


Joint Detection and Communication over Type-Sensitive Networks
{kind=link}
{kind=link}
Abstract
:1. Introduction
- We formulate a framework for distributed inference in which the agents’ observations are correlated through both the hypothesis and the empirical distribution (or type) of the network state. This formulation captures a high level of coupling between agents.
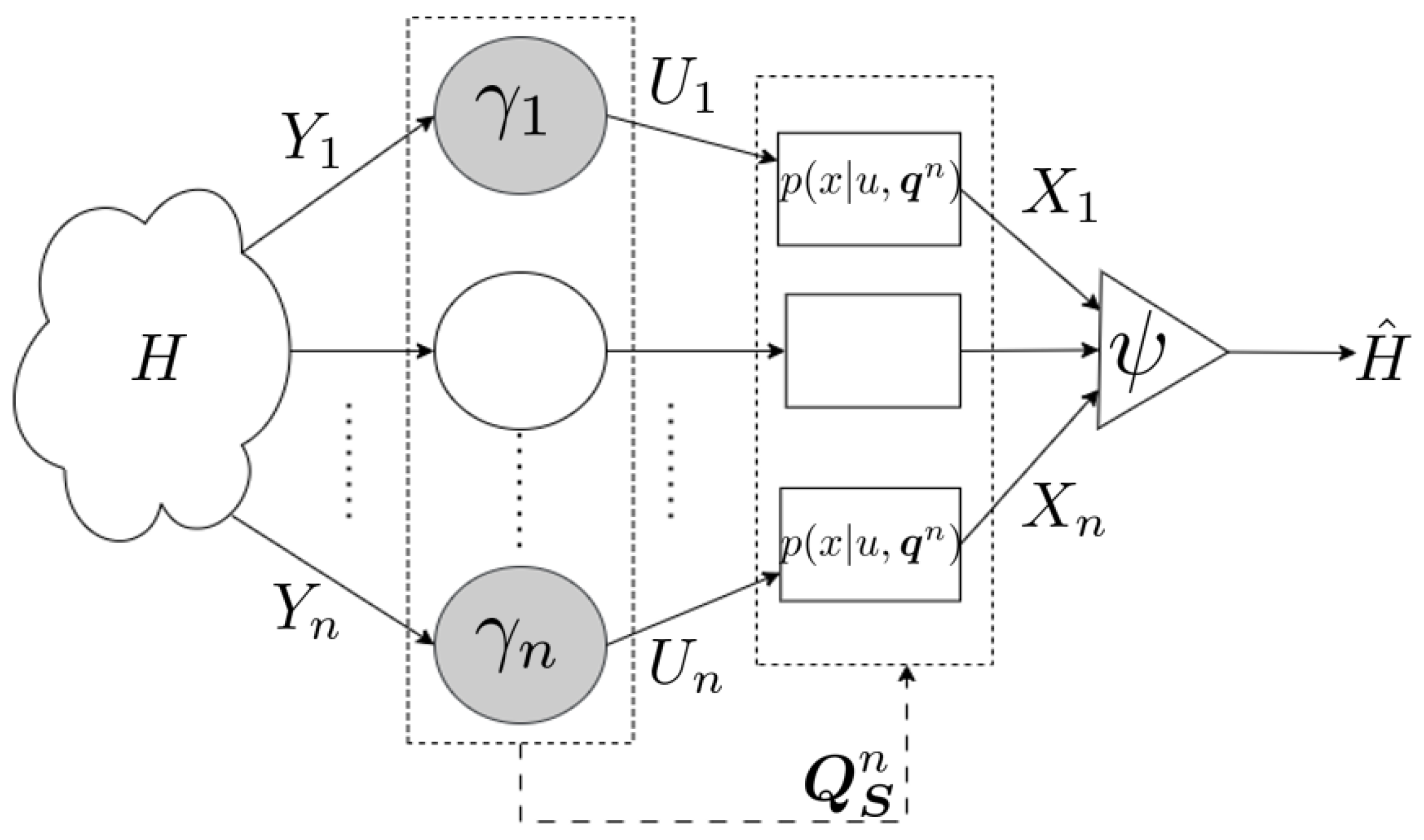
- We consider a distributed inference problem with a communication link between the agents and the fusion center, with the additional caveat that the noise over the link is dependent on the agents. Hence, our framework captures joint sensing with correlated observations as well as joint communications with correlated noise.
- We derive expressions for the error exponent for a single class of agents, then extend our results to the case of heterogeneous groups of identical agents. In particular, assuming that identical agents use a common rule, the optimal error exponent depends only on the ratios of the groups, not on the actual size of the groups themselves. This allows a wide range of problems to be studied in which there are multiple classes of agents that interfere with each other.
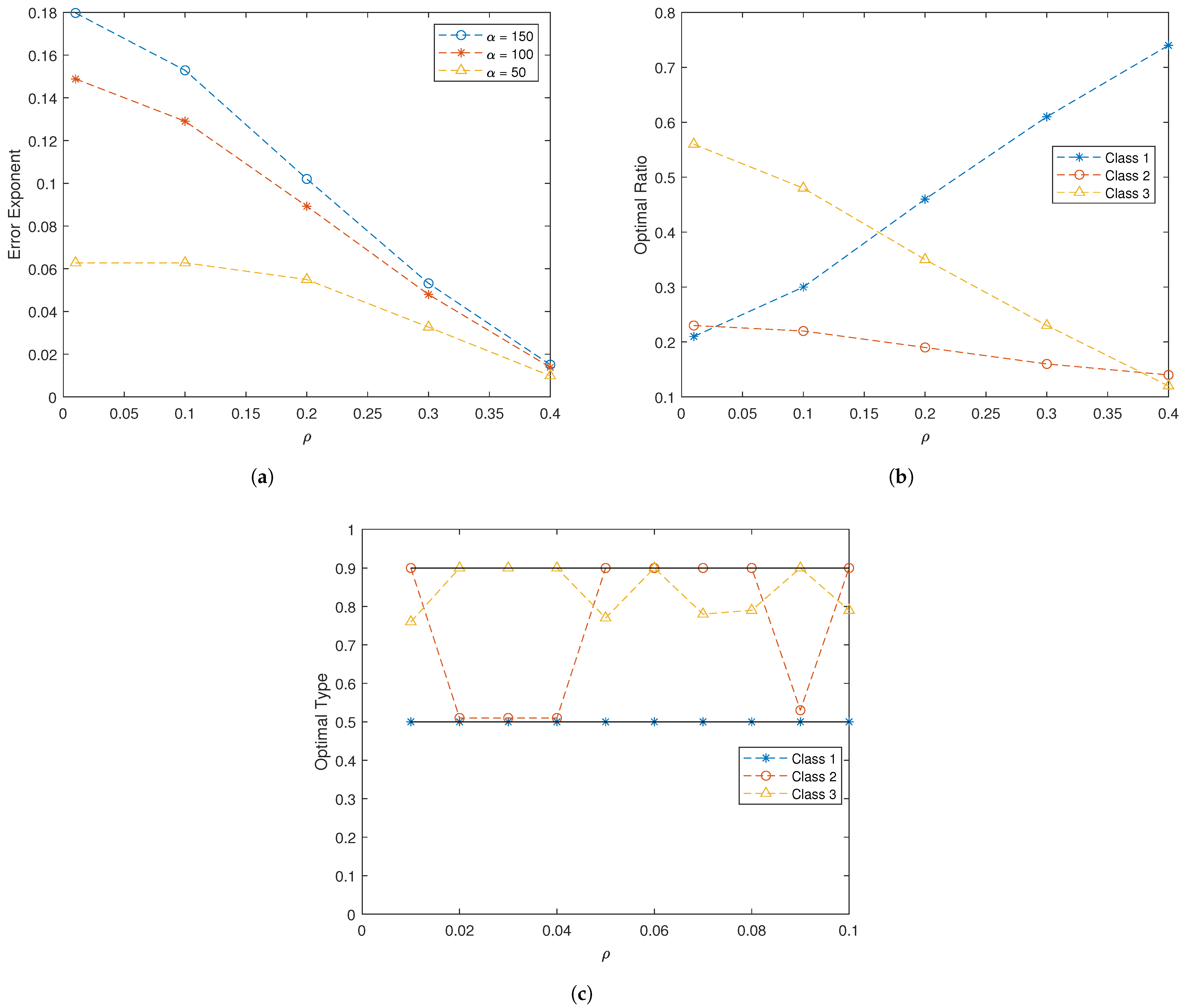
- We present a numerical example for a three-class case to highlight the utility of the proposed expression for the error exponent. In particular, we show how this expression can be used to optimize the ratios of heterogeneous groups in the presence of cross-class interference. This example further illustrates the fact that the true distribution may not dominate the asymptotics. The effect of the channel is observed as well.
Notation
2. Materials and Methods
3. Problem Formulation, Definitions, and Assumptions
3.1. Problem Setup
3.2. Definitions
- 1.
- for all , , , .
- 2.
- for all , , , .
- 3.
- The agent states are i.i.d. a priori, i.e., .
3.3. Key Assumptions
- (a)
- All agents are identical, as provided in Definition 3. Hence, we remove the notational dependence on k in the sequel.
- (b)
- The hypothesis model obeys the following:
- (c)
- The signal model is continuous in for all agents, that is, if is a sequence in such that , then ,
- (d)
- The channel model is continuous in for all agents. That is, if is a sequence in such that , then , ,
4. Main Results and Important Corollaries
4.1. Single-Class Results
- The maximization occurs over instead of ; hence, we have directly removed the dependence on . Because the expression in Theorem 1 is continuous over the compact set , it always achieves its maximum (versus supremum). This is due to Assumptions 5.c and 5.d.
- Note that the second term is the classical Chernoff information corresponding to the fixed distributions , and that the KL divergence term can be thought of as a bias. Hence, we only need to consider the m-dimensional probability vector that yields the worst Chernoff information biased by the KL divergence. In a certain sense, is sufficiently close to the true state distribution p, such that its poor performance (under strategy ) cannot be ignored even in asymptotically large networks. Only one distribution in dominates the asymptotic performance, as expected, although it may not be the true distribution p. An instantiation of this is provided in the numerical results.
- The maximization for takes place over all of ; however, it is only necessary to search a subset of to find the maximum, thereby reducing the computational cost. To determine the subset of interest, observe thatwhere both and are due to Hölder’s inequality. Using the fact that the Chernoff information is non-negative [44], it can be seen that the distribution that achieves the maximum over must satisfyThe right-hand side of (24) is the Chernoff information for the signal model under distribution p; hence, the maximizing must live in a ball defined by the Kullback–Leibler divergence centered at the distribution p with radius , thereby reducing the search space for the optimization. In fact, the Chernoff information admits a closed-form solution for a wide range of distributions, such as members of the exponential family [48]
4.2. Multi-Class Results
- (a)
- The hypothesis model obeys the following.
- (b)
- The signal model is continuous in for all classes, that is, if ; are sequences in such that , , then ,
- (c)
- The channel model is continuous in for all classes, that is, if ; are sequences in such that , , then , ,
- Observe that all agents are coupled through the distributions , and recall that for a given class c, depends on all agents in class c through their states . Hence, the distributions collectively depend on all agents in the network, meaning that the received signal, decision, and message for a given agent are dependent on all agents in the network. As a result, Theorem 2 captures a very strong form of coupling.
- Note that the expression in Theorem 2 is not expressed as a limit, does not depend on n, and does not depend on the actual size of the classes. Hence, Theorem 2 provides an objective function that can be used to design rules that do not depend on the size of the network.
- Theorem 2 depends only on the ratios of the classes; that is, Theorem 2 provides an explicit objective function to find the optimal ratios for asymptotically large networks. Specifically, to find the optimal ratios we can solveIn the next section, we present a numerical example that highlights the utility of the proposed framework.
5. Numerical Example
- When , the signal model for Class 1 depends only on the number of agents in Class 2 that are in State 1.
- The signal models for Classes 2 and 3 are constant with respect to the underlying hypothesis as well as the distributions , , and ; hence, agents in Class 2 or 3 cannot distinguish between the two hypotheses.
6. Proofs
6.1. Proof of Theorem 1
6.1.1. Definitions
6.1.2. Key Lemmas
6.2. Intermediate Lemmas
- (a)
- There exists a non-negative function such that and , , , , and
- (b)
- We have
- Because both and depend on n, does as well; however, because depends only on , any type in satisfies Equation (52) regardless of n or .
- Observe that for any there exists a type such that . Hence, such that for all and for any , such that . That is, is non-empty for all . Because depends only on and depends only on , depends only on , and the same works for all agents and all .
6.3. Proof of Theorem 2
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1. Proofs of Lemmas for Theorem 1
Appendix A.2. Extension of Theorem 1
References
- Shanthamallu, U.S.; Spanias, A.; Tepedelenlioglu, C.; Stanley, M. A brief survey of machine learning methods and their sensor and IoT applications. In Proceedings of the 2017 8th International Conference on Information, Intelligence, Systems & Applications (IISA), Larnaca, Cyprus, 27–30 August 2017; pp. 1–8. [Google Scholar]
- Tajer, A.; Kar, S.; Poor, H.V.; Cui, S. Distributed joint cyber attack detection and state recovery in smart grids. In Proceedings of the 2011 IEEE International Conference on Smart Grid Communications (SmartGridComm), Brussels, Belgium, 17–20 October 2011; pp. 202–207. [Google Scholar]
- Patel, A.; Ram, H.; Jagannatham, A.K.; Varshney, P.K. Robust cooperative spectrum sensing for MIMO cognitive radio networks under csi uncertainty. IEEE Trans. Signal Process. 2018, 66, 18–33. [Google Scholar] [CrossRef]
- Chawla, A.; Singh, R.K.; Patel, A.; Jagannatham, A.K.; Hanzo, L. Distributed detection for centralized and decentralized millimeter wave massive MIMO sensor networks. IEEE Trans. Veh. Technol. 2021, 70, 7665–7680. [Google Scholar] [CrossRef]
- Geng, B.; Cheng, X.; Brahma, S.; Kellen, D.; Varshney, P.K. Collaborative human decision making with heterogeneous agents. IEEE Trans. Comput. Soc. Syst. 2022, 9, 469–479. [Google Scholar] [CrossRef]
- Gupta, S.S.; Mehta, N.B. Ordered transmissions schemes for detection in spatially correlated wireless sensor networks. IEEE Trans. Commun. 2021, 69, 1565–1577. [Google Scholar] [CrossRef]
- Gangan, M.S.; Vasconcelos, M.M.; Mitra, U.; Câmara, O.; Boedicker, J.Q. Intertemporal trade-off between population growth rate and carrying capacity during public good production. iScience 2022, 25, 104117. [Google Scholar] [CrossRef]
- Tsitsiklis, J.; Athans, M. On the complexity of decentralized decision making and detection problems. IEEE Trans. Autom. Control 1985, 30, 440–446. [Google Scholar] [CrossRef]
- Aalo, V.; Viswanathou, R. On distributed detection with correlated sensors: Two examples. IEEE Trans. Aerosp. Electron. Syst. 1989, 25, 414–421. [Google Scholar] [CrossRef]
- Willett, P.; Swaszek, P.F.; Blum, R.S. The good, bad and ugly: Distributed detection of a known signal in dependent Gaussian noise. IEEE Trans. Signal Process. 2000, 48, 3266–3279. [Google Scholar]
- Gül, G. Minimax robust decentralized hypothesis testing for parallel sensor networks. IEEE Trans. Inf. Theory 2020, 67, 538–548. [Google Scholar] [CrossRef]
- Chen, H.; Chen, B.; Varshney, P.K. A new framework for distributed detection with conditionally dependent observations. IEEE Trans. Signal Process. 2012, 60, 1409–1419. [Google Scholar] [CrossRef]
- Hanna, O.A.; Li, X.; Fragouli, C.; Diggavi, S. Can we break the dependency in distributed detection? In Proceedings of the 2022 IEEE International Symposium on Information Theory (ISIT), Espoo, Finland, 26 June–1 July 2022; pp. 2720–2725. [Google Scholar]
- Kasasbeh, H.; Cao, L.; Viswanathan, R. Soft-decision-based distributed detection with correlated sensing channels. IEEE Trans. Aerosp. Electron. Syst. 2019, 55, 1435–1449. [Google Scholar] [CrossRef]
- Maleki, N.; Vosoughi, A. On bandwidth constrained distributed detection of a known signal in correlated Gaussian noise. IEEE Trans. Veh. Technol. 2020, 69, 11428–114440. [Google Scholar] [CrossRef]
- Shaska, J.; Mitra, U. State-dependent decentralized detection. IEEE Trans. Inf. Theory 2023. submitted. [Google Scholar]
- Csiszar, I. The method of types [information theory]. IEEE Trans. Inf. Theory 1998, 44, 2505–2523. [Google Scholar] [CrossRef]
- Raginsky, M. Empirical processes, typical sequences, and coordinated actions in standard borel spaces. IEEE Trans. Inf. Theory 2013, 59, 1288–1301. [Google Scholar] [CrossRef]
- Schuurmans, M.; Patrinos, P. A general framework for learning-based distributionally robust mpc of markov jump systems. IEEE Trans. Autom. Control 2023, 68, 2950–2965. [Google Scholar] [CrossRef]
- Haghifam, M.; Tan, V.Y.; Khisti, A. Sequential classification with empirically observed statistics. IEEE Trans. Inf. Theory 2021, 67, 3095–3113. [Google Scholar] [CrossRef]
- Guo, F.R.; Richardson, T.S. Chernoff-type concentration of empirical probabilities in relative entropy. IEEE Trans. Inf. Theory 2021, 67, 549–558. [Google Scholar] [CrossRef]
- Weinberger, N.; Merhav, N. The dna storage channel: Capacity and error probability bounds. IEEE Trans. Inf. Theory 2022, 68, 5657–5700. [Google Scholar] [CrossRef]
- Lalitha, A.; Javidi, T.; Sarwate, A.D. Social learning and distributed hypothesis testing. IEEE Trans. Inf. Theory 2018, 64, 6161–6179. [Google Scholar] [CrossRef]
- Inan, Y.; Kayaalp, M.; Telatar, E.; Sayed, A.H. Social learning under randomized collaborations. In Proceedings of the 2022 IEEE International Symposium on Information Theory (ISIT), Espoo, Finland, 26 June–1 July 2022; pp. 115–120. [Google Scholar]
- Goetz, C.; Humm, B. Decentralized real-time anomaly detection in cyber-physical production systems under industry constraints. Sensors 2023, 23, 4207. [Google Scholar] [CrossRef]
- Shaska, J.; Mitra, U. Decentralized decision making in multi-agent networks: The state-dependent case. In Proceedings of the 2021 IEEE Global Communcations Conference, Madrid, Spain, 7–11 December 2021. [Google Scholar]
- Tsitsiklis, J.N. Decentralized detection by a large number of sensors. Math. Control Signals Syst. 1988, 1, 167–182. [Google Scholar] [CrossRef]
- Chen, B.; Tong, L.; Varshney, P.K. Channel-aware distributed detection in wireless sensor networks. IEEE Signal Process. Mag. 2006, 23, 16–26. [Google Scholar] [CrossRef]
- Duman, T.; Salehi, M. Decentralized detection over multiple-access channels. IEEE Trans. Aerosp. Electron. Syst. 1998, 34, 469–476. [Google Scholar] [CrossRef]
- Liu, B.; Chen, B. Channel-optimized quantizers for decentralized detection in sensor networks. IEEE Trans. Inf. Theory 2006, 52, 3349–3358. [Google Scholar]
- Gelfand, S.I.; Pinsker, M.S. Coding for channel with random parameters. Probl. Control Inf. Theory 1980, 9, 19–31. [Google Scholar]
- Choudhuri, C.; Kim, Y.H.; Mitra, U. Causal state communication. IEEE Trans. Inf. Theory 2013, 59, 3709–3719. [Google Scholar] [CrossRef]
- Miretti, L.; Kobayashi, M.; Gesbert, D.; De Kerret, P. Cooperative multiple-access channels with distributed state information. IEEE Trans. Inf. Theory 2021, 67, 5185–5199. [Google Scholar] [CrossRef]
- Zhang, W.; Vedantam, S.; Mitra, U. Joint transmission and state estimation: A constrained channel coding approach. IEEE Trans. Inf. Theory 2011, 57, 7084–7095. [Google Scholar] [CrossRef]
- Kobayashi, M.; Caire, G.; Kramer, G. Joint state sensing and communication: Optimal tradeoff for a memoryless case. In Proceedings of the 2018 IEEE International Symposium on Information Theory (ISIT), Vail, CO, USA, 17–22 June 2018; pp. 111–115. [Google Scholar]
- Bross, S.I.; Lapidoth, A. The rate-and-state capacity with feedback. IEEE Trans. Inf. Theory 2018, 64, 1893–1918. [Google Scholar] [CrossRef]
- Moon, J.; Park, J. Pattern-dependent noise prediction in signal-dependent noise. IEEE J. Sel. Areas Commun. 2001, 19, 730–743. [Google Scholar] [CrossRef]
- Tsiatmas, A.; Baggen, C.P.; Willems, F.M.; Linnartz, J.P.M.; Bergmans, J.W. An illumination perspective on visible light communications. IEEE Commun. Mag. 2014, 52, 64–71. [Google Scholar] [CrossRef]
- Kavcic, A.; Moura, J.M. Correlation-sensitive adaptive sequence detection. IEEE Trans. Magn. 1998, 34, 763–771. [Google Scholar] [CrossRef]
- Hareedy, A.; Amiri, B.; Galbraith, R.; Dolecek, L. Non-binary ldpc codes for magnetic recording channels: Error floor analysis and optimized code design. IEEE Trans. Commun. 2016, 64, 3194–3207. [Google Scholar] [CrossRef]
- Kuan, D.T.; Sawchuk, A.A.; Strand, T.C.; Chavel, P. Adaptive noise smoothing filter for images with signal-dependent noise. IEEE Trans. Pattern Anal. Mach. Intell. 1985, 2, 165–177. [Google Scholar] [CrossRef]
- JMeola, J.; Eismann, M.T.; Moses, R.L.; Ash, J.N. Modeling and estimation of signal-dependent noise in hyperspectral imagery. Appl. Opt. 2011, 50, 3829–3846. [Google Scholar]
- Michelusi, N.; Boedicker, J.; El-Naggar, M.Y.; Mitra, U. Queuing models for abstracting interactions in bacterial communities. IEEE J. Sel. Areas Commun. 2016, 34, 584–599. [Google Scholar] [CrossRef]
- Shannon, C.E.; Gallager, R.G.; Berlekamp, E.R. Lower bounds to error probability for coding on discrete memoryless channels. I. Inf. Control 1967, 10, 65–103. [Google Scholar] [CrossRef]
- Chamberland, J.-F.; Veeravalli, V. Asymptotic results for decentralized detection in power constrained wireless sensor networks. IEEE J. Sel. Areas Commun. 2004, 22, 1007–1015. [Google Scholar] [CrossRef]
- Yin, D.; Chen, Y.; Kannan, R.; Bartlett, P. Byzantine-robust distributed learning: Towards optimal statistical rates. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 5650–5659. [Google Scholar]
- Li, S.; Zhao, S.; Yang, P.; Andriotis, P.; Xu, L.; Sun, Q. Distributed consensus algorithm for events detection in cyber-physical systems. IEEE Internet Things J. 2019, 6, 2299–2308. [Google Scholar] [CrossRef]
- Nielson, F. Revisiting Chernoff information with likelihood ratio exponential families. Entropy 2022, 24, 1400. [Google Scholar] [CrossRef] [PubMed]
- Graves, L.M. The Theory of Functions of Real Variables; Courier Corporation: North Chelmsford, MA, USA, 2012. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; Wiley-Interscience: Hoboken, NJ, USA, 2006. [Google Scholar]
- Williams, D. Probability with Martingales; Cambridge University Press: Cambridge, MA, USA, 1991. [Google Scholar]
- Bartle, R.G.; Sherbert, D.R. Introduction to Real Analysis; Wiley: New York, NY, USA, 2000; Volume 2. [Google Scholar]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shaska, J.; Mitra, U. Joint Detection and Communication over Type-Sensitive Networks. Entropy 2023, 25, 1313. https://doi.org/10.3390/e25091313
Shaska J, Mitra U. Joint Detection and Communication over Type-Sensitive Networks. Entropy. 2023; 25(9):1313. https://doi.org/10.3390/e25091313
Chicago/Turabian StyleShaska, Joni, and Urbashi Mitra. 2023. "Joint Detection and Communication over Type-Sensitive Networks" Entropy 25, no. 9: 1313. https://doi.org/10.3390/e25091313
APA StyleShaska, J., & Mitra, U. (2023). Joint Detection and Communication over Type-Sensitive Networks. Entropy, 25(9), 1313. https://doi.org/10.3390/e25091313