In this section, we briefly introduce BNC and then formulate BAR.
2.2. Batched Network Coding
Suppose we want to send a file from a source node to a destination node through a multi-hop network. The file is divided into multiple input packets, where each packet is regarded as a vector over a fixed finite field. A BNC has three main components: the encoder, the recoder and the decoder.
The encoder of a BNC is applied at the source node to generate batches from the input packets, where each batch consists of a small number of coded packets. Recently, a reinforcement learning approach to optimize the generation of batches was proposed in [
61]. Nevertheless, batches are commonly generated using the traditional approach as follows. To generate a batch, the encoder samples a predefined degree distribution to obtain a degree, where the degree is the number of input packets that constitute the batch. Depending on the application, there are various ways to formulate the degree distribution [
62,
63,
64,
65]. According to the degree, a set of packets is chosen randomly from the input packets. The size of the input packets may be obtained via certain optimizations, such as in [
66], to minimize the overhead. Each packet in the batch is formed by taking random linear combinations on the chosen set of packets. The encoder generates
M packets per batch, where
M is known as the batch size.
Each packet in a batch has a coefficient vector attached to it. Two packets in a batch are defined as linearly independent of each other if and only if their coefficient vectors are linearly independent from each other. Immediately after a batch is generated, the packets within it are assigned as linearly independent from each other. This is accomplished by suitably choosing the initial coefficient vectors [
59,
67].
A recoder is applied at each intermediate node, performing network coding operations on the received batches to generate recoded packets. This procedure is known as recoding. Some packets of a batch may be lost when they pass through a network link. Each recoded packet of a batch is formed by taking a random linear combination of the received packets in a given batch. The number of recoded packets depends on the recoding scheme. For example, baseline recoding generates the same number of recoded packets for every batch. Optionally, we can also apply a recoder at the source node so that we can have more than M packets per batch at the beginning. After recoding, the recoded packets are sent to the next network node.
At the destination node, a decoder is applied to recover the input packets. Depending on the specific BNC, we can use different decoding algorithms, such as Gaussian elimination, belief propagation and inactivation [
68,
69].
2.3. Expected Rank Functions
The rank of a batch at a network node is defined by the number of linearly independent packets remaining in the batch, a measure of the amount of information carried by the batch. Adaptive recoding aims to maximize the sum of the expected value of the rank distribution of each batch arriving at the next network node. For simplicity, we called this expected value the expected rank.
For batch
b, we denote its rank by
and the number of recoded packets to be generated by
. The expectation of
at the next network node, denoted as
, is known as the expected rank function. We have
where
is the random variable of the number of packets of a batch received by the next network node when we send
t packets for this batch at the current node, and
is the probability that a batch of rank
r at the current node with
i received packets at the next network node has rank
j at the next network node. The exact formulation of
can be found in [
38], which is
, where
q is the field size for the linear algebra operations and
. It is convenient to use
in practice as each symbol in this field can be represented by 1 byte. For a sufficiently large field size, say
,
is very close to 1 if
, and is very close to 0 otherwise. That is, we can approximate
by
where
is the Kronecker delta. This approximation has also been used in the literature, see, e.g., [
45,
70,
71,
72,
73,
74,
75,
76].
Besides generating all recoded packets by taking random linear combinations, systematic recoding [
39,
47,
59,
67], which concerns received packets as recoded packets, can be applied to save computational time. Systematic recoding can achieve a nearly indistinguishable performance compared with methods which generate all recoded packets by taking random linear combinations [
39]. Therefore, we can also use (
1) to approximate the expected rank functions for systematic recoding accurately.
For the independent packet loss model with packet loss rate
p, we have
, a binomial distribution. If
, then a store-and-forward technique can guarantee the maximal expected rank. If
, then no matter how many packets we transmit, the next network node must receive no packets. Thus, we assume
in this paper. It is easy to prove that the results in this paper are also valid for
or 1 when we define
, which is a convention in combinatorics such that
and
are well-defined with correct interpretation. In the remaining text, we assume
. That is, for the independent packet loss model, we have
A demonstration of the accuracy of the approximation
can be found in
Appendix A.
We also consider the expected rank functions for burst packet loss channels modelled by Gilbert–Elliott (GE) models [
77,
78], where the GE model was also used in other BNC literature such as [
52,
55,
70]. A GE model is a two-state Markov chain, as illustrated in
Figure 2. In each state, there is an independent event to decide whether a packet is lost or not. We define
, where
is the random variable of the state of the GE model after sending
t packets of a batch. By exploiting the structure of the GE model, computation of
f can be performed by dynamic programming. Then, we have
It is easy to see that it would take more steps to compute (
3) than (
2). Therefore, a natural question to ask is that for burst packet loss channels, is the throughput gap small between adaptive recoding with (
2) and (
3)? We demonstrate in
Section 4.2 that the gap is small so we use (
2) any time a nice throughput is received. Therefore, in our investigation we mainly focus on (
2).
In the rest of this paper, we refer to
as
unless otherwise specified. From [
50], we know that when the loss pattern follows a stationary stochastic process, the expected rank function
is a non-negative, monotonically increasing concave function with respect to
t, which is valid for arbitrary field sizes. Further,
for all
r. However, we need to calculate the values of
or its supergradients to apply adaptive recoding in practice. To cope with this issue, we first investigate the recursive formula for
.
We define the probability mass function of the binomial distribution
by
For integers
and
, we define
When
, the function
is the partial sum of the probability masses of a binomial distribution
. The case where
is used in the approximation scheme in
Section 3 and is discussed in that section.
The regularized incomplete beta function, defined as
([
79], Equation 8.17.2), can be used to express the partial sum of the probability masses of a binomial distribution. When
, we can apply ([
79], Equation 8.17.5) and obtain
There are different implementations of
available for different languages. For example, the GNU Scientific Library [
80] for C and C++, or the built-in function betainc in MATLAB. However, most available implementations consider non-negative real parameters and calculate different queries independently. This consideration is too general for our application, as we only need to query the integral points efficiently. In other words, this formula may be sufficient for prototyping or simulation, but it is not efficient enough for real-time deployment on devices with limited computational power. Nevertheless, this formula is useful for proving the following properties:
Lemma 1. Assume . Let Λ be an index set.
- (a)
for ;
- (b)
where the equality holds if and only if or ;
- (c)
where the equality holds if and only if ;
- (d)
where the equality holds if and only if ;
- (e)
for all and any non-negative integer s;
- (f)
for all and any non-negative integer s such that .
With the notation of , we can now write the recursive formula for .
Lemma 2. , where t and r are non-negative integers.
Proof. Let be independent and identically distributed Bernoulli random variables, where for all i. When , the i-th packet is received by the next hop.
When we transmit one more packet at the current node, indicates whether this packet is received by the next network node or not. If , i.e., the packet is lost, then the expected rank will not change. If , then the packet is linearly independent from all the already received packets at the next network node if the number of received packets at the next network node is less than r. That is, the rank of this batch at the next network node increases by 1 if . Therefore, the increment of is . Note that . As are all independent and identically distributed, we have . □
The formula shown in Lemma 2 can be interpreted as a newly received packet that is linearly independent of all the already received packets with a probability tends to 1 unless the rank has already reached r. This can also be interpreted as with a probability tends to 1. The above lemma can be rewritten in a more useful form as stated below.
Lemma 3. Let t and r be non-negative integers.
- (a)
if ;
- (b)
.
2.4. Blockwise Adaptive Recoding
The idea of adaptive recoding was presented in [
47], and then independently formulated in [
48,
49]. The former formulation imposes an artificial upper bound on the number of recoded packets and then applies a probabilistic approach to avoid integer programming. The latter investigates the properties of the integer programming problem and proposed efficient algorithms to directly tackle this problem. These two formulations were unified in [
50] as a general recoding framework for BNC. This framework requires the distribution of the ranks of the incoming batches, also called the incoming rank distribution. This distribution, however, is not known in advance, and can continually change due to environmental factors. A rank distribution inference approach was proposed in [
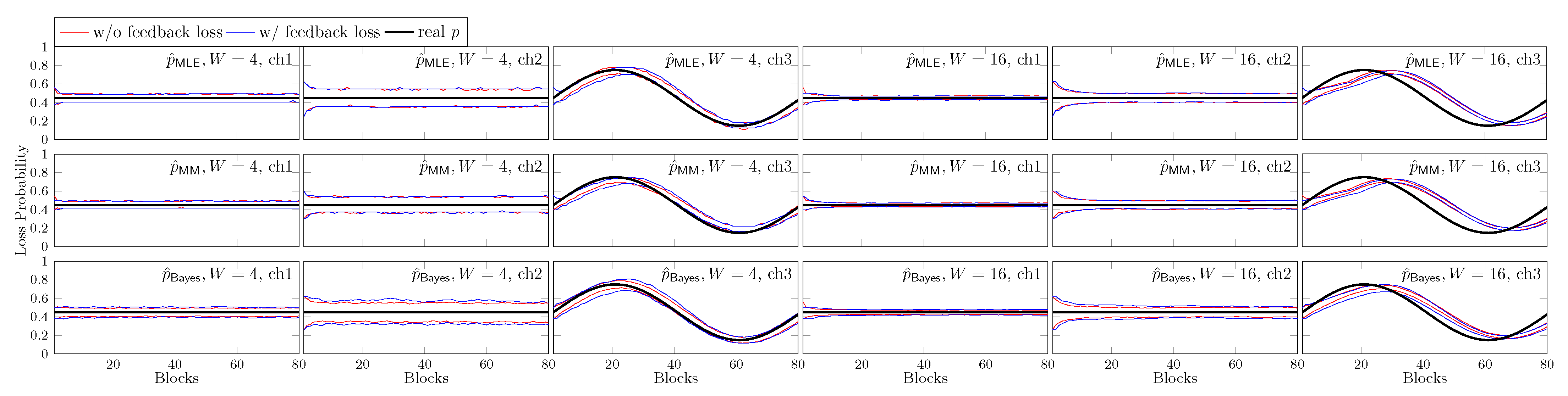
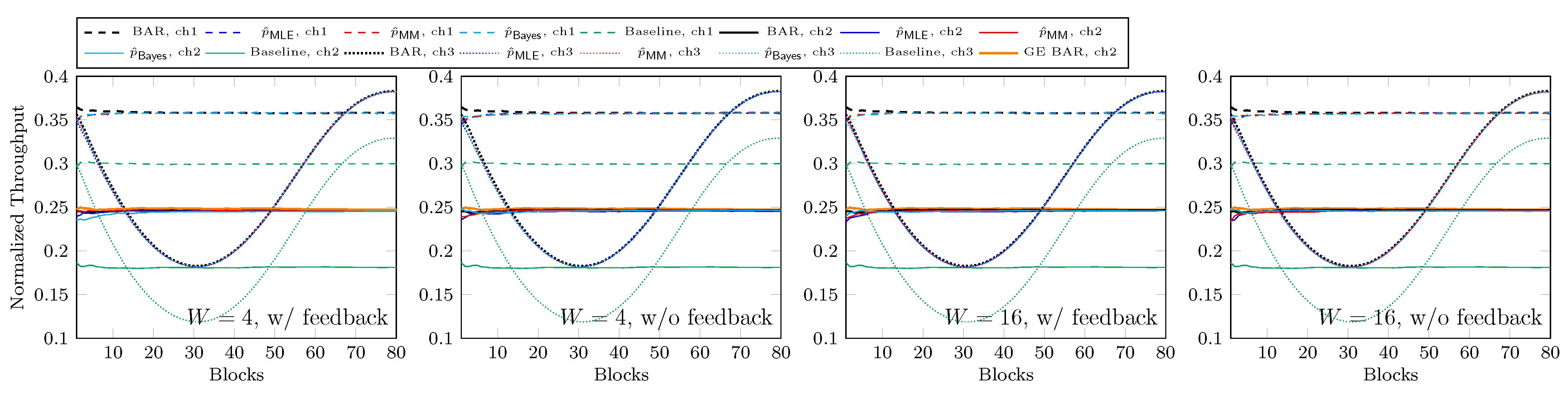
81], but the long solving time hinders its application in real-time scenarios.
A more direct way to obtain up-to-date statistics is to use the ranks of the few latest batches, a trade-off between a latency of a few batches and the throughput of the whole transmission. This approach was proposed in [
49], and later called BAR in [
51,
52]. In other words, BAR is a recoding scheme which groups batches into blocks and jointly optimizes the number of recoded packets for each batch in the block.
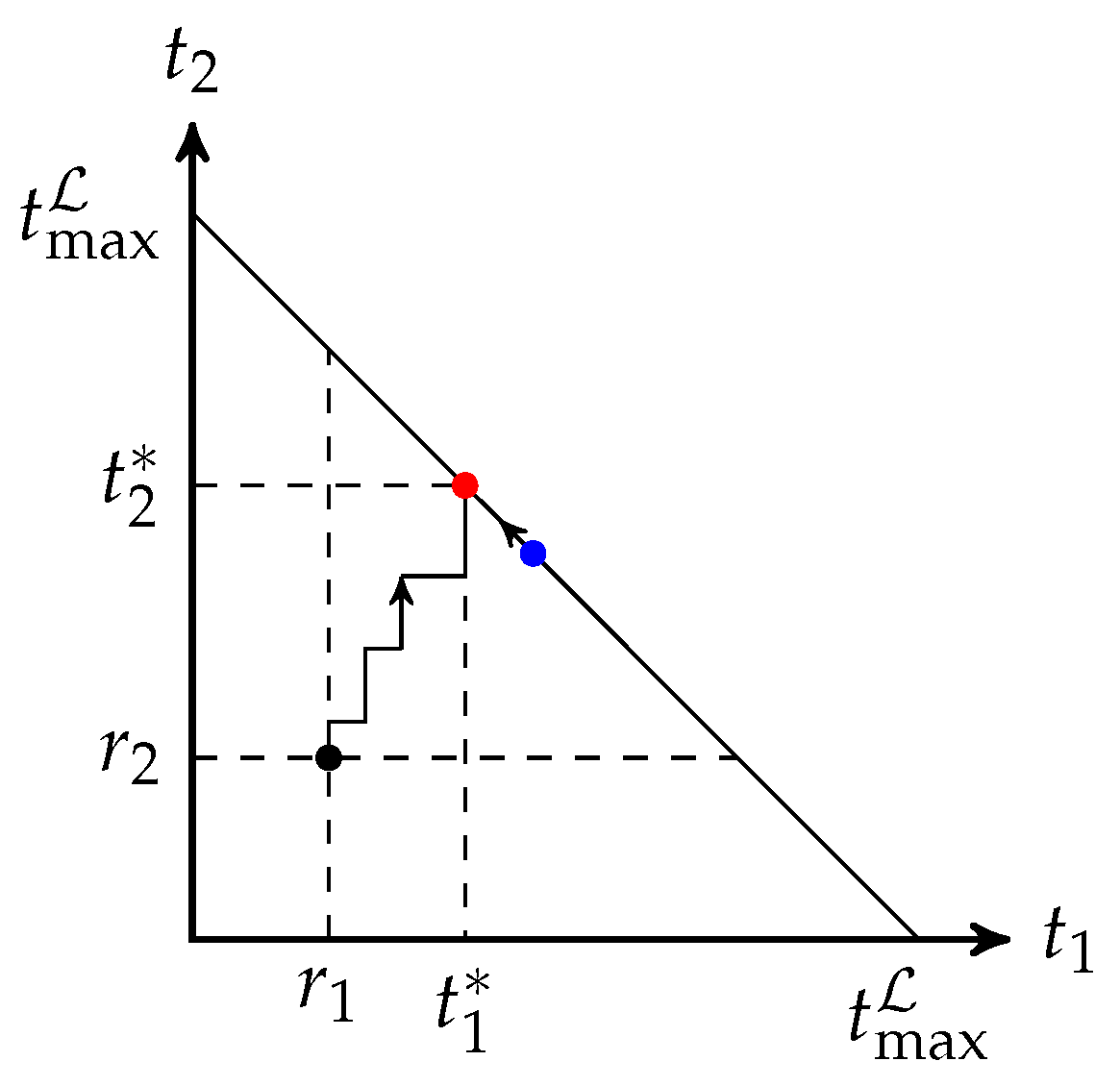
We first describe the adaptive recoding framework and its relation to BAR. We fix an intermediate network node. Let
be the incoming rank distribution,
the number of recoded packets to be sent for a batch of rank
r, and
the average number of recoded packets to be sent per batch. The value of
is a non-negative real number that is interpreted as follows. Let
be the fractional part of
. There is an
chance to transmit
recoded packets, and a
chance to transmit
packets. That is, the fraction is the probability of transmitting one more packet. Similarly,
is defined as the linear interpolation by
. The framework maximizes the expected rank of the batches at the next node, which is the optimization problem:
For BAR, the incoming rank distribution is obtained from the recently received few batches. Let a block be a set of batches. We assume that the blocks at a network node are mutually disjoint. Suppose the node receives a block
. For each batch
, let
and
be the rank of
b and the number of recoded packets to be generated for
b, respectively. Let
be the number of recoded packets to be transmitted for the block
. The batches of the same rank are considered individually with the notations
and
, and the total number of packets to be transmitted for a block is finite; therefore, we assume
for each
is a non-negative integer, and
is a positive integer. By dividing both the objective and the constraint of the framework by
, we obtain the simplest formulation of BAR:
To support scenarios with multiple outgoing links for the same batch, e.g., load balancing, we may impose an upper bound on the number of recoded packets per batch. Let
be a non-negative integer that represents the maximum number of recoded packets allowed to be transmitted for the batch
b. This value may depend on the rank of
b at the node. Subsequently, we can formulate the following optimization problem based on (
8):
Note that we must have
. In the case where this inequality does not hold, we can include more batches in the block to resolve this issue. When
is sufficiently large for all
, (
9) degenerates into (
8).
The above optimization only depends on the local knowledge at the node. The batch rank
can be known from the coefficient vectors of the received packets of batch
b. As a remark, the value of
can affect the stability of the packet buffer. For a general network transmission scenario with multiple transmission sessions, the value of
can be determined by optimizing the utility of certain local network transmissions [
82,
83].
Though we do not discuss such optimizations in this paper, we consider solving BAR with a general value of .
On the other hand, note that the solution to (
9) may not be unique. We only need to obtain one solution for recoding purpose. In general, (
9) is a non-linear integer programming problem. A linear programming variant of (
9) can be formulated by using a technique in [
81]. However, such a formulation has a huge amount of constraints and requires the values of
for all
and all possible
t to be calculated beforehand. We defer the discussion of this formulation to
Appendix H.
A network node will keep receiving packets until it has received enough batches to form a block
. A packet buffer is used to store the received packets. Then, the node solves (
9) to obtain the number of recoded packets for each batch in the block, i.e.,
. The node then generates and transmits
-recoded packets for every batch
. At the same time, the network node continually receives new packets. After all the recoded packets for the block
are transmitted, the node drops the block from its packet buffer and then repeats the procedure by considering another block.
We do not specify the transmission order of the packets. Within the same block, the ordering of packets can be shuffled to combat burst loss, e.g., [
43,
44,
52]. Such shuffling can reduce the burst error length experienced by each batch so that the packet loss events are more “independent” from each other. On the other hand, we do not specify the rate control mechanism, as it should be separated as another module in the system. This can be reflected in BAR by choosing suitable expected rank functions, e.g., modifying the parameters in the GE model. BAR is only responsible for deciding the number of recoded packets per batch.
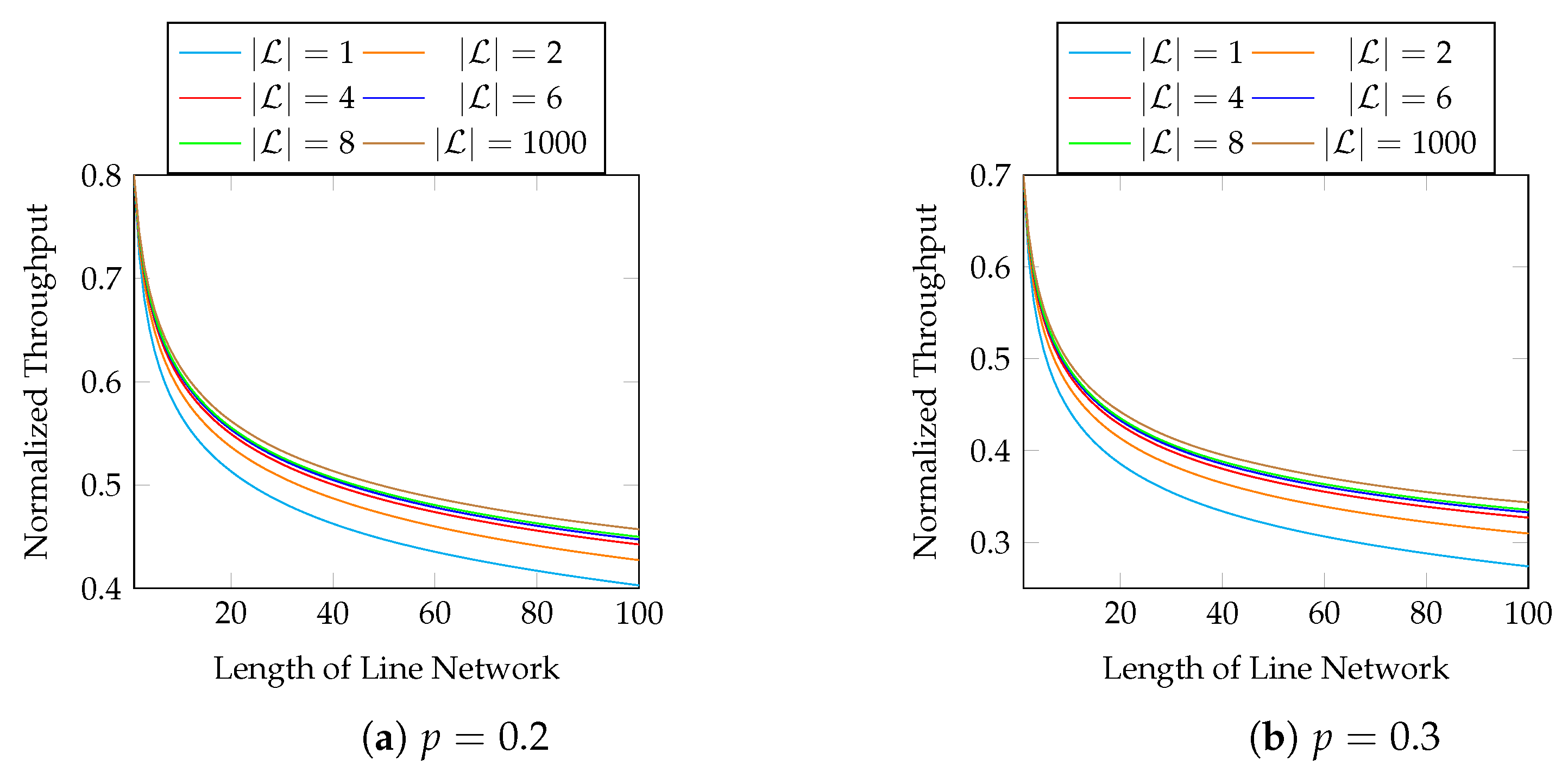
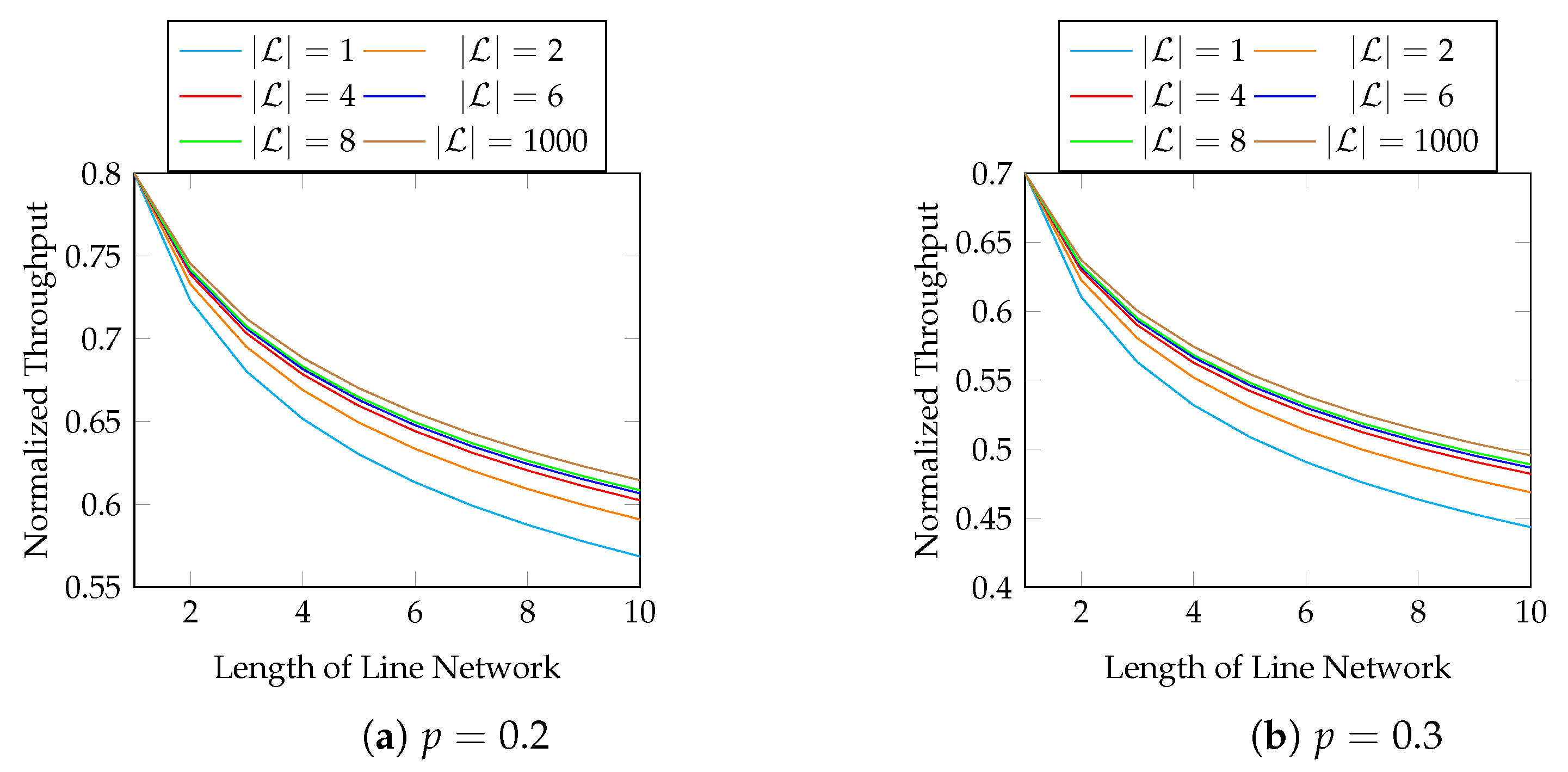
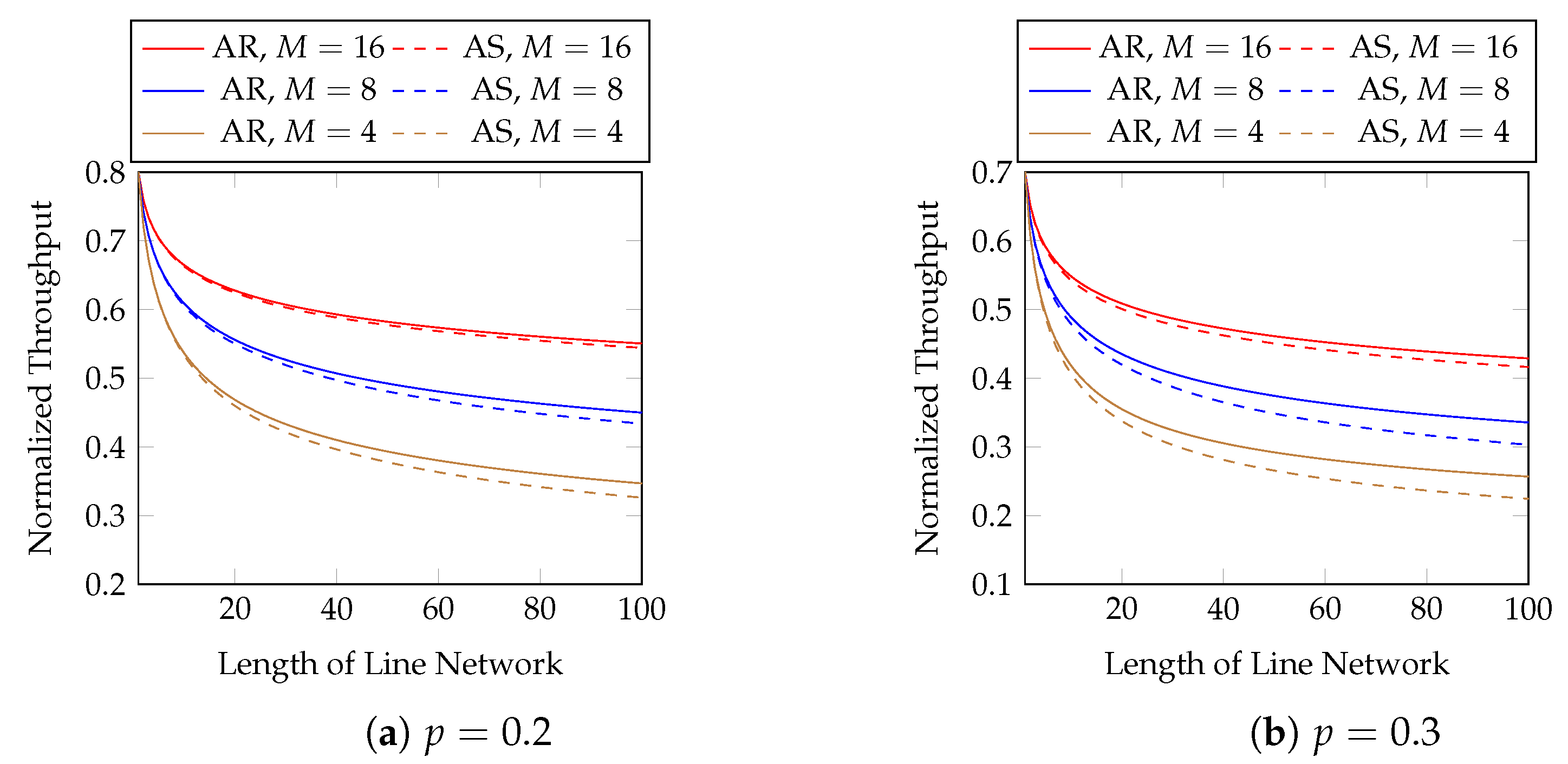
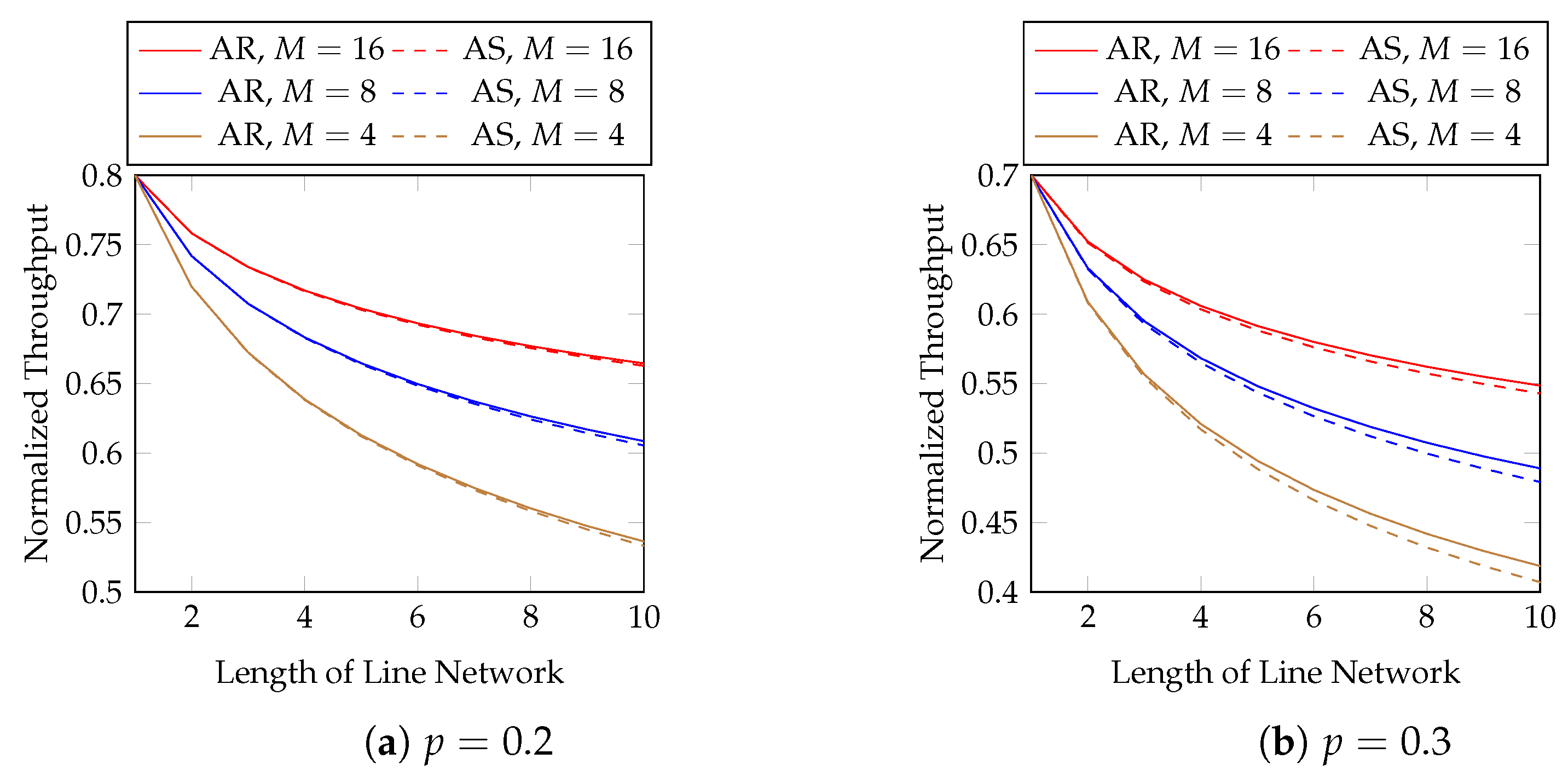
The size of a block depends on its application. For example, if an interleaver is applied to
L batches, we can group the
L batches as a block. When
, the only solution is
, which degenerates into baseline recoding. Therefore, we need to use a block size of at least 2 in order to utilize the throughput enhancement of BAR. Intuitively, it is better to optimize (
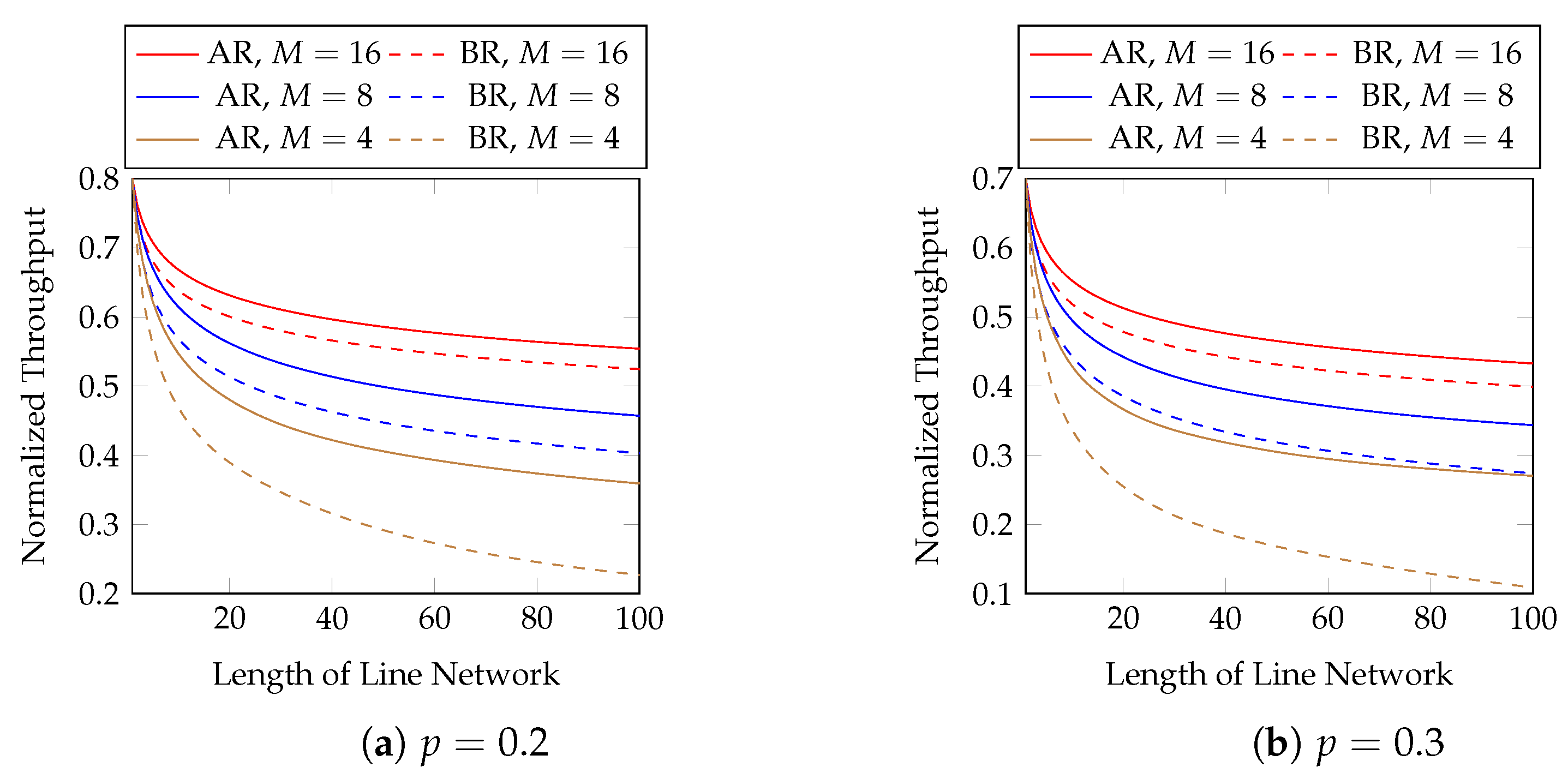
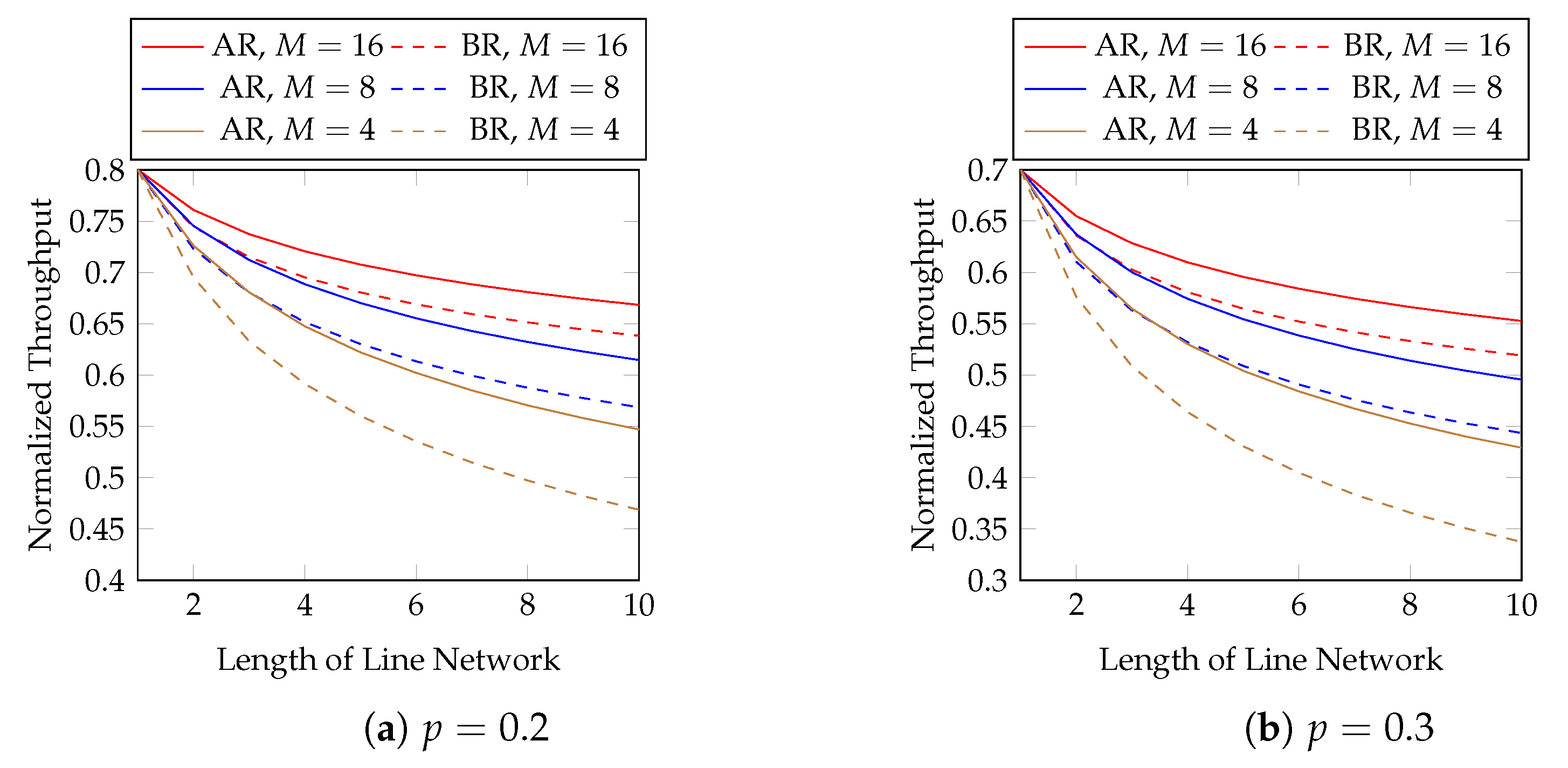
9) with a larger block size. However, the block size is related to the transmission latency as well as the computational and storage burdens at the network nodes. Note that we cannot conclude the exact rank of each batch in a block until the previous network node finishes sending all the packets of this block. That is, we need to wait for the previous network node to send the packets of all the batches in a block until we can solve the optimization problem. Numerical evaluations in
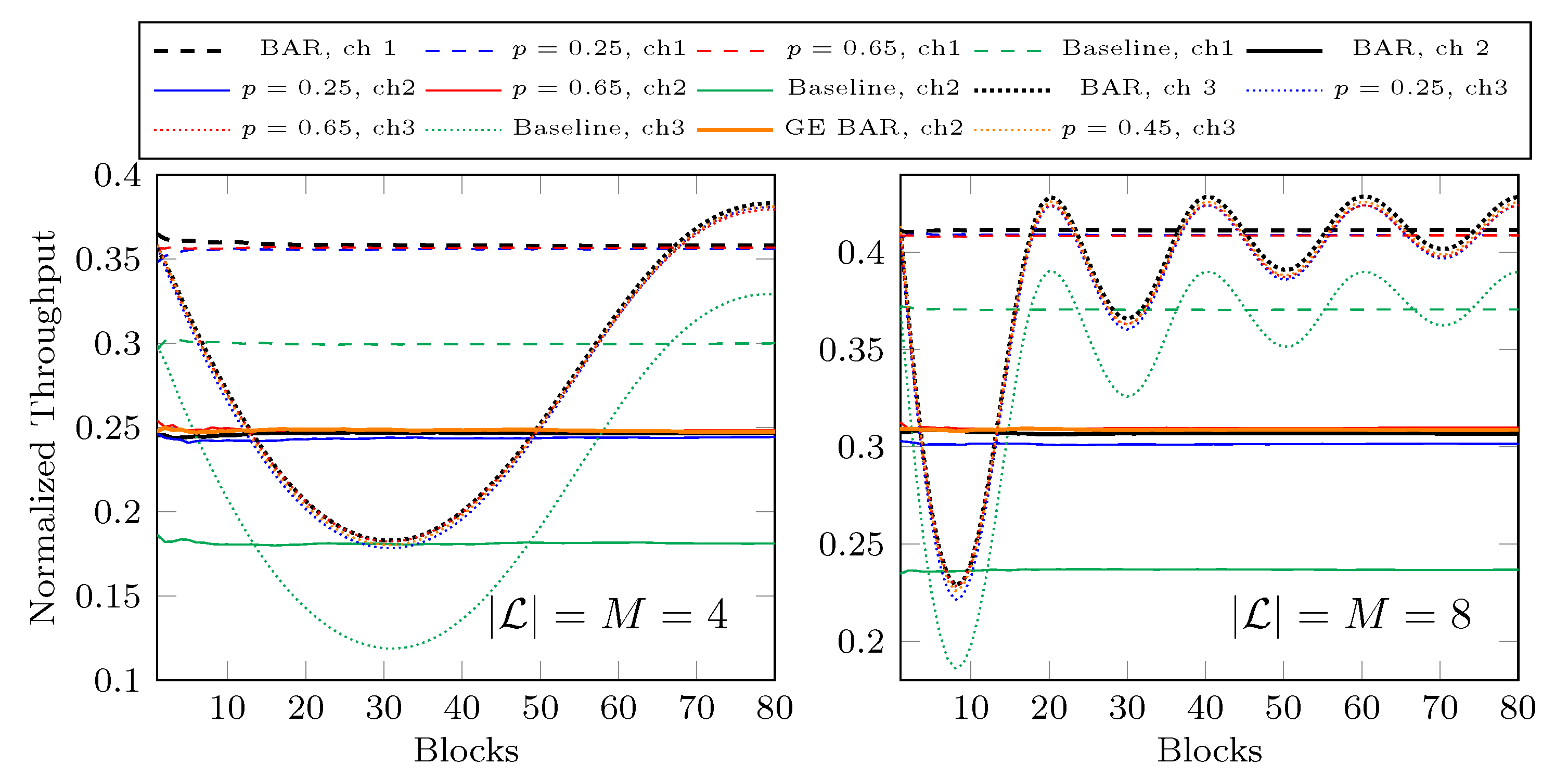
Section 3.5 show that
already has obvious advantage over
, and it may not be necessary to use a block size larger than eight.









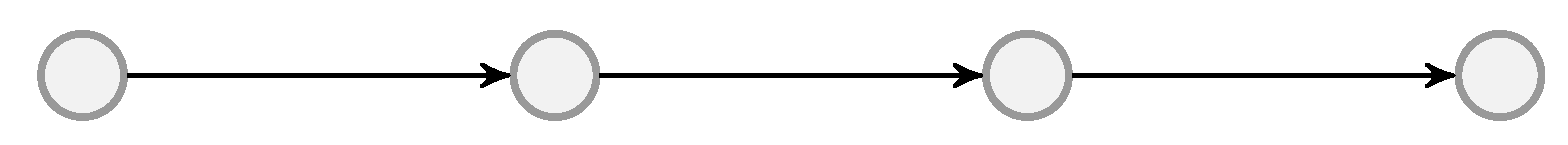{kind=link}
{kind=link}
{kind=link}
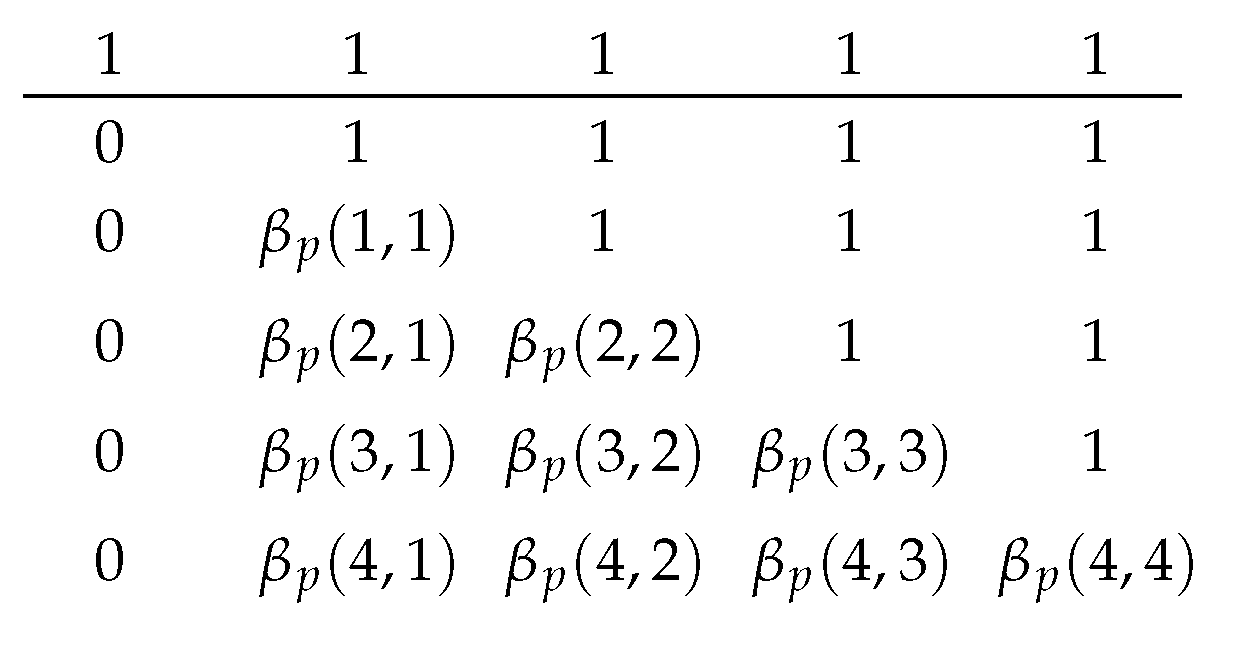{kind=link}
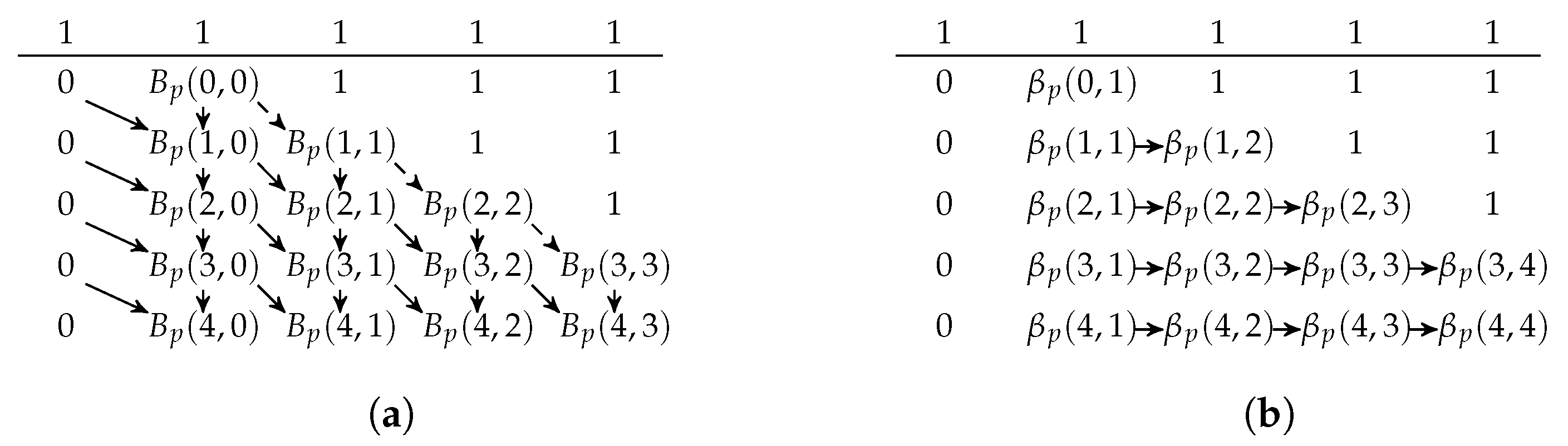{kind=link}
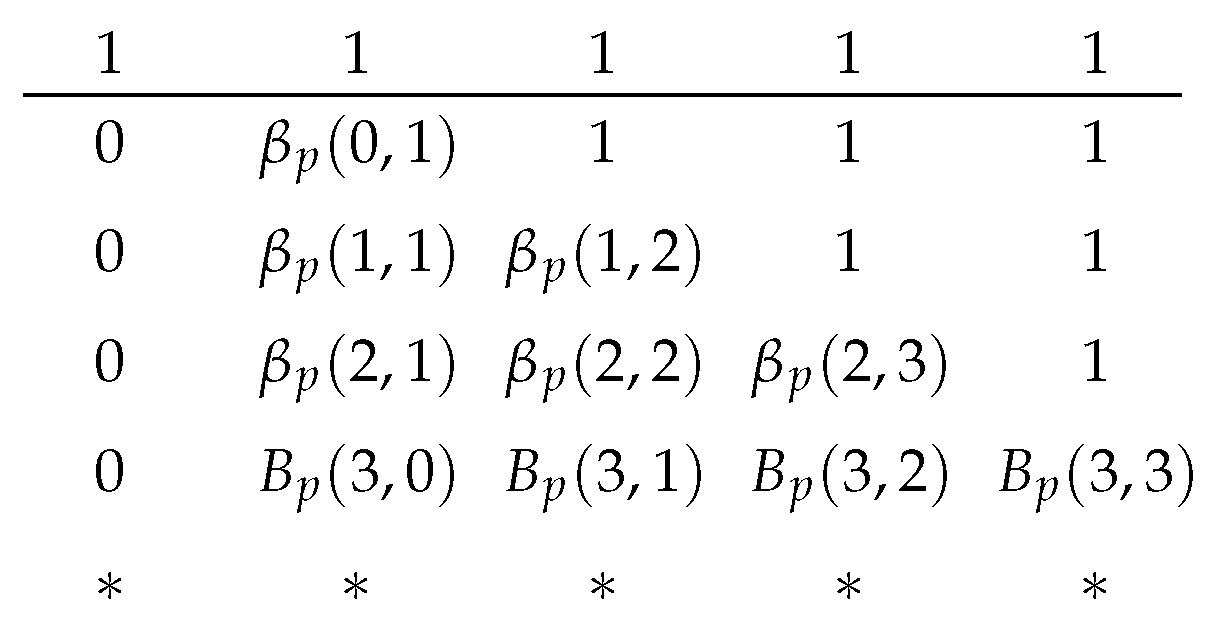{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
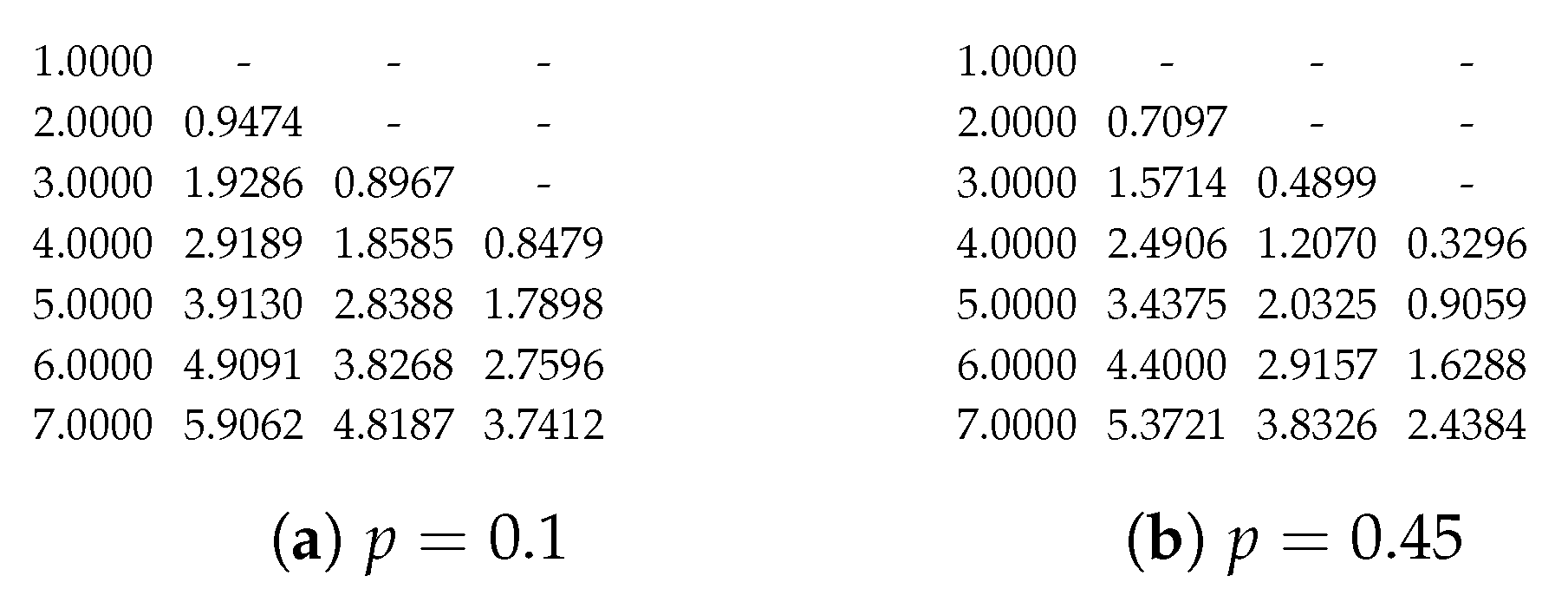{kind=link}
{kind=link}
{kind=link}
{kind=link}
















