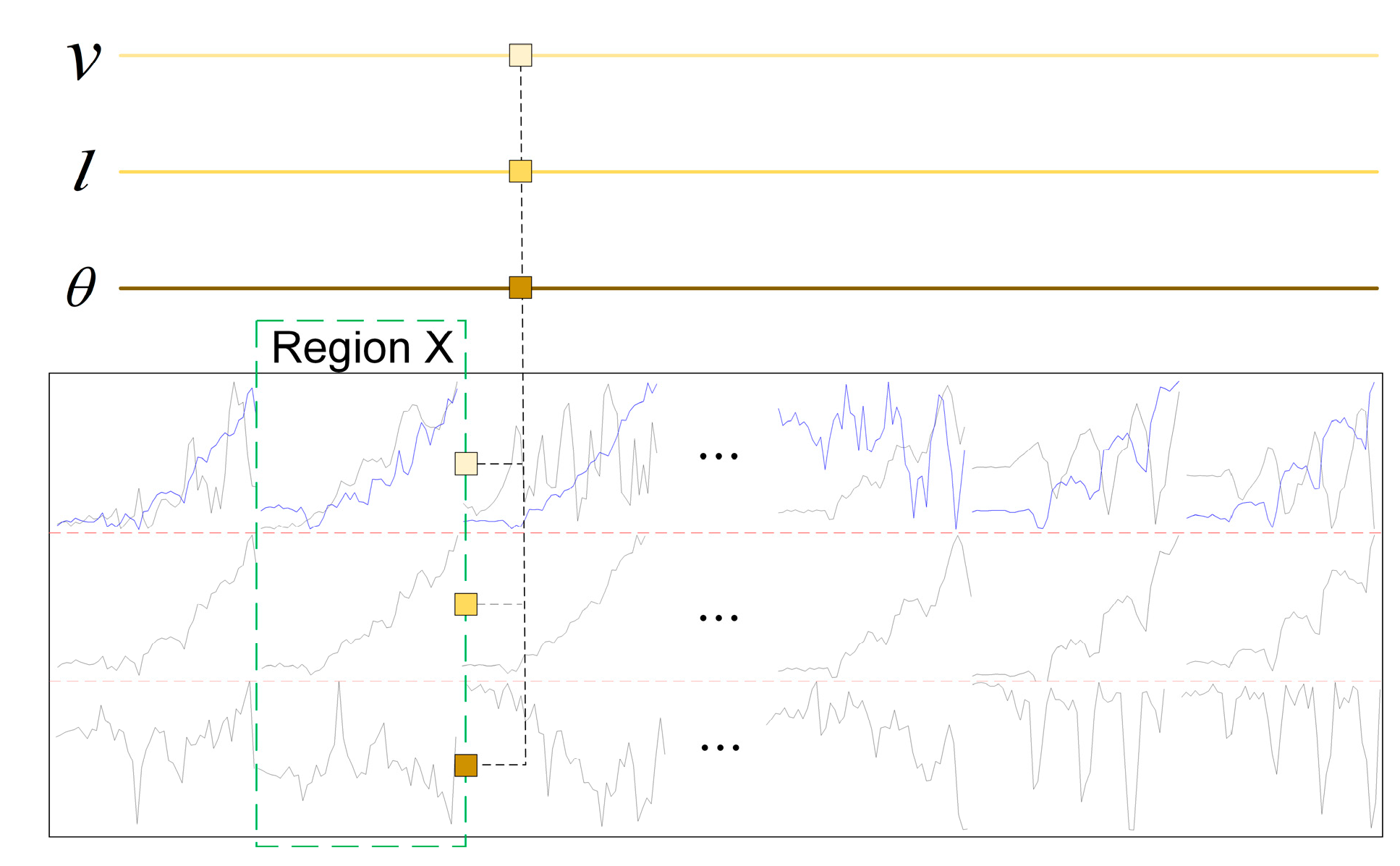
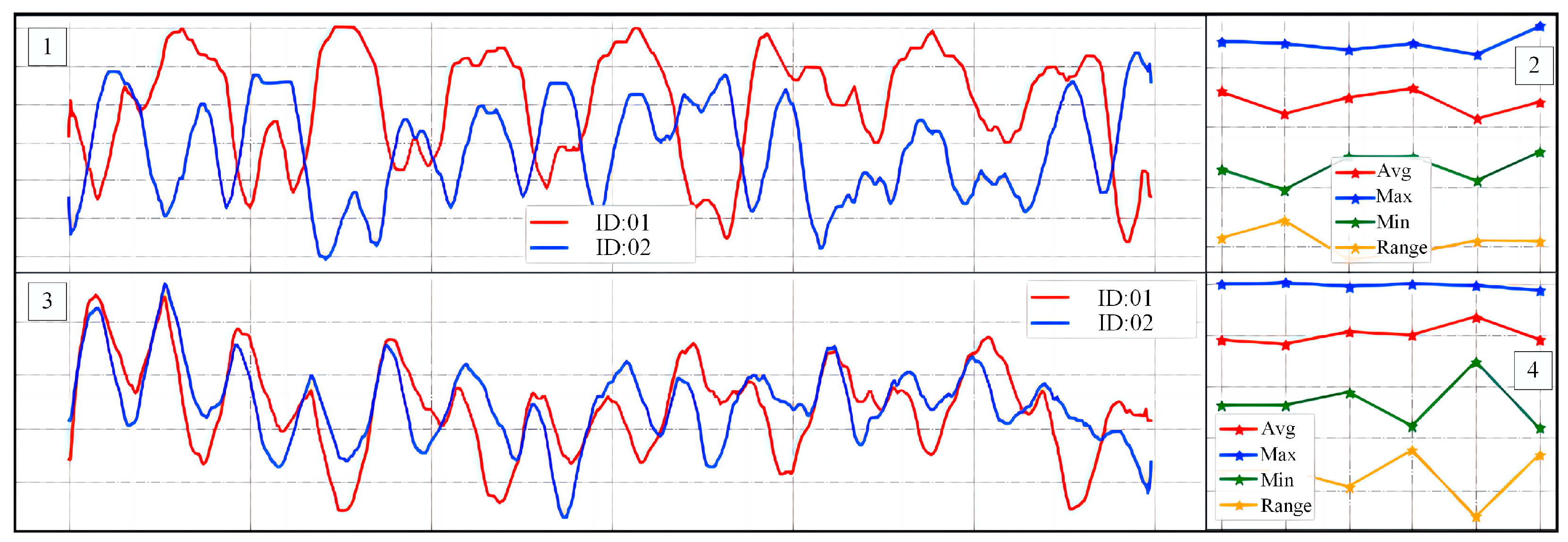
In
Figure 16, region 1 shows the curve obtained after min-max normalization of the fused feature vectors, and the data in region 2 are the first five larger and the last five smaller data extracted from region 1. Region 3 is the curve obtained after Z-score normalization of the fused feature vectors, and the data in region 4 are the first five larger and the last five smaller data extracted from region 3. From
Figure 16, we can see that different walkers show different movement patterns in their bodies while walking. According to these patterns, we can effectively identify the walkers in the video.
To verify that the module we designed has better feature fusion effects, we chose three fusion methods—Concatenation, Squeeze-and-Excitation Networks (SENet) [
43], and Feature Pyramid Network (FPN) [
44]—for comparison. The experimental results are shown in
Table 8. Compared with Concatenation, the method based on bilinear pooling decomposition can utilize the acquired feature information more effectively and reduce the data loss due to information fusion. Compared with SENet, the computational process of our method is simpler. It can still obtain good feature fusion results with reduced computing resources. FPN is a commonly used feature fusion method that maintains high quality information during feature fusion by adding lateral connections to the feature pyramid at different levels. Our method is a bit more complex than FPN, mainly due to the addion of a bilinear matrix decomposition computational process before feeding into FPN. The purpose of this is to utilize the feature information as much as possible and to reduce the dimensionality of the computed fused features by horizontal pyramid pooling. Therefore, our method achieves better results than using only FPN.
The Rank-1 and Rank-5 accuracy of recognition with data collected in real scenes is shown in
Table 9. Rank-1 accuracy is the percentage of the number of predicted category labels with the maximum probability that the true label is equal to the total number of samples. Rank-5 accuracy is the percentage of the predicted category with the maximum probability that one of the five categories is the same as the true label, and the prediction result is true.
Finally, there is the qualitative evaluation part. We used a short-time video taken for recognition effect testing, and the duration of the pedestrian walking video is 5 s. In order to systematize the recognition process, we designed the upper computer interface of the gait recognition system using PyQt5, as shown in
Figure 17.
By recording the video and analyzing it, the feature data extracted from the two branch networks are fused to achieve human-gait-based identity recognition. The time duration and effect of each stage of the recognition process are shown in
Table 10, which proves the feasibility and practicality of the design of this paper.
4. Discussion
Gait recognition technology has a wide range of prospects in the real world. In practical applications, the large amount of data required for gait recognition has been an important factor affecting the recognition results. In this paper, we have considered a combination of human time-series feature extraction and gait data expansion to achieve gait recognition with less data. In
Section 3.3.1, we analyzed the regional time-series data in order to obtain the motion pattern of human walking and to observe the effect of our designed time-series feature extraction network. By visualizing and analyzing the joint vectors, inter-joint distances, and joint angles, we found that the distribution of our regional time-series data has different patterns when a person is walking. This laid the foundation for our next step of quantitative analysis. After comparing with the commonly used time-series feature extraction networks, we found that the time-series feature extraction network we used has better results. To evaluate the effectiveness of the multi-view gait silhouette generation, we performed KL scatter analysis by calculating the Inception Score and proved that our gait silhouette generation network is effective. After classification using a unified feature extraction algorithm, it was also demonstrated that the gait dataset after data expansion showed more significant identity feature information than the original dataset. Tests in real scenarios also provided proof of the effectiveness of our approach. In this paper, our main work is the extraction of time-series features of human motion and the data expansion of gait silhouette images. In future work, we will conduct a more detailed study, including the optimization of the time-series feature extraction network and the gait silhouette feature extraction network, especially the design of the Transformer-based feature extraction network. For example, the CSTL [
45] network constructed based on Transformer and the Significant Spatial Feature Learning (SSFL) module has achieved good results in feature extraction of gait silhouette image using the global relationship modeling capability of the proposed network. Also, we can add a regularization method similar to ReverseMask [
46] to improve the feature extraction capability for gait images, and to improve the accuracy of gait recognition.



 ,
, 

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}