
Shannon Entropy and Herfindahl-Hirschman Index as Team’s Performance and Competitive Balance Indicators in Cyclist Multi-Stage Races


Abstract
:1. Introduction
“A large proportion of cyclists in a race take part in support of another rider, meaning that they do not care about their personal result but instead try to help their team leader(s). Moreover, a team leader generally has one specific objective among a range of possible ones.”
1.1. Team Ranking
1.2. Competitive Balance
1.3. Shannon Entropy and Herfindahl–Hirschman Index
1.3.1. Shannon Entropy
1.3.2. Herfindahl–Hirschman Index
2. Materials and Method
2.1. Application to Multi-Stage Races
2.2. Data
2.3. Notations
3. Results: Data Analysis
3.1. Team Ordering Results
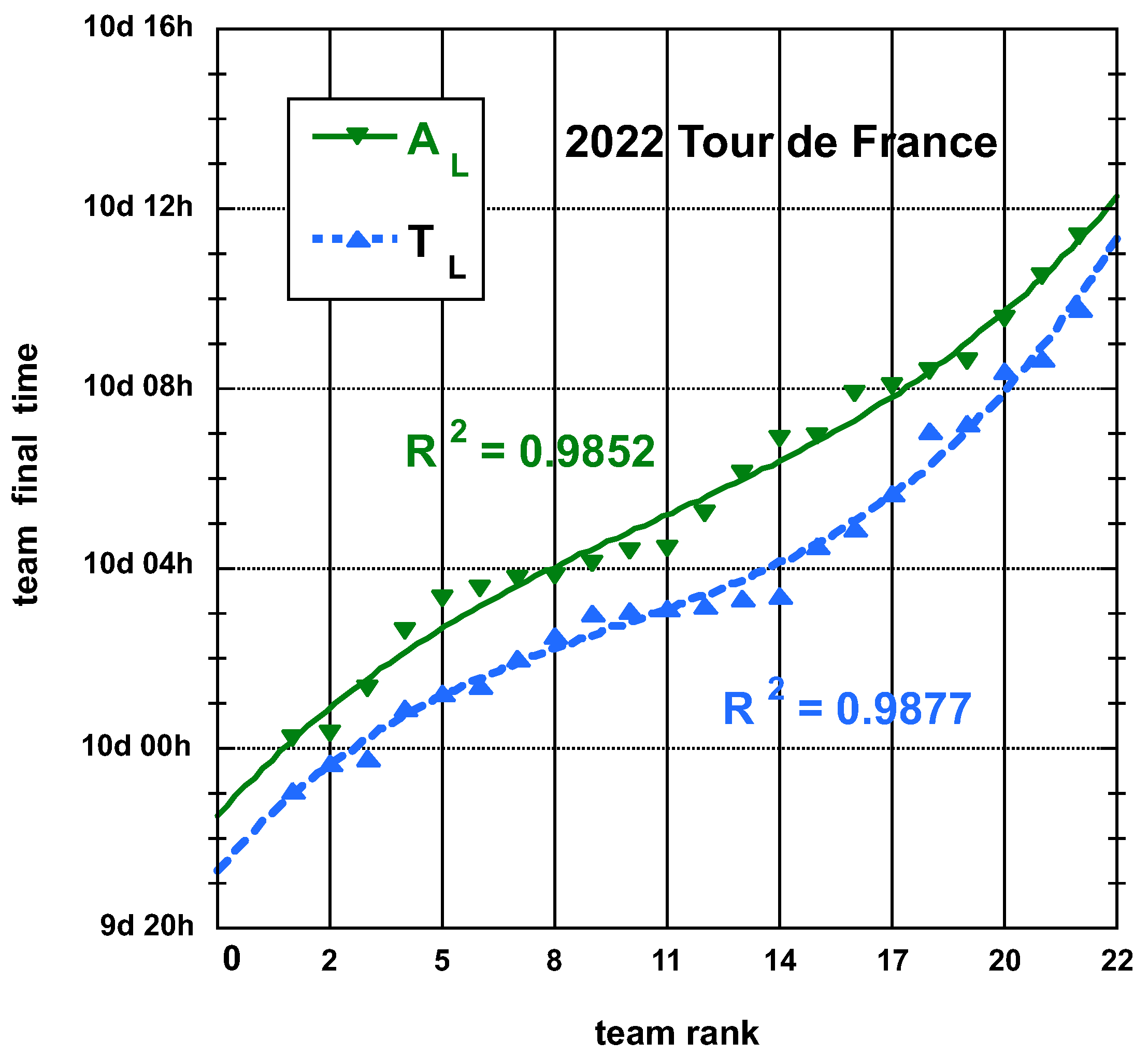
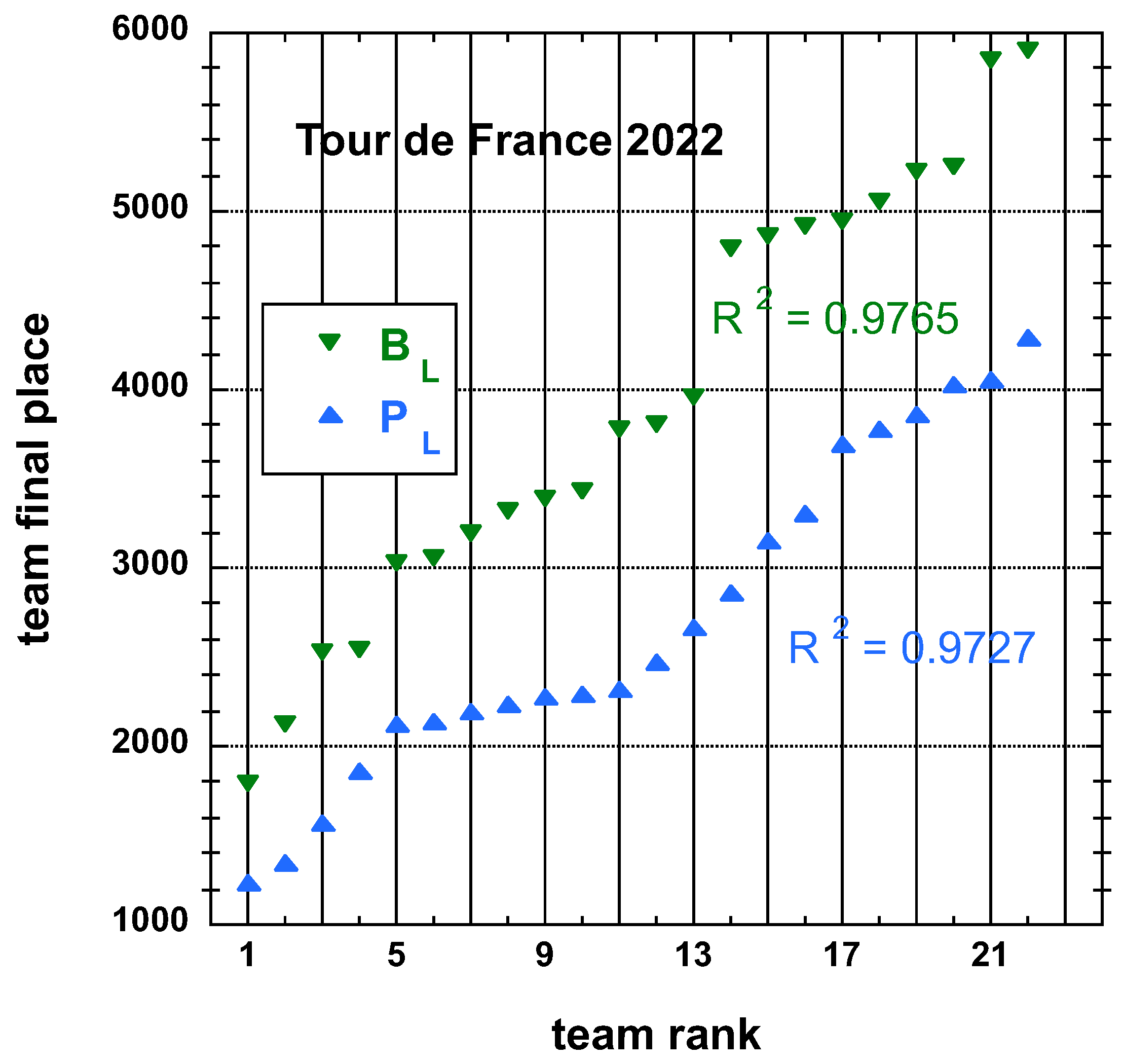
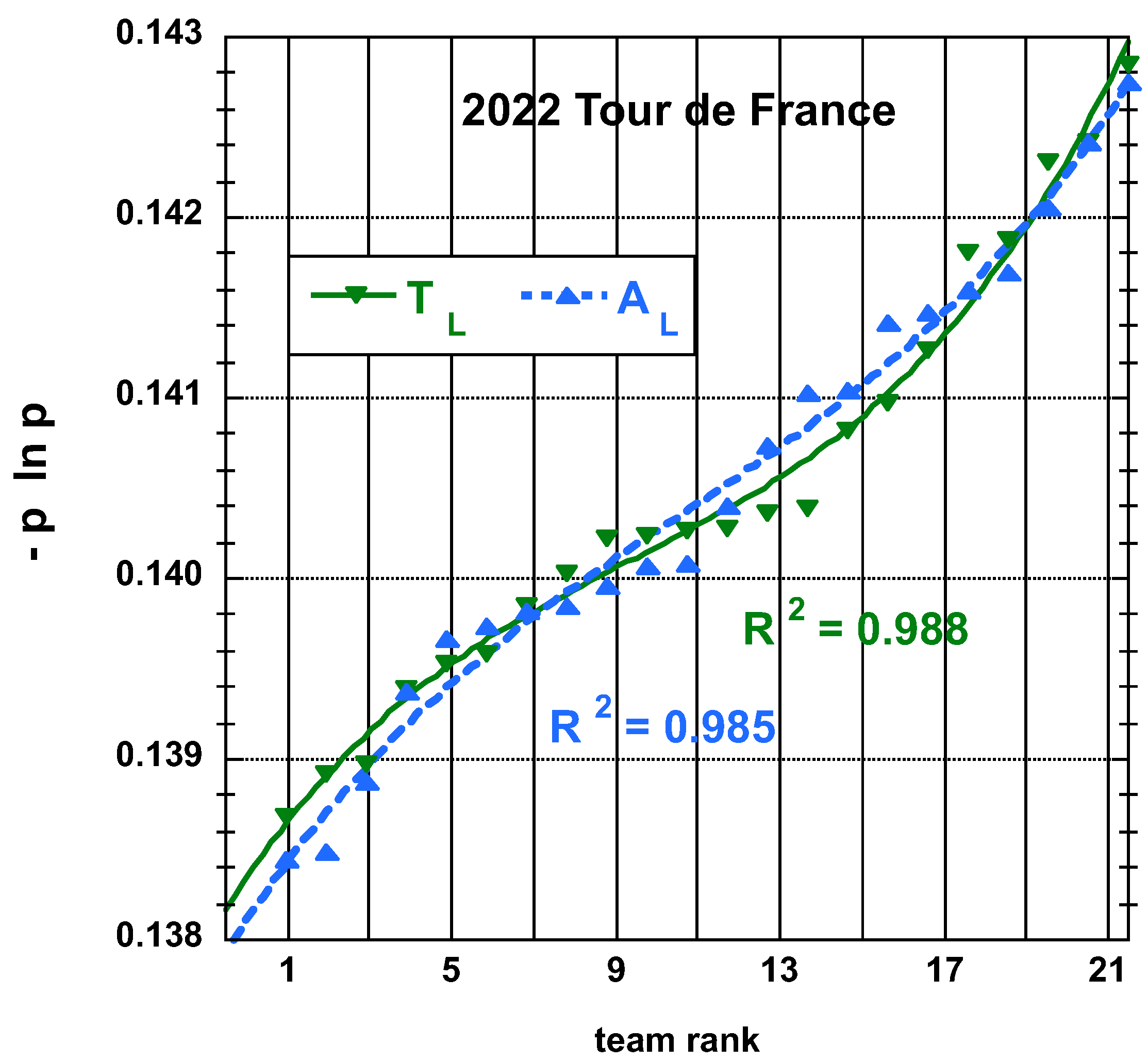
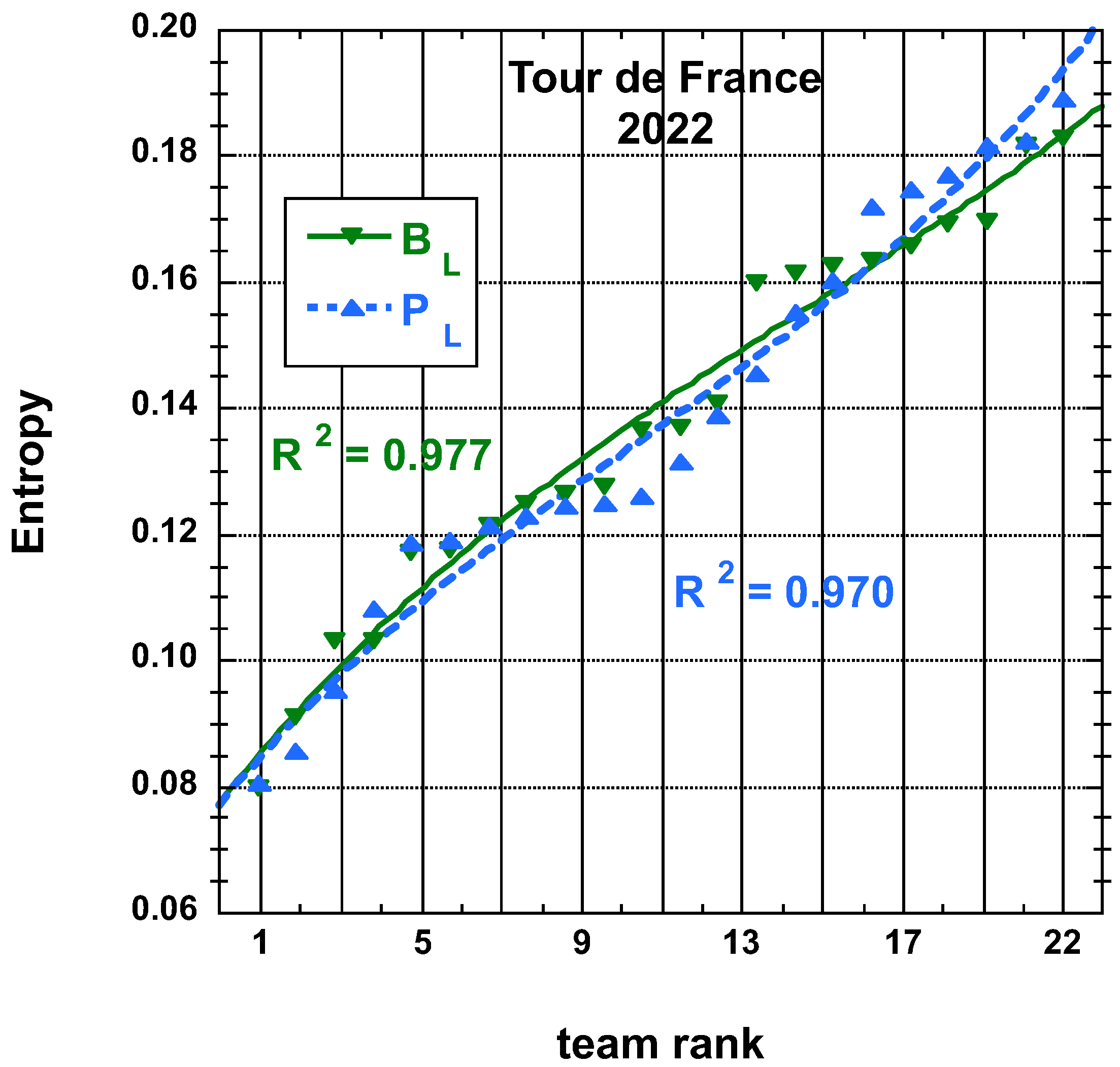
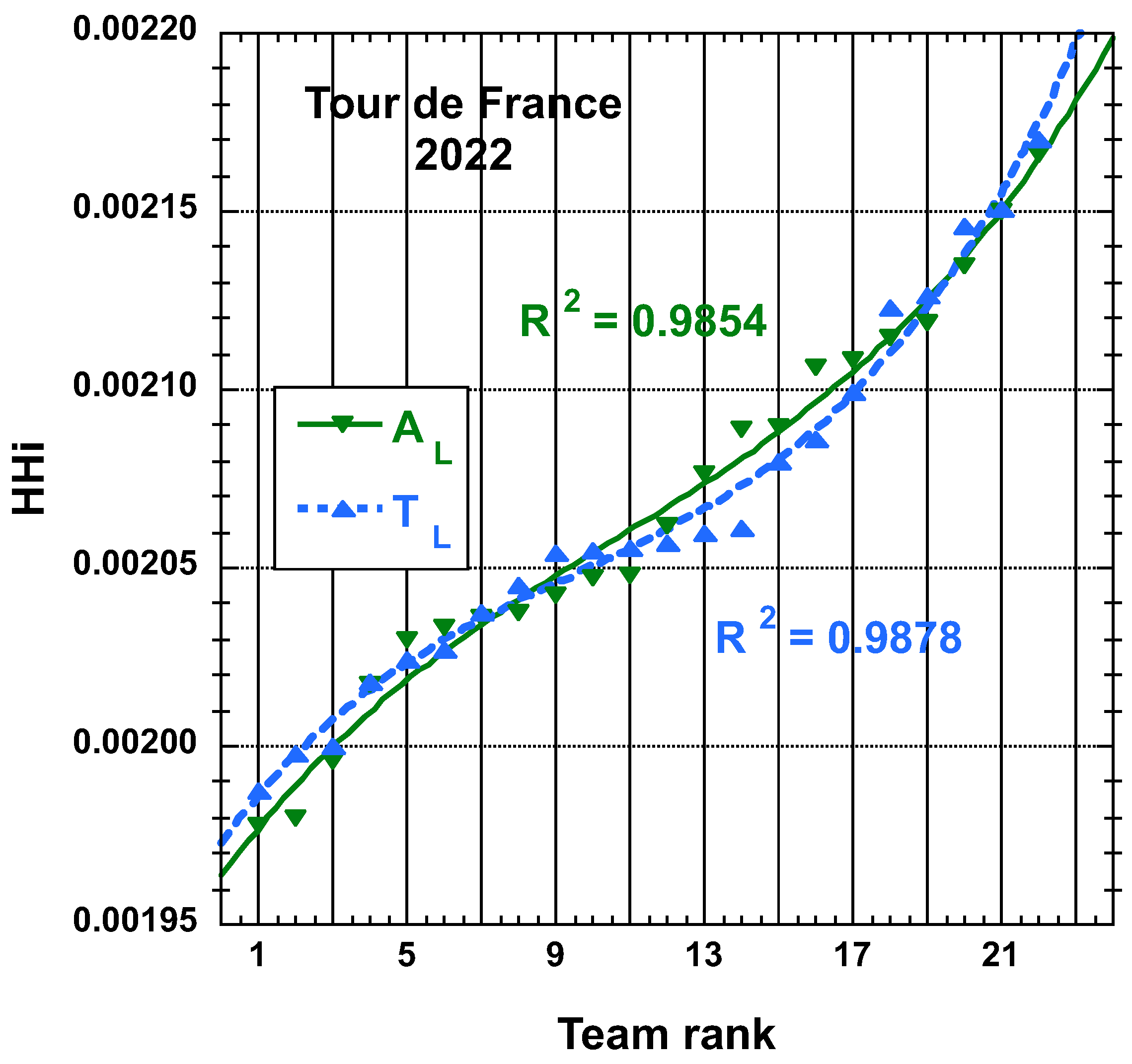
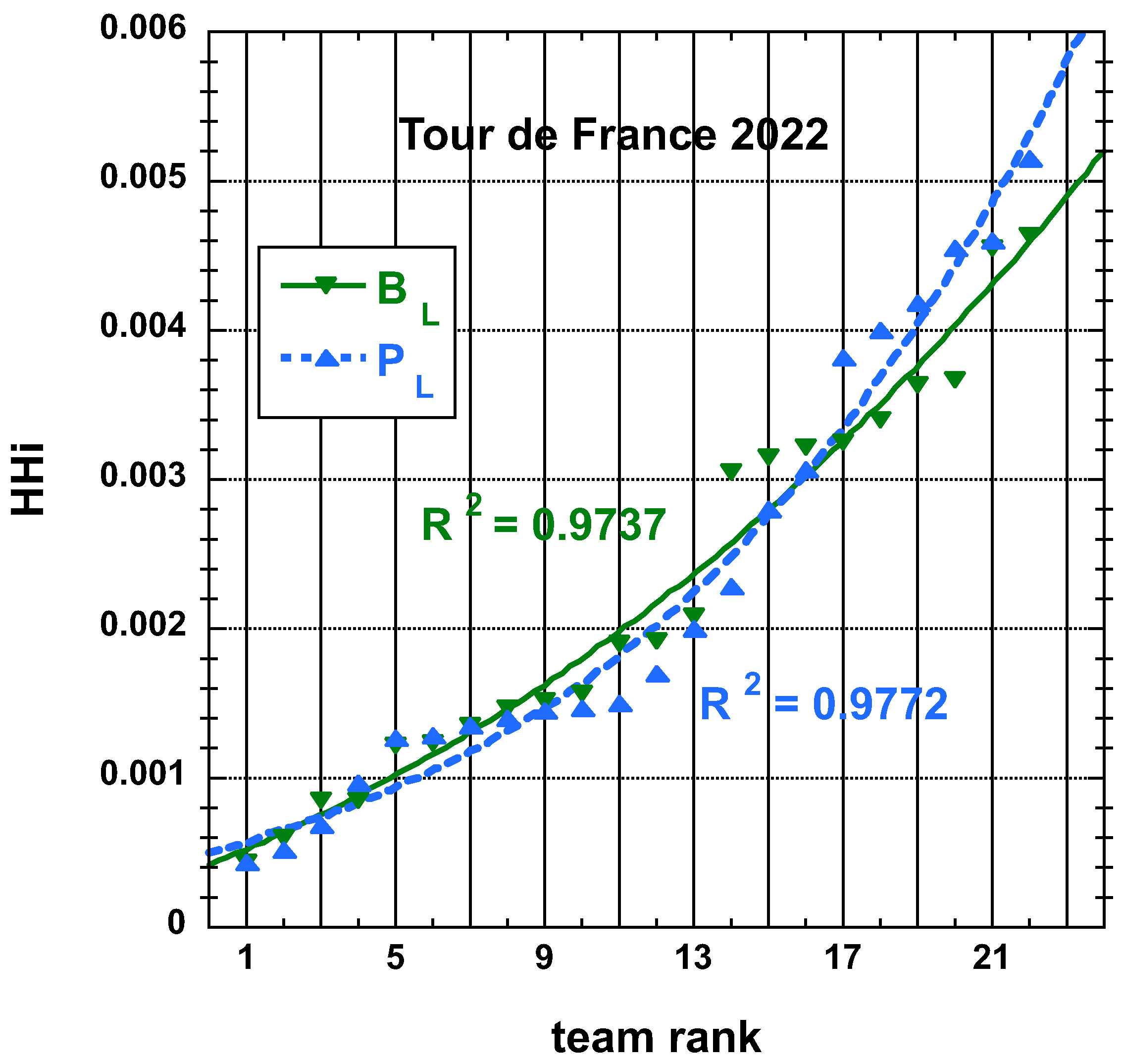
3.1.1. 2022 Tour de France (TdF)
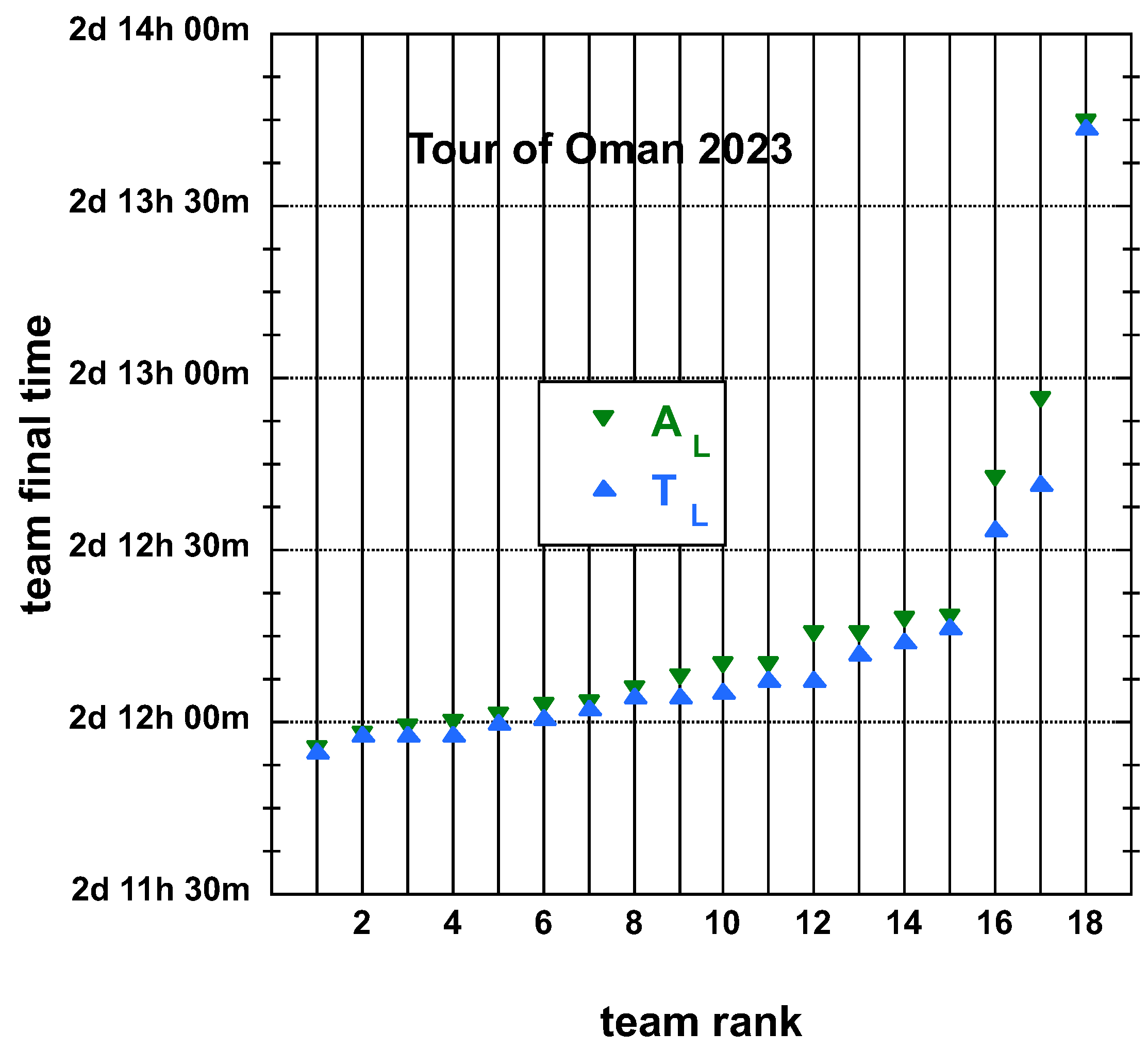
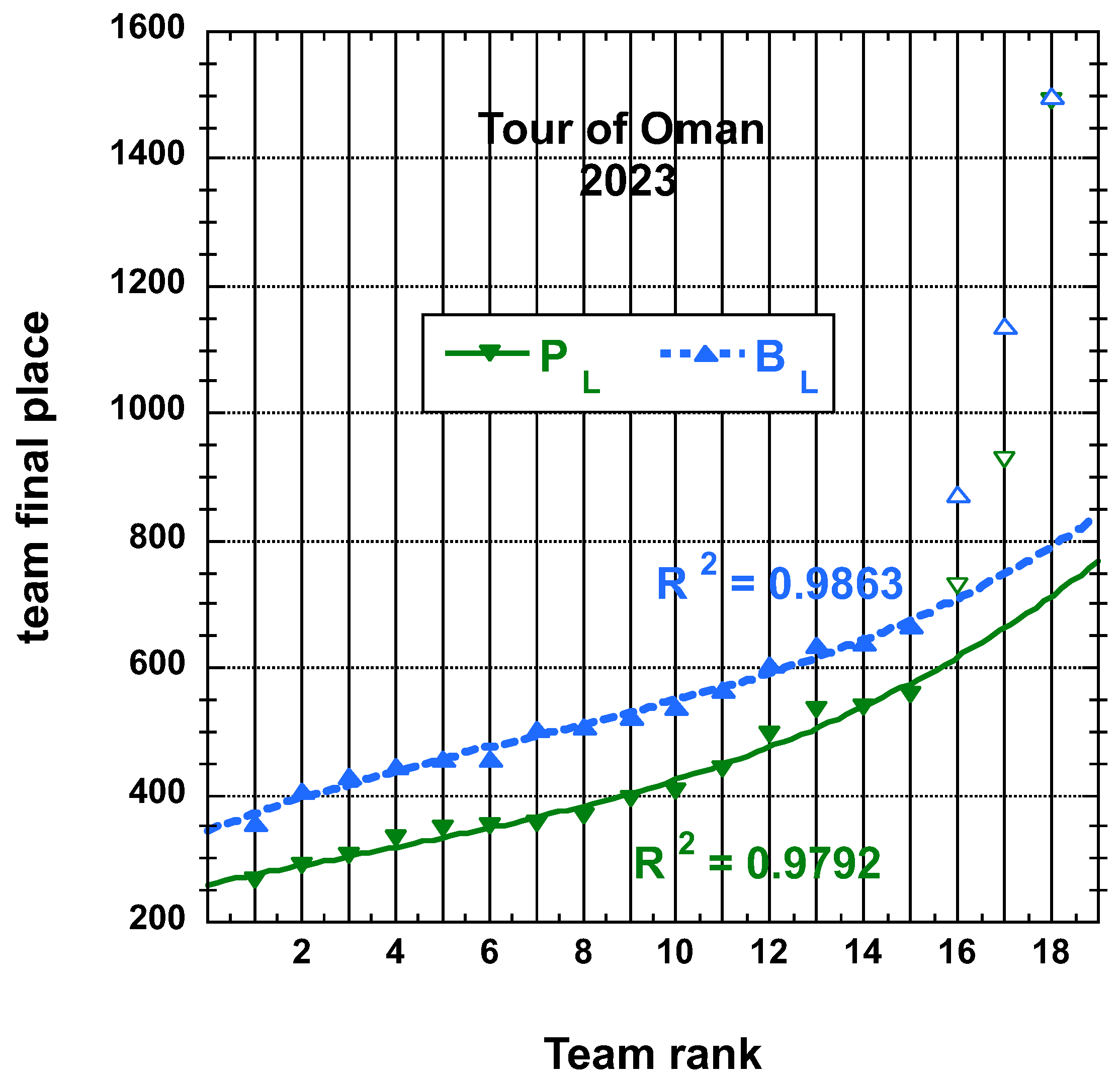
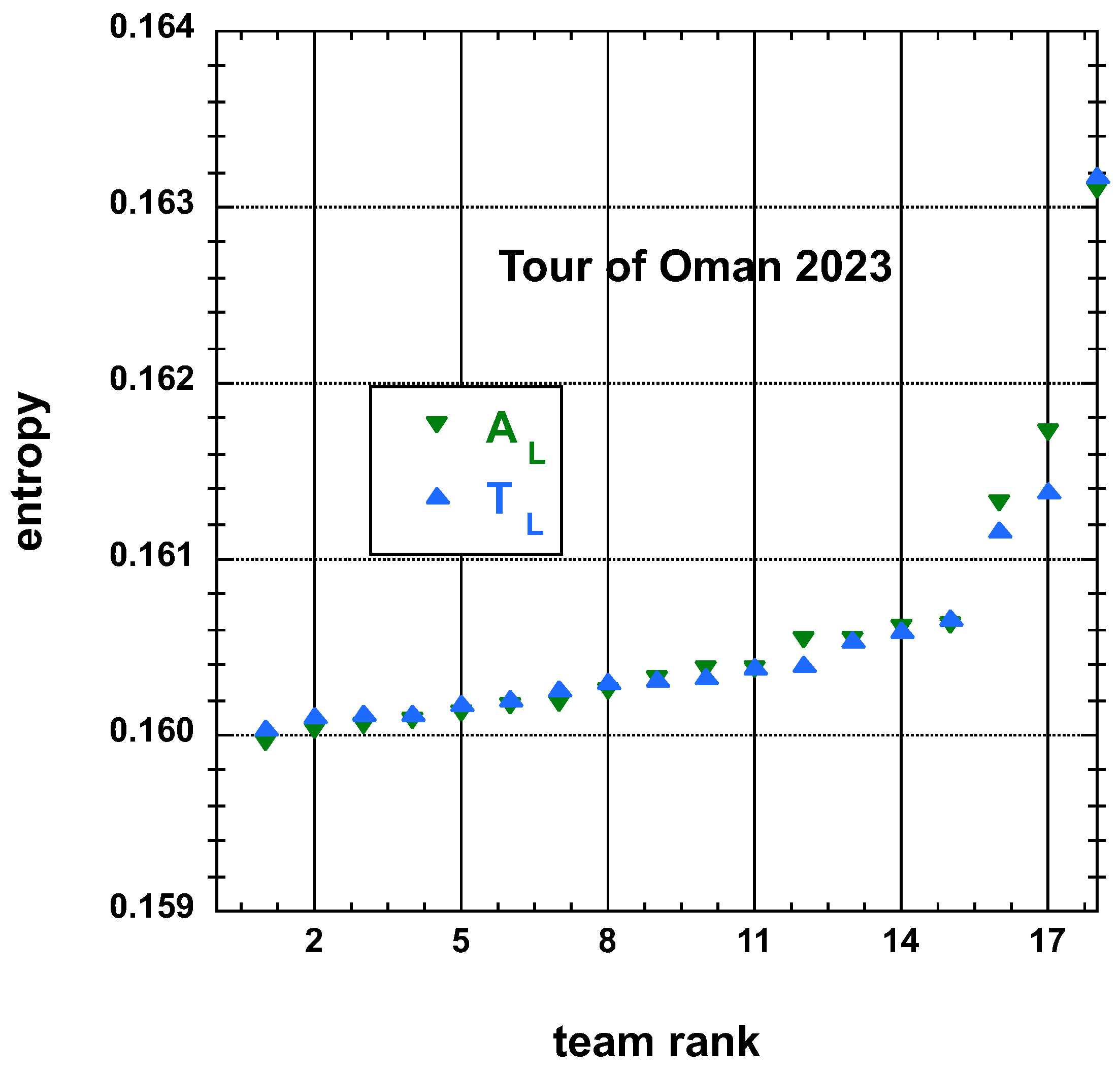
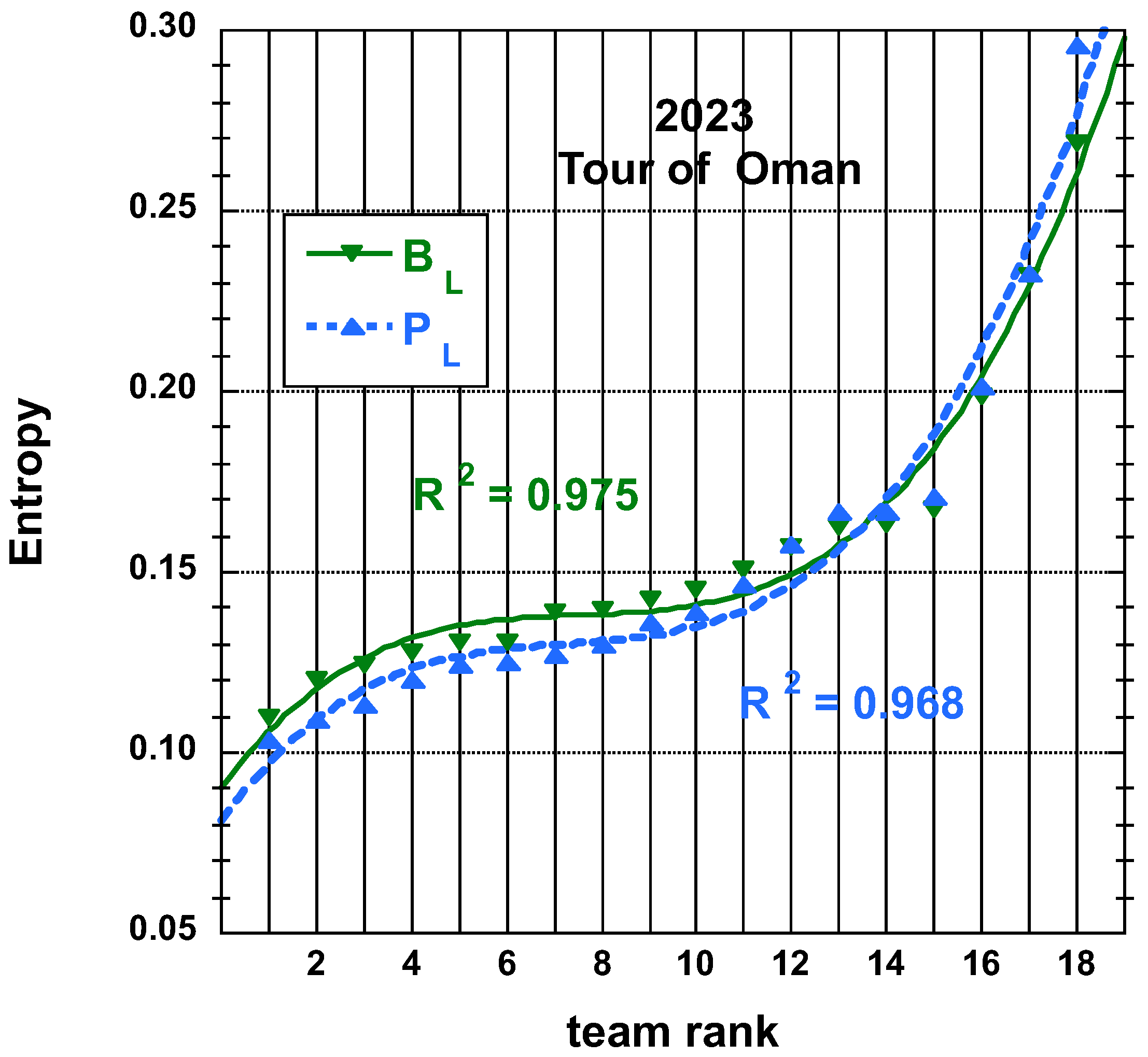
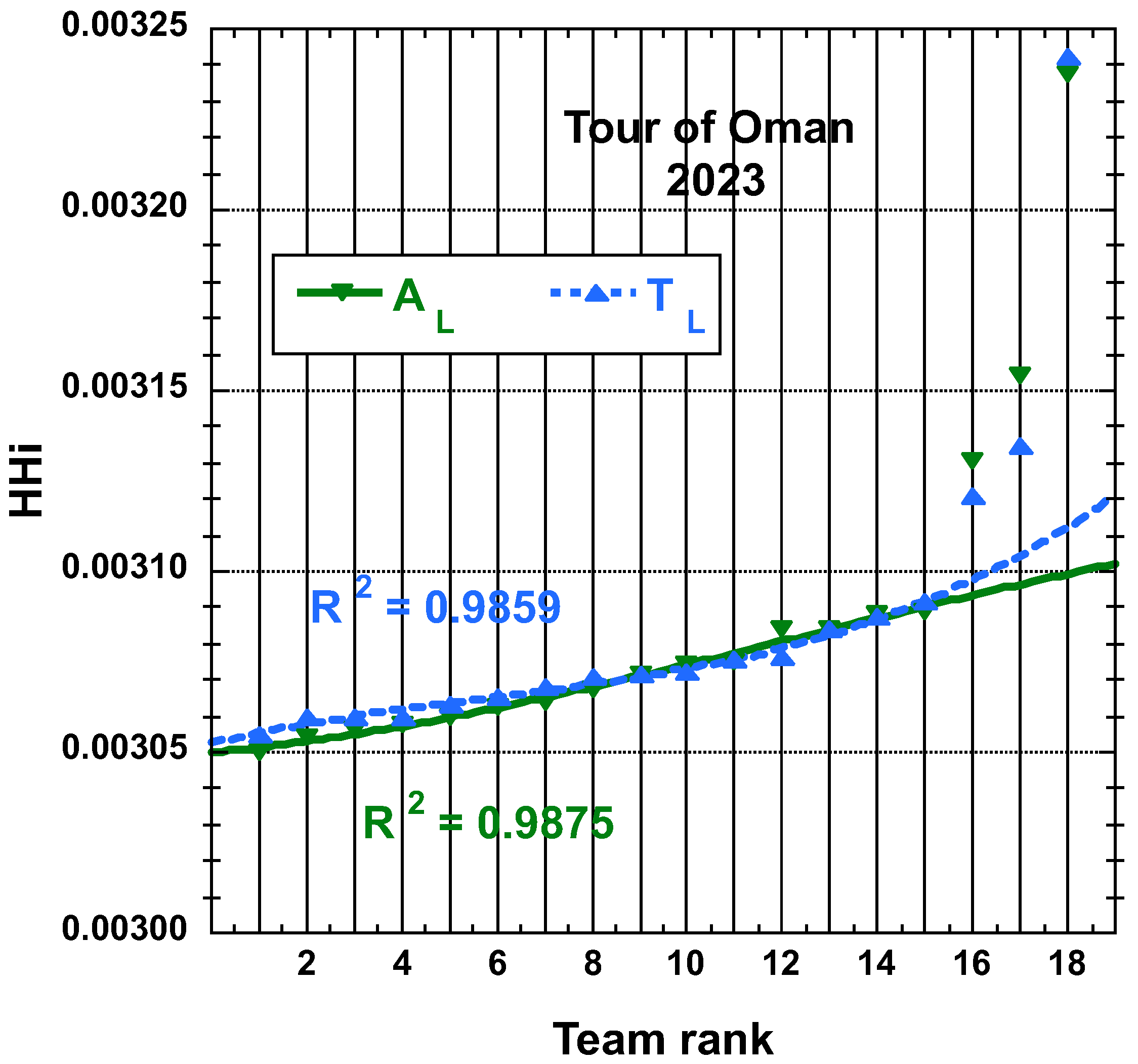
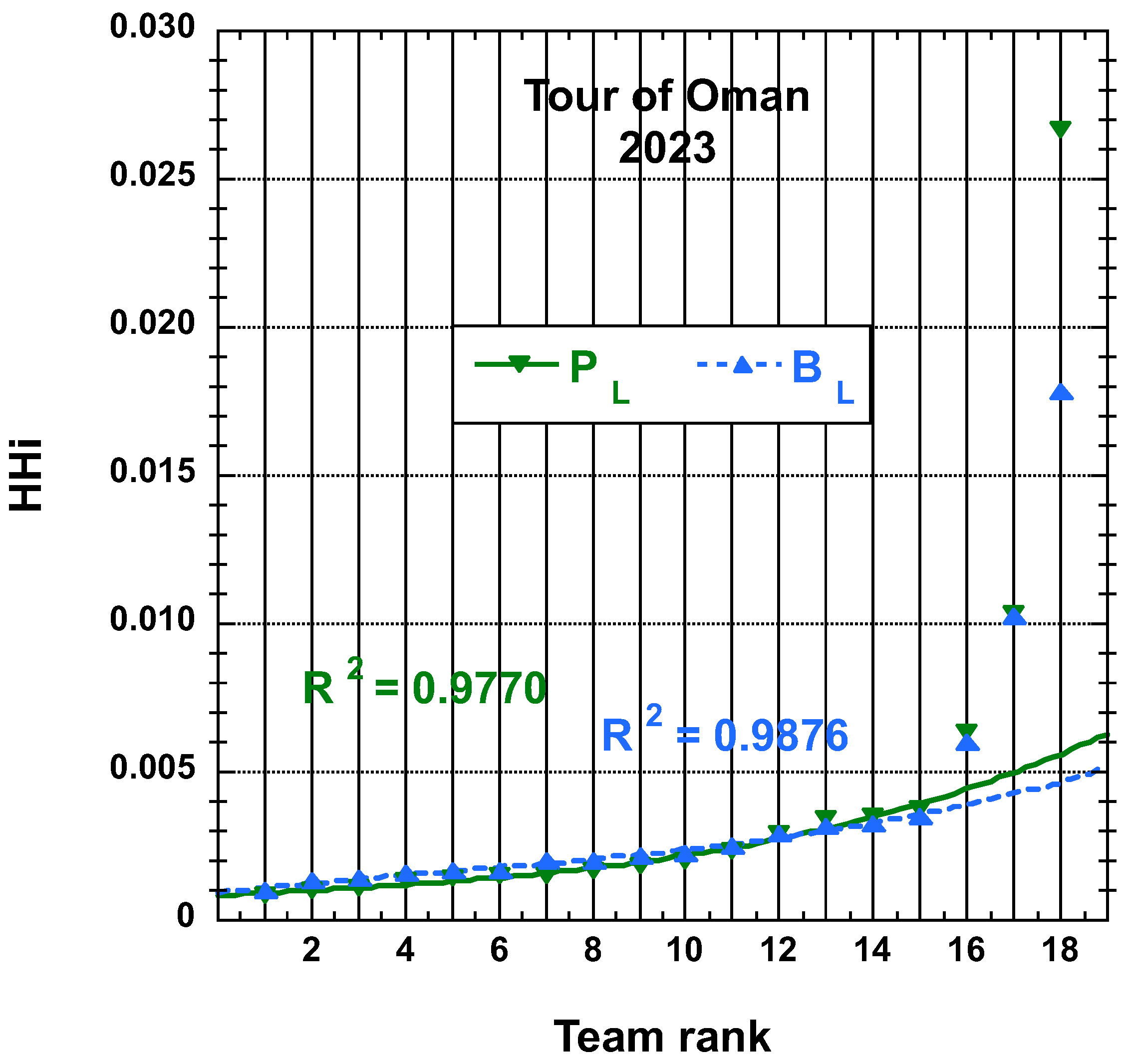
3.1.2. 2023 Tour of Oman (ToO)
3.2. Statistical Characteristics
4. Discussion
5. Conclusions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- De Condorcet, N. Essai sur L’application de L’analyse a la Probabilité des Décisions Rendues à la Pluralité des Voix; Imprimerie Royale: Paris, France, 1785; Reprinted by Chelsea Press: New York, NY, USA, 1973. [Google Scholar]
- Arrow, K. A difficulty in the theory of social welfare. J. Political Econ. 1950, 58, 328–346. [Google Scholar] [CrossRef]
- Collingwood, J.A.; Wright, M.; Brooks, R.J. Evaluating the effectiveness of different player rating systems in predicting the results of professional snooker matches. Eur. J. Oper. Res. 2022, 296, 1025–1035. [Google Scholar] [CrossRef]
- Stefani, R.T. Survey of the major world sports rating systems. J. Appl. Stat. 1997, 24, 635–646. [Google Scholar] [CrossRef]
- Wilson, R.L. Ranking college football teams: A neural network approach. Interfaces 1995, 25, 44–59. [Google Scholar] [CrossRef]
- Albert, E. Riding a line: Competition and cooperation in the sport of bicycle racing. Sociol. Sport J. 1991, 8, 341–361. [Google Scholar] [CrossRef]
- Cabaud, B.; Scelles, N.; François, A.; Morrow, S. Modeling performances and competitive balance in road cycling competitions. In The Economics of Professional Road Cycling; Springer International Publishing: Cham, Switzerland, 2022; pp. 253–281. [Google Scholar]
- Sorensen, S.P. An Overview of Some Methods for Ranking Sports Teams. University of Tennessee. Knoxville. 2000. Available online: http://sorensen.info/rankings/Documentation/Sorensen_documentation_v1.pdf (accessed on 14 February 2023).
- Vaziri, B.; Dabadghao, S.; Yih, Y.; Morin, T.L. Properties of sports ranking methods. J. Oper. Res. Soc. 2018, 69, 776–787. [Google Scholar] [CrossRef]
- Ausloos, M. Rank–size law, financial inequality indices and gain concentrations by cyclist teams. The case of a multiple stage bicycle race, like Tour de France. Physica A 2020, 540, 123161. [Google Scholar] [CrossRef] [Green Version]
- Ficcadenti, V.; Cerqueti, R.; Vardeí, C.H. A rank-size approach to analyse soccer competitions and teams: The case of the Italian football league “Serie A”. Ann. Oper. Res. 2023, 325, 85–113. [Google Scholar] [CrossRef]
- Sanderson, A.R. The many dimensions of competitive balance. J. Sport. Econ. 2002, 3, 204–228. [Google Scholar] [CrossRef]
- Rodríguez, C.; Pérez, L.; Puente, V.; Rodríguez, P. The determinants of television audience for professional cycling: The case of Spain. J. Sport. Econ. 2015, 16, 26–58. [Google Scholar] [CrossRef]
- Rodríguez-Gutiérrez, C.; Fernández-Blanco, V. Continuous TV demand in road cycling: The 2015 Vuelta a España. Eur. Sport Manag. Q. 2017, 17, 349–369. [Google Scholar] [CrossRef]
- Bačik, V.; Klobučník, M.; Mignot, J.F. What made the tour successful? Competitive balance in the tour de France, 1947–2017. Sport Soc. 2020, 24, 147–159. [Google Scholar] [CrossRef]
- Andreff, W.; Mignot, J.F. The Tour de France: A Success Story in Spite of Competitive Imbalance. In The Economics of Professional Road Cycling; Springer International Publishing: Cham, Switzerland, 2022; pp. 163–180. [Google Scholar]
- Lenten, L.J. Measurement of competitive balance in conference and divisional tournament design. J. Sport. Econ. 2015, 16, 3–25. [Google Scholar] [CrossRef]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef] [Green Version]
- Da Silva, S.; Matsushita, R.; Silveira, E. Hidden power law patterns in the top European football leagues. Phys. A Stat. Mech. Appl. 2013, 392, 5376–5386. [Google Scholar] [CrossRef] [Green Version]
- Silva, P.; Duarte, R.; Sampaio, J.; Aguiar, P.; Davids, K.; Araújo, D.; Garganta, J. Field dimension and skill level constrain team tactical behaviours in small-sided and conditioned games in football. J. Sport. Sci. 2014, 32, 1888–1896. [Google Scholar] [CrossRef]
- Silva, P.; Duarte, R.; Esteves, P.; Travassos, B.; Vilar, L. Application of entropy measures to analysis of performance in team sports. Int. J. Perform. Anal. Sport 2016, 16, 753–768. [Google Scholar] [CrossRef]
- Trandel, G.A.; Maxcy, J.G. Adjusting winning-percentage standard deviations and a measure of competitive balance for home advantage. J. Quant. Anal. Sport. 2011, 7. [Google Scholar] [CrossRef] [Green Version]
- Humphreys, B.R. Alternative Measures of Competitive Balance in Sports Leagues. J. Sport. Econ. 2002, 3, 133–148. [Google Scholar] [CrossRef]
- Triguero Ruiz, F.; Avila-Cano, A. The distance to competitive balance: A cardinal measure. Appl. Econ. 2019, 51, 698–710. [Google Scholar] [CrossRef]
- Owen, P.D.; Ryan, M.; Weatherston, C.R. Measuring competitive balance in professional team sports using the Herfindahl-Hirschman index. Rev. Ind. Organ. 2007, 31, 289–302. [Google Scholar] [CrossRef]
- Owen, P.D.; Owen, C.A. Simulation evidence on Herfindahl-Hirschman measures of competitive balance in professional sports leagues. J. Oper. Res. Soc. 2022, 73, 285–300. [Google Scholar] [CrossRef]
- Hirschman, A.O. The paternity of an index. Am. Econ. Rev. 1964, 54, 761–762. [Google Scholar]
- Ausloos, M. Toward fits to scaling-like data, but with inflection points & generalized Lavalette function. J. Appl. Quant. Methods 2014, 9, 1–21. [Google Scholar]
- Ausloos, M. Two-exponent Lavalette function: A generalization for the case of adherents to a religious movement. Phys. Rev. E 2014, 89, 062803. [Google Scholar] [CrossRef] [Green Version]
- Tahmasebi, S.; Behboodian, J. Shannon entropy for the Feller-Pareto (FP) family and order statistics of FP subfamilies. Appl. Math. Sci. 2010, 4, 495–504. [Google Scholar]
- Eliazar, I.; Cohen, M.H. The universal macroscopic statistics and phase transitions of rank distributions. Physica A 2011, 390, 4293–4303. [Google Scholar] [CrossRef]
- Cerqueti, R.; Rotundo, G.; Ausloos, M. Investigating the configurations in cross-shareholding: A joint copula-entropy approach. Entropy 2018, 20, 134. [Google Scholar] [CrossRef] [Green Version]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Min. | Max. | Sum | Mean | St. Dev. | Skew. | Kurt. | |
|---|---|---|---|---|---|---|---|
| 2022 Tour de France; ; | |||||||
| 239:03:03 | 249:46:16 | 5361:45:14 | 243:42:58 | 3:01:12 | 0.43693 | −0.70860 | |
| 240:13:39 | 251:22:06 | 5401:26:40 | 245:31:13 | 3:09:10 | 0.08616 | −0.86863 | |
| 1242 | 4288 | 59,753 | 2716.05 | 921.67 | 0.22809 | −1.10963 | |
| 1788 | 5899 | 86,725 | 3942.05 | 1209.34 | −0.01383 | −1.12467 | |
| 2023 Tour of Oman; ; | |||||||
| 59:55:12 | 61:43:42 | 1084:04:36 | 60:13:35 | 0:25:39 | 2.6427 | 6.66372 | |
| 59:55:26 | 61:44:32 | 1085:04:31 | 60:16:55 | 0:26:50 | 2.2287 | 4.50161 | |
| 267 | 1491 | 9131 | 507.28 | 296.60 | 2.2798 | 4.89609 | |
| 357 | 1500 | 11,245 | 624.72 | 285.83 | 1.9770 | 3.26794 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ausloos, M. Shannon Entropy and Herfindahl-Hirschman Index as Team’s Performance and Competitive Balance Indicators in Cyclist Multi-Stage Races. Entropy 2023, 25, 955. https://doi.org/10.3390/e25060955
Ausloos M. Shannon Entropy and Herfindahl-Hirschman Index as Team’s Performance and Competitive Balance Indicators in Cyclist Multi-Stage Races. Entropy. 2023; 25(6):955. https://doi.org/10.3390/e25060955
Chicago/Turabian StyleAusloos, Marcel. 2023. "Shannon Entropy and Herfindahl-Hirschman Index as Team’s Performance and Competitive Balance Indicators in Cyclist Multi-Stage Races" Entropy 25, no. 6: 955. https://doi.org/10.3390/e25060955
APA StyleAusloos, M. (2023). Shannon Entropy and Herfindahl-Hirschman Index as Team’s Performance and Competitive Balance Indicators in Cyclist Multi-Stage Races. Entropy, 25(6), 955. https://doi.org/10.3390/e25060955