

Utility–Privacy Trade-Offs with Limited Leakage for Encoder

Abstract
:1. Introduction
1.1. Background
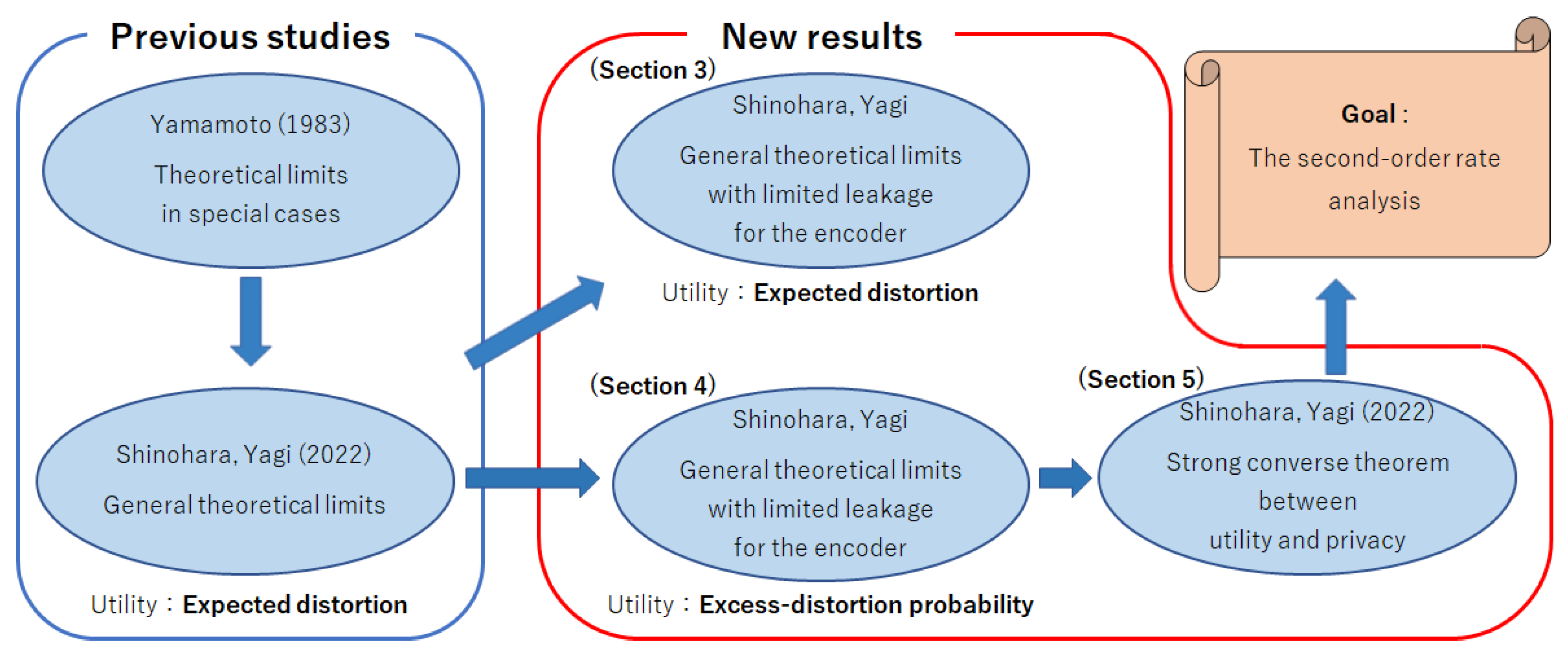
1.2. Motivation and Contributions
- The rate analysis among the coding rate, utility, privacy for the decoder, and privacy for the encoder in which utility is measured using the expected distortion (Section 3).
- The rate analysis among the coding rate, utility, privacy for the decoder, and privacy for the encoder in which utility is measured using the excess-distortion probability (Section 4).
- The strong converse theorem for utility–privacy trade-offs in which utility is measured using the excess-distortion probability (Section 5).
1.3. Related Work
1.4. Organization
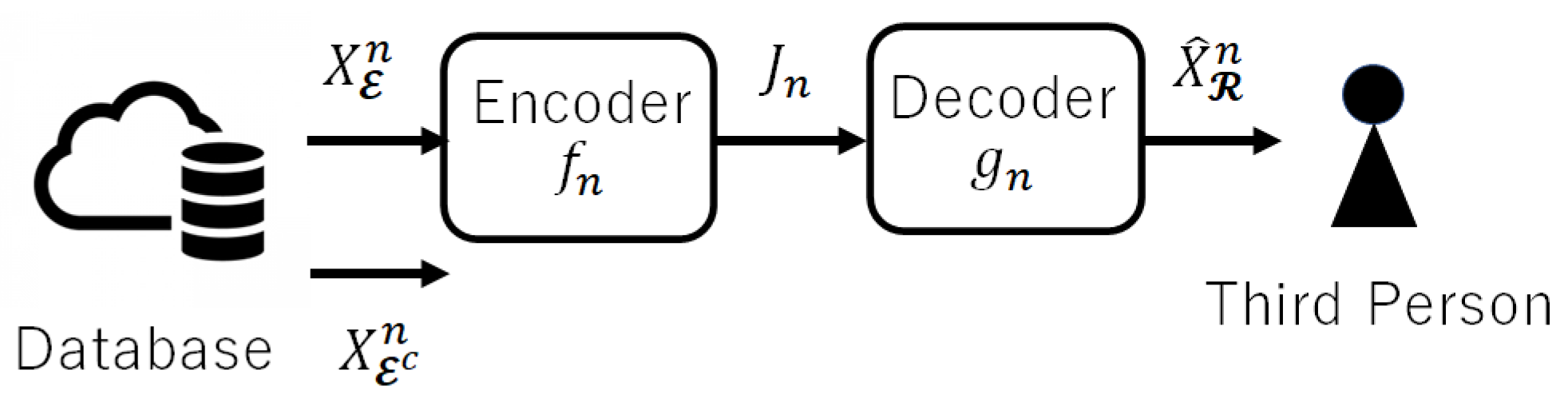
2. Notation and System Model
2.1. Information Source
2.2. Encoder and Decoder
3. First-Order Rate Analysis with Expected Distortion
3.1. Performance Measures
3.2. Achievable Region and Theorem
3.3. Proof Preliminaries for First-Order Rate Analysis
3.4. Proof of Converse Part
- (a)
- follows from (14),
- (b)
- follows because ,
- (c)
- is due to the fact that ,
- (d)
- follows because each is independent and is a function of ,
- (e)
- follows because conditioning reduces entropy,
- (f)
- is due to the definition of Q,
- (g)
- follows because , and
- (h)
- follows because conditioning reduces entropy, where .
- (i)
- is due to (15),
- (j)
- is derived from the definition of Q,
- (k)
- follows because ,
- (l)
- is due to (16),
- (m)
- follows because ,
- (n)
- follows because ,
- (o)
- follows from the fact that conditioning reduces entropy,
- (p)
- is derived from the definition of Q, and
- (q)
- follows because conditioning reduces entropy, where ,
- (r)
- is due to chain rule for mutual information,
- (s), (t)
- follow because .
3.5. Proof of Direct Part
- (a)
- follows because of ,
- (b)
- is due to the inequality proved in Appendix D,
- (c)
- follows by removing the term for .
- (d)
- follows from the fact that
- (e)
- is due to the inequality proved in Appendix E, and
- (f)
- follows because of the number of strongly typical sequences.
4. First-Order Rate Analysis with Excess-Distortion Probability
4.1. Performance Measures
4.2. Achievable Region and Theorem
4.3. Proof of Converse Part
4.4. Proof of the Direct Part
- (a)
- follows because of ,
- (b)
- is due to the inequality proved in Appendix D, and
- (c)
- follows by removing the term for .
- (d)
- follows from the fact that
- (e)
- is due to the inequality proved in Appendix E, and
- (f)
- follows because of the number of strongly typical sequences.
5. Strong Converse Theorem for Utility–Privacy Trade-Offs
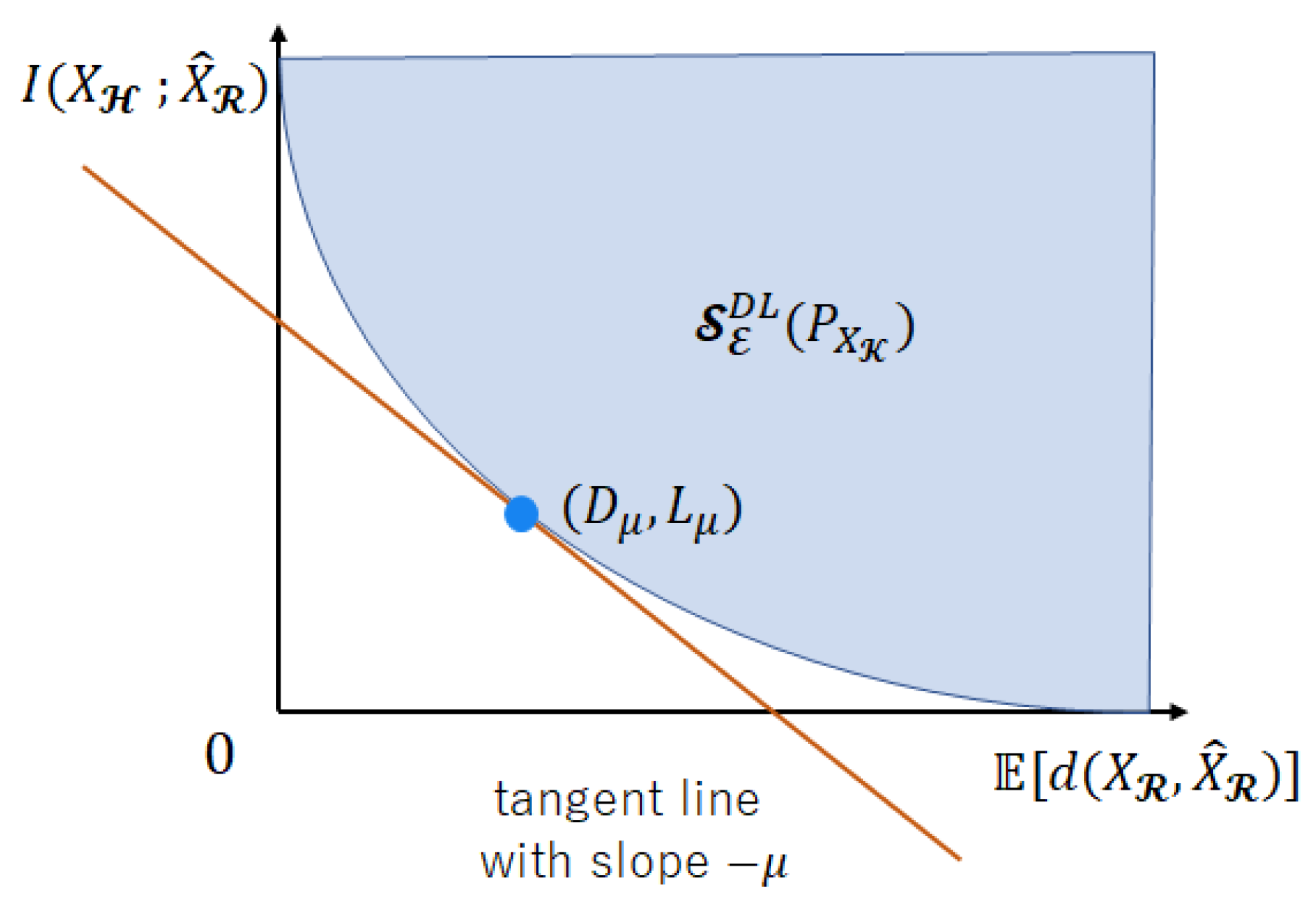
5.1. Another Expression of the Achievable Region
5.2. Proof Preliminaries
- (a)
- follows from the memoryless property of source ;
- (b)
- holds because .
- (c)
- follows from the data processing inequality and
- (d)
- holds because of Jensen’s inequality.
- (e)
- holds because .
- (f)
- follows from the log sum inequality.
5.3. Strong Converse Theorem
5.4. Proof of Lemma 7
- (a)
- follows from .
5.5. Proof of Strong Converse Theorem
- (a)
- follows from (149) and ,
- (b)
- is due to (134).
6. Discussion
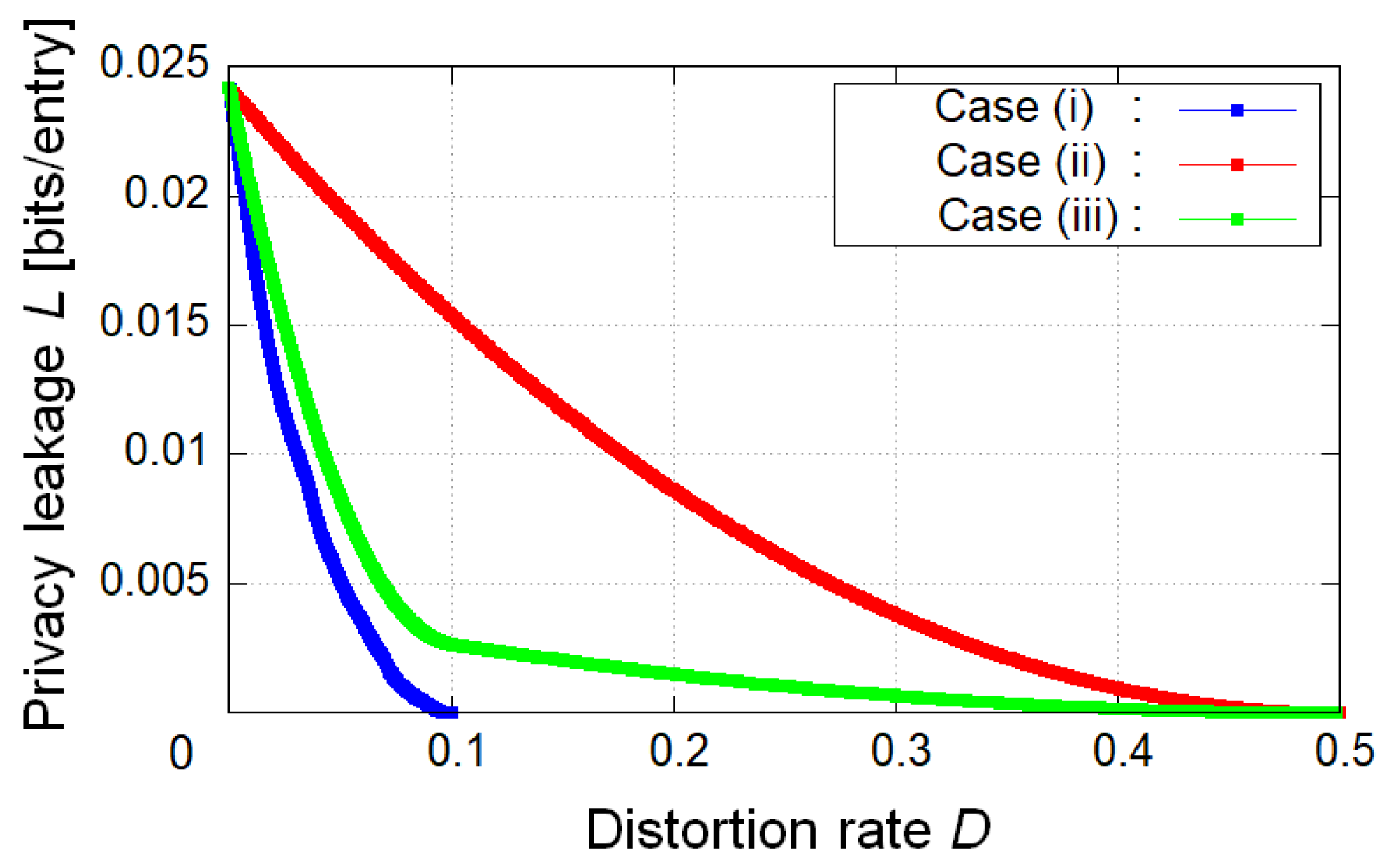
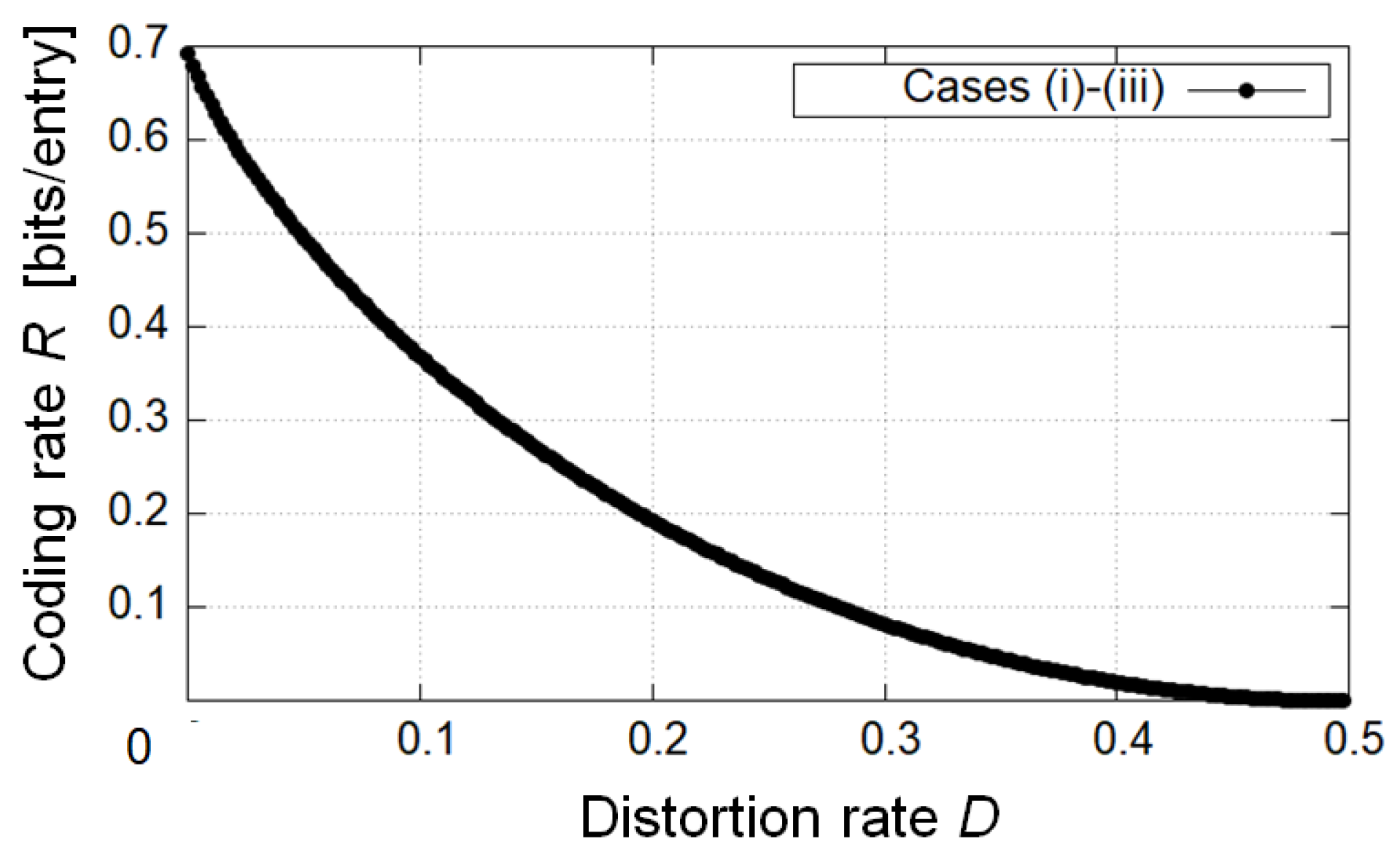
6.1. Numerical Calculation of Coding Rate, Utility, and Privacy for Decoder
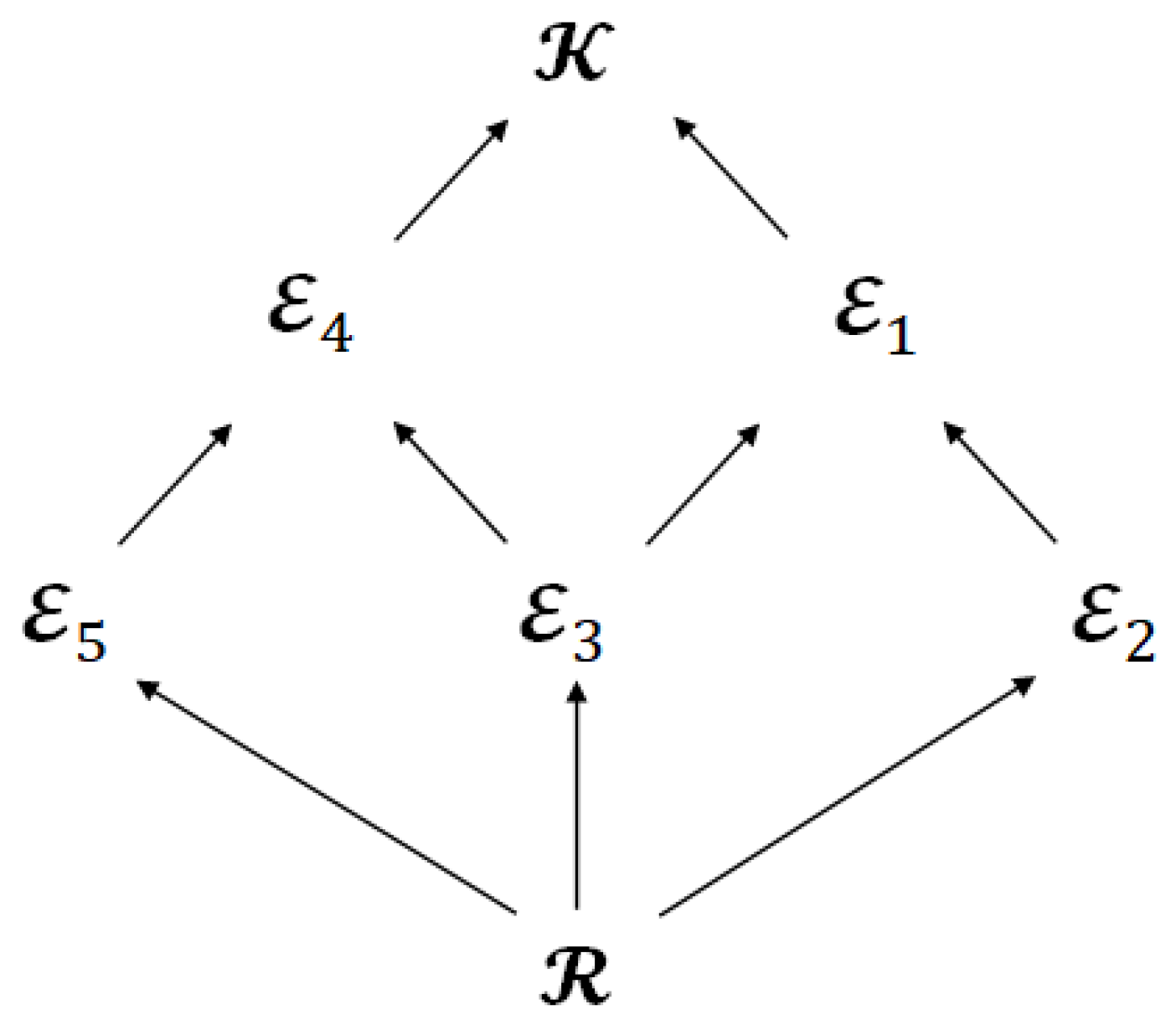
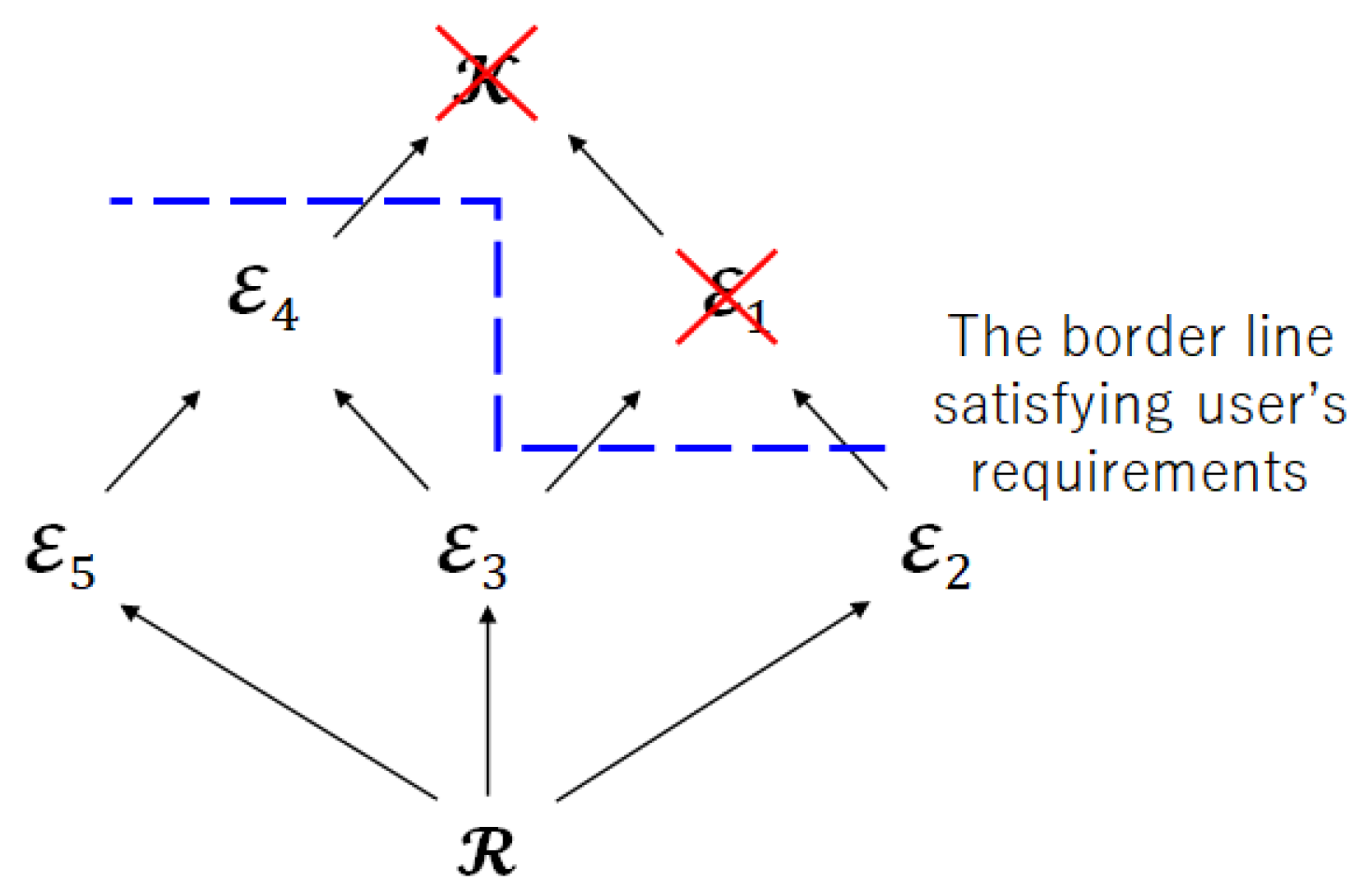
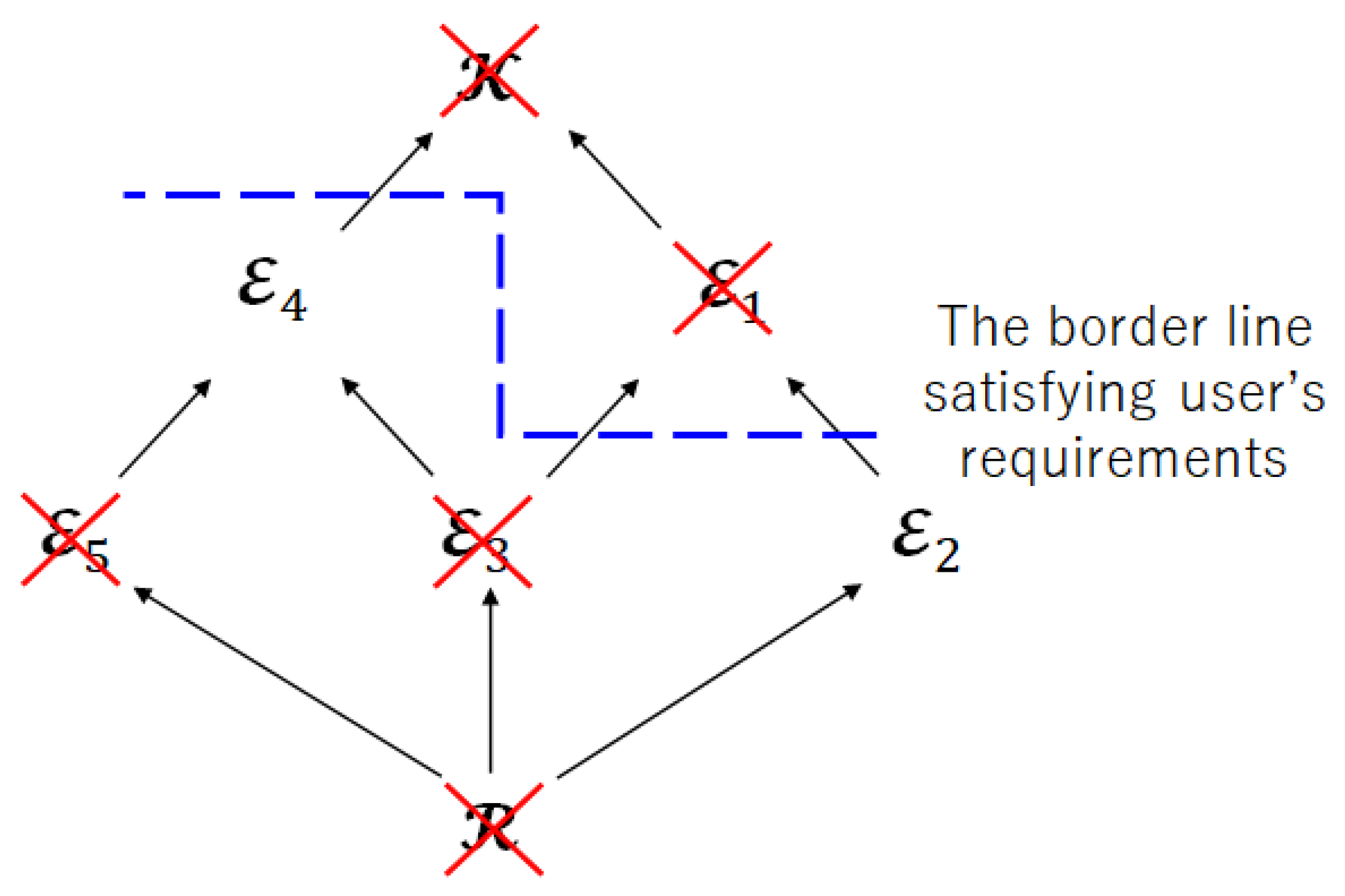
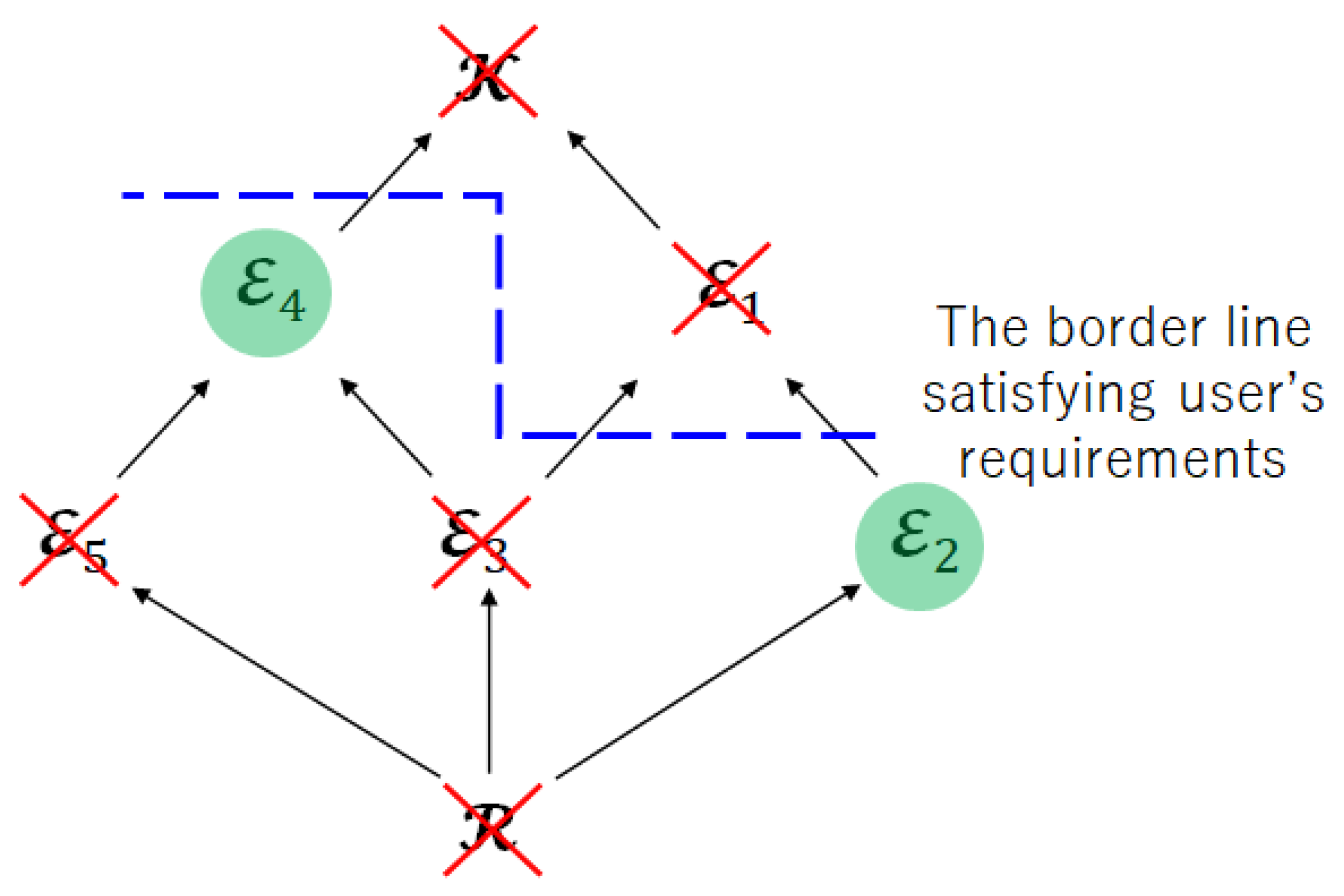
6.2. Significance of Limited Leakage for Encoder
- Pros:
- The achievable regions and become larger.
- Cons:
- The leakage for the encoder increases.
- Step 1:
- Check the user’s requirements and impose the restriction on the privacy leakage for the encoder.
- Step 2:
- Check the inclusion relation between index sets.
6.3. Discussion on Measures for Privacy Leakage
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Proof of the Markov Chain –– in Converse Part of Theorem 1
- (a)
- is due to the Markov chain –– and
- (b)
- follows from the stationary memoryless source.
- (c)
- follows because
- (d)
- is due to the Markov chain ––,
- (e)
- follows from the stationary memoryless source, and
- (f)
- follows because
Appendix B. Proof of Equation (56)
- (a)
- is due to the Markov chain –– and
- (b)
- follows from Lemma 6.
Appendix C. Proof of Existence of Code Satisfying Equations (57)–(62)
- (a)
- is owing to (A11),
- (b)
- is due to the symmetry about indexes of random coding,
- (c)
- follows from the same way as in (Section 3.6.3 in [31]), and
- (d)
- because is fixed to satisfy (49).
- (i)
- :where
- (e)
- because from Lemma 4, if , then and from Lemma 3, if and , then .
- (ii)
- :where
- (f)
- is due to the definition of .
- (g)
- follows from (A18).
- (h)
- is due to chain rule for mutual information and
- (i), (j)
- follows because .
- (i)
- The first term:where
- (k)
- is because of (A14).
- (ii)
- The second term:If the event in the second term occurs, and . Therefore, from Lemma 5, holds. Hence,where
- (l)
- is due to the Markov chain ,
- (m)
- follows since and Lemma 6, and
- (n)
- follows because are disjoint for each j.
Appendix D. Derivation of Inequality in Equation (63)
- (i)
- The first term:where
- (a)
- follows because is disjoint for each ,
- (b)
- is owing to (61).
- (ii)
- The second term:where
- (c)
- follows because and
- (d)
- follows from (61).
- (i)
- The first term:where
- (e)
- follows since is disjoint for each ,
- (f)
- is due to (61).
- (ii)
- The second term:where
- (g)
- follows because and
- (h)
- is due to (61).
- (i)
- is because of the triangle inequality.
- (j)
- follows from the definition that and .
Appendix E. Proof of Equation (65)
Appendix F. Proof of the Existence of Code Satisfying Equations (111)–(116)
- (a)
- is owing to (A59),
- (b)
- is due to the symmetry about indexes of random coding,
- (c)
- follows from the same way as in ([31], Section 3.6.3), and
- (d)
- because is fixed to satisfy (103).
- Strongly typical sequences such that there exists a codeword for some that is conditionally strongly typical with In this case, from Lemma 3, . Since the codeword is jointly strongly typical with , the continuity of the distortion as a function of the joint distribution ensures that they are also typical distortions (see [2], Chapters 10.5 and 10.6). Hence, the distortion between these and their codewords is bounded by where goes to 0 as . In the first-order analysis, that is, , we can regard as D.
- Strongly typical sequences such that .
- Non-strongly typical sequences .
- (e)
- is due to chain rule for mutual information and
- (f), (g)
- follows because .
- (i)
- The first term:where
- (h)
- is because of (A62).
- (ii)
- The second term:If the event in the second term occurs, and . Therefore, from Lemma 5, holds. Hence,where
- (i)
- is due to the Markov chain ,
- (j)
- follows since and Lemma 6,
- (k)
- follows because is disjoint for each j.
References
- Yamamoto, H. A source coding problem for sources with additional outputs to keep secret from the receiver or wiretappers. IEEE Trans. Inf. Theory 1983, 29, 918–923. [Google Scholar] [CrossRef] [Green Version]
- Sankar, L.; Rajagopalan, S.R.; Poor, H.V. Utility–Privacy tradeoff in databases: An information-theoretic approach. IEEE Trans. Inf. Forensics Secur. 2013, 8, 838–852. [Google Scholar] [CrossRef] [Green Version]
- Shinohara, N.; Yagi, H. Unified expression of utility–privacy trade-off in privacy-constrained source coding. In Proceedings of the 2022 International Symposium on Information Theory and Its Applications (ISITA2022), Tsukuba, Japan, 17–19 October 2022; pp. 198–202. [Google Scholar]
- Ingber, A.; Kochman, Y. The dispersion of lossy source coding. In Proceedings of the 2011 Data Compression Conference, Snowbird, UT, USA, 29–31 March 2011; pp. 53–62. [Google Scholar]
- Kostina, V.; Verdú, S. Fixed length lossy compression in the finite blocklength regime: Discrete memoryless sources. IEEE Trans. Inf. Theory 2012, 58, 3309–3338. [Google Scholar] [CrossRef] [Green Version]
- Watanabe, S. Second-order region for Gray-Wyner network. IEEE Trans. Inf. Theory 2017, 63, 1006–1018. [Google Scholar] [CrossRef] [Green Version]
- Tyagi, H.; Watanabe, S. Strong converse using change of measure arguments. IEEE Trans. Inf. Theory 2020, 66, 689–703. [Google Scholar] [CrossRef] [Green Version]
- Dwork, C.; McSherry, F.; Nissim, K.; Smith, A. Calibrating noise to sensitivity in private data analysis. In Proceedings of the 3rd Conference Theory Cryptograph (TCC), New York, NY, USA, 4–7 March 2006; pp. 265–284. [Google Scholar]
- Dwork, C. Differential privacy. In Proceedings of the 33rd International Conference Automata, Languages and Programming (ICALP), Venice, Italy, 10–14 July 2006; pp. 1–12. [Google Scholar]
- Soria-Comas, J.; Domingo-Ferrer, J.; Sánchez, D.; Megías, D. Individual differential privacy: A utility-preserving formulation of differential privacy guarantees. IEEE Trans. Inf. Forensics Secur. 2017, 12, 1418–1429. [Google Scholar] [CrossRef] [Green Version]
- Kalantari, K.; Sankar, L.; Sarwate, A.D. Robust privacy-utility tradeoffs under differential privacy and hamming distortion. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2816–2830. [Google Scholar] [CrossRef] [Green Version]
- Makhdoumi, A.; Fawaz, N. Privacy-utility tradeoff under statistical uncertainty. In Proceedings of the 2013 51st Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 2–4 October 2013; pp. 1627–1634. [Google Scholar]
- Basciftci, Y.O.; Wang, Y.; Ishwar, P. On privacy-utility tradeoffs for constrained data release mechanisms. In Proceedings of the 2016 Information Theory and Applications Workshop (ITA), La Jolla, CA, USA, 31 January–5 February 2016; pp. 1–6. [Google Scholar]
- Günlü, O.; Schaefer, R.F.; Boche, H.; Poor, H.V. Secure and private source coding with private key and decoder side information. In Proceedings of the 2022 IEEE Information Theory Workshop (ITW), Mumbai, India, 6–9 November 2022; pp. 226–231. [Google Scholar]
- Issa, I.; Wagner, A.B.; Kamath, S. An operational approach to information leakage. IEEE Trans. Inf. Theory 2020, 66, 1625–1657. [Google Scholar] [CrossRef] [Green Version]
- Liao, J.; Kosut, O.; Sankar, L.; Calmon, F.P. Privacy under hard distortion constraints. In Proceedings of the 2018 IEEE Information Theory Workshop (ITW2018), Guangzhou, China, 25–29 November 2018; pp. 1–5. [Google Scholar]
- Liao, J.; Kosut, O.; Sankar, L.; Calmon, F.P. Tunable measures for information leakage and applications to privacy-utility tradeoffs. IEEE Trans. Inf. Theory 2019, 65, 8043–8066. [Google Scholar] [CrossRef] [Green Version]
- Saeidian, S.; Cervia, G.; Oechtering, T.J.; Skoglund, M. Quantifying membership privacy via information leakage. IEEE Trans. Inf. Forensics Secur. 2020, 16, 3096–3108. [Google Scholar] [CrossRef]
- Rassouli, B.; Gündüz, D. Optimal utility–privacy trade-off with total variation distance as a privacy measure. IEEE Trans. Inf. Forensics Secur. 2019, 15, 594–603. [Google Scholar] [CrossRef] [Green Version]
- Wang, W.; Ying, L.; Zhang, J. On the relation between identifiability, differential privacy, and mutual-information privacy. IEEE Trans. Inf. Theory 2016, 62, 5018–5029. [Google Scholar] [CrossRef] [Green Version]
- Liao, J.; Sankar, L.; Kosut, O.; Calmon, F.P. Maximal α-leakage and its properties. In Proceedings of the 2020 IEEE Conference on Communications and Network Security (CNS), Virtual, 29 June–1 July 2020; pp. 1–6. [Google Scholar]
- Shinohara, N.; Yagi, H. Strong converse theorem for utility–privacy trade-offs. In Proceedings of the 45th Symposium on Information Theory and Its Applications (SITA2022), Noboribetsu, Japan, 29 November–2 December 2022; pp. 338–343. [Google Scholar]
- Guan, Z.; Si, G.; Wu, J.; Zhu, L.; Zhang, Z.; Ma, Y. Utility–privacy tradeoff based on random data obfuscation in internet of energy. IEEE Access 2017, 5, 3250–3262. [Google Scholar] [CrossRef]
- Asikis, T.; Pournaras, E. Optimization of privacy-utility trade-offs under informational self-determination. Future Gener. Comput. Syst. 2020, 109, 488–499. [Google Scholar] [CrossRef]
- Lu, J.; Xu, Y.; Zhu, Z. On scalable source coding problem with side information privacy. In Proceedings of the 2022 14th International Conference on Wireless Communications and Signal Processing (WCSP), Nanjing, China, 1–3 November 2022; pp. 415–420. [Google Scholar]
- Makhdoumi, A.; Salamatian, S.; Fawaz, N.; Médard, M. From the information bottleneck to the privacy funnel. In Proceedings of the 2014 IEEE Information Theory Workshop (ITW), Hobart, Australia, 2–5 November 2014; pp. 501–505. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory, 2nd ed.; John & Wiley Sons, Inc.: Hoboken, NJ, USA, 2006. [Google Scholar]
- Uyematsu, T. Gendai Shannon Riron, 1st ed.; Baihukan: Tokyo, Japan, 1998. (In Japanese) [Google Scholar]
- Csizar, L.; Korner, J. Information Theory: Coding Theorems for Discrete Memoryless Systems, 2nd ed.; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Sason, I.; Verdú, S. Improved bounds on lossless source coding and guessing moments via Rényi measures. IEEE Trans. Inf. Theory 2018, 64, 4323–4346. [Google Scholar] [CrossRef] [Green Version]
- El Gamal, A.; Kim, Y.H. Network Information Theory, 1st ed.; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cases | Leakage L | Coding Rate R |
|---|---|---|
| case (ii) | 0.019512 | 0.494629 |
| case (iii) | 0.008298 | 0.527700 |
| case (i) | 0.005107 | 0.539478 |
| Cases | Leakage L | Coding Rate R |
|---|---|---|
| case (ii) | 0.015378 | 0.368062 |
| case (iii) | 0.002656 | 0.418826 |
| case (i) | 0.000000 | 0.429490 |
| Cases | Leakage L | Coding Rate R |
|---|---|---|
| case (ii) | 0.011748 | 0.270436 |
| case (iii) | 0.002032 | 0.294424 |
| case (i) | 0.000000 | 0.382211 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shinohara, N.; Yagi, H. Utility–Privacy Trade-Offs with Limited Leakage for Encoder. Entropy 2023, 25, 921. https://doi.org/10.3390/e25060921
Shinohara N, Yagi H. Utility–Privacy Trade-Offs with Limited Leakage for Encoder. Entropy. 2023; 25(6):921. https://doi.org/10.3390/e25060921
Chicago/Turabian StyleShinohara, Naruki, and Hideki Yagi. 2023. "Utility–Privacy Trade-Offs with Limited Leakage for Encoder" Entropy 25, no. 6: 921. https://doi.org/10.3390/e25060921
APA StyleShinohara, N., & Yagi, H. (2023). Utility–Privacy Trade-Offs with Limited Leakage for Encoder. Entropy, 25(6), 921. https://doi.org/10.3390/e25060921