6.1. Building the Posterior Distribution
In Bayesian theory, the observed data
are fixed, while the state variable
and the parameter
are considered as random variables. In this setting, Bayes’ theorem defines the posterior distribution as
where
(called the prior distribution) codifies our belief about the unknown parameter
before the data were observed and
(called the likelihood distribution) codifies all the information available regarding how the observed data
were obtained. From the Bayesian perspective, (
9) constitutes an inverse problem which may be solved by using the
Maximum a posteriori (MAP), an argument that maximizes the posterior (
), the posterior mean (
), or posterior median as the optimal value
of
.
As we consider count data in this study—which, by their very nature, are events that occur within a given period of time—a Poisson process would be a natural and meaningful starting point for modeling and performing inference on the observed cases. However, count data, especially epidemiological observations, usually exhibit more variation than is implied by the Poisson distribution, pointing to inherent over-dispersion in the data. Such variations may be due to sampling, aggregation, environmental variability, or a combination of these factors, causing count data to have inherent over-dispersion. Therefore, it is not possible that count epidemiological data present an equal mean-variance relationship, as is assumed by the Poisson distribution. In fact, ref. [
124] posited that most commonly used approaches assume a quadratic mean-variance relationship. The mean-variance relationship in modeling count data, such as epidemiological data, can be adequately described by the negative-binomial distribution, given that it includes an additional parameter that permits the variance to be larger than the mean [
125,
126,
127]. Moreover, the negative binomial distribution is a mixture of Poisson and Gamma distributions [
127,
128], indicating that the Poisson distribution is still involved in the modeling process, even when the negative binomial distribution is used.
We assume that the observed data follow the negative binomial distribution with one dispersion parameter
and write
, where
p is the probability of success. This distribution has the form
where
It is worth noting that is the additional variance allowed by the Negative Binomial distribution with respect to the Poisson distribution, and that the parameter can be viewed as controlling the dispersion of the observed data.
We acknowledge that there are other forms of the Negative binomial distribution; for example, ref. [
49] achieved success in modeling COVID-19 cases and hospital demand in Mexico using a Negative binomial distribution with two over-dispersion parameters. This distribution was proposed by [
124]. However, in a model with numerous parameters to estimate—as is the case for the model considered here—it is our view that additional parameters would further increase the dimensionality of the already complex optimization problem.
We now detail the construction of the posterior distribution for the present multi-patch model study. Using the observed data and the variable
described above, we assume that the observed cases in each patch follow a negative-binomial distribution with over-dispersion parameter (i.e., the number of failures before first success)
and success probabilities
where
is the theoretical mean of the negative binomial distribution, which can be taken as the incidence in patch
iWith this setting in mind, we have that, if
represents the incidence in Patch
i observed in day
j with theoretical mean
, as in (
11), then we have
Then, the likelihood from Patch
i,
, corresponds to
Hence, the likelihood of the combined data from the n patches is given as .
To establish the prior distribution, we define the joint prior distribution as the product of the marginal; that is, if we denote
, where
is the
ℓ parameter associated with Patch
i, then
where
is the number of parameters for Patch
i.
Thus, the posterior distribution of the parameters from all
n patches can be obtained as the product of (
9) and (
12), as (
9).
6.2. Results
From the deterministic inversion section, we can note that we are interested in estimating the transmission, incubation, and recovery rates
,
and
for each zone
i (
), as well as the exposed and infected incidence initial conditions
and
. For the Bayesian inference (also called probabilistic inversion), four over-dispersion parameters
are included, related to each zone’s observed incidence data. The dispersion parameters can be loosely defined as the number of trials before we encounter the first successful infection in each zone. These parameters come with the negative binomial distribution, which we use as the distribution of the observed zonal incidences. Thus, we have a total of 24 parameters for the Bayesian inference in this section, which we must estimate:
An important problem that has been the topic of recent research is the selection of adequate prior distributions, their corresponding hyper-parameters, and the delimitations of the parametric spaces of the parameters to be estimated [
129,
130,
131]. In this research, for the epidemiological parameters, we chose prior distributions with 95% of their body falling within the parametric spaces (upper and lower bounds) determined from the COVID-19 literature, as detailed in
Table 2.
In this way, we considered the following prior distributions for each of the parameters:
Furthermore, the hyper-parameters for the log-Normal prior distributions of the contact parameters were , , , , and ; while those for the initial conditions of the exposed state were , , , , , , and , . These prior probability distributions, which we selected using the above-mentioned criteria, are versatile and allow for the assumption that some parameter values could occur with lower, equal, or higher probability densities.
To avoid generalizations, it is imperative to perform a diagnostic analysis regarding the adequacy and correctness of the selected prior distributions before sampling. These prior distributions should be coherent with our expectations and correspond to the domain knowledge of each parameter obtained from the deterministic inversion in the previous section. We desire priors that—in accordance with our deterministic inversion domain experience—permit every conceivable configuration of the data while excluding blatantly ludicrous scenarios.
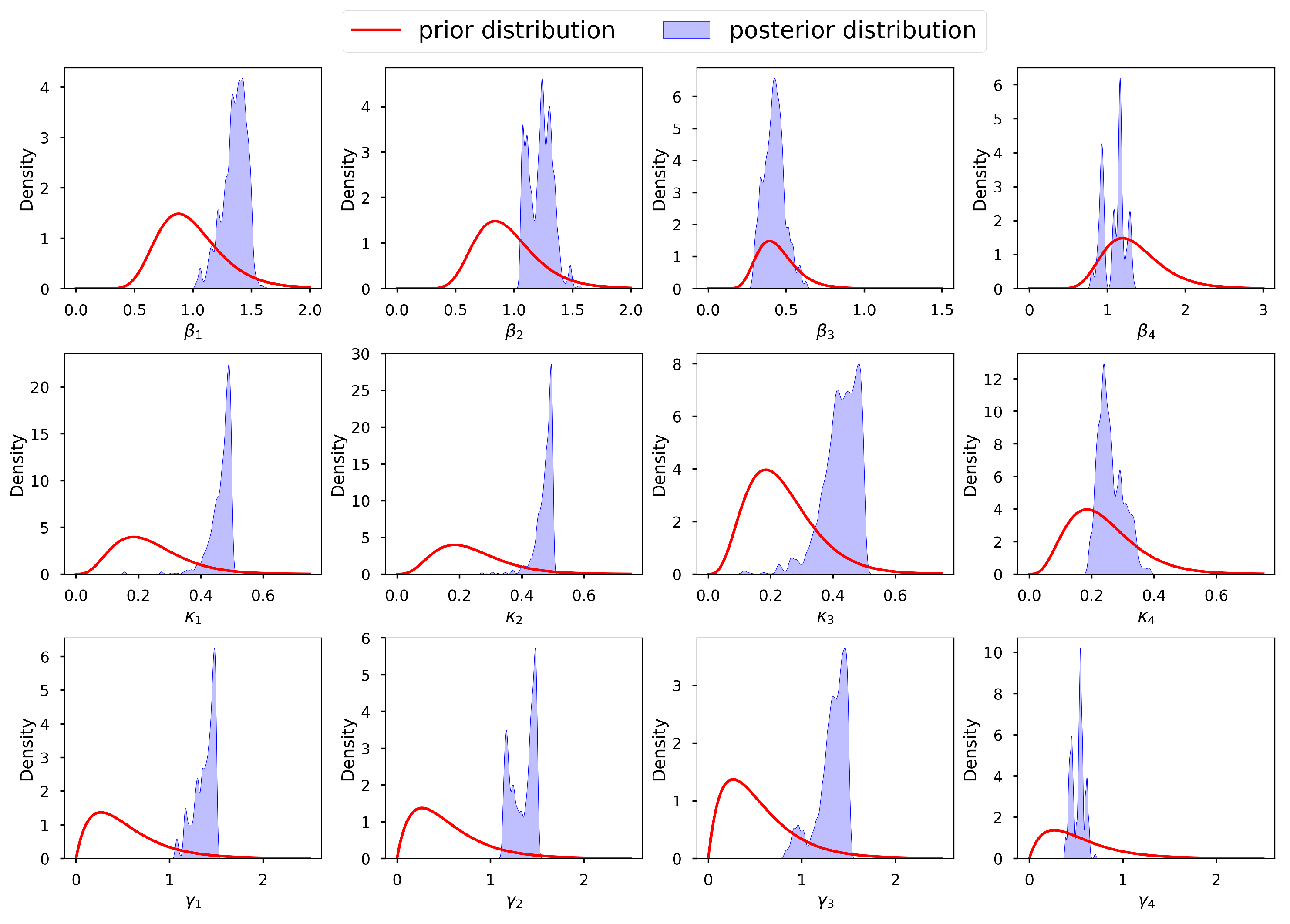
Figure 8 shows a graph of the selected prior distributions for the infection, incubation, and recovery parameters, vis-à-vis the corresponding posterior distributions. We can observe that, for most parameters, we allowed for low informative priors and the posterior distributions were within their respective prior probability support. This conforms with the suggestion of [
132], who stated that the model should not be overly confined by the priors, which should instead be too wide to encompass a wide variety of situations and data that are incredibly improbable. We thus conclude that our selected prior distributions were adequate and capable of regularizing our estimates to avoid non-identifiability. We acknowledge that [
131] also proposed an interesting criterion for selecting prior distributions together with their corresponding hyper-parameters, based on parametric intervals. Applying the assumption of independence of the parameters, the joint prior distribution is
.
The likelihood for the four zonal incidences is calculated as
where
is the total number of days that the incidence is observed for each zone
,
is the
observed incidence for zone
i, and
is the incidence provided by model (
1). Thus, the posterior distribution is given as
.
The incidence values output from the epidemic model (
1) were very sensitive and exhibited a lot of uncertainty in response to slight changes, especially in terms of the contact, incubation, and recovery parameters. As a consequence, it was challenging to provide a wide range of values as support for the posterior distribution in Stan and t-walk. We addressed this challenge by beginning with deterministic inversion of the epidemic model using GA, as discussed in the previous section. The results of this inversion are given in
Table 5. Consequently, we used the point parameter estimates obtained from the GA as the initial sampling points for t-walk and Stan. Moreover, as there is no literature reporting the parametric spaces for the initial conditions of the incubation and prevalence states, we delimited their support in the posterior distribution to within certain neighborhoods of their point parameter estimates obtained from the GA.
After performing the prior predictive checks, using the t-walk package [
133], we obtained posterior samples for each of the 24 parameters (
13). MCMC methods, by definition, produce samples with high correlation, harboring some level of redundant information. One way of measuring the level of information redundancy in the posterior sample is through use of the effective sample size (ESS). Theoretically, the ESS is the sample size we would obtain if we independently sampled the posterior distribution. The ESS and the proportion of ESS (pESS) for the simulated samples are given in the last two columns of
Table A1. Going by how low (high) the ESS (pESS) values are, we can tell that the simulated chains were highly correlated and, thus, the utilized MCMC method required a very high number of iterations. In other words, in order to obtain samples with insignificant auto-correlations, thinning at large lags should be conducted, which can remarkably reduce the chain size. To obtain chains with reasonable sample sizes for analysis, after running the MCMC method for 1,000,000 iterations, we discarded 360,000 burn-in samples and thinned the chains at lag 20.
The summary statistics of the generated samples are provided in
Table A1 (in the
Appendix A). The presented summary statistics include the mean, variance, 95% credible interval (CI), median, ESS, and pESS. From this table, we can conclude that, in general, all the samples exhibited low variability and that their means were close to the estimates obtained by the GA in the previous section. Furthermore, we can conclude that the means (and medians) were all within the relevant 95% CIs. The former and the latter observations can be confirmed from
Figure 9, which shows the 95% CIs of the samples, the means, and the estimates from the GA. Based on the scales of the values in the intervals, we can conclude that the credible intervals (CIs) were generally short—an indication of good estimates.
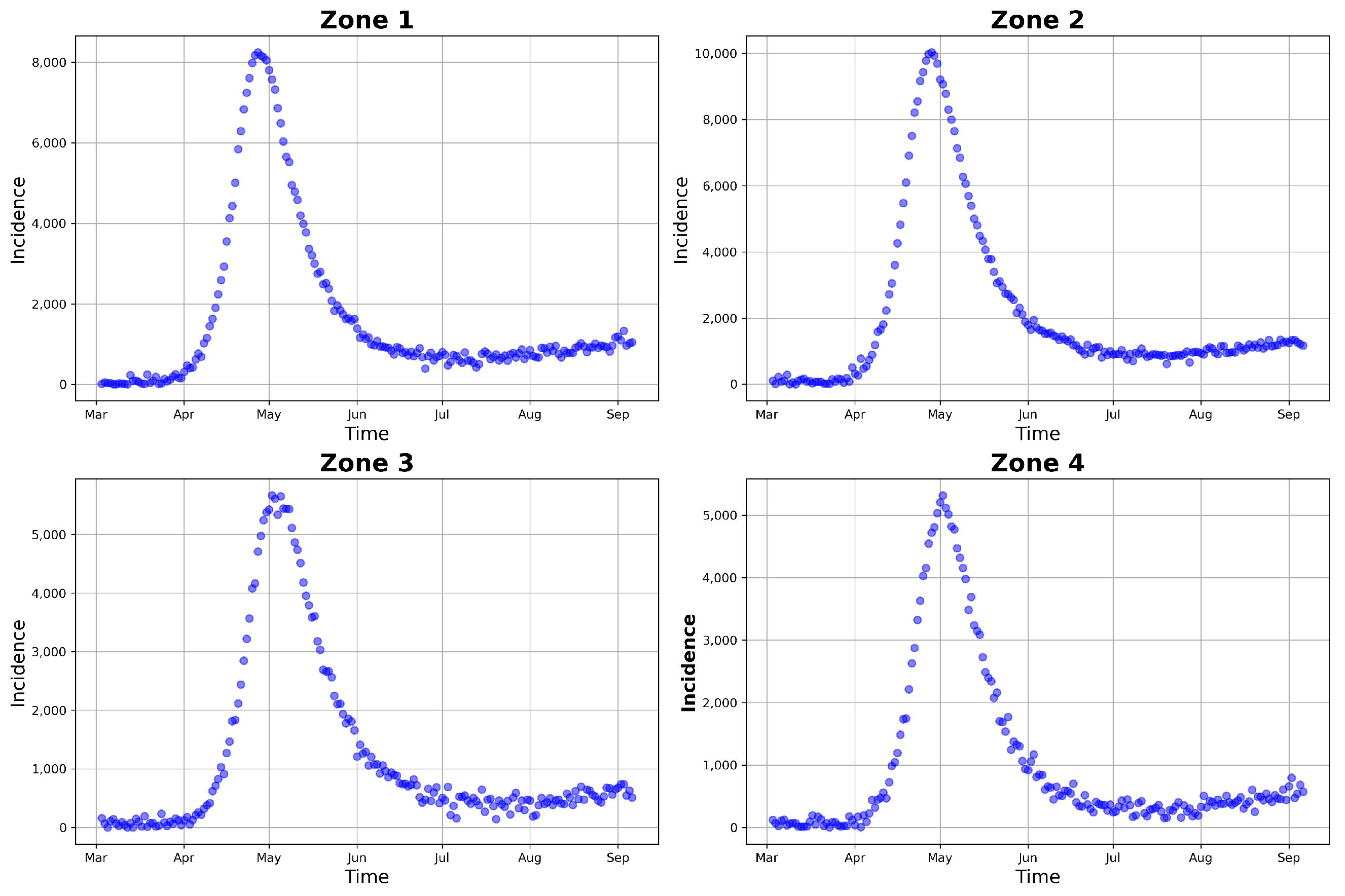
Figure 10 and
Figure 11 present the posterior predictive checks. These figures graph the incidence simulations of model (
1) from 26 February 2020 to 17 October 2020. This period includes all of the dates within which the incidence data were observed (26 February 2020 to 6 September 2020) and 41 prediction dates (7 September 2020 to 17 October 2020).
Figure 10 shows 30,000 model incidences (gray curves) from the first 30,000 MCMC iterations, the observed incidence, and the maximum a posteriori (MAP) model incidence. Here, the MAP model incidence—which is apparently covered by the gray curves—is the model incidence output obtained from the parameter values that maximize the posterior distribution. We can observe, from this figure, that: (1) Our fitted model produced simulations that are consistent with the observed incidence data; and (2) the simulated trajectories did not present diverse or variable changes. Indeed, the latter observation is consistent with our previous observation that there was low variability in the simulated samples.
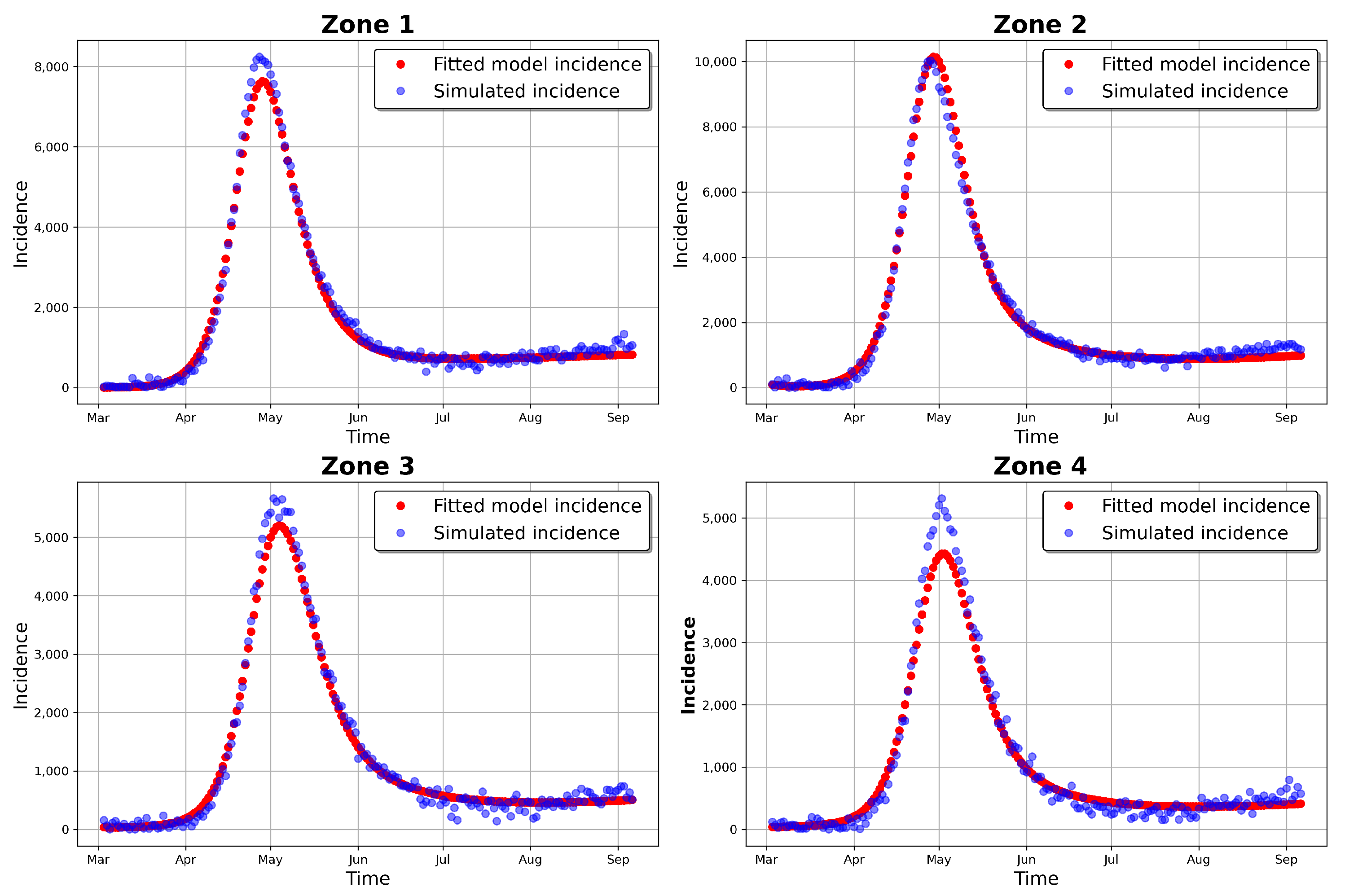
Figure 11 shows the 95% posterior credible intervals (CIs), mean, median, and MAP of the simulated model incidences. From this figure, we can see that most of the observed training incidences for the four zones fell outside the 95% CI of the simulated model incidence, with the zone 1 and zone 3 simulated model incidences providing the narrowest 95% CIs. In contrast, zones 2 and 4 had larger 95% prediction CIs, covering more of the observed incidences. The zone 1 model prediction interval provided the worst coverage of the observed prediction incidences. The proportions of the observed prediction incidences covered by the 95% CIs of the simulated model incidence from t-walk are presented in
Table 6. As the CIs for the four zones were generally not too wide and covered a small proportion of the training observed incidence, and considering the prediction observed incidences for zones 3 and 4, we can conclude that the point estimates from t-walk seem to be adequate; however, the uncertainty associated with the estimated parameters tended to be underestimated.
We can observe, from both
Figure 10 and
Figure 11, that the model predicted that there will still be some infection levels beyond 6 September 2020—the date when we observed the last incidence. In fact, the figures reveal that, in the four zones, some individuals will still be infected up until 17 October 2020, with the median and MAP incidences being within the 95% CI.
After checking the adequacy of the prior distributions with respect to the posterior distribution and sampling, using the t-walk package, we also performed sampling of the posterior distribution using the Stan package. Stan is a Hamiltonian Monte Carlo (HMC)-based package designed for Bayesian statistical analysis; we refer the reader to [
134] for more details about the software and [
132,
135] for insight into how the package can be used to perform inference and uncertainty quantification for compartmental epidemic models.
For Stan, we used the same support for the prior distribution as for t-walk, except for the incubation initial conditions. Using the same support for the incubation initial conditions in t-walk led to a very low overall proposal acceptance rate. As such, we used a different, shorter support range for all the incubation initial conditions prior distributions in t-walk, in order to obtain a reasonable proposal acceptance rate for the algorithm. However, in Stan, the support range for the same parameters were larger, as Stan is more robust. For the over-dispersion parameters, we used the transformed versions and sampled their inverses in Stan.
For the model at hand, we ran one chain with 1000 iterations for each of the 24 parameters and took the first 300 iterations as burn-in samples. The number of iterations was not the same as those obtained with t-walk, as Stan requires longer periods of time than t-walk to complete each iteration. However, from the analysis, we observed that the chains were importantly less correlated, and we thus obtained bigger effective sample sizes.
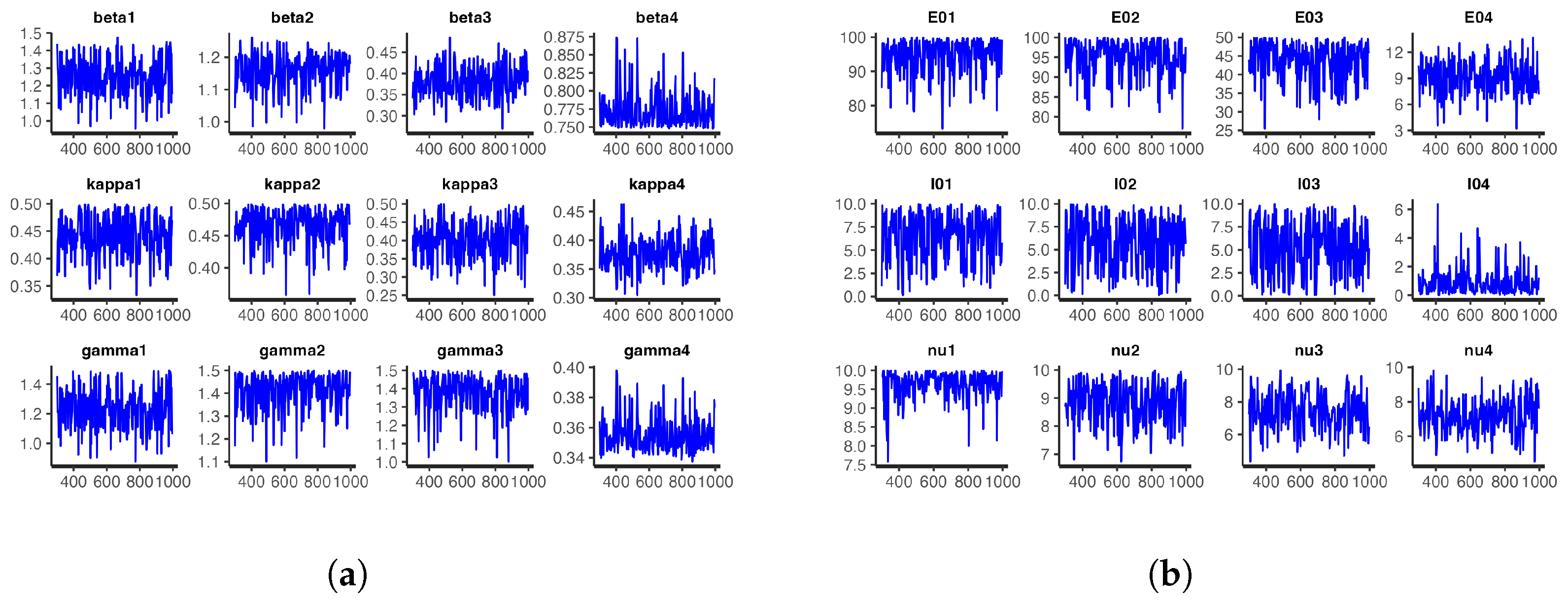
Figure 12 and
Figure 13, respectively, show the trace plots and the posterior densities for the samples of the estimated parameters. We obtained unit Rhat values from the Stan summary statistics output, an indication that all but two of the transitions converged. Additional Stan statistics—particularly, the diagnosis of the pairs plot of a subset of the estimated parameters (see
Figure 14)—confirmed the convergence of all but two of the transitions of the chain during sampling.
Figure 15 shows the 95% CIs of the posterior distributions obtained from Stan. All the parameters, except for
,
,
, and
, had short CIs. It is worth noting that (just as in t-walk) the samples of the inverse of the over-dispersion parameters
from Stan had very narrow intervals.
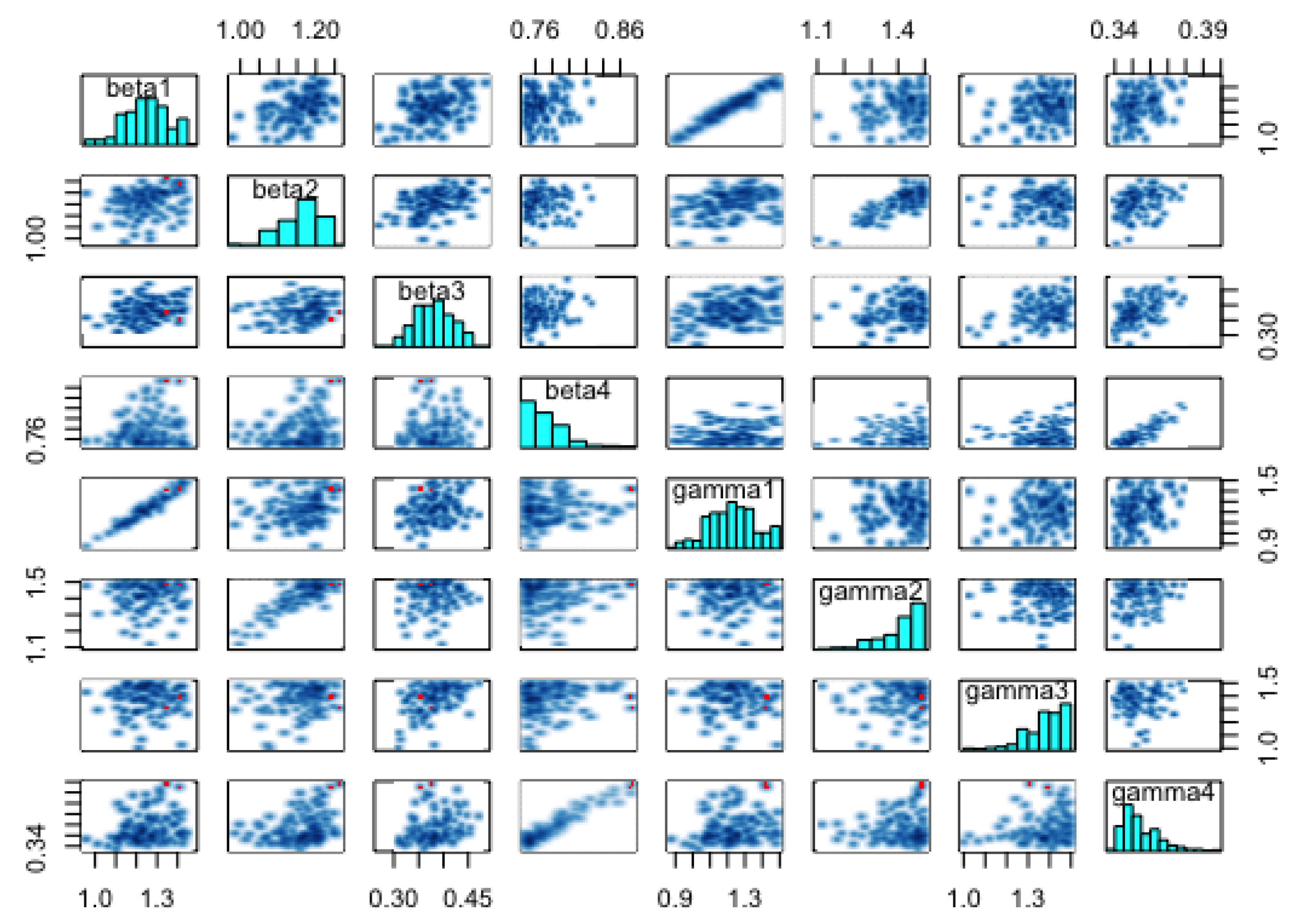
The pair plots in
Figure 14 show the posterior distributions of the infection and recovery parameters (diagonal figures) and scatter plots (off-diagonal figures) presenting the relationships between each of the samples. As there were many (24) parameters to estimate, it was not appealing to create a joint pairs plot for all of them. Inasmuch as this is the ideal procedure, doing this would lead to a figure with very tiny, non-visualizable figure entries. Thus, we chose to pair the infection and recovery rates (see
Figure 14), as the scatter plots of these parameters exhibited interesting relationships. For instance, we can observe from the figure that there were strong linear positive posterior correlations between
and
,
and
, and
and
. In contrast, the infection parameters for the four zones did not exhibit any important relationships among themselves. This was also the case for the recovery parameters.
The summary statistics of the samples obtained from Stan are shown in
Table A2. These statistics were slightly different from those obtained with t-walk, as displayed in
Table A1. The differences in the statistics of the prevalence initial conditions and the over-dispersion parameters were obvious, as we have already mentioned that, besides using different support ranges for the distributions of the prevalence initial conditions, we transformed and sampled the inverses of the over-dispersion parameters
,
. Otherwise, the slight differences in the statistics of the other parameters could have been due to the difference in how the t-walk and Stan packages perform sampling. Notably, these differences would not lead to a different conclusion regarding the potency of COVID-19 infections in Hermosillo in 2020. The statistics in
Table A2 reveal that the point estimates for the parameters were within the 95% CIs, as was the case for the estimated parameters in t-walk, as shown in
Table A1.
The differences in the summary statistics of the samples obtained from both packages are further reflected in
Figure 11 and
Figure 16, which show the posterior predictive check figures for t-walk and Stan, respectively. We can observe that the mean, median, and observed incidences for each zone were all covered by the respective 95% CIs. In comparison, we can observe, from the t-walk output in
Figure 11, that the 95% CI of the epidemic model incidences did not cover some observed daily incidences, while the same interval with Stan covered all of the training observed zonal incidences. We can thus conclude that the estimated parameters from Stan capture a more realistic uncertainty level, compared to those estimated by t-walk.
Figure 11 and
Figure 16 reveal that the COVID-19 infections in the four zones—and consequently, the whole of Hermosillo—peaked in mid-July of 2020, with a prediction of continued infections beyond 6 September 2020 (i.e., the last date of observed training daily incidences).
Table 2 provides the ranges for the parameters of the model, as obtained with reference to the COVID-19 literature. Our results from the GA, t-walk, and Stan packages (see
Table 5,
Table A1 and
Table A2, respectively) indicated that the point estimates of the infection and incubation parameters (
and
,
) that best fit the incidences for the four zones were within the ranges derived from the literature. However, this was not the case for the recovery parameters (
), whose estimates were generally close to the one-day recovery period average for the four zones. This result is not surprising, as our incidence data for the four zones were inflated by a large under-reporting factor. This inflation, besides indicating a possible lack of systematic testing for COVID-19 in Hermosillo, also accounted for the existence of sub-clinical and asymptomatic COVID-19 patients in the four zones under study. Going by how well the models fit the data (see
Figure 7,
Figure 10,
Figure 11 and
Figure 16), we believe that accounting for incidence under-reporting by a factor of 15 (as reported by [
86]) is realistic.
We further evaluated the prediction capability of the multi-patch model by checking the proportion of observed zonal prediction incidences that were within the 95% CIs of the zone model incidences.
Table 6 shows these proportions obtained from Stan (see
Figure 16) and t-walk (see
Figure 11). From this table, we can see that Stan produced 95% prediction bands covering more than 50% of the observed prediction incidences for all of the zones. On the other hand, t-walk provided 95% CIs large enough to cover less than 50% of observed prediction incidences for all the four zones, with zone 1 providing the narrowest simulated model incidence CIs, covering only 22.22% of the observed prediction incidence. In effect, we can conclude that Stan outperforms t-walk, with regard to the percentage of covered observed daily prediction incidence for all of the considered zones.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
















