



Enhancing Zero-Shot Stance Detection with Contrastive and Prompt Learning

Abstract
:1. Introduction
- We propose a novel stance detection model that combines the advantages of prompt learning and contrastive learning, thus enabling effective stance detection in zero-shot scenarios.
- We introduce a gating mechanism that can dynamically adjust the influence of the gate on prompt tokens based on the semantic features of the instance, thereby enhancing the relevance between instances and prompts.
- We conducted experiments on two benchmark datasets, VAST and SEM16, and the results demonstrate that our model outperforms existing state-of-the-art methods on both datasets.
2. Related Work
2.1. Zero-Shot Stance Detection
2.2. Prompt Learning
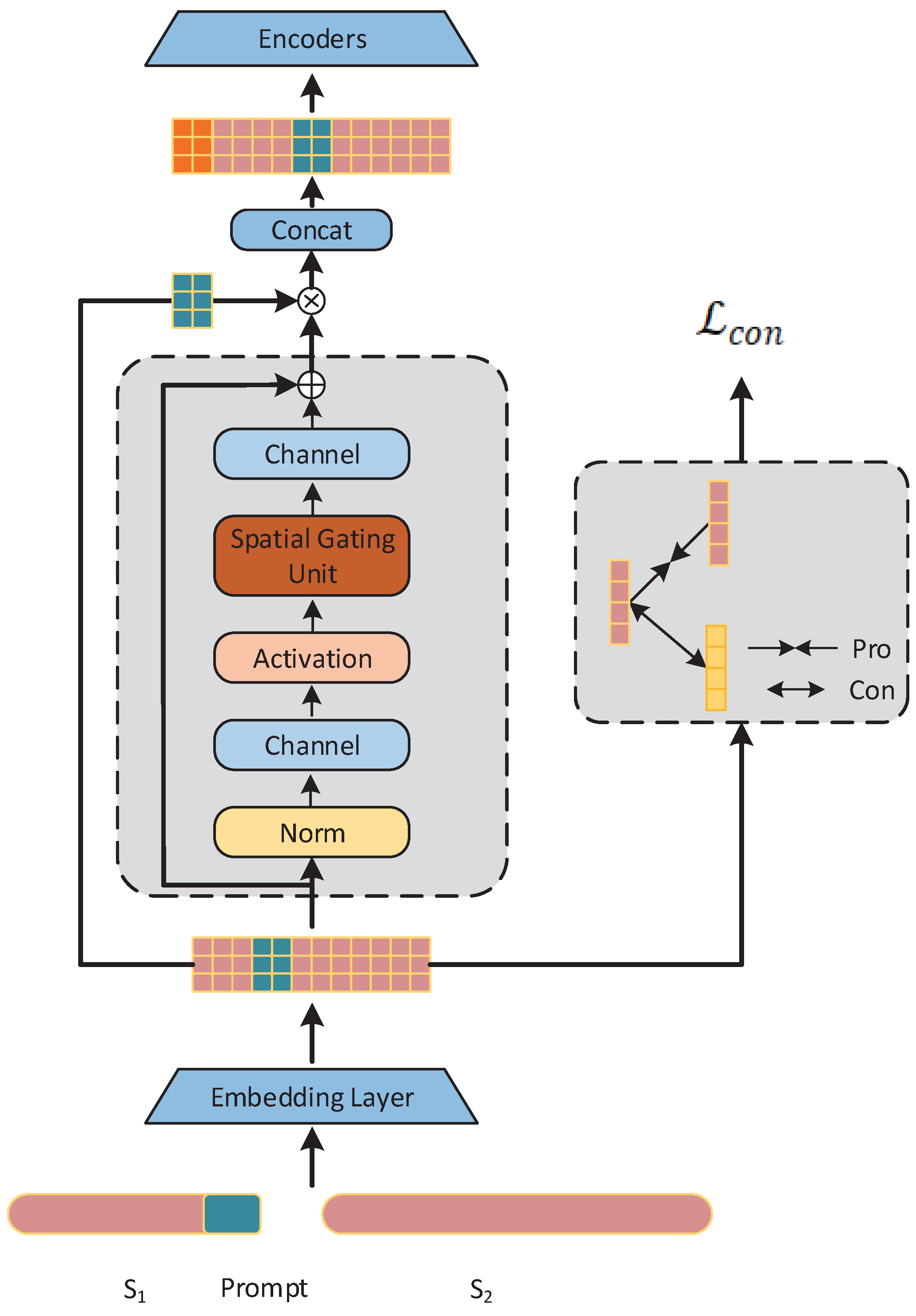
3. Methodology
3.1. Task Description
3.2. Encoding Module
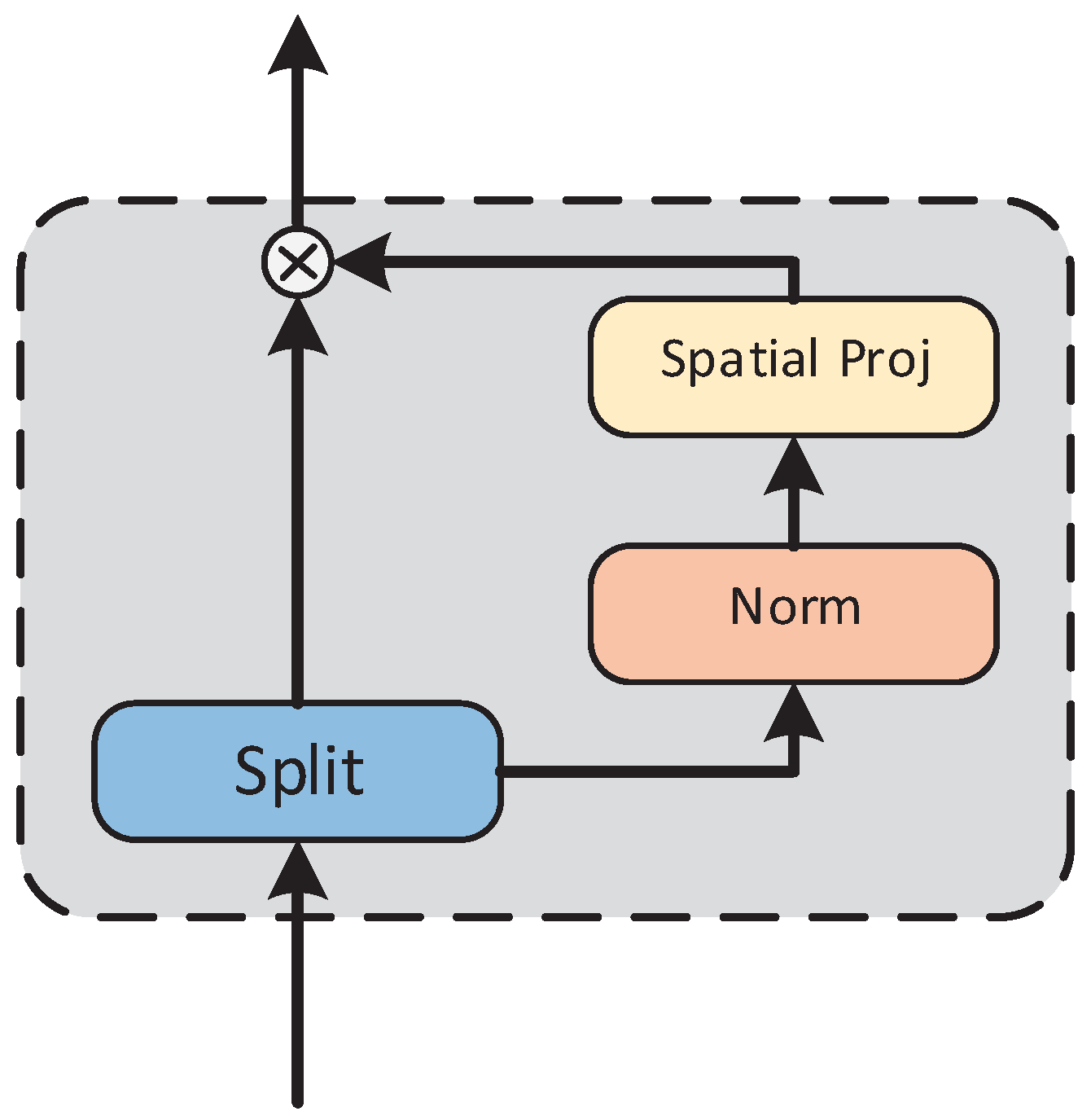
3.3. gMLP Module
3.4. Stance Contrastive Learning
3.5. Concat Module
3.6. Training
| Algorithm 1 Calculation of the stance contrastive and crossentropy losses | |
| 1: Input: , | |
| 2: Output: | |
| 3: | ▹p is the prompt token |
| 4: | ▹ Compute contrastive learning loss |
| 5: | ▹ Get channel gating |
| 6: | ▹ Control prompt weights |
| 7: | ▹ Concatenate processed embeddings with original |
| 8: | ▹ Classification probability predicted by PLM |
| 9: | ▹ Compute classification loss |
| 10: | ▹ Total loss |
| 11: return | |
4. Experiments
4.1. Datasets and Evaluation Indicators
4.2. Experimental Implementation
4.3. Baseline Method
- BERT-joint [5]: Contextual conditional encoding followed by a two-layer feedforward neural network.
- TGA Net [5]: The model using contextual conditional encoding and topic-grouped attention.
- DTCL [39]: The model introduces a latent topic cluster embedding and a discrete latent topic variable to build a bridge between various targets.
- ST-PL [40]: The model designs an agent task framework that combines self-supervised learning and cue learning for automatically identifying and exploiting goal-irrelevant gestural expression features while excluding goal-relevant expression features through a data augmentation strategy.
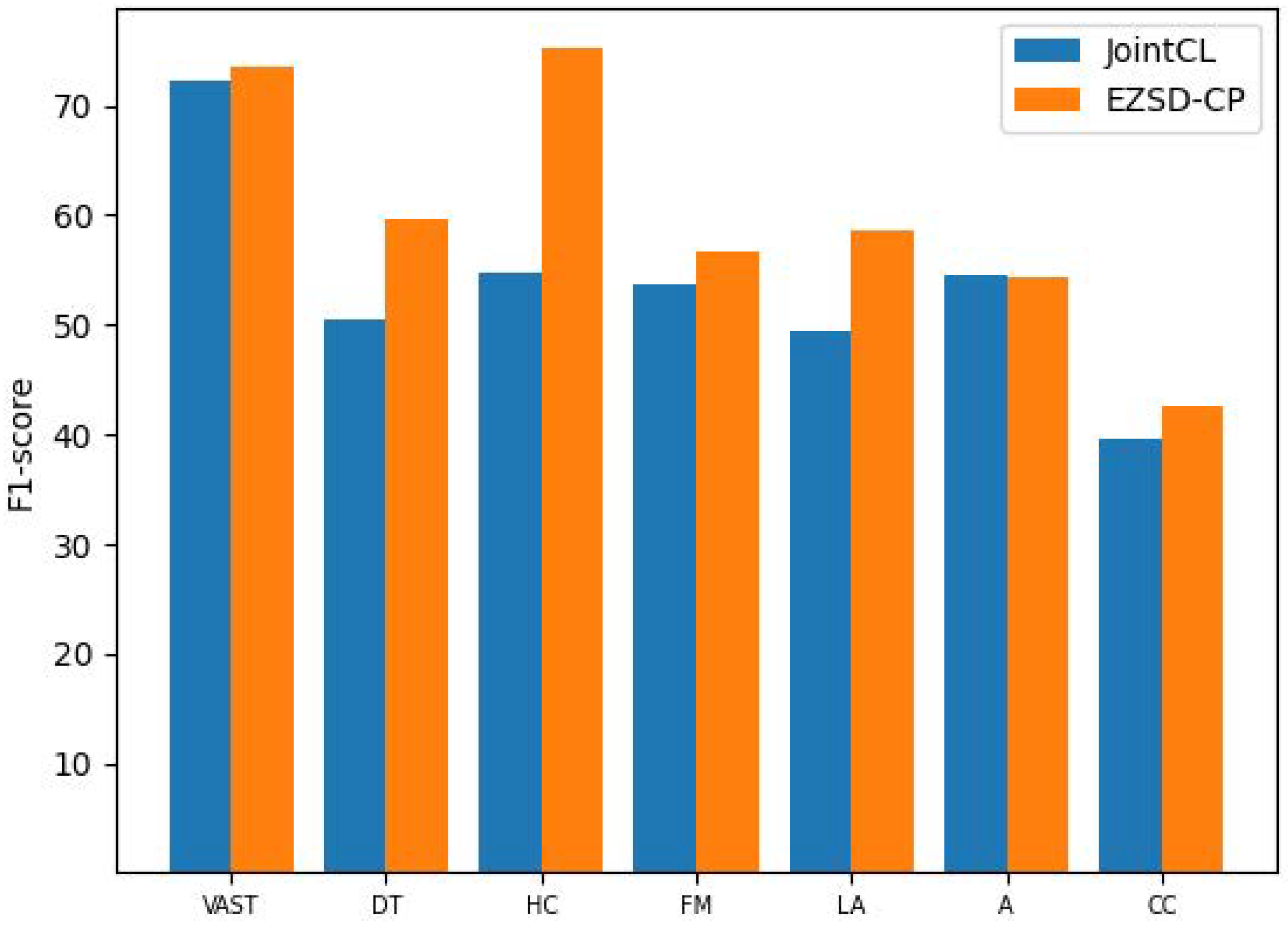
- JointCL [29]: The model consists of stance contrastive learning and target-aware prototypical graph contrastive learning.
4.4. Main Results
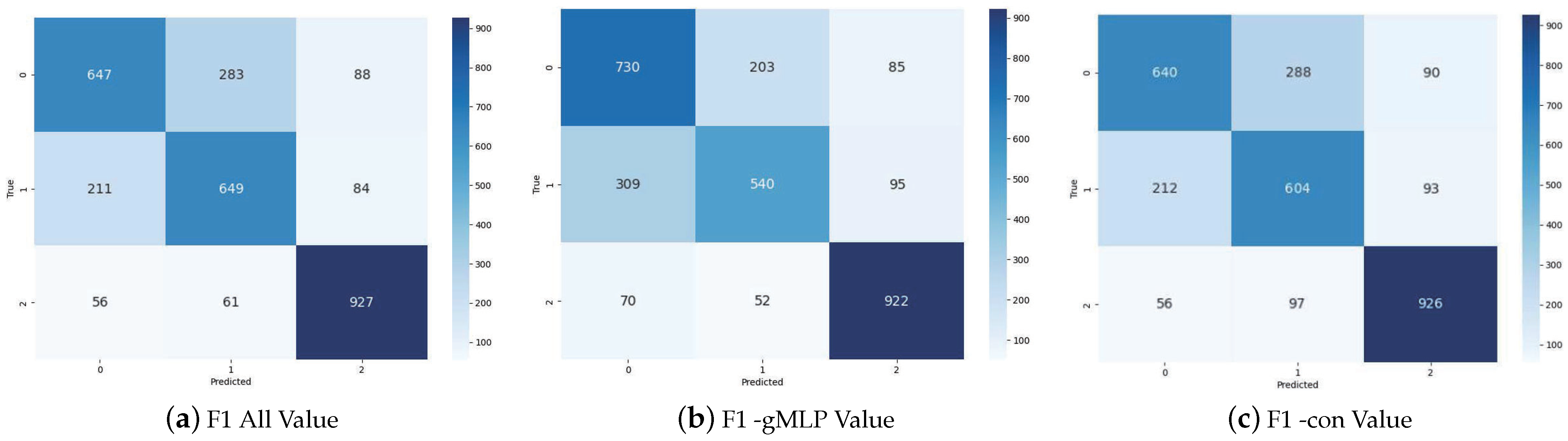
4.5. Ablation Experiments
4.6. Confounding Experiment
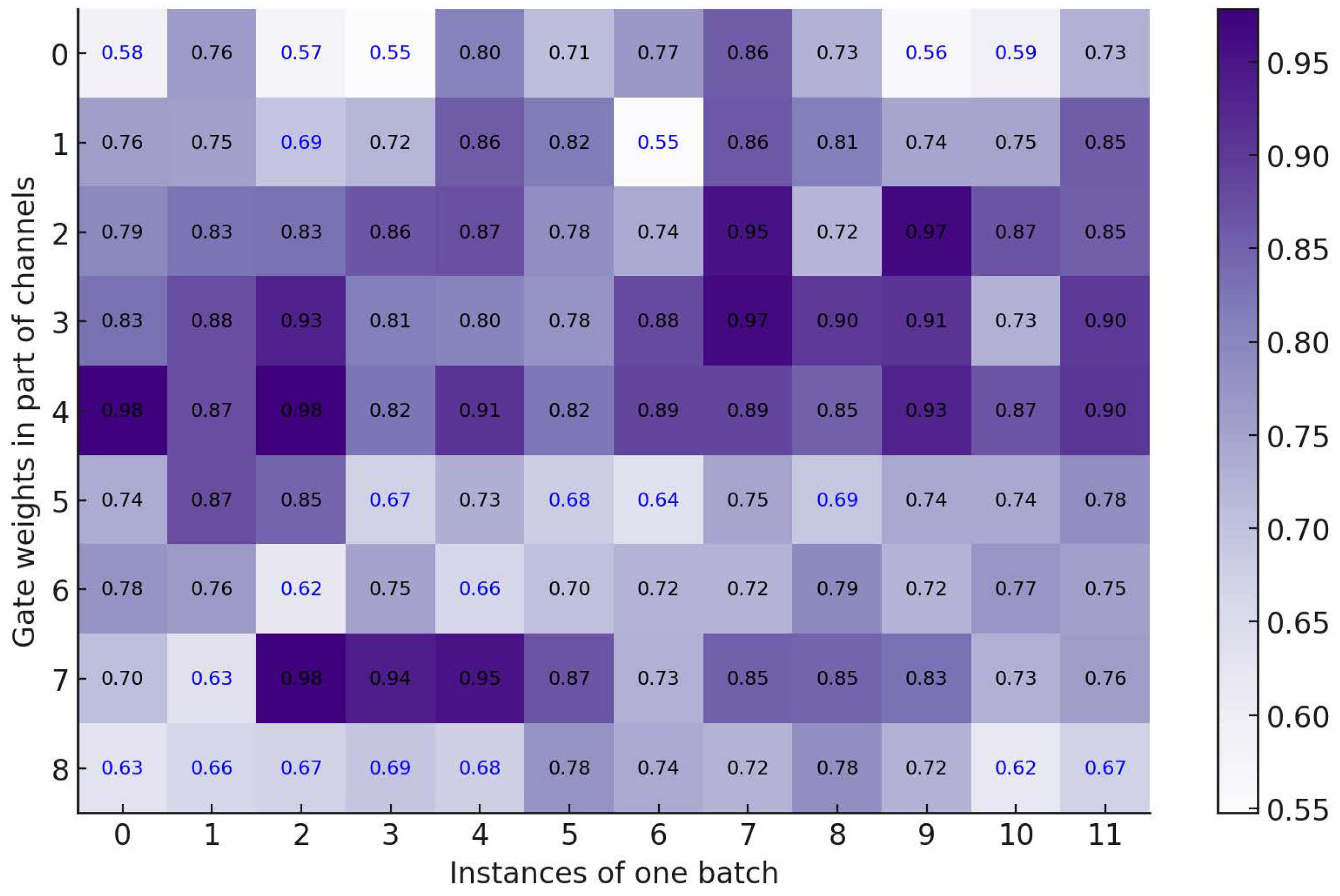
4.7. Analysis and Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Somasundaran, S.; Wiebe, J. Recognizing Stances in Online Debates. In Proceedings of the ACL 2009, Proceedings of the 47th Annual Meeting of the Association for Computational Linguistics and the 4th International Joint Conference on Natural Language Processing of the AFNLP, Singapore, 2–7 August 2009; Su, K., Su, J., Wiebe, J., Eds.; The Association for Computer Linguistics: Stroudsburg, PA, USA, 2009; pp. 226–234. [Google Scholar]
- Augenstein, I.; Rocktäschel, T.; Vlachos, A.; Bontcheva, K. Stance Detection with Bidirectional Conditional Encoding. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, EMNLP 2016, Austin, TX, USA, 1–4 November 2016; Su, J., Carreras, X., Duh, K., Eds.; The Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 876–885. [Google Scholar] [CrossRef]
- Mohammad, S.M.; Kiritchenko, S.; Sobhani, P.; Zhu, X.; Cherry, C. SemEval-2016 Task 6: Detecting Stance in Tweets. In Proceedings of the 10th International Workshop on Semantic Evaluation, SemEval@NAACL-HLT 2016, San Diego, CA, USA, 16–17 June 2016; Bethard, S., Cer, D.M., Carpuat, M., Jurgens, D., Nakov, P., Zesch, T., Eds.; The Association for Computer Linguistics: Stroudsburg, PA, USA, 2016; pp. 31–41. [Google Scholar] [CrossRef]
- Sobhani, P.; Inkpen, D.; Zhu, X. A Dataset for Multi-Target Stance Detection. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, EACL 2017, Valencia, Spain, 3–7 April 2017; Volume 2: Short Papers. Lapata, M., Blunsom, P., Koller, A., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; pp. 551–557. [Google Scholar] [CrossRef]
- Allaway, E.; McKeown, K.R. Zero-Shot Stance Detection: A Dataset and Model using Generalized Topic Representations. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, Online, 16–20 November 2020; Webber, B., Cohn, T., He, Y., Liu, Y., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 8913–8931. [Google Scholar] [CrossRef]
- Liang, B.; Chen, Z.; Gui, L.; He, Y.; Yang, M.; Xu, R. Zero-Shot Stance Detection via Contrastive Learning. In Proceedings of the WWW’22: The ACM Web Conference 2022, Lyon, France, 25–29 April 2022; Laforest, F., Troncy, R., Simperl, E., Agarwal, D., Gionis, A., Herman, I., Médini, L., Eds.; ACM: New York, NY, USA, 2022; pp. 2738–2747. [Google Scholar] [CrossRef]
- Allaway, E.; Srikanth, M.; McKeown, K.R. Adversarial Learning for Zero-Shot Stance Detection on Social Media. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2021, Online, 6–11 June 2021; Toutanova, K., Rumshisky, A., Zettlemoyer, L., Hakkani-Tür, D., Beltagy, I., Bethard, S., Cotterell, R., Chakraborty, T., Zhou, Y., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 4756–4767. [Google Scholar] [CrossRef]
- Liu, R.; Lin, Z.; Tan, Y.; Wang, W. Enhancing Zero-shot and Few-shot Stance Detection with Commonsense Knowledge Graph. In Proceedings of the Findings of the Association for Computational Linguistics: ACL/IJCNLP 2021, Online Event, 1–6 August 2021; Zong, C., Xia, F., Li, W., Navigli, R., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; Volume ACL/IJCNLP 2021, Findings of ACL, pp. 3152–3157. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; Volume 1 (Long and Short Papers). Burstein, J., Doran, C., Solorio, T., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://gwern.net/doc/www/s3-us-west-2.amazonaws.com/d73fdc5ffa8627bce44dcda2fc012da638ffb158.pdf (accessed on 3 March 2024).
- Liu, P.; Yuan, W.; Fu, J.; Jiang, Z.; Hayashi, H.; Neubig, G. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Comput. Surv. 2023, 55, 1–35. [Google Scholar] [CrossRef]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Proceedings of the Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, Virtual, 6–12 December 2020. [Google Scholar]
- Schick, T.; Schütze, H. Exploiting Cloze-Questions for Few-Shot Text Classification and Natural Language Inference. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, EACL 2021, Online, 19–23 April 2021; Merlo, P., Tiedemann, J., Tsarfaty, R., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 255–269. [Google Scholar] [CrossRef]
- Gao, T.; Fisch, A.; Chen, D. Making Pre-trained Language Models Better Few-shot Learners. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP 2021, (Volume 1: Long Papers), Virtual Event, 1–6 August 2021; Zong, C., Xia, F., Li, W., Navigli, R., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 3816–3830. [Google Scholar] [CrossRef]
- Shin, T.; Razeghi, Y.; Logan, R.L., IV; Wallace, E.; Singh, S. AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, Online, 16–20 November 2020; Webber, B., Cohn, T., He, Y., Liu, Y., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 4222–4235. [Google Scholar] [CrossRef]
- Zhong, Z.; Friedman, D.; Chen, D. Factual Probing Is [MASK]: Learning vs. Learning to Recall. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2021, Online, 6–11 June 2021; Toutanova, K., Rumshisky, A., Zettlemoyer, L., Hakkani-Tür, D., Beltagy, I., Bethard, S., Cotterell, R., Chakraborty, T., Zhou, Y., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 5017–5033. [Google Scholar] [CrossRef]
- Gu, Y.; Han, X.; Liu, Z.; Huang, M. PPT: Pre-trained Prompt Tuning for Few-shot Learning. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; pp. 8410–8423. [Google Scholar]
- Li, X.L.; Liang, P. Prefix-Tuning: Optimizing Continuous Prompts for Generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP 2021, (Volume 1: Long Papers), Virtual Event, 1–6 August 2021; Zong, C., Xia, F., Li, W., Navigli, R., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021; pp. 4582–4597. [Google Scholar] [CrossRef]
- Liu, X.; Ji, K.; Fu, Y.; Tam, W.; Du, Z.; Yang, Z.; Tang, J. P-Tuning: Prompt Tuning Can Be Comparable to Fine-tuning Across Scales and Tasks. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Dublin, Ireland, 22–27 May 2022; pp. 61–68. [Google Scholar]
- Zhou, Y.; Maharjan, S.; Liu, B. Scalable Prompt Generation for Semi-supervised Learning with Language Models. In Proceedings of the Findings of the Association for Computational Linguistics: EACL 2023, Dubrovnik, Croatia, 2–6 May 2023; Vlachos, A., Augenstein, I., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2023; pp. 758–769. [Google Scholar] [CrossRef]
- Deng, B.; Wang, W.; Feng, F.; Deng, Y.; Wang, Q.; He, X. Attack Prompt Generation for Red Teaming and Defending Large Language Models. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, 6–10 December 2023; Bouamor, H., Pino, J., Bali, K., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2023; pp. 2176–2189. [Google Scholar]
- Gao, J.; Xiang, L.; Wu, H.; Zhao, H.; Tong, Y.; He, Z. An Adaptive Prompt Generation Framework for Task-oriented Dialogue System. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, 6–10 December 2023; Bouamor, H., Pino, J., Bali, K., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2023; pp. 1078–1089. [Google Scholar]
- Liu, H.; Dai, Z.; So, D.R.; Le, Q.V. Pay Attention to MLPs. In Proceedings of the Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, Virtual, 6–14 December 2021; pp. 9204–9215. [Google Scholar]
- Du, J.; Xu, R.; He, Y.; Gui, L. Stance classification with target-specific neural attention networks. In Proceedings of the International Joint Conferences on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017. [Google Scholar]
- Liang, B.; Fu, Y.; Gui, L.; Yang, M.; Du, J.; He, Y.; Xu, R. Target-adaptive Graph for Cross-target Stance Detection. In Proceedings of the WWW’21: The Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; pp. 3453–3464. [Google Scholar] [CrossRef]
- Xu, C.; Paris, C.; Nepal, S.; Sparks, R. Cross-Target Stance Classification with Self-Attention Networks. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, ACL 2018, Melbourne, Australia, 15–20 July 2018; Volume 2: Short Papers. Gurevych, I., Miyao, Y., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 778–783. [Google Scholar] [CrossRef]
- Zhang, B.; Yang, M.; Li, X.; Ye, Y.; Xu, X.; Dai, K. Enhancing Cross-target Stance Detection with Transferable Semantic-Emotion Knowledge. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, 5–10 July 2020; Jurafsky, D., Chai, J., Schluter, N., Tetreault, J.R., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 3188–3197. [Google Scholar] [CrossRef]
- Conforti, C.; Berndt, J.; Pilehvar, M.T.; Giannitsarou, C.; Toxvaerd, F.; Collier, N. Will-They-Won’t-They: A Very Large Dataset for Stance Detection on Twitter. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, 5–10 July 2020; Jurafsky, D., Chai, J., Schluter, N., Tetreault, J.R., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 1715–1724. [Google Scholar] [CrossRef]
- Liang, B.; Zhu, Q.; Li, X.; Yang, M.; Gui, L.; He, Y.; Xu, R. JointCL: A Joint Contrastive Learning Framework for Zero-Shot Stance Detection. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2022, Dublin, Ireland, 22–27 May 2022; Muresan, S., Nakov, P., Villavicencio, A., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 81–91. [Google Scholar] [CrossRef]
- Petroni, F.; Rocktäschel, T.; Riedel, S.; Lewis, P.S.H.; Bakhtin, A.; Wu, Y.; Miller, A.H. Language Models as Knowledge Bases? In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, 3–7 November 2019; Inui, K., Jiang, J., Ng, V., Wan, X., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 2463–2473. [Google Scholar] [CrossRef]
- Jiang, Z.; Xu, F.F.; Araki, J.; Neubig, G. How Can We Know What Language Models Know. Trans. Assoc. Comput. Linguist. 2020, 8, 423–438. [Google Scholar] [CrossRef]
- Yuan, W.; Neubig, G.; Liu, P. BARTScore: Evaluating Generated Text as Text Generation. In Proceedings of the Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, Virtual, 6–14 December 2021; pp. 27263–27277. [Google Scholar]
- Wang, Y.; Wang, W.; Chen, Q.; Huang, K.; Nguyen, A.; De, S. Prompt-based Zero-shot Text Classification with Conceptual Knowledge. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics: Student Research Workshop, ACL 2023, Toronto, ON, Canada, 9–14 July 2023; Padmakumar, V., Vallejo, G., Fu, Y., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2023; pp. 30–38. [Google Scholar] [CrossRef]
- Zhu, Y.; Wang, Y.; Mu, J.; Li, Y.; Qiang, J.; Yuan, Y.; Wu, X. Short text classification with Soft Knowledgeable Prompt-tuning. Expert Syst. Appl. 2024, 246, 123248. [Google Scholar] [CrossRef]
- Goswami, K.; Lange, L.; Araki, J.; Adel, H. SwitchPrompt: Learning Domain-Specific Gated Soft Prompts for Classification in Low-Resource Domains. In Proceedings of the Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, EACL 2023, Dubrovnik, Croatia, 2–6 May 2023; Vlachos, A., Augenstein, I., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2023; pp. 2681–2687. [Google Scholar] [CrossRef]
- Gunel, B.; Du, J.; Conneau, A.; Stoyanov, V. Supervised Contrastive Learning for Pre-trained Language Model Fine-tuning. In Proceedings of the 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Vashishth, S.; Sanyal, S.; Nitin, V.; Talukdar, P.P. Composition-based Multi-Relational Graph Convolutional Networks. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Liu, R.; Lin, Z.; Fu, P.; Liu, Y.; Wang, W. Connecting Targets via Latent Topics And Contrastive Learning: A Unified Framework For Robust Zero-Shot and Few-Shot Stance Detection. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2022, Virtual and Singapore, 23–27 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 7812–7816. [Google Scholar] [CrossRef]
- Chen, Z.; Liang, B.; Xu, R. A Topic-based Prompt Learning Method for Zero-Shot Stance Detection. In Proceedings of the 21st Chinese National Conference on Computational Linguistics, Nanchang, China, 14–16 October 2022; pp. 535–544. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Statistics | Train | Dev | Test |
|---|---|---|---|
| # Examples | 13,477 | 2062 | 3006 |
| # Documents | 1845 | 682 | 786 |
| # Zero-shot Topics | 4003 | 383 | 600 |
| # Few-shot Topics | 638 | 114 | 159 |
| Topic | # Ex | # Unlabeled | Keywords |
|---|---|---|---|
| DT | 707 | 2194 | trump, Trump |
| HC | 984 | 1898 | hillary, clinton |
| FM | 949 | 1951 | femini |
| LA | 933 | 1899 | aborti |
| CC | 564 | 1900 | climate |
| A | 733 | 1900 | atheism, atheist |
| Model | VAST (%) | SEM16 (%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Pro | Con | Neu | All | DT | HC | FM | LA | A | CC | |
| BERT-joint [5] | 54.6 | 58.4 | 85.3 | 66.1 | - | - | - | - | - | - |
| TGA Net [5] | 55.4 | 58.5 | 85.8 | 66.6 | 41.5 | 48.7 | 46.6 | 45.3 | 54.2 | 35.4 |
| BERT-GCN [8] | 58.3 | 60.6 | 86.9 | 68.6 | 42.3 | 50.0 | 44.3 | 44.2 | 53.6 | 35.5 |
| CKE-Net [8] | 61.2 | 61.2 | 88.0 | 70.2 | - | - | - | - | - | - |
| DTCL [39] | 60.0 | 64.7 | 87.6 | 70.8 | - | - | - | - | - | - |
| ST-PL [40] | - | - | - | - | 48.4 | 53.7 | 51.2 | 48.1 | 52.2 | 35.2 |
| JointCL [29] | 64.9 | 63.2 | 88.9 | 72.3 | 50.5 | 54.8 | 53.8 | 49.5 | 54.5 | 39.7 |
| EZSD-CP_bert (ours) | 65.4 | 64.5 | 90.6 | 73.6 | 59.58 | 75.2 | 56.7 | 58.5 | 54.48 | 42.5 |
| EZSD-CP_roberta (ours) | 65.2 | 64.3 | 89.5 | 73.0 | 68.8 | 76.3 | 62.2 | 64.4 | 54.44 | 37.3 |
| Model | VAST (%) | SEM16 (%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Pro | Con | Neu | All | DT | HC | FM | LA | A | CC | |
| EZSD-CP (ours) | 65.4 | 64.5 | 90.6 | 73.6 | 59.58 | 75.2 | 56.7 | 58.5 | 54.48 | 42.5 |
| gMLP | 62.1 | 68.6 | 85.9 | 72.2 | 56.2 | 74.0 | 54.9 | 56.4 | 35.7 | 32.0 |
| con | 63.6 | 66.5 | 88.3 | 71.6 | 53.3 | 73.2 | 53.4 | 55.6 | 37.1 | 32.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yao, Z.; Yang, W.; Wei, F. Enhancing Zero-Shot Stance Detection with Contrastive and Prompt Learning. Entropy 2024, 26, 325. https://doi.org/10.3390/e26040325
Yao Z, Yang W, Wei F. Enhancing Zero-Shot Stance Detection with Contrastive and Prompt Learning. Entropy. 2024; 26(4):325. https://doi.org/10.3390/e26040325
Chicago/Turabian StyleYao, Zhenyin, Wenzhong Yang, and Fuyuan Wei. 2024. "Enhancing Zero-Shot Stance Detection with Contrastive and Prompt Learning" Entropy 26, no. 4: 325. https://doi.org/10.3390/e26040325
APA StyleYao, Z., Yang, W., & Wei, F. (2024). Enhancing Zero-Shot Stance Detection with Contrastive and Prompt Learning. Entropy, 26(4), 325. https://doi.org/10.3390/e26040325