

A Novel Trajectory Feature-Boosting Network for Trajectory Prediction

Abstract
:1. Introduction
- A novel approach for trajectory prediction is proposed, which maps the original trajectory data to a high-dimensional space to better mine the object’s motion intention. The experimental results demonstrate that this approach can improve the accuracy of trajectory prediction by capturing the change law of the object’s motion trajectory more effectively.
- A dilated attention gating structure (DAGConv) is introduced and applied to both the CVAE module and the goal aggregation module. The results show that DAGConv can effectively extract useful information and significantly enhance the accuracy of trajectory prediction.
- A goal feedback structure is designed, which not only provides real-time feedback to the model, but also evaluates the output results of the trajectory representation module.
- A goal aggregation module is developed, which integrates the attention mechanism and the dilated attention gating structure. This module can evaluate multiple prediction goals, select effective ones adaptively, and generate the final predicted trajectory.
2. Related Work
3. Proposed Model
3.1. Problem Formulation
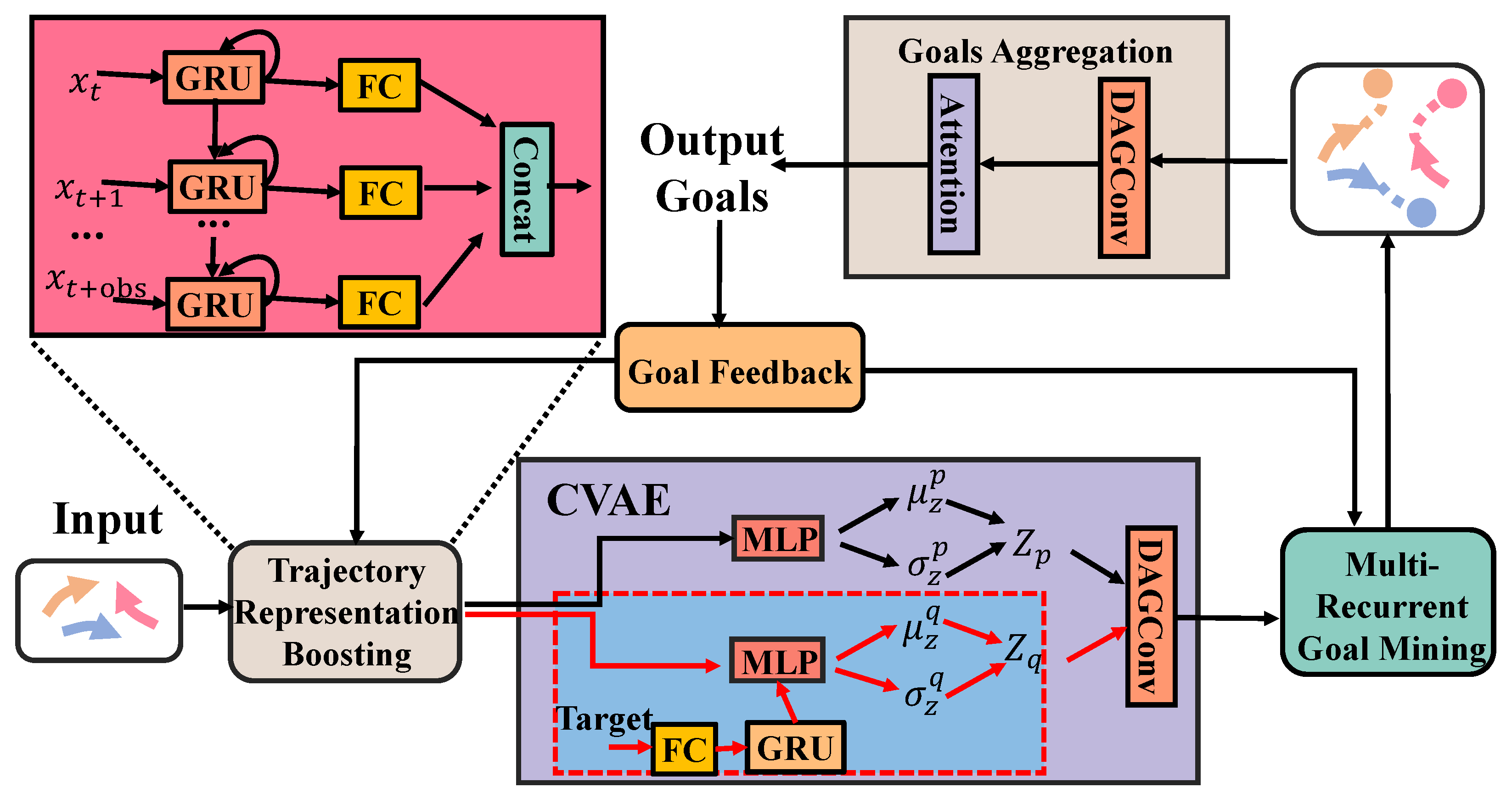
3.2. The Architecture of TFBNet
3.3. Trajectory Feature Boosting
3.3.1. Trajectory Representation Boosting
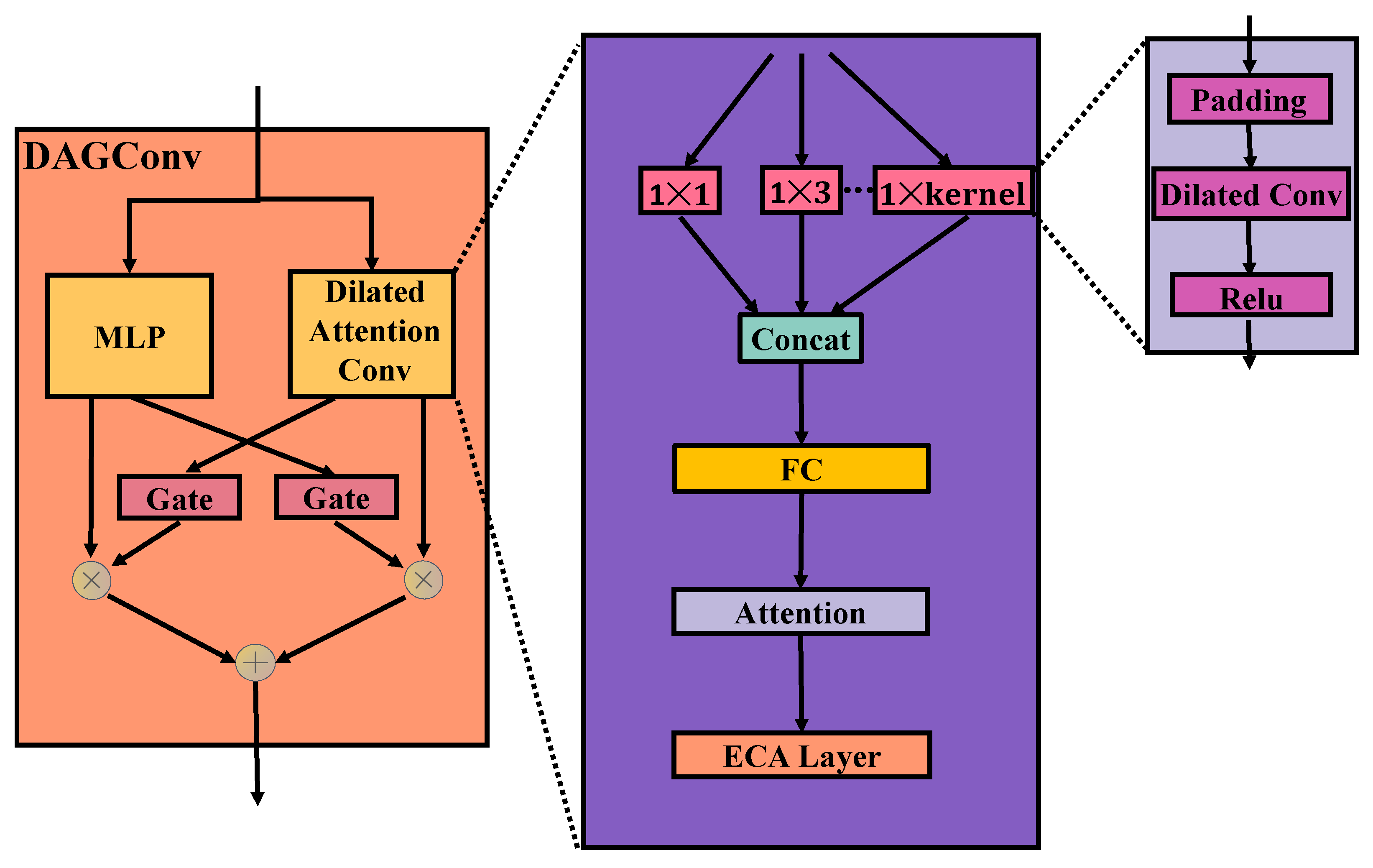
3.3.2. Dilated Attention Gating
3.3.3. CVAE
3.4. Multi-Recurrent Goal Mining
3.5. Goals Aggregation
3.6. Goal Feedback
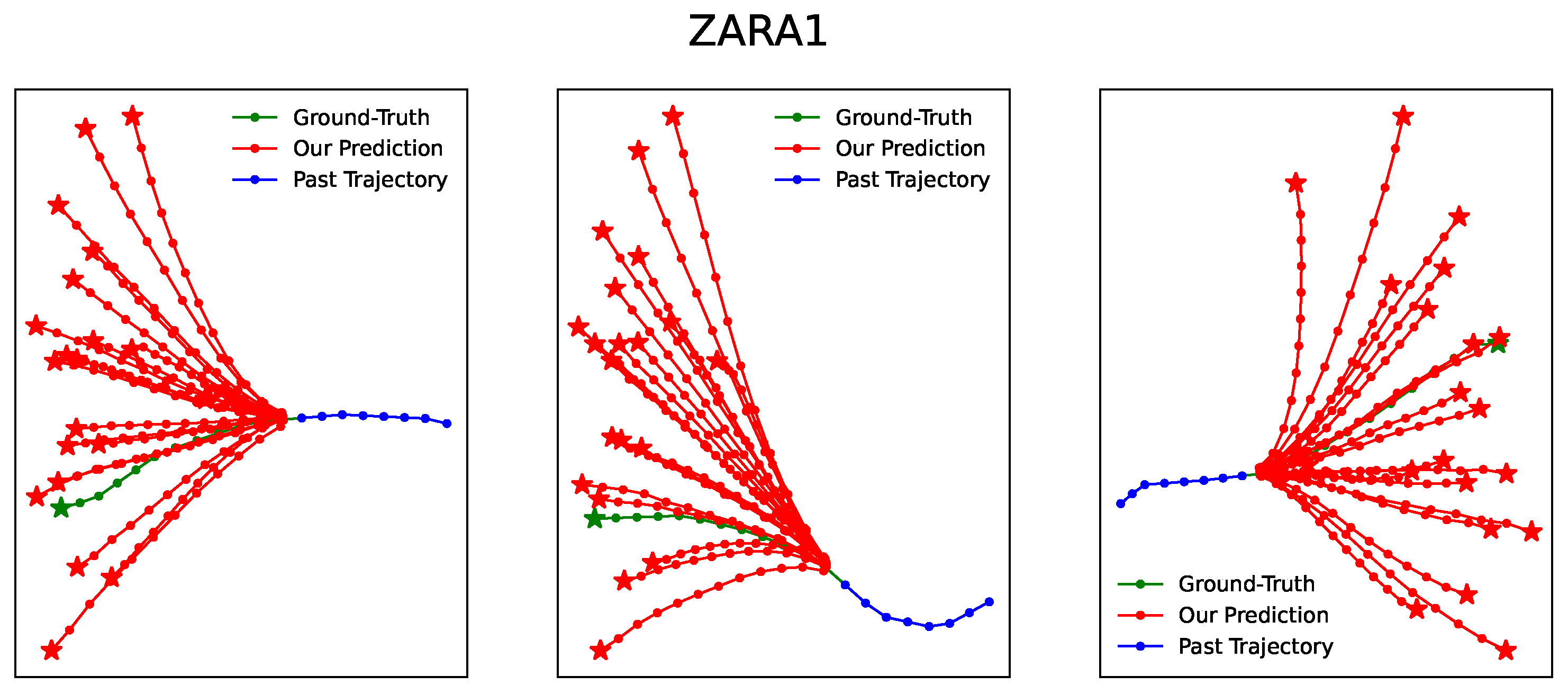
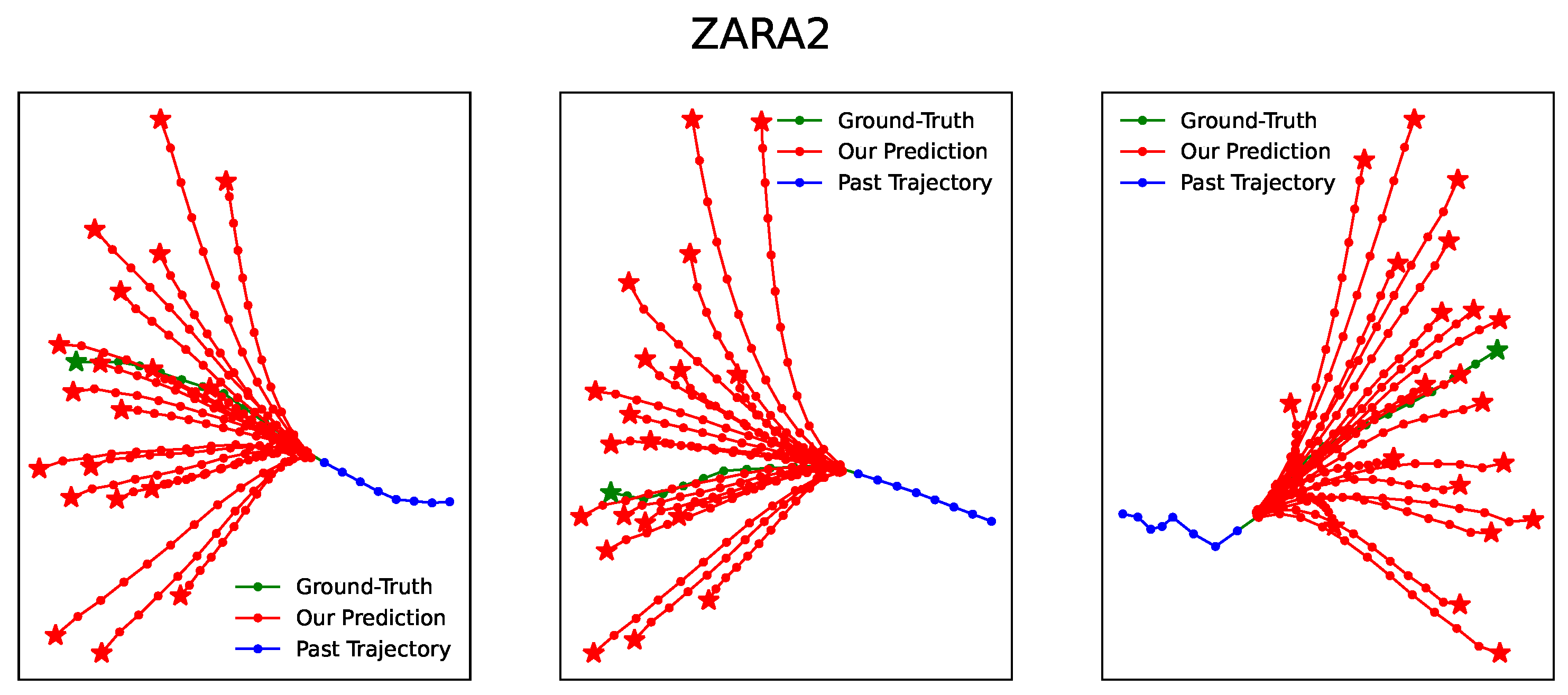
4. Experimental Results
4.1. Datasets
4.2. Experimental Settings
4.2.1. Evaluation Metrics
4.2.2. Baselines
- Social-LSTM [13]: This model introduces a “social” pooling layer that allows LSTMs of spatially adjacent sequences to share their hidden states with each other.
- SGAN [26]: This model combines sequence prediction and generating adversarial networks to predict trajectories.
- Sophie [27]: This model utilizes two information sources, namely all path history and scene context information in the scene, and combines physical and social information using a social attention mechanism and physical attention.
- Social-bigat [19]: This model is based on a graphical attention network, encoding reliable feature representations of social interactions between humans in the scene, and combining them with generative adversarial networks to generate multiple future trajectories.
- RSBG [22]: A group-based social interaction model, which uses a graph convolution neural network to disseminate social interaction information in such a graph by recursively extracting social representation.
- MATF GAN [42]: This model encodes the past trajectories and scene contexts of multiple agents into multi-agent tensors, and then applies convolutional fusion to capture multi-agent interactions while preserving the spatial structure and scene context of the agents.
- PSA-GRU [17]: The model adopts a human social dual-attention network based on gated recursive units, fully utilizing important location nodes of personal historical trajectories and social information between pedestrians.
- Social-STGCNN [20]: This model replaces aggregation methods by modeling interactions as graphs.
- CGNS [43]: This model combines the advantages of conditional potential space learning and variable dispersity minimization, and uses an attention mechanism to utilize static context and interactive information.
- PIF [44]: Adopting an end-to-end multitasking learning model that utilizes rich visual features about human behavior information and its interaction with the surrounding environment.
- NMMP [28]: This model uses a separate branch to simulate the behavior of a single agent, an interaction branch to simulate the interaction between agents, and different wrappers to handle different input formats and features.
- FvTraj [45]: This model is based on a multi-head attention mechanism and uses a social perception attention module to simulate social interaction between pedestrians, as well as a view perception attention module to capture the relationship between historical motion states and visual features.
- DSCMP [46]: This model simulates dynamic interaction between agents by learning the spatial and temporal consistency of agents, as well as understanding the layout of contextual scenes. At the same time, a differentiable queue mechanism is designed, which can clarify the correlation between memory and learning long trajectories.
- STGAT [23]: This model is based on a sequence-to-sequence architecture to predict the future trajectory of pedestrians. In addition to the spatial interaction captured by the graph attention mechanism at each time step, additional LSTM is also used to encode the temporal correlation of the interaction.
- TPNet [47]: This model is divided into two stages to predict trajectories: first creating some suggested target trajectories, and then classifying and refining these trajectories to obtain the final predicted trajectory.
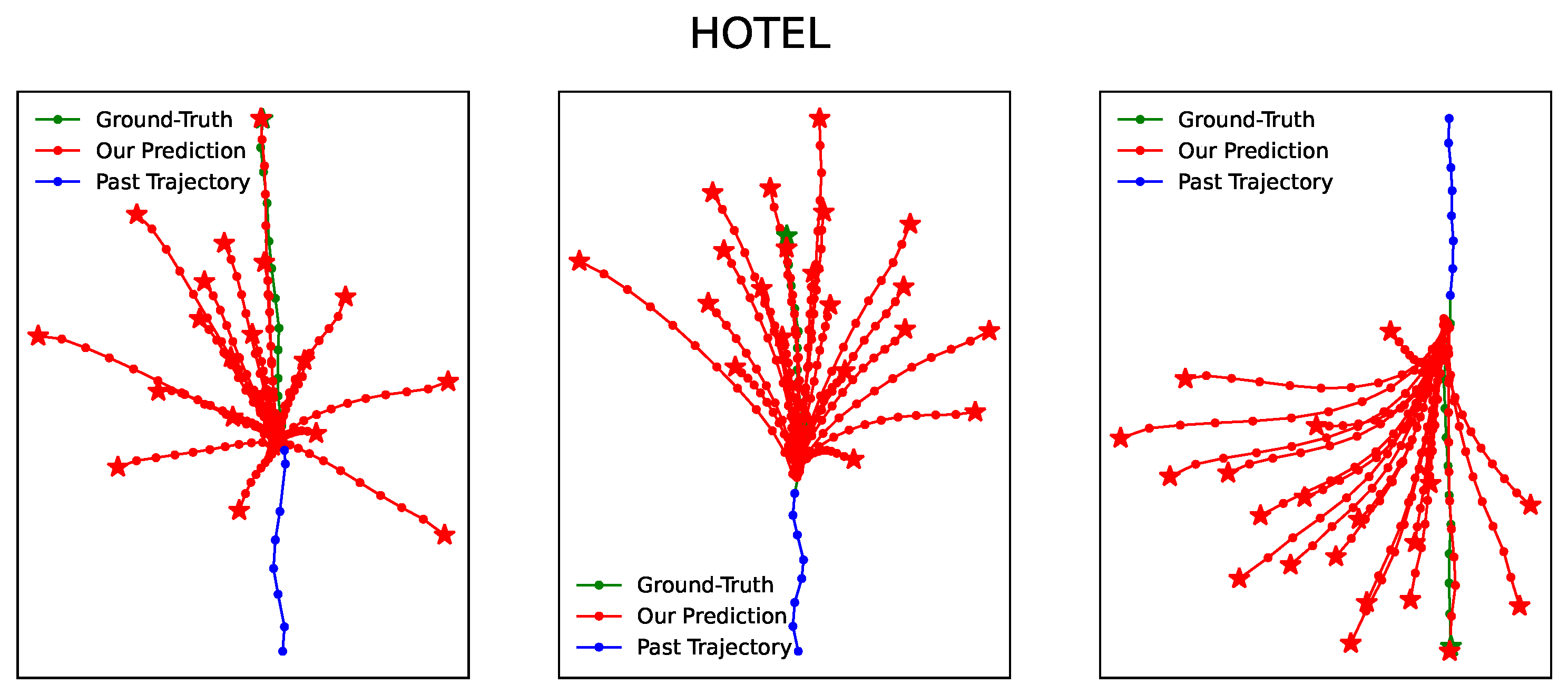
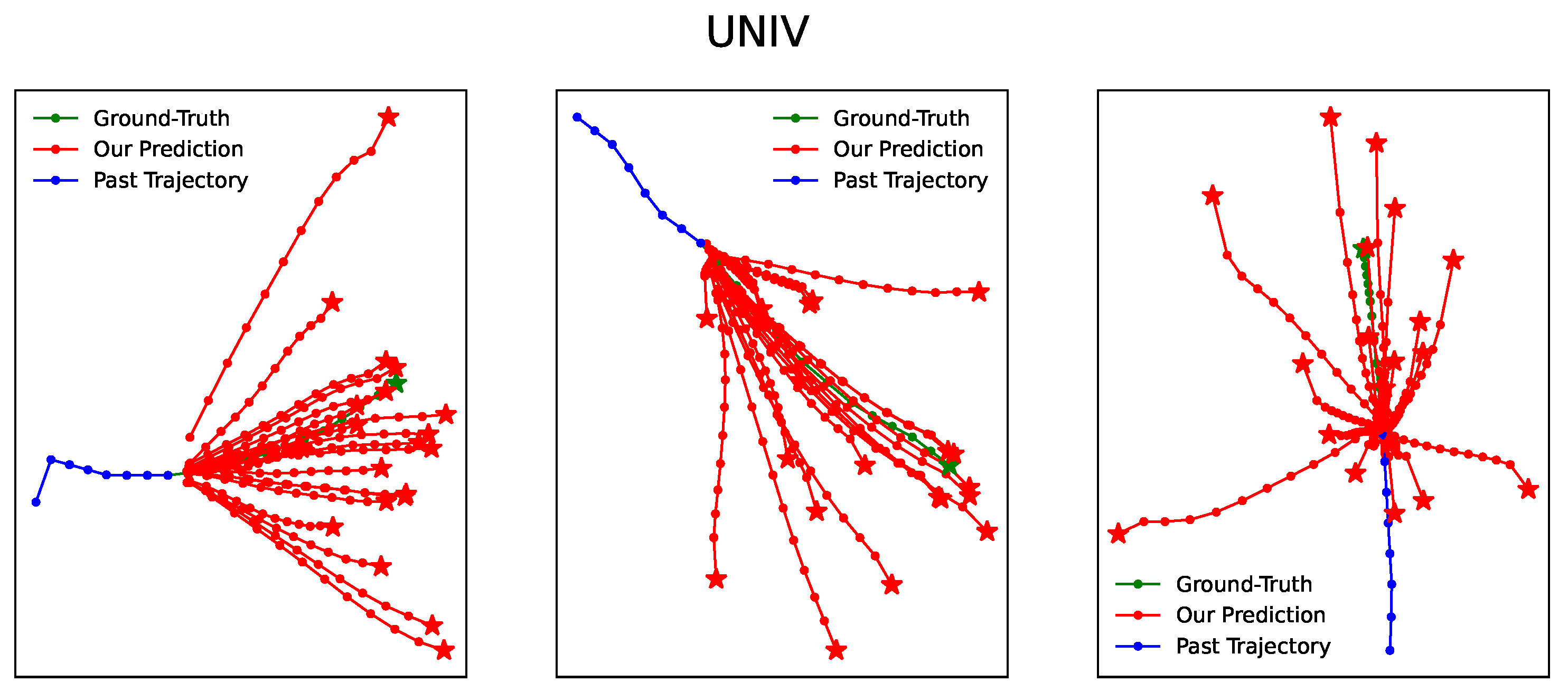
4.3. Experiment Results and Analysis
4.4. Ablation Experiments
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yurtsever, E.; Lambert, J.; Carballo, A.; Takeda, K. A survey of autonomous driving: Common practices and emerging technologies. IEEE Access 2020, 8, 58443–58469. [Google Scholar] [CrossRef]
- Garcia, E.; Jimenez, M.A.; De Santos, P.G.; Armada, M. The evolution of robotics research. IEEE Robot. Autom. Mag. 2007, 14, 90–103. [Google Scholar] [CrossRef]
- Valera, M.; Velastin, S.A. Intelligent distributed surveillance systems: A review. IEE Proc.-Vis. Image Signal Process. 2005, 152, 192–204. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.M.; Fleet, D.J.; Hertzmann, A. Gaussian process dynamical models for human motion. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 30, 283–298. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kitani, K.M.; Ziebart, B.D.; Bagnell, J.A.; Hebert, M. Activity forecasting. In Computer Vision—ECCV 2012: 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 201–214. [Google Scholar]
- Helbing, D.; Molnar, P. Social force model for pedestrian dynamics. Phys. Rev. E 1995, 51, 4282. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mehran, R.; Oyama, A.; Shah, M. Abnormal crowd behavior detection using social force model. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 935–942. [Google Scholar]
- Li, R.; Qin, Y.; Wang, J.; Wang, H. AMGB: Trajectory prediction using attention-based mechanism GCN-BiLSTM in IOV. Pattern Recognit. Lett. 2023, 169, 17–27. [Google Scholar] [CrossRef]
- Zhang, X.; Angeloudis, P.; Demiris, Y. Dual-branch Spatio-Temporal Graph Neural Networks for Pedestrian Trajectory Prediction. Pattern Recognit. 2023, 142, 109633. [Google Scholar] [CrossRef]
- Hui, F.; Wei, C.; ShangGuan, W.; Ando, R.; Fang, S. Deep encoder–Cdecoder-NN: A deep learning-based autonomous vehicle trajectory prediction and correction model. Phys. A Stat. Mech. Its Appl. 2022, 593, 126869. [Google Scholar] [CrossRef]
- Shi, K.; Wu, Y.; Shi, H.; Zhou, Y.; Ran, B. An integrated car-following and lane changing vehicle trajectory prediction algorithm based on a deep neural network. Phys. A Stat. Mech. Its Appl. 2022, 599, 127303. [Google Scholar] [CrossRef]
- Morton, J.; Wheeler, T.A.; Kochenderfer, M.J. Analysis of recurrent neural networks for probabilistic modeling of driver behavior. IEEE Trans. Intell. Transp. Syst. 2016, 18, 1289–1298. [Google Scholar] [CrossRef]
- Alahi, A.; Goel, K.; Ramanathan, V.; Robicquet, A.; Fei-Fei, L.; Savarese, S. Social lstm: Human trajectory prediction in crowded spaces. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 961–971. [Google Scholar]
- Vemula, A.; Muelling, K.; Oh, J. Social attention: Modeling attention in human crowds. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 4601–4607. [Google Scholar]
- Fernando, T.; Denman, S.; Sridharan, S.; Fookes, C. Soft+ hardwired attention: An lstm framework for human trajectory prediction and abnormal event detection. Neural Netw. 2018, 108, 466–478. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lee, N.; Choi, W.; Vernaza, P.; Choy, C.B.; Torr, P.H.; Chandraker, M. Desire: Distant future prediction in dynamic scenes with interacting agents. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 336–345. [Google Scholar]
- Yan, X.; Yang, J.; Song, L.; Liu, Y. PSA-GRU: Modeling Person-Social Twin-Attention Based on GRU for Pedestrian Trajectory Prediction. In Proceedings of the 2021 40th Chinese Control Conference (CCC), Shanghai, China, 26–28 July 2021; pp. 8151–8157. [Google Scholar]
- Bilro, P.; Barata, C.; Marques, J.S. Pedestrian Trajectory Prediction Using LSTM and Sparse Motion Fields. In Proceedings of the 2022 26th International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022; pp. 3529–3535. [Google Scholar]
- Kosaraju, V.; Sadeghian, A.; Martín-Martín, R.; Reid, I.; Rezatofighi, H.; Savarese, S. Social-bigat: Multimodal trajectory forecasting using bicycle-gan and graph attention networks. Adv. Neural Inf. Process. Syst. 2019, 32, 137–146. [Google Scholar]
- Mohamed, A.; Qian, K.; Elhoseiny, M.; Claudel, C. Social-STGCNN: A Social Spatio-Temporal Graph Convolutional Neural Network for Human Trajectory Prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Ivanovic, B.; Pavone, M. The trajectron: Probabilistic multi-agent trajectory modeling with dynamic spatiotemporal graphs. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2375–2384. [Google Scholar]
- Sun, J.; Jiang, Q.; Lu, C. Recursive social behavior graph for trajectory prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 660–669. [Google Scholar]
- Huang, Y.; Bi, H.; Li, Z.; Mao, T.; Wang, Z. Stgat: Modeling spatial-temporal interactions for human trajectory prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6272–6281. [Google Scholar]
- Li, J.; Ma, H.; Zhang, Z.; Tomizuka, M. Social-wagdat: Interaction-aware trajectory prediction via wasserstein graph double-attention network. arXiv 2020, arXiv:2002.06241. [Google Scholar]
- Shi, L.; Wang, L.; Long, C.; Zhou, S.; Zhou, M.; Niu, Z.; Hua, G. SGCN: Sparse graph convolution network for pedestrian trajectory prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8994–9003. [Google Scholar]
- Gupta, A.; Johnson, J.; Fei-Fei, L.; Savarese, S.; Alahi, A. Social gan: Socially acceptable trajectories with generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2255–2264. [Google Scholar]
- Sadeghian, A.; Kosaraju, V.; Sadeghian, A.; Hirose, N.; Rezatofighi, H.; Savarese, S. Sophie: An attentive gan for predicting paths compliant to social and physical constraints. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1349–1358. [Google Scholar]
- Hu, Y.; Chen, S.; Zhang, Y.; Gu, X. Collaborative motion prediction via neural motion message passing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6319–6328. [Google Scholar]
- Yao, Y.; Atkins, E.; Johnson-Roberson, M.; Vasudevan, R.; Du, X. Bitrap: Bi-directional pedestrian trajectory prediction with multi-modal goal estimation. IEEE Robot. Autom. Lett. 2021, 6, 1463–1470. [Google Scholar] [CrossRef]
- Wang, C.; Wang, Y.; Xu, M.; Crandall, D.J. Stepwise goal-driven networks for trajectory prediction. IEEE Robot. Autom. Lett. 2022, 7, 2716–2723. [Google Scholar] [CrossRef]
- Mangalam, K.; Girase, H.; Agarwal, S.; Lee, K.H.; Adeli, E.; Malik, J.; Gaidon, A. It is not the journey but the destination: Endpoint conditioned trajectory prediction. In Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 759–776. [Google Scholar]
- Salzmann, T.; Ivanovic, B.; Chakravarty, P.; Pavone, M. Trajectron++: Dynamically-feasible trajectory forecasting with heterogeneous data. In Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 683–700. [Google Scholar]
- Yuan, Y.; Weng, X.; Ou, Y.; Kitani, K.M. Agentformer: Agent-aware transformers for socio-temporal multi-agent forecasting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 9813–9823. [Google Scholar]
- Yu, C.; Ma, X.; Ren, J.; Zhao, H.; Yi, S. Spatio-temporal graph transformer networks for pedestrian trajectory prediction. In Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 507–523. [Google Scholar]
- Xia, B.; Wong, C.; Peng, Q.; Yuan, W.; You, X. CSCNet: Contextual semantic consistency network for trajectory prediction in crowded spaces. Pattern Recognit. 2022, 126, 108552. [Google Scholar] [CrossRef]
- Mangalam, K.; An, Y.; Girase, H.; Malik, J. From goals, waypoints & paths to long term human trajectory forecasting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 15233–15242. [Google Scholar]
- Yue, J.; Manocha, D.; Wang, H. Human trajectory prediction via neural social physics. In Proceedings of the European Conference on Computer Vision; Springer: Cham, Switzerland, 2022; pp. 376–394. [Google Scholar]
- Zhao, H.; Gao, J.; Lan, T.; Sun, C.; Sapp, B.; Varadarajan, B.; Shen, Y.; Shen, Y.; Chai, Y.; Schmid, C.; et al. Tnt: Target-driven trajectory prediction. In Proceedings of the Conference on Robot Learning, PMLR, London, UK, 8–11 November 2021; pp. 895–904. [Google Scholar]
- Rhinehart, N.; McAllister, R.; Kitani, K.; Levine, S. Precog: Prediction conditioned on goals in visual multi-agent settings. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2821–2830. [Google Scholar]
- Xu, C.; Mao, W.; Zhang, W.; Chen, S. Remember Intentions: Retrospective-Memory-based Trajectory Prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 6488–6497. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11531–11539. [Google Scholar]
- Zhao, T.; Xu, Y.; Monfort, M.; Choi, W.; Baker, C.; Zhao, Y.; Wang, Y.; Wu, Y.N. Multi-agent tensor fusion for contextual trajectory prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 12126–12134. [Google Scholar]
- Li, J.; Ma, H.; Tomizuka, M. Conditional generative neural system for probabilistic trajectory prediction. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 6150–6156. [Google Scholar]
- Liang, J.; Jiang, L.; Niebles, J.C.; Hauptmann, A.G.; Fei-Fei, L. Peeking into the future: Predicting future person activities and locations in videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5725–5734. [Google Scholar]
- Bi, H.; Zhang, R.; Mao, T.; Deng, Z.; Wang, Z. How can i see my future? fvtraj: Using first-person view for pedestrian trajectory prediction. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020, Proceedings, Part VII 16; Springer: Cham, Switzerland, 2020; pp. 576–593. [Google Scholar]
- Tao, C.; Jiang, Q.; Duan, L.; Luo, P. Dynamic and static context-aware lstm for multi-agent motion prediction. In Proceedings of the European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 547–563. [Google Scholar]
- Fang, L.; Jiang, Q.; Shi, J.; Zhou, B. Tpnet: Trajectory proposal network for motion prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6797–6806. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | ADE/FDE ↓ , Best of 20 | |||||
|---|---|---|---|---|---|---|
| ETH | HOTEL | UNIV | ZARA1 | ZARA2 | Average | |
| Social-LSTM | 1.09/2.35 | 0.79/1.76 | 0.67/1.40 | 0.47/1.00 | 0.56/1.17 | 0.72/1.54 |
| SGAN | 0.81/1.52 | 0.72/1.61 | 0.60/1.26 | 0.34/0.69 | 0.42/0.84 | 0.58/1.18 |
| Sophie | 0.70/1.43 | 0.76/1.67 | 0.54/1.24 | 0.30/0.63 | 0.38/0.78 | 0.54/1.15 |
| Social-bigat | 0.69/1/29 | 0.49/1.01 | 0.55/1.32 | 0.30/0.62 | 0.36/0.75 | 0.48/1.00 |
| RSBG | 0.80/1.53 | 0.33/0.64 | 0.59/1.25 | 0.40/0.86 | 0.30/0.65 | 0.48/0.99 |
| MATF GAN | 1.01/1.75 | 0.43/0.80 | 0.44 0.91 | 0.26/0.45 | 0.26/0.57 | 0.48/0.90 |
| PSA-GRU | 0.79/1.63 | 0.52/1.07 | 0.53/1.13 | 0.41/0.77 | 0.34/0.74 | 0.52/1.07 |
| Social-STGCNN | 0.64/1.11 | 0.49/0.85 | 0.44/0.79 | 0.34/0.53 | 0.30/0.48 | 0.44/0.75 |
| CGNS | 0.62/1.40 | 0.70/0.93 | 0.48/1.22 | 0.32/0.59 | 0.35/0.71 | 0.49/0.97 |
| PIF | 0.73/1.65 | 0.30/0.59 | 0.60/1.27 | 0.38/0.81 | 0.31/0.68 | 0.46/1.00 |
| NMMP | 0.61/1.08 | 0.33/0.63 | 0.52/1.11 | 0.32/0.66 | 0.43/0.85 | 0.41/0.82 |
| FvTraj | 0.56/1.14 | 0.28/0.55 | 0.52/1.12 | 0.37/0.78 | 0.32/0.68 | 0.41/0.85 |
| DSCMP | 0.66/1.21 | 0.27/0.46 | 0.50/1.07 | 0.33/0.68 | 0.28/0.60 | 0.41/0.80 |
| STGAT | 0.65/1.12 | 0.35/0.66 | 0.52/1.10 | 0.34/0.69 | 0.29/0.60 | 0.43/0.83 |
| TPNet | 0.84/1.73 | 0.24/0.46 | 0.42/0.94 | 0.33/0.75 | 0.26/0.60 | 0.42/0.90 |
| TFBNet | 0.42/0.58 | 0.15/0.25 | 0.29/0.52 | 0.15/0.25 | 0.11/0.18 | 0.22/0.36 |
| IMP | 25%/46% | 37%/45% | 30%/34% | 42%/44% | 57%/62% | 46%/52% |
| Method | ADE/FDE ↓ , Best of 20 | |||||
|---|---|---|---|---|---|---|
| ETH | HOTEL | UNIV | ZARA1 | ZARA2 | Average | |
| Social-LSTM | 0.73/1.48 | 0.49/1.01 | 0.41/0.84 | 0.27/0.56 | 0.33/0.70 | 0.45/0.91 |
| SGAN | 0.61/1.22 | 0.48/0.95 | 0.36/0.75 | 0.21/0.42 | 0.27/0.54 | 0.39/0.78 |
| PSA-GRU | 0.58/1.17 | 0.44/0.87 | 0.33/0.69 | 0.25/0.40 | 0.22/0.46 | 0.36/0.72 |
| STGAT | 0.56/1.10 | 0.27/0.50 | 0.32/0.66 | 0.21/0.42 | 0.20/0.40 | 0.31/0.62 |
| TPNet | 0.54/1.12 | 0.19/0.37 | 0.24/0.53 | 0.19/0.41 | 0.16/0.36 | 0.27/0.56 |
| TFBNet | 0.29/0.38 | 0.10/0.15 | 0.19/0.32 | 0.09/0.15 | 0.07/0.11 | 0.15/0.22 |
| IMP | 46%/65% | 47%/59% | 20%/39% | 52%/62% | 56%/69% | 44%/60% |
| Metric | Dataset | K = 1 | K = 5 | K = 10 | K = 15 | K = 20 | K = 160 |
|---|---|---|---|---|---|---|---|
| ADE | ETH | 0.58 | 0.38 | 0.33 | 0.32 | 0.29 | 0.20 |
| HOTEL | 0.25 | 0.17 | 0.15 | 0.12 | 0.10 | 0.07 | |
| UNIV | 0.42 | 0.27 | 0.24 | 0.21 | 0.18 | 0.13 | |
| ZARA1 | 0.24 | 0.16 | 0.12 | 0.12 | 0.09 | 0.07 | |
| ZARA2 | 0.16 | 0.11 | 0.09 | 0.08 | 0.07 | 0.05 | |
| FDE | Dataset | K = 1 | K = 5 | K = 10 | K = 15 | K = 20 | K = 160 |
| ETH | 1.01 | 0.63 | 0.50 | 0.49 | 0.38 | 0.23 | |
| HOTEL | 0.45 | 0.30 | 0.25 | 0.18 | 0.15 | 0.07 | |
| UNIV | 0.79 | 0.49 | 0.43 | 0.38 | 0.32 | 0.18 | |
| ZARA1 | 0.48 | 0.29 | 0.21 | 0.20 | 0.15 | 0.09 | |
| ZARA2 | 0.33 | 0.21 | 0.15 | 0.13 | 0.11 | 0.07 |
| Metric | Dataset | K = 1 | K = 5 | K = 10 | K = 15 | K = 20 | K = 160 |
|---|---|---|---|---|---|---|---|
| ADE | ETH | 0.85 | 0.58 | 0.49 | 0.47 | 0.42 | 0.31 |
| HOTEL | 0.39 | 0.27 | 0.23 | 0.18 | 0.15 | 0.11 | |
| UNIV | 0.64 | 0.42 | 0.37 | 0.33 | 0.29 | 0.21 | |
| ZARA1 | 0.39 | 0.25 | 0.2 | 0.19 | 0.15 | 0.12 | |
| ZARA2 | 0.27 | 0.18 | 0.14 | 0.13 | 0.11 | 0.09 | |
| FDE | Dataset | K = 1 | K = 5 | K = 10 | K = 15 | K = 20 | K = 160 |
| ETH | 1.62 | 1.05 | 0.81 | 0.75 | 0.58 | 0.38 | |
| HOTEL | 0.87 | 0.57 | 0.49 | 0.33 | 0.25 | 0.14 | |
| UNIV | 1.25 | 0.8 | 0.71 | 0.62 | 0.52 | 0.29 | |
| ZARA1 | 0.82 | 0.47 | 0.36 | 0.33 | 0.25 | 0.14 | |
| ZARA2 | 0.58 | 0.34 | 0.26 | 0.23 | 0.18 | 0.11 |
| Method | ETH | HOTEL | UNIV | ZARA1 | ZARA2 | Average |
|---|---|---|---|---|---|---|
| TFBNet-DAGConv | 0.49/0.80 | 0.19/0.36 | 0.31/0.57 | 0.18/0.31 | 0.13/0.24 | 0.26/0.46 |
| TFBNet-GA | 0.43/0.64 | 0.19/0.36 | 0.34/0.60 | 0.16/0.27 | 0.13/0.23 | 0.25/0.42 |
| TFBNet-MR | 0.46/0.71 | 0.19/0.37 | 0.31/0.57 | 0.18/0.31 | 0.11/0.18 | 0.25/0.43 |
| TFBNet-GF | 0.43/0.67 | 0.18/0.36 | 0.31/0.56 | 0.16/0.26 | 0.11/0.19 | 0.24/0.41 |
| TFBNet | 0.42/0.58 | 0.15/0.25 | 0.29/0.52 | 0.15/0.25 | 0.11/0.18 | 0.22/0.36 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ni, Q.; Peng, W.; Zhu, Y.; Ye, R. A Novel Trajectory Feature-Boosting Network for Trajectory Prediction. Entropy 2023, 25, 1100. https://doi.org/10.3390/e25071100
Ni Q, Peng W, Zhu Y, Ye R. A Novel Trajectory Feature-Boosting Network for Trajectory Prediction. Entropy. 2023; 25(7):1100. https://doi.org/10.3390/e25071100
Chicago/Turabian StyleNi, Qingjian, Wenqiang Peng, Yuntian Zhu, and Ruotian Ye. 2023. "A Novel Trajectory Feature-Boosting Network for Trajectory Prediction" Entropy 25, no. 7: 1100. https://doi.org/10.3390/e25071100
APA StyleNi, Q., Peng, W., Zhu, Y., & Ye, R. (2023). A Novel Trajectory Feature-Boosting Network for Trajectory Prediction. Entropy, 25(7), 1100. https://doi.org/10.3390/e25071100