


Prediction of Contact Fatigue Performance Degradation Trends Based on Multi-Domain Features and Temporal Convolutional Networks

Abstract
:1. Introduction
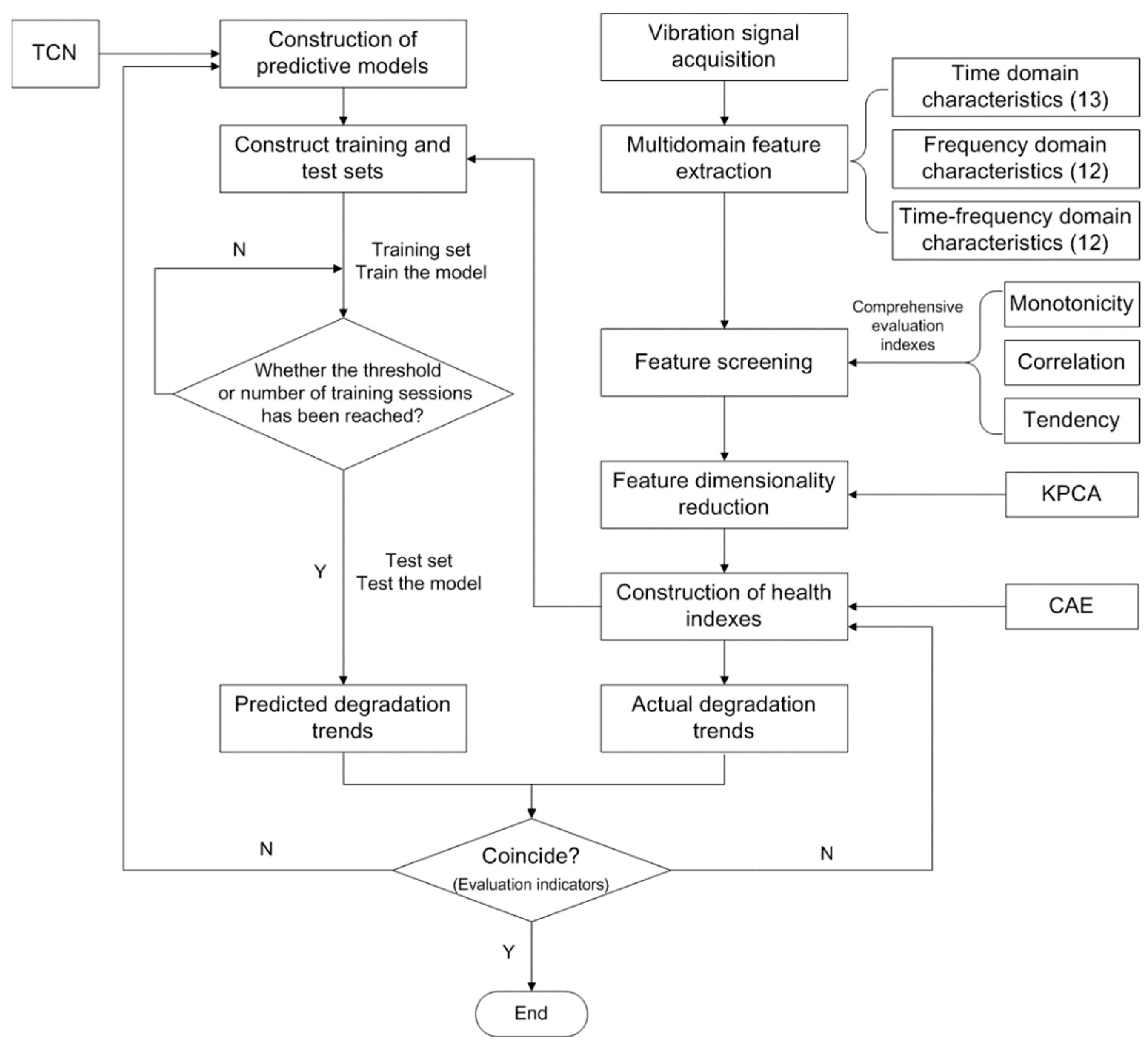
2. Theory and Method
2.1. Multi-Domain Feature Extraction and Feature Screening
2.1.1. Multi-Domain Feature Extraction
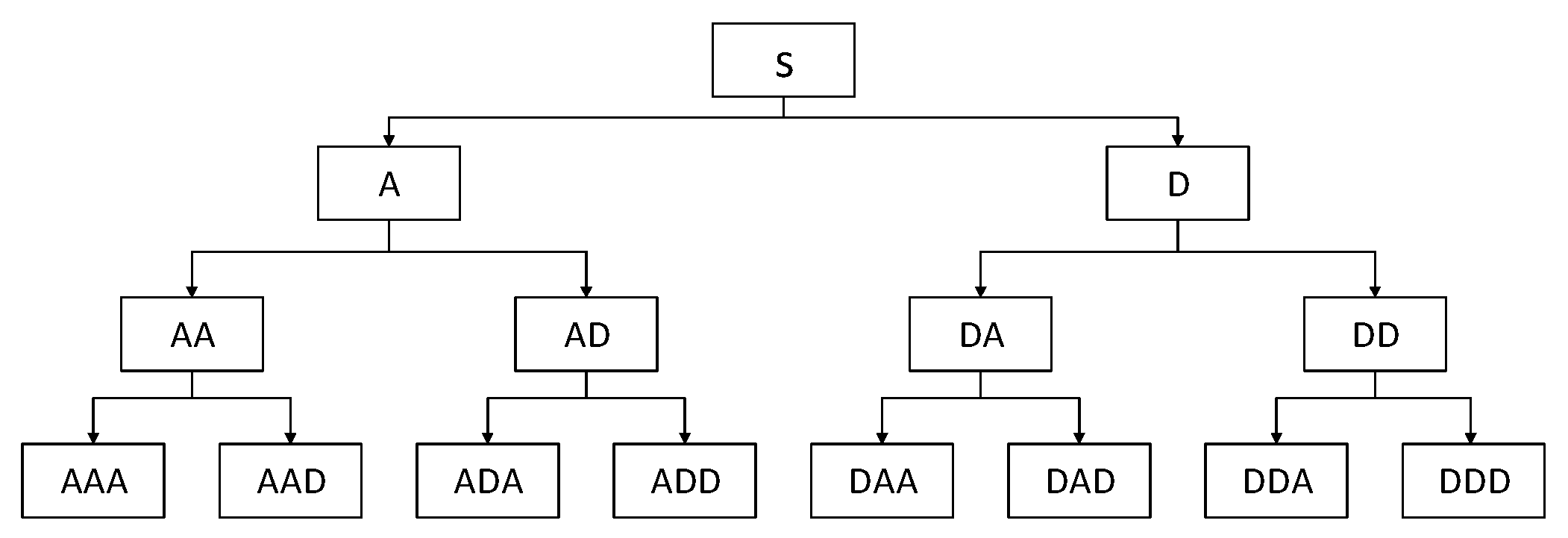
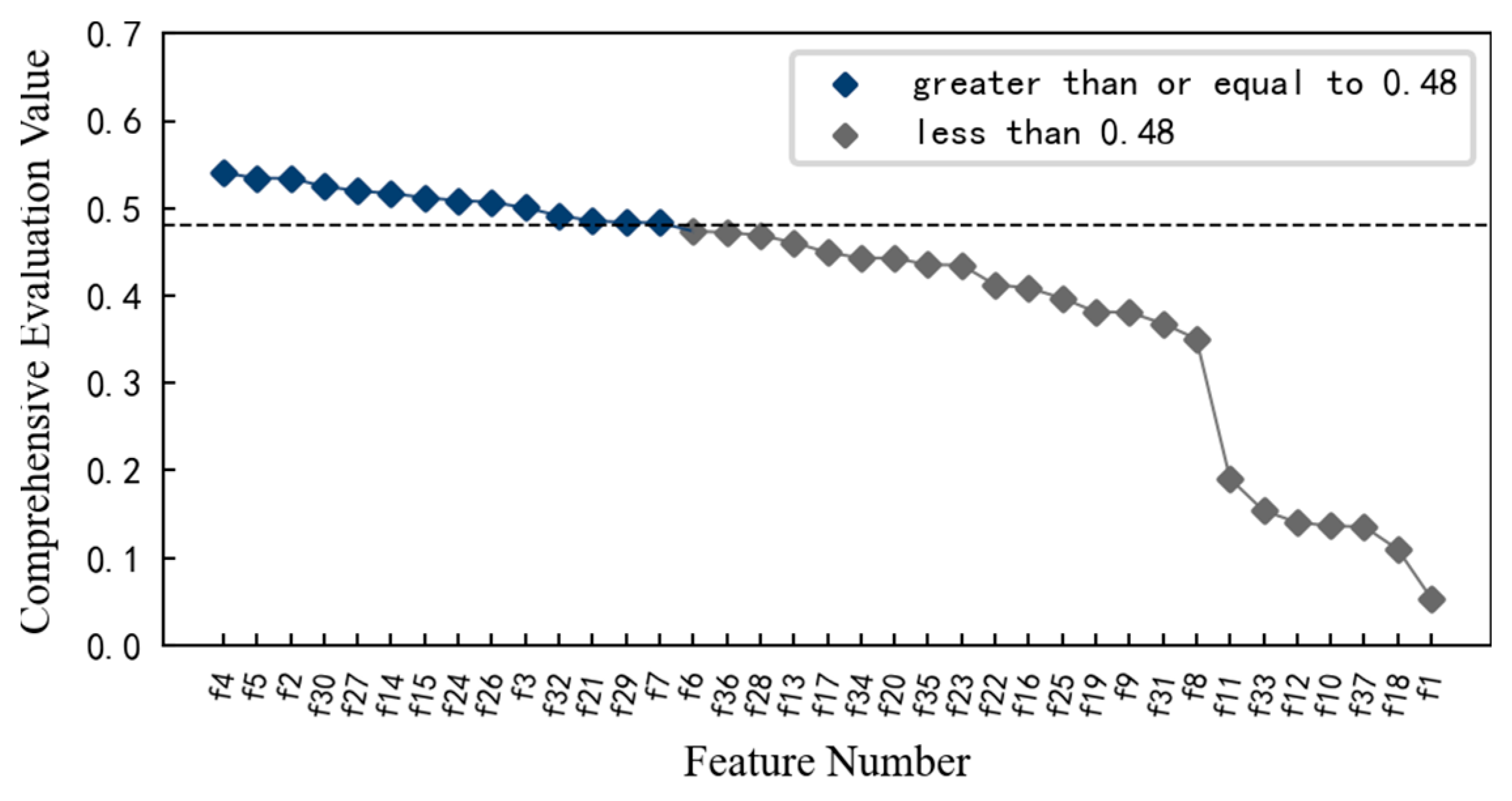
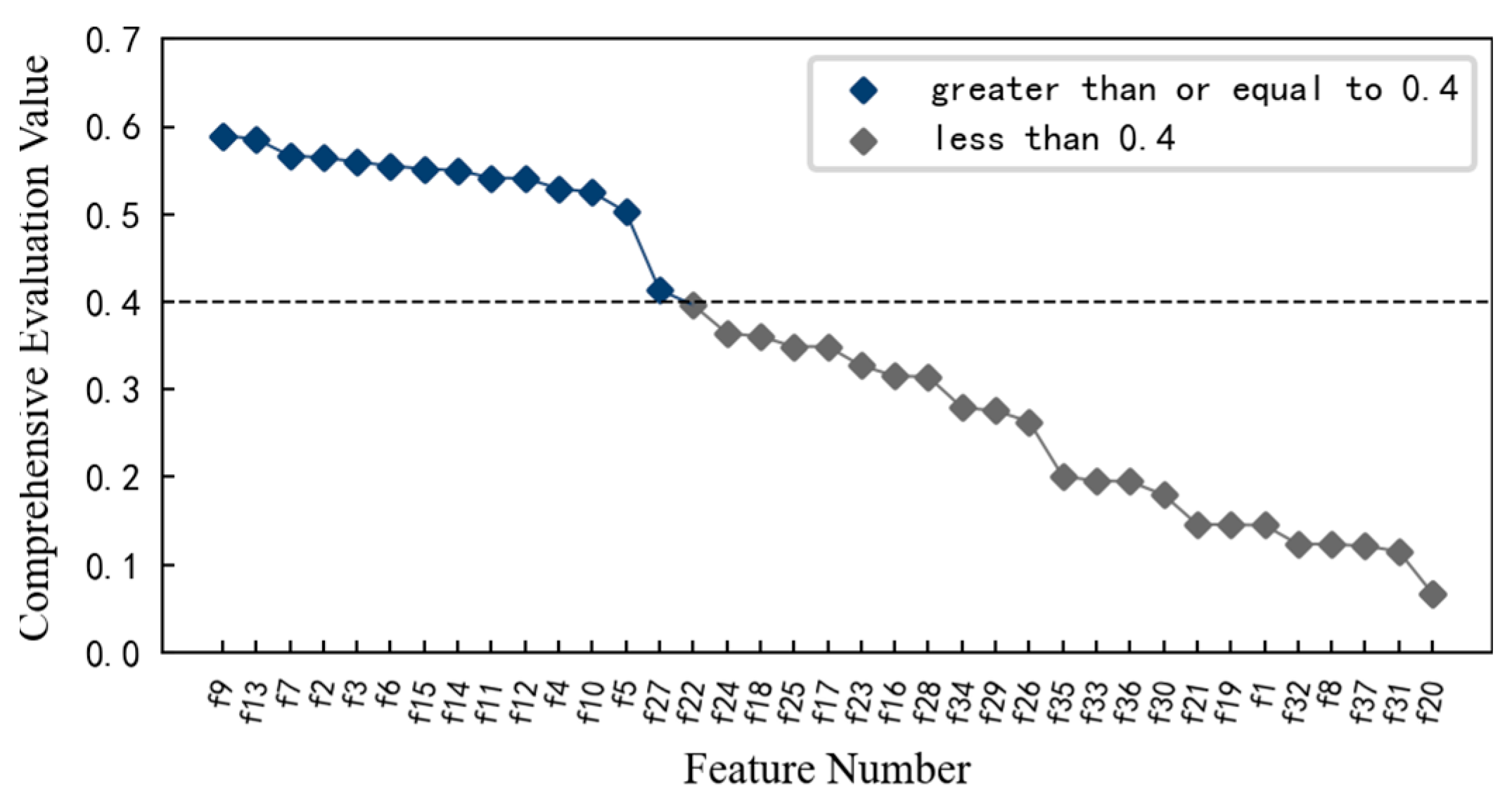
2.1.2. Feature Screening
2.2. Construction of Health Indexes
2.2.1. Feature Dimensionality Reduction Based on KPCA
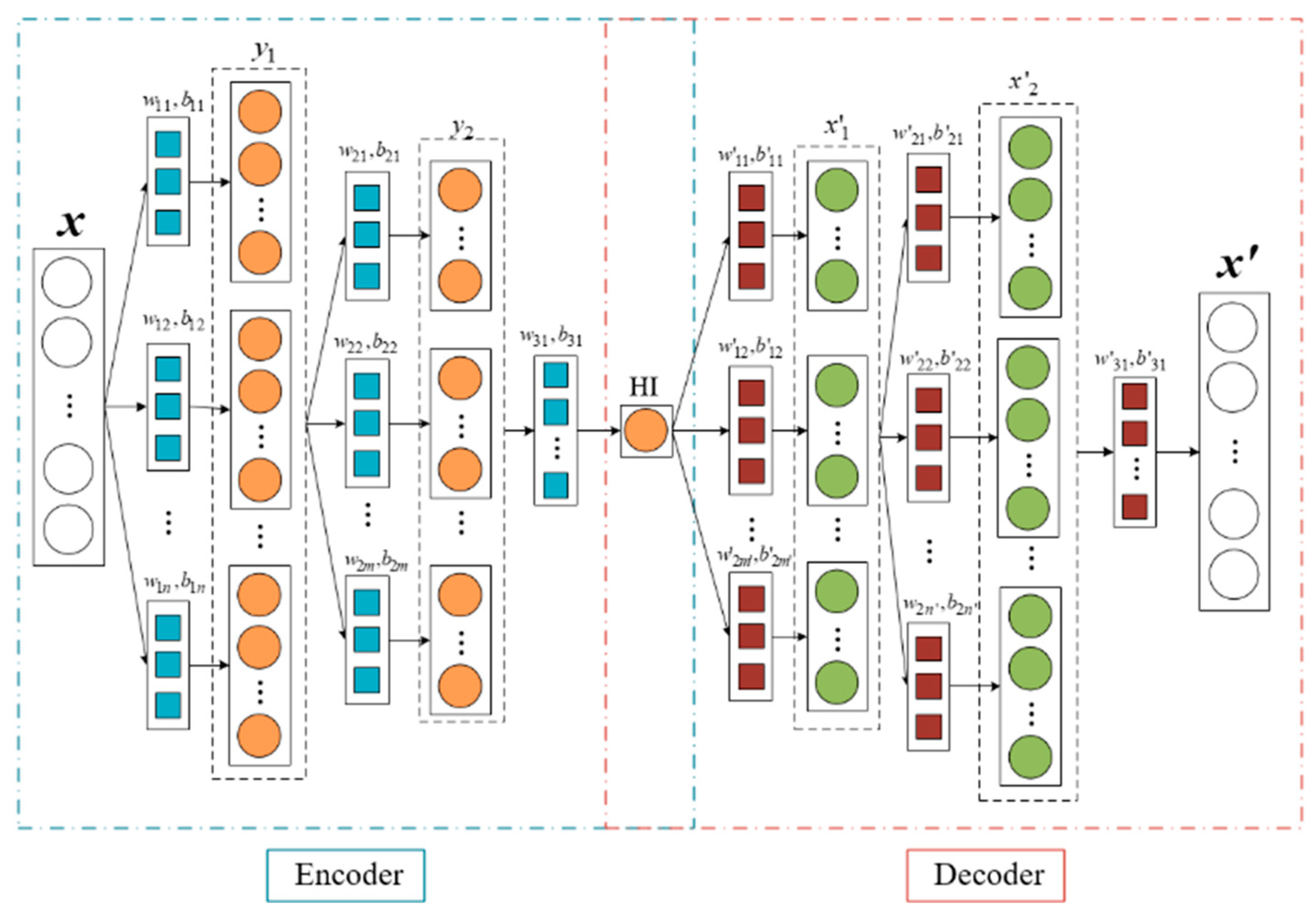
2.2.2. Construction of the HI Based on a CAE Network
2.3. Performance Degradation Prediction
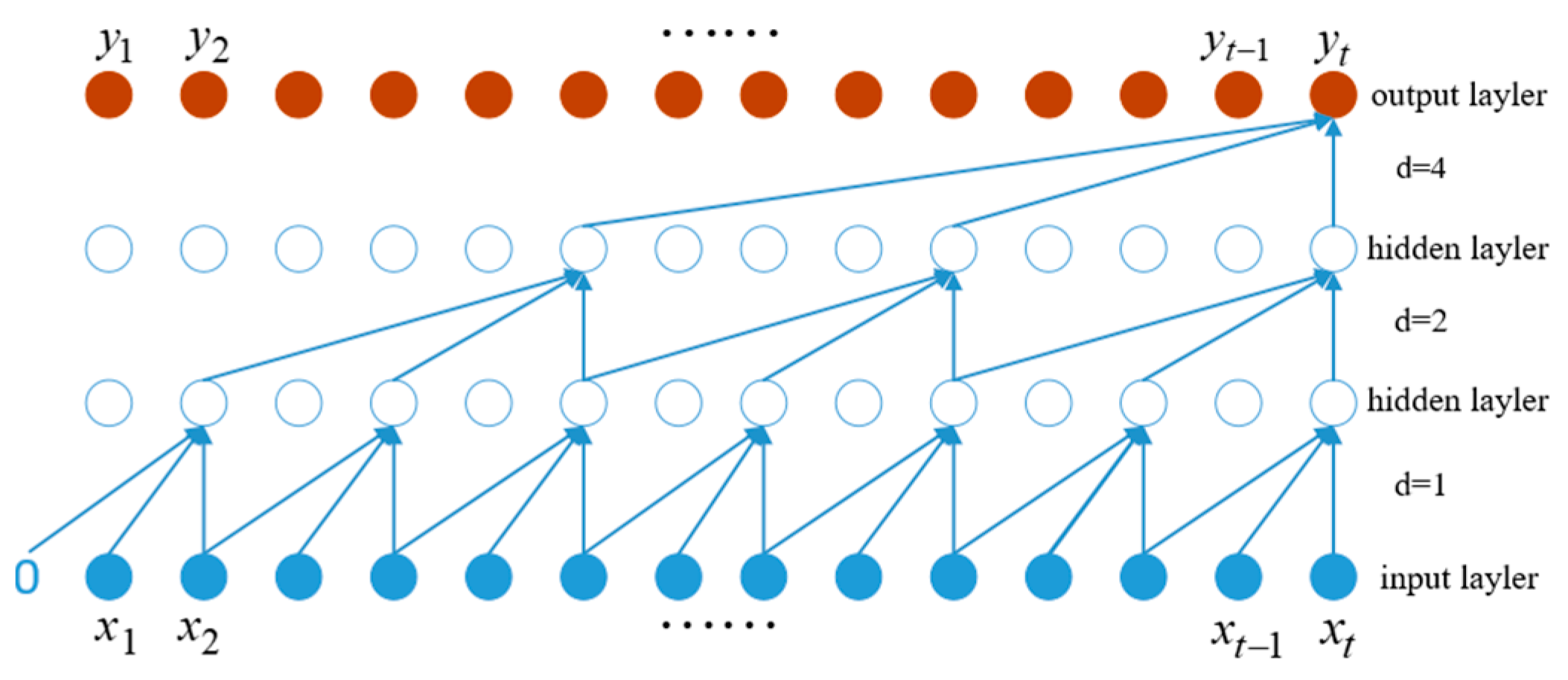
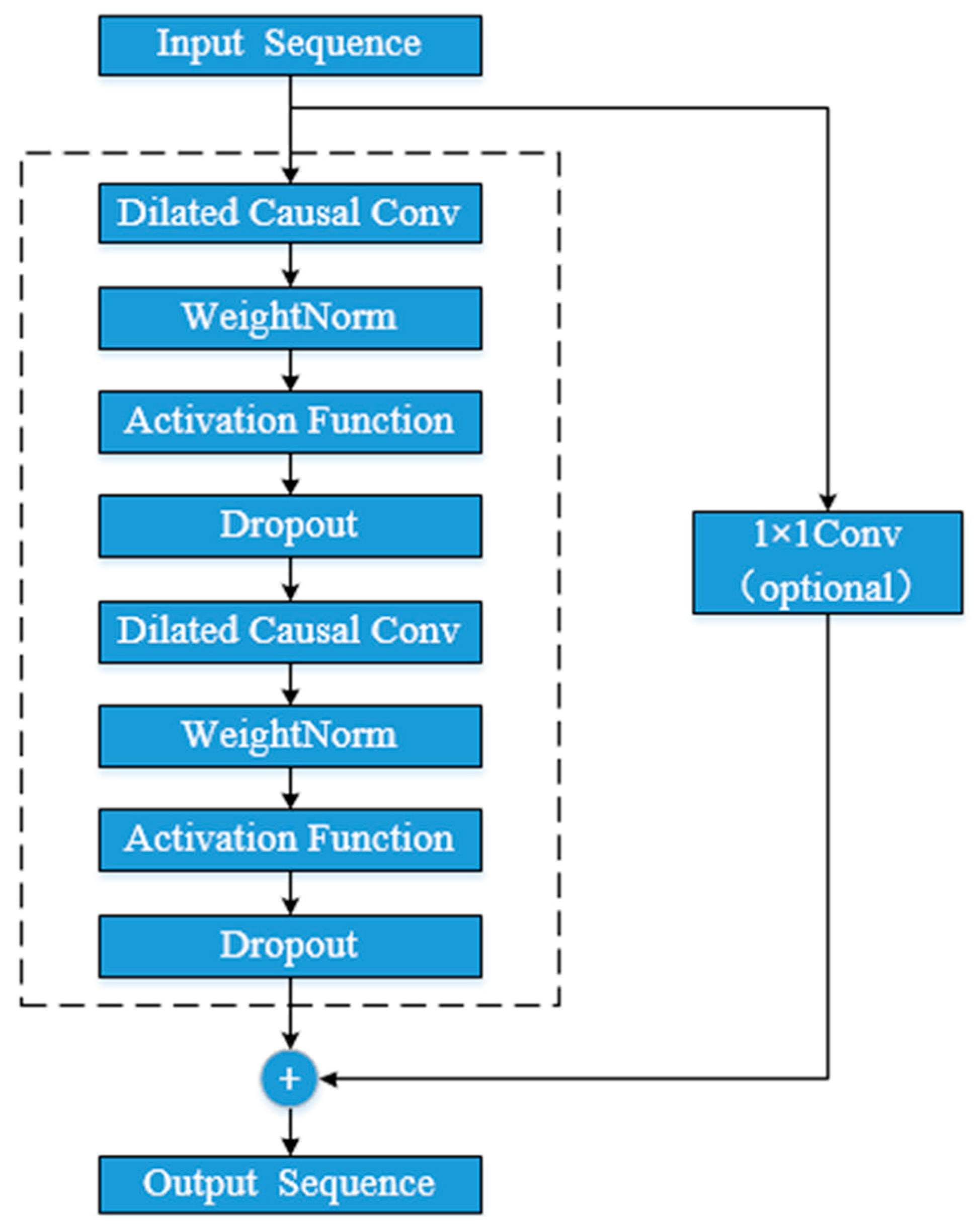
2.3.1. Temporal Convolutional Networks
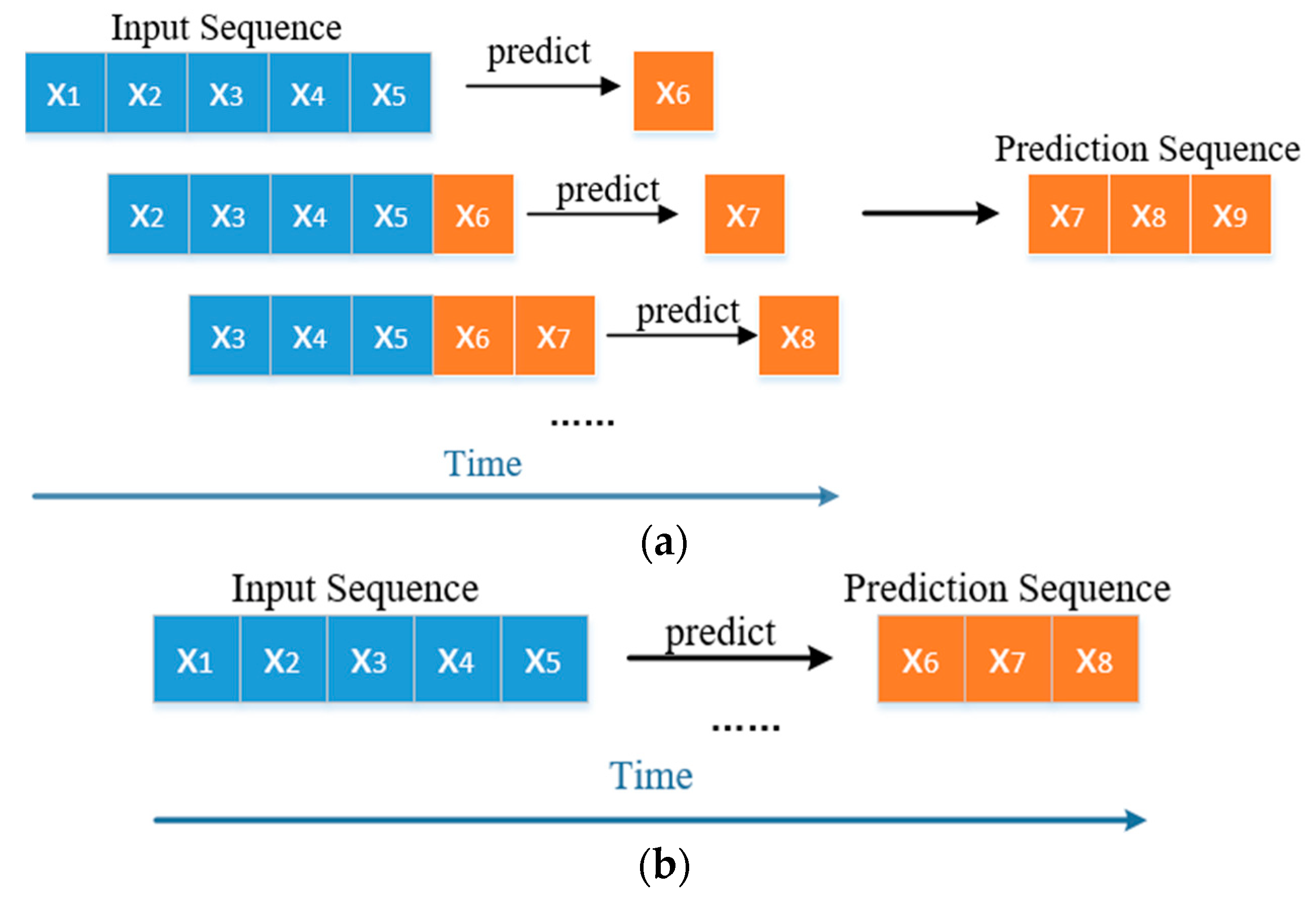
2.3.2. Performance Degradation Prediction Based on TCN
3. Verification
3.1. Verification of the Feature Screening Method
3.2. Verification of the HI Construction Method
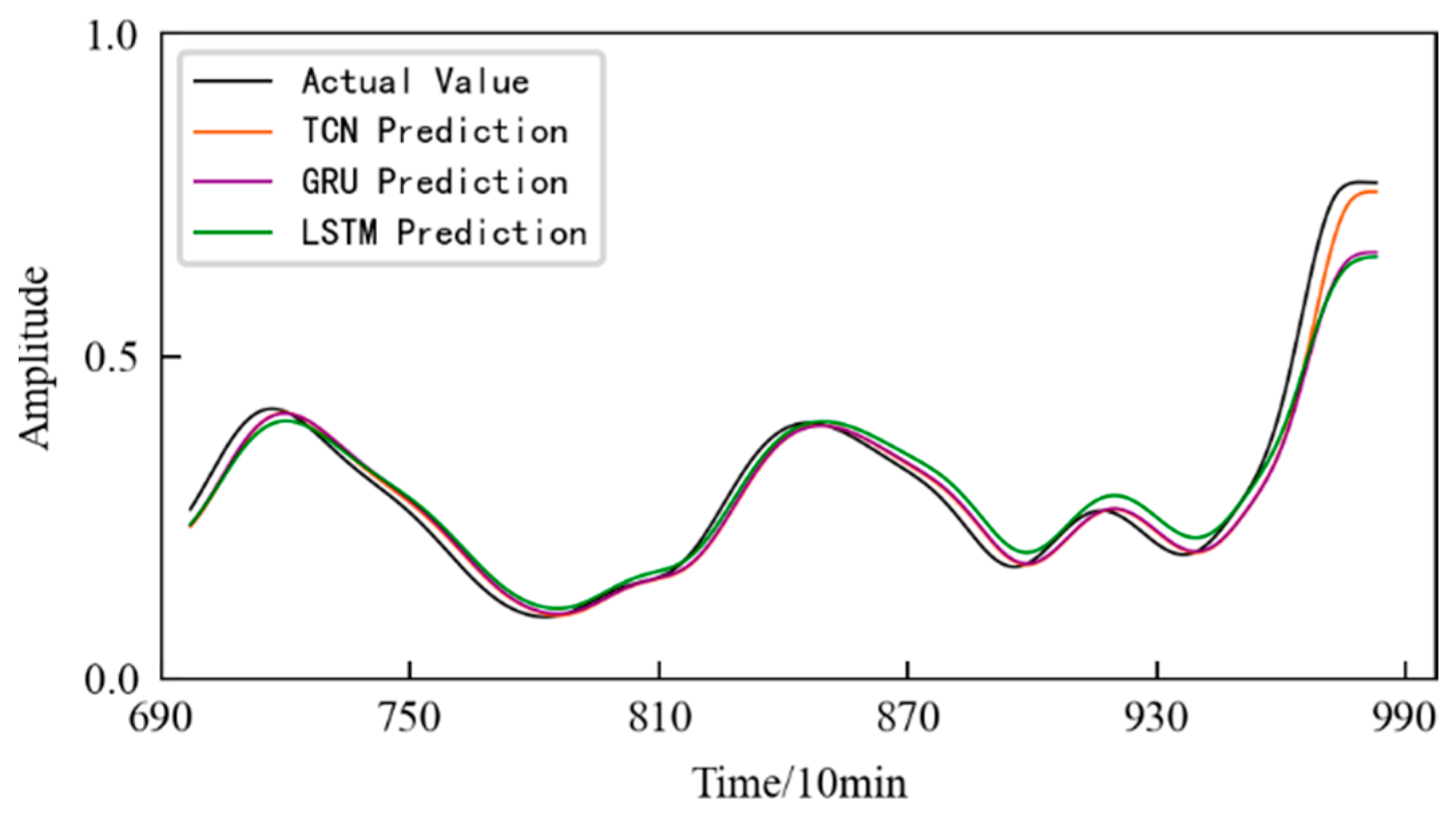
3.3. Verification of the Performance Degradation Prediction Model
4. Application
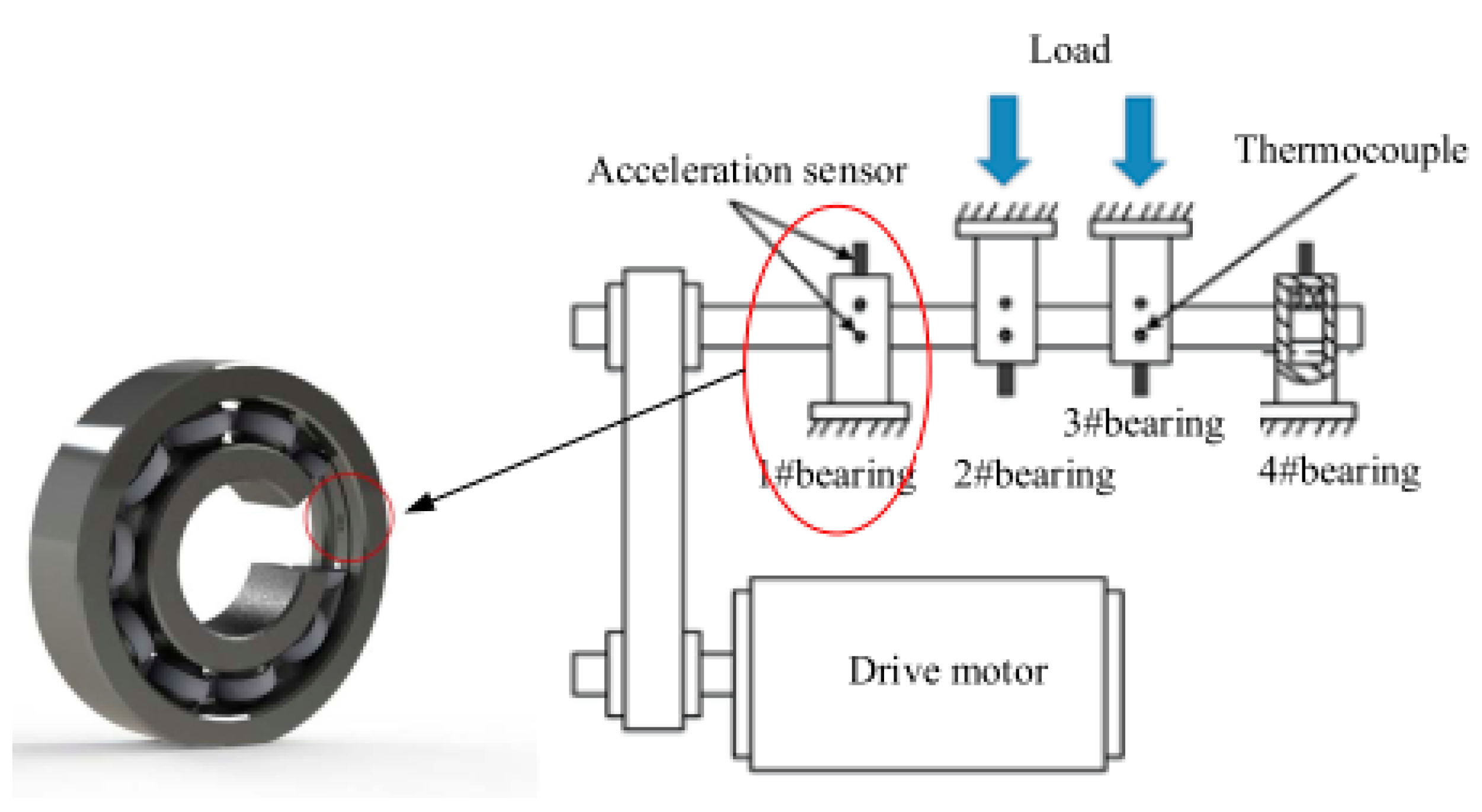
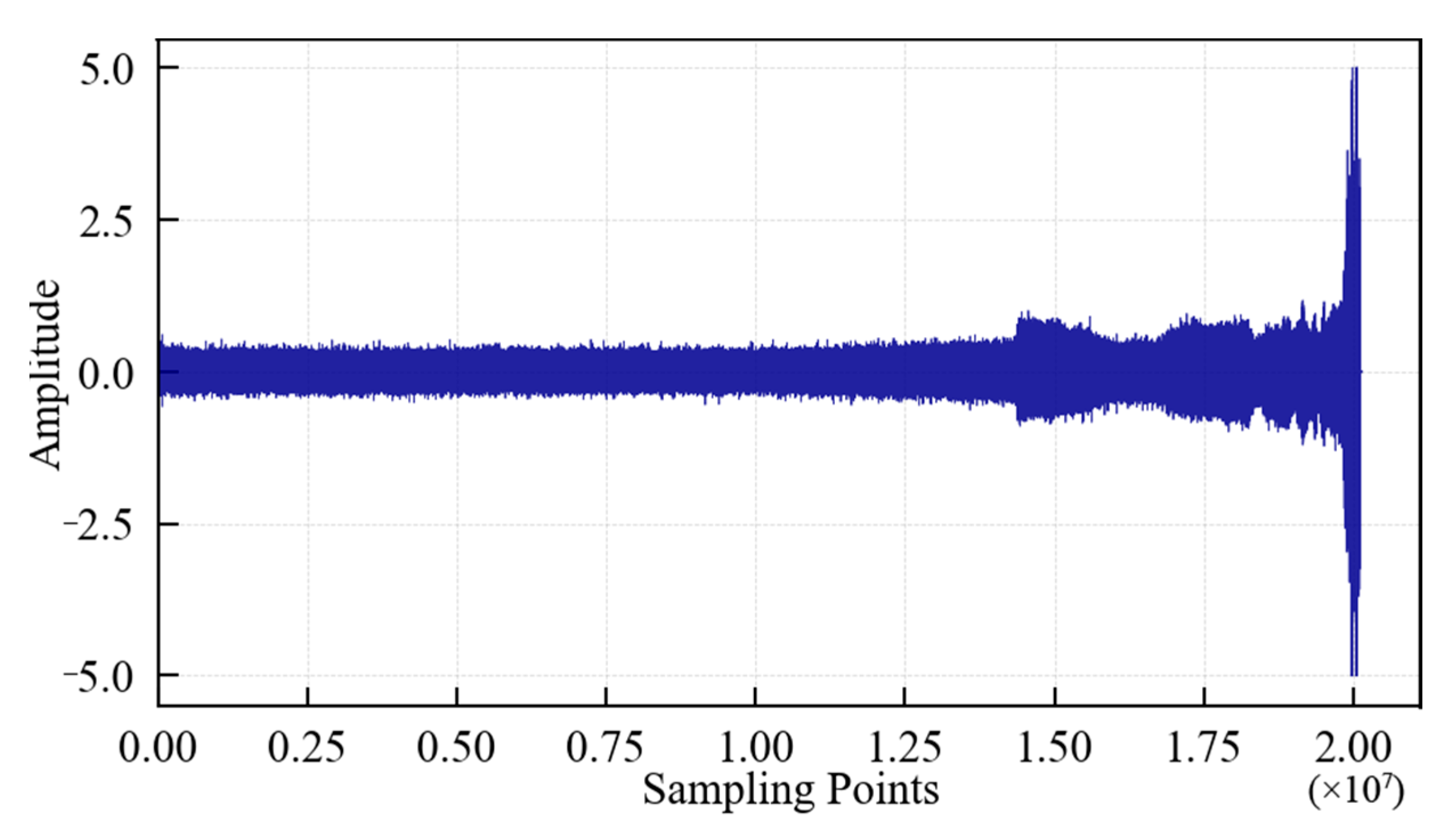
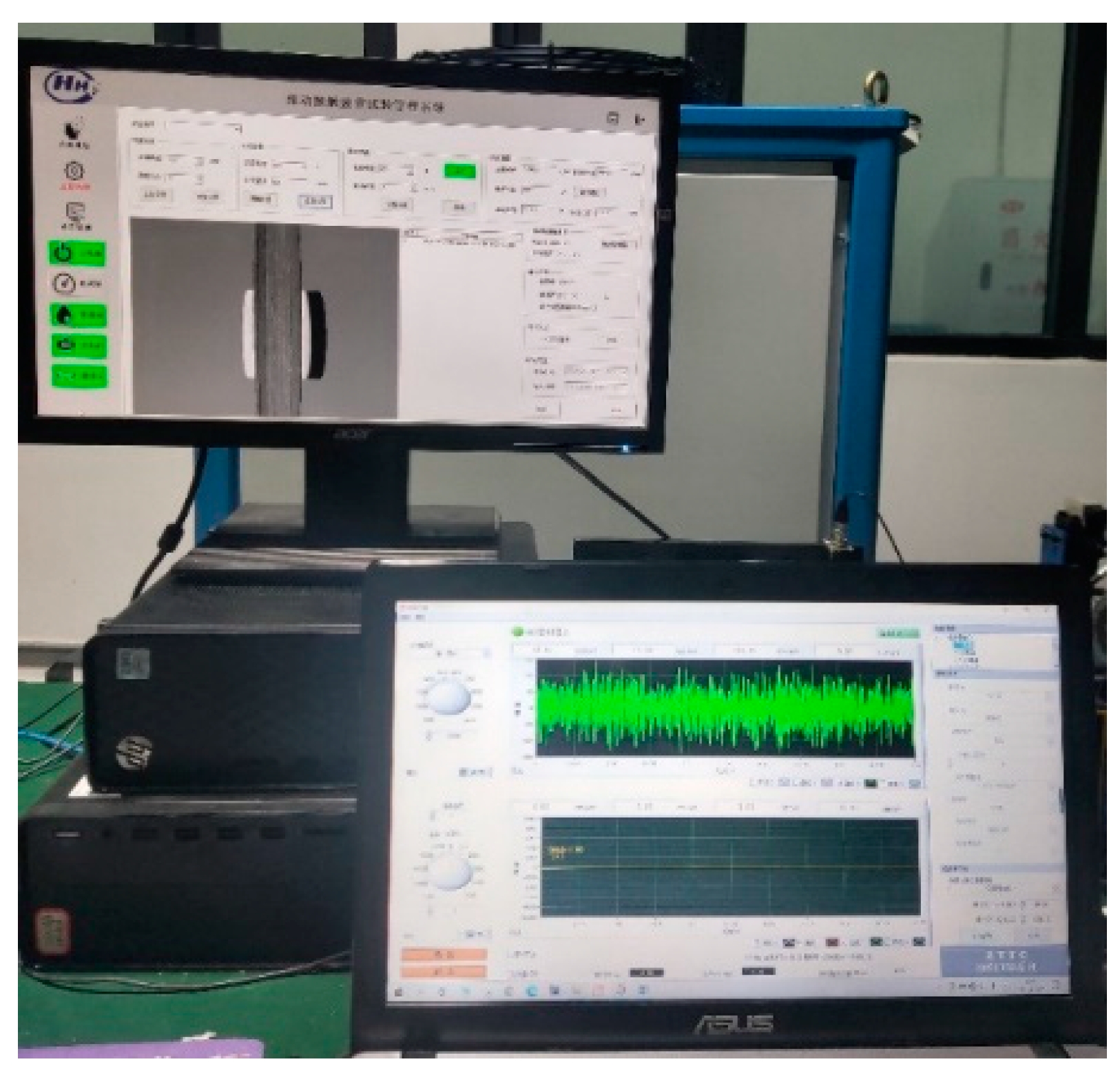
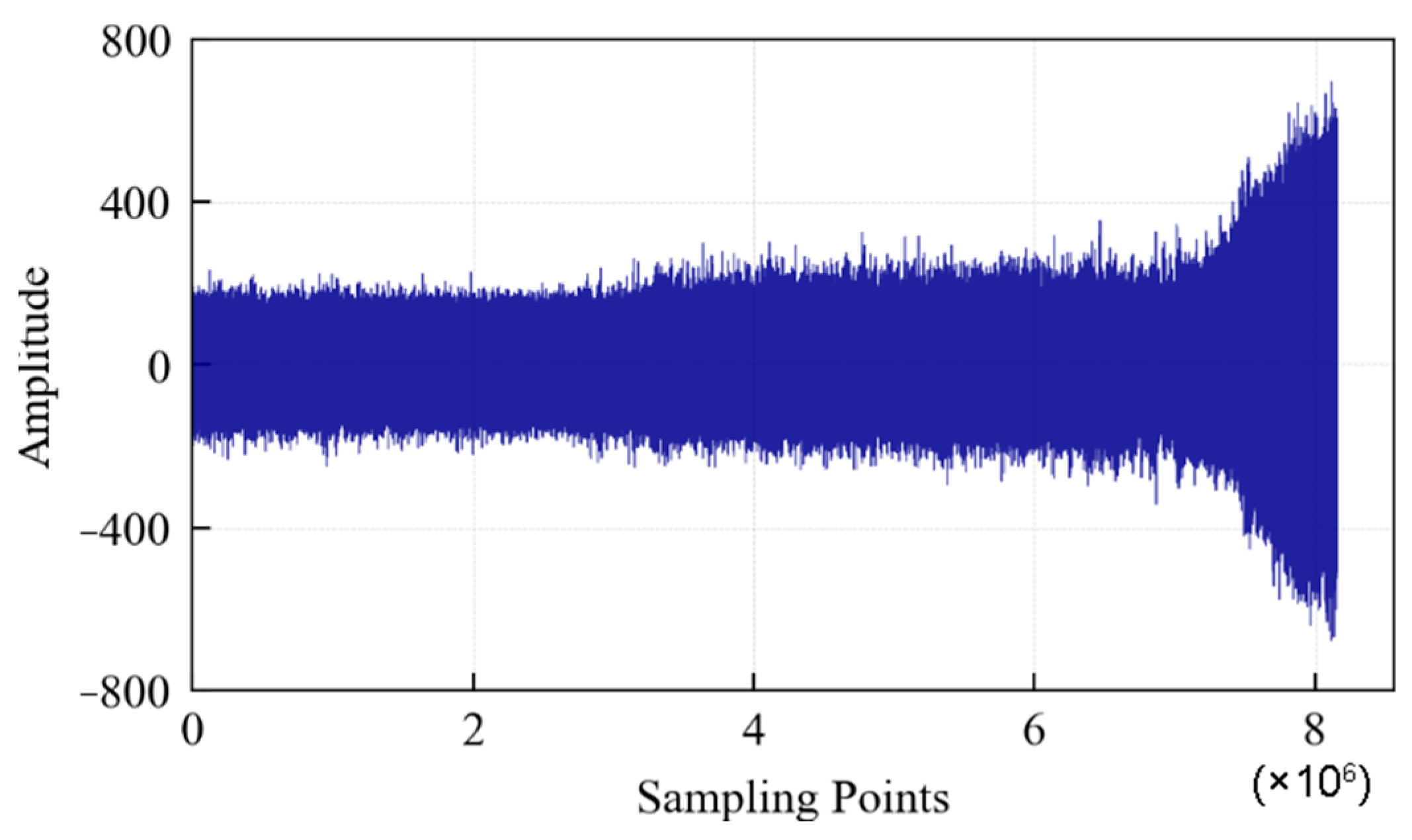
4.1. Rolling Contact Fatigue Test
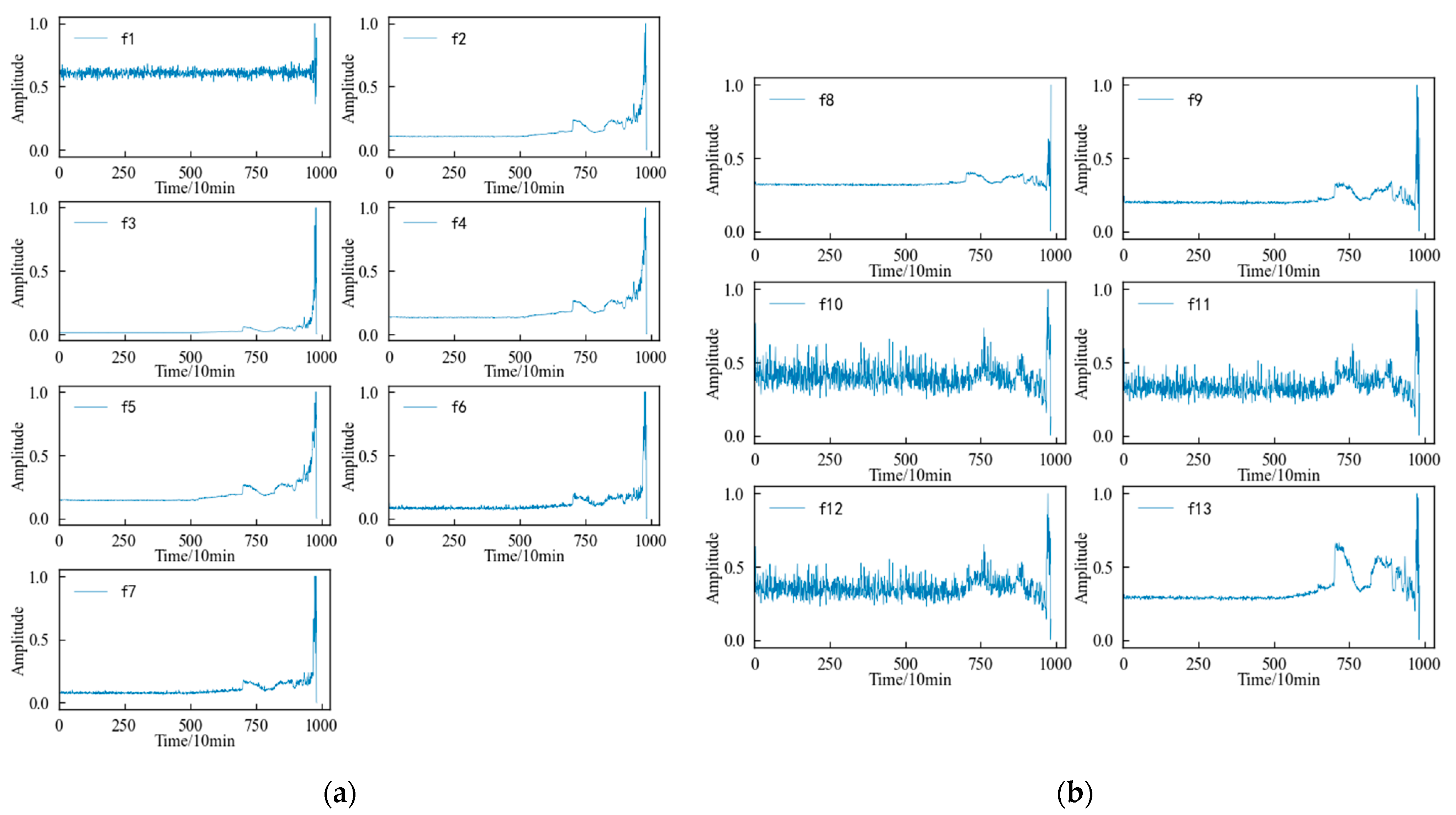
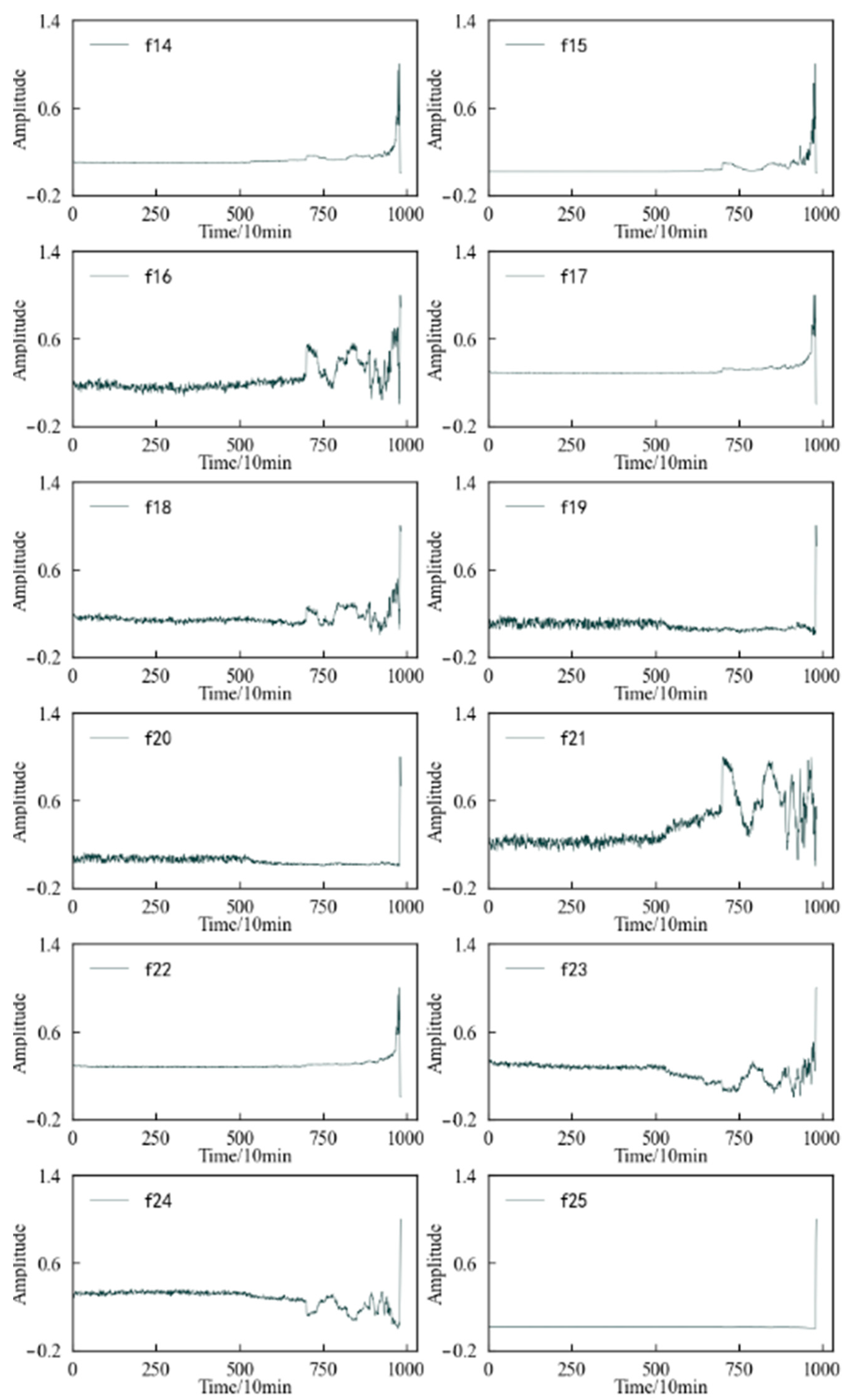
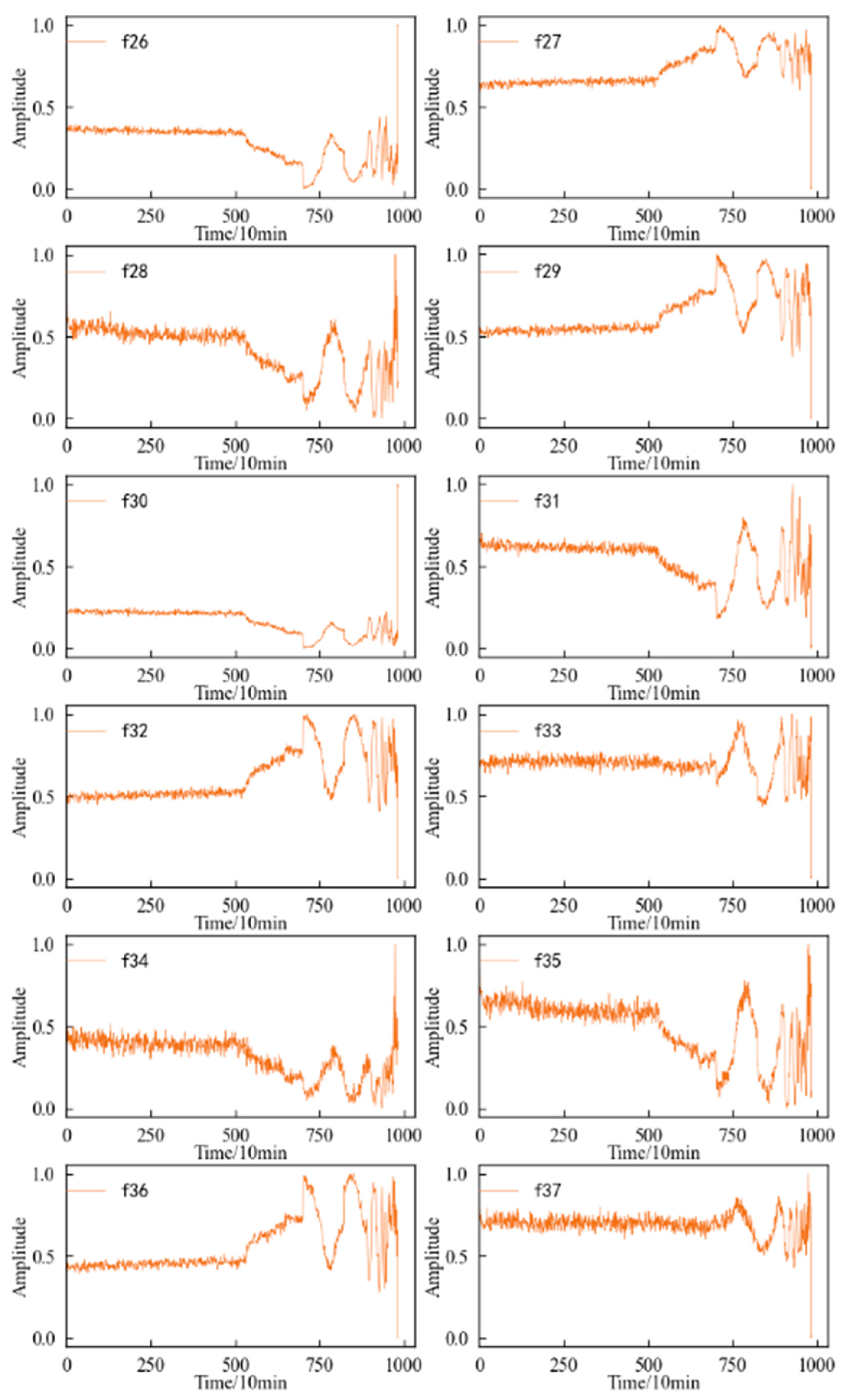
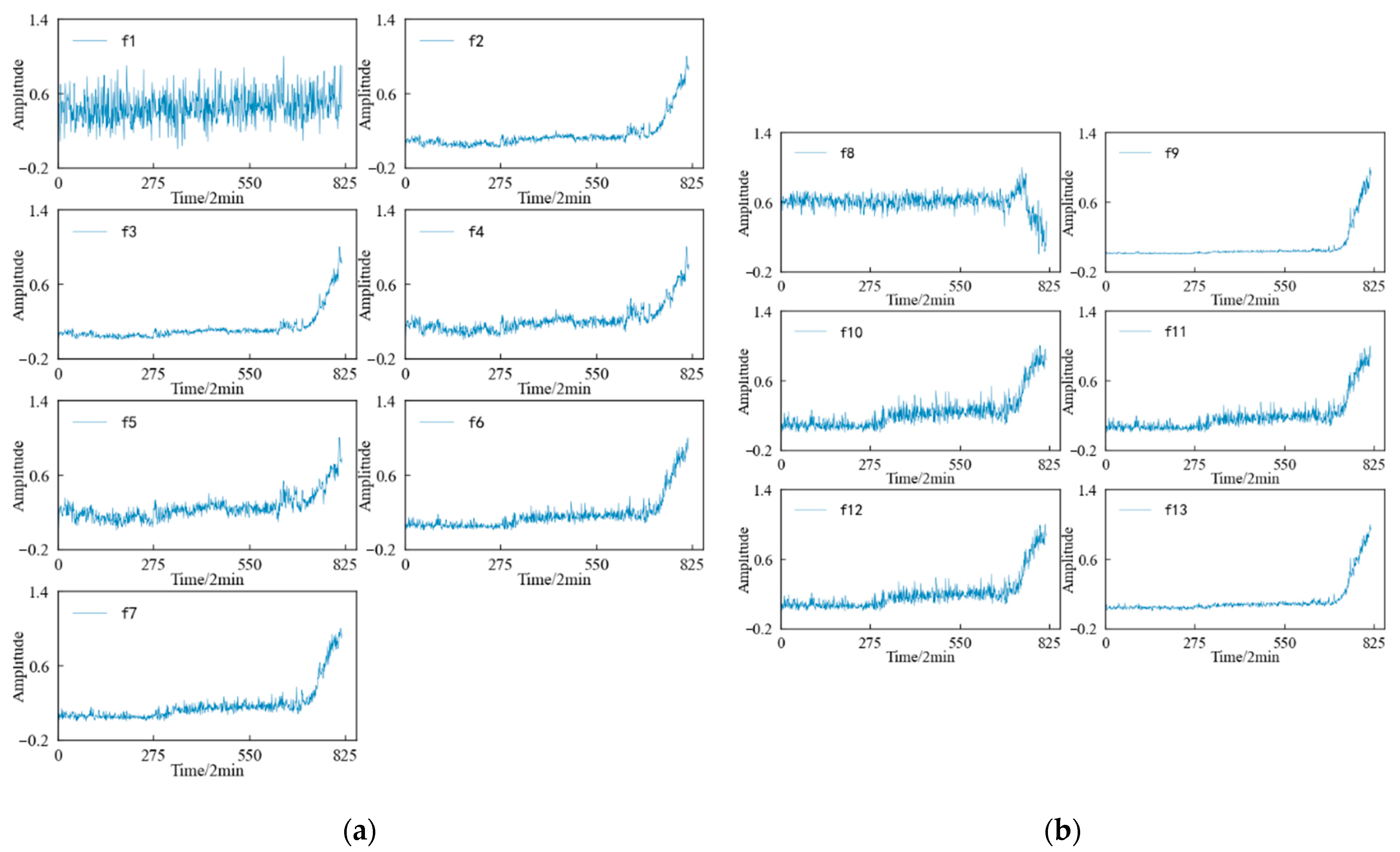
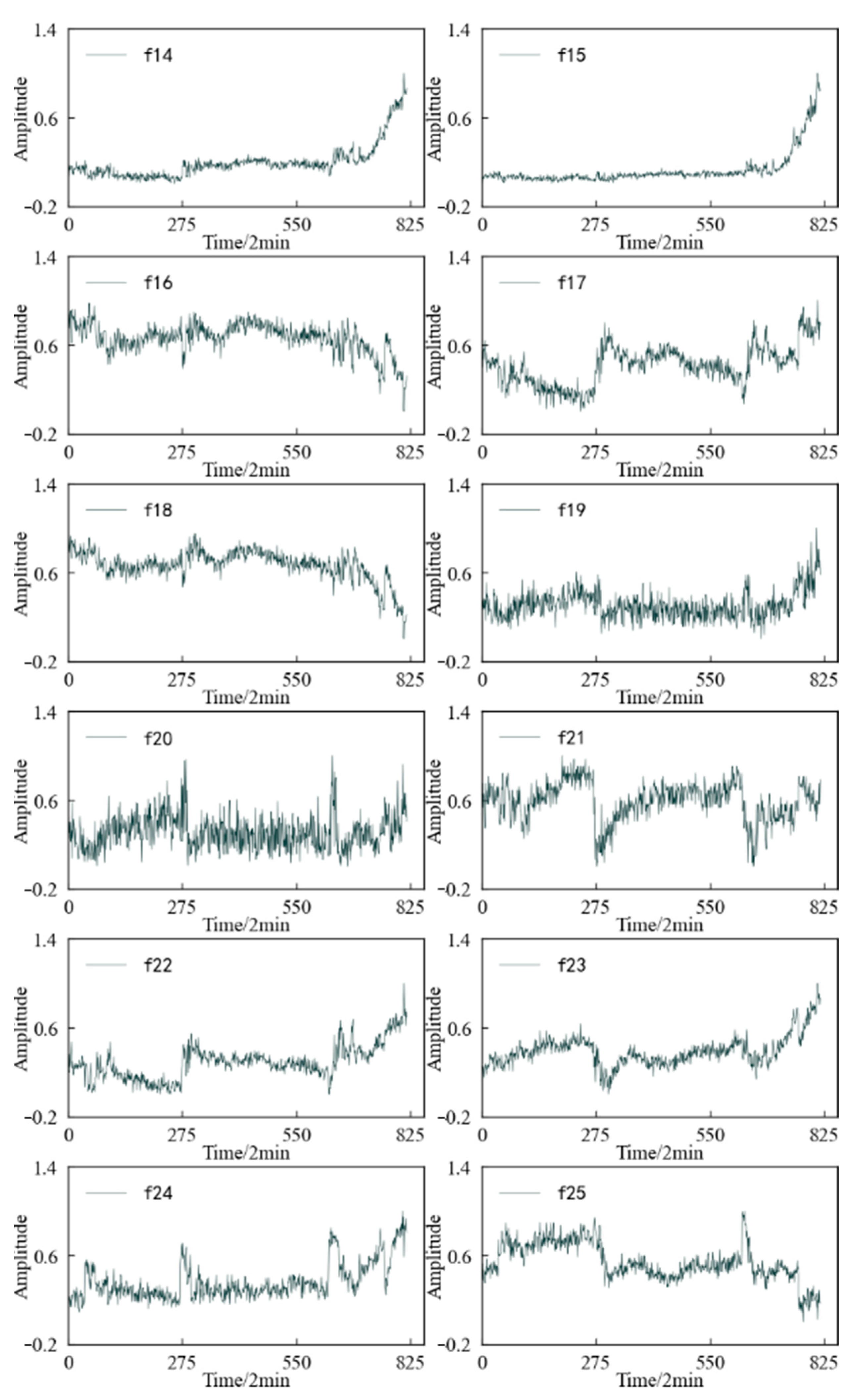
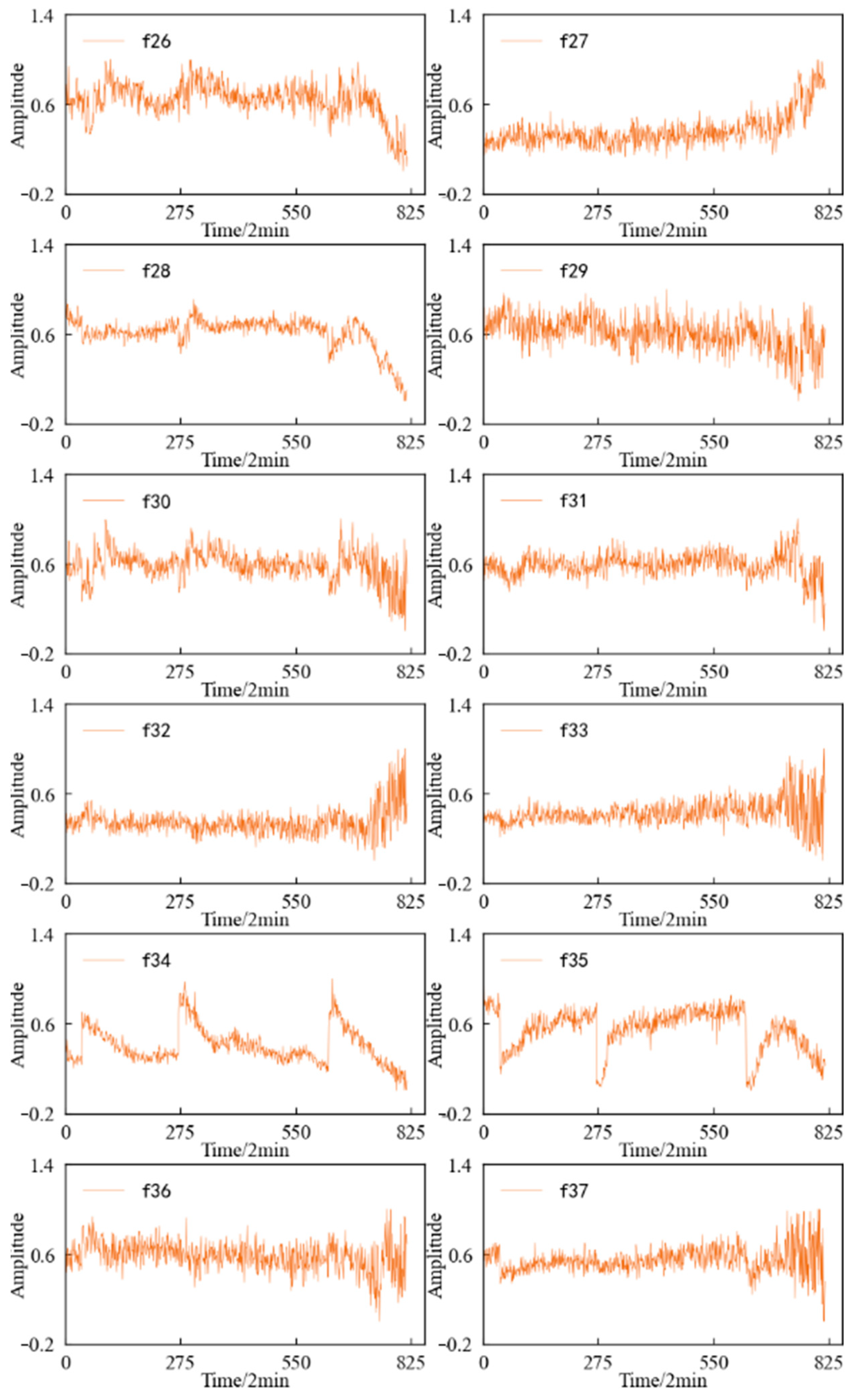
4.2. Feature Screening
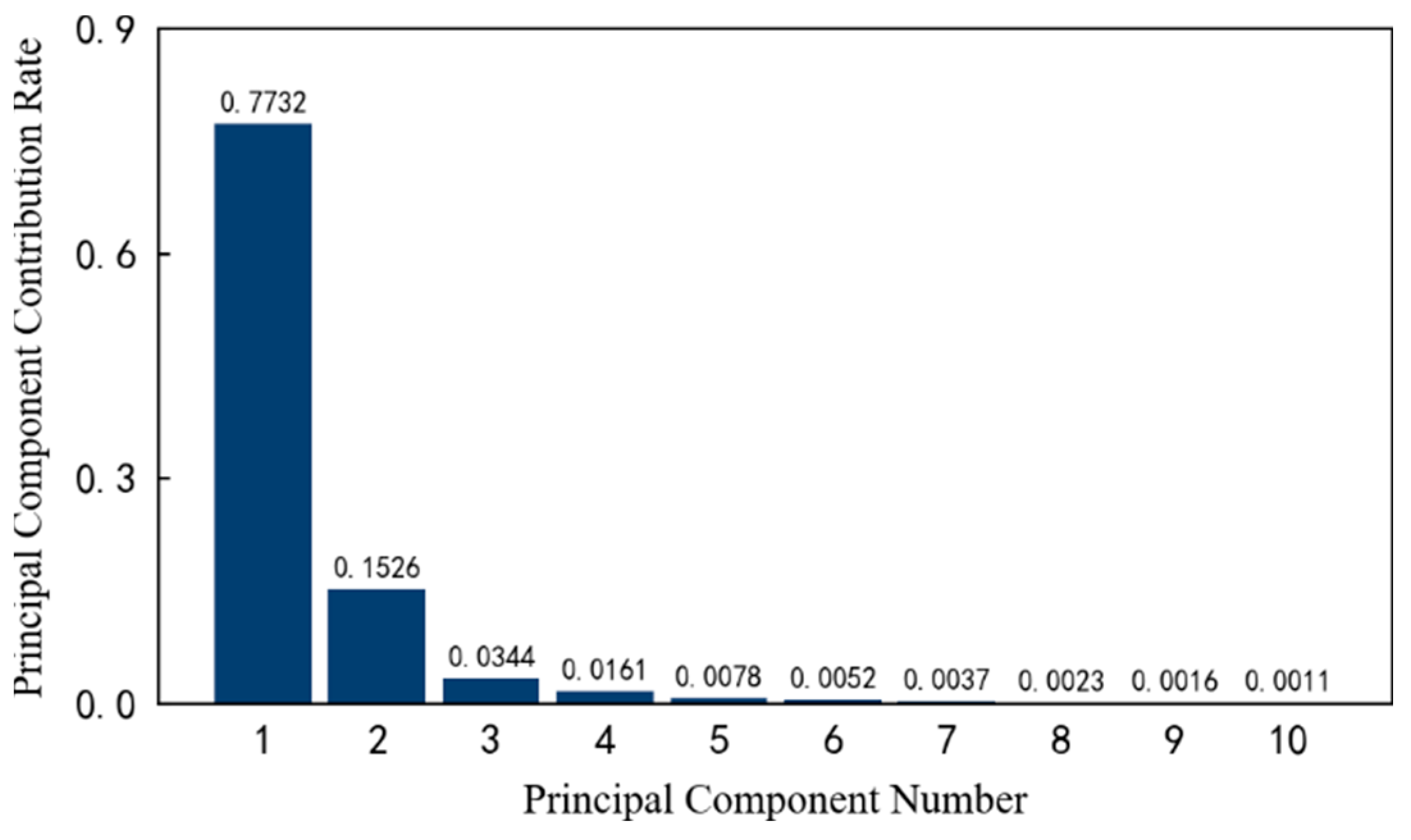
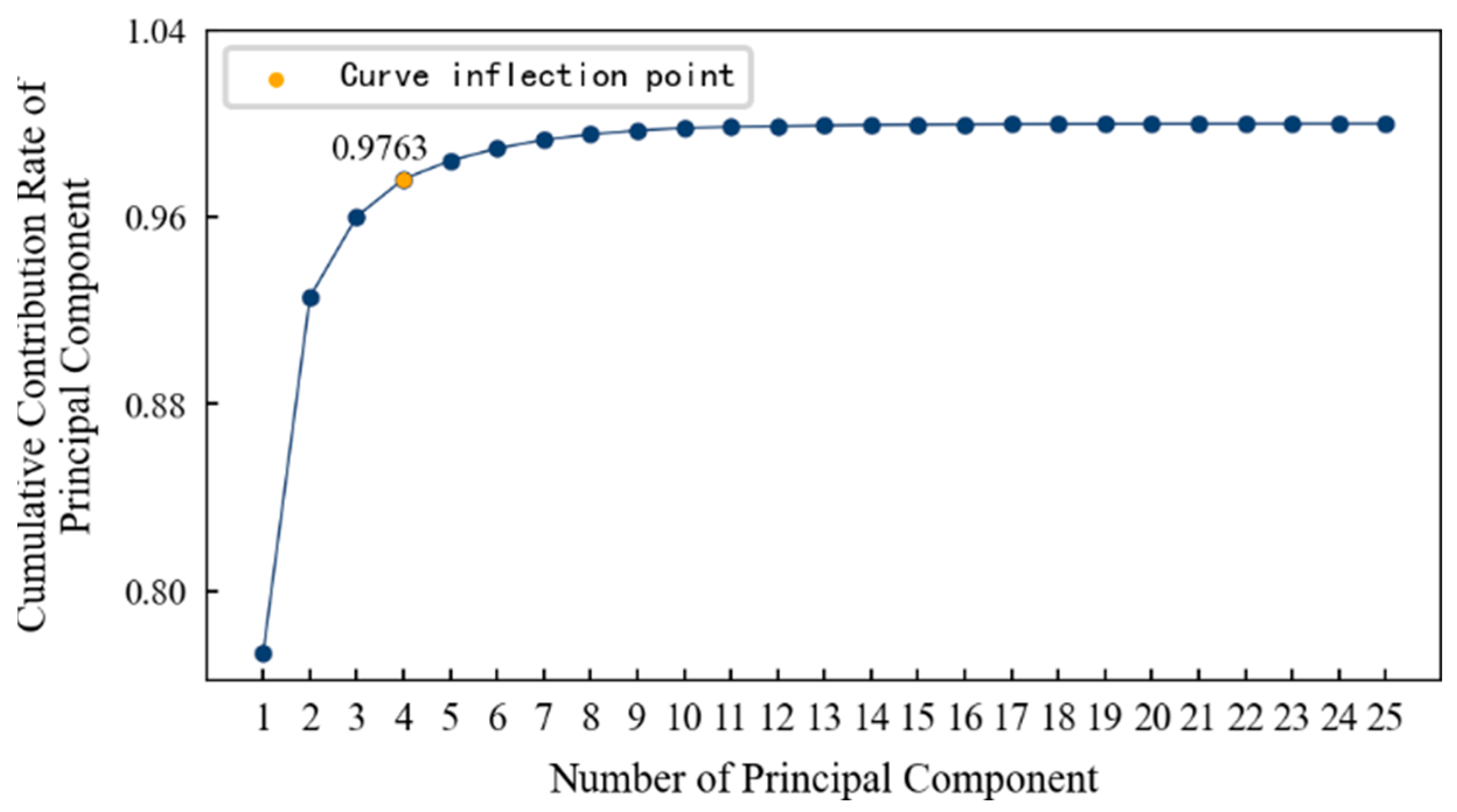
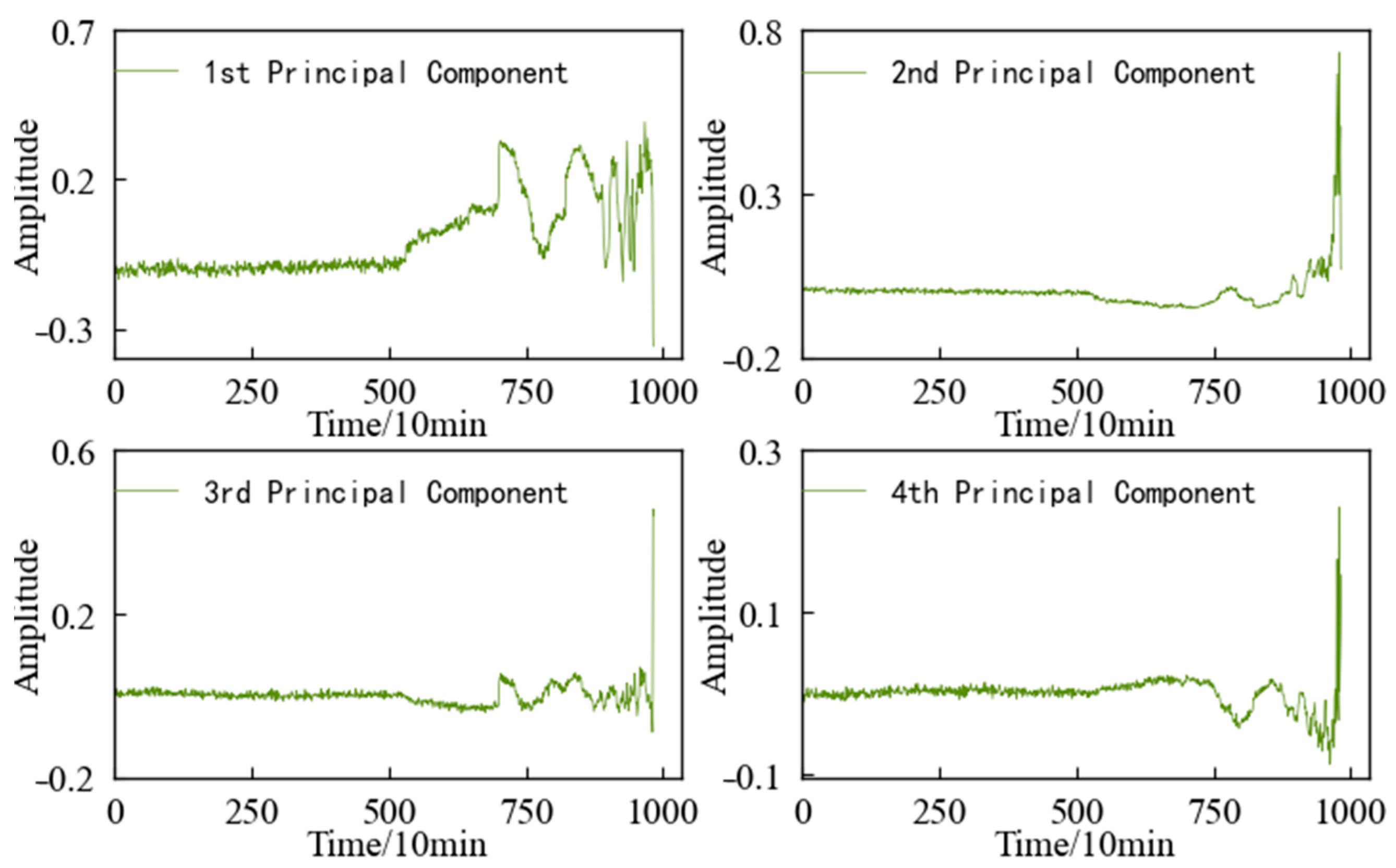
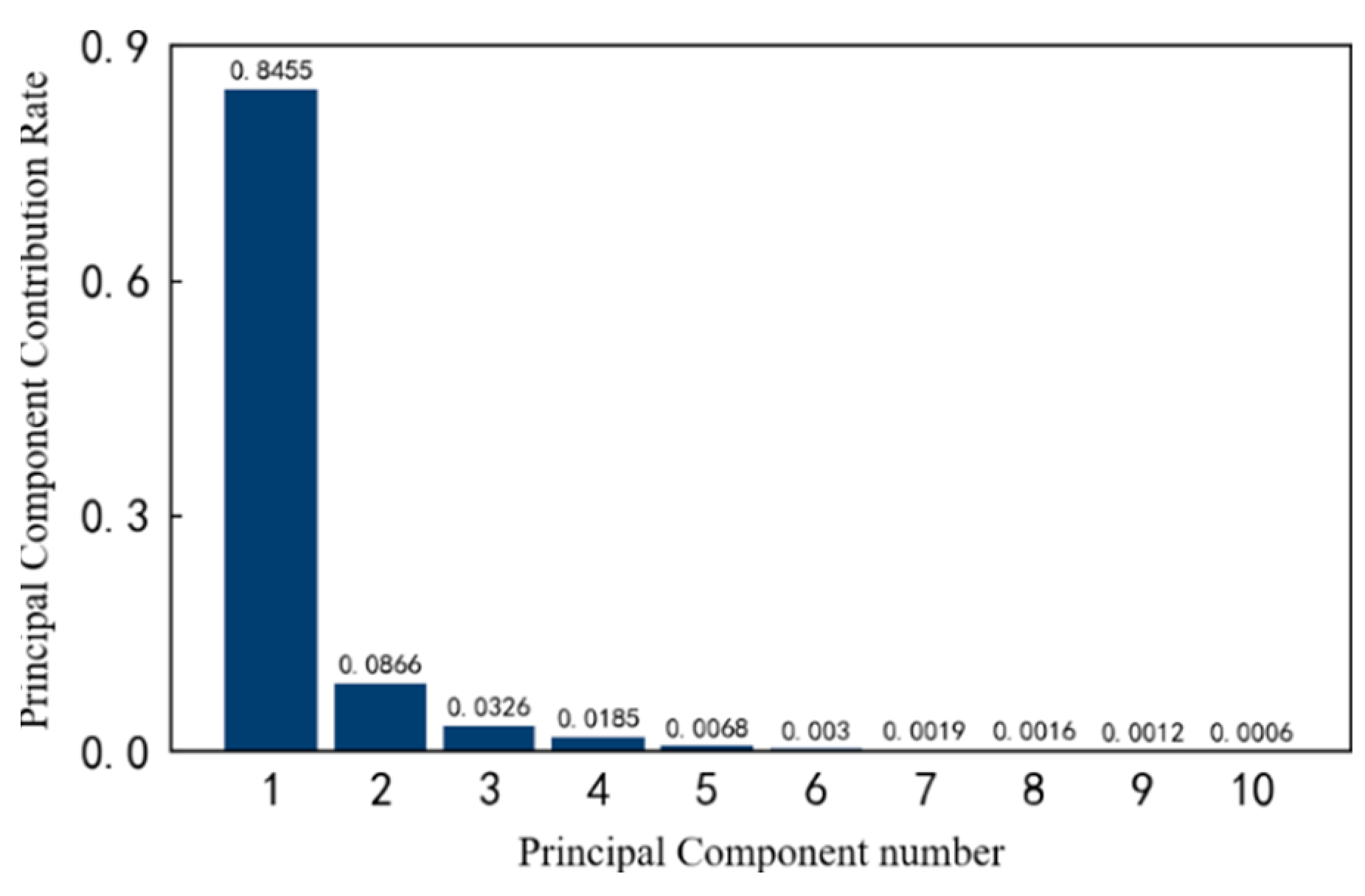
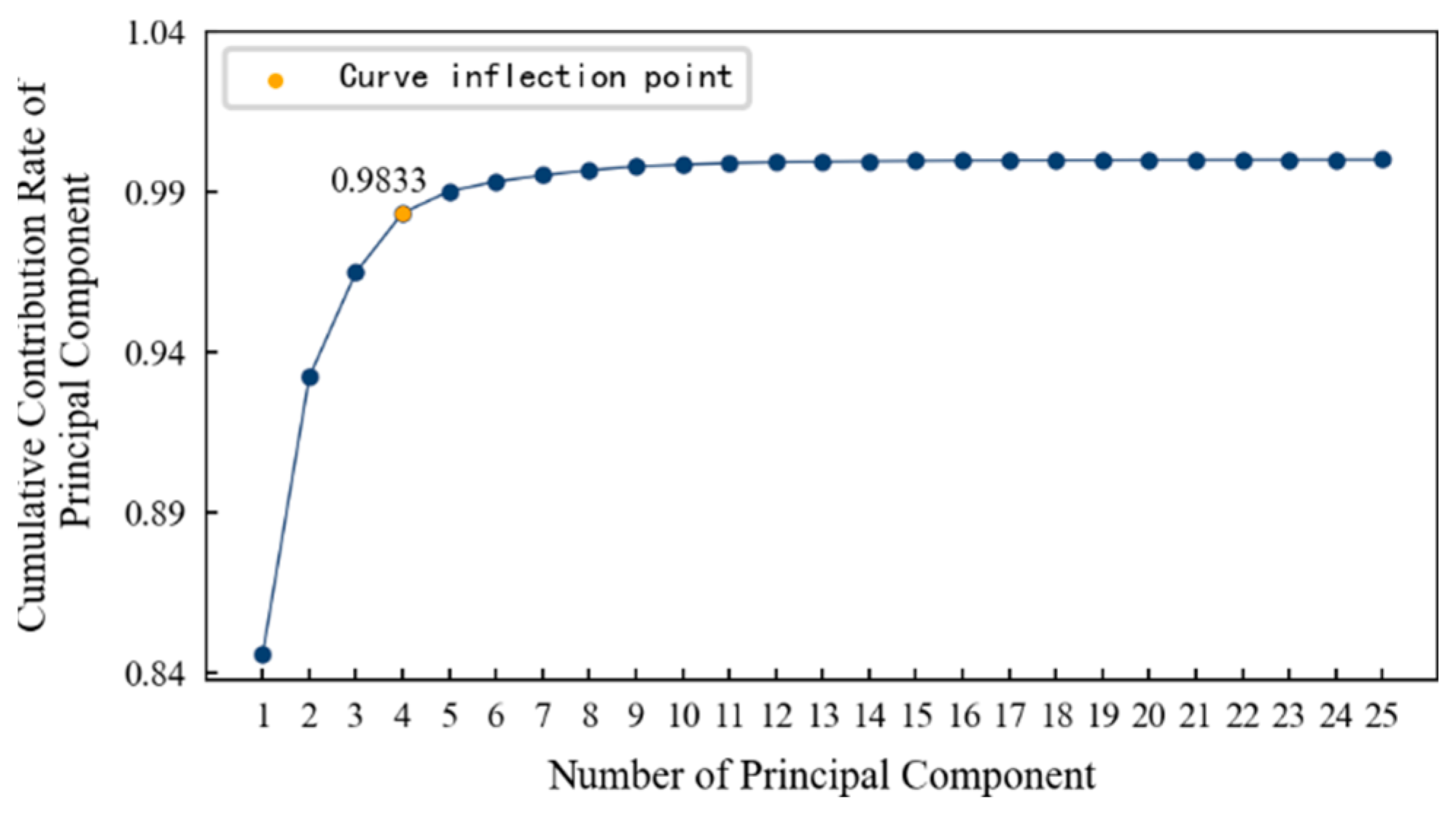
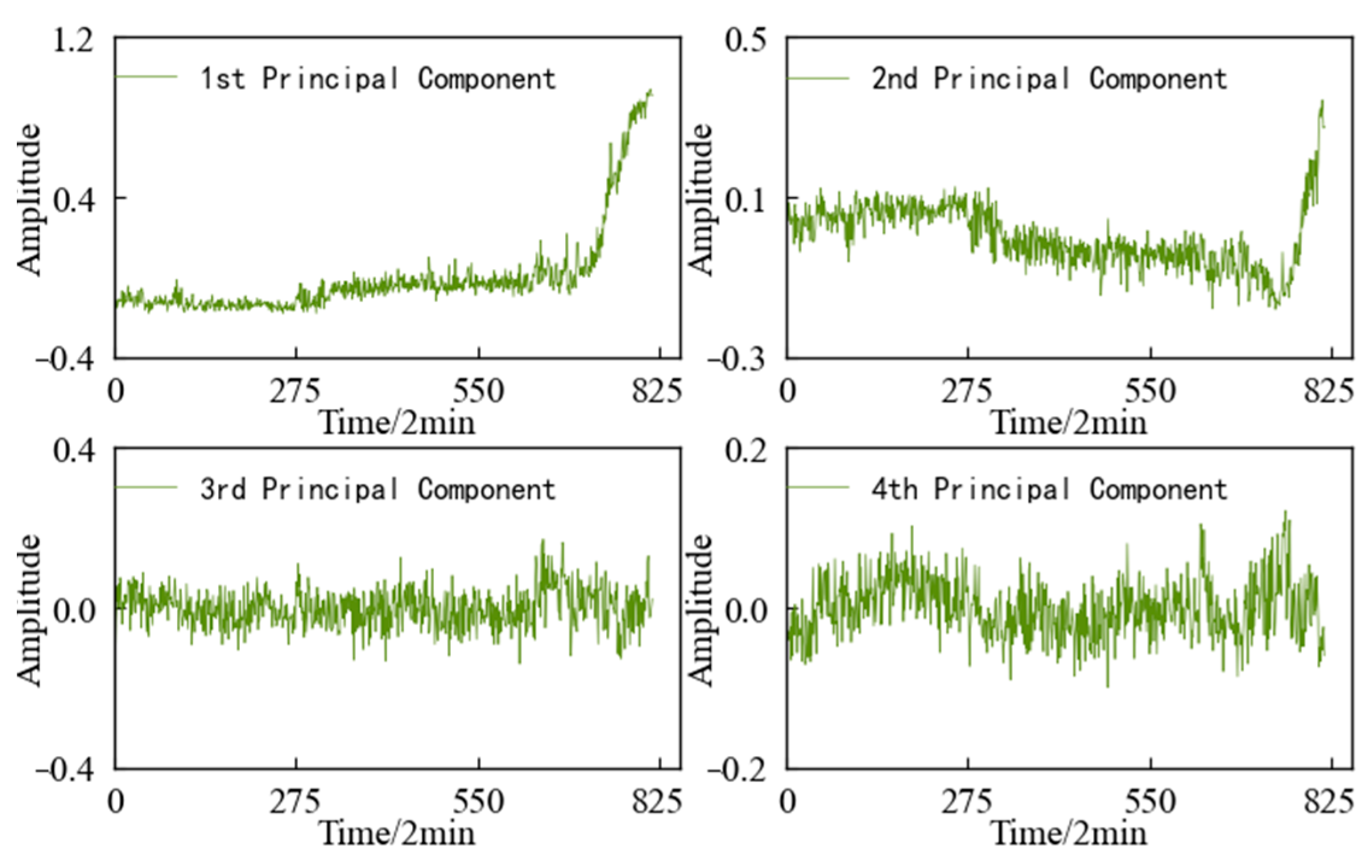
4.3. Feature Dimensionality Reduction
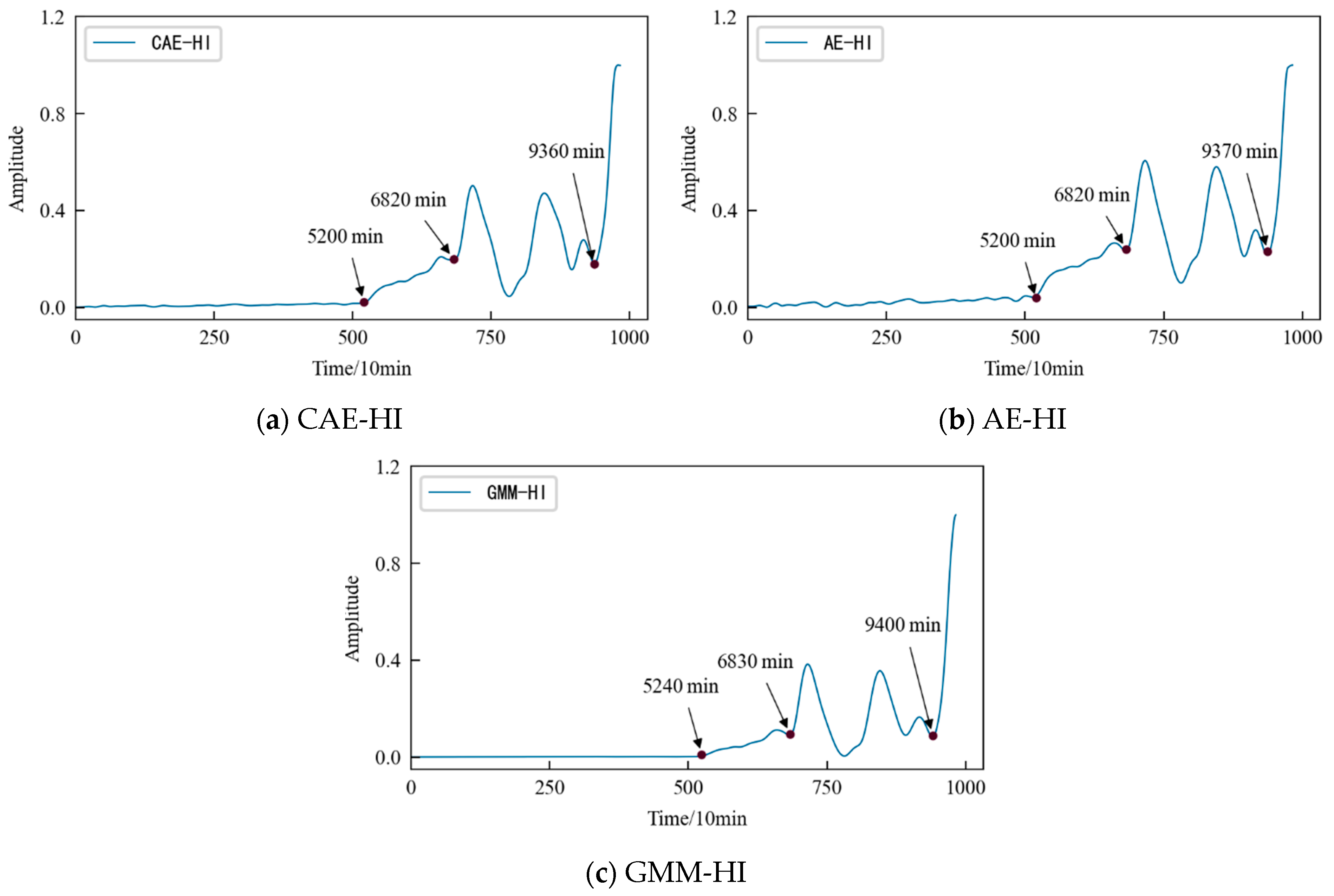
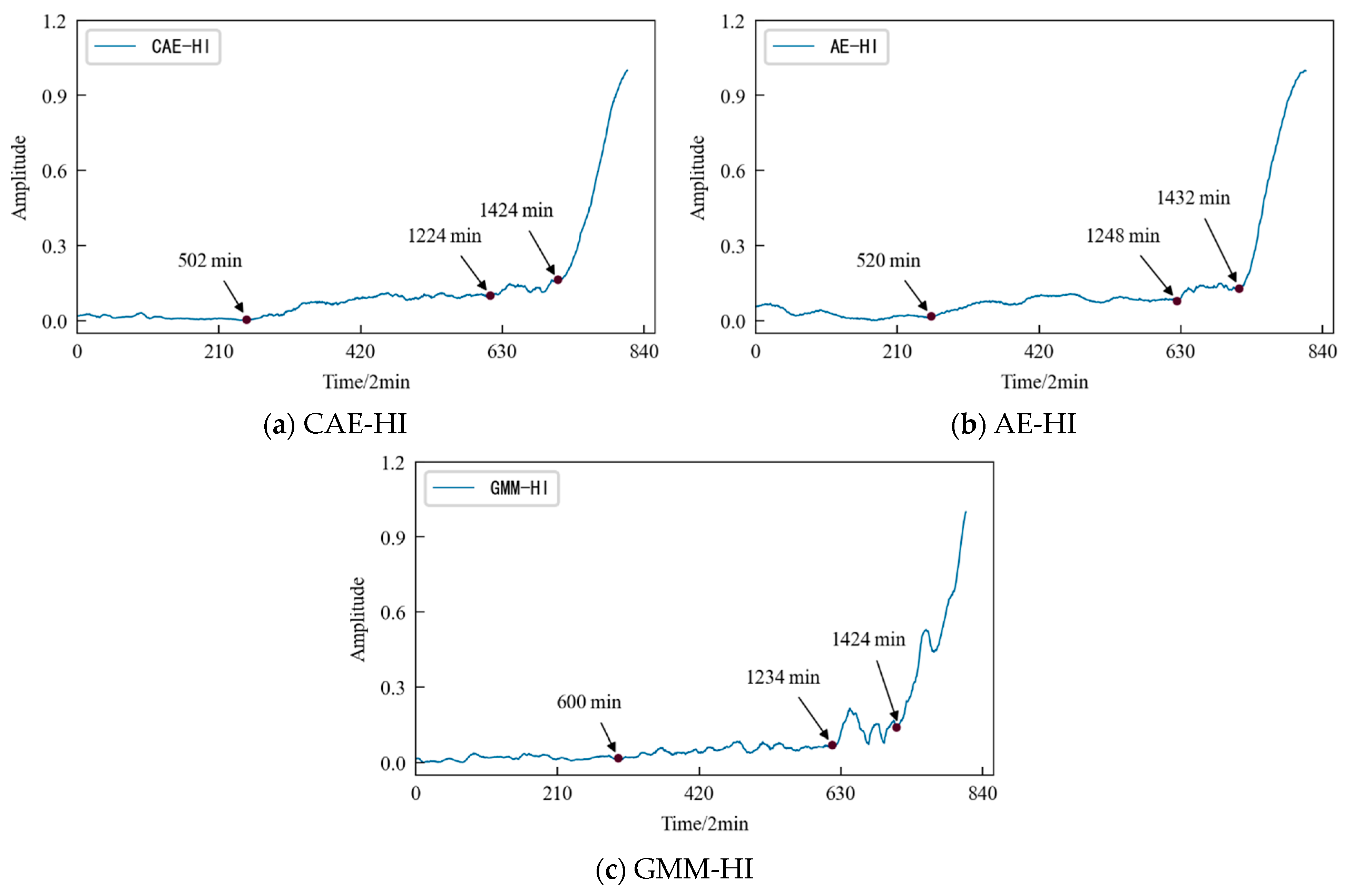
4.4. Construction of the HI
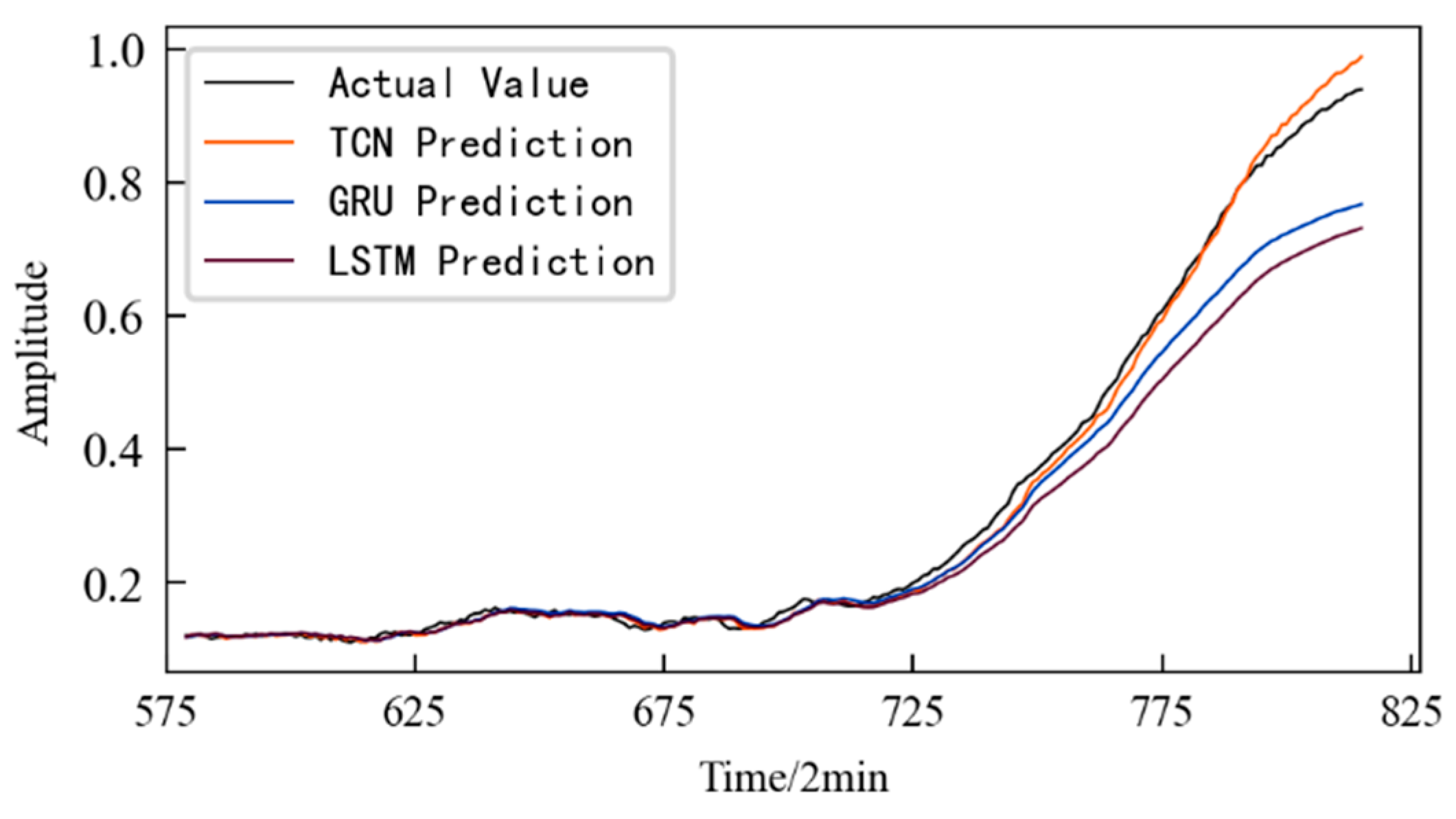
4.5. Performance Degradation Prediction of Rolling Contact Fatigue
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Pei, H.; Hu, C.H.; Si, X.S.; Zhang, J.X.; Pang, Z.N.; Zhang, P. Review of machine learning based on remaining useful life prediction methods for equipment. J. Mech. Eng. 2019, 55, 1. [Google Scholar] [CrossRef]
- Li, X.D.; Zhang, S.C.; Liu, Y. Review of Rolling Contact Fatigue Life Prediction. Aviat. Precis. Manuf. Technol. 2017, 53, 1–4. [Google Scholar]
- Lei, Y.; Jia, F.; Zhou, X.; Lin, J. A deep learning-based method for machinery health monitoring with big data. J. Mech. Eng. 2015, 51, 49–56. [Google Scholar] [CrossRef]
- Liu, Z.Y.; Liu, Y.B.; Yang, F.; Lu, K.X.; Liu, Y. Remaining life prediction of contact fatigue based on optimized BP neural network model on Spark platform. J. Chongqing Univ. Technol. (Nat. Sci.) 2021, 35, 111–119. [Google Scholar]
- Ahmad, W.; Khan, S.A.; Kim, J.M. A hybrid prognostics technique for rolling element bearings using adaptive predictive models. IEEE Trans. Ind. Electron. 2017, 65, 1577–1584. [Google Scholar] [CrossRef]
- Wu, J.; Wu, C.Y.; Cao, S.; Or, S.W.; Deng, C.; Shao, X.Y. Degradation data-driven time-to-failure prognostics approach for rolling element bearings in electrical machines. IEEE Trans. Ind. Electron. 2018, 66, 529–539. [Google Scholar] [CrossRef]
- Zhu, J.K. Research on Prediction Method of Rolling Bearing Performance Degradation Trend Based on Deep Learning. Master’s Thesis, Chongqing Jiaotong University, Chongqing, China, 2021. [Google Scholar]
- Liu, J.H. Research on Prediction of Performance Degradation Trend of Wind Turbine Bearings. Master’s Thesis, North China Electric Power University, Beijing, China, 2020. [Google Scholar]
- Wang, F.T.; Chen, X.T.; Liu, C.X. Reliability evaluation and life prediction of rolling bearing based on KPCA and WPHM. J. Vib. Meas. Diagn. 2017, 37, 476–483 + 626. [Google Scholar]
- Zhang, Y.Q.; Zou, J.H.; Ma, J. Rolling Bearing Residual Life Prediction Based on Grey Prediction Model with Multiple Degenerate Variables. J. Detect. Control 2019, 41, 112–120. [Google Scholar]
- Qiao, W.; Ni, X.; Wang, L.; Lv, X.; Chen, L.; Sun, F. New degradation feature extraction method of planetary gearbox based on alpha stable distribution. J. Mech. Sci. Technol. 2021, 35, 1–19. [Google Scholar] [CrossRef]
- Zhang, B.; Zhang, S.; Li, W. Bearing performance degradation assessment using long short-term memory recurrent network. Comput. Ind. 2019, 106, 14–29. [Google Scholar] [CrossRef]
- Zheng, X.X.; Qian, Y.Q.; Wang, S. GRU prediction for performance degradation of rolling bearings based on optimal wavelet packet and Mahalanobis distance. J. Vib. Shock 2019, 106, 14–29. [Google Scholar]
- Fang, B. Research on Health Status Assessment Method of Rolling Bearings. Master’s Thesis, Harbin Institute of Technology, Harbin, China, 2019. [Google Scholar]
- Yang, C.; Yang, X.X.; Li, L.F. Prediction of Bearing Performance Degradation Trend Based on Grey Relational Degree and ELM. Modul. Mach. Tool Autom. Manuf. Tech. 2019, 4, 105–108. [Google Scholar]
- Zhai, W.R. Study on Performance Degradation Evaluation of Shearer. Master’s Thesis, China University of Mining, Beijing, China, 2020. [Google Scholar]
- Jin, Q.; Wang, Y.R.; Wang, J. Planetary Gearbox Fault Diagnosis Based on Multiple Feature Extraction and Information Fusion Combine with Deep Learning. China Mech. Eng. 2019, 30, 196–204. [Google Scholar]
- Chen, X.L.; Wu, C.Z. Prediction for Rolling Bearing Performance Degradation Based on 1-DCNN. Chin. J. Ordnance Equip. Eng. 2021, 42, 222–227. [Google Scholar]
- Yu, J.; Wen, Y.; Yang, L.; Zhao, Z.B.; Guo, Y.J.; Guo, X. Monitoring on Triboelectric Nanogenerator and Deep Learning Method. Nano Energy 2022, 92, 106698. [Google Scholar] [CrossRef]
- Zhao, G.Q.; Ge, Q.Q.; Liu, X.Y.; Peng, X.Y. Fault feature extraction and diagnosis method based on deep belief network. Chin. J. Sci. Instrum. 2016, 37, 1946–1953. [Google Scholar]
- Dai, S.W.; Chen, Q.Q.; Ding, Y. Prediction for Rolling Bearing Remaining Life Based on Time Domain Features. Comput. Meas. Control 2019, 27, 60–63. [Google Scholar]
- Shen, Z.J.; Chen, X.F.; He, Z.J.; Sun, C.; Zhang, X.L.; Liu Z., W. Remaining Life Predictions of Rolling Bearing Based on Relative Features and Multivariable Support Vector Machine. J. Mech. Eng. 2013, 49, 183–189. [Google Scholar] [CrossRef]
- Chen, Q.Q.; Dai, S.W.; Dai, H.D.; Zhu, M.; Sun, Y.Y. Performance degradation trend prediction of rolling bearings based on SPA-FIG and optimized ELM. J. Vib. Shock 2020, 39, 187–194. [Google Scholar]
- Mei, W.J.; Gao, Y.; Du, L.; Liu, Z.; Wang, H.J. Online sequential regularized correntropy criterion extreme learning machine on spark streaming signal prediction for electronic device degradation. Chin. J. Sci. Instrum. 2019, 40, 212–224. [Google Scholar]
- Zhou, F.N.; Gao, Y.L.; Wang, J.Y.; Wen, C.L. Early Diagnosis and Life Prognosis for Slowly Varying Fault Based on Deep Learning. J. Shandong Univ. (Eng. Sci.) 2017, 47, 30–37. [Google Scholar]
- Zhang, N. A Method of Rolling Bearings Life Prediction Based on Deep Belief Network. Master’s Thesis, Hunan University, Changsha, China, 2018. [Google Scholar]
- Yang, Y.; Zhang, N.; Cheng, S.J. Global parameters dynamic learning deep belief networks and its application in rolling bearing life prediction. J. Vib. Shock 2019, 38, 199–205 + 249. [Google Scholar]
- Janssens, O.; Slavkovikj, V.; Vervisch, B.; Stockman, K.; Loccufier, M.; Verstockt, S.; Van de Walle, R.; Van Hoecke, S. Convolutional neural network based fault detection for rotating machinery. J. Sound Vib. 2016, 377, 331–345. [Google Scholar] [CrossRef]
- Sun, S.E.; Yao, L.; Zhao, Y. Time Series Data Fusion Algorithm Based on Convolutional Neural Network. J. Xi’an Shiyou Univ. (Nat. Sci. Ed.) 2021, 36, 136–142. [Google Scholar]
- Wang, X.; Wu, J.; Liu, C.; Yang, H.Y.; Du, Y.L.; Niu, W.S. Fault Time Series Prediction Based on LSTM Recurrent Neural Network. J. Beijing Univ. Aeronaut. Astronaut. 2018, 44, 772–784. [Google Scholar]
- Li, F.; Chen, Y.; Xiang, W.; Wang, J.X.; Tang, B.P. State degradation trend prediction based on quantum weighted long short-term memory neural network. Chin. J. Sci. Instrum. 2018, 39, 217–225. [Google Scholar]
- Wang, P.; Deng, L.; Tang, B.P.; Han, Y. Degradation trend prediction of rolling bearing based on auto-encoder and GRU neural network. J. Vib. Shock 2020, 39, 106–111 + 133. [Google Scholar]
- Lei, Y.G.; Jia, F.; Lin, J.; Xing, S.B.; Ding, S.X. An intelligent fault diagnosis method using unsupervised feature learning towards mechanical big data. IEEE Trans. Ind. Electron. 2016, 63, 3137–3147. [Google Scholar] [CrossRef]
- Li, J. Research on State Evaluation Based on Similarity Analysis of Principal Curves in Manifold Space. Master’s Thesis, Chongqing University, Chongqing, China, 2017. [Google Scholar]
- Lei, Y.G.; Li, N.P.; Guo, L.; Li, N.B.; Yan, T.; Lin, J. Machinery health prognostics: A systematic review from data acquisition to RUL prediction. Mech. Syst. Signal Process. 2018, 104, 799–834. [Google Scholar]
- Schölkopf, B.; Smola, A.J.; Müller, K.R. Kernel principal component analysis. In Proceedings of the International Conference on Artificial Neural Networks, Lausanne, Switzerland, 8–10 October 1997; Springer: Berlin/Heidelberg, Germany, 1997; pp. 583–588. [Google Scholar]
- Lee, J.M.; Yoo, C.K.; Choi, S.W.; Vanrolleghem, P.A.; Lee, I.B. Nonlinear process monitoring using kernel principal component analysis. Chem. Eng. Sci. 2004, 59, 223–234. [Google Scholar] [CrossRef]
- Bishop, C.M.; Nasrabadi, N.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006; pp. 586–590. [Google Scholar]
- Bai, S.; Kolter, J.Z.; Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. Arxiv Prepr. 2018, arXiv:1803.01271. [Google Scholar]
- Yu, C.C.; Ning, Y.Q.; Qin, Y.; Gao, K.K. Prediction of rolling bearing state degradation trend based on T-SNE sample entropy and TCN. Chin. J. Sci. Instrum. 2019, 40, 39–46. [Google Scholar]
- YB/T 5345.2014; Test Method for Rolling Contact Fatigue of Metallic Materials. Ministry of Industry and Information Technology of the People’s Republic of China: Beijing, China, 2014.



































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Feature | Calculation Formula |
|---|---|---|
| Dimensional Time Domain Features | ||
| f1 | mean | |
| f2 | rms value | |
| f3 | variance | |
| f4 | absolute mean | |
| f5 | root amplitude | |
| f6 | peak | |
| f7 | peak to peak | |
| Dimensionless time domain features | ||
| f8 | skewness index | |
| f9 | kurtosis index | |
| f10 | peak indicator | |
| f11 | margin indicator | |
| f12 | impulse indicator | |
| f13 | waveform indicator | |
| No. | Feature | Calculation Formula |
|---|---|---|
| f14 | frequency amplitude mean | |
| f15 | frequency amplitude variance | |
| f16 | first-order center of gravity | |
| f17 | second-order center of gravity | |
| f18 | rms frequency | |
| f19 | frequency domain features 1 | |
| f20 | frequency domain features 2 | |
| f21 | frequency domain features 3 | |
| f22 | frequency domain features 4 | F9 = F4/F3 |
| f23 | frequency domain features 5 | |
| f24 | frequency domain features 6 | |
| f25 | frequency domain features 7 |
| Network Layer | Dimensions Entered | Size of Convolution Kernel | Number of Convolution Kernels | Dimensions of the Output |
|---|---|---|---|---|
| Convolutional layer 1 | 4 × 1 | 2 × 1 | 5 | 3 × 5 |
| Convolutional layer 2 | 3 × 5 | 2 × 1 | 5 | 2 × 3 |
| Convolutional layer 3 | 2 × 3 | 2 × 1 | 1 | 1 × 1 |
| Transpose convolutional layer 1 | 1 × 1 | 2 × 1 | 4 | 2 × 4 |
| Transpose convolutional layer 2 | 2 × 4 | 2 × 1 | 4 | 3 × 4 |
| Transpose convolutional layer 3 | 3 × 4 | 2 × 1 | 2 | 4 × 1 |
| Evaluation Indicator | CAE-HI | AE-HI | GMM-HI |
|---|---|---|---|
| Monotonicity | 0.2513 | 0.2411 | 0.1801 |
| Trend | 0.9462 | 0.9430 | 0.9454 |
| Evaluation Indicator | Predictive Model | ||
|---|---|---|---|
| TCN | LSTM | GRU | |
| RMSE | 0.0257 | 0.0385 | 0.0366 |
| MAE | 0.0187 | 0.0264 | 0.0234 |
| Specimen Material | Rotational Speed (r/min) | Slip Rate | Radial Load (N) | Sampling | |||
|---|---|---|---|---|---|---|---|
| Main Shaft (Specimen) | Accompanying Shaft (Accompanying Specimen) | Frequency (kHz) | Single Sample Duration (s) | Sampling Interval (min) | |||
| 40Cr | 1000 | 1100 | 10% | 2071 | 10 | 1 | 2 |
| Evaluation Indicators | Predictive Model | ||
|---|---|---|---|
| TCN | GRU | LSTM | |
| RMSE | 0.0146 | 0.0555 | 0.0744 |
| MAE | 0.0105 | 0.0308 | 0.0423 |
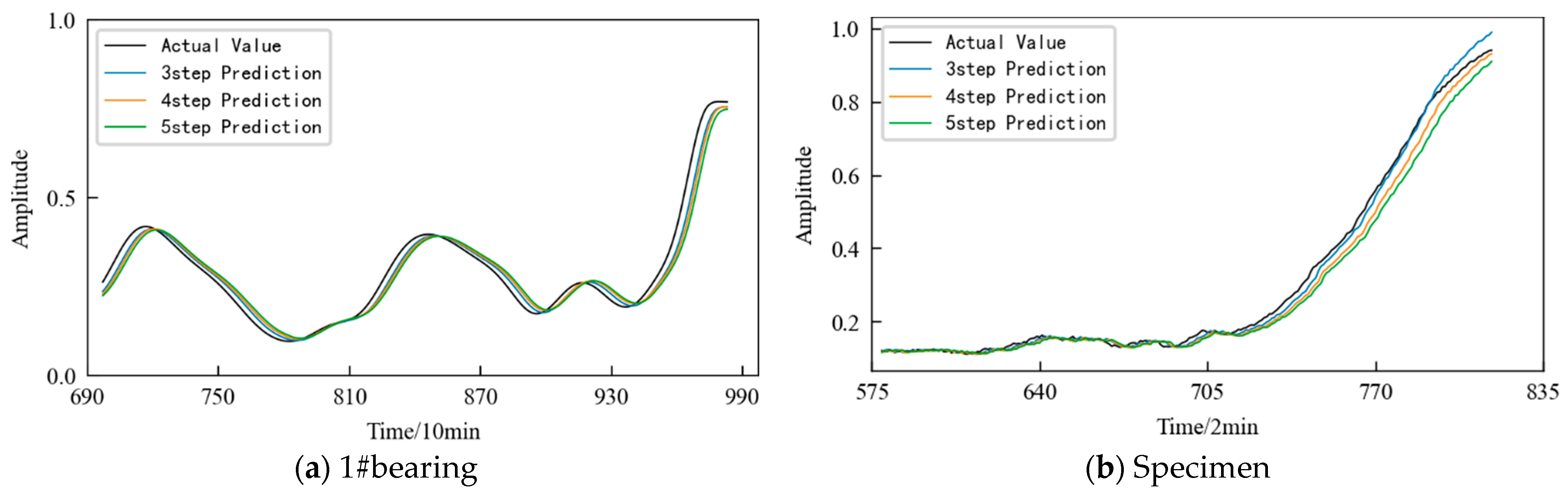
| Evaluation Indicator | 1#Bearing | Specimen | ||||
|---|---|---|---|---|---|---|
| Prediction Step Size | ||||||
| 3 | 4 | 5 | 3 | 4 | 5 | |
| RMSE | 0.0257 | 0.0333 | 0.0418 | 0.0146 | 0.0259 | 0.0393 |
| MAE | 0.0187 | 0.0243 | 0.0305 | 0.0105 | 0.0164 | 0.0270 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Liu, Y.; Yang, Y. Prediction of Contact Fatigue Performance Degradation Trends Based on Multi-Domain Features and Temporal Convolutional Networks. Entropy 2023, 25, 1316. https://doi.org/10.3390/e25091316
Liu Y, Liu Y, Yang Y. Prediction of Contact Fatigue Performance Degradation Trends Based on Multi-Domain Features and Temporal Convolutional Networks. Entropy. 2023; 25(9):1316. https://doi.org/10.3390/e25091316
Chicago/Turabian StyleLiu, Yu, Yuanbo Liu, and Yan Yang. 2023. "Prediction of Contact Fatigue Performance Degradation Trends Based on Multi-Domain Features and Temporal Convolutional Networks" Entropy 25, no. 9: 1316. https://doi.org/10.3390/e25091316
APA StyleLiu, Y., Liu, Y., & Yang, Y. (2023). Prediction of Contact Fatigue Performance Degradation Trends Based on Multi-Domain Features and Temporal Convolutional Networks. Entropy, 25(9), 1316. https://doi.org/10.3390/e25091316