Deep Convolutional Neural Network-Based Early Automated Detection of Diabetic Retinopathy Using Fundus Image

Abstract
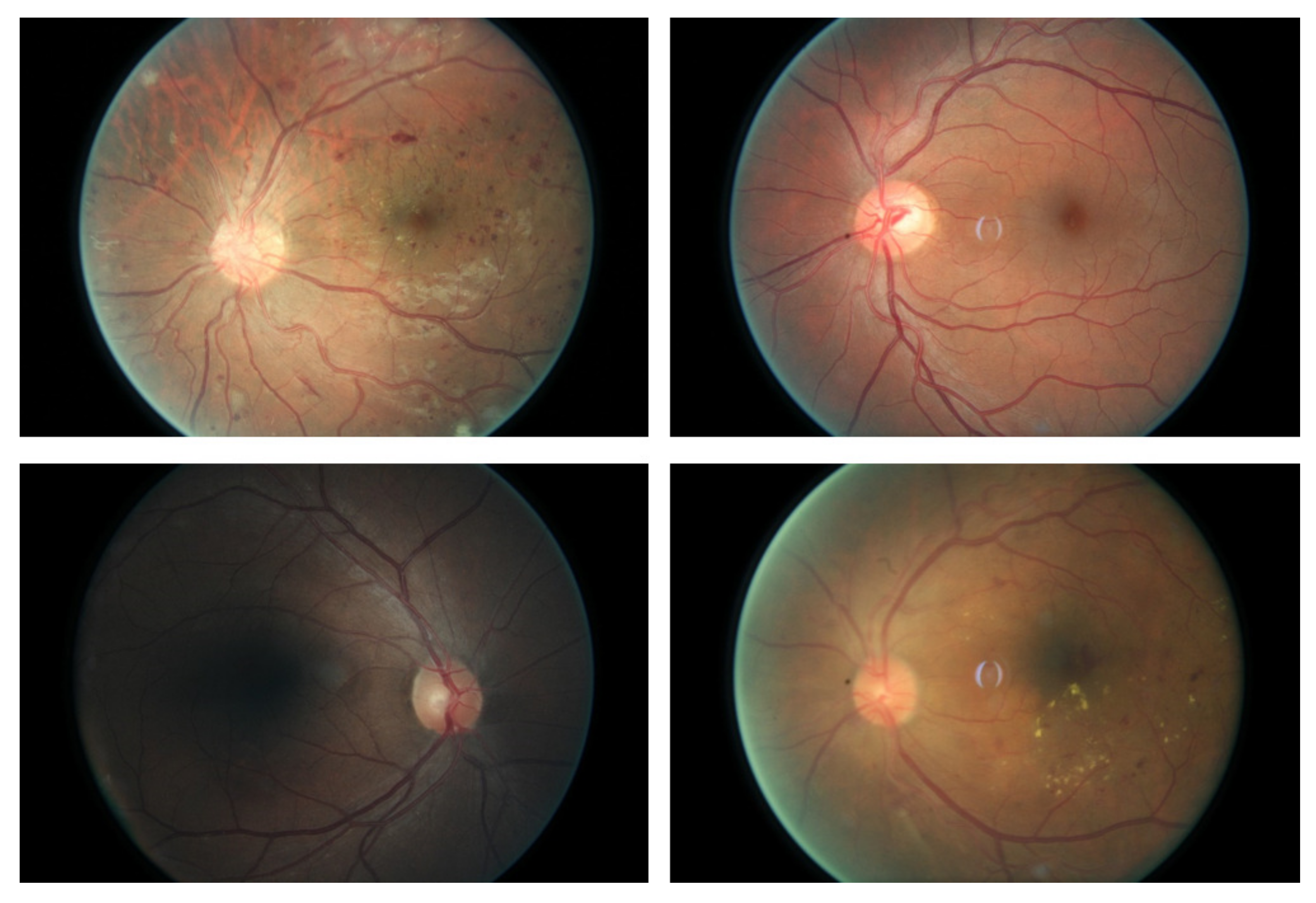
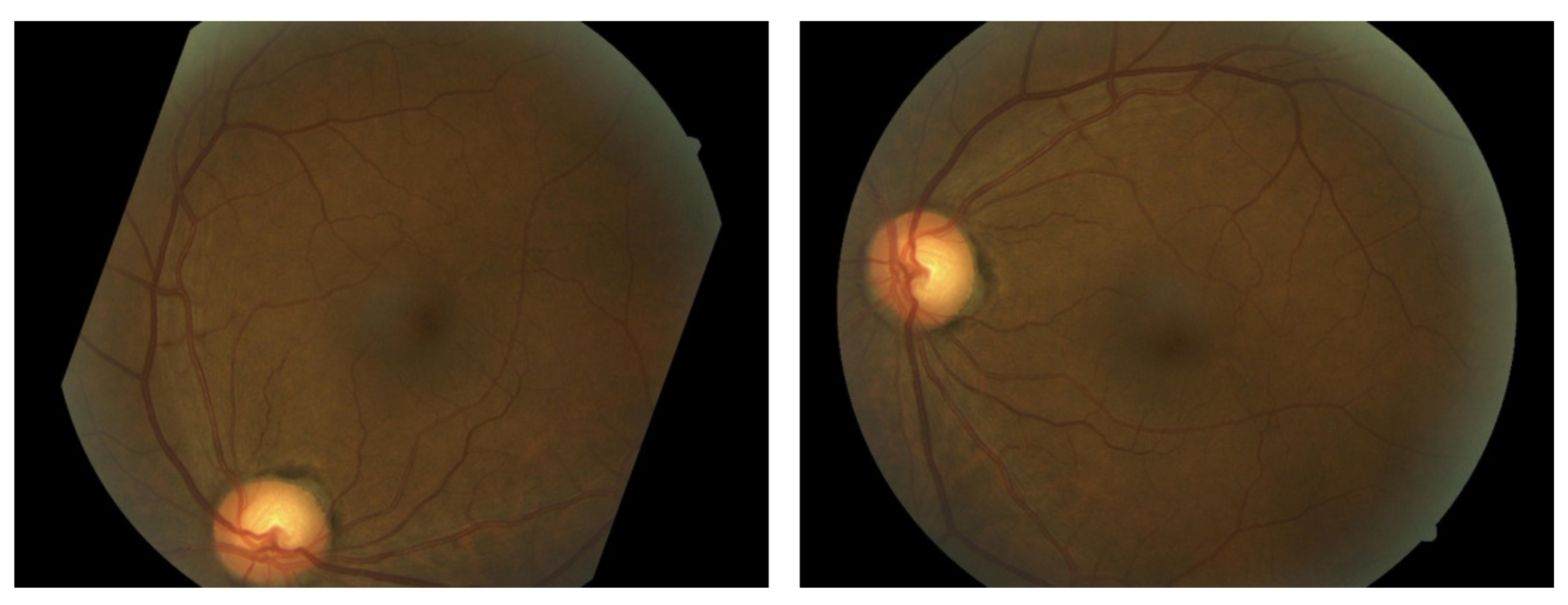
:1. Introduction
2. Methodology
2.1. Data Augmentation
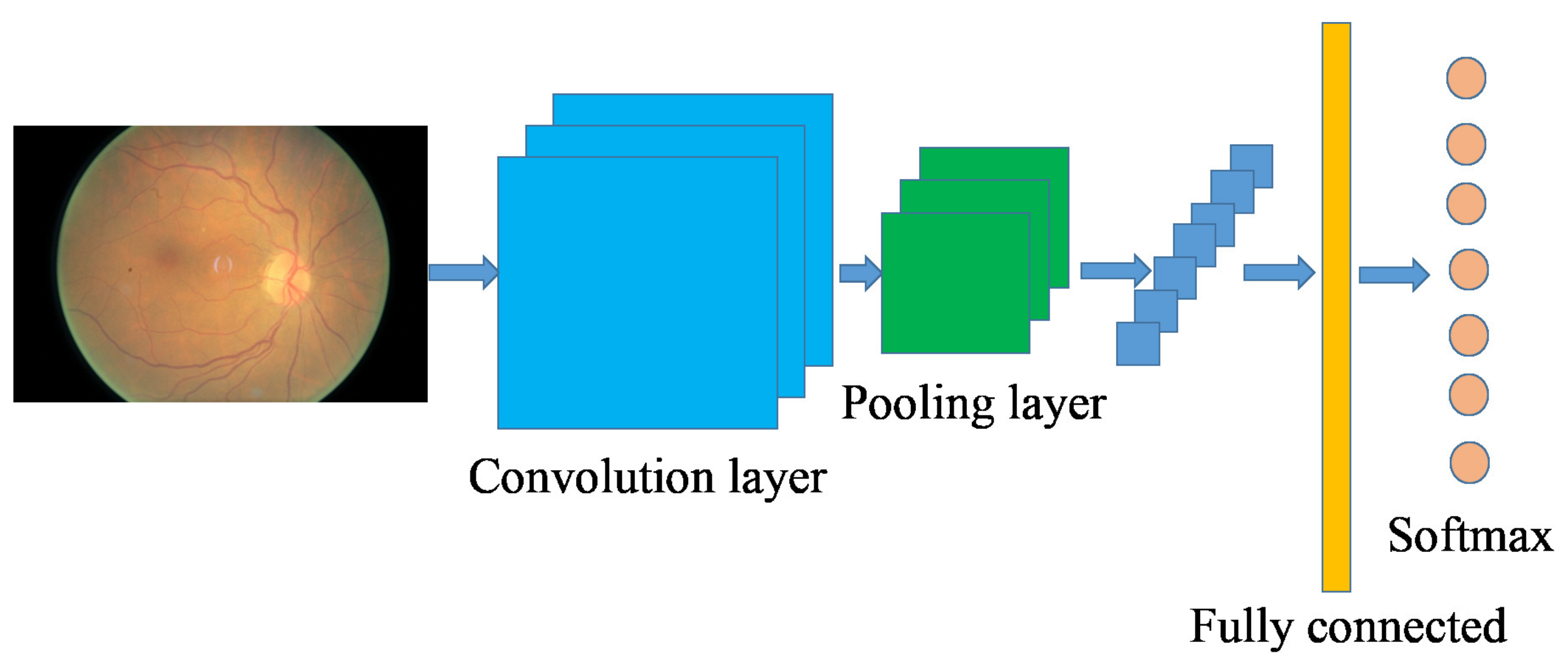
2.2. Convolutional Neural Network-Based Image Classification
3. Experimental Results
4. Discussion and Conclusions
Author Contributions
Conflicts of Interest
References
- Walter, T.; Klein, J.C.; Massin, P.; Erginay, A. A contribution of image processing to the diagnosis of diabetic retinopathy-detection of exudates in color fundus images of the human retina. IEEE Trans. Med. Imaging 2002, 21, 1236–1243. [Google Scholar] [CrossRef] [PubMed]
- Zheng, Y.; He, M.; Congdon, N. The worldwide epidemic of diabetic retinopathy. Indian J. Ophthalmol. 2012, 60, 428–431. [Google Scholar] [CrossRef] [PubMed]
- Sánchez, C.I.; García, M.; Mayo, A.; López, M.I.; Hornero, R. Retinal image analysis based on mixture models to detect hard exudates. Med. Image Anal. 2009, 13, 650–658. [Google Scholar] [CrossRef] [PubMed]
- Giancardo, L.; Meriaudeau, F.; Karnowski, T.P.; Li, Y.; Garg, S.; Tobin, K.W.; Chaum, E. Exudate-based diabetic macular edema detection in fundus images using publicly available datasets. Med. Image Anal. 2012, 16, 216–226. [Google Scholar] [CrossRef] [PubMed]
- Sánchez, C.I.; Hornero, R.; López, M.I.; Aboy, M.; Poza, J.; Abásolo, D. A novel automatic image processing algorithm for detection of hard exudates based on retinal image analysis. Med. Eng. Phys. 2008, 30, 350–357. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, B.; Karray, F.; Li, Q.; Zhang, L. Sparse Representation Classifier for microaneurysm detection and retinal blood vessel extraction. Inf. Sci. 2012, 200, 78–90. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. Comput. Vis. Pattern Recognit. 2013, arXiv:1312.6229. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ma, C.; Huang, J.B.; Yang, X.; Yang, M.H. Hierarchical Convolutional Features for Visual Tracking. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Shen, W.; Wang, X.; Wang, Y.; Bai, X.; Zhang, Z. DeepContour: A Deep Convolutional Feature Learned by Positive-sharing Loss for Contour Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Available online: https://www.kaggle.com/c/diabetic-retinopathy-detection (accessed on 10 March 2016).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Hubel, D.H.; Wiesel, T.N. Receptive fields and functional architecture of monkey striate cortex. J. Physiol. 1968, 195, 215–243. [Google Scholar] [CrossRef] [PubMed]
- Scherer, D.; Müller, A.; Behnke, S. Evaluation of pooling operations in convolutional architectures for object recognition. In Proceedings of the International Conference on Artificial Neural Networks, Thessaloniki, Greece, 15–18 September 2010. [Google Scholar]
- Chatfield, K.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Return of the devil in the details: Delving deep into convolutional nets. In Proceedings of the British Machine Vision Conference, Nottingham, UK, 1–5 September 2014. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Chatfield, K.; Simonyan, K.; Vedaldi, A.; Zisserman, A. MXNet: A Flexible and Efficient Machine Learning Library for Heterogeneous Distributed Systems. In Proceedings of the Neural Information Processing Systems, Workshop on Machine Learning Systems, Barcelona, Spain, 5–10 December 2016; MIT Press: Cambridge, MA, USA. [Google Scholar]
- Valverde, C.; Garcia, M.; Hornero, R.; López-Gálvez, M.I. Automated detection of diabetic retinopathy in retinal images. Indian J. Ophthalmol. 2016, 64, 26–32. [Google Scholar] [CrossRef] [PubMed]
- Hansen, M.B.; Abràmoff, M.D.; Folk, J.C.; Mathenge, W.; Bastawrous, A.; Peto, T. Results of Automated Retinal Image Analysis for Detection of Diabetic Retinopathy from the Nakuru Study. PLoS ONE 2015, 10, e0139148. [Google Scholar] [CrossRef] [PubMed]
- Tufail, A.; Kapetanakis, V.V.; Salas-Vega, S.; Egan, C.; Rudisill, C.; Owen, C.G.; Anderson, V.; Louw, J.; Liew, G.; Bolter, L. An observational study to assess if automated diabetic retinopathy image assessment software can replace one or more steps of manual imaging grading and to determine their cost-effectiveness. Health Technol. Assess. 2016, 20, 1–72. [Google Scholar] [CrossRef] [PubMed]
Sample Availability: Not available. |





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Transformation Type | Description |
|---|---|
| Rotation | 0–360 |
| Flipping | 0 (without flipping) or 1 (with flipping) |
| Shearing | Randomly with angle between −15 and 15 |
| Rescaling | Randomly with scale factor between 1/1.6 and 1.6 |
| Translation | Randomly with shift between −10 and 10 pixels |
| Output Shape | Description |
|---|---|
| 224 × 224 × 3 | input |
| 222 × 222 × 32 | 3 × 3 convolution, 32 filter |
| 220 × 220 × 32 | 3 × 3 convolution, 32 filter |
| 110 × 110 × 32 | 2 × 2 max-pooling |
| 108 × 108 × 64 | 3 × 3 convolution, 64 filter |
| 106 × 106 × 64 | 3 × 3 convolution, 64 filter |
| 53 × 53 × 64 | 2 × 2 max-pooling |
| 53 × 53 × 128 | 3 × 3 convolution, 128 filter |
| 51 × 51 × 128 | 3 × 3 convolution, 128 filter |
| 49 × 49 × 128 | 2 × 2 max-pooling |
| 24 × 24 × 256 | 3 × 3 convolution, 256 filter |
| 22 × 22 × 256 | 3 × 3 convolution, 256 filter |
| 11 × 11 × 256 | 2 × 2 max-pooling |
| 4096 | flatterned and fully connected |
| 1024 | fully connected |
| 2 | softmax |
| Method | Accuracy |
|---|---|
| Hard exudates + GBM | 89.4% |
| Red lesions + GBM | 88.7% |
| Micro-aneurysms + GBM | 86.2% |
| Blood vessel detection + GBM | 79.1% |
| CNN without data augmentation | 91.5% |
| CNN with data augmentation | 94.5% |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, K.; Feng, D.; Mi, H. Deep Convolutional Neural Network-Based Early Automated Detection of Diabetic Retinopathy Using Fundus Image. Molecules 2017, 22, 2054. https://doi.org/10.3390/molecules22122054
Xu K, Feng D, Mi H. Deep Convolutional Neural Network-Based Early Automated Detection of Diabetic Retinopathy Using Fundus Image. Molecules. 2017; 22(12):2054. https://doi.org/10.3390/molecules22122054
Chicago/Turabian StyleXu, Kele, Dawei Feng, and Haibo Mi. 2017. "Deep Convolutional Neural Network-Based Early Automated Detection of Diabetic Retinopathy Using Fundus Image" Molecules 22, no. 12: 2054. https://doi.org/10.3390/molecules22122054
APA StyleXu, K., Feng, D., & Mi, H. (2017). Deep Convolutional Neural Network-Based Early Automated Detection of Diabetic Retinopathy Using Fundus Image. Molecules, 22(12), 2054. https://doi.org/10.3390/molecules22122054