
Reinforcement Learning-Based Decentralized Safety Control for Constrained Interconnected Nonlinear Safety-Critical Systems


Abstract
:1. Introduction
- The reinforcement learning algorithm is used to solve the optimal DSC problem for restricted interconnected nonlinear safety-critical systems, and the asymmetric input constraint is successfully solved. The method optimizes the control strategy by minimizing the performance function, ensuring the safety of the system’s state, while considering the asymmetric input constraints.
- Nonlinear interconnected safety-critical systems with asymmetric input constraints and safety constraints are converted to equivalent systems that satisfy user-defined safety constraints using barrier functions. Unlike the nonlinear safety-critical systems [3,9,10,13], this paper solves the security constraint problem of the interconnection term through the potential barrier function, which ensures the interconnected nonlinear safety-critical system satisfies the security constraint.
- The asymmetric input constraints are solved by utilizing a single CNN architecture for online approximation of the performance function. Theoretical demonstrations show that the optimal DSC method can achieve uniformly ultimately bounded (UUB) system states and neural network weight estimation errors. In addition, a simulation example verified the feasibility and effectiveness of the developed DSC method.
2. Preliminaries
2.1. Problem Descriptions
2.2. Security Conversion Issues
- 1.
- 2.
- When the system’s state approaches the boundary of the safety area, the barrier function changes as follows:
- 3.
- The barrier function fails to function when the system state reaches equilibrium, i.e.,
3. Decentralized Optimal DSC Design
3.1. Barrier Function Conversion
3.2. Designing the Optimal DSC Strategy by Solving n HJB Equations
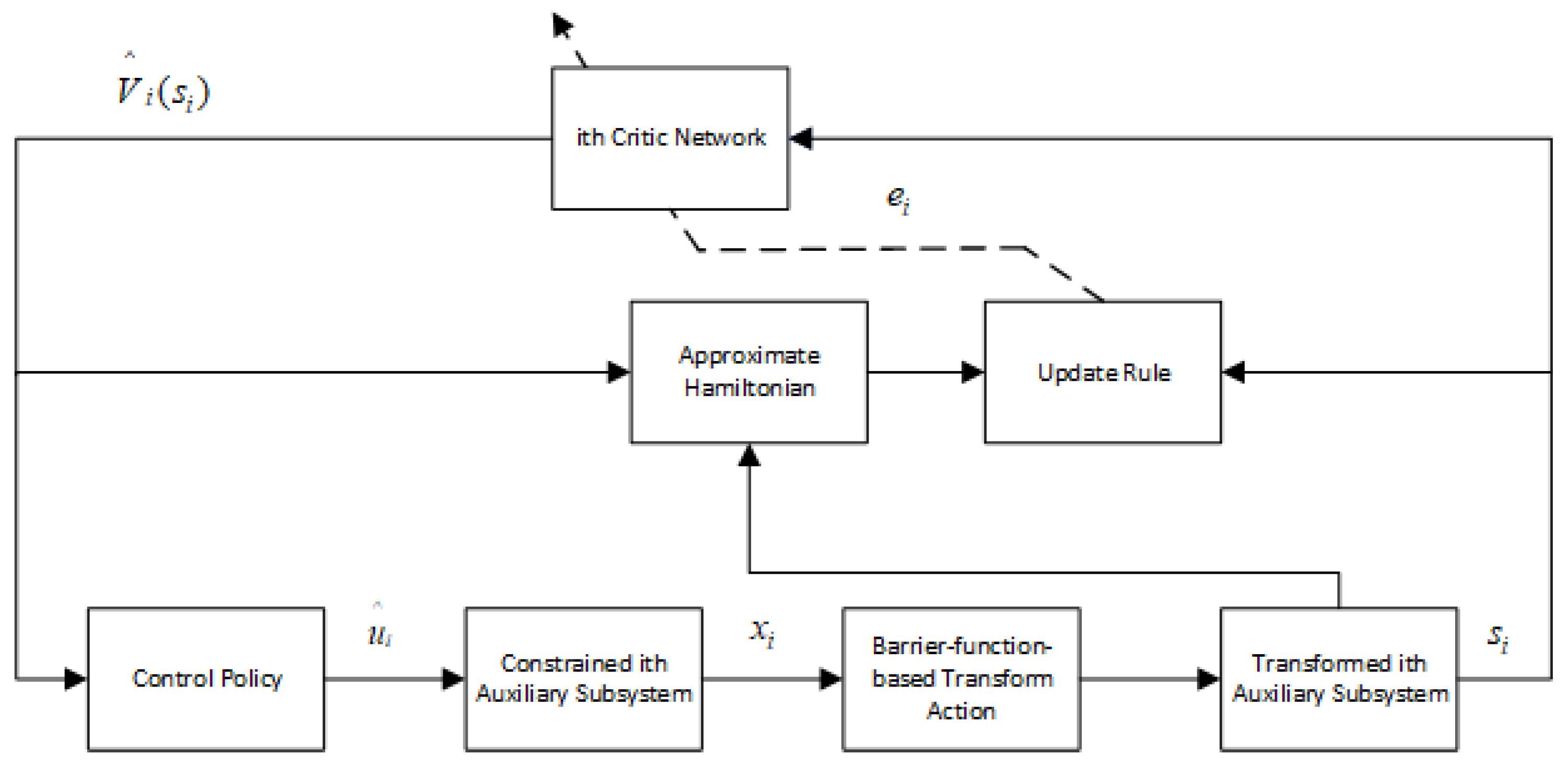
4. Critic Network for Approximation
5. Stability Analysis
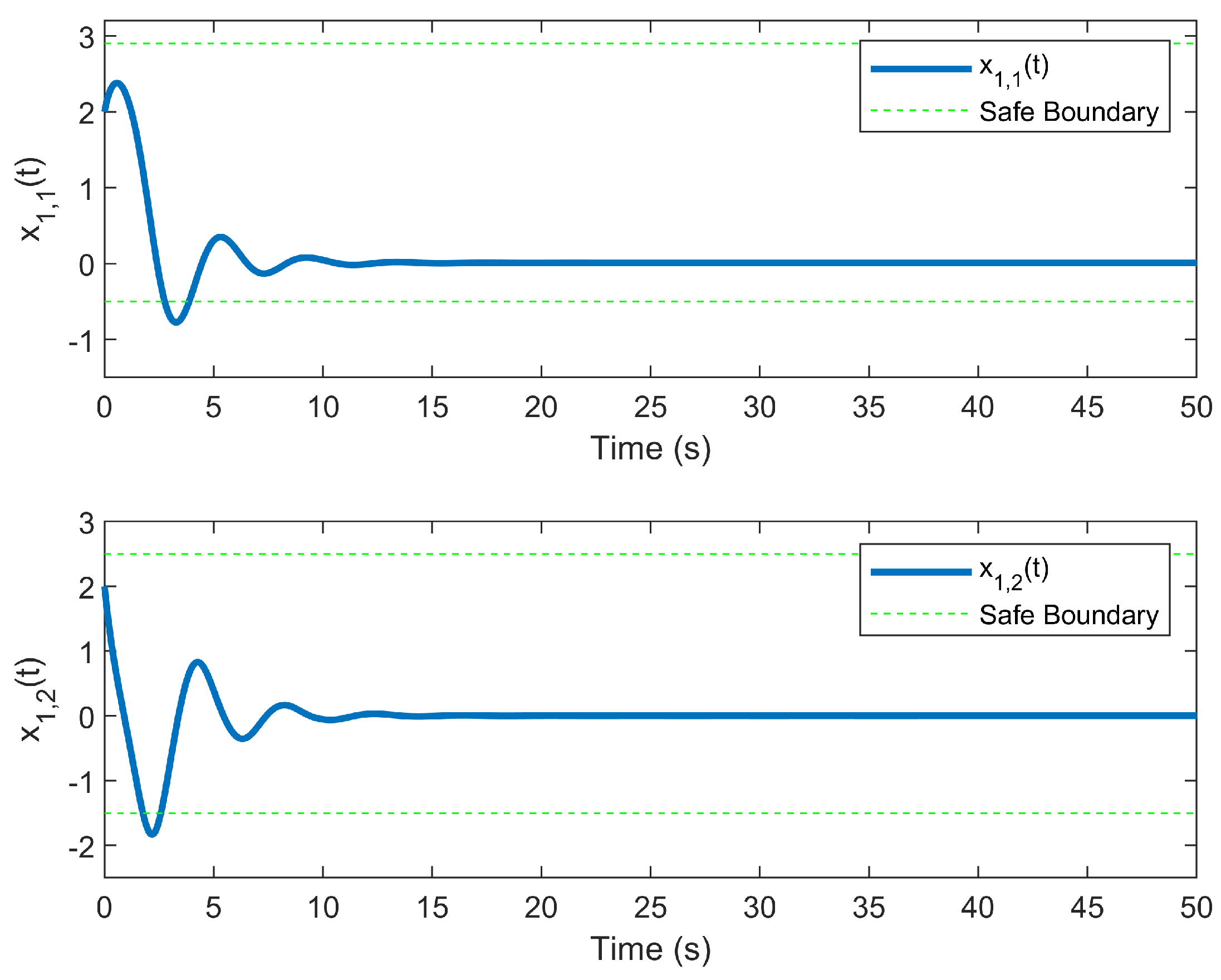
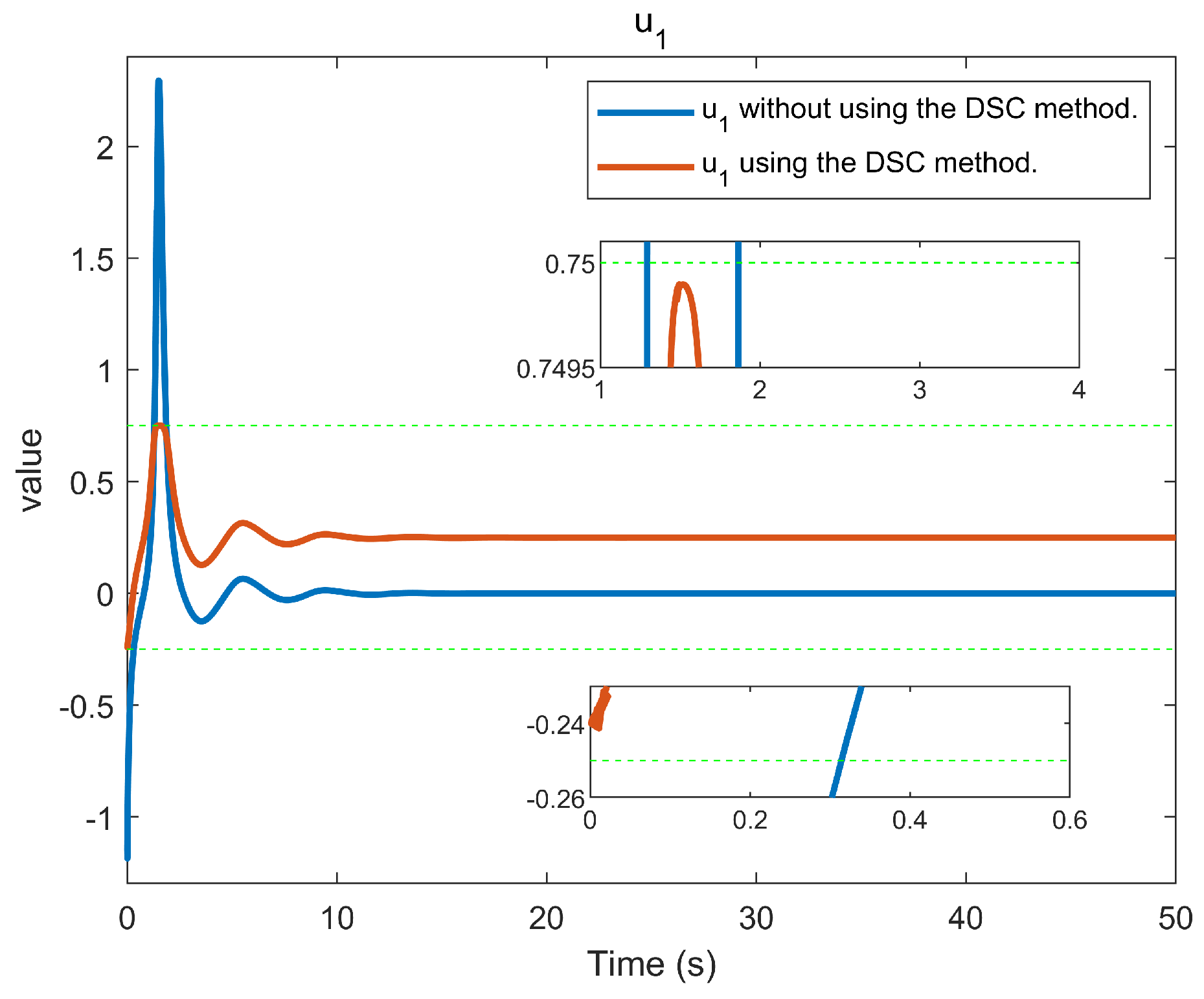
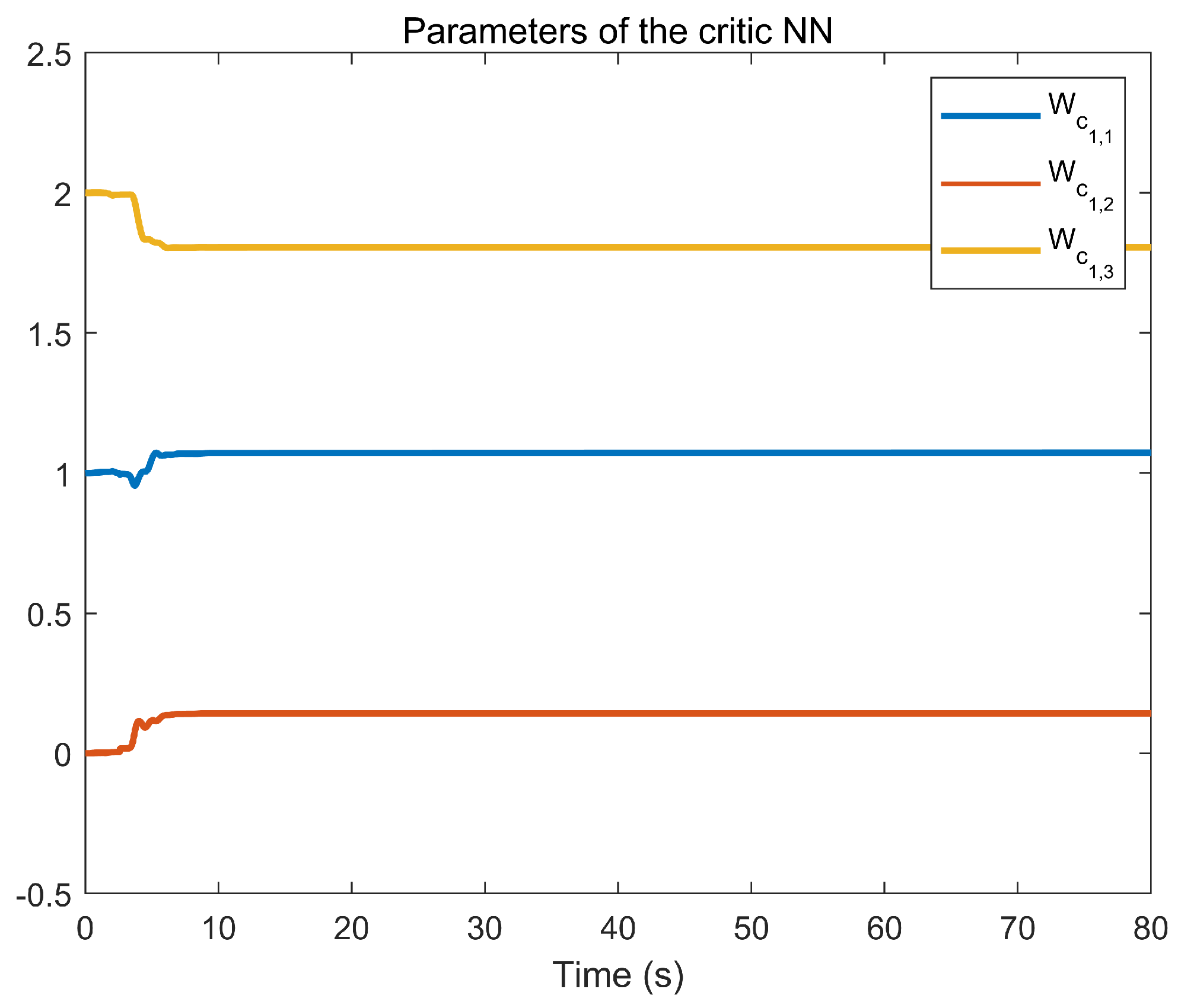
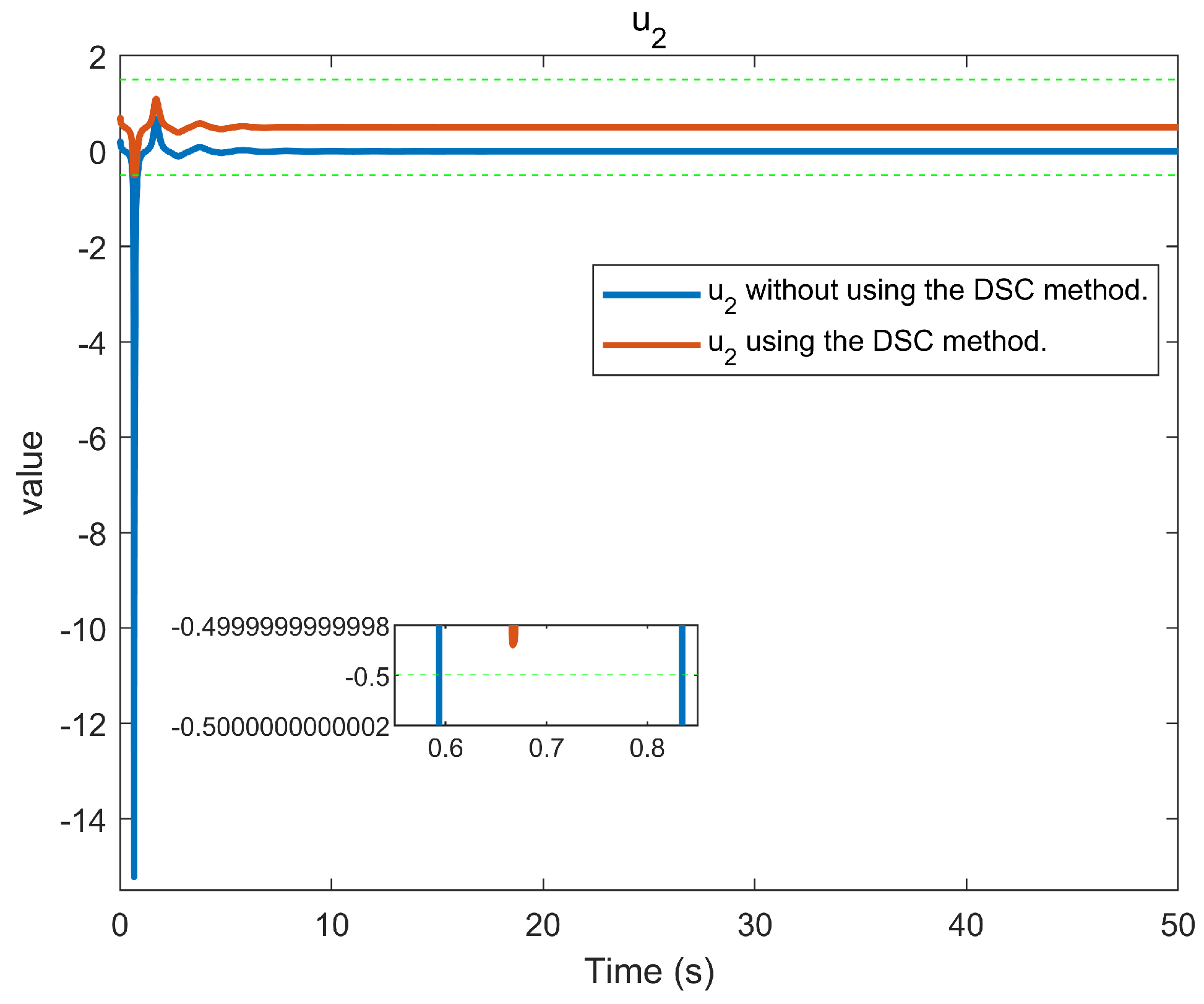
6. Simulation Example
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Son, T.D.; Nguyen, Q. Safety-critical control for non-affine nonlinear systems with application on autonomous vehicle. In Proceedings of the 2019 IEEE 58th Conference on Decision and Control (CDC), Nice, France, 11–13 December 2019; pp. 7623–7628. [Google Scholar]
- Manjunath, A.; Nguyen, Q. Safe and robust motion planning for dynamic robotics via control barrier functions. In Proceedings of the 2021 60th IEEE Conference on Decision and Control (CDC), Austin, TX, USA, 14–17 December 2021; pp. 2122–2128. [Google Scholar]
- Wang, J.; Qin, C.; Qiao, X.; Zhang, D.; Zhang, Z.; Shang, Z.; Zhu, H. Constrained optimal control for nonlinear multi-input safety-critical systems with time-varying safety constraints. Mathematics 2022, 10, 2744. [Google Scholar] [CrossRef]
- Liu, Z.; Yuan, Q.; Nie, G.; Tian, Y. A multi-objective model predictive control for vehicle adaptive cruise control system based on a new safe distance model. Int. J. Automot. Technol. 2021, 22, 475–487. [Google Scholar] [CrossRef]
- Ames, A.D.; Xu, X.; Grizzle, J.W.; Tabuada, P. Control barrier function based quadratic programs for safety critical systems. IEEE Trans. Autom. Control 2016, 62, 3861–3876. [Google Scholar] [CrossRef]
- Qin, C.; Wang, J.; Zhu, H.; Zhang, J.; Hu, S.; Zhang, D. Neural network-based safe optimal robust control for affine nonlinear systems with unmatched disturbances. Neurocomputing 2022, 506, 228–239. [Google Scholar] [CrossRef]
- Qin, C.; Wang, J.; Zhu, H.; Xiao, Q.; Zhang, D. Safe adaptive learning algorithm with neural network implementation for H∞ control of nonlinear safety-critical system. Int. J. Robust Nonlinear Control 2023, 33, 372–391. [Google Scholar] [CrossRef]
- Srinivasan, M.; Abate, M.; Nilsson, G.; Coogan, S. Extent-compatible control barrier functions. Syst. Control Lett. 2021, 150, 104895. [Google Scholar] [CrossRef]
- Yang, Y.; Yin, Y.; He, W.; Vamvoudakis, K.G.; Modares, H. Safety-aware reinforcement learning framework with an actor-critic-barrier structure. In Proceedings of the 2019 American Control Conference (ACC), Philadelphia, PA, USA, 10–12 July 2019; pp. 2352–2358. [Google Scholar]
- Yang, Y.; Vamvoudakis, K.G.; Modares, H.; Yin, Y.; Wunsch, D.C. Safe intermittent reinforcement learning with static and dynamic event generators. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 5441–5455. [Google Scholar] [CrossRef]
- Xu, J.; Wang, J.; Rao, J.; Zhong, Y.; Wang, H. Adaptive dynamic programming for optimal control of discrete-time nonlinear system with state constraints based on control barrier function. Int. J. Robust Nonlinear Control 2022, 32, 3408–3424. [Google Scholar] [CrossRef]
- Brunke, L.; Greeff, M.; Hall, A.W.; Yuan, Z.; Zhou, S.; Panerati, J.; Schoellig, A.P. Safe learning in robotics: From learning-based control to safe reinforcement learning. Annu. Rev. Control Robot. Auton. Syst. 2022, 5, 411–444. [Google Scholar] [CrossRef]
- Qin, C.; Zhu, H.; Wang, J.; Xiao, Q.; Zhang, D. Event-triggered safe control for the zero-sum game of nonlinear safety-critical systems with input saturation. IEEE Access 2022, 10, 40324–40337. [Google Scholar] [CrossRef]
- Bakule, L. Decentralized control: An overview. Annu. Rev. Control. 2008, 32, 87–98. [Google Scholar] [CrossRef]
- Xu, L.X.; Wang, Y.L.; Wang, X.; Peng, C. Decentralized Event-Triggered Adaptive Control for Interconnected Nonlinear Systems With Actuator Failures. IEEE Trans. Fuzzy Syst. 2022, 31, 148–159. [Google Scholar] [CrossRef]
- Guo, B.; Dian, S.; Zhao, T. Robust NN-based decentralized optimal tracking control for interconnected nonlinear systems via adaptive dynamic programming. Nonlinear Dyn. 2022, 110, 3429–3446. [Google Scholar] [CrossRef]
- Feng, Z.; Li, R.B.; Wu, L. Adaptive decentralized control for constrained strong interconnected nonlinear systems and its application to inverted pendulum. IEEE Trans. Neural Netw. Learn. Syst. 2023, 1–11. [Google Scholar] [CrossRef]
- Zouhri, A.; Boumhidi, I. Stability analysis of interconnected complex nonlinear systems using the Lyapunov and Finsler property. Multimed. Tools Appl. 2021, 80, 19971–19988. [Google Scholar] [CrossRef]
- Li, X.; Zhan, Y.; Tong, S. Adaptive neural network decentralized fault-tolerant control for nonlinear interconnected fractional-order systems. Neurocomputing 2022, 488, 14–22. [Google Scholar] [CrossRef]
- Tan, Y.; Yuan, Y.; Xie, X.; Tian, E.; Liu, J. Observer-based event-triggered control for interval type-2 fuzzy networked system with network attacks. IEEE Trans. Fuzzy Syst. 2023, 1–10. [Google Scholar] [CrossRef]
- Zhang, J.; Li, S.; Ahn, C.K.; Xiang, Z. Adaptive fuzzy decentralized dynamic surface control for switched large-scale nonlinear systems with full-state constraints. IEEE Trans. Cybern. 2021, 52, 10761–10772. [Google Scholar] [CrossRef]
- Huo, X.; Karimi, H.R.; Zhao, X.; Wang, B.; Zong, G. Adaptive-critic design for decentralized event-triggered control of constrained nonlinear interconnected systems within an identifier-critic framework. IEEE Trans. Cybern. 2021, 52, 7478–7491. [Google Scholar] [CrossRef]
- Bao, C.; Wang, P.; Tang, G. Data-Driven Based Model-Free Adaptive Optimal Control Method for Hypersonic Morphing Vehicle. IEEE Trans. Aerosp. Electron. Syst. 2022, 1–15. [Google Scholar] [CrossRef]
- Farzanegan, B.; Suratgar, A.A.; Menhaj, M.B.; Zamani, M. Distributed optimal control for continuous-time nonaffine nonlinear interconnected systems. Int. J. Control 2022, 95, 3462–3476. [Google Scholar] [CrossRef]
- Heydari, M.H.; Razzaghi, M. A numerical approach for a class of nonlinear optimal control problems with piecewise fractional derivative. Chaos Solitons Fractals 2021, 152, 111465. [Google Scholar] [CrossRef]
- Liu, S.; Niu, B.; Zong, G.; Zhao, X.; Xu, N. Data-driven-based event-triggered optimal control of unknown nonlinear systems with input constraints. Nonlinear Dyn. 2022, 109, 891–909. [Google Scholar] [CrossRef]
- Niu, B.; Liu, J.; Wang, D.; Zhao, X.; Wang, H. Adaptive decentralized asymptotic tracking control for large-scale nonlinear systems with unknown strong interconnections. IEEE/CAA J. Autom. Sin. 2021, 9, 173–186. [Google Scholar] [CrossRef]
- Zhao, B.; Luo, F.; Lin, H.; Liu, D. Particle swarm optimized neural networks based local tracking control scheme of unknown nonlinear interconnected systems. Neural Netw. 2021, 134, 54–63. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Y.; Niu, B.; Zong, G.; Xu, N.; Ahmad, A.M. Event-triggered optimal decentralized control for stochastic interconnected nonlinear systems via adaptive dynamic programming. Neurocomputing 2023, 539, 126163. [Google Scholar] [CrossRef]
- Wang, T.; Wang, H.; Xu, N.; Zhang, L.; Alharbi, K.H. Sliding-mode surface-based decentralized event-triggered control of partially unknown interconnected nonlinear systems via reinforcement learning. Inf. Sci. 2023, 641, 119070. [Google Scholar] [CrossRef]
- Lewis, F.L.; Vrabie, D. Reinforcement learning and adaptive dynamic programming for feedback control. IEEE Circuits Syst. Mag. 2009, 9, 32–50. [Google Scholar] [CrossRef]
- Tang, F.; Niu, B.; Zong, G.; Zhao, X.; Xu, N. Periodic event-triggered adaptive tracking control design for nonlinear discrete-time systems via reinforcement learning. Neural Netw. 2022, 154, 43–55. [Google Scholar] [CrossRef]
- Sun, J.; Liu, C. Backstepping-based adaptive dynamic programming for missile-target guidance systems with state and input constraints. J. Frankl. Inst. 2018, 355, 8412–8440. [Google Scholar] [CrossRef]
- Zhao, S.; Wang, J.; Wang, H.; Xu, H. Goal representation adaptive critic design for discrete-time uncertain systems subjected to input constraints: The event-triggered case. Neurocomputing 2022, 492, 676–688. [Google Scholar] [CrossRef]
- Liu, C.; Zhang, H.; Xiao, G.; Sun, S. Integral reinforcement learning based decentralized optimal tracking control of unknown nonlinear large-scale interconnected systems with constrained-input. Neurocomputing 2019, 323, 1–11. [Google Scholar] [CrossRef]
- Sun, H.; Hou, L. Adaptive decentralized finite-time tracking control for uncertain interconnected nonlinear systems with input quantization. Int. J. Robust Nonlinear Control 2021, 31, 4491–4510. [Google Scholar] [CrossRef]
- Duan, D.; Liu, C. Finite-horizon optimal tracking control for constrained-input nonlinear interconnected system using aperiodic distributed nonzero-sum games. IET Control Theory Appl. 2021, 15, 1199–1213. [Google Scholar] [CrossRef]
- Li, Y.; Li, Y.-X.; Tong, S. Event-based finite-time control for nonlinear multi-agent systems with asymptotic tracking. IEEE Trans. Autom. Control 2023, 68, 3790–3797. [Google Scholar] [CrossRef]
- Zhang, H.; Zhao, X.; Zong, G.; Xu, N. Fully distributed consensus of switched heterogeneous nonlinear multi-agent systems with bouc-wen hysteresis input. IEEE Trans. Netw. Sci. Eng. 2022, 9, 4198–4208. [Google Scholar] [CrossRef]
- Yang, X.; Zhou, Y.; Dong, N.; Wei, Q. Adaptive critics for decentralized stabilization of constrained-input nonlinear interconnected systems. IEEE Trans. Syst. Man Cybern. Syst. 2021, 52, 4187–4199. [Google Scholar] [CrossRef]
- Zhao, Y.; Wang, H.; Xu, N.; Zong, G.; Zhao, X. Reinforcement learning-based decentralized fault tolerant control for constrained interconnected nonlinear systems. Chaos Solitons Fractals 2023, 167, 113034. [Google Scholar] [CrossRef]
- Cui, L.; Zhang, Y.; Wang, X.; Xie, X. Event-triggered distributed self-learning robust tracking control for uncertain nonlinear interconnected systems. Appl. Math. Comput. 2021, 395, 125871. [Google Scholar] [CrossRef]
- Tang, Y.; Yang, X. Robust tracking control with reinforcement learning for nonlinear-constrained systems. Int. J. Robust Nonlinear Control 2022, 32, 9902–9919. [Google Scholar] [CrossRef]
- Yang, X.; Zhao, B. Optimal neuro-control strategy for nonlinear systems with asymmetric input constraints. IEEE/CAA J. Autom. Sin. 2020, 7, 575–583. [Google Scholar] [CrossRef]
- Beard, R.W.; Saridis, G.N.; Wen, J.T. Galerkin approximations of the generalized Hamilton-Jacobi-Bellman equation. Automatica 1997, 33, 2159–2177. [Google Scholar] [CrossRef]
- Liu, D.; Yang, X.; Wang, D.; Wei, Q. Reinforcement-learning-based robust controller design for continuous-time uncertain nonlinear systems subject to input constraints. IEEE Trans. Cybern. 2015, 45, 1372–1385. [Google Scholar] [CrossRef]
- Pishro, A.; Shahrokhi, M.; Sadeghi, H. Fault-tolerant adaptive fractional controller design for incommensurate fractional-order nonlinear dynamic systems subject to input and output restrictions. Chaos Solitons Fractals 2022, 157, 111930. [Google Scholar] [CrossRef]
- Zhang, L.; Zhao, X.; Zhao, N. Real-time reachable set control for neutral singular Markov jump systems with mixed delays. IEEE Trans. Circuits Syst. II Express Briefs 2021, 69, 1367–1371. [Google Scholar] [CrossRef]
- Lakmesari, S.H.; Mahmoodabadi, M.J.; Ibrahim, M.Y. Fuzzy logic and gradient descent-based optimal adaptive robust controller with inverted pendulum verification. Chaos Solitons Fractals 2021, 151, 111257. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| The ith Subsystem | Parameter | Meaning | Value |
|---|---|---|---|
| Mass of payload | 5 kg | ||
| Viscous friction | 2 N | ||
| The first subsystem | Length of the arm | 0.5 m | |
| Moment of inertia | 10 kg | ||
| Acceleration of gravity | 9.81 m/s | ||
| Mass of payload | 10 kg | ||
| Viscous friction | 2 N | ||
| The second subsystem | Length of the arm | 1 m | |
| Moment of inertia | 10 kg | ||
| Acceleration of gravity | 9.81 m/s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qin, C.; Wu, Y.; Zhang, J.; Zhu, T. Reinforcement Learning-Based Decentralized Safety Control for Constrained Interconnected Nonlinear Safety-Critical Systems. Entropy 2023, 25, 1158. https://doi.org/10.3390/e25081158
Qin C, Wu Y, Zhang J, Zhu T. Reinforcement Learning-Based Decentralized Safety Control for Constrained Interconnected Nonlinear Safety-Critical Systems. Entropy. 2023; 25(8):1158. https://doi.org/10.3390/e25081158
Chicago/Turabian StyleQin, Chunbin, Yinliang Wu, Jishi Zhang, and Tianzeng Zhu. 2023. "Reinforcement Learning-Based Decentralized Safety Control for Constrained Interconnected Nonlinear Safety-Critical Systems" Entropy 25, no. 8: 1158. https://doi.org/10.3390/e25081158
APA StyleQin, C., Wu, Y., Zhang, J., & Zhu, T. (2023). Reinforcement Learning-Based Decentralized Safety Control for Constrained Interconnected Nonlinear Safety-Critical Systems. Entropy, 25(8), 1158. https://doi.org/10.3390/e25081158